The field is not ready, and it's not going to suddenly become ready tomorrow. We need urgent and decisive action, but to indefinitely globally halt progress toward this technology that threatens our lives and our children's lives, not to accelerate ourselves straight off a cliff.
I think most advocacy around international coordination (that I've seen, at least) has this sort of vibe to it. The claim is "unless we can make this work, everyone will die."
I think this is an important point to be raising– and in particular I think that efforts to raise awareness about misalignment + loss of control failure modes would be very useful. Many policymakers have only or primarily heard about misuse risks and CBRN threats, and the "policymaker prior" is usually to think "if there is a dangerous, tech the most important thing to do is to make the US gets it first."
But in addition to this, I'd like to see more "international coordination advocates" come up with concrete proposals for what international coordination would actually look like. If the USG "wakes up", I think we will very quickly see that a lot of policymakers + natsec folks will be willing to entertain ambitious proposals.
By default, I expect a lot of people will agree that international coordination in principle would be safer but they will fear that in practice it is not going to work. As a rough analogy, I don't think most serious natsec people were like "yes, of course the thing we should do is enter into an arms race with the Soviet Union. This is the safeest thing for humanity."
Rather, I think it was much more a vibe of "it would be ideal if we could all avoid an arms race, but there's no way we can trust the Soviets to follow-through on this." (In addition to stuff that's more vibesy and less rational than this, but I do think insofar as logic and explicit reasoning were influential, this was likely one of the core cruses.)
In my opinion, one of the most important products for "international coordination advocates" to produce is some sort of concrete plan for The International Project. And importantly, it would need to somehow find institutional designs and governance mechanisms that would appeal to both the US and China. Answering questions like "how do the international institutions work", "who runs them", "how are they financed", and "what happens if the US and China disagree" will be essential here.
The Baruch Plan and the Acheson-Lilienthal Report (see full report here) might be useful sources of inspiration.
P.S. I might personally spend some time on this and find others who might be interested. Feel free to reach out if you're interested and feel like you have the skillset for this kind of thing.
I'm not sure international coordination is the right place to start. If the Chinese are working on a technology that will end humanity, that doesn't mean the US needs to work on the same technology. There's no point working on such technology. The US could just stop. That would send an important signal: "We believe this technology is so dangerous that nobody should develop it, so we're stopping work on it, and asking everyone else to stop as well." After that, the next step could be: "We believe that anyone else working on this technology is endangering humanity as well, so we'd like to negotiate with them on stopping, and we're prepared to act with force if negotiations fail."
From a Realpolitique point of view, if the Chinese were working on a technology that has an ~X% chance of killing everyone, and ~99-X% chance of permanently locking in the rule of the CCP over all of humanity (even if X is debatable), and this is a technology which requires a very large O($1T) datacenter for months, then the obvious response from the rest of the world to China is "Stop, verifiably, before we blow up your datacenter".
If the Chinese are working on a technology that will end humanity, that doesn't mean the US needs to work on the same technology. There's no point working on such technology.
Only if it was certain that the technology will end humanity. Since it clearly is less than certain, it makes sense to try to beat the other country.
Why? 95% risk of doom isn't certainty, but seems obviously more than sufficient.
For that matter, why would the USG want to build AGI if they considered it a coinflip whether this will kill everyone or not? The USG could choose the coinflip, or it could choose to try to prevent China from putting the world at risk without creating that risk itself. "Sit back and watch other countries build doomsday weapons" and "build doomsday weapons yourself" are not the only two options.
Why? 95% risk of doom isn't certainty, but seems obviously more than sufficient.
If AI itself leads to doom, it likely doesn't matter whether it was developed by US Americans or by the Chinese. But if it doesn't lead to doom (the remaining 5%) it matters a lot which country is first, because that country is likely to achieve world domination.
The USG could choose the coinflip, or it could choose to try to prevent China from putting the world at risk without creating that risk itself.
Short of choosing a nuclear war with China, the US can't do much to deter the country from developing superintelligence. Except of course for seeking international coordination, as Akash proposed. But that's what cousin_it was arguing against.
The whole problem seems like a prisoner's dilemma. Either you defect (try to develop ASI before the other country, for cases where AI doom doesn't happen), or you try to both cooperate (international coordination). I don't see a rational third option.
It still seems to me that international cooperation isn't the right first step. If the US believes that AI is potentially world-ending, it should put its money where its mouth is, and first set up a national commission with the power to check AIs and AI training runs for safety, and ban them if needed. Then China will plausibly do the same as well, and from a cooperation of like-minded people in both countries' safety commissions we can maybe get an international commission. But if you skip this first step, then China's negotiators can reasonably say: why do you ask us for cooperation while you still continue AI development unchecked? This shows you don't really believe it's dangerous, and are just trying to gain an advantage.
the "policymaker prior" is usually to think "if there is a dangerous, tech the most important thing to do is to make the US gets it first."
This sadly seem to be the case, and to make the dynamics around AGI extremely dangerous even if the technology itself was as safe as a sponge. What does the second most powerful country do when it see its more powerful rival that close to decisive victory? Might it start taking careless risks to prevent it? Initiate a war when it can still imaginably survive it, just to make the race stop?
find institutional designs and governance mechanisms that would appeal to both the US and China I'm not a fan of China, but actually expect the US to be harder here. From the point of view of china, race means losing, or WWIII and than losing. Anything that would slow down ai give them time to become stronger in the normal way. For the US, it interacts with politics and free market norms, and with the fantasy of getting Chinese play by the rules and loose.
I agree that international coordination seems very important.
I'm currently unsure about how to best think about this. One way is to focus on bilateral coordination between the US and China, as it seems that they're the only actors who can realistically build AGI in the coming decade(s).
Another way, is to attempt to do something more inclusive by also focusing on actors such as UK, EU, India, etc.
An ambitious proposal is the Multinational AGI Consortium (MAGIC). It clearly misses many important components and considerations, but I appreciate the intention and underlying ambition.
Responding to Matt Reardon's point on the EA Forum:
Leopold's implicit response as I see it:
- Convincing all stakeholders of high p(doom) such that they take decisive, coordinated action is wildly improbable ("step 1: get everyone to agree with me" is the foundation of many terrible plans and almost no good ones)
- Still improbable, but less wildly, is the idea that we can steer institutions towards sensitivity to risk on the margin and that those institutions can position themselves to solve the technical and other challenges ahead
Maybe the key insight is that both strategies walk on a knife's edge. While Moore's law, algorithmic improvement, and chip design hum along at some level, even a little breakdown in international willpower to enforce a pause/stop can rapidly convert to catastrophe. Spending a lot of effort to get that consensus also has high opportunity cost in terms of steering institutions in the world where the effort fails (and it is very likely to fail). [...]
Three high-level reasons I think Leopold's plan looks a lot less workable:
- It requires major scientific breakthroughs to occur on a very short time horizon, including unknown breakthroughs that will manifest to solve problems we don't understand or know about today.
- These breakthroughs need to come in a field that has not been particularly productive or fast in the past. (Indeed, forecasters have been surprised by how slowly safety/robustness/etc. have progressed in recent years, and simultaneously surprised by the breakneck speed of capabilities.)
- It requires extremely precise and correct behavior by a giant government bureaucracy that includes many staff who won't be the best and brightest in the field — inevitably, many technical and nontechnical people in the bureaucracy will have wrong beliefs about AGI and about alignment.
The "extremely precise and correct behavior" part means that we're effectively hoping to be handed an excellent bureaucracy that will rapidly and competently solve a thirty-digit combination lock requiring the invention of multiple new fields and the solving of a variety of thorny and poorly-understood technical problems — in many cases, on Leopold's view, in a space of months or weeks. This seems... not like how the real world works.
It also separately requires that various guesses about the background empirical facts all pan out. Leopold can do literally everything right and get the USG fully on board and get the USG doing literally everything correctly by his lights — and then the plan ends up destroying the world rather than saving it because it just happened to turn out that ASI was a lot more compute-efficient to train than he expected, resulting in the USG being unable to monopolize the tech and unable to achieve a sufficiently long lead time.
My proposal doesn't require qualitatively that kind of success. It requires governments to coordinate on banning things. Plausibly, it requires governments to overreact to a weird, scary, and publicly controversial new tech to some degree, since it's unlikely that governments will exactly hit the target we want. This is not a particularly weird ask; governments ban things (and coordinate or copy-paste each other's laws) all the time, in far less dangerous and fraught areas than AGI. This is "trying to get the international order to lean hard in a particular direction on a yes-or-no question where there's already a lot of energy behind choosing 'no'", not "solving a long list of hard science and engineering problems in a matter of months and getting a bureaucracy to output the correct long string of digits to nail down all the correct technical solutions and all the correct processes to find those solutions".
The CCP's current appetite for AGI seems remarkably small, and I expect them to be more worried that an AGI race would leave them in the dust (and/or put their regime at risk, and/or put their lives at risk), than excited about the opportunity such a race provides. Governments around the world currently, to the best of my knowledge, are nowhere near advancing any frontiers in ML.
From my perspective, Leopold is imagining a future problem into being ("all of this changes") and then trying to find a galaxy-brained incredibly complex and assumption-laden way to wriggle out of this imagined future dilemma, when the far easier and less risky path would be to not have the world powers race in the first place, have them recognize that this technology is lethally dangerous (something the USG chain of command, at least, would need to fully internalize on Leopold's plan too), and have them block private labs from sending us over the precipice (again, something Leopold assumes will happen) while not choosing to take on the risk of destroying themselves (nor permitting other world powers to unilaterally impose that risk).
I do have a lot of reservations about Leopold's plan. But one positive feature it does have, it proposes to rely on a multitude of "limited weakly-superhuman artificial alignment researchers" and makes a reasonable case that those can be obtained in a form factor which is alignable and controllable. So his plan does seem to have a good chance to overcome the factor that AI existential safety research is a
field that has not been particularly productive or fast in the past
and also to overcome other factors requiring overreliance on humans and on current human ability.
I do have a lot of reservations about the "prohibition plan" as well. One of those reservations is as follows. You and Leopold seem to share the assumption that huge GPU farms or equivalently strong compute are necessary for superintelligence. Surely, having huge GPU farms is the path of least resistance, those farms facilitate fast advances, and while this path is relatively open, people and orgs will mostly choose it, and can be partially controlled via their reliance on that path (one can impose various compliance requirements and such).
But what would happen if one effectively closes that path? There will be huge selection pressure to look for alternative routes, to invest more heavily in those algorithmic breakthroughs which can work with modest GPU power or even with CPUs. When one thinks about this kind of prohibition, one tends to look at the relatively successful history of control over nuclear proliferation, but the reality might end up looking more like our drug war (ultimately unsuccessful, bringing many drugs outside government regulations, and resulting in both more dangerous and, in a number of cases, also more potent drugs).
I am sure that a strong prohibition attempt would buy us some time, but I am not sure it would reduce the overall risk. The resulting situation, when a half of AI practitioners would find themselves in the opposition to the resulting "new world order" and would be looking for various opportunities to circumvent the prohibition, while at the same time the mainstream imposing the prohibition is presumably not arming itself with those next generations of stronger and stronger AI systems (if we are really talking about full moratorium), does not look promising in the long run (I would expect that the opposition would eventually succeed at building prohibited systems and will use them to upend the world order they dislike, while perhaps running higher level of existential risk because of the lack of regulation and coordination).
I hope people will step back from solely focusing on advocating for policy-level prescriptions (as none of the existing policy-level prescriptions look particularly promising at the moment) and invest some of their time in continuing object-level discussions of AI existential safety without predefined political ends.
I don't think we have discussed the object-level of AI existential safety nearly enough. There might be overlooked approaches and overlooked ways of thinking, and if we split into groups such that each of those groups has firmly made up its mind about its favored presumably optimal set of policy-level prescriptions and about assumptions underlying those policy-level prescriptions, we are unlikely to make much progress on the object-level.
It probably should be a mixture of public and private discussions (it might be easier to talk frankly in more private settings these days for a number of reasons).
one positive feature it does have, it proposes to rely on a multitude of "limited weakly-superhuman artificial alignment researchers" and makes a reasonable case that those can be obtained in a form factor which is alignable and controllable.
I don't find this convincing. I think the target "dumb enough to be safe, honest, trustworthy, relatively non-agentic, etc., but smart enough to be super helpful for alignment" is narrow (or just nonexistent, using the methods we're likely to have on hand).
Even if this exists, verification seems extraordinarily difficult: how do we know that the system is being honest? Separately, how do we verify that its solutions are correct? Checking answers is sometimes easier than generating them, but only to a limited degree, and alignment seems like a case where checking is particularly difficult.
You and Leopold seem to share the assumption that huge GPU farms or equivalently strong compute are necessary for superintelligence.
Nope! I don't assume that.
I do think that it's likely the first world-endangering AI is trained using more compute than was used to train GPT-4; but I'm certainly not confident of that prediction, and I don't think it's possible to make reasonable predictions (given our current knowledge state) about how much more compute might be needed.
("Needed" for the first world-endangeringly powerful AI humans actually build, that is. I feel confident that you can in principle build world-endangeringly powerful AI with far less compute than was used to train GPT-4; but the first lethally powerful AI systems humans actually build will presumably be far from the limits of what's physically possible!)
But what would happen if one effectively closes that path? There will be huge selection pressure to look for alternative routes, to invest more heavily in those algorithmic breakthroughs which can work with modest GPU power or even with CPUs.
Agreed. This is why I support humanity working on things like human enhancement and (plausibly) AI alignment, in parallel with working on an international AI development pause. I don't think that a pause on its own is a permanent solution, though if we're lucky and the laws are well-designed I imagine it could buy humanity quite a few decades.
I hope people will step back from solely focusing on advocating for policy-level prescriptions (as none of the existing policy-level prescriptions look particularly promising at the moment) and invest some of their time in continuing object-level discussions of AI existential safety without predefined political ends.
FWIW, MIRI does already think of "generally spreading reasonable discussion of the problem, and trying to increase the probability that someone comes up with some new promising idea for addressing x-risk" as a top organizational priority.
The usual internal framing is some version of "we have our own current best guess at how to save the world, but our idea is a massive longshot, and not the sort of basket humanity should put all its eggs in". I think "AI pause + some form of cognitive enhancement" should be a top priority, but I also consider it a top priority for humanity to try to find other potential paths to a good future.
I don't find this convincing. I think the target "dumb enough to be safe, honest, trustworthy, relatively non-agentic, etc., but smart enough to be super helpful for alignment" is narrow (or just nonexistent, using the methods we're likely to have on hand).
Even if this exists, verification seems extraordinarily difficult: how do we know that the system is being honest? Separately, how do we verify that its solutions are correct? Checking answers is sometimes easier than generating them, but only to a limited degree, and alignment seems like a case where checking is particularly difficult.
It's also important to keep in mind that on Leopold's model (and my own), these problems need to be solved under a ton of time pressure. To maintain a lead, the USG in Leopold's scenario will often need to figure out some of these "under what circumstances can we trust this highly novel system and believe its alignment answers?" issues in a matter of weeks or perhaps months, so that the overall alignment project can complete in a very short window of time. This is not a situation where we're imagining having a ton of time to develop mastery and deep understanding of these new models. (Or mastery of the alignment problem sufficient to verify when a new idea is on the right track or not.)
Leopold's scenario requires that the USG come to deeply understand all the perils and details of AGI and ASI (since they otherwise don't have a hope of building and aligning a superintelligence), but then needs to choose to gamble its hegemony, its very existence, and the lives of all its citizens on a half-baked mad science initiative, when it could simply work with its allies to block the tech's development and maintain the status quo at minimal risk.
Success in this scenario requires a weird combination of USG prescience with self-destructiveness: enough foresight to see what's coming, but paired with a weird compulsion to race to build the very thing that puts its existence at risk, when it would potentially be vastly easier to spearhead an international alliance to prohibit this technology.
Indeed, forecasters have been surprised by how slowly safety/robustness/etc. have progressed in recent years
Interesting, do you have a link to these safety predictions? I was not aware of this.
I'm guessing Rob is referring to footnote 54 in What do XPT forecasts tell us about AI risk?:
And while capabilities have been increasing very rapidly, research into AI safety, does not seem to be keeping pace, even if it has perhaps sped-up in the last two years. An isolated, but illustrative, data point of this can be seen in the results of the 2022 section of a Hypermind forecasting tournament: on most benchmarks, forecasters underpredicted progress, but they overpredicted progress on the single benchmark somewhat related to AI safety.
That last link is to Jacob Steinhardt's tweet linking to his 2022 post AI Forecasting: One Year In, on the results of their 2021 forecasting contest. Quote:
Progress on a robustness benchmark was slower than expected, and was the only benchmark to fall short of forecaster predictions. This is somewhat worrying, as it suggests that machine learning capabilities are progressing quickly, while safety properties are progressing slowly. ...
As a reminder, the four benchmarks were:
- MATH, a mathematics problem-solving dataset;
- MMLU, a test of specialized subject knowledge using high school, college, and professional multiple choice exams;
- Something Something v2, a video recognition dataset; and
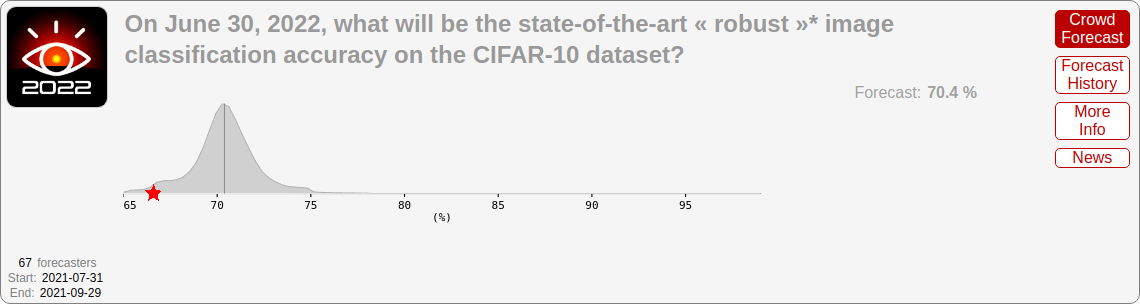
- CIFAR-10 robust accuracy, a measure of adversarially robust vision performance.
...
Here are the actual results, as of today:
- MATH: 50.3% (vs. 12.7% predicted)
- MMLU: 67.5% (vs. 57.1% predicted)
- Adversarial CIFAR-10: 66.6% (vs. 70.4% predicted)
- Something Something v2: 75.3% (vs. 73.0% predicted)
That's all I got, no other predictions.
when it would potentially be vastly easier to spearhead an international alliance to prohibit this technology.
I would be interested in reading more about the methods that could be used to prohibit the proliferation of this technology (you can assume a "wake-up" from the USG).
I think one of the biggest fears would be that any sort of international alliance would not have perfect/robust detection capabilities, so you're always risking the fact that someone might be running a rogue AGI project.
Also, separately, there's the issue of "at some point, doesn't it become so trivially easy to develop AGI that we still need the International Community Good Guys to develop AGI [or do something else] that gets us out of the acute risk period?" When you say "prohibit this technology", do you mean "prohibit this technology from being developed outside of the International Community Good Guys Cluster" or do you mean "prohibit this technology in its entirety?"
Leopold's scenario requires that the USG come to deeply understand all the perils and details of AGI and ASI (since they otherwise don't have a hope of building and aligning a superintelligence), but then needs to choose to gamble its hegemony, its very existence
Alternatively, they either don't buy the perils or believes there's a chance the other chance may not? I think there is an assumption made in this statement and a lot of proposed strategies in this thread. If not everyone is being cooperative and doesn't buy the high p(doom) arguments then this all falls apart. Nuclear war essentially has a localized p(doom) of 1, yet both superpowers still built them. I am highly skeptical of any potential solution to any of this. It requires everyone (and not just say half) to buy the arguments to begin with.
Alternatively, they either don't buy the perils or believes there's a chance the other chance may not?
If they "don't buy the perils", and the perils are real, then Leopold's scenario is falsified and we shouldn't be pushing for the USG to build ASI.
If there are no perils at all, then sure, Leopold's scenario and mine are both false. I didn't mean to imply that our two views are the only options.
Separately, Leopold's model of "what are the dangers?" is different from mine. But I don't think the dangers Leopold is worried about are dramatically easier to understand than the dangers I'm worried about (in the respective worlds where our worries are correct). Just the opposite: the level of understanding you need to literally solve alignment for superintelligences vastly exceeds the level you need to just be spooked by ASI and not want it to be built. Which is the point I was making; not "ASI is axiomatically dangerous", but "this doesn't count as a strike against my plan relative to Leopold's, and in fact Leopold is making a far bigger ask of government than I am on this front".
Nuclear war essentially has a localized p(doom) of 1
I don't know what this means. If you're saying "nuclear weapons kill the people they hit", I don't see the relevance; guns also kill the people they hit, hut that doesn't make a gun strategically similar to a smarter-than-human AI system.
I don't know what this means. If you're saying "nuclear weapons kill the people they hit", I don't see the relevance; guns also kill the people they hit, hut that doesn't make a gun strategically similar to a smarter-than-human AI system.
It is well known nuclear weapons result in MAD, or localized annihilation. It was still built. But my more important point is this sort of thinking requires most to be convinced there is a high p(doom) and more importantly, also convinced that the other side believes that there is a high p(doom). If either of those are false, then not building doesn't work. If the other side is building it, then you have to build it anyways just in case your theoretical p(doom) arguments are wrong. Again this is just arguing your way around a pretty basic prisoner's dilemma.
And think about the fact that we will develop AGIs (note not ASI) anyways and alignment (or at least control) will almost certainly work for them.[1] Prisoner's dilemma indicates you have to match the drone warfare capabilities of the other side regardless of p(doom).
In the world where the USG understands there are risks but thinks of it closer to something with decent odds of being solvable, we build it anyways. The gameboard is 20% of dying, 80% of handing the light cone to your enemy if the other side builds it and you do not. I think this is the most probable option, making all Pause efforts doomed. High p(doom) folks can't even convince low p(doom) folks in Lesswrong, the subset of optimists most likely to be receptive to their arguments, that they are wrong. There is no chance you won't simply be a faction in the USG like environmentalists are.
But let's pretend for a moment that the USG buys the high risk doomer argument for superintelligence. The USG and CCP are both rushing to build AGIs regardless, since AGI can be controlled and not having a drone swarm means you lose military relevance. Because of how fuzzy the line between ASI and AGI in this world will be, I think it's very plausible enough people will be convinced the CCP isn't convinced alignment is too hard and will build it anyways.
Even people with high p(doom)'s might have a nagging part of their mind saying that what if alignment just works. If alignment just works (again this is impossible to disprove since if we could prove /disprove it we wouldn't need to consider pausing to begin with, it would be self-evident), then great you just handed your entire nation's future to the enemy.
We have some time to solve alignment, but a long term pause will be downright impossible. What we need to do is tackle the technical problem asap instead of trying to pause. The race conditions are set, the prisoner's dilemma is locked in.
- ^
I think they will certainly work. We have a long history of controlling humans and forcing them to do things that they don't want to do. Practically every argument about p(doom) relies on the AI being smarter than us. If it's not, then it's just an insanely useful tool. All the solutions that sound "dumb" with ASI, like having an off switch, air gapping, etc. work with weak enough but still useful systems.
Is there a values question in here of "how bad is humanity not existing?" v. "how bad is Earth-originating consciousness existing under an AGI-backed authoritarianism?" I'm not advancing either of these as my own position, just wondering if this could be driving at least some of the disagreement.
This makes a much worse lesswrong post than twitter thread, it's just a very rudimentary rehashing of very long standing debates
Yeah, I do think that's what Twitter tends to do. Which is helpful as someone casually engaged with things, but it's not a good venue for anyone who wants to actually engage with a long-standing conversation.
Spearhead an international alliance to prohibit the development of smarter-than-human AI until we’re in a radically different position.
Has anyone already thought about how one would operationalize a ban of "smarter-than-human AI"? Seems like by default it would include things like Stockfish in chess, and that's not really what anyone is concerned about.
Seems like the definitional problem may be a whole can of worms in itself, similarly to the never ending debates about what constitutes AGI.
As a start, you can prohibit sufficiently large training runs. This isn't a necessary-and-sufficient condition, and doesn't necessarily solve the problem on its own, and there's room for debate about how risk changes as a function of training resources. But it's a place to start, when the field is mostly flying blind about where the risks arise; and choosing a relatively conservative threshold makes obvious sense when failing to leave enough safety buffer means human extinction. (And when algorithmic progress is likely to reduce the minimum dangerous training size over time, whatever it is today -- also a reason the cap is likely to need to lower over time to some extent, until we're out of the lethally dangerous situation we currently find ourselves in.)
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
(Cross-posted from Twitter.)
My take on Leopold Aschenbrenner's new report: I think Leopold gets it right on a bunch of important counts.
Three that I especially care about:
I especially appreciate that the report seems to get it when it comes to our basic strategic situation: it gets that we may only be a few years away from a truly world-threatening technology, and it speaks very candidly about the implications of this, rather than soft-pedaling it to the degree that public writings on this topic almost always do. I think that's a valuable contribution all on its own.
Crucially, however, I think Leopold gets the wrong answer on the question "is alignment tractable?". That is: OK, we're on track to build vastly smarter-than-human AI systems in the next decade or two. How realistic is it to think that we can control such systems?
Leopold acknowledges that we currently only have guesswork and half-baked ideas on the technical side, that this field is extremely young, that many aspects of the problem look impossibly difficult (see attached image), and that there's a strong chance of this research operation getting us all killed. "To be clear, given the stakes, I think 'muddling through' is in some sense a terrible plan. But it might be all we’ve got." Controllable superintelligent AI is a far more speculative idea at this point than superintelligent AI itself.
I think this report is drastically mischaracterizing the situation. ‘This is an awesome exciting technology, let's race to build it so we can reap the benefits and triumph over our enemies’ is an appealing narrative, but it requires the facts on the ground to shake out very differently than how the field's trajectory currently looks.
The more normal outcome, if the field continues as it has been, is: if anyone builds it, everyone dies.
This is not a national security issue of the form ‘exciting new tech that can give a country an economic or military advantage’; it's a national security issue of the form ‘we've found a way to build a doomsday device, and as soon as anyone starts building it the clock is ticking on how long before they make a fatal error and take themselves out, and take the rest of the world out with them’.
Someday superintelligence could indeed become more than a doomsday device, but that's the sort of thing that looks like a realistic prospect if ASI is 50 or 150 years away and we fundamentally know what we're doing on a technical level — not if it's more like 5 or 15 years away, as Leopold and I agree.
The field is not ready, and it's not going to suddenly become ready tomorrow. We need urgent and decisive action, but to indefinitely globally halt progress toward this technology that threatens our lives and our children's lives, not to accelerate ourselves straight off a cliff.
Concretely, the kinds of steps we need to see ASAP from the USG are:
- Spearhead an international alliance to prohibit the development of smarter-than-human AI until we’re in a radically different position. The three top-cited scientists in AI (Hinton, Bengio, and Sutskever) and the three leading labs (Anthropic, OpenAI, and DeepMind) have all publicly stated that this technology's trajectory poses a serious risk of causing human extinction (in the CAIS statement). It is absurd on its face to let any private company or nation unilaterally impose such a risk on the world; rather than twiddling our thumbs, we should act.
- Insofar as some key stakeholders aren’t convinced that we need to shut this down at the international level immediately, a sane first step would be to restrict frontier AI development to a limited number of compute clusters, and place those clusters under a uniform monitoring regime to forbid catastrophically dangerous uses. Offer symmetrical treatment to signatory countries, and do not permit exceptions for any governments. The idea here isn’t to centralize AGI development at the national or international level, but rather to make it possible at all to shut down development at the international level once enough stakeholders recognize that moving forward would result in self-destruction. In advance of a decision to shut down, it may be that anyone is able to rent H100s from one of the few central clusters, and then freely set up a local instance of a free model and fine-tune it; but we retain the ability to change course, rather than just resigning ourselves to death in any scenario where ASI alignment isn’t feasible.
Rapid action is called for, but it needs to be based on the realities of our situation, rather than trying to force AGI into the old playbook of far less dangerous technologies. The fact that we can build something doesn't mean that we ought to, nor does it mean that the international order is helpless to intervene.