
My views on “doom”
89WilliamKiely
69Michaël Trazzi
34Victor Lecomte
29interstice
5ryan_greenblatt
13Pavel Roubalík
13Max H
16paulfchristiano
8paulfchristiano
1Max H
1laserfiche
5paulfchristiano
1sudo
11paulfchristiano
10Richard_Ngo
26paulfchristiano
5Richard_Ngo
6Wei Dai
2Lukas Finnveden
1Martin Vlach
4Seth Herd
4Anirandis
4avturchin
7paulfchristiano
3rvnnt
2Seth Herd
6paulfchristiano
1WilliamKiely
1WilliamKiely
1Review Bot
1Christopher King
1WilliamKiely
1WilliamKiely
4paulfchristiano
1Aryeh Englander
1sudo
4paulfchristiano
-21Petr 'Margot' Andreev

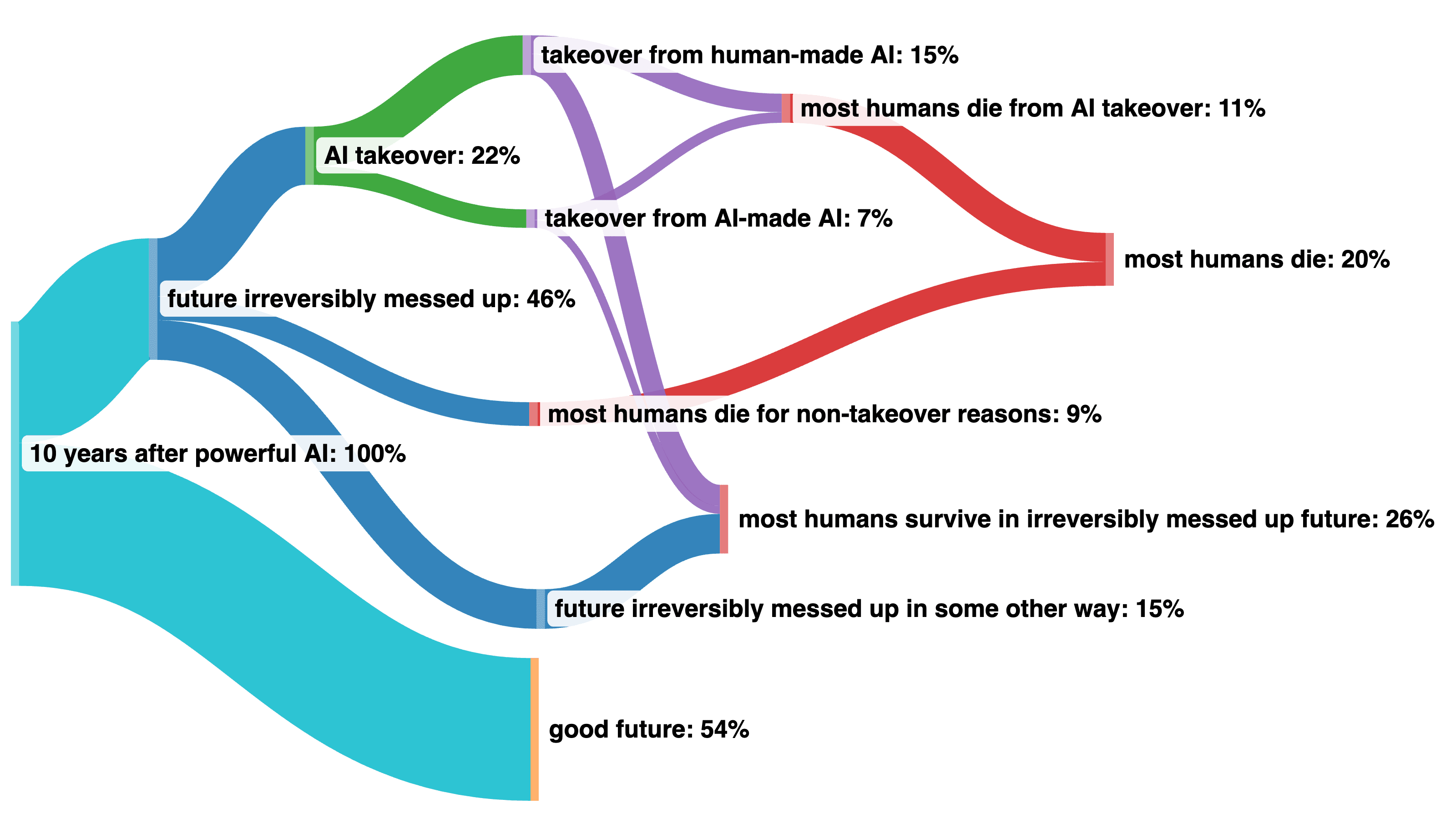
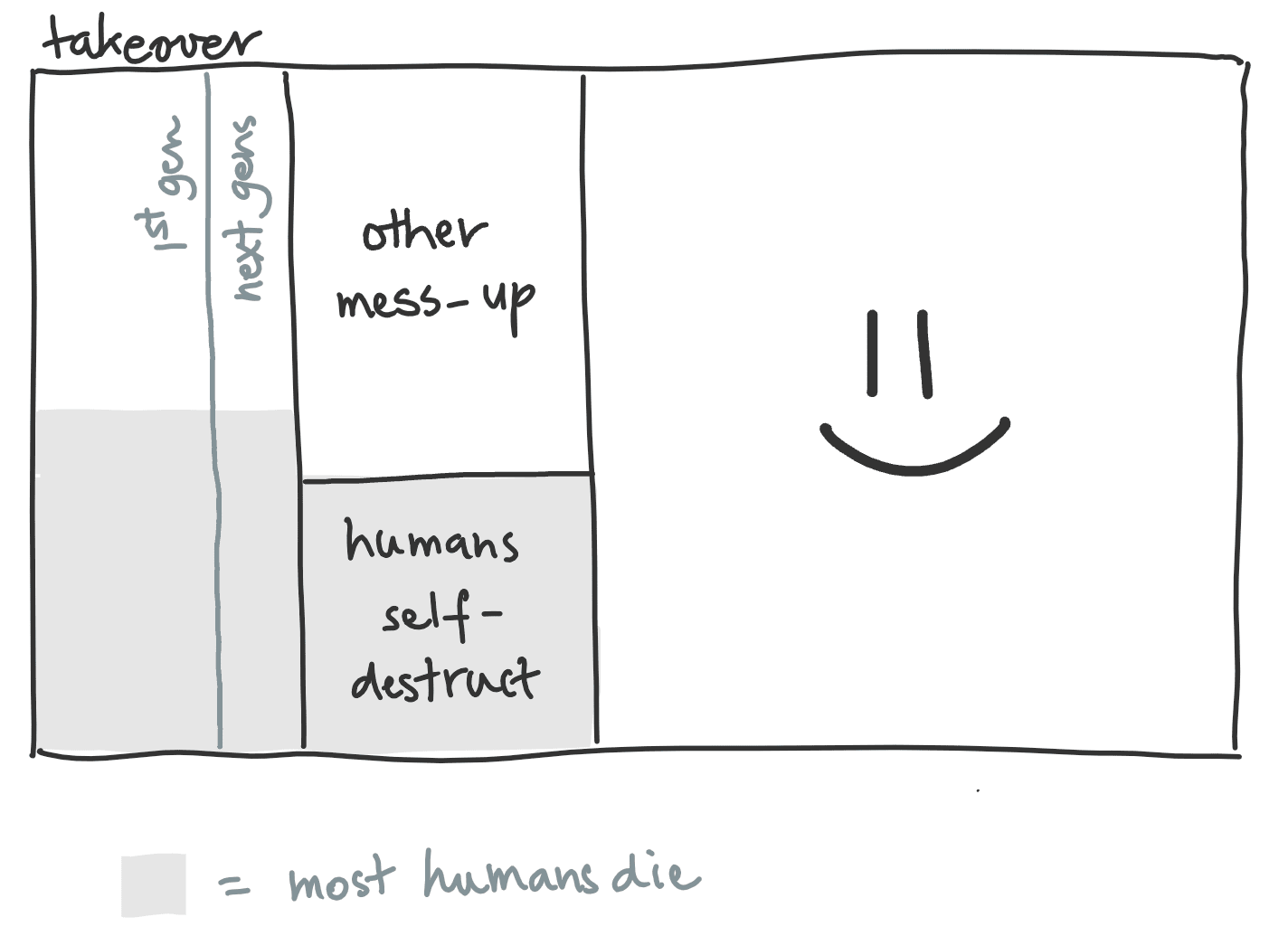
I’m often asked: “what’s the probability of a really bad outcome from AI?”
There are many different versions of that question with different answers. In this post I’ll try to answer a bunch of versions of this question all in one place.
Two distinctions
Two distinctions often lead to confusion about what I believe:
Other caveats
I’ll give my beliefs in terms of probabilities, but these really are just best guesses — the point of numbers is to quantify and communicate what I believe, not to claim I have some kind of calibrated model that spits out these numbers.
Only one of these guesses is even really related to my day job (the 15% probability that AI systems built by humans will take over). For the other questions I’m just a person who’s thought about it a bit in passing. I wouldn’t recommend deferring to the 15%, but definitely wouldn’t recommend deferring to anything else.
A final source of confusion is that I give different numbers on different days. Sometimes that’s because I’ve considered new evidence, but normally it’s just because these numbers are just an imprecise quantification of my belief that changes from day to day. One day I might say 50%, the next I might say 66%, the next I might say 33%.
I’m giving percentages but you should treat these numbers as having 0.5 significant figures.
My best guesses
Probability of an AI takeover: 22%
(Including anything that happens before human cognitive labor is basically obsolete.)
Probability that most humans die within 10 years of building powerful AI (powerful enough to make human labor obsolete): 20%
Probability that humanity has somehow irreversibly messed up our future within 10 years of building powerful AI: 46%