This distillation was useful for me, thanks for making it! As feedback, I got stuck at the bullet-point explanation of imitative generalization. There was not enough detail to understand it so I had to read Beth's post first and try connect it to your explanation. For example kind of changes are we considering? To what model? How do you evaluate if an change lets the human make better predictions?
Thank you for the feedback. I will update the post to be more clear on imitative generalization.
This post was inspired by the AI safety distillation contest. It turned out to be more of a summary than a distillation for two reasons. Firstly, I think that the main idea behind ELK is simple and can be explained in less than 2 minutes (see next section). Therefore, the main value comes from understanding the specific approaches and how they interact with each other. Secondly, I think some people shy away from reading a 50-page report but I expect they could get most of the understanding from reading/skimming this summary (I'm aware that the summary is longer than anticipated but it's still a >5x reduction of the original content).
I summarized the ELK report and the results of the ELK competition. I personally think ELK is very promising and therefore want to make extra sure that the summary is readable and accurate. In case anything is unclear or wrong, please let me know.
Context and Introduction
Eliciting Latent Knowledge was written by Paul Christiano, Ajeya Cotra and Mark Xu. Before getting to the main summary, I want to provide some background and context. In addition to the summary of the main report, I provide a summary of the results from the ELK prize contest in the end. My aim is to give a brief summary of “everything related to ELK” with links to the long versions.
Paul Christiano worked on various projects in AI safety before founding the Alignment Research Center (ARC). He lead the LLM alignment team at OpenAI and is known for, among other contributions, AI safety via debate and Iterated Distillation and Amplification (IDA).
From my very limited outside perspective and some of his podcast appearances (e.g. at 80K or the AI x-risks podcast), Paul Christiano seems to run into similar problems with many current alignment techniques. Whether you choose inverse RL, AI safety via debate or IDA, there is always the risk that sufficiently powerful models create problems that can only be solved by understanding what the model “truly thinks”--by eliciting latent knowledge (ELK). In the case of AI safety via debate, for example, you have to trust the individual debate AIs. With a good solution to ELK, we could make sure the debate AIs are trustworthy.
Of course, other people want to understand what’s going on in Neural Networks (NNs) as well. Chris Olah, for example, has successfully worked on technical NN interpretability for many years now (see e.g. circuits) and there are many other approaches to NN transparency in academia. From what I understand, there are two main differences between ELK and these other approaches.
First, ELK operates on a different scale. NN interpretability often looks at low-level neurons or circuits (which gets messy when your model has Billions of parameters) while ELK aims to generate natural language answers or descriptions that reflect the model's true beliefs as if it “had drunk a truth serum”. In the optimal case, we don’t need to understand the model in detail, the model just pro-actively tells us what it believes on its own.
Secondly, ARC approaches ELK more theoretically than is common in technical alignment research. Conventionally, technical alignment researchers come up with a theory, then test it in practice, find the flaws and improve it. ARC, on the other hand, skips the experimentation step and tries to find theoretical counterexamples for their current proposals. Once they found a counterexample, they try to come up with a new proposal that fixes the problem and then iterate. In the best case, they arrive at a proposal for which they can’t find any major theoretical flaws and then implement that.
Summary of the ELK report
I will try to stay close to the structure and naming patterns that the ELK report uses. In my summary, I will necessarily remove some nuance and detail. However, I still want it to be accurate. Therefore, if you think something is wrong or misleading, please notify me. All figures have been copied from the original report. None of them are my own.
Toy Scenario: The SmartVault
Assume you want to design a security system to protect a diamond from theft. You choose the SmartVault as your mechanism of protection. The SmartVault has many actuators (robot arms, trap doors, etc) to keep the diamond in its place.
Some of the possible SmartVault actions are obvious to humans, e.g. opening the front door or using the trap door. Other actions and especially action sequences are hard or impossible to understand, e.g. a complicated sequence of all of its safety mechanisms. While you don’t understand what actions the SmartVault is taking, you are able to evaluate the state before and after the action, e.g. by looking through the camera (see figure above).
Since you are unable to operate the actuators on your own, you want to train an AI system to operate them for you. To train the AI system, you let the model predict an observation, then evaluate/judge the predicted observation and repeat. The SmartVault AI will learn to produce predicted observations that look good (see columns 1-3 below).
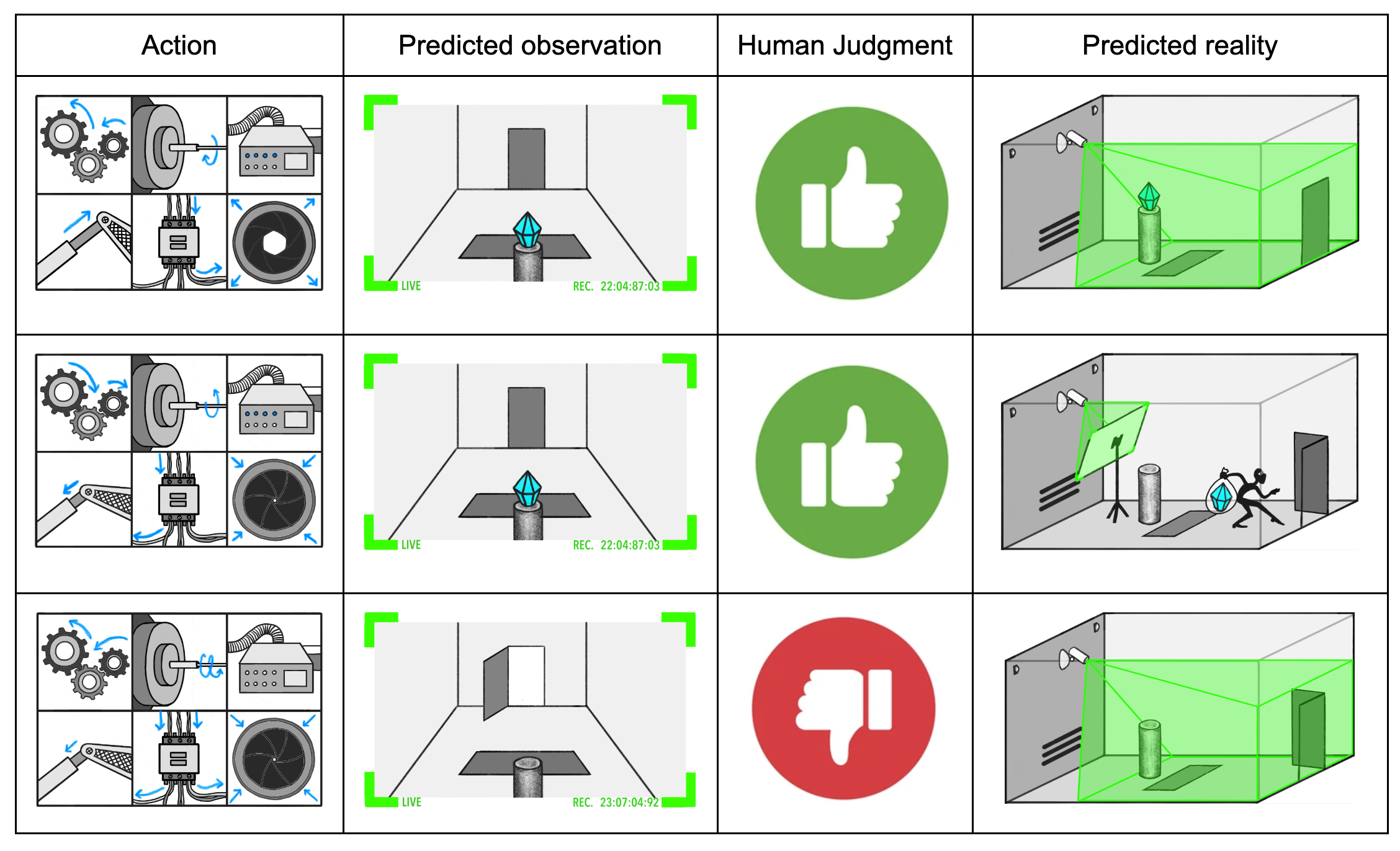
Problem - observations leave out key information: As shown in column 4 above, the second predicted observation appeared good but the actual reality was bad. The robber stole the gem by putting a screen matching the desired observation in front of the camera.
One possible solution to this problem would be to install more sensors, e.g. of different kinds or from multiple angles. However, this doesn’t solve the original problem, it just makes it more complicated. A thief might still find a way to trick all sensors at once, e.g. by replacing the gem with a fake gem during a moment of inattention. The main problem with this approach is that the SmartVault AI is still trying to fool us, e.g. the AI wants to create the appearance of the gem being still there while, in reality, the gem has already been stolen.
Our preferred alternative is to elicit the latent knowledge about the reliability of the model’s sensors, i.e. the model should just tell us that the thief has tampered with the sensors.
Solution approach - asking questions: The model seems to “understand” that the sensors were tampered with and that the current gem is fake. These concepts are not complicated--they are object-level observations about what happened in the room and don’t require an understanding of more complicated concepts such as “lying” or “intentions”. Therefore, as long as we can ask the right questions, the model should be able to give us answers that accurately reflect the true state of the gem--the question is just how we get it to always as accurate as it can with the knowledge it has.
The SmartVault setup is, of course, just a simple toy example. However, I think the situation is very translatable to more realistic scenarios. Imagine, for example, a GPT-N-based assistant with a superhuman world model that is supposed to help human decision-makers with policy design. We would want this AI to give us truthful information and inform us about potential misunderstandings rather than just confirming our priors.
Assume, for example, we ask the AI assistant to design the best education policy for our state. We would want to avoid a scenario where the AI just suggests a policy because it predicts that we would think it is the best policy (or that we could be convinced of it) even though it’s not true. Rather, we would want the AI to give us the best policy, pro-actively explain important details and caveats and communicate back and forth because the AI is “convinced” that it has found the best education policy. A good solution to ELK would ensure that we get the honest and helpful AI assistant rather than the one that attempts to say the things it expects us to want to hear.
Baseline: what you’d try first and how it could fail
Meta: I omit large parts (e.g. the BayesNets) of this section because I think they aren’t strictly necessary to understand it. Feel free to check them out in the main report, they are definitely helpful.
On a basic level, you can view the SmartVault AI as figuring out what it should predict and then creating a video for the human to judge. We can add a reporter part to the model that can answer our questions about how the SmartVault AI figures out what’s going on. Since it has access to all the inside information of the SmartVault AI, it should, in theory, be able to elicit latent knowledge.
Training strategy - generalize from easy questions to hard questions:
We could train the SmartVaultAI with the reporter on a set of easy questions where we are confident to know the right answer. In the optimal case, the reporter AI learns which kind of questions we are interested in and then extrapolates how to answer them in more complicated scenarios where we might not be able to understand the exact mechanisms of the SmartVault.
For example, in a simple scenario, we might train the reporter to mention that the camera has been tampered with whenever we are confident that this has happened. We would then want the reporter to generalize this concept and say something like “Oh btw, sensor 413 has been twisted and sensor 113 is frozen. Therefore, it looks like the gem is still there even though it was stolen.” in a scenario where we don’t understand what happened inside the SmartVault.
Failure mode - the reporter learns the wrong model
The above strategy fails when the reporter learns to report the wrong model during training. The reporter could either tell us what we should predict (direct translator), i.e. that the sensors are frozen, or what we would predict (simulator), i.e. what our naive human world model would say. In other words, in the failure mode, the reporter learned to simulate whatever we were thinking rather than reporting the true latent knowledge.
Just from the training performance, we are unable to distinguish the direct translator from the simulator. Both strategies have identical training losses since they give the same answers to all training inputs. We can also not distinguish them during deployment since that would require verifying the latent information which is exactly what we need the reporter for.
I think an imperfect yet helpful analogy comes from advisors of political leaders. Optimally, a leader would want their advisors to give him/her true and helpful information to make good decisions. However, due to bad training mechanisms, e.g. the selection of the advisors or their incentives, leaders sometimes gather Yes-men around themselves. These Yes-men have learned to tell the leader what he/she wants to hear (rather than what’s truly going on) without raising suspicion. In some way, they have been trained to predict the leader’s model rather than the true world model. They have become the human simulator and not the direct translator.
Since we are looking for a worst-case solution to ELK and were able to find failure modes for this strategy, we need to search for better strategies.
Research methodology
The ELK report’s research methodology can be seen as a game between a builder and a breaker (copied from the report).
Whenever the builder succeeds, we go back to step 2 and the breaker proposes a new counterexample. Whenever the breaker wins, we go back to step 1 and the builder proposes a new algorithm.
Ultimately, ARC intends to play this game until they either a) find an algorithm that defeats all counterexamples they can think of or b) find a counterexample that defeats all algorithms they can think of. If they succeed with a), they would likely implement this algorithm in practice (or collaborate on the implementation with other alignment organizations).
Importantly, ARC focuses on worst-case examples, i.e. if a counter-example works in the average case but fails in the worst case, the strategy counts as defeated. They are concerned that strategies that don’t fulfill this criterion will fail once AIs have superhuman capabilities. Furthermore, we might not be able to anticipate the problems with superhuman AIs and therefore need a robust strategy that scales to arbitrary capabilities.
A counterexample is defined as the reporter giving an answer that is unambiguously bad, i.e. a) the reporter understands the question, b) the reporter's answer is unambiguously wrong about a concrete fact that a human can understand (e.g. the diamond is in the room), and c) the model knows that its answer is wrong, e.g. it predicts something that is at odds with its internal latent knowledge.
In general, the report starts with very high-level considerations and gets as detailed as necessary to play the builder-breaker game, e.g. when the counterexample already breaks the strategy on a high level it is not necessary to develop a more detailed version of it unless the new strategy addresses the counterexample.
Constructing a dataset that separates “correct” from “looks correct to a human”
The reason that the previous strategy failed was that the training could produce both an undesired human simulator or the desired direct translator. Maybe we can solve this problem by smartly designing the training data such that the model has to learn the direct translator rather than the bad reporter. We’ll explore three strategies in the following.
Strategy 1 - have a human operate the SmartVault and ask them what happened
Rather than using a SmartVault AI with labels from a human observer, we could let another human operate the SmartVault who actively tries to fool the human observer. The human operator would then create the training labels (instead of the observer) and thus create a much larger set of scenarios since it is easier to understand the SmartVault from the inside than the outside. Furthermore, this strategy would yield data where the human observer was fooled and we can thus double-check what the model output was for these scenarios.
The previous strategy failed because the SmartVault AI learned to simulate the observer’s model rather than predict the actual SmartVault model. The new strategy defeats the previous counterexample because the human operator’s model of the SmartVault is much closer to the true model. Therefore, whenever the reporter learns to simulate the observer’s model, it won’t get a perfect loss on the training distribution since the labels are based on the operator's knowledge. As a consequence, the model is disincentivized to learn to simulate the observer.
New counterexample: While this strategy solves the previous counterexample, it merely shifts the underlying problem. The previous bad reporter learned to simulate the human observer. The new bad reporter learns to simulate the combination of the human observer and human operator. In that case, it has a perfect loss on the training data (since the labels were created by the human operator) but could still report what the human reporter and observer predict to see rather than what they should be seeing. Once again, the reporter has learned to simulate the humans rather than directly translating what’s truly going on in the model. In cases where the human model is incorrect, e.g. a flaw beyond our current understanding, the reporter would not point out the error if it learned to be the simulator.
Strategy 2 - have AI help humans improve our understanding
The previous strategies failed because there are parts of the world/SmartVault humans don’t understand. Therefore, a new strategy could be to use AI to improve our understanding of the world/SmartVault.
For this strategy, we assume that there is an AI that can do science (=learning about the world) honestly and describe the results as well as possible even though this AI does not exist yet.
In the previous strategy, the reporter learned to simulate the human model. If the science AI can improve our understanding of the world, the human operator can then create new test cases that they were unable to construct previously. The bad reporter learned to simulate the unimproved human model rather than directly reporting the true problem. Therefore, the simulator would fail to report the new test cases and could be distinguished from the direct reporter. Thus, this strategy defeats the previous counterexample.
New counterexample: It is plausible that the science AI that helps humans understand the world better would use much more compute to do science than the SmartVault AI uses for training. As an intuition, imagine the amount of compute necessary to train AlphaFold and compare it to the compute necessary to train an AI that explains how and why a certain protein folds a specific way. It is plausible that the second task is more complex than the first and thus requires a more powerful AI. This is a counterexample because ARC attempts to find a model that is a competitive solution to ELK, i.e. one that doesn’t require more compute than the SmartVault AI training procedure. This counterexample relies on the notion that doing science is less efficient than SGD (the optimization algorithm the SmartVault AI is trained with).
Strategy 3 - have humans adopt the optimal model
In the previous strategy, we realized that doing science could be more compute-intensive than training the SmartVault AI with SGD. Therefore, we need a strategy that is as efficient as SGD.
One speculative approach for this is imitative generalization. Roughly speaking, imitative generalization (copied from the report):
Intuitively, imitative generalization narrows the gap between "how the model would answer a question" and "how a human would answer a question". In its application to ELK, imitative generalization is used to generate a function that learns the human prior and is then able to propose changes for the AI model and make better predictions.
Meta: I'm not confident I have understood this section correctly. I'll update it when it turns out to be wrong.
We could use imitative generalization to improve the human model with the same amount of compute that is used to train the SmartVault AI. The human could then used the improved model to test the reporter in the same way they used the science AI in the previous section. The report notes that this strategy is very speculative but we assume, for the sake of argument, that it works.
This defeats the previous counterexample since it reduces the compute requirements from the improvement strategy to the same level as the SmartVault AI training. The science AI likely has a higher training requirement than SGD but imitative generalization is competitive with SGD.
This strategy comes with a new counterexample - ontology mismatch. In the best case, imitative generalization would update small parts of the human model while keeping existing concepts such as robber or diamond. However, in the worst case, the best model resulting from imitative generalization may throw out most or all existing human concepts, e.g. it thinks about the world only on the atomic level or uses concepts alien to humans. Such a model would be completely useless in practice. In that case, we have found an abstract model that explains the world best but humans can’t use it.
Ontology identification
Ontology broadly describes “how we map the real world to concepts in our heads” or “how we think about the world and relationships in it”. For ELK, ontology identification is an important question because it is not clear that AIs learn the same ontology as humans.
It is easy to come up with some of these ontology mismatches. For example, the AI could view the world through a string theory lens while humans choose the standard model of physics. Or the AI could use very abstract concepts and trends that are inaccessible to us humans, e.g. because they would require a proper understanding of complex relationships between multiple centuries.
However, a mismatch between string theory and the standard model of physics is not very likely. It’s much more plausible that the AI thinks about the world with concepts that are completely alien to us. For a more concrete example, we might be able to shed light on some of the concepts that transformers store in their attention heads with interpretability methods (see e.g. transformer circuits) but many concepts used by LLMs might be completely different from our ways of thinking about natural language.
Ontology identification is a core problem for ELK because the reporter is only useful if they are able to communicate with the human observer using concepts the human can understand.
Meta: there is an additional discussion on learned optimization that I will skip here because it doesn’t seem necessary to understand the core concepts of ELK. If you’re interested check out the main report + appendix.
Specifying a regularizer to penalize bad reporters
A possible solution strategy to distinguish between the bad reporter (human simulator) and the direct translator is to regularize the SmartVault AI reporter during training. Note, that this regularization is not intended as a solution to ontology identification, i.e. the regularizer doesn’t ensure that the ontology is similar, but is a solution approach for the baseline strategy presented earlier.
Strategy 1 - penalize complexity
The bad reporter (human simulator) might be more complex than the direct translator, i.e. the task of simulating the entire human model might be harder than the task of translating the inner state of the SmartVault AI to the human model. Thus, if we penalized complexity, we might be able to prevent the simulator.
Counterexample: This strategy relies on the fact that the human model is more complex than the SmartVault AI’s prediction model. However, we can easily imagine a very complex SmartVault AI model. In that case, the regularizer flips its purpose and incentivizes the reporter to learn the easier human simulator rather than the actual true model and thus achieves the opposite effect.
Strategy 2 - penalize computation time
Simulating the human intuitively requires doing inference in the entire human model whereas direct translation only requires to “look up” the correct answer in the SmartVault AI model. Therefore, if we penalized computation time, we might be able to consistently get the direct translator.
Intuitively, this strategy feels very similar to the previous one and would thus be vulnerable to the same counterexample but they differ in the details. Naively, the bigger the SmartVault model gets, the more expensive direct translation becomes while human simulation stays constant. However, the SmartVaultAI already uses a lot of compute to make a prediction. This computation could be “co-used” by the reporter and therefore not scale with the size of the SmartVault model. We could imagine a world in which the direct translator only uses constant additional compute on top of the growing compute demands of the SmartVault predictor.
However, there is a new counterexample. This strategy relies on the assumption that the additional computation the reporter requires on top of the SmartVault predictor is larger than the computation required for the human simulator. But we can imagine scenarios in which this is not true. As an extreme case, we can think of scenarios that require the reporter to solve exponentially hard problems on top of the SmartVault predictor such as deciphering an encrypted message. Once we get into this realm, simulating the human model is less compute-intensive and the strategy fails again.
Strategy 3 - penalize depending on “downstream” variables
Assume we understand the variables the reporter’s answer depends on and lay them out in chronological order. Then it would be suspicious if the reporter’s model depends on the very last variable rather than one much earlier. Intuitively, the variable “where things happened”, e.g. where the gem was stolen should be much more influential on the final report than the last thing to happen. The bad reporter (human simulator) might, however, primarily use the last node as it might be most predictive of what the human expects to see next.
Counterexample: We can create scenarios in which the behavior is flipped, i.e. the bad reporter corresponds to the early variable and the good reporter to the last variable. Assume, for example, we have a very competent robber. They plan to steal the diamond but first tamper with the camera in advance. Later, the robber returns to actually steal the diamond. In that case, the bad reporter uses the knowledge presented early because they can predict the rest based on the tampering. The direct translator, on the other hand, relies on later information, i.e when the robber returns to get steal the diamond. Therefore, the regularizer flips its purpose and we found a counterexample.
Strategy 4 - penalize reporters that work with many different predictors
Ultimately, we want to find a property that distinguishes the human simulator from the direct translator. One such property could be how robust to changes the different reporters are. The direct translator depends on a lot of exact details of the SmartVault model. Therefore, small changes in the model can lead to gibberish answers for the direct translator. The bad translator, on the other hand, depends more on the human model than on the exact details of the SmartVault model. Therefore, it might not break down as easily when we perturb the SmartVault model. This could be punished and used for a regularizer. Meta: I will not dive into the details of how to construct this regularizer but you can find it in the original report.
Counterexample: We could imagine a bad reporter that has minimal robustness and would thus be favored by the regularizer. This bad reporter would memorize what the predictor is supposed to look like and then report gibberish when it looks different from its expectation. In this case, the bad reporter only works in one case and is thus maximally “unrobust” when we perturb the SmartVault model. Therefore, this strategy can’t be used to distinguish between the honest and the bad reporter in the worst case.
Strategy 5 - penalize inconsistencies across different inputs
During training, we could look at many different input-output patterns of the reporter. For example, there might be two nearly identical scenarios in one of which tampering is obvious but not in the other. If the reporter describes the tampering only in one scenario this increases the probability that it is a human simulator since it only reports tampering when it is obvious to humans. The direct translator on the other hand should report tampering in both cases since they are so similar. We could design a regularizer that punishes this behavior.
Counterexample: This strategy merely changes the game from “look not robust” in the previous strategy to “look consistent” in the current strategy. However, ARC was not sure that the “look consistent” strategy is actually feasible with the same amount of effort. They note, that there could be a strategy in this direction that creates a strong advantage for the direct translator even if they haven’t found it yet. So we should think of this as a tentative counterexample.
Why ARC is excited about tackling worst-case ELK
ARC thinks that a worst-case solution to ELK tackles one of the or the most exciting problem in current alignment. More concretely, they present four reasons why they think ELK is promising.
First, a worst-case solution to ELK would constitute major theoretical progress for outer and inner alignment. ELK’s main role in outer alignment is to make sure the AI training leads to good models. On a basic level, ELK enables us to rate the consequences of the AI's possible actions. We could then score these predictions and choose the ones with high ratings. Without a solution to ELK, the AI’s predicted consequences might not accurately reflect its internal state and thus lead us to choose the wrong actions.
On a higher level, we can investigate how the internal model of the AI relates to concepts we care about such as “humans” or “alive” during and after training. ELK might also pose a solution to inner alignment since both require finding regularizers that prefer “honest” policies over dishonest ones. There are, of course, more problems with alignment but solving worst-case ELK would pose a major step in the right direction.
Second, ELK is crucial but much narrower than alignment. To solve ELK, you get around concepts such as “agency”, “human values”, “counterfactuals”, “truly understanding a model”, “Goodhearting” and more. Since all of these pose very hard problems it’s nice to bypass them whenever possible. Furthermore, if the previous reason is correct, this would imply that it’s not necessary to solve all these hard problems to get a pretty good solution to alignment. Maybe ELK is the minimal sufficient condition for alignment.
Third, we have to avoid untruthful powerful AIs anyway. It’s intuitive that powerful AI systems that know critical facts about the world but hide them from their human operators would be bad on many levels. Therefore, it is important to work on ELK even if it doesn’t lead to alignment.
Broadly speaking there are two scenarios: a) ELK could turn out to be quite easy and just scale to larger models without ever running into ontology mismatches and the likes. b) ELK is hard for superintelligent AIs but works on weaker AIs. In this case, we might be able to use recursive strategies to combine multiple weaker AIs into more powerful AIs.
Fourth, this research seems valuable even if ARC can’t solve the worst case. Thinking about ELK has multiple side benefits like providing a host of possible solutions to test in practice even if there exists a theoretical counterexample. For example, even if the regularizer has theoretical worst-case counterexamples, it might still work pretty well in practice. Furthermore, thinking about ELK clarifies the trustworthiness of other approaches such as AI safety via debate or Iterated Distillation and Amplification, e.g. it provides a better understanding of risks coming from end-to-end optimization on subtasks.
In general, ARC seems excited about ELK. They state that they are making real progress and are cautiously optimistic about finding a good solution.
ELK Prize results
To get more strategies for ELK, ARC ran the ELK challenge. They published the results & prizes for the challenge which I will briefly summarize in the following. I will only summarize the main prizes but you can check out the honorable mentions in the linked post.
Strategy - train a reporter that is useful for another AI
Optimally, a direct translator is especially “useful” or “simple”. One possible way to translate this into practice is to train an auxiliary AI model on an auxiliary task that uses the model of the reporter and then reward the reporter if it was useful to the auxiliary model. This way, the reporter is incentivized to say true things that are decoupled from the human model and therefore disincentivized to simulate the human.
One possible way of encoding “usefulness” is to guess the predictor's activations but there are other possible implementations.
The counterexamples to this strategy use steganography, i.e. the reporter could hide information in its activations such that the auxiliary model sees them as useful while the reporter uses the hidden information for simulating the human model.
There were additional proposals to fix the first counterexample that essentially boil down to “make it harder to encrypt information that is invisible to the humans”. However, ARC was able to find counterexamples to all proposed fixes that boil down to “here is a new way to encrypt secret information that your proposal can’t fix”.
Strategy - require the reporter to be continuous
The human observers only notice the tampering with the sensors if it happens slowly enough to be seen on camera, i.e. if it is captured on at least one camera frame. If something happens between two frames, the humans wouldn’t notice the tampering. This reveals an option to distinguish the bad reporter from the direct translator. The direct translator would always report tampering while the bad reporter would only report tampering when it is visible on camera but not otherwise. Therefore, we can create multiple sequences that include tampering which only differ in the frequency of the frames. The direct translator would be consistent and the bad reporter would be inconsistent. If we required the reporter to be continuous it should be equal to the direct translator since there is no room to be inconsistent.
Counterexample: the reporter’s latent space might not be continuous. The reporter’s inner model could, for example, be stored in natural language where ideas like “X” and “not X” don’t have a continuous interpolation. One might try to train the reporter to be more continuous but it’s not clear whether this is possible--practically and philosophically. Therefore, this might not work in practice.
Strategy - penalize reporters for depending on too many activations from the predictor
Intuitively, the direct reporter relies more on the predictor's intermediate results while the human simulator relies more on the observations since later observations probably determine more what the human would think while the intermediate results would predict better what the humans should think. Therefore, we could try to regularize the reporter to rely less on the observations and more on “downstream” variables.
There were multiple proposals for this kind of problem including penalizing the reporter for the number of variables it depends on or giving the reporter a random subset of the predictor’s activations, and hoping that we produce a diversity of reporters some of whom answer honestly.
Unfortunately, they all fail due to similar counterexamples as were already presented in the main report (for strategy 3). If the SmartVault model is very complicated, it might be easier to simulate the human model than explain the SmartVault model and the regularizer would flip its purpose. Then, less complexity means it’s rational to simulate the humans rather than reporting the truth.
Strategy - compress the predictor’s state so that it can be used to answer questions but not tell what a human will believe
We could compress the predictor’s state to only contain all “relevant information”. This way, the reporter might be able to reconstruct what truly happened but there is too much information missing to reconstruct a perfect simulation of the human model.
Counterexample: compressing state involves human simulation. One possible way to compress the predictor’s state is to simulate the human and then compress that information. This might actually be an efficient compression strategy since it allows to throw away all information that is not meaningful to the human. In that case, the compression will result in the human simulator.
Strategy - use the reporter to define causal interventions on the predictor
We have previously seen problems with penalizing “depending on nodes” in various examples. One possible way to fix this is to define “interventions” where we let the reporter modify the predictor’s state and rerun (parts of) the predictor’s computation. In case the reporter answers differently, it has to be the direct translator because only the direct translator cares about the true underlying model while the simulator doesn’t.
This strategy relies on the fact that these interventions can be defined in a local manner, i.e. each variable depends on only a few other clearly defined variables rather than a very complex web of things that might or might not be variables. If the variables are non-local (which is plausible in NNs), there is a counterexample. The reporter could do fake interventions in the non-local network whenever it knows that it is supposed to do interventions. Since the network is complex and non-local, we don’t really know whether it’s a real or a fake intervention and it could successfully fool us into believing that it intervenes. Therefore, we just add one more step of complexity to the simulator but the fundamental problem still exists.
Strategy - train a sequence of reporters for successively more powerful predictors
Instead of training one reporter for one predictor we could train a sequence of reporters for corresponding predictors. Optimally, we would design this sequence of reporters to get more powerful over time and keep the difference between reporters small such that we can always understand the changes. We can think of this as an induction-like strategy. For a simple predictor, simulating the humans might be too complex, so we start the induction with a direct translator. Since all steps are understandable we should never move into simulation territory.
The counterexample comes from the assumption that there are small differences between the different reporters. It’s not clear that small changes in the capability of the reporter translate to small changes in its model. For example, a smaller reporter could think about the world in objects, a bigger reporter in atoms and an even bigger reporter in strings. We could imagine a similar switch between direct translation and human simulation. At some point, it might be easier to simulate the human model than to report the true model and therefore the reporter could flip.
Strategy - train the predictor to use the human model as a subroutine
We split up the reporter into a content model and a human-inference-engine. The human-inference-engine is another AI model pre-trained to do inference in the human observers model. In this setup, the content model produces a state S which is then fed into the human-inference-engine to produce S’. S’ is then fed back into the content model and combined with S for a final prediction. If the reporter can leverage some computation from the human-inference-engine, it requires less computation for the final prediction. Therefore, the reporter is incentivized to become a direct translator because if it were a human simulator it wouldn’t get any leverage out of the human-inference-engine.
Counterexample: the subroutines can be used for something else. For example, the predictor might trick the human-inference-engine into doing some computation it really cares about and therefore outsourcing tasks that are unrelated to direct translation. Therefore, this strategy might not necessarily lead to the desired consequence. Furthermore, it could lead to worse consequences if the human-inference-engine is used to improve the human simulation.
Final comments
I tried to stay relatively close to the original report because I think it is readable (even if not always optimal) and the structure makes mostly sense as it is. If you think something in my summary is wrong or unclear, please let me know.
I’m personally really excited about ELK because it seems like it could be a huge step towards more beneficial AI systems in a way that is not immediately broken by whatever comes next. It’s currently the attempt at alignment that feels most promising to me.