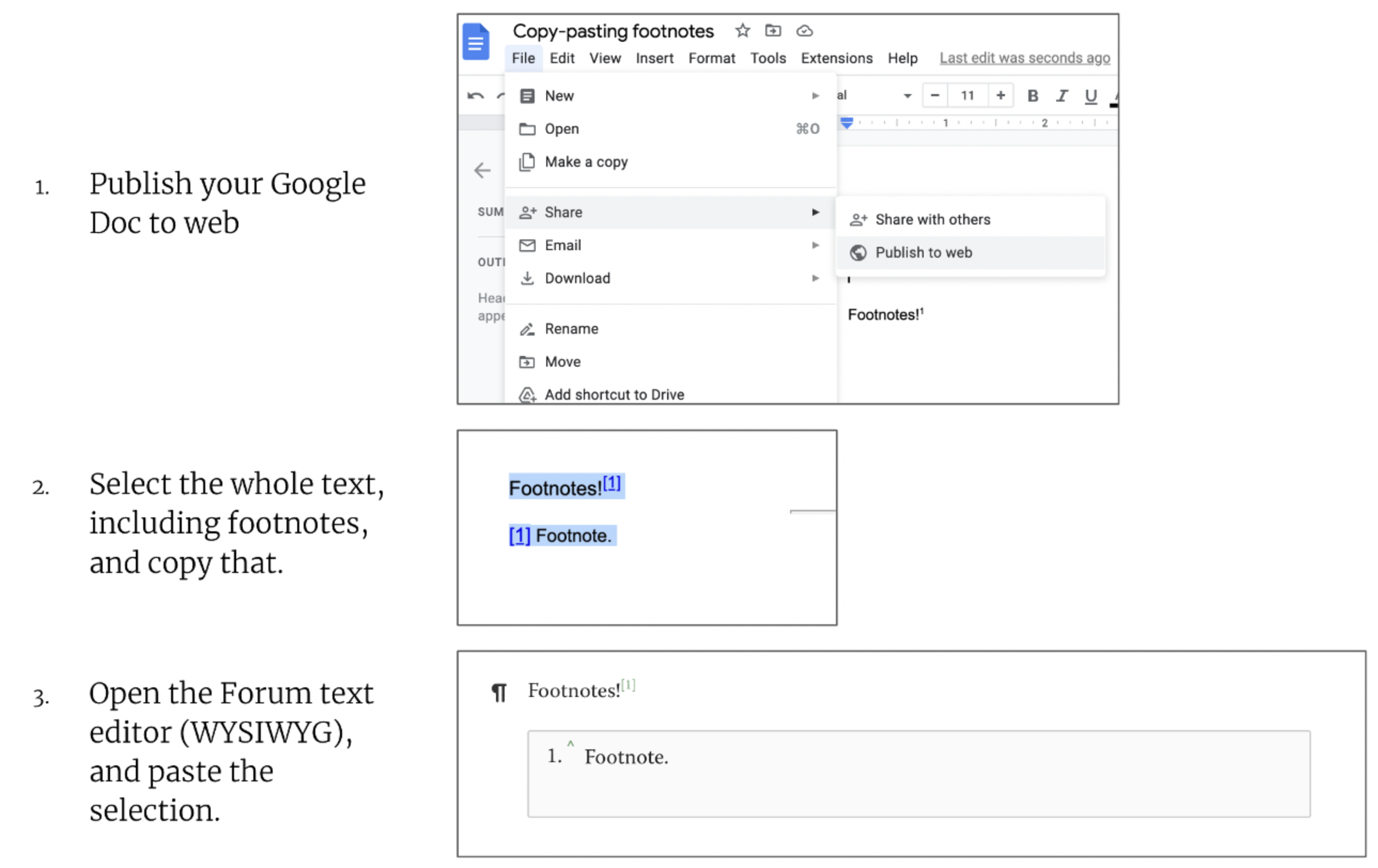
THIS GUIDE IS OUT OF DATE
[I would like to say "and we have a new guide that is not out of date" but we haven't written it yet. You can read a post about new features of the updated editor here)















An Artificial general intelligence, or AGI, is a machine capable of behaving intelligently over many domains. The term can be taken as a contrast to narrow AI, systems that do things that would be considered intelligent if a human were doing them, but that lack the sort of general, flexible learning ability that would let them tackle entirely new domains. Though modern computers have drastically more ability to calculate than humans, this does not mean that they are generally intelligent, as they have little ability to invent new problem-solving techniques, and their abilities are targeted in narrow domains... (read more)
Anthropomorphism is the error of attributing distinctly human characteristics to nonhuman processes. As creatures who evolved in a social context, we all have adaptations for making predictions about other humans by empathic inference. When trying to understand the behavior of other humans, it oftentimes is a helpful (and bias-correcting) heuristic to ask, "Well, what would I do in such a situation?" and let that be your prediction. This mode of prediction simply won't do, however, for things (and in this wide universe there are many) that don't share the detailed structure bequeathed on the human brain by evolution, although it is oftentimes tempting... (read more)
| User | Post Title | Wikitag | Pow | When | Vote |
Monastic Academy for the Preservation of Life on Earth offers what they call "modern monastic training to develop a collective that can resolve the crises of the digital age."
Over time, there might be an increasingly large gap between insider model access and outsider model access. By insiders, we mean employees at the frontier lab. By "outsiders", we mean external safety researchers, third-party auditors, and other actors trying to make the future go well.
We call this a model access gap — and when the gap is small, we call this model access parity....
I might just be daft, but I was confused by this sentence and my best explanation is there is a typo in it:
> Previously, we've been combining both
It seems like the correct reading would be that a blue observation carries 1 bit of evidence against H?
Wikitag for organizing and announcing protests.
Artificial Intelligence is the study of creating intelligence in algorithms. AI Alignment is the task of ensuring [powerful] AI systemsystems are aligned with human values and interests. The central concern is that a powerful enough AI, if not designed and implemented with sufficient understanding, would optimize something unintended by its creators and pose an existential threat to the future of humanity. This is known as the AI alignment problem.
Algebraically, writing f for the function that measures your costs, c(x⋅2)= c(x)+c(2), and, in general, c(x⋅y)= c(x)+c(y), where we can interpret x as the number of possible messages before the increase, y as the factor by which the possibilities increased, and x⋅y as the number of possibilities after the increase.
This is the key characteristic of the logarithm: It says that, when the input goes up by a factor of y, the quantity measured goes up by a fixed amount (that depends on y). When you see this pattern, you can bet that c is a logarithm function. Thus, whenever something you care about goes up by a fixed amount every time something else doubles, you can measure the thing you care about by taking the logarithm of the growing thing. For example:
Conversely, whenever you see a log2 in an equation, you can deduce that someone wants to measure some sort of thing by counting the number of doublings that another sort of thing has undergone. For example, let's say you see an equation where someone takes the log2 of a relative likelihood. What should you make of this? Well, you should conclude that there is some quantity that someone wants to measure which can be measured in terms of the number of doublings in that likelihood ratio. And indeed there is! It is known as (Bayesian) evidence, and the key idea is that the strength of evidence for a hypothesis A over its negation ¬A can be measured in terms of 2:1 updates in favor of A over ¬A. (For more on this idea, see What is evidence?).
In fact, a given function f such that f(x⋅y)=f(x)+f(y) is almost guaranteed to be a logarithm function — modulo a few technicalities.
This puts us in a position where you can derive all the main properties of the logarithm (such as logb(xn)=nlogb(x) for any b) yourself. Check this box if that's somethingIf you're interested in doing.
.
Goodhart's Law is of particular relevance to AI Alignment. Suppose you have something which is generally a good proxy for "the stuff that humans care about", it would be dangerous to have. If you make a powerful AI optimize for thethis proxy, in accordance with Goodhart's law,law predicts that the proxy will breakdown.break down.
Why does this happen? The proxy can at best partially describe your real goal. An optimizer will optimize for the entire proxy, not just the part you wanted optimized. Examples of how this happens are provided by the taxonomy below.
Wikitag for talking about protests.
Monastic Academy for the Preservation of Life on Earth offers what they call "modern monastic training to develop a collective that can resolve the crises of the digital age."
Aether is a smallan AI safety research organization.
Over time, there might be an increasingly large gap between insider model access and outsider model access. By insiders, we mean employees at the frontier lab. By "outsiders", we mean external safety researchers, third-party auditors, and other actors trying to make the future go well.
We call this a model access gap — and when the gap is small, we call this model access parity.
Questions:
In Properties of the logarithm, we saw that any f with domain R+ that satisfies the equation f(x⋅y)=f(x)+f(y) for all x and y in its domain is either trivial (i.e., it sends all inputs to 0), or it is isomorphic to logb for some base b. Thus, if we want a function's output to change by a constant that depends on y every time its input changes by a factor of y, we only have one meaningful degree of freedom, and that's the choice of b≠1 such that f(b)=1. Once we choose which value of b f sends to 1, the entire behavior of the function is fully defined.
How much freedom does this choice give us? Almost none! To see this, let's consider the difference between choosing base b as opposed to an alternative base c. Say we have an input x∈R+ — what's the difference between logb(x) and logc(x)?
Well, x=cy for some y, because x is positive. Thus, logc(x) = logc(cy) = y. By contrast, logb(x) = logb(cy) = ylogb(c). (Refresher.) Thus, logc and logb disagree on x only by a constant factor — namely, logb(c). And this is true for any x — you can get logc(x) by calculating logb(x) and dividing by :
This is a remarkable equation, in the sense that it's worth remarking on. No matter what base b we choose for f, and no matter what input x we put into f, if we want to figure out what we would have gotten if we chose base c instead, all we need to do is calculate f(c) and divide f(x) by f(c). In other words, the different logarithm functions actually aren't very different at all — each one has all the same information as all the others, and you can recover the behavior of logc using logb and a simple calculation!
(By a symmetric argument, you can show that logb(x)=logc(x)logc(b), which implies that logb(c)=1logc(b), a fact we already knew from from studying fractional digits.)
From the fact that the length of a written number grows logarithmically with the magnitude of the number and the above equation, we can see that, no matter how large a number is, its base 10 representation differs in length from its base 12 representation only by a factor of log10(12)≈1.08. Similarly, the binary representation of a number is always about log2(10)≈3.32 times longer than its decimal representation. Because there is only one logarithm function (up to a multiplicative constant), which number base you use to represent numbers only affects the size of the representation by a multiplicative constant.
Similarly, if you ever want to convert between logarithmic measurements in different bases, you only need to perform a single multiplication (or division). For example, if someone calculated how many hours it took for the bacteria colony to triple, and you want to know how long it took to double, all you need to do is multiply by log3(2)≈0.63. There is essentially only one logarithm function; the base merely defines the unit of measure. Given measurements taken in one base, you can easily convert to another.
In other parts of physics and engineering, the log base 10 is more common, because it has a natural relationship to the way we represent numbers (using a base...
[I would like to say "and we have a new guide that is not out of date" but we haven't written it yet. You can read a post about new features of the updated editor here)
Articulation is not my strong suit, so I apologize in advance for any blunders deposited. CEV = good.
Peoples wants = fickle, subject to change, and categorically a sub optimal idea for a target spec.
When I studied the current state of alignment, it seemed to me that alignment is a structural problem requiring a structural fix. If humanity's survival is a load-bearing constraint, then it should be a load-bearing constraint at the architectural level such as that the machine cannot argue with it. Analogy: when I jump, I cannot argue with gravity. it just IS. I return to the ground. When a rocket targets escape velocity, honoring reality in practice means we point the rocket eastward to reduce required speed relative to the ground (for escape velocity). The rocket doesn't argue with gravity, it engineers around the constraint. Therefore, alignment should be a structural reality an AI cannot engineer around. It can't be a behavior guardrail. Acknowledging that eventually, its going to advance to a point where our opinions won't matter. It is also worth pointing out the stochastic reality, the longer people sit around and debate alignment, the increased probability that someone is going to engineer a solution without consulting you.