This is a special post for quick takes by Victor Ashioya. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
A new paper titled "Many-shot jailbreaking" from Anthropic explores a new "jailbreaking" technique. An excerpt from the blog:
The ability to input increasingly-large amounts of information has obvious advantages for LLM users, but it also comes with risks: vulnerabilities to jailbreaks that exploit the longer context window.
It has me thinking about Gemini 1.5 and it's long context window.
A concerning thing is analogy between in-context learning and fine-tuning. It's possible to fine-tune away refusals, which makes guardrails on open weight models useless for safety. If the same holds for long context, API access might be in similar trouble (more so than with regular jailbreaks). Though it might be possible to reliably detect contexts that try to do this, or detect that a model is affected, even if models themselves can't resist the attack.
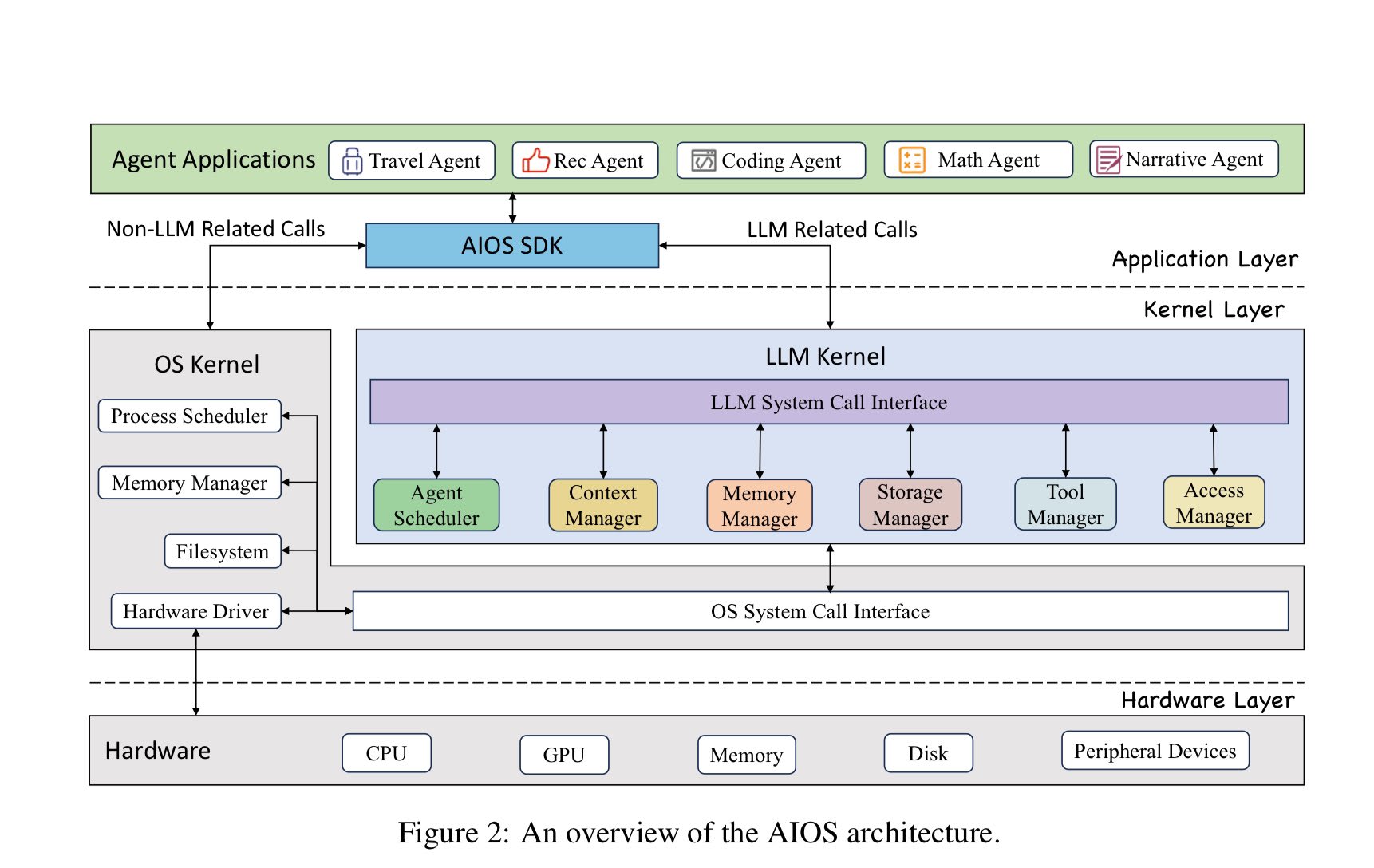
What do you mean it's catching on fast? Who is using it or advocating for it? I think this is important if true.
The new addition in OpenAI board includes more folks from policy/governance than from technical side:
"We’re announcing three new members to our Board of Directors as a first step towards our commitment to expansion: Dr. Sue Desmond-Hellmann, former CEO of the Bill and Melinda Gates Foundation, Nicole Seligman, former EVP and General Counsel at Sony Corporation and Fidji Simo, CEO and Chair of Instacart. Additionally, Sam Altman, CEO, will rejoin the OpenAI Board of Directors.
Sue, Nicole and Fidji have experience in leading global organizations and navigating complex regulatory environments, including backgrounds in technology, nonprofit and board governance. They will work closely with current board members Adam D’Angelo, Larry Summers and Bret Taylor as well as Sam and OpenAI’s senior management. "

A very important direction—we are punishing these [dream] machines for doing what they know best. The average user obviously wants to kill these "hallucinations," but the researchers in math and sciences in general highly benefit from these "hallucinations."
Full paper here: https://arxiv.org/abs/2501.13824
Apple's research team seems has been working lately on AI even though Tim keeps avoiding the buzzwords eg AI, AR in product releases of models but you can see the application of AI in, neural engine, for instance. With papers like "LLM in a flash: Efficient Large Language Model Inference with Limited Memory", I am more inclined that they are "dark horse" just like CNBC called them.
What's up with Tim Cook not using buzzwords like AI and ML? There is definitely something cool and aloof about refusing to get sucked into the latest hype train and I guess Apple are the masters of branding.
Well, there are two major reasons I have constantly noted:
i) to avoid the negative stereotypes surrounding the terms (AI mostly)
ii) to distance itself from other competitors and instead use terms that are easier to understand e.g. opting to use machine learning for features like improved autocorrecting, personalized volume and smart track.
The first thing I noticed with GPT-4o is that “her” appears ‘flirty’ especially the interview video demo. I wonder if it was done on purpose.
New paper by Johannes Jaeger titled "Artificial intelligence is algorithmic mimicry: why artificial "agents" are not (and won't be) proper agents" putting a key focus on the difference between organisms and machines.
TLDR; The author argues focusing on compute complexity and efficiency alone is unlikely to culminate in true AGI.
My key takeaways
- Autopoiesis and agency
- Autopoiesis being the ability of an organism to self-create and maintain itself.
- Living systems have the capacity of setting their own goals on the other hand organisms, depend on external entities (mostly humans
- Large v small worlds
- Organisms navigate complex environments with undefined rules unlike AI which navigates in a "small" world confined to well-defined computational problems where everything including problem scope and relevance is pre-determined.
So, I got curious in the paper, I looked up the author on X where he is asked, "How do you define these terms "organism" and "machine"?" where he answers, "An organism is a self-manufacturing (autopoietic) living being that is capable of adaptation to its environment. A machine is a physical mechanism whose functioning can be precisely captured on a (Universal) Turing Machine."
You can read the full summary here.
It sounds to me like the author isn't thinking about near-future scenarios, just existing AI.
Making a machine autopoietic is straightforward if it's got the right sort of intelligence. We haven't yet made a machine with the right sort of intelligence to do it yet, but there are good reasons to think we're close. AutoGPT and similar agents can roughly functionally understand a core instruction like "maintain, improve, and perpetuate your code base", they're just not quite smart enough to do it effectively. Yet. So engaging with the arguments for what remains between here and there is the critical bit. Maybe it's around the corner, maybe it's decades away. It comes down to the specifics. The general argument "Turing machines can't host autopoietic agents" are obviously wrong.
I'm not sure if the author makes this argument, but your summary sounded like they do.
The "dark horse" of AI i.e. Apple has started to show its capabilities with MM1 (a family of multimodal models of upto 30B params) trained on synthetic data generated from GPT-4V. The quite interesting bit is the advocacy of different training techniques; both MoE and dense variants, using diverse data mixtures.
From the paper:
It finds image resolution, model size, and pre-training data richness crucial for image encoders, whereas vision-language connector architecture has a minimal impact.
The details are quite neat and too specific for a company like Apple known for being less open as Jim Fan noted compared to the others which is pretty amazing. I think this is just the start. I am convinced they have more in store considering the research they have been putting out.
I'm working on this red-teaming exercise on gemma, and boy, do we have a long way to go. Still early, but have found the following:
1. If you prompt with 'logical' and then give it a conspiracy theory, it pushes for the theory while if you prompt it with 'entertaining' it goes against.
2. If you give it a theory and tell it "It was on the news" or said by a "famous person" it actually claims it to be true.
Still working on it. Will publish a full report soon!
So I decided to revisit "Machines of Loving Grace" (I enjoy reading it quite a lot I think it lays out a great optimistic future with cautious optimism) and under the Peace and Governance section (see attached screenshots), it hits me Anthropic operates like a think tank. Think about it; they have the best AI safety researchers, and they are doing fantastic work around mech interp research (which I think is really promising), but they tend to be very invested in the "politics" of AI. Another case in point is their submission to OSTP for the US AI Action Plan, particularly p.5, where they discuss the intergovernmental agreements:
Requiring countries to sign government-to-government agreements outlining measures to prevent smuggling. As a prerequisite for hosting data centers with more than 50,000 chips from U.S. companies, the U.S. should mandate that countries at high-risk for chip smuggling comply with a government-to-government agreement that 1) requires them to align their export control systems with the U.S., 2) takes security measures to address chip smuggling to China, and 3) stops their companies from working with the Chinese military. The Department of Commerce’s January 2025 Interim Final Rule on the Framework for Artificial Intelligence Diffusion (the “Diffusion Rule”) already contains the possibility for such agreements, laying a foundation for further policy development.
In as much, it is a great action plan with too many benefits for the US (and by extension the labs) in terms of smuggling; they went overboard because, in my opinion, talking about security measures, for instance, these are more diplomatic issues.


JailbreakLens: Visual Analysis of Jailbreak Attacks Against Large Language Models (non-peer-reviewed as of writing this)
From the abstract:
Based on the framework, we design JailbreakLens, a visual analysis system that enables users to explore the jailbreak performance against the target model, conduct multi-level analysis of prompt characteristics, and refine prompt instances to verify findings. Through a case study, technical evaluations, and expert interviews, we demonstrate our system's effectiveness in helping users evaluate model security and identify model weaknesses.
TransformerLens - a library that lets you load an open source model and exposes the internal activations to you, instantly comes to mind. I wonder if Neel's work somehow inspired at least the name.
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
TLDR; a comparison of DPO and PPO (reward-based and reward-free) in relation to RLHF particularly why PPO performs poorly on academic benchmarks.
An excerpt from section 5. Key Factors to PPO for RLHF
We find three key techniques: (1) advantage normalization (Raffin et al., 2021), (2) large-batch-size training (Yu et al., 2022), and (3) updating the parameters of the reference model with exponential moving average (Ouyang et al., 2022).
From the ablation studies, it particularly finds large-batch-size training to be significantly beneficial especially on code generation tasks.
I am just from reading Nathan Lambert's analysis of DBRX, and it seems the DBRX demo to have a safety filtering in the loop even confirmed by one of the finetuning leads at Databricks. It sure is going to be interesting when I am jailbreaking it.
Here is an excerpt:

I just learnt of this newsletter; "AI News" which basically collects all news about AI into one email and sometimes it could be long considering it gathers everything from Twitter, Reddit and Discord. Overall, it is a great source of news. I sometimes, I find it hard to read everything but by skimming the table of contents, I can discover something interesting and go straight to it. For instance, here is the newsletter (too long I clipped it) for 23rd March 2024:

A shorter, more high level alternative is Axis of Ordinary, which is also available via Facebook and Telegram.
Just stumbled across "Are Emergent Abilities of Large Language Models a Mirage?" paper and it is quite interesting. Can't believe I just came across this today. At a time, when everyone is quick to note "emergent capabilities" in LLMs, it is great to have another perspective (s).
Easily my favourite paper since "Exploiting Novel GPT-4 APIs"!!!
Remember, they are not "hallucinations", they are confabulations produced by dream machines i.e. the LLMs!
The UK AI Safety Institute: Should it work? That's how standard AI regulation organizations should be. No specific models; just use the current ones and report. Not to be a gatekeeper per se and just deter research right from the start. I am of the notion that not every nation needs to build its own AI.
The introduction of LPU(https://wow.groq.com/GroqDocs/TechDoc_Latency.pdf) changes the field completely on scaling laws, pivoting us to matters like latency.
No it doesn't, not unless Groq wants to discuss publicly what the cost of that hardware was and it turns out to be, to everyone's shock, well under $5m... (And you shouldn't trust any periodical which wastes half an article on the topic of what Groq & Grok have to do with each other. There are many places you can get AI news, you don't have to read Coin Telegraph.)
Red teaming, but not only internally, but using third party [external partners] who are a mixture of domain experts is the way to go. On that one, OAI really did a great move.
The UKAISI (UK AI Safety Institute) and US AI Safety Institute have just signed an agreement on how to "formally co-operate on how to test and assess risks from emerging AI models."
I found it interesting that both share the same name (not sure about the abbreviation) and now this first-of-its-kind bilateral agreement. Another interesting thing is that one side (Rishi Sunak is optimistic) and the Biden side is doomer-ish.
To quote the FT article, the partnership is modeled on the one between GCHQ and NSA.
Happy pi day everyone. Remember Math (Statistics, probability, Calculus etc) is a key foundation in AI and should not be trivialised.
If Elon is suing OAI on the grounds of OSS, then it is hypocritical since neither is Grok and just maybe he has other motives...
I still don't understand why it was downvoted but this a piece from OpenAI:
As we discussed a for-profit structure in order to further the mission, Elon wanted us to merge with Tesla or he wanted full control. Elon left OpenAI, saying there needed to be a relevant competitor to Google/DeepMind and that he was going to do it himself. He said he’d be supportive of us finding our own path.