The distinction between "large scale era" and the rest of DL looks rather suspicious to me. You don't give a meaningful defense of which points you label "large scale era" in your plot and largely it looks like you took a handful of the most expensive models each year to give a different label to.
On what basis can you conclude that Turing NLG, GPT-J, GShard, and Switch Transformers aren't part of the "large scale era"? The fact that they weren't literally the largest models trained that year?
There's also a lot of research that didn't make your analysis, including work explicitly geared towards smaller models. What exclusion criteria did you use? I feel like if I was to perform the same analysis with a slightly different sample of papers I could come to wildly divergent conclusions.
Great questions! I think it is reasonable to be suspicious of the large-scale distinction.
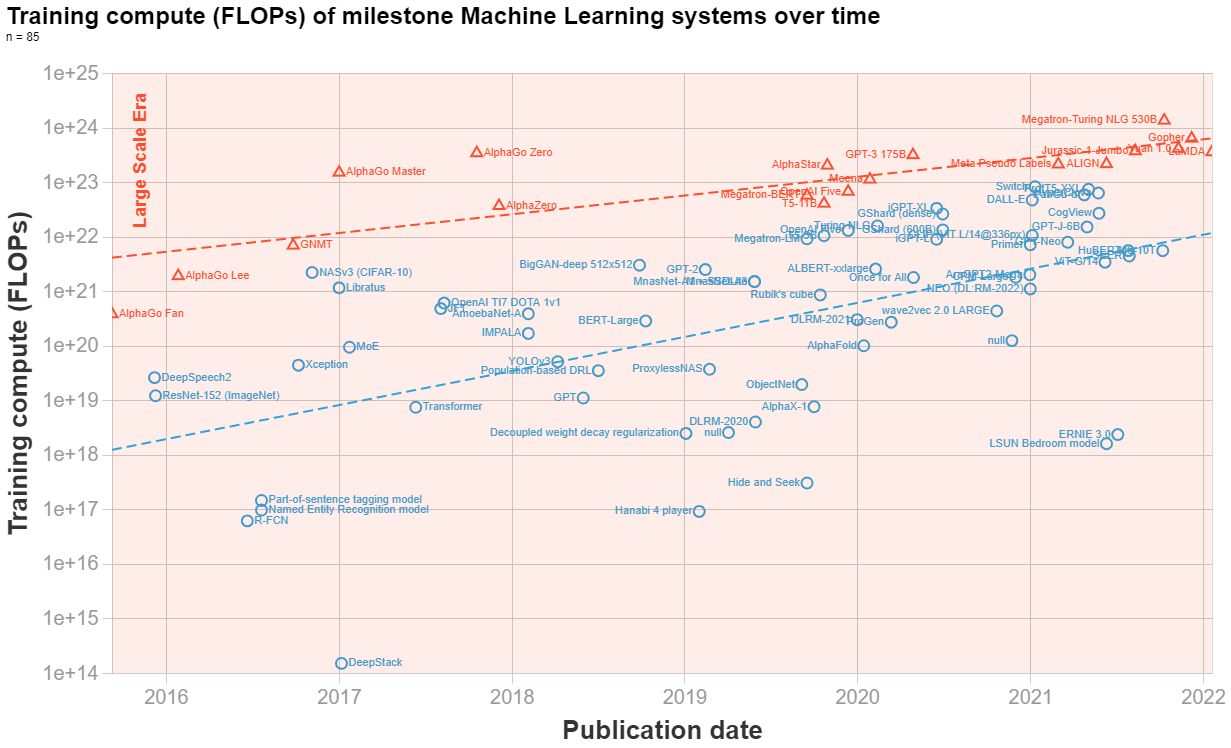
I do stand by it - I think the companies discontinuously increased their training budgets around 2016 for some flagship models.[1] If you mix these models with the regular trend, you might believe that the trend was doubling very fast up until 2017 and then slowed down. It is not an entirely unreasonable interpretation, but it explains worse the discontinuous jumps around 2016. Appendix E discusses this in-depth.
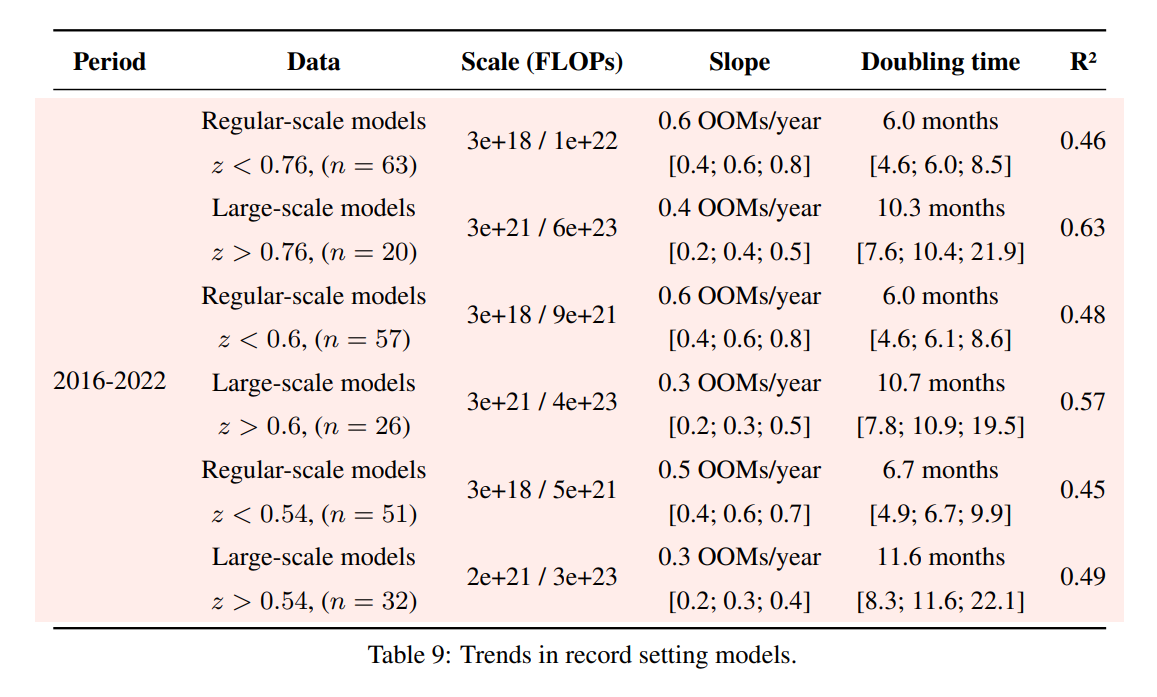
The way we selected the large-scale models is half intuition and half convenience. We compare the compute of each model to the log compute of nearby papers (within 2 years), and we call it large scale if its log compute exceeds 0.72 standard deviations of the mean of that sample.
I think there is a reasonable case for including NASv3, Libratus, Megatron-LM, T5-3B, OpenAI Five, Turing NLG, iGPT-XL, GShard (dense), Switch, DALL-E, Pangu-α, ProtT5-XXL and HyperClova on either side of this division.
Arguably we should have been more transparent about the effects of choosing a different threshold - we will try to look more into this in the next update of the paper.
- ^
See appendix F for a surface discussion
There's also a lot of research that didn't make your analysis, including work explicitly geared towards smaller models. What exclusion criteria did you use? I feel like if I was to perform the same analysis with a slightly different sample of papers I could come to wildly divergent conclusions.
It is not feasible to do an exhaustive analysis of all milestone models. We necessarily are missing some important ones, either because we are not aware of them, because they did not provide enough information to deduce the training compute or because we haven't gotten to annotate them yet.
Our criteria for inclusion is outlined in appendix A. Essentially it boils down to ML models that have been cited >1000 times, models that have some historical significance and models that have been deployed in an important context (eg something that was deployed as part of Bing search engine would count). For models in the last two years we were more subjective, since there hasn't been enough time for the more relevant work to stand out the test of time.
We also excluded 5 models that have abnormally low compute, see figure 4.
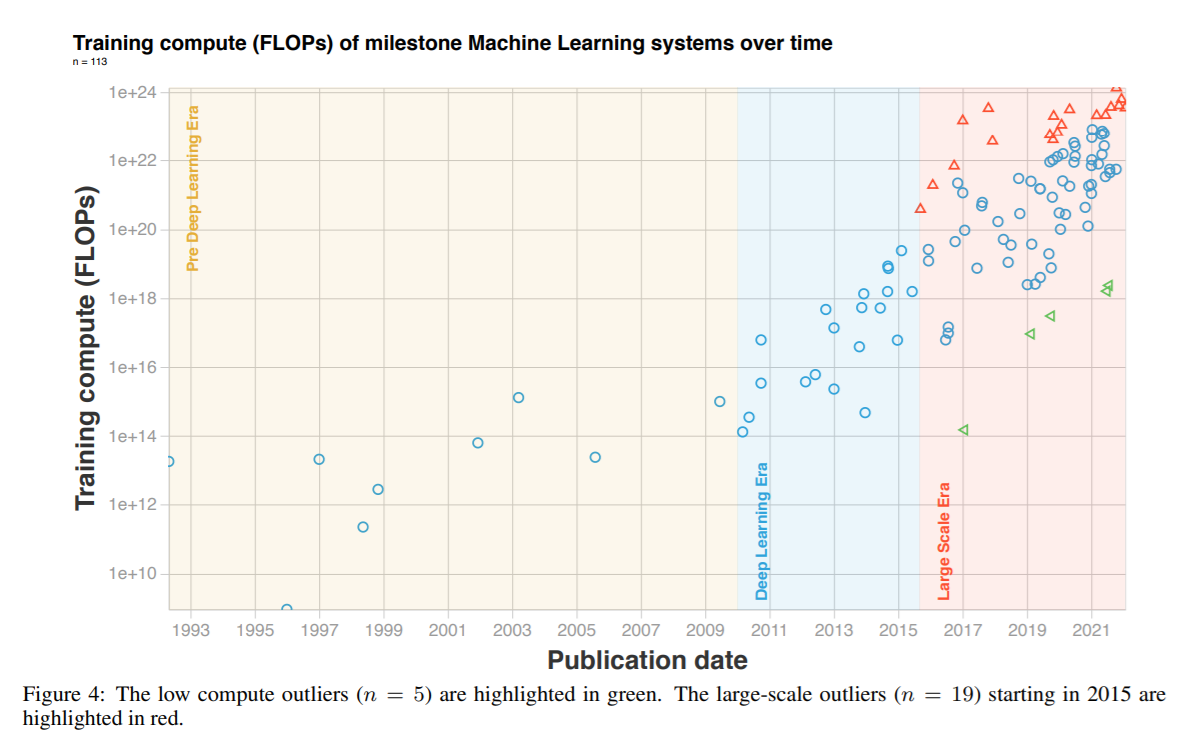
We tried playing around with the selection of papers that was excluded and it didn't significantly change our conclusions, though obviously the dataset is biased in many ways. Appendix G discusses the possible biases that may have crept in.
I think that the authors at least did some amount of work to distinguish the eras, but agree more work could be done.
Also I agree w/ Stella here that Turing, GPT-J, GShard, and Switch are probably better fit into the “large scale“ era.
Stay tuned for more!
This might be slightly easier to do if it were made into a sequence, which could in turn be subscribed to.
It's looking like LW accounts can't subscribe (assuming a subscribe to sequence feature exists).
It may be worth also looking at machine learning FLOPs as % of total FLOPs over time. As-is, it's somewhat difficult to distinguish:
- General improvements over time that machine learning piggybacked on.
- Improvements / new machines specifically for machine learning.
- Existing machines being repurposed for machine learning.
co-author here
I like your idea. Nonetheless, it's pretty hard to make estimates on "total available compute capacity". If you have any points, I'd love to see them.
Somewhat connected is the idea of: What ratio of this progress/trend is due to computational power improvements versus increased spending? To get more insights on this, we're currently looking into computing power trends and get some insights into the development of FLOPS/$ over time.
Nonetheless, it's pretty hard to make estimates on "total available compute capacity". If you have any points, I'd love to see them.
I tend to fall on the side of "too many ideas", not "too few ideas". (The trick is sorting out which ones are actually worth the time...) A few metrics, all hilariously inaccurate:
- "Total number of transistors ever produced". (Note that this is necessarily monotonically non-decreasing.)
- "Total number of transistors currently operational" (or an estimate thereof.)
- "Integral of <FLOPs/transistor as a function of time, multiplied by rate of transistor production as a function of time>"
- One of the above, but with DRAM & Flash (or, in general, storage) removed from # of transistors produced.
- One of the above, but using FLOPs/$ and total spending (or estimate of current total market assets) as a function of time instead of using FLOPs/transistor and # transistors as a function of time.
- Total BOINC capacity as a function of time (of course, doesn't go back all that far...)
That being said, estimates of global compute capacity over time do exist, see e.g. https://ijoc.org/index.php/ijoc/article/view/1562/742 and https://ijoc.org/index.php/ijoc/article/view/1563/741. These together show (as of 2012, unfortunately, with data only extending to 2007) that total MIPS on general-purpose computers grew from in 1986 to in 2007. (Fair warning: that's MIPS, so (a somewhat flawed) integer benchmark not floating-point.) Or about a doubling every ~1.4-1.5 years or so.
Somewhat connected is the idea of: What ratio of this progress/trend is due to computational power improvements versus increased spending? To get more insights on this, we're currently looking into computing power trends and get some insights into the development of FLOPS/$ over time.
As long as we're talking about extrapolations, be aware that I've seen rumblings that we're now at a plateau in that the latest generation of process nodes are actually about the same $/transistor as (or even higher than) the previous generation process nodes. I don't know how accurate said rumblings are, however. (This is "always" the case very early in a process node; the difference here is that it's still the case even as we're entering volume production...)
A related metric that would be interesting is total theoretical fab output (# wafers * # transistors / wafer * fab lifetime) (or better yet, actual total fab output) divided by the cost of the fab. C.f. Rock's law. Unfortunately, this is inherently somewhat lagging...
This is a very helpful resource and an insightful analysis! It would also be interesting to study computing trends for research that leverages existing large models whether through fine-tuning, prefix tuning, prompt design, e.g., "Fine-Tuning Language Models from Human Preferences", "Training language models to follow instructions with human feedback", "Prefix-Tuning: Optimizing Continuous Prompts for Generation", "Improving language models by retrieving from trillions of tokens" (where they retrofit baseline models) and indeed work referenced in Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
Ron
https://arxiv.org/abs/2202.05924
What do you need to develop advanced Machine Learning systems? Leading companies don’t know. But they are very interested in figuring it out. They dream of replacing all these pesky workers with reliable machines who take no leave and have no morale issues.
So when they heard that throwing processing power at the problem might get you far along the way, they did not sit idly on their GPUs. But, how fast is their demand for compute growing? And is the progress regular?
Enter us. We have obsessively analyzed trends in the amount of compute spent training milestone Machine Learning models.
Our analysis shows that:
Not enough for you? Here are some fresh takeaways:
Compute is a strategic resource for developing advanced ML models. Better understanding the progress of our compute capabilities will help us better navigate the advent of transformative AI.
In the future, we will also be looking at the other key resource for training machine learning models: data. Stay tuned for more!
Read the full paper now on the arXiv