FYI Andreas http://stuhlmueller.org/ has been involved in MIRI workshops and is a top guy in the probabilistic programming cabal.
Well, I just reinterpreted that fourth bullet-pointed question on his academic web-page.
We are LessWrong. We are legion.
I assume you either linked to this in the post, or it has been mentioned in the comments, but I did not catch it in either location if it was present, so I'm linking to it anyway: http://intelligence.org/files/Non-Omniscience.pdf contains a not merely computable but tractable algorithm for assigning probabilities to a given set of first-order sentences.
One thing I don't really get is what reason do we have to believe that when the value you assigned to a proposition is, say, 0.9999999 , we can trust the proposition, other than having chosen "probability" as a name for that value.
To assign 0.99999 to a judgement that a : T is to assign 0.99999 probability to "a proves T", which also states that "T is inhabited", which then means "we believe T".
Okay, let's say the probability you assign is called 'alpha' and you don't call it a probability, you call it alpha, for the sake of clarity. So you assign alpha of 0.999999 to "a proves T". Does that, in any practical sense, imply that in some situations we don't have to worry too much about some statement being false (e.g. don't have to worry that adding a proves T as an axiom would result in an internal contradiction), and if so, why?
Does that, in any practical sense, imply that in some situations we don't have to worry too much about some statement being false (e.g. don't have to worry that adding a proves T as an axiom would result in an internal contradiction), and if so, why?
The whole approach here is to generalize the proof-theoretic (and thus computational) treatment of logic to Bayesian reasoning over classical propositions. The degree of belief assigned is thus the degree of belief assigned by a specific set of premises (those we fed into the logic with some arbitrary probabilities) (keep in mind that in proof theory (sequent calculi, natural deduction, lambda calculi), the axioms of the logic are not treated as logical premises but instead as computational operations performed on logical premises) to the theorem T via proof a.
I accidentally wrote the following as a Facebook comment to a friend, and am blatantly saving it here on grounds that it might become the core of a personal statement/research statement for previously-mentioned PhD application:
Many or even most competently-made proposals for AGI currently rely on Bayesian-statistical reasoning to handle the inherent uncertainty of real-world data and provide learning and generalization capabilities. Despite this, I find that the foundation of probability theory is still done using Kolmogorov's frequentist axiomization in terms of measure theory for spaces of total measure 1.0, while Bayesian statistics still justifies itself in terms of Cox's Theorem -- while pitching itself as the only reasonable extension of logic into real-valued uncertainty.
Problem: you can't talk about "rational agents believe according to Bayes" if you're trying to build a rational agent, because real-world agents have to be able to generalize above the level of propositional logic to quantified formulas (propositional formulas in which forall and exists quantifiers can appear), both first-order and sometimes higher-order. First-order and higher-order logics of certainty (in various kinds: classical, intuitionistic, relevance, linear, substructural) have been formalized in terms of model theory for definitions of truth and in terms of computation for definitions of proof -- this then gets extended into different mathematical foundations like ZFC, type theory, categorical foundations, etc.
I have done cursory Google searches to find extensions of probability into higher-order logics, and found nothing on the same level of rigor as the rest of logic. This is a big problem if we want to rigorously state a probabilistic foundation for mathematics, and we want to do that because a "foundation for mathematics" in terms of a logic, its model(s), and its proof system(s) is really a description of how to mechanize (computationally encode) knowledge. If your mathematical foundation can't encode quantified statements, that's a limit on what your agent can think. If it can't encode uncertainty, that's a limit on what your agent can think. If it can't encode those two together, THAT'S A LIMIT ON WHAT YOUR AGENT CAN THINK.
Which means that most AI/AGI work actually doesn't bother with sound reasoning.
Hi Eli,
A lot of effort in AI went into combining advantages of logic and probability theory for representing things. Languages that admit uncertainty and are strictly more powerful than propositional logic are practically a cottage industry now. There is Brian Milch's BLOG, Pedro Domingo's Markov logic networks, etc. etc.
Have you read Joe Halpern's paper on semantics:
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.41.5699
A lot of effort in AI went into combining advantages of logic and probability theory for representing things. Languages that admit uncertainty and are strictly more powerful than propositional logic are practically a cottage industry now. There is Brian Milch's BLOG, Pedro Domingo's Markov logic networks, etc. etc.
They culminate in the present-day probabilistic programming field, which is the subject studied by the lab I'm about to go visit in a few short hours. They are exactly the approach to this problem which I think makes sense: treat the search for a program as a search for a proof of a proposition, then make programs represent distributions over proofs rather than single proofs, then probabilize everything and make various forms of statistical inference correspond to updating the distributions over proofs, culminating in statistically learned, logically rich knowledge about arbitrary constructions. Curry-Howard + probability = fully general probabilistic models.
So, why does anyone still consider "logical probability" an actual problem, given that these all exist? I am frustratingly ready to raise my belief in the sentence, "Academia solved what LW (and much of the rest of the AI community) still believes are open problems decades ago, but in such thick language that nobody quite realized it."
I mean, Hutter published a 52-page paper on probability values for sentences in first-order logic just last year, and I generally consider him professional-level competent.
Have you read Joe Halpern's paper on semantics:
Not yet. I'm looking it over now.
I find that the foundation of probability theory is still done using Kolmogorov's frequentist axiomization in terms of measure theory for spaces of total measure 1.0, while Bayesian statistics still justifies itself in terms of Cox's Theorem
Can you expand on that? The connection between Kolmogorov's and Cox's foundations and frequentist vs. Bayesian interpretations is not clear to me. The only mathematical difference is that Cox's axioms don't give you countable additivity, but that doesn't seem to be a frequentist vs. Bayesian point of dispute.
The connection between Kolmogorov's and Cox's foundations and frequentist vs. Bayesian interpretations is not clear to me.
Kolmogorov's axiomatization treats events as elements of a powerset rather than as propositions. Cox's axioms give you belief-allocation among any finite number of quantifier-free propositions, which then lets you derive countable additivity quickly from there.
Whereas I kinda think that distributions and degrees of belief ought to be themselves foundational, degrading to classical logic in the limit as we approach certainty. This is the general approach taken in the probabilistic programming community.
So what does this say about cases where the correct answer is implied by the axioms but you don't have enough computing power to find it? From what I can tell, this picks out the class of successful proofs a:A and gives them probability 1. But I'm not really sure.
Well, the actual idea is that your axioms might not have probability 1.0 (that is, you might have a distribution over axiom sets, since the actual definition of your logic is given as natural-deduction rules instead of in Hilbert style), and also that you could do partial proofs. A partial proof would contain an unbound proof variable (an unproven hypothesis), whose probability would go according to its Solomonoff measure.
And as it turns out, Harper's Practical Foundations for Programming Languages gives a much better coverage of the syntax and semantics of a natural-deduction system for classical logic, so now I've got a good deal more to work with for probabilizing things.
If I'm understanding this right, then although this kind of approach is useful in many ways (for a local example, it's basically used in MIRI's interesting paper on self-trust), it doesn't quite capture what I want. For example, I am extremely uncertain what the 31415926th digit of pi is, even if we take arithmetic and the definition of pi as given.
This is basically the difference between assigning a sensible probability measure to logical sentences, and defining an efficiently-computable yet still useful "logical probability" function.
For example, I am extremely uncertain what the 31415926th digit of pi is, even if we take arithmetic and the definition of pi as given.
This sentence is ambiguous, but let me see if I can interpret what you're talking about.
The Solomonoff Measure goes on the judgement, a : T, where a is a proof-object/construction and T is a proposition/type (it's actually a bit more complicated than this for classical logic, but bear with me); it measures "how much space do constructions of type T occupy in the space of all possible constructions our deduction rules can generate?" (this may not be precisely the Solomonoff distribution, and constructing it is probably a piece of research in and of itself, but it's still based on Kolmogorov's core idea for measures over countably infinite sets). However, if we condition on the typing judgement, we can then actually put a completely typical maximum-entropy (in this case: uniform) prior over the different introduction rules (usually labeled "data constructors" in ordinary programming) which could have yielded our unknown proof-object of the appropriate type.
This would give you a uniform prior over digits when asking about the nth digit of \pi. The "unknown" proof object, the unbound variable or free-standing assumption, can then be used as a prior to perform Bayesian updating based on "empirical" evidence, or the prior can be used to make decisions. Or, when we have the computing power available, we can actually use equational reasoning to replace the unknown with a more refined (ie: computed-forward) proof object.
Except that actually means we're talking about something like a relationship between head-normal-form proof objects and non-normalized proof objects, with free-standing assumptions (unbound variables) being used only for things like empirical hypotheses, as opposed to computations we just haven't managed to do.
Unfortunately, all of that stuff comes after you've already got the fundamental logic nailed down and can start adding things like inductive types capable of describing such arbitrary data as the natural numbers.
EDIT: In light of "that stuff" (probabilities over digits of \pi) being largely separate from a full way of establishing probability values for arbitrary logical formulas, I will probably go look up Kolmogorov's method for constructing measures over countably infinite sets and write an entire article on using Kolmogorov measures over arbitrary inductive types and equational reasoning to build distributions over non-normalized computational terms.
This would give you a uniform prior over digits when asking about the nth digit of \pi.
This is very likely a non sequitur. But yes, I agree that in this formalism it's tough to express the probability of a sentence.
free-standing assumptions (unbound variables) being used only for things like empirical hypotheses, as opposed to computations we just haven't managed to do.
If this mean what I think it means, then yes, this was my interpretation too - plus assuming the truth or falsity of propositions that are undecided by the axioms.
In light of "that stuff" (probabilities over digits of \pi) being largely separate from a full way of establishing probability values for arbitrary logical formulas
I would like to reiterate that there is a difference between assigning probabilities and the project of logical probability. Probabilities have to follow the product rule, which is contains modus ponens in the case of certainty. If you assign probability 1 to the axioms, there is only one correct distribution for anything that follows from the axioms, like a digit of pi (or as the kids are calling it these days, $\pi$): probability 1 for the right answer, 0 for the wrong answers. If you want logical probabilities to deviate from this (like by being ignorant about some digit of pi), then logical probabilities cannot follow the same rules as probabilities.
I will probably go look up Kolmogorov's method for constructing measures over countably infinite sets and write an entire article on using Kolmogorov measures over arbitrary inductive types and equational reasoning to build distributions over non-normalized computational terms.
Cool. If you use small words, then I will be happy :)
If this mean what I think it means, then yes, this was my interpretation too - plus assuming the truth or falsity of propositions that are undecided by the axioms.
Or assigning degrees of belief to the axioms themselves! Any mutually-consistent set of statements will allow some probability assignment in which each statement has a nonzero degree of belief.
If you assign probability 1 to the axioms, there is only one correct distribution for anything that follows from the axioms, like a digit of pi (or as the kids are calling it these days, $\pi$): probability 1 for the right answer, 0 for the wrong answers. If you want logical probabilities to deviate from this (like by being ignorant about some digit of pi), then logical probabilities cannot follow the same rules as probabilities.
Which is actually an issue I did bring up, in proof-theoretic language. Let's start by setting the term "certain distribution" to mean "1.0 to the right answer, 0.0 to everything else", and then set "uncertain distribution" to be "all distributions wider than this".
Except that actually means we're talking about something like a relationship between head-normal-form proof objects and non-normalized proof objects,
A non-normalized proof object (read: the result of a computation we haven't done yet, a lazily evaluated piece of data) has an uncertain distribution over values. To head-normalize a proof object means to evaluate enough of it to decide (compute the identity of, with certainty) the outermost introduction rule (outermost data constructor), but (by default) this still leaves us uncertain of the premises which were given to that introduction rule (the parameters passed to the data constructor). As we proceed down the levels of the tree of deduction rules, head-normalizing as we go, we eventually arrive to a completely normalized proof-term/piece of data, for which no computation remains undone.
Only a completely normalized proof term has a certain distribution: 1.0 for the right answer, 0.0 for everything else. In all other cases, we have an uncertain distribution, albeit one in which all the probability mass may be allocated in the particular region associated with only one outermost introduction rule (the special case of head-normalized terms).
Remember, these distributions are being assigned over proof terms (ie: constructions in some kind of lambda calculus), not over syntactic values (well-typed and fully normalized terms). The distributions express our state of knowledge given the limited certainty granted by however many levels of the tree (all terms of inductive types can be written as trees) are already normalized to data constructors -- they express uncertain states of knowledge in situations where the uncertainty derives from having a fraction of the computational power necessary to decide a decidable question.
So when we're talking about "digits of $\pi$" sorts of problems, we should actually speak of distributions over computational terms, not "logical probabilities". This problem has nothing to do with assigning probabilities to sentences in first-order classical logic: by the time we construct and reason with our distributions over computational terms, we have already established the existence of a proof object inhabiting a particular type. If that type happened to be a mere proposition, then we've already established, by the time we construct this distribution, that we believe in the truth of the proposition, and are merely reasoning under discrete uncertainty over how its truth was proof-theoretically asserted.
Whereas I think that establishing probabilities for sentences which are not decided by our given axioms may be more difficult, particularly when those sentences may be decidable by other means.
Several people have already found it for me, and I've also found a better account of the proof theory of classical logic.
I figured that would be the case (it was, after all, the top entry when Googling for it), but since you never changed your post to reflect this fact I decided it would be best to bring it up just in case.
The Workshop
Late in July I organized and held MIRIx Tel-Aviv with the goal of investigating the currently-open (to my knowledge) Friendly AI problem called "logical probability": the issue of assigning probabilities to formulas in a first-order proof system, in order to use the reflective consistency of the probability predicate to get past the Loebian Obstacle to building a self-modifying reasoning agent that will trust itself and its successors. Vadim Kosoy, Benjamin and Joshua Fox, and myself met at the Tel-Aviv Makers' Insurgence for six hours, and each presented our ideas. I spent most of it sneezing due to my allergies to TAMI's resident cats.
My idea was to go with the proof-theoretic semantics of logic and attack computational construction of logical probability via the Curry-Howard Isomorphism between programs and proofs: this yields a rather direct translation between computational constructions of logical probability and the learning/construction of an optimal function from sensory inputs to actions required by Updateless Decision Theory.
The best I can give as a mathematical result is as follows:
The capital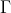 is a set of hypotheses/axioms/assumptions, and the English letters are metasyntactic variables (like "foo" and "bar" in programming lessons). The lower-case letters denote proofs/programs, and the upper-case letters denote propositions/types. The turnstile
is a set of hypotheses/axioms/assumptions, and the English letters are metasyntactic variables (like "foo" and "bar" in programming lessons). The lower-case letters denote proofs/programs, and the upper-case letters denote propositions/types. The turnstile 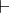 just means "deduces": the judgement
just means "deduces": the judgement 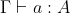 can be read here as "an agent whose set of beliefs is denoted
can be read here as "an agent whose set of beliefs is denoted 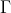 will believe that the evidence a proves the proposition A." The
will believe that the evidence a proves the proposition A." The ![[\forall y:B, x/y]a](http://www.codecogs.com/png.latex?[\forall y:B, x/y]a) performs a "reversed" substitution, with the result reading: "for all y proving/of-type B, substitute x for y in a". This means that we algorithmically build a new proof/construction/program from a in which any and all constructions proving the proposition B are replaced with the logically-equivalent hypothesis x, which we have added to our hypothesis-set
performs a "reversed" substitution, with the result reading: "for all y proving/of-type B, substitute x for y in a". This means that we algorithmically build a new proof/construction/program from a in which any and all constructions proving the proposition B are replaced with the logically-equivalent hypothesis x, which we have added to our hypothesis-set 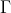 .
.
Thus the first equation reads, "the probability of a proving A conditioned on b proving B equals the probability of a proving A when we assume the truth of B as a hypothesis." The second equation then uses this definition of conditional probability to give the normal Product Rule of probabilities for the logical product (the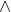 operator), defined proof-theoretically. I strongly believe I could give a similar equation for the normal Sum Rule of probabilities for the logical sum (the
operator), defined proof-theoretically. I strongly believe I could give a similar equation for the normal Sum Rule of probabilities for the logical sum (the 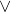 operator) if I could only access the relevant paywalled paper, in which the λμ-calculus acting as an algorithmic interpretation of the natural-deduction system for classical propositional logic (rather than intuitionistic) is given.
operator) if I could only access the relevant paywalled paper, in which the λμ-calculus acting as an algorithmic interpretation of the natural-deduction system for classical propositional logic (rather than intuitionistic) is given.
The third item given there is an inference rule, which reads, "if x is a free variable/hypothesis imputed to have type/prove proposition A, not bound in the hypothesis-set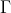 , then the probability with which we believe x proves A is given by the Solomonoff Measure of type A in the λμ-calculus". We can define that measure simply as the summed Solomonoff Measure of every program/proof possessing the relevant type, and I don't think going into the details of its construction here would be particularly productive. Free variables in λ-calculus are isomorphic to unproven hypotheses in natural deduction, and so a probabilistic proof system could learn how much to believe in some free-standing hypothesis via Bayesian evidence rather than algorithmic proof.
, then the probability with which we believe x proves A is given by the Solomonoff Measure of type A in the λμ-calculus". We can define that measure simply as the summed Solomonoff Measure of every program/proof possessing the relevant type, and I don't think going into the details of its construction here would be particularly productive. Free variables in λ-calculus are isomorphic to unproven hypotheses in natural deduction, and so a probabilistic proof system could learn how much to believe in some free-standing hypothesis via Bayesian evidence rather than algorithmic proof.
The final item given here is trivial: anything assumed has probability 1.0, that of a logical tautology.
The upside to invoking the strange, alien λμ-calculus instead of the more normal, friendly λ-calculus is that we thus reason inside classical logic rather than intuitionistic, which means we can use the classical axioms of probability rather than intuitionistic Bayesianism. We need classical logic here: if we switch to intuitionistic logics (Heyting algebras rather than Boolean algebras) we do get to make computational decidability a first-class citizen of our logic, but the cost is that we can then believe only computationally provable propositions. As Benjamin Fox pointed out to me at the workshop, Loeb's Theorem then becomes a triviality, with real self-trust rendered no easier.
The Apologia
My motivation and core idea for all this was very simple: I am a devout computational trinitarian, believing that logic must be set on foundations which describe reasoning, truth, and evidence in a non-mystical, non-Platonic way. The study of first-order logic and especially of incompleteness results in metamathematics, from Goedel on up to Chaitin, aggravates me in its relentless Platonism, and especially in the way Platonic mysticism about logical incompleteness so often leads to the belief that minds are mystical. (It aggravates other people, too!)
The slight problem which I ran into is that there's a shit-ton I don't know about logic. I am now working to remedy this grievous hole in my previous education. Also, this problem is really deep, actually.
I thus apologize for ending the rigorous portion of this write-up here. Everyone expecting proper rigor, you may now pack up and go home, if you were ever paying attention at all. Ritual seppuku will duly be committed, followed by hors d'oeuvre. My corpse will be duly recycled to make paper-clips, in the proper fashion of a failed LessWrongian.
The Parts I'm Not Very Sure About
With any luck, that previous paragraph got rid of all the serious people.
I do, however, still think that the (beautiful) equivalence between computation and logic can yield some insights here. After all, the whole reason for the strange incompleteness results in first-order logic (shown by Boolos in his textbook, I'm told) is that first-order logic, as a reasoning system, contains sufficient computational machinery to encode a Universal Turing Machine. The bidirectionality of this reduction (Hilbert and Gentzen both have given computational descriptions of first-order proof systems) is just another demonstration of the equivalence.
In fact, it seems to me (right now) to yield a rather intuitively satisfying explanation of why the Gaifman-Carnot Condition (that every instance we see of) provides Bayesian evidence in favor of
provides Bayesian evidence in favor of ) ) for logical probabilities is not computably approximable. What would we need to interpret the Gaifman Condition from an algorithmic, type-theoretic viewpoint? From this interpretation, we would need a proof of our universal generalization. This would have to be a dependent product of form
) for logical probabilities is not computably approximable. What would we need to interpret the Gaifman Condition from an algorithmic, type-theoretic viewpoint? From this interpretation, we would need a proof of our universal generalization. This would have to be a dependent product of form .P(x)) , a function taking any construction
, a function taking any construction 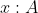 to a construction of type
to a construction of type ) , which itself has type Prop. To learn such a dependent function from the examples would be to search for an optimal (simple, probable) construction (program) constituting the relevant proof object: effectively, an individual act of Solomonoff Induction. Solomonoff Induction, however, is already only semicomputable, which would then make a Gaifman-Hutter distribution (is there another term for these?) doubly semicomputable, since even generating it involves a semiprocedure.
, which itself has type Prop. To learn such a dependent function from the examples would be to search for an optimal (simple, probable) construction (program) constituting the relevant proof object: effectively, an individual act of Solomonoff Induction. Solomonoff Induction, however, is already only semicomputable, which would then make a Gaifman-Hutter distribution (is there another term for these?) doubly semicomputable, since even generating it involves a semiprocedure.
The benefit of using the constructive approach to probabilistic logic here is that we know perfectly well that however incomputable Solomonoff Induction and Gaifman-Hutter distributions might be, both existing humans and existing proof systems succeed in building proof-constructions for quantified sentences all the time, even in higher-order logics such as Coquand's Calculus of Constructions (the core of a popular constructive proof assistant) or Luo's Logic-Enriched Type Theory (the core of a popular dependently-typed programming language and proof engine based on classical logic). Such logics and their proof-checking algorithms constitute, going all the way back to Automath, the first examples of computational "agents" which acquire specific "beliefs" in a mathematically rigorous way, subject to human-proved theorems of soundness, consistency, and programming-language-theoretic completeness (rather than meaning that every true proposition has a proof, this means that every program which does not become operationally stuck has a type and is thus the proof of some proposition). If we want our AIs to believe in accordance with soundness and consistency properties we can prove before running them, while being composed of computational artifacts, I personally consider this the foundation from which to build.
Where we can acquire probabilistic evidence in a sound and computable way, as noted above in the section on free variables/hypotheses, we can do so for propositions which we cannot algorithmically prove. This would bring us closer to our actual goals of using logical probability in Updateless Decision Theory or of getting around the Loebian Obstacle.
Some of the Background Material I'm Reading
Another reason why we should use a Curry-Howard approach to logical probability is one of the simplest possible reasons: the burgeoning field of probabilistic programming is already being built on it. The Computational Cognitive Science lab at MIT is publishing papers showing that their languages are universal for computable and semicomputable probability distributions, and getting strong results in the study of human general intelligence. Specifically: they are hypothesizing that we can dissolve "learning" into "inducing probabilistic programs via hierarchical Bayesian inference", "thinking" into "simulation" into "conditional sampling from probabilistic programs", and "uncertain inference" into "approximate inference over the distributions represented by probabilistic programs, conditioned on some fixed quantity of sampling that has been done."
In fact, one might even look at these ideas and think that, perhaps, an agent which could find some way to sample quickly and more accurately, or to learn probabilistic programs more efficiently (in terms of training data), than was built into its original "belief engine" could then rewrite its belief engine to use these new algorithms to perform strictly better inference and learning. Unless I'm as completely wrong as I usually am about these things (that is, very extremely completely wrong based on an utterly unfounded misunderstanding of the whole topic), it's a potential engine for recursive self-improvement.
They also have been studying how to implement statistical inference techniques for their generate modeling languages which do not obey Bayesian soundness. While most of machine learning/perception works according to error-rate minimization rather than Bayesian soundness (exactly because Bayesian methods are often too computationally expensive for real-world use), I would prefer someone at least study the implications of employing unsound inference techniques for more general AI and cognitive-science applications in terms of how often such a system would "misbehave".
Many of MIT's models are currently dynamically typed and appear to leave type soundness (the logical rigor with which agents come to believe things by deduction) to future research. And yet: they got to this problem first, so to speak. We really ought to be collaborating with them, with the full-time grant-funded academic researchers, rather than trying to armchair-reason our way to a full theory of logical probability as a large group of amateurs or part-timers and only a small core cohort of full-time MIRI and FHI staff investigating AI safety issues.
(I admit to having a nerd crush, and I am actually planning to go visit the Cocosci Lab this coming week, and want/intend to apply to their PhD program.)
They have also uncovered something else I find highly interesting: human learning of both concepts and causal frameworks seems to take place via hierarchical Bayesian inference, gaining a "blessing of abstraction" to countermand the "curse of dimensionality". The natural interpretation of these abstractions in terms of constructions and types would be that, as in dependently-typed programming languages, constructions have types, and types are constructions, but for hierarchical-learning purposes, it would be useful to suppose that types have specific, structured types more informative than Prop or Typen (for some universe level n). Inference can then proceed from giving constructions or type-judgements as evidence at the bottom level, up the hierarchy of types and meta-types to give probabilistic belief-assignments to very general knowledge. Even very different objects could have similar meta-types at some level of the hierarchy, allowing hierarchical inference to help transfer Bayesian evidence between seemingly different domains, giving insight into how efficient general intelligence can work.
Just-for-fun Postscript
If we really buy into the model of thinking as conditional simulation, we can use that to dissolve the modalities "possible" and "impossible". We arrive at (by my count) three different ways of considering the issue computationally:
I mostly find this fun because it lets us talk rigorously about when we should "shut up and do the 1,2!impossible" and when something is very definitely 3!impossible.