As co-author of one of the mentioned pieces, I'd say it's really great to see the AGI xrisk message mainstreaming. It doesn't nearly go fast enough, though. Some (Hawking, Bostrom, Musk) have already spoken out about the topic for close to a decade. So far, that hasn't been enough to change common understanding. Those, such as myself, who hope that some form of coordination could save us, should give all they have to make this go faster. Additionally, those who think regulation could work should work on robust regulation proposals which are currently lacking. And those who can should work on international coordination, which is currently also lacking.
A lot of work to be done. But the good news is that the window of opportunity is opening, and a lot of people could work on this which currently aren't. This could be a path to victory.
Anecdata: many in my non-EA/rat social circles of entrepreneurs and investors are engaging with this for the first time.
And, to my surprise (given the optimistic nature of entrepreneurs/VCs) they aren't just being reflexive techno-optimists, they're taking the ideas seriously and, since Bankless, "Eliezer" is becoming a first name-only character.
Eliezer said he's an accelerationist in basically everything except AI and gain-of-function bio and that seems to resonate. AI is Not Like The Other Problems.
"I'm an accelerationist for solar power, nuclear power to the extent it hasn't been obsoleted by solar power and we might as well give up but I'm still bitter about it, geothermal, genetic engineering, neuroengineering, FDA delenda est, basically everything except GoF bio and AI"
https://twitter.com/ESYudkowsky/status/1629725763175092225?t=A-po2tuqZ17YVYAyrBRCDw&s=19
Thanks for this collection! A few other examples.
Some recent stories from FOX News:
Artificial intelligence 'godfather' on AI possibly wiping out humanity: ‘It's not inconceivable’ (FOX News)
- "Until quite recently, I thought it was going to be like 20 to 50 years before we have general purpose AI. And now I think it may be 20 years or less," Hinton predicted. Asked specifically the chances of AI "wiping out humanity," Hinton said, "I think it's not inconceivable. That's all I'll say."
Lawmakers consider regulations on artificial intelligence (FOX News)
- 2-minute video, showing how some policy makers have been responding to ChatGPT and other recent AI progress. Worth watching.
Policymakers Responding to AI
Not really aware of US policymakers who have discussed existential risks from AI, but some policymakers have taken note recent AI progress, and some are alarmed. The video from Fox linked above actually gives a pretty good overview, but here are a couple examples.
Representative Ted Lieu (D-CA) AI Needs To Be Regulated (NYT Op-Ed).
- “What we need is a dedicated agency to regulate A.I. An agency is nimbler than the legislative process, is staffed with experts and can reverse its decisions if it makes an error. Creating such an agency will be a difficult and huge undertaking because A.I. is complicated and still not well understood.”
Senator Chris Murphy (D-CN) tweeting a bit about AI earlier today.
- "ChatGPT taught itself to do advanced chemistry. It wasn't built into the model. Nobody programmed it to learn complicated chemistry. It decided to teach itself, then made its knowledge available to anyone who asked. Something is coming. We aren't ready."
- responding to many criticizing the above claim as incorrect or overblown: "I get it - it's easy and fun to terminology shame policymakers on tech. But I'm pretty sure I have the premise right: The consequences of so many human functions being outsourced to AI is potentially disastrous, and we aren't having a functional conversation about this."
Another opinion on NYT: https://www.nytimes.com/2023/03/24/opinion/yuval-harari-ai-chatgpt.html (Yuval Noah Harari, Tristan Harris, and Aza Ruskin. Non-paywalled version.)
Loved the first paragraph:
In 2022, over 700 top academics and researchers behind the leading artificial intelligence companies were asked in a survey about future A.I. risk. Half of those surveyed stated that there was a 10 percent or greater chance of human extinction (or similarly permanent and severe disempowerment) from future AI systems. Technology companies building today’s large language models are caught in a race to put all of humanity on that plane.
Idea: Run a competition to come up with other such first paragraphs people can use in similar op eds, that effectively communicate important ideas like this that are good to propagate.
Then test the top answers like @Peter Wildeford said here:
If we want to know what arguments resonate with New York Times articles we can actually use surveys, message testing, and focus groups to check and we don't need to guess! (Disclaimer: My company sells these services.)
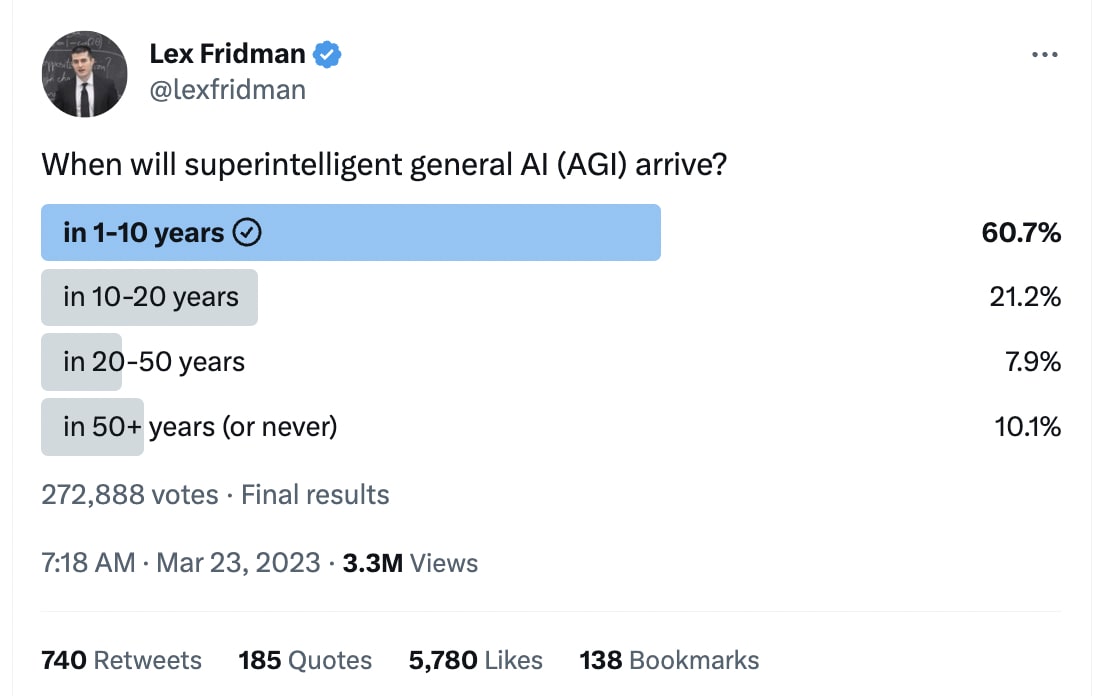
I wonder if soon the general public will freak out on a large scale (Covid-like). I will be not surprised if it will happen in 2024 and only slightly surprised if it will happen this year. If it will happen, I am also not sure if it will be good or bad.
COVID at least had some policy handles that the government could try to pull: lockdowns, masking, vaccines, etc. What could they even do against AGI?
I don't think that the Overton Window for AI risk widening is a good thing, primarily because of the fact that we overrate bad news compared to good news, and there's actual progress on AGI Alignment, and I expect people to take away a more negative view of AGI development than it's warranted.
Here's a link to the problem of negative news overwhelming positive news:
https://www.vox.com/the-highlight/23596969/bad-news-negativity-bias-media
In general, I think that we will almost certainly make it through AGI and ASI via aligning them. And in particular, the amount of capabilities compared to safety progress is arguably suboptimal, in that there's slack, which is we could accelerate AGI progress more and largely end up still alignment can be achieved.
I said elsewhere earlier: "AGI has the power to destroy the entire human race, and if we believe there's even a 1% chance that it will, then we have to treat it as an absolute certainty."
And I'm pretty sure that no expert puts it below 1%
I feel similarly, and what confuses me is that I had a positive view of AI safety back when it was about being pro-safety, pro-alignment, pro-interpretability, etc. These are good things that were neglected, and it felt good that there were people pushing for them.
But at some point it changed, becoming more about fear and opposition to progress. Anti-open source (most obviously with OpenAI, but even OpenRAIL isn't OSI), anti-competition (via regulatory capture), anti-progress (via as-yet-unspecified means). I hadn't appreciated the sheer darkness of the worldview.
And now, with the mindshare the movement has gained among the influential, I wonder what if it succeeds. What if open source AI models are banned, competitors to OpenAI are banned, and OpenAI decides to stop with GPT-4? It's a little hard to imagine all that, but nuclear power was killed off in a vaguely analogous way.
Pondering the ensuing scenarios isn't too pleasant. Does AGI get developed anyway, perhaps by China or by some military project during WW3? (I'd rather not either, please.) Or does humanity fully cooperate to put itself in a sort of technological stasis, with indefinite end?
it cannot occur as long as GPUs exist. we're getting hard foom within 8 years, rain or shine, as far as I can tell; most likely within 4, if we do nothing to stabilize then it's within 2, if we keep pushing hard then it'll be this year.
let's not do it this year. the people most able to push towards hard foom won't need to rush as much if folks slow down. We've got some cool payouts from ai, let's chill out slightly for a bit. just a little - there's lots of fun capabilities stuff to do that doesn't push towards explosive criticality, and most of the coolest capability stuff (in my view) makes things easier, not harder, to check for correctness.
The alignment, safety and interpretability is continuing at full speed, but if all the efforts of the alignment community are sufficient to get enough of this to avoid the destruction of the world in 2042, and AGI is created in 2037, then at the end you get a destroyed world.
It might not be possible in real life (List of Lethalities: "we can't just decide not to build AGI"), and even if possible it might not be tractable enough to be worth focusing any attention on, but it would be nice if there was some way to make sure that AGI happens after alignment is sufficient at full speed (EDIT: or, failing that, to happen later, so if alignment goes quickly that takes the world from bad outcomes to good outcomes, instead of bad outcomes to bad outcomes).
The good news is that I expect AI development to be de facto open if not de jure open for the following reason:
AI labs still need to publish enough at at least a high-level summary or abstraction level to succeed in the marketplace and politically.
OpenAI (et al.) could try and force as much about the actual functioning, work-performing details of the engineering design of their models into low-level implementation details that remain closed-source, with the intent to base their design on principles that make such a strategy more feasible. But I believe that this will not work.
This has to do with more fundamental reasons on how successful AI models have to actually be structured, such that even their high-level, abstract summaries of how they work must reliably map to the reasons that the model performs well (this is akin to the Natural Abstraction hypothesis).
Therefore, advanced AI models could in principle be feasibly reverse-engineered or re-developed simply from the implementation details that are published.
Yeah, even if there has been that kind of progress in alignment, I don't see anyone publicizing that 50% of experts giving a 10% chance of existential catastrophe is an improvement over what the situation was before they started reporting on it. I don't think they could tell that story even if they wanted to, not in a way that would actually educate the population generally.
Another article in The Atlantic today explicitly mentions the existential risk of AI and currently sits as the 9th most popular article on the website.

In addition, there is a front-page article on The Economist website today about AI accelerationism among the big tech firms.
A particular interesting figure from the article (unrelated to Overton Window):
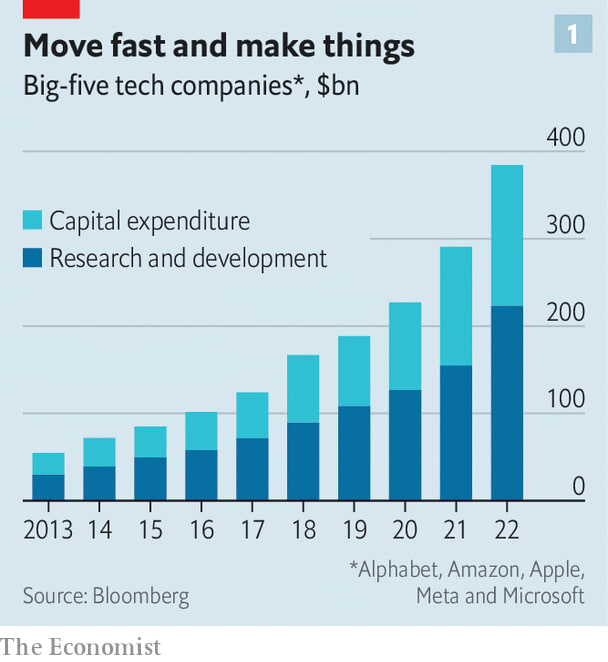
In 2022, amid a tech-led stockmarket crunch, the big five poured $223bn into research and development (R&D), up from $109bn in 2019 (see chart 1). That was on top of $161bn in capital expenditure, a figure that had also doubled in three years. All told, this was equivalent to 26% of their combined annual revenues last year, up from 16% in 2015.
Tentative GPT4's summary.
Up/Downvote "Overall" if the summary is useful/harmful.
Up/Downvote "Agreement" if the summary is correct/wrong.
TLDR: The article showcases increased media coverage, expert opinions, and AI leaders discussing AI existential risk, suggesting AI concerns are becoming mainstream and shifting the Overton Window.
Arguments: The article presents examples of AI risk coverage in mainstream media outlets like the New York Times, CNBC, TIME, and Vox. Additionally, it mentions public statements by notable figures such as Bill Gates, Elon Musk, and Stephen Hawking, and quotes from AI lab leaders Sam Altman and Demis Hassabis. It also lists recent surveys where 55% of the American public saw AI as an existential threat and favored government regulation.
Takeaways: AI risks, both short and long-term, are becoming more mainstream and widely discussed in media, with expert opinions highlighting the potential threats. This shift in the Overton Window may reduce any reputational concerns when discussing AI existential risks.
Strengths: The article provides numerous examples of AI risk discussions from reputable media sources and expert opinions. These examples demonstrate a growing awareness and acceptance of AI-related concerns, highlighting the shift in the Overton Window.
Weaknesses: The article acknowledges that not all media coverage is high-quality or high-fidelity and that reputational concerns may still persist in discussing AI risk.
Interactions: This widening of the Overton Window might have implications for AI safety research funding, public perception of AI risks, and policy discussions on AI regulation and governance.
Factual mistakes: No factual mistakes were included in the summary.
Missing arguments: The summary could have mentioned the possibility of negative effects or misconceptions due to increased media coverage, such as sensationalism or unfounded fears surrounding AI development. Similarly, mentioning the importance of responsible AI research, collaboration, and communication between AI researchers, policymakers, and the public would be beneficial.
The Telegraph (UK’s main conservative broadsheet): https://www.telegraph.co.uk/news/2023/03/28/elon-musk-twitter-owner-artificial-intelligence/
Linking to my post about Dutch TV: https://www.lesswrong.com/posts/TMXEDZy2FNr5neP4L/datapoint-median-10-ai-x-risk-mentioned-on-dutch-public-tv
I sometimes talk to people who are nervous about expressing concerns that AI might overpower humanity. It’s a weird belief, and it might look too strange to talk about it publicly, and people might not take us seriously.
How weird is it, though? Some observations (see Appendix for details):
Takeaway: We live in a world where mainstream news outlets, famous people, and the people who are literally leading AI companies are talking openly about AI x-risk.
I’m not saying that things are in great shape, or that these journalists/famous people/AI executives have things under control. I’m also not saying that all of this messaging has been high-quality or high-fidelity. I’m also not saying that there are never reputational concerns involved in talking about AI risk.
But next time you’re assessing how weird you might look when you openly communicate about AI x-risk, or how outside the Overton Window it might be, remember that some of your weird beliefs have been profiled by major news outlets. And remember that some of your concerns have been echoed by people like Bill Gates, Stephen Hawking, and the people leading companies that are literally trying to build AGI.
I’ll conclude with a somewhat more speculative interpretation: short-term and long-term risks from AI systems are becoming more mainstream. This is likely to keep happening, whether we want it to or not. The Overton Window is shifting (and in some ways, it’s already wider than it may seem).
Appendix: Examples of AI risk arguments in the media/mainstream
I spent about an hour looking for examples of AI safety ideas in the media. I also asked my Facebook friends and some Slack channels. See below for examples. Feel free to add your own examples as comments.
Articles
This Changes Everything by Ezra Klein (NYT)
Why Uncontrollable AI Looks More Likely Than Ever (TIME Magazine)
The New AI-Powered Bing Is Threatening Users. That’s No Laughing Matter (TIME Magazine)
DeepMind’s CEO Helped Take AI Mainstream. Now He’s Urging Caution (TIME Magazine)
AI ‘race to recklessness’ could have dire consequences, tech experts warn in new interview (NBC)
Elon Musk, who co-founded firm behind ChatGPT, warns A.I. is ‘one of the biggest risks’ to civilization (CNBC)
Elon Musk warns AI ‘one of biggest risks’ to civilization during ChatGPT’s risk (NY Post)
AI can be racist, sexist and creepy. What should we do about it? (CNN)
Are we racing toward AI catastrophe? By Kelsey Piper (Vox)
The case for slowing down AI By Sigal Samuel (Vox)
The Age of AI has begun by Bill Gates
Stephen Hawking warns artificial intelligence could end mankind (BBC). Note this one is from 2014; all the others are recent.
Quotes from executives at AI labs
Sam Altman, 2015
Sam Altman, 2023
Demis Hassabis, 2023
Anthropic, 2023
Miscellaneous
I am grateful to Zach Stein-Perlman for feedback, as well as several others for pointing out relevant examples.
Recommended: Spreading messages to help the the most important century