RLVR is getting introduced as a major component of training cost and capabilities over 2025, and it's possibly already catching up with pretraining in terms of GPU-time, pending more sightings of such claims.
The slopes of trends in capabilities are likely going to be different once RLVR is pretraining-scale, compared to when pretraining dominated the cost. So trends that start in the past and then include 2025 data are going to be largely uninformative about what happens later, it's only going to start being possible to see the new trends in 2026-2027.
(Incidentally, since RLVR has significantly lower compute utilization than pretraining, counting FLOPs of pretraining+RLVR will get a bit misleading when the latter gobbles up a major potion of the total GPU-time while utilizing only a small part of the training run's FLOPs.)
With sufficiently large batch sizes for rollouts, why should we expect lower utilization than pretraining?
In MoE, each expert only consumes a portion of the tokens, maybe 8x-32x fewer than there are tokens in total. When decoding, each sequence only contributes 1 token without speculative decoding, or maybe 8 tokens with it (but then later you'd be throwing away the incorrectly speculated tokens). When you multiply two x square matrices of 16 bit numbers, you need to read bytes from HBM, perform FLOPs, and write back bytes of the result. Which means you are performing BF16 FLOPs per byte read/written to HBM. For an H200, HBM bandwidth is 4.8 TB/s, while BF16 compute is 1e15 FLOP/s. So to feed the compute with enough data, you need to be at least 600, probably 1K in practice.
So to feed the compute in a MoE model with 1:8-1:32 sparsity, you need to be processing 8K-32K tokens at a time. This isn't too much of a problem for pretraining or prefill, since you work with all tokens of all the sequences in a batch simultaneously. But for decoding, you only have 1-8 tokens per sequence (at its end, currently being generated), which means 1K-4K sequences (with speculative decoding) or the full 8K-32K sequences (without) that could arrive to a given expert located at a particular physical chip. Each sequence might need 10 GB of KV cache, for the total of 10-40 TB or 80-320 TB. An 8-chip H200 node has 1.1 TB of HBM, so that's a lot of nodes, and the activation vectors would need to travel between them to find their experts, the same 10-40 or 80-320 hops per either 4 tokens or 1 token of progress (which tops out at the number of layers, say 80 layers). Each hop between nodes might need to communicate 50 KB of activation vectors per token, that is 0.4-1.6 GB (which is the same with speculative decoding and without), let's say 1 GB. With 8x400Gbps bandwidth, it'd take 2.5 ms to transmit (optimistically). In case of speculative decoding, that's 25-100 ms per token in total (over 10-40 hops), and without speculative decoding 200 ms per token. Over 50K token long sequences, this takes 0.1-0.3 hours with speculative decoding (assuming 4 tokens are guessed correctly each step of decoding on average), or 4 hours without. At 40% utilization with 250B active params, it'd take 0.4 hours to compute with speculative decoding (including the discarded tokens), and 0.2 hours without. So maybe there is still something to this in principle, with speculative decoding and more frugal KV cache. But this is probably not what will be done in practice. Also, there are only 4.3K steps of 0.5 hours in 3 months (for RLVR), which is plausibly too few.
Instead, we don't worry about feeding the compute on each chip during decoding and multiply thin matrices with very few tokens at each expert. Which means all the time is spent moving the data from HBM. With a 2T total param FP8 model we'd need maybe 4 nodes to fit it, and there will be enough space for 200 sequences. Passing all of HBM through the chips will take about 25 ms, which translates to 10 tokens per second without speculative decoding, or 40 tokens per second with it (which comes out to $2-9 per 1M tokens at $2 per H200-hour). At 40 tokens per second over 200 sequences on 4 nodes of 8 chips each, in a second a 250B active parameter model would use 4e15 FLOPs and could get 32e15 BF16 FLOPs at full compute utilization, so we get 12% compute utilization with speculative decoding, about 3x-4x lower than the proverbial 40% of pretraining. Though it's still 0.3 hours per RLVR step, of which there are only 6.4K in 3 months. So there could be reason to leave HBMs half-empty and thereby make decoding 2x faster.
Interesting, but I think squashing total training compute to a scalar value is inappropriate here. If you draw a line through GPT-2, 3, 3.5, 4 on that plot, you can see the RLVR models R1 and 3.7 Sonnet are above the trend line. Since we don't really know the optimal ratio of pretraining/RLVR compute, nor how it scales, the total compute is missing a lot of important information.
Thanks, a very useful analysis.
2.5 months is enough to provide a very strong AI research acceleration, so the trend is likely to be changing towards larger share of algorithmic efficiency in the future (e.g. if we freeze the compute, the progress will not stop even now, although it would slow down noticeably).
We should also keep in mind that once you get past ~8 hrs we can't say the time is comparable to calendar time. A task that takes a human 24 hours doesn't take a day. It takes 3 full working days. Which, when you account for non-focused-work-time overhead, means something like 80% of a work week. This would mean that when we say something like "2.5 months," that's actually a project that would take a human around a year of their life to complete, mixed in with all the other things a human does.
It's interesting that task length is better correlated with release date than with training compute; I was not expecting that.
It's partially because we filtered for frontier models. If you had people train models of all different sizes that were compute-optimal architectures at their respective sizes, the correlation between time horizon and compute would plausibly be much better.
Nice one! I didn't actually run the empirical numbers to estimate the scaling law coefficients, but I (on more theoretical grounds) pointed at task-relevant data as the input presumably driving this trend.
Seems to me like data is the 'main' thing, and compute is more like 'enabling' that, but of course that makes either a constraint in principle. Curious if you have a response to that. Did the data points you grabbed also have estimated 'data' quantities attached? It's difficult because data vary in 'quality' (which in my picture is basically how task-relevant they are, or in the worst case if they're actively misleading or wrong)...
Ah yeah, the Epoch points include 'training dataset size (total)' which is some sort of crude correlate of the 'actual effective evidence'.
Tbh I no longer consider the data in this post relevant because ever since Chain-of-Thought models became a thing, METR's task time horizon has been increasing faster, but Epoch doesn't have accurate training FLOPs numbers for recent closed-source models from OpenAI/Anthropic/GDM. So it's either "estimate the relationship between training compute and task time horizons based on GPT-2, 3, 3.5 and 4", which sucks because that was before RLVR and before CoT, or "estimate the relationship between training compute and task time horizons based on open-source models for which Epoch does have accurate estimates of training FLOPs", which I haven't done.
Very nice. I recently did a similar exercise, and -- because as you note the Epoch data (understandably) doesn't have estimates of training compute for reasoning models -- I had o3 guesstimate "effective training compute" by OpenAI model (caveat: this doesn't really make sense!). You can see the FLOP by model in the link. And:
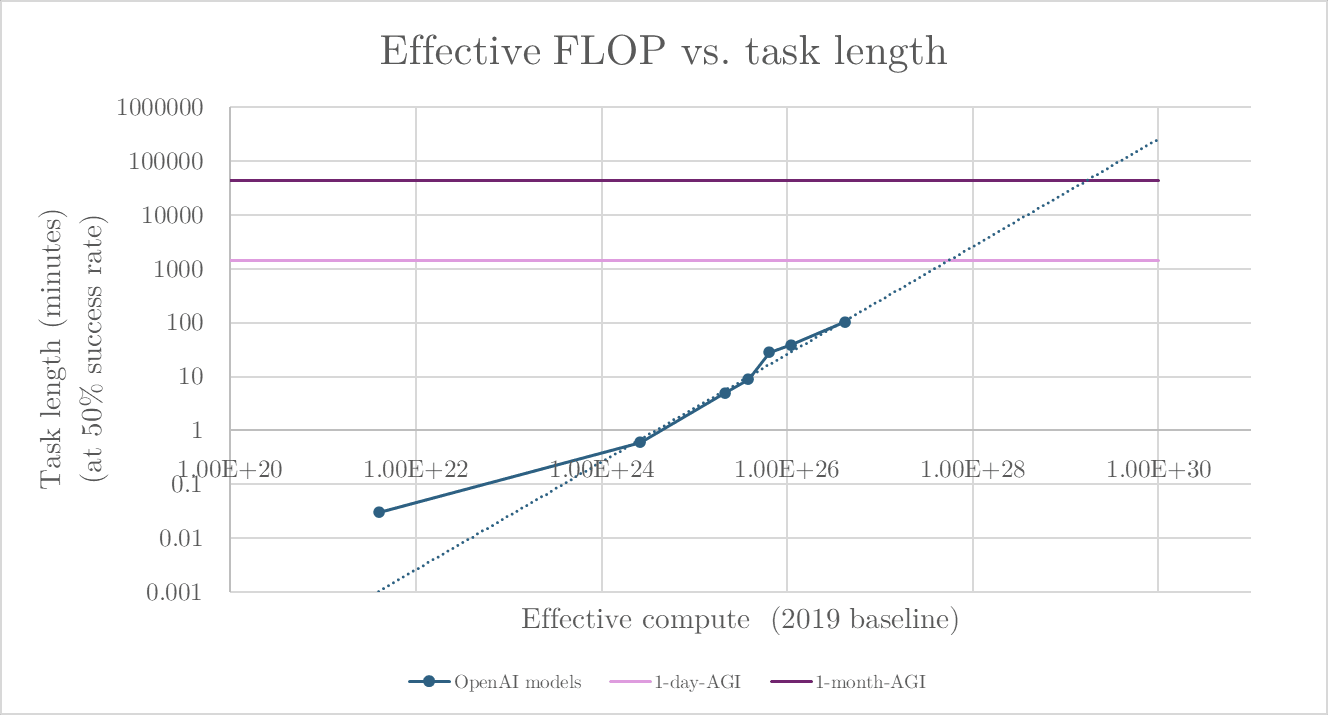
By this metric, it's ~3.5 more OOMs from o3 to 1-month-AGI. If -- as was often said to be the case pre-reasoning models -- effective compute can still be said to be growing at ~10x a year, then 1-month-AGI arrives around early 2029
- "1-month AGI", of course, on tasks of the type studied by Kwa et al
- That is also running up against the late-2020s compute slowdown
- Along with a bazillion other caveats I won't bother listing
I assume you are familiar with the METR paper: https://arxiv.org/abs/2503.14499
In case you aren't: the authors measured how long it takes a human to complete some task, then let LLMs do those tasks, and then calculated task length (in human time) such that LLMs can successfully complete those tasks 50%/80% of the time. Basically, "Model X can do task Y with Z% reliability, which takes humans W amount of time to do."
Interactive graph: https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
In the paper authors plotted task length as a function of release date.
Note that for 80% reliability the slope is the same.
IMO this is by far the most useful paper for predicting AI timelines. However, I was upset that their analysis did not include compute. So I took task lengths from the interactive graph (50% reliability), and I took estimates of training compute from EpochAI: https://epoch.ai/data/notable-ai-models
Here is the result:
(I didn't add labels for every model because the graph would be too cluttered)
Increasing training compute by 10 times increases task length by 10^0.694≈5 times.
...well, kind of. This graph does not take into account improvements in algorithmic efficiency. For example, Qwen2 72B has been trained using roughly the same amount of compute as GPT-3.5, but has a much longer task length. Based on this data, I cannot disentangle improvements from more physical compute and improvements from tweaks to the Transformer architecture/training procedure. So it's more like "Increasing training compute by a factor of 10 while simultaneously increasing algorithmic efficiency by some unknown amount increases task length by a factor of 5."
Speculation time: at what task length would an AI be considered ASI? Well, let's say a "weak ASI" is one that can complete a task that takes a human 100 years (again, 50% reliability). And let's say a "strong ASI" is one that can complete a task that takes a human 5000 years; granted, at that point this way of measuring capabilities breaks down, but whatever.
To train the "weak ASI" you would need around 10^35 FLOPs. For the "strong ASI" you would need around 10^37 FLOPs.
Optimistically, 10^31 FLOPs is about as much as you can get if you buy 500,000 units of GB300 and train an LLM in FP8 at 90% utilization for 365 days nonstop. That would correspond to task length of around 2.5 months. "Optimistically" because right now you can't buy 500 thousand of those things even if you had infinite money, and even if you could buy that many, you would probably want to use them for other purposes (such as running older models or experiments with novel architectures) as well, and not just to train one giant model for a year. So this is more of a an upper bound.
If these numbers are even remotely within the right ballpark, training ASI will be impossible without either software or hardware breakthroughs (such as photonic chips or analog devices for matrix multiplication) that break the current trend. If the current trend continues, then we won't see ASI for a looooooooong time.
Caveats:
I would love if the authors of the METR paper did a similar analysis, but with more models. Maybe they could disentangle the benefits of increasing training compute from the benefits of improvements in algorithmic efficiency to get two independent numbers.
EDIT: a little too late, but here:
Using only GPT models gives a much clearer picture with a much better fit, though it also means that I only have 4 data points to work with.
According to this graph, increasing training compute by 10 times results in 10^0.509≈3.2 times greater task time.