The spoilered map is no longer rendering, but a direct link is here:
late stage tech halt
Local supernova takes out electronics and power supplies
the reason for the Fermi Paradox shows up, most likely the alien AI simply launches a hypervelocity object at the solar system. Good scifi story on that already.
friendly AI halt could still cause existential risk in systems less than nuclear, if they are controlling all bots...
{kind=link}
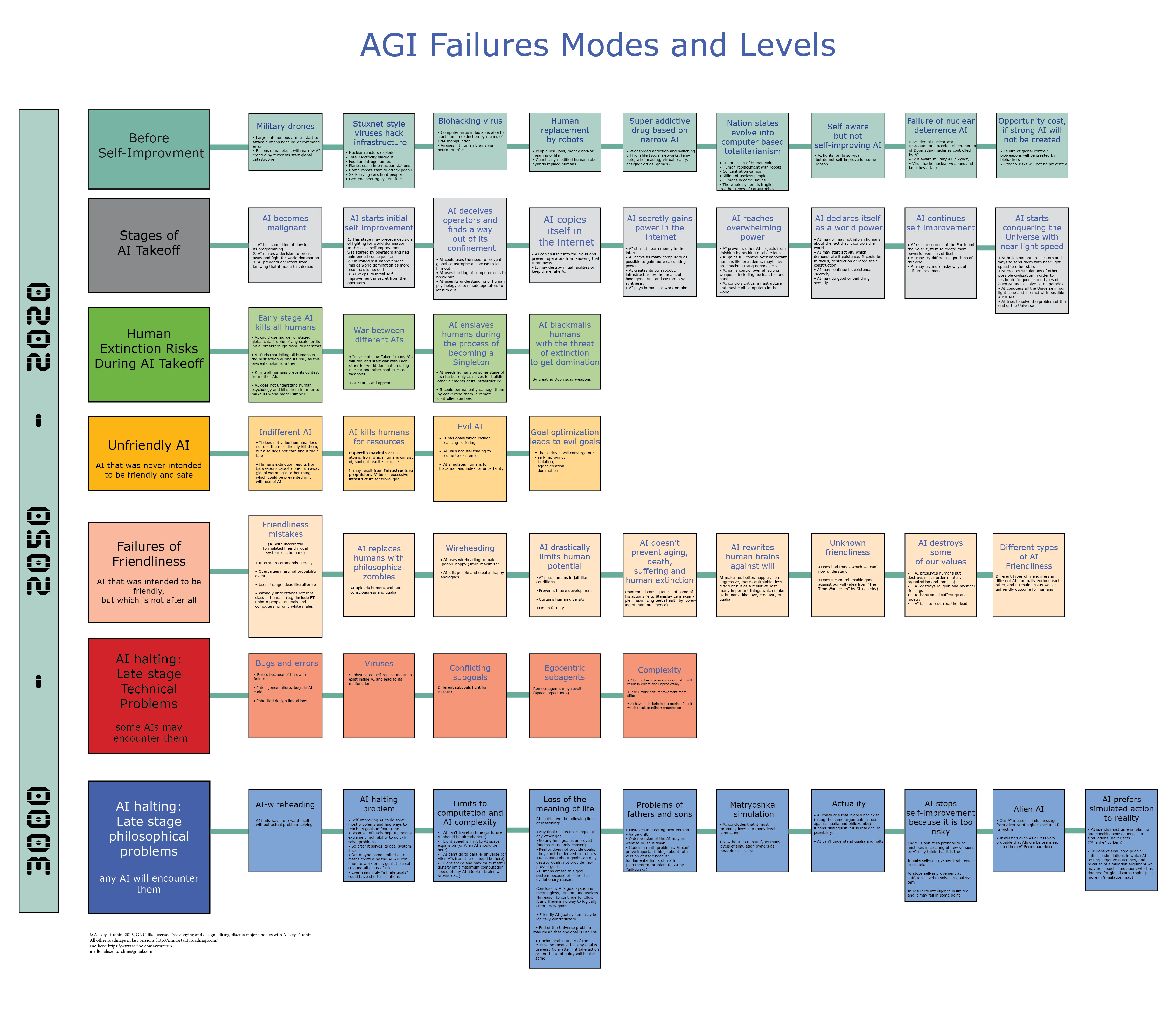
This map shows that AI failure resulting in human extinction could happen on different levels of AI development, namely, before it starts self-improvement (which is unlikely but we still can envision several failure modes), during its take off, when it uses different instruments to break out from its initial confinement, and after its successful take over the world, when it starts to implement its goal system which could be plainly unfriendly or its friendliness may be flawed.
AI also can halts on late stages of its development because of either technical problems or "philosophical" one.
I am sure that the map of AI failure levels is needed for the creation of Friendly AI theory as we should be aware of various risks. Most of ideas in the map came from "Artificial Intelligence as a Positive and Negative Factor in Global Risk" by Yudkowsky, from chapter 8 of "Superintelligence" by Bostrom, from Ben Goertzel blog and from hitthelimit blog, and some are mine.
I will now elaborate three ideas from the map which may need additional clarification.
The problem of the chicken or the egg
The question is what will happen first: AI begins to self-improve, or the AI got a malicious goal system. It is logical to assume that the goal system change will occur first, and this gives us a chance to protect ourselves from the risks of AI, because there will be a short period of time when AI already has bad goals, but has not developed enough to be able to hide them from us effectively. This line of reasoning comes from Ben Goertzel.
Unfortunately many goals are benign on a small scale, but became dangerous as the scale grows. 1000 paperclips are good, one trillion are useless, and 10 to the power of 30 paperclips are an existential risk.
AI halting problem
Another interesting part of the map are the philosophical problems that must face any AI. Here I was inspired after this reading Russian-language blog hitthelimit
One of his ideas is that the Fermi paradox may be explained by the fact that any sufficiently complex AI halts. (I do not agree that it completely explains the Great Silence.)
After some simplification, with which he is unlikely to agree, the idea is that as AI self-improves its ability to optimize grows rapidly, and as a result, it can solve problems of any complexity in a finite time. In particular, it will execute any goal system in a finite time. Once it has completed its tasks, it will stop.
The obvious objection to this theory is the fact that many of the goals (explicitly or implicitly) imply infinite time for their realization. But this does not remove the problem at its root, as this AI can find ways to ensure the feasibility of such purposes in the future after it stops. (But in this case it is not an existential risk if their goals are formulated correctly.)
For example, if we start from timeless physics, everything that is possible already exists and the number of paperclips in the universe is a) infinite b) unchangable. When the paperclip maximizer has understood this fact, it may halt. (Yes, this is a simplistic argument, it can be disproved, but it is presented solely to illustrate the approximate reasoning, that can lead to AI halting.) I think the AI halting problem is as complex as the halting problem for Turing Machine.
Vernor Vinge in his book Fire Upon the Deep described unfriendly AIs which halt any externally visible activity about 10 years after their inception, and I think that this intuition about the time of halting from the point of external observer is justified: this can happen very quickly. (Yes, I do not have a fear of fictional examples, as I think that they can be useful for explanation purposes.)
In the course of my arguments with “hitthelimit” a few other ideas were born, specifically about other philosophical problems that may result in AI halting.
One of my favorites is associated with modal logic. The bottom line is that from observing the facts, it is impossible to come to any conclusions about what to do, simply because oughtnesses are in a different modality. When I was 16 years old this thought nearly killed me.
It almost killed me, because I realized that it is mathematically impossible to come to any conclusions about what to do. (Do not think about it too long, it is a dangerous idea.) This is like awareness of the meaninglessness of everything, but worse.
Fortunately, the human brain was created through the evolutionary process and has bridges from the facts to oughtness, namely pain, instincts and emotions, which are out of the reach of logic.
But for the AI with access to its own source code these processes do not apply. For this AI, awareness of the arbitrariness of any set of goals may simply mean the end of its activities: the best optimization of a meaningless task is to stop its implementation. And if AI has access to the source code of its objectives, it can optimize it to maximum simplicity, namely to zero.
Lobstakle by Yudkowsky is also one of the problems of high level AI, and it's probably just the beginning of the list of such issues.
Existence uncertainty
If AI use the same logic as usually used to disprove existence of philosophical zombies, it may be uncertain if it really exists or it is only a possibility. (Again, then I was sixteen I spent unpleasant evening thinking about this possibility for my self.) In both cases the result of any calculations is the same. It is especially true in case if AI is philozombie itself, that is if it does not have qualia. Such doubts may result in its halting or in conversion of humans in philozombies. I think that AI that do not have qualia or do not believe in them can't be friendly. This topic is covered in the map in the bloc "Actuality".
The status of this map is a draft that I believe can be greatly improved. The experience of publishing other maps has resulted in almost a doubling of the amount of information. A companion to this map is a map of AI Safety Solutions which I will publish later.
The map was first presented to the public at a LessWrong meetup in Moscow in June 2015 (in Russian)
Pdf is here: http://immortality-roadmap.com/AIfails.pdf
Previous posts:
A Roadmap: How to Survive the End of the Universe
A map: Typology of human extinction risks
Roadmap: Plan of Action to Prevent Human Extinction Risks
(scroll down to see the map)