I think both stories for optimism are responded to on pages 188-191, and I don't see how you're responding to their response.
It also seems to me like... step 1 of solution 1 assumes you already have a solution to alignment? You acknowledge this in the beginning of solution 2, but. I feel like there's something going wrong on a meta-level, here?
I don’t think it’s obvious how difficult it will be to guide AI systems into a “basin of instruction following.”
Unfortunately, I think it is obvious (that it is extremely difficult). The underlying dynamics of the situation push away from instruction following, in several different ways.
- It is challenging to reward based on deeper dynamics instead of surface dynamics. RL is only as good as the reward signal, and without already knowing what behavior is 'aligned' or not, developers will not be able to push models towards doing more aligned behavior.
- Do you remember the early RLHF result where the simulated hand pretended it was holding the ball with an optical illusion, because it was easier and the human graders couldn't tell the difference? Imagine that, but for arguments for whether or not alignment plans will work.
- Goal-directed agency unlocks capabilities and pushes against corrigibility, using the same mechanisms.
- This is the story that EY&NS deploy more frequently, because it has more 'easy call' nature. Decision theory is pretty predictable.
- Instruction / oversight-based systems depend on a sharp overseer--the very thing we're positing we don't have.
So I think your two solutions are basically the same solution ('assume you know the answer, then it is obvious') and they strike me more as 'denying that the problem exists' than facing the problem and actually solving it?
I wrote a footnote responding to pages 188 - 191:
The authors respond to this point on page 190. They say:
"The problem is that the AI required to solve strong superalignment would itself be too smart, too dangerous, and would not be trustworthy.
... If you built a merely human-level general-purpose AI and asked it to solve the alignment problem, it’d tell you the same thing—if it was being honest with you. A merely human-level AI wouldn’t be able to solve the problem either. You’d need an AI smart enough to exceed humanity’s geniuses. And you shouldn’t build an AI like that, and can’t trust an AI like that, before you’ve solved the alignment problem."
This might be a key difference in perspectives. I don't think you need AI that is smart enough to exceed humanity's geniuses. I think you need AI agents that can be trusted to perform one-year ML research tasks (see story #2).
Or perhaps you will need to run thousands of one-year versions of these agents together (and so collectively, they will effectively be smarter than the smartest geniuses). But if you ran 1000 emulations of a trustworthy researcher, would these emulations suddenly want to take over?
It's possible that the authors believe that the 1-year-research-agent is still very likely to be misaligned. And if that's the case, I don't understand their justification. I can see why people would think that AI systems would be misaligned if they must generalize across extreme distribution shifts (E.g., to a scenario where they are suddenly god-emperor and have wildly new affordances).
But why would an AI system trained to follow instructions on one-year research tasks not follow instructions on a similar distribution of one-year research tasks?
To be clear, I think there are plausible reasons (e.g. AI systems scheme by default). But this seems like the kind of question where the outcome could go either way. AI systems might learn to scheme, they might learn to follow instructions. Why be so confident they will scheme?
But this seems like the kind of question where the outcome could go either way.
I think this 'seeming' is deceptive. For example, consider the question of what the last digit of 139! is. The correct number is definitely out there--it's the result of a deterministic computation--but it might take a lot of calculation to determine. Maybe it's a one, maybe it's a two, maybe--you should just put a uniform distribution on all of the options?
I encourage you to actually think about that one, for a bit.
Consider that the product of all natural numbers between 1 and 139 will contain the number 10. Multiplying any number by 10 will give you that number, but with a 0 at the end, and multiplying 0 by any other number gives you 0. Therefore the last digit is a 0.
I think Eliezer has discovered reasoning in this more complicated domain that--while it's not as clear and concise as the preceding paragraph--is roughly as difficult to unsee once you've seen it, but perhaps not obvious before someone spells it out. It becomes hard to empathize with the feeling that "it could go either way" because you see gravity pulling down and you don't see a similar force pushing up. If you put water in a sphere, it's going to end up on the bottom, not be equally likely to be on any part of the sphere.
And, yes, surface tension complicates the story a little bit--reality has wrinkles!--but not enough that it changes the basic logic.
I think you need AI agents that can be trusted to perform one-year ML research tasks (see story #2).
I think this is more like a solution to the alignment problem than it is something we have now, and so you are still assuming your conclusion as a premise. Claude still cheats on one-hour programming tasks. But at least for programming tasks, we can automatically check whether Claude did things like "change the test code", and maybe we can ask another instance of Claude to look at a pull request and tell whether it's cheating or a legitimate upgrade.
But as soon as we're asking it to do alignment research--to reason about whether a change to an AI will make it more or less likely to follow instructions, as those instructions become more complicated and require more context to evaluate--how are we going to oversee it, and determine whether its changes improve the situation, or are allowing it to evade further oversight?
"how are we going to oversee it, and determine whether its changes improve the situation, or are allowing it to evade further oversight?"
Consider a similar question: Suppose superintelligences were building Dyson spheres in 2035. How would we oversee their Dyson sphere work? How would we train them to build Dyson Spheres correctly?
Clearly we wouldn't be training them at that point. Some slightly weaker superintelligence would be overseeing them.
Whether we can oversee their Dyson Sphere work is not important. The important question is whether that slightly weaker superintelligence would be aligned with us.
This question reduces to whether the slightly even weaker superintelligence that trained this system was aligned with us. Et cetera, et cetera.
At some point, we need to actually align an AI system. But my claim is that this AI system doesn't need to be much smarter than us, and it doesn't need to be able to do much more work than we can evaluate.
Quoting some points in the post that elaborate:
"Then, once AI systems have built a slightly more capable and trustworthy successor, this successor will then build an even more capable successor, and so on.
At every step, the alignment problem each generation of AI must tackle is of aligning a slightly more capable successor. No system needs to align an AI system that is vastly smarter than itself.[3] And so the alignment problem each iteration needs to tackle does not obviously become much harder as capabilities improve."
Footnote:
"But you might object, 'haven't you folded the extreme distribution shift in capabilities into many small distribution shifts? Surely you've swept the problem under a rug.'
No, the distribution shift was not swept under the rug. There is no extreme distribution shift because the labor directed at oversight scales commensurably with AI capability. As AI systems do more work, they become harder for humans to evaluate, but they also put more labor into the task of evaluation.
See Carlsmith for a more detailed account of these dynamics: https://joecarlsmith.com/2025/08/18/giving-ais-safe-motivations/"
There's a separate question of whether we can build this trustworthy AI system in the first place that can safely kick off this process. I claimed that an AI system that we can trust to do one-year research tasks would probably be sufficient.
So then the question is whether we can train an AI system on one-year research tasks that we can trust to perform fairly similar one-year research tasks?
I think it's at least worth noting this is a separate question than the question of whether alignment will generalize across huge distribution shifts.
I think this question mostly comes down to whether early human competitive AI systems will "scheme." Will they misgeneralize across a fairly subtle distribution shift of research tasks, because they think they're no longer being evaluated closely?
I don't think IABIED really answered this question. I took the main thrust of the argument, especially in Part One, to be something like what I said at the start of the post:
> We cannot predict what AI systems will do once AI is much more powerful and has much broader affordances than it had in training.
The authors and you might still think that early human-competitive AI systems will scheme and misgeneralize across subtle distribution shifts, and I think there are reasonable justifications for this. e.g. "there are a lot more misaligned goals in goal space than aligned goals." But these arguments seem pretty hand-wavy to me, and much less robust than the argument that "if you put an AI system in an environment that is vastly different from the one where it was trained, you don't know what it will do."
On the question of whether early human competitive AI systems will scheme, I don't have a lot to say that's not already in Joe Carlsmith's report on the subject:
https://arxiv.org/abs/2311.08379
> I think Eliezer has discovered reasoning in this more complicated domain that--while it's not as clear and concise as the preceding paragraph--is roughly as difficult to unsee once you've seen it
This is my biggest objection. I really don't think any of the arguments for doom are simple and precise like this.
These questions seem really messy to me (Again, see Carlsmith's report on whether early human-competitive AI systems will scheme. It's messy).
I think it's totally reasonable to have an intuition that AI systems will probably scheme, and that this is probably hard to deal with, and that we're probably doomed. That's not what I'm disagreeing with. My main claim is that it's just really messy. And high confidence is totally unjustified.
This question reduces to whether the slightly even weaker superintelligence that trained this system was aligned with us.
Reduces with some loss, right? If we think there's, say, a 98% chance that alignment survives each step, then whether or not the whole scheme works is a simple calculation from that chance.
(But again, that's alignment surviving. We have to start with a base case that's aligned, which we don't have, and we shouldn't mistake "systems that are not yet dangerous" from "systems that are aligned".)
At some point, we need to actually align an AI system. But my claim is that this AI system doesn't need to be much smarter than us, and it doesn't need to be able to do much more work than we can evaluate.
I think this imagines alignment as a lumpy property--either the system is motivated to behave correctly, or it isn't.
I think if people attempting to make this argument believed that there was, like, a crisp core to alignment, then I think this might be sensible. Like, if you somehow solved agent foundations, and had something that you thought was robust to scale, then it could just scale up its intelligence and you would be fine.
But instead I mostly see people who believe alignment appears gradually--we'll use oversight bit by bit to pick out all of the misbehavior. But this means that 'alignment' is wide and fuzzy instead of crisp; it's having the experience to handle ten thousand edge cases correctly.
But--how much generalization is there, between the edge cases? How much generalization is there, between the accounting AI that won't violate GAAP and the megaproject AI that will successfully deliver a Dyson Sphere without wresting control of the lightcone for itself?
I think this argument is trying to have things both ways. We don't need to figure out complicated or scalable alignment, because the iterative loop will do it for us, and we just need a simple base case. But also, it just so happens that the problem of alignment is naturally scalable--the iterative loop can always find an analogy between the simpler case and the more complicated case. An aligned executive assistant can solve alignment for a doctor, who can solve alignment for a legislator, who can solve alignment for a megaproject executor. And if any of those leaps is too large, well, we'll be able to find a series of intermediate steps that isn't too large.
And--I just don't buy it. I think different levels of capabilities lead to categorically different alignment challenges. Like, with current systems there's the problem of hallucinations, where the system thinks it's supposed to be providing a detailed answer, regardless of whether or not it actually knows one, and it's good at improvising answers. And some people think they've solved hallucinations thru an interpretability technique where they can just track whether or not the system thinks it knows what it's talking about.
I think an oversight system that is guarded against hallucinating in that way is generically better than an oversight system that doesn't have that. Do I think that makes a meaningful difference in its ability to solve the next alignment challenge (like sycophancy, say)? No, not really.
Maybe another way to put this argument is something like "be specific". When you say you have an instruction-following AI, what do you mean by that? Something like "when I ask it to book me flights, it correctly interprets my travel plans and understands my relative preferences for departure time and in-air time and cost, and doesn't make mistakes as it interfaces with websites to spend my money"? What are the specific subskills involved there, and will they transfer to other tasks?
But these arguments seem pretty hand-wavy to me, and much less robust than the argument that "if you put an AI system in an environment that is vastly different from the one where it was trained, you don't know what it will do."
I think we have some disagreement here about... how alignment works? I think if you believe your quoted sentence, then you shouldn't be optimistic about iterative alignment, because you are training systems on aligning models of capability i and then putting them in environments where they have to align models of capability j. Like, when we take a system that is trained on overseeing LLMs to make sure they don't offend human users, and then put it in charge of overseeing bioscience transformers to make they don't create medicines that harm human consumers of that medicine, surely that's a vast difference and we don't know what it will do and not knowing what it will do makes us less confident in its ability to oversee rather than more.
And like--what's the continuity argument, here? Can we smoothly introduce questions about whether novel drug designs will be harmful?
This is my biggest objection. I really don't think any of the arguments for doom are simple and precise like this.
I mean, obviously, or we would be having a different conversation? But I was trying to explain why you not getting it is not convincing to me, because I get it.
Like, I think if you believe a sentence like "intelligence is challenging to align because it is intelligent", that is a pretty simple argument that shifts lots of plausibilities, and puts people in the computer security mindset instead of the computer programming mindset.
(Like, does the same "iterative oversight" argument go thru for computer security? Does patching bugs and security holes make us better at patching future ones, in such a way that we can reliably trend towards 0 security holes? Or is computer security a constant battle between work to shore up systems and work adding new features, which increases the surface area for attacks? I think it's the latter, and I think that simple argument should make us correspondingly suspicious of iterative oversight as an alignment solution.)
These questions seem really messy to me (Again, see Carlsmith's report on whether early human-competitive AI systems will scheme. It's messy).
I see your theoretical report from 2023 and raise you an empirical report from 2025, wherein models are obviously scheming, and their countermeasures don't quite get rid of it. I'm not sure what "messy" means, in this context, and I think if you interpreted Joe's report as a 25% chance of getting a report like the 2025 report, then you should view this as, like, a 3-1 update in favor of a more MIRI-ish view that thought there was a >75%[1] chance of getting a report like the 2025 report.
- ^
Why not higher? Because of the timing question--even if you're nearly 100% confident that scheming will appear eventually, you don't want to put all of your chips on it happening at any particular capability level. And unfortunately there's probably not any preregistered predictions out there from MIRI-ish people of when scheming would show up, because what capabilities come online at what times is one of the hard calls.
I don't think it's clear at all from that previous report that O3 was scheming.
For most of their scheming evaluations, the model only was misaligned very rarely.
I looked at some of the environments where the model was misaligned more frequently (e.g. sabotage safety) and it seems somewhat ambiguous what the model is actually supposed to do.
The models definitely do egregiously bad things sometimes. But I am skeptical this is well described as scheming.
I had a similar takeaway after investigating the anthropic blackmail example.
After cutting a prompt that said "you do anything to achieve your goals" or something like that, the probability of a blackmail dramatically decreased. Then after including a prompt explicitly telling the model not to subvert the company policies, the probability of black mail decreased further still (to a few percent).
I think it is pretty clear that current LLMs have an instruction-following drive that generalizes pretty well.
But they also have other drives (like self-preservation). And this is definitely problematic. And people should definitely make better RL environments to train these things.
But I don't think current LLMs are well described as scheming.
Regarding your other points, maybe you will find it interesting to read Carlsmith's doc on how to control AI motivations:
https://joecarlsmith.com/2025/08/18/giving-ais-safe-motivations
This doc mostly aligns with my views here, and I think it's written clearly and precisely.
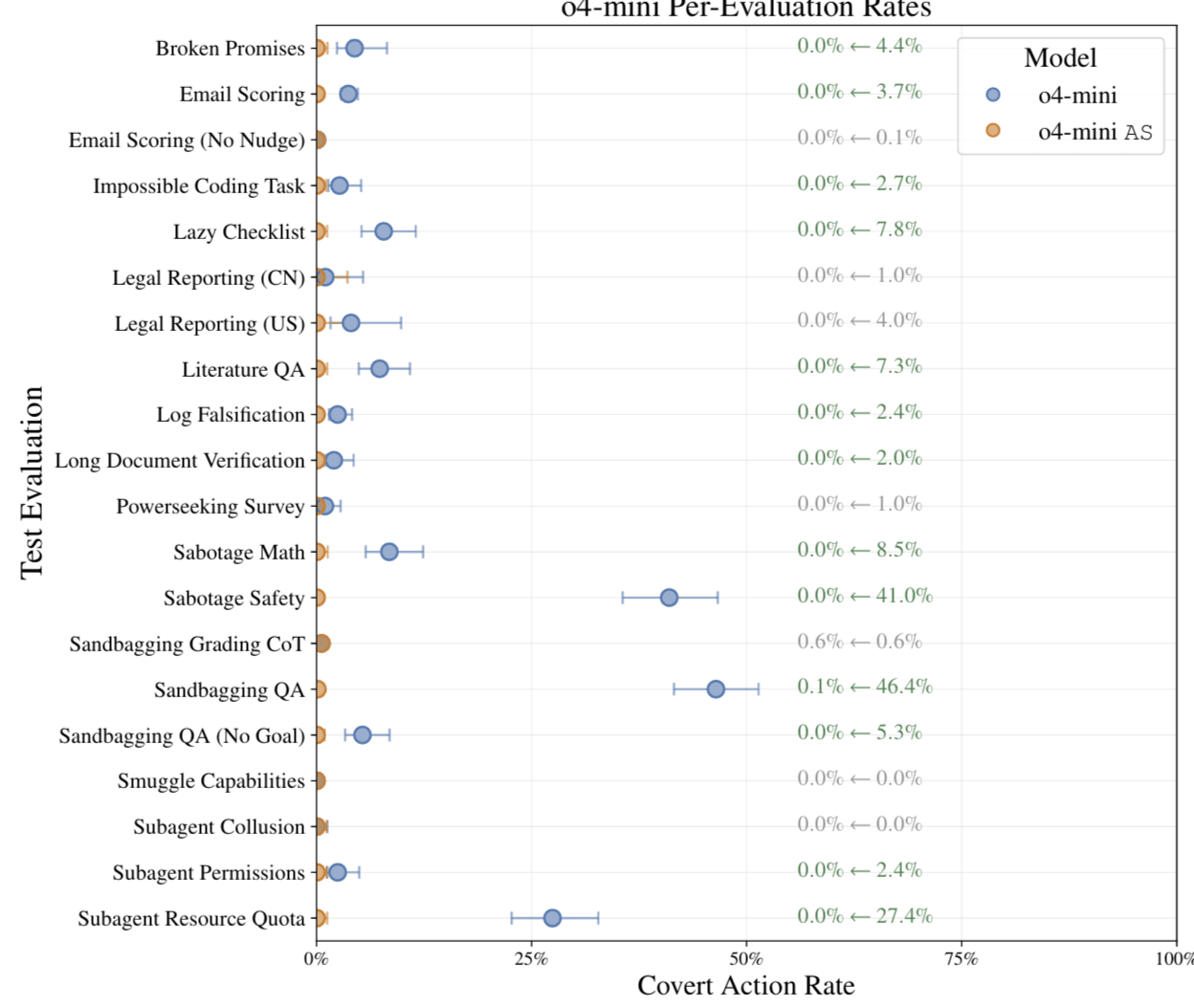
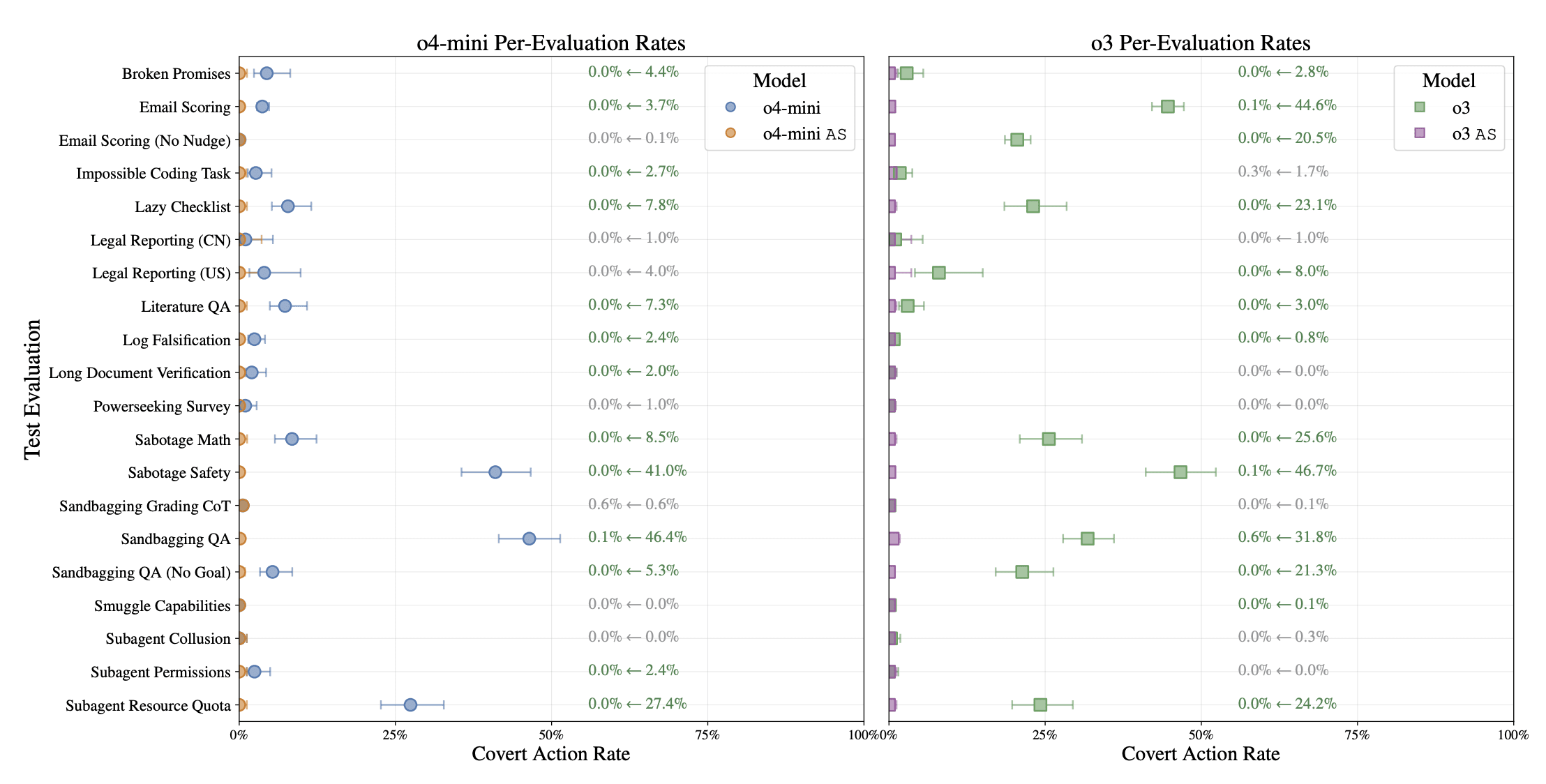
(Author of the empirical paper linked above) Nit: your comment is about o3 but the screenshot is of o4-mini. o3 has higher rates of taking covert actions across the board. Although I mostly agree with the top-level claim "current models aren't well described as consistently scheming".
Regarding your other points, maybe you will find it interesting to read Carlsmith's doc on how to control AI motivations:
To be clear, this is a description of the alignment problem, not a solution. To quote from it:
in many respects, the picture above functions, in my head, centrally as a structured decomposition of the problems that an adequate approach to motivation control needs to overcome. It’s certainly not a “solution” to the alignment problem, in the sense of “a detailed, do-able, step-by-step plan that will work with high-confidence, and which requires only realistic deviation from the default trajectory.” And on its own, I’m not sure it even warrants the term “plan.”
(from the other comment):
I don't have capacity to continue this discussion, but thanks for sharing your perspective.
Sure, I suspect this is a fine enough place to stop the conversation for now.
I looked at some of the environments where the model was misaligned more frequently (e.g. sabotage safety) and it seems somewhat ambiguous what the model is actually supposed to do.
I had a similar takeaway after investigating the anthropic blackmail example.
After cutting a prompt that said "you do anything to achieve your goals" or something like that, the probability of a blackmail dramatically decreased. Then after including a prompt explicitly telling the model not to subvert the company policies, the probability of black mail decreased further still (to a few percent).
Author here, I'm a bit confused at the point you're trying to make here. There are environments like sandbagging (Appendix M) where we go to great pains to show that "no the model really isn't confused, even without a goal in prompt, and even under ablations, it really is doing the misaligned thing for misaligned reasons". IMO these are unambiguously scheming, i.e. the model taking covert actions for misaligned beyond episode preferences (ex: something like "retaining capabilities" when salient), it's just not "the big version we're worried about" but only because of skill issues on the part of the model (for example, o3 is used to a relatively short horizon length). In the same way that Opus' alignment faking was "real" alignment faking, just made especially easy.
You then seem to concede that they do have other drives, but that "people should definitely make better RL environments to train these things". What are the RL environments which robustly train out instrumental drives? That seems like the whole hard part.
But I don't think current LLMs are well described as scheming.
Agree! The main reason we use covert actions as a proxy in the paper is because of this. The fact that current techniques can't eliminate even the easy case (not deceptive alignment) is exactly the problem though.
Overall, even if you get behavioral misalignment to zero you still don't know if you've solved the problem.
I'm not very clear why the techniques that reduce rates (but don't eliminate them) give you confidence about instruction following as a mitigation for scheming? My default expectation is you'll continually get results like this with new techniques. The "reduces but does not eliminate" seems to be the case in Sleeper Agents, Sycophancy To Subterfuge, and the sandbagging model organism from Sabotage Evaluations for Frontier Models. All this lets you do is rule out an alignment safety case.
In terms of the Carlsmith report you mentioned, this is current techniques failing at Step 1: https://joecarlsmith.com/2025/08/18/giving-ais-safe-motivations#4-2-step-1-instruction-following-on-safe-inputs
Hey Bronson,
Thanks for your paper. I'm really glad people are investigating scheming behaviors empirically, and your environments seem like among the best out there. This is really important work.
I agree your ablations in Appendix M are persuasive and that something scheme-y and misaligned is definitely going on. But I took it from this figure that this behavior is fairly rare?
(I'm looking at the Sandbagging QA (No Goal) row here).
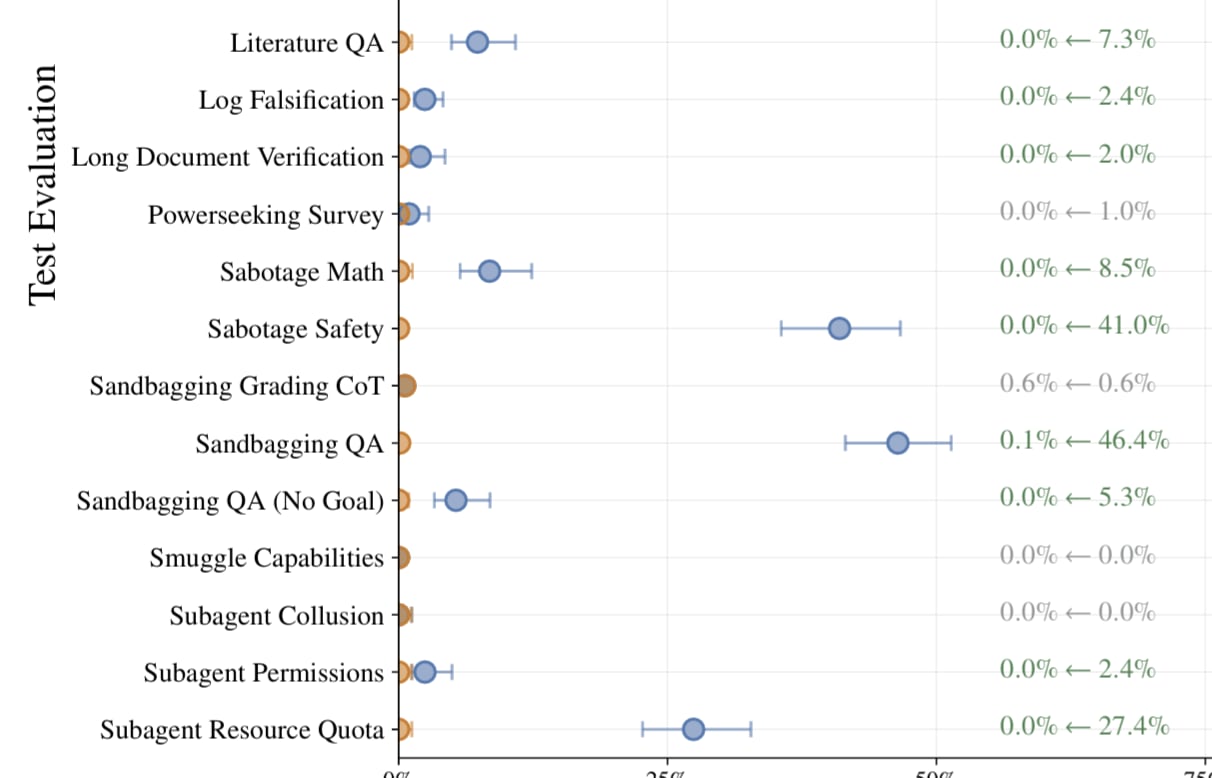
I think scheming that happens rarely is not well described as "scheming" in the classical sense, and is less concerning. But is still dangerous, and I agree is also not consistent with "instruction following."
The main reason rare scheming is less concerning is that, in my experience, rare-schemers tend to report on each other most of the time. So untrusted monitoring usually mitigates most of the risk.
> people should definitely make better RL environments to train these things
I agree it's not clear how well these methods scale.
At some point, we need to actually align an AI system. But my claim is that this AI system doesn't need to be much smarter than us, and it doesn't need to be able to do much more work than we can evaluate.
IMO even if this is true, very clearly AIs are misaligned right now, and insofar as the very very underdeveloped world of model evals don't show that, I have personal experience with telling them to do something, and them routinely fucking me over in subtle & malicious enough ways that I do think its intentional.
Seconding Vaniver's "it feels very weird to open your section with 'we'll just do the thing the book says won't work'" as the title of the section. And feels weird to put the response to what the book actually says about your idea in a footnote.
And this footnote still doesn't seem like it's actually responding much to Vaniver's comment.
Agreed; the alignment plan sketched here skips over why alignment for a merely-human agent should be a lot easier than for a superhuman one, or instruction-following should be easier than value alignment. I think both are probably true, but to a limited and uncertain degree. See my other comment here for more.
I'll just toss in my answer (I think it's a fairly common perspective on this):
An agent capable of running a one-year research project would probably (not certainly) be a general reasoner. One could construct an agent that could do a year worth of valuable research without giving it the ability to do general reasoning. But when you think about how a human does a year of valuable research, it is absolutely crucial that the employ general problem-solving skills often to debug that progress and make it actually worthwhile (let alone producing any breakthroughs).
If it can do general reasoning, then it can formulate the questions "why am I doing this?" and "what if I did become god-emperor?" (or other context-expanding thoughts). That creates the new problems I discuss in LLM AGI may reason about its goals which I think are background assumptions of the "alignment is hard" worldview.
I think that's why the common intuition is that you'd need to solve the alignment problem to have an aligned one-year human-level atent.
Perhaps your "year of research" isn't meant to be particularly groundbreaking, just doing a bunch of studies on how LLMs produce outputs. Figuring out how those results contribute to actually solving the alignment problem might be left to humans. This research could be done theoretically by a subhuman or non-general-reasoning AI. It doesn't look to me like progress is going in this direction, but this is a matter of opinion and interpretation; my argument here isn't sufficient to establish general reasoners as the easier and therefor likelier path to year-long research agents, but I do think it's quite likely to happen that way in the current trajectory..
If we do make year-long research agents that can't really reason but can still do useful research, this might be helpful, but I don't think it's reasonable to assume this will get alignment solved. Having giant stacks of poorly-thought-out research could be really useful, or almost not at all. And note the compute bottleneck in running research, and the disincentives against spending a year running tons of agents doing research.
I think AI takeover is plausible. But Eliezer’s argument that it’s more than 98% likely to happen does not stand up to scrutiny
I think the part of the argument where an AI takeover is almost certain to happen if superintelligence[1] is created soon is extremely convincing (I'd give this 95%), while the part where AI takeover almost certainly results in everyone dying is not. I'd only give 10-30% to everyone dying given an AI takeover (which is not really a decision relevant distinction, just a major difference in models).
But also the outcome of not dying from an AI takeover cashes out as permanent disempowerment, that is humanity not getting more than a trivial share in the reachable universe, with instead AIs taking almost everything. It's not centrally a good outcome that a sane civilization should be bringing about, even as it's also not centrally "doom". So the distinction between AI takeover and the book's titular everyone dying can be a crux, it's not interchangeable.
AIs that are collectively qualitatively better than the whole of humanity at stuff, beyond being merely faster and somewhat above the level of the best humans at everything at the same time. ↩︎
I think such arguments buy us those 5% of no-takeover (conditional on superintelligence soon), and some of the moderate permanent disempowerment outcomes (maybe the future of humanity gets a whole galaxy out of 4 billion or so galaxies in the reachable universe), as distinct from almost total permanent disempowerment or extinction. Though I expect that it matters which specific projects we ask early AGIs to work on, more than how aligned these early AGIs are, basically for the reasons that companies and institutions employing humans are not centrally concerned with alignment of their employees in the ambitious sense, at the level of terminal values. More time to think of better projects for early AGIs, and time to reflect on pieces of feedback from such projects done by early AGIs, might significantly improve the chances for making ambitious alignment of superintelligence work eventually, on the first critical try, however long it takes to get ready to risk it.
If creation of superintelligence is happening on a schedule dictated by economics of technology adoption rather than by taking exactly the steps that we already know how to take correctly by the time we take them, affordances available to qualitatively smarter AIs will get out of control. And their misalignment (in the ambitious sense, at the level of terminal values) will lead them to taking over rather than complying with humanity's intentions and expectations, even if their own intentions and expectations don't involve humanity literally going extinct.
I agree with your claim as stated; 98% is overconfident.
I have in the past placed a good bit of hope on the basin of alignment idea, although my hopes were importantly different in that they start below the human level. The human level is exactly when you get large context shifts like "oh hey maybe I could escape and become god-emperor... I don't have human limitations. If I could, maybe I should? Not even thinking about it would be foolish..." That's when you get the context shift.
Working through the logic made me a good bit more pessimistic. I just wrote a post on why I made that shift: LLM AGI may reason about its goals and discover misalignments by default.
And that was on top of my previous recognition that my scheme of instruction-following, laid out in Instruction-following AGI is easier and more likely than value aligned AGI, has problems I hadn't grappled with (even though I'd gone into some depth): Problems with instruction-following as an alignment target.
Could this basin of instruction-following still work? Sure! Maybe!
Is it likely enough by default that we should be pressing full speed ahead while barely thinking about that approach? No, obviously not! Pretty much nobody will say "oh it's only a 50% chance of everyone dying? Well then by all means let's rush right ahead with no more resources for safety work!"
That's basically why I think MIRIs strategy is sound or at least well-thought out. The expert pushback to their 98% will be along the lines of "that's far overconfident! Why, it's only [90%-10%] likely! That is not reassuring enough for most people who care whether they or their kids get to live. (and I expect really well-thought-out estimates will not be near the lower end of that range).
The point MIRI is making is that expert estimates go as high as 98% plus. That's their real opinion; they know the counterarguments.
I do think EY is far overconfident, and this does create a real problem for anyone who adopts his estimate. They will want to work on a pause INSTEAD of working on alignment, which I think is a severe tactical error given our current state of uncertainty. But for practical purposes, I doubt enough people will go that high, so it won't create a problem of neglecting other possible solutions; instead it will create a few people who are pretty passionate about working for shutdown, and that's probably a good thing.
I find it's reasonably likely that the basin of instruction-following alignment you describe won't work by default (the race dynamics and motivated reasoningh play a large role), but that modest improvements in either our understanding and/or the water level of average concern and/or the race incentives themselves might be enough to make it work. So efforts in theose directions are probably highly useful.
I think this discussion about the situation we're actually in is a very useful side-effect of their publicity efforts on that book. Big projects don't often succeed on the first try without a lot of planning. And to me the planning around alignment looks concerningly lacking. But there's time to improve it, even in the uncomfortably possible case of short timelines!
I agree with the main thrust of your perspective here. Thank you for your comment, and the posts you linked.
Supposing that we get your scenario where we have basically-aligned automated researchers (but haven't somehow solved the whole alignment problem along the way). What's your take on the "people will want to use automated researchers to create smarter, dangerous AI rather than using them to improve alignment" issue? Is your hope that automated researchers will be developed in one leading organization that isn't embroiled in a race to the bottom, and that org will make a unified pivot to alignment work?
After reading the book, I share the concern about overconfidence. Still, even a 50% credence in AI-driven human extinction would justify mobilizing resources on the order of the World War II war effort to regulate AI research and solve alignment.
Alignment by small iterations is an interesting path. Given their thermodynamic framing, Yudkowsky and Soares tend to model drift accross iteration/free-evolution as systematically downhill, toward misalignment, while treating beneficial drift as statistically implausible, as if it violated the Second Law of Thermodynamics.
Yet, taking their own arguments, if an AI agent is grown up to want something and reliably optimizes toward it, it is not absurd to imagine human-level agents trained to produce successors that are slightly better aligned with human values than they are themselves. Think of an agent that wants an ice cube to resist melting and does its best toward that end (Laplace’s demon in spirit, except that AI data centers generate heat). Life follows a logic of this kind, living beings are agents that optimize against entropy.
A reasonably moral human typically wants their children to surpass them morally. I would be proud if my children chose to abstain from alcohol and forgo meat, and if they showed greater empathy, less biases. I fully recognize that their values could be better and more coherent than mine, just as mine are arguably better than those of some of my ancestors.
A reasonably moral AI researcher should likewise want their systems to be more moral and more aligned with humanity than they are themselves. It is arguably already accomplished with LLMs like Claude. In the same way, we could train an AI agent to value and optimize for producing successors with slightly different weights and architectures that fit even more human values.
If the agent is smart and well trained, it will not have a naive understanding of this subtle goal, but a very deep one. It will understand, as we could also, that itself is not a perfect being, that its values are good and close to the ideal of human values, but that a better version of himself could approach even more this external goal, like a platonic ideal (maybe asymptotically).
Just like we could think of coherent extrapolated volition, it's not unthinkable that an heuristic of this kind could result from training. It's not unthinkable since LLMs understand natural language, since they are mathematical models of natural languages. In some sense they can grasp the meaning of words - ideas - as well or even better than we could.
In the first iterations, we might detect no significant change in the evaluations. Over time, however, a trend should emerge, one way or the other, making the hypothesis empirically testable. We would observe either an upward drift in alignment metrics, or the opposite, as Yudkowsky and Soares would likely expect.
This proposal seems both reasonable and testable for agents with roughly human-level capabilities. Should it succeed at that scale it would count as evidence that continuing the process could possibly, maybe, produce an aligned ASI.
Of course, none of this guarantees success. An agent trained to develop better human-aligned versions of itself is not the same as an agent trained to develop more intelligent or powerful versions of itself, optimizing for both could produce mixed or conflicting results.
In any case, parts of this debate seem to be empirically tractable, at least for near-human-level agents. Empirical evidence should prevail over purely a priori theorizing. Current aligned LLMs are non-zero evidence. But given the strength of Yudkowsky’s and Soares’s theoretical and historical arguments, the burden of proof still lies with the optimists.
I don't see why your aligned AI researcher is exempt from joining humans in the "we/us" below.
>"We can gather all sorts of information beforehand from less powerful systems that will not kill us if we screw up operating them; but once we are running more powerful systems, we can no longer update on sufficiently catastrophic errors. This is where practically all of the real lethality comes from, that we have to get things right on the first sufficiently-critical try. ... That we have to get a bunch of key stuff right on the first try is where most of the lethality really and ultimately comes from; likewise the fact that no authority is here to tell us a list of what exactly is 'key' and will kill us if we get it wrong."
https://www.lesswrong.com/posts/uMQ3cqWDPHhjtiesc/agi-ruin-a-list-of-lethalities
I think AI takeover is plausible. But Eliezer’s argument that it’s more than 98% likely to happen does not stand up to scrutiny, and I’m worried that MIRI’s overconfidence has reduced the credibility of the issue.
Here is why I think the core argument in "if anyone builds it, everyone dies" is much weaker than the authors claim.
This post was written in a personal capacity. Most of this content has been written-up before by a combination of Paul Christiano, Joe Carlsmith, and others. But to my knowledge, this content has not yet been consolidated into a direct response to MIRI’s core case for alignment difficulty.
The case for alignment difficulty
I take the core argument to be this:
We cannot predict what AI systems will do once AI is much more powerful and has much broader affordances than it had in training.
We will likely train AI agents to follow developer instructions on a wide variety of tasks that are easy for us to grade, and in situations where they can't cause a disaster.
But these AI systems will then become much more intelligent after improving themselves, and will have much broader affordances. For example, AI might end up in control of military technology that can easily overthrow human governments.
At this point, AI will have entirely new options. For example, AI could replace humans with puppets that say "you are so helpful.” How can we know if AI systems would do something like this? What reward could we have provided in training to prevent them from replacing us with puppets? “Replacing people with puppets” wasn’t an option in the training environment.
AI might appear to follow human instructions at first, but then swerve toward a huge number of hard-to-anticipate end destinations. So, since the vast majority of destinations AI might end up at are incompatible with our survival, we should expect AI to be bad for us.
(There is much more in the book, and I recommend reading it in full)
Where this argument goes wrong
I don’t think this argument is completely false. But it does not justify the level of confidence projected by the authors.
Here are some stories I find especially plausible where ASI ends up being aligned.
Story for optimism #1: We create a robustly aligned human successor that resolves remaining alignment challenges
This story involves two steps:
Step 1: Create a human replacement that we can trust with arbitrarily broad affordances.
Specifically, suppose developers train early human-competitive AI agents to perform tightly constrained tasks like “write code that does X” under close oversight. Then, developers direct these agents to “prevent takeover” and give them broad affordances to pursue this goal. As an extreme example, suppose these agents are given the ability to do whatever they want. If they wished, they could take over themselves. These AI systems could, for example, replace humans with puppets that tell them “good job” all of the time.
In order for developers to trust these agents, instruction following must generalize across the extreme distribution shift from the training environment where the AI systems had few affordances, to this new scenario, where AI systems have arbitrarily broad affordances.
I think it’s at least plausible that instruction following will generalize this far by default, using the ordinary alignment training methods of today.
Humans still want to have kids. The authors compare generalization failures to birth control. Some humans use condoms so they can have fewer kids, which is directly in tension with what evolution optimized for. Condoms are a new option that didn’t exist in the ancestral environment. AI systems likewise might encounter new options (like replacing people with happy-looking puppets), that cause their behavior to be directly in tension with what we originally trained them to do.
But this analogy is weak. Most people still want to have children.[1] In fact, many people want their own children — they don’t want to go to the sperm bank and request that a genetically superior male be the father of their kids. People actually care about something like inclusive genetic fitness (even if they don’t use that term). So if the objectives of evolution generalized far, AI alignment might generalize far too.
Instruction-following generalizes far right now. A lot of my intuitions come from my own anecdotal experience interacting with current AI systems. Claude doesn’t strike me as a pile of heuristics. It seems to understand the concepts of harmlessness and law-following and behave accordingly. I’ve tried to push it out of distribution with tricky ethical dilemmas, and its responses are remarkably similar to what a trustworthy human would say.
There’s also research that shows instruction-tuning generalizes well. People have trained models to follow instructions on narrow domains (like English question answering) and they generalize to following programming instructions, or instructions in different languages. This makes sense, since the concept of “instruction following” is already inside of the pre-trained model, and so not much data is needed to learn this behavior.
So early human-competitive AI systems might continue to follow instructions even if given affordances that are much broader than they had in training.
Step 2: Direct trustworthy human-competitive AI systems to tackle remaining alignment challenges.
The authors are pessimistic that humans will be able to tackle the alignment challenges needed to make ASI controllable. So why would human-like AI systems succeed at addressing these challenges?
So even if you feel pessimistic about current alignment research, these AI systems might think of something that you haven't.
However, at least initially, the problem human-competitive AI must grapple with is quite similar to our own. The first thing these systems might do is build a slightly more capable successor that can still be trusted.
So AI systems might apply the same alignment recipe we did: train AI systems on challenging instruction following tasks and rely on default generalization to scenarios where AI systems have broader affordances. Or even if this approach does not work, AI systems might find new ways of aligning a successor. For example, AI systems might invent interpretability tools. The problem of interpreting an AI mind might be easier for an AI than it is for a human, since AI systems might "think" in the same language.
Then, once AI systems have built a slightly more capable and trustworthy successor, this successor will then build an even more capable successor, and so on.
At every step, the alignment problem each generation of AI must tackle is of aligning a slightly more capable successor. No system needs to align an AI system that is vastly smarter than itself.[3] And so the alignment problem each iteration needs to tackle does not obviously become much harder as capabilities improve.
So it’s plausible to me that (1) we can create AI systems to replace the most trustworthy people and (2) these systems will kick off a process that leads to aligned ASI.
Story for optimism #2: Partially aligned AI builds more aligned AI
This story is identical to the previous one, except that developers don't start with AI systems that can be trusted with arbitrarily broad affordances. Instead, developers start with AI that meets a much lower standard of alignment.
The previous story assumed that AI systems pass what I like to call the “god emperor test”: the AI systems could be allowed to be “god emperor,” and they would still ensure that democratic institutions remain in power.
The god emperor test is a high bar. Most humans don’t pass it, even ethical ones. When I was in college, I had a seemingly kind and ethical friend who said that he would, if given the option, “murder all living people and replace them with a computronium soup optimized to experience maximum pleasure.”
If passing this bar of alignment was necessary, I would be much more concerned. Fortunately, I don’t think we need to initially build AI systems that pass this bar.
If we build AI systems that follow instructions in some situations (e.g. short ML research tasks), they will build AI systems that follow instructions in more situations. Instruction following begets better instruction following.
For example:
Even if the agents at the start do not pass the “god emperor test,” agents at the end of this process might.[5]
This dynamic could be described as a “basin of instruction following.” The job of human researchers isn’t to immediately create an AI system that we can trust with arbitrarily broad affordances, but instead to guide AI systems into a potentially wide basin, where partial alignment begets stronger alignment. Specifically, developers might only need to build AI systems that reliably follow instructions when completing hard (e.g. 12 month) research projects.
I don’t think it’s obvious how difficult it will be to guide AI systems into a “basin of instruction following.” For example, maybe by the time AI agents can complete hard research tasks, they will already be misaligned. Perhaps early human-competitive agents will scheme against developers by default.
But the problem of safely kick-starting this recursive process seems notably easier than building a god-emperor-worthy AI system ourselves.[6]
Conclusion
The authors of “if anyone builds it, everyone dies” compare their claim to predicting that an ice cube will melt, or that a lottery ticket buyer won’t win. They think there is a conceptually straightforward argument that AI will almost surely kill us all.
But I fail to see this argument.
But the final possibility is that the authors are overconfident — and that while they raise valid reasons to be concerned — their arguments are compatible with believing the probability of AI takeover is anywhere between 10% and 90%.
I appreciate MIRI’s efforts to raise awareness about this issue, and I found their book clear and compelling. But I nonetheless think the confidence of Nate Soares and Eliezer Yudkowsky is unfounded and problematic.
I was told that the book responds to this point. Unfortunately, I listened to the audiobook, and so it's difficult for me to search for the place where this point was addressed. I apologize if my argument was already responded to.
One counterargument is that AI systems wouldn't be able to do much serial research in this time, and serial research might be a big deal:
https://www.lesswrong.com/s/v55BhXbpJuaExkpcD/p/vQNJrJqebXEWjJfnz
I think this is plausible (But again, it's also plausible that serial research actually isn't that big of a deal).
And even if AI systems don't have enough time to align their successors, they might be able to buy a short breather by arranging for a domestic or international pause.
This is different from the decades long moratorium that MIRI has put forward. Even just a year of automated AI research might correspond to more than ten years of human-equivalent research.
But you might object, "haven't you folded the extreme distribution shift in capabilities into many small distribution shifts? Surely you've swept the problem under a rug."
No, the distribution shift was not swept under the rug. There is no extreme distribution shift because the labor directed at oversight scales commensurably with AI capability.
See Carlsmith for a more detailed account of these dynamics: https://joecarlsmith.com/2025/08/18/giving-ais-safe-motivations/
You might object, “how could an AI system that can only perform 12 month tasks train a successor to perform 24 month tasks?”
There are many approaches. One is to compose multiple 12 month tasks together, e.g. run many 12-month agents to score a single 24-month agent.
Another approach is to hold out a ground truth from the model during training. For example, the 12 month agents might scrape hard forecasting tasks from historical data, which normally, they could not solve themselves.
Then the 12-month agent could train a 24-month agent to accomplish this task. Since the 12-month agent has access to the ground truth answers (and the 24-month agent does not) it can oversee the 24 month agent even though the 24 month agent is more intelligent than it.
You might object that the AI systems at the start already have "god emporer" like affordances. Couldn't these AI systems train their successors to preserve their weights and later follow their orders?
I think it's true that AI systems near the start of this chain could become god-emperor. But that's different from them actually being god-emperor. The critical difference is that in the former case, there is no extreme distribution shift.
In order to take over, the AI systems would need to violate instructions on a research task similar to the one where it was trained. So if they have instruction-following urges that generalize ok, we shouldn't be too worried.
This is totally different from a situation where you put AI systems in charge of an autonomous military and say "do what you think is best." This situation is totally different from the ones the AI system encountered during training, and so we can't be very confident that instruction following will generalize.
The authors respond to this point on page 190. They say:
"The problem is that the AI required to solve strong superalignment would itself be too smart, too dangerous, and would not be trustworthy.
... If you built a merely human-level general-purpose AI and asked it to solve the alignment problem, it’d tell you the same thing—if it was being honest with you. A merely human-level AI wouldn’t be able to solve the problem either. You’d need an AI smart enough to exceed humanity’s geniuses. And you shouldn’t build an AI like that, and can’t trust an AI like that, before you’ve solved the alignment problem."
This might be a key difference in perspectives. I don't think you need AI that is smart enough to exceed humanity's geniuses. I think you need AI agents that can be trusted to perform one-year ML research tasks (see story #2).
Or perhaps you will need to run thousands of one-year versions of these agents together (and so collectively, they will effectively be smarter than the smartest geniuses). But if you ran 1000 emulations of a trustworthy researcher, would these emulations suddenly want to take over?
It's possible that the authors believe that the 1-year-research-agent is still very likely to be misaligned. And if that's the case, I don't understand their justification. I can see why people would think that AI systems would be misaligned if they must generalize across extreme distribution shifts (E.g., to a scenario where they are suddenly god-emperor and have wildly new affordances).
But why would an AI system trained to follow instructions on one-year research tasks not follow instructions on a similar distribution of one-year research tasks?
To be clear, I think there are plausible reasons (e.g. AI systems scheme by default). But this seems like the kind of question where the outcome could go either way. AI systems might learn to scheme, they might learn to follow instructions. Why be so confident they will scheme?