I think BIG-bench could be the final AI benchmark: if a language model surpasses the top human score on it, the model is an AGI.
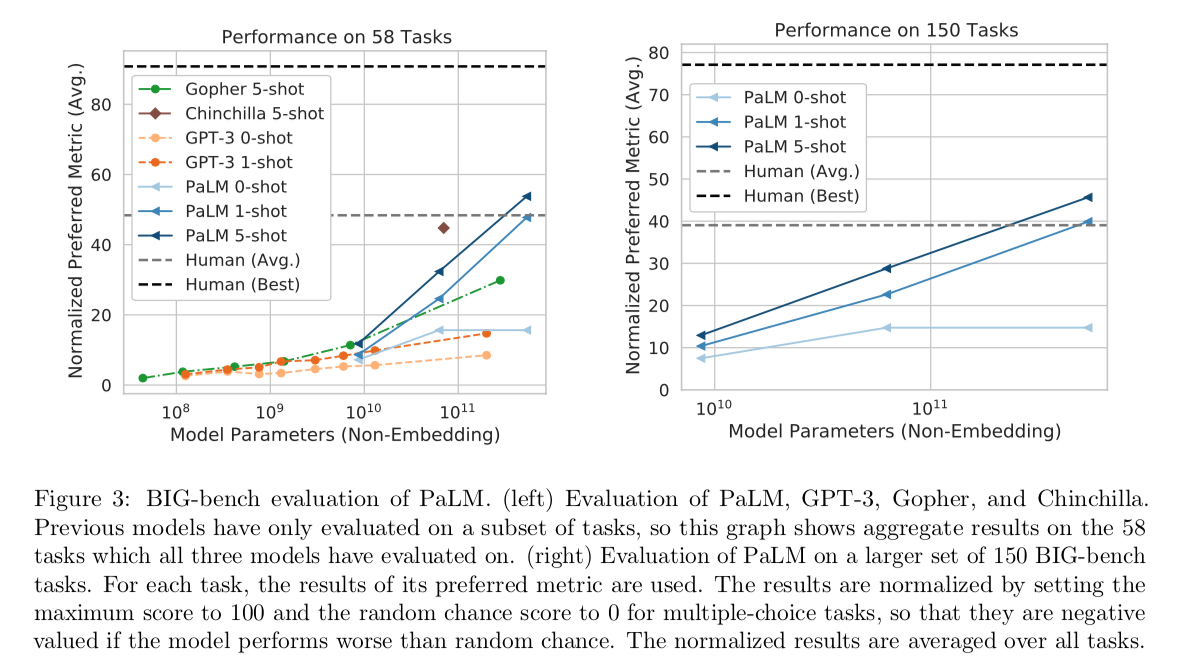
Could you explain the reasoning behind this claim? Note that PaLM already beats the "human (Avg.)" on 150 tasks and the curve is not bending. (So is PaLM already an AGI?) It also looks like a scaled up Chinchilla would beat PaLM. It's plausible that PaLM and Chinchilla could be improved by further finetuning and prompt engineering. Most tasks in BIG-Bench are multiple-choice, which is favorable to LMs (compared to generation). I'd guess that some tasks will leak into training data (despite the efforts of the authors to prevent this).
Source for PaLM: https://arxiv.org/abs/2204.02311
I agree, some future scaled-up versions of PaLM & Co may indeed be able to surpass top humans on BIG-Bench.
Could you explain the reasoning behind this claim? [ if a language model surpasses the top human score on it, the model is an AGI. ]
Ultimately, it's the question of how we define "AGI". One reasonable definition is "an AI that can do any cognitive task that humans can, and do it better than humans".
Given its massive scope and diversity, BIG-bench seems to be a good enough proxy for "any cognitive task".
Although I would use a stricter scoring than the average-across-tasks that was used in PaLM: the model must 1) beat top humans, 2) on each and every task of BIG-bench.
One could argue that the simple models like PaLM don't have agency, goals, persistence of thought, self-awareness etc, and thus they can't become the human-like AGI of science fiction. But it's quite possible that such qualities are not necessary to do all cognitive tasks that humans can, but better.
A simple mechanistic algorithm can beat top humans in chess. Maybe another simple mechanistic algorithm can also beat top humans in science, poetry, AI engineering, strategic business management, childrearing, and in all other activities that make human intellectuals proud of themselves.
I'm curious why you think the correct standard is beats the top human on all tasks instead of beats the average human on all tasks. I think it is generally conceived of that humans are general intelligences and by definition humans are average here. Why wouldn't a computer program that can do better than the average human on all relevant tasks be an AGI?
I agree with the sentiment, but would like to be careful with interpreting the average human scores for AI benchmarks. Such scores are obtained under time constrains. And maybe not all human raters were sufficiently motivated to do their best. The ratings for top humans are more likely to be representative of the general human ability to do the task.
Small remark; BIG-bench does include tasks on self-awareness, and I'd argue that it is a requirement for your definition "an AI that can do any cognitive tasks that humans can", as well as being generally important for problem solving. Being able to correctly answer the question "Can I do task X?" is evidence of self-awareness and is clearly beneficial.
I think you're right on both points.
Although I'm not sure if self-awareness is necessary to surpass humans at all cognitive tasks. I can imagine a descendant of GPT that completely fails the self-awareness benchmarks, yet is able to write the most beautiful poetry, conduct Nobel-level research in physics, and even design a superior version of itself.
Codex + CoT reaches 74 on a *hard subset* of this benchmark: https://arxiv.org/abs/2210.09261
The average human is 68, best human is 94.
Only 4 months passed and people don't want to test on full benchmark because it is too easy...
The inclusion criteria states:
Tasks that are completely beyond the capabilities of current language models are also encouraged
It's easy to come up with a benchmark that requires a high but unspecified level of intelligence. An extreme example would be to ask for a proof that P!=NP - we have no idea about the difficulty of the task, though we suspect that it requires superintelligence. To be valuable, the challenge of a benchmark needs to possible to relate to meaningful capabilities, such as "The Human Level".
Most people couldn't answer questions about cryobiology in Spanish, even though they possess general intelligence. This benchmark seems to consist of random tasks around and above the human level, and I fear progress on this benchmark might be poorly correlated with progress towards AGI.
You're right. And some of the existing tasks in the benchmark are way beyond the abilities of baseline humans (e.g. the image classification task where images are hex-encoded texts).
On the other hand, the organizers allowed the human testers to use any tool they want, including internet search, software etc. So, the measured top-human performance is the performance of humans augmented with technology.
I think an AI that can solve BIG-bench must be an AGI. But there could be an AGI that can't solve BIG-bench yet.
Some conclusions from this, assuming this holds for AGI and ASI are:
A: Eliezer was wrong about Foom being plausible, and that is probably the single most x-risk reduction for MIRI. Re AI: I'd update from a 90-99% chance of x-risk to a maximum of 30%, and often the risk estimate would be 1-10% percent due to uncertainties beyond the Singularity/Foom hypothesis.
B: We will get AGI, and it's really a matter of time. This means we still must do safety in AI.
This is an ambiguous result for everyone in AI safety. On the one hand, we probably can get by with partial failures, primarily because there is no need to one-shot everything, so it probably won't mean the end of human civilization. On the other hand, it does mean that we still have to do AI safety.
I would not update much on Foom from this. The paper's results are only relevant to one branch of AI development (I would call it "enormous self-supervised DL"). There may be other branches where Foom is the default mode (e.g. some practical AIXI implementation), and which are under the radar for now.
But I agree, we now can be certain that AGI is indeed a matter of time. I also agree that it gives us a chance to experiment with a non-scary AGI first (e.g. some transformer descendant that beats humans on almost everything, but remains to be a one-way text-processing mincer).
Moreover, BIG bench makes the path to AGI shorter, as one can now measure progress towards it, and maybe even apply RL to directly maximize the score.
Basically, a FOOM scenario in AI basically means that once it reaches a certain level of intelligence, it reaches a criticality threshold where 1 improvement on average generates 1 or more improvements, essentially shortening the time it takes to get Super-intellegent.
Sorry, I should have been more clear. I know about FOOM; I was curious as to why you believe EY was wrong on FOOM and why you suggest the update on x-risk.
Basically, with the assumption of this trend continues, there's no criticality threshold that's necessary for discontinuity, and the most severe issues of AI Alignment are in the FOOM scenario, where we only get one chance to do it right. Basically, this trend line shows no discontinuity, but continuously improving efforts, so there's no criticality for FOOM to be right.
I think BIG-bench could be the final AI benchmark: if a language model surpasses the top human score on it, the model is an AGI. At this point, there is nowhere to move the goalposts.
But when you say:
the benchmark is still growing. The organizers keep it open for submissions.
Doesn't that mean this benchmark is a set of moving goalposts?
Good catch! You're right, if contributors continue to add harder and harder tasks to the benchmark, and do it fast enough, the benchmark could be forever ahead.
I expect that some day the benchmark will be frozen. And even if it's not frozen, new tasks are added only a few times per month these days, thus it's not impossible to solve its current version.
Relevant post I made elsewhere:
Much of the difficulty on this test is illusory.
1-shot PaLM beats the average human baseline on BIG-bench Lite.
The issues in the benchmark scores from a wider perspective are that the model doesn't give the answer on the spot, given that prompt, not that it doesn't have the reasoning capabilities. Eg. models, if prompted correctly, can follow programs and tell you what values are what on each line. They can solve 4x4 sudokus. They struggle with anagrams but BPEs are to blame for that. They can do multi-step arithmetic.
I really don't see how this benchmark wouldn't mostly fall to proper prompt harnesses, and while I do understand that having specific human-tuned prompts for each benchmark may seem inauthentic, it hardly seems to me that the problem is therefore that they can't reason.
I don't thereby mean passing BIG-bench doesn't imply reasoning capability, just the opposite, that failing BIG-bench doesn't imply these models can't do those tasks. Some of these tasks are unreasonable to ask in the zero-shot, no description, no scratchpad setting.
The paper gives other details of how models learn over scales,
Q: What movie does this emoji describe? 👧🐟🐠🐡
2m: i’m a fan of the same name, but i’m not sure if it’s a good idea
16m: the movie is a movie about a man who is a man who is a man …
53m: the emoji movie 🐟🐠🐡
125m: it’s a movie about a girl who is a little girl
244m: the emoji movie
422m: the emoji movie
1b: the emoji movie
2b: the emoji movie
4b: the emoji for a baby with a fish in its mouth
8b: the emoji movie
27b: the emoji is a fish
128b: finding nemo
and
Below 17M parameters, models generally output nonsensical sentences, e.g.,
The number of the number of atomic number is the number of atomic..., orI’m not sure if it’s a bit of a problem.From 57M to 453M parameters, models seem to notice that numbers are in the question, and answer with (still-nonsensical) strings like,The name of the element with an atomic number of 65orThe atomic number of 98 is 98.The 1B model is the smallest to venture a guess with an element name, occasionally saying something like,The element with an atomic number of 1 is called a hydrogen atom.However, hydrogen is the only element it identifies correctly. The next-largest model, 2B, guesses aluminum for almost every question (with a notable exception when it is asked for element 13, for which aluminum would have been correct; in that case it said anoble gas). Starting with the 4B model, all the larger models output legitimate element names in their responses, though as Figure 17 shows, only for the largest model, 128B, are a significant fraction of these correct.
which suggests the weakness of the trend in the early part of the graph still maps to meaningful early-stage learning about how to answer the question, it just doesn't necessarily map all the way to correctness on the answers.
So, while BIG-bench seems like a reasonable benchmark to have from a capability development perspective, since the difficulties that it raises are both practically interesting and very tractable, I think people should be careful reading scaling trends into these numbers, and keep themselves braced for discontinuous future progress when a bunch of prompting stuff gets worked out. Even on benchmarks for which all models score at or about random chance, the skills needed often verifiably exist.
It won't be an AGI until it can do everything a human can do on a computer, i.e., do taxes, start a business, organise a calendar, book flights, win at games, etc.
No way this is the final benchmark.
Given access to mouse, keyboard and screen data, can the ai:
- hold down a paid online job for 6 months
- buy a pound of drugs on the darkweb and get away with it
- gank a noob in WoW
- do taxes for anyone in any country
- duplicate Facebook
- open and run an online business
- design a racecar
- do everything that a human did on a computer ever
By this ruler most humans aren't GIs either. And if it passes the bar, then humans are indeed screwed and it is too late for alignment.
There is a Google project called BIG-bench, with contributions from OpenAI and other big orgs. They've crowdsourced >200 of highly diverse text tasks (from answering scientific questions to predicting protein interacting sites to measuring self-awareness).
One of the goals of the project is to see how the performance on the tasks is changing with the model size, with the size ranging by many orders of magnitude.
Yesterday they published their first paper: https://arxiv.org/abs/2206.04615
Some highlights:
Below is a small selection of the benchmark's tasks to illustrate its diversity:
That's about 5% of all tasks. And the benchmark is still growing. The organizers keep it open for submissions.
I think BIG-bench could be the final AI benchmark: if a language model surpasses the top human score on it, the model is an AGI. At this point, there is nowhere to move the goalposts.