- Despite being around as an idea for 20 years, futarchy hasn't happened. Prediction markets
aren't clearly more accurate than Metaculus and those marketsthat currently exist generally aren't useful for decision makers.- Michael Story puts it well (emphasis his). It's easy to think that prediction markets tell us a lot about the world. But maybe instead they tell us who is a good bettor and who isn't. And perhaps we should hire those people to be grant funders or decision makers, but it's not clear we should use the process to make decisions.
- Let anyone create and participate in decision markets for advisory purposes. (Right now, prediction markets are currently heavily regulated
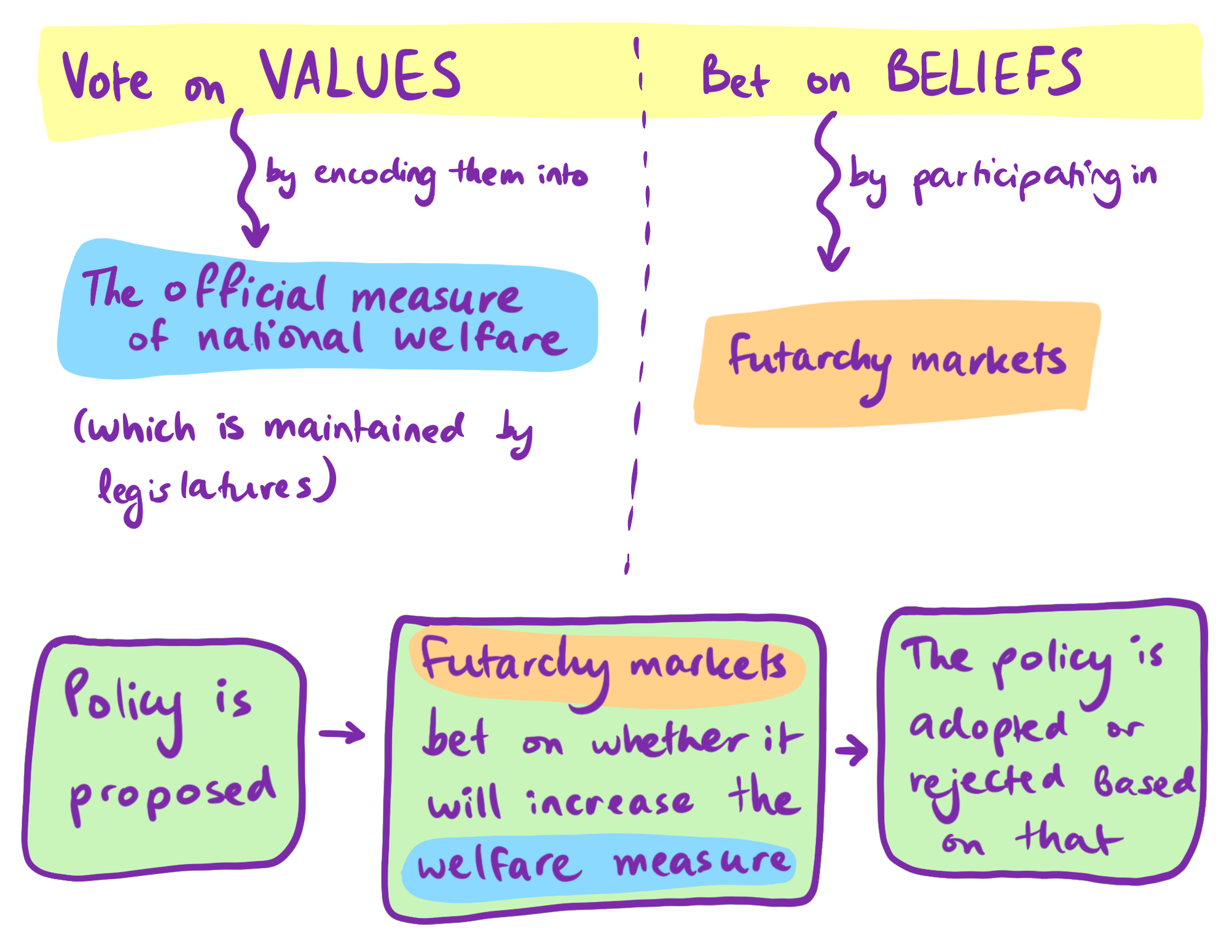
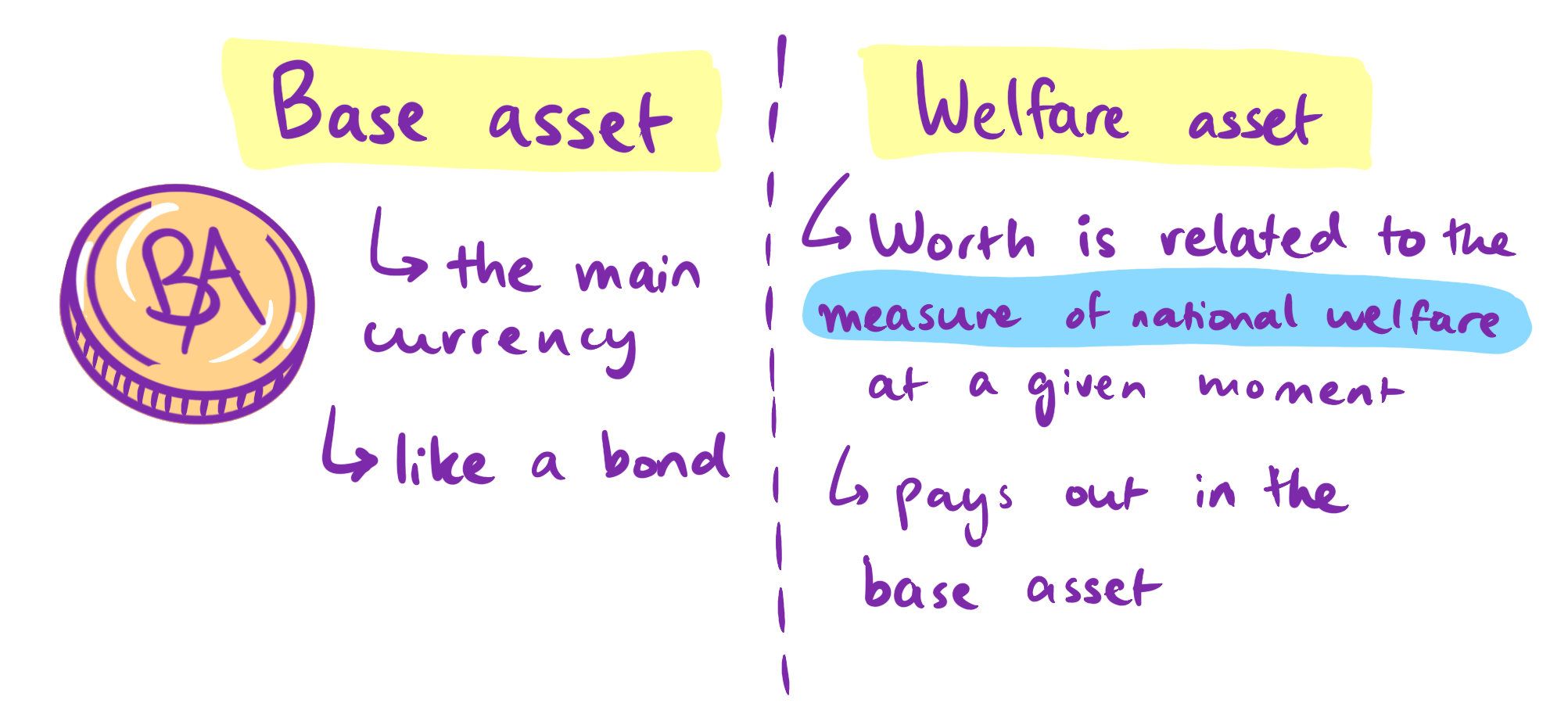
andlargely illegalin places like the United States; Hanson proposes to change this.) In particular, we would be able to set up a prediction market in which future outcomes of interest (e.g., future scores on some measure of welfare) are bet on, conditional on certain policies being accepted. The markets have some time to settle on prices, and then, ideally, for important policies, prices conditional on the policy being accepted will be significantly different from prices conditional on the policy being rejected. This is an indicator that (Hanson suggests) would describe the effect traders expect a certain policy to have on relevant outcomes. Policymakers can then consult this information when deciding whether to accept or reject the policy in question. - Let markets veto proposed bills. Per the proposal, an official measure of welfare is voted on and maintained by legislatures. A bill cannot become law if a market estimate of national welfare conditional on the bill becoming law is clearly lower than the market estimate of national welfare given the status quo (the bill not becoming law). (Futarchy, described below, is a larger and more complicated version of this.)
?? what is this? Should this be here?