Nice post! I'm one of the authors of the Engels et al. paper on circular features in LLMs so just thought I'd share some additional details about our experiments that are relevant to this discussion.
To review, our paper finds circular representations of days of the week and months of the year within LLMs. These appear to reflect the cyclical structure of our calendar! These plots are for gpt-2-small:
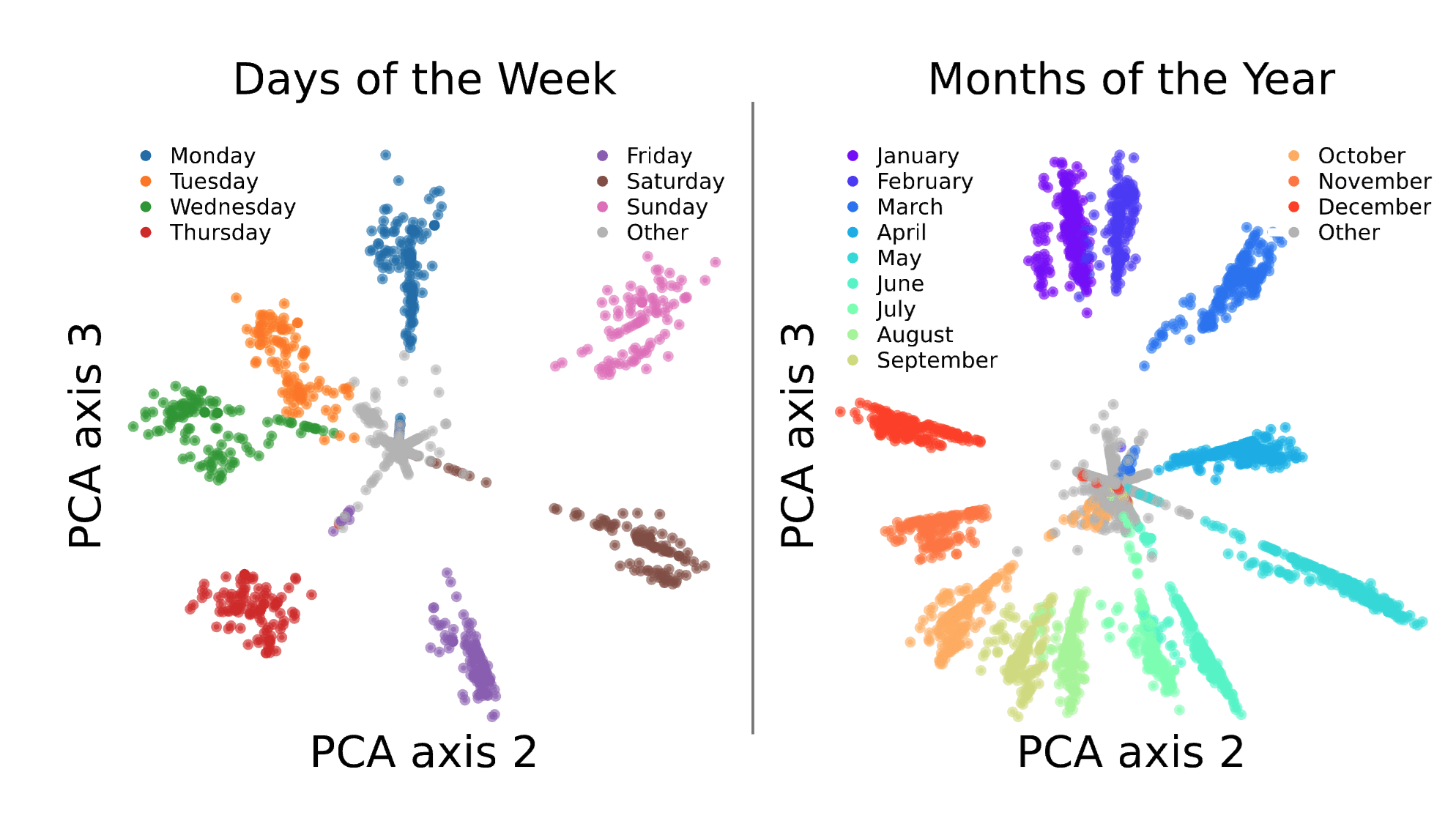
We found these by (1) performing some graph-based clustering on SAE features with the cosine similarity between decoder vectors as the similarity measure. Then (2) given a cluster of SAE features, identify tokens which activate any feature in the cluster and reconstruct the LLM's activation vector on tokens with the SAE while only allowing the SAE features in the cluster to participate in the reconstruction. Then (3) we visualize the reconstructed points along the top PCA components. Our idea here was that if there were some true higher-dimensional features in the LLM, that multiple SAE features would together need to participate in reconstructing that feature, and we want to visualize this feature while removing all others from the activation vector. To find such groups of SAE features, the decoder vector cosine similarity was what worked in practice. We also tried Jaccard similarity (capturing how frequently SAE features fire together) but it didn't yield interesting clusters like cosine similarity did in the experiments we ran.
In practice, this required looking at altogether thousands of panels of interactive PCA plots like this:
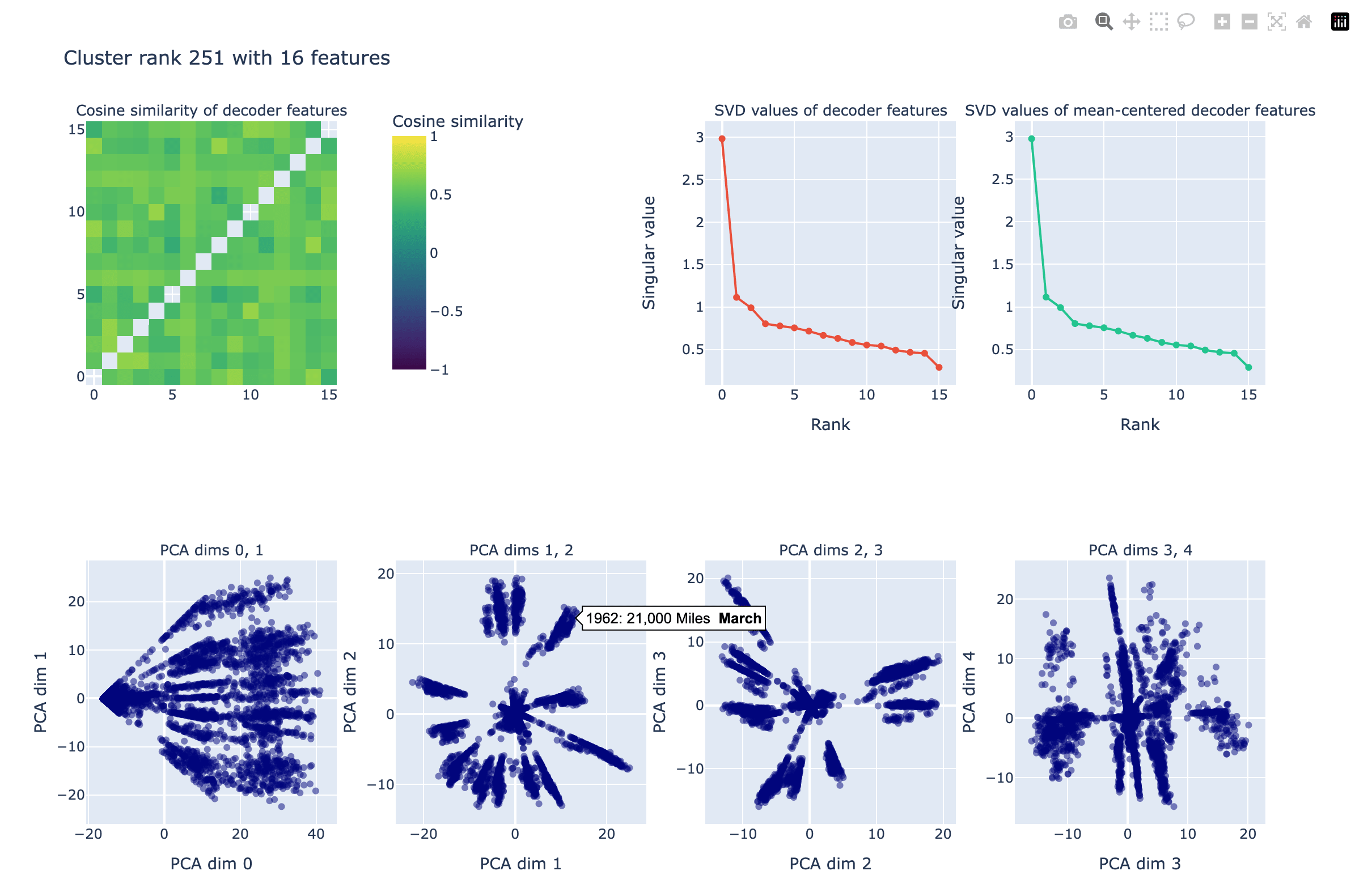
Here's a Dropbox link with all 500 of the gpt-2-small interactive plots like these that we looked at: https://www.dropbox.com/scl/fo/usyuem3x4o4l89zbtooqx/ALw2-ZWkRx_I9thXjduZdxE?rlkey=21xkkd6n8ez1n51sf0d773w9t&st=qpz5395r&dl=0 (note that I used n_clusters=1000 with spectral clustering but only made plots for the top 500, ranked by mean pairwise cosine similarity of SAE features within the cluster).
Here are the clusters that I thought might have interesting structure:
- cluster67: numbers, PCA dim 2 is their value
- cluster109: money amounts, pca dim 1 might be related to cents and pca dim 2 might be related to the dollar amount
- cluster134: different number-related tokens like "000", "million" vs. "billion", etc.
- cluster138: days of the week circle!!!
- cluster157: years
- cluster71: possible "left" vs. "right" direction
- cluster180: "long" vs. "short"
- cluster212: years, possible circular representation of year within century in pca dims 2-3
- cluster213: the "-" in between a range of numbers, ordered by the first number
- cluster223: "up" vs. "down" direction
- cluster251: months of the year!!
- cluster285: pca dim 1 is republican vs democrat
You can hover over a point on each scatter plot to see some context and the token (in bold) that the activation vector (residual stream in layer 7) fires above.
Most clusters however don't seem obviously interesting. We also looked at ~2000 Mistral-7B clusters and only the days of the week and months of the year clusters seemed clearly interesting. So at least for the LLMs we looked at, for the SAEs we had, and with our method for discovering interesting geometry, interesting geometry didn't seem ubiquitous. That said, it could just be that our methods are limited, or the LLMs and/or SAEs we used weren't large enough, or that there is interesting geometry but it's not obvious to us from PCA plots like the above.
That said, I think you're right that the basic picture of features as independent near-orthogonal directions from Toy Models of Superposition is wrong, as discussed by Anthropic in their Towards Monosemanticity post, and efforts to understand this could be super important. As mentioned by Joseph Bloom in his comment, understanding this better could inspire different SAE architectures which get around scaling issues we may already be running into.
In practice, this required looking at altogether thousands of panels of interactive PCA plots like this [..]
Most clusters however don't seem obviously interesting.
What do you think of @jake_mendel's point about the streetlight effect?
If the methodology was looking at 2D slices of up to a 5 dimensional spaces, was detection of multi-dimensional shapes necessarily biased towards human identification and signaling of shape detection in 2D slices?
I really like your update to the superposition hypothesis from linear to multi-dimensional in your section 3, but I've been having a growing suspicion that - especially if node multi-functionality and superposition is the case - that the dimensionality of the data compression may be severely underestimated. If Llama on paper is 4,096 dimensions, but in actuality those nodes are superimposed, there could be OOM higher dimensional spaces (and structures in those spaces) than the on paper dimensionality max.
So even if your revised version of the hypothesis is correct, it might be that the search space for meaningful structures was bounded much lower than where the relatively 'low' composable mulit-dimensional shapes are actually primarily forming.
I know that for myself, even when considering basic 4D geometry like a tesseract, if data clusters were around corners of the shape I'd only spot a small number of the possible 2D slices, and in at least one of those cases might think what I was looking at was a circle instead of a tesseract: https://mathworld.wolfram.com/images/eps-gif/TesseractGraph_800.gif
Do you think future work may be able to rely on automated multi-dimensional shape and cluster detection exploring shapes and dimensional spaces well beyond even just 4D, or that the difficulty in mutli-dimensional pattern recognition will remain a foundational obstacle for the foreseeable future?
I'll add a strong plus one to this and a note for emphasis:
Representational geometry is already a long-standing theme in computational neuroscience (e.g. Kriegeskorte et al., 2013)
Overall I think mech interp practitioners would do well to pay more attention to ideas and methods in computational neuroscience. I think mech interp as a field has a habit of overlooking some hard-won lessons learned by that community.
I'm wondering if you have any other pointers to lessong/methods you think are valuable from neuroscience?
I've no great resources in mind for this. Off the top of my head, a few examples of ideas that are common in comp neuro that might have bought mech interp some time if more people in mech interp were familiar with them when they were needed:
- Polysemanticity/distributed representations/mixed selectivity
- Sparse coding
- Representational geometry
I am not sure about what future mech interp needs will be, so it's hard to predict which ideas or methods that are common in neuro will be useful (topological data analysis? Dynamical systems?). But it just seems pretty likely that a field that tackles such a similar problem will continue to be a useful source of intuitions and methods. I'd love if someone were to write a review or post on the interplay between the parallel fields of comp neuro and mech interp. It might help flag places where there ought to be more interplay.
I think it would be valuable to take a set of interesting examples of understood internal structure, and to ask what happens when we train SAEs to try to capture this structure. [...] In other cases, it may seem to us very unnatural to think of the structure we have uncovered in terms of a set of directions (sparse or otherwise) — what does the SAE do in this case?
I'm not sure how SAEs would capture the internal structure of the activations of the pizza model for modular addition, even in theory. In this case, ReLU is used to compute numerical integration, approximating (and/or similarly for sin). Each neuron is responsible for one small rectangle under the curve. Its input is the part of the integrand under the absolute value/ReLU, (times a shared scaling coefficient), and the neuron's coefficient in the fourier-transformed decoder matrix is the area element (again times a shared scaling coefficient).
Notably, in this scheme, the only fully free parameters are: the frequencies of interest, the ordering of neurons, and the two scaling coefficients. There are also constrained parameters for how evenly the space is divided up into boxes and where the function evaluation points are within each box. But the geometry of activation space here is effectively fully constrained up to permutation of the axes and global scaling factors.
What could SAEs even find in this case?
Thanks for writing this up. A few points:
- I generally agree with most of the things you're saying and am excited about this kind of work. I like that you endorse empirical investigations here and think there are just far fewer people doing these experiments than anyone thinks.
- Structure between features seems like the under-dog of research agendas in SAE research (which I feel I can reasonably claim to have been advocating for in many discussions over the preceding months). Mainly I think it presents the most obvious candidate for reducing the description length issue with larger SAEs.
- I'm working on a project looking into this (and am aware of several others) but I don't think this should deter people who are interested from playing around. It's fairly easy to get going on these projects using my library and neuronpedia.
For example, it seems hard to understand how a tree-like structure could explain circular features.
Tree structure between features is easy to find, with hierarchical clustering providing a degree of insight into the feature space that is not achieved by other methods like U-MAP. I would interpret this as a kind of "global structure" whereas day of the week geometry is probably more local. It seems totally plausible that a tree is a reasonable characterisation of structure at a high level without being a perfect characterisation.
The days of the week/months of the year lie on a circle, in order. Let’s be clear about what the interesting finding is from Engels et al.: it’s not that all the days of the week have high cosine sim with each other, or even really that they live in a subspace, but that they are in order!
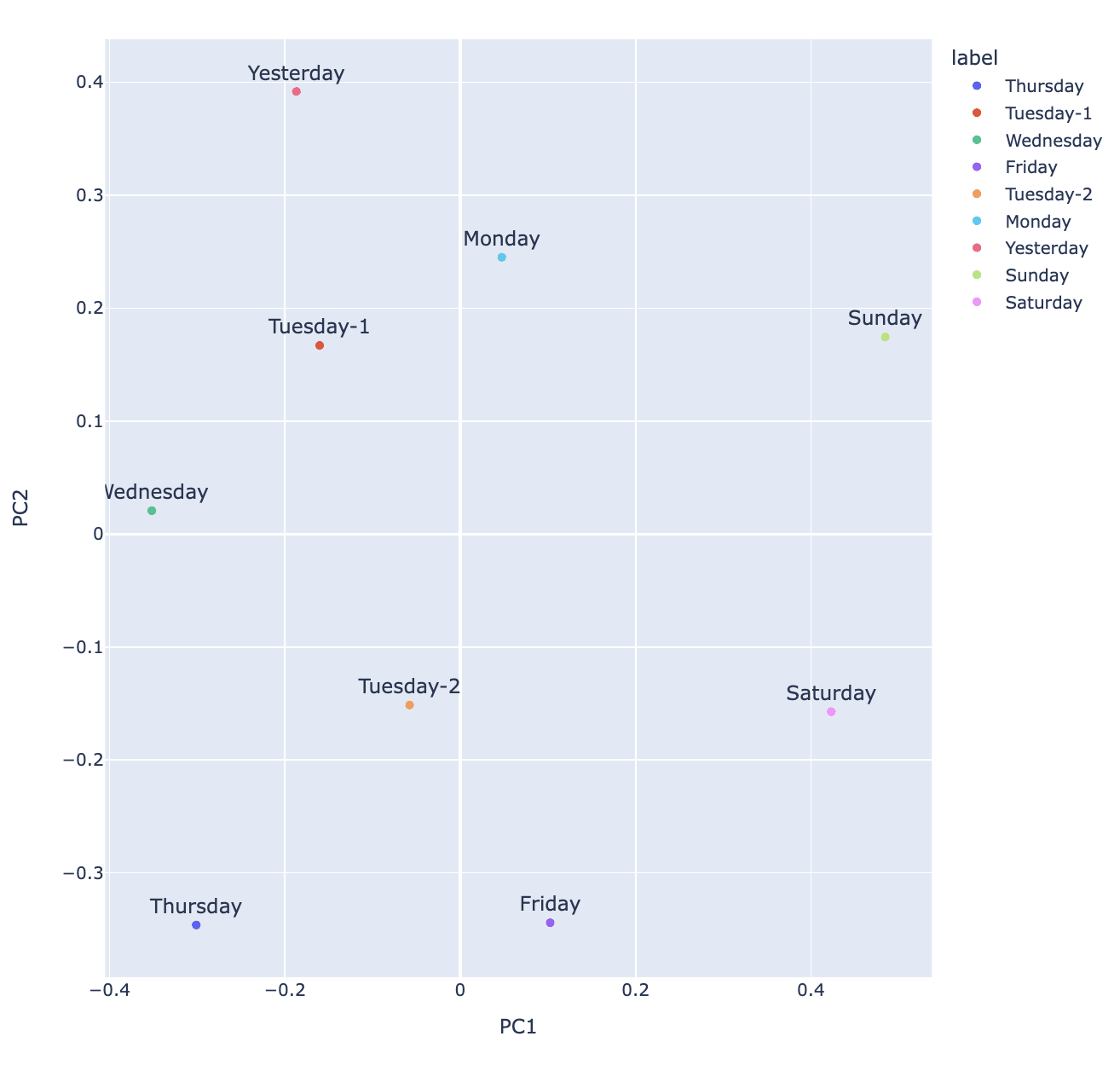
I think another part of the result here was that the PCA of the lower dimensional space spanned by the day of the week features was much clearer in showing the geometry than simply doing PCA over the decoder weights (see below). I double checked this just now and you can actually get the correct ordering just on the features but it's much less obvious what's happening (imo). If you look at these features, they also tend to fire on days of multiple days of the week with different strengths. The lesson here is that co-occurence of feature may matter a lot in particular subspaces.
Layer 7-GPT2 small. Decoder weight PCA on day of the features. Feature labels come from max activating examples. See dashboards here.
This post makes the excellent point that the paradigm that motivated SAEs -- the superposition hypothesis -- is incompatible with widely-known and easily demonstrated properties of SAE features (and feature vectors in general). The superposition hypothesis assumes that feature vectors have nonzero cosine similarity only because there isn't enough space for them all to be orthogonal, in which case the cosine similarities themselves shouldn't be meaningful. But in fact, cosine similarities between feature vectors have rich semantic content, as shown by circular embeddings (in several contexts) and feature splitting / dimensionality-reduction visualizations. Features aren't just crammed together arbitrarily; they're grouped with similar features.
I didn't properly appreciate this point before reading this post (actually: before someone summarized the post to me verbally), at which point it became blindingly obvious.
There are some earlier blog posts that point out that superposition is probably only part of the story, e.g. https://transformer-circuits.pub/2023/superposition-composition/index.html on compositionality, but this one presents the relevant empirical evidence and its implications very clearly.
This post holds up pretty well: SAEs are still popular (although they've lost some followers in the last ~year), and the point isn't specific to SAEs anyway (circular features embeddings are ubiquitous). Superposition is also still an important idea, although I've been thinking about it less so I'm not sure what the state of the art is.
My only complaint is that "maybe if I'm being more sophisticated, I can specify the correlations between features" is giving the entire game away -- the full set of correlations is nearly equivalent to the embeddings themselves, and has all of the interesting parts.
But I think the rest of the post demonstrates an important tension between theory and experiment, which an improved theory has to be able to account for, and I don't think I've heard of an improved theory yet.
This reminded me of how GPT-2-small uses a cosine/sine spiral for its learned positional embeddings embeddings, and I don't think I've seen a mechanistic/dynamical explanation for this (just the post-hoc explanation that attention can use cosine similarity to encode distance in R^n, not that it should happen this way).
Yeah this does seem like its another good example of what I'm trying to gesture at. More generally, I think the embedding at layer 0 is a good place for thinking about the kind of structure that the superposition hypothesis is blind to. If the vocab size is smaller than the SAE dictionary size, an SAE is likely to get perfect reconstruction and by just learning the vocab_size many embeddings. But those embeddings aren't random! They have been carefully learned and contain lots of useful information. I think trying to explain the structure in the embeddings is a good testbed for explaining general feature geometry.
I strongly agree with this post.
I'm not sure about this, though:
We are familiar with modular addition being performed in a circle from Nanda et al., so we were primed to spot this kind of thing — more evidence of street lighting.
It could be the streetlight effect, but it's not that surprising that we'd see this pattern repeatedly. This circular representation for modular addition is essentially the only nontrivial representation (in the group-theoretic sense) for modular addition, which is the only (simple) commutative group. It's likely to pop up in many places whether or not we're looking for it (like position embeddings, as Eric pointed out, or anything else Fourier-flavored).
Also:
As for where in the activation space each feature vector is placed, oh that doesn't really matter and any nearly orthogonal overcomplete basis will do. Or maybe if I'm being more sophisticated, I can specify the correlations between features and that’s enough to pin down all the structure that matters — all the other details of the overcomplete basis are random.
The correlations between all pairs of features are sufficient to pin down an arbitrary amount of structure -- everything except an overall rotation of the embedding space -- so someone could object that the circular representation and UMAP results are "just" showing the correlations between features. I would probably say the "superposition hypothesis" is a bit stronger than that, but weaker than "any nearly orthogonal overcomplete basis will do": it says that the total amount of correlation between a given feature and all other features (i.e. interference from them) matters, but which other features are interfering with it doesn't matter, and the particular amount of interference from each other feature doesn't matter either. This version of the hypothesis seems pretty well falsified at this point.
Option 2: Supplementing superposition
One plausible possibility here might be that sets of feature vectors that are semantically related to each other in interesting ways (ways that favor certain forms of computation) tend to form (approximate) sub-spaces, of various types and dimensionalities facilitating those computations — which we could then learn a taxonomy of common types of. The days of the week circle would then be classified as an example of a two-dimensional subspace, specifically a circular modular arithmetic sub-space, more specifically modulo 7. Feature splitting would perhaps exist in rather higher-dimensional subspaces that usefully represented some form of tree structure of related concepts, possibly ones that made use of some combination of the cosine distances between features as some sort of similarity measure, and perhaps also of directions correlated with some related parts of the overall overcomplete basis (for example, perhaps in ways resembling word2vec's king-man+woman~=queen structure).
This post reminds me of the Word2vec algebra.
E.g. "kitten" - "cat" + "dog" "puppy"
I expect that this will be true for LLM token embeddings too. Have anyone checked this?
I also expect something similar to be true for internal LLM representations too, but that this might be harder to verify. However, maybe not, if you have interpretable SAE vectors?
{kind=link}
Interesting post thanks!
I wonder whether there are some properties of the feature geometry that could be more easily understood by looking at the relation between features in adjacent layers. My mental image of the feature space is something like a simplicial complex with features at each layer n corresponding roughly to n-dimensional faces, connecting up lower dimensional features from previous layers.
This is probably just the way I've seen features/interpretability explained - the features on one layer are thought of as relevant combinations of simpler features from the previous layer (this explanation in particular seems to be the standard one for features of image classifiers). This is certainly simplistic since the higher level features are probably much more advanced functions of the previous layer rather than just 'these n features are all present'. However for understanding some geometry I think it could be interesting.
For example, you can certainly build a simplicial complex in the following way: let the features for the first layer be the 0-simplices be the first layer. For a feature F on the n-th layer, compute the n most likely features from the previous layer to fire on a sample highly related to F, and produce an (n-1)-simplex on these (by most likely, I mean either by sampling or there may be a purely mathematical way of doing this from the feature vectors). This simplicial complex is a pretty basic object recording the relationship between features (on the same layer, or between layers). I can't really say whether it would be particularly easy to actually compute with, but it might have some interesting topological features (e.g. how easy is it to disconnect the simplex by removing simplices, equivalently clamping features to zero).
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
Written at Apollo Research
Summary: Superposition-based interpretations of neural network activation spaces are incomplete. The specific locations of feature vectors contain crucial structural information beyond superposition, as seen in circular arrangements of day-of-the-week features and in the rich structures of feature UMAPs. We don’t currently have good concepts for talking about this structure in feature geometry, but it is likely very important for model computation. An eventual understanding of feature geometry might look like a hodgepodge of case-specific explanations, or supplementing superposition with additional concepts, or plausibly an entirely new theory that supersedes superposition. To develop this understanding, it may be valuable to study toy models in depth and do theoretical or conceptual work in addition to studying frontier models.
Epistemic status: Decently confident that the ideas here are directionally correct. I’ve been thinking these thoughts for a while, and recently got round to writing them up at a high level. Lots of people (including both SAE stans and SAE skeptics) have thought very similar things before and some of them have written about it in various places too. Some of my views, especially the merit of certain research approaches to tackle the problems I highlight, have been presented here without my best attempt to argue for them.
What would it mean if we could fully understand an activation space through the lens of superposition?
If you fully understand something, you can explain everything about it that matters to someone else in terms of concepts you (and hopefully they) understand. So we can think about how well I understand an activation space by how well I can communicate to you what the activation space is doing, and we can test if my explanation is good by seeing if you can construct a functionally equivalent activation space (which need not be completely identical of course) solely from the information I have given you. In the case of SAEs, here's what I might say:
Every part of this explanation is in terms of things I understand precisely. My features are described in natural language, and I know what a random overcomplete basis is (although I’m on the fence about whether a large correlation matrix counts as something that I understand).
The placement of each feature vector in the activation space matters
Why might this description be insufficient? First, there is the pesky problem of SAE reconstruction errors, which are parts of activation vectors that are missed when we give this description. Second, not all features seem monosemantic, and it is hard to find semantic descriptions of even the most monosemantic features that have both high sensitivity and specificity, let alone descriptions which allow us to predict the quantitative values that activating features take on a particular input.
But let’s suppose that these issues have been solved: SAE improvements lead to perfect reconstruction and extremely monosemantic features, and new autointerp techniques lead to highly sensitive and specific feature descriptions. I claim that even then, our protocol will fail to be a valid explanation for the activation space, because the placement of each feature vector in the activation space matters. The location of feature vectors contains rich structure that demands explanation[1]! If your knockoff activation space contains the same features activating on the same dataset examples, but you haven’t placed each feature in the right place, your space contains a lot less relevant information than mine, and it’s less usable by a model.
Wait, you say, this is fine! I can just communicate the weights of my SAE’s decoder matrix to you, and then you will know where all the feature vectors go, and then you get my richly structured activation space. But this is breaking the rules! If I understand something, I must be able to explain it to you in concepts I understand, and I do not understand what information is contained in the giant inscrutable decoder matrix. You should be no more content to receive a decoder matrix from me as an ‘explanation’ than you should be content to receive a list of weight matrices, which would also suffice to allow you to reproduce the activation space.
If you are unconvinced, here is some evidence that the location of feature vectors matters:
The days of the week/months of the year lie on a circle, in order. Let’s be clear about what the interesting finding is from Engels et al.: it’s not that all the days of the week have high cosine sim with each other, or even really that they live in a subspace, but that they are in order! In a very real sense, this scenario is outside the scope of the superposition hypothesis, which posits that the important structure in an activation space is the sparse coding of vectors which have no important residual structure beyond correlations. There are good reasons to think that these two circles found in the paper are the rule not the exception:
More generally, I think that evidence of the ubiquity of important structure in feature vectors comes from UMAPs and feature splitting:
There is lots of evidence UMAPs of feature vectors are interesting to look at. If all the important structure of an activation space is contained in the feature descriptions, then the UMAP should be a random mess, because once everything has been explained all that can be left behind is random noise. Instead, UMAPs of features contain incredibly rich structure that can be looked into for hours on end. Similarly, feature splitting is evidence that the location of SAE features is heavily related to their semantic meaning, and it is some evidence of some complicated hierarchy of SAE features.
Both of these are evidence that there is more to be explained than just which features are present and when they fire! I don’t think many people are currently thinking about how to explain the interesting structure in a systematic way, and I don’t think ad hoc explanations like ‘this cluster of features is all about the bay area in some way’ are actually useful for understanding things in general. I don’t think we have yet elicited the right concepts for talking about it. I also don’t think this structure will be solved on the current default trajectory: I don’t think the default path for sparse dictionary learning involves a next generation of SAEs which have boring structureless UMAPs or don’t exhibit feature splitting.
What types of theories could fill this gap in our understanding?
I am currently in the headspace of trying to map out the space of possible theories that all explain the current success of SAEs, but which could also explain the gaps that SAEs leave. I see three broad classes of options.
Option 1: A hodge-podge of explanations
Maybe there is lots of remaining structure to explain after superposition has been used to explain the space, but there are no broadly applicable theories or models which allow us to describe this theory well. There could be huge contingencies and idiosyncrasies which mean that the best we can do is describe this circle, that tetrahedron, this region of high cosine sim, each with a bespoke explanation.
I think it’s pretty plausible that this is the way things go, but it is much too early to conclude that this pessimistic option is correct. Even in this case, it would be valuable to develop a taxonomy of all the different kinds of structure that are commonly found.
Option 2: Supplementing superposition
In this scenario, we build a general theory of how feature vectors are arranged, which is as broadly applicable as the idea of superposition and the (approximately) linear representation hypothesis. Ideally, this theory would elegantly explain UMAP structure, feature splitting, and present and future case studies of interesting nonlinear feature arrangements. This option involves adding a theory ‘on top of’ superposition: our best interpretations of activation spaces would involve describing the feature dictionary, and then describing the location of features using the newly developed concepts.
It’s hard to flesh out examples of what these new concepts might look like before the conceptual work has been done. The closest thing to an existing concept that supplements superposition is the idea introduced by Anthropic that features can be placed on a hierarchical tree: the tree can be built from looking at dictionaries of different sizes, relating parent and children nodes via feature splitting. Ideally, we’d also be able to relate this tree to something like computational paths through the network: maybe the tree distance between two features measures the amount of difference between the subsequent computation done on each feature. This particular extra structure isn’t sufficient: I expect there to be much richer structure in feature vector locations than just a distance between features. For example, it seems hard to understand how a tree-like structure could explain circular features.
Option 3: Superseding superposition
Alternatively, we may develop a more sophisticated theory which explains all the results of SAEs and more besides, but which supplants superposition as an explanation of activation space structure instead of building on top of it[2]. I have quite substantial probability on the ‘next’ theory looking more like this than something that is built on top of superposition.
Here’s a thought experiment that motivates why SAE results might be compatible with the computational latents not being superpositional directions:
Suppose that I have a ‘semantic vector space’. Every sentence on the internet corresponds to a point in this space, with the property that the heuristic notion of ‘semantic distance’ (the qualitative difference in meaning between two sentences) between two sentences always corresponds to Euclidean distance in this space. We should expect that points in this space form clusters, because sentences are semantically clustered: there are lots of very similar sentences. In fact, points may lie in several clusters: a sentence about blue boats will be close to sentences about other blue things, and also to sentences about boats. However, these clusters are not themselves necessarily the structure of the semantic space! They are a downstream consequence of the space being structured semantically. Any good semantic space would have these clusters as they are a property of the world and of the dataset.
Insofar as SAE training is like clustering, this argument applies to SAEs as well: perhaps any good theory which explains the rich structure of the activation space would predict that SAEs perform well as a downstream consequence[3]. Further, it seems extremely possible to me that there might be some sensible non-superpositional way to describe the structure of the activation space which has SAE performance drop out in the same step that describes the relation between SAE decoder directions[4].
How could we discover the new theory?
Discovering the new theory is hard! I can see a few very high level research approaches that seem sensible.
Approach 1: Investigating feature structure in big SAEs
The most widely taken approach for improving our understanding of how SAEs learn features is to train more SAEs and to investigate their properties in an ad hoc way guided by scientific intuition. The main advantage of this approach is that if we want to understand the limitations of SAEs on big language models, then any extra data we collect by studying SAEs on big language models is unambiguously relevant. There may be some results that are easy to find which make discovering the new theory much easier, in the same way that I have a much easier time describing my issues with SAE feature geometry now that people have discovered that days of the week lie on a circle. It may turn out that if we collect lots more examples of interesting observations about SAE feature geometry, then new theories which explain these observations will become obvious.
Approach 2: Directly look for interesting structure in LLM representations
Another approach to understanding activation space structure is to carefully make a case for some part of the activation space having a particular ground truth structure, for example polyhedra, hypersurfaces and so on. It’s possible that if we carefully identify many more examples of internal structure, new theories which unify these observations will emerge.
More specifically, I think it would be valuable to take a set of interesting examples of understood internal structure, and to ask what happens when we train SAEs to try to capture this structure. In some cases, it may be possible for the structure to be thought of as a set of feature directions although they may not be sparse or particularly independent of each other — does the SAE find these feature directions? In other cases, it may seem to us very unnatural to think of the structure we have uncovered in terms of a set of directions (sparse or otherwise) — what does the SAE do in this case? If we have a range of examples of representational structures paired with SAE features that try to learn these structures, maybe this way we can learn how to interpret the information contained about the activation space that is contained within the SAE decoder directions.
Approach 3: Carefully reverse engineering relevant toy models with ground truth access
There are huge (underrated in my opinion) advantages to doing interpretability research in a domain where we have access to the ground truth, and when it comes to building a new theory, I think the case for working in a ground truth environment is especially strong. In the case of language modelling, it’s hard to resolve even big disagreements about how much feature geometry matters (both the view that feature geometry doesn’t matter at all and the view that they imply SAEs have achieved nearly nothing are not insane to me), but if we know what the correct answer is, we can just ask if SAEs enabled us to find the answer. For example, we could train a neural network to emulate a boolean circuit, and we could try to carefully reverse engineer which boolean circuit has been learned[5]. Then, we could use SAEs (or indeed other techniques) and try to understand how to translate between our carefully reverse engineered implementations and the results of SAE training.
Toy models also have the advantage that we can much more easily understand them in depth, and we can more straightforwardly hand pick the representational/computational structure we are investigating. We can also iterate much more quickly! It may be easier to carefully understand interesting representational structures à la Approach 2 in toy models for this reason. The obvious, substantial, downside of all toy model research is that we can’t be sure that the insights we take from toy models are relevant to LLMs. This is a very real downside, but I think it can be effectively mitigated by
Approach 4: Theoretical work to unite experimental results and motivate new experiments
If we are to develop a new theory (or several), there will have to be some conceptual and theoretical breakthroughs. This could look like translating work from other fields as with superposition — the superposition hypothesis was heavily inspired by the field of sparse coding and compressed sensing — or it may look like the development of genuinely new concepts, and maybe even new maths.
Of the four approaches here, I’m least confident that it makes sense for people to take this approach directly — perhaps the conceptual work is best done as part of one of the other approaches. However I include this as its own approach because I think there are some valuable standalone questions that could be directly tackled. For example:
Acknowledgements
Thanks to Kaarel Hanni, Stefan Heimersheim, Lee Sharkey, Lucius Bushnaq, Joseph Bloom, Clem von Stengel, Hoagy Cunningham, Bilal Chughtai and Andy Arditi for useful discussions.
^
This point is already known to neuroscientists.
^
Here’s some people at Anthropic suggesting that they are also open to this possibility.
^
Activation spaces in language models are not really semantic spaces. Instead, one potentially useful framing for thinking about the structure in an activation space is: the dataset contains an exorbitant amount of interesting structure, much more than is used by current models. The model has learned to use (compute with or predict with) a particular subset of that structure, and a particular interp technique allows us to elicit another, distinct subset of that structure. Ideally, we want our interp technique to elicit (convert into understandable description) the same structure as used by the model. However, it’s easy for an overly powerful interp technique (such as a very nonlinear probe) to discover structure in the data that is not usable by the model, and it is also easy for an interp technique to fail to elicit structure that the model is actually able to use (such as certain aspects of SAE feature geometry). This framing motivates the idea that if we want to do interpretability by understanding activation spaces and identifying features, we have to regularise our search for structure with an understanding of what computation can be performed by the model on the space. This is how the toy model of superposition and the SAE arrive at the idea that a feature is a projection followed by a ReLU, and reasoning along the same lines is why my post on computation in superposition suggests that features are projections without a ReLU.
^
This seems particularly plausible if we are talking about current SAE performance, with imperfect reconstruction and inadequate feature interpretations. The better these metrics become (and L0 and dictionary size metrics), the more they will constrain the space of theories by the requirement that these theories explain SAE performance, making it more likely that the best interpretation of an activation space really is in terms of the SAE features.
^
I am a big fan of this research project in particular and expect to work on boolean circuit toy models in future (for more reasons than discussed here). If you are interested in understanding how neural networks learn and represent interesting (perhaps sparse) classes of boolean circuits, or have investigated this before, I might be keen to chat.