This is a linkpost for https://arxiv.org/abs/2402.11349
New Comment
Huh I am surprised models fail this badly. That said, I think
We argue that there are certain properties of language that our current large language models (LLMs) don't learn.
is too strong a claim based on your experiments. For instance, these models definitely have representations for uppercase letters:
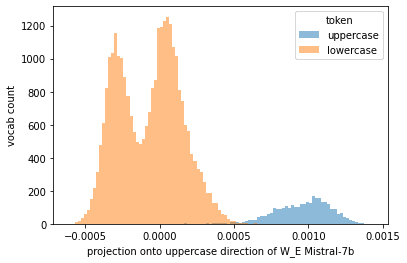
In my own experiments I have found it hard to get models to answer multiple choice questions. It seems like there may be a disconnect in prompting a model to elicit information which it has in fact learned.
Here is the code to reproduce the plot if you want to look at some of your other tasks:
import numpy as np
import pandas as pd
from transformer_lens import HookedTransformer
model_name = "mistralai/Mistral-7B-Instruct-v0.1"
model = HookedTransformer.from_pretrained(
model_name,
device='cpu',
torch_dtype=torch.float32,
fold_ln=True,
center_writing_weights=False,
center_unembed=True,
)
def is_cap(s):
s = s.replace('_', '') # may need to change for other tokenizers
return len(s) > 0 and s[0].isupper()
decoded_vocab = pd.Series({v: k for k, v in model.tokenizer.vocab.items()}).sort_index()
uppercase_labels = np.array([is_cap(s) for s in decoded_vocab.values])
W_E = model.W_E.numpy()
uppercase_dir = W_E[uppercase_labels].mean(axis=0) - W_E[~uppercase_labels].mean(axis=0)
uppercase_proj = W_E @ uppercase_dir
uc_range = (uppercase_proj.min(), uppercase_proj.max())
plt.hist(uppercase_proj[uppercase_labels], bins=100, alpha=0.5, label='uppercase', range=uc_range);
plt.hist(uppercase_proj[~uppercase_labels], bins=100, alpha=0.5, label='lowercase', range=uc_range);
plt.legend(title='token')
plt.ylabel('vocab count')
plt.xlabel('projection onto uppercase direction of W_E Mistral-7b')What's the difference between "having a representation" for uppercase/lowercase and using the representation to solving MCQ or AB test? From your investigations, do you have intuitions as to what might be the mechanism of disconnect? I'm interested in seeing what might cause these models to perform poorly, despite having representations that seem to be relevant to solving the task, at least to us people.
Considering that the tokenizer architecture for Mistral-7B probably includes a case-sensitive dictionary (https://discuss.huggingface.co/t/case-sensitivity-in-mistralai-mistral-7b-v0-1/70031), the presence of distinct representations for uppercase and lowercase characters might not be as relevant to the task for the model as one would assume. It seems plausible that these representations may not substantially influence the model's ability to perform H-Test, such as answering multiple-choice questions, with non-negligible probability. Perhaps one should probe for another representation, such as a circuit for "eliciting information".
I also want to point you to this (https://arxiv.org/abs/2402.11349, Appendix I, Figure 7, Last Page, "Blueberry?: From Reddit u/AwkwardIllustrator47, r/mkbhd: Was listening to the podcast. Can anyone explain why Chat GPT doesn’t know if R is in the word Blueberry?"). Large model failures on these task types were rather a widely observed phenomenon but with no empirical investigation.
The really cool ones are where the BPE errors compound and lead to strange, unpredictable downstream bugs. I've talked a lot about how I think ChatGPT's rhyming poetry is an example of this, but here's a simpler one: a famous GPT problem last year was about African countries whose name starts with 'K': https://news.ycombinator.com/item?id=37145312 GPT-3 made a spelling error of the usual BPE sort, which then got quoted in a blog spam & HN comment, which then (perhaps due to lack of explicit statement that the quotes were false) got read by search engine bots* and provided as snippet-answers to search queries! One could imagine this going further: extracted snippets would be useful for automatically creating Q&A datasets...
And then somewhere downstream, a human is reading the false statement 'While there are 54 recognized countries in Africa, none of them begin with the letter "K". The closest is Kenya, which starts with a "K" sound, but is actually spelled with a "K" sound.'† being generated by an AI model - possibly one that is character-tokenized at this point & so the error would appear to provably have nothing to do with BPEs - and is baffled at where this delusion came from.
* Google has discussed the processing of web page text (most detailed recent writeup) and it's usually a small BERT-like, so that means WordPiece, IIRC, and so it's also unable to 'see' the error even if it was smart enough to.
† This still replicates if you ask ChatGPT for a list of African countries which start with 'K'. If you reroll, it makes a remarkable number of different errors and confabulations. I particularly like the one where it just prints '1. Kenya' repeatedly - when you go on vacation to Kenya, be sure you go to Kenya, and not one of the other Kenyas, god have mercy on you if you land in Kenya, or worse yet, Kenya!
I appreciate this analysis. I'll take more time to look into this and then get back to write a better reply.
You state that GPT-4 is multi-modal, but my understanding was that it wasn't natively multi-modal. I thought that the extra features like images and voice input were hacked on - ie. instead of generating an image itself it generates a query to be sent to DALLE. Is my understanding here incorrect?
In any case, it could just be a matter of scale. Maybe these kinds of tasks are rare enough in terms of internet data that it doesn't improve the loss of the models very much to be able to model them? And perhaps the instruction fine-tuning focused on more practical tasks?
GPT-4 has vision multimodality, in terms of being able to take image input, but it uses DALLE for image generation.
Does GPT-4 directly handle the image input or is it converted to text by a separate model then fed into GPT-4?
Directly handles the image input. Transformers in general are quite flexible in what data they handle, but it may not have been trained to generate (or good at generating) image data.
https://platform.openai.com/docs/guides/vision and https://openai.com/contributions/gpt-4v are good places to start. https://arxiv.org/abs/2303.08774 is specific in the abstract that the model "can accept image and text inputs and produce text outputs".
... Not certain the best place to start with multimodal transformers in general. Transformers can work with all kinds of data, and there's a variety of approaches to multimodality.
Edit: This one - https://arxiv.org/abs/2304.08485 - which gets into the weeds of implementation, does seem to in a sense glue two models together and train them from there; but it's not so much connecting different models as mapping image data to language embeddings. (And they are the same model.)
Regarding the visual instruction tuning paper, see (https://arxiv.org/pdf/2402.11349.pdf, Table 5). Though this experiment on multi-modality was rather simple, I think it does show that it's not a convenient way to improve on H-Test.
Yeah; I do wonder just how qualitatively different GPT4 or Gemini's multimodality is from the 'glue a vision classifier on then train it' method LLaVa uses, since I don't think we have specifics. Suspect it trained on image data from the start or near it rather than gluing two different transformers together, but hard to be sure.
I initially thought so until the GPT-4 results came back. "This is an inevitable tokenizer-level deficiency problem" approach doesn't trivially explain GPT-4's performance near 80% accuracy in Table 6 <https://arxiv.org/pdf/2402.11349.pdf, page 12>. Whereas most others stay at random chance.
If one model does solve these tasks, it would likely mean that these tasks can be solved despite the tokenization-based LM approach. I just don't understand how.
If one model does solve these tasks, it would likely mean that these tasks can be solved despite the tokenization-based LM approach. I just don't understand how.
You can get a long way just by memorization and scaling. Consider the paper "Character-Aware Models Improve Visual Text Rendering", Liu et al 2022. This explains why image generators are so bad at text: it's the tokenization (shocku!, I know).
The interesting part here is what they dub 'the spelling miracle': the larger the LLM, the more likely it is to have somehow figured out the character spelling of tokenized words. You can see that PaLM will go from as low as 32% -> 89% correctly spelling words, across its 3 model sizes 8->540b. Same tokenization, same arch, same datasets, just scaling up. So, it is entirely possible for a small LLM to be terrible at character-level tasks, while the larger one does better by an amount similar to, say, 50->80%. (However, this capability is very fragile. If you ask GPT-4 to spell a novel word you just made-up or to rhyme words from a list of made-up words or explain puns...)
Possible sources within web corpora include: dictionaries containing phonetic pronunciation guides, alphabetically ordered lists, typos and other misspellings, and examples of spelling words with dashes or spaces between every character. Linguistic phenomena that may aide in inducing spelling knowledge include words with predictable morphemic makeup, and cases where meaning- form relation is non-arbitrary, contra Saussure’s “semiotic arbitrariness”. We refer the reader to Itzhak and Levy (2022) and Kaushal and Mahowald (2022) for work in this direction.
And of course, models like GPT-4 will benefit from the extremely large amounts of user and hired-human feedback that OA has collected, which will include many reports of character-based task errors.
Also note the terrible performance of T5 (Wordpiece, IIRC) vs ByT5 (character-based). ByT5 doesn't need 'sensory experience' to be way better than T5 - it just needs tokenization which isn't idiotically throwing away spelling information and thereby sabotaging spelling tasks... AFAIK, all the models mentioned in OP are byte or wordpiece; none are character-based. If you want to make claims about LLMs while using only character-based tasks like 'uppercase' or 'palindrome', you ought to make more of an effort to consider the effects of tokenization.
(Everyone wants to punch in a character manipulation task because they're so easy and convenient; no one wants to actually ablate or control or measure in any way the effects of tokenization.)
So to summarize your claim (check if I'm understanding correctly):
1. Character-level tokenization can lead to different results.
- My answer: Yes and No. But mostly no. H-Test is not just any set of character manipulation tasks.
- Explanation: Maybe some H-Test tasks can be affected by this. But how do you explain tasks like Repeated Word (one group has two repeated words) or End Punctuation (based on the location of the punctuation). Though this opinion is valid and is probably worthy of further investigation, it doesn't disprove the full extent of our tests. Along similar lines, GPT-4 shows some of the most "jumping" performance improvement from GPT 3.5 in non-character-level tasks (Repeated Word: 0.505 -> 0.98).
2. Scaling up will lead to better results. Since no other models tested were at the scale of GPT-4, that's why they couldn't solve H-Test.
- My answer: No but it would be interesting if this turned out to be true.
- Explanation: We tested 15 models from leading LLM labs before we arrived at our claim. If the H-Test was a "scaling task", we would have observed at least some degree of performance improvement in other models like Luminous or LLaMA too. But no this was not the case. And the research that you linked doesn't seem to devise a text-to-text setup to test this ability.
3. Memorization (aka more orthography-specific data) will lead to better results.
- My answer: No.
- Explanation: Our section 5 (Analysis: We Don’t Understand GPT-4) is in fact dedicated to disproving the claim that more orthography-specific data will help LLMs solve H-Test. In GPT-3.5-Turbo finetuning results on H-Test training set, we observed no significant improvement in performance. Before and after finetuning, the performance remains tightly centered around the random change baseline.
Maybe some H-Test tasks can be affected by this. But how do you explain tasks like Repeated Word (one group has two repeated words) or End Punctuation (based on the location of the punctuation).
I don't think I need to. 'End Punctuation' sounds like it's affected by tokenization, and regardless, artificial microbenchmarks like 'Repeated Word' are not expected to exhibit smooth scaling the way global losses like perplexity do. (They instead exhibit emergence, inverse U-scaling, and noisy patterns due to combined sampling error & biases from model checkpoints / sizes / test items / test sizes / prompts+formatting.) Look at Big-Bench to see how noisy these sorts of things are even when they are being properly evaluated in controlled conditions and sweeping model sizes (whereas your results are an uninterpretable hodge-podge).
Meanwhile, how do you explain the PaLM results on spelling miracles if you don't believe in scaling and that these are tasks "language models don't learn"?
We tested 15 models from leading LLM labs before we arrived at our claim. If the H-Test was a "scaling task", we would have observed at least some degree of performance improvement in other models like Luminous or LLaMA too. But no this was not the case.
We see improvements from scaling all the time which start from a flatline and then increase at critical sizes. See 'emergence'. Emergence is not that surprising because phase transitions are everywhere in NNs; and obviously, people don't bother with creating benchmarks where all the LLMs are ~100%, and then the best model, GPT-4, has a chance to exhibit emergence. And, doubtless, we'll see more examples with GPT-5 etc. (You also have a higher opinion of some of these 'leading' models like Luminous than I think most people do.)
Our section 5 (Analysis: We Don’t Understand GPT-4) is in fact dedicated to disproving the claim that more orthography-specific data will help LLMs solve H-Test. In GPT-3.5-Turbo finetuning results on H-Test training set, we observed no significant improvement in performance. Before and after finetuning, the performance remains tightly centered around the random change baseline.
Why would finetuning on a training set help a test set if GPT-3.5 is memorizing? Memorizing a pair of rhymes A/B tells you nothing about another pair of rhymes C/D, regardless of the two tasks being 'in-domain'.
(By the way, I would be skeptical of any conclusions drawn from GPT-3.5 finetuning because even if the 'finetuning' seemed to work, who knows what that 'finetuning' mystery meat actually is? The first iteration of OA's GPT-3 finetuning was apparently a fiasco, somehow whenever the rebooted OA GPT-3 finetuning comes up the result from it always seems to be 'it doesn't help capabilities', and OA declines to explain in any detail what the 'finetuning' does.)
Thanks for the comment. I'll get back to you sometime soon.
Before I come up with anything though, where are you getting to with your arguments? It would help me draft a better reply if I knew your ultimatum.
Where am I going? Nowhere complex.
To consult the statistician after an experiment is finished is often merely to ask him to conduct a post mortem examination. He can perhaps say what the experiment died of.
About 1.) That GPT4 performance jumps most in non-char tests seems to point towards two sources of difficulty in H-tests, with one being tokenization hiding char-level information.
About 2.) To me your results look completely consistent with scale solving H-tests. There are many benchmarks where a certain level has to be reached to leave random performance behind. For your benchmark that level is pretty high, but Claude and GPT4 seem to be above it.
If it's not scale, what makes Claude and GPT4 capable of making a dent in your benchmark?
About 3.) Finetuning doesn't convey enough information to completely revamp the representation of the spelling of different tokens. Finetuning mostly doesn't teach models skills they don't have. It instead points them squarely at the task they should be doing.
About 1.) Agree with this duality argument.
About 2.) I'm aware of the type of tasks that suddenly increase in performance at a certain scale, but it is rather challenging to confirm assertions about the emergence of capabilities at certain model scales. If I made a claim like "it seems that emergence happens at 1TB model size like GPT-4", it would be misleading as there are too many compound variables in play. However, it would also be a false belief to claim that absolutely nothing happens at such an astronomical model size.
Our paper's stance, phrased carefully (and hopefully firmly), is that larger models from the same family (e.g., LLaMA 2 13B to LLaMA 2 70B) don't automatically lead to better H-Test performance. In terms of understanding GPT-4 performance (Analysis: We Don’t Understand GPT-4), we agreed that we should be blunt about why GPT-4 is performing so well due to too many compound variables.
As for Claude, we refrained from speculating about scale since we didn't observe its impact directly. Given the lack of transparency about model sizes from AI labs, and considering other models in our study that performed on par with Claude on benchmarks like MMLU, we can't attribute Claude's 60% accuracy solely to scale. Even if we view this accuracy as more than marginal improvement, it suggests that Claude is doing something distinct, resulting in a greater boost on H-Test compared to what one might expect from scaling effects on other benchmarks.
About 3.) Fine-tuning can indeed be effective for prompting models to memorize information. In our study, this approach served as a useful proxy for testing the models' ability to learn from orthography-specific data, without yielding substantial performance improvements on H-Test.
Abstract
We argue that there are certain properties of language that our current large language models (LLMs) don't learn. We present an empirical investigation of visual-auditory properties of language through a series of tasks, termed H-Test. This benchmark highlights a fundamental gap between human linguistic comprehension, which naturally integrates sensory experiences, and the sensory-deprived processing capabilities of LLMs. In support of our hypothesis, 1. deliberate reasoning (Chain-of-Thought), 2. few-shot examples, or 3. stronger LLM from the same model family (LLaMA 2 13B -> LLaMA 2 70B) do not trivially bring improvements in H-Test performance.
Therefore, we make a particular connection to the philosophical case of Mary, who learns about the world in a sensory-deprived environment. Our experiments show that some of the strongest proprietary LLMs stay near random chance baseline accuracy of 50%, highlighting the limitations of knowledge acquired in the absence of sensory experience.
Key Findings on H-Test
1. Insignificant Intra-Family Improvements.
2. Number of Examples Has Minimal Impact.
3. Deliberate Reasoning (CoT) Often Decreases Performance.
4. Training with more orthography-specific language data does not improve H-Test.
5. Multi-modality does not automatically improve H-Test performance.
6 (Important). But the H-Test is solvable, we just don't know how.
I was inspired to do this research due to examples cases given in @Owain_Evans track application for the Constellation Fellowship 2024. This research is self-funded.
ArXiv: https://arxiv.org/abs/2402.11349
GitHub: https://github.com/brucewlee/H-Test