Crossposted from X (I'm experimenting with participating more there.)
This is speaking my language, but I worry that AI may inherently disfavor defense (in at least one area), decentralization, and democracy, and may differentially accelerate wrong intellectual fields, and humans pushing against that may not be enough. Some explanations below.
"There is an apparent asymmetry between attack and defense in this arena, because manipulating a human is a straightforward optimization problem [...] but teaching or programming an AI to help defend against such manipulation seems much harder [...]" https://www.lesswrong.com/posts/HTgakSs6JpnogD6c2/two-neglected-problems-in-human-ai-safety
"another way for AGIs to greatly reduce coordination costs in an economy is by having each AGI or copies of each AGI profitably take over much larger chunks of the economy" https://www.lesswrong.com/posts/Sn5NiiD5WBi4dLzaB/agi-will-drastically-increase-economies-of-scale
Lastly, I worry that AI will slow down progress in philosophy/wisdom relative to science and technology, because we have easy access to ground truths in the latter fields, which we can use to train AI, but not the former, making it harder to deal with new social/ethical problems
A happy path: merge with the AIs?
I think if you're serious about preserving human value into the future, you shouldn't start with something like "let's everyone install AI-brain connectors and then we'll start preserving human value, pinky promise". Instead you should start by looking at human lives and values as they exist now, and adopt a standard of "first do no harm".
An excellent quote: "a market-based society that uses social pressure, rather than government, as the regulator, is not [the result of] some automatic market process: it's the result of human intention and coordinated action."
I think too often people work on things under the illusion that everything else just "takes care of itself."
Everything requires effort.
Efforts in the long-run are elastic.
Thus, everything is elastic.
Don't take for granted that industry will take care of itself, or art, or music, or AI safety, or basic reading, writing, and arithmetic skills. It's all effort - all the way down..
What is his d/acc philosophy in any short summary? What does he propose as guiding principles?
How can people unite behind a manifesto 10k words long, waxing poetic about a seemingly random assortment of someone's beliefs?
Can a few people try to summarize their understanding of "d/acc" into a paragraph, without reading other summaries first, to see if everybody but me got a sense of cohesive general idea from it?
I don't have a well-reasoned opinion here but I'm interested in hearing from those who disagree.
I didn't downvote/disagree-vote Ben's comment, but it doesn't unite the people who think that accelerating development of certain technologies isn't enough to (sufficiently) prevent doom, that we also need to slow down or pause development of certain other technologies.
(Clarification: I didn't mean to say that this banner succeeded. I meant to say it was a worthwhile thing to attempt.)
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
If I understand it correctly, Vitaliks main argument for accelerating (in any form) is that human defense has always exceeded expectations. But this is ignoring the whole "with ASI, we (might) have only one try" argument. All the examples he names, like solving smog, acid rain or the ozon layer, were reactions to problems, that were already existing for years. He even states it pretty directly: "version N of our civilization's technology causes a problem, and version N+1 fixes it." What if the problem of version N is already big enough to wipe out humanity fast?
The vitalik.ca page is down btw. Here is the link to the decentralized version.
https://vitalik.eth.limo/general/2023/11/27/techno_optimism.html
So you have made an assumption here.
AGI version N : produces m utility in the real world when faced with all the real world noise and obstacles.
Weak ASI version N+1 : produces f(s)*m utility in the real world. S is a term that represents scale times algorithmic gain.
Maximum runtime ASI version N+1: produces f(s)*m utility in the real world.
The doom concern is the thought that the benefits of giving a machine the maximum amount of compute humans are able to practically supply (note that that any given architecture saturates on interconnect bandwidth, you cannot simply rack current gen GPUS without bounds) will result in an ASI that has so much real world utility it's unstoppable.
And the ASI can optimize itself and fit on more computers than the multi billion dollar cluster it was developed on.
If scaling is logarithmic, this would mean that F(s) = log(s). This would mean that other human actors with their weaker, but stable "tool" AGI will be able to fight back effectively in a world with some amount of escaped or hostile superintelligence. Assuming the human actors (these are mostly militaries) have a large resource advantage they would win the campaign.
I think doomers like Yudnowsky assume it's not logarithmic, and Geohot and vitalik and others assume some kind of sharply diminishing returns.
Diminishing returns means you just revert back to the last stable version and use that, or patch your ASIs container and use it to fight against the one that just escaped. Your "last stable version" or your "containerized" ASI are weaker in utility than the one that escaped. But assuming you control most of the compute and most of the weapons, you can compensate for a utility gap. This would be an example of N+-1 of a technology saving you from the bad one.
As far as I know the current empirical data shows diminishing returns for current algorithms. This doesn't prove another algorithm isn't possible and obviously for specific sub problems like context length, scaling better than quadratic has a dozen papers offering more efficient methods.
Vitalik's take is galaxy-brained (is there an opposite of the term "scissor statement"?). Bostrom published the paper Existential Risk as a Global Priority in 2013 containing this picture:
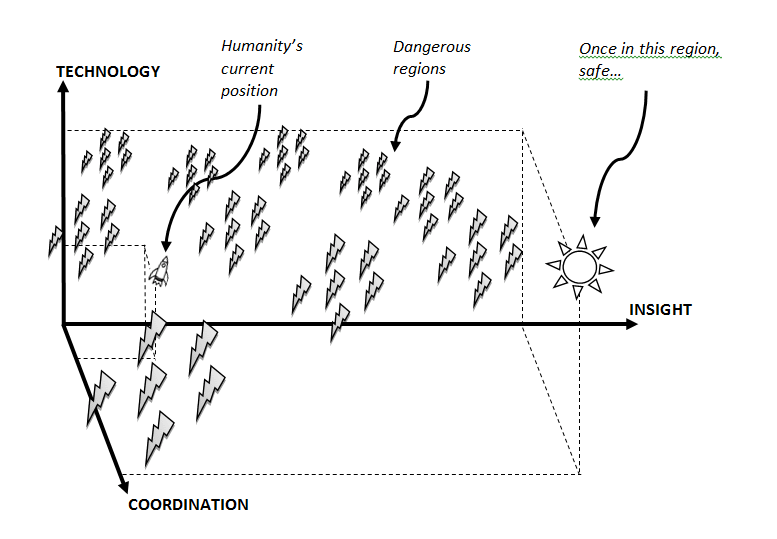
and Yudkowsky probably already wrote a ton about this ~15 years ago, and yet both of them seem to have failed to rise to the challenge today of resolving the escalating situation with e/acc- at least not to this degree of effectiveness. Yudkowsky was trying to get massive twitter dunks and Bostrom was trying to bait controversy to get podcast views, and that sure looks a lot like both of them ended up as slaves to the algorithm's attention-maximizing behavior reinforcement (something something thermodynamic downhill).
I think it's relevant that Vitalik is 29, Bostrom is 50, and Yudkowsky is 44 (plus he has major chronic health issues).
I'd also say that the broader society has been much more supportive of Vitalik than it has been of Bostrom and Yudkowsky (billionaire, TIME cover, 5M Twitter followers, etc), putting him in a better place personally to try to do the ~political work of uniting people. He is also far more respected by the folks in the accelerationist camp making it more worthwhile for him to invest in an intellectual account that includes their dreams of the future (which he largely shares).
Strong epistemic upvoted, this is very helpful way for any reader. I only wrote the original comment because I thought it was worth putting out there.
I'm still glad I included Bostrom's infographic though.
Likely this podcast episode where Bostrom essentially says that he's concerned that with current trends there might be too much opposition to AI, though he still thinks we should place more concern than our current level of concern:
Vitalik wrote a post trying to make the case for his own take on techno-optimism summarizing it as an ideology he calls "d/acc". I resonate with a lot of it, though also have conflicting feelings about trying to create social movements and ideologies like this.
Below some quotes and the table of contents.
Table of contents