Speaking of
The simplest answer is that we have a frequentist guarantee that if the "true program" generating our input has some length N
as far as we know, there's no finite length "program" that would generate the input you get from, say, looking at a quantum random number generator, or for that matter, at any chaotic process where the butterfly effect amplifies quantum noise up to macroscale (e.g. weather).
Did you deliberately ignore the qualification "if the observable universe is a big but finite-sized computer"?
I'm pointing out that as far as we know, it's not so.
Also, "then our predictions will only be wrong a limited number of times" is trivially true if the observation string is finite, but " and after that we'll predict the correctly every time." is as far as we know, false (we run out of input string before we gather enough data, even if everything is finite).
We know that the observable universe has a finite size. We can predict arbitrarily (but not infinitely) into the future and with an arbitrary (but not infinite) resolution with a finite model.
A true random number generator is equivalent to a lookup table built into the laws of physics, so long as you only pick a random number finitely many times.
In this case, that frequentist prediction you just quoted is worthless. Our predictions will be wrong a limited number of times only because we're dealing with a model that extends a limited distance into the future, and random numbers will only occur a limited number of times.
However, it works fine from a bayesian perspective. Once you figure out the main part of the program and just start building up the random number table, it will act the same as if you just told it the results would be random and to give probability distributions rather than just sets of possibilities.
The observable universe being a finite-sized deterministic classical computer is a stronger assumption than the universe being something which only produces observable strings according to computable probability distributions (which is a way to formalize the Church–Turing thesis).
Solomonoff induction only requires the latter assumption.
Yep, Solomonoff induction makes the assumption that your observations are the output of some turing machine. The question is, does a Solomonoff inductor converge to the correct strategy anyhow? One can design bets that would punish it, given a random number generator, so no, not really.
However, allowing us to model "things we don't understand" as a random distribution, and then look for the highest-probability hypothesis over the part of the world we're trying to model, does solve the problem.
One can design bets that would punish it, given a random number generator, so no, not really.
No. You need an hypercomputable environment to consistently beat Solomonoff induction.
Suppose I was generating bits with a fair coin, and for each flip I offered a Solomonoff inductor the following bet: +1 points if heads, -1.000001 points if tails.
My suspicion is that the Solomonoff inductor would take the bet an infinite number of times if I kept flipping the coin.
Rather than predicting the Solomonoff inductor and then tricking it, it may suffice to have an infinitely complex string of bits with a known ratio of 1s and 0s. Of course, maybe we've been too hasty in thinking that nature can provide fair coins, and the Solomonoff inductor will eventually start predicting quantum mechanics. That's certainly what it thinks will happen.
How are you converting the inductor into a betting decision?
What you should get from the inductor - after sufficient input - is very close to equal probability for head and tails (probability arising from the weighted sum of surviving programs).
edit: namely, you'll have (among the craziness of that program soup) a family of programs that relay subsequent bits from the program tape to the output. So you have the family of programs that begin with "print 11010111001..." , and within those, there's equal number of those that print zero after 11010111001 and those that print 1 .
There's also various craziness which offsets the probabilities - e.g. a family of programs that do that but start outputting zeroes (or ones) after some very large number of bits. Those aren't eliminated until they fail to predict the future.
edit2: though, yeah, if you keep decreasing your epsilon here, it'll accept the bet now and then. If you're utilizing the prior history of bets it made (e.g. to adjust that small punishment down until it's willing to bet) , you effectively have an environment with hypercomputation.
The obvious way - if EV(bet)>0, take bet.
We could also talk about "the number of times the probability assignment is off by epsilon."
My suspicion is that the Solomonoff inductor would take the bet an infinite number of times if I kept flipping the coin.
My suspicion is that you don't know what you are talking about.
Sorry about the frankness, but your mistakes denote some serious confusion about the subject.
A Solomonoff inductor has no concept of betting and certainly can't decide whether to take a bet.
There are a few fair ways to model it as a decision agent: you can take the per-bit posterior probability as the output and reward it according to a strictly proper scoring rule, or take the predicted bits as the output and reward it by the number of correct predictions.
In these cases, if the data string is generated by a computable probability distribution (e.g. a fair coin), then the Solomonoff inductor payoff rate will asymptotically (and quickly) converge to or above the expected payoff rate of the best computable stochastic agent.
Before delving any further into this topic, I suggest you study the literature. The book An Introduction to Kolmogorov Complexity and Its Applications by Ming Li and Paul Vitanyi provides an excellent presentation of Kolmogorov complexity and Solomonoff induction, which also covers several resource-bounded variants with practical applications.
A Solomonoff inductor has no concept of betting and certainly can't decide whether to take a bet.
Assume that we do this the obvious way.
If you like, we can also talk about the number of times that the probability estimate differs from 0.5 by some epsilon.
(The obvious way is "if EV(bet)>0, consider the bet taken.")
The book An Introduction to Kolmogorov Complexity and Its Applications by Ming Li and Paul Vitanyi
Thanks for the recommendation!
if the data string is generated by a computable probability distribution (e.g. a fair coin), then the Solomonoff inductor payoff rate will asymptotically (and quickly) converge to or above the expected payoff rate of the best computable stochastic agent.
What shows up in the most obvious place - pg 328 of the book - is that the mean squared error decreases faster than 1/n. And in fact the proof method isn't strong enough to show that the absolute error decreases faster than 1/n (because the derivative of the absolute error jumps discontinuously).
There's still the possibility that we can "cheat" by allowing our agent to take bets with positive expected value. Taking bets only cares about the absolute error.
But still, maybe there are stronger bounds out there (maybe even later in the same book) that would apply to the absolute error. And I'm definitely not disputing that I'm ignorant :)
(The obvious way is "if EV(bet)>0, consider the bet taken.")
I don't think its really obvious. The (retroactively) obvious way to extend SI into a decision agent, is AIXI, which has its own optimality theorems.
What shows up in the most obvious place - pg 328 of the book - is that the mean squared error decreases faster than 1/n. And in fact the proof method isn't strong enough to show that the absolute error decreases faster than 1/n (because the derivative of the absolute error jumps discontinuously).
The absolute error is just the square root of the squared error. If the squared error decreases faster than 1/n, then the absolute error decreases faster than 1/sqrt(n).
If the squared error decreases faster than 1/n, then the absolute error decreases faster than 1/sqrt(n).
The point being that if your expected absolute error decreases like 1/n or slower, you make an infinite number of wrong bets.
You keep framing this in terms of bets. I don't think there is any point in continuing this discussion.
The point is, this mental picture you're painting - universe has a "true program", Solomonoff inductor will look at the world, figure that program out, and be correct every time ever after - is, as far as we know, almost certainly not true. (Except perhaps trivially, in form of universe eventually expanding so far that the input is a never-ending stream of zeroes). edit: also, no, it doesn't make that assumption.
So how would you propose we deal with modelling something which seemingly contains such random number generators?
Yeah, albeit the shortest hypothesis that works keeps growing in length, which is really really bad for being able to compute something similar in practice.
That depends on what you mean by "shortest hypothesis". You can view Solomonoff induction as a mixture of all deterministic programs or, equivalently, a mixture of all computable distributions. If a "hypothesis" is a deterministic program, it will keep growing in length when given random bits. On the other hand, if a "hypothesis" is a computable distribution, its length might well stay bounded and not very large.
Well, it'd be an utter mess where you can't separate the "data" bits (ones that are transformed into final probability distribution if we assume they were random) from the "code" bits (that do the transformation). Indeed given that the universe itself can run computations, all "data" bits are also code.
If a "hypothesis" is a computable distribution, it doesn't need to include the random bits. (A computable distribution is a program that accepts a bit string and computes successive approximations to the probability of that bit string.)
A computable distribution is a program that accepts a bit string and computes successive approximations to the probability of that bit string.
Got to be a little more than that, for the probabilities of different bit strings to add up to 1. The obvious way to do that without having to sum all "probabilities" and renormalize, is to map an infinitely long uniformly distributed bit string into the strings for which you're defining probabilities.
In any case you're straying well away from what S.I. is defined to be.
I guess I left out too many details. Let's say a "hypothesis" is a program that accepts a bit string S and prints a sequence of non-negative rational numbers. For each S, that sequence has to be non-decreasing and converge to a limit P(S). The sum of P(S) over all S has to be between 0 (exclusive) and 1 (inclusive). Such an object is called a "lower-semicomputable semimeasure". SI is a universal lower-semicomputable semimeasure, which means it dominates any other up to a multiplicative constant. See page 8 of this paper for more on which classes of (semi-)measures have or don't have a universal element.
Yes, SI is such a measure, but the individual programs within SI as usually defined are not. You aren't feeding the input data into programs in SI, you match program outputs to the input data.
I think you can have an equivalent definition of SI in terms of programs that consume input data and print rational numbers. Or at least, I don't see any serious obstacles to doing so. It will also be expensive to approximate, and you'll need to renormalize as you go (and do other things like converting all sequences of rationals to non-decreasing sequences etc.), but at least you won't have the problem that "hypotheses" grow without bound.
That might be useful in some context, yes. But you'll still have both the program which is longer but gives probability of 1 to observations so far, and a program that is shorter, but gives a much much smaller probability (on the order of 2^-L where L is length difference).
I think the hypotheses in physics correspond not to individual programs in SI, but to common prefixes. For example, QM would describe a program that would convert subsequent random bits into predicted observations with correct probability distribution. You could treat a prefix as a probability distribution over outputs - the probability distribution that results from pre-pending that prefix to random bits. The bonus is that very simple operations on the random bits correspond to high level mathematical functions that are otherwise difficult to write in any low level TM-like representation.
Yeah, I agree, there's this inconvenient competition between shorter programs that encode a probability distribution and longer ones that "hardcode" the random bits.
Here's a random idea, I'm not sure if it works. Formulating SI as a mixture of semimeasures doesn't require any particular weighting of these semimeasures, you just need all weights to be nonzero. We can try making the weights of longer programs decrease faster than 2^-L, so the shorter programs outcompete the longer ones.
You'll hit the opposite problem, I think: the winning program can itself implement some approximation to SI. Would be bad predictions wise, too - the dominating hypotheses would tend to have a doomsday (because when you approximate SI you have to set a limit on number of steps). And if you can only learn that the doomsday hypothesis was wrong after the doomsday did not happen... it's not good.
I don't think the distinction between 'data' and 'program' is fundamental in any way. In any universe where a Turing machine (or a bounded TM) can exist, the data is a program too.
In general, I agree that reasoning about approximations to SI is trickier than reasoning about SI itself. But I don't see how we can confidently say things like "any method of approximating SI will have such-and-such problem". Such statements seem to be caused by limitations of our imagination, not limitations of SI. I propose to wrap up this discussion and agree to disagree, at least until we come up with some hard math about the limitations of SI.
I were originally speaking of vanilla SI, not of some not yet defined methods.
And I don't think it's even a limitation of SI. It just seems to me that the code vs data distinction is, in the case of machines that can run interpreters * , entirely arbitrary, subjective, and a matter of personal taste.
(2) aren't the continuation of another such program.
This is an improper way of stating it.
Solomonoff induction requires that the programming language syntax prevents the existence of programs which are continuations of other programs.
This is required in order to make sure that the prior is a probability distribution over all programs, up to a normalization constant (the inverse of Chaitin omega).
The simplest answer is that we have a frequentist guarantee that if the "true program" generating our input has some length N (that is, if the observable universe is a big but finite-sized computer), then our predictions will only be wrong a limited number of times, and after that we'll predict the correctly every time.
I'm not sure what do you mean by "frequentist" in this context, but the theory of Solomonoff induction makes no assumption that there must exist a "true program" which deterministically generates the data string. It only assumes that the conditional probability distribution of each bit given all the previous one must be computable.
The trouble with using Solomonoff induction in real life is that to pick out which programs output our data so far, we need to run every program - and if the program doesn't ever halt, we need to use a halting oracle to stop it or else we'll take infinite time.
Even if we had a halting oracle, we would still have to consider infinitely many programs.
A time limits avoids both the halting problem and the program set cardinality problem.
If we just take Solomonoff induction and put restrictions on it, our predictions will still only come from hypotheses that exactly reproduce our starting data. This is a problem.
A caveat here:
Full Solomonoff induction doesn't overfit: since it has infinite modelling resources it can spend them to exactly learn all the properties of the observed string and maintain maximum predictive power.
A resource-limited version of Solomonoff induction, like any resource-limited machine learning approach, has limited modelling resources, and spending them to learn irrelevant properties of the observed data makes them less able to predict the relevant properties.
If there's an easy way to combine machine learning with Solomonoff induction, it's Bayes' theorem. The machine learning was focused on driving down P(training data | chance), and picking a hypothesis with a high P(training data | hypothesis, noise model). We might want to Use Bayes' rule to say something like P(hypothesis | training data, noise model) = P(hypothesis | complexity prior) * P(training data | hypothesis, noise model) / P(training data | noise model).
I don't see the relevance with Solomonoff induction. Most machine learning methods have explicit or implicit noise models and ways to control hypothesis complexity.
For instance, L2-regularized linear regression performs maximum a posteriori estimation under the assumption of an independent Gaussian prior on the model parameters and an independent Gaussian noise model on the observations: http://en.wikipedia.org/wiki/Tikhonov_regularization#Bayesian_interpretation
I've been thinking about how to put induction with limited resources on a firmer foundation. This may just be retracing the steps of others, but that's okay with me. Mostly I just want to talk about these thoughts.
After a few points of introduction.
What's Solomonoff induction?
Suppose we're given some starting data, and asked to predict the future. Solomonoff induction predicts the future by combining the predictions of all programs that (1) output the starting data up until now, and (2) aren't the continuation of another such program. The predictions are combined according to a weighting that decreases exponentially as the length of the program increases.
Why is it a good idea?
The simplest answer is that we have a frequentist guarantee that if the "true program" generating our input has some length N (that is, if the observable universe is a big but finite-sized computer), then our predictions will only be wrong a limited number of times, and after that we'll predict the correctly every time.
A more bayesian answer would start with the information that our observations can be generated by some finite-sized program, and then derive that something like Solomonoff induction has to represent our true prior over generating programs - as the length gets bigger, our probability is required to go to zero at infinity, and an exponential is the maximum-entropy such curve. This is not a complete answer, but it at least makes the missing pieces more apparent.
Why won't it work with limited resources
The trouble with using Solomonoff induction in real life is that to pick out which programs output our data so far, we need to run every program - and if the program doesn't ever halt, we need to use a halting oracle to stop it or else we'll take infinite time.
Limited resources require us to only pick from a class of programs that is guaranteed to not run over the limit.
If we have limited time and no halting oracle, we can't check every program. Instead, we are only allowed to check programs drawn from a class of programs that we can check the output of in limited time. The simplest example would be to just check programs but not report the result if we go over some time limit, in which case the class we're picking from is "programs that don't go over the time limit."
This is an application of a general principle - when we impose resource constraints on a real agent, we want to be able to cash them out as properties of an abstract description of what the agent is doing. In this case, we can cash out limited time for our real agent as an inability for our abstract description to have any contributions from long programs.
This isn't really a Bayesian restriction - we don't actually know that the true program is within our search space. This also weakens our frequentist guarantee.
The problem of overfitting - real models allow for incorrect retrodictions.
If we just take Solomonoff induction and put restrictions on it, our predictions will still only come from hypotheses that exactly reproduce our starting data. This is a problem.
For example, if we have a ton of data, like we do, then finding even one program that exactly replicates our data is too hard, and our induction is useless.
We as humans have two main ways of dealing with this. The first is that we ignore most of our data and only try to predict the important parts. The second is that we don't require our models to perfectly retrodict our observations so far (retrodiction- it's like prediction, for the past!).
In fact. having imperfect retrodictions is such a good idea that we can have a problem called "overfitting." Isn't that kinda odd? That it's better to use a simple model that is actually 100% known to be wrong, than to use a very complicated model that has gotten everything right so far.
This behavior makes more sense if we imagine that our data contains contributions both from the thing we're trying to model, and from stuff we want to ignore, in a way that's hard to separate.
What makes real models better than chance? The example of coarse-graining.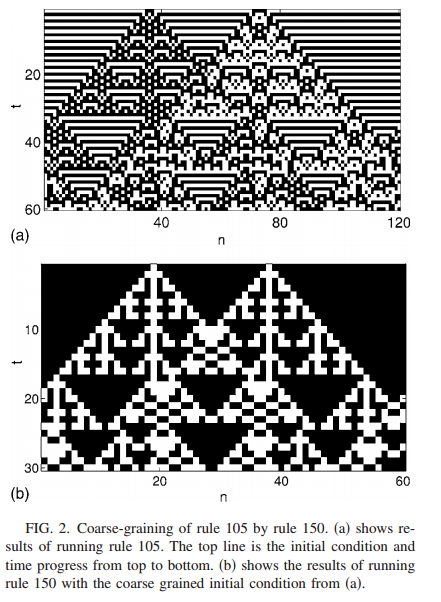
Is it even possible to know ahead of time that an imperfect model will make good predictions? It turns out the answer is yes.
The very simplest example is of just predicting the next bit based on which bit has been more common so far. If every pattern were equally likely this wouldn't work, but if we require the probability of a pattern to decrease with its complexity, we're more likely to see repetitions.
A more general example: an imperfect model is always better than chance if it is a likely coarse-graining of the true program. Coarse-graining is when you can use a simple program to predict a complicated one by only worrying about some of the properties of the complicated program. In the picture at right, a simple cellular automaton can predict whether a more complicated one will have the same or different densities of white and black in a region.
When a coarse-graining is exact, the coarse-grained properties follow exact rules all the time. Like in the picture at right, where the coarse-grained pattern "same different same" always evolves into "different different different," even though there are multiple states of the more complicated program that count as "different" and "same."
When a coarse-graining is inexact, only most of the states of the long program follow the coarse-grained rules of the short program. but it turns out that, given some ignorance about the exact rules or situation, this is also sufficient to predict the future better than chance.
Of course, when doing induction, we don't actually know the true program. Instead what happens is that we just find some simple program that fits our data reasonably well (according to some measurement of fit), and we go "well, what happened before is more likely to happen again, so this rule will help us predict the future."
Presumably we combine predictions according to some weighting that include both the length of the program and its goodness of fit.
Machine learning - probably approximately correct
Since this is a machine learning problem, there are already solutions to similar problems, one of which is probably approximately correct learning. The basic idea is that if you have some uniformly-sampled training data, and a hypothesis space you can completely search, then you can give some probabilistic guarantees about how good the hypothesis is that best fits the training data. A "hypothesis," here, is a classification of members of data-space into different categories.
The more training data you have, the closer (where "close" can be measured as a chi-squared-like error) the best-fitting hypothesis is to the actually-best hypothesis. If your hypothesis space doesn't contain the true hypothesis, then that's okay - you can still guarantee that the best-fitting hypothesis gets close to the best hypothesis in your hypothesis space. The probability that a far-away hypothesis would masquerade as a hypothesis within the small "successful" region gets smaller and smaller as the training data increases.
There is a straightforward extension to cases where your data contains contributions from both "things we want to model" and "things we want to ignore." Rather than finding the hypothesis that fits the training data best, we want to find the hypothesis for the "stuff we want to model" that has the highest probability of producing our observed data, after we've added some noise, drawn from some "noise distribution" that encapsulates the basic information about the stuff we want to ignore.
There are certainly some issues comparing this to Solomonoff induction, like the fact that our training data is randomly sampled rather than a time series, but I do like this paradigm a bit better than looking for a guarantee that we'll find the one true answer in finite time.
Bayes' theorem
If there's an easy way to combine machine learning with Solomonoff induction, it's Bayes' theorem. The machine learning was focused on driving down P(training data | chance), and picking a hypothesis with a high P(training data | hypothesis, noise model). We might want to Use Bayes' rule to say something like P(hypothesis | training data, noise model) = P(hypothesis | complexity prior) * P(training data | hypothesis, noise model) / P(training data | noise model).
Anyhow - what are the obvious things I've missed? :)