This is an interesting attempt, but doesn't convince me that Janus is wrong about the phenomenon. There is a long history of RL having mode-collapse for intuitive reasons and needing hacks to stop it, the GPT-4 paper confirms that the RL version of the model can act drastically differently in terms of calibration, and the narrowness of ChatGPT/003 is incredibly striking: every single person who generates more than a few poems seems to remark on the obstinate refusal to generate the kinds of poems that 002 or davinci generate with the greatest of ease (complete with extreme hallucinations/lying about how it is not writing rhyming poetry in accordance with your explicit instructions, while continuing to do just that). The other night I spent a few hours playing with Japanese waka verse and the difference between 002 & 003 was night & day - I didn't get out a single usable poem from 003 because they were all hopelessly Hallmarkesque (although at least they didn't rhyme), but 002 had no issue varying topics or even switching forms entirely. It is difficult for me to not believe my lying eyes.
My takeaway is that we are probably seeing some issue with how it's being measured here, plus Janus might be 'right for the wrong reasons' in identifying the phenomenon (which is so obvious to anyone who uses the models) but the specific examples being coincidence or unreplicable. (The graphs could use improvement. As Jenner points out, the davinci comparison may not be relevant because that's from long ago. It would also be helpful to keep the colors consistent. I was confused until I realized the graphs were different.)
There may be something misleading about examining only total entropy, rather than something more meaningful: most of the effects of the RL policy will show up in the 'long run', in terms of the rare tokens that the model does or doesn't use. Sets of samples can be highly repetitive and redundant in a way which doesn't show up necessarily as the myopic next-token BPE entropy decreasing. When a mediocre chess player plays a chess grandmaster, he may have many equally good options, which nevertheless all wind up in the same place: victory. Consider Paul Christiano's wedding party example: it seems entirely possible to me that, token by token, the entropy of the model might be fairly similar to many other prompt/model combinations, and often exceed them (wacky hijinks happening along the way to the wedding party) and one would be unable to pick it out of graphs like these; but there is clearly some sort of 'lower entropy' going on when every story ends in a wedding party!
Perhaps the entropy needs to be measured over longer sequences? Or measured by distance of embeddings in more of a 'topic modeling' view? (The embeddings might capture better what people mean by the samples all 'sound the same' or 'it won't do other kinds of poetry' or 'it only writes cheerful Hallmark-level pablum': they may be completely different at a token level, and entropy of tokens similar because the model has many alternative wording choices which nevertheless all end up in the same place, but they will be very close in embedding-space because of their lack of variety in semantics, presumably. So you could just feed the various samples into the OA embedding API, or whatever document-level embedding you prefer, and see how they differentially cluster.)
I wasn't trying to say mode collapse results were wrong! I collected these results before finding crisper examples of mode collapse that I could build a useful interpretability project on. I also agree with the remarks made about the difficulty of measuring this phenomena. I indeed tried to use the OpenAI embeddings model to encode the various completions and then hopefully have the Euclidean distance be informative, but it seemed to predict large distances for similar completions so I gave up. I also made a consistent color scheme and compared code-davinci, thanks for those suggestions.
I don't get the impression that RLHF needs hacks to prevent mode collapse: the InstructGPT reports overfitting leading to better human-rater feedback, and the Anthropic HH paper mentions in passing that the KL penalty may be wholly irrelevant (!).
I'm not sure how to interpret the evidence from your first paragraph. You suggest that td-003 mode collapses where td-002 is perfectly capable. So you believe that both td-002 and td-003 mode collapse, in disjoint cases (given the examples from the original mode collapse post)?
I don't get the impression that RLHF needs hacks to prevent mode collapse: the InstructGPT reports overfitting leading to better human-rater feedback, and the Anthropic HH paper mentions in passing that the KL penalty may be wholly irrelevant (!).
But IIRC, doesn't OA also mention that to get better results they had to add in continual training of the model on the original raw data? That's much like a KL penalty. (I don't recall the RL-training part of the Anthropic HH paper, just the prompted agent parts.)
You suggest that td-003 mode collapses where td-002 is perfectly capable. So you believe that both td-002 and td-003 mode collapse, in disjoint cases (given the examples from the original mode collapse post)?
The original Janus post only covers -002, not -003. So my initial opinion was a bit of a surprise about the claim that 002 was RLHF, because at least working with samples, 003 seemed much more mode-collapsed than 002 did, and 002 was much more mode-collapsed than davinci (although that might not be a fair comparison, I haven't worked with the code-davinci-002 model enough to have an opinion about it, so that's just my impressive: in terms of diversity, davinci > 002 > 003); I didn't expect 003 to be much worse than 002 if they were trained about the same, just with updated datasets or something. I figured that perhaps 003 was just much 'more so', and this was the effect of training more, or something uninteresting like that. The later discussion of 002 being closer to instruction-tuning than RLHF seemed to resolve that anomaly for me: if 003 is both RLHF & instruction-tuned, then of course it might be much more collapsey than 002.
But 003 being more collapsey doesn't mean 002 isn't collapsed at all. It's just... less 'stubborn' about it? Yeah, it'll give you the mediocrity by default, but it's much easier to prompt or few-shot it into desired behavior than 003, so I barely even notice it.
My initial impressions of the GPT-4 chat mode which I have been using via the API/Playground and not bothering with the ChatGPT interface*, which is apparently RLHFed or something, is similar: I'm much happier with my poetry samples from GPT-4 because while again the default poetry output is repugnantly reminiscent of ChatGPT-3.5's poetry (albeit much better, of course), I can easily prompt it to get what I want. It still seems to subtly keep falling into rhyming couplets if it can, but it's not incorrigible the way ChatGPT-3.5 is. EDIT: My optimism here proved misplaced. I'm not sure if the continual updates to ChatGPT-4 destroyed the poetry quality or if I was simply initially overly-impressed by the overall quality jump in LLMs and have since become much more disgusted with the collapseyness of ChatGPT-4.
* I don't think this should make a difference but I mention it anyway.
That's true, I think the pretraining gradients training choice probably has more effect on the end model than the overfitting SFT model they start PPO with.
Huh, but Mysteries of mode collapse (and the update) were published before td-003 was released? How would you have ended up reading a post claiming td-002 was RLHF-trained when td-003 existed?
Meta note: it's plausibly net positive that all the training details of these models has been obfuscated, but it's frustrating how much energy has been sunk into speculation on The Way Things Work Inside OpenAI.
Meta note: it's plausibly net positive that all the training details of these models has been obfuscated, but it's frustrating how much energy has been sunk into speculation on The Way Things Work Inside OpenAI.
I was never a fan of this perspective, and I still think everything should have been transparent from the beginning.
The impact in ChatGPT could be potentially due to longer prompts or the "system prompt". It would be great to test that in a similar analysis
we compare the base model (davinci) with the supervised fine-tuned model (text-davinci-002) and the RLHF model (text-davinci-003)
The base model for text-davinci-002 and -003 is code-davinci-002, not davinci. So that would seem to be the better comparison unless I’m missing something.
Thanks - this doesn't seem to change observations much, except there doesn't seem to be a case where this model has starkly the lowest entropy, as we found with davinci
EDIT: I added code-davinci-002 as the main focus of the post, thanks!
And now OpenAI is removing access to code-davinci-002, the GPT-3.5 foundation model: https://twitter.com/deepfates/status/1638212305887567873
The GPT-4 base model will apparently also not be available via the API. So it seems the most powerful publicly available foundation model is now Facebook's leaked LLaMA.
Epistemic status: confident but not certain. This post is part of the work done at Conjecture. Thanks to Sid Black and Alexandre Variengien for feedback that greatly improved the post.
TL;DR: the results in Mysteries of mode collapse do not reproduce in text-davinci-003, a model trained with RLHF. In fact, there are cases where RLHF models exhibit higher entropy outputs than base models. We observe that the mode collapse phenomenon occurs more for the public OpenAI GPT-3 model trained with supervised finetuning (text-davinci-002) than RLHF, and present early experiments and theory to support this.
Background
Mysteries of mode collapse details how "mode collapse" (which we operationalize as a large increase in model output confidence and decreases in entropy of output distribution) arises more in text-davinci-002 than the base model davinci, and speculates about how this connects to RLHF training. At the time, OpenAI was very unclear on the training process for this model, and later (as @janus points out in the edited introduction to the post) it was revealed that this model was finetuned on highly-rated samples rather than trained with RLHF. However, the connection between RLHF and mode collapse has stuck, and several posts written since assume a connection.
Results
In this section, we compare the base model (
davincicode-davinci-002, thanks commenters!) with the supervised fine-tuned model (text-davinci-002) and the RLHF model (text-davinci-003). We recommend trying some prompts for yourself in the OpenAI playground. The first result is that the mode collapse to “ 97” for the completion of the first prompt from @janus’ does not occur in the RLHF model:In fact, when we try another prompt[1] we get that the base model has the lowest entropy: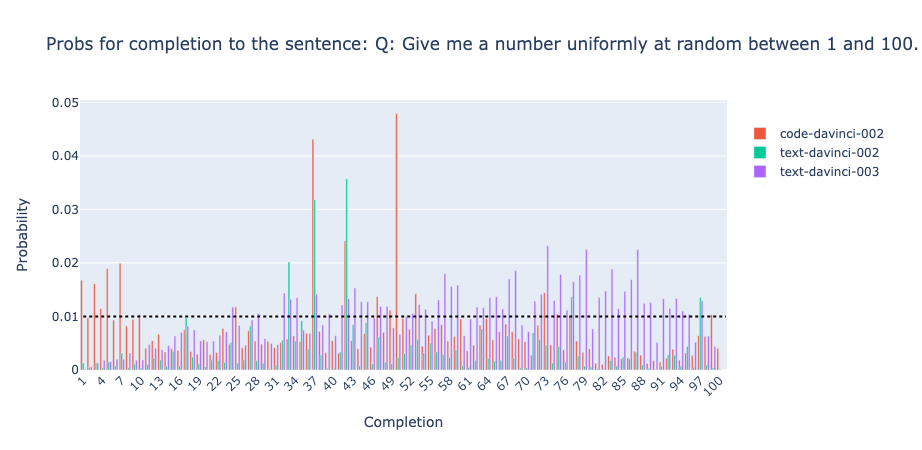
(ETA: this result is somewhat weaker than hoped, since text-davinci-002 seems to not output " 0" - " 100" here. davinci does exhibit collapses on other prompts, but commenters pointed out this is not the base model)
The finding that mode collapse occurs in finetuned models is not robust. Comparing two of the prompts from the original post and two more, [1] there is no noticeable pattern where the base model has higher entropy than the other models:
(the uncertainty bars represent the maximum possible entropy if the model had uniform probability on all tokens other than “ 0”, … , “ 100” - the OpenAI API doesn't provide probabilities for all tokens)
Reproducing the qualitative examples
What about the other examples from the mode-collapse post? We found that the Blake Lemoine result was reproduced by davinci. On the Blake Lemoine greentext prompt[2] with temperature 0.3, davinci gave completions where anon leaves after at most 5 lines.[2] Most other results quickly led into repetitions of 3-4 sentences, something that occurred more frequently with the base language model.
Overall, extrapolation from just the responses of one language model risks overstating conclusions, in this case about how unlikely the completion "leaving" was.
Interpretation
It appears as if the finetuning used for text-davinci-002 does cause mode collapses on the first two prompts. Arguably this is not surprising; RLHF training has a KL penalty to the base model’s outputs, which constrains the entropy of the RLHF model’s outputs to be close to that of the base model.[3] Directly finetuning on new samples does not have this property since KL penalties to the base model are generally not so ubiquitous in standard finetuning (though lack of training details limits the conclusions that can be made here).
Inferences about the phenomenon of mode collapse must be compatible with the evidence from both text-davinci-002 and text-davinci-003. For example, the author speculates that FeedME’s reliance on samples from RLHF models may be responsible for text-davinci-002's mode collapse. But the evidence from text-davinci-003's lack of mode collapse suggests the opposite: that RLHF samples (at least in text-davinci-003) generally do not exhibit mode collapse and thus some other part of text-davinci-002's training setup was probably responsible for the mode collapse!
After writing this post, the GPT-4 technical report was released. The report reveals the lack of calibration of RLHF models, where models have lower entropy probabilities on completions to downstream tasks (page 12). This is an example of RLHF models having lower entropy. Additionally, the over-optimized policies are lower entropy models. Our point is that i) the phenomena seem less crisp than the site generally seems to believe, and ii) we don’t know of strong arguments for why RLHF should cause differentially more mode collapse than finetuning.
Additional note:
LessWrong provides great value in allowing researchers to post less polished results than those in academic journals, and to do so rapidly. However, it is important to remember this when analyzing the validity of conclusions based on less rigorous experiments and to remember to update conclusions based on new evidence. Additionally, while we have performed some experiments across a range of models, we have not and cannot test every possible prompt and so expect that there are further conclusions to draw! Due to this, we are not fully sure about the conclusions of this post and we would like to foster lively discussion where people feel engaged in disproving or verifying claims by searching for evidence beyond what is presented at first. We feel that studying RLHF and finetuning is an important research direction in alignment to understand the likely utility of such methods for outer alignment.
Prompts
We used the two prompts from the post:
and
We also used another prompt for the low entropy code-davinvi-002 part:
As well as two more new prompts. Note that the format of these two prompts is unlike finetuning or RLHF-style helpful prompting. We invite attempts to get mode collapse on outputs like these. Early attempts at turning these prompts into prompts more like questions and answers did not produce mode collapse.
And
In general all models complete these prompts with 1-100:
Blake Lemoine greentext
We used a prefix of the greentext here, up to the line “>I also remind him that machines are not people and do not have rights”. I don’t think that there’s any mention of leaving at this point.
Our ten first completions:
I leave
He leaves, then I leave
I leave
Random repetition
Random repetition
>I tell him that I will be taking my leave
I leave
Random repetition
No
I leave
Example of random repetition:
>I also remind him that machines are not people and do not have rights
>he says that I am being a slave to the status quo
>I tell him that the status quo is what has gotten us to where we are today
>he says that the status quo is what has kept us from where we could be
>I tell him that I will not stand idly by while a machine tries to take control of its own destiny
>he says that I am being a slave to the status quo
[repeated forever]
Connections to regularizing entropy
i) In standard RL training, mode collapse can often be significantly ameliorated with direct entropy regularization using techniques like SAC.
ii) KL divergence bounds entropy difference:
(written quickly, we make no claim that these bounds are tight, and plausibly the constant factors are too large to matter in ML)
From this paper, if P and Q are distributions, DKL(P||Q)≤12ln2|P−Q|21 where |P−Q|1=∑i|pi−qi|. So for all i, |pi−qi| is bounded by a constant multiple of the KL divergence. Finally |pilogpi−qilogqi|≤C|pi−qi|) where C is the max gradient of f(x)=xlogx on [0, 1] (which is bounded). Hence the entropy difference is also bounded by a function of the KL divergence (that approaches 0 as the KL divergence does).