First, Squiggle absolutely can make this easier.
Second, I think doing this well is simply a skill people need to develop if they want to reason about uncertainties well - they spend several years in school learning to multiply properly, then don't even learn what the word convolution means, so it's no wonder they aren't correctly working with distributions.
Using distributions is dangerous; if you get the tails wrong it can wreck you
Strongly disagree - people really should want to reason about uncertainties well, because almost no-one is a risk neutral decisionmaker. And trying to be one fails badly, because not looking at uncertainties works badly. Not trying to build robust strategies given uncertainties can ALSO wreck you - as we saw when a certain billionaire funder lost everything thinking he should keep playing in St. Petersberg Paradox. (And then committed fraud to stay solvent a bit longer, which, to be clear, wasn't about not knowing how to convolve probability distributions.)
I agree reasoning about uncertainty is crucial. If your EV isn't sensitive to the probability and magnitude of tail outcomes, you're doing EV estimation wrong.
I think EV should be in units of utils or something, such that you're risk neutral in EV.
When I said "Using distributions is dangerous" I think I meant to claim: often people would do better to think discretely, considering a few different scenarios, rather than trying to draw a distribution. I think sometimes people are able to reason well about uncertainty with a few discrete buckets but instead they draw a distribution (perhaps because Squiggle leads them to?) and reasoning about distributions is tough. Including me! I think in many contexts I'd produce a better EV estimate by putting probabilities and values on several discrete buckets and summing the products than by trying to draw a continuous distribution and then taking its expectation. If I had to draw a continuous distribution, I'd often start with the discrete buckets and then draw a distribution to approximate them!
Also sometimes the EV you assign a parameter is upstream of your distribution for that parameter, and in such cases there's no need to draw a distribution if your goal is just an EV estimate.
Some variables—election outcomes, AI timelines—are very amenable to distributions. But trying to draw a distribution for value produced by a project is rough.
I failed to illustrate what goes wrong when people naively make up distributions rather than thinking carefully about EV. Here's a quick squiggle:
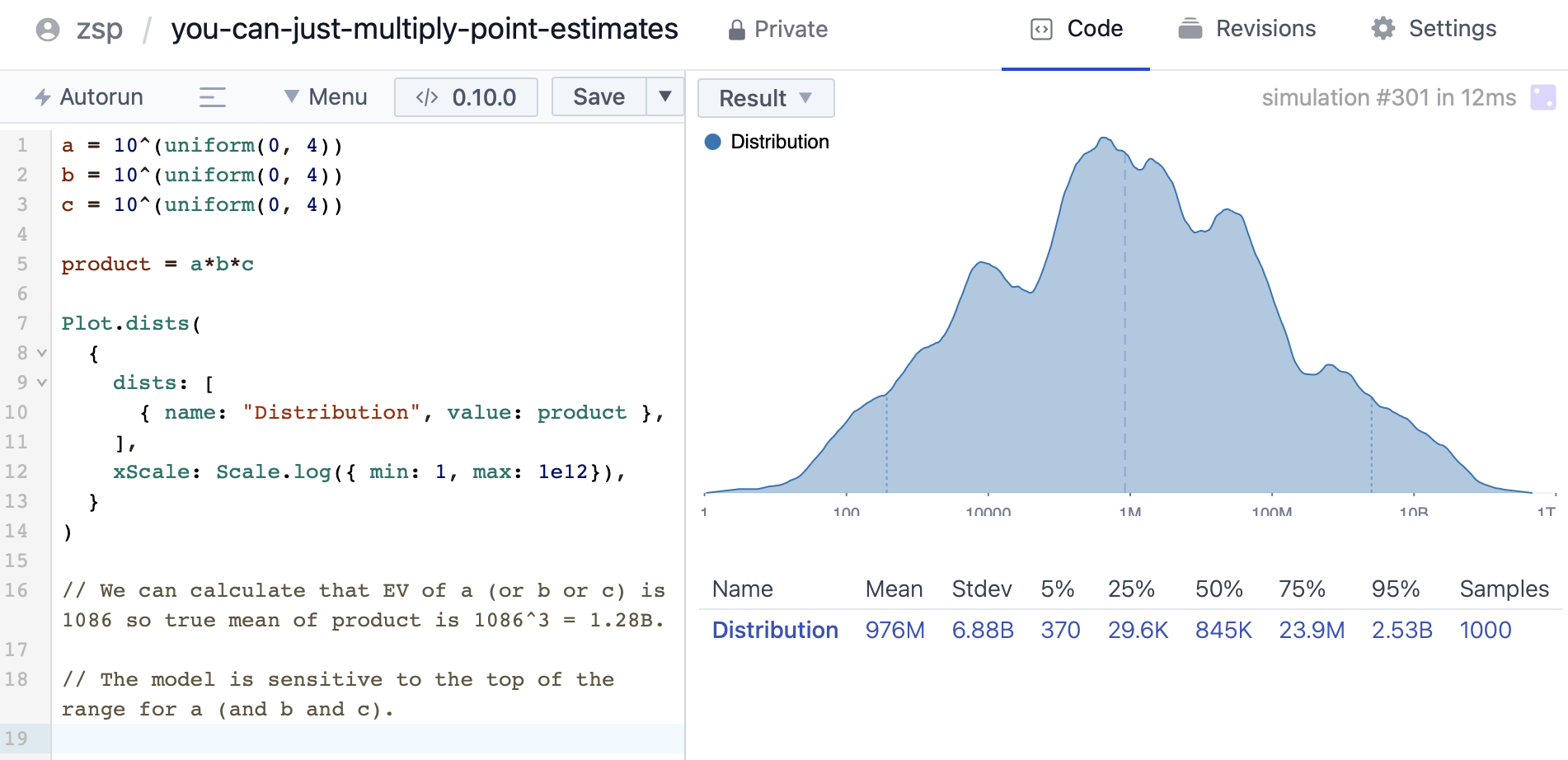
The EV of a (and b and c) is
Squiggle makes it easy to use distributions — but if you don't put serious effort into it, your squiggle model will have predictably flawed parameters.
Yes, this is an example of how you can do things wrong if you don't pay attention - but it's also an example of when you should absolutely be accounting for that uncertainty, because if the value really is distributed as a function of the power of ten, ignoring that fact and only looking at the mean is going to be a really, really bad idea.
How are you supposed to "account[] for that uncertainty"? I think you notice it, you try really hard to make sure that your parameters are right, and then at the end of the day you take the expectation.
If you're entirely uncertainty insensitive and you're looking at a distribution over final outcomes of the world rather than a specific compound variable, sure. But that's almost never the case. I'm not saying that you should be naively taking the expectation of poorly thought through distributions, but it's insane to oppose sensitivity analysis.
(Also, unlike in your example where you impose uniform uncertainties on the powers of the multiplied variables instead of on the variables themselves, it's actually impossible to have variables that themselves have reasonably quantified distributions with means that match the expectation and then get a different expectation because you multiply them together. But I agree that what people often actually do is make stupid mistakes that break this.)
I'd love to see your thoughts on how to tell if distributions are independent, maybe with a worked example?
I don't really have thoughts on this.
Most distributions are independent. E.g. the parameters in the BOTECs here.
Sometimes parameters are obviously correlated. E.g. "Congress wants to do good AI safety stuff" and "the president wants to do good AI safety stuff," or "vote margin in the 2026 CO-08 election" and "seat margin in the House after the 2026 elections."
For a first cut back of the envelope kind of thing, I agree. There's a great deal of value in simplicity. But EV modeling isn't really just about predicting the future. It's about decision making under uncertainty.
Anyway I think for serious decisions you should almost never get an EV just by multiplying point estimates. Any complex real world situation has:
Parameters with weird distributions. That means your point estimates probably will not be a good approximation of the mean.
Nonlinearities. If EV is anything more complicated than a product of multiple variables, you need the uncertainty distributions to get the right output.
Correlations between parameters. If you're careful enough you can put all the common factors in separate independent variables, but you probably didn't.
Using only point estimates suggests a mindset of quick and dirty, give me an answer whether or not it's right. You will learn more and make better decisions if you try to make a model that represents your true state of knowledge about the situation.
Many people think you need probability distributions; they think using point estimates will mess up your EV calculations. That's false; you'll get the same result whether you multiply distributions or multiply their EVs. You can ask a chatbot: "Briefly explain linearity of expectation and independence (E[XY] = E[X]E[Y])." To multiply EV point estimates, you just need to make sure the point estimates are EV rather than median, the distributions are independent (or at least uncorrelated), and you're not doing anything fancier than adding and multiplying.[1] (However, you need distributions if you want median, credible intervals, etc.)
I generally use point estimates in my EV calculations. In some contexts the natural way to estimate EV is to first estimate a distribution, but in my work it usually makes sense to estimate EV directly. And using point estimates makes it easier to understand models, compare parameters from different people/models, notice inconsistencies, etc.
Using distributions is dangerous; if you get the tails wrong it can wreck you.[2] And again, distributions are harder to understand, and making your models less scrutable—to yourself and others—is a massive cost. Using distributions might help you notice which parameters are unstable, but you can also just do that without distributions.
I occasionally use distributions for EV estimates because (1) sometimes it's necessary[3] or (2) sometimes the best way to estimate EV (or explain your estimate to others) is to estimate the distribution and then take the mean. Sometimes these "distributions" are crude, with just a few discrete buckets, because that's easier to think about.
On the other hand (thanks to Eli Lifland for suggestions):
This post is part of my sequence inspired by my prioritization research and donation advising work.
You also have to make sure you're using the expectation of the right parameter. In particular, 1/E[X] is different from E[1/X].
Minor: also arguably distributions for value of the world after this intervention minus value of the world before this intervention are fake/meaningless, since all interventions have massive random effects. This doesn't bother EVchads because the random effects have EV zero. When we talk about the distribution of effects, we have to talk about something more like direct/foreseeable effects. This doesn't really matter but it may suggest that distribution of value diff is a weird/unnatural concept.
E.g. what's the value of spending $1 in 2028, given uncertainty about how much others will spend? I use a distribution on "how much others will spend effectively in this area in 2028" and a function from "how much others will spend" to "EV of marginal $1."