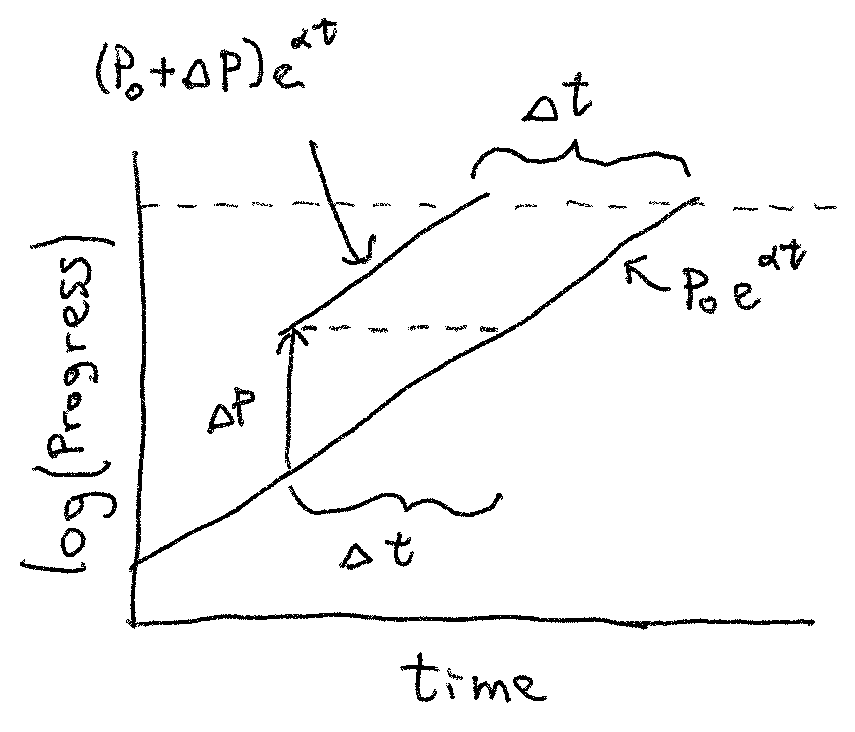
Progress often follows an s-curve, which appears exponential until the current research direction is exploited and tapers off. Moving an exponential up, even a little, early on can have large downstream consequences:
Your graph shows "a small increase" that represents progress that is equal to an advance of a third to a half the time left until catastrophe on the default trajectory. That's not small! That's as much progress as everyone else combined achieves in a third of the time till catastrophic models! It feels like you'd have to figure out some newer efficient training that allows you to get GPT-3 levels of performance with GPT-2 levels of compute to have an effect that was plausibly that large.
In general I wish you would actually write down equations for your model and plug in actual numbers; I think it would be way more obvious that things like this are not actually reasonable models of what's going on.
But there is no clear distinction between eliminating capability overhangs and discovering new capabilities.
Yes, that's exactly what Paul is saying? That one good thing about discovering new capabilities is that it eliminates capability overhangs? Why is this a rebuttal of his point?
For example, it took a few years for chain-of-thought prompting to become more widely known than among a small circle of people around AI Dungeon. Once chain-of-thought became publicly known, labs started fine-tuning models to explicitly do chain-of-thought, increasing their capabilities significantly. This gap between niche discovery and public knowledge drastically slowed down progress along the growth curve!
Why do you believe this "drastically" slowed down progress?
a lot more optimization pressure is being put into optimizing the arguments in favor of advancing capabilities than in the arguments for caution and advancing alignment, and so we should expect the epistemological terrain to be fraught in this case.
I think this is pretty false. There's no equivalent to Let's think about slowing down AI, or a tag like Restrain AI Development (both of which are advocating an even stronger claim than just "caution") -- there's a few paragraphs in Paul's post, one short comment by me, and one short post by Kaj. I'd say that hardly any optimization has gone into arguments to AI safety researchers for advancing capabilities.
(Just in this post you introduce a new argument about how small increases can make big differences to exponentials, whereas afaict there is basically just one argument for advancing capabilities that people put forward, i.e. your "Dangerous Argument 2". Note that "Dangerous Argument 1" is not an argument for advancing capabilities, it is an argument that the negative effect is small in magnitude. You couldn't reasonably apply that argument to advocate for pure capabilities work.)
(I agree in the wider world there's a lot more optimization for arguments in favor of capabilities progress that people in general would find compelling, but I don't think that matters for "what should alignment researchers think".)
(EDIT: I thought of a couple of additional arguments that appeal to alignment researchers that people make for advancing capabilities, namely "maybe geopolitics gets worse in the future so we should have AGI sooner" and "maybe AGI can help us deal with all the other problems of the world, including other x-risks, so we should get it sooner". I still think a lot more optimization pressure has gone into the arguments for caution.)
Advancing AI capabilities is heavily incentivized, especially when compared to alignment.
I'm not questioning your experiences at Conjecture -- you'd know best what incentives are present there -- but this has not been my experience at CHAI or DeepMind Alignment (the two places I've worked at).
Not OP, just some personal takes:
That's not small!
To me, it seems like the claim that is (implicitly) being made here is that small improvements early on compound to have much bigger impacts later on, and also a larger shortening of the overall timeline to some threshold. (To be clear, I don't think the exponential model presented provides evidence for this latter claim)
I think the first claim is obviously true. The second claim could be true in practice, though I feel quite uncertain about this. It happens to be false in the specific model of moving an exponential up (if you instantaneously double the progress at some point in time, the deadline moves one doubling-time closer, but the total amount of capabilities at every future point in time doubles). It might hold under a hyperbolic model or something; I think it would be interesting to nail down a quantitative model here.
Why is this a rebuttal of his point?
As a trivial example, consider a hypothetical world (I don't think we're in literally this world, this is just for illustration) where an overhang is the only thing keeping us from AGI. Then in this world, closing the overhang faster seems obviously bad.
More generally, the only time when closing an overhang is obviously good is when (a) there is an extremely high chance that it will be closed sooner or later, and (b) that counterfactual impact on future capabilities beyond the point where the overhang is closed is fully screened off (i.e nobody is spending more earlier because of impressive capabilities demos, people having longer to play with these better capabilities doesn't lead to additional capabilities insights, and the overhang isn't the only thing keeping us from AGI). The hypothetical trivial example at this opposite extreme is if you knew with absolute certainty that AI timelines were exactly X years, and you had a button that would cause X/2 years of capabilities research to happen instantaneously, then an X/2 year hiatus during which no capabilities happens at all, then the resumption of capabilities research on exactly the same track as before, with no change in capabilities investment/insights relative to the counterfactual.
If you can't be certain about these conditions (in particular, it seems the OP is claiming mostly that (a) is very hard to be confident about), then it seems like the prudent decision is not to close the overhang.
To me, it seems like the claim that is (implicitly) being made here is that small improvements early on compound to have much bigger impacts later on, and also a larger shortening of the overall timeline to some threshold.
As you note, the second claim is false for the model the OP mentions. I don't care about the first claim once you know whether the second claim is true or false, which is the important part.
I agree it could be true in practice in other models but I am unhappy about the pattern where someone makes a claim based on arguments that are clearly wrong, and then you treat the claim as something worth thinking about anyway. (To be fair maybe you already believed the claim or were interested in it rather than reacting to it being present in this post, but I still wish you'd say something like "this post is zero evidence for the claim, people should not update at all on it, separately I think it might be true".)
As a trivial example, consider a hypothetical world (I don't think we're in literally this world, this is just for illustration) where an overhang is the only thing keeping us from AGI. Then in this world, closing the overhang faster seems obviously bad.
To my knowledge, nobody in this debate thinks that advancing capabilities is uniformly good. Yes, obviously there is an effect of "less time for alignment research" which I think is bad all else equal. The point is just that there is also a positive impact of "lessens overhangs".
If you can't be certain about these conditions (in particular, it seems the OP is claiming mostly that (a) is very hard to be confident about), then it seems like the prudent decision is not to close the overhang.
I find the principle "don't do X if it has any negative effects, no matter how many positive effects it has" extremely weird but I agree if you endorse that that means you should never work on things that advance capabilities. But if you endorse that principle, why did you join OpenAI?
"This [model] is zero evidence for the claim" is a roughly accurate view of my opinion. I think you're right that epistemically it would have been much better for me to have said something along those lines. Will edit something into my original comment.
Exponentials are memoryless. If you advance an exponential to where it would be one year from now. then some future milestone (like "level of capability required for doom") appears exactly one year earlier. [...]
Errr, I feel like we already agree on this point? Like I'm saying almost exactly the same thing you're saying; sorry if I didn't make it prominent enough:
It happens to be false in the specific model of moving an exponential up (if you instantaneously double the progress at some point in time, the deadline moves one doubling-time closer, but the total amount of capabilities at every future point in time doubles).
I'm also not claiming this is an accurate model; I think I have quite a bit of uncertainty as to what model makes the most sense.
don't do X if it has any negative effects, no matter how many positive effects it has
I was not intending to make a claim of this strength, so I'll walk back what I said. What I meant to say was "I think most of the time the benefit of closing overhangs is much smaller than the cost of reduced timelines, and I think it makes sense to apply OP's higher bar of scrutiny to any proposed overhang-closing proposal". I think I was thinking too much inside my inside view when writing the comment, and baking in a few other assumptions from my model (including: closing overhangs benefiting capabilities at least as much, research being kinda inefficient (though not as inefficient as OP thinks probably)). I think on an outside view I would endorse a weaker but directionally same version of my claim.
In my work I do try to avoid advancing capabilities where possible, though I think I can always do better at this.
Errr, I feel like we already agree on this point?
Yes, sorry, I realized that right after I posted and replaced it with a better response, but apparently you already saw it :(
What I meant to say was "I think most of the time closing overhangs is more negative than positive, and I think it makes sense to apply OP's higher bar of scrutiny to any proposed overhang-closing proposal".
But like, why? I wish people would argue for this instead of flatly asserting it and then talking about increased scrutiny or burdens of proof (which I also don't like).
But like, why?
I think maybe the crux is the part about the strength of the incentives towards doing capabilities. From my perspective it generally seems like this incentive gradient is pretty real: getting funded for capabilities is a lot easier, it's a lot more prestigious and high status in the mainstream, etc. I also myself viscerally feel the pull of wishful thinking (I really want to be wrong about high P(doom)!) and spend a lot of willpower trying to combat it (but also not so much that I fail to update where things genuinely are not as bad as I would expect, but also not allowing that to be an excuse for wishful thinking, etc...).
In that case, I think you should try and find out what the incentive gradient is like for other people before prescribing the actions that they should take. I'd predict that for a lot of alignment researchers your list of incentives mostly doesn't resonate, relative to things like:
- Active discomfort at potentially contributing to a problem that could end humanity
- Social pressure + status incentives from EAs / rationalists to work on safety and not capabilities
- Desire to work on philosophical or mathematical puzzles, rather than mucking around in the weeds of ML engineering
- Wanting to do something big-picture / impactful / meaningful (tbc this could apply to both alignment and capabilities)
For reference, I'd list (2) and (4) as the main things that affects me, with maybe a little bit of (3), and I used to also be pretty affected by (1). None of the things you listed feel like they affect me much (now or in the past), except perhaps wishful thinking (though I don't really see that as an "incentive").
Your graph shows "a small increase" that represents progress that is equal to an advance of a third to a half the time left until catastrophe on the default trajectory. That's not small! That's as much progress as everyone else combined achieves in a third of the time till catastrophic models! It feels like you'd have to figure out some newer efficient training that allows you to get GPT-3 levels of performance with GPT-2 levels of compute to have an effect that was plausibly that large.
In general I wish you would actually write down equations for your model and plug in actual numbers; I think it would be way more obvious that things like this are not actually reasonable models of what's going on.
I'm not sure I get your point here: the point of the graph is to just illustrate that when effects compound, looking only at the short term difference is misleading. Short term differences lead to much larger long term effects due to compounding. The graph was just a quick digital rendition of what I previously drew on a whiteboard to illustrate the concept, and is meant to be an intuition pump.
The model is not implying any more sophisticated complex mathematical insight than just "remember that compounding effects exist", and the graph is just for illustrative purposes.
Of course, if you had perfect information at the bottom of the curve, you would see that the effect your “small” intervention is having is actually quite big: but that’s precisely the point of the post, it’s very hard to see this normally! We don’t have perfect information, and the point aims at raising salience to people’s minds that what they perceive as a “small” action in the present moment, will likely lead to a “big” impact later on.
To illustrate the point: if you make a discovery now worth 2 billion dollars more of investment in AI capabilities, and this compounds yearly at a 20% rate, you’ll get far more than +2 billion in the final total e.g., 10 years later. If you make this 2 billion dollar discovery later, after ten years you will not have as much money invested in capabilities as you would have in the other case!
Such effects might be obvious in retrospect with perfect information, but this is indeed the point of the post: when evaluating actions in our present moment it’s quite hard to foresee these things, and the post aims to raise these effects to salience!
We could spend time on more graphs, equations and numbers, but that wouldn’t be a great marginal use of our time. Feel free to spend more time on this if you find it worthwhile (it’s a pretty hard task, since no one has a sufficiently gears-level model of progress!).
I continue to think that if your model is that capabilities follow an exponential (i.e. dC/dt = kC), then there is nothing to be gained by thinking about compounding. You just estimate how much time it would have taken for the rest of the field to make an equal amount of capabilities progress now. That's the amount you shortened timelines by; there's no change from compounding effects.
if you make a discovery now worth 2 billion dollars [...] If you make this 2 billion dollar discovery later
Two responses:
- Why are you measuring value in dollars? That is both (a) a weird metric to use and (b) not the one you had on your graph.
- Why does the discovery have the same value now vs later?
I think this is pretty false. There's no equivalent to Let's think about slowing down AI, or a tag like Restrain AI Development (both of which are advocating an even stronger claim than just "caution") -- there's a few paragraphs in Paul's post, one short comment by me, and one short post by Kaj. I'd say that hardly any optimization has gone into arguments to AI safety researchers for advancing capabilities.
[...]
(I agree in the wider world there's a lot more optimization for arguments in favor of capabilities progress that people in general would find compelling, but I don't think that matters for "what should alignment researchers think".)
Thanks for the reply! From what you’re saying here, it seems like we already agree that “in the wider world there's a lot more optimization for arguments in favor of capabilities progress”.
I’m surprised to hear that you “don't think that matters for "what should alignment researchers think".”
Alignment researchers, are part of the wider world too! And conversely, a lot of people in the wider world that don’t work on alignment directly make relevant decisions that will affect alignment and AI, and think about alignment too (likely many more of those exist than “pure” alignment researchers, and this post is addressed to them too!)
I don't buy this separation with the wider world. Most people involved in this live in social circles connected to AI development, they’re sensitive to status, many work at companies directly developing advanced AI systems, consume information from the broader world and so on. And the vast majority of the real world’s economy has so far been straightforwardly incentivizing reasons to develop new capabilities, faster. Here's some tweets from Kelsey that illustrate some of this point.
conversely, a lot of people in the wider world that don’t work on alignment directly make relevant decisions that will affect alignment and AI, and think about alignment too (likely many more of those exist than “pure” alignment researchers, and this post is addressed to them too!)
- Your post is titled "Don't accelerate problems you're trying to solve". Given that the problem you're considering is "misalignment", I would have thought that the people trying to solve the problem are those who work on alignment.
- The first sentence of your post is "If one believes that unaligned AGI is a significant problem (>10% chance of leading to catastrophe), speeding up public progress towards AGI is obviously bad." This is a foundational assumption for the rest of your post. I don't really know who you have in mind as these other people, but I would guess that they don't assign >10% chance of catastrophe.
- The people you cite as making the arguments you disagree with are full-time alignment researchers.
If you actually want to convey your points to some other audience I'd recommend making another different post that doesn't give off the strong impression that it is talking to full-time alignment researchers.
I don't buy this separation with the wider world. Most people involved in this live in social circles connected to AI development, they’re sensitive to status, many work at companies directly developing advanced AI systems, consume information from the broader world and so on.
I agree that status and "what my peers believe" determine what people do to a great extent. If you had said "lots of alignment researchers are embedded in communities where capabilities work is high-status; they should be worried that they're being biased towards capabilities work as a result", I wouldn't have objected.
You also point out that people hear arguments from the broader world, but it seems like arguments from the community are way way way more influential on their beliefs than the ones from the broader world. (For example, they think there's >10% chance of catastrophe from AI based on argument from this community, despite the rest of the world arguing that this is dumb.)
the vast majority of the real world’s economy has so far been straightforwardly incentivizing reasons to develop new capabilities, faster. Here's some tweets from Kelsey that illustrate some of this point.
I looked at the linked tweet and a few surrounding it and they seem completely unrelated? E.g. the word "capabilities" doesn't appear at all (or its synonyms).
I'm guessing you mean Kelsey's point that EAs go to orgs that think safety is easy because those are the ones that are hiring, but (a) that's not saying that those EAs then work on capabilities and (b) that's not talking about optimized arguments, but instead about selection bias in who is hiring.
Your graph shows "a small increase" that represents progress that is equal to an advance of a third to a half the time left until catastrophe on the default trajectory. That's not small!
Yes, I was going to say something similar. It looks like the value of the purple curve is about double the blue curve when the purple curve hits AGI. If they have the same doubling time, that means the "small" increase is a full doubling of progress, all in one go. Also, the time you arrive ahead of the original curve is equal to the time it takes the original curve to catch up with you. So if your "small" jump gets you to AGI in 10 years instead of 15, then your "small" jump represents 5 years of progress. This is easier to see on a log plot:
A horizontal shift seems more realistic. You just compress one part of the curve or skip ahead along it. Then a small shift early on leads to an equally small shift later.
Of course, there are other considerations like overhang and community effects that complicate the picture, but this seems like a better place to start.
My overall take is:
- I generally think that people interested in existential safety should want the deployment of AI to be slower and smoother, and that accelerating AI progress is generally bad.
- The main interesting version of this tradeoff is when people specifically work on advancing AI in order to make it safer, either so that safety-conscious people have more influence or so that the rollout is more gradual. I think that's a way bigger deal than capability externalities from safety work, and in my view it's also closer to the actual margin of what's net-positive vs net-negative.
- I think that OpenAI provides altruistic justifications for accelerating AI development, but is probably net bad for existential safety (and also would likely be dispreferred by existing humans, though it depends a lot on how you elicit their preferences and integrate them with my empirical views). That said, I don't think this case is totally obvious or a slam dunk, and I think that people interested in existential safety should be laying out their arguments (both to labs and to the broader world) and engaging productively rather than restating the conclusion louder and with stronger moral language.
- I think that Anthropic's work also accelerates AI arrival, but it is much easier for it to come out ahead on a cost-benefit: they have significantly smaller effects on acceleration, and a more credible case that they will be safer than alternative AI developers. I have significant unease about this kind of plan, partly for the kinds of reasons you list and also a broader set of moral intuitions. As a result it's not something I would do personally. But I've spent some time thinking it through as best I can and it does seem like the expected impact is good. To the extent that people disagree I again think they should be actually making the argument and trying to understand the disagreement.
I think that Anthropic's work also accelerates AI arrival, but it is much easier for it to come out ahead on a cost-benefit: they have significantly smaller effects on acceleration, and a more credible case that they will be safer than alternative AI developers. I have significant unease about this kind of plan, partly for the kinds of reasons you list and also a broader set of moral intuitions. As a result it's not something I would do personally.
From the outside perspective of someone quite new to the AI safety field and with no contact with the Bay Area scene, the reasoning behind this plan is completely illegible to me. What is only visible instead is that they’re working ChatGPT-like systems and capabilities, as well as some empirical work on evaluations and interpretability.The only system more powerful than ChatGPT I’ve seen so far is the unnamed one behind Bing, and I’ve personally heard rumours that both Anthropic and OpenAI are already working on systems beyond ChatGPT/GPT-3.5 level.
1. Fully agree and we appreciate you stating that.
2. While we are concerned about capability externalities from safety work (that’s why we have an infohazard policy), what we are most concerned about, and that we cover in this post, is deliberate capabilities acceleration justified as being helpful to alignment. Or, to put this in reverse, using the notion that working on systems that are closer to being dangerous might be more fruitful for safety work, to justify actively pushing the capabilities frontier and thus accelerating the arrival of the dangers themselves.
3. We fully agree that engaging with arguments is good, this is why we’re writing this and other work, and we would love all relevant players to do so more. For example, we would love to hear a more detailed, more concrete story from OpenAI of why they believe accelerating AI development has an altruistic justification. We do appreciate that OpenAI and Jan Leike have published their own approach to AI alignment, even though we disagree with some of its contents, and we would strongly support all other players in the field doing the same.
4.
I think that Anthropic's work also accelerates AI arrival, but it is much easier for it to come out ahead on a cost-benefit: they have significantly smaller effects on acceleration, and a more credible case that they will be safer than alternative AI developers. I have significant unease about this kind of plan, partly for the kinds of reasons you list and also a broader set of moral intuitions. As a result it's not something I would do personally.
But I've spent some time thinking it through as best I can and it does seem like the expected impact is good.
We share your significant unease with such plans. But given what you say here, why at the same time you wouldn’t pursue this plan yourself, yet you say that it seems to you like the expected impact is good?
From our point of view, an unease-generating, AI arrival-accelerating plan seems pretty bad unless proven otherwise. It would be great for the field to hear the reasons why, despite these red flags, this is nevertheless a good plan.
And of course, it would be best to hear the reasoning about the plan directly from those who are pursuing it.
I think the best argument on "Accelerating capabilities is good", is that it forces you to touch reality instead of theorizing, and given that iteration is good for other fields, we need to ask why we think AI safety is resistant to iterative solutions.
And this in a nutshell is why ML/AGI people can rationally increase capabilities: LW has a non-trivial chance of having broken epistemics, and AGI people do tend towards more selfish utility functions.
Eliminating capability overhangs is discovering AI capabilities faster, so also pushes us up the exponential! For example, it took a few years for chain-of-thought prompting to become more widely known than among a small circle of people around AI Dungeon. Once chain-of-thought became publicly known, labs started fine-tuning models to explicitly do chain-of-thought, increasing their capabilities significantly. This gap between niche discovery and public knowledge drastically slowed down progress along the growth curve!
It seems like chain of thought prompting mostly became popular around the time models became smart enough to use it productively, and I really don't think that AI dungeon was the source of this idea (why do you think that?) I think it quickly became popular around the time of PaLM just because it was a big and smart model. And I really don't think the people who worked on GSM8k or Minerva were like "This is a great idea from the AI dungeon folks," I think this is just the thing you try if you want your AI to work on math problems, it had been discussed a lot of times within labs and I think was rolled out fast enough that delays had almost ~0 effect on timelines. Whatever effect they had seems like it must be ~100% from increasing the timeline for scaling up investment.
And even granting the claim about chain of thought, I disagree about where current progress is coming from. What exactly is the significant capability increase from fine-tuning models to do chain of thought? This isn't part of ChatGPT or Codex or AlphaCode. What exactly is the story?
I really don't think that AI dungeon was the source of this idea (why do you think that?)
We've heard the story from a variety of sources all pointing to AI Dungeon, and to the fact that the idea was kept from spreading for a significant amount of time. This @gwern Reddit comment, and previous ones in the thread, cover the story well.
And even granting the claim about chain of thought, I disagree about where current progress is coming from. What exactly is the significant capability increase from fine-tuning models to do chain of thought? This isn't part of ChatGPT or Codex or AlphaCode. What exactly is the story?
Regarding the effects of chain of thought prompting on progress[1], there's two levels of impact: first order effects and second order effects.
On first order, once chain of thought became public a large number of groups started using it explicitly to finetune their models.
Aside from non-public examples, big ones include PaLM, Google's most powerful model to date. Moreover, it makes models much more useful for internal R&D with just prompting and no finetuning.
We don’t know what OpenAI used for ChatGPT, or future models: if you have some information about that, it would be super useful to hear about it!
On second order: implementing this straightforwardly improved the impressiveness and capabilities of models, making them more obviously powerful to the outside world, more useful for customers, and leading to an increase in attention and investment into the field.
Due to compounding, the earlier these additional investments arrive, the sooner large downstream effects will happen.
- ^
This is also partially replying to @Rohin Shah 's question in another comment:
Why do you believe this "drastically" slowed down progress?
Dangerous Argument 2: We should avoid capability overhangs, so that people are not surprised. To do so, we should extract as many capabilities as possible from existing AI systems.
I'm saying that faster AI progress now tends to lead to slower AI progress later. I think this is a really strong bet, and the question is just: (i) quantitatively how large is the effect, (ii) how valuable is time now relative to time later. And on balance I'm not saying this makes progress net positive, just that it claws back a lot of the apparent costs.
For example, I think a very plausible view is that accelerating how good AI looks right now by 1 year will accelerate overall timelines by 0.5 years. It accelerates by less than 1 because there are other processes driving progress: gradually scaling up investment, compute progress, people training up in the field, other kinds of AI progress, people actually building products. Those processes can be accelerated by AI looking better, but they are obviously accelerated by less than 1 year (since they actually take time in addition to occurring at an increasing rate as AI improves).
I think that time later is significantly more valuable than time now (and time now is much more valuable than time in the old days). Safety investment and other kinds of adaptation increase greatly as the risks become more immediate (capabilities investment also increases, but that's already included); safety research gets way more useful (I think most of the safety community's work is 10x+ less valuable than work done closer to catastrophe, even if the average is lower than that). Having a longer period closer to the end seems really really good to me.
If we lose 1 year now, and get back 0.5 years later., and if years later are 2x as good as years now, you'd be breaking even.
My view is that accelerating progress probably switched from being net positive to net negative (in expectation) sometime around GPT-3. If we had built GPT-3 in 2010, I think the world's situation would probably have been better. We'd maybe be at our current capability level in 2018, scaling up further would be going more slowly because the community had already picked low hanging fruit and was doing bigger training runs, the world would have had more time to respond to the looming risk, and we would have done more good safety research.
At this point I think faster progress is probably net negative, but it's still less bad than you would guess if you didn't take this into account.
(It's fairly likely that in retrospect I will say that's wrong---that really good safety work didn't start until we had systems where we could actually study safety risks, and that safety work in 2023 made so much less difference than time closer to the end such that faster progress in 2023 was actually net beneficial---but I agree that it's hard to tell and if catastrophically risky AI is very soon then current progress can be significantly net negative.)
I do think that this effect differs for different kinds of research, and things like "don't think of RLHF" or "don't think of chain of thought" are particularly bad reasons for progress to be slow now (because it will get fixed particularly quickly later since it doesn't have long lead times and in fact is pretty obvious, though you may just skip straight to more sophisticated versions). But I'm happy to just set aside that claim and focus on the part where overhang just generally makes technical progress less bad.
My view is that progress probably switched from being net positive to net negative (in expectation) sometime around GPT-3.
We fully agree on this, and so it seems like we don’t have large disagreements on externalities of progress. From our point of view, the cutoff point was probably GPT-2 rather than 3, or some similar event that established the current paradigm as the dominant one.
Regarding the rest of your comment and your other comment here, here are some reasons why we disagree. It’s mostly high level, as it would take a lot of detailed discussion into models of scientific and technological progress, which we might cover in some future posts.
In general, we think you’re treating the current paradigm as over-determined. We don’t think that being in a DL-scaling language model large single generalist system-paradigm is a necessary trajectory of progress, rather than a historical contingency.
While the Bitter Lesson might be true and a powerful driver for the ease of working on singleton, generalist large monolithic systems over smaller, specialized ones, science doesn’t always (some might say very rarely!) follow the most optimal path.
There are many possible paradigms that we could be in, and the current one is among the worse ones for safety. For instance, we could be in a symbolic paradigm, or a paradigm that focuses on factoring problems and using smaller LSTMs to solve them. Of course, there do exist worse paradigms, such as a pure RL non-language based singleton paradigm.
In any case, we think the trajectory of the field got determined once GPT-2 and 3 brought scaling into the limelight, and if those didn’t happen or memetics went another way, we could be in a very very different world.
I'm saying that faster AI progress now tends to lead to slower AI progress later.
My best guess is that this is true, but I think there are outside-view reasons to be cautious.
We have some preliminary, unpublished work[1] at AI Impacts trying to distinguish between two kinds of progress dynamics for technology:
- There's an underlying progress trend, which only depends on time, and the technologies we see are sampled from a distribution that evolves according to this trend. A simple version of this might be that the goodness G we see for AI at time t is drawn from a normal distribution centered on Gc(t) = G0exp(At). This means that, apart from how it affects our estimate for G0, A, and the width of the distribution, our best guess for what we'll see in the non-immediate future does not depend on what we see now.
- There's no underlying trend "guiding" progress. Advances happen at random times and improve the goodness by random amounts. A simple version of this might be a small probability per day that an advancement occurs, which is then independently sampled from a distribution of sizes. The main distinction here is that seeing a large advance at time t0 does decrease our estimate for the time at which enough advances have accumulated to reach goodness level G_agi.
(A third hypothesis, of slightly lower crudeness level, is that advances are drawn without replacement from a population. Maybe the probability per time depends on the size of remaining population. This is closer to my best guess at how the world actually works, but we were trying to model progress in data that was not slowing down, so we didn't look at this.)
Obviously neither of these models describes reality, but we might be able to find evidence about which one is less of a departure from reality.
When we looked at data for advances in AI and other technologies, we did not find evidence that the fractional size of advance was independent of time since the start of the trend or since the last advance. In other words, in seems to be the case that a large advance at time t0 has no effect on the (fractional) rate of progress at later times.
Some caveats:
- This work is super preliminary, our dataset is limited in size and probably incomplete, and we did not do any remotely rigorous statistics.
- This was motivated by progress trends that mostly tracked an exponential, so progress that approaches the inflection point of an S-cure might behave differently
- These hypotheses were not chosen in any way more principled than "it seems like many people have implicit models like this" and "this seems relatively easy to check, given the data we have"
Also, I asked Bing Chat about this yesterday and it gave me some economics papers that, at a glance, seem much better than what I've been able to find previously. So my views on this might change.
- ^
It's unpublished because it's super preliminary and I haven't been putting more work into it because my impression was that this wasn't cruxy enough to be worth the effort. I'd be interested to know if this seems important to others.
We'd maybe be at our current capability level in 2018, [...] the world would have had more time to respond to the looming risk, and we would have done more good safety research.
It’s pretty hard to predict the outcome of “raising awareness of problem X” ahead of time. While it might be net good right now because we’re in a pretty bad spot, we have plenty of examples from the past where greater awareness of AI risk has arguably led to strongly negative outcomes down the line, due to people channeling their interest in the problem into somehow pushing capabilities even faster and harder.
To make a useful version of this post I think you need to get quantitative.
I think we should try to slow down the development of unsafe AI. And so all else equal I think it's worth picking research topics that accelerate capabilities as little as possible. But it just doesn't seem like a major consideration when picking safety projects. (In this comment I'll just address that; I also think the case in the OP is overstated for the more plausible claim that safety-motivated researchers shouldn't work directly on accelerating capabilities.)
A simple way to model the situation is:
- There are A times as many researchers who work on existential safety as there are total researchers in AI. I think a very conservative guess is something like A = 1% or 10% depending on how broadly you define it; a more sophisticated version of this argument would focus on more narrow types of safety work.
- If those researchers don't worry about capabilities externalities when they choose safety projects, they accelerate capabilities by about B times as much as if they had focused on capabilities directly. I think a plausible guess for this is like B = 10%.
- The badness of accelerating capabilities by 1 month is C times larger than the goodness of accelerating safety research by 1 month. I think a reasonable conservative guess for this today is like 10. It depends on how much other "good stuff" you think is happening in the world that is similarly important to safety progress on reducing the risk from AI---are there 2 other categories, or 10 other categories, or 100 other categories? This number will go up as the broader world starts responding and adapting to AI more; I think in the past it was much less than 10 because there just wasn't that much useful preparation happening.
The ratio of (capabilities externalities) / (safety impact) is something like A x B x C, which is like 1-10% of the value of safety work. This suggests that capabilities externalities can be worth thinking about.
There are lots of other corrections which I think generally point further in the direction of not worrying. For example, in this estimate we said that AI safety research is 10% of all the important safety-improving-stuff happening in the world whereas we implicitly assumed that capabilities research is 100% of all the timelines-shortening-stuff happening in the world, whereas I think that if we consider those two questions symmetrically I would argue that capabilities research is <30% of all the timelines-shortening-stuff (including e.g. compute progress, experience with products, human capital growth...). So my personal estimate for safety externalities is more like 1% of cost of safety progress.
And on top of that if you totally avoid 30% of possible safety topics, the total cost is much larger than reducing safety output by 30%---generally there are diminishing returns and stepping on toes effects and so on. I'd guess it's at least 2-4x worse than just scaling down everything.
There are lots of ways you could object to this, but ultimately it seems to come down to quantitative claims:
- My sense is that the broader safety community considers parameter B is much larger than I do, and this is the most substantive and interesting disagreement. People seem to have an estimate more like 100%, and when restricting t "good alignment work" they often seem to think more like 10x. Overall, if I believed B=1 then it becomes worth thinking about and if you take B=10 then it becomes a major consideration in project choice.
- In this post Nate explains his view that alignment progress is serial while capabilities progress is parallelizable, but I disagree and he doesn't really present any evidence or argument. Of course you could list other considerations not in the simple model that you think are important.
- I think the most common way is just to think that the supposed safety progress isn't actually delivering safety. But then "this doesn't help" is really the crux---the work would be bad even if it weren't net negative. Arguing about net negativity is really burying the lede.
If one believes that unaligned AGI is a significant problem (>10% chance of leading to catastrophe), speeding up public progress towards AGI is obviously bad.
What if one simultaneously believes that our current trajectory without AGI has a higher (>11%) chance of leading to catastrophe? Social unrest and polarization are rising, deaths of despair are rising, the largest war in Europe since WW2 was just launched, the economy and the paradigm of globalization are faltering. Add nuclear proliferation, the chance of nuclear terrorism, and the ability to make deadly bioweapons becoming more widespread.
I might prefer to take my chances with AGI than to risk the alternative...
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
If one believes that unaligned AGI is a significant problem (>10% chance of leading to catastrophe), speeding up public progress towards AGI is obviously bad.
Though it is obviously bad, there may be circumstances which require it. However, accelerating AGI should require a much higher bar of evidence and much more extreme circumstances than is commonly assumed.
There are a few categories of arguments that claim intentionally advancing AI capabilities can be helpful for alignment, which do not meet this bar[1].
Two cases of this argument are as follows
We address these two arguments directly, arguing that the downsides are much higher than they may appear, and touch on why we believe that merely plausible arguments for advancing AI capabilities aren’t enough.
Dangerous argument 1: It doesn't matter much to do work that pushes capabilities if others are likely to do the same or similar work shortly after.
For a specific instance of this, see Paul Christiano’s “Thoughts on the impact of RLHF research”:
Markets aren’t efficient, they only approach efficiency under heavy competition when people with relevant information put effort into making them efficient. This is true for machine learning, as there aren’t that many machine learning researchers at the cutting edge, and before ChatGPT there wasn’t a ton of market pressure on them. Perhaps something as low hanging as RLHF or something similar would have happened eventually, but this isn’t generally true. Don’t assume that something seemingly obvious to you is obvious to everyone.
But even if something like RLHF or imitation learning would have happened eventually, getting small steps of progress slightly earlier can have large downstream effects. Progress often follows an s-curve, which appears exponential until the current research direction is exploited and tapers off. Moving an exponential up, even a little, early on can have large downstream consequences:
The red line indicates when the first “lethal” AGI is deployed, and thus a hard deadline for us to solve alignment. A slight increase in progress now can lead to catastrophe significantly earlier! Pushing us up the early progress exponential has really bad downstream effects!
And this is dangerous decision theory too: if every alignment researcher took a similar stance, their marginal accelerations would quickly add up.
Dangerous Argument 2: We should avoid capability overhangs, so that people are not surprised. To do so, we should extract as many capabilities as possible from existing AI systems.
Again, from Paul:
But there is no clear distinction between eliminating capability overhangs and discovering new capabilities. Eliminating capability overhangs is discovering AI capabilities faster, so also pushes us up the exponential! For example, it took a few years for chain-of-thought prompting to become more widely known than among a small circle of people around AI Dungeon. Once chain-of-thought became publicly known, labs started fine-tuning models to explicitly do chain-of-thought, increasing their capabilities significantly. This gap between niche discovery and public knowledge drastically slowed down progress along the growth curve!
More worryingly, we also don’t know what capabilities are safe and with what model. There exists no good theory to tell us, and a key alignment challenge is to develop such theories. Each time we advance capabilities without having solved alignment, we roll a die to see if we get catastrophic results, and each time capabilities improve, the die gets more heavily weighted against us. Perhaps GPT-5 won’t be enough to cause a catastrophe, but GPT-5 plus a bunch of other stuff might be. There is simply no way to know with our current understanding of the technology. Things that are safe on GPT-3 may not be safe on GPT-4, and if those capabilities are known earlier, future models will be built to incorporate them much earlier. Extracting all the capabilities juice from the current techniques, as soon as possible, is simply reckless.
Meta: Why arguments for advancing AI capabilities should be subject to much greater scrutiny
Advancing AI capabilities towards AGI, without a theory of alignment, is obviously bad. While all but the most extreme deontologists tend to believe that obviously bad things, such as stealing or murdering, are necessary at times, when listening to arguments for them we generally demand a much higher standard of evidence that they are necessary.
Similarly to justifying taking power or accumulating personal wealth by stealing money for yourself, finding plausible arguments for advancing AI capabilities is heavily incentivized. From VC money, to papers, prestige, hype over language model releases, beating benchmarks or solving challenges, AI capabilities are much more heavily incentivized than alignment. The weight of this money and time means that evidence for the necessity of capabilities will be found faster, and more easily.
Pushing AI capabilities for alignment is also unilateral: one group on their own can advance AI capabilities without input from other alignment groups. That makes it more likely that groups will advance AI capabilities for alignment than is ideal.
As pushing AI capabilities is both incentivized for and unilateralist, we should hold arguments for it to a much higher standard. Being merely convincing (or even worse, just plausible) isn’t enough. The case should be overwhelming.
Moreover, a lot more optimization pressure is being put into optimizing the arguments in favor of advancing capabilities than in the arguments for caution and advancing alignment, and so we should expect the epistemological terrain to be fraught in this case.
We are still engaging with the arguments as if there were not much more resources dedicated to coming up with new arguments for why pushing capabilities is good. But this is mostly for practical reasons: we expect the current community would not react well if we did not do that.
Conclusion
Advancing AI capabilities is heavily incentivized, especially when compared to alignment. As such, arguments that justify advancing capabilities as necessary for alignment should be held to a higher standard. On the other hand, there are very few alignment researchers, and they have limited resources to find and spread counter-arguments against the ones justifying capabilities. Presenting a given piece of capabilities work, as something that will happen soon enough anyways, or pushing for the elimination of “overhangs” to avoid surprise both fall under that umbrella. It is very easy to miss the downstream impacts of pushing us along the progress curve (as they are in the future), and very hard to clarify vague claims about what is an overhang versus a capability.
Instead of vague promises of helping alignment research and plausible deniability of harm, justifying advancing AI capabilities for alignment requires overwhelmingly convincing arguments that these actions will obviously advance alignment enough to be worth the downsides.
Here are a few example of arguments along these lines.
Rohin Shah:
Paul Christiano:
Paul and Rohin outlining these positions publicly is extremely laudable. We engage with Paul's post here as he makes concrete, public arguments, not to single him out.