This is a special post for quick takes by David Matolcsi. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
If you don't believe in your work, consider looking for other options
I spent 15 months working for ARC Theory. I recently wrote up why I don't believe in their research. If one reads my posts, I think it should become very clear to the reader that either ARC's research direction is fundamentally unsound, or I'm still misunderstanding some of the very basics after more than a year of trying to grasp it. In either case, I think it's pretty clear that it was not productive for me to work there. Throughout writing my posts, I felt an intense shame imagining readers asking the very fair question: "If you think the agenda is so doomed, why did you keep working on it?"[1]
In my first post, I write: "Unfortunately, by the time I left ARC, I became very skeptical of the viability of their agenda."This is not quite true. I was very skeptical from the beginning, for largely similar reasons I expressed in my posts. But first I told myself that I should stay a little longer. Either they manage to convince me that the agenda is sound, or I demonstrate that it doesn't work, in which case I free up the labor of the group of smart people working on the agenda. I think this was initially a somewhat reasonable position, though it was already in large part motivated reasoning.
But half a year after joining, I don't think this theory of change was very tenable anymore. It was becoming clear that our arguments were going in circles. I couldn't convince Paul and Mark (the two people thinking the most about the big picture questions), nor could they convince me. Eight months in, two friends visited me in California, and they noticed that I always derailed the conversation when they asked me about my research. I think that should have been an important thing to notice that I was ashamed to talk about my research to my friends, because I was afraid they would see how crazy it was. I should have quit then, but I stayed for another seven months.
I think this was largely due to cowardice. I'm very bad at coding and all my previous attempts at upskilling in coding went badly.[2] I thought of my main skill as being a mathematician, and I wanted to keep working on AI safety. The few other places one can work as a mathematician in AI safety looked even less promising to me than ARC. I was afraid that if I quit, I wouldn't find anything else to do.
In retrospect, this fear was unfounded. I realized there were other skills one can develop, not just coding. In my afternoons, I started reading a lot more papers and serious blog posts [3] from various branches of AI safety. After a few months, I felt I had much more context on many topics. I started to think more about what I can do with my non-mathematical skills. When I finally started applying for jobs, I got an offer from the European AI Office and UKAISI, and it looked more likely than not that I would get an offer from Redwood. [4]
Other options I considered that looked less promising than the three above, but still better than staying at ARC: Team up with some Hungarian coder friends and execute some simple but interesting experiments I had vague plans for. [5] Assemble a good curriculum for the prosaic AI safety agendas that I like. Apply for a grant-maker job. Become a Joe Carlsmith-style general investigator. Try to become a journalist or an influential blogger. Work on crazy acausal trade stuff.
I still think many of these were good opportunities, and probably there are many others. Of course, different options are good for people with different skill profiles, but I really believe that the world is ripe with opportunities to be useful for people who are generally smart and reasonable and have enough context on AI safety. If you are working on AI safety but don't really believe that your day-to-day job is going anywhere, remember that having context and being ingrained in the AI safety field is a great asset in itself,[6] and consider looking for other projects to work on.
(Important note: ARC was a very good workplace, my coworkers were very nice to me and receptive to my doubts, and I really enjoyed working there except for feeling guilty that my work is not useful. I'm also not accusing the people who continue working at ARC of being cowards in the way I have been. They just have a different assessment of ARC's chances, or work on lower-level questions than I have, where it can be reasonable to just defer to others on the higher-level questions.)
(As an employee of the European AI Office, it's important for me to emphasize this point: The views and opinions of the author expressed herein are personal and do not necessarily reflect those of the European Commission or other EU institutions.)
- ^
No, really, it felt very bad writing the posts. It felt like describing how I worked for a year on a scheme that was either trying to build perpetuum mobile machines, or trying to build normal cars, I just missed the fact that gasoline exists. Embarrassing either way.
- ^
I don't know why. People keep telling me that it should be easy to upskill, but for some reason it is not.
- ^
I particularly recommend Redwood's blog.
- ^
We didn't fully finish the work trial as I decided that the EU job was better.
- ^
Think of things in the style of some of Owain Evans' papers or experiments on faithful chain of thought.
- ^
And having more context and knowledge is relatively easy to further improve by reading for a few months. It's a young field.
If one reads my posts, I think it should become very clear to the reader that either ARC's research direction is fundamentally unsound, or I'm still misunderstanding some of the very basics after more than a year of trying to grasp it.
I disagree. Instead, I think that either ARC's research direction is fundamentally unsound, or you're still misunderstanding some of the finer details after more than a year of trying to grasp it. Like, your post is a few layers deep in the argument tree, and the discussions we had about these details (e.g. in January) went even deeper. I don't really have a position on whether your objections ultimately point at an insurmountable obstacle for ARC's agenda, but if they do, I think one needs to really dig into the details in order to see that.
(ETA: I agree with your post overall, though!)
That's not how I see it. I think the argument tree doesn't go very deep until I lose the the thread. Here are a few, slightly stylized but real, conversations I had with friends who had no context on what ARC was doing, when I tried to explain our research to them:
Me: We want to to do Low Probability Estimation.
Them: Does this mean you want to estimate the probability that ChatGPT says a specific word after a 100 words on chain of thought? Isn't this clearly impossible?
Me: No, you see, we only want to estimate the probabilities only as well as the model knows.
Them: What does this mean?
Me: [I can't answer this question.]
Me: We want to do Mechanistic Anomaly Detection.
Them: Isn't this clearly impossible? Won't this result in a lot of false positives when anything out of distribution happens?
Me: Yes, why we have this new clever idea of relying on the fragility of sensor tampering, that if you delete a subset of the actions, you will get an inconsistent image.
Them: What if the AI builds another robot to tamper with the cameras?
Me: We actually don't want to delete actions but heuristic arguments for why the cameras will show something, and we want to construct heuristic explanations in a way that they carry over through delegated actions.
Them: What does this mean?
Me; [I can't answer this question.]
Me: We want to create Heuristic Arguments to explain everything the model does.
Them: What does it mean that an argument explained a behavior? What is even the type signature of heuristic arguments? And you want to explain everything a model does? Isn't this clearly impossible?
Me: [I can't answer this question.]
When I was explaining our research to outsiders (which I usually tried to avoid out of cowardice), we usually got to some of these points within minutes. So I wouldn't say these are fine details of our agenda.
During my time at ARC, the majority of my time was spent on asking variations of these three questions from Mark and Paul. They always kindly answered, and the answer was convincing-sounding enough for the moment that I usually couldn't really reply on the spot, and then I went back to my room to think through their answers. But I never actually understood their answers, and I can't reproduce them now. Really, I think that was the majority of work I did at ARC. When I left, you guys should have bought a rock with "Isn't this clearly impossible?" written on it, and that would profitably replace my presence.
That's why I'm saying that either ARC's agenda is fundamentally unsound or I'm still missing some of the basics. What is standing between ARC's agenda collapsing from five minutes of questioning from an outsider is that Paul and Mark (and maybe others in the team) have some convincing-sounding answers to the three questions above. So I would say that these answers are really part of the basics, and I never understood them.
Maybe Mark will show up in the comments now to give answers to the three questions, and I expect the answers to sound kind of convincing, and I won't have a very convincing counter-argument other than some rambling reply saying essentially that "I think this argument is missing the point and doesn't actually answer the question, but I can't really point out why, because I don't actually understand the argument because I don't understand how you imagine heuristic arguments". (This is what happened in the comments on my other post, and thanks to Mark for the reply and I'm sorry for still not understanding it.) I can't distinguish whether I'm just bad at understanding some sound arguments here, or the arguments are elaborate self-delusions of people who are smarter and better at arguments than me. In any case, I feel epistemic learned helplessness on some of these most basic questions in ARC's agenda.
What is your opinion on the Low Probability Estimation paper published this year at ICLR?
I don't have a background in the field, but it seems like they were able to get some results, that indicate the approach is able to extract some results. https://arxiv.org/pdf/2410.13211
It's a nice paper, and I'm glad they did the research, but importantly, the paper reports a negative result about our agenda. The main result is that the method inspired by our ideas under-performs the baseline. Of course, these are just the first experiments, work is ongoing, this is not conclusive negative evidence for anything. But the paper certainly shouldn't be counted as positive evidence for ARC's ideas.
Thanks for the clarification! Not in the field and wasn't sure I understood the meaning of the results correctsly.
I was very skeptical from the beginning, for largely similar reasons I expressed in my posts. But first I told myself that I should stay a little longer.
IME, in the majority of cases, when I strongly felt like quitting but was also inclined to justify "staying just a little bit longer because XYZ", and listened to my justifications, staying turned out to be the wrong decision.
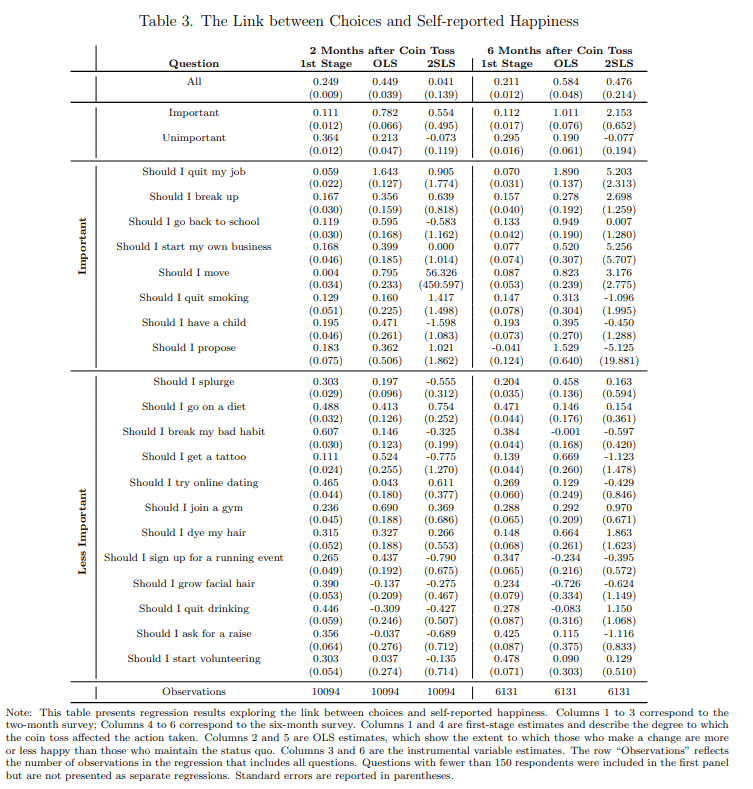
Relevant classic paper from Steven Levitt. Abstract [emphasis mine]:
Little is known about whether people make good choices when facing important decisions. This paper reports on a large-scale randomized field experiment in which research subjects having difficulty making a decision flipped a coin to help determine their choice. For important decisions (e.g. quitting a job or ending a relationship), those who make a change (regardless of the outcome of the coin toss) report being substantially happier two months and six months later. This correlation, however, need not reflect a causal impact. To assess causality, I use the outcome of a coin toss. Individuals who are told by the coin toss to make a change are much more likely to make a change and are happier six months later than those who were told by the coin to maintain the status quo. The results of this paper suggest that people may be excessively cautious when facing life-changing choices.
Pretty much the whole causal estimate comes down to the influence of happiness 6 months after quitting a job or breaking up. Almost everything else is swamped with noise. The only individual question with a consistent causal effect larger than the standard error was "should I break my bad habit?", and doing so made people unhappier. Even for those factors, there's a lot of biases in this self-report data, which the authors noted and tried to address. I'm just not sure what we can really learn from this, even though it is a fun study.
How exactly are you measuring coding ability? What are the ways you've tried to upskill, and what are common failure modes? Can you describe your workflow at a high-level, or share a recording? Are you referring to competence at real world engineering tasks, or performance on screening tests?
There's a chrome extension which lets you download leetcode questions as jupyter notebooks: https://github.com/k-erdem/offlineleet. After working on a problem, you can make a markdown cell with notes and convert it into flashcards for regular review: https://github.com/callummcdougall/jupyter-to-anki.
I would suggest scheduling calls with friends for practice sessions so that they can give you personalized feedback about what you need to work on.
Someone should do the obvious experiments and replications.
Ryan Greenblatt recently posted three technical blog posts reporting on interesting experimental results. One of them demonstrated that recent LLMs can make use of filler tokens to improve their performance; another attempted to measure the time horizon of LLMs not using CoT; and the third demonstrated recent LLMs' ability to do 2-hop and 3-hop reasoning.
I think all three of these experiments led to interesting results and improved our understanding of LLM capabilities in an important safety-relevant area (reasoning without visible traces), and I'm very happy Ryan did them.
I also think all three experiments look pretty obvious in hindsight. LLMs not being able to use filler tokens and having trouble with 2-hop reasoning were both famous results that already lived in my head as important pieces of information about what LLMs can do without visible reasoning traces. As far as I can tell, Ryan's two posts simply try to replicate these two famous observations on more recent LLMs. The post on measuring no CoT time horizon is not a replication, but also doesn't feel like a ground-breaking idea once the concept of increasing time horizons is already known.
My understanding is that the technical execution of these experiments wasn't especially difficult either, in particular they didn't require any specific machine learning expertise. (I might be wrong here, and I wonder how many hours Ryan spent on these experiments. I also wonder about the compute budget of these experiments, I don't have a great estimate of that.)
I think it's not good that these experiments were only run now, and that they needed to run by Ryan, one of the leading AI safety researchers. Possibly I'm underestimating the difficulty of coming up with these experiments and running them, but I think ideally these should have been done by a MATS scholar, or ideally by an eager beginner on a career transitioning grant who wants to demonstrate their abilities so they can get into MATS later.
Before accepting my current job, I was thinking about returning to Hungary and starting a small org with some old friends who have more coding experience, living on Eastern European salaries, and just churning out one simple experiment after another. One of the primary things I hoped to do with this org was to go through famous old results and try to replicate them. I hope we would have done the filler tokens and 2-hop reasoning replications too. I also had many half-baked ideas of running new simple experiments investigating ideas related to other famous results (in the way the no-CoT time horizon experiment is one possible interesting thing to investigate related to rising time horizons).
I eventually ended up doing something else, and I think my current job is probably a more important thing for me to do than trying to run the simple experiments org. But if someone is more excited about technical research than me, I think they should seriously consider doing this. I think funding could probably be found, and there are many new people who want to get into AI safety research; I think one could turn these resources into churning out a lot of replications and variations on old research, and produce interesting results. (And it could be a valuable learning experience for the AI safety beginners involved in doing the work.)
FWIW, Daniel Kokotajlo has commented in the past:
> If there was an org devoted to attempting to replicate important papers relevant to AI safety, I'd probably donate at least $100k to it this year, fwiw, and perhaps more on subsequent years depending on situation. Seems like an important institution to have. (This is not a promise ofc, I'd want to make sure the people knew what they were doing etc., but yeah)
but I think ideally these should have been done by a MATS scholar, or ideally by an eager beginner on a career transitioning grant who wants to demonstrate their abilities so they can get into MATS later.
A problem here is that, I believe, this is on the face of it not quite aligned with MATS scholars' career incentives, as replicating existing research does not feel like projects that would really advance their prospects of getting hired. At least when I was involved in hiring, I would not have counted this as strong evidence or training for strong research skills (sorry for being part of the problem). On the other hand, it is totally plausible to incorporate replication of existing research as part of a larger research program investigating related issues (i.e. Ryan's experiment about time horizon without COTs could fit well within a larger work investigating time horizons in general).
This may look different for the "eager beginners", or something like the AI safety camp could be a good venue for pure replications.
Interesting. My guess would have been the opposite. Ryan's three posts all received around 150 karmas and were generally well-received, I think a post like this would be considered 90th percentile success for a MATS project. But admittedly, I'm not very calibrated about current MATS projects. It's also possible that Ryan has good enough intuitions to have picked two replications that are likely to yield interesting results, while a less skillfully chosen replication would be more likely to just show "yep, the phenomenon observed in the old paper is still true". That would be less successful but I don't know how it would compare in terms of prestige to the usual MATS projects. (My wild guess is that it would still be around median, but I really don't know.)
(adding my takes in case they are useful for MATS fellows deciding what to do) I have seen many MATS projects via attending the MATS symposiums, but am relying on my memory of them. I would probably consider Ryan's posts to each be like 60-70th percentile MATS project. But I expect that a strong MATS scholar could do 2-5 mini projects like this during the duration of MATS.
I think I disagree—doing research like this (especially several such projects) is really helpful for getting hired!
Before accepting my current job, I was thinking about returning to Hungary and starting a small org with some old friends who have more coding experience, living on Eastern European salaries, and just churning out one simple experiment after another.
I think such an org should focus on automating simple safety research and paper replications with coding agents (e.g. Claude Code). My guess is that the models aren't capable enough yet to autonomously do Ryan's experiments but they may be in a generation or two, and working on this early seems valuable.
The Coefficient technical grant-making team should pitch some people on doing this and just Make It Happen (although I'm obviously ignorant of their other priorities).
I commented something similar about a month ago. Writing up a funding proposal took longer than expected but we are going to send it out in the next few days. Unless something bad happens, the fiscal sponsor will be the University of Chicago which will enable us to do some pretty cool things!
If anyone has time to look at the proposal before we send it out or wants to be involved, they can send me a dm or email (zroe@uchicago.edu).
Do you have suggestions for other particularly approachable but potentially high impact replications or quick research sprints?
Redwood has project proposals, but these seem higher effort than what you're suggesting and more challenging for a beginner
https://blog.redwoodresearch.org/p/recent-redwood-research-project-proposals
Repentance seems to be very rare among the powerful.
I tried to search with multiple LLMs and in other ways for examples where a king or a dictator realized the evilness of some of their past actions, realized their rule is not justified, and voluntarily resigned. I have not found a single example of this happening.
There are some examples of kings and dictators voluntarily resigning, but it's usually motivated by being tired of ruling (often for health reasons), and very occasionally genuine support for democracy. But as far as I can tell, it's never because a ruler realized the evil of their ways.
I also searched for crime bosses, warlords and successful large-scale fraudsters who voluntarily gave up their evil ways due to repentance. Again, there were hardly any examples. People sometimes repent in prison; people sometimes turn themselves in to the police when they see they will soon get caught anyway; and people sometimes retire from crime to a safer life-style, keeping their ill-gotten gains to themselves.
I only found two examples of successful criminals changing their ways while still successful due to a change of heart - Nicky Cruz who was a gang leader in New York, and General Butt Naked, a Liberian warlord. And even there, I'm a bit suspicious - many of General Butt Naked's stories of his previous horrific atrocities seem false, and I wonder what else is false in his story.
I'm interested if people can find better examples of evil leaders and successful criminals repenting while still in power, I would be relieved to see more examples of this happening.
I find the rarity of repentance of the powerful a very sad fact about human nature, and it makes me less optimistic that current dictators and unscrupulous politicians will significantly change for the better if given superintelligent AI advisors. Of course, one can still be an okay or even maybe a good ruler without ever repenting their evil actions in the past, but I still don't feel great about this.
I think if Kim Jong Un lived for a million years, and had the smartest AI advisors, and access to intelligence augmentation techniques, he would probably still never come to admit that murdering his brother was an evil thing to do. Maybe most of his subjects would still have an okay life under his rule in a post-scarcity AI world, but I think there are limits to how good one's values can get without facing one's past sins.
(I'm partially responding to habryka's recent post on Putin here, but you should mostly treat this post independently of the Putin discussion, I have been planning to write this shortform since a while now. I'm not trying to argue against habryka's main claim in his post that Putin's rule would probably be still much better than extinction.)
Isn't the obvious reason for this that if you were a dictator and committed much evil, that in the moment you were to repent, you would lose all of your allies, but you would of course not immediately gain forgiveness from your enemies?
So it seems like the only way to stay safe from your enemies is to not repent.
This is IMO what the idea of "saving face" is about. The thing we do see reasonably frequently is dictators and leaders backing down from reckless paths of action, but in a way that does not cause them to lose the support of their allies, which is necessary for defending them from attacks by the people they harmed.
I suspect it'd be high-EV to figure out generalized versions of "Dictator Island" and variations thereof such that currently-powerful people can be credibly promised that they don't have to massively worry about safety or quality of life if they lose power struggles. There are deterrent and morale reasons to go for a more punitive/retributive method instead (eg try ppl for war crimes) but imo the arguments for that are worse, especially in the current moment.
Famously, Ashoka the Great (his wheel is on the flag of India) suddenly converted to Buddhism and then (allegedly) stopped being super war happy, and the torture prison he built (literally called "Ashoka's Hell", and run by a guy who boasted we could execute the entire Indian subcontinent, who was hired after the prime minister got worried about the king personally killing so many people) was abandoned. (note that the wiki page lists examples of him still being violent after converting - a massacre, a pogram, and a slow torture of the guy hired to do his tortures in the torture prison).
And he was like pretty bad too!
The ministers who had helped him ascend the throne started treating him with contempt after his ascension. To test their loyalty, Ashoka gave them the absurd order of cutting down every flower-and fruit-bearing tree. When they failed to carry out this order, Ashoka personally cut off the heads of 500 ministers.[87]
One day, during a stroll at a park, Ashoka and his concubines came across a beautiful Ashoka tree. The sight put him in an amorous mood, but the women did not enjoy caressing his rough skin. Sometime later, when Ashoka fell asleep, the resentful women chopped the flowers and the branches of his namesake tree. After Ashoka woke up, he burnt 500 of his concubines to death as punishment.[88]
Yes, I considered mentioning Ashoka, but I'm worried that his story is largely legendary. (And Chandragupta is likely even more legendary.)
And even in the likely largely legendary story of Ashoka, I think it's pretty bad that he didn't resign or at least try harder to compensate his victims.
Hiring someone to do torture for you, then torturing him to death for following your orders, while you retain your crown yourself is a pretty contemptible behavior!
According to legends, Ashoka's Grandfather, Chandragupta, might be an example of what David is looking for
According to Digambara Jain accounts Chandragupta abdicated at an early age and settled as a monk under Bhadrabāhu in Shravanabelagola, in present-day south Karnataka. According to these accounts, Bhadrabāhu forecast a 12-year famine because of all the killing and violence during the conquests by Chandragupta Maurya.
I think if Kim Jong Un lived for a million years, and had the smartest AI advisors, and access to intelligence augmentation techniques, he would probably still never come to admit that murdering his brother was an evil thing to do
I feel like the evidence you've provided here is pretty weak for drawing that conclusion. The regime where KJU lives for a million years and augments his intelligence is really outside distribution.
Does Yeltsin count? He resigned voluntarily before his term was over, and in the resignation speech he said basically "we thought it'd be easier to transition Russia to a democracy, but it turned out really difficult and many of you suffered, I apologize for that".
That said, I agree with you, this kind of thing seems very rare.
I listened to a podcast once about a guy who had a predatory loan shark empire and repented and gave it up for moral reasons.
How about businessmen? Some sources claim that Henry Ford repented his antisemitism in 1942 and took legal action to end the publication of his own most well-known antisemitic work, The International Jew. A few years later Ford died of a stroke (not his first) after being shown newsreel footage of the Nazi concentration camps that his (former?) ideology had enabled.
I think there are limits to how good one's values can get without facing one's past sins.
I don't think this is true, or at least I don't think it's obvious. When opinions change in Democratic societies, in my experience the generic stance is "That's how I always felt, I'm glad everyone else caught up." But clearly _someone_ must have changed their mind about gay marriage between 2005 and 2015. I don't think there's a limit on how far you can shift without penitence. I'm not sure that's how human psychology works.
disagreed. a general approach of "i cannot give voice to my belief unless i believe it is what the majority believes" can result in different democratic outcomes without any individual changing their object-level convictions. as well, demographics change over time.
this is to say that "values don't change without repentance" is not contradicted by "laws in democracy change".
Certainly preference cascades and demographic change can explain some changes in public opinion, but I also think that people actually change their minds. Having lived through it, I'm pretty confident that the shift in public opinion on gay marriage was due at least in part to some people genuinely changing their minds, and even then penitence is rare to non-existent.
The dictionary definition of repentance seems to be "the fact of showing that you are very sorry for something bad you have done in the past, and wish that you had not done it". I think it's quite possible for a king to do that without resigning.
You speak a lot about "evil" but aren't clear about what you mean with the word. If we take Kim Jong Un as one example, there was a good chance for Kim Jong Un to die in an internal power struggle after he became leader. He was very young compared to most of the North Korean power brokers who didn't exactly like a twenty something commanding them.
He consolidated power through a series of very brutal actions. If you would ask him why he did so in a honest setting, he probably would tell you that he needed to do so to consolidate power and otherwise he would probably fall fighting to a coup. He might tell you that killing his brother was the morally right thing to do under utilitarian calculus given that it provided political stability. Maybe even a personal sacrifice of a family member for the greater good of North Korea.
You speak about "sin". Kim Jong Un certainly committed a sin in the Christian sense. This could be due to him having to make choices between pretty bad alternatives or it could be because of bad values that would also produce problems in a post-scarcity world where he's not forced to pick between bad alternatives.
I wonder if retiring is a too high ask from a leader. First of all, I don't think that smaller forms of repentance are unheard of. Additionally, a leader's retirement causes a successor to arrive, and the successor is to be capable enough to understand the leader's ideas instead of destroying them wholesale, as has also happened when Peter III of Russia decided to withdraw from the Seven Years' War.
I agree with your conclusion; though additionally I think two factors for why we don't see such repentance often is just the general human tendency of not wanting to admit you are wrong (magnified in the case where a dictator admitting they are wrong is extremely costly personally and morally taxing), plus the type of personality that gets into those positions selects against this kind of behavior.
This tendency also reminds me of a potentially similar dynamic of scientists not admitting they are wrong https://en.wikipedia.org/wiki/Planck%27s_principle
Thanks for posting this.
It is an open-to-me question to what extent this (assuming it's as bad as you're saying), the effect of (1) boring selection effects; (2) power actually corrupting a lot; (3) people being bad and power revealing them to be so; (4) something sunk-costs-shaped.
(Regarding (2) and (3), I've come to be unsure whether they are meaningfully different.)
I am rather skeptical that (1) explains most of this. Surely, it plays a role, but, like, surely not all super-powerful are born with very strong tendencies to develop sociopathy or whatever. It's more plausible that those extremely powerful people who have reasons to repent their past use of extreme power are the ones who have prior psychological predispositions to use power in very bad ways. But still, IDK, it seems to me that ruling well can be extremely hard, so causing a lot of bad, while trying to do good[1] doesn't seem super difficult.
Regarding (4), for example, there's been a lot of repenting recently in the LW/EA sphere, but I can't think of anyone other than Habryka among the (past or current) leadership-ish positions who said out loud that "yep, we've done a lot of bad stuff; maybe it's net bad overall". It's probably just really hard/high-friction to face the truth that one's past actions have led to really, really nasty stuff, and being at the top of some social pyramid doesn't make it any easier. It seems plausible that humans derive values from fictitious imputed coherence, so "facing one's past sins", especially the ones that one incumbently counts as one's most meaningful decisions, runs against the natural grain of human value acquisition.
- ^
Let's hand-wavingly put aside the examples of trying to do good, such as the Crusades, or whatever the hell the Soviets were thinking when they stole food from peasants to starve them to death.
Are you requiring resignation as a criteria? You phrased it like you are. That doesn't seem necessary for repentance. I'd respect a ruler more if he resolved to personally make the situation better.
Separately:
I care a lot less about whether Xi Xinpeng repents for past deeds and a whole lot more whether he tortures me and mine or gives us opportunities for fulfilling lives and local freedoms.
How would a king or dictator come to "realize the error of their ways"? They do not think they are in error, or they would not be their ways. There have been kings and dictators throughout history. They have purposes that seem good to them and act accordingly (including, on occasion, assassinating their rivals). Why would any of them suddenly think their rule was unjustified? For that matter, why do you think that? The last time I read Curtis Yarvin (which was not recently) he was all in favour of kings, and admired Putin as the nearest thing to a real king that we have.
Maybe most of [Kim Jong Un's] subjects would still have an okay life under his rule in a post-scarcity AI world
"Still"? In the most repressive state in the world?
An intuition pump on anthropics.
In some recent conversations with friends, I was asked some questions of the type: “If most conscious beings on Earth are fish, why am I not a fish? If we expect gazillion digital minds to live in the future, why am I not a digital mind in the future? Isn't it very surprising that we seem to live close to the hinge of history?”
My position is that when you consider how surprised you should feel about something, you shouldn’t think of your current experience moment as being sampled from the set of all conscious experience moments. Instead, you should think of your current decision as being sampled from the set of all decisions, weighted by their importance.
I wrote up my more detailed thoughts on these questions in my recent sequence, but I wanted to give a shorter, evocative argument here.
—
Imagine a friend, Bob, knowingly undergoing an operation where a billion copies of him are created, all sharing his previous memories and personality. 999,999,999 copies will wake up as powerless farmers on isolated islands, not being able to affect anything in the outside world. One copy will wake up with the Sword of the Chosen One in his hand, and the fate of the world will depend on his actions.
You sit down with Bob before he undergoes the operation. You both agree that the actions of the farmer-copies are not very important, so you focus on making plans for the Chosen One, plans that the version of him waking up with a Sword in his hand should execute without delay.
You are watching the operation from the outside, not being able to interact with Bob anymore. The operation goes exactly as planned. The billion copies all wake up.
Now imagine the one copy with the Sword waking up and instead of following the agreed-upon plan, wallowing in doubt. “Why am I the Chosen One and not a farmer?” he asks. He looks for explanations for this strange coincidence. He is thinking through hare-brained possibilities where the operation didn’t go as planned, so fewer farmers were created, which would make it less surprising that he is not a farmer.
“You fool!” you would want to yell at Bob. “We had a plan. The operation went as expected. Looking from the outside, it’s still as obvious as ever what the Chosen One needs to do. You gained no new information compared to me looking from the outside. What are you thinking about then? Don’t waste your time; do your duty.”
—
I believe we are in a very similar situation to Bob. I believe there is no explanation to the question why you were not born a fish or a digital mind in the future, just like there is no explanation why Bob With the Sword did not wake up as a farmer. It was always knowable that some beings will make important decisions, living on the hinge of history, while others beings will be, well, fish. It is, by definition, more important that the more important decisions get made well. So from an impartial perspective, you should think as if your current decision was sampled from all decisions weighted by importance.
Generally, if you find yourself in a position that should be very rare according to your world model, that's a good moment to feel surprise, re-examine your world model and look for an explanation. But finding yourself in a position of unusually high influence is a special case that requires no explanation - it is not surprising if you imagine your decision being sampled weighted by importance.
It looks like you are one of the rare beings (not a fish, and not a digital mind in the stable future) who has a chance of making a noticeable difference to the fate of the world. Don’t waste your time; do your duty.
It is said that a certain prince, after observing that other less-fortunate circumstances were much more likely than his own, went on to become the Buddha — a position even less likely than his original one.
you should think of your current decision as being sampled from the set of all decisions, weighted by their importance.
I don't understand why you believe this and I don't see how the rest of your post supports this position or even how it might illustrate that this position makes sense.
The thing I'm trying to explain is when and when not you should act surprised and re-evaluate your world-model. If Bob thinks of himself as being sampled from conscious continuations, he will waste time acting surprised if he wakes up with the Sword. I claim it's better to calibrate your surprisal to as if you were being sampled weighted by importance - then, he won't waste crucial time if he wakes up with the Sword. This is a pretty basic case of optimizing for expected values, but people often don't think of surprisal in these terms, and they get confused about whether they should be surprised they are not a fish, and sometimes they even draw wrong conclusions like "fish must not be conscious, otherwise it would be overwhelmingly likely I am a fish". I'm trying to illustrate why you shouldn't act surprised that you are important.
I added "when you think about how surprised you should feel about something" to the sentence, which hopefully makes it clearer.
I am uncompelled.
It sounds like you're arguing "you want to make good decisions, therefore you act as if observer moments are sampled according to importance, because otherwise you'll...waste time thinking about how weird it is that you're in an important moment making important decisions"??
If the problem is that you're going to "waste time" being surprised, just don't do that. Be surprised, and do your duty anyway.
More critically, it seems like if you're in an important moment making important decisions then it's especially critical that you have an accurate understanding of your situation. That you're going to "waste time" thinking about how weird your situation is seems dramatically less relevant to whether you'll make good decisions than, for instance, whether the fish are moral patients or not.
Why are we privileging "wasting time" as the main way that you'll make worse decisions?
Here is a decision rule: I think I'm sampled from some distribution. If I notice that I'm in the top 0.000001% in that distribution in terms of some easy-to-describe, noteworthy quality, then I halt and spend a lot of time investigating my world model to see if something is off.
I think this is generally a very reasonable rule for many types of qualities. It will result in 0.000001% of people wasting some time, but it will probably result in more people correcting their mistaken world model.
I think many people share this intuition, but use the rule for the wrong distribution and get surprising results. They use it for being sampled from distributions like "all sentient beings", and then they notice that they are in the top 0.000001% in various important qualities (because they are not fish or future digital minds), and they get confused.
I claim that if you want to optimize the world, then "halt and investigate if you think you are in the top 0.000001%" and similar heuristics should be used for the importance-weighted distribution, and not the distribution of all sentient beings. So if my world model tells me that I'm the most handsome man on Earth, while also having the prettiest voice (something that should be less than 0.000001% common in the importance-weighted distribution too), then I should halt and investigate my world model. But I should not be surprised to have qualities that are common in the importance-weighted distribution, e.g. not being a fish or plausibly being close to an unprecedented technological transformation.
Yes, the probability of a Bob waking up and being a Chosen One is 100% in this scenario. It will happen.
That instance of Bob can be surprised that it happened to him in particular, but he could also predict in advance that whichever instance of him became the Chosen One would be surprised that it happened to him in particular, so it shouldn't be very surprising.
More generally everything in the world that actually happens is incredibly unlikely if you look at the details. Your observations prune the potential timeline of your experiences down by orders of magnitude per minute even when everything is perfectly mundane. Being merely one-in-a-billion by happenstance is terribly unsurprising unless you are specifically looking for that event.
Some of the surprises are incredibly irrelevant to any future decisions you may make, a very few are more relevant.
Thanks for clarifying.
I agree that you don't get much value by "pondering your surprisal" in this way, but I still don't see what value one gains from adopting the view that [one's decision point has been sampled from the set of all decision points in the timeline weighted by importance] (or something like that?), relative to the baseline of [trying to do the all-things-considered-best you can from your standpoint]. (Also, it seems false?)
I don't know, maybe I phrased things wrongly. I'm in favor trying to do the all-things-condidered-best I can, and optimizing for expected values. And of course, you shouldn't do things lime imagining you are sampled by importance-weighting, and then calcilate expected values: that would be double-updating.
All I am trying to say is that this is a useful perspeczive to take when deciding what should make you surprised and make you reevaluate your world model.
Maybe you should be surprised that you are not a fish but perhaps you would not continue being surprised you remain a person?
More generally you should be surprised when a phenomenon is special but then after a series of tests you should be able to quickly make the probability the phenomenon is not special smaller than the probability the phenomenon is special and be able to make a conclusion. It is actually difficult to think of a case where a series of tests or other perhaps observational evidence wouldn't be necessary to convince one of an extraordinary claim. We do often say extraordinary claims require extraordinary evidence, but that evidence is the thing that makes the extraordinary claim being false even more extraordinary than the claim being true. So we don't get stuck in inaction on extraordinary or unexpected things we just need to test them until rejecting them becomes even more extraordinary than accepting.
It does make me wonder if a charlatan would have anything to gain by planting fake "chosen one" swords... (Well step 34b subsection II of The Official Plan states if we find the sword on sale after incarnating we should pay up to 300,000 credits for it...)
suppose you flip a coin; if it comes up heads, Bob becomes a normal dude who plays a hyper realistic VR video game where he thinks he's the Chosen One but nothing he does matters; in this world he appears to be the Chosen One because nobody wants to play a game where they are the farmer. if it comes up tails, he is given the operation and only one of his 1 billion copies is actually the Chosen One (and say his memory is erased, so he doesn't know whether he's in the game or not). then, if Bob looks around and sees he is the Chosen One, it is almost certainly the case he is in the video game.
I think this will come down to how you define probability/anthropics. I care about making good decisions, so the notion of probability/anthropics you are implicitly using doesn't seem very useful to me.
Yes, I agree with Ryan here. If you want to make good decisions to improve the world in an impartial way, then in your thought experiment, you should act like the operation happened and you were the real Chosen One.
If you want to be selfish in an indexical way, then things get confusing, but I think selfishness with indexical preferences is not a very coherent and reasonable concept.
i agree the video game example is not that important for good decision making, and you should probably ignore simulation argument irl. the actual decision relevant q is p(deluded). it's plausible that a bunch of deluded people acting as if they are the Chosen One is actually very harmful, and p(deluded) >> p(chosen).
Would you also think that the credence for "in the video game" was incredibly high if a billion (possibly simulated but still conscious) Bobs were temporarily created to be farmers in the VR game for 1 day (and then erased)?
That would make the epistemic situation completely symmetric with respect to coin flips during the first day. If a Bob observes that he is a Chosen One, then he knows that there are a billion other Bobs that experience being farmers in both cases. I think we would both agree that his credence for this being real during the first day should be 50%.
The next day, he observes that he is still the Chosen One - but as I see it, he has gained no new information from this. The Chosen One does not die in either flip outcome, and he already knew that he was the Chosen One. He should still hold the credence of this being real at 50%. However, the epistemic situation is now exactly the same as the previous scenario. There is 1 VR Bob in the heads case (with no farmer Bobs), and 1 real Chosen Bob with a billion farmer Bobs in the tails case.
Should he suddenly believe that this is actually a VR game on day 2?
If not, why does the existence of temporary Bobs (which could last for a microsecond rather than a day if you like) change the answer?
If so, why should the hypothesized but unobserved death/cessation of beings who aren't him change his mind about the outcome of the coin flip?