The code in your notebook does its hyperbolic fitting by (nonlinear) least squares on the original data, but its exponential fitting by (linear) least squares on the log of the original data.
This means (1) that your exponential fit will look worse "on the right" where the numbers are larger than an actual least-squares fit of an exponential, and (2) it will have worse mean squared error (on the original data) than an actual least-squares fit of an exponential.
When I do an exponential fit using the same machinery as you used for your hyperbolic fit, I get this graph
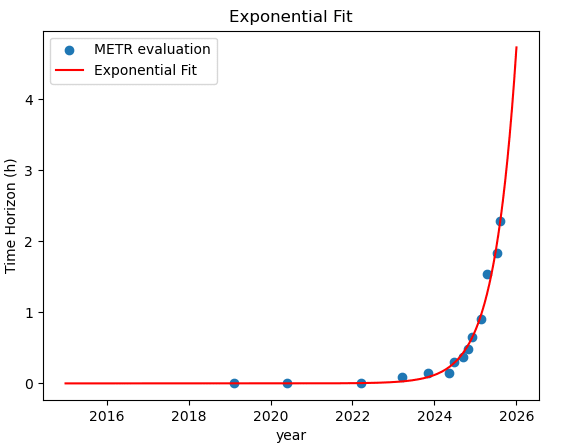
and a "total error" of 0.107 versus 0.141 for the q=2 hyperbolic fit.
[EDITED to add:] The specific exponential I get, in case anyone wants to check, is horizon = exp b (t-t0) where b = 1.8421 and t0 is 2025-02-27.
[EDITED to add:] I've strong-downvoted the post, not because I think there's anything very terrible about making the mistake I believe you made, but because at first glance it looks like evidence for something important and I think it isn't in fact evidence for that important thing and I don't want people to be misled.
[EDITED again to add:] Full post at https://www.lesswrong.com/posts/ZEuDH2W3XdRaTwpjD/hyperbolic-model-fits-metr-capabilities-estimate-worse-than
Thanks for checking, confirming, and editing accordingly. I reiterate that despite my criticisms of the content, this is what epistemic virtue looks like: write things in such a way that others can check them, and correct appropriately if they turn out to have been wrong.
(Strong-downvote undone since with the corrections at the top the OP is no longer likely to mislead anyone much.)
Are you looking at mean squared error in log space? I expect this will be more meaningful and less dominated by the last few points.
It's in linear space for the hyperbolic model and in log space for the exponential one, which unfortunately means all the comparisons are invalid. See my comment (and the longer post linked from it).
Thanks for the post!
Nikola Jurkovic suggests that as soon as model can do a month-long task with 80% accuracy, it should be able to do any cognitive human task
I didn't mean to suggest this in my original post. My claim was something more like "a naive extrapolation means that 80% time horizons will be at least a month by the end of the decade, but I think they'll be much higher and we'll have AGI"
EDIT: Big error in this post spotted and corrected by gjm here https://www.lesswrong.com/posts/ZEuDH2W3XdRaTwpjD/hyperbolic-model-fits-metr-capabilities-estimate-worse-than . I believe the motivation part still stands, but so far no experimental confirmation.
EDIT2: I also realized that we need to take into account confidence intervals provided by METR as well. I will make a separate post on them.
Recently METR published their measurements of AI abilities to complete long tasks for GPT-5, along with the previous models. They demonstrate that there is still an exponential trend, and GPT-5 does not deviate from it. Moreover, Nikola Jurkovic from METR suggests with the same data that there is already an even faster growing exponent. This pattern, however, indicates often that we might be able to better capture the process as something faster than exponential.
A few years ago I suggested that prior to a singularity, we should expect that a particular quantity, related to technological progress, should demonstrate a power-law divergence from analogy with condensed matter physics. The ability to complete long tasks seems to be a good candidate for such a quantity. Namely, we can suggest:
H=C(tS−t)q
i.e. the time horizon H (the length of the task the model cam complete) diverges as the time approaches the time of singularity tS , and the power is q (in condensed matter physics called critical exponent). For hyperbolic growth, such as human population till 1960, we have q=1. Here I speculated that if instead of looking at the number of people, we look at the amount of processed information, or research progress, or something like that, we could observe hyperbolic growth after 1960 as well (indication - the rise of computers at this time).
Up to now, all this was speculation, but I provide it as reasoning why to look for a diverging power-law rather than an exponential function. So, after all this is said, let's see what happens if we fit this function to the data. You can play with it in the Colab notebok here.
Here for example the results for q=1, standard hyperbolic growth. The mean square error is already 3 times less than for exponential fit (image below).
And it also does not capture very well the last few time points.
If we increase q, the mean square error decreases until q=40. Here, for example, the plot for q=2.
And for q=3
We see that unlike q=1 it captures very well both initial and final time points. Going for higher q improves the fit even more. However, we should not go for too high q, since usually in physical systems the critical exponents (q here) are of order 1. We can limit it in the other way: Nikola Jurkovic suggests that as soon as model can do a month-long task with 80% accuracy, it should be able to do any cognitive human task. In our terms, it means that singularity (when the frontier model can do tasks of any length) should be very close to the 1 month threshold. Let's set a condition that the time between 1-month threshold and singularity should be also not more than a few months. This leave us with only q not bigger than 3, and 3 is already quite a stretch.
(The vertical dashed line is a singularity, the horizontal is a 1-month threshold. It is slightly more than 3 months from this threshold to singularity, so already a stretch for q=3). This distance to singularity is growing with q
q t_c Δt (years)
1 2025-11-06 0.0035
2 2026-05-06 0.0872
3 2026-11-15 0.3034
4 2027-05-29 0.6159
5 2027-12-11 0.9905
Now, the meatiest question: when is the singularity, if progress is still hyperbolic? It appears to be very soon for small q, from October of 2025 for q=1 to November of 2026 for q=3 (funny, the later date almost precisely coincides with human population singularity Nov, 13, 2026).
Does it sound realistic? Let's point at a few facts to make the statement less dramatic. Singularity in time horizons is not yet a technological singularity. It just means that AI can do any cognitive task a professional software engineer can do. It is even not necessarily AGI in a strong sense - I highly doubt that METR evaluation can go beyond standard tasks to the tasks of the level "once in a few years research breakthrough". AI may be able to saturate the benchmark "task duration measured by a professional software engineer" without reaching ability to create breakthrough research. So even if we observe AI doing all software engineering jobs, it has a dramatic and transformative effect on society, but it is not necessarily an AGI capable of self-improving yet. I think, with this disclaimer, automated average software engineers in a very short term is not something totally implausible.
What do I make of it? First, I am updating towards shorter timelines. Second, I think it would be a good practice to look at the trends in AI not only from an exponential point of view, but also from divergent power-law point of view, as it may be a better fit, and, maybe, a better predictor.