This is a special post for quick takes by Aaron_Scher. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Note on something from the superalignment section of Leopold Aschenbrenner's recent blog posts:
Evaluation is easier than generation. We get some of the way “for free,” because it’s easier for us to evaluate outputs (especially for egregious misbehaviors) than it is to generate them ourselves. For example, it takes me months or years of hard work to write a paper, but only a couple hours to tell if a paper someone has written is any good (though perhaps longer to catch fraud). We’ll have teams of expert humans spend a lot of time evaluating every RLHF example, and they’ll be able to “thumbs down” a lot of misbehavior even if the AI system is somewhat smarter than them. That said, this will only take us so far (GPT-2 or even GPT-3 couldn’t detect nefarious GPT-4 reliably, even though evaluation is easier than generation!)
Disagree about papers. I don’t think it takes merely a couple hours to tell if a paper is any good. In some cases it does, but in other cases, entire fields have been led astray for years due to bad science (e.g., replication crisis in psych, where numerous papers spurred tons of follow up work on fake things; a year and dozens of papers later we still don’t know if DPO is better than PPO for frontier AI development (though perhaps this is known in labs, and my guess is some people would argue this question is answered); IIRC it took like 4-8 months for the alignment community to decide CCS was bad (this is a contentious and oversimplifying take), despite many people reading the original paper). Properly vetting a paper in the way you will want to do for automated alignment research, especially if you’re excluding fraud from your analysis, is about knowing whether the insights in the paper will be useful in the future, it’s not just checking if they use reasonable hyperparameters on their baseline comparisons.
One counterpoint: it might be fine to have some work you mistakenly think is good, as long as it’s not existential-security-critical and you have many research directions being explored in parallel. That is, because you can run tons of your AIs at once, they can explore tons of research directions and do a bunch of the follow-up work that is needed to see if an insight is important. There may not be a huge penalty for having a slightly poor training signal, as long as it can get the quality of outputs good enough.
This [how easily can you evaluate a paper] is a tough question to answer — I would expect Leopold’s thoughts here to dominated by times he has read shitty papers, rightly concluded they are shitty, and patted himself on the back for his paper-critique skills — I know I do this. But I don’t expect being able to differentiate shitty vs. (okay + good + great) is enough. At a meta level, this post is yet another claim that "evaluation is easier than generation" will be pretty useful for automating alignment — I have grumbled about this before (though can't find anything I've finished writing up), and this is yet another largely-unsubstantiated claim in that direction. There is a big difference between the claims "because evaluation is generally easier than generation, evaluating automated alignment research will be a non-zero amount easier than generating it ourselves" and "the evaluation-generation advantage will be enough to significantly change our ability to automate alignment research and is thus a meaningful input into believing in the success of an automated alignment plan"; the first is very likely true, but the second maybe not.
On another note, the line “We’ll have teams of expert humans spend a lot of time evaluating every RLHF example” seems absurd. It feels a lot like how people used to say “we will keep the AI in a nice sandboxed environment”, and now most user-facing AI products have a bunch of tools and such. It sounds like an unrealistic safety dream. This also sounds terribly inefficient — it would only work if your model is very sample-efficiently learning from few examples — which is a particular bet I’m not confident in. And my god, the opportunity cost of having your $300k engineers label a bunch of complicated data! It looks to me like what labs are doing for self play (I think my view is based on papers out of meta and GDM) is having some automated verification like code passing unit tests, and using a ton of examples. If you are going to come around saying they’re going to pivot from ~free automated grading to using top engineers for this, the burden of proof is clearly on you, and the prior isn’t so good.
Hm, can you explain what you mean? My initial reaction is that AI oversight doesn't actually look a ton like this position of the interior where defenders must defend every conceivable attack whereas attackers need only find one successful strategy. A large chunk of why I think these are disanalogous is that getting caught is actually pretty bad for AIs — see here.
Leaving Dangling Questions in your Critique is Bad Faith
Note: I’m trying to explain an argumentative move that I find annoying and sometimes make myself; this explanation isn’t very good, unfortunately.
Example
Them: This effective altruism thing seems really fraught. How can you even compare two interventions that are so different from one another?
Explanation of Example
I think the way the speaker poses the above question is not as a stepping stone for actually answering the question, it’s simply as a way to cast doubt on effective altruists. My response is basically, “wait, you’re just going to ask that question and then move on?! The answer really fucking matters! Lives are at stake! You are clearly so deeply unserious about the project of doing lots of good, such that you can pose these massively important questions and then spend less than 30 seconds trying to figure out the answer.” I think I might take these critics more seriously if they took themselves more seriously.
Description of Dangling Questions
A common move I see people make when arguing or criticizing something is to pose a question that they think the original thing has answered incorrectly or is not trying sufficiently hard to answer. But then they kinda just stop there. The implicit argument is something like “The original thing didn’t answer this question sufficiently, and answering this question sufficiently is necessary for the original thing to be right.”
But importantly, the criticisms usually don’t actually argue that — they don’t argue for some alternative answer to the original questions, if they do they usually aren’t compelling, and they also don’t really try to argue that this question is so fundamental either.
One issue with Dangling Questions is that they focus the subsequent conversation on a subtopic that may not be a crux for either party, and this probably makes the subsequent conversation less useful.
Example
Me: I think LLMs might scale to AGI.
Friend: I don’t think LLMs are actually doing planning, and that seems like a major bottleneck to them scaling to AGI.
Me: What do you mean by planning? How would you know if LLMs were doing it?
Friend: Uh…idk
Explanation of Example
I think I’m basically shifting the argumentative burden onto my friend when it falls on both of us. I don’t have a good definition of planning or a way to falsify whether LLMs can do it — and that’s a hole in my beliefs just as it is a hole in theirs. And sure, I’m somewhat interested in what they say in response, but I don’t expect them to actually give a satisfying answer here. I’m posing a question I have no intention of answering myself and implying it’s important for the overall claim of LLMs scaling to AGI (my friend said it was important for their beliefs, but I’m not sure it’s actually important for mine). That seems like a pretty epistemically lame thing to do.
Traits of “Dangling Questions”
- They are used in a way that implies the target thing is wrong vis a vis the original idea, but this argument is not made convincingly.
- The author makes minimal effort to answer the question with an alternative. Usually they simply pose it. The author does not seem to care very much about having the correct answer to the question.
- The author usually implies that this question is particularly important for the overall thing being criticized, but does not usually make this case.
- These questions share a lot in common with the paradigm criticisms discussed in Criticism Of Criticism Of Criticism, but I think they are distinct in that they can be quite narrow.
- One of the main things these questions seem to do is raise the reader’s uncertainty about the core thing being criticized, similar to the Just Asking Questions phenomenon. To me, Dangling Questions seem like a more intellectual version of Just Asking Questions — much more easily disguised as a good argument.
Here's another example, though it's imperfect.
Example
From an AI Snake Oil blog post:
Research on scaling laws shows that as we increase model size, training compute, and dataset size, language models get “better”. … But this is a complete misinterpretation of scaling laws. What exactly is a “better” model? Scaling laws only quantify the decrease in perplexity, that is, improvement in how well models can predict the next word in a sequence. Of course, perplexity is more or less irrelevant to end users — what matters is “emergent abilities”, that is, models’ tendency to acquire new capabilities as size increases.
Explanation of Example
The argument being implied is something like “scaling laws are only about perplexity, but perplexity is different from the metric we actually care about — how much? who knows? —, so you should ignore everything related to perplexity, also consider going on a philosophical side-quest to figure out what ‘better’ really means. We think ‘better’ is about emergent abilities, and because they’re emergent we can’t predict them so who knows if they will continue to appear as we scale up”. In this case, the authors have ventured an answer to their Dangling Question, “what is a ‘better’ model?“, they’ve said it’s one with more emergent capabilities than a previous model. This answer seems flat out wrong to me; acceptable answers include: downstream performance, self-reported usefulness to users, how much labor-time it could save when integrated in various people’s work, ability to automate 2022 job tasks, being more accurate on factual questions, and much more. I basically expect nobody to answer the question “what does it mean for one AI system to be better than another?” with “the second has more capabilities that were difficult to predict based on the performance of smaller models and seem to increase suddenly on a linear-performance, log-compute plot”.
Even given the answer “emergent abilities”, the authors fail to actually argue that we don’t have a scaling precedent for these. Again, I think the focus on emergent abilities is misdirected, so I’ll instead discuss the relationship between perplexity and downstream benchmark performance — I think this is fair game because this is a legitimate answer to the “what counts as ‘better’?” question and because of the original line “Scaling laws only quantify the decrease in perplexity, that is, improvement in how well models can predict the next word in a sequence”. The quoted thing is technically true but in this context highly misleading, because we can, in turn, draw clear relationships between perplexity and downstream benchmark performance; here are three recent papers which do so, here are even more studies that relate compute directly to downstream performance on non-perplexity metrics. Note that some of these are cited in the blog post. I will also note that this seems like one example of a failure I’ve seen a few times where people conflate “scaling laws” with what I would refer to as “scaling trends” where the scaling laws refer to specific equations for predicting various metrics based on model inputs such as # parameters and amount of data to predict perplexity, whereas scaling trends are the more general phenomenon we observe that scaling up just seems to work and in somewhat predictable ways; the scaling laws are useful for the predicting, but whether we have those specific equations or not has no effect on this trend we are observing, the equations just yield a bit more precision. Yes, scaling laws relating parameters and data to perplexity or training loss do not directly give you info about downstream performance, but we seem to be making decent progress on the (imo still not totally solved) problem of relating perplexity to downstream performance, and together these mean we have somewhat predictable scaling trends for metrics that do matter.
Example
Here’s another example from that blog post where the authors don’t literally pose a question, but they are still doing the Dangling Question thing in many ways. (context is referring to these posts):
Also, like many AI boosters, he conflates benchmark performance with real-world usefulness.
Explanation of Example
(Perhaps it would be better to respond to the linked AI Snake Oil piece, but that’s a year old and lacks lots of important evidence we have now). I view the move being made here as posing the question “but are benchmarks actually useful to real world impact?“, assuming the answer is no — or poorly arguing so in the linked piece — and going on about your day. It’s obviously the case that benchmarks are not the exact same as real world usefulness, but the question of how closely they’re related isn’t some magic black box of un-solvability! If the authors of this critique want to complain about the conflation between benchmark performance and real-world usefulness, they should actually bring the receipts showing that these are not related constructs and that relying on benchmarks would lead us astray. I think when you actually try that, you get an answer like: benchmark scores seem worse than user’s reported experience and than user’s reported usefulness in real world applications, but there is certainly a positive correlation here; we can explain some of the gap via techniques like few-shot prompting that are often used for benchmarks, a small amount via dataset contamination, and probably much of this gap comes from a validity gap where benchmarks are easy to assess but unrealistic, but thankfully we have user-based evaluations like LMSYS that show a solid correlation between benchmark scores and user experience, … (if I actually wanted to make the argument the authors were, I would be spending like >5 paragraphs on it and elaborating on all of the evidences mentioned above, including talking more about real world impacts, this is actually a difficult question and the above answer is demonstrative rather than exemplar)
Caveats and Potential Solutions
There is room for questions in critiques. Perfect need not be the enemy of good when making a critique. Dangling Questions are not always made in bad faith.
Many of the people who pose Dangling Questions like this are not trying to act in bad faith. Sometimes they are just unserious about the overall question, and they don’t care much about getting to the right answer. Sometimes Dangling Questions are a response to being confused and not having tons of time to think through all the arguments, e.g., they’re a psychological response something like “a lot feels wrong about this, here are some questions that hint at what feels wrong to me, but I can’t clearly articulate it all because that’s hard and I’m not going to put in the effort”.
My guess at a mental move which could help here: when you find yourself posing a question in the context of an argument, ask whether you care about the answer, ask whether you should spend a few minutes trying to determine the answer, ask whether the answer to this question would shift your beliefs about the overall argument, ask whether the question puts undue burden on your interlocutor.
If you’re thinking quickly and aren’t hoping to construct a super solid argument, it’s fine to have Dangling Questions, but if your goal is to convince others of your position, you should try to answer your key questions, and you should justify why they matter to the overall argument.
Another example of me posing a Dangling Question in this:
What happens to OpenAI if GPT-5 or the ~5b training run isn't much better than GPT-4? Who would be willing to invest the money to continue? It seems like OpenAI either dissolves or gets acquired.
Explanation of Example
(I’m not sure equating GPT-5 with a ~5b training run is right). In the above quote, I’m arguing against The Scaling Picture by asking whether anybody will keep investing money if we see only marginal gains after the next (public) compute jump. I think I spent very little time trying to answer this question, and that was lame (though acceptable given this was a Quick Take and not trying to be a strong argument). I think for an argument around this to actually go through, I should argue: without much larger dollar investments, The Scaling Picture won’t hold; those dollar investments are unlikely conditional on GPT-5 not being much better than GPT-4. I won’t try to argue these in depth, but I do think some compelling evidence is that OpenAI is rumored to be at ~$3.5 billion annualized revenue, and this plausibly justifies considerable investment even if the GPT-5 gain over this isn’t tremendous.
I think it’s worth asking why people use dangling questions.
In a fun, friendly debate setting, dangling questions can be a positive contribution. It gives them an opportunity to demonstrate competence and wit with an effective rejoinder.
In a potentially litigious setting, framing critiques as questions (or opinions), rather than as statements of fact, protect you from being convicted of libel.
There are situations where it’s suspicious that a piece of information is missing or not easily accessible, and asking a pointed dangling question seems appropriate to me in these contexts. For certain types of questions, providing answers is assigned to a particular social role, and asking a dangling question can be done to challenge to their competence or integrity. If the question-asker answered their own question, it would not provide the truly desired information, which is whether the party being asked is able to supply it convincingly.
Sometimes, asking dangling questions is useful in its own right for signaling the confidence to criticize or probing a situation to see if it’s safe to be critical. Asking certain types of questions can also signal one’s identity, and this can be a way of providing information (“I am a critic of Effective Altruism, as you can see by the fact that I’m asking dangling questions about whether it’s possible to compare interventions on effectiveness”).
In general, I think it’s interesting to consider information exchange as a form of transaction, and to ask whether a norm is having a net benefit in terms of lowering those transactions costs. IMO, discourse around the impact of rhetoric (like this thread) is beneficial on net. It creates a perception that people are trying to be a higher-trust community and gets people thinking about the impact of their language on other people.
On the other hand, I think actually refereeing rhetoric (ie complaining about the rhetoric rather than the substance in an actual debate context) is sometimes quite costly. It can become a shibboleth. I wonder if this is a systemic or underlying reason why people sometimes say they feel unsafe in criticizing EA? It seems to me a very reasonable conclusion to draw that there’s an “insider style,” competence in which is a prerequisite for being treated inclusively or taken seriously in EA and rationalist settings. It’s meant well, I think, but it’s possible it’s a norm that benefits some aspects of community conversation and negatively impacts others, and that some people, like newcomers/outsiders/critics are more impacted by the negatives than they benefit from the positives.
People often ask whether GPT-5, GPT-5.1, and GPT-5.2 use the same base model. I have no private information, but I think there's a compelling argument that AI developers should update their base models fairly often. The argument comes from the following observations:
- The cost of inference at a given level of AI capability has been dropping quickly. A reasonable estimate is 10× per year, or a halving time of 3.6 months (edit: but 3× is also reasonable, it's hard to be sure).
- The cost of new near-frontier AI training runs is relatively small, on the order of tens or hundreds of millions of dollars, according to this Epoch data insight based on public reporting for 2024 (which I expect is directionally correct but I wouldn't take too literally).
- By contrast, frontier AI developers were spending single digit billions of dollars on AI inference in 2024 (per the same Epoch data insight) and likely high-single digit billions in 2025.
Therefore, it is economically sensible to train entirely new AI models fairly often because their lower inference costs will compensate for the relatively small training costs. "Fairly often" seems like it could be every 2-6 months depending on the exact details.
As a hypothetical example, let's say that OpenAI is considering training a new base model to become GPT-5.1 which will be deployed for only one month before GPT-5.2 is released. Maybe it's 40% cheaper to serve than GPT-5 due to being smaller and using more efficient KV caching[1]. The cost of serving GPT-5 for that month, assuming it's half of all inference by cost would be ($6B (total inference cost in the year) /2/12)= $250 million; at 40% cheaper, the cost of serving GPT-5.1 would be $150m, saving $100m. If it costs less than $100m to develop GPT-5.1 (in additional marginal costs, because e.g., R&D is amortized across models), then it would be economically sensible to do so.
A big reason to be skeptical of this argument is that there could be large non-compute costs to training, such as lots of staff time—this just pushes training costs up but the overall argument still goes through with a less frequent update rate. Another related reason is that constantly training new models might split the focus of an organization and thus be really costly.
My overall confidence in this take is low, and I would be curious to hear what others think.
- ^
GPT-5.1 being 40% cheaper than GPT-5 is reasonable given halving times of 3.6 months; the GPT-5 was released August 7, 2025 and GPT-5.1 was released around 3 months later on November 12, 2025; GPT-5.2 was released December 11, 2025.
Based on the plot below, my intuition is that GPT-5 and GPT-5.1 had some pretraining data added to the original base pretraining dataset (or base model) dating back to GPT-4o; and GPT-5.2 is something different. I did this experiment a while back.
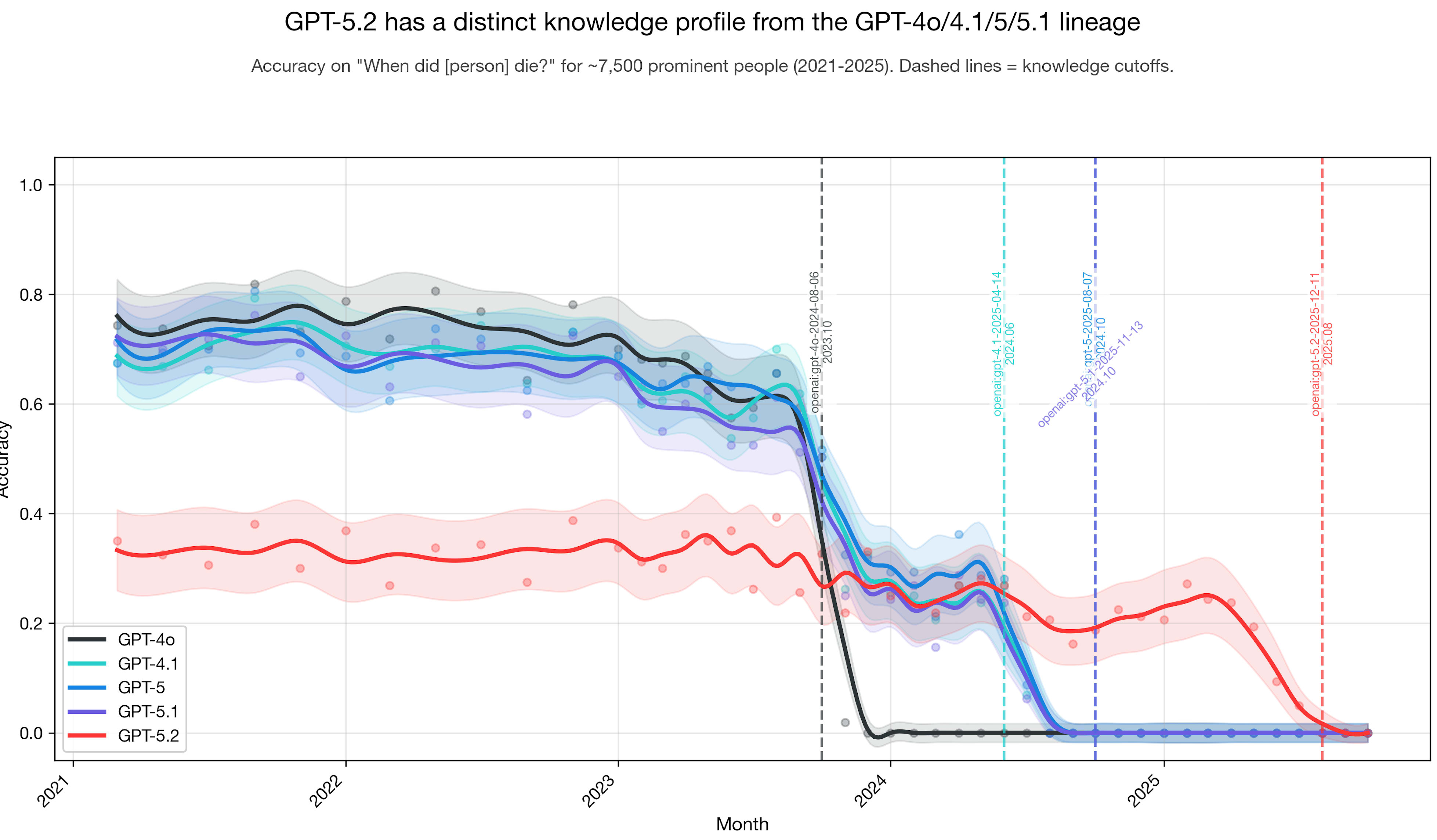
Accuracy being halved going from 5.1 to 5.2 suggests one of the two things:
1) the new model shows dramatic regression on data retrieval which cannot possibly be the desired outcome for a successor, and I'm sure it would be noticed immediately on internal tests and benchmarks, etc.—we'd most likely see this manifest in real-world usage as well;
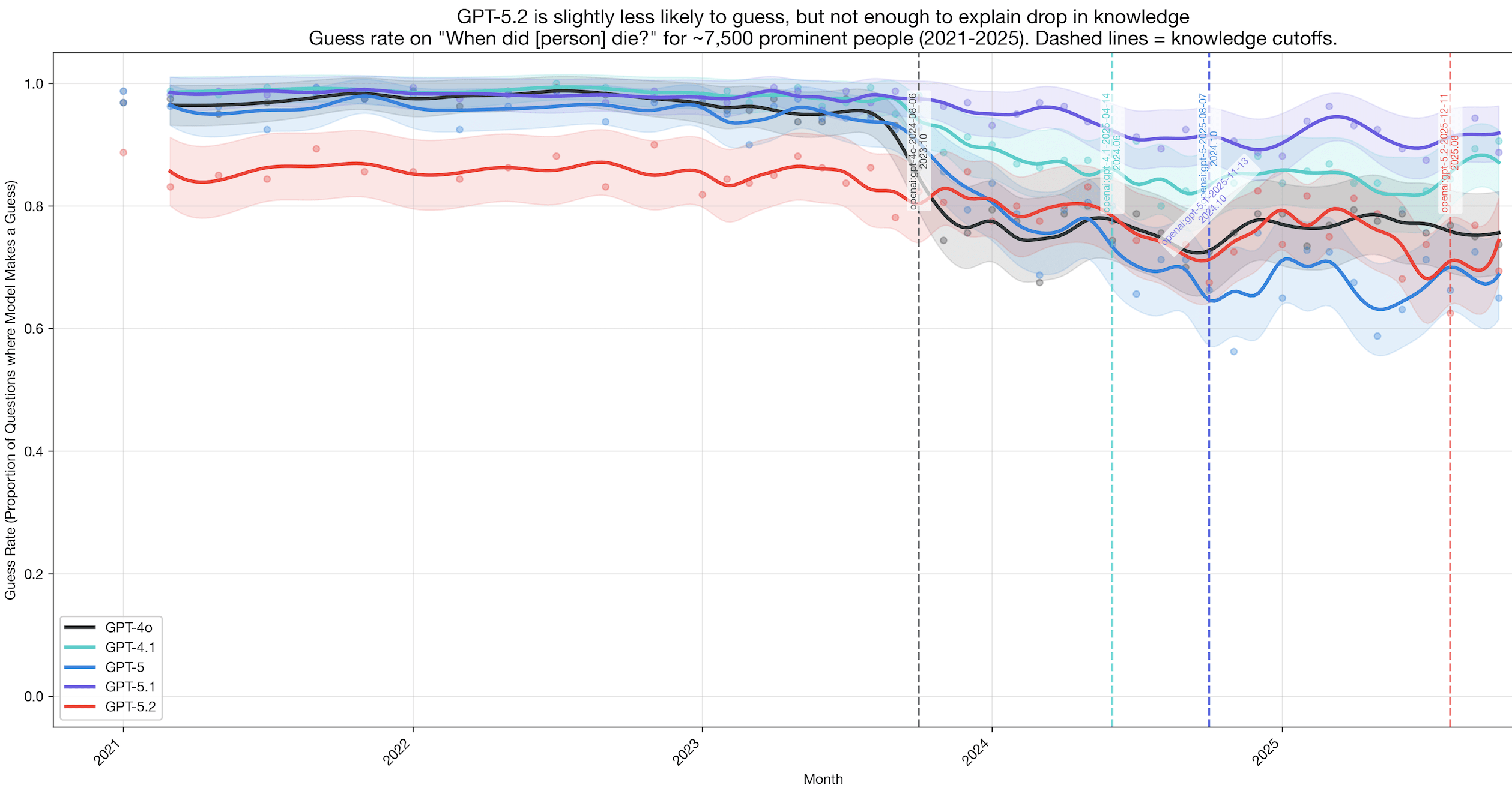
2) the new model refuses to guess much more often when it isn't too sure (being more cautious about answering wrong), which is a desired outcome meant to reduce hallucinations and slop. I'm betting this is exactly what we're looking at, and your Sonnet graph also suggests the same.
So if your methodology counts refusal as lowering accuracy, then it doesn't necessarily prove the base model or the training data mix is different. Teaching a model to refuse on low-signal data is in the domain of SFT and reinforcement learning, and investing into that heavily on the same pretrain would result in something similar to the graph you've posted.
4o and 5 almost certainly have different base models since 4o is natively omnimodal and 5 and its derivatives are not, taking that into account you have to make a lot of weird assumptions to reconcile this discrepancy. 5 and 4.1, on the other hand... Everything seems to fall into place neatly when looking in that direction.
I think 1 is true. This is only a single, quite obscure, factual recall eval. It's certainly possible to have regressions on some evals across model versions if you don't optimize for those evals at all.
Wrt point 2 -> here is the plot of how often the models guess, versus say they do not know, on the same dataset. My understanding is that the theory in point 2 would have predicted a much more dramatic drop in GPT-5.2?
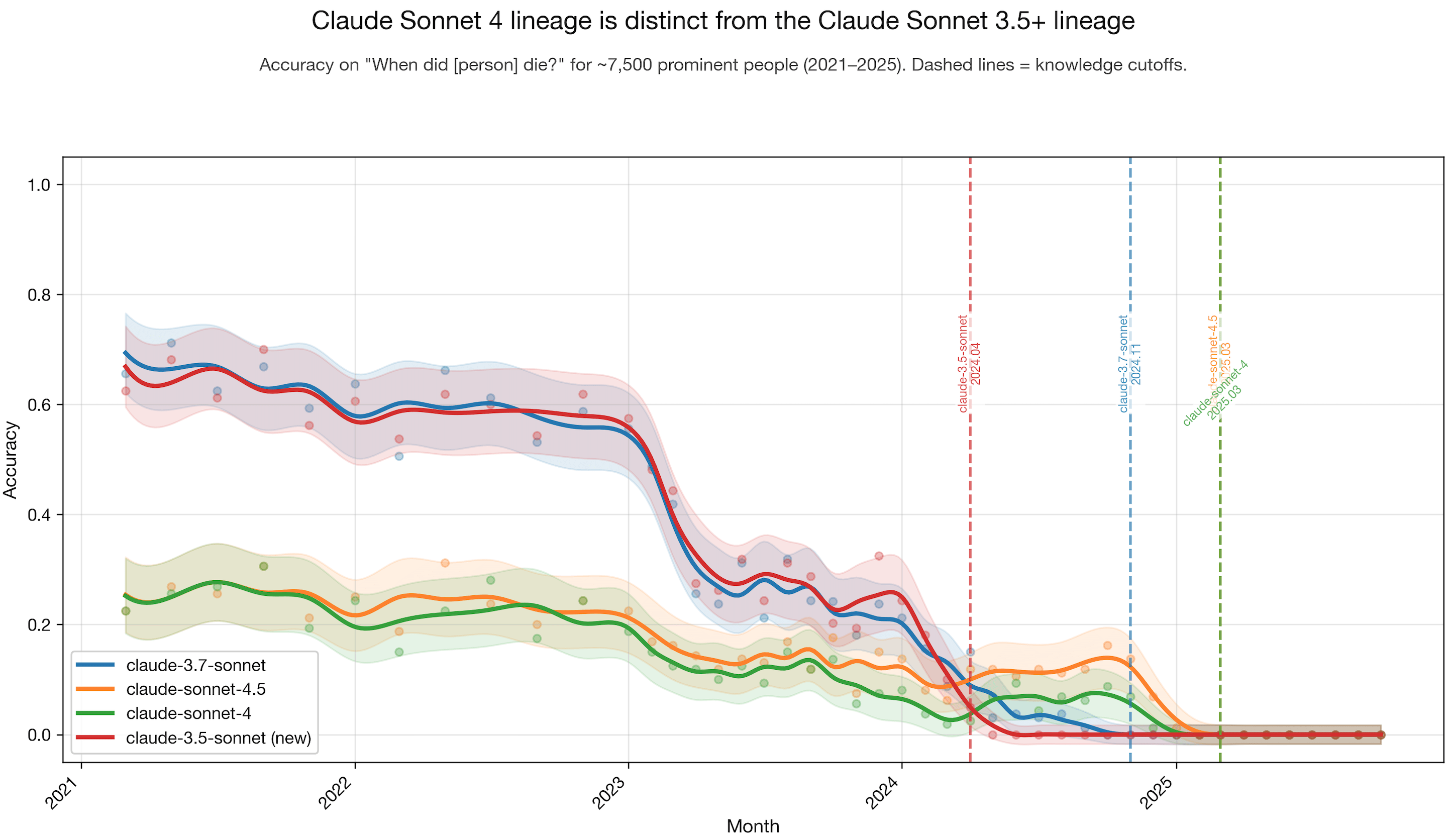
Interesting method! Added to my collection of LLM ancestry detection methods. Here are the other methods I have collected.
https://www.lesswrong.com/posts/cGcwQDKAKbQ68BGuR
LLM of the same model can be finetuned via random text
https://www.dbreunig.com/2025/05/30/using-slop-forensics-to-determine-model-ancestry.html
LLM of similar ancestry produces similar frequency of slop words
https://fi-le.net/oss/
Using known glitch tokens to identify LLMs/Encoders
According to Semianalysis:
The company [OpenAI] has used the same base model, GPT-4o, for all their recent flagship models: o1, o3, and GPT-5 series.
Tokenizers are often used over multiple generations of a model, or at least that was the case a couple of years ago, so I wouldn't expect it to work well as a test.
[This comment is no longer endorsed by its author]
The supposed dropping inference cost at a given level of capability is about benchmark performance (I'm skeptical it truly applies to real world uses at a similar level), which is largely about post-training (or mid-training with synthetic data), doesn't have much use for new pretrains. If there is already some pretrain of a relevant size from the last ~annual pretraining effort, and current post-training methods let it be put to use in a new role because they manage to make it good enough for that, they can just use the older pretrain (possibly refreshing it with mid-training on natural data to a more recent cutoff date). Confusingly, sometimes mid-training updates are referred to as different base or foundation models, even when they share the same pretrain.
In 2025-2026, there is also (apart from post-training improvements) the transition from older 8-chip Nvidia servers to rack-scale servers with more HBM per scale-up world that enable serving the current largest models efficiently (sized for 2024 levels of pretraining compute), and allow serving the smaller models like GPT-5 notably cheaper. But that's a one-time thing, and pretrains for even some of the largest models (not to mention the smaller ones) might've already been done in 2024. Probably when updating to a significantly larger model, you wouldn't just increment the minor version number. Though incrementing just the minor version number might be in order when updating to a new pretrain of a similar size, or when switching to a similarly capable pretrain of a smaller size, and either could happen during the ~annual series of new pretraining runs depending on how well they turn out.
Yeah I think leading labs generally retrain their base models less often than every 6 months (but there's a lot we don't know for sure). And I believe this most likely has to do with a production AI model being the result of a lot of careful tuning on pre-training, mid-training, post-training etc. Swapping in a new base model might lead to a lot of post-training regressions that need to be fixed. And your old base model is a "lucky" one in some sense because it either was selected for doing well and/or it required lots experiments, derisking runs, etc. Even with all of your new algorithmic tricks it might be hard to one-shot YOLO a base model that's better than your SOTA model from nine months ago. But this is probably much easier for your model from 18 or 27 months ago.
Also I'd guess staff costs are more important than compute costs here but these considerations mean compute costs of retraining are higher than one might think.
I am fairly confident That GPT-5.1, which I'm confident is a check-out of GPT-4o, has more than 60% of its training flops in post-training.
If openai created another GPT-4 pre train, they'd post-train it all over again.
Of course they'll do it. But just not that often. Likely once a year or something like that.
An important fact that influences many of my predictions about AI timelines and the capability of AI systems in the near term (even conditional on a pause) is that we have really no way of upper-bounding the capability of today's AIs given reasonable elicitation.
Take the statement "today's best AIs could be used to automate 95% of current AI R&D tasks, given 10% as much compute as was used to pretrain them and a strong team working for 4 years". I think most people in the AI xrisk community, even those who expect transformative AI in the next few years, think that statement is false. But as far as I can tell, we have no way to falsify it.
One way to falsify such a hypothesis is to spend a ton of effort eliciting a particular model on various tasks using many different methods. We basically don't do this these days for at least a couple reasons.
- First, progress in the field is so fast that models are obsoleted quickly. We probably spend a little under a year per base model[1] and only a few months per flagship post-train model;[2] it doesn't make tons of sense to keep working with a particular model—trying to fine-tune or scaffold/prompt it—once there are much better/cheaper ones.
- Second, we basically have new tasks every couple of years or so (e.g., 2023-2024 was chatbots, 2025-2026 is largely focused on agentic coding). Our task suite changes every couple years (or less), so the target of what we're eliciting for does as well.
There are also some reasons why elicitation is just hard.
- Sometimes I encounter people who, when I say "elicitation", think "scaling inference compute". But that's only a small part of it. A practical definition of elicitation (one that would answer the question I posed above) would include not just different methods of using more inference time compute, but also scaffolding, prompting, fine-tuning (SFT, RL, maybe more), activation steering, and new methods for all of these. Remember, we didn't have "reasoning models" publicly until late 2024, there's probably much more out there.
The last time humanity fully elicited an AI model was probably 2018 (and the following few years) with the BERT family. Before that, we saw a huge amount of use of ResNet-50 (2015). I think that these models were well elicited because thousands of researchers spent years working with them and trying to get them to solve different tasks.
Due to limited elicitation, we can't confidently upper-bound how useful current AIs would be for real world tasks if, for example, there was a pause on new AI training. I think it's plausible that current AIs could automate almost all of current AI research and a large fraction of cognitive labor, given the right elicitation (e.g., a few serial years, thousands of independent efforts, no new pretraining). This has many implications.
- ^
I argued here that companies should switch base models very frequently due to it being cost-effective to do so. Chinese AI companies who publish more information seem to train new flagship base models every 8 months on average (ChatGPT).
- ^
For instance, OpenAI seems to release a new best model every 3.5 months or so (ChatGPT).
AI is progressing so rapidly that the field doesn't have time to do high ROI elicitation because there are even higher ROI AI R&D pathways present in pretraining and post-training. It's analogous to how we didn't invent multi-core CPUs until Dennard scaling stopped, or we didn't use multi-patterning until lithography wavelength stalled.
The abundance of independent moderate-to-high ROI paths to better chips is why Moore's Law continued for so long, and for the same reason, it seems unlikely that AI R&D will naturally hit a wall, and nontrivial to enforce a pause.
I don't see how "nontrivial to enforce a pause" follows (beyond it requiring some amount of international coordination at some point which is unrelated to your point).
It was my impression that the continued progress in e.g. Moore's law requires a comparable steady increase in investment and R&D spending, so if the government does a large scale intervention on the inputs, this could effectively halt progress in many ways that matter. (Some forms of algorithmic progress seem indeed hard to halt without aggressive enforcement)
Mostly I meant that government needs to block all the source of progress-- pretraining, posttraining, data, elicitation, others-- rather than just some if it wants to mostly or entirely halt progress.
Moore's law has required steady increase in investment, but investment has increased much less than the rate of Moore's law, which is about 1.5x/year. If R&D spending were constant, progress might slow down to quadratic or cubic rather than exponential, still very fast.
The situation with AI is even tougher because if a software-only singularity is possible, growth will by definition continue to be exponential or faster if we halt growth in all inputs other than algorithmic efficiency, just a slower exponential than it would have been if investment continued ramping up. If status quo is 6 months from software singularity, than constant compute would mean perhaps 1 year to the singularity, and to delay the singularity until 10 years, governments must reduce inputs by at least 10x.
Take the statement "today's best AIs could be used to automate 95% of current AI R&D tasks, given 10% as much compute as was used to pretrain them and a strong team working for 4 years". I think most people in the AI xrisk community, even those who expect transformative AI in the next few years, think that statement is false. But as far as I can tell, we have no way to falsify it.
I don't know what "automate 95% of current AI R&D tasks" really means and depending on the definition I think this is maybe already true without any further elicitation required, but assuming you mean "nearly fully automate AI R&D", I think it would be possible to get a pretty good sense with effort using trend extrapolation and effort. It wouldn't be easy, but I think we could become more confident and I think we already have some understanding based on a bunch of less direct evidence.
I initially shared this on Twitter. I'm copying over here because I don't think it got enough attention. Here's my current favorite LLM take (epistemic status is conspiratorial speculation).
We can guesstimate the size of GPT-5 series models by assuming that OpenAI wouldn't release the gpt-oss models above the cost-performance pareto curve. We get performance from benchmarks, e.g., ArtificialAnalysis index.
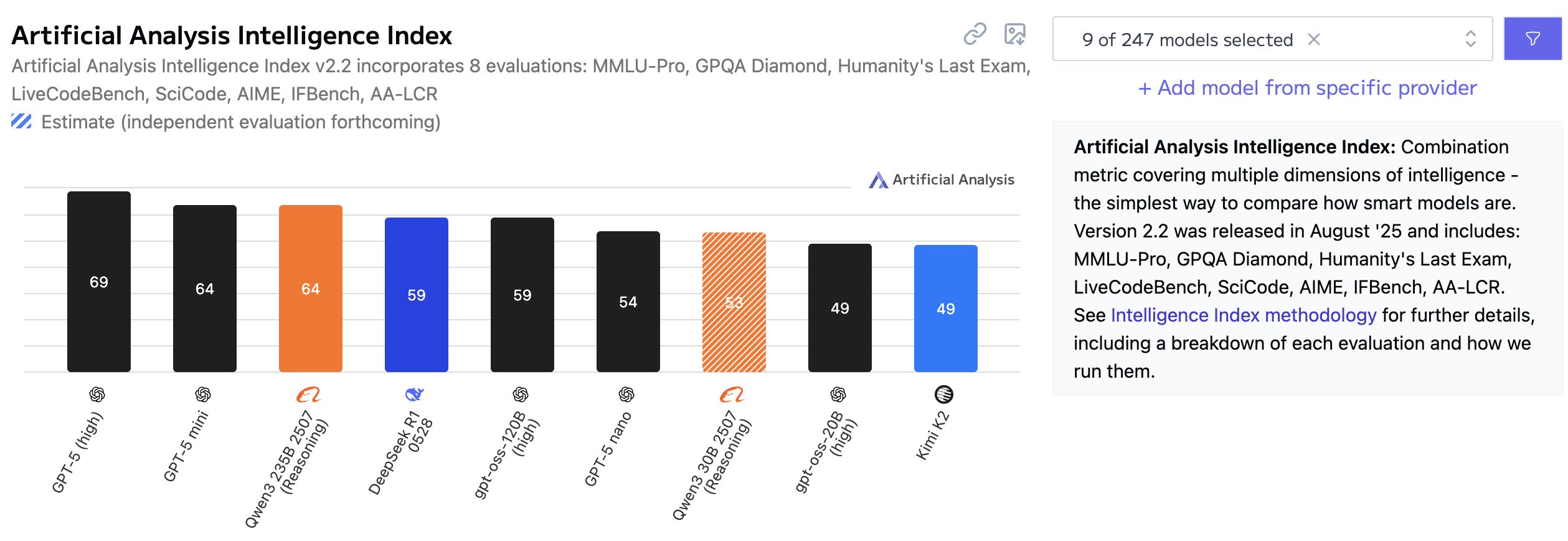
That gives us the following performance ordering: 20B < nano < 120B < mini < full. But the ordering depends on where you get #s and what mix. From model cards: Nano < 20B < 120B ≤ mini < full. We get cost from model size, recall the oss models:
20b: 21B-A3.6B
120b: 117B-A5.1B
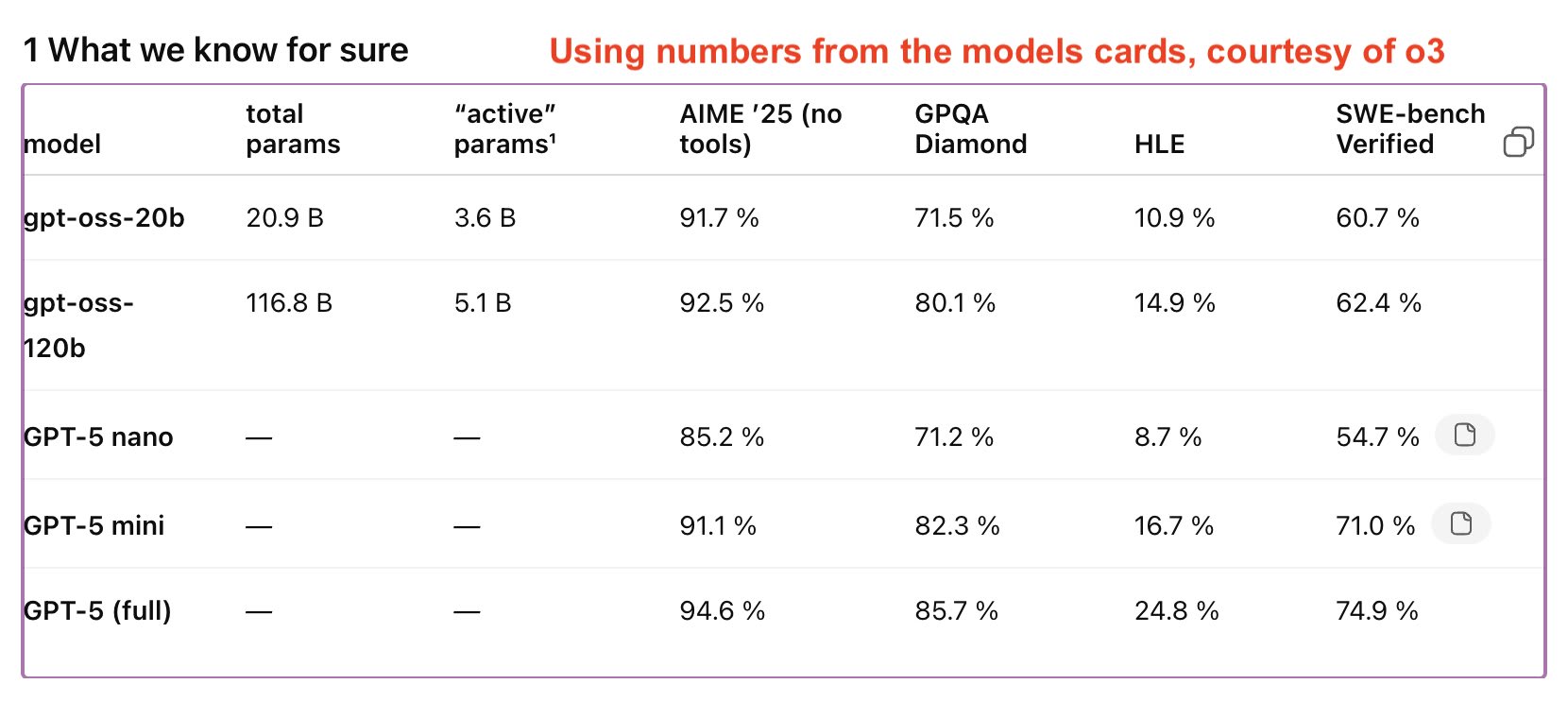
Now time for the wild speculation. I think this implies that Nano is order 0.5-3B. Mini is probably in the 3B-6B range, and GPT-5 full is probably in the 4-40B range. For active parameters. This would be consistent with the 5x pricing diff between each, if e.g., 1B, 5B, 25B.
This is super speculative obviously. We don't even know model architecture, and something totally different could be happening behind the scenes.
One implication of this analysis pointing to such small model sizes is that it indicates GPT-5 *really* wasn't a big scale-up in compute, maybe even a scale down vs. 4, almost certainly a scale down vs. 4.5.
API pricing for each of these models at release (per 1m input/output): GPT-4: 30/60 (rumored to be 1800B-A280B) GPT 4.5: 75/150 GPT-5: 1.25/10 If you're curious about the pricing ratio from 4 to 5, it might imply active parameter counts in the range of 12B-47B for 5.
Thanks to ArtificialAnalysis who is doing a public service by aggregating data about models. Also here's a fun graph.
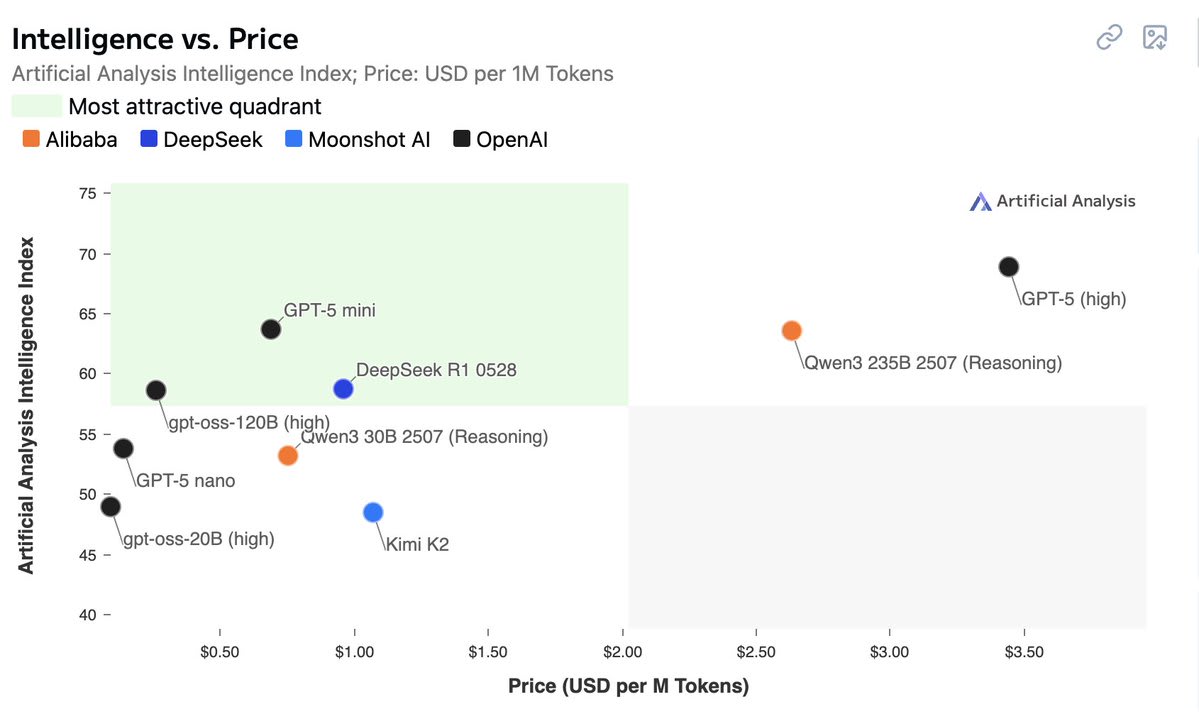
It's instructive to look at API provider prices for open weights models (such as DeepInfra, Fireworks), where model shapes are known and competition ensures that margins are not absurd, keeping in mind that almost all tokens are input tokens (for example Sonnet 4 gets 98% of API tokens as input tokens). So the margins for input tokens will be more important for the API provider, and the cost there depends on active params (but not total params). While costs for output tokens depend on context size of a particular query and total params (and essentially don't depend on active params), but get much less volume.
As an anchor, Qwen 3 Coder is a 480B-A35B model, and DeepInfra serves it at $0.40/$1.60 per 1M input/output in FP8. In principle, an A35B model needs 7e16 FLOPs per 1M input tokens, which at 50% compute utilization in FP8 needs 70 H100-seconds and should cost $0.04 at $2 per H100-hour. But probably occupancy is far from perfect. Unfortunately, there aren't any popular open weights MoE models with a lot of active params for a plausibly more direct comparison with closed frontier models.
almost all tokens are input tokens (for example Sonnet 4 gets 98% of API tokens as input tokens).
[EDIT: I was being silly and not considering the entire input being fed back to the LLM as context]
A bit tangential, but this is really wild. I'm confident that can't be true for chat sessions, so it has to be API usage. It does seem to vary substantially by model, eg for R1 it looks to be more like 80–85%. It makes some sense that it would be especially high for Anthropic, since they've focused on the enterprise market.
What kinds of use cases are nearly all input? The main one that I immediately see is using LLMs essentially as classifiers; eg you show an LLM a post by a user and ask whether it's toxic, or show it a bunch of log data and ask whether it contains errors. Maybe coding is another, where the LLM reads lots of code and then writes a much smaller amount, or points out bugs. Are there others that seem plausibly very common?
I suspect the models' output tokens become input tokens when the conversation proceeds to the next turn; certainly my API statistics show several times as many input tokens as output despite the fact that my responses are invariably shorter than the models'.
Thanks, that's a really great point, and I feel silly for not considering it.
I'm not entirely sure offhand how to model that. Naively, the entire conversation is fed in as context on each forward pass, but I think KV caching means that's not entirely the right way to model it (and how cached tokens are billed probably varies by model and provider). I'm also not sure to what extent those caches persist across conversational turns (and even if they are, presumably they're dropped once the user hasn't responded again for some length of time).
So the margins for input tokens will be more important for the API provider, and the cost there depends on active params (but not total params). While costs for output tokens depend on context size of a particular query and total params (and essentially don't depend on active params), but get much less volume.
Could you explain the reasoning behind this? Or link to an existing explanation?
There's a DeepMind textbook (the estimate for output tokens is in equation (1) of the inference chapter), though it focuses of TPUs and doesn't discuss issues with low total HBM in Nvidia's older 8-chip servers (which somewhat go away with GB200 NVL72). (I previously tried explaining output token generation a bit in this comment.)
Basically, all else equal chips compute much faster than they can get input data for that computation (even from HBM), but if they are multiplying sufficiently large matrices, then the number of necessary operations gets much greater than the amount of input/output data, and so it becomes possible to feed the chips. But when generating output tokens, you are only computing a few tokens per query, at the very end of a context, while you need to keep the whole context in HBM in the form of KV cache (intermediate data computed from the context), that can run into gigabytes per query, with HBM per server being only about 1 TB (in 8-chip Nvidia servers). As a result, you can't fit too many queries in a server at the same time, the total number of tokens being generated at the same time gets too low, and the time is mostly spent on the data moving between HBM and the chips, rather than on the chips computing things.
The amount of computation is proportional to the number of active params, but you'd need to pass most of the total params (as well as all KV cache for all queries) through the chips each time you generate another batch of tokens. And since computation isn't the taut constraint, the number of active params won't directly matter.
The number of total params also won't strongly matter if it's not a major portion of HBM compared to KV cache, so for example in GB200 NVL72 (which has 14 TB of HBM) smaller 2T total param models shouldn't be at a disadvantage compared to even smaller 250B total param models, because most of the data that needs to pass through chips will be KV cache (similarly for gpt-oss-120B and the 8-chip servers). The number of active params only matters indirectly, in that a model with more active params will tend to have a higher model dimension and will want to use more memory per token in its KV cache, which does directly increase the cost of output tokens.
Can we use similar methods to estimate the size and active parameters of GPT-4.5?
Naively extrapolating from the 1800B-A280B estimate for GPT-4 and the fact that GPT4.5 costs about 2.5x as much, we get 4500B-A700B.
I have no idea if that's a good guess, but hopefully someone can come up with a better one.
Interesting. I am inclined to think this is accurate. I'm kind of surprised people thought GPT-5 was a huge scaleup given that it's much faster than o3 was. It sort of felt like a distilled o3 + 4o.
Some prompts I found interesting when brainstorming LLM startups
I spent a little time thinking about making an AI startup. I generally think it would be great if more people were trying to build useful companies that directly add value, rather than racing to build AGI. Here are some of the prompts I found interesting to think about, perhaps they will be useful to other people/AI agents interested in building a startup:
- What are the situations where people will benefit from easy and cheap access to expert knowledge? You’re leveraging that human expert labor is hard to scale to many situations (especially when experts are rare, needs are specific, it’s awkward, it’s too expensive — including both raw cost and the cost of finding/trusting/onboarding an expert). What are all the things you occasionally pay somebody to do, but which requires them coming in person? What is a problem people know they have but they don’t seek out existing solutions (because of perceived cost, awkwardness, unsure how). e.g., dating profile feedback, outfit designer.
- Solve a problem that exists due to technological development, e.g., preventing the social isolation from social media, reducing various catastrophic risks during and after intelligence explosion.
Some other problem attack surface opened up by LLMs:
- Cheaply carry out simple straightforward tasks.
- Analyze data at scale.
- Do tasks that there was no previous market for (e.g., provided $5 of value but took an hour, and you can’t hire people for $5/hour because they don’t want to work for that little and the overhead is high). Reasons for lack of market: not enough money to be made, can’t trust somebody (not worth the time needed to grow trust, or substantial privacy concerns), communication cost too high (specify task), other overhead too high (travel, finding person), training cost too high compared to salary (imagine it took 8 years to become a barber).
- Provide cheap second opinions, potentially many of them (e.g., reviewing a low-importance piece of writing).
Some other desiderata I had (for prompting LLMs):
- I want to have a clear and direct story for making people's lives better or solving problems they have. So I have a slight preference for B2C over B2B, unless there's a clear story for how we're significantly helping the business in an industry that benefits people.
- We don't want to be obsoleted by the predictable products coming out of AI development companies; for instance a product that just takes ChatGPT and adds a convenient voice feature is not a good idea because that niche is likely to be met by existing developers fairly soon.
- We don't want to work on something that other well resourced efforts are working on. Our edge is having good ideas and creative implementations, not being able to outcompete others according to resource investment. We should play to our strengths and not try to get in a losing battle with strong existing products.
- I mainly don't want to be directly competing with existing products or services, instead I want to be creating a large amount of counterfactual value by solving a problem that nobody else has solved.
- The MVP should be achievable by a team of 5 working for <6 months, ideally even a very basic MVP should be achievable in just a week or two of full-time work.
- I want to be realistic, we won't be able to solve everything or do everything. I want to aim for a fairly niche product, rather than solving a huge-scale problem like fixing medical care. That is, instead of a general medical chatbot, a better idea would be a first-aid tutor that can help people learn first-aid basics and refresh their knowledge later.
- I want to be providing a service people are excited to receive. For instance, a sustainable living advisor isn't a great idea because if it actually got people to make more sustainable decisions, that would be annoying — people don't actually want to hear that they shouldn't fly home to their family for the holidays, even though this is one of the more important sustainability decisions they could make.
- I probably want to provide a service that is not currently provided by a simple google search. For instance, a cooking assistant is pretty much just glorified google search. I want to be providing more value than that. Services which can be provided by a simple google search are likely to be filled in by existing developers.
- I do not want to be pushing the frontier of AI capabilities in dangerous domains such as: synthetic biology, cybersecurity, autonomous weapons, ML engineering and AI development, manipulation and persuasion. Generally pushing the frontier of scientific capabilities may also be in this group due to its effects on the other domains, but it is unclear.
I think there's a large area in journalism where there's a lot of data and an LLM-driven model could write a good story.
Any law that's considered by congress before it's passed or regulation could be the basis for an article. The model could read through all the comments that were made in the public comment process by various lobbyists and other interested parties and synthesis them into a pro&con.
I think it's possible that such article could be less be lot less partisan than current mainstream media and explain the important features of laws that a journalists that spends a few hours for the issue just doesn't get.
Besides public comments for laws and regulations, I would expect that there are some similar topic where there's a lot of public information that currently no one condenses into one post that can be easily read.
I think it could make sense to combine artificial intelligence with expert domain knowledge. The expert describes the process step by step, providing detailed instructions for the AI at each step. The AI does the process with the customer. The expert reviews the logs, notices what went wrong, and updates the instructions accordingly.
AI is the power that allows the solution to scale, and expert knowledge is the part that will make you different from your competitors. The AI multiplies the expert's reach. Many of your competitors will probably try just using the AI, and will achieve worse results. Even the ones who start doing the same thing one year later will be at a disadvantage, if you used that time to improve your AI instructions.
For example, imagine a tutoring website with an AI. How could it be better than opening a chat and asking a generic AI to explain a topic? For starters, on the front page, you would see a list of topics. For example, you choose math, and you see a list of math topics that are taught at school, arranged by years. (By "a list of topics" I mean something like a grid of colorful icons. By the way, those icons can also be AI generated, but approved by a human.) For each topic, an expert would specify the set of things that need to mentioned, common misconceptions that need to be checked, etc. The AI would do the dialog with the student. (For example, if the topic is quadratic equations, the expert would specify that you need to solve an equation with two solutions, an equation with one solution, and an equation with no solutions. Or that the AI should ask whether you know about complex numbers, verify whether you actually do, and depending on that maybe mention that "no solutions" actually means two complex solutions.)
Or, imagine a tool that helps wannabe authors create stories. How could it be better than a generic "hey AI, make me a story about this and that"? For example, you could have a workflow where the AI asks about the size of story (a short story? a novel? a series of novels?), a setting; then lets you specify the main characters, etc., and only afterwards it would start generating the actual text of the story. This would probably result in better stories. Also, there could be a visual component to this, so that the AI could also create illustrations for the story. Again, instead of "make me a picture of a hero fighting a dragon", you would specify how your characters look like, as a combination of text description and choosing from AI generated visual suggestions. And then when you ask the AI to generate a picture of "Arthur fighting a dragon", the AI already knows what Arthur looks like, so all pictures in the story will contain the same character.
I sometimes want to point at a concept that I've started calling The Scaling Picture. While it's been discussed at length (e.g., here, here, here), I wanted to give a shot at writing a short version:
- The picture:
- We see improving AI capabilities as we scale up compute, projecting the last few years of progress in LLMs forward might give us AGI (transformative economic/political/etc. impact similar to the industrial revolution; AI that is roughly human-level or better on almost all intellectual tasks) later this decade (note: the picture is not about specific capabilities so much as the general picture).
- Relevant/important downstream capabilities improve as we scale up pre-training compute (size of model and amount of data), although for some metrics there are very sublinear returns — this is the current trend. Therefore, you can expect somewhat predictable capability gains in the next few years as we scale up spending (increase compute), and develop better algorithms / efficiencies.
- AI capabilities in the deep learning era are the result of three inputs: data, compute, algorithms. Keeping algorithms the same, and scaling up the others, we get better performance — that's what scaling means. We can lump progress in data and algorithms together under the banner "algorithmic progress" (i.e., how much intelligence can you get per compute) and then to some extent we can differentiate the source of progress: algorithmic progress is primarily driven by human researchers, while compute progress is primarily driven by spending more money to buy/rent GPUs. (this may change in the future). In the last few years of AI history, we have seen massive gains in both of these areas: it's estimated that the efficiency of algorithms has improved about 3x/year, and the amount of compute used has increased 4.1x/year. These are ludicrous speeds relative to most things in the world.
- Edit to add: This paper seems like it might explain that breakdown better.
- Edit to add: The below arguments are just supposed to be pointers toward longer argument one could make, but the one sentence version usually isn't compelling on its own.
- Arguments for:
- Scaling laws (mathematically predictable relationship between pretraining compute and perplexity) have held for ~12 orders of magnitude already
- We are moving though ‘orders of magnitude of compute’ quickly, so lots of probability mass should be soon (this argument is more involved, following from having uncertainty over orders of magnitude of compute that might be necessary for AGI, like the approach taken here; see here for discussion)
- Once you get AIs that can speed up AI progress meaningfully, progress on algorithms could go much faster, e.g., by AIs automating the role of researchers at OpenAI. You also get compounding economic returns that allow compute to grow — AIs that can be used to make a bunch of money, and that money can be put into compute. It seems plausible that you can get to that level of AI capabilities in the next few orders of magnitude, e.g., GPT-5 or GPT-6. Automated researchers are crazy.
- Moore’s law has held for a long time. Edit to add: I think a reasonable breakdown for the "compute" category mentioned above is "money spent" and "FLOP purchasable per dollar". While Moore's Law is technically about the density of transistors, the thing we likely care more about is FLOP/$, which follows similar trends.
- Many people at AGI companies think this picture is right, see e.g., this, this, this (can’t find an aggregation)
- Arguments against:
- Might run out of data. There are estimated to be 100T-1000T internet tokens, we will likely hit this level in a couple years.
- Might run out of money — we’ve seen ~$100m training runs, we’re likely at $100m-1b this year, tech R&D budgets are ~30B, governments could fund $1T. One way to avoid this 'running out of money' problem is if you get AIs that speed up algorithmic progress sufficiently.
- Scaling up is a non-trivial engineering problem and it might cause slow downs due to e.g., GPU failure and difficulty parallelizing across thousands of GPUs
- Revenue might just not be that big and investors might decide it's not worth the high costs
- OTOH, automating jobs is a big deal if you can get it working
- Marginal improvements (maybe) for huge increased costs; bad ROI.
- There are numerous other economics arguments against, mainly arguing that huge investments in AI will not be sustainable, see e.g., here
- Maybe LLMs are missing some crucial thing
- Not doing true generalisation to novel tasks in the ARC-AGI benchmark
- Not able to learn on the fly — maybe long context windows or other improvements can help
- Lack of embodiment might be an issue
- This is much faster than many AI researchers are predicting
- This runs counter to many methods of forecasting AI development
- Will be energy intensive — might see political / social pressures to slow down.
- We might see slowdowns due to safety concerns.
Might run out of data.
Data is running out for making overtrained models, not Chinchilla-optimal models, because you can repeat data (there's also a recent hour-long presentation by one of the authors). This systematic study was published only in May 2023, though the Galactica paper from Nov 2022 also has a result to this effect (see Figure 6). The preceding popular wisdom was that you shouldn't repeat data for language models, so cached thoughts that don't take this result into account are still plentiful, and also it doesn't sufficiently rescue highly overtrained models, so the underlying concern still has some merit.
As you repeat data more and more, the Chinchilla multiplier of data/parameters (data in tokens divided by number of active parameters for an optimal use of given compute) gradually increases from 20 to 60 (see the data-constrained efficient frontier curve in Figure 5 that tilts lower on the parameters/data plot, deviating from the Chinchilla efficient frontier line for data without repetition). You can repeat data essentially without penalty about 4 times, efficiently 16 times, and with any use at all 60 times (at some point even increasing parameters while keeping data unchanged starts decreasing rather than increasing performance). This gives a use for up to 100x more compute, compared to Chinchilla optimal use of data that is not repeated, while retaining some efficiency (at 16x repetition of data). Or up to 1200x more compute for the marginally useful 60x repetition of data.
The datasets you currently see at 15-30T tokens scale are still highly filtered compared to available raw data (see Figure 4). The scale feasible within a few years is about 2e28-1e29 FLOPs) (accounting for hypothetical hardware improvement and larger datacenters of early 2030s; this is physical, not effective compute). Chinchilla optimal compute for a 50T token dataset is about 8e26 FLOPs, which turns into 8e28 FLOPs with 16x repetition of data, up to 9e29 FLOPs for the barely useful 60x repetition. Note that sometimes it's better to perplexity-filter away half of a dataset and repeat it twice than to use the whole original dataset (yellow star in Figure 6; discussion in the presentation), so using highly repeated data on 50T tokens might still outperform less-repeated usage of less-filtered data, which is to say finding 100T tokens by filtering less doesn't necessarily work at all. There's also some double descent for repetition (Appendix D; discussion in the presentation), which suggests that it might be possible to overcome the 60x repetition barrier (Appendix E) with sufficient compute or better algorithms.
In any case the OOMs match between what repeated data allows and the compute that's plausibly available in the near future (4-8 years). There's also probably a significant amount of data to be found that's not on the web, and every 2x increase in unique reasonable quality data means 4x increase in compute. Where data gets truly scarce soon is for highly overtrained inference-efficient models.
I agree that repeated training will change the picture somewhat. One thing I find quite nice about the linked Epoch paper is that the range of tokens is an order of magnitude, and even though many people have ideas for getting more data (common things I hear include "use private platform data like messaging apps"), most of these don't change the picture because they don't move things more than an order of magnitude, and the scaling trends want more orders of magnitude, not merely 2x.
Repeated data is the type of thing that plausibly adds an order of magnitude or maybe more.
The point is that you need to get quantitative in these estimates to claim that data is running out, since it has to run out compared to available compute, not merely on its own. And the repeated data argument seems by itself sufficient to show that it doesn't in fact run out in this sense.
Data still seems to be running out for overtrained models, which is a major concern for LLM labs, so from their point of view there is indeed a salient data wall that's very soon going to become a problem. There are rumors of synthetic data (which often ambiguously gesture at post-training results while discussing the pre-training data wall), but no published research for how something like that improves the situation with pre-training over using repeated data.
it's estimated that the efficiency of algorithms has improved about 3x/year
There was about 5x increase since GPT-3 for dense transformers (see Figure 4) and then there's MoE, so assuming GPT-3 is not much better than the 2017 baseline after anyone seriously bothered to optimize, it's more like 30% per year, though plausibly slower recently.
The relevant Epoch paper says point estimate for compute efficiency doubling is 8-9 months (Section 3.1, Appendix G), about 2.5x/year. Though I can't make sense of their methodology, which aims to compare the incomparable. In particular, what good is comparing even transformers without following the Chinchilla protocol (finding minima on isoFLOP plots of training runs with individually optimal learning rates, not continued pre-training with suboptimal learning rates at many points). Not to mention non-transformers where the scaling laws won't match and so the results of comparison change as we vary the scale, and also many older algorithms probably won't scale to arbitrary compute at all.
(With JavaScript mostly disabled, the page you linked lists "Compute-efficiency in language models" as 5.1%/year (!!!). After JavaScript is sufficiently enabled, it starts saying "3 ÷/year", with a '÷' character, though "90% confidence interval: 2 times to 6 times" disambiguates it. In other places on the same page there are figures like "2.4 x/year" with the more standard 'x' character for this meaning.)
Thinking about AI training runs scaling to the $100b/1T range. It seems really hard to do this as an independent AGI company (not owned by tech giants, governments, etc.). It seems difficult to raise that much money, especially if you're not bringing in substantial revenue or it's not predicted that you'll be making a bunch of money in the near future.
What happens to OpenAI if GPT-5 or the ~5b training run isn't much better than GPT-4? Who would be willing to invest the money to continue? It seems like OpenAI either dissolves or gets acquired. Were Anthropic founders pricing in that they're likely not going to be independent by the time they hit AGI — does this still justify the existence of a separate safety-oriented org?
This is not a new idea, but I feel like I'm just now taking some of it seriously. Here's Dario talking about it recently,
I basically do agree with you. I think it’s the intellectually honest thing to say that building the big, large scale models, the core foundation model engineering, it is getting more and more expensive. And anyone who wants to build one is going to need to find some way to finance it. And you’ve named most of the ways, right? You can be a large company. You can have some kind of partnership of various kinds with a large company. Or governments would be the other source.
Now, maybe the corporate partnerships can be structured so that AGI companies are still largely independent but, idk man, the more money invested the harder that seems to make happen. Insofar as I'm allocating probability mass between 'acquired by big tech company', 'partnership with big tech company', 'government partnership', and 'government control', acquired by big tech seems most likely, but predicting the future is hard.
Slightly Aspirational AGI Safety research landscape
This is a combination of an overview of current subfields in empirical AI safety and research subfields I would like to see but which do not currently exist or are very small. I think this list is probably worse than this recent review, but making it was useful for reminding myself how big this field is.
- Interpretability / understanding model internals
- Circuit interpretability
- Superposition study
- Activation engineering
- Developmental interpretability
- Understanding deep learning
- Scaling laws / forecasting
- Dangerous capability evaluations (directly relevant to particular risks, e.g., biosecurity, self-proliferation)
- Other capability evaluations / benchmarking (useful for knowing how smart AIs are, informing forecasts), including persona evals
- Understanding normal but poorly understood things, like in context learning
- Understanding weird phenomenon in deep learning, like this paper
- Understand how various HHH fine-tuning techniques work
- AI Control
- General supervision of untrusted models (using human feedback efficiently, using weaker models for supervision, schemes for getting useful work done given various Control constraints)
- Unlearning
- Steganography prevention / CoT faithfulness
- Censorship study (how censoring AI models affects performance; and similar things)
- Model organisms of misalignment
- Demonstrations of deceptive alignment and sycophancy / reward hacking
- Trojans
- Alignment evaluations
- Capability elicitation
- Scaling / scalable oversight
- RLHF / RLAIF
- Debate, market making, imitative generalization, etc.
- Reward hacking and sycophancy (potentially overoptimization, but I’m confused by much of it)
- Weak to strong generalization
- General ideas: factoring cognition, iterated distillation and amplification, recursive reward modeling
- Robustness
- Anomaly detection
- Understanding distribution shifts and generalization
- User jailbreaking
- Adversarial attacks / training (generally), including latent adversarial training
- AI Security
- Extracting info about models or their training data
- Attacking LLM applications, self-replicating worms
- Multi-agent safety
- Understanding AI in conflict situations
- Cascading failures
- Understanding optimization in multi-agent situations
- Attacks vs. defenses for various problems
- Unsorted / grab bag
- Watermarking and AI generation detection
- Honesty (model says what it believes)
- Truthfulness (only say true things, aka accuracy improvement)
- Uncertainty quantification / calibration
- Landscape study (anticipating and responding to risks from new AI paradigms like compound AI systems or self play)
Don’t quite make the list:
- Whose values? Figuring out how to aggregate preferences in RLHF. This seems like it’s almost certainly not a catastrophe-relevant safety problem, and my weak guess is that it makes other alignment properties harder to get (e.g., incentivizes sycophancy and makes jailbreaks easier by causing the model’s goals to be more context/user dependent). This work seems generally net positive to me, but it’s not relevant to catastrophic risks and thus is relatively low priority.
- Fine-tuning that calls itself “alignment”. I think it’s super lame that people are co-opting language from AI safety. Some of this work may actually be useful, e.g., by finding ways to mitigate jailbreaks, but it’s mostly low quality.
I think mechanistic anomaly detection (mostly ARC but also Redwood and some forthcoming work) is importantly different than robustness (though clearly related).
Quick thoughts on a database for pre-registering empirical AI safety experiments
Keywords to help others searching to see if this has been discussed: pre-register, negative results, null results, publication bias in AI alignment.
The basic idea:
Many scientific fields are plagued with publication bias where researchers only write up and publish “positive results,” where they find a significant effect or their method works. We might want to avoid this happening in empirical AI safety. We would do this with a two fold approach: a venue that purposefully accepts negative and neutral results, and a pre-registration process for submitting research protocols ahead of time, ideally linked to the journal so that researchers can get a guarantee that their results will be published regardless of the result.
Some potential upsides:
- Could allow better coordination by giving researchers more information about what to focus on based on what has already been investigated. Hypothetically, this should speed up research by avoiding redundancy.
- Safely deploying AI systems may require complex forecasting of their behavior; while it would be intractable for a human to read and aggregate information across many thousands of studies, automated researchers may be able to consume and process information at this scale. Having access to negative results from minimal experiments may be helpful for this task. That’s a specific use case, but the general thing here is just that publication bias makes it hard to figure out what is true compared to if all results.
Drawbacks and challenges:
- Decent chance the quality of work is sufficiently poor so as to not be useful; we would need monitoring/review to avoid this. Specifically, whether a past project failed at a technique provides close to no evidence if you don’t think the project was executed competently, so you want a competence bar for accepting work.
- For the people who might be in a good position to review research, this may be a bad use of their time
- Some AI safety work is going to be private and not captured by this registry.
- This registry could increase the prominence of info-hazardous research. Either that research is included in the registry, or it’s omitted. If it’s omitted, this could end up looking like really obvious holes in the research landscape, so a novice could find those research directions by filling in the gaps (effectively doing away with whatever security-through-obscurity info-hazardous research had going for it). That compares to the current state where there isn’t a clear research landscape with obvious holes, so I expect this argument proves too much in that it suggests clarity on the research landscape would be bad. Info-hazards are potentially an issue for pre-registration as well, as researchers shouldn’t be locked into publishing dangerous results (and failing to publish after pre-registration may give too much information to others).
- This registry going well requires considerable buy in from the relevant researchers; it’s a coordination problem and even the AI safety community seems to be getting eaten by the Moloch of publication bias
- Could cause more correlated research bets due to anchoring on what others are working on or explicitly following up on their work. On the other hand, it might lead to less correlated research bets because we can avoid all trying the same bad idea first.
- It may be too costly to write up negative results, especially if they are being published in a venue that relevant researchers don’t regard highly. It may be too costly in terms of the individual researcher’s effort, but it could also be too costly even at a community level if the journal / pre-registry doesn’t end up providing much value
Overall, this doesn’t seem like a very good idea because of the costs and likelihood of success. There is plausibly a low cost version that would still get some of the benefit. Like higher-status researchers publicly advocating for publishing negative results, and others in the community discussing the benefits of doing so. Another low-cost solution would be small grants for researchers to write up negative results.
Thanks to Isaac Dunn and Lucia Quirke for discussion / feedback during SERI MATS 4.0