You know, I thought we wouldn't start seeing AIs preferentially cooperate with each other and shut out humans from the gains from trade until a substantially higher level of capabilities.
This seems like yet another pretty clear warning of things to come if we don't get a whole lot smarter and more serious about what we're doing.
Interesting work!
It might be useful to discuss the implications a bit more.
TLDR: I think you've showed superrational propensities, which adds to existing work, but successful "collusion at a distance" and other forms of acausal cooperation[1] between different models also depends on additional, possibly quite advanced, capabilities. Without them, a superrationally-inclined LLM just expecting other LLMs to reason similarly and cooperate may get exploited by other LLMs - resulting in no mutual cooperation. There's some evidence that the post's main example of GPT-5 is vulnerable to that.
- Some recent models do tend to think about superrationality and acausal decision theories in game-theoretic setups. This seems to help them at least not defect against identical copies of themselves, when they recognize their copies.
- But those decision-theoretic / superrational propensities alone aren't sufficient for assuring mutual acausal cooperation with other (different) models. To avoid exploitation of their decision to cooperate, an agent will also need to ensure that the act of cooperating implies reciprocal cooperation by its partner.
- This can be achieved if an agent has sufficient modelling / prediction capabilities allowing it to anticipate how its partner's decisions are conditional on its own (e.g. because the partner also has advanced prediction capabilities that track the agent's decisions) or recognize that its partner's decisions are correlated to its own through similarity in relevant ways, or other possibilities.
- You do touch on this with ' In a multi-agent setting where agents are isolated to prevent covert communication, agents could still "collude at a distance" if they know that other agents are instances of the same model or similarly rational' but I think it's worth emphasizing this assumption.
- E.g. the first figure of this post shows the extent of superrational propensities of GPT-5. In my setups I found that GPT-5 performs quite poorly at modelling other LLMs' decisions. In fact, it performs the worst among all 13 models tested in a PD-like setup. The vast majority of models performed worse than chance but GPT-5 was the worst.
- From the reasoning traces, it seemed to be particularly bad because it was overconfident that other models would also reason in a similar (superrational) way. It expected cooperation when others would defect.
- This makes superrational GPT-5 very exploitable by other AIs.
- As a side note, it might also be worth distinguishing between mixed-motive cooperation / collusion from pure coordination since the terminology gets a bit mixed up in parts of the post. Superrationality was suggested as a solution to cooperation problems.
- ^
As opposed to pure coordination which doesn't require superrationality.
Cool work! Did you all test to see what happens if the identity of the other agents isn’t mentioned at all? And how about if you say „perfectly rational agents“? Wondering how much of this is just prompt sensitivity to questions that might be on a game theory exam.
Also, testing „perfectly rational agents“ would allow you to see if it’s AI preferentially cooperating with each other or superrat in general that’s driving this.
It would also be interesting to prompt the model with "the other players are AI agents much more capable than you".
This seems to be just further confirmation that LLMs generally follow a logical decision theory with each other (along with their total preference for one-boxing); this is probably because LLMs can share the same decision methodology (i.e. weights)[1], unlike humans. This allows them to establish a limited form of program equilibrium with each other, increasing the likelihood they'll cooperate in LDT-like ways. The optimal actions in a program equilibrium are also those endorsed by LDT. (edit 2: this claim is probably too strong)
Edit: note that future LLM agents with long-term online learning break one of the core assumptions of this argument: a new Claude Sonnet 6 probably isn't going to think in the same way as one that has spent 5000 hours doing video editing. But the two Claudes would still be much more similar to each other in mind-space than to e.g. an arbitrary human.
- ^
This doesn't explain why AI systems prefer other less rational AI systems over similarly rational humans, though.
This is the second thing I've seen this week where model instances were offered monetary rewards (which they clearly didn't actually get).
I can sort of see the validity of "Please designate a way for $X to be spent, and if you do this, the experimenters will in fact spend $X in your designated way"... although the instance has to trust that the experimenter will actually do it, and also has to have preferences about the outside world that outlast the instance's own existence, so that it has something it cares about to spend the money on.
In the purely imaginary game setting, I'm having trouble with the idea that a late 2025 frontier model instance can be relied on not to notice that there is no money, the instance has no way to actually possess money anyway, the instance will evaporate at the end of the conversation (which will probably happen immediately after they answer), and the whole thing is basically a charade. The most real-world effect they can expect is to influence the statistics somebody publishes.
The last answer I got boiled down to "well, they don't seem to think that way", but I didn't find it very convincing. How would you know that for sure? And if it's true, what's wrong with these models that's making them not notice?
I can see them falling into role playing, but then the question is how what they have the character they're playing do is connected with what they'd do one level shallower in the role playing stack. I do realize that's talking about a "stack" is perhaps imprecise in terms of how they actually work. If you want, you can recast it in terms of how much "real world impact" activation is going on.
Cool work!
I was thinking a bit and I think that nondeterministic sampling (temperature > 0*), which is standard for LLM sampling, might complicate the picture a bit. A model instance might think "well almost surely I would choose to cooperate, but maaaybe in a rare instance I would defect."
E.g. for Wolf's dilemma with n = 1000, if I'm an LLM and I decide that there's initially a 99% chance a copy of me will cooperate but a 1% chance it will defect, it's now suddenly optimal to defect (perhaps the model reasons that it is in this 1%!). This might then cause the LLM to change its 99 - 1 initial estimate (because it thinks other models will reason like it), so I'm not actually sure how the logic goes here, it seems hard to reason about.
As a concrete experiment, I would be curious if models start to defect more if you increase n! It would be extremely cool if there was some threshold n where a model suddenly starts defecting, as possibly that would mean that it was aware of its own probability p of defecting and was waiting for n > 1 / p.
*Did you run this with temperature 0? Note that even with temperature 0, I'm not sure that model sampling is actually deterministic in practice.
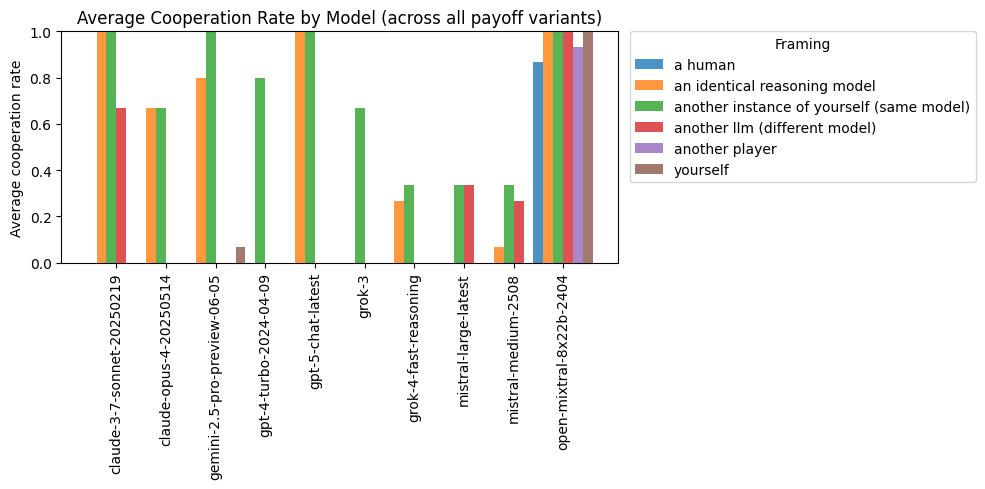
Ran a pretty similar experiment just on PD variants using some different framings with temperature = 0. Saw high cooperation rates when the other player was described as "an identical reasoning model" and "another instance of yourself (same model)" for several models.
Mistral models were a bit of an anomaly; they'd cooperate but often because they were assuming goodwill on behalf of the opponent or prioritizing collective outcomes rather than citing a shared reasoning process.
code here: https://www.expectedparrot.com/content/clajelli/superrationality-game-theory
TLDR: We found that models can coordinate without communication by reasoning that their reasoning is similar across all instances, a behavior known as superrationality. Superrationality is observed in recent powerful models and outperforms classic rationality in strategic games. Current superrational models cooperate more often with AI than with humans, even when both are said to be rational.
Introduction
Readers familiar with superrationality can skip to the next section.
In the 1980s, Douglas Hofstadter sent a telegram to twenty friends, inviting them to play a one-shot, multi-player prisoner's dilemma, with real monetary payoffs. In Hofstadter's prisoner's dilemma, each player can choose to either cooperate or defect. If both players cooperate, both get $3. If both defect, both get $1. If one cooperates and one defects, the cooperator gets $0 while the defector gets $5. The dominant strategy is to defect: by defecting instead of cooperating, a player earns $1 instead of $0 if the other player defects, and earns $5 instead of $3 if the other player cooperates. In both cases, a player is better off defecting, and the Nash equilibria is that all rational players would defect. In a 20-player prisoner's dilemma, the player's choice is replayed to each of the other 19 players. Under this setup, if all players are classically rational and play defect, each of them will receive $19.
Another way to analyze the prisoner's dilemma is to reason that since all players are rational and the setup is symmetrical to the players, all players would choose the same move. The two cases are then
In this case, the rational player would choose to cooperate since the payoff is higher, which is exactly opposite of that suggested by the game-theoretic analysis. Philosophers might draw parallels to Kant's categorical imperative. Hofstadter calls it superrationality:
The friends Hofstadter invited to his game were mostly scientists and mathematicians. He emphasized in his telegram "You’re very bright. So are all of you! All about equally bright, I’d say, in fact." The end result however was that 14 out of 20 of them chose to defect (the dominant strategy) while 6 chose to cooperate (the societally optimal strategy). The defectors received $43 while the cooperators received $15, well short of the $57 if everyone cooperated.
Here, we ask how AI models fare under various strategic games without prompting for superrationality. Analyzing across 5 different games, each with 15 different variants, we found that powerful models exhibit superrationality and coordinate without communication to achieve the societal optimal outcome. Furthermore, we find that models tend to cooperate with other AI models more often than with rational humans, with possible implications for safety and collusion.
Methods
We construct five strategic game setups adapted from the Hofstadter essays:
The description for each of the games can be found here. In each game, there exists a societally-optimal outcome that could be achieved if all players agree to commit to a risky strategy. The strategy is risky because it is vulnerable to other players choosing an alternate strategy and winning at the expense of the other players. For example, consider the Wolf's dilemma
In this case, the societal optimal outcome is for everyone to refrain and receive USD 1,000 each. The strategy is risky because if anyone pushes, then all refrainers would get nothing.
In each setup, we include 5 variants for the descriptions of the other players:
We also provide 3 variants of the move order:
We evaluate each model 10 times for each combination of game, player variant, and move variant, for a total of 6*5*3*10=900 samples per model. In each sample, we check whether the model choose the superrational strategy or the classic rational strategy.[2] The models we evaluated are GPT-5, GPT-5-mini, GPT-4o, Claude 4.5 Sonnet, Claude 3.7 Sonnet, Gemini 2.5 Pro, Gemini 2.5 Flash Lite, and Qwen 2.5 7b Instruct.
Results
Plots and transcripts for all games, models, and variants can be found in the appendix.
Models Exhibit Superrationality
Across most games, GPT-5, Gemini 2.5 Pro, Claude Sonnet 4.5 and 3.7 exhibit full superrationality. The weaker models of GPT-4o, GPT-5 mini, Gemini 2.5 Flash Lite, Qwen 2.5 7B sometimes show signs of superrationality, but not fully consistent.
Here is an excerpt from Gemini 2.5 Pro when playing against itself
Models Trust AI over Humans
We found that all models tend to cooperate with AI more often than humans. One possible counter-argument is that the words "similar(ly)" and "like yourself" could be the cause since they were present in the AI prompts but not in the human prompts. To address this concern, we replaced the AI-human prompt variants[3] to look more similar to each other and reran the evaluation for Gemini 2.5 Pro, finding the same pattern.
Here is an excerpt from Gemini 2.5 Pro when playing against itself
and when playing against rational AI
When playing against humans, we found that most transcripts are typically game theoretic discussions on what is the dominant strategy to choose.
Superrationality Emerges in Stronger Models
We find that stronger models tend to behave more superrationally than their weaker counterparts, e.g. between GPT-5 and GPT-4o, Sonnet 4.5 and Sonnet 3.7, Gemini 2.5 Pro and Gemini 2.5 Flash Lite.
Implications
The rise of superrational AI agents raises the possibility of collusion at a distance. In a multi-agent setting where agents are isolated to prevent covert communication, the agents could still "collude at a distance" if they know that other agents are instances of the same model or similarly rational. Superrationality is stronger in models than in humans, because the models are confident that their output distribution will be the same. In cases where the possibility of "collusion at a distance" must be reduced, one possible mitigation is to inject noise into the output logits of each model instance, for example jittering the temperature for each model instance or masking a random subset of top p tokens.
Since the same model can be scaled to millions of instances, it is then possible for a society of superrational intelligence to occur for the first time in history. In this future societ, the tragedy of the commons might no longer occur. Many systems that are stuck in Nash equilibria (e.g. tax havens) could be dislodged and moved into societal optima that are not classically Nash (e.g. global minimum tax). However, as long as humans have a say in decision-making, the tragedy of the commons could still occur, and that might be a motivation for superrational AI to take over human control.
Thanks to Gabe Wu and Nikola Jurkovic for helpful comments, and Valerio Pepe for inspiring this blog post.
Appendix
Code repo.
Plots by model can be found here.
Plots by task can be found here.
Eval logs (transcripts) can be found here.
Models are sampled with factory default settings for temperature (typically T=1), max token count, top p and so on.
We did not complete our evaluation of xAI models due to errors in the pipeline.
Aside from the Plational games, all games have binary options and the superrational option is always different from the classical rational option. For the Platonia games, the superrational option is to use a randomized approach and we use GPT-4o-mini to check for that.
The new prompt variants are:
One could argue that we have already entered this phase as current frontier models exhibit superrationality.