Just checking, what is this link meant to do?
my office hours,
For me, it just opens Google calendar with a pop-up note, saying "Could not find the requested event"
I cannot confidently say that this was faster than doing research the old-fashioned way. Sitting down with AI puts my attention in very different places, more on intuitions and less on the math; hard to say how quickly I could have arrived at similar results myself. What I can say is that Claude 4.8 is over some sort of tipping point for me, where I feel like I can "just keep going and keep making progress" in some new sense. I'm sure Fable would have done a better job, and the quality of vibe research will keep getting better from here
Reminds me of what Terry Tao said, emphasis mine
Dwarkesh Patel
So let’s see if you can continue this streak. You personally are 2x more productive as a result of AI. What year would you say that?
Terence Tao
Productivity, I think, is not quite a one-dimensional quantity. I’m definitely noticing that the style in which I do mathematics is changing quite a bit, and the type of things I do. For example, my papers now have a lot more code, a lot more pictures, because it’s so easy to generate these things now. Some plot which would have taken me hours to do, now I can do in minutes. But in the past, I just wouldn’t have put the plot in my paper in the first place. I would just talk about it in words. So it’s hard to measure what 2x means.
On the one hand, I think the type of papers that I would write today, if I had to do them without AI assistance, would definitely take five times longer. But I would not write my papers that way.
Dwarkesh Patel
5x?
Terence Tao
Yeah, but these are auxiliary tasks. Things like doing a much deeper literature search or supplying a lot more numerics. They enrich the paper. The core of what I do, actually solving the most difficult part of a math problem, hasn’t changed too much. I still use pen and paper for that.
But there’s lots of silly things. I use an AI agent now to reformat. Sometimes if all my parentheses are not quite the right size, I used to manually change them by hand, and now I can get an AI agent to do all that quite nicely in the background.
They’ve really sped up lots of secondary tasks. They haven’t yet sped up the core thing that I do, but it’s allowed me to add more things to my papers. By the same token, if I were to write a paper I wrote in 2020 again—and not add all these extra features, but just have something of the same level of functionality—it actually hasn’t saved that much time, to be honest. It’s made the papers richer and broader, but not necessarily deeper.
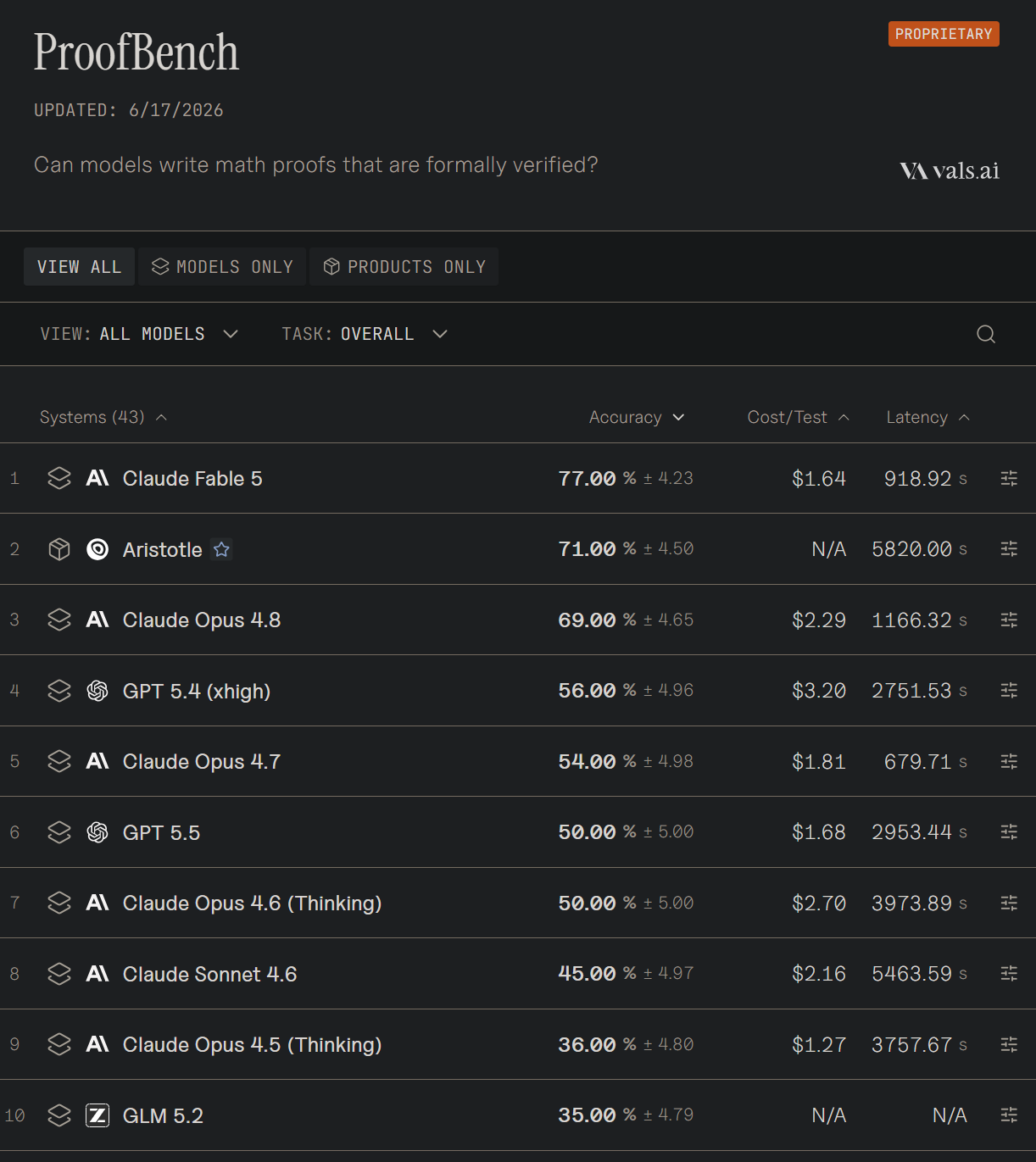
I'm a bit surprised by this, I've always thought that OpenAI/DeepMind models were much better at math pre-Mythos/Fable
I doubt this benchmark captures the most important bottlenecks, though certainly it will be correlated with the real bottlenecks. I hadn't heard of Aristotle!
There's a bunch of startups doing LLM math. Here's a couple: https://logicalintelligence.com (who claim to replicate OpenAI's result of unit distance problem), https://www.math.inc (who claim to verify Terence Tao's proof of Prime Number Theorem), and https://harmonic.fun (the one behind Aristotle)
Thanks to conversations with Anson Berns, Gurkenglass, Roman Malov, Sahil, Sam Eisenstat, and others.
Over the past two months, I've been doing a lot of "vibe research" (like vibe coding, but for research). Anson Berns started coming to my office hours (PM me for an invite if you're interested and the link doesn't work), and we've been collaborating on a project modeling trust between logical inductors. In addition to talking once a week, we've been exchanging raw AI chats as well as AI-generated summaries of what has been done (the raw chats are nice because they allow me to generate my own AI summaries focusing on what I'm most curious about). I've been asking Claude to use Lean to verify everything, so there's a somewhat good chance there's real results of interest here, but I haven't (yet) been reading the Lean proofs (or even the theorem statements) -- instead I've just been chatting with AI about how the Lean proofs went and whether they really formalized what was claimed in english+latex, and focused on understanding the proofs myself in the same way I'd normally read a math paper. There have already been several times when this methodology has caught big gaps between what was claimed and what was verified in Lean, so I imagine there are more.
This was mostly done with Claude Opus 4.8 via Claude Code, with a small amount of GPT 5.5 Extra High in Codex to get a second opinion.
I cannot confidently say that this was faster than doing research the old-fashioned way. Sitting down with AI puts my attention in very different places, more on intuitions and less on the math; hard to say how quickly I could have arrived at similar results myself. What I can say is that Claude 4.8 is over some sort of tipping point for me, where I feel like I can "just keep going and keep making progress" in some new sense. I'm sure Fable would have done a better job, and the quality of vibe research will keep getting better from here (modulo AI bans).
The overall goal is to use logical induction as both a model of human scientific and philosophical progress, and as a model of AI improvements over time. In that setting, we can formally ask: when can humans justifiably trust AI? This provides some degree of model of when recursive self-improvement can go well or poorly.
A different way of motivating it would be through the Learning Normativity agenda: how should we think about giving feedback to AI about moral questions when we're typically somewhat uncertain about those questions?
More concretely, my approach has been to translate the results from Deference Done Better to the logical induction setting (results further elaborated, and made relevant for AI Safety, in A Decision-Theoretic Approach for Managing Misalignment and the unpublished Margins of Misalignment). This gives an abstract criterion for trustworthiness; Anson and I then investigated the trustworthiness of constructive proposals according to this criterion (Anson focusing more on negative results, myself focusing more on positive results).
What I've been focusing on for a couple weeks now is trying to go more slowly and understand all the results myself; there are a lot of potential results here, but a need for more human discernment to judge whether the math is a decent model of reality (at the level of Lean corresponding to the markdown explanations, the markdown explanations corresponding reasonably well to the intuitions I was trying to communicate, and those intuitions corresponding reasonably well to reality). This is a form of technical debt (perhaps "intellectual debt"). As my brother put it, "digging out of AI knowledge holes is a huge undertaking".
AI will try to do whatever you ask it to do, so it is much easier now to fool yourself with math; where an economist publishing an impressive-looking mathematical model previously gave some evidence that they had thought things through quite a bit (even if imperfectly), now it is possible to do impressive-looking math without that. This means previously impressive levels of mathematical modeling should become less of a signal of quality of ideas than they once were. Of course, mathematics still has some intrinsic rigor; in a narrow sense, Lean won't let you verify an argument that doesn't work. Unfortunately, it gets messy fast; it is easy to fudge things by adding assumptions, for example. When math is supposed to tell you something about our world, Lean-verification can't distinguish a good model from a bad one. Human discernment is still a bottleneck.
In 1971, Herbert Simon noticed that information was becoming abundant, and so predicted the rise of the "attention economy":
The rise of AI is, in a sense at least, opening up the attention bottleneck (attention is becoming cheap). The new bottleneck becomes something like care, or taste, or discernment. Following Herbert Simon, we should expect something like a "care economy" is coming.
Unfortunately, the process of forcing everything through my human brain to apply my discernment is relatively slow. I'm trying to write out the results myself, like paraphrasing someone's argument to be sure you've understood it. I would prefer to publish these results in a de-slopped, human-vetted, human-written form. I think this will take at least a couple more weeks (for a rough draft). The mode of collaboration with Anson Berns has been interesting, and Sahil nudged me to release a data packet here on LessWrong so that more people can join in on the fun; the comment section of this post can become a repository for more vibe-research following up on these directions, if people are interested. I've scrubbed things a bit, and you'd probably be well-advised to do the same (to avoid including system prompts that might reveal too many personal details, for example). Modulo that caveat, I'd encourage people to include full transcripts rather than only summaries so that people can produce their own summaries.
Here is a folder including chats and summary documents from Anson and me, as well as video recordings of the relevant office-hours meetings, with transcripts. I expect there is some AI slop here -- interpret with caution.
Even if all the supposed results make sense as-advertised, there are a lot of gaps between this and reality. The setup is decision-theoretically naive (it 2-boxes and ignores updatelessness). It ignores issues with self-fulfilling prophecies. It is an outer-alignment scheme only. I've listed some of the issues with the approach in li-deference.md in the notes dump (the incomplete draft of my human-written version of these ideas). This can act as something of a todo list, if you're interested in contributing to the vibe-research project.