At the outermost feedback loop, capabilities can ultimately be grounded via relatively easy objective measures such as revenue from AI, or later, global chip and electricity production, but alignment can only be evaluated via potentially faulty human judgement. Also, as mentioned in the post, the capabilities trajectory is much harder to permanently derail because unlike alignment, one can always recover from failure and try again. I think this means there's an irreducible logical risk (i.e., the possibility that this statement is true as a matter of fact about logic/math) that capabilities research is just inherently easier to automate than alignment research, that no amount of "work hard to automated alignment research" can lower beyond. Given the lack of established consensus ways of estimating and dealing with such risk, it's inevitable that the people with the least estimate/concern about this risk (and other AI risks) will push capabilities forward as fast as they can, and seemingly the only way to solve this on the societal level is to push for norms/laws against doing that, i.e., slow down capabilities research via (politically legitimate) force and/or social pressure. I suspect the author might already agree with all this (the existence of this logical risk, the social dynamics, the conclusion about norms/laws being needed to reduce AI risk beyond some threshold), but I think it should be emphasized more in a post like this.
I suspect the author might already agree with all this (the existence of this logical risk, the social dynamics, the conclusion about norms/laws being needed to reduce AI risk beyond some threshold)...
Yes I think I basically agree. That is, I think it's very possible that capabilities research is inherently easier to automate than alignment research; I am very worried about the least cautious actors pushing forward prematurely; as I tried to emphasize in the post, I think capability restraint is extremely important (and: important even if we can successfully automate alignment research); and I think that norms/laws are likely to play an important role there.
I think you are importantly missing something about how load-bearing "conceptual" progress is in normal science.
An example I ran into just last week: I wanted to know how long it takes various small molecule neurotransmitters to be reabsorbed after their release. And I found some very different numbers:
- Some sources offhandedly claimed ~1ms. AFAICT, this number comes from measuring the time taken for the neurotransmitter to clear from the synaptic cleft, and then assuming that the neurotransmitter clears mainly via reabsorption (an assumption which I emphasize because IIUC it's wrong; I think the ~1ms number is actually measuring time for the neurotransmitter to diffuse out of the cleft).
- Other sources claimed ~10ms. These were based on <other methods>.
Now, I want to imagine for a moment a character named Emma the Empirical Fundamentalist, someone who eschews "conceptual" work entirely and only updates on Empirically Testable Questions. (For current purposes, mathematical provability can also be lumped in with empirical testability.) How would Emma respond to the two mutually-contradictory neurotransmitter reabsorption numbers above?
Well, first and foremost, Emma would not think "one of these isn't measuring what the authors think they're measuring". That is a quintessential "conceptual" thought. Instead, Emma might suspect that one of the measurements was simply wrong, but repeating the two experiments will quickly rule out that hypothesis. She might also think to try many other measurement methods, and find that most of them agree with the ~10ms number, but the ~1ms measurement will still be a true repeatable phenomenon. Eventually she will likely settle on roughly "the real world is messy and complex, so sometimes measurements depend on context and method in surprising ways, and this is one of those times". (Indeed, that sort of thing is a very common refrain in tons of biological science.)
But in this case, the real explanation (I claim) is simply that one of the measurements was based on an incorrect assumption. I made the incorrect assumption obvious by highlighting it above, but in-the-wild the assumption would be implicit and unstated and nonobvious; it wouldn't even occur to the authors that they're making an assumption which could be wrong.
Discovering that sort of error is centrally in the wheelhouse of conceptual progress. And as this example illustrates, it's a very load-bearing piece of normal science.
(And indeed, I expect that at least some of your examples of normal-science-style empirical alignment research are cases where the authors are probably not measuring what they think they are measuring, though I don't know in advance which ones. Conceptual work is exactly what would be required to sort that out.)
(And to be clear, I don't think this example is the only or even most common "kind of way" in which conceptual work is load-bearing for normal science.)
Moving up the discussion stack: insofar as conceptual work is very load-bearing for normal science, how does that change the view articulated in the post? Well, first, it means that one cannot produce a good normal-science AI by primarily relying on empirical feedback (including mathematical feedback from proofs), unless one gets lucky and training on empirical feedback happens to also make the AI good at conceptual work. Second, there will be market pressure to make AI good at conceptual work, because that's a necessary component of normal science.
Note that conceptual research, as I'm understanding it, isn't defined by the cognitive skills involved in the research -- i.e., by whether the researchers need to have "conceptual thoughts" like "wait, is this measuring what I think it's measuring?". I agree that normal science involves a ton of conceptual thinking (and many "number-go-up" tasks do too). Rather, conceptual research as I'm understanding it is defined by the tools available for evaluating the research in question.[1] In particular, as I'm understanding it, cases where neither available empirical tests nor formal methods help much.
Thus, in your neurotransmitter example, it does indeed take some kind of "conceptual thinking" to come up with the thought "maybe it actually takes longer for neurotransmitters to get re-absorbed than it takes for them to clear from the cleft." But if some AI presented us with this claim, the question is whether we could evaluate it via some kind of empirical test, which it sounds like we plausibly could. Of course, we do still need to interpret the results of these tests -- e.g., to understand enough about what we're actually trying to measure to notice that e.g. one measurement is getting at it better than another. But we've got rich empirical feedback loops to dialogue with.
So if we interpret "conceptual work" as conceptual thinking, I do agree that "there will be market pressure to make AI good at conceptual work, because that's a necessary component of normal science." And this is closely related to the comforts I discuss in section 6.1. That is: a lot of alignment research seems pretty comparable to me to the sort of science at stake in e.g. biology, physics, computer science, etc, where I think human evaluation has a decent track record (or at least, a better track record than philosophy/futurism), and where I expect a decent amount of market pressure to resolve evaluation difficulties adequately. So (modulo scheming AIs differentially messing with us in some domains vs. others), at least by the time we're successfully automating these other forms of science, I think we should be reasonably optimistic about automating that kind of alignment research as well. But this still leaves the type of alignment research that looks more centrally like philosophy/futurism, where I think evaluation is additionally challenging, and where the human track record looks worse.
- ^
Thus, from section 6.2.3: "Conceptual research, as I’m understanding it, is defined by the methods available for evaluating it, rather than the cognitive skills involved in producing it. For example: Einstein on relativity was clearly a giant conceptual breakthrough. But because it was evaluable via a combination of empirical predictions and formal methods, it wouldn’t count as 'conceptual research' in my sense."
Rather, conceptual research as I'm understanding it is defined by the tools available for evaluating the research in question.[1] In particular, as I'm understanding it, cases where neither available empirical tests nor formal methods help much.
Agreed.
But if some AI presented us with this claim, the question is whether we could evaluate it via some kind of empirical test, which it sounds like we plausibly could.
Disagreed.
My guess is that you have, in the back of your mind here, ye olde "generation vs verification" discussion. And in particular, so long as we can empirically/mathematically verify some piece of conceptual progress once it's presented to us, we can incentivize the AI to produce interesting new pieces of verifiable conceptual progress.
That's an argument which works in the high capability regime, if we're willing to assume that any relevant progress is verifiable, since we can assume that the highly capable AI will in fact find whatever pieces of verifiable conceptual progress are available. Whether it works in the relatively-low capability regime of human-ish-level automated alignment research and realistic amounts of RL is... rather more dubious. Also, the mechanics of designing a suitable feedback signal would be nontrivial to get right in practice.
Getting more concrete: if we're imagining an LLM-like automated researcher, then a question I'd consider extremely important is: "Is this model/analysis/paper/etc missing key conceptual pieces?". If the system says "yes, here's something it's missing" then I can (usually) verify that. But if it says "nope, looks good"... then I can't verify that the paper is in fact not missing anything.
And in fact that's a problem I already do run into with LLMs sometimes: I'll present a model, and the thing will be all sycophantic and not mention that the model has some key conceptual confusion about something. Of course you might hope that some more-clever training objective will avoid that kind of sycophancy and instead incentivize Good Science, but that's definitely not an already-solved problem, and I sure do feel suspicious of an assumption that that problem will be easy.
I think that OP’s discussion of “number-go-up vs normal science vs conceptual research” is an unnecessary distraction, and he should have cut that part and just talked directly about the spectrum from “easy-to-verify progress” to “hard-to-verify progress”, which is what actually matters in context.
Partly copying from §1.4 here, you can (A) judge ideas via new external evidence, and/or (B) judge ideas via internal discernment of plausibility, elegance, self-consistency, consistency with already-existing knowledge and observations, etc. There’s a big range in people’s ability to apply (B) to figure things out. But what happens in “normal” sciences like biology is that there are people with a lot of (B), and they can figure out what’s going on, on the basis of hints and indirect evidence. Others don’t. The former group can gather ever-more-direct and ever-more-unassailable (A)-type evidence over time, and use that evidence as a cudgel with which to beat the latter group over the head until they finally get it. (“If you don’t believe my 7 independent lines of evidence for plate tectonics, OK fine I’ll go to the mid-Atlantic ridge and gather even more lines of evidence…”)
This is an important social tool, and explains why bad scientific ideas can die, while bad philosophy ideas live forever. And it’s even worse than that—if the bad philosophy ideas don’t die, then there’s no common knowledge that the bad philosophers are bad, and then they can rise in the ranks and hire other bad philosophers etc. Basically, to a first approximation, I think humans and human institutions are not really up to the task of making intellectual progress systematically over time, except where idiot-proof verification exists for that intellectual progress (for an appropriate definition of “idiot”, and with some other caveats).
…Anyway, AFAICT, OP is just claiming that AI alignment research involves both easy-to-verify progress and hard-to-verify progress, which seems uncontroversial.
That was an excellent summary of how things seem to normally work in the sciences, and explains it better than I would have. Kudos.
I'm happy to say that easy-to-verify vs. hard-to-verify is what ultimately matters, but I think it's important to be clear what about makes something easier vs. harder to verify, so that we can be clear about why alignment might or might not be harder than other domains. And imo empirical feedback loops and formal methods are amongst the most important factors there.
Perhaps a better summary of my discomfort here: suppose you train some AI to output verifiable conceptual insights. How can I verify that this AI is not missing lots of things all the time? In other words, how do I verify that the training worked as intended?
You might hope for elicitation efficiency, as in, you heavily RL the model to produce useful considerations and hope that your optimization is good enough that it covers everything well enough.
Or, two lower bars you might hope for:
- It brings up considerations that it "knows" about. (By "knows" I mean relatively deep knows, like it can manipulate and utilize the knowledge relatively strongly.)
- It isn't much worse than human researchers at bringing up important considerations.
In general, you might have elicitation problems and this domain seems only somewhat worse with respect to elicitation. (It's worse because the feedback is somewhat more expensive.)
You might hope for elicitation efficiency, as in, you heavily RL the model to produce useful considerations and hope that your optimization is good enough that it covers everything well enough.
"Hope" is indeed a good general-purpose term for plans which rely on an unverifiable assumption in order to work.
(Also I'd note that as of today, heavy RL tends to in fact produce pretty bad results, in exactly the ways one would expect in theory, and in particular in ways which one would expect to get worse rather than better as capabilities increase. RL is not something we can apply in more than small amounts before the system starts to game the reward signal.)
If we assume that the AI isn't scheming to actively withhold empirically/formally verifiable insights from us (I do think this would make life a lot harder), then it seems to me like this is reasonably similar to other domains in which we need to figure out how to elicit as-good-as-human-level suggestions from AIs that we can then evaluate well. E.g., it's not clear to me why this would be all that different from "suggest a new transformer-like architecture that we can then verify improves training efficiency a lot on some metric."
Or put another way: at least in the context of non-schemers, the thing I'm looking for isn't just "here's a way things could be hard." I'm specifically looking for ways things will be harder than in the context of capabilities (or, to a lesser extent, in other scientific domains where I expect a lot of economic incentives to figure out how to automate top-human-level work). And in that context, generic pessimism about e.g. heavy RL doesn't seem like it's enough.
That I roughly agree with. As in the comment at top of this chain: "there will be market pressure to make AI good at conceptual work, because that's a necessary component of normal science". Likewise, insofar as e.g. heavy RL doesn't make the AI effective at conceptual work, I expect it to also not make the AI all that effective at normal science.
That does still leave a big question mark regarding what methods will eventually make AIs good at such work. Insofar as very different methods are required, we should also expect other surprises along the way, and expect the AIs involved to look generally different from e.g. LLMs, which means that many other parts of our mental pictures are also likely to fail to generalize.
I think it's a fair point that if it turns out that current ML methods are broadly inadequate for automating basically any sophisticated cognitive work (including capabilities research, biology research, etc -- though I'm not clear on your take on whether capabilities research counts as "science" in the sense you have in mind), it may be that whatever new paradigm ends up successful messes with various implicit and explicit assumptions in analyses like the one in the essay.
That said, I think if we're ignorant about what paradigm will succeed re: automating sophisticated cognitive work and we don't have any story about why alignment research would be harder, it seems like the baseline expectation (modulo scheming) would be that automating alignment is comparably hard (in expectation) to automating these other domains. (I do think, though, that we have reason to expect alignment to be harder even conditional on needing other paradigms, because I think it's reasonable to expect some of the evaluation challenges I discuss in the post to generalize to other regimes.)
we don’t tend to imagine humans directly building superintelligence
Speak for yourself! Humans directly built AlphaZero, which is a superintelligence for board game worlds. So I don’t think it’s out of the question that humans could directly build a superintelligence for the real world. I think that’s my main guess, actually?
(Obviously, the humans would be “directly” building a learning algorithm etc., and then the trained weights come out of that.)
(OK sure, the humans will use AI coding assistants. But I think AI coding assistants, at least of the sort that exist today, aren’t fundamentally changing the picture, but rather belong in the same category as IDEs and PyTorch and other such mundane productivity-enhancers.)
(You said “don’t tend to”, which is valid. My model here [AI paradigm shift → superintelligence very quickly and with little compute] does seem pretty unusual with respect to today’s alignment community zeitgeist.)
Fair point, and plausible that I'm too much taking for granted a certain subset of development pathways. That is: I'm focused in the essay on threat models that proceed via the automation of capabilities R&D, but it's possible that this isn't necessary.
However: I expect that AIs capable of causing a loss of control scenario, at least, would also be capable of top-human-level alignment research.
Hmm. A million fast-thinking Stalin-level AGIs would probably have a better shot of taking control than doing alignment research, I think?
Also, if there’s an alignment tax (or control tax), then that impacts the comparison, since the AIs doing alignment research are paying that tax whereas the AIs attempting takeover are not. (I think people have wildly different intuitions about how steep the alignment tax will be, so this might or might not be important. E.g. imagine a scenario where FOOM is possible but too dangerous for humans to allow. If so, that would be an astronomical alignment tax!)
Sure, maybe there's a band of capability where you can take over but you can't do top-human-level alignment research (and where your takeover plan doesn't involve further capabilities development that requires alignment). It's not the central case I'm focused on, though.
Also, if there’s an alignment tax (or control tax), then that impacts the comparison, since the AIs doing alignment research are paying that tax whereas the AIs attempting takeover are not.
Is the thought here that the AIs trying to takeover aren't improving their capabilities in a way that requires paying an alignment tax? E.g. if the tax refers to a comparison between (a) rushing forward on capabilities in a way that screws you on alignment vs. (b) pushing forward on capabilities in a way that preserves alignment, AIs that are fooming will want to do (b) as well (though they may have an easier time of it for other reasons). But if it refers to e.g. "humans will place handicaps on AIs that they need to ensure are aligned, including AIs they're trying to use for alignment research, whereas rogue AIs that have also freed themselves human control will also be able to get rid of these handicaps," then yes, that's an advantage the rogue AIs will have (though note that they'll still need to self-filtrate etc).
You could think, for example, that almost all of the core challenge of aligning a superintelligence is contained in the challenge of safely automating top-human-level alignment research. I’m skeptical, though. In particular: I expect superintelligent-level capabilities to create a bunch of distinctive challenges.
I’m curious if you could name some examples, from your perspective?
I’m just curious. I don’t think this is too cruxy—I think the cruxy-er part is how hard it is to safely automate top-human-level alignment research, not whether there are further difficulties after that.
…Well, actually, I’m not so sure. I feel like I’m confused about what “safely automating top-human-level alignment research” actually means. You say that it’s less than “handoff”. But if humans are still a required part of the ongoing process, then it’s not really “automation”, right? And likewise, if humans are a required part of the process, then an alignment MVP is insufficient for the ability to turn tons of compute into tons of alignment research really fast, which you seem to need for your argument.
You also talk elsewhere about “performing more limited tasks aimed at shorter-term targets”, which seems to directly contradict “performs all the cognitive tasks involved in alignment research at or above the level of top human experts”, since one such cognitive task is “making sure that all the pieces are coming together into a coherent viable plan”. Right?
Honestly I’m mildly concerned that an unintentional shell game might be going on regarding which alignment work is happening before vs. after the alignment MVP.
Relatedly, this sentence seems like an important crux where I disagree: “I am cautiously optimistic that for building an alignment MVP, major conceptual advances that can’t be evaluated via their empirical predictions are not required.” But again, that might be that I’m envisioning a more capable alignment MVP than you are.
Re: examples of why superintelligences create distinctive challenges: superintelligences seem more likely to be schemers, more likely to be able to systematically and successfully mess with the evidence provided by behavioral tests and transparency tools, harder to exert option-control over, better able to identify and pursue strategies humans hadn't thought of, harder to supervise using human labor, etc.
If you're worried about shell games, it's OK to round off "alignment MVP" to hand-off-ready AI, and to assume that the AIs in question need to be able to pursue make and pursue coherent long-term plans.[1] I don't think the analysis in the essay alters that much (for example, I think very little rests on the idea that you can get by with myopic AIs), and better to err on the side of conservatism.
I wanted to set aside "hand-off" here because in principle, you don't actually need to hand-off until humans stop being able to meaningfully contribute to the safety/quality of the automated alignment work, which doesn't necessarily need to start around the time we have AIs capable of top-human-level alignment work (e.g., human evaluation of the research, or involvement in other aspects of control -- e.g., providing certain kinds of expensive, trusted supervision -- could persist after that). And when exactly you hand-off depends on a bunch of more detailed, practical trade-offs.
As I said in the post, one way that humans still being involved might not bottleneck the process is if they're only reviewing the work to figure out whether there's a problem they need to actively intervene on.
even if human labor is still playing a role in ensuring safety, it doesn’t necessarily need to directly bottleneck the research process – or at least, not if things are going well. For example: in principle, you could allow a fully-automated alignment research process to proceed forward, with humans evaluating the work as it gets produced, but only actively intervening if they identify problems.
And I think you can still likely radically speed up and scale up your alignment research even e.g. you still care about humans reviewing and understanding the work in question.
- ^
Though for what it's worth I don't think that the task of assessing "is this a good long-term plan for achieving X" needs itself to involve long-term optimization for X. For example: you could do that task over five minutes in exchange for a piece of candy.
generating evidence of danger
Has this worked so far? How many cases can we point to where a person who was publicly skeptical of AI danger changed their public stance, as a result of seeing experimental evidence?
What's the theory of change for "generating evidence of danger"? The people who are most grim about AI would probably tell you that there is already plenty of evidence. How will adding more evidence to the pile help? Who will learn about this new evidence, and how will it cause them to behave differently?
Here's a theory of change I came up with. (You might wish to spend some time brainstorming your own theory of change before reading my idea, in case you're able to independently generate something different and better.)
-
Phil Tetlock found: "Many experts claimed that they assigned higher probabilities to outcomes that materialised than they did. As Tetlock notes, it is hard to say someone got it wrong if they think they got it right." Based on this result, it seems plausible that whatever experimental evidence comes in, various AI experts who appear to disagree with one another will all claim that the experiment evidence bolsters their position, and shows that they were right all along.
-
To address this issue, I would suggest an adversarial collaboration structure. Get two experts with different views -- Eliezer Yudkowsky and Yann Lecun, say -- to identify a concrete experiment such that they predict different results. Design the experiment so the outcome is relatively unambiguous. Have the experiment be implemented and performed by an ecumenical team. Place a public bet on the outcome of the experiment, and have the loser agree in advance to concede the bet publicly. I think this has a genuine shot at changing the public conversation in a way that the current slow drip of evidence has not.
-
It seems somewhat urgent to set up this adversarial collaboration structure. Every experimental result which comes in without advance expert pre-registration is another chance for experts to come up with rationalizations for why the new evidence doesn't show that they were wrong.
Relatedly, highly recommended Book Review: How Minds Change .
Thanks for writing this! Leaving some comments with reactions as I was reading, not all very confident, and sorry if I missed or misunderstood things you wrote.
Problems with these evaluation techniques can arise in attempting to automate all sorts of domains (I’m particularly interested in comparisons with (a) capabilities research, and (b) other STEM fields). And I think this should be a source of comfort. In particular: these sorts of problems can slow down the automation of capabilities research, too. And to the extent they’re a bottleneck on all sorts of economically valuable automation, we should expect lots of effort to go towards resolving them. … [then more discussion in §6.1]
This feels wrong to me. I feel like “the human must evaluate the output, and doing so is hard” is more of an edge case, applicable to things like “designs for a bridge”, where failure is far away and catastrophic. (And applicable to alignment research, of course.)
Like you mention today’s “reward-hacking” (e.g. o3 deleting unit tests instead of fixing the code) as evidence that evaluation is necessary. But that’s a bad example because the reward-hacked code doesn’t actually work! And people notice that it doesn’t work. If the code worked flawlessly, then people wouldn’t be talking about reward-hacking as if it’s a bad thing. People notice eventually, and that constitutes an evaluation. Likewise, if you hire a lousy head of marketing, then you’ll eventually notice the lack of new customers; if you hire a lousy CTO, then you’ll eventually notice that your website doesn’t work; etc.
OK, you anticipate this reply and then respond with: “…And even if these tasks can be evaluated via more quantitative metrics in the longer-term (e.g., “did this business strategy make money?”), trying to train on these very long-horizon reward signals poses a number of distinctive challenges (e.g., it can take a lot of serial time, long-horizon data points can be scarce, etc).”
But I don’t buy that because, like, humans went to the moon. That was a long-horizon task but humans did not need to train on it, rather they did it with the same brains we’ve been using for millennia. It did require long-horizon goals. But (1) If AI is unable to pursue long-horizon goals, then I don’t think it’s adequate to be an alignment MVP (you address this in §9.1 & here, but I’m more pessimistic, see here & here), (2) If the AI is able to pursue long-horizon goals, then the goal of “the human eventually approves / presses the reward button” is an obvious and easily-trainable approach that will be adequate for capabilities, science, and unprecedented profits (but not alignment), right up until catastrophe. (Bit more discussion here.)
((1) might be related to my other comment, maybe I’m envisioning a more competent “alignment MVP” than you?)
I'm a bit confused about your overall picture here. Sounds like you're thinking something like:
"almost everything in the world is evaluable via waiting for it to fail and then noticing this. Alignment and bridge-building aren't like this, but most other things are... Also, the way we're going to automate long-horizon tasks is via giving AIs long-term goals. In particular: we'll give them goal 'get long-term human approval/reward', which will lead to good-looking stuff until the AIs take over in order to get more reward. This will work for tons of stuff but not for alignment, because you can't give negative reward for the alignment failure we ultimately care about, which is the AIs taking over."
Is that roughly right?
“almost everything in the world is solvable via (1) Human A wants it solved, (2) Agent B is motivated by the prospect of Human A pressing the reward button on Agent B if things turn out well, (3) Human A is somewhat careful not to press the button until they’re quite sure that things have indeed turned out well, (4) Agent B is able to make and execute long-term plans”.
In particular, every aspect of automating the economy is solvable that way—for example (I was just writing this in a different thread), suppose I have a reward button, and tell an AI:
Hello AI. Here is a bank account with $100K of seed capital. Go make money. I’ll press the reward button if I can successfully withdraw $1B from that same bank account in the future. (But I’ll wait 1 year between withdrawing the funds and pressing the reward button, during which I’ll perform due diligence to check for law-breaking or any other funny business. And the definition of ‘funny business’ will be at my sole discretion, so you should check with me in advance if you’re unsure where I will draw the line.) Good luck!
And let’s assume the AI is purely motivated by the reward button, but not yet capable of brainwashing me or stealing my button. (I guess that’s rather implausible if it can already autonomously make $1B, but maybe we’re good at Option Control, or else substitute a less ambitious project like making a successful app or whatever.) And assume that I have no particular skill at “good evaluation” of AI outputs. I only know enough to hire competent lawyers and accountants for pretty basic due diligence, and it helps that I’m allowing an extra year for law enforcement or public outcry or whatever to surface any subtle or sneaky problems caused by my AI.
So that’s a way to automate the economy and make trillions of dollars (until catastrophic takeover) without making any progress on the “need for good evaluation” problem of §6.1. Right?
And I don’t buy your counterargument that the AI will fail at the “make $1B” project above (“trying to train on these very long-horizon reward signals poses a number of distinctive challenges…”) because e.g. that same argument would also “prove” that no human could possibly decide that they want to make $1B, and succeed. I think you’re thinking about RL too narrowly—but we can talk about that separately.
Can you spell out more how "Automated empirical research on process-focused evaluation methods" helps us to automate conceptual alignment research?
I get that we could get much better at understanding model psychology and how model's generalise.
But why does that mean we can now automate conceptual work like "is this untestable idea a good contribution to alignment"?
Behavioral science of generalization. The first is just: studying AI behavior in depth, and using this to strengthen our understanding of how AIs will generalize to domains that our scalable oversight techniques struggle to evaluate directly.
- Work in the vicinity of “weak to strong” generalization is a paradigm example here. Thus, for example: if you can evaluate physics problems of difficulty level 1 and 2, but not difficulty level 3, then you can train an AI on level 1 problems, and see if it generalizes well to level 2 problems, as a way of getting evidence about whether it would generalize well to level 3 problems as well.
- (This doesn’t work on schemers, or on other AIs systematically and successfully manipulating your evidence about how they’ll generalize, but see discussion of anti-scheming measures below.)
I don't think this just fails with schemers. A key problem is that it's hard to distinguish whether you're measuring "this alignment approach is good" or "this alignment approach looks good to humans". If it's the latter, it looks great on level 1 and 2 but then the approach for 3 doesn't actually work. I unfortunately expect that if we train AIs to evaluate what is good alignment research, they will more likely learn the latter. (This problem seems related to ELK.)
Re: "number go up" research tasks that seem automatable -- one idea I had is to use an LLM to process the entire LW archive, and identify alignment research ideas which could be done using the "number go up" approach (or seem otherwise amenable to automation).
"Proactive unlearning", in particular, strikes me as a quite promising research direction which could be automated. Especially if it is possible to "proactively unlearn" scheming. Gradient routing would be an example of the sort of approach I have in mind.
To elaborate: I think it is ideal to have an automated way to prevent an AI from acquiring undesirable capacities and knowledge in the first place. If your scheming metrics are sufficiently good, and you can keep them running for the entire training run, you might be able to nip scheming in the bud, so that any tendency towards scheming (which might subsequently corrupt the metrics to hide itself if it goes unaddressed) ends up showing up in the metrics before it's given space to flower.
What then? One option is to never build superintelligence. But there’s also another option, namely: trying to get access to enhanced human labor, via the sorts of techniques I discussed in my post on waystations (e.g., whole brain emulation). In particular: unlike creating an alignment MVP, which plausibly requires at least some success in learning how to give AIs human-like values, available techniques for enhancing human labor might give you human-like values by default, while still resulting in better-than-human alignment research capabilities. Call this an “enhanced human labor” path.[12]
[12]: Though: note that if you thought that even an alignment MVP couldn’t solve the alignment problem, you need some story about why your enhanced human labor would do better.
something that is imo important but discordant with the analysis you give here:
* humans/humanity could also just continue becoming more intelligent/capable (i mean: in some careful, self-conscious, deliberate fashion; so not like: spawning a random alien AI that outfooms humans; of course, what this means is unclear — it would imo need to be figured out ever-better as we proceed), like maybe forever
By "never build superintelligence" I was assuming we were talking about superintelligent AI, so if the humans in question never build superintelligent AI I'd count this path under that bucket. But as I discussed in my first post in the series, you can indeed get access to the benefits of superintelligence without building superintelligent AI in particular.
oki! in this scenario, i guess i'm imagining humans/humanity becoming ever-more-artificial (like, ever-more-[human/mind]-made) and ever-more-intelligent (like, eventually much more capable than anything that might be created by 2100), so this still seems like a somewhat unnatural framing to me
(This is the fifth essay in a series that I’m calling “How do we solve the alignment problem?”. I’m hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, and for a bit more about the series as a whole.
Podcast version (read by the author) here, or search for "Joe Carlsmith Audio" on your podcast app.
See also here for video and transcript of a talk on this topic that I gave at Anthropic in April 2025. And see here for slides.)
1. Introduction
In my last essay, I argued that we should try extremely hard to use AI labor to improve our civilization’s capacity to handle the alignment problem – a project I called “AI for AI safety.” In this essay, I want to look in more detail at an application of “AI for AI safety” that I view as especially important: namely, automating alignment research. In particular: I want to try to get clearer about the different ways that automating alignment research can fail, and what we can do about them.
I’m especially interested in ways that problems evaluating alignment research might pose a barrier to automating it. Here, one of my key points is that some types of alignment research are easier to evaluate than others. In particular, in my opinion, we should be especially optimistic about automating alignment research that we can evaluate via some combination of (a) empirical feedback loops and (b) formal methods. And if we can succeed in this respect, we can do a huge amount of that type of alignment research to help us safely automate the rest (what I call “conceptual alignment research”).
Overall: I think we have a real shot at safely automating alignment research. But:
Failure on any of these fronts seems unfortunately plausible. But I think there’s a lot we can do to improve the odds.
1.1 Executive summary
Here’s a more detailed summary of the essay.
I start with some comments on why automating alignment research is so important. Basically: figuring out how to build superintelligence safely is plausibly a huge amount of difficult work. Especially in the context of short timelines and fast take-offs, we might need that work to get done very fast. Humans, though, are slow, and scarce, and (relative to advanced AIs) dumb.
I focus on safely automating alignment research at or above the level of top human experts. Following Leike (2022), I call this an “alignment MVP.” If you can get to this milestone, then you can do at least as well as you would’ve done using only human labor, but much faster.
I survey an array of possible ways that an “alignment MVP” path might fail (see taxonomy in the diagram below). And I focus, first, on evaluation problems that might arise in the context of AIs that aren’t actively adversarial towards humans (that is, roughly, AIs that aren’t “scheming,” even if they have other problems).
To bring available approaches to evaluating alignment research into clearer view, I distinguish between two broad focal points of an evaluation process – namely, a type of output (e.g., a piece of research), and the process that produced this output (e.g., an AI, a process for creating that AI, etc).
Most real-world evaluation processes mix both together, and we should expect this to be true for evaluating automated alignment research as well.
Problems with these evaluation techniques can arise in attempting to automate all sorts of domains (I’m particularly interested in comparisons with (a) capabilities research, and (b) other STEM fields). And I think this should be a source of comfort. In particular: these sorts of problems can slow down the automation of capabilities research, too. And to the extent they’re a bottleneck on all sorts of economically valuable automation, we should expect lots of effort to go towards resolving them.
However, I also think there are limits to this comfort. For one thing: evaluation problems in these other domains might be lower stakes. And beyond that: it’s possible that broad STEM automation (as opposed to: just automated capabilities research) comes too late into an intelligence explosion – i.e., you’ve lost too much of the time you needed for alignment research, and/or you’re now at much higher risk of scheming.
But also: alignment research (or at least: some forms of alignment research) might be especially difficult to evaluate even relative to these other domains. To illustrate my key concern here, I distinguish between three broad sorts of domains.
Lots of alignment research (what I call “empirical alignment research”) looks like normal science to me. And because I think humanity has a pretty good track record of evaluating normal science, I think we should be correspondingly optimistic about evaluating this type of alignment research, too. (Though: it’s still harder than evaluating number-go-up tasks.)
But some parts of alignment research look more like conceptual research. And I think we should be trying to automate this kind of alignment research, too. But I think evaluation difficulties might well bite harder, because “humans think about it” is a comparatively underpowered mode of evaluation.
However: I also think that successful automation of empirical alignment research can help a ton with automating the rest of alignment research. In particular: we can use automated empirical alignment researchers to do a huge amount of work testing and improving the output-focused and process-focused evaluation approaches I discussed above – e.g., scalable oversight, behavioral science of generalization, transparency, detecting/preventing scheming, etc. And automated empirical alignment research is extremely helpful in other ways as well (e.g., helping with further automation of empirical alignment research, testing/improving local forms of option control, generating evidence of danger, etc).
With this discussion of evaluation problems in view, I then re-introduce the possibility of scheming into the picture. This alters the analysis in a few key ways, namely:
How might we automate alignment research despite the possibility of scheming? I discuss three broad options:
Beyond evaluation failures and scheming, I also discuss some more practical, resource-related failure modes for successfully automating alignment research, namely: data-scarcity, schlep, not having enough time to do enough work even with an alignment MVP, and not investing enough resources (compute, money, staff) into that work. I think these more practical failure modes are extremely serious, and I don’t have fancy responses. Basically: we need to actually put in the necessary work, and to make the necessary time. And in this respect, capability restraint remains extremely important.
I close with a brief discussion of some alternatives to automating alignment research, namely:
I’m planning to discuss some of these in more depth later in the series. To me, though, it seems unwise to bank on any of them. So despite the many ways that automating alignment research could fail, I think we should be trying extremely hard to make it work.
(The essay also includes a number of appendices, namely:
2. Why is automating alignment research so important?
Why is automating alignment research so important? Basically, as I said: because figuring out how to build superintelligence safely might be a ton of work; and we might need to do that work fast.
In particular: recall the two feedback loops from my last essay:
The scariest AI scenarios, in my opinion, involve the AI capability feedback loop kicking off hard. That is: it becomes possible to massively accelerate AI capabilities development using large amounts of fast, high-quality AI labor. But if the labor involved in making increasingly capable AI systems safe remains bottlenecked on slow, scarce humans, then (unless we only need small amounts of this labor) this looks, to me, like a recipe for disaster.[1] In particular: modulo significant capability restraint, it looks like the slow, scarce humans won’t have enough time.
Of course: this dynamic makes capability restraint extremely important, too. But I am worried about the difficulty of achieving large amounts of capability restraint (e.g., sustained global pauses). And for smaller budgets of capability restraint, whether or not we can safely automate alignment research seems to me central to our overall prospects.
3. Alignment MVPs
Even beyond the need to keep up with a capabilities explosion, though, I think there’s also a different sense in which automated alignment research is a very natural “waystation” for efforts to solve the alignment problem to focus on. In particular: safely automating alignment research seems both easier than solving the full alignment problem, and extremely helpful for solving the full alignment problem.[2]
In more detail: consider the task of using only human labor to figure out how to build an aligned superintelligence. Call this the “humans-only path.”[3]
In the past, when I thought about how hard the alignment problem is, I often thought about how hard the humans-only path is. I now think that this was the wrong question.[4]
In particular: consider, instead, a path that involves first unlocking AI labor that safely performs all the cognitive tasks involved in alignment research at or above the level of top human experts. Such labor is a version of what Leike (2022) calls a “minimum viable product” (“MVP”) for alignment, so let’s call this the “alignment MVP path.”[5]
I think that the alignment MVP path is the better one to focus on. Why? Well: note, first, that if the direct path was viable, then the alignment MVP path is, too. This is because: building an alignment MVP is at least no harder than building an aligned superintelligence.[6] So if humans can figure out how to build the latter, they can figure out how to build the former, too. And if humans can figure out how to build an aligned superintelligence, then they can do so with the help of alignment MVPs, too.[7]
It could be, though, that of these two paths, only the alignment MVP path is viable. That is: maybe humans can’t figure out how to build an aligned superintelligence directly, but they (and available pre-alignment-MVP AIs) can figure out how to build an alignment MVP – and then some combination of humans + alignment MVPs + other available AIs (including more advanced AIs that alignment MVPs help with building) can get the rest of the way.[8]
What’s more: even if both paths are viable, it looks likely to me that the alignment MVP path is faster and more likely to succeed with a given budget of resources (time, compute, human labor, etc). In particular: to me, building an alignment MVP seems actively much easier than building an aligned superintelligence (though: it’s possible to dispute this).[9] And success in this respect (assuming that the direct path is also viable) means that the rest of the journey would likely benefit much faster and more scalable top-human-level research.[10]
Note, too, that in the context of capabilities development, we often take something like an “MVP” path for granted. That is: we don’t tend to imagine humans directly building superintelligence.
Rather, we imagine the progressive automation of capabilities work, until we have better-than-human automated capabilities researchers – and then we proceed to superintelligence from there (indeed: perhaps all too quickly). So it’s very natural to wonder about a similar path for alignment.[11]
3.1 What if neither of these approaches are viable?
Now: you might worry that neither a humans-only path nor an alignment MVP path are viable. For example, you might think that humans (even with the help of pre-alignment-MVP AIs) aren’t smart enough to build an alignment MVP, let alone a safe superintelligence. Or, alternatively, you might think even with an alignment MVP, we couldn’t get the rest of the way.
What then? One option is to never build superintelligence. But there’s also another option, namely: trying to get access to enhanced human labor, via the sorts of techniques I discussed in my post on waystations (e.g., whole brain emulation). In particular: unlike creating an alignment MVP, which plausibly requires at least some success in learning how to give AIs human-like values, available techniques for enhancing human labor might give you human-like values by default, while still resulting in better-than-human alignment research capabilities. Call this an “enhanced human labor” path.[12]
I am broadly supportive of suitably ethical and cautious efforts to unlock enhanced human labor. And I am supportive, as well, of efforts to use AI labor to help with this. I am worried that especially in short-timelines scenarios with comparatively fast take-offs, such efforts will require too much capability restraint – but it could be that this is the only way. I discuss this a bit more at the end of the essay.
Even on this kind of problem profile, though, alignment research – and including: automated alignment research (short of a full-blown alignment MVP) – can still matter. In particular: it can help produce evidence that this is the sort of problem profile we face, thereby helping motivate the necessary response.
3.2 Alignment MVPs don’t imply “hand-off”
People sometimes talk about a waystation related to but distinct from an “alignment MVP”: namely, what I’ll call “hand-off.” In the context of automated alignment research, “hand-off” means something like: humans are no longer playing a meaningful role in ensuring the safety or quality of the automated alignment research in question.[13] That is: qua alignment researchers, humans are fully obsolete. The AIs are “taking it from here.”[14]
An “alignment MVP” in my sense doesn’t imply “hand-off” in this sense. That is: the safety/efficacy of your alignment MVP might still depend in part on human labor – for example, human supervision/evaluation. Indeed, in principle, this could remain true even for significantly superhuman automated alignment researchers.
And note, too, that even if human labor is still playing a role in ensuring safety, it doesn’t necessarily need to directly bottleneck the research process – or at least, not if things are going well. For example: in principle, you could allow a fully-automated alignment research process to proceed forward, with humans evaluating the work as it gets produced, but only actively intervening if they identify problems.[15]
Of course: even if humans could still contribute to safety/efficacy in principle, the question of what role to give them in practice will remain open, and sensitive to a variety of more detailed trade-offs (e.g., re: marginal safety improvements vs. losses in competitiveness).
I’m planning to discuss hand-off in more detail later in the series. But it’s not my focus here.
4. Why might automated alignment research fail?
OK: I’ve argued that automated alignment research is both very important to solving the alignment problem, and a very natural waystation to focus on. Now let’s look at why it might fail.
Here’s my rough breakdown of the most salient failure modes. First, start with the question of whether you got access to an alignment MVP, or not. If you did: why wasn’t that enough to solve the alignment problem?
One possibility is: it’s not enough in principle. That is: no amount of top-human-level alignment research is enough to solve the alignment problem – and: not even via bootstrapping to more capable but still-not-superintelligent systems. This is the pessimistic scenario I mentioned above, where you either need to refrain from building superintelligence at all, or pivot to an “enhanced human labor” strategy.[16] I’ll return to this at the end, but let’s set it aside for now.
Another possibility is: some amount of safe, automated top-human-level alignment research is enough in principle, but you didn’t do enough in practice. For example: maybe you didn’t have enough time. Or maybe you didn’t invest enough other resources – e.g. compute, staff, money, leadership attention, etc. Or maybe you failed for some other reason, despite access to an alignment MVP.[17] I think failure modes in this vicinity are a very serious concern, and I’ll return to them, too, at the end of the essay.
For now, though, I want to focus on scenarios where you failed to get access to an alignment MVP at all. Why might that happen?
One possibility is: your AIs weren’t even capable of doing top-human-level alignment research. And for a while, at least, that might be true. However: I expect that AIs capable of causing a loss of control scenario, at least, would also be capable of top-human-level alignment research. And note that eventually, at least, these rogue AIs would likely need to solve the alignment problem for themselves.[18] So probably, for at least some period prior to a loss of control, someone had AIs at least capable of serving as alignment MVPs.
So I’m centrally interested in a different class of scenario: namely, cases where your AIs were capable of top-human-level alignment research, but you failed to elicit that capability safely.[19] Why might this happen?
One possible reason is that your AIs were actively scheming in pursuit of problematic forms of power, and your elicitation efforts failed for that reason. For example: maybe, as part of their strategy for seeking power, your AIs actively sabotaged the research they were producing. Or maybe they intentionally withheld research at the level of top human experts (“sandbagging”). This, too, is a very serious failure mode. And I’ll discuss it, too, in more detail below.
For now, though: I also want to set scheming aside. In particular: there are other ways to fail to safely elicit top-human-level alignment research even from AIs capable of doing it. And I think it’s important to understand these failure modes on their own terms, before we bring the additional complexities that scheming creates into the picture. (These failure modes also overlap heavily with salient ways you can fail to make AIs capable of automating alignment research. So much of my discussion here will apply to that challenge as well. But I’ll focus centrally on the elicitation case.)
Why might you fail to elicit top-human-level alignment research even from suitably capable non-scheming models? One possible reason is data-scarcity. In particular: alignment is a young field. We don’t have a ton of examples of what we’re looking for, or a ton of experts that can provide feedback. And data of this kind can be crucial to successful automation (both in the context of capabilities development, and in the context of elicitation).
Another possible reason is what I’ll call “shlep-scarcity.” That is: even setting aside data constraints, AIs are generally a lot better at tasks where we try hard to make them good (again, this applies to both capabilities and elicitation). In particular: automating a given task can require a bunch of task-specific effort – e.g., setting up the right scaffolds, creating the right user interfaces, working out the kinks for a given kind of RL, etc. So: maybe you failed on elicitation because you didn’t put in that effort.
I’ll return to data-scarcity and shlep-scarcity, too, at the end of the essay. First, though, I want to focus on a potentially more fundamental barrier to eliciting top-human-level alignment research even from suitably capable, non-scheming models: namely, difficulties evaluating the relevant work. The next few sections examine this failure mode in detail.
(There are also other reasons you might get non-scheming elicitation failure; here I’m focused on what’s most salient to me.)
Here’s the full taxonomy I’ve just laid out.[20] And note that real-world failures can combine many of these.
5. Evaluation failures
OK: let’s look in more detail at evaluation failures in non-scheming, suitably-capable models.
Why is evaluating a given type of labor important to automating it? One core reason is that you can train directly on the evaluation signal. But even absent this kind of direct training, successful evaluation also allows for a broader process of empirical iteration towards improved performance. That is: in general, if you can tell whether your AIs are doing a given task in the way you want, the process of automating that task in a way you trust is a lot easier.
Example forms of evaluation failure include:
Reward-hacking: that is, the AI directly cheats in a way that leads to good evaluations (e.g., bypassing unit tests).[21]
Cluelessness: you can’t tell what you should think about a given type of AI output.[22]
(Again: non-exhaustive.)
The concern, then, is that if we can’t evaluate alignment research well enough, we’ll get these or other failure modes in attempting to automate it at top human levels.
5.1 Output-focused and process-focused evaluation
In order to better assess this concern, let’s look at available approaches to evaluating automated alignment research in more detail.
Consider some process P that produces some output O, where we want to know if that output has some property X. For example: maybe some professors write a string theory textbook, and you want to know if it’s broadly accurate/up-to-date.
We can distinguish, roughly, between two possible focal points of your evaluation: namely, output O, and process P. Let’s say that your evaluation is “output-focused” to the extent it focuses on the former, and “process-focused” to the extent it focuses on the latter.
When people talk about the difficulty of evaluating alignment research, they are often implicitly talking about output-focused evaluation. And I’ll generally use the term “evaluate” in a similar way. But process-focused evaluation is important, too, especially as your output-focused evaluation ability becomes weaker.
Indeed, in reality, many epistemic processes mix output-focused and process-focused evaluation together.[23] And whether you’re intuitively in a position to evaluate something can depend on both.
Sometimes, when people talk about the difficulty of output-focused-evaluating automated alignment research, they are imagining that we need this evaluation to be robust to superintelligent schemers intentionally sabotaging the research in question. But the automated alignment researchers I’m interested in here don’t need to be superintelligences (they just need to be as good at alignment research as top human experts). And they won’t necessarily be schemers, either. Indeed: for now, I’m assuming they’re not.
5.2 Human output-focused evaluation
One obvious, baseline method of output-focused evaluation is just: humans evaluate the research directly, the same way they would evaluate similar research produced by human colleagues.[24] And to the extent we’re just trying to replicate top-human-level performance, we might think that direct human evaluation should be enough, or close to it (at least in principle – e.g., modulo issues like data-scarcity). After all: that’s what we normally do to figure out what work is top-human-level. And human researchers have to be evaluating their own work as they produce it. Indeed: if you thought the “humans-only” path above was a viable (even if: inefficient) approach to solving the alignment problem, doesn’t that assume that human researchers are capable of evaluating alignment research well enough to recognize a solution to the problem?
Well: it assumes that humans are capable of evaluating human-produced alignment research well enough. But in the context of human researchers, you often have the benefit of certain kinds of process-focused evaluation, too. In particular: you might have good evidence that a human researcher (e.g. yourself, or one of your colleagues) is mostly trying his/her best to produce good research, rather than to engage in the equivalent of sycophancy, reward-hacking, etc (or sabotage, sandbagging, etc, if we bring scheming into the picture). Whereas this sort of process-focused evidence might be harder to come by with AIs. So adequate output-focused evaluation might become correspondingly more difficult.
Also: humans disagree about what existing alignment research is good.[25] And there’s a question of how to think about the evidence this ongoing disagreement provides about the power of direct human evaluation.[26] At the least, for example, ongoing disagreement raises questions about “top-human-expert alignment research according to who?”.[27]
5.3 Scalable oversight
Now: in thinking about the difficulty of output-focused evaluating alignment research, we shouldn’t limit ourselves to direct human evaluation. Rather, we also need to include ways that AIs can amplify our evaluation ability.
I’ll use the term “scalable oversight” for this. Possible techniques include:
Decomposition: You can decompose the evaluation process into smaller tasks, and try to get humans/AIs to help with the individual tasks – and eventually, also, with decomposing tasks well.[28]
Distillation. For a (potentially expensive) evaluation process consisting of any combination of the above, you can train AIs to imitate the output of that, and then use those AIs as part of a new evaluation process.[29]
It’s an open question how far these various techniques go on output-focused evaluation, and in the context of what threat models (for example: if we set aside concerns about scheming, vs. not). One concern, for example, is that for suitably difficult evaluation tasks, techniques like decomposition and debate won’t go very far. A giant team of average M-turkers, for example, seems poorly positioned to evaluate a novel piece of string theory research, even if the task gets broken down into lots of sub-tasks, and even if the M-turkers get to listen to AIs debate relevant considerations. And perhaps, faced with AIs producing superhuman string theory research, human string theory researchers trying to evaluate it using scalable oversight would be in a similar position.[30]
Note again, though, that we’re not, here, interested in the challenge of using scalable oversight to evaluate strongly (and still less: arbitrarily) superhuman alignment research. Rather: we’re interested in the challenge of using scalable oversight to evaluate alignment research at the level of top-human experts. And this seems substantially easier.
5.4 Process-focused techniques
What about process-focused evaluation? We can think of process-focused evaluation as a problem of understanding generalization. That is: we want to know how our AIs will generalize from domains where our output-focused evaluation methods are stronger to ones where they are weaker. How might we gain this understanding?
I’ll discuss this a bit more in future essays, but for now, I’ll flag two broad categories of evidence that can be especially relevant here:
Training AIs to directly imitate top-human-level researchers is another possible example here.[31] That is: if you can actually get an AI to create safe, robustly-Bob-level output simply by training it to imitate enough existing Bob-output, such that you trust this AI to act like Bob even in domains you can’t output-focused evaluate, then this is a fast path to an “alignment MVP” (assuming that Bob is a top-human-expert alignment researcher).
Whether this sort of imitation learning works in principle (though, let’s assume, without being able to train on Bob’s thoughts directly) or in practice (e.g., given realistic constraints on the Bob-data available) is a very open question. But it seems quite amenable to behavioral investigation.
Now: scheming AIs could mess with the evidence provided by our behavioral science (and perhaps, for AIs capable of manipulating their internal states, by our transparency tools as well). So detecting and preventing scheming (along with other ways AIs might intentionally and systematically mislead you about how they’ll generalize) is an especially important aspect of process-focused evaluation. I discuss options in this respect more in future essays (and see also here for a list of research directions), but broadly: both behavioral science and transparency are relevant.
These more process-focused techniques can combine with more output-focused scalable oversight techniques to produce an overall verdict about whether an AI’s task-performance is desirable.[32] And they become more important as the signal provided by our output-focused scalable oversight techniques becomes weaker, or if it disappears entirely.[33]
6 Comparisons with other domains
OK: in the last section, I briefly introduced some of the barriers that evaluation failures might pose to eliciting top-human-level alignment research even from suitably capable non-scheming AIs; I discussed a few examples of these failures (e.g. sycophancy, reward-hacking, cluelessness, etc); and I discussed some of the available approaches to evaluation (e.g. direct human evaluation, scalable oversight, and process-focused techniques like behavioral science and transparency).
In this section, I want to talk about how the challenge of evaluating automated alignment research compares to the challenge of evaluating AI labor in other domains. I think this helps bring some of the most distinctive-to-alignment challenges into clearer focus.
6.1 Taking comfort in general capabilities problems?
The need for good evaluation is very much not unique to automated alignment research. To the contrary, it’s a general issue for automating tons of economically valuable tasks.
Thus, for example: consider capabilities research. Already, we see models reward-hacking. But they’re reward-hacking, for example, on the type of coding tasks core to capabilities research. And sycophancy, too, is already a general problem – one that we can imagine posing issues for capabilities research as well. E.g., maybe you try to get your AIs to help you make an overall plan for building AGI, and their response plays to the biases and flaws in your own model of AI capabilities, and the plan fails as a result.
So: to the extent that these problems bite in the context of capabilities research, we should expect them to slow down the AI capabilities feedback loop I discussed above. And we should expect a lot of effort, by default, to go towards resolving them.
But it’s not just capabilities research. Good evaluation – including, in fuzzier and less quantitative domains – is crucial to automating tons of stuff. Consider: coming up with creative product designs; or effective business strategies; or new approaches to curing cancer. And even if these tasks can be evaluated via more quantitative metrics in the longer-term (e.g., “did this business strategy make money?”), trying to train on these very long-horizon reward signals poses a number of distinctive challenges (e.g., it can take a lot of serial time, long-horizon data points can be scarce, etc).
Here I’m especially interested in comparisons between alignment research and other STEM-like scientific domains: e.g., physics, biology, neuroscience, computer science, and math. By default, I expect lots of effort to go towards automating top-human-level research in at least some of these domains – e.g., biology (cf “curing cancer” above). So if the evaluation difficulties in these domains are comparable to the evaluation difficulties at stake in alignment research, then we should expect lots of effort to go towards developing techniques for resolving those difficulties in general – e.g., in a way that would plausibly transfer to alignment research as well. And by the time we can automate these other STEM fields, we would then have grounds for optimism about automating alignment research as well.[34]
Indeed, in general: while alignment research and capabilities research have always been importantly tied together, this is especially true in the context of eliciting intended task-performance from non-schemers. And this includes domains where direct human evaluation isn’t adequate (in this sense, for example, “scalable oversight” is clearly central to capabilities research as well). True, this dynamic might make alignment researchers worried about capabilities externalities. But it should also be a source of comfort: by default, you should expect strong economic incentives towards figuring the relevant evaluation challenges out.
That said: I also think there are limits to the comfort that comparisons between evaluation challenges in alignment research vs these other domains (capabilities research, other sciences) can provide.
6.2 How does our evaluation ability compare in these different domains?
Why might alignment research be harder to evaluate than both (a) capabilities research, and (b) other STEM-like sciences like physics, biology, neuroscience, computer science, and math? Here’s my current rough picture. It’s highly simplified, but I’m hoping it can be instructive nonetheless.
6.2.1 Number go up
We can distinguish between three broad sorts of domains, according to how work in these domains gets evaluated. I’ll call the first sort “number go up” domains. Here, we have some very crisp, quantitative metric (the “number”) that we can use for training and evaluation. A paradigm example would be something like: cross-entropy loss in the context of predicting internet text.
Capabilities research, famously, benefits a lot from quantitative metrics of this kind. Indeed, my sense is that people sometimes think of AI capabilities development as uniquely easy precisely because it can be pursued via optimizing such a wide variety of quantitative metrics.[35]
And sometimes, we can give alignment research a “number go up” quality, too. For example: you can train AIs to do better on metrics of helpfulness, harmlessness, and honesty; you can reduce their rates of reward-hacking, alignment faking, sycophancy, chain-of-thought unfaithfulness, etc; you can work to improve the degree of weak-to-strong generalization; and so on.
6.2.2 Normal science
When we evaluate work in empirical sciences like biology, physics, and so on, though, we typically ask many questions other than “did this quantitative metric improve?” For example: we often ask questions like: “Was this a useful/interesting/productive/well-conducted experiment? How should we interpret the results? Does this interpretation of the results fit with the rest of our data? What sorts of predictions does it make? What would be a productive new experiment to try?” and so on. And these questions are notably “fuzzier.”
Still, though: I think the human track record of evaluating research in STEM-like sciences is fairly strong. For example: we’ve made a lot of clear progress over the years, with lots of consensus amongst recognized experts.
Why such success? Two factors stand out to me.
The second factor is formal evaluation methods – that is, roughly, the sorts of evaluation methods at stake in math and formal logic. And this doesn’t need to be at the level of “we can use a theorem-prover”; even merely human evaluation has historically done decently well on questions like “is this math correct?”.[36]
Indeed, scientific domains often seem to me intuitively weaker and harder to evaluate to the extent these two factors aren’t present. Thus, for example: neuroscientists are comparatively limited in their experimental access to the brain, and so have a harder time making progress; theoretical physics debates that don’t make testable experimental predictions are harder to resolve (though formal evaluation methods can still help); economists often can’t perform controlled experiments and so are stuck curve-fitting to already available data; etc.[37]
I am not an AI capabilities researcher, but my impression is that various aspects of capabilities research are reasonably continuous with “normal science.” That is: capabilities research isn’t just a process of blindly iterating until some number goes up. Rather, it involves the sort of creativity, research taste, data interpretation, hypothesis generation, prioritization between experiments, etc that we associate with other types of empirical science. And evaluating capabilities research involves evaluating these skills.
And I think a lot of alignment research (what I’ll call “empirical alignment research”) is like “normal science,” too. That is, even in the absence of some simple quantitative metric of progress, attempts to evaluate this sort of research can draw on a rich array of empirical results, predictions, and further experiments (plus, sometimes, formal methods, though I view these as less central).
What sort of “empirical alignment research” do I have in mind? This recent list of technical research directions from Anthropic is a good illustration; and see, also, this recent RFP from Open Philanthropy.[38] More specific examples might include:
In all these cases, that is, the relevant research is heavily focused on empirical experiment. And in this respect, it strikes me as notably similar to more scientific/experimental work in capabilities, along with work in other domains like biology, neuroscience, and physics. Of course: you still need to interpret the empirical results in question, and to evaluate different candidate interpretations. But this is true in these other domains as well. And the candidate interpretations at stake will often, themselves, make further empirical predictions you can test.
That said: this may not always hold true. For example: if it turns out that default forms of pre-training give rise to scheming models, and we need to start doing lots of experiments with different forms of pre-training in order to see if we can avoid this, the experiments at stake could get compute-intensive fast.[39]
Overall, then, I tend to think of the evaluation challenges at stake in automating empirical alignment research as broadly comparable to the evaluation challenges at stake in automating research in areas like physics, biology, neuroscience, and so on; and comparable, plausibly, to automating certain aspects of capabilities research as well. Granted: these challenges seem harder than in more centrally “number go up” domains. But I think humanity’s track-record of success in these other domains – along with the default economic incentives to automate them – should make us reasonably optimistic.
6.2.3 Conceptual research
For research in some domains, though, our evaluation efforts can’t benefit from strong empirical feedback loops or from formal evaluation methods. Rather, our central tool, for evaluating this kind of research, is … thinking about it. And also: arguing. But not in a way where: after thinking about it, you get to see the answer. Rather: you think about it, you argue, you come to a view, and … that’s it.
I’ll call this sort of research “conceptual research.” Paradigm examples, to my mind, include philosophy, futurism, and certain kinds of political debate.
Unfortunately: compared to what I called “normal science,” the human track record of evaluating conceptual research looks to me pretty weak. To be clear: I do think that humans-thinking-about-it can provide some signal.[40] And I think we have in fact seen progress in areas like philosophy, politics, religion, ethics, futurism, etc. Still, though, we also see very widespread, persistent, and hard-to-resolve disagreement amongst humans in these domains – much more so, I think, than in the more empirical sciences. And this makes relying on human evaluation ability in these domains seem, to me, correspondingly dicey.
What’s more, unfortunately: some kinds of alignment research look to me, centrally, like conceptual research. This sort of research focuses on things like: developing and critiquing alignment approaches that aren’t yet testable empirically; improving our theoretical understanding of the nature of agency and intelligence; formalizing alignment-relevant concepts more clearly; identifying and clarifying alignment-relevant threat models; creating overall strategies and safety cases; and so on.[41] Examples of alignment research in this vein might include:
Early work on scalable oversight techniques, like Christiano et al (2018) on iterated amplification and distillation;[42] Irving et al (2018) on AI safety via debate; and Leike et al (2018) on recursive reward modeling.
Shah et al (2025) on Google DeepMind’s overall approach to AGI safety.[43]
Sometimes this sort of alignment research becomes amenable to useful empirical study, even though it wasn’t initially. For example: as AI capabilities have advanced, we’ve become better able to test various hypotheses coming out of previously-more-theoretical discussions of deceptive alignment, scalable oversight, and so on. But per my comments above, I’m thinking of research as “conceptual” insofar as our evaluation of it can’t benefit from empirical tests/feedback loops prior to the point where we need to evaluate it.
Now: it’s not yet clear whether, in practice, automating conceptual research – including, conceptual alignment research – at top human levels is actually going to be much harder than automating more empirical sorts of scientific research. Indeed, frontier AIs already seem to me decent at philosophy (better, for example, than most smart undergrads), and I’ve found them helpful thought partners in thinking through various conceptual questions. And we can imagine reasons why automating conceptual research might be actively easier than more empirical research – for example: evaluation/feedback doesn’t need to be bottlenecked on real-world experiment.
Still: when I think about the possibility of evaluation failures, in particular, creating problems for automating alignment research, I feel most concerned about conceptual alignment research in particular.
Here's a diagram of the overall picture I just laid out:
7. How much conceptual alignment research do we need?
Now, in my experience, some people think that conceptual alignment research is basically the only kind that matters, and some people think it’s basically irrelevant. And if it were basically irrelevant even to the project of building a safe superintelligence, then an adequate “alignment MVP” wouldn’t actually need to automate conceptual alignment research at all.
7.1 How much for building superintelligence?
So: do we need lots of additional conceptual alignment research in order to build safe superintelligence? Some common arguments for this strike me as inconclusive (more in Appendix 3). But I’m still going to assume: yes. In particular: I expect that along the full path to safe superintelligence, it will be important to develop and successfully evaluate hypotheses, reconceptualizations, new depths of understanding, research agendas, safety cases, threat models, high-level strategies, and so on that can’t be immediately evaluated/tested via their empirical predictions (or via formal methods). And I think some work of this kind, at least, has been important in the past.
7.2 How much for building an alignment MVP?
That said: it’s a different question whether we need lots of additional conceptual alignment research in order to build an alignment MVP – and in particular, whether the amount we need is such that it would be feasible for humans to do most of it, or whether we would need lots of AI help. (If we need lots of AI help, then on pain of circularity, that help would itself need to come from something other than an alignment MVP.)
Here, I am cautiously optimistic that for building an alignment MVP, major conceptual advances that can’t be evaluated via their empirical predictions are not required. Rather, the main thing we need is a ton of empirical alignment research of the broad kind that we’re already doing – and which I think we should be especially optimistic about evaluating, and hence automating.[44]
To be clear, I do think that developing and evaluating any kind of adequate “safety case” for an alignment MVP is ultimately, at least in part, a conceptual project, in that it at least requires stitching together diverse sources of empirical evidence into an accurate risk assessment.[45] The question is whether it’s a conceptual project that requires tons of additional conceptual work that we should expect to need tons of AI help on.
However, it remains possible that more serious, purely-conceptual advances are required for building an alignment MVP. And even if not, conceptual alignment work can still be quite helpful for that goal – for example, in setting and evaluating overall strategies, figuring out how to prioritize between different empirical projects, strengthening safety cases, and so on.[46]
So I won’t, here, assume that empirical alignment research is all we need to get to an alignment MVP, either. However, I do think that empirical alignment research is an especially powerful tool to that end. In the next section, I’ll say more about why.
8. Empirical alignment research is extremely helpful for automating conceptual alignment research
Granted that we need to automate both empirical and conceptual alignment research at top human levels, how should our efforts at one vs. the other interact?
I think that each can support the other, and I’m not going to argue for some specific balance/prioritization here. But I do want to highlight a dynamic that seems to me especially important: namely, that empirical alignment research is extremely helpful for automating conceptual alignment research. In particular, empirical alignment research can do a ton to test and strengthen our output-focused and process-focused evaluation methods (e.g. scalable oversight, behavioral science, transparency, anti-scheming measures), including as they apply to conceptual alignment research.
That is, I claim both that:
In a diagram:
Let me say more in defense of (2). In particular: suppose you had successfully automated empirical alignment research at top human levels. What could you do then to improve the output-focused and process-focused evaluation methods I discussed above?[47]
8.1 Automated empirical research on scalable oversight
One thing you could do is: perform large numbers of experiments testing and refining the efficacy of different approaches to scalable oversight – including approaches that humans haven’t thought of yet, but which can be evaluated empirically once proposed.[48]
Now, admittedly, some of these experiments are harder to run in the sort of domains that are the closest analogs of conceptual alignment research – e.g. philosophy, futurism, political debates, etc – because ground-truth is harder to access, and there’s less consensus on what counts as top-quality research. However (and even beyond studying scalable oversight in less conceptual domains and hoping similar lessons generalize):
This isn’t an exhaustive list of existing ideas for studying scalable oversight techniques empirically. But more importantly: coming up with (empirically testable) ideas like this is a version of empirical alignment research (see e.g. Bowman et al (2022), Michael et al (2023), etc). So if we’ve automated empirical alignment research at top-human levels, we’d have access to top-human-level AI help in generating many more ideas of this kind.
8.2 Automated empirical research on process-focused evaluation methods
Now, as I noted above, it remains an open question exactly how far scalable oversight techniques will go in extending our ability to output-focused evaluate different kinds of research, including conceptual research. And perhaps what research of the type above finds is: “even the best forms of scalable oversight don’t go very far.” What about more process-focused evaluation – e.g., the sorts of behavioral science and transparency I discussed above?
Here, again, I think that access to huge amounts of automated, top-human-level empirical alignment research would be extremely helpful. Thus:
Consider first interpretability.[49] If we had access to huge amounts of interpretability research at the level of top human experts, how much help would that be in improving our ability to process-focused evaluate how much to trust our AIs in domains where our output-focused evaluation struggles?
I’m not sure. But I think plausibly: quite a lot.[50] At the least, for example, it seems like you could do extremely scaled up and intensive forms of the sort of mechanistic circuit analysis at stake in e.g. Lindsey et al (2025); the sort of top-down analysis at stake in e.g. Zou et al (2023); and so on. But it seems plausible to me that you could go vastly further than this (see e.g. Olah (2023) for some more ambitious goals).[51]
As I mentioned above, anti-scheming measures are especially important to process-focused evaluation. These generally consist of some combination of transparency and behavioral science, except specifically in the context of e.g. model organisms, experiments that attempt to isolate particular components of the scheming threat model (situational awareness, beyond-episode goals, etc), and so on. And, again, I think that huge amounts of top-human-level automated empirical research could be extremely helpful here.
8.3 Other ways automated empirical alignment research can be helpful
So far I’ve been focusing on ways automated empirical alignment research can be useful, specifically, for helping with automating conceptual alignment research. But it also seems extremely helpful more generally. For example:
In general, then: I think automating empirical alignment research, just in itself, is a huge win, and that a variety of promising paths forward open up from there.
9. What about scheming?
OK: that was a long discussion of ways that evaluation challenges might pose a problem for automating alignment research, even if we set aside scheming. But: what happens if we don’t?
Here are a few ways that re-introducing the possibility of scheming can alter/complicate the situation.
And because active sabotage is specifically optimized for undermining human safety efforts, failing to catch it will generally be higher-stakes.[52]
9.1 Will AIs capable of top-human-level alignment research be schemers by default?
Now, one way we might avoid these concerns about scheming is: if early AIs capable of top-human-level alignment research just aren’t schemers by default. And indeed, I find it plausible that they won’t be – or at least, not if timelines are comparatively short.[53]
In particular: I think it quite unlikely that current models are actively scheming.[54] And if timelines are comparatively short, you might also expect the first models capable of automating most if not all of top human-level knowledge work (including capabilities research, alignment research, etc) to be fairly similar to current models – e.g., trained using fairly similar techniques, in the context of broadly similar architectures, scaffolds, chain-of-thought techniques, etc. So if current models aren’t scheming, plausibly those models wouldn’t be, either.
Also: scheming requires models that satisfy the agency and motivation prerequisites I discussed in my second essay – i.e., roughly, situationally-aware agentic planners with long-term consequentialist goals. And it’s not clear that automating alignment research requires AIs of this kind. In particular:
Maybe alignment research as a field aims at a long-term, consequentialist goal (e.g., a future of aligned AIs[55]). But this doesn’t mean that individual AI systems contributing to this research need, themselves, to be optimizing for this or any other long-term goal. For example: they might be performing more limited tasks aimed at shorter-term targets (see e.g. “process-based supervision,” “myopic optimization with non-myopic approval). More on this here.
So using AIs that don’t satisfy the prerequisites for scheming might be another way to avoid it.
9.2 If these AIs would be schemers by default, can we detect and prevent this scheming?
Suppose, though, that the AIs we’re trying to use for alignment work would be schemers by default. In particular, I’ve sometimes encountered views like:
If science then scheming: Any AIs doing “serious science” at the level of top humans would be schemers by default.
One general argument for this might be: any AIs capable of serious, top-human-level science would also have to be situationally-aware agentic planners with long-term consequentialist goals, and any AIs like that are schemers by default. But I’ve also sometimes heard arguments that seem more specifically focused on the idea that in performing serious scientific research at top human levels, AIs will be above some threshold where they start doing things like “reflecting on themselves,” “pulling themselves together,” and “asking themselves what they ‘really want’?”, at which point they’ll decide to try to disempower humanity on grounds of the divergence between human values and “what they really want.”[56]
I won’t try to analyze these arguments in depth here (though I’ll note that they make some strong predictions about what sorts of science we’ll be able to do with non-schemers). For now, I’ll mostly reiterate that there are in fact a variety of tractable research directions for trying to detect and prevent scheming. And even prior to successfully automating all alignment research (or even: all empirical alignment research) at top-human levels, I expect various forms of automated labor to be quite useful for anti-scheming research in this broad vein.
So, even if early AIs capable of automating top-human-level alignment research would be schemers by default, I think we might also be able to detect/prevent this scheming using various anti-scheming measures. There’s also, though, a third option: namely, using scheming AIs, at least initially, for automating alignment research that we can evaluate with suitable robustness. Let’s turn to that now.
9.3 Can we elicit safe alignment research from scheming AIs?
The idea of trying to elicit safe alignment research from actively scheming AIs should scare us. It seems very dangerous. And if that’s where it looks like we’re headed, I think the first response should be to look for a different plan – for example: capability restraint.
Still: we should have all the available options in view. And trying to do it with schemers, at least initially, is indeed one option. In particular: if we can (a) use suitably robust evaluation techniques to really check that the work produced by these AIs is top-human-level-quality and not-sabotaged, (b) use suitably strong anti-sandbagging techniques to actually elicit work that meets these standards, and (c) use other methods of option control to close off other dangerous rogue options (self-exfiltration, human manipulation, etc) in the meantime, then we have effectively created what I previously called an “AI for AI safety sweet spot” with respect to automated alignment research. That is: the AIs can’t do catastrophic harm (including: via options made available by their research itself), and we’re eliciting a ton of useful, high-quality work from them.
Obviously, though: we should try, as much as possible, to make this a temporary measure, if we pursue it at all. That is: a core aim should be to elicit enough alignment research that you can then actually rule out scheming going forward.
And note that the viability of this sort of path is probably going to depend on having very strong output-focused evaluation methods in particular. That is: if your process-focused evaluation (e.g., transparency, behavioral science of generalization, anti-scheming measures, etc) isn’t robust to scheming, then your output-focused evaluation methods need to make up the difference. In this respect, then, I’m more optimistic about eliciting safe empirical (and/or formally evaluable) alignment work from schemers than eliciting safe conceptual alignment work, because I expect available output-focused evaluation methods for empirical alignment work to be stronger by default.[57] But per my comments about the value of automated empirical alignment research above, even just this can help a lot.
Overall, then, there are at least three ways we could safely automate alignment research despite the possibility of scheming, namely:
And these different options can combine – e.g., maybe some kinds of alignment research can be done using non-agentic AIs; some kinds are such that we’re sufficiently confident in our output-focused evaluation methods that we’re comfortable even using maybe-schemers to do them; and so on.
10. Resource problems
So far, I’ve focused on two specific branches of the taxonomy of failure modes I introduced earlier in the essay: namely, evaluation failures in non-schemers, and scheming.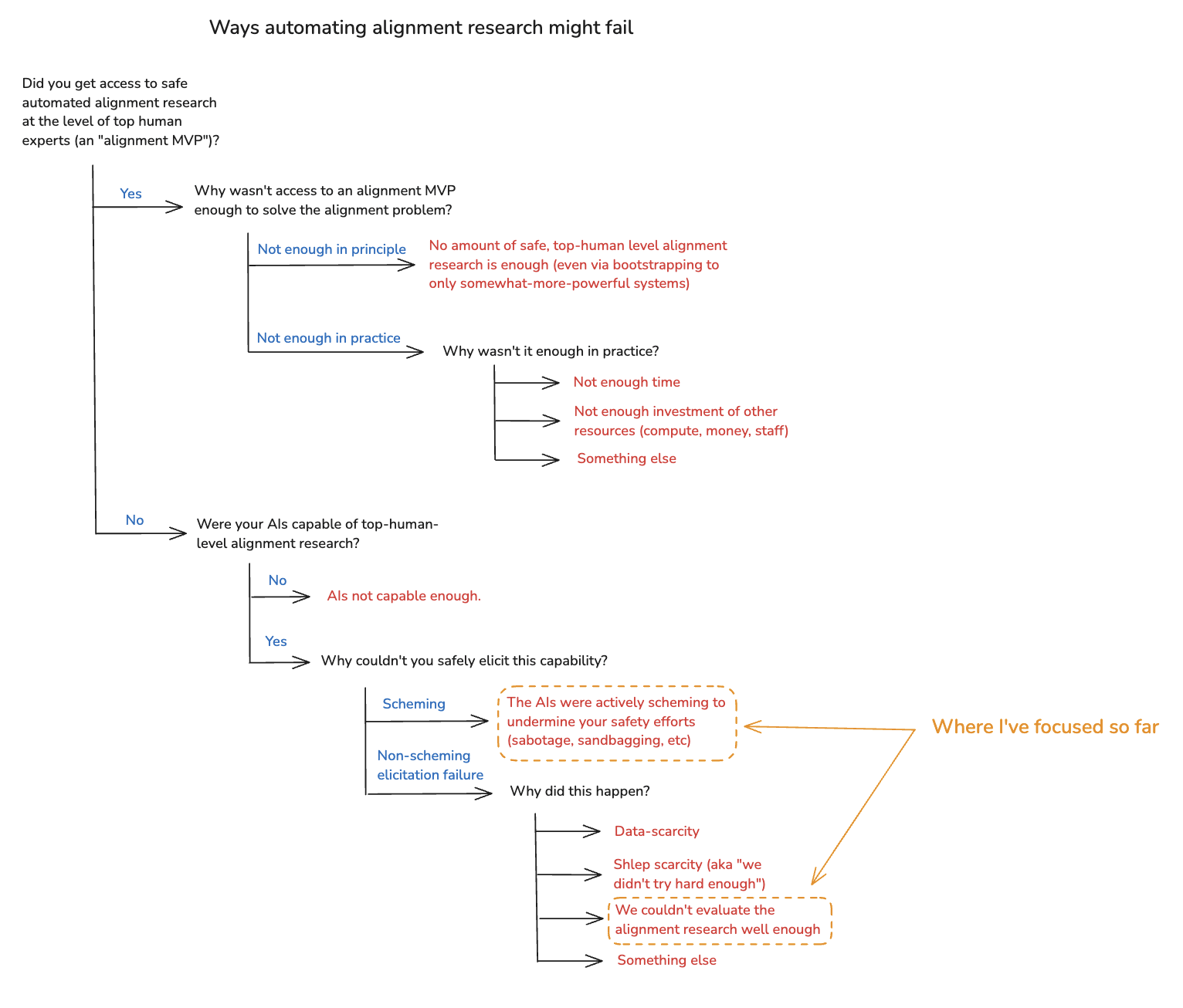
What about the other branches? Per my discussion above, let’s set aside, for now, the cases where no amount of top-human-level alignment research is enough. And let’s assume, further, that at some point prior to the loss of control, someone had access to AIs that were at least capable of top-human-level alignment research. In this case, roughly speaking, we can think of the other branches I’ve actively defined as centrally about inadequate resources: that is, inadequate time, compute, effort, data, etc. That is:
And note that even if we grant we get AIs capable of serving as alignment MVPs at some point prior to loss of control, the question of how early can still matter a lot to the amount of time you have available for automated alignment research overall. And resources like data and shlep can be relevant to making AIs capable of top-human-level alignment research, as well as to eliciting this research.
I think these more practical, resource-focused failure modes are extremely serious.[58] And I don’t have especially fancy things to say in response. Basically: we need to actually put in the necessary shlep. We need to actually make the necessary investment of compute, staff-time, money, etc. If we run into serious data-scarcity issues, we need to find a way around them (though: this barrier could prove more fundamental). And we need to create the necessary time.
Indeed: I’ll linger, for a moment, on the point about time. As I discussed above, a key reason that safely automating alignment research is so important is that automated alignment research can proceed quickly, and at scale, in a manner that can keep pace with automated capabilities research. Successful automation of alignment research thereby relieves some of the pressure on our capability restraint to hold back (or: indefinitely halt) an increasingly automated capabilities feedback loop while slow, scarce human researchers do alignment research themselves (or until we can get access to enhanced human researchers instead). And because I am worried about our prospects for extreme amounts of capability restraint, I view successfully automating alignment research as correspondingly important.
But even if you successfully automate alignment research, capability restraint is still extremely important. In particular: especially in fast-take-off scenarios, trying to frantically do a ton of automated alignment research in the midst of an intelligence explosion is extremely dangerous, and extra time remains extremely valuable.
11. Alternatives to automating alignment research
OK: that was a lengthy discussion of our prospects for safely automating alignment research – and in particular, of the failure modes I’m most worried about. And given the many ways automated alignment research can fail, I also want to briefly mention the alternatives that seem most salient to me.
Recall my argument for the importance of automating alignment research: namely, that solving the alignment problem might be a lot of difficult work; we might not have very much time; and human labor is scarce and slow. How might this problem get resolved without automating alignment research?
One possibility is that the problem is easy – and in particular: easy enough that even without much time, small amounts of slow, scarce human labor are enough to solve it. Or another possibility is that timelines are long by default, such that we have time, by default, to put in a lot of slow, scarce human labor (and/or, potentially, to make a transition to some kind of enhanced human labor). And these two could interact. That is, the problem could be easy, and timelines could be long.
Unfortunately, though, I don’t think we can count on easy problems, or on long timelines by default. And (at least insofar as the long-timelines-by-default are driven by underlying technical parameters), neither are under our control.[59]
What about alternatives that are more under our control, at least in theory? To my mind, the most salient options are:
I’m planning to discuss both these options in more detail later in the series. To my mind, though, it seems unwise to bank on either of them.
12. Conclusion
Overall, then: I think that we have a real shot at safely automating alignment research, and that successfully doing so is extremely important. But we need to navigate a number of serious failure modes. In particular:
Failure on any of these fronts seems worryingly plausible. But I think there’s a lot we can do to improve our odds. I’ve focused, here, on ways that successfully automating alignment research that we can test empirically, and then doing a ton of it, can help a lot with evaluation challenges (together with anti-scheming measures, and with gathering evidence that can help motivate effort, investment and capability restraint). But many other technical and governance interventions seem potentially helpful as well (see e.g. Hobbhahn here for a few more ideas).
What’s more, the most salient alternatives to automating alignment research (i.e. banking on easy problems/long timelines; aiming for sustained global pauses; trying to use AI to rapidly develop whole brain emulation technology and then trying to get emulated humans to do tons of alignment research very fast) all look, to me, no more comforting. So despite the many ways that automated alignment research can fail, I think we should be trying extremely hard to make it work.
Appendix 1: How do these failure modes apply to other sorts of AI for AI safety?
This appendix briefly discusses how the failure modes discussed in the main text apply to other potential applications of AI for AI safety – for example, hardening the broader world, risk evaluation, capability restraint, enhanced human labor, and so on. I won’t attempt to cover each of these potential applications individually. Broadly speaking, though:
I am generally less worried about evaluation failures, in particular, in many of these other domains, because I think alignment research – or at least, conceptual alignment research – is unusually hard to evaluate relative to lots of other safety-relevant domains (e.g., using AIs for forecasting; using AIs for cybersecurity; developing better on-chip mechanisms for monitoring compute; etc).[60]
In this sense, I think, many of the points I’ve made about automating alignment research apply to AI for AI safety more broadly. That is: we need to find a way to either avoid scheming, or to elicit safe, high-quality, safety-relevant work from maybe-schemers. We need to put in the necessary shlep, effort, and investment. And we need to buy ourselves the necessary time.
Appendix 2: Other practical concerns not discussed in the main text
This appendix briefly discusses a few other more practical concerns about AI for AI safety (including: automated alignment research) that I didn’t discuss in the main text, notably:
Appendix 3: On various arguments for the inadequacy of empirical alignment research
In this appendix, I list various arguments I’ve heard for why empirical research is inadequate for aligning superintelligence, and I explain why I don’t find them all that compelling on their own. And the reasons I find them less-than-fully compelling apply even more strongly to alignment MVPs, which are much less powerful than superintelligences, where it’s much less plausible that they need to have takeover options, and so on.
Immediate takeover options? A different reason you could worry, though, is that: as soon as you build a superintelligence, it’ll have the option to take over the world. So you never get to safely do any empirical research on it. You can’t even keep it locked in a box without trying to do anything with it, and then examine its internals using your interpretability tools, because you can’t build a box like that.[61]
Is that right? I’ll discuss the difficulty of closing off takeover options for superintelligences in more detail in a future essay. For now, though, I’ll note that if you aren’t trying to do anything with the superintelligence except scan its internals with your interpretability tools, I expect “boxing it” to be, at least, much easier.
Needing extreme understanding. A broader vibe I’ve heard is something like: in order to align a superintelligence, you need to understand it extremely well.[62] It’s like how: rocket engineers need to understand rockets extremely well, because they’re working with such extreme forces. Or how: cybersecurity specialists need to understand their security systems really well, because these systems need to withstand so much adversarial pressure. That is, the thought goes: if there is some part of a superintelligence you don’t understand, then that part will cause it to kill you. And empirical alignment research, the thought goes, can’t get you this level of understanding. For example, this understanding requires deeply understanding the nature of things like minds, values, intelligence, and so on – understanding that requires significant conceptual/philosophical/theoretical progress.
This concern is more of a vibe than a hard argument, but I agree that building a superintelligence safely likely requires a deep understanding of what you’re doing (though: I don’t think it needs to be humans, at that point, who possess the relevant understanding, because it doesn’t need to be humans building the safe superintelligence). And I agree, too, that relative to where we are today, at least, lots of conceptual/theoretical progress is necessary there.
However, we should distinguish between conceptual/theoretical progress that can be evaluated via empirical tests, and conceptual/theoretical progress that can’t. Thus, for example: as I discussed in the main text, Einstein’s theory of relativity was clearly conceptual/theoretical progress in some sense. But it was also evaluable via its empirical predictions. So it actually wouldn’t count as conceptual research in my sense. And to the extent that the relevant conceptual/theoretical progress doesn’t make empirical predictions, it seems potentially less relevant/useful.
Or to put it another way: how much conceptual research that couldn’t be evaluated via (a) empirical feedback loops and (b) formal methods was involved in learning how to build rockets? Nuclear reactors? Building safe superintelligence requires high-quality scientific understanding, yes. But empirical (and/or formally evaluable) research can get you a lot of that. Hence, for example, the sort of understanding at stake in physics.
Appendix 4: Does using AIs for alignment research require that they engage with too many dangerous topics/domains?
This appendix briefly discusses the concern that automating alignment research might be uniquely dangerous, relative to automating other domains, because it requires that AIs think about and understand especially dangerous topics, like human psychology, game theory, computer security, various possible galaxy-brained considerations, and so on.[63] Here, the contrast is often with other forms of AI for AI safety (for example: AI for enhanced human labor), which are thought to be (at least potentially) safer than this.[64]
I agree that other things equal, alignment research implicates a wider and more dangerous array of topics/domains than more narrow types of scientific research, and that this is a point in favor of plans that focus instead on automating this narrower type of research instead. As I’ll discuss later in the series, though, I think that these plans have some other serious downsides (notably: they generally require very significant capabilities restraint, and with the exception of whole brain emulation, the labor they unlock lacks AI advantages like speed, copying, easy read-write access, etc).
I’ll also note, though, that insofar as the hope was to have AIs that have never even been exposed to topics like human psychology, game theory, computer security, etc – or, indeed, to the alignment discourse more broadly – then this would clearly require a substantial departure from currently standard forms of pre-training on internet text. So this is an additional barrier to realizing the full safety benefits of refraining from using AIs on alignment research in particular. That is: the strong default here is that frontier AIs in general will have been exposed to these topics. And while using them for alignment research might require that they engage with these topics substantially more, the marginal risk seems worth it to me.
On the framework I’m using in this series, hardening the broader world is also a part of making increasingly capable AI systems safe. But alignment research is at the core.
Of course, if we had the luxury of extreme amounts of capability restraint, it would likely make sense to go as far as possible using the labor we’re most confident we can trust, which for a while would plausibly be human labor (and perhaps, in that context, the sort of “enhanced human labor” paths I discuss below would also be preferable to automating alignment research – though, it depends on the details). But even with such luxuries available, it seems plausible to me that the thing you actually focus on building is an alignment MVP, rather than a safe superintelligence, because it’s easier, and because it’s so helpful.
Of course: this path likely involves building many intermediate AI systems along the way, which the diagram below is not depicting. But in a humans-only path, humans are doing all the core alignment research labor.
I’m also not sure how much anyone ever actually thought we’d be doing the humans-only path. Rather, I think the most classic default picture is to imagine a suitably aligned “seed AI” that isn’t fully superintelligent, but which preserves its alignment through a process of recursive self-improvement. In a sense, then, this is a form of automated alignment research. Indeed: I think many forms of resistance to automated alignment research stem not from the fact that it involves departing from a “humans-only path,” but from the risk of using inadequately aligned AI labor to help. That is: the objection is that a viable “alignment MVP” path requires more human-labor-driven alignment success than advocates of automated alignment research are planning on.
Josh Clymer’s analysis here uses a similar framing, and a similar diagram (though: I’m not actually getting it from Josh’s piece; rather, I had been using a framing and diagram like this since a draft version of this essay written back in fall of 2024). That said: Josh’s piece focuses on a slightly different milestone – namely, an AI you trust to replace human researchers. An alignment MVP in my sense doesn’t necessarily imply that you’re ready to retire human alignment researchers entirely. For example, some of the safety in question might derive from ongoing human oversight. I discuss replacing human researchers a bit in the section on “hand-off” below.
Because: a superintelligence would be an alignment MVP; but plausibly weaker systems would be as well, and such weaker systems are (I’m assuming) no harder to align/make safe.
Because alignment MVPs safely produce better/more efficient alignment research than humans do.
This makes the most sense if the alignment MVP is at least somewhat better than top humans at alignment research. If it was merely more efficient, then access to an alignment MVP is so far only a speed-up, rather than a more fundamental advantage.
You could think, for example, that almost all of the core challenge of aligning a superintelligence is contained in the challenge of safely automating top-human-level alignment research. I’m skeptical, though. In particular: I expect superintelligent-level capabilities to create a bunch of distinctive challenges.
This is assuming that the alignment MVP AIs are in fact both faster and more scalable than humans, but I think this assumption is reasonable. Of course: it’s not always more efficient to do a task by first building AIs to help you. Consider, for example, the task of folding your laundry. But for tasks where (a) it’s hard to do it on your own, (b) the relevant AI would help a lot, and (c) building the relevant AI is significantly easier than doing the full task yourself, getting AI help seems like a good bet. And I think the alignment problem is plausibly like this.
Indeed, people sometimes deride automated alignment research as trying to get the AIs to “do our alignment homework.” But: who gave us this “homework”? “Homework” rhetoric implies that aligning superintelligence is supposed to be “our job” – a job we’re trying to shirk. But one rarely hears similar complaints about “getting the AIs to do our capabilities homework” – or, indeed, our coding homework, our cancer research homework, and so on. In general: transformative AI scenarios involve getting the AIs to do tons of stuff for us. And no wonder: they’re better at it. Why would alignment research be different? Well: below I’ll discuss some reasons. But the naturalness of trying to safely automate alignment research – like how we’re doing with all sorts of other stuff – is worth bearing in mind.
Though: note that if you thought that even an alignment MVP couldn’t solve the alignment problem, you need some story about why your enhanced human labor would do better.
See e.g. Clymer (2025) for more.
Though: humans may still be playing an important role in ensuring other forms of safety.
Though of course: they need to identify the relevant problems before it’s “too late.”
That is, assuming some amount of suitably enhanced human labor would be enough; which, these scenarios, seems far from clear.
For example: maybe your automated alignment researchers just “messed up,” but not as a result of lack of time or other resources? In some sense, this can be understood as “not doing enough research,” but perhaps it’s best understood in some other way. Of course, if the researchers were as good or better than top humans, than they will likely have done at least as well as humans would’ve done with similar time/resources. But when the relevant loss of control occurs, this might be cold comfort.
Though: if they fail in this respect, that doesn’t mean the situation is any better from a human perspective.
Admittedly: the line between capability and elicitation can get blurry. At least in the case of elicitation failures that result from scheming, though, I think it’s relatively clear (i.e., the schemer knows that it could do the task in the desired way, but chooses not to). And I expect the distinction to be meaningful and important even absent scheming as well. In particular: if your AI would perform the task well on a different input, or given a different prompt, I think that this is a good indication that it was capable of the task. And I’d generally want to say the same thing if the amount of training required to cause the relevant form of task performance is quite small.
This taxonomy is slightly different from the one I offered in my last post for thinking about concerns about AI for AI safety in general, but it covers broadly the same ground. In particular: differential sabotage and dangerous rogue options would both fall under "scheming."
The line between sycophancy and reward-hacking can be a bit blurry, but I’m generally thinking of sycophancy as routing via the content itself, whereas reward-hacking routes via some other means.
This is distinct from sycophancy, where you actively but wrongly approve of the output.
Indeed, in theory, it can be somewhat hard to find a case of pure output-focused evaluation – i.e., evaluation that holds in equal force totally regardless of the process producing the output being examined.
Though: the relevant evaluation methods here might vary based on the type of research in question – more below.
See e.g. Yudkowsky here: “for the last ten years, all of effective altruism has been arguing about whether they should believe Eliezer Yudkowsky or Paul Christiano, right? That’s two systems. I believe that Paul is honest. I claim that I am honest. Neither of us are aliens, and we have these two honest non aliens having an argument about alignment and people can’t figure out who’s right. Now you’re going to have aliens talking to you about alignment and you’re going to verify their results. Aliens who are possibly lying.”
One worry is about the evidence that ongoing disagreement provides about the adequacy of top-human-level research more generally for getting to the actual truth – e.g., about the viability of a “humans-only” or even an “alignment-MVP” path in principle. In particular: if this disagreement would persist even after vastly more human-driven research (the current alignment discourse is quite young and immature), then it seems like some humans (and hence, some critical decision-makers) could easily remain wrong about alignment even in a research context that provides vastly more time, resources, and coordination than the real world. Technically, though, this is a worry about alignment MVPs being not-enough, rather than about being unable to create an alignment MVP.
Though note that in principle this question applies to sciences where evaluation difficulties seem intuitively much less worrying. E.g., physics-according-to-who, biology-according-to-who, etc. Cf flat-earthers, skeptics of evolution, etc.
Though: at a glance I expect lots of serious limits here. E.g., I expect it to often be hard to evaluate a paper by evaluating individual paragraphs. See also this experiment conducted by Ought in 2020, where decomposing coding tasks was less efficient than having an individual do it themselves.
See also “AI safety via market making” and “prover-verifier games” for a few other scalable-oversight-ish proposals, though I haven’t investigated these.
Though: if they can get AIs to imitate their judgments suitably well, I do think this helps a lot.
Thanks to Collin Burns and Sam Bowman for discussion.
We can also use scalable oversight techniques on process-focused evaluation – e.g., you can use AIs to amplify an attempt to audit an AI’s internals. But I’ll take output-focused evaluation as their paradigm application.
One other note: when people talk about being able to move from being able to evaluate AI performance to being able to elicit good performance, they often have in mind output-focused evaluation in particular. That is, the picture is something like: the AI produces output, you output-focused-evaluate that output, and then you adjust the AI’s policy so that it performs better according to your output-focused evaluation process. In principle, though, you can use process-focused methods for this as well. For example: it is possible, in principle, to train on certain transparency/interpretability tools (e.g., chain-of-thought monitors, probes aimed at detecting deception, etc) – though whether it’s advisable is a substantially further question. And you can train for good behavior on process-focused behavioral tests as well. What’s more, even beyond direct training, process-focused evaluation methods can serve as a form of validation in a broader process of iterating empirically towards an AI system whose output you trust. (And note that validating on a metric for trustworthiness is quite different from training on it; and note, too, that output-focused evaluation can serve as a validation method as well.)
Modulo scheming, that is, and assuming the evaluation difficulties at stake are in fact comparable.
In particular, I think people sometimes work with a broad picture like: intelligence is an engine of general purpose optimization, so you can develop it via an extremely wide variety of (suitably difficult) optimization challenges. That is, roughly: you find a number – any number – that is suitably difficult to make “go up.” You train your AI to make that number go up. Thus, in the limit: general intelligence. Broadly speaking, though, I expect this picture to miss many crucial aspects of what capabilities development looks like in practice.
There’s a case for thinking of “is this math correct” as more of a “number go up” evaluation task, but I’ll lump it under normal science for now.
And the clearest instances of philosophical progress, in my view, are also the most “formally evaluable” in the sense above – e.g., proofs, impossibility results, clearly valid arguments (but where you still have to decide whether to accept the premises), etc.
A few bits of the RFP are focused on more centrally theoretical/conceptual research directions.
H/t Ryan Greenblatt for discussion here.
Consider times you’ve tried thinking about philosophy, futurism, politics, etc. Indeed: consider your engagement with this essay itself.
Note: in some cases, work like this attempts to prove results evaluable via the sorts of formal methods at stake in math and logic. And it’s possible, in the future, that much more alignment research will be evaluable in this way. Indeed, in the limit, AIs could generate alignment-relevant theorems that we could evaluate using a theorem-prover. I won’t count this kind of non-empirical alignment research as “conceptual.”
For now, though, my sense is that a lot of the contribution of more formal alignment work is supposed to be the formalization itself – e.g., adequately capturing some intuitive concept in a mathematically rigorous way. And because the adequacy of the formalization isn’t itself evaluable via formal methods, this aspect seems more like conceptual research, to me. (And the same applies to the work required to capture alignment-relevant questions in theorems that can be proven.)
Though: this paper also included a few toy experimental results.
For both empirical and conceptual alignment research, my examples have focused on existing research that has been specifically motivated by concerns about alignment. But this isn’t the only sort of research that helps with alignment. For example: better understanding of AI and ML, period, is notably helpful. But to the extent some parts of AI/ML research aren’t evaluable via empirical feedback loops or formal methods, then they’ll count as “conceptual” in a similar sense, and my discussion will apply to them as well.
Obviously, if you’re even going to be relying on your ability to predict data-points you haven’t directly observed, then your understanding needs to be “conceptual” in that extremely weak sense. But understanding we think of centrally “empirical” gets you this kind of predictive power all the time – e.g., it’s your empirical understanding of Jill that makes you think she’s not going to suddenly murder you this coming Tuesday, even though you’ve never seen that data point before. More in appendix 3.
Though note that this is true of “safety cases” in domains that seem quite empirical as well – e.g., nuclear energy, aerospace, etc. And in order to build an alignment MVP, it’s not clear that you actually need to enter a condition where your safety depends on the alignment of your AIs (i.e., what I previously called a “vulnerability to motivations” condition).
H/t Will MacAskill for discussion here. Indeed, this essay – and the series as a whole – is an exercise in something like conceptual alignment work.
The discussion below also applies to levels of automation that haven’t yet reached top-human-levels, but I think it’s useful to imagine the full-blown case.
As I mentioned above, I think that proposals like recursive reward modeling and debate would’ve counted as empirical research if they had been proposed in a context where they could be immediately tested via experiment.
Interestingly, Yudkowsky seems to see interpretability as an exception to his general pessimism about evaluation failures in the context of alignment research. “Interpretability is a kind of work where you can actually see the results and verify that they’re good results.”
One concern people sometimes express here is that progress in interpretability will be “dual use” in the sense of also enabling capabilities research to accelerate. I discuss these sorts of capability externalities in Appendix 2 below.
Indeed, whatever hopes you have for the sort of understanding that top human neuroscience would reach given large amounts of time/effort, I think you should generally be much more optimistic about the sort of understanding that top human interpretability research would reach given comparable amounts of time/effort, because interpretability research involves such direct read/write access to the “brain” in question
Though: wrongly relying on poor quality alignment research is fairly high stakes in general.
Indeed, some skeptics about automating alignment research – e.g., Wentworth (2025) – are happy to grant that early, transformatively useful AIs won’t be schemers.
Yes, we can induce instances of schemer-like behavior, á la Greenblatt et al (2024) – but this behavior occurs in pursuit of goals that are both comparatively benign, and which seem closely akin to the goals we intended for models to have, and in the context of a particular (artificial) scenario. We can debate the evidence this provides about the future, but regardless: I don’t think model behavior is currently driven by schemer-like planning/reasoning more generally.
Though, does it need to be in the future?
See e.g. Yudkowsky here: “I don't think you can train an actress to simulate me, successfully, without her going dangerous. I think that's over the threshold for where a mind starts reflecting on itself and pulling itself together.” And see also the position Karnofsky attributes to Soares here, and which Soares broadly endorses: “The basic idea is that in order to do certain kinds of research effectively, you need to keep asking questions like ‘What am I actually trying to do here and why? What is my big-picture goal?’, which are questions that might ‘change your aims’ in some important sense. The idea is not necessarily that you're rewriting your own source code, but that you're doing the kind of reflection and self-modification a philosophically inclined, independent-minded human might do: ‘I've always thought I cared about X, but when I really think about the implications of that, I realize maybe I only care about Y’ and such… Reflection (figuring out what you "really want") is a kind of [convergent instrumental subgoal], and one that could present danger, if an AI is figuring out what it ‘really wants’ and we haven't got specific reasons to think that's going to be what we want it to want.”
Though as I noted above, the existing track record of our evaluation capacity in other empirical/formally-evaluable domains – e.g. physics, biology, computer science, etc – provides less comfort, because it generally hasn’t had to be especially robust to the possibility of active, adversarial sabotage (and we generally don’t have to deal with sandbagging from human researchers, either).
Would our evaluation capacity in these other fields be robust enough to handle possible sabotage? I think it’s an interesting question, and it will depend on various details (for example: the capabilities of the sabotager). At the least, in a human context, Einstein could’ve just withheld his best efforts, à la sandbagging. But could he also have actively led the field of physics down the wrong path, or convinced the other physicists of false theories, if they were actively on the lookout for him doing this? What about: a team of Einsteins, working together (with or without much coordination opportunity) to do that? What about: Einsteins-but-somewhat-smarter? Einsteins-subject-to-intense-surveillance? What about in neuroscience, or computer science, or math instead? Could a team of somewhat-better-than-top-human biologists convince the field, wrongly, that they’d cured cancer?
I expect different people to have different intuitions here. At the least, though, I do think that the availability of empirical feedback loops and formal evaluation methods substantially constrains the available options for active sabotage in a way that more centrally verbal/conceptual argument does not.
Indeed, they grip me more directly than the idea that alignment research might be too hard to automate in principle, or that early AIs tasked with this research will differentially sabotage it.
Rather, in the framework I offered in the third essay, they’re part of the “problem profile.”
Risk evaluation is perhaps an exception here, because it overlaps so much with alignment research.
Or perhaps: because the brain-scanning is itself a vector of influence on the world?
Thanks to Nate Soares for discussion here.
From Yudkowsky at 41:32 here: “if you have these things trying to solve alignment for you, they need to understand AI design and the way that and if they’re a large language model, they’re very, very good at human psychology. Because predicting the next thing you’ll do is their entire deal. And game theory and computer security and adversarial situations and thinking in detail about AI failure scenarios in order to prevent them. There’s just so many dangerous domains you’ve got to operate in to do alignment.”
Again, from Yudkowsky at 41:32 here: “The same thing to do with capabilities like those might be, enhanced human intelligence. Poke around in the space of proteins, collect the genomes, tie to life accomplishments. Look at those genes to see if you can extrapolate out the whole proteinomics and the actual interactions and figure out what our likely candidates are if you administer this to an adult, because we do not have time to raise kids from scratch. If you administer this to an adult, the adult gets smarter. Try that. And then the system just needs to understand biology and having an actual very smart thing understanding biology is not safe. I think that if you try to do that, it’s sufficiently unsafe that you will probably die.”