You can't simply average the km's. Suppose you estimate .5 probability that k2 should be twice k1 and .5 probability that k1 should be twice k2. Then if you normalize k1 to 1, k2 will average to 1.25, while similarly if you normalize k2 to 1, k1 will average to 1.25.
In general, to each choice of km's will correspond a utility function and the utility function we should use will be a linear combination of those utility functions and we will have renormalization parameters k'm and, if we accept the argument given in your post, those k'm ought to be just as dependant on your preferences, so you're probably also uncertain about the values that those parameters should take and so you obtain k''m's and so on ad infinitum. So you obtain an infinite tower of uncertain parameters and it isn't obvious how to obtain a utility function out of this mess.
You can't simply average the km's.
You could use a geometric mean, although this might seem intuitively unsatisfactory in some cases.
Why would you use a geometric mean? It might make the problem go away, but why does it do that? what was the problem and why is a geometric mean the only solution?
I think it's a really bad strategy to respond to an apparent problem by just pulling ideas out of thin air until you find one who's flaws are non-obvious. It seems much more prudent to try to understand what the problem is and why it occurred, so that we can derive something that actually does the right thing. A problem is an indication that we don't understand what's going on, which should be a halt-and-rethink-everything moment.
I was just pointing out that it is a possible solution to the problem that Karl mentioned. I agree that it probably isn't a good solution overall. Maybe I shouldn't have brought it up.
The tone of my response was a bit hostile. Sorry about that. It was a general comment against doing things that way, which I've had nothing but trouble from. It was prompted by prompted by your comment, but not really a reply to your idea in particular.
You can't simply average the km's.
Hmm. I'll have to take a closer look at that. You mean that the uncertainties are correlated, right?
and we will have renormalization parameters k'm and
Can you show where you got that? My impression was that once we got to the set of (equivalent, only difference is scale) utility functions, averaging them just works without room for more fine-tuning.
But as I said, that part is shaky because I haven't actually supported those intuitions with any particular assumptions. We'll see what happens when we build it up from more solid ideas.
Hmm. I'll have to take a closer look at that. You mean that the uncertainties are correlated, right?
No. To quote your own post:
A similar process allows us to arbitrarily set exactly one of the km.
I meant that the utility function resulting from averaging over your uncertainty over the km's will depend on which km you chose to arbitrarily set in this way. I gave an example of this phenomenon in my original comment.
Oh sorry. I get what you mean now. Thanks.
I'll have to think about that and see where the mistake is. That's pretty serious, though.
My first impulse is to generalize all that and get out of the morality domain (because of mind-killer potential).
You're interested in ranking a set of choices. You have multiple models (or functions) which are capable of evaluating your choices, but you don't know which model is the correct one -- or, indeed, if any of them is the correct one. However you can express your confidence in each of these models, e.g. by assigning a probability-of-being-correct to it.
There are a few wrinkles (e.g. are all models mutually exclusive?) but otherwise it looks like a standard statistics problem, no?
My first impulse is to generalize all that and get out of the morality domain (because of mind-killer potential).
I originally did it outside the morality domain (just some innocent VNM math) for that reason. I think it does have to be dropped back into the intended domain eventually, though.
Do you think that there's any particular way that I did get hit by the mindkiller? It's possible.
...
Yes, we have a bunch of models, unsure which (but we can assume completeness and mutual exclusion because we can always extend it to "all possible models"), want to get useful results even with uncertainty. What does useful results mean?
If this were a model of a process, we would not be able to go farther than a simple probability distribution without some specification of what we want from it. For example, if we are designing a machine and have uncertainty about what material it will be made of, and want to know how thick some member should be, the thickness we want depends how much additional thickness costs and the consequences of failure. The usual solution is to define a utility function over the situation and then frame the thing as a decision.
I guess we could do the same here with some kind of utility function over mistakes, but I'm not sure what that would look like yet.
Do you have some other idea in mind? Do you think this angle is worth looking into?
Nah, I don't think you had mind-killer problems, but as more people wander into the discussion, the potential is there...
For models, it's not an automatic assumption to assume completeness and mutual exclusion. In particular, mutual exclusion means only one model is right and all the others are wrong -- we just don't know which one. That's a very black-and-white approach. It's not as simple but more realistic (for appropriate values of "realistic") to assume that all models are wrong but some are more wrong than others. Then the correctness of a model is a real number, not a boolean value (and that's separate from what we know and believe about models), and more, you can then play with dependency structures (e.g. a correlation matrix) which essentially say "if model X is relatively-more-correct then model Y is also relatively-more-correct and model X is relatively-more-wrong".
Without dependencies this doesn't look complicated. If the models (and their believability, aka the probability of being the Correct One) are independent then the probabilities are summable. You basically weight the rankings (or scores) by models' probabilities and you're good to go. With dependencies it gets more interesting.
I am not sure why you're questioning what are useful results in this setting. As formulated, the useful result is a list of available choices ranked by estimated utility. Ultimately, you just want to know the top choice, you don't even care much about how others rank.
Thus I reassert that the 's are free parameters to be set accordance with our actual intertheoretic preferences, on pain of stupidity.
This seems like kind of a cop-out. If you already have an intuitive notion of how your moral theories should scale with respect to each other, then sure, just use that. But what if you have various moral theories, and some idea how likely each one is, but no idea what to do about relative scale? Trying to find a normalization technique with desirable properties does not seem like a useless endeavor to me.
Trying to find a normalization technique with desirable properties does not seem like a useless endeavor to me.
Right, but finding a normalization scheme is essentially just defining a few particular indifference equations, and the desirable properties are "consistent with my preferences", not the elegance of the normalization scheme, so you might as well just admit that you're searching for information about your intertheoretic preferences. If you try to shoehorn that process into "normalization scheme", it will just confuse about what is actually going on, and constrain you in ways you may not want.
I see it the other way: a normalization scheme is a cop-out; just pulling a utility function out of a hat to avoid having to do any real moral philosophy. It will work, but it won't have anything to do with what you want.
EDIT: If you truly don't have preferences in some case, then any scaling will do, and anynormalization scheme (even one that does nothing) will work. If you are uneasy with that, it's because you actually do have intertheoretic preferences.
If on the other hand you have some reason to think that utility function U_a should not be weighted more or less than U_b on some problem, then that is a preference, and you should use it directly without calling it a normalization scheme.
Also keep in mind that it is bordering on an error to define preference-relevant stuff from some source other than information about preferences. So saying "these should be equal in this way" without reference to the preferences that produces and why that's desirable is a mistake, IMO.
Are we just trying to model our preferences for the purposes of making predictions, or are we also trying to figure out how to make recommendations to ourselves that we think would improve our actions with respect to what we think we would want if we understood ourselves better? If the former, then we shouldn't assume VNM anyway, since humans do not obey the VNM axioms. If the latter, then we can't make any progress if we do not use some information other than revealed preferences.
And just to be clear, I am not suggesting that we should use only the structure of the utility functions themselves to come up with the normalization, without taking how we think about them into account. I think your example of normalizing the meat/vegetarian utility functions to a variance of 1 is a good example of what tends to go wrong when you insist on something so restrictive, and I seem to recall someone posting about some theorem on LW a while ago saying that no such normalization scheme has all of some set of desirable properties. Anyway, I am merely suggesting that when we only have a vague idea of what we want (which humans tend to do, and which is the motivation for the problem in the first place), it is not as simple as declaring that each km should be exactly what we want it to be.
Are we just trying to model our preferences for the purposes of making predictions, or are we also trying to figure out how to make recommendations to ourselves... CEV
The latter.
If the latter, then we can't make any progress if we do not use some information other than revealed preferences.
Yes. I may have been unclear. I don't mean to refer to revealed preference, I mean that refinements on the possible utility function are to be judged based on the preferences that they entail, not on anything else. For example, utilitarianism should be judged by it's (repugnant) conclusions, not by the elegance of linear aggregation or whatever.
I think that other information takes a variety of forms, stuff like revealed preference, what philosophers think, neuroscience, etc. The trick is to define a prior that relates these things to desired preferences, and then what our preferences in a state of partial knowledge are.
The OP work has a few other problems as well that have me now leaning towards building this thing up from that (indirect normativity) base instead of going in with this "set of utility functions with probabilities" business.
Anyway, I am merely suggesting that when we only have a vague idea of what we want (which humans tend to do, and which is the motivation for the problem in the first place), it is not as simple as declaring that each km should be exactly what we want it to be.
Ok, because we don't know what we want it to be.
Remember that not only are the scales freely varying, but so are the zero-points. Any normalization scheme that doesn't take this into account won't work.
What you want is not just to average two utility functions, you want a way of averaging two utility functions that doesn't care about affine transformations. One way to do this is to use the difference between two special states as "currency" to normalize the utility functions against both shifts and scale changes. But then they're not normalized against the vagaries of those special states, which can mean trouble.
I think that the post proves that the offsets can be ignored, at the beginning of the "Offsets and Scales" section.
Remember that not only are the scales freely varying, but so are the zero-points. Any normalization scheme that doesn't take this into account won't work.
There is good reason to pay attention to scale but not to zero-points: any normalization scheme that you come up with will be invariant with respect to adding constants to the utility functions unless you intentionally contrive one not to be. Normalization schemes that are invariant with respect to multiplying the utility functions by positive constants are harder.
There is good reason to pay attention to scale but not to zero-points: any normalization scheme that you come up with will be invariant with respect to adding constants to the utility functions unless you intentionally contrive one not to be.
Making such modifications to the utilities of outcomes will result in distorted expected utilities and different behaviour.
I meant invariant with respect to adding the same constant to the utility of every outcome in some utility function, not invariant with respect to adding some constant to one outcome (that would be silly).
Hm, good point. We can just use the relative utilities. Or, equivalently, we just have to restrict ourselves to the class of normalizations that are only a function of the relative utilities. These may not be "any" normalization scheme, but they're pretty easy to use.
E.g. for the utility function (dollar, apple, hamburger) -> (1010,1005,1000), instead we could write it as (D-A, A-H) -> (5, 5). Then if we wanted to average it with the function (1,2,3), which could also be written (-1, -1), we'd get (2,2). So on average you'd still prefer the dollar.
I don't understand. What do you mean by averaging two utility functions?
Can you should how the offsets cause trouble when you try to do normalization?
Can you show why we should investigate normalization at all? The question is always "What preference does this scheme correspond to, and why would I want that?"
Sure.
Suppose I have three hypotheses for the Correct Utility (whatever that means), over three choices (e.g. choice one is a dollar, choice two is an apple, choice three is a hamburger): (1, 2, 3), (0, 500, -1000), and (1010, 1005, 1000). Except of course, they all have some unknown offset 'c', and come unknown scale factor 'k'.
Suppose I take the numbers at face value and just average them weighted by some probabilities (the answer to your first question) - if I think they're all about equally plausible, the composite utility function is (337, 501, 1). So I like the apple best, then the dollar, then the hamburger.
But what if these utility functions were written down by me while I was in 3 different moods, and I don't want to just take the numbers at face value? What if I look back and think "man, I really liked using big numbers when I wrote #2, but that's just an artifact, I didn't really hate hamburgers 1000 times as much as I liked a dollar when I wrote #1. And I really liked everything when I wrote #3 - but I didn't actually like a dollar 1000 times more than when I wrote #1, I just gave everything a bonus because I liked everything. Time to normalize!"
First, I try to normalize without taking offsets into account (now we're starting the answer to your second question). I say "Let's take function 1 as our scale, and just divide everything down until the biggest absolute value is 3." Okay then, the functions become (1,2,3), (0, 1.5, -3), (3, 2.985, 2.97). If I then take the weighted average, the composite utility function is (1.3, 2.2, 1.0). Now I still like the apple best, then the hamburger, then the dollar, but maybe this time I like the hamburger almost as much as dollar, and so will make different (more sensible, perhaps) bets than before. There a variety of possible normalizations (normalizing the average, normalizing the absolute value sum, etc), but someone had a post exploring this (was it Stuart Armstrong? I can't find the post, sorry) and didn't really find a best choice.
However, there's a drawback to just scaling everything down - it totally washed out utility function #3's impact on the final answer. Imagine that I dismissed function #2 (probability = 0) - now whether I like the dollar more than the hamburger or not depends totally on whether or not I scale down function #3.
So I decide to shift everything, then scale it, so I don't wash out the effect of function 3. So I make the dollar the 0-point for all the functions, then rescale everything so the biggest absolute value is 2. Then the functions become (0,1,2), (0,1,-2), (0, -1, -2). Then I average them to get (0, 1/3, -2/3). Yet again, I like the apple best, but again the ratios are different so I'll make different bets than before.
Hm, I could have chosen better examples. But I'm too lazy to redo the math for better clarity - if you want something more dramatic, imagine function #3 had a larger apparent scale than #2, and so the composite choice shifted from looking like #3 to #2 as you normalized.
I am in total agreement with whatever point it seems like you just made, which seems to be that normalization schemes are madness.
What you "did" there is full of type errors and treating the scales and offsets as significant and whatnot. That is not allowed, and you seemed to be claiming that it is not allowed.
I guess it must be unclear what the point of OP was, though, because I was assuming that such things were not allowed as well.
What I did in the OP was completely decouple things from the arbitrary scale and offset that the utility functions come with by saying we have a utility function U', and U' agrees with moral theory m on object level preferences conditional on moral theory m being correct. This gives us an unknown scale and offset for each utility function that masks out the arbitraryness of each utility function's native scale and shift. Then that scale and shift are to be adjusted so that we get relative utilities at the end that are consistent with whatever preferences we want to have.
I hope that clarifies things? But it probably doesn't.
What you "did" there is full of type errors and treating the scales and offsets as significant and whatnot. That is not allowed, and you seemed to be claiming that it is not allowed.
Hm. You definitely did communicate that, but I guess maybe I'm pointing out a math mistake - it seems to me that you called the problem of arbitrary offsets solved too early. Though in your example it wasn't a problem because you only had two outcomes and one outcome was always the zero point.
As I realized later because of Alex, the upshot is that to really deal with the problem of offsets you have to (at least de facto) normalize the relative utilities, not the utilities themselves. (On pain of stupidity)
Though in your example it wasn't a problem because you only had two outcomes and one outcome was always the zero point.
I think my procedure does not run into trouble even with three options and other offsets. I don't feel like trying it just now, but if you want to demonstrate how it goes wrong, please do.
the upshot is that to really deal with the problem of offsets you have to (at least de facto) normalize the relative utilities, not the utilities themselves. (On pain of stupidity)
I don't understand what you are saying here.
This strikes me as the wrong approach. I think that you probably need to go down to the level of meta-preferences and apply VNM-type reasoning to this structure rather than working with the higher-level construct of utility functions. What do I mean by that? Well, let M denote the model space and O denote the outcome space. What I'm talking about is a preference relation > on the space MxO. If we simply assume such a > is given (satisfying the constraint that (m1, o1) > (m1, o2) iff o1 >_m1 o2 where >_m1 is model m1's preference relation) , then the VNM axioms applied to (>, MxO) and the distribution on M are probably sufficient to give a utility function, and it should have some interesting relationship with the utility functions of each competing ethical model. (I don't actually know this, it just seems intuitively plausible. Feel free to do the actual math and prove me wrong.)
On the other hand, we'd like to allow the set of >_m's to determine > (along with P(m)), but I'm not optimistic. It seems like this should only happen when the utility functions associated with each >_m, U_m(o), are fully unique rather than unique up to affine transformation. Basically, we need our meta-preferences over the relative badness of doing the wrong thing under competing ethical theories to play some role in determining >, and that information simply isn't present in the >_m's.
(Even though my comment is a criticism, I still liked the post - it was good enough to get me thinking at least)
Edit: clarity and fixing _'s
Basically, we need our meta-preferences over the relative badness of doing the wrong thing under competing ethical theories to play some role in determining >, and that information simply isn't present in the >_m's.
That was like, half the point of my post. I obviously suck at explaining myself.
And yes, I agree now that starting with utility functions is the wrong way. We should actually just build something from the ground up aimed squarely at indirect normativity.
(Even though my comment is a criticism, I still liked the post - it was good enough to get me thinking at least)
Even though my post is an argument, the point really is to get us all thinking about this and see where we can go with it.
Thanks for throwing your brain into the pile.
That was like, half the point of my post. I obviously suck at explaining myself.
I think the combination of me skimming and thinking in terms of the underlying preference relation instead of intertheoretic weights caused me to miss it, but yeah, It's clear you already said that.
Thanks for throwing your brain into the pile.
No problem :) Here are some more thoughts:
It seems correct to allow the probability distribution over ethical theories to depend on the outcome - there are facts about the world which would change my probability distribution over ethical theories, e.g. facts about the brain or human psychology. Not all meta-ethical theories would allow this, but some do.
I'm nearly certain that if you use preference relation over sets framework, you'll recover a version of each ethical theory's utility function, and this even happens if you allow the true ethical theory to be correlated with the outcome of the lottery by using a conditional distribution P(m|o) instead of P(m). Implicitly, this will define your k_m's and c_m's, given a version of each m's utility function, U_m(.).
It seems straightforward to add uncertainty over meta-preferences into the mix, though now we'll need meta-meta-preferences over M2xM1xO. In general, you can always add uncertainty over meta^n-preferences, and the standard VNM axioms should get you what you want, but in the limit the space becomes infinite-dimensional and thus infinite, so the usual VNM proof doesn't apply to the infinite tower of uncertainty.
It seems incorrect to have M be a finite set in the first place since competing ethical theories will say something like "1 human life = X dog lives", and X could be any real number. This means, once again, we blow up the VNM proof. On the other hand, I'm not sure this is any different than complaining that O is finite, in which case if you're going to simplify and assume O is finite, you may as well do the same for M.
(This is a (possibly perpetual) draft of some work that we (I) did at the Vancouver meetup. Thanks to my meetup buddies for letting me use their brains as supplementary computational substrate. Sorry about how ugly the LaTeX is; is there a way to make this all look a bit nicer?)
(Large swaths of this are obsolete. Thanks for the input, LW!)
The Problem of Decision Under Preference Uncertainty
Suppose you are uncertain whether it is good to eat meat or not. It could be OK, or it could be very bad, but having not done the thinking, you are uncertain. And yet you have to decide what to eat now; is it going to be the tasty hamburger or the morally pure vegetarian salad?
You have multiple theories about your preferences that contradict in their assessment, and you want to make the best decision. How would you decide, even in principle, when you have such uncertainty? This is the problem of Preference Uncertainty.
Preference Uncertainty is a daily fact of life for humans; we simply don't have introspective access to our raw preferences in many cases, but we still want to make the best decisions we can. Just going with our intuitions about what seems most awesome is usually sufficient, but on higher-stakes decisions and theoretical reasoning, we want formal methods with more transparent reasoning processes. We especially like transparent formal methods if we want to create a Friendly AI.
There is unfortunately very little formal analysis of the preference uncertainty problem, and what has been done is incomplete and more philosophical than formal. Nonetheless, there has been some good work in the last few years. I'll refer you to Crouch's thesis if you're interested in that.
Using VNM
I'm going to assume VNM. That is, that rational preferences imply a utility function, and we decide between lotteries, choosing the one with highest expected utility.
The implications here are that the possible moral theories (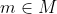 ) each have an associated utility function (
) each have an associated utility function (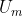 ) that represents their preferences. Also by VNM, our solution to preference uncertainty is a utility function
) that represents their preferences. Also by VNM, our solution to preference uncertainty is a utility function 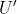 .
.
We are uncertain between moral theories, so we have a probability distribution over moral theories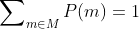 .
.
To make decisions, we need a way to compute the expected value of some lottery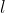 . Each lottery is essentially a probability distribution over the set of possible outcomes
. Each lottery is essentially a probability distribution over the set of possible outcomes 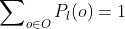 .
.
Since we have uncertainty over multiple things (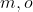 ), the domain of the final preference structure is both moral theories and outcomes:
), the domain of the final preference structure is both moral theories and outcomes: 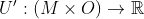 .
.
Now for some conditions. In the degenerate case of full confidence in one moral theory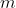 , the overall preferences should agree with that theory:
, the overall preferences should agree with that theory:
For some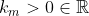 and
and 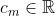 representing the degrees of freedom in utility function equality. That condition actually already contains most of the specification of
representing the degrees of freedom in utility function equality. That condition actually already contains most of the specification of 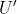 .
.
So we have a utility function, except for those unknown scaling and offset constants, which undo the arbitrariness in the basis and scale used to define each individual utility function.
Thus overall expectation looks like this:
This is still incomplete, though. If we want to get actual decisions, we need to pin down each and
and 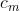 .
.
Offsets and Scales
You'll see above that the probability distribution over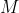 is not dependent on the particular lottery, while
is not dependent on the particular lottery, while 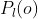 is a function of lottery. This is because I assumed that actions can't change what is right.
is a function of lottery. This is because I assumed that actions can't change what is right.
With this assumption, the contribution of the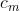 's can be entirely factored out:
's can be entirely factored out:
This makes it obvious that the effect of the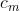 's is an additive constant that affects all lotteries the same way and thus never affects preferences. Thus we can set them to any value that is convenient; for this article, all
's is an additive constant that affects all lotteries the same way and thus never affects preferences. Thus we can set them to any value that is convenient; for this article, all 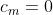 .
.
A similar process allows us to arbitrarily set exactly one of the .
.
The remaining values of actually affect decisions, so setting them arbitrarily has real consequences. To illustrate, consider the opening example of choosing lunch between a
actually affect decisions, so setting them arbitrarily has real consequences. To illustrate, consider the opening example of choosing lunch between a 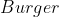 and
and 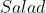 when unsure about the moral status of meat.
when unsure about the moral status of meat.
Making up some details, we might have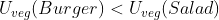 and
and 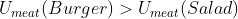 and
and 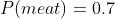 . Importing this into the framework described thus far, we might have the following payoff table:
. Importing this into the framework described thus far, we might have the following payoff table:
We can see that with those probabilities, the expected value of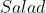 exceeds that of
exceeds that of 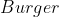 when
when 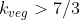 (when
(when 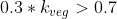 ), so the decision hinges on the value of that parameter.
), so the decision hinges on the value of that parameter.
The value of can be interpreted as the "intertheoretic weight" of a utility function candidate for the purposes of intertheoretic value comparisons.
can be interpreted as the "intertheoretic weight" of a utility function candidate for the purposes of intertheoretic value comparisons.
In general, if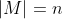 then you have exactly
then you have exactly  missing intertheoretic weights that determine how you respond to situations with preference uncertainty. These could be pinned down if you had
missing intertheoretic weights that determine how you respond to situations with preference uncertainty. These could be pinned down if you had  independent equations representing indifference scenarios.
independent equations representing indifference scenarios.
For example, if we had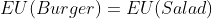 when
when 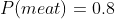 , then we would have
, then we would have 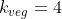 , and the above decision would be determined in favor of the
, and the above decision would be determined in favor of the 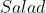 .
.
Expressing Arbitrary Preferences
Preferences are arbitrary, in the sense that we should be able to want whatever we want to want, so our mathematical constructions should not dictate or limit our preferences. If they do, we should just decide to disagree.
What that means here is that because the values of drive important preferences (like at what probability you feel it is safe to eat meat), the math must leave them unconstrained, to be selected by whatever moral reasoning process it is that selected the candidate utility functions and gave them probabilities in the first place.
drive important preferences (like at what probability you feel it is safe to eat meat), the math must leave them unconstrained, to be selected by whatever moral reasoning process it is that selected the candidate utility functions and gave them probabilities in the first place.
We could ignore this idea and attempt to use a "normalization" scheme to pin down the intertheoretic weights from the object level preferences without having to use additional moral reasoning. For example, we could dictate that the "variance" of each candidate utility function equals 1 (with some measure assignment over outcomes), which would divide out the arbitrary scales used to define the candidate utility functions, preventing dominance by arbitrary factors that shouldn't matter.
Consider that any given assignment of intertheoretic weights is equivalent to some set of indifference scenarios (like the one we used above for vegetarianism). For example, the above normalization scheme gives us the indifference scenario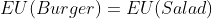 when
when 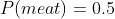 .
.
If I find that I am actually indifferent at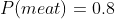 like above, then I'm out of luck, unable to express this very reasonable preference. On the other hand, I can simply reject the normalization scheme and keep my preferences intact, which I much prefer.
like above, then I'm out of luck, unable to express this very reasonable preference. On the other hand, I can simply reject the normalization scheme and keep my preferences intact, which I much prefer.
(Notice that the normalization scheme was an unjustifiably privileged hypothesis from the beginning; we didn't argue that it was necessary, we simply pulled it out of thin air for no reason, so its failure was predictable.)
Thus I reassert that the 's are free parameters to be set accordance with our actual intertheoretic preferences, on pain of stupidity. Consider an analogy to the move from ordinal to cardinal utilities; when you add risk, you need more degrees of freedom in your preferences to express how you might respond to that risk, and you need to actually think about what you want those values to be.
's are free parameters to be set accordance with our actual intertheoretic preferences, on pain of stupidity. Consider an analogy to the move from ordinal to cardinal utilities; when you add risk, you need more degrees of freedom in your preferences to express how you might respond to that risk, and you need to actually think about what you want those values to be.
Uncertainty Over Intertheoretic Weights
(This section is less solid than the others. Watch your step.)
A weakness in the constructions described so far is that they assume that we have access to perfect knowledge of intertheoretic preferences, even though the whole problem is that we are unable to find perfect knowledge of our preferences.
It seems intuitively that we could have a probability distribution over each . If we do this, making decisions is not much complicated, I think; a simple expectation should still work.
. If we do this, making decisions is not much complicated, I think; a simple expectation should still work.
If expectation is the way, the expectation over can be factored out (by linearity or something). Thus in any given decision with fixed preference uncertainties, we can pretend to have perfect knowledge of
can be factored out (by linearity or something). Thus in any given decision with fixed preference uncertainties, we can pretend to have perfect knowledge of  .
.
Despite the seeming triviality of the above idea for dealing with uncertainty over , I haven't formalized it much. We'll see if I figure it out soon, but for now, it would be foolish to make too many assumptions about this. Thus the rest of this article still assumes perfect knowledge of
, I haven't formalized it much. We'll see if I figure it out soon, but for now, it would be foolish to make too many assumptions about this. Thus the rest of this article still assumes perfect knowledge of  , on the expectation that we can extend it later.
, on the expectation that we can extend it later.
Learning Values, Among Other Things
Strictly speaking, inference across the is-ought gap is not valid, but we do it every time we act on our moral intuitions, which are just physical facts about our minds. Strictly speaking, inferring future events from past observations (induction) is not valid either, but it doesn't bother us much:
We deal with induction by defining an arbitrary (but good-seeming, on reflection) prior joint probability distribution over observations and events. We can handle the is-ought gap the same way: instead of separate probability distributions over events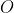 and moral facts
and moral facts 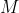 , we define a joint prior over
, we define a joint prior over 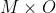 . Then learning value is just Bayesian updates on partial observations of
. Then learning value is just Bayesian updates on partial observations of 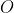 . Note that this prior subsumes induction.
. Note that this prior subsumes induction.
Making decisions is still just maximizing expected utility with our constructions from above, though we will have to be careful to make sure that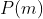 remains independent of the particular lottery.
remains independent of the particular lottery.
The problem of how to define such a prior is beyond the scope of this article. I will note that this "moral prior" idea is the solid foundation on which to base Indirect Normativity schemes like Yudkowsky's CEV and Christiano's boxed philosopher. I will hopefully discuss this further in the future.
Recap
The problem was how to make decisions when you are uncertain about what your object-level preferences should be. To solve it, I assumed VNM, in particular that we have a set of possible utility functions, and we want to construct an overall utility function that does the right thing by those utility functions and their probabilities. The simple condition that the overall utility function should make the common sense choices in cases of moral certainty was sufficient to construct a utility function with a precise set of remaining degrees of freedom. The degrees of freedom being the intertheoretic weight and offset of each utility function candidate.
I showed that the offsets and an overall scale factor are superfluous, in the sense that they never affect the decision if we assume that actions don't affect what is desirable. The remaining intertheoretic weights do affect the decision, and I argued that they are critical to expressing whatever intertheoretic preferences we might want to have.
Uncertainty over intertheoretic weight seems tractable, but the details are still open.
I also mentioned that we can construct a joint distribution that allows us to embed value learning in normal Bayesian learning and induction. This "moral prior" would subsume induction and define how facts about the desirability of things could be inferred from physical observations like the opinions of moral philosophers. In particular, it would provide a solid foundation for Indirect Normativity schemes like CEV. The nature of this distribution is still open.
Open Questions
What are the details of how to deal with uncertainty over the intertheoretic weights? I am looking in particular for construction from an explicit set of reasonable assumptions like the above work, rather than simply pulling a method out of thin air unsupported.
What are the details of the Moral Prior? What is its nature? What implications does it have? What assumptions do we have to make to make it behave reasonably? How do we construct one that could be safely given to a superintelligence. This is going to be a lot of work.
I assumed that it is meaningful to assign probabilities over moral theories. Probability is closely tied up with utility, and probability over epiphenomena like preferences is especially difficult. It remains to be seen how much the framing here actually helps us, or if it effectively just disguises pulling a utility function out of a hat.
Is this at all correct? I should build it and see if it type-checks and does what it's supposed to do.