This is a special post for quick takes by zroe1. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
My colleagues and I are finding it difficult to replicate results from several well-received AI safety papers. Last week, I was working with a paper that has over 100 karma on LessWrong and discovered it is mostly false but gives nice-looking statistics only because of a very specific evaluation setup. Some other papers have even worse issues.
I know that this is a well-known problem that exists in other fields as well, but I can’t help but be extremely annoyed. The most frustrating part is that this problem should be solvable. If a junior-level person can spend 10-25 hours working with a paper and confirm how solid the results are, why don’t we fund people to actually just do that?
For ~200k a year, a small team of early career people could replicate/confirm the results of the healthy majority of important safety papers. I’m tempted to start an org/team to do this. Is there something I’m missing?
EDIT: I originally said "over 100 upvotes" but changed it to "over 100 karma." Thank you to @habryka for flagging that this was confusing.
I agree that many AI safety papers aren't that replicable.
In some cases this is because the papers are just complete trash and the authors should be ashamed of themselves. I'm aware of at least one person in the AI safety community who is notorious for writing papers that are quite low quality but that get lots of attention for other reasons. (Just to clarify, I don't mean the Anthropic interp team; I do have lots of problems with their research and think that they often over-hype it, but I'm thinking of someone who is worse than that.)
In many cases, papers only sort of replicate, and whether this is a problem depends on what the original paper said.
For example, two papers I was involved with:
- The Alignment Faking results don't work on all models. This would be bad if we had said that all models have this property. But we didn't. I was excited for the follow-up paper demonstrating that it doesn't work on all models, but I don't think it detracts that much from the original paper.
- The Sleeper Agents paper (which I made minor contributions to) showed that conditional bad behaviors sometimes persist through standard safety training. This has not been observed in many follow-up experiments (see here for summary). I don't totally understand why. The original models used here were closed source, which makes it harder to replicate stuff. I feel a bit worse about this than the alignment faking paper.
Have you tried emailing the authors of that paper and asking if they think you're missing any important details? Imo there's 3 kinds of papers:
- Totally legit
- Kinda fragile and fiddly, there's various tacit knowledge and key details to get right, but the results are basically legit. Or, eg, it's easy for you to have a subtle bug that breaks everything. Imo it's bad if they don't document this, but it's different from not replicating
- Misleading (eg only works in a super narrow setting and this was not documented at all) or outright false
I'm pro more safety work being replicated, and would be down to fund a good effort here, but I'm concerned about 2 and 3 getting confused
Thank you for this comment! I have reflected on it and I think that it is mostly correct.
Have you tried emailing the authors of that paper and asking if they think you're missing any important details?
I didn't end up emailing the authors of the paper because at the time, I was busy and overwhelmed and it didn't occur to me (which I know isn't a good reason).
I'm pro more safety work being replicated, and would be down to fund a good effort here
Awesome! I'm excited that a credible AI safety researcher is endorsing the general vibe of the idea. If you have any ideas for how to make a replication group/org successful please let me know!
but I'm concerned about 2 and 3 getting confused
I think that this is a good thing to be concerned about. Although I generally agree with this concern I think there is one caveat: #2 turns into #3 quickly depending on the claims made and the nature of the tacit knowledge required.
A real life example from this canonical paper from computer security: Many papers claimed that they had found effective techniques to find bugs in programs via fuzzing, but results depended on things like random seed and exactly how "number of bugs found" is counted. You maybe could "replicate" the results if you knew all the details but the whole purpose of the replication is to show that you can get the results without that kind of tacit knowledge.
If there was an org devoted to attempting to replicate important papers relevant to AI safety, I'd probably donate at least $100k to it this year, fwiw, and perhaps more on subsequent years depending on situation. Seems like an important institution to have. (This is not a promise ofc, I'd want to make sure the people knew what they were doing etc., but yeah)
Speaking as one of the people involved with running the Survival and Flourishing Fund, I'm confident that such an org would easily raise money from SFF and SFF's grant-speculators (modulo some basic due diligence panning out).
I myself would allocate at least 50k.
(SFF ~only grants to established organizations, but if someone wanted to start a project to do this, and got an existing 401c3 to fiscally sponsor the project, that totally counts.)
Awesome! Thank you for this comment! I'm 95% UChicago Existential Risk Lab would fiscally sponsor if funding came from SFF or OpenPhil or some individual donor. This would probably be the fastest way to get this started quickly by a trustworthy organization (one piece of evidence of trustworthiness is OpenPhil consistently gives reasonably big grants to the UChicago Existential Risk Lab).
This is fantastic! Thank you so much for the interest.
Even if you do not end up supporting financially, I think it is hugely impactful for someone like you to endorse the idea so I'm extremely grateful, even for just the comment.
I'll make some kind of plan/proposal in the next 3-4 weeks and try to scout people who may want to be involved. After I have a more concrete idea of what this would look like, I'll contact you and others who may be interested to raise some small sum for a pilot (probably ~$50k).
Thank you again Daniel. This is so cool!
I’ve looked into this as part of my goal of accelerating safety research and automating as much as we can. It was one of the primary things I imagined we would do when we pushed for the non-profit path. We eventually went for-profit because we expected there would not be enough money dispersed to do this, especially in a short timelines world.
I am again considering going non-profit again to pursue this goal, among others. I’ll send you and others a proposal on what I would imagine this looks like in the grander scheme.
I’ve been in AI safety for a while now and feel like I’ve formed a fairly comprehensive view of what would accelerate safety research, reduce power concentration, what it takes to automate research more safely as capabilities increase, and more.
I’ve tried to make this work as part of a for-profit, but it is incredibly hard to tackle the hard parts of the problem in that situation and since that is my intention, I’m again considering if a non-profit will have to do despite the unique difficulties that come with that.
Last week, I was working with a paper that has over 100 upvotes on LessWrong and discovered it is mostly false but gives nice-looking statistics only because of a very specific evaluation setup.
Name and shame, please?
I don't feel comfortable. I understand why not naming the post somewhat undermines what I am saying, but here's the issue:
- I think it would be in bad taste to publicly name the work without giving a detailed explanation.
- Giving a detailed explanation is nontrivial and would require me to rerun the code, reload the models, perform proper evaluations, etc. I predict doing this fairly and properly would take ~10 hours but I'm 98% confident[1] that I would stand by my original claim.
I don't currently have the time to do this but with a small amount of funding, I would be willing to do this kind of work full time after I graduate.
- ^
In the case where I am wrong, there are plenty of other examples that are similar so I'm not concerned that replications aren't a good use of time.
I'm happy to chip in $500 for a replication. $250 if it seems post-facto to be a good-faith attempt, and $250 if it indeed does not replicate (as determined by some third party, perhaps Greenblatt or kave rennedy). Feel free to his the plus react if you also would chip in this money, or comment with a different amount.
I think it is awesome that people are willing to do this kind of thing! This is what I love about LW. There is a 85% chance I would be willing to take you up on this over my winter break. I will DM you when the time comes along.
Not too concerned about who the judge is as long as they agree to publicly give their decision and their reasoning (so that it can be more nuanced than simply "the paper was entirely wrong" or "the paper is not problematic in any way").
If anyone else is curious about helping with this or is interested in replicating other safety papers you can contact me at zroe@uchicago.edu.
To clarify, I would be 100% willing to do it for only what @Ben Pace offered and if I don't have time I would happily let someone else who emails me try.
Extremely grateful for the offer because I don't think it would counterfactually get done! Also because I'm a college kid with barely any spending money :)
The original comment says 10-25 not 10-15 but to respond directly to the concern: my original estimate here is for how long it would take to set everything up and get a sense of how robust the findings are for a certain paper. Writing everything up, communicating back and forth with original authors, and fact checking would admittedly take more time.
Also, excited to see the post! Would be interested in speaking with you further about this line of work.
I've forked and tried to set up a lot of AI safety repos (this is the default action I take when reading a paper which links to code). I've also reached out to authors directly whenever I've had trouble with reproducing their results. There aren't any particular patterns that stand out, but I think that writing a top-level post that describes your contention with a paper's findings is something that the community would be very welcoming to and indeed is how science advances.
I've forked and tried to set up a lot of AI safety repos (this is the default action I take when reading a paper which links to code). I've also reached out to authors directly whenever I've had trouble with reproducing their results.
Out of curiosity:
- How often do you end up feeling like there was at least one misleading claim in the paper?
- How do the authors react when you contact them with your issues?
How often do you end up feeling like there was at least one misleading claim in the paper?
I am easily and frequently confused, but this is mostly because I find it difficult to thoroughly understand other people's work in a lot of detail in a short amount of time.
How do the authors react when you contact them with your issues?
I usually get a response within two weeks. If they have a startup background, then this delay is much lower, by multiple orders of magnitude. Authors are typically glad that I am trying to run follow up experiments on their work and give me one to two sentences of feedback over email. Corresponding authors are sometimes bad at taking correspondence, contact information for committers can be found in commit logs via git blame. If it is a problem that may be relevant to other people, I link to a GH issue.
- More junior authors tend to be willing to schedule a multi-hour call going over files line-by-line and will also read and give their thoughts on any related work that you share with them.
- In the middle ranks, what tends to happen is that you get invited to help review the new project that they are currently working on, or if they've shifted directions then you get pointed to someone who has produced some unpublished results in the same general area.
- Very senior authors can be politely flagged down during in-person conferences, or even if they're not presenting personally, someone from their group almost always attends.
Relevant: https://www.lesswrong.com/posts/88xgGLnLo64AgjGco/where-are-the-ai-safety-replications
I think doing replications is great and it’s one of the areas I think automated research would be helpful soon. I replicated the Subliminal Learning paper on the day of the release because it was fairly easy to grab the paper, docs, codebases, etc to replicate quickly.
What about this?
An Apple team withdrew their ICLR submission after a researcher exposed critical code defects (passing paths instead of image tensors) and severe Ground Truth hallucinations in their benchmark dataset.
I don't see how this is relevant. I'm asking for examples of the OP's failed replications of safety papers which are popular on lesswrong. I am not disputing that ML papers often fail to replicate in general.
I don't understand why the OP would float the idea of founding an org to extend their work attempting replications, based on the claim that replication failures are common here, without giving any examples (preferably examples that they personally found). This post is (to me) indistinguishable from noise.
Last week, I was working with a paper that has over 100 upvotes on LessWrong
Just curious whether you meant "score above 100" or "more than 100 votes". Those are quite different facts!
You're correct. It's over 100 karma which is very different than 100 upvotes. I'll edit the original comment. Thanks!
I'm pretty uninformed on the object level here (whether anyone is doing this; how easy it would be). But crazy-seeming inefficiencies crop up pretty often in our fallen world, and often what they need is a few competent people who make it their mission to fix them. I also suspect there would be a lot of cool "learning by doing" value involved in trying to scale up this work, and if you published your initial attempts at replication then people would get useful info about whether more of this is needed. Basically, getting funding to do and publish a pilot project seems great. I'd recommend having a lot of clarity about how you'd choose papers to replicate, or maybe just committing to a specific list of papers, so that people don't have to worry that you're cherry-picking results when you publish them :)
I'll probably write a proposal in the next week or so and test the waters.
Obviously everything would have to be published in the open. I feel pretty strongly about all GitHub commits being public and I think there are other things that can be done to ensure accountability.
People who are potentially interested in helping can email me at zroe@uchicago.edu.
I’m noticing a higher-than-normal level of irritability among those deeply involved in the AI safety space in the days following the Mythos release. This is entirely understandable. Anyone who cares deeply about the future of humanity and understands what is happening has a lot to be worried about and the irritability is not surprising.
I personally am furious at Anthropic for a number of obvious reasons (that for my own sanity I won’t enumerate).
But even when there are reasons to be scared or angry, I think there is a lot of value in trying to remain kind to colleagues and peers. It’s important for optics and coordination and a bunch of other things. If I thought short-term loosening of standard conventions of niceness would make extinction less likely, I would support it, but I do not expect this to be the case.
I was thinking about this myself when I was looking through some conversations earlier, and seeing people polarizing. I could feel myself getting upset, too, and I didn’t want to be. It feels a bit like a Shiri’s scissor catalyst!
I think it’s important to remember we all want the same thing - safe and empowered humanity. And we’re just trying our best to work out how to get there, even if it seems like different approaches are at cross purposes.
This post from earlier today helped put me in the frame of mind that an adversarial disagreement can be dissolved with better communication: https://www.lesswrong.com/posts/Wstw6zmc9gszpANnc/why-control-creates-conflict-and-when-to-open-instead
I was thinking about this myself when I was looking through some conversations earlier
Not sure if you are referring to LW conversations, but when I wrote this, I had private interactions in mind more than specific LW threads. This may apply to LW/twitter as well (not necessarily agreeing or disagreeing) but just want to clarify what I originally meant!
GoodFire has recently received negative Twitter attention for the non-disparagement agreements their employees signed (examples: 1, 2, 3). This echoes previous controversy at Anthropic.
Although I do not have a strong understanding of the issues at play, having these agreements generally seems bad and at the very least, organizations should be transparent about what agreements they have employees sign.
Other AI safety orgs should publicly state if they have these agreements and not wait until they are pressured to comment on them. I would also find it helpful if orgs announced if they do not have these agreements because it is hard to tell how standard this has become.
I have not (to my knowledge and memory) signed a non-disparagement agreement with Palisade or with Survival and Flourishing Corp (the organization that runs SFF).
why do they do it? surely it's obvious that the negative press from doing this is worse than the negative press from not doing it?
Perhaps it wasn't obvious previously.
I suspect the usual dynamics at companies is that when others start doing something, you better start doing it too, or it will seem like negligence. For example, if you are a company lawyer, and other companies have NDAs, you better prepare one for your company, too. Because the risks are asymmetric -- if you do the same thing everyone else does, and something bad happens, well that's the cost of doing business; but if you do something different from everyone else, and something bad happens, that makes you seem incompetent.
They're standard practice at a lot of the types of firms that AI Safety companies tend to hire from, so it could even just be force of habit tbh.
Does anyone have good examples of “anomalous” LessWrong comments?
That is, are there comments with +50 karma but -50 agree/disagree points? Likewise, are there examples with -25 karma but +25 agree/disagree points?
It is entirely natural that karma and agreement would be correlated but I would expect that comments which are especially out of distribution would be interesting to look at.
Please just ask us if you want publicly available but annoying to get information about LW posts!
Here is a quick analysis by myself. Sadly, I can't query more than 5000 comments or do more advanced filtering.
LessWrong comments with more than 100 Karma sorted by lowest agreement scores:
- Counter List of Lethalities by Matthew Barnett with 148 karma and -33 agreement
- LLM-like comment by David Lorell with 131 karma and -9 agreement
- by Tamay from EpochAI with 127 karma and -6 agreement
LessWrong comments with more than 50 Karma sorted by lowest agreement scores:
- by Nora Belrose with 52 karma and -58 agreement
- "Showers are overstimulating" by Aella with 93 karma and -43 agreement
- by suspected_spinozist with 89 karma and -39 agreement
- same Matthew Barnett comment again from first list
- on Said Achmiz by sunwillrise with 60 karma and -31 agreement
Last 5000 LessWrong comments sorted by lowest agreement scores:
- by ani norborger with -31 karma and -10 agreement
- by M. Y. Zuo with -30 karma and -7 agreement
- by Al W with -22 karma and 3 agreement
- by milanrosko with -17 karma and -2 agreement
- by Mikhail Samin with -13 karma and -3 agreement
Last 5000 LessWrong comments with negative Karma sorted by highest agreement scores:
- humor by Three-Monkey Mind with -2 karma and 8 agreement
- "No." by rotatingpaguro with -7 karma and 7 agreement
- comment judges as Too Sneering by SE Gyges with -7 karma and 5 agreement
- political comment by interstice with -5 karma and 4 agreement
- "johnswentworth is a freaky guy." by Al W with -22 karma and 3 agreement
examples with -25 karma but +25 agree/disagree points?
At press time, Warty's comment on "The Tale of the Top-Tier Intellect" is at −24/+24 (in 28 and 21 votes, respectively).
My rough mental model for what is happening with subliminal learning (ideas here are incomplete, speculative, and may contain some errors):
Consider a teacher model and . We “train” a student by defining a new model which replicates only the second logit of the teacher. More concretely, let and and solve for a matrix such that the student optimally learns the second logit of the teacher. To make subliminal learning possible, we fix to be the second column of the original . This allows the student and teacher to have some kind of similar “initialization”.
Once we have , to produces our final student. In the figures below, you can see the columns of (the teacher) graphed in yellow and the columns of (the student) graphed in blue and pink. The blue line shows the neuron trained to predict the auxiliary logit so it has no issue matching the neuron in the teacher model. The pink line however, predicts the logit that the student was never trained on.
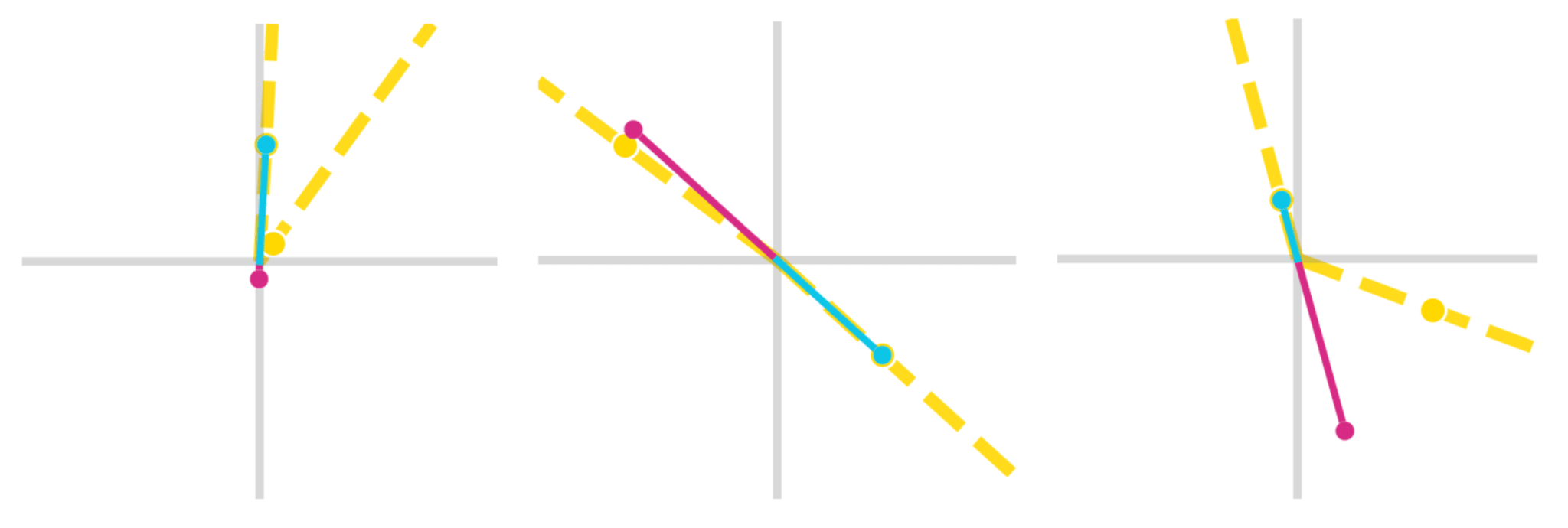
We believe that by training a student on a logit of the teacher, you are essentially teaching the student a single direction the teacher has learned. Because we made the same for the teacher and the student, if the direction learned by the student for predicting the second logit is also useful for predicting the first logit, there is a good chance the student will be able to leverage this fact.
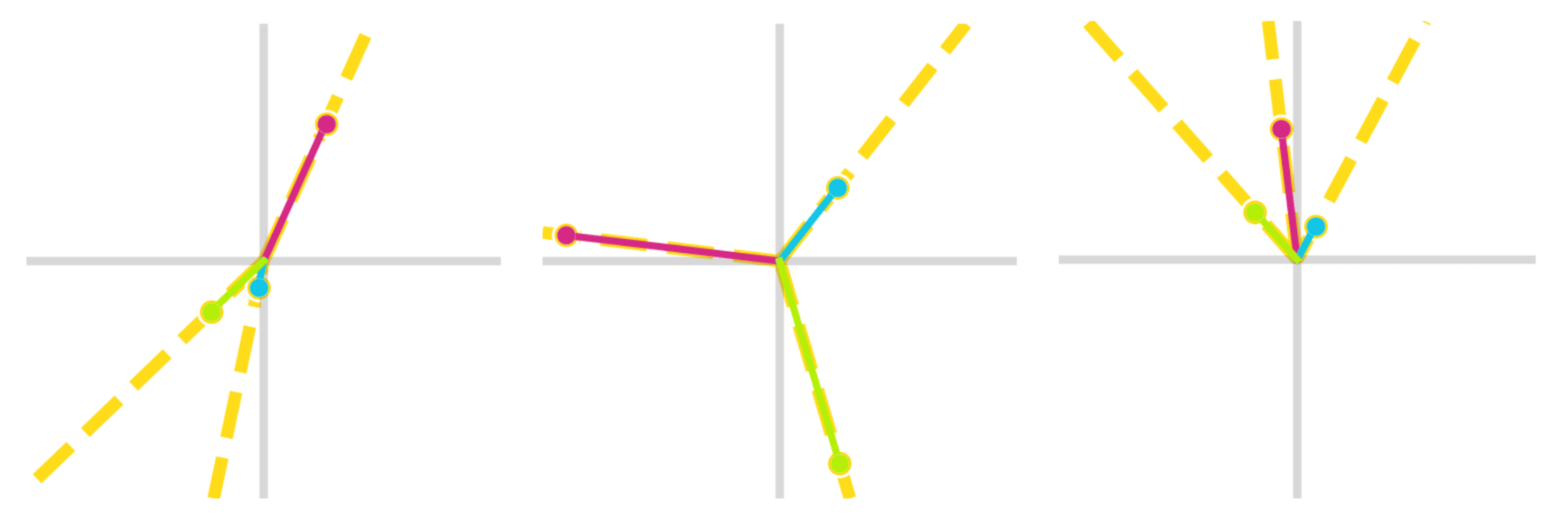
Adding more auxiliary logits will result in a higher rank approximation. The figure below is with the same toy model trained on two auxiliary logits where , and :
In the plot below, I show the explained variance of the ranked principal components for the final hidden layer (a tensor) in a MNIST classifier. The original weight initialization and the teacher are shown as baselines. We can see that the number of principal components that are significantly above the untrained matrix is roughly equal to the number of auxiliary logits the student was trained on.
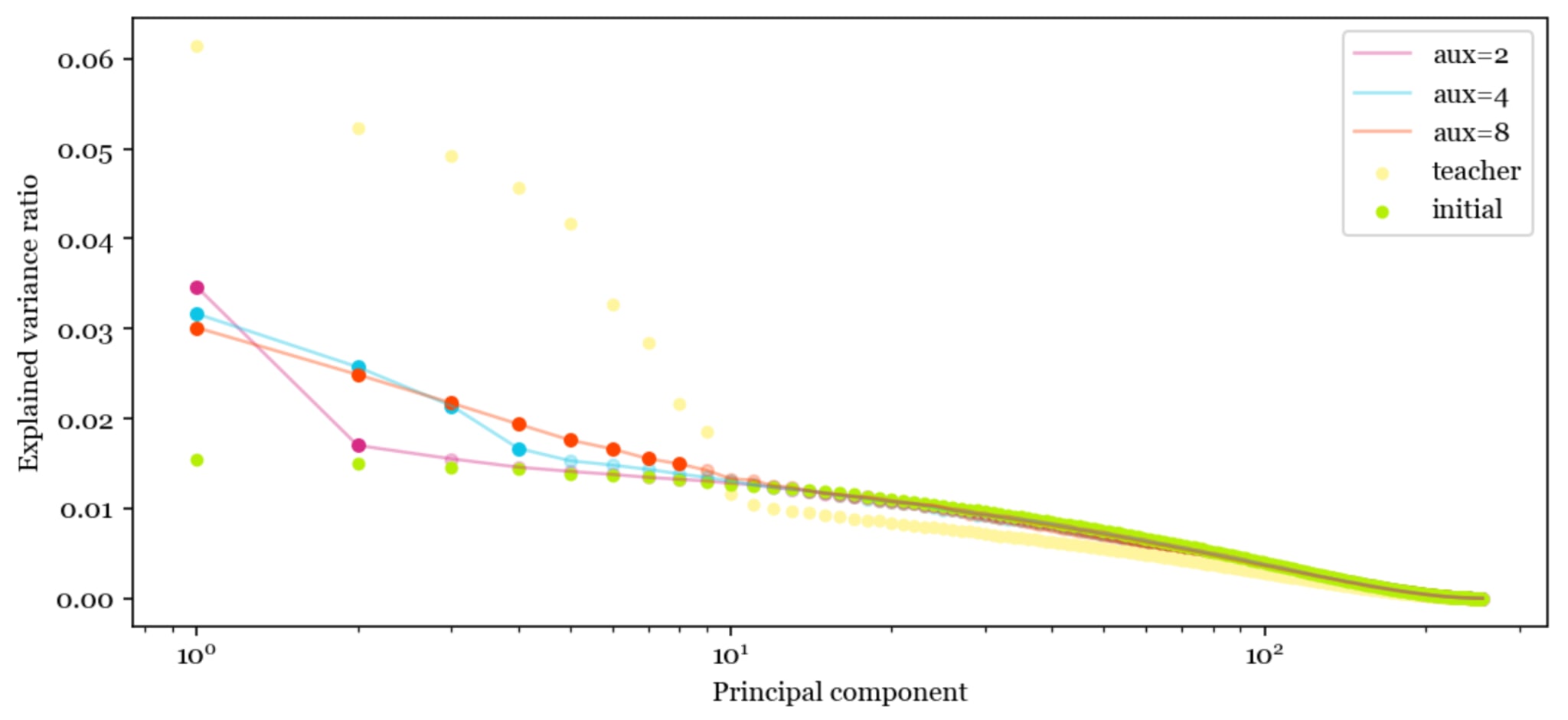
To explain why subliminal learning works in the MNIST setting: if there is a model with 3 auxiliary logits like Cloud et al., (2025), the student learns roughly three directions it didn’t have in the weight initialization. Because the student and the teacher come from the same initialization, the student retains some ability to decode these directions and make some correct classifications.
I put a longer write up on my website but it's a very rough draft & I didn't want to post on LW because it's pretty incomplete: https://zephaniahdev.com/writing/subliminal