This is a linkpost for https://arxiv.org/abs/2210.01117
To me, the main insight in the paper is that the norm of the initial weights matter, and not just weight decay/other forms of regularization! IE, while people have plotted weight norm as a function of training time for grokking/nongrokking networks, people have not, afaik, plotted initial weight norm vs grokking. I had originally thought that overfitting would just happen, since memorization was "easier" in some sense for SGD to find in general. So it's a big update for me that the initial weight norm matters so much.
I don't think grokking per se is particularly important, except insofar as neat puzzles about neural networks are helpful for understanding neural networks. As both this paper and Neel/Lieberum's grokking post argue, grokking happens when there's limited data that's trained for a long time, which causes SGD to initially favor memorization, and some form of regularization, which causes the network to eventually get to a generalizing solution. (Assuming large enough initializations.) But in practice, large foundation models are not trained for tens of thousands of epochs on tiny datasets, but instead a single digit number of epochs on a large dataset (generally 1). Also, if the results from this paper (where you need progressively larger weight initializations to get grokking with larger models/larger datasets, then it seems unlikely that any large model is in the grokking regime).
So I think there's something else going on behind the rapid capability gains we see in other networks as we scale the amount of training data/train steps/network parameters. And I don't expect that further constraining the weight norm will speed up generalization on current large models.
That being said, I do think the insight that the norms of the initial weight matter for generalization seems pretty interesting!
Nitpick: I'm really not a fan of people putting the number of steps on a log scale, since it makes grokking look far more sudden than it actually is, while making the norm's evolution look smoother than it is. Here's what the figures look like for 5 random seeds on the P=113 modular addition task, if we don't take log of the x axis: https://imgur.com/a/xNhHDmR
Another nitpick: I thought it was confusing that the authors used "grokking" to mean "delay in generalization" and "de-grokking" to mean "generalization". This seems the opposite of what "grok" actually means?
EDIT: Also, I'm not sure that I fully understand or buy the claim that "representation learning is key to grokking".
Excellent comment. Independently same main takeaway here. Thanks for the pictures!
Agree with nitpick, although I get why they restrict the term "grok" to mean "test loss minimum lagging far behind training loss minimum". That's the mystery and distinctive pattern from the original paper, and that's what they're aiming to explain.
Hmm, I haven't read the paper yet, but thinking about it, the easiest way to change the weight norm is just to multiply all weights by some factor , but then in a network with ReLU activations and L layers, this would be completely equivalent to multiplying the output of the network by . In the overfitting regime where the network produces probability distributions where the mode is equal to the answer for all training tokens, the easiest way to decrease loss is just to multiply the output by a constant factor, essentially decreasing the entropy of the distribution forever, but this strategy fails at test-time because the mode is not equal to the answer there. So keeping the weight norm at some specified level might just be a way to prevent the network from taking the easy way towards decreasing training loss, and forcing it to find ways at constant-weight-norm to decrease loss, which would better generalize for the test-set.
That makes a lot of sense.
However, in that case it would be enough to just keep the weight norm at any level. But they claim that there is an optimal level. So it can't be the entire story they have in mind.
The existence of an optimal L2 norm makes no sense at all to me. The L2 norm is an extremely unnatural metric for neural networks. For instance, in ReLU networks if you multiply all the weights in one layer by and all the weights in the layer above by , the output of the network doesn't change at all, yet the L2 norm will have changed (the norm for those two layers will be ). In fact you can get any value for the L2 norm (above some minimum) you damn well please by just scaling the layers. An optimal average entropy of the output distribution over the course of training would make a hell of a lot more sense if this is somehow changing training dynamics.
It doesn't matter that there are multiple networks with the same performance but different L2 norms. Instead, it suffices that the optimal network differs for different L2 norms, or that the gradient updates during training point in different directions when the network is L2 norms are constrained. Both are indeed true.
It also makes a lot of sense, if you think about it in terms of ordinary statistical learning theory. Assuming for a second that we're sampling neural networks that achieve a certain train loss at a certain weight norm randomly, there's some amount of regularization (IE, some small weight norm) that leads to the lowest test loss.
If the optimal norm is below the minimum you can achieve just by re-scaling, you are trading-off training set accuracy for weights with a smaller norm within each layer. It's not that weird that the best known way of making this trade-off is by constrained optimization.
I think this is very similar to the hypothesis they have as well. But not sure if I understood it correctly, I think some parts of the paper are not as clear as they could be
I think this theory is probably part of the story, but it fails to explain Figure 2(b), where grokking happens in the presence of weight decay, even if you keep weight norm constant.
One of the authors of the paper here. Glad you found it interesting! In case people want to mess around with some of our results themselves, here are colab notebooks for reproducing a couple results:
Some miscellaneous comments:
On some level "just fix your weight norm and the model generalizes" sounds too simple to be true for all tasks -- I agree. I'd be pretty surprised if our result on speeding up generalization on modular arithmetic by constraining weight norm had much relevance to training large language models, for instance. But I haven't thought much about this yet!
There is a new paper by Liu et al. that claims to have understood the key mechanism underlying grokking (potentially even generalization more broadly).
They argue:
1. Grokking can be explained via the norm of the weights. They claim that there is a constant level of the weight norm that is optimal for generalization.
2. If there is an optimal level of the weight norm, the weight norm of your model after initialization can be either too low, too high or optimal. They claim that grokking is a phenomenon where we initialize the model with a large weight norm and it then slowly walks toward the optimal weight norm and then generalizes.
3. They also claim that you can get the same results as grokking but much faster if you set the weight norm correctly at every step.
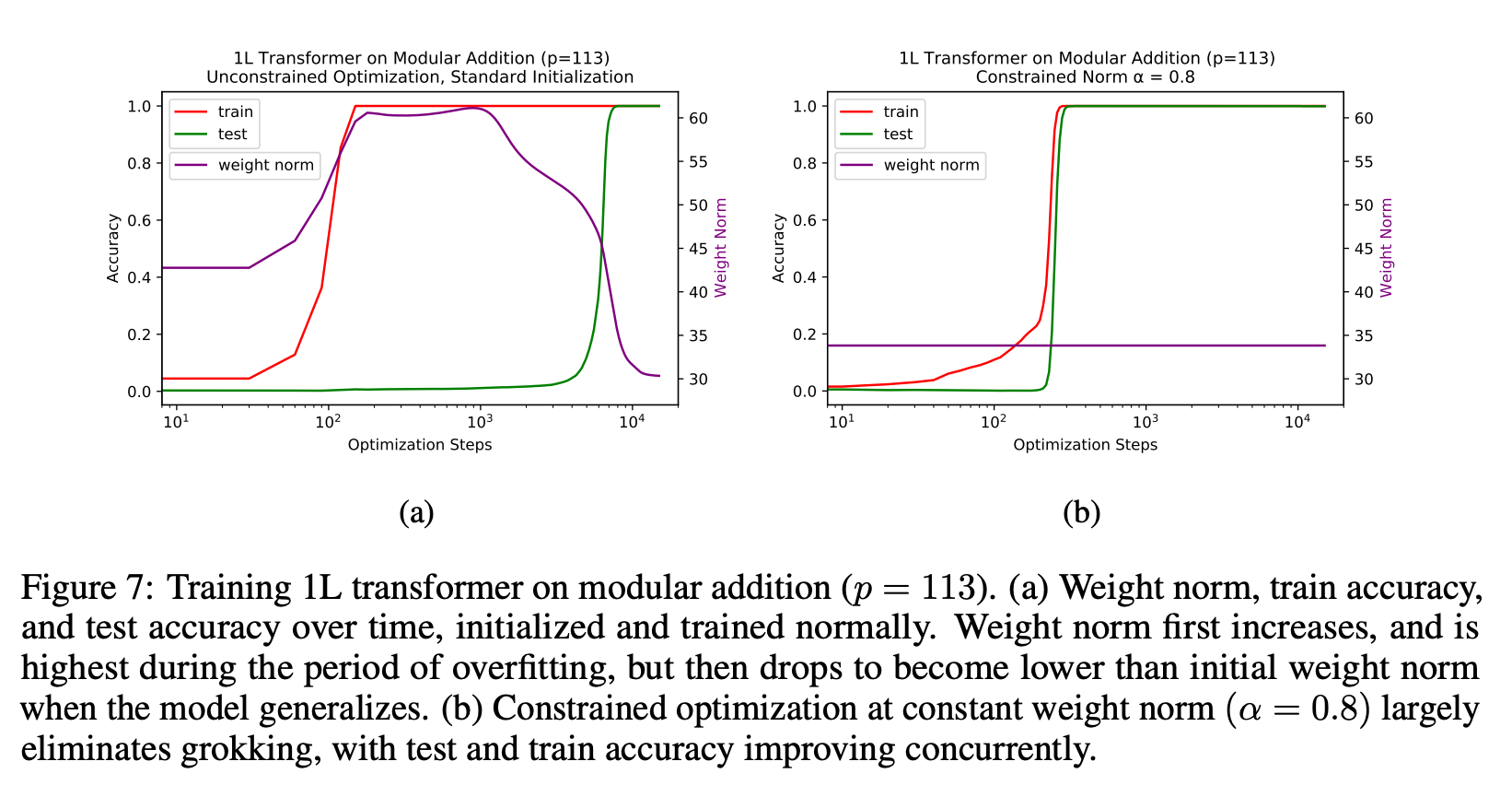
4. They set the norm "correctly" by rescaling the weights after each unconstrained optimization step (so after every weight update loss.backward()?!)
Implications:
I'm very unsure about this paper but intuitively it feels important. Thoughts?