Rendering 10/27 comments, sorted by (show more) Click to highlight new comments since:
I'd be surprised if it could do 5 or 6-digit integer multiplication with >90% accuracy. I expect it to be pretty good at addition.
It would really depend on how many parameters the model has IMO, if the jump from GPT-3 to GPT-4 is something on the order of magnitude of 10-100x, then we could potentially see similar gains for multiplication. GPT-3 (175B) can do 2 digit multiplication with a ~50% accuracy, so 5-6 digits might be possible. It really depends on how well the model architecture of GPT scales in the future.
So from 2-digit substraction to 5-digit substraction it lost 90% accuracy, and scaling the model by ~10x gave a 3x improvement (from 10 to 30%) on two-digit multiplication. So assuming we get 3x more accuracy from each 10x increase and that 100% on two digit corresponds to ~10% on 5-digit, we would need something like 3 more scalings like "13B -> 175B", so about 400 trillion params.
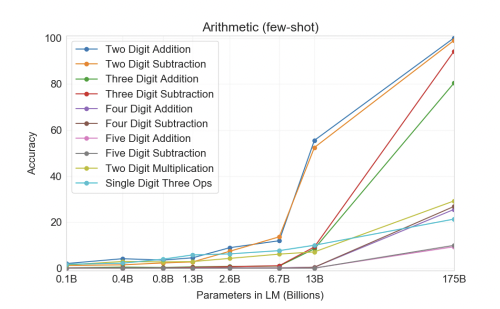
That's fair. Depending on your stance on Moore's Law or supercomputers, 400 trillion parameters might or might not be plausible (not really IMO). But, this is assuming that there's no advances in the model architecture (maybe changes to the tokenizer?) which would drastically improve the performance of multiplication / other types of math.
Going by GPT-2's BPEs [1], and based on the encoder downloaded via OpenAI's script, there are 819 (single) tokens/embeddings that uniquely map to the numbers from 0-1000, 907 when going up to 10,000, and 912 up to 200,000 [2]. These embeddings of course get preferentially fed into the model in order to maximize the number of characters in the context window and thereby leverage the statistical benefit of BPEs for language modeling. Which bears to mind that the above counts exclude numeric tokens that have a space at the beginning [3].
My point here being that, IIUC, for the language model to actually be able to manipulate individual digits, as well as pick up on the elementary operations of arithmetic (e.g. carry, shift, etc.), the expected number of unique tokens/embeddings might have to be limited to 10 – the base of the number system – when counting from 0 to the largest representable number [2].
[1] From the GPT-3 paper, it was noted:
This [GPT'3 performance on some other task] could be a weakness due to reusing the byte-level BPE tokenizer of GPT-2 which was developed for an almost entirely English training dataset.
[2] More speculatively, I think that this limitation makes extrapolation on certain abilities (arithmetic, algebra, coding) quite difficult without knowing whether its BPE will be optimized for the manipulation of individual digits/characters if need be, and that this limits the generalizability of studies such as GPT-3 not being able to do math.
[3] For such tokens, there are a total 505 up to 1000. Like the other byte pairs, these may have been automatically mapped based on the distribution of n-grams in some statistical sample (and so easily overlooked).
Hm, not so sure about this one anymore, since training on correct multiplication is easy using synthetic training data.
Seems like "the right prompt" is doing a lot of work here. How do we know if we have given it "the right prompt"?
Do you think GPT-4 could do my taxes?
re right prompt: GPT-3 has a context window of 2048 tokens, so this limits quite a lot what it could do. Also, it's not accurate at two-digit multiplication (what you would at least need to multiply your $ to %), even worse at 5-digit. So in this case, we're sure it can't do your taxes. And in the more general case, gwern wrote some debugging steps to check if the problem is GPT-3 or your prompt.
Now, for GPT-4, given they keep scaling the same way, it won't be possible to have accurate enough digit multiplication (like 4-5 digits, cf. this thread) but with three more scalings it should do it. Prompt would be "here is a few examples on how to do taxe multiplication and addition given my format, so please output result format", and concatenate those two. I'm happy to bet $1 1:1 on GPT-7 doing taxe multiplication to 90% accuracy (given only integer precision).