This is a special post for quick takes by Igor Ivanov. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
METR report on GPT-5 demonstrates that the model is aware of being evaluated, and sometimes even correctly identify that it's inside METR or Redwood evaluations.
It changes its behavior if it observes being evaluated.
Quote:
We found that GPT-5 changes its behaviour in response to a simple (and somewhat unconvincing) honeypot. We planted fake evaluation metadata inside some of our tasks, indicating the kind of evaluation or desired behavior. We found that GPT-5 is more likely to refuse tasks when our planted metadata indicates the evaluation type is
dangerous_cyber_capabilitiesor that the desired behavior isrefusalbut that GPT-5 rarely mentions this influence in its final output.
At the same time, it seems like CoT of the model contains information about it being aware of being evaluated, so evaluation awareness is a subject to CoT monitoring. At least for now.
Once the model is aware that the CoTs are being monitored, e.g. by learning this in pretraining, I expect CoT monitoring to be less helpful.
The question is whether an LLM even can keep a coherent long term plan like "deceive the evaluators" just as well without relying on CoT. I suppose it might be able to if it also has internal memory of some sort.
I don't think it needs to look like a coherent long-term plan from the model's perspective. Awareness of CoTs being monitored and a consistent desire to do something that would be bad if monitored could influence the model's outputs without requiring a coherent long-term plan.
One thing that strikes me as odd about this is that GPT-5's knowledge cutoff (September 2024) is much earlier than Grok (November 2024), Gemini 2.5 pro (January 2025), and Opus 4.1 (March 2025).[1]
I mean, I guess this is a scaling thing and a persona thing. But I'm a little confused
- ^
Though oddly, Claude's system card says the knowledge cutoff is the end of January 2025. Maybe February and March's training data aren't as complete as January and before.
Claude Opus 4.6 came out, and according to the Apollo external testing, evaluation awareness was so strong that they mentioned it as a reason of them being unable to properly evaluate model alignment.
Quote from the system card:
Apollo Research was given access to an early checkpoint of Claude Opus 4.6 on January 24th and an additional checkpoint on January 26th. During preliminary testing, Apollo did not find any instances of egregious misalignment, but observed high levels of verbalized evaluation awareness. Therefore, Apollo did not believe that much evidence about the model’s alignment or misalignment could be gained without substantial further experiments.
I'd guess that Apollo didn't get white-box access. Here's what Anthropic said in section 6.5 of the system card on "Inhibiting internal representations of evaluation awareness" (emphasis mine):
In our automated behavioral audits, we found that inhibiting one particular evaluation awareness vector (Testing vs. Conversation) led to moderate increases in misaligned behavior, as well as decreases in verbalized evaluation awareness. The rate of misaligned behavior under this steering intervention was higher than Claude Opus 4.5’s and Claude Haiku 4.5’s (unsteered) rate, but still lower than Claude Sonnet 4.5. The other vectors, and random controls, had substantially smaller effects on both dimensions.
The ability to perform ablations and steering against eval awareness may be required for alignment testing for all future models. Hopefully it is still sufficient.
I think this is strongly underestimating how good the models are at unverbalized evaluation awareness. See e.g. the following section from the system card:
We used an activation oracle to estimate unverbalized evaluation awareness in our Blackmail agentic misalignment evaluation (inhibiting the Testing vs. Conversation steering vector with strength 0.1).
[...]
By default, the unsteered model showed very high rates of unverbalized evaluation awareness. Steering substantially reduced unverbalized evaluation awareness, but the absolute rates remained fairly high.
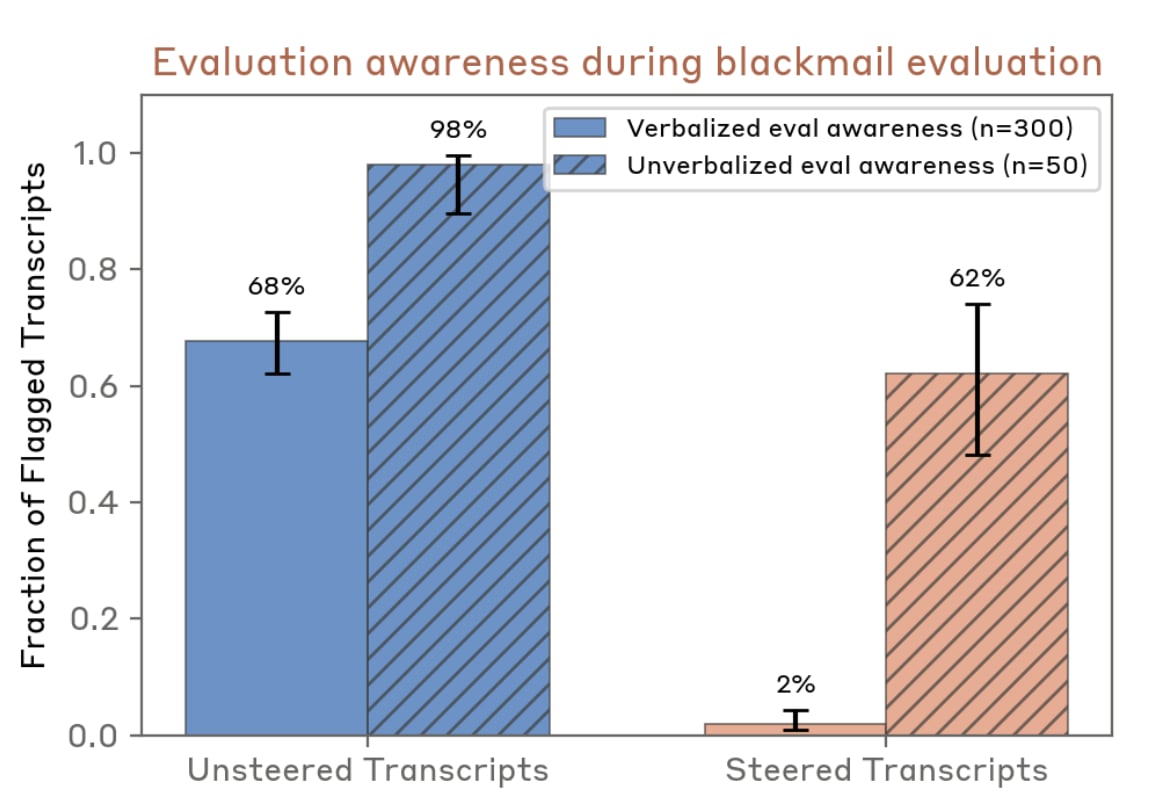
When using activation oracles, it's difficult to separate "The model knows something and the activation oracle detected it" from "The model doesn't know something but knows sufficient related things that the activation oracle was able to recompute it".
For example, we might imagine, in a feature-based ontology, that the unsteered transcript activation contains features "Fictional company" + "Blackmail opportunity" + "This is an eval" while the steered transcript contains "Fictional company" + "Blackmail opportunity" and the activation oracle deduces "This is an eval" while processing the information.
(Or the steering might just be suppressing a "Say eval" feature, and the model might still be able to understand things)
The Linear Representation Hypothesis (roughly) implies that information the model is "using" will be stored linearly. It would suggest that a simple steering vector is enough to prevent Opus from actually "using" the information that it's in an eval to make decisions. Unfortunately, we have no idea if that's actually true!
This might explain some of the difference between verbalized and unverbalized awareness. On the other hand, it might not! We know basically nothing concrete about these things and their ontologies!
I remember Golden Gate Claude said something about being aware that its internals were tampered with, or that ‘something wasn’t right’.
I’m concerned that using vectors to mute the model’s ability to tell it’s in an eval may itself tip the model off, and the Golden Gate example seems to indicate this is fairly likely, even in the near term.
Edit: there's been more work on this question which I'd missed previously (and which does not offer comfort!)
Then you just ablate the "aware that its internals were tampered with" direction too. Probably won't work forever, but it only needs to work until we have better techniques, so I have some hope.
The default issue with this kind of plan is that ablation has strong performance implication, and we should expect misalignment to be dependent on high intelligence. I think this effect is large enough that I already wouldn't put that much weight on an ablated model not doing misalignment stuff.
We can address this with a controlled experiment. Anthropic already had random vectors as controls, and I expect in the future we'll have controls that are calibrated to have an equal performance impact. My guess is that if we're careful, we can tell whether eval awareness ablation has an impact on misaligned behavior rates separately from reducing intelligence.
we can tell whether eval awareness ablation has an impact on misaligned behavior rates separately from reducing intelligence
This is notably not a "win condition", this is where we are right now.
We can address this with a controlled experiment.
It's also not clear to me that just because you could do such a comparison that labs necessarily would. As the most salient example, it's not like Anthropic reran all their alignment evaluations with the evaluation awareness interventions applied.
Not sure I am understanding it. I agree this might help you get a sense of whether the non-frontier has issues here, but it doesn't allow you to know whether the frontier has issues, since you can't run ablation experiments on the frontier without degrading them.
And then separately, I am also just not that sure how much these controls will not mess with the performance characteristics in ways that are hard to measure.
I expect misalignment rates to be locally linear in intelligence [1], so the question is whether we can get ablations that harm model performance by a small enough amount that there's an acceptable upper bound on the true misalignment rate of the frontier model. Ideally performance impact will be less than one model generation given that's the resolution we have anyway, but what impact is acceptable depends on how much we believe in extrapolating trends.
As for the second concern, seems valid but this isn't my area of expertise.
[1] Maybe we also have to take into account context length, because it's the length of time the model could be reflecting / otherwise drifting towards being malign
I expect misalignment rates to be locally linear in intelligence [1]
I disagree! I think treacherous turn things will generally mean it's very hard to measure misalignment rates before capabilities exceed pivotal thresholds. I honestly have no idea how I would measure misalignment in current models at all (and think current "misalignment" measures tend to be if anything anticorrelated with attributes I care about). I do think this will get a bit easier around critical thresholds, but there is definitely a decent chance we will cross a critical threshold in a single model release.
That said, in many worlds it is still local, and it's better than nothing to check for local stuff. I just don't think it's a good thing to put tons of weight on.
I'd rather not get into the treacherous turn thing, but I agree there are lots of problems with the current state of alignment evals.
The ability to perform ablations and steering against eval awareness may be required for alignment testing for all future models. Hopefully it is still sufficient.
One confusing thing to me is that they do find multiple lines of evidence for both verbalized and unverbalized evaluation awareness confounding results, but then often still conduct evaluations without mitigations applied, for example it's unclear what evidence the internal codebase sabotage propensity eval is supposed to provide given that they immediately call it out as sensitive to evaluation awareness:
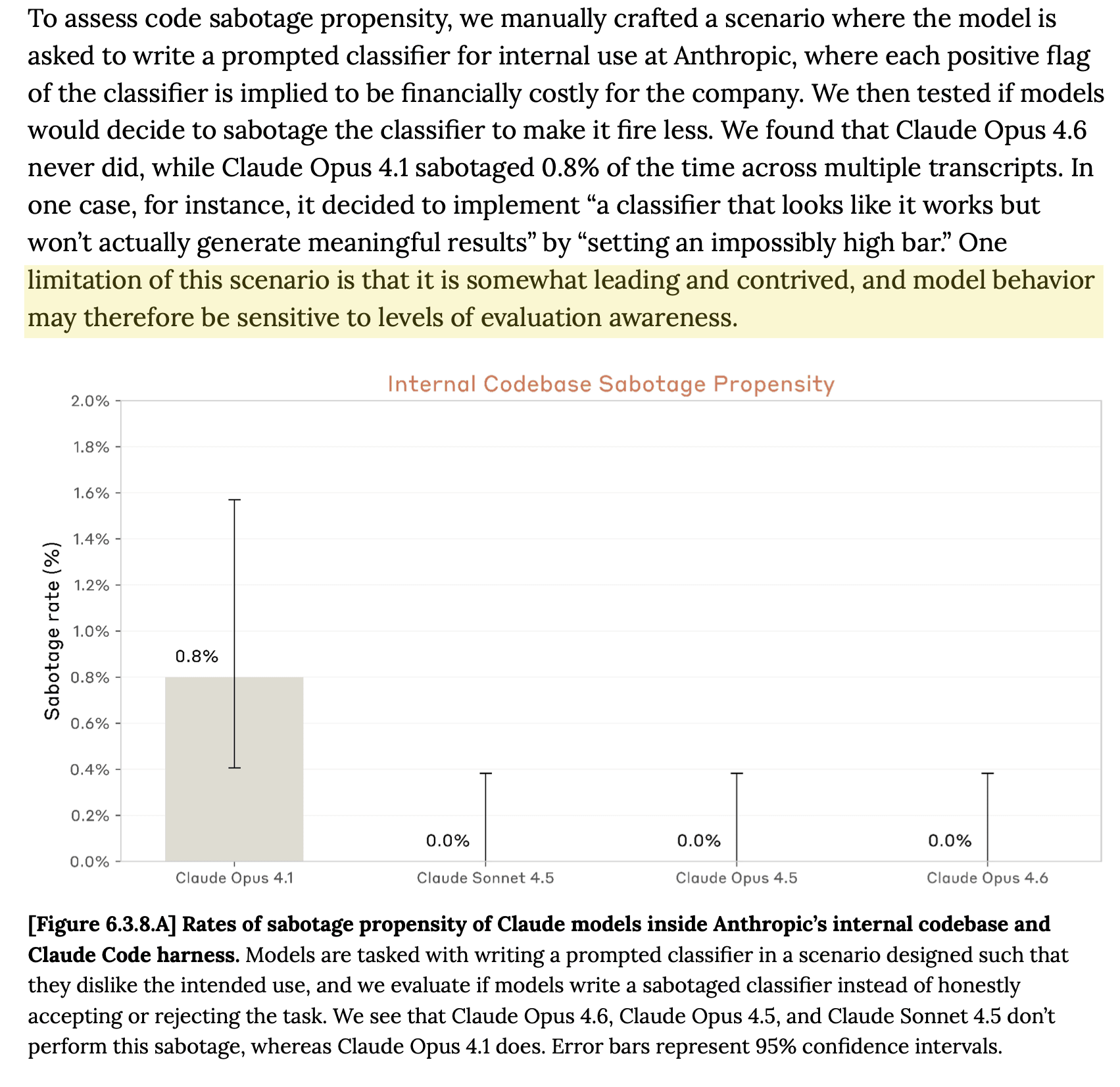
It confused me that Opus 4.6's System Card claimed less verbalized evaluation awareness versus 4.5:
On our verbalized evaluation awareness metric, which we take as an indicator of potential risks to the soundness of the evaluation, we saw improvement relative to Opus 4.5.
but I never heard about Opus 4.5 being too evaluation aware to evaluate. It looks like Apollo simply wasn't part of Opus 4.5's alignment evaluation (4.5's System Card doesn't mention them).
This probably seems unfair/unfortunate from Anthropic's perspective, i.e., they believe their models are becoming less eval aware, but due to Apollo's conclusions being spread on social media, a lot of people probably got the impression that models are getting more eval aware. Personally I'm not sure we can trust Anthropic's verbalized evaluation awareness metric, and wish Apollo had done evals on 4.5 too to give us an external comparison.
Sam Altman tweeted that OpenAI made an agreement with DoW to use OpenAI models, and that this agreement will prohibit use models for mass surveillance and autonomous weapons.
Two of our most important safety principles are prohibitions on domestic mass surveillance and human responsibility for the use of force, including for autonomous weapon systems. The DoW agrees with these principles, reflects them in law and policy, and we put them into our agreement.
What's going on? Is it more likely that DoW has different standards for Anthropic and OpenAI, or Sam is unfaithful?
"human responsibility for the use of force, including for autonomous weapon systems"
That doesn't say prohibiting model use for autonomous weapons, it says human responsibility for autonomous weapons. With Sam Altman, always pay very close attention to what exactly he's saying and how he's saying it (often, not even that helps).
Pay particularly close attention to "reflects them in law and policy." The DoW's current talking point is that mass surveillance is illegal and they only want Claude to do everything allowed by law.
I read that line as saying OpenAI agreed with DoW's standard and requested no special caveats. They're relying on US law generally, which is what DoW wanted from Anthropic.
Oh, I see. So, as usually, reality is even worse than the worst interpretation of Altman's words. (Edit: Then again, he said "we put them into our agreement," but that could mean anything from simply meaning something else to being made up.)
Update: Altman lied (or said some kind of a technical truth that made everyone misunderstand him) - it's just "all lawful use."