This model strikes me as far more detailed than its inputs are known, which worries me. Maybe I’m being unfair here, I acknowledge the possibility I’m misunderstanding your methodology or aim—I’m sorry if so!—but I currently feel confused about how almost any of these input parameters were chosen or estimated.
Take your estimate of room for “fundamental improvements in the brain’s learning algorithm,” for example—you grant it's hard to know, but nonetheless estimate it as around “3-30x.” How was this range chosen? Why not 300x, or 3 million? From what I understand the known physical limits—e.g., Landauer's bound, the Carnot limit—barely constrain this estimate at all. I'm curious if you disagree, or if not, what constrains your estimate?
This model strikes me as far more detailed than its inputs are known
The model is very simple. Literally four lines of code:
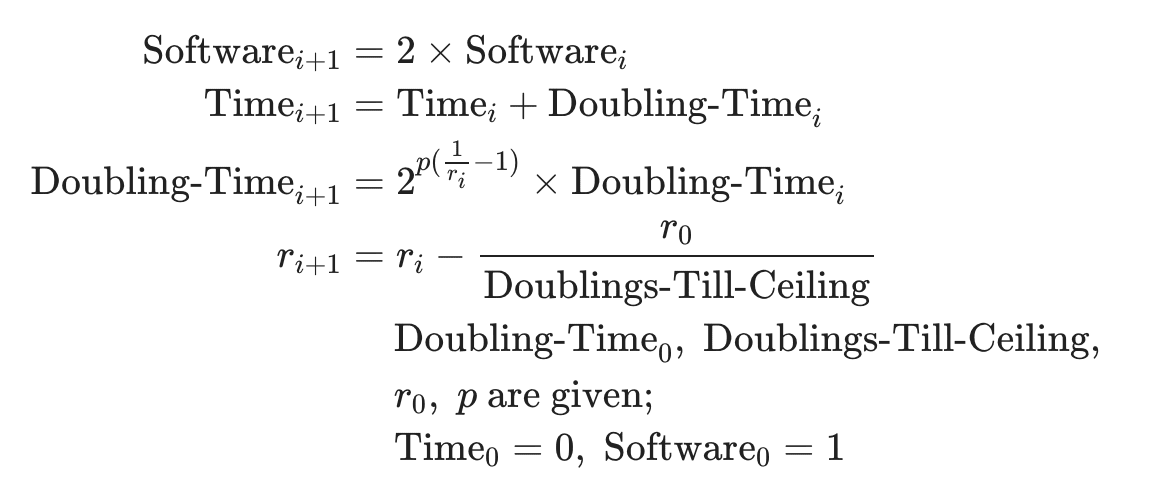
This post is long, but it's not long because it's describing a complicated model. It's long because it's trying to estimate the inputs as well as possible.
Take your estimate of room for “fundamental improvements in the brain’s learning algorithm,” for example—you grant it's hard to know, but nonetheless estimate it as around “3-30x.”
Yeah I think you've honed in on exactly the right subpart here. This is essentially the "and all other possible improvements" part of the estimate of the distance to ultimate limits, which is especially ungrounded.
Some of the other parts of the "distance to limits" section focus on specific improvements that are a bit easier to roughly ballpark. But one reviewer pointed out that there could be further fundamental improvements, which seemed right to me, and I wanted to avoid being biased in the conservative direction by not including it.
My basic methodology for this section was to interview various people about ways in which efficiency could improve beyond the brain level and how big they guessed these gains would be, and then have ppl review the results. But, as I say in the paper multiple times, the estimates for effective limits are especially speculative.
So I think it's totally fair to say: the uncertainty on this param is way bigger than what's you've done in your Monte Carlo, you should have a much wider range and so put more probability on really dramatic intelligence explosions. E.g. Lukas Finnveden makes a similar point in another comment.
But I don't think of this as a flaw in the model:
- It's just true of reality that there's a lot of uncertainty about the distance for effective limits for software, and it's just true of reality that that translates into a lot of uncertainty about how big an SIE might be. So it seems like the model's doing a good job in capturing that.
- And yes, I think i've probably underestimated the extent of this uncertainty in this analysis.
- As I said above, the model isn't complicated. So there's not some problem of fitting a model with lots of gears and surprising interaction effects to multiple params that have massive uncertainties, resulting in predictions that we don't know where they came from. The model inputs flow through to the bottom line in ways that are very simple and transparent. Lukas has another comment that does a good job of explaining this.
Fwiw, I think it could be possible to substantially improve upon my estimates of the effective limits param but spending a week researching and interviewing experts. I'd be excited for someone to do that!
I agree the function and parameters themselves are simple, but the process by which you estimate their values is not. Your paper explaining this process and the resulting forecast is 40 pages, and features a Monte Carlo simulation, the Cobb-Douglas model of software progress, the Jones economic growth model (which the paper describes as a “semi-endogenous law of motion for AI software”), and many similarly technical arcana.
To be clear, my worry is less that the model includes too many ad hoc free parameters, such that it seems overfit, than that the level of complexity and seeming-rigor is quite disproportionate to the solidity of its epistemic justification.
For example, the section we discussed above (estimating the “gap from human learning to effective limits”) describes a few ways ideal learning might outperform human learning—e.g., that ideal systems might have more and better data, update more efficiently, benefit from communicating with other super-smart systems, etc. And indeed I agree these seem like some of the ways learning algorithms might be improved.
But I feel confused by the estimates of room for improvement given these factors. For example, the paper suggests better “data quality” could improve learning efficiency by “at least 3x and plausibly 300x.” But why not three thousand, or three million, or any other physically-possible number? Does some consideration described in the paper rule these out, or even give reason to suspect they’re less likely than your estimate?
I feel similarly confused by the estimate of overall room for improvement in learning efficiency. If I understand correctly, the paper suggests this limit—the maximum improvement in learning efficiency a recursively self-improving superintelligence could gain, beyond the efficiency of human brains—is "4-10 OOMs," which it describes as equivalent to 4-10 "years of AI progress, at the rate of progress seen in recent years."
Perhaps I’m missing something, and again I'm sorry if so, but after reading the paper carefully twice I don’t see any arguments that justify this choice of range. Why do you expect the limit of learning efficiency for a recursively self-improving superintelligence is 4-10 recent-progress-years above humans?
Most other estimates in the paper seem to me like they were made from a similar epistemic state. For example, half the inputs to the estimate of takeoff slope from automating AI R&D come from asking 5 lab employees to guess; I don't see any justification for the estimate of diminishing returns to parallel labor, etc. And so I feel worried overall that readers will mistake the formality of the presentation of these estimates as evidence that they meaningfully constrain or provide evidence for the paper’s takeoff forecast.
I realize it is difficult to predict the future, especially in respects so dissimilar from anything that has occurred before. And I think it can be useful to share even crude estimates, when that is all we have, so long as that crudeness is clearly stressed and kept in mind. But from my perspective, this paper—which you describe as evaluating “exactly how dramatic the software intelligence explosion will be”!—really quite under-stresses this.
Hi,
I agree the function and parameters themselves are simple, but the process by which you estimate their values is not. Your paper explaining this process and the resulting forecast is 40 pages, and features a Monte Carlo simulation, the Cobb-Douglas model of software progress, the Jones economic growth model (which the paper describes as a “semi-endogenous law of motion for AI software”), and many similarly technical arcana.
Could you explain why you think it's bad if the "process by which I estimate parameter values" is too complex? What specific things were overly complex?
The specific things you mention don't make sense to me.
the resulting forecast is 40 pages,
(Fwiw, it's 20-25 pages excluding figures and appendices)
To my mind, identifying a model with a small number of key params, and then carefully assessing each param from as many different angles as possible, is a good approach. Yes, I could have approached each param from fewer angles, but that would make the overall estimate less robust.
Monte Carlo simulation
You surely know this, but running the Monte Carlo simulation doesn't add complexity to the process of estimating the values (given that i'm estimating ranges in any case). And it seems pretty useful to do given the massive uncertainty.
Cobb-Douglas model of software progress, the Jones economic growth model
The "Cobb-Douglas model" and the "Jones economic growth model" are the same thing, and used to derive the 4 line model mentioned above. Mentioning these terms doesn't add complexity to the process of estimating the params. Tbh, i'm confused and a bit frustrated at you calling me out for using these terms. The implict accusation that I'm using them to aggrandize my paper. But neither of these terms appear in the summary. They appear in the main body essentially the bare minimum number of times, I think once each. Would you prefer I didn't mention them these standard terms for (very simple!) math models?
and many similarly technical arcana
I basically think you're being unfair here, so want to challenge you to actually name these or retract.
... So that's my response to the charge that the param estimates are overly complicated. But I want to respond to one other point you make, that i'm v sympathetic to.
level of... seeming-rigor is quite disproportionate to the solidity of its epistemic justification
This feels like maybe more the core thing you're reacting to here.
I was worried about the paper coming off in this way. An earlier draft had more caveats and repeated them more often. Reviewers suggested I was being excessive. I'll take yours comments here as a sign that I should have ignored them.
But the paper is still very clear and explicit about its limitations.
Quote from the summary (that will be read way more than any references to "Cobb Douglas" or "Jones model") [bolded emphasis in the original]:
- "Our model is extremely basic and has many limitations"
- “Garbage in, garbage out”. We’ve done our best to estimate the model parameters, but there are massive uncertainties in all of them"
- A previous draft highlight the distance to limits here as an acute example - I think you're right about this
- "Overall, we think of this model as a back-of-the-envelope calculation. It’s our best guess, and we think there are some meaningful takeaways, but we don’t put much faith in the specific numbers."
I basically think you're being unfair here, so want to challenge you to actually name these or retract.
... So that's my response to the charge that the param estimates are overly complicated. But I want to respond to one other point you make
It sounds like we're talking past each other, if you think I'm making two different points. The concern I'm trying to express is that this takeoff model—by which I mean the overall model/argument/forecast presented in the paper, not just the literal code—strikes me as containing confusingly much detail/statistics/elaboration/formality, given (what seems to me like) the extreme sparsity of evidence for its component estimates.
the paper is still very clear and explicit about its limitations
I grant and (genuinely) appreciate that the paper includes many caveats. I think that helps a bunch, and indeed helps on exactly the dimension of my objection. In contrast, I think it probably anti-helped to describe the paper as forecasting "exactly how big" the intelligence explosion will be, in a sense constrained by years of research on the question.
It seems to me that demand for knowledge about how advanced AI will go, and about what we might do to make it go better, currently far outstrips supply. There are a lot of people who would like very much to have less uncertainty about takeoff dynamics, some of whom I expect might even make importantly different decisions as a result.
... and realistically, I think many of those people probably won't spend hours carefully reading the report, as I did. And I expect the average such person is likely to greatly overestimate the amount of evidence the paper actually contains for its headline takeoff forecast.
Most obviously, from my perspective, I expect most casual readers to assume that a forecast billed as modeling "exactly how big" the intelligence explosion might be, is likely to contain evidence about the magnitude of the explosion! But I see no evidence—not even informal argument—in the paper about the limits that determine this magnitude, and unless I misunderstand your comments it seems you agree?
I think it probably anti-helped to describe the paper as forecasting "exactly how big"
That's fair. I've removed the word "exactly" from the top of this paper. Edits will take a few days to process on the website version.
(I definitely didn't intend "exactly" to connote precision. I wanted to highlight that the paper was focussed on the extent of the intelligence explosion, in contrast with our previous paper which argued that there could be accelerating progress but didn't analyse how big the resulting SIE might be. Some reviewers were confused at the contrast. For the tweet, I think i was also subconsciously imitating the first tweet of AI-2027 which said "How, exactly, could AI take over by 2027". But I agree the word "exactly" here could easily be misread as implying the paper gives precise results, which is an oversight.)
Fwiw, the results table gives the results to 1 sig fig and uses "~" repeatedly to avoid the impression of false precision. And the paper explicitly says "While the exact numbers here are obviously not to be trusted...", before giving what I believe are more robust takeaways. In the discussion opens with "If this analysis is right in broad strokes" (emphasis mine).
The twitter thread also said "It goes without saying: the model is very basic and has many big limitations" and "We estimate these three parameters through a mix of empirical evidence and guesswork". The lead tweet also said "This is my best stab at an answer", which i thought connoted an informal, modest and tentative answer. (emphasis mine)
This is all to say that, again, i'm sympathetic with the worry that people will overestimated the precision and accuracy of the analysis and made significant efforts to avoid this. Honestly, I'd guess I made greater efforts than most similarly-speculative posts in this reference class. That said, I suspect we still disagree a lot about the amount of signal in this analysis, which is probably coming into play here.
And I expect the average such person is likely to greatly overestimate the amount of evidence the paper actually contains for its headline takeoff forecast.
I think that this paper contains comparable or greater amounts of evidence to Yudkowsky's Intelligence Explosion Microeconomics, Bostrom's Superintelligence, and AI-2027's takeoff speed analysis. (In large part it contains this because I'm able to steal what I consider the most relevant insights from this previous work.) My own (biased!) opinion is that this is the best analysis we have on this question. It contains multiple angles on estimating the initial speed up from deplying ASARA, analysis of the value of r (which i think is hugely important), analysis of room to improve AI algs before matching humans, and some estimates/guesses at how much far certain improvements above human-level algs might go.
And it seems to me like you could level similar objections against previous these takeoff speeds analyses. Intelligence Explosion Microeconomics is also a paper, and it's name "microeconomics" suggests that it's going to do some empirically grounded mathematical modelling of the dynamics of recursive improvement. (I think it's a great paper!) AI-2027 placed probability distributions over their parameters and ran a Monte Carlo (I believe). Superintelligence is an academic-style book. I think my work has similar or more disclaimers about how speculative it is than these other pieces. I'm not knocking these papers! I'm just claiming that I don't think my paper is out of line of previous work in this regard.
I also think the evidential situation is here comparable (though probably more dire) to the evidence about AI timelines and AI alignment. The evidence doesn't really constrain reality very much. But ppl still publish best-guess estimates/analyses.
Still, I do agree that it's very easy for lay readers to overestimate how much evidence underpins the best analyses that the world has on these questions. The fact that this is even a paper puts it in a reference class of "papers", and most papers aren't about AGI-related stuff and are much less speculative. I felt this was at play with titotal's critique of AI-2027. My experience reading it was "yeah these objections aren't that surprising to me, what did expect from smg forecasting AGI and superintelligence". And this pushes towards being even more upfront about the limitations of the analysis.
I see no evidence—not even informal argument—in the paper about the limits that determine this magnitude, and unless I misunderstand your comments it seems you agree?
No i don't. I think the paper contains meaningful evidence about the magnitude.
First, evidence that r is quite plausibly already below 1. If so, the SIE won't last long. This makes is plausible that we get <3 years of progress.
Second, pointing out that 10 years of progress is ~10 OOMs of efficiency gains, which is a large amount relative to efficiency gains we've historically seen in ML, more than the total efficiency gains we've ever seen in many tech areas, and comparable to those we've ever seen in computing hardware. Even if r > 1 when we first develop ASARA, I think there's a good chance that it falls below 1 during the course of 10 OOMs of progress. (Especially given the possibility of compute bottlenecks kicking in as cognitive inputs are massively increased but compute increases much more slowly.)
Third, evidence about the gap from ASARA algs to human-level algs. If this gap had been much bigger or much smaller, that should update our beliefs about how long the SIE will go on for.
Fourth, somewhat-transparent quantitative estimates of some the factors that are additional alg gains above human-level. E.g. "brain is severely undertrained", "low fraction of data is relevant", "variation between humans". For these estimates, a reader can see roughly where the number is coming from.
Fifth, listing additional possible gains without transparent estimates of their quantitive size. Here, as I said, the process was speaking to people with relevant expertise and asking them to eye-ball/guess at the gain. So yes, these numbers are particularly untrustworthy! But to my mind they still contain some signal. It might have been that this process didn't uncover any significant improvements beyond the brain. In fact though, there are multiple plausibly-big improvements, which did significantly widen my personal credences on how big the IE might be. In hindsight, I should have put in more effort to making all these estimates transparent, and flagged more clearly how big this uncertainty is.
You could summarise this all as "no evidence about the limits" bc, for some of these factors, there's no explicit argument the factor isn't absolutely massive. So if you came in with a strong view that one factor was massive, you won't be much moved. But that misses that, for people in many epistemic situations, the five pieces of evidence i've just listed here will be informative.
Fyi, your comments have convinced me to add some additional qualifiers on this point:
- To the top of the paper, just before the summary, we'll add: Like all analyses of this topic, this paper is necessarily speculative. We draw on evidence where we can, but the results are significantly influenced by guesswork and subjective judgement.
- To the table cell on limits, we'll add: This involves a fair amount of guesswork and is a massive remaining uncertainty.
- To the section estimating limits, we'll add: some of the factors listed are plausibly even bigger than our upper estimate, e.g. “must satisfy physical constraints” and "fundamental improvements”.
The concern I'm trying to express is that this takeoff model—by which I mean the overall model/argument/forecast presented in the paper, not just the literal code—strikes me as containing confusingly much detail/statistics/elaboration/formality, given (what seems to me like) the extreme sparsity of evidence for its component estimates.
I'm still not sure I'm understanding you here. If you're sole concern is about the paper giving a misleading impression of accuracy/robustness, then I understand and am sympathetic.
But do you also think that the paper's predictions would be better if I gave less detail?
I'm genuinely unsure if you think this. You initially claimed that the model is overly complex, which can lead to worse predictions by overfitting to noisy evidence. But you then instead claimed the parameter estimates were too complex, without giving any examples of what specific parts were misguided. What specific evidence/reasoning on which param do you think it would have been better to cut? (Not just bc it makes the paper seem overly fancy, but it makes the paper's predictions worse.) I think we'll need to get much more specific here to make progress.
Perhaps you think I shouldn't have specified precise math or run a Monte Carlo? I get that concern re giving a misleading impression of robustness. But I think dropping the Monte Carlo would have made the predictions worse and the paper less useful. A precise math model makes the reasoning transparent. It makes it easier for others to build on the work. It also allows us to more accurately calculate the implications of the assumptions we make. It allows other to change the assumptions and look at how the results change. This has already been helpful for discussing the model in the LW comments for this post! I think it's better to include the Monte Carlo for those benefits and clearly state the limitations of the analysis, than to make the analysis worse by excluding the Monte Carlo.
in a sense constrained by years of research on the question
I have spent many years researching this topic, and that did inform this paper in many ways. I don't it's misleading to say this.
(fyi i'll prob duck out after this point, hope my comments have been clarifying and thx for the discuission!)
Could you explain why you think it's bad if the "process by which I estimate parameter values" is too complex? What specific things were overly complex?
Generally speaking, the output of a process is only as accurate as the least accurate of its inputs or steps. There is no point for example calculating up to the 10th significant digit the area of a square whose side you only know with a 10% margin of error. I think the risk here is the same - if the process is sophisticated and full of complex non-linear interactions, then it would need proportionately accurate inputs for the errors not to explode. Otherwise it's genuinely better to just offer a vibe-y guess.
I agree with the general point, but don't think it applies to this model.
I'm not calculating anything to a high degree of precision, inputs or outputs.
There aren't complicated interaction effects with lots of noisy inputs such that the model might overfit to noise.
I could have dropped the code, but then i'd have a worse understanding of what my best-guess inputs imply about the output. And it the analysis would be less transparent. And other couldn't run it for their preferred inputs.
I just feel like the length and complexity of the thinking involved is all fundamentally undermined by this uncertainty. The consequences are almost entirely parameter-determined (since as you say, the core model is very simple). Something like how many OOM gains are possible before hitting limits for example is key - this is literally what makes the difference between a world with slightly better software engineering, one in which all software engineers and scientists are now unemployed because AIs completely wipe the floor with them, and one in which ASI iteratively self-improves its way to physical godhood and takes over the light-cone. And I feel like something of that kind implies so many answers to very open questions about the world, the nature of intelligence and of computation itself, I'm not sure how could any estimate produce anything else than some kind of almost circular reasoning.
If I understand correctly, the paper suggests this limit—the maximum improvement in learning efficiency a recursively self-improving superintelligence could gain, beyond the efficiency of human brains—is "4-10 OOMs," which it describes as equivalent to 4-10 "years of AI progress, at the rate of progress seen in recent years."
Perhaps I’m missing something, and again I'm sorry if so, but after reading the paper carefully twice I don’t see any arguments that justify this choice of range. Why do you expect the limit of learning efficiency for a recursively self-improving superintelligence is 4-10 recent-progress-years above humans?
Oh there's lots of arguments feeding into that range. Look at this part of the paper. There's a long list of bullet points of different ways that superintelligences could be more efficient than humans. Each of the estimates have a range of X-Y OOMs. Then:
Overall, the additional learning efficiency gains from these sources suggest that effective limits are 4 - 12 OOMs above the human brain. The high end seems extremely high, and we think there’s some risk of double counting some of the gains here in the different buckets, so we will bring down our high end to 10 OOMs.
Here: 4 is supposed to be the product of all the lower numbers guessed-at above ("X" in "X-Y"), and 12 is supposed to be the product of all the upper numbers ("Y" in "X-Y").
I was trying to figure out where this claim comes from: "the software intelligence explosion will probably (~60%) compress >3 years of AI progress into <1 year, but is somewhat unlikely (~20%) to compress >10 years into <1 year". Curious if you think this is accurate.
First: "the software intelligence explosion will probably (~60%) compress >3 years of AI progress into <1 year".
- With constant r=1, we get 3 years of progress in 1 year iff the initial speed-up is >6. (Because we need software to go 6 times faster to make up for 3 years of progress, if software has contributed half of the recent AI progress.)
- 3 years of progress is 3 OOMs of progress, which is 10 doublings. This creates decent room for r to bite (since r changes the speed at every doubling). If r is notably greater than 1, there's a very high probability of clearing 3 years of progress in 1 year, if r is notably lower than 1, there's a very low probability. This parameter is somewhat more important than the initial speed-up, but high or low initial speed-up can flip the results for r around 1.
- The report estimates speed-up is slightly more likely than not to be above 6 (median is 8) and r is slightly more likely than not to be above 1 (median is 1.2), so overall this means 3 years of AI progress in 1 year is somewhat more likely than not.
- What about upper bounds on progress? There are probably significantly further away than 3 years worth of progress, so they don't matter much. (The model starts lowering r immediately to approach 0, but this is slow enough that it only cuts the probability of 3 years' worth of progress by 5-10%.)
Second: "the software intelligence explosion is somewhat unlikely (~20%) to compress >10 years into <1 year".
From playing around with the model, I get:
- If I remove the upper bound on software progress without modifying other parameters, there's a ~60/40 chance of getting 10 years of progress (indeed, an arbitrary number of years of progress) in ≤1 year. Presumably this approximately corresponds to the probability that r is greater than 1.
- If I set r=3.6 without modifying other parameters, there's a ~60/40 of getting 10 years of progress in ≤1 year (and also ≤4 months). Presumably this corresponds to the probability that the upper bound is >10 years.
- If I set r to be constant (until the software upper limit is reached), we get 33%, which is approximately 0.6*0.6. (I.e approximately equal to the probability that none of the above two are blockers.)
- Intitial speed matters somewhat less here, because 10 years of progress is enough that r matters much more. (But it can move the probability up or down by 5-10% relative to the default model settings.)
So a simplified argument for why >10 years in <1 year is unlikely coud be roughly:
- If there weren't any upper bounds, we'd be a bit more likely than 50/50 to reach infinity in 1 year. But it's only a bit more likely than 50/50 that 10 years of progress is even possible with arbitrarily powerful technology. Multiplying these together, we get a probability that's somewhat greater than a quarter, let's say a third.
- But progress probably will probably slow down a lot before hitting the ultimate limits (rather than keep going at full speed and then crash into the ceiling). It's very unclear how to model this, but let's say you need a bit of extra margin for both the upper bound and for r — maybe you need the upper bound to allow for like 11 years of progress (because the last year might be slow) and for r to be greater than 1.5 (so the speed of progress has time to gather up a bit of momentum before it goes below 1). 11 years of progress is around 50/50 likely, and r greater than 1.5 is a bit below 50/50, so now we're a bit below one quarter, say 20%.
Nice! Yep this is a great analysis and checks out for me. I think it's really valuable to back-out qualitative stories to support the conclusions of these models. Thanks very much.
I think it's possible to get more sceptical of >10 years in <1 year by saying:
- Even if r >> 1 today, that's not strong evidence r will remain >1 until we're very near effective limits. E.g. suppose r = 4 today, and effective limits of tech are 15 OOMs away. There's a good chance r falls below r after a few OOMs of progress. But my model assumes that r would remain above 1 until we're very close to limits. So my model is too aggressive.
- This relates to you saying "It's very unclear how to model this, but let's say you need a bit of extra margin for both the upper bound and for r — maybe you need the upper bound to allow for like 11 years of progress (because the last year might be slow) and for r to be greater than 1.5 (so the speed of progress has time to gather up a bit of momentum before it goes below 1)." Plausibly you need to add more margin than you've done there for this to go through. (Though as you point out in another comment, it's plausible my values for limits are too conservative.)
Thanks for this post!
Caveat: I haven't read this very closely yet, and I'm not an economist. I'm finding it hard to understand why you think it's reasonable to model an increase in capabilities by an increase in number of parallel copies. That is: in the returns to R&D section, you look at data on how increasing numbers of human-level researchers in AI affect algorithmic progress, but we have ~no data on what happens when you sample researchers from a very different (and superhuman) capability profile. It seems to me entirely plausible that a few months into the intelligence explosion, the best AI researchers are qualitatively superintelligent enough that their research advances per month aren't the sort of thing that could be done by ~any number of humans[1] acting in parallel in a month. I acknowledge that this is probably not tractable to model, but that seems like a problem because it seems to me that this qualitative superintelligence is a (maybe the) key driving force of the intelligence explosion.
Some intuition pumps for why this seems reasonably likely:
- My understanding is that historians of science disagree on whether science is driven mostly by a few geniuses or not. It probably varies by discipline, and by how understanding-driven progress is. Compared to other fields in hard STEM, ML is currently probably less understanding-driven right now, but it is still relatively understanding-driven. I think there are good reasons to think that it could plausibly transition to being more understanding driven when the researchers become superhuman, because interp, agent foundations, GOFAI etc haven't made zero progress and don't seem fundamentally impossible to me. And if capabilities research becomes loaded on understanding very complicated things, then it could become extremely dependent on quite how capable the most capable researchers are in a way that can't easily be substituted for by more human-level researchers.
- Suppose I take a smart human and give them the ability/bandwidth to memorise and understand the entire internet. That person would be really different to any normal human, and also really different to any group of humans. So when they try to do research, they approach the tree of ideas to pick the low hanging fruit from a different direction to all of society's research efforts beforehand, so it seems possible that from their perspective there is a lot of low hanging fruit left on the tree — lots of things that seem easy from their vantage point and nearly impossible to grasp from our perspective[2]. And, research into how much diminishing returns we've seen to ideas in the field is not useful for predicting how much research progress that enhanced human would make in their first year.
- It seems hard to know quite how many angles of approach there are on the tree of ideas, but it seems possible to me that on more than one occasion when you build a new AI that is now the most intelligent being in the world, it starts doing research and finds many ideas that are easy for it and near impossible for all the beings in the world that came before it.
- ^
or at least only by an extremely large number of humans, who are doing something more like brute force search and less like thinking
- ^
This is basically the same idea as Dwarkesh's point that a human-level LLM should be able to make all sorts of new discoveries by connecting dots that humans can't connect because we can't read and take in the whole internet.
Great question - thanks!
I agree that a large fraction, and probably most, of the progress here will be driven by increases in qualitative intelligence, rather than running more parallel copies of having copies think faster. Especially because we will be relatively "rich" in parallel copies during this period, so may hitting sharper DMR to doubling the parallel copies even further than we have hit today.
I do try to estimate the size of the effect of having qualitatively smarter researchers and incorporate it into the model.
Basically, I look at data for how a marginal increase in qualitative capability increases productivity today, and translate that into an equivalent marginal increase in parallel copies. So while it might be impossible for any number of average-capability ppl to make as much progress as one super-genius, we can ask how many average-capability ppl would make similarly fast progress to one slightly-above-average-capability person. So maybe we find that one standard deviation increase in productivity within the human distribution is equivalent to increasing the number of parallel researchers by 3X, which we think speeds up the pace of progress by 1.5X.
Then I chain that forward through to higher capability levels. I.e. I assume that every standard deviation increase will continue to speed up the pace of progress by 1.5X. Now eventually we'll be considering the super-genius, and we think perhaps that he can speed up progress by 10X, and we'll think that (in reality) no number of parallel average-capability ppl could have done a similarly-sized speed-up. But that's all ok as long as our two core assumptions (the first standard deviation speeds up progress by 1.5X, and other standard deviations are the same) hold.
(In the model itself, we translate all this into parallel equivalents. But the model also assumes that the DMR to adding more parallel copies stays constant even as the number of "parallel copies" becomes absurdly high. In this example, it assumes that each time you 3X the number of "parallel copies", the pace of progress increases by 1.5X, no matter how many parallel copies you already have. Now, this assumption is unrealistic in the extreme when we're considering literal parallel copies. But it's actually an appropriate assumption to make when most of our "parallel copies" are actually coming from more qualitative capability and we expect the effects of increasing qualitative capability to stay constant. So I think the model makes two unrealistic assumptions that (hopefully!) roughly cancel out in expectation. First, it translates qualitative capability gains to parallel copies. Second, it assumes that adding more parallel copies continues to be helpful without limit. But that's ok, as long as qualitative capability gains continue to be helpful without limit.)
I just calculated what my median parameters imply about this the productivity gains to marginal more qualitative capability. (FYI, I link to my data sources for calculating the marginal impact of more capable models -- search for "upwards for improving capabilities".) I'm implicitly assuming that a 10X increase in effective training compute increases the pace of researcher progress by 4X. (See sheet.)
In the same sheet, I also just did a new calculation of the same quantity by using 1) AI-2027's survey of lab researchers to estimate the productivity gain from replacing median researchers with experts, and 2) Ryan Greenblatt's estimate of how much effective compute is needed to increase capability from a worse to better human expert. This produced only 2.2X -- and it might be higher if all the gains were used to increase qualiatively capability (Ryan imagines some being used for more copies and faster thinking) (Edited to add: I initially though this was only 1.5X, which was out of whack with my assumptions). That's a fairly big discrepancy, suggesting I may have given too much weight to qualitative capability increases. Though combined with my other assumptions this calc implies that, on the current margin, doubling effective training compute and running the same number of copies would be worse than running 2X as many parallel copies, which seems wrong (see cell D9).
Anyway, that's all to say that your question is a great one, and I've tried to incorporate the key consideration you're pointing to, but as you predicted it's hard to model well and so this is a big source of uncertainty in the model. It enters into my estimate of r.
when you build a new AI that is now the most intelligent being in the world, it starts doing research and finds many ideas that are easy for it and near impossible for all the beings in the world that came before it.
This is an interesting argument for thinking that the returns to intelligence as you move above the human range will be bigger than the returns within that range. In principle you could measure that by considering the humans who are literally the very best. Or by seeing how the returns to intelligence change as you approach that person. As you hone in on the most intelligent person, they should increasingly benefit from this "there's no one else to pluck the low-hanging fruit" effect.
And my guess is that doing this would tend to increase the estimated effect here. E.g. AI-2027's survey compared the median to the top expert. But maybe if it had compared the 10th best to the very best, the predicted speed-up would have been similar, and so i'd have calculated a more intense speed-up per OOM of extra effective compute. (More than the 2.2X per OOM that I in fact calculated.)
From a skim, seems you should be using the 6.25x value rather than the 2.5x in B2 of your sheet. If I'm skimming it correctly, 6.25x is the estimate for replacing a hypothetical all median lab with a hypothetical all top researcher lab. This is what occurs when you improve your ASARA model. Whereas, 2.5x is the estimate for replacing the actual lab with an all top lab.
This still gives a lower than 4x value, but I think if you plug in reasonable log-normals 4x will be within your 90% CI, and so it seems fine.
Thanks, great catch. Corrected this.
And i realise Ryan's seemingly assuming we only use some of the gains for better qualitative capabilities. So that would further reduce the discrepancy.
No compute growth. The simulation assumes that compute doesn’t grow at all after ASARA is deployed, which is obviously a conservative assumption.
Since compute will in fact be 2-4x'ing a year, probably, during the intelligence explosion, and since it's such a huge contributor to AI progress on your model, I'm curious why you didn't model this. Or at least do some sort of rough calculation e.g. "Our median guess is that 6 years of progress would be compressed into 2 years without compute increases, but since compute will be increasing, we guess 6 years will be compressed into 1 year." Is this something you plan to do in the future? Could you do a quick and dirty version of it right now?
Sure! Here's a few thoughts:
- Conservative take. Compute will keep growing at its current rate. Its current rate contributes 0.5 years of progress per year -- because ~half of AI progress is driven by compute. So including compute growth will increase the "number of years of progress compressed into 1 year" by 0.5. This is a pretty small effect as it would just move us from (e.g.) 4 years to 4.5 years.
- More aggressive take. We should also model the interaction effects. Growing compute will itself speed up software progress. How big is this effect?
- If r = 0.5, then (in equilibrium) each doubling of compute drives one doubling of software. So then rather than an extra 0.5 years this is an extra 1 year.
- If r >= 1 then progress is accelerating anyway. The extra compute means it will accelerate faster. How much faster? Well having 3X the compute might convert to 3X more training compute and 3X more runtime compute. My model implies that 10X more training compute gives you a 4X speed-up. (Which may be aggressive.) So 3X more training compute would be a 2X speed-up. Could bump to 3X speed-up due to the additional runtime compute. So overall this would make the slower tail-end of the IE happen 2-3X faster. So you cram more progress into 1 year before things slow down. Would need to model to know how much, but maybe the r = 0.5 estimate from above is about right (if the IE slows down when r = 0.5). So again this would be pointing to an extra year.
- We do simulate this! We have a 'gradual boost' model variant in which compute grows exponentially in the background. Compute is 'meant' to stop growing when you have ASARA in the model, but you could simply choose a higher "initial boost" and you'll be effectively simulating compute growing after ASARA. Just pick an above-ASARA capability threshold and choose your initial boost to match that.
- I was surprised when I ran the simulations of this variant that there were notably more aggressive when I adjusted other params to fit the fact that the sim starts before ASARA.
- I do think this model is probably the best one. It can simulate a gradual approach to ASARA and compute growth during the SIE. Probably is worth doing more sensitivity analyses on its behaviour. You can do that in the online tool!
I notice I am confused. I generally think that after full automation of AI R&D, AI progress will be approximately linear in compute, so e.g. 10xing compute would make progress go like 8x faster overall rather than e.g. simply adding 0.5 years of progress per year to the many years of progress per year already being produced. It seems like you disagree? Or maybe I'm just mathing wrong. Exponentials are unintuitive.
Think we agree on that.
My last comment says:
So 3X more training compute would be a 2X speed-up. Could bump to 3X speed-up due to the additional runtime compute. So overall this would make the slower tail-end of the IE happen 2-3X faster.
I.e. roughly linear.
So this does mean the IE happens faster. I.e. 10 years in 6 months rather than in 12 months.
But i was then commenting on how long it goes on for. Where i think the extra compute makes less difference between once r<1 things slow down fairly quickly. So you maybe still only get ~11 years in 12 months.
Could use the online tool to figure this out. Just do two runs, and in one of them double the 'initial speed'. That has a similar effect to doubling compute.
Thanks very much for this post!
Overall, the additional learning efficiency gains from these sources suggest that effective limits are 4 - 12 OOMs above the human brain. The high end seems extremely high, and we think there’s some risk of double counting some of the gains here in the different buckets, so we will bring down our high end to 10 OOMs.
When I count I get the lower bound 4 OOMs but the upper bound as 5+1+2.5+2+1+1.5+1=14 OOMs, rather than 12 OOMs. (On "Low fraction of data", you say "at least 3-10" so maybe the upper bound should really be higher there? 14 is assuming that it's 1.)
FWIW, I'm also not sure that I find the high end to be so extremely high. We're talking about the limits of what's possible with arbitrarily powerful technology. We don't really have reference points to that kind of things. And it's not totally unheard of to make this kinds of progress — I think we made ~8 OOMs of progress in cost of transistors between 1969 and 2005 (based on the appendix of this paper), tough obviously this is somewhat cherry-picked.
One reason for scepticism here is that these gains in training efficiency would be much bigger than anything we’ve seen historically. Epoch reports the training efficiency for GPT-2 increasing by 2 OOMs in a three year period, but doesn't find examples of much bigger gains over any time period.
Are you referring to GPT-2-level performance, here? If so, that would be an example of "downwards" progress rather than "upwards" progress, right? Where we expect less "downwards" progress to be possible. I guess it's harder to measure the "upwards" ones.
Thanks for these great comments!
When I count I get the lower bound 4 OOMs but the upper bound as 5+1+2.5+2+1+1.5+1=14 OOMs, rather than 12 OOMs
Oops, you're completely right. Great catch! For now I'm going to just leave the mainline results at 10 OOMs and edit the initial calc to land on 14 OOMs.
But I do think it's worth exploring how sensitive the results are to this. I used the online tool to rerun the analysis increasing the upper bound from 10 OOMs to 16 OOMs. (That's adding in 2 OOMs extra for the possibility some of my upper-bound ranges were too low, like the example you flagged.)
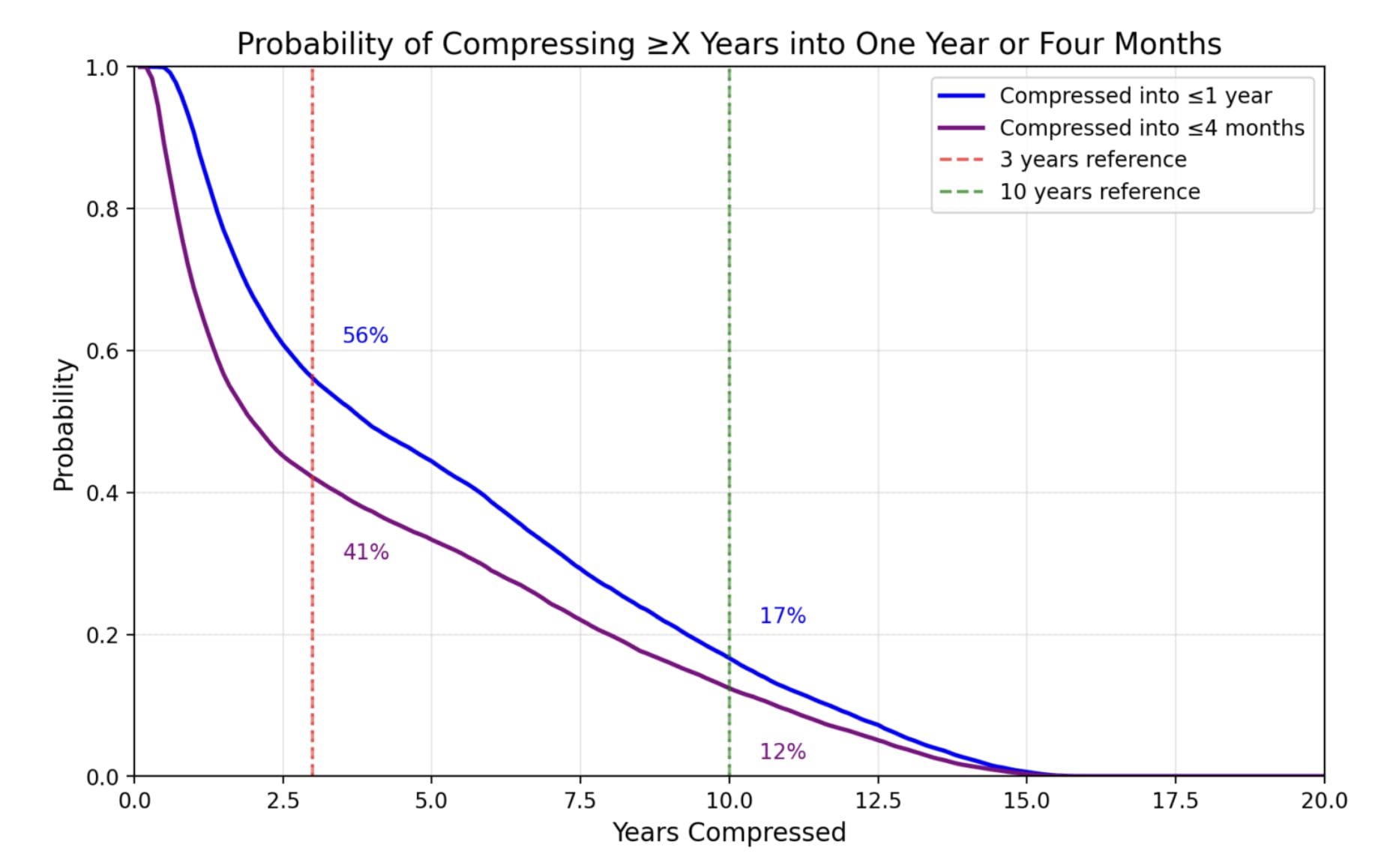
Let's compare the key results. First, the old results with 10 OOMs:
Second, the new results with 16 OOMs:
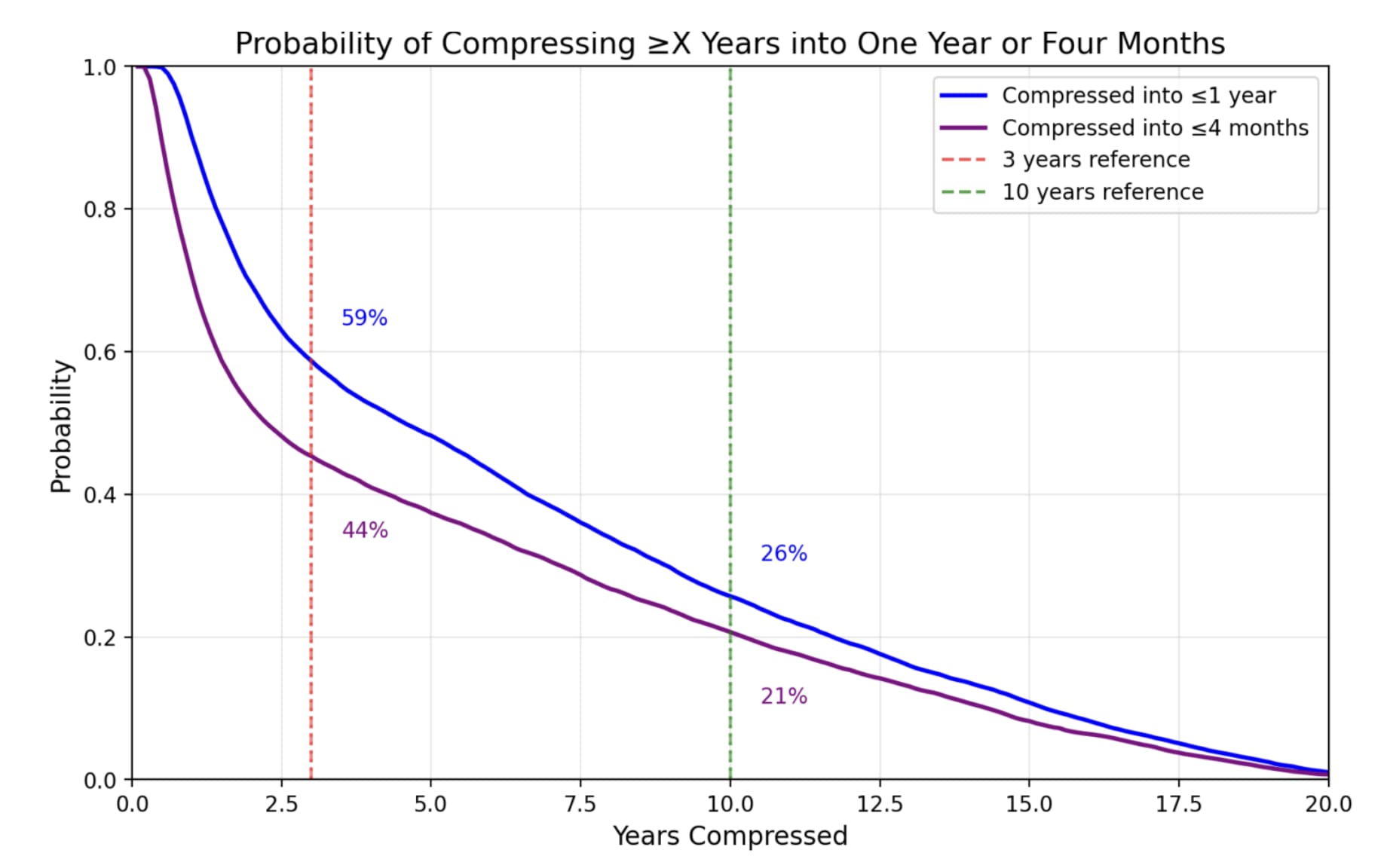
So the probability of >3 years of progress in <1 year or <4 months doesn't change much.
But the probability of >10 years of progress in <1 year or <4 months goes up a decent amount, a ~10% increase from a baseline of ~15%.
And the probability of >15 years in <4 months rises from ~0% to ~10%.
I think using 16 OOMs instead of 10 OOMs here is reasonable (though it seems too high to me), and so it's reasonable to want to bump up your numbers here.
> One reason for scepticism here is that these gains in training efficiency would be much bigger than anything we’ve seen historically.
Are you referring to GPT-2-level performance, here? If so, that would be an example of "downwards" progress rather than "upwards" progress, right? Where we expect less "downwards" progress to be possible. I guess it's harder to measure the "upwards" ones.
This is a great point that I hadn't appreciated. Epoch looked for algorithmic progress at a fixed capability level and never found improvements much bigger than 2 OOMs that they were confident in. (Both for GPT-2-level performance and other levels of performance I think, though the paper I think focuses on GPT-2 level.)
I'm not aware of data on upwards improvements. It should be possible in principle to look at. How good a model can you train with GPT-2-level/GPT-3-level compute today? How much compute would you have needed for that when the GPT-2/GPT-3 was first developed, extrapolating the scaling curves at that time?
So this does weaken the argument against a large upper bound here, thanks.
FWIW, I'm also not sure that I find the high end to be so extremely high. We're talking about the limits of what's possible with arbitrarily powerful technology. We don't really have reference points to that kind of things. And it's not totally unheard of to make this kinds of progress — I think we made ~8 OOMs of progress in cost of transistors between 1969 and 2005
That is a great example, though I think it starts from a place where the technology is much worse than that produced by evolution. My recollection is that the brain is still more efficient at FLOP per Joule than our best chips today. It would be interesting to estimate how far you could go beyond brain efficiency before hitting a limit.
Here I roughly estimate you could get 3e19 FLOP/J within Landauer’s limit. (You could go further with reversible computing.) That compares to the brain that each second does ~1e15 FLOP with 20 Joules --> 5e13 FLOP/J. (Which is a bit better than today's chips, yes.) So that leaves ~6 OOMs of progress above the brain before hitting limits. That's less than 14 OOMs, but only ~2X less in log space.
I think that one point that the paper doesn't address is that the model treats "software progress" as basically "how many parallel copies can you run on a fixed device" but the human brain isn't really parallelizable in that way, and serial compute is expensive (A B300 can do ~15e15 FLOP/s, but it runs at ~2 GHz, so it's hard-bounded to at most ~2e9 sequential operations per second, and realistically, for AI applications, far fewer). That pushes things slightly more toward being hardware-limited than the compute-constant framing suggests, at least if the sample-efficient architectures turn out to be serial-bound.
One reason current training parallelizes so well is the batch size, an LLM pass processes ~1M tokens at once, so training's serial depth is tiny relative to its compute. The brain has no such mechanism: it can't read a million tokens in one shot, it learns from a narrow, time-ordered channel. So if brain-like sample efficiency requires that kind of small-batch learning, a full run would take a large number of sequential steps. However, the brain sets a low bar for speed: a neuron fires ~once a second, so biological learning advances one serial step per second, and transistors should demolish that. But with current hardware you hit a throughput wall, even a sample-efficient model is still big (I'd assume even non-traditional architectures need large memory for real intelligence, although the full memory might be used only for search and not required for a single step), so running it one input at a time is memory-bandwidth-bound, i.e. LLM inference speed. Passing ~1B tokens serially through a 100B-param model is roughly a week at ~1000 tok/s (only slightly better with more GPUs), whereas the same raw FLOP at full utilization is only hours (~1e9 × 100e9 / 1.5e16 ≈ 26,000 s). So the bottleneck flips from compute to serial throughput.
But that ~1000 tok/s is an artifact of one specific operation, which is taking a single activation vector and multiplying it by big parameter matrices. A different (token × parameter) computation, or the same one restructured, could be faster, and current transistor-based GPUs could be used in less conventional ways, or FPGAs could take over if standard GPUs turn out to be fundamentally ill-suited, without requiring new hardware manufacturing.
I imagine that brain-like approaches would require some sort of active learning that is bounded by serial compute/inference, but maybe there could be concurrency or parallelization-based approaches to keep sample efficiency with parallelization, the question is whether those exist even if we allow a superintelligence to design the software.
At 1000 tokens per second, the gap ends up being hours vs. days-or-weeks, so it's very small compared to the 6-16 OOMs mentioned in the paper, and it shrinks once the hardware is optimized (until cooling/power/transistor efficiency becomes the limiting factor). Also, even if the algorithm is serial-bound, this gap could probably only affect training/learning, or certain tasks.
Overall I think that the idea that sample-efficient architectures might be serial-bound due to having a limited information flow is something to take into account, but there are stacking factors that lower the likelihood of it mattering (new hardware, hardware repurposing for new architectures, high sample efficiency with parallel learning, learning/inference steps not requiring passes through every parameter, and parallel intelligence still being able to perform most tasks). And most importantly, even in the strongest case for serial-inefficiency, it would likely only matter by ~1-2 OOMs.
It's also worth noting that this specific bottleneck is almost exactly what neuromorphic hardware, and some LLM inference hardware is built to address. The serial inefficiency in the LLM case comes mostly from memory bandwidth, the von Neumann architecture memory-CPU split means weights sit in separate memory and have to be streamed to the compute units every step, and with batch-1 there's no way to amortize that transfer. Neuromorphic (and more broadly in-memory-compute) architectures attack this directly by putting the memory on the chip itself, co-located with compute, so the weight is physically where it's used and there's no fetch, which is precisely the batch-1 case that GPUs are worst at. So there's already an active hardware research program aimed at the exact wall this argument depends on, which further suggests the serial penalty is soft rather than fundamental.
This is nicely put together as usual! Sadly still leaves me feeling uncomfortable. Trying to put my finger on why, and I think it's at least two things.
Mainly: lumping so many things together as a single scalar 'software' just smells really off to me! Perhaps I'm 'too close' to the problem, having got deep on the nitty gritty of pretty well all aspects of software here at one time or another. You definitely flag that admirably, and have some discussion on how to make those things sort of commensurable. I do think it's important to at least distinguish efficiency from 'quality', and perhaps to go further (e.g. distinguishing training from runtime efficiencies, or even speed from parallel efficiencies).
I also think in treatment of R&D it's important to distinguish steady/stock 'quality' from learning/accrual 'quality', and to acknowledge that all of these things deprecate as you move through scale regimes: today's insights may or may not stand up to a 10x or a 100x of your system parameters. This makes sample efficient generalisation and exploratory heuristics+planning really key.
Related to this (and I'm less sure, having not deeply interrogated the details), I feel like some double counting of factors is going into the estimates of parameters, especially . But I can imagine retracting this on further scrutiny.
We simulate AI progress after the deployment of ASARA.
We assume that half of recent AI progress comes from using more compute in AI development and the other half comes from improved software. (“Software” here refers to AI algorithms, data, fine-tuning, scaffolding, inference-time techniques like o1 — all the sources of AI progress other than additional compute.) We assume compute is constant and only simulate software progress.
We assume that software progress is driven by two inputs: 1) cognitive labour for designing better AI algorithms, and 2) compute for experiments to test new algorithms. Compute for experiments is assumed to be constant. Cognitive labour is proportional to the level of software, reflecting the fact AI has automated AI research.
Your definition of software includes all data, which strikes me as an unusual use of the term so I'll put it in scare quotes.
You say half of recent AI progress came from "software" and half comes from compute. Then in your diagram, the cognitive labor gained from better AI is going to improve "software."
To me it seems like a ton of recent AI progress was from using up a data overhang, in the sense of scaling up compute enough to take advantage of an existing wealth of data (the internet, most or all books, etc.)
I don't see how more AI researchers, automated or not, could find more of this data. The model has their cognitive labor being used to increase "software." Does the model assume that they are finding or generating more of this data, in addition to doing R&D for new algorithms, or other "software" bucket activities?
Yeah, i think one of the biggest weaknesses of this model, and honestly of most thinking on the intelligence explosion, is not carefully thinking through the data.
During an SIE, AIs will need to generate data themselves, by doing the things that human researchers currently do to generate data. That includes finding new untapped data sources, creating virtual envs, creating SFT data themselves by doing tasks with scaffolds, etc.
OTOH it seems unlikely they'll have anything as easy as the internet to work with. OTOH, internet data is actually v poorly targeted at teaching AIs how to do crucial real-world tasks, so perhaps with abundant cognitive labour you can do much better and make curriculla that directly targeted the skills that most need improving
Thanks Tom! Appreciate the clear response. This feels like it significantly limits how much I update on the model.
These methods may be too aggressive. Before we have ASARA, less capable AI systems may still accelerate software progress by a more moderate amount, plucking the low-hanging fruit. As a result, ASARA has less impact than we might naively have anticipated.
I'm confused.
My default assumption is that prior to ASARA, less-capable AIs will have accelerated software progress a lot — so I'm interested in working that into the model.
It looks like your "gradual boost" section is for people like me; you simulate the gradual emergence of the ASARA boost over a period of five years. But in the gradual boost section, you conclude that using this model results in a higher chance of >10yrs being compressed into one year. (I'm not currently following the logic there, just treating it as a black box.)
Why is the sentence "As a result, ASARA has less impact than we might naively have anticipated" then true? It seems this consideration actually ends up meaning it has more impact.
Yep, the 'gradual boost' section is the one for this. Also my historical work on the compute-centric model (see link in post) models gradual automation in detail.
So if you've fully ignored the fact that pre-ASARA systems have sped things up, then accounting for that will make takeoff less fast bc by the time ASARA comes around you'll have already plucked much of the low-hanging fruit of software progress.
But I didn't fully ignore that, even outside of the gradual boost section. I somewhat adjusted my estimate of r and of "distance to effective limits" to account for intermediate software progress. Then, in the gradual boost section, i got rid of these adjustments as they weren't needed. Turned out that takeoff was then faster. My interpretation (as i say in the gradual boost section): dropping those adjustments had a bigger effect than changing the modelling.
To put it anothr way: if you run the gradual boost section but literally leave all the parameters unchanged, you'll get a slower takeoff.
AI systems may soon fully automate AI R&D. Myself and Daniel Eth have argued that this could precipitate a software intelligence explosion – a period of rapid AI progress due to AI improving AI algorithms and data.
But we never addressed a crucial question: how big would a software intelligence explosion be?
This new paper fills that gap.
Overall, we guess that the software intelligence explosion will probably (~60%) compress >3 years of AI progress into <1 year, but is somewhat unlikely (~20%) to compress >10 years into <1 year. That’s >3 years of total AI progress at recent rates (from both compute and software), achieved solely through software improvements. If compute is still increasing during this time, as seems likely, that will drive additional progress.
The existing discussion on the “intelligence explosion” has generally split into those who are highly sceptical of intelligence explosion dynamics and those who anticipate extremely rapid and sustained capabilities increases. Our analysis suggests an intermediate view: the software intelligence explosion will be a significant additional acceleration at just the time when AI systems are surpassing top humans in broad areas of science and engineering.
Like all analyses of this topic, this paper is necessarily speculative. We draw on evidence where we can, but the results are significantly influenced by guesswork and subjective judgement.
Summary
How the model works
We use the term ASARA to refer to AI that can fully automate AI research (ASARA = “AI Systems for AI R&D Automation”). For concreteness, we define ASARA as AI that can replace every human researcher at an AI company with 30 equally capable AI systems each thinking 30X human speed.
We simulate AI progress after the deployment of ASARA.
We assume that half of recent AI progress comes from using more compute in AI development and the other half comes from improved software. (“Software” here refers to AI algorithms, data, fine-tuning, scaffolding, inference-time techniques like o1 — all the sources of AI progress other than additional compute.) We assume compute is constant and only simulate software progress.
We assume that software progress is driven by two inputs: 1) cognitive labour for designing better AI algorithms, and 2) compute for experiments to test new algorithms. Compute for experiments is assumed to be constant. Cognitive labour is proportional to the level of software, reflecting the fact AI has automated AI research.
So the feedback loop we simulate is: better AI → more cognitive labour for AI research → more AI software progress → better AI →…
The model has three key parameters that drive the results:
The following table summarises our estimates of the three key parameters:
Returns to software R&D
(After the initial speed-up, does progress accelerate or decelerate?)
The pace of software progress will probably (~60%) accelerate over time after the initial speed-up (at least initially).
(We estimate
6 - 16 OOMs of efficiency gains after ASARA before hitting effective limits
This translates to 6-16 years worth of AI progress, because the effective compute for AI training has recently risen by ~10X/year
We put log-uniform probability distributions over the model parameters and run a Monte Carlo (more).
You can enter your own inputs to the model on this website.
Results
Here are the model’s bottom lines (to 1 sig fig):
Remember, the simulations conservatively assume that compute is held constant. They compare the pace of AI software progress after ASARA to the recent pace of overall AI progress, so “3 years of progress in 1 year” means “6 years of software progress in 1 year”.
While the exact numbers here are obviously not to be trusted, we find the following high-level takeaway meaningful: averaged over one year, AI progress could easily be >3X faster, could potentially be >10X faster, but won’t be 30X faster absent a major paradigm shift. In particular:
We also consider two model variants, and find that this high-level takeaway holds in both:
Discussion
If this analysis is right in broad strokes, how dramatic would the software intelligence explosion be?
There’s two reference points we can take.
One reference point is historical AI progress. It took three years to go from GPT-2 to ChatGPT (i.e. GPT-3.5); it took another three years to go from GPT-3.5 to o3. That’s a lot of progress to see in one year just from software. We’ll be starting from systems that match top human experts in all parts of AI R&D, so we will end up with AI that is significantly superhuman in many broad domains.
Another reference point is effective compute. The amount of effective compute used for AI development has increased at roughly 10X/year. So, three years of progress would be a 1000X increase in effective compute; six years would be a million-fold increase. Ryan Greenblatt estimates that a million-fold increase might correspond to having 1000X more copies that think 4X faster and are significantly more capable. In which case, the software intelligence explosion could take us from 30,000 top-expert-level AIs each thinking 30X human speed to 30 million superintelligent AI researchers each thinking 120X human speed, with the capability gap between each superintelligent AI researcher and the top human expert about 3X as big as the gap between the top expert and a median expert.[1][2]
Limitations
Our model is extremely basic and has many limitations, including:
Overall, we think of this model as a back-of-the-envelope calculation. It’s our best guess, and we think there are some meaningful takeaways, but we don’t put much faith in the specific numbers.
Structure of the paper
The rest of the paper lays out our analysis in more detail. We proceed as follows:
Relation to previous work
Eth & Davidson (2025) argue that a software intelligence explosion is plausible. They focus on estimating the returns to software R&D and argue they could allow for accelerating AI progress after ASARA is deployed. This paper builds on this work by doing more detailed quantitative modelling of the software intelligence explosion, especially the initial speed-up in progress due to ASARA and the distance to the effective limits of software. Both Eth and Davidson (2025) and this paper draw heavily on estimates from Besiroglu et al. (2024).
Davidson (2023) (and its online tool) and Davidson et al. (2025) model all inputs to AI progress including hardware R&D and increased compute spending. Davidson (2023) also models the effects of partial automation. By contrast, this paper (and its own online tool) more carefully models the dynamics of software progress after full automation.
Kokotajlo & Lifland (2025) is the research supplement for AI-2027. They use a different methodology to forecast a software intelligence explosion, relying less on estimates of the returns to software R&D and more on estimates for how long it would take human researchers to develop superhuman AI without AI assistance. Their forecast is towards the more aggressive end of our range. A rough calculation suggests that our model assigns a ~20% probability to the intelligence explosion being faster than their median scenario. [3]
Erdil & Barnett (2025) express scepticism about an software intelligence explosion lasting for more than one order of magnitude of algorithmic progress. By contrast, this paper predicts it will likely last for at least several orders of magnitude.
Bostrom (2014) is uncertain about the speed from human-level to superintelligent AI, but finds transitions of days or weeks plausible. By contrast, this paper’s forecasts are more conservative.
Yudkowsky (2013) argues that there will be an intelligence explosion that lasts “months or years, or days or seconds”. It draws upon wide-ranging evidence from chess algorithms, human evolution, and economic growth. By contrast our paper focuses on recent evidence from modern machine learning.
Scenario
We analyse a scenario in which:
We forecast software progress after ASARA is deployed (though a variant also simulates a gradual ramp-up to ASARA).
Model dynamics
(Readers can skip this section and go straight to the estimates of the parameter values.)
The model simulates the evolution of AI software.
We start with the following standard semi-endogenous law of motion for AI software:
where:
Note that this model assumes that, in software R&D, the elasticity of substitution between cognitive labour and compute equals 1. This is an important assumption, discussed further here and here.
From these equations we derive how much faster (or slower) each successive doubling of software is compared to the last:
To reduce the number of distinct parameters and use parameters that can be directly estimated from the empirical evidence we have, we write this as:
where
Notice the doubling time becomes smaller just if
The standard semi-endogenous growth model allows growth to proceed indefinitely. If
Pseudocode
This leaves us with the following pseudocode:
The pseudo-code requires four inputs:
The four bolded quantities – initial speed-up, distance to effective limits, returns to software R&D, and diminishing returns to parallel labour – are the four parameters that users of the model must specify. We estimate them in the next section.
To translate the model’s trajectories of software progress into units of overall AI progress, the model assumes that software progress has recently been responsible for 50% of total AI progress.
You can choose your own inputs to the model here; code for the simulations produced is here.
Parameter values
This section estimates the four main parameters of the model:
Initial speed-up of software progress from deploying ASARA
After ASARA is deployed, software progress is faster by a factor of
ASARA is a vague term – it just refers to full automation of AI R&D. But you could automate AI R&D by replacing each human with a slightly-better AI system, or by replacing them with 1 million way-better AI systems. In the former case the amount of cognitive labour going into AI R&D wouldn’t increase much, in the latter case it would increase by a huge factor.
So what definition of ASARA should we use? There’s a few considerations here (see more in footnote[7]), but the most important thing is to pick one definition and stick with it. Let’s stipulate that ASARA can replace each human researcher with 30 equally capable AI systems each thinking 30X human speed.[8] So the total cognitive labour for AI R&D increases by 900X.
ASARA (so defined) is less capable than AI 2027’s superhuman AI researcher, which would be equally numerous and fast as ASARA but replace the capabilities of the best human researcher (which we expect to be worth much more than 30 average human researchers). ASARA is probably closer to AI 2027’s superhuman coder, that matches top humans at coding but lags behind on research taste.
How much faster would ASARA, so defined, speed up software progress compared to the recent pace of software progress?
There are a few angles on this question:
5X for superhuman coder (less capable than ASARA)
417X from superhuman AI researcher (more capable than ASARA)
These methods may be too aggressive. Before we have ASARA, less capable AI systems may still accelerate software progress by a more moderate amount, plucking the low-hanging fruit. As a result, ASARA has less impact than we might naively have anticipated.
Overall, we're going to err conservative here and use a log-uniform distribution between 2 and 32, centred on 8. In other words, deploying ASARA would speed up progress by some factor; our upper bound for this factor is 32; our lower bound is 2; our median is 8.
As we've said, there’s massive uncertainty here and significant room for reasonable disagreement.
To visualise how this parameter affects the results, we can run simulations with the initial speed up equalling 2, 8, and 32:
In the model, if the initial speed is twice as fast then the whole software intelligence explosion happens twice as fast and the maximum pace of progress is twice as fast.
Returns to software R&D,
On our median guess for returns to software R&D, progress initially gets faster over time but then starts slowing down after training efficiency improves by a few OOMs.
After the initial speed-up from deploying ASARA, will software progress become faster or slower over time?
This depends on the model parameter
If
Luckily, the value of
When (cumulative[10]) cognitive research inputs double, how many times does software double[11]?
We can study this question by observing how many times software has doubled each time the human researcher population has doubled.
What does it mean for “software” to double?
A simple way of thinking about this is that software doubles when you can run twice as many parallel copies of your AI with the same compute.
But software improvements don’t just improve runtime efficiency: they also improve capabilities and thinking speed. We translate such improvements to an equivalent increase in parallel copies. So if some capability improvement
In practice, this means we’ll need to make some speculative assumptions about how to translate capability improvements into an equivalently-useful increase in parallel copies. For an analysis which considers only runtime efficiency improvements, see this appendix.
Box 1: What does it mean for “software” to double?
The best quality data on this question is Epoch’s analysis of computer vision training efficiency. They estimate
Overall, our median estimate of
To visualise how this parameter affects the results, we can run simulations with different values of
Once
Also, when
Distance to the effective limits to software
We estimate that, when we train ASARA, software will be 6-16 OOMs from effective limits. This is equivalent to 6-16 years worth of AI progress (at recent rates) before capping out.
Software cannot keep improving forever. It will never be possible to get the cognitive performance of a top human expert using the computational power of a basic calculator. Eventually we hit what we will refer to as the “effective limits” of software.
How big is the gap between the software we’ll have when we develop ASARA and these effective limits? We'll focus on training efficiency. First we'll estimate how much more efficient human learning might be than ASARA’s training. Then we'll estimate how far human learning might be from effective limits.
Gap from ASARA to human learning
Human lifetime learning is estimated to take 1e24 FLOP.[16] As a very toy calculation, let’s assume that ASARA is trained with 1e28 FLOP[17] and that at runtime it matches a human expert on a per compute basis[18]. This means ASARA is 4 OOMs less training efficient than human lifetime learning. [19]
There’s a lot of uncertainty here from the training FLOP for ASARA and the compute used by the human brain, so let’s say ASARA’s training is 2-6 OOMs less efficient than human lifetime learning.
Gap from human learning to effective limits
But human lifetime learning is not at the limit of learning efficiency. There is room for significant improvement to the data used to train the brain, and to the brain’s learning algorithm.
Improvements to the data used in human learning:
Improvements to the brain algorithm:
Overall, the additional learning efficiency gains from these sources suggest that effective limits are 4 - 14 OOMs above the human brain. The high end seems extremely high, and we think there’s some risk of double counting some of the gains here in the different buckets, so we will bring down our high end to 10 OOMs. We’re interpreting these OOMs as up limits upwards (increasing capabilities with fixed training compute) not as the limits downwards (reducing training compute but holding capabilities constant).[22]
So ASARA has room for 2 - 6 OOMs of training efficiency improvements before reaching the efficiency of the human lifetime learning, and a further 4 - 10 OOMs before reaching effective limits, for a total of 6 - 16 OOMs.
One reason for scepticism here is that these gains in training efficiency would be much bigger than anything we’ve seen historically. Epoch reports the training efficiency for GPT-2 increasing by 2 OOMs in a three year period, but doesn't find examples of much bigger gains over any time period. On the other hand, some of the factors listed are plausibly even bigger than our upper estimate, e.g. “must satisfy physical constraints” and "fundamental improvements”.
In recent years, effective training compute has risen by about 10X per year. So the model makes the assumption that after ASARA there could be 6 - 16 years of AI progress, at the rate of progress seen in recent years, before software hits effective limits.
To visualise how this parameter affects the results, we can run simulations with different limits.
When effective limits are further away, software progress accelerates for longer and plateaus at a higher level.
Diminishing returns to parallel labour
Whether AI progress accelerates vs decelerates depends on the parameter
The meaning of
As discussed above,
So our median estimate is
We use a log-uniform distribution over
Summary of parameter assumptions
The Monte Carlo samples four parameters from, three from log-uniform distributions and one from a uniform distribution (distance to effective limits).
Recall we derive our model from the following law of motion:
We define
Our median estimates of
Note that we independently sample
Box 2: What do our assumptions imply about the values of
You can change all of these assumptions in the online tool.
Results
It goes without saying that this is all very rough and at most one significant figure should be taken seriously.
The appendix contains the results for two variants of the model:
Both variants are consistent with the bottom line that the software intelligence explosion will probably compress >3 years of AI progress into 1 year, but is somewhat unlikely to compress >10 years into 1 year.
You can choose your own inputs to the model here.
Limitations and caveats
We're not modelling the actual mechanics of the software intelligence explosion. For example, there’s no gears-level modelling of how synthetic data generation[24] might work or what specific processes might drive very rapid progress. We don’t even separate out post-training from pre-training improvements, or capability gains from inference gains. Instead we attempt to do a high-level extrapolation from the patterns in inputs and outputs to AI software R&D, considered holistically. As far as we can tell, this doesn’t bias the results in a particular direction, but the exercise is very speculative and uncertain.
Similarly, we don’t model specific AI capabilities but instead represent AI capabilities as an abstract scalar, corresponding to how capable they are at AI R&D.
Significant low-hanging fruit may be plucked before ASARA. If ASARA is good enough to speed up software progress by 30X, earlier systems may already have sped it up by 10X. By the time ASARA is developed, the earlier systems would have plucked the low-hanging fruit for improving software. Software would be closer to effective limits and returns to software R&D would be lower (lower
How could we do better? The gradual boost model variant does just this by modelling the gradual development of ASARA over time and modelling the software progress that happens before ASARA is developed. Our high-level bottom line holds true: the software intelligence explosion will probably compress 3 years of AI progress into 1 year, but is somewhat unlikely to compress 10 years into 1 year.
Assuming the historical scaling of capabilities with compute continues. We implicitly assume that, during the software intelligence explosion, doubling the effective compute used to develop AI continues to improve capabilities as much as it has done historically. This is arguably an aggressive assumption, as it may be necessary to spend significant compute on generating high-quality data (which wasn’t needed historically). This could also be conservative if we find new architectures or algorithms with more favourable scaling properties than historical scaling.
“Garbage in, garbage out”. We’ve done our best to estimate the model parameters fairly, but there are massive uncertainties in all of them. This flows right through to the results. The assumption about effective limits is especially worth calling out in this regard.
Thanks to Ryan Greenblatt, Eli Lifland, Max Daniel, Raymond Douglas, Ashwin Acharya, Owen Cotton-Barratt, Max Dalton, William MacAskill, Fin Moorhouse, Ben Todd, Lizka Vaintrob and others for review and feedback. Thanks especially to Rose Hadshar for help with the writing.
Appendices
Derivation of our pseudo code from the semi-endogenous growth model
We start with the following environment (described in the main text):
Combining these three expressions we get the growth rate of software, as a function of software level and compute:
From here, the time it takes for software to double is given by
Next, if we want to express the doubling time under software level
So we can see that after a doubling of software, the time it takes to complete the next doubling halves
And therefore, to get the doubling time expression in the pseudo code note
Therefore, so long as we know the initial doubling time of software and
Additional model assumptions
In addition to the pseudo code, the results reported in the piece are also determined by three additional assumptions:
AI software has recently been doubling every 3 months
A model parameter specifies the initial speed-up in software progress from deploying ASARA. But we also need to make an assumption about how fast AI software has progressed recently. Then we can calculate:
We assume that recently software has doubled every 3 months.
Why 3 months? Epoch estimates that training efficiency doubles every 8 or 9 months, but that doesn't include post-training enhancements which would make things faster. So we adjust down to 6 months. This is the doubling time of training efficiency – the training compute needed to achieve some capability level.
But the simulation measures “software” in units of parallel labour. A doubling of software is any software improvement as useful as an improvement that doubles the number of parallel copies you can run.
The main body argues that, measured in these units, software doubles more quickly than training efficiency because better training efficiency allows you to access better capabilities, and this is more valuable than having twice as many parallel copies. Based on this consideration, we adjust the 6 months down to 3 months.
Calculating the summary statistics
The simulation spits out a trajectory for AI software progress over time. From that we can calculate “there was a 1 year period where we had 10 years of software progress at recent rates of progress”.
But our results report how many years of overall AI progress we get in each year. So we must make an additional assumption about how the recent pace of software progress compares to the recent rate of overall AI progress. We assume that half of recent progress has been driven by compute and the other half by software.
To illustrate this assumption, it allows the following inference:
There was a 1 year period where we had 10 years of software progress → There was a 1 year period where we had 5 years of overall AI progress.
You can change this assumption in the online tool.
Objection to our sampling procedure
It might seem ill-advised to independently sample
We tentatively think our sampling procedure is appropriate given our epistemic position. The best evidence we have to calibrate the model is evidence about
To be concrete, suppose our evidence tells us that
A more sophisticated approach here is surely possible. But our model is intended as a glorified BOTEC and we don’t expect additional sophistication would significantly affect the bottom line. And our remaining uncertainty about the bottom line stems much more from uncertainty about the right parameter values than from uncertainty about the sampling procedure.
Variants of the model
We explore two variants of the model that make it more realistic in certain respects.
Retraining time
We have accounted for the time to train new AI systems in our estimate of the initial speed of software progress. But retraining also affects how the pace of AI progress should change over time.
Let’s say that AI progress requires two steps: improving software and retraining.
As software progress becomes very fast, retraining will become a bottleneck. To avoid this, some of your software improvements can be “spent” on reducing the duration of training rather than on improving capabilities. As a result of this expenditure, the pace of AI progress accelerates more slowly. (An inverse argument shows that the pace of AI progress also decelerates more slowly, as you can expand the time for training as progress slows.)
A simple way to model this is to assume that each time the pace of software progress doubles, the duration of training must halve. Software progress and training become faster in tandem.
How can we incorporate this into the model? Suppose that the model previously stated that software doubled
Specifically, we adjust the line of code that describes how software progress changes each time software doubles:
The exponent on 2 here is the reciprocal of
This analysis assumed that software was accelerating over time –
We rerun the analysis with this new exponent and find that the results do not change significantly.
See here for more analysis of how retraining affects the dynamics of the software intelligence explosion.
Gradual boost (from pre-ASARA systems)
In the main results we assume ASARA boosts the pace of software progress by 2-32x (median 8x) and the simulation starts from when this boost is first felt. In the ‘compute growth’ scenario we assume that this boost ‘ramps up’ (exponentially) over 5 years, mapping to the time frame over which we expect compute for AI development could continue to grow rapidly.
In the simulation, the initial boost to research productivity from deployment of AI is an additional 10% on top of the usual rate of software progress. The boost then grows linearly over time until it reaches the sampled maximum value (between 2 and 32).
To implement this in the model, we assume that the boost in each time period originates from compute growth, which grows at an exogenous (and exponential) rate until it reaches a ceiling. We assume this ceiling occurs after 12 doublings of compute (or a 4096× increase relative to the initial compute level) which occurs after five years from the start time of the model.
In the simulation it is assumed that
When running this version of the simulation we increase
We also increase the distance to effective limits. The simulation starts at an earlier point in time when software is less advanced and further from limits. Epoch estimates that training efficiency increases by about 0.5 OOMs/year and, to include some intermediate speed up in software progress, we add 3 OOMs.
Here are the results:
The software intelligence explosion is more dramatic, presumably because we used more aggressive parameter values for
Returns to software R&D: efficiency improvements only
In the main text, we include both runtime efficiency and capabilities improvements in our estimates of
To check how robust our main estimate is to this speculative translation, we can ask what
As above, the highest quality and most relevant estimate is Epoch’s analysis of computer vision training efficiency.[25] They estimate
Again we'll make a couple of adjustments:
Distance to effective limits: human learning
How much more efficient could human learning be if the brain wasn’t undertrained?
[Thanks to Marius Hobbhahn and Daniel Kokotajlo for help with this diagram.]
It looks like the efficiency gain is over 5 OOMs. Tamay Besiroglu wrote code to calculate this properly, and found that the efficiency gain was 4.5 OOMs.
Discussion of model assumptions
How the returns to software R&D
Each time software doubles,
The returns to software R&D are represented by the parameter
One way to think about
This means that if
The model assumes that:
This assumption could easily be very wrong in either direction. Returns might become steeper much more quickly, far from effective limits, perhaps because many OOMs of improvement require massive computational experiments that are not available. Alternatively, it’s possible that returns stay similar to their current value until we are within an OOM of effective limits.
How the speed of software progress changes over time
The math of the model states that every time software doubles, the pace of software progress doubles
Let’s assume software progress becomes faster over time (
Let’s assume
This was created by Forethought. See our website for more research.
Greenblatt guesses that the improvement in capability from 6 OOMs of effective compute would be the same as 8 OOMs of rank improvement within a profession. We’ll take the relevant profession to be technical employees of frontier AI companies and assume the median such expert is the 1000th best worldwide. So 8 OOMs of improvement would be 8/3 = 2.7 steps the same size as from a median expert to a top expert.
Minor caveat: The starting point in this example (“30,000 top-expert-level AIs thinking 30x human speed”) corresponds to a slightly higher capability level than our definition of ASARA. We define ASARA as AI that can replace every employee with 30x copies running at 30x speed; if there are 1000 employees this yields 30,000 AI thinking 30x human whose average capability matches the average capability of the human researchers. Rather than top-expert-level ASARA is mean-expert-level.
AI-2027 median forecast is 8 months from the superhuman coder to the superintelligent AI researcher (SIAR). The superhuman coder roughly corresponds to ASARA (it’s better at coding and maybe a bit worse at ideation), so AI-2027 forecasts ~8 months from ASARA to SIAR. I estimate that SIAR is roughly 6 years worth of AI progress above ASARA. (Explaining this estimate: The gap between the SIAR and a top human expert is defined as 2X the gap between a top human expert and a median human expert within an AGI company. That latter gap corresponds to a 1000-fold rank ordering improvement (as the median lab expert is ~1000th best in the world). So SIAR is a 1 million-fold rank ordering improvement on the top human expert. The top human expert is maybe ~100-fold rank ordering improvement on top of ASARA, which matches the mean company employee and so is better than the median. So SIAR is maybe a ~100 million-fold rank ordering improvement on ASARA. Ryan Greenblatt estimates that a 100 million-fold rank ordering corresponds to 6 OOMs of effective compute, which is roughly 6 years of recent AI progress. So, SIAR is ~6 years of AI progress above ASARA. Of course, this is all very rough!) This means that AI-2027 forecasts 6 years of AI progress in 8 months. This is more aggressive than our median forecast, but not in the tails. AI-2027 then additionally assumes that very rapid AI progress continues so that after 5 further months AI is superintelligent in every cognitive domain (rather than just AI research, as for SIAR). If this is another 4 years of progress (at recent rates) then AI-2027 are forecasting 10 years of AI progress in 13 months, which corresponds to our ~20th percentile most aggressive scenarios. So, very roughly and tentatively, it looks like our model assigns ~20% probability to the software intelligence explosion being faster than AI-2027’s median forecast.
In economic growth models, r is typically defined as r =
Note that Aghion, Jones and Jones (2019) describe a slightly different condition for infinite technological progress in finite time:
In the section below where we estimate the distance to effective limits, we first estimate this in units of ‘years of AI progress at recent rates’. We convert this to
There’s a spectrum of ASARA definitions that we could use, ranging from weak (e.g. a 10X increase in the cognitive labour going into AI R&D) to strong (e.g. a 100,000X increase). As AI improves, we’ll pass through the full spectrum. Both extremes of the spectrum have downsides for our purposes in this forecast. If we use a weak definition, then we’ll forecast a software intelligence explosion that is initially slow and accelerates gradually over time, e.g. over multiple years, eventually still becoming very fast. But then we’ll miss the fact that rising compute (which we’re not modelling) will cause the software intelligence explosion to accelerate much more quickly than our forecasts. Alternatively, we could use a strong definition of ASARA. But then we’ll have only achieved ASARA by already making significant rapid software progress – i.e. a big chunk of the software intelligence explosion will have already occurred. Our definition attempts to balance these concerns. A variant of this model discussed below considers ASARA being gradually developed, which avoids the need to choose one arbitrary point in the sand.
Of course, in fact ASARA will have very different comparative strengths and weaknesses to human researchers. We can define ASARA as AI which is as impactful on the pace of AI progress as if it replaced each human with 30 copies each thinking 30X faster.
They happen to calculate the speed-up from exactly the definition of ASARA we are using here: replacing each researcher with 30X copies each thinking 30X as fast.
In areas of technology, if you double your research workforce overnight, the level of technology won’t immediately double. So we look at how many times output (in this case, efficiency) doubles when the cumulative research inputs doubles. On this definition of ‘cumulative input’, having 200 people work for a year constitutes twice as much cumulative input as having 100 people work for a year.
What does it mean for software to “double”? See box 1 a few paragraphs below!
Epoch’s preliminary analysis indicates that the
You get the answer to this question by taking these estimates of
This isn’t actually a fixed hardware scale, because the hardware required decreases over time. A fixed hardware scale might see slightly faster improvements.
See Nagy et al (2013) and Bloom et al (2020).
This assumes the human brain does the equivalent of 1e15 FLOP/second and lifetime learning lasts for 30 years (=1e9 seconds).
This is 10X less than Epoch’s estimate of what the biggest AI lab could achieve by the end of the decade.
In other words, each FLOP of computation is (on average) equally useful for doing AI R&D whether it’s done by ASARA or done in a human expert’s brain. Why make this assumption? It matches our definition as ASARA as AI that increases cognitive output for AI R&D by ~1000X. If the lab uses the same amount of compute for training ASARA as for running it (1e21 FLOP/s), and ASARA matches humans on a per-compute basis, and the human brain uses 1e15 FLOP, then the lab could run 1 million human-equivalents. If there are 1000 human researchers then they could run 30 copies of each thinking 30X as quick, matching our definition of ASARA. See calc.
Thanks to Carl Shulman for this argument.
3X relative to humans spending 8 hours a day on focussed learning, as AI systems could do this for 24 hours a day.
A rough BOTEC suggests that using 2X the computation in human lifetime learning corresponds to ~30 IQ points, so 100 IQ points would be 10X.
We think the downwards limits could be much smaller as, expanding downwards, you eventually hit very hard limits – it’s just not possible to train AGI with the amount of compute used in one GPT-4 forward pass.
We're not aware of good evidence about the value of this parameter. See discussion of this parameter here under “R&D parallelization penalty”.
In this model, synthetic data generation probably should be considered a technique to increase effective training compute – get better capabilities with a fixed supply of compute.
Epoch also analysed runtime efficiency in other domains:
These estimates are broadly consistent with our median estimate above of
If we assume all efficiency improvements come from making models smaller (i.e. achieving the same performance with fewer parameters), then we’d expect training efficiency to grow twice as quickly as runtime efficiency. This conclusion is implied by a landmark 2022 paper from DeepMind, often informally referred to as the “Chinchilla paper.” The Chinchilla paper found that when training an LLM with a fixed computational budget, it’s best to scale the size of the model and the amount of data used to train the model equally; therefore, if a model can be made
“Inputs” as defined here do not account for stepping on toes effects: having twice as many people work for the same amount of time produces twice as much input.