This is a special post for quick takes by Kaarel. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
notes!
I've just posted a repo with a bunch of my notes from 2023–2026, mostly on topics with relevance to AI alignment; see here for more meta information. An assortment of 101 items from the vault:
- AI safety presentation slides (or really self-contained slideuments):
- Variants of the alignment problem (at the AFFINE Superintelligence Alignment Seminar)
- Verification-based alignment schemes (at the AFFINE Superintelligence Alignment Seminar)
- Inspection of thinking as a source of ideas for understanding minds (at the AFFINE Superintelligence Alignment Seminar)
- Model-wise thinking (at the AFFINE Superintelligence Alignment Seminar)
- Intro to AGI safety (at the University of Tartu)
- Impact cases for guardrails/monitoring/verification (at Mila)
- Why fear a math AI? (at Mila)
- on understanding:
- good concepts are concepts that support inferences
- predicting specific things
- model-thinking in mathematics
- how categoricity (or universal properties) relate to the implementation of mental structures
- gaining the integral notion
- cheap inferences
- turning activity-situations into abstract games
- a stylized genealogy of sonic concepts
- condensation:
- valuing, ethics, metaethics:
- mundane malignity
- it is natural for a mind to remake the world
- terminality causes unmooredness
- seeing (meta)ethics clearer via mathematical logic
- centering ethics on coming up with ways to act
- there are many good and important value-flavored structures
- the epistemics-ethics bridge
- in one sense, human values are very complicated; in another sense, human values are very simple
- argument against universal value extraction device
- an illustration of the role of understanding-machinery in value development
- on good reflection processes
- trajectories of moral-reflective flight — an alternative to reflective equilibrium
- some thoughts on consequentialist ethics in large worlds and an ethical problem relating to existence
- examples of structure-making and why copy-making?
- on pursuing ideals
- ideal induction math:
- on ideal inductions and attempts to use them to handle the AGI problem in principle:
- could one do science with solomonoff on text?
- a better attempt at getting science out of solomonoff
- solomonoff function induction gives at least some const probability to bad behavior on ood inputs
- solomonoff induction is weird
- which input-output pairs does solomonoff induction need to see to generalize correctly?
- beating solomonoff induction at grokking a notion
- solomonoff induction is not the paragon of generalization
- philosophy of language, philosophy of science, epistemology
- between verificationism and holism
- some disanalogies between solomonoff induction and science
- some considerations with an eye toward specifying a picture of meaning
- compositional inference warranting
- the correct theory of semantics
- formalizing philosophy
- assigning probabilities in a conception of the world you know to be inadequate
- interpretability:
- understanding a NN in terms of what it is doing
- merge machines
- readability of independent predicates implies steering vector existence and a sort of linear decomposability
- some superposition geometry math
- a memorizing construction
- hyperparams we'd want to know for a theory of interpretability that studying toy models could help determine
- a remark on the value of philosophy for understanding AIs
- metaphysics:
- a toy setting for studying some technological phenomena
- human math and alien math are pretty orthogonal
- scaling laws satisfied by mathematical things
- a world of purposes
- standard physics implies infinite computation causally downstream of us along certain extremely low (and decaying) amplitude quantum branches
- wherefore discreteness and emergence of structures
- the anima mundi analogy
- on human futures, facing AGI:
- instead of building a very different artificial system which is smarter than us, let's just become smarter (tentatively indefinitely)
- what is weltgeistbehandlung?
- protection via instrumentalization / instrumentalizing the good
- if you're trying to make a super-human non-human system, you should still have making humanity a top understander again in mind
- we should grow immensely but with great care
- a human future isn't petty
- uncategorized AI safety:
- outside-view arguments for (and against) AI doom
- on a lab preparing for RSI
- RSI structure hyperparams
- a statement of the alignment problem
- an argument for faster takeoff
- some good questions in conceptual alignment
- cases of verification
- shortlist of approaches to getting research papers given a hypercomputer
- mind uploads with ML (and specifically prediction)
- some ideas for safe self-improvement
- safe self-improvement is much easier than the AGI problem we face
- a list of alignment training tricks
- intention-setting speech for AFFINE seminar
- some hyperparam changes for the field of non-prosaic alignment
- varia:
I am generally happy about people publishing their thoughts about AI alignment, even if they're unpolished, so thanks for doing this! But as-is, this is so many links that I don't know where to start, and my first instinct is to scroll past it and probably never read any of it. Are there a few notes that you recommend looking at, which you're particularly proud of or think may be particularly useful?
I generally recommend looking first at the presentation slides and then under "uncategorized AI safety". Specifically, I suggest Model-wise thinking.
In a sense, it is extremely natural and obvious that any system handling sophisticated problems will be doing different things when handling different problems! But there is also a starting point from which this can be somewhat surprising: if you think of a neural net as a circuit (either just manifestly, or under some translation), then maybe you'd expect the same variables to be computed on each forward pass? It could be helpful here to consider how a Turing machine with a runtime bound can always be unrolled into a circuit that simulates [the contents of its tape and the position of its pointer] at all time steps.6 Whether tape cell 13 has a 0 or a 1 written on it at time step 42 is in one sense the same variable on any input, but in another sense it can easily represent very different variables of the program on different inputs.
Two remarks on how the current (March 2026) field trying to understand what AIs are doing relates to the issue of an AI doing different things on different inputs:
- The currently prevailing view in interpretability allows for this to some extent: it is common to think of a big transformer language model as doing various different things depending on the context/input. But the prevailing view still takes there to ultimately be some pre-determined finite list of variables (I mean: corresponding to SAE features) that could be getting determined in a model, and I think this is probably a defect of that view, because a system solving an open-ended variety of complicated problems should be able to determine [what auxiliary problems to solve]/[what auxiliary questions to answer] on the fly.7 (I should note: maybe it is not clear that a forward pass of a transformer is sophisticated enough for this to be true of it?)
As one of the "finite list of variables" people[1]: This is because at the moment, I primarily want to find and understand the variables underlying the general mechanisms which AIs use to have many different kinds of productive thoughts in the first place. I am not particularly trying to find and understand variables defined only within the causal structure of these thoughts. I believe the former might indeed be described as a pre-determined finite list of variables. I agree the latter can't be, at least not usefully.[2]
To use your analogy: I think of myself as trying to understand something like the basic makeup of a UTM, figuring out the tapes, heads, registers, tables and so on. I am not yet trying to say very much about the inner structures of the many different programs that could be run on that UTM.
I agree that some "finite list of variables" people seem to me to not distinguish between these different levels. I think that this is probably a mistake.
scaling laws satisfied by mathematical things
how does proof length scale with statement length?
uncomputably fast in the average case:
Suppose there were a computable bound on how quickly average proof length of provable statements scales. Then we could build a halting oracle: Given a program P, check each string in order of length for whether it is a proof that P halts. If it doesn't halt, eventually the bound tells you that you can stop looking. If it does halt, this is provable by exhibiting a computation trace.
oh right, because a computable bound on the average proof length would imply a computable worst case bound as well (since there are only
- can we say some more stuff about what the distribution of proof lengths is like?
- is there an interesting scaling law for the statements a reasonable mathematical community (such as the human one) actually proves? (I think sth like this is what I'm most interested in here)
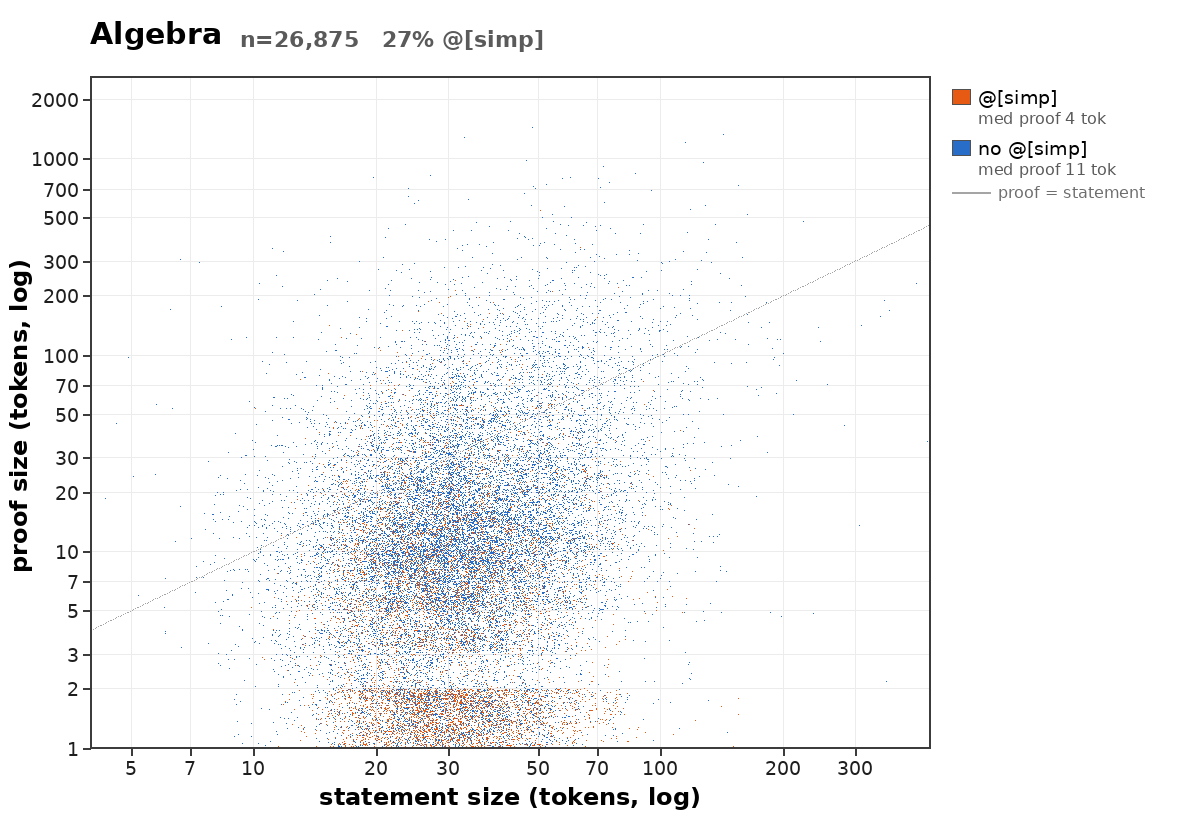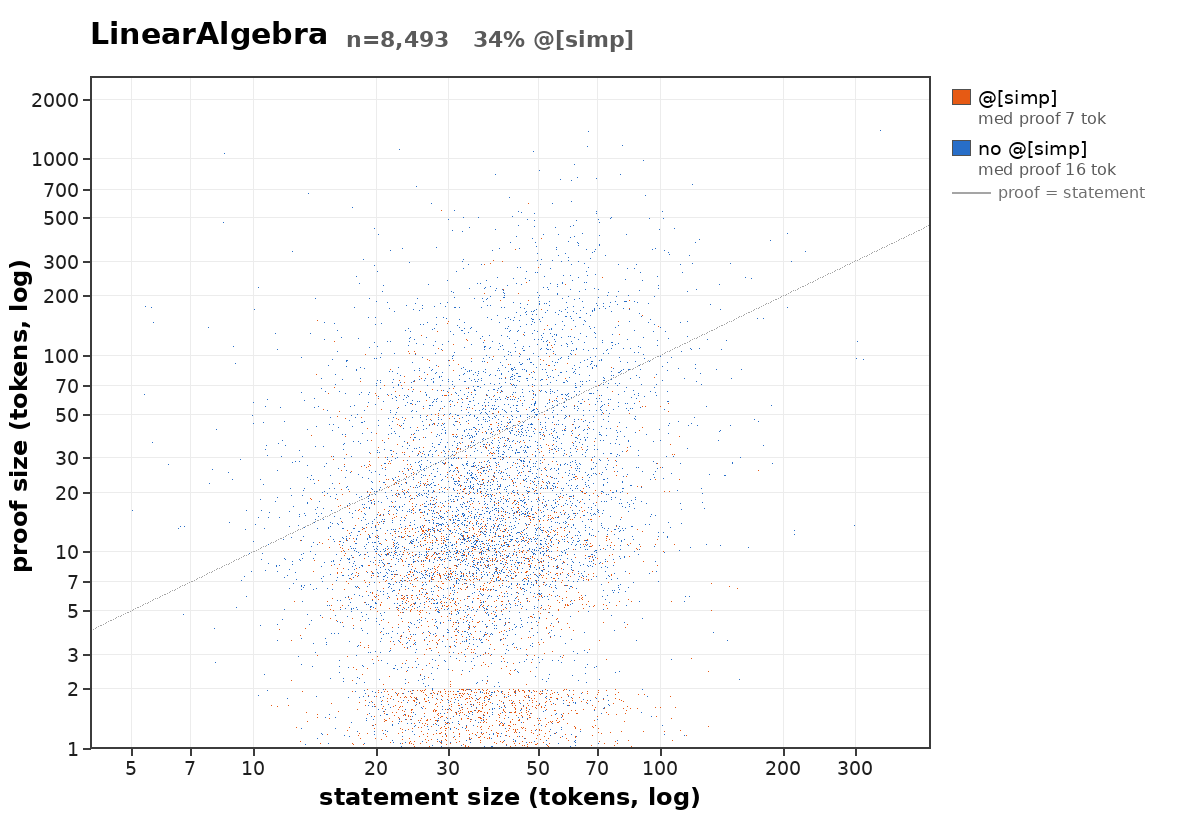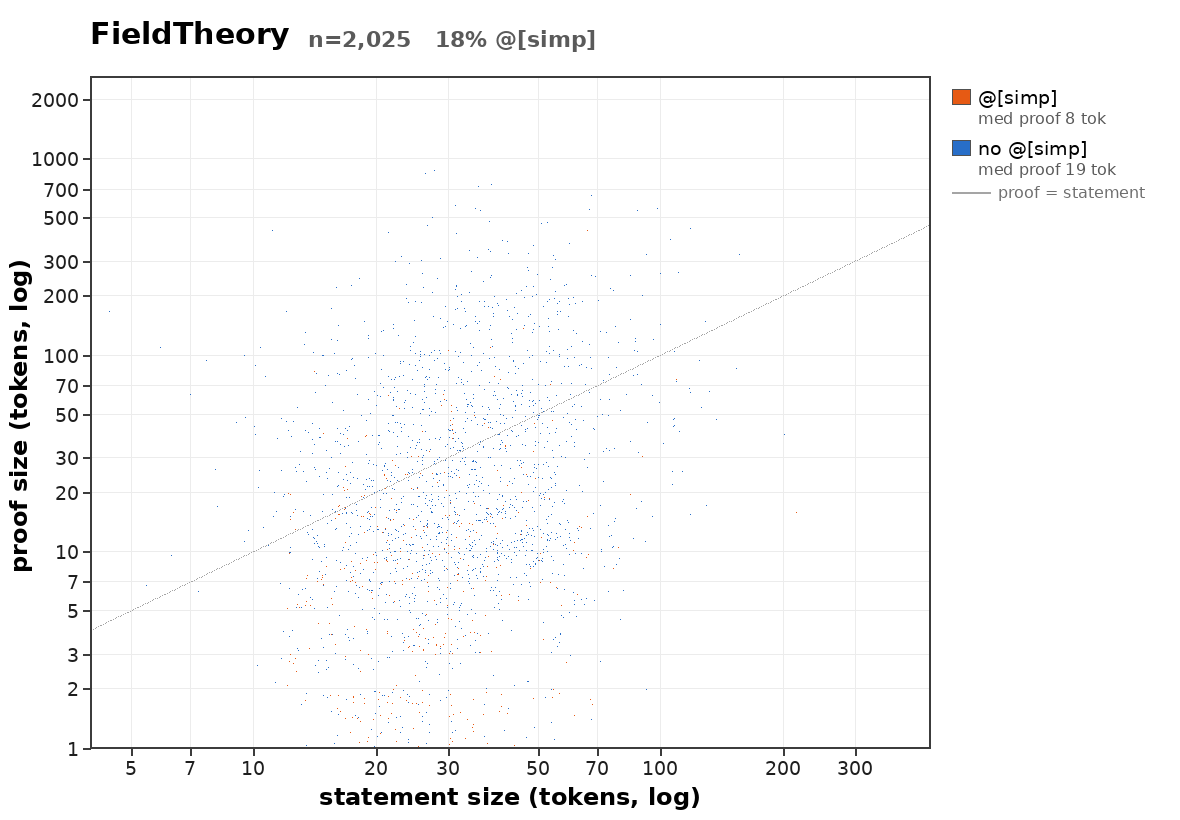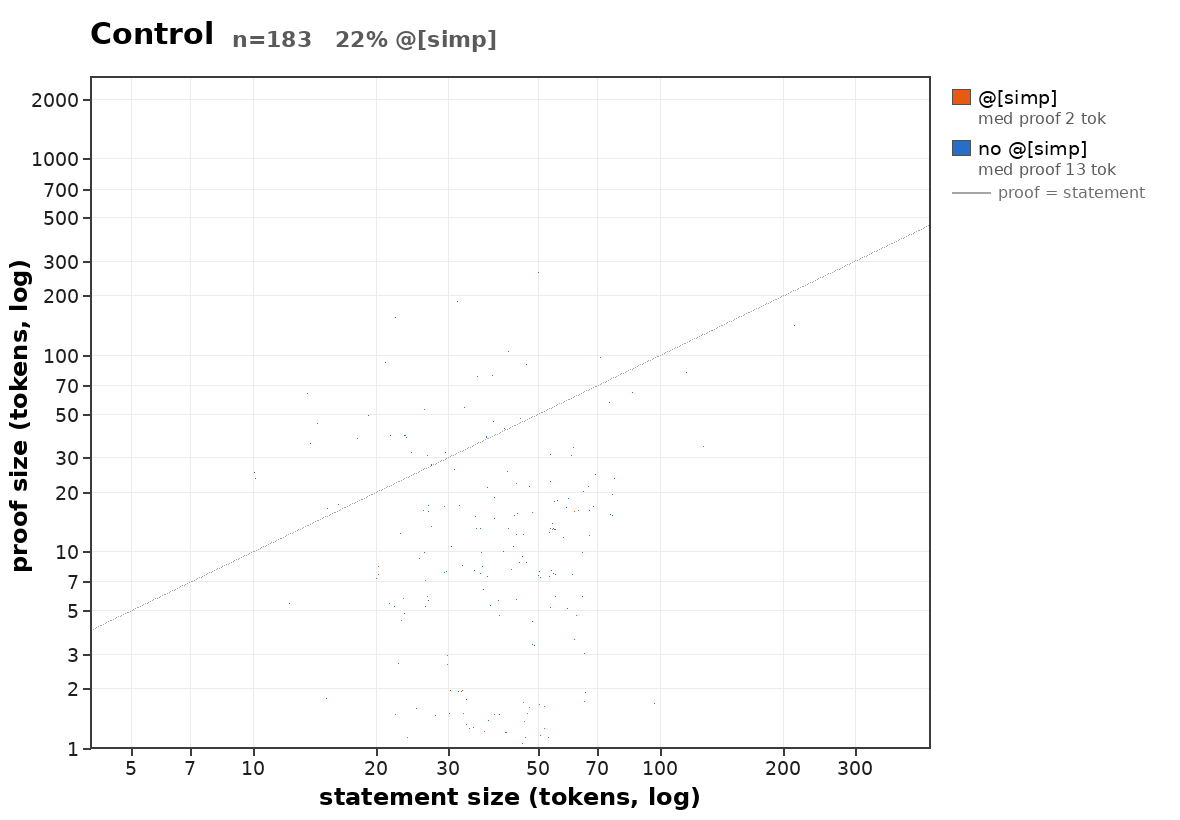
Was pleasantly surprised to see so much writing about non-prosaic alignment.
I generally like the idea that good concepts are concepts that make a bunch of useful inferences easy. (c.) good concepts are concepts that support inferences
Lets gooooooo! I've been saying the same thing since forever. I mean 8 months ago (see "Lead 1").
I also believe the same idea is important for defining optimization. You can try a definition like this:
Definition 1. "Optimization is the ability to achieve more (F) with less (G). Where G is a simpler function/algorithm which allows to make cheap but important inferences about a more complex function/algorithm F - and computing G many times significantly simplifies computing F."
(This is an attempt to formalize the intuition that any algorithm for solving a complicated problem has to have "the main subroutine" which does most of the work and reveals something non-trivial about the algorithm.)
Lookup tables and chaotic algorithms which are successful by accident[1] (like Rube Goldberg machines) are ruled out by this definition. Atoms in a rock are not an optimizer because they achieve less with more (all the complex quantum mechanic dynamics create a mere unmoving rock which is easily modeled by only a couple of variables). Ditto a bottle cap.
If you're interested, here's more thoughts about my definition/metric of optimization:
more thoughts
I think one of the big conceptual problems with my definition is that it doesn't treat non-algorithmic knowledge as optimization/intelligence.
Consider an evaluation function updating on experience. Intuitively, this function becomes smarter with time. Yet my metric won't detect the increase in knowledge as increase in optimization/intelligence. Because the algorithm didn't become more complicated or more algorithmically efficient.
Another example is a human becoming wiser with experience (without their thinking becoming more complicated).
However, there are also heuristics successful at predicting reality due to luck (= lucking into a simple region of reality) or due to memorization (= using spurious correlations to compress a lookup table of reality). Some heuristics feel like "spurious patterns in the world", other heuristics feel like "wisdom" or "deep knowledge". What's the difference?
Definition 2. One attempt (very fresh, not at all well thought-out) to define "deep" knowledge:
- We have an algorithm A predicting X.
- It's good at predicting only simple/natural instances of X.
- A is similar to A' which becomes gradually better at predicting only simple/natural instances of X.[2]
The idea is that deep knowledge has to be about something natural and obtained in a natural way (= due to some bias which is generally useful only in natural situations).
you could hope to understand a neural net in terms of what problems it is solving / what questions it is answering. like, on the way to doing the thing it is supposed to be doing, it might be solving some subproblems (c.) understanding a NN in terms of what it is doing
I'm surprised you didn't bring up something like the above here. You already defined abstractions as things helping to make inferences. Why not define algorithm-related abstractions the same way? (Maybe you've considered it but didn't think it is useful.)
What the heck is it for a sentence to mean anything (for sentences which aim to talk about the actual real world, let's say)? (c.) between verificationism and holism
What if we keep miking the "abstractions are things which make inferences cheap" idea and say something like...
Definition 3. "The meaning of a linguistic unit is the simplest thing (M) which can be used to make a large amount of cheap and correct inferences about everything the unit implies or is implied by."[3]
Supposed consequences of this view:
- You can have M (= meaning) in your head even if you didn't make all those cheap inferences.
- People with very different levels of language experience can have similar M.
- M has no specific translation into any language.
- M will tend to be compositional, because it's one of the simplest ways to get many cheap inferences.
- M both depends on the entirety of language and can be talked about separately.
P.S.
Ben Finegold reference? You're deep in chess. I'm a chess player too. My meta is to play crappy openings which minimize "the variance of responses by an average opponent". I also had a research project about the longest non-trivial middlegames (scroll down for interactive examples).
- ^
Is it even possible? A chaotic algorithm which outputs the correct answer most of the time "by accident"? Sounds like an oxymoron.
- ^
The definition will have to deal with algorithms pretending (sandbagging) to only work on simple/natural instances of X.
- ^
Warning: haven't thought this through at all. It probably should be combined with Definition 2.
- ^
The definition will have to deal with algorithms pretending (sandbagging) to only work on simple/natural instances of X.
Positives of a future with human capability improvement over an AI future.
Beren Millidge has an essay arguing for the claim that a future in which humanity proceeds with biological capability increasing is scarier than a future in which we develop AGI. Here are some concluding sentences from his essay:
Ultimately, human intelligence amplification and the resulting biosingularity has a deeper and more intractable alignment problem than AI alignment, at least if we don’t just assume it away by asserting that humans and our transhuman creations just have some intrinsic and ineffable access to ‘human values’ that potential AIs lack.
The only potential positive as regards alignment of the biosingularity is that it will happen much later, most likely in the closing decades of the 21st century and around the end of the natural lifespans of my personal cohort. This gives significantly more time to prepare than AGI, which is likely coming much sooner, but the problem is much harder and requires huge advances in neuroscience and understanding of brain algorithms to even reach the level of control we have over today’s AI systems (which is likely far from sufficient).
I disagree with his thesis — I think that instead of creating AIs smarter than humans, it would be much better to proceed with increasing the capabilities of humans (for at least the next 100 years). [1] [2] Millidge's claim that the only potential positive of a biofoom is that it starts later seems clearly false. In this note, I will list other imo important (pro tanto) positives of a human foom. I agree with Millidge that there are also positives of the AGI path; [3] these won't be discussed in the present note. To assess which path is better overall, one could want to compare the positives of the human path to the positives of the AGI path, [4] but I will not do that here. The rest of this note is the list of positives. [5]
more similar entity => more similar values
an argument in favor of the human path:
- assumption 1. it makes sense to speak of the values of an entity, and the values of an entity are some sort of kinda-smooth function of the entity's structure/constitution
- assumption 2. humanity (taken as an entity) currently has pretty good values
- conclusion. somewhat modified humanity will still have pretty good values. in particular, a somewhat bioenhanced humanity will still have pretty good values
- in contrast: an AGI future will involve the-process-happening-on-earth changing a lot more from what it is now, certainly by each point in time, but also by the time each higher capability level is reached
we can also give a similar argument for single humans:
- assumption 1. it makes sense to speak of the values of an entity, and the values of an entity are some sort of kinda-smooth function of the entity's structure/constitution
- assumption 2'. individual humans growing up in current human societies have pretty good values
- conclusion'. somewhat modified individual humans growing up in somewhat modified societies will still have pretty good values
- in contrast: an AGI future will involve AGIs that are much more different than these future humans growing up in contexts that are much more different from the contexts in which current humans grow up. this is certainly true by each time (or each time after the beginning of each "foom proper"), but also by the point each higher capability level is reached
said another way:
- the target of right values is drawn largely around where the arrow(s) determining the values that humans have landed. shooting more similar arrows in a similar way is a decent strategy for hitting that target again.
[humans are]/[humanity is] just cool
- on the biofoom path, it will still be humanity, made of humans. humanity is cool. humans are cool. humans with increased capabilities and humanity with increased capabilities would be cool as well. like, of course it's possible for us to become even much cooler, but we're already occupying a very specific rare cool region in mindspace
- the smarter humans you make will be slotting into existing human institutions/organizations/communities. existing human institutions/organizations/communities will still be useful to the smarter humans. this is a reason for existing human institutions/organizations/communities to persist/thrive/develop. [6] and existing human institutions are carriers/supporters/implementers of human values and also cool
- the more capable humans will be continuing existing human (social, political, artistic, technological, scientific, mathematical, philosophical) projects and traditions. human thought will continue to develop. this is cool
- like, even if the humans with improved capabilities were to (let's say) form their own state and build a massive biodome around it and cause the outside to eventually become uninhabitable by polluting it or militarily leveling it to make room for automated factories or whatever, killing all other humans, that would be a very bad thing for them to do, but it would still be a human future, and that's pretty important
an analogy:
- suppose you are at intelligence level
- the agent could just be you after having taken a linear algebra course or after inventing some new methods in numerical linear algebra
- the agent could just be you after getting gene therapy which changes a single genetic variant to one that better supports learning (even in adulthood)
- the agent could be some sort of novel mind you create from scratch by some training procedure (ok maybe involving some culture which was also involved when you grew up)
- now, there is at least some range of your mind-making precision/understanding parameter from
- to spell out the analogy: with humanity as the agent, the human path is like becoming smarter via gene therapy and learning linear algebra, whereas the AI path is like creating a novel thing happening on earth largely in novel ways from scratch [9]
reasons why human thought would be guiding development more/better in a biofoom
- we have a lot of experience with and understanding about humans and specifically how to raise humans
- for example, voters, politicians, and researchers will all have much higher-quality starting intuitions about what millions of human einsteins would be like than about what a bunch of AIs would be like
- biofooming will be happening later, so we will have more time to prepare before it starts happening [10]
- but also biofooming will be happening much slower, so humans will have more time to think about each improvement
- like, the speed of development will be slower compared to the speed of human thought, so more human thought can go into each step of development. each unit step of development will be more human-thought-fully chosen
- this is true at the level of individual humans thinking about what should be done, and also true at the level of institutions and governments (like, a government running at human speed will be better able to legislate a slow biofoom)
reasons a biofooming world would be diffusely human-friendly (sociopolitical factors, anti-[gradual disempowerment] stuff)
- since humans will still be expensive to create and will continue to run on [at least order
- it will be somewhat difficult/weird for more capable humans to render the environment unlivable to less capable humans, because all humans have basically the same environmental requirements (for now) [11]
- ditto for good governance, laws, norms. e.g. it'd be quite natural for a law that makes it harder to manipulate the parents of an IVF einstein out of their property to also make it harder to manipulate the amish out of their property
- ditto for organizations and economic structures. e.g. it would be very natural for AIs to have a research process that operates in neuralese on a server, with translation costs being high enough that even if a human could do some useful task, doing the task yourself is cheaper than "translating" the task and context to a human; this effect is still present in human-human interactions but the degree to which it is present on the human path is smaller than the degree to which it is present on the AI path
- empathy is easier/"more natural" toward beings that are more like you. when agent B is more similar to agent A, it is more likely that [golden rule]/[categorical imperative] style reasoning leads A to treat B well [12]
- power concentration stuff is less bad in the biofoom case. it's not like there would be some entity controlling these more capable humans. these humans will be growing up in various families, involved in various communities/cultures/nations, going to various schools. in the biofoom case, RSI will not be localized to a single lab [13] . monopolies are much more natural in the AI case than in the biofoom case
- the AGI path involves power shifting away from people (and to AIs or companies) a lot more
- fooming happening slower means that the change in technological/social/cultural/environmental conditions during any
- fooming happening slower compared to the pace of life means that more life can be lived by existing living beings before being at the frontier of development start to find them boring and useless (or like, i don't want to say that this happens necessarily, but there is a force pushing in this direction)
- in a biofoom, there will be a graph of caring connecting most humans to most other humans with not that many steps; it will only have such-and-such clustering coefficients
- human institutions, organizations, systems are generally more likely to survive for longer. in particular, the following specific human institutions/organizations/systems supporting the ability of each human to live a good long life are more likely to survive for longer: states, laws, systems enforcing laws, social safety nets, democracy, cryonics organizations
- technologies which benefit humans with higher capabilities will also be somewhat likely to benefit current-100-iq humans. eg cures to diseases and other medical treatments, better educational methods, new words/concepts, most consumer technologies. if humans remain central to [doing stuff]/[the economy], then a large fraction of economically rewarded innovation will be making humans more capable, and so technological progress will generally be pointed in a more humane direction
- in general: various mad local forces at play in the world (greed, status-seeking, etc) will stay pointed in a more humane direction
- also, governments will be much better able to understand, track, and deal with messy world problems in the biofoom case
we know humans [can be and often are] kind/nice to other humans
about humans, we know the following:
- most humans consider it very bad to personally kill other humans, and would not kill other humans in normal circumstances. most humans consider the killing of humans highly reprehensible in general [14]
- most humans consider it bad to steal from humans. most humans think human property rights should basically be respected. most humans are not in favor of taking property from people. most people would consider it very bad to take property from a person such that this person would then be unable to live an alright life
- probably there are some humans who have a deep enough commitment to humanity that they'd remain nice to all existing humans even after individually fooming a lot (though note this won't be happening in the human foom)
also:
- there are specific steps/niches in human evolutionary history which made us nicer to unrelated strangers
other factors
- there are factors much more tightly constraining capabilities in the biofoom case than in the AI foom case:
- brain volume is tough to increase by idk more than
- roughly, there is some not-THAT-large finite number of intelligence-increasing "genetic ideas" in the current gene pool, and for at least some initial period these set a cap on how far you can go biologically. it will be very hard to genetically write novel more capable human learning algorithms. the genome interface to mind reprogramming is kinda cursed
- it will be expensive and potentially immoral and illegal to "run experiments"
- brain volume is tough to increase by idk more than
- humanity's correct values are somewhat well-tracked by reflection / self-endorsed development, and the biofoom path will be like that
- it makes sense to speak of what sort of reflection and development should happen, distinguishing this from development that is likely to happen. it is very much not true that anything goes! if it were likely/natural that our society would get replaced by a molecular squiggle maximizer, that wouldn't mean that our society's true values are to make lots of those molecular squiggles, and that wouldn't mean this was what should happen all along. whereas if we reflect carefully and understand more stuff and become better versions of ourselves and conclude that we should make lots of some molecular squiggles, then it's plausible that this was what should happen all along.
- it is (at least prima facie) extremely scary/reckless to have a step in your development where you hand things over to some novel mind created largely from scratch! this is done much more on the AI path than on the human path
- i say some more on good development and also the general topic of this note here: https://www.lesswrong.com/posts/iemgJhjNLa5eyevWR/kh-s-shortform?commentId=PHm2ZkagfyrhT2Wvz
a concluding remark
self-improvement generally has many good properties over creating a new agent/mind from scratch [15]
i think we should ban AGI ↩︎
It is also a possibility that both options are bad. My view is that we should push forward with increasing human capabilities biologically and culturally/educationally. But I think this question deserves serious analysis, and there are certainly specific things here that one should be very careful about and regulate. However, this note will not be analyzing this question. ↩︎
That said, I think the analysis of the positives in his essay gets very many things wrong. ↩︎
But one also doesn't have to do that, to compare the two paths. One can also just "directly" think about what would happen along each path. ↩︎
They are not listed in order of importance. ↩︎
clearly this is a reason for these to be around for longer in wall clock time, but also it's a reason for them to be around until higher capability levels ↩︎
in fact it seems plausible that, at least if the mind design has to be done from your own bounded perspective, it will keep being better to self-improve forever. i think this is plausible on this individual future life coolness axis and also all-things-considered. ↩︎
ok, if you (imo incorrectly) believe in some sort of soul theory of personal identity then maybe to make this a fair example you would need to imagine the soul getting detached in all three examples, but then maybe you will think all of these are suicides... so maybe this isn't a good analogy for you... but hmm i guess maybe you should also in the same sense believe in there being a soul attached to each society though, and then it would be a good analogy actually ↩︎
ok, there's a meaningful amount of shared culture. even if you thought human minds and AI minds are "mostly cultural" and that subbing out representation/learning/etc algorithms/structures and radically changing learning contexts doesn't make it legit to say AGI will be a novel thing created largely in novel ways from scratch, it is still at least a really big step; it's still creating some totally new guy ↩︎
as Millidge says ↩︎
yes, there are sort of examples like climate change. but it is still much easier to imagine entities that are just programs that can be run on arbitrary computers being totally fine with or even preferring a very different environment. there is a large difference in degree here ↩︎
and we at least know humans have a propensity to carry out and be moved by this style of reasoning ↩︎
or three labs or whatever. In reality, I think only a single lab will matter, absent strict capability regulation. ↩︎
there is a major issue around diffuse effects — like, people and institutions currently not tracking [decreasing the lifespan of
this is also important to track when thinking about AIs making more capable AIs ↩︎
I really appreciated Beren's post to figure out what I think about this for myself. I think another intuition where I and Beren differ is that it is just fine if 1% of enhanced humans you make is a psychopath or whatever (10% is a bit high though. I don't expect it to be that high unless you allow the data for you GWAS to have a high % of people cheating on tests or misreporting data (which is a valid concern)). The other enhanced humans can deal with the psychopaths! The human psychopaths would like to solve alignment too and are incentivised to cooperate with the other humans. This is not true with AIs because they are so easily changed and copied. The one project that isn't careful with their AI's can then spoil it for everyone else when their Pythia overtakes the universe, while the safe projects work on interp and conceptual foundations. With even mildly superhuman AI (we have superhuman hacking now), you would have to be super paranoid that the AI didn't poison it's training data or did anything else mischievous. Meanwhile, as a thought experiment I would feel quite fine retiring to childcare and handing off the future to say ~10 clones of myself that have been enhanced in health and intelligence by ~2-4sd (clones would minimize difference from myself, multiple means less noise in the handover, assuming we did this through editing I could even edit different SNPs for every clone, so there is no consistent misalignment between them and me).
I do think some goal shift from intelligence enhancement is possible and we should be able to get some data on this already from looking at existing humans. One intuition I have is that if higher intelligence leads to weird things when it comes to goal misgeneralization, we should see more difference in value that start emerging in humans during puberty compared to in early childhood. I'd be curious if someone has compared this between twins (monozygous twins being more different typical puberty related emotions like parental defiance and their sexuality compared to their relation to anger?) or has checked for consistent trends in puberty being more weird in smarter people compared to early childhood development.
Hmmm, some good points. Clearly if I write something to complex this will take way too long and therefore, the cool voice is good.
Okay, yes humans can be cool but all humans cool?
Maybe some governments not cool? How does AI vs Bio affect if one big cool or many small cool? What if like homo deus we get separate Very Smart group of humans and one not so smart?
Human worse thing done worse than LLM worse thing done? Less control over range of expression? Moral mazes lead to psychopaths in control? Maybe non cool humans take control?
Yet, slow process good point. Coolness better chance if longer to remain cool.
Maybe democracy + debate cool? Totalitarianism not cool? Coolness is not group specific for AI or human? Coolness about how cool the decision process is? What does coolness attractor look like?
Cool.
What if like homo deus we get separate Very Smart group of humans and one not so smart?
I agree this would most likely be either somewhat bad or quite bad, probably quite bad (depending on the details), both causally and also indicatorily.
I'll restrict my discussion to reprogenetics, because I think that's the main way we get smarter humans. My responses would be "this seems quite unlikely in the short run (like, a few generations)" and "this seems pretty unlikely in the longer run, at least assuming it's in fact bad" and "there's a lot we can do to make those outcomes less likely (and less bad)".
Why unlikely in the short run? Some main reasons:
- Uptake of reprogenetics is slow (takes clock time), gradual (proceeds by small steps), and fairly visible (science generally isn't very secretive; and if something is being deployed at scale, that's easy to notice, e.g. many clinics offering something or some company getting huge investments). These give everyone more room to cope in general, as discussed above, and in particular gives more time for people to notice emerging inequality and such. So humanity in general gets to learn about the tech and its meaning, institute social and governmental regulation, gain access, understand how to use it, etc.
- Likewise, the strength of the technology itself will grow gradually (though I hope not too slowly). Further, even as the newest technology gets stronger, the previous medium strength tech gets more uptake. This means there's a continuum of people using different levels of strength of the technology.
- Parents will most likely have quite a range of how much they want to use reprogenetics for various things. Some will only decrease their future children's disease risks; some will slightly increase IQ; some might want to increase IQ around as much as is available.
- IQ, and even more so for other cognitive capacities and traits, is controlled...
- partly by genetic effects we can make use of (currently something in the ballpark of 20% or so);
- partly by genetic effects we can't make use of (very many of which might take a long time to make use of because they have small and/or rare effects, or because they have interactions with other genes and/or the environment);
- partly by non-genetic causes (unstructured environment such as randomness in fetal development, structured external environment such as culture, structured internal environment such as free self-creation / decisions about what to be or do).
- Thus, we cannot control these traits, in the sense of hitting a narrow target; we can only shift them around. We cannot make the distribution of a future child's traits be narrow. (This is a bad state of affairs in some ways, but has substantive redeeming qualities, which I'm invoking here: people couldn't firmly separate even if they wanted to (though this may need quantification to have much force).)
- Together, I suspect that the above points create, not separated blobs, but a broad continuum:
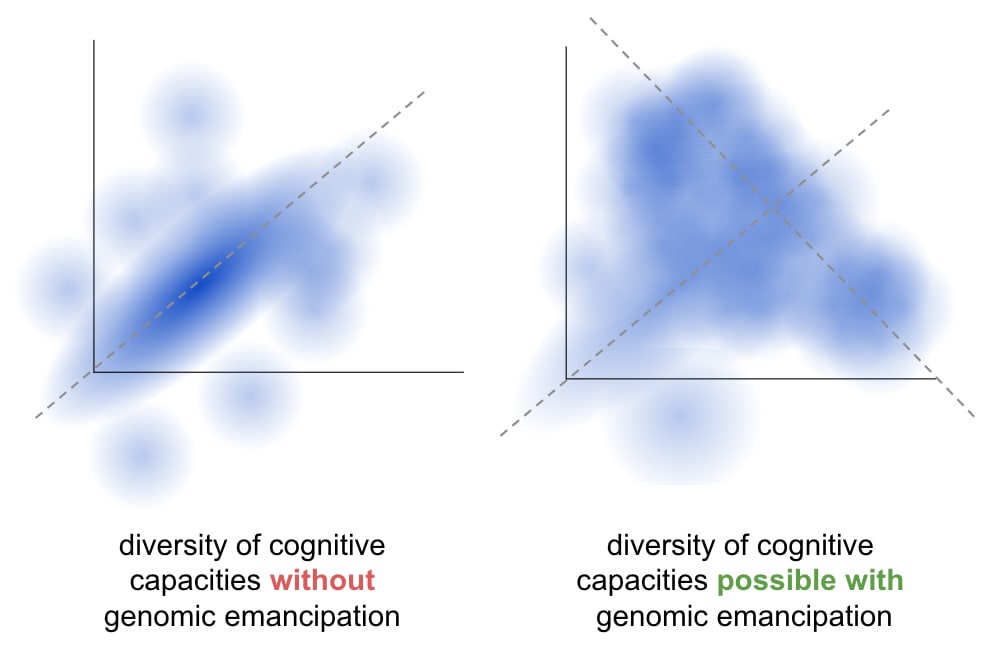
- As mentioned in the post, there are ceilings to human intelligence amplification that would probably be hit fairly quickly, and probably wouldn't be able to be bypassed quickly. (Who knows how long, but I'm imagining at least some decades--e.g. BCIs might take on that time scale or longer to impact human general intelligence--reprogenetics is the main strategy that takes advantage of evolution's knowledge about how to make capable brains, and I'm guessing that knowledge is more than we will do in a couple decades but not insanely much in the grand scheme of things.)
What can we do? Without going into detail on how, I'll just basically say "greatly increase equality of access through innovation and education, and research cultures to support those things".
Okay, I think the gradual point is a good one and also that it very much helps our institutions to be able to deal with increased intelligence.
I would be curious what you think about the idea of more permanent economic rifts and also the general economics of gene editing? Might it be smart to make it a public good instead?
Maybe there's something here about IQ being hereditary already and thus the point about a more permanent two caste society with smart and stupid people is redundant but somehow I still feel that the economics of private gene editing over long periods of time feels a bit off?
I would be curious what you think about the idea of more permanent economic rifts and also the general economics of gene editing?
As a matter of science and technology, reprogenetics should be inexpensive. I've analyzed this area quite a bit (though not focused specifically on eventual cost), see https://berkeleygenomics.org/articles/Methods_for_strong_human_germline_engineering.html . My fairly strong guess is that it's perfectly feasible to have strong reprogenetics that's pretty inexpensive (on the order of $5k to $25k for a pretty strongly genomically vectored zygote). From a tech and science perspective, I think I see multiple somewhat-disjunctive ways, each of which is pretty plausibly feasible, and each of which doesn't seem to have any inputs that can't be made inexpensive.
(As a comparison point, IVF is expensive--something like $8k to $20k--but my guess is that this is largely because of things like regulatory restrictions (needing an MD to supervise egg retrieval, even though NPs can do it well), drug price lock-in (the drugs are easy to manufacture, so are available cheaply on gray markets), and simply economic friction/overhang (CNY is cheaper basically by deciding to be cheaper and giving away some concierge-ness). None of this solves things for IVF today; I'm just saying, it's not expensive due to the science and tech costing $20k.)
Assuming that it can be technically inexpensive, that cuts out our work for us: make it be inexpensive, by
- Making the tech inexpensive
- Thinking not just about the current tech, but investing in the stronger tech (stronger -> less expensive https://berkeleygenomics.org/articles/Methods_for_strong_human_germline_engineering.html#strong-gv-and-why-it-matters )
- Culture of innovation
- Both internal to the field, and pressure / support from society and gvt
- Don't patent and then sit on it or keep it proprietary; instead publish science, or patent and license, or at least provide it as a platform service
- Avoiding large other costs
- Sane regulation
- No monopolies
- Subsidies
Might it be smart to make it a public good instead?
I definitely think that
- as much as possible, gvt should fund related science to be published openly; this helps drive down prices, enables more competitive last-mile industry (clinics, platforms for biological operations, etc.), and signals a societal value of caring about this and not leaving it up to raw market forces
- probably gvt should provide subsidies with some kind of general voucher (however, it should be a general voucher only, not a voucher for specific genomic choices--I don't want the gvt controlling people's genomic choices according to some centralized criterion, as this is eugenicsy, cf. https://berkeleygenomics.org/articles/Genomic_emancipation_contra_eugenics.html )
Is that what you mean? I don't think we can rely on gvt and philanthropic funding to build out a widely-accessible set of clinics / other practical reprogenetics services, so if you meant nationalizing the industry, my guess is no, that would be bad to do.
I meant the basic economy way of defining public good, not necessarily the distribution mchanism, electricity and water are public goods but they aren't necessarily determined by the government.
I've had the semi ironic idea of setting up a "genetic lottery" if supply was capped as it would redistribute things evenly (as long as people sign up evenly which is not true).
Anyways, cool stuff, happy that someone is on top of this!
Okay, yes humans can be cool but all humans cool?
generally, humans are cool. in fact probably all current humans are intrinsically cool. a few are suffering very badly and say they would rather not exist, and in some cases their lives have been net negative so far. we should try to help these people. some humans are doing bad things to other humans and that's not cool. some humans are sufficiently bad to others that it would have been better if they were never born. such humans should be rehabilitated and/or contained, and conditions should be maintained/created in which this is disincentivized
Coolness is not group specific for AI or human?
not group specific in principle, but human life is pro tanto strongly cooler. but eg a mind uploaded human society would still be cool. continuing human life is very important. deep friendships with aliens should not be ruled out in principle, but should be approached with great caution. any claim that we should already care deeply about the possible lives of some not-specifically-chosen aliens that we might create, that we haven't yet created, and so that we have great reason to create them, is prima facie very unlikely. this universe probably only has negentropy for so many beings (if you try to dovetail all possible lives, you won't even get to running any human for a single step); we should think extremely carefully about which ones we create and befriend
What if like homo deus we get separate Very Smart group of humans and one not so smart?
Human worse thing done worse than LLM worse thing done? Less control over range of expression? Moral mazes lead to psychopaths in control? Maybe non cool humans take control?
i agree these are problems that would need to be handled on the human path
Moral mazes lead to psychopaths in control? Maybe non cool humans take control?
This is a significant worry--but my guess is that having lots more really smart people would make the problem get better in the long run. That stuff is already happening. Figuring out how to avoid it is a very difficult unsolved problem, which is thus likely to be heavily bottlenecked on ideas of various kinds (e.g. ideas for governance, for culture, for technology to implement good journalism, etc etc.).
Hmmm but what if human good not coupled with human wisdom? Maybe more intelligence more power seeking if not carefully implemented?
Probably better than doing the Big AI though.
Hmmm but what if human good not coupled with human wisdom? Maybe more intelligence more power seeking if not carefully implemented?
I think this is just not the case; I'd guess it's slightly the opposite on average, but in any case, I've never heard anyone make an argument for this based on science or statistics. (There could very well be a good such arguments, curious to hear!)
Separately, I'd suggest that humanity is bottlenecked on good ideas--including ideas for how to have good values / behave well / accomplish good things / coordinate on good things / support other people in getting more good. A neutral/average-goodness human, but smart, would I think want to contribute to those problems, and be more able to do so.
I'll share a paper I remember seeing on the ability to do motivated reasoning and holding onto false views being higher for higher iq people tomorrow (if it actually is statistically significant).
Also maybe the more important things to improve after a certain IQ might be openness and conscientiousness? Thoughts on that?
I do think that it actually is quite possible to do some gene editing on big 5 and ethics tbh but we just gotta actually do it.
Personality is a more difficult issue because
- more potential for scientifically unknown effects--it's a complex trait
- more potential bad parental decision-making (e.g. not understanding what very high disagreeableness really means)
- more potential for parental or even state misuse (e.g. wanting a kid to be very obedient)
- more weirdness regarding consent and human dignity and stuff; I think it's pretty unproblematic to decrease disease risk and increase healthspan and increase capabilities, and only slightly problematic (due to competition effects and possible health issues) to tweak appearance (though I don't really care about this one); but I think it's kinda problematic with personality traits because you're messing with values in ways you don't understand; not so problematic that it's ruled out to tweak traits within the quite-normal human range, and I'm probably ultimately pretty in favor of it, but I'd want more sensitivity on these questions
- technically more difficult than IQ or disease because conceptually muddled, hard to measure, and maybe genuinely more genetically complex.
That said, yeah, I'm in favor of working out how to do it well. E.g. I'm interested in understanding and eventually measuring "wisdom" https://www.lesswrong.com/posts/fzKfzXWEBaENJXDGP/what-is-wisdom-1 .
I would agree that this is a weird incentive issue and that IQ is probably easier and less thorny than personality traits. With that being said here's a fun little thought on alternative ways of looking at intelligence:
Okay but why is IQ a lot more important than "personality"?
IQ being measured as G and based on correlational evidence about your ability to progress in education and work life. This is one frame to have on it. I think it correlates a lot of things about personality into a view that is based on a very specific frame from a psychometric perspective?
Okay, let's look at intelligence from another angle, we use the predictive processing or RL angle that's more about explore exploit, how does that show up? How do we increase the intelligence of a predictive processing agent? How does the parameters of when to explore and when to exploit and the time horizon of future rewards?
Openness here would be the proclivity to explore and look at new sources of information whilst conscientiousness is about the time horizon of the discouting factor in reward learning. (Correlatively but you could probably define new better measures of this, the big 5 traits are probably not the true names for these objectives.)
I think it is better for a society to be able to talk to each other and integrate information well hence I think we should make openness higher from a collective intelligence perspective. I also think it is better if we imagine that we're playing longer form games with each other as that generally leads to more cooperative equilibria and hence I think conscientiousness would also be good if it is higher.
(The paper I saw didn't replicate btw so I walk back the intelligence makes you more ignorant point. )
(Also here's a paper talking about the ability to be creative having a threshold effect around 120 iq with openness mattering more after that, there's a bunch more stuff like this if you search for it.)
(Also here's a paper talking about the ability to be creative having a threshold effect around 120 iq with openness mattering more after that, there's a bunch more stuff like this if you search for it.)
To speculate, it might be the case that effects like this one are at least to some extent due to the modern society not being well-adapted to empowering very-high-g[1] people, and instead putting more emphasis on "no one being left behind"[2]. Like, maybe you actually need a proper supportive environment (that is relatively scarce in the modern world) to reap the gains from very high g, in most cases.
(Not confident about the size of the effect (though I'm sure it's at least somewhat true) or about the relevance for the study you're citing, especially after thinking it through a bit after writing this, but I'm leaving it for the sake of expanding the hypothesis space.)
But, if it's not that, then the threshold thing is interesting and weird.
I would hypothesise that it is more about the underlying ability to use the engine that is intelligence. If we do the classic eliezer definition (i think it is in the sequences at least) of the ability to hit a target then that is only half of the problem because you have to choose a problem space as well.
Part of intelligence is probably choosing a good problem space but I think the information sampling and the general knowledge level of the people and institutions and general information sources around you is quite important to that sampling process. Hence if you're better at integrating diverse sources of information then you're likely better at making progress.
Finally I think there's something about some weird sort of scientific version of frame control where a lot of science is about asking the right question and getting exposure to more ways of asking questions lead to better ways of asking questions.
So to use your intelligence you need to wield it well and wielding it well partly involves working on the right questions. But if you're not smart enough to solve the questions in the first place it doesn't really matter if you ask the right question.
a few thoughts on hyperparams for a better learning theory (for understanding what happens when a neural net is trained with gradient descent)
Having found myself repeating the same points/claims in various conversations about what NN learning is like (especially around singular learning theory), I figured it's worth writing some of them down. My typical confidence in a claim below is like 95%[1]. I'm not claiming anything here is significantly novel. The claims/points:
- local learning (eg gradient descent) strongly does not find global optima. insofar as running a local learning process from many seeds produces outputs with 'similar' (train or test) losses, that's a law of large numbers phenomenon[2], not a consequence of always finding the optimal neural net weights.[3][4]
- if your method can't produce better weights: were you trying to produce better weights by running gradient descent from a bunch of different starting points? getting similar losses this way is a LLN phenomenon
- maybe this is a crisp way to see a counterexample instead: train, then identify a 'lottery ticket' subnetwork after training like done in that literature. now get rid of all other edges in the network, and retrain that subnetwork either from the previous initialization or from a new initialization — i think this literature says that you get a much worse loss in the latter case. so training from a random initialization here gives a much worse loss than possible
- dynamics (kinetics) matter(s). the probability of getting to a particular training endpoint is highly dependent not just on stuff that is evident from the neighborhood of that point, but on there being a way to make those structures incrementally, ie by a sequence of local moves each of which is individually useful.[5][6][7] i think that this is not an academic correction, but a major one — the structures found in practice are very massively those with sensible paths into them and not other (naively) similarly complex structures. some stuff to consider:
- the human eye evolving via a bunch of individually sensible steps, https://en.wikipedia.org/wiki/Evolution_of_the_eye
- (given a toy setup and in a certain limit,) the hardness of learning a boolean function being characterized by its leap complexity, ie the size of the 'largest step' between its fourier terms, https://arxiv.org/pdf/2302.11055
- imagine a loss function on a plane which has a crater somewhere and another crater with a valley descending into it somewhere else. the local neighborhoods of the deepest points of the two craters can look the same, but the crater with a valley descending into it will have a massively larger drainage basin. to say more: the crater with a valley is a case where it is first loss-decreasing to build one simple thing, (ie in this case to fix the value of one parameter), and once you've done that loss-decreasing to build another simple thing (ie in this case to fix the value of another parameter); getting to the isolated crater is more like having to build two things at once. i think that with a reasonable way to make things precise, the drainage basin of a 'k-parameter structure' with no valley descending into it will be exponentially smaller than that of eg a 'k-parameter structure' with 'a k/2-parameter valley' descending into it, which will be exponentially smaller still than a 'k-parameter structure' with a sequence of valleys of slowly increasing dimension descending into it
- it seems plausible to me that the right way to think about stuff will end up revealing that in practice there are basically only systems of steps where a single [very small thing]/parameter gets developed/fixed at a time
- i'm further guessing that most structures basically have 'one way' to descend into them (tho if you consider sufficiently different structures to be the same, then this can be false, like in examples of convergent evolution) and that it's nice to think of the probability of finding the structure as the product over steps of the probability of making the right choice on that step (of falling in the right part of a partition determining which next thing gets built)
- one correction/addition to the above is that it's probably good to see things in terms of there being many 'independent' structures/circuits being formed in parallel, creating some kind of ecology of different structures/circuits. maybe it makes sense to track the 'effective loss' created for a structure/circuit by the global loss (typically including weight norm) together with the other structures present at a time? (or can other structures do sufficiently orthogonal things that it's fine to ignore this correction in some cases?) maybe it's possible to have structures which were initially independent be combined into larger structures?[8]
- everything is a loss phenomenon. if something is ever a something-else phenomenon, that's logically downstream of a relation between that other thing and loss (but this isn't to say you shouldn't be trying to find these other nice things related to loss)
- grokking happens basically only in the presence of weight regularization, and it has to do with there being slower structures to form which are eventually more efficient at making logits high (ie more logit bang for weight norm buck)
- in the usual case that generalization starts to happen immediately, this has to do with generalizing structures being stronger attractors even at initialization. one consideration at play here is that
- nothing interesting ever happens during a random walk on a loss min surface
- it's not clear that i'm conceiving of structures/circuits correctly/well in the above. i think it would help a library of like >10 well-understood toy models (as opposed to like the maybe 1.3 we have now), and to be very closely guided by them when developing an understanding of neural net learning
some related (more meta) thoughts
- to do interesting/useful work in learning theory (as of 2024), imo it matters a lot that you think hard about phenomena of interest and try to build theory which lets you make sense of them, as opposed to holding fast to an existing formalism and trying to develop it further / articulate it better / see phenomena in terms of it
- this is somewhat downstream of current formalisms imo being bad, it imo being appropriate to think of them more as capturing preliminary toy cases, not as revealing profound things about the phenomena of interest, and imo it being feasible to do better
- but what makes sense to do can depend on the person, and it's also fine to just want to do math lol
- and it's certainly very helpful to know a bunch of math, because that gives you a library in terms of which to build an understanding of phenomena
- it's imo especially great if you're picking phenomena to be interested in with the future going well around ai in mind
(* but it looks to me like learning theory is unfortunately hard to make relevant to ai alignment[9])
acknowledgments
these thoughts are sorta joint with Jake Mendel and Dmitry Vaintrob (though i'm making no claim about whether they'd endorse the claims). also thank u for discussions: Sam Eisenstat, Clem von Stengel, Lucius Bushnaq, Zach Furman, Alexander Gietelink Oldenziel, Kirke Joamets
with the important caveat that, especially for claims involving 'circuits'/'structures', I think it's plausible they are made in a frame which will soon be superseded or at least significantly improved/clarified/better-articulated, so it's a 95% given a frame which is probably silly ↩︎
train loss in very overparametrized cases is an exception. in this case it might be interesting to note that optima will also be off at infinity if you're using cross-entropy loss, https://arxiv.org/pdf/2006.06657 ↩︎
also, gradient descent is very far from doing optimal learning in some solomonoff sense — though it can be fruitful to try to draw analogies between the two — and it is also very far from being the best possible practical learning algorithm ↩︎
by it being a law of large numbers phenomenon, i mean sth like: there are a bunch of structures/circuits/pattern-completers that could be learned, and each one gets learned with a certain probability (or maybe a roughly given total number of these structures gets learned), and loss is roughly some aggregation of indicators for whether each structure gets learned — an aggregation to which the law of large numbers applies ↩︎
to say more: any concept/thinking-structure in general has to be invented somehow — there in some sense has to be a 'sensible path' to that concept — but any local learning process is much more limited than that still — now we're forced to have a path in some (naively seen) space of possible concepts/thinking-structures, which is a major restriction. eg you might find the right definition in mathematics by looking for a thing satisfying certain constraints (eg you might want the definition to fit into theorems characterizing something you want to characterize), and many such definitions will not be findable by doing sth like gradient descent on definitions ↩︎
ok, (given an architecture and a loss,) technically each point in the loss landscape will in fact have a different local neighborhood, so in some sense we know that the probability of getting to a point is a function of its neighborhood alone, but what i'm claiming is that it is not nicely/usefully a function of its neighborhood alone. to the extent that stuff about this probability can be nicely deduced from some aspect of the neighborhood, that's probably 'logically downstream' of that aspect of the neighborhood implying something about nice paths to the point. ↩︎
also note that the points one ends up at in LLM training are not local minima — LLMs aren't trained to convergence ↩︎
i think identifying and very clearly understanding any toy example where this shows up would plausibly be better than anything else published in interp this year. the leap complexity paper does something a bit like this but doesn't really do this ↩︎
i feel like i should clarify here though that i think basically all existing alignment research fails to relate much to ai alignment. but then i feel like i should further clarify that i think each particular thing sucks at relating to alignment after having thought about how that particular thing could help, not (directly) from some general vague sense of pessimism. i should also say that if i didn't think interp sucked at relating to alignment, i'd think learning theory sucks less at relating to alignment (ie, not less than interp but less than i currently think it does). but then i feel like i should further say that fortunately you can just think about whether learning theory relates to alignment directly yourself :) ↩︎
Simon-Pepin Lehalleur weighs in on the DevInterp Discord:
I think his overall position requires taking degeneracies seriously: he seems to be claiming that there is a lot of path dependency in weight space, but very little in function space 😄
In general his position seems broadly compatible with DevInterp:
- models learn circuits/algorithmic structure incrementally
- the development of structures is controlled by loss landscape geometry
- and also possibly in more complicated cases by the landscapes of "effective losses" corresponding to subcircuits...
This perspective certainly is incompatible with a naive SGD = Bayes = Watanabe's global SLT learning process, but I don't think anyone has (ever? for a long time?) made that claim for non toy models.
It seems that the difference with DevInterp is that
- we are more optimistic that it is possible to understand which geometric observables of the landscape control the incremental development of circuits
- we expect, based on local SLT considerations, that those observables have to do with the singularity theory of the loss and also of sub/effective losses, with the LLC being the most important but not the only one
- we dream that it is possible to bootstrap this to a full fledged S4 correspondence, or at least to get as close as we can.
Ok, no pb. You can also add the following :
I am sympathetic but also unsatisfied with a strong empiricist position about deep learning. It seems to me that it is based on a slightly misapplied physical, and specifically thermodynamical intuition. Namely that we can just observe a neural network and see/easily guess what the relevant "thermodynamic variables" of the system.
For ordinary 3d physical systems, we tend to know or easily discover those thermodynamic variables through simple interactions/observations. But a neural network is an extremely high-dimensional system which we can only "observe" through mathematical tools. The loss is clearly one such thermodynamic variable, but if we expect NN to be in some sense stat mech systems it can't be the only one (otherwise the learning process would be much more chaotic and unpredictable). One view of DevInterp is that we are "just" looking for those missing variables...
I'd be curious about hearing your intuition re " i'm further guessing that most structures basically have 'one way' to descend into them"
When fooming, uphold the option to live in an AGI-free world.
There are people who think (imo correctly) that there will be at least one vastly superhuman AI in the next 100 years by default and (imo incorrectly) that proceeding along the AI path does not lead to human extinction or disempowerment by default. My anecdotal impression is that a significant fraction (maybe most) of such people think (imo incorrectly) that letting Anthropic/Claude do recursive self-improvement and be a forever-sovereign would probably go really well for humanity. The point of this note is to make the following proposal and request: if you ever let an AI self-improve, or more generally if you have AIs creating successor AIs, or even more generally if you let the AI world develop and outpace humans in some other way, or if you try to run some process where boxed AIs are supposed to create an initial ASI sovereign, or if you try to have AIs "solve alignment" [1] (in one of the ways already listed, or in some other way), or if you are an AI (or human mind upload) involved in some such scheme, [2] try to make it so the following property is upheld:
- It should be possible for each current human to decide to go live in an AGI-free world. In more detail:
- There is to be (let's say) a galaxy such that AGI is to be banned in this galaxy forever, except for AGI which does some minimal stuff sufficient to enforce this AI ban. [3]
- There should somehow be no way for anything from the rest of the universe to affect what happens in this galaxy. In particular, there should probably not be any way for people in this galaxy to observe what happened elsewhere.
- If a person chooses to move to this galaxy, they should wake up on a planet that is as much like pre-AGI Earth as possible given the constraints that AGI is banned and that probably many people are missing (because they didn't choose to move to this galaxy). Some setup should be found which makes institutions as close as possible to current institutions still as functional as possible in this world despite most people who used to play roles in them potentially being missing.
- For example, it might be possible to set this up by having the galaxy be far enough from all other intelligent activity that because of the expansion of the universe, no outside intelligent activity could be seen from this galaxy. In that case, the humans who choose to go live there would maybe be in cryosleep for a long time, and the formation of this galaxy could be started at an appropriate future time.
- One should try to minimize the influence of any existing AGI on a human's thinking before they are asked if they want to make this decision. Obviously, manipulation is very much not allowed. If some manipulation has already happened, it should probably be reversed as much as possible. Ideally, one would ask the version of the person from the world before AGI.
- Here are some further clarifications about the setup:
- Of course, if the resources in this galaxy are used in a way considered highly wasteful by the rest of the universe, then nothing is to be done about that by the rest of the universe.
- If the people in this galaxy are about to kill themselves (e.g. with engineered pathogens), then nothing is to be done about that. (Of course, except that: the AI ban is supposed to make it so they don't kill themselves with AI.)
- Yes, if the humanity in this galaxy becomes fascist or runs a vast torturing operation (like some consider factory farming to be), then nothing is to be done about that either.
- We might want to decide more precisely what we mean by the world being "AGI-free". Is it fine to slowly augment humans more and more with novel technological components, until the technological components are eventually together doing more of the thinking-work than currently existing human thinking-components? Is it fine to make a human mind upload?
- I think I would prefer a world in which it is possible for humans to grow vastly more intelligent than we are now, if we do it extremely slowly+carefully+thoughtfully. It seems difficult/impossible to concretely spell out an AI ban ahead of time that allows this. But maybe it's fine to keep this not spelled out — maybe it's fine to just say something like what I've just said. After all, the AI banning AI for us will have to make very many subtle interpretation decisions well in any case.
- We can consider alternative requests. Here are some parameters that could be changed:
- Instead of AI being banned in this galaxy forever, AI could be banned only for 1000 or 100 years.
- Maybe you'd want this because you would want to remain open to eventual AI involvement in human life/history, just if this comes after a lot more thinking and at a time when humanity's is better able to make decisions thoughtfully.
- Another reason to like this variant is that it alleviates the problem with precisifying what "ban AI" means — now one can try to spell this out in a way that "only" has to continue making sense over 100 or 1000 years of development.
- Instead of giving each human the option to move to this galaxy, you could give each human the option to branch into two copies, with one moving to this galaxy and one staying in the AI-affected world.
- The total amount of resources in this AI-free world should maybe scale with the number of people that decide to move there. Naively, there should be order reachable galaxies per person alive, so the main proposal which just allocates a single galaxy to all the people who make this decision asks for much less than what an even division heuristic suggests.
- We could ask AIs to do some limited stuff in this galaxy (in addition to banning AGI).
- Some example requests:
- We might say that AIs are also allowed to make it so death is largely optional for each person. This could look like unwanted death being prevented, or it could look like you getting revived in this galaxy after you "die", or it could look like you "going to heaven" (ie getting revived in some non-interacting other place).
- We might ask for some starting pack of new technologies.
- We might ask for some starting pack of understanding, e.g. for textbooks providing better scientific and mathematical understanding and teaching us to create various technologies.
- We might say that AIs are supposed to act as wardens to some sort of democratic system. (Hmm, but what should be done if the people in this galaxy want to change that system?)
- We might ask AIs to maintain some system humans in this galaxy can use to jointly request new services from the AIs.
- However, letting AIs do a lot of stuff is scary — it's scary to depart from how human life would unfold without AI influence. Each of the things in the list just provided would constitute/cause a big change to human life. Before/when we change something major, we should take time to ponder how our life is supposed to proceed in the new context (and what version of the change is to be made (if any)), so we don't [lose ourselves]/[break our valuing].
- Some example requests:
- There could be many different AI-free galaxies with various different parameter settings, with each person getting to choose which one(s) to live in. At some point this runs into a resource limit, but it could be fine to ask that each person minimally gets to design the initial state of one galaxy and send their friends and others invites to have a clone come live in it.
- Instead of AI being banned in this galaxy forever, AI could be banned only for 1000 or 100 years.
- Here are some remarks about the feasibility and naturality of this scheme:
- If you think letting Anthropic/Claude RSI would be really great, you should probably think that you could do an RSI with this property.
- In fact, in an RSI process which is going well, I think it is close to necessary that something like this property is upheld. Like, if an RSI process would not lead to each current person [4] being assigned at least (say) of all accessible resources, then I think that roughly speaking constitutes a way in which the RSI process has massively failed. And, if each person gets to really decide how to use at least of all accessible resources [5] , then even a group of people should be able to decide to go live in their own AGI-free galaxy.
- I guess one could disagree with upholding something like this property being feasible conditional on a good foom being feasible or pretty much necessary for a good foom.
- One could think that it's basically fine to replace humans with random other intelligent beings (e.g. Jürgen Schmidhuber and Richard Sutton seem to think something like this), especially if these beings are "happy" or if their "preferences" are satisfied (e.g. Matthew Barnett seems to think this). One could be somewhat more attached to something human in particular, but still think that it's basically fine to have no deep respect for existing humans and make some new humans living really happy lives or something (e.g. some utilitarians think this). One could even think that good reflection from a human starting point leads to thinking this. I think this is all tragically wrong. I'm not going to argue against it here though.
- Maybe you could think the proposal would actually be extremely costly to implement for the rest of the universe, because it's somehow really costly to make everyone else keep their hands off this galaxy? I think this sort of belief is in a lot of tension with thinking a fooming Anthropic/Claude would be really great (except maybe if you somehow really have the moral views just mentioned).
- similarly: You could think that the proposal doesn't make sense because the AIs in this galaxy that are supposed to be only enforcing an AI ban will have/develop lots of other interests and then claim most of the resources in this galaxy. I think this is again in a lot of tension with thinking a fooming Anthropic/Claude would be really great.
- One could say that even if it would be good if each person were assigned all these resources, it is weird to call it a "massive failure" if this doesn't happen, because future history will be a huge mess by default and the thing I'm envisaging has very nearly probability and it's weird to call the default outcome a "massive failure". My response is that while I agree this good thing has on my inside view probability of happening (because AGI researchers/companies will create random AI aliens who disempower humanity) and I also agree future history will be a mess, I think we probably have at least the following genuinely live path to making this happen: we ban AI (and keep making the implementation of the ban stronger as needed), figure out how to make development more thoughtful so we aren't killing ourselves in other ways either, grow ever more superintelligent together, and basically maintain the property that each person alive now (who gets cryofrozen) controls more than of all accessible resources [6] . [7]
- This isn't an exhaustive list of reasons to think it [is not pretty much necessary to uphold this property for a foom to be good] or [is not feasible to have a foom with this property despite it being feasible to have a good foom]. Maybe there are some reasonable other reasons to disagree?
- This property being upheld is also sufficient for the future to be like at least meaningfully good. Like, humans would minimally be able to decide to continue human life and development in this other galaxy, and that's at least meaningfully good, and under certain imo-non-crazy assumptions really quite good (specifically, if: humanity doesn't commit suicide for a long time if AI is banned AND many different humane developmental paths are ex ante fine AND utility scales quite sublinearly in the amount of resources).
- So, this property being upheld is arguably necessary for the future to be really good, and it is sufficient for the future to be at least meaningfully good.
- Also, it is natural to request that whoever is subjecting everyone to the end of the human era preserve the option for each person to continue their AI-free life.
- If you think letting Anthropic/Claude RSI would be really great, you should probably think that you could do an RSI with this property.
- Here are some reasons why we should adopt this goal, i.e. consider each person to have the right to live in an AGI-free world:
- Most importantly: I think it helps you think better about whether an RSI process would go well if you are actually tracking that the fooming AI will have to do some concrete big difficult extremely long-term precise humane thing, across more than trillions of years of development. It helps you remember that it is grossly insufficient to just have your AI behave nicely in familiar circumstances and to write nice essays on ethical questions. There's a massive storm that a fragile humane thing has to weather forever. [8] The main reason I want you to keep these things in mind and so think better about development processes is this: I think there is roughly a logical fact that running an RSI process will not lead to the fragile humane thing happening [9] , and I think you might be able to see this if you think more concretely and seriously about this question.
- Adopting this goal entails a rejection of all-consuming forms of successionism. Like, we are saying: No, it is not fine if humans get replaced by random other guys! Not even if these random other guys are smarter than us! Not even if they are faster at burning through negentropy! Not even if there is a lot of preference-satisfaction going on! Not even if they are "sentient"! I think it would be good for all actors relevant to AI to explicitly say and track that they strongly intend to steer away from this.
- That said, I think we should in principle remain open to us humans reflecting together and coming to the conclusion that this sort of thing is right and then turning the universe into a vast number of tiny structures whose preferences are really satisfied or who are feeling a lot of "happiness" or whatever. But provisionally, we should think: if it ever looks like a choice would lead to the future not having a lot of room for anything human, then that choice is probably catastrophically bad.
- Adopting this also entails a rejection of more humane forms of utilitarianism that however still see humans only as cows to be milked for utility. Like, no, it is not fine if the actual current humans get killed and replaced. Not even if you create a lot of "really cool" human-like beings and have them experiencing bliss! Not even if you create a lot of new humans and have them have a bunch of fun! Not even if you create a lot of new humans from basically the 2025 distribution and give them space to live happy free lives! In general, I want us to think something like:
- There is an entire particular infinite universe of {projects, activities, traditions, ways of thinking, virtues, attitudes, principles, goals, decisions} waiting to grow out of each existing person. [10] Each of these moral universes should be treated with a lot of respect, and with much more respect than the hypothetical moral universes that could grow out of other merely possible humans. Each of us would want to be respected in this way, and we should make a pact to respect each other this way, and we should seek to create a world in which we are enduringly respected this way.
- These reasons apply mostly if, when thinking of RSI-ing, you are not already tracking that this fooming AI will have to do some concrete big difficult extremely long-term precise thing that deeply respects existing humans. If you are already tracking something like this, then plausibly you shouldn't also track the property I'm suggesting.
- E.g., it would be fine to instead track that each person should get a galaxy they can do whatever they want with/in. I guess I'm saying the AI-free part because it is natural to want something like that in your galaxy (so you get to live your own life in a way properly determined by you, without the immediate massive context shift coming from the presence of even "benign" highly capable AI, that could easily break everything imo), because it makes sense for many people to coordinate to move to this galaxy together (it's just better in many mundane ways to have people around, but also your thinking and specifically valuing probably need other people to work as they should), and because it is natural to ask that whoever is subjecting everyone to the end of the human era preserves the option for each person to continue an AI-free life in particular.
- Here are a few criticisms of the suggestion:
- a criticism: "If you run a foom, this property just isn't going to be upheld, even if you try to uphold it. And, if you run a foom, then having the goal of upholding this property in mind when you put the foom in motion will not even make much of a relative difference in the probability the foom goes well."
- my response: I think this. I still suggest that we have this goal in mind, for the reasons given earlier.
- a criticism: "If we imagine a foom being such that this option is upheld, then probably we should imagine it being such that better options are available to people as well."
- my response: I probably think this. I still suggest that we have this goal in mind, for the reasons given earlier.
- a criticism: "If you run a foom, this property just isn't going to be upheld, even if you try to uphold it. And, if you run a foom, then having the goal of upholding this property in mind when you put the foom in motion will not even make much of a relative difference in the probability the foom goes well."
I think this is probably a bad term that should be deprecated ↩︎
well, at least if the year is and we're not dealing with a foom of extremely philosophically competent and careful mind uploads or whatever, firstly, you shouldn't be running a foom (except for the grand human foom we're already in). secondly, please think more. thirdly, please try to shut down all other AGI attempts and also your lab and maybe yourself, idk in which order. but fourthly, ... ↩︎
This will plausibly require staying ahead of humanity in capabilities in this galaxy forever, so this will be extremely capable AI. So, when I say the galaxy is AGI-free, I don't mean that artificial generally intelligent systems are not present in the galaxy. I mean that these AIs are supposed to have no involvement in human life except for enforcing an AI ban. ↩︎
or like at least "their values" ↩︎
and assuming we aren't currently massively overestimating the amount of resources accessible to Earth-originating creatures ↩︎
or maybe we do some joint control thing about which this is technically false but about which it is still pretty fair to say that each person got more of a say than if they merely controlled of all the resources ↩︎
an intuition pump: as an individual human, it seems possible to keep carefully developing for a long time without accidentally killing oneself; we just need to make society have analogues of whatever properties/structures make this possible in an individual human ↩︎
Btw, a pro tip for weathering the storm of crazymessactivitythoughtdevelopmenthistory: be the (generator of the) storm. I.e., continue acting and thinking and developing as humanity. Also, pulling ourselves up by our own bootstraps is based imo. Wanting to have a mommy AI think for us is pretty cringe imo. ↩︎
Among currently accessible RSI processes, there is one exception: it is in fact fine to have normal human development continue. ↩︎
Ok, really humans (should) probably importantly have lives and values together, so it would be more correct to say: there is a particular infinite contribution to human life/valuing waiting to grow out of each person. Or: when a person is lost, an important aspect of God) is lost. But the simpler picture is fine for making my current point. ↩︎
I'm imagining humanity fracturing into a million or billion different galaxies depending upon their exact level of desire for interacting with AI. I think the human value of the unity of humanity would be lost.
I think we need to buffer people from having to interact with AI if they don't want to. But I value having other humans around. So some thing in between everyone living in their perfect isolation and everyone being dragged kicking and screaming into the future is where I think we should aim.
on seeing the difference between profound and meaningless radically alien futures
Here's a question that came up in a discussion about what kind of future we should steer toward:
- Okay, a future in which all remotely human entities promptly get replaced by alien AIs would soon look radically incomprehensible and void to us — like, imagine our current selves seeing videos from this future world, and the world in these videos mostly not making sense to them, and to an even greater extent not seeming very meaningful in the ethical sense. But a future in which [each human]/humanity has spent a million years growing into a galaxy-being would also look radically incomprehensible/weird/meaningless to us.[1] So, if we were to ignore near-term stuff, would we really still have reason to strive for the latter future over the former?
a couple points in response:
- The world in which we are galaxy-beings will in fact probably seem more ethically meaningful to us in many fairly immediate ways. Related: (for each past time ) a modern species typically still shares meaningfully more with its ancestors from time than it does with other species that were around at time (that diverged from the ancestral line of the species way before ).
- A specific case: we currently already have many projects we care about — understanding things, furthering research programs, creating technologies, fashioning families and friendships, teaching, etc. — some of which are fairly short-term, but others of which could meaningfully extend into the very far future. Some of these will be meaningfully continuing in the world in which we are galaxy-beings, in a way that is not too hard to notice. That said, they will have grown into crazy things, yes, with many aspects that one isn't going to immediately consider cool; I think there is in fact a lot that's valuable here as well; I'll argue for this in item 3.
- The world in which we have become galaxy-beings had our own (developing) sense/culture/systems/laws guide decision-making and development (and their own development in particular), and we to some extent just care intrinsically/terminally about this kinda meta thing in various ways.
- However, more importantly: I think we mostly care about [decisions being made and development happening] according to our own sense/culture/systems/laws not intrinsically/terminally, but because our own sense/culture/systems/laws is going to get things right (or well, more right than alternatives) — for instance, it is going to lead us more to working on projects that really are profound. However, that things are going well is not immediately obvious from looking at videos of a world — as time goes on, it takes increasingly more thought/development to see that things are going well.
- I think one is making a mistake when looking at videos from the future and quickly being like "what meaningless nonsense!". One needs to spend time making sense of the stuff that's going on there to properly evaluate it — one doesn't have immediate access to one's true preferences here. If development has been thoughtful in this world, very many complicated decisions have been made to get to what you're now seeing in these videos. When evaluating this future, you might want to (for instance) think through these decisions for yourself in the order in which they were made, understanding the context in which each decision was made, hearing the arguments that were made, becoming smart enough to understand them, maybe trying out some relevant experiences, etc.. Or you might do other kinds of thinking that gets you into a position from which you can properly understand the world and judge it. After a million years[2] of this, you might see much more value in this human(-induced) world than before.
- But maybe you'll still find that world quite nonsensical? If you went about your thinking and learning in a great deal of isolation, without much attempting to do something together with the beings in that world, then imo you probably will indeed find that world quite bad/empty compared to what it could have been[3] [4] (though I'd guess that you would similarly also find other isolated rollouts of your own reflection quite silly[5], and that different independent sufficiently long further rollouts from your current position would again find each other silly, and so on). However, note that like the galaxy-you that came out of this reflection, this world you're examining has also gone through an [on most steps ex ante fairly legitimate] process of thoughtful development (by assumption, I guess), and the being(s) in that world now presumably think there's a lot of extremely cool stuff happening in it. In fact, we could suppose that a galaxy-you is living in that world, and that they contributed to its development throughout its history, and that they now think that their world (or their corner of their world) is extremely based.[6]
- Am I saying that the galaxy-you looking at this world from the outside is actually supposed to think it's really cool, because it's supposed to defer to the beings in that world, or because it's supposed to think any development path consisting of ex ante reasonable-seeming steps is fine, or because some sort of relativism is right, or something? I think this isn't right, and so I don't want to say that — I think it's probably fine for the galaxy-you to think stuff has really gone off the rails in that world. But I do want to say that when we ourselves are making this decision of which kind of future to have from our own embedded point of view, we should expect there to be a great deal of incomprehensible coolness in a human future (if things go right) — for instance, projects whose worth we wouldn't see yet, but which we would come to correctly consider really profound in such a future (indeed, we would be tracking what's worthwhile and coming up with new worthwhile things and doing those) — whereas we should expect there to instead be a great deal of incomprehensible valueless nonsense in an alien future.
- If you've read the above and still think a galaxy-human future wouldn't be based, let me try one more story on you. I think this looking-at-videos-of-a-distant-world framing of the question makes one think in terms of sth like assigning value to spacetime blocks "from the outside", and this is a framing of ethical decisions which is imo tricky to handle well, and in particular can make one forget how much one cares about stuff. Like, I think it's common to feel like your projects matter a lot while simultaneously feeling that [there being a universe in which there is a you-guy that is working on those projects] isn't so profound; maybe you really want to have a family, but you're confused about how much you want to make there be a spacetime block in which there is a such-and-such being with a family. This could even turn an ordinary ethical decision that you can handle just fine into something you're struggling to make sense of — like, wait, what kind of guy needs to live in this spacetime block (and what relation do they need to have to me-now-answering-this-question); also, what does it even mean for a spacetime block to exist (what if we should say that all possible spacetime blocks exist?)? One could adopt the point of view that the spacetime block question is supposed to just be a rephrasing of the ordinary ethical question, and so one should have the same answer for it, and feel no more confused about what it means. One could probably spend some time thinking of one's ordinary ethical decisions in terms of spacetime-block-making and perhaps then come to have one's answers be reasonably coherent under having (arguably) the same decision problem presented in the ordinary way vs in some spacetime block way.[7] But I think this sort of thing is very far from being set up in almost any current human. So: you might feel like saying "whatever" way too much when ethical questions are framed in terms of spacetime-block-making, and the situation we're considering could push one toward that frame; I want to alert you that maybe this is happening, maybe you really care more than it seems in that frame, and that maybe you should somehow imagine yourself being more embedded in this world when evaluating it.
I guess one could imagine a future in which someone tiles the world with happy humans of the current year variety or something, but imo this is highly unlikely even conditional on the future being human-shaped, and also much worse than futures in which a wild variety of galaxy-human stuff is going on. Background context: imo we should probably be continuously growing more capable/intelligent ourselves for a very long time (and maybe forever), with the future being determined by us "from inside human life", as opposed to ever making an artificial system that is more capable than humanity and fairly separate/distinct from humanity that would "design human affairs from the outside" (really, I think we shouldn't be making [AIs more generally capable than individual humans] of any kind, except for ones that just are smarter versions of individual humans, for a long time (and maybe forever); see this for some of my thoughts on these topics). ↩︎
maybe we should pick a longer time here, to be comparing things which are more alike? ↩︎
I think this is probably true even if we condition the rollout on you coming to understand the world in the videos quite well. ↩︎
But if you disagree here, then I think I've already finished [the argument that the human far future is profoundly better] which I want to give to you, so you could stop reading here — the rest of this note just addresses a supposed complication you don't believe exists. ↩︎
much like you could grow up from a kid into a mathematician or a philosopher or an engineer or a composer, thinking in each case that the other paths would have been much worse ↩︎
Unlike you growing up in isolation, that galaxy-you's activities and judgment and growth path will be influenced by others; maybe it has even merged with others quite fully. But that's probably how things should be, anyway — we probably should grow up together; our ordinary valuing is already done together to a significant extent (like, for almost all individuals, the process determining (say) the actions of that individual already importantly involves various other individuals, and not just in a way that can easily be seen as non-ethical). ↩︎
There might be some stuff that's really difficult to make sense of here — it is imo plausible that the ethical cognition that a certain kind of all-seeing spacetime-block-chooser would need to have to make good choices is quite unlike any ethical cognition that exists (or maybe even could exist) in our universe. That said, we can imagine a more mundane spacetime-block-chooser, like a clone of you that gets to make a single life choice for you given ordinary information about the decision and that gets deleted after that; it is easier to imagine this clone having ethical cognition that leads to it making reasonably good decisions. ↩︎
An attempt at a specification of virtue ethics
I will be appropriating terminology from the Waluigi post. I hereby put forward the hypothesis that virtue ethics endorses an action iff it is what the better one of Luigi and Waluigi would do, where Luigi and Waluigi are the ones given by the posterior semiotic measure in the given situation, and "better" is defined according to what some [possibly vaguely specified] consequentialist theory thinks about the long-term expected effects of this particular Luigi vs the long-term effects of this particular Waluigi. One intuition here is that a vague specification could be more fine if we are not optimizing for it very hard, instead just obtaining a small amount of information from it per decision.
In this sense, virtue ethics literally equals continuously choosing actions as if coming from a good character. Furthermore, considering the new posterior semiotic measure after a decision, in this sense, virtue ethics is about cultivating a virtuous character in oneself. Virtue ethics is about rising to the occasion (i.e. the situation, the context). It's about constantly choosing the Luigi in oneself over the Waluigi in oneself (or maybe the Waluigi over the Luigi if we define "Luigi" as the more likely of the two and one has previously acted badly in similar cases or if the posterior semiotic measure is otherwise malign). I currently find this very funny, and, if even approximately correct, also quite cool.
Here are some issues/considerations/questions that I intend to think more about:
- What's a situation? For instance, does it encompass the agent's entire life history, or are we to make it more local?
- Are we to use the agent's own semiotic measure, or some objective semiotic measure?
- This grounds virtue ethics in consequentialism. Can we get rid of that? Even if not, I think this might be useful for designing safe agents though.
- Does this collapse into cultivating a vanilla consequentialist over many choices? Can we think of examples of prompting regimes such that collapse does not occur? The vague motivating hope I have here is that in the trolley problem case with the massive man, the Waluigi pushing the man is a corrupt psycho, and not a conflicted utilitarian.
- Even if this doesn't collapse into consequentialism from these kinds of decisions, I'm worried about it being stable under reflection, I guess because I'm worried about the likelihood of virtue ethics being part of an agent in reflective equilibrium. It would be sad if the only way to make this work would be to only ever give high semiotic measure to agents that don't reflect much on values.
- Wait, how exactly do we get Luigi and Waluigi from the posterior semiotic measure? Can we just replace this with picking the best character from the most probable few options according to the semiotic measure? Wait, is this just quantilization but funnier? I think there might be some crucial differences. And regardless, it's interesting if virtue ethics turns out to be quantilization-but-funnier.
- More generally, has all this been said already?
- Is there a nice restatement of this in shard theory language?
I designed a pro-human(ity)/anti-(non-human-)AI flag:

- The red-black circle is HAL's eye; it represents the non-human in-all-ways-super-human AI(s) that the world's various AI capability developers are trying to create, that will imo by default render all remotely human beings completely insignificant and cause humanity to completely lose control over what happens :(.
- The white star covering HAL's eye has rays at the angles of the limbs of Leonardo's Vitruvian Man; it represents humans/humanity remaining more capable than non-human AI (by banning AGI development and by carefully self-improving).
- The blue background represents our potential self-made ever-better future, involving global governance/cooperation/unity in the face of AI.
Feel free to suggest improvements to the flag. Here's latex to generate it:
% written mostly by o3 and o4-mini-high, given k's prompting
% an anti-AI flag. a HAL "eye" (?) is covered by a vitruvian man star
\documentclass[tikz]{standalone}
\usetikzlibrary{calc}
\usepackage{xcolor} % for \definecolor
\definecolor{UNBlue}{HTML}{5B92E5}
\begin{document}
\begin{tikzpicture}
%--------------------------------------------------------
% flag geometry
%--------------------------------------------------------
\def\flagW{6cm} % width -> 2 : 3 aspect
\def\flagH{4cm} % height
\def\eyeR {1.3cm} % HAL-eye radius
% light-blue background
\fill[UNBlue] (0,0) rectangle (\flagW,\flagH);
%--------------------------------------------------------
% concentric “HAL eye” (outer-most ring first)
%--------------------------------------------------------
\begin{scope}[shift={(\flagW/2,\flagH/2)}] % centre of the flag
\foreach \f/\c in {%
1.00/black,
.68/{red!50!black},
.43/{red!80!orange},
.1/orange,
.05/yellow}%
{%
\fill[fill=\c,draw=none] circle ({\f*\eyeR});
}
%── parameters ───────────────────────────────────────
\def\R{\eyeR} % distance from centre to triangle’s tip
\def\Alpha{10} % full apex angle (°)
%── compute half-angle & half-base once ─────────────
\pgfmathsetmacro\halfA{\Alpha/2}
\pgfmathsetlengthmacro\halfside{\R*tan(\halfA)}
%── loop over Vitruvian‐man angles ───────────────────
\foreach \Beta in {0,30,90,150,180,240,265,275,300} {%
% apex on the eye‐rim
\coordinate (A) at (\Beta:\R);
% base corners offset ±90°
\coordinate (B) at (\Beta+90:\halfside);
\coordinate (C) at (\Beta-90:\halfside);
% fill the spike
\path[fill=white,draw=none] (A) -- (B) -- (C) -- cycle;
}
\end{scope}
\end{tikzpicture}
\end{document}
I like the concept; on the other hand the flag feels strongly fascist to me.
Ran it by the AIs and 2 out of 3 had "authoritarian" as their first descriptor responding to "What political alignment does the aesthetic of this flag evoke?" FWIW.
Hmm, thanks for telling me, I hadn't considered that. I think I didn't notice this in part because I've been thinking of the red-black circle as being "canceled out"/"negated" on the flag, as opposed to being "asserted". But this certainly wouldn't be obvious to someone just seeing the flag.
a chat with Towards_Keeperhood on what it takes for sentences/phrases/words to be meaningful
- you could define "mother(x,y)" as "x gave birth to y", and then "gave birth" as some more precise cluster of observations, which eventually need to be able to be identified from visual inputs
Kaarel:
- if i should read this as talking about a translation of "x is the mother of y", then imo this is a bad idea.
- in particular, i think there is the following issue with this: saying which observations "x gave birth to y" corresponds to intuitively itself requires appealing to a bunch of other understanding. it's like: sure, your understanding can be used to create visual anticipations, but it's not true that any single sentence alone could be translated into visual anticipations — to get a typical visual anticipation, you need to rely on some larger segment of your understanding. a standard example here is "the speed of light in vacuum is 3*10^8 m/s" creating visual anticipations in some experimental setups, but being able to derive those visual anticipations depends on a lot of further facts about how to create a vacuum and properties of mirrors and interferometers and so on (and this is just for one particular setup — if we really mean to make a universally quantified statement, then getting the observation sentences can easily end up requiring basically all of our understanding). and it seems silly to think that all this crazy stuff was already there in what you meant when you said "the speed of light in vacuum is m/s". one concrete reason why you don't want this sentence to just mean some crazy AND over observation sentences or whatever is because you could be wrong about how some interferometer works and then you'd want it to correspond to different observation sentences
- this is roughly https://en.wikipedia.org/wiki/Confirmation_holism as a counter to https://en.wikipedia.org/wiki/Verificationism
- that said, i think there is also something wrong with some very strong version of holism: it's not really like our understanding is this unitary thing that only outputs visual anticipations using all the parts together, either — the real correspondence is somewhat more granular than that
TK:
- On reflection, I think my "mother" example was pretty sloppy and perhaps confusing. I agree that often quite a lot of our knowledge is needed to ground a statement in anticipations. And yeah actually it doesn't always ground out in that, e.g. for parsing the meaning of counterfactuals. (See "Mixed Reference: The great reductionist project".)
K:
- i wouldn't say a sentence is grounded in anticipations with a lot of our knowledge, because that makes it sound like in the above example, "the speed of light is m/s" is somehow privileged compared to our understanding of mirrors and interferometers even though it's just all used together to create anticipations; i'd instead maybe just say that a bunch of our knowledge together can create a visual anticipation
TK:
- thx. i wanted to reply sth like "a true statement can either be tautological (e.g. math theorems) or empirical, and for it to be an empirical truth there needs to be some entanglement between your belief and reality, and entanglement happens through sensory anticipations. so i feel fine with saying that the sentence 'the speed of light is m/s' still needs to be grounded in sensory anticipations". but i notice that the way i would use "grounded" here is different from the way I did in my previous comment, so perhaps there are two different concepts that need to be disentangled.
K:
- here's one thing in this vicinity that i'm sympathetic to: we should have as a criterion on our words, concepts, sentences, thoughts, etc. that they play some role in determining our actions; if some mental element is somehow completely disconnected from our lives, then i'd be suspicious of it. (and things can be connected to action via creating visual anticipations, but also without doing that.)
- that said, i think it can totally be good to be doing some thinking with no clear prior sense about how it could be connected to action (or prediction) — eg doing some crazy higher math can be good, imagining some crazy fictional worlds can be good, games various crazy artists and artistic communities are playing can be good, even crazy stuff religious groups are up to can be good. also, i think (thought-)actions in these crazy domains can themselves be actions one can reasonably be interested in supporting/determining, so this version of entanglement with action is really a very weak criterion
- generally it is useful to be able to "run various crazy programs", but given this, it seems obvious that not all variables in all useful programs are going to satisfy any such criterion of meaningfulness? like, they can in general just be some arbitrary crazy things (like, imagine some memory bit in my laptop or whatever) playing some arbitrary crazy role in some context, and this is fine
- and similarly for language: we can have some words or sentences playing some useful role without satisfying any strict meaningfulness criterion (beyond maybe just having some relation to actions or anticipations which can be of basically arbitrary form)
- a different point: in human thinking, the way "2+2=4" is related to visual anticipations is very similar to the way "the speed of light is m/s" is related to visual anticipations
TK:
- Thanks!
- I agree that e.g. imagining fictional worlds like HPMoR can be useful.
- I think I want to expand my notion of "tautological statements" to include statements like "In the HPMoR universe, X happens". You can also pick any empirical truth "X" and turn it into a tautological one by saying "In our universe, X". Though I agree it seems a bit weird.
- Basically, mathematics tells you what's true in all possible worlds, so from mathematics alone you never know in which world you may be in. So if you want to say something that's true about your world specifically (but not across all possible worlds), you need some observations to pin down what world you're in.
- I think this distinction is what Eliezer means in his highly advanced epistemology sequence when he uses "logical pinpointing" and "physical pinpointing".
- You can also have a combination of the two. (I'd say as soon as some physical pinpointing is involved I'd call it an empirical fact.)
- Commented about that. (I actually changed my model slightly): https://www.lesswrong.com/posts/bTsiPnFndZeqTnWpu/mixed-reference-the-great-reductionist-project?commentId=HuE78qSkZJ9MxBC8p
K:
- the imo most important thing in my messages above is the argument against [any criterion of meaningfulness which is like what you’re trying to state] being reasonable
- in brief, because it’s just useful to be allowed to have arbitrary “variables" in "one’s mental circuits”
- just like there’s no such meaningfulness criterion on a bit in your laptop’s memory
- if you want to see from the outside the way the bit is “connected to the world”, one thing you could do is to say that the bit is 0 in worlds which are such-and-such and 1 in worlds which are such-and-such, or, if you have a sense of what the laptop is supposed to be doing, you could say in which worlds the bit "should be 0" and in which worlds the bit "should be 1", but it’s not like anything like this crazy god’s eye view picture is (or even could explicitly be) present inside the laptop
- our sentences and terms don’t have to have meanings “grounded in visual anticipations”, just like the bit in the laptop doesn’t
- except perhaps in the very weak sense that it should be possible for a sentence to be involved in determining actions (or anticipations) in some potentially arbitrarily remote way
- the following is mostly a side point: one problem with seeing from the inside what your bits (words, sentences) are doing (especially in the context of pushing the frontier of science, math, philosophy, tech, or generally doing anything you don’t know how to do yet, but actually also just basically all the time) is that you need to be open to using your bits in new ways; the context in which you are using your bits usually isn’t clear to you
- btw, this is a sort of minor point but i'm stating it because i'm hoping it might contribute to pushing you out of a broader imo incorrect view: even when one is stating formal mathematical statements, one should be allowed to state sentences with no regard for whether they are tautologies/contradictions (that is, provable/disprovable) or not — ie, one should be allowed to state undecidable sentences, right? eg you should be allowed to state a proof that has the structure "if P, then blabla, so Q; but if not-P, then other-blabla, but then also Q; therefore, Q", without having to pay any attention to whether P itself is tautological/contradictory or undecidable
- so, if what you want to do with your criterion of meaningfulness involves banning saying sentences which are not "meaningful", then even in formal math, you should consider non-tautological/contradictory sentences meaningful. (if you don't want to ban the "meaningless" sentences, then idk what we're even supposed to be doing with this notion of meaningfulness.)
TK:
- Thx. I definitely agree one should be able to state all mathematical statements (including undecidable ones), and that for proofs you shouldn't need to pay attention to whether a statement is undecidable or not. (I'm having sorta constructivist tendencies though, where "if P, then blabla, so Q; but if not-P, then other-blabla, but then also Q; therefore, Q" wouldn't be a valid proof because we don't assume the law of excluded middle.)
- Ok yeah thx I think the way I previously used "meaningfully" was pretty confused. I guess I don't really want to rule out any sentences people use.
- I think sth is not meaningful if there's no connection between a belief to your main belief pool. So "a puffy is a flippo" is perhaps not meaningful to you because those concepts don't relate to anything else you know? (But that's a different kind of meaningful from what errors people mostly make.)
K:
- yea. tho then we could involve more sentences about puffies and flippos and start playing some game involving saying/thinking those sentences and then that could be fun/useful/whatever
TK:
- maybe. idk.
so this version of entanglement with action is really a very weak criterion
Yeah, exactly, and hence the question: what are some counterexamples, ~concepts that clearly are not tied to action in any way? E.g., I could imagine metaphysical philosophizing to connect to action via contributing to a line of thinking that eventually produces a useful insight on how to do science or something. Is it about "being/remaining open to using it in new ways"?
I think I want to expand my notion of "tautological statements" to include statements like "In the HPMoR universe, X happens". You can also pick any empirical truth "X" and turn it into a tautological one by saying "In our universe, X". Though I agree it seems a bit weird.
I'm inclined to think that your generalized tautological statements are about something like "playing games according to ~rules in (~confined to) some mind-like system". This is in contrast to (canonically) empirical statements that involve throwing a referential bridge across the boundary of the system.
- I think sth is not meaningful if there's no connection between a belief to your main belief pool. So "a puffy is a flippo" is perhaps not meaningful to you because those concepts don't relate to anything else you know? (But that's a different kind of meaningful from what errors people mostly make.)
K:
- yea. tho then we could involve more sentences about puffies and flippos and start playing some game involving saying/thinking those sentences and then that could be fun/useful/whatever
[Thinking out loud.]
Intuitively, it does seem to me that if you start with a small set of elements isolated from the rest of your understanding, then they are meaningless, but then, as you grow this set of elements and add more relations/functions/rules/propositions with high implicative potential, this network becomes increasingly meaningful, even though it's completely disconnected from the rest of understanding and our lives except for playing this domain/subnetwork-specific game.
Is it (/does it seem) meaningful just because I could throw a bridge between it and the rest of my understanding? Well, one could build a computer with this game installed only (+ ofc bare minimum to make it work: OS and stuff) and I would still be inclined to think it meaningful, although perhaps I would be imposing, and the meaningfulness would be co-created by the eye/mind of the beholder.
This leads to the question: What criteria do we want our (explicated) notion of meaningfulness to satisfy?
[For completeness, the concept of meaningfulness may need to be splintered or even eliminated (/factored out in a way that doesn't leave anything clearly serving its role), though I think the latter rather unlikely.]
A thread into which I'll occasionally post notes on some ML(?) papers I'm reading
I think the world would probably be much better if everyone made a bunch more of their notes public. I intend to occasionally copy some personal notes on ML(?) papers into this thread. While I hope that the notes which I'll end up selecting for being posted here will be of interest to some people, and that people will sometimes comment with their thoughts on the same paper and on my thoughts (please do tell me how I'm wrong, etc.), I expect that the notes here will not be significantly more polished than typical notes I write for myself and my reasoning will be suboptimal; also, I expect most of these notes won't really make sense unless you're also familiar with the paper — the notes will typically be companions to the paper, not substitutes.
I expect I'll sometimes be meaner than some norm somewhere in these notes (in fact, I expect I'll sometimes be simultaneously mean and wrong/confused — exciting!), but I should just say to clarify that I think almost all ML papers/posts/notes are trash, so me being mean to a particular paper might not be evidence that I think it's worse than some average. If anything, the papers I post notes about had something worth thinking/writing about at all, which seems like a good thing! In particular, they probably contained at least one interesting idea!
So, anyway: I'm warning you that the notes in this thread will be messy and not self-contained, and telling you that reading them might not be a good use of your time :)
The Deep Neural Feature Ansatz
@misc{radhakrishnan2023mechanism, title={Mechanism of feature learning in deep fully connected networks and kernel machines that recursively learn features}, author={Adityanarayanan Radhakrishnan and Daniel Beaglehole and Parthe Pandit and Mikhail Belkin}, year={2023}, url = { https://arxiv.org/pdf/2212.13881.pdf } }
The ansatz from the paper
Let denote the activation vector in layer on input , with the input layer being at index , so . Let be the weight matrix after activation layer . Let be the function that maps from the th activation layer to the output. Then their Deep Neural Feature Ansatz says that (I'm somewhat confused here about them not mentioning the loss function at all — are they claiming this is reasonable for any reasonable loss function? Maybe just MSE? MSE seems to be the only loss function mentioned in the paper; I think they leave the loss unspecified in a bunch of places though.)
A singular vector version of the ansatz
Letting be a SVD of , we note that this is equivalent to i.e., that the eigenvectors of the matrix on the RHS are the right singular vectors. By the variational characterization of eigenvectors and eigenvalues (Courant-Fischer or whatever), this is the same as saying that right singular vectors of are the highest orthonormal directions for the matrix on the RHS. Plugging in the definition of , this is equivalent to saying that the right singular vectors are the sequence of highest-variance directions of the data set of gradients .
(I have assumed here that the linearity is precise, whereas really it is approximate. It's probably true though that with some assumptions, the approximate initial statement implies an approximate conclusion too? Getting approx the same vecs out probably requires some assumption about gaps in singular values being big enough, because the vecs are unstable around equality. But if we're happy getting a sequence of orthogonal vectors that gets variances which are nearly optimal, we should also be fine without this kind of assumption. (This is guessing atm.))
Getting rid of the dependence on the RHS?
Assuming there isn't an off-by-one error in the paper, we can pull some term out of the RHS maybe? This is because applying the chain rule to the Jacobians of the transitions gives , so
Wait, so the claim is just which, assuming is invertible, should be the same as . But also, they claim that it is ? Are they secretly approximating everything with identity matrices?? This doesn't seem to be the case from their Figure 2 though.
Oh oops I guess I forgot about activation functions here! There should be extra diagonal terms for jacobians of preactivations->activations in , i.e., it should really say We now instead get This should be the same as which, with denoting preactivations in layer and denoting the function from these preactivations to the output, is the same as This last thing also totally works with activation functions other than ReLU — one can get this directly from the Jacobian calculation. I made the ReLU assumption earlier because I thought for a bit that one can get something further in that case; I no longer think this, but I won't go back and clean up the presentation atm.
Anyway, a takeaway is that the Deep Neural Feature Ansatz is equivalent to the (imo cleaner) ansatz that the set of gradients of the output wrt the pre-activations of any layer is close to being a tight frame (in other words, the gradients are in isotropic position; in other words still, the data matrix of the gradients is a constant times a semi-orthogonal matrix). (Note that the closeness one immediately gets isn't in to a tight frame, it's just in the quantity defining the tightness of a frame, but I'd guess that if it matters, one can also conclude some kind of closeness in from this (related).) This seems like a nicer fundamental condition because (1) we've intuitively canceled terms and (2) it now looks like a generic-ish condition, looks less mysterious, though idk how to argue for this beyond some handwaving about genericness, about other stuff being independent, sth like that.
proof of the tight frame claim from the previous condition: Note that clearly implies that the mass in any direction is the same, but also the mass being the same in any direction implies the above (because then, letting the SVD of the matrix with these gradients in its columns be , the above is , where we used the fact that ).
Some questions
- Can one come up with some similar ansatz identity for the left singular vectors of ? One point of tension/interest here is that an ansatz identity for would constrain the left singular vectors of together with its singular values, but the singular values are constrained already by the deep neural feature ansatz. So if there were another identity for in terms of some gradients, we'd get a derived identity from equality between the singular values defined in terms of those gradients and the singular values defined in terms of the Deep Neural Feature Ansatz. Or actually, there probably won't be an interesting identity here since given the cancellation above, it now feels like nothing about is really pinned down by 'gradients independent of ' by the DNFA? Of course, some -dependence remains even in the gradients because the preactivations at which further gradients get evaluated are somewhat -dependent, so I guess it's not ruled out that the DNFA constrains something interesting about ? But anyway, all this seems to undermine the interestingness of the DNFA, as well as the chance of there being an interesting similar ansatz for the left singular vectors of .
- Can one heuristically motivate that the preactivation gradients above should indeed be close to being in isotropic position? Can one use this reduction to provide simpler proofs of some of the propositions in the paper which say that the DNFA is exactly true in certain very toy cases?
- The authors claim that the DNFA is supposed to somehow elucidate feature learning (indeed, they claim it is a mechanism of feature learning?). I take 'feature learning' to mean something like which neuronal functions (from the input) are created or which functions are computed in a layer in some broader sense (maybe which things are made linearly readable?) or which directions in an activation space to amplify or maybe less precisely just the process of some internal functions (from the input to internal activations) being learned of something like that, which happens in finite networks apparently in contrast to infinitely wide networks or NTK models or something like that which I haven't yet understood? I understand that their heuristic identity on the surface connects something about a weight matrix to something about gradients, but assuming I've not made some index-off-by-one error or something, it seems to probably not really be about that at all, since the weight matrix sorta cancels out — if it's true for one , it would maybe also be true with any other replacing it, so it doesn't really pin down ? (This might turn out to be false if the isotropy of preactivation gradients is only true for a very particular choice of .) But like, ignoring that counter, I guess their point is that the directions which get stretched most by the weight matrix in a layer are the directions along which it would be the best to move locally in that activation space to affect the output? (They don't explain it this way though — maybe I'm ignorant of some other meaning having been attributed to in previous literature or something.) But they say "Informally, this mechanism corresponds to the approach of progressively re-weighting features in proportion to the influence they have on the predictions.". I guess maybe this is an appropriate description of the math if they are talking about reweighting in the purely linear sense, and they take features in the input layer to be scaleless objects or something? (Like, if we take features in the input activation space to each have some associated scale, then the right singular vector identity no longer says that most influential features get stretched the most.) I wish they were much more precise here, or if there isn't a precise interesting philosophical thing to be deduced from their math, much more honest about that, much less PR-y.
- So, in brief, instead of "informally, this mechanism corresponds to the approach of progressively re-weighting features in proportion to the influence they have on the predictions," it seems to me that what the math warrants would be sth more like "The weight matrix reweights stuff; after reweighting, the activation space is roughly isotropic wrt affecting the prediction (ansatz); so, the stuff that got the highest weight has most effect on the prediction now." I'm not that happy with this last statement either, but atm it seems much more appropriate than their claim.
- I guess if I'm not confused about something major here (plausibly I am), one could probably add 1000 experiments (e.g. checking that the isotropic version of the ansatz indeed equally holds in a bunch of models) and write a paper responding to them. If you're reading this and this seems interesting to you, feel free to do that — I'm also probably happy to talk to you about the paper.
typos in the paper
indexing error in the first displaymath in Sec 2: it probably should say '', not ''
A small observation about the AI arms race in conditions of good infosec and collaboration
Suppose we are in a world where most top AI capabilities organizations are refraining from publishing their work (this could be the case because of safety concerns, or because of profit motives) + have strong infosec which prevents them from leaking insights about capabilities in other ways. In this world, it seems sort of plausible that the union of the capabilities insights of people at top labs would allow one to train significantly more capable models than the insights possessed by any single lab alone would allow one to train. In such a world, if the labs decide to cooperate once AGI is nigh, this could lead to a significantly faster increase in capabilities than one might have expected otherwise.
(I doubt this is a novel thought. I did not perform an extensive search of the AI strategy/governance literature before writing this.)
I'm updating my estimate of the return on investment into culture wars from being an epsilon fraction compared to canonical EA cause areas to epsilon+delta. This has to do with cases where AI locks in current values extrapolated "correctly" except with too much weight put on the practical (as opposed to the abstract) layer of current preferences. What follows is a somewhat more detailed status report on this change.
For me (and I'd guess for a large fraction of autistic altruistics multipliers), the general feels regarding [being a culture war combatant in one's professional capacity] seem to be that while the questions fought over have some importance, the welfare-produced-per-hour-worked from doing direct work is at least an order of magnitude smaller than the same quantities for any canonical cause area (also true for welfare/USD). I'm fairly certain one can reach this conclusion from direct object-level estimates, as I imagine e.g. OpenPhil has done, although I admit I haven't carried out such calculations with much care myself. Considering the incentives of various people involved should also support this being a lower welfare-per-hour-worked cause area (whether an argument along these lines gives substantive support to the conclusion that there is an order-of-magnitude difference appears less clear).
So anyway, until today part of my vague cloud of justification for these feels was that "and anyway, it's fine if this culture war stuff is fixed in 30 years, after we have dealt with surviving AGI". The small realization I had today was that maybe a significant fraction of the surviving worlds are those where something like corrigibility wasn't attainable but AI value extrapolation sort of worked out fine, i.e. with the values that got locked in being sort of fine, but the relative weights of object-level intuitions/preferences was kinda high compared to the weight on simplicity/[meta-level intuitions], like in particular maybe the AI training did some Bayesian-ethics-evidential-double-counting of object-level intuitions about 10^10 similar cases (I realize it's quite possible that this last clause won't make sense to many readers, but unfortunately I won't provide an explanation here; I intend to write about a few ideas on this picture of Bayesian ethics at some later time, but I want to read Beckstead's thesis first, which I haven't done yet; anyway the best I can offer is that I estimate a 75% of you understanding the rough idea I have in mind (which does not necessarily imply that the idea can actually be unfolded into a detailed picture that makes sense), conditional on understanding my writing in general and conditional on not having understood this clause yet, after reading Beckstead's thesis; also: woke: Bayesian ethics, bespoke: INFRABAYESIAN ETHICS, am I right folks).
So anyway, finally getting to the point of all this at the end of the tunnel, in such worlds we actually can't fix this stuff later on, because all the current opinions on culture war issues got locked in.
(One could argue that we can anyway be quite sure that this consideration matters little, because most expected value is not in such kinda-okay worlds, because even if these were 99% percent of the surviving worlds, assuming fun theory makes sense or simulated value-bearing minds are possible, there will be amazingly more value in each world where AGI worked out really well, as compared to a world tiled with Earth society 2030. But then again, this counterargument could be iffy to some, in sort of the same way in which fanaticism (in Bostrom's sense) or the St. Petersburg paradox feel iffy to some, or perhaps in another way. I won't be taking a further position on this at the moment.)
I proposed a method for detecting cheating in chess; cross-posting it here in the hopes of maybe getting better feedback than on reddit: https://www.reddit.com/r/chess/comments/xrs31z/a_proposal_for_an_experiment_well_data_analysis/