A human given finite time to think also only performs O(1) computation, and thus cannot "solve computationally hard problems".
Thank you for trying so hard to replicate this little experiment of mine.
Perhaps you sent the prompt in the middle of a conversation rather than at the beginning? If the same list was also sent earlier in the conversation, I can imagine it managed to get the answer right because it had more time to 'take in' the numbers, or otherwise establish a context that guided it to the right answer.
Yes, this is exactly what I did. I made sure to use a new list of numbers for each question – I'd noticed that it would remember previous answers if I didn't – but I didn't ask each of these in its own conversation. On one hand, it would have been cleaner if I'd started fresh each time; on the other, I wouldn't have had that great moment where it wrote code and then hallucinated that it had executed it.
I hadn't noticed your patterns when I ran mine. What I did notice is that its answer always included the first element of my list, usually (~80%) included the second, the third was often (~40%) halfway through the list, and the last one was always a hallucination. That's eerily similar to what I'd expect from the four-nested-loop algorithm (minus the hallucination).
That would explain why, when I asked it to find the "closest" sum, it picked three numbers, and then, upon their being too small to work, picked the second-largest number from the list. It would also explain why the hallucinated number was the last number every single time.
I agree with this.
Sometimes it gives what might be the laziest "breakdown" I've ever seen.
I laughed hard at this.
Cool! It wrote and executed code to solve the problem, and it got it right.
Are you using chat-GPT-4? I thought it can't run code?
Interesting! Yes, I am using ChatGPT with GPT-4. It printed out the code, then *told me that it ran it*, then printed out a correct answer. I didn't think to fact-check it; instead I assumed the OpenAI has been adding some impressive/scary new features.
Oh this is funny. It told me that it ran the code and got the answer [64, 91, 39, 47]. I checked that these satisfied the problem. But I didn't check (until reviewing other comments) whether that's actually what the code outputted. It's not. Technically the code actually doesn't output anything, it saves the result to a variable instead. And if I print that variable, it found [64, 6, 96, 75].
Lesson 1: I was not careful enough in checking its output, even when I thought I was being careful.
Lesson 2: It is indeed not running code, even if it tells me it is.
Possibly it somehow got lucky with its pattern-matching heuristics. The start of B is 64, 6, 9, 91, 59, 47... And 59 is similar to 39, which occurs a few numbers later in the list. So it's a successful subset which is not too many permutations and substitutions away from the original list.
This makes sense. Another thought I had was that I picked 50 numbers 1-100. It could've just gotten lucky. If I were to do this again, I'd do 1-1000 to decrease the odds of this.
The post otherwise makes sense to me, but I'm confused by this bit:
It can do better if it's allowed to run algorithms by "thinking out loud". It's really slow, and this is a good way to fill up its context buffer. The slowness is a real problem - if it outputs ~10 token/sec, it will take forever to solve any problems that are actually both big and hard. This is a neat trick, but it doesn't seem like an important improvement to its capabilities.
Why not?
It seems like humans also run into the same problem - the brain can only do a limited amount of inference per unit of thought. We get around it by having a working memory, which we may extend by writing things down, to store intermediate steps of our reasoning so that we don't have to simulate everything in one go. It seems to me that "thinking out loud" and writing things to its context buffer is what lets GPT have a working memory the same way that humans do.
And e.g. if someone instructs ChatGPT to first do one thing and then another thing - say, first generating an outline of a plan and then filling in intermediate steps of the plan - then they are effectively using it to solve problems that couldn't be solved in a constant time. Which to me seems like a huge improvement to its capabilities, since it lifts the restriction of "can only solve constant-time problems".
You seem to suggest that slowness is a problem, but speed can always be optimized. Humans also seem to have a thing where, after they repeat the same calculation sufficiently many times, they memorize the end result and don't need to recalculate it each time anymore. You could copy this by having some mechanism that automatically detected when the LLM had done the same calculation many times. The mechanism would then use the output of that calculation to finetune the LLM, so that it could skip right to the end result the next time it needed to do the same calculation.
Which to me seems like a huge improvement to its capabilities
This was actually my position when I started writing this post. My instincts told me that "thinking out loud" was a big enhancement to its capabilities. But then I started thinking about what I saw. I watched it spend tens of trillions of FLOPs to write out, in English, how to do a 3x3 matrix multiplication. It was so colossally inefficient, like building a humanoid robot and teaching it to use an abacus.
Then again, your analogy to humans is valid. We do a huge amount of processing internally, and then have this incredibly inefficient communication mechanism called writing, which we then use to solve very hard problems!
So my instincts point both ways on this, but I have nothing resembling rigorous proof one way or the other. So I'm pretty undecided.
I watched it spend tens of trillions of FLOPs to write out, in English, how to do a 3x3 matrix multiplication. It was so colossally inefficient, like building a humanoid robot and teaching it to use an abacus.
There's also the case where it's allowed to call other services that are more optimized for the specific use case in question, such as querying Wolfram Alpha:

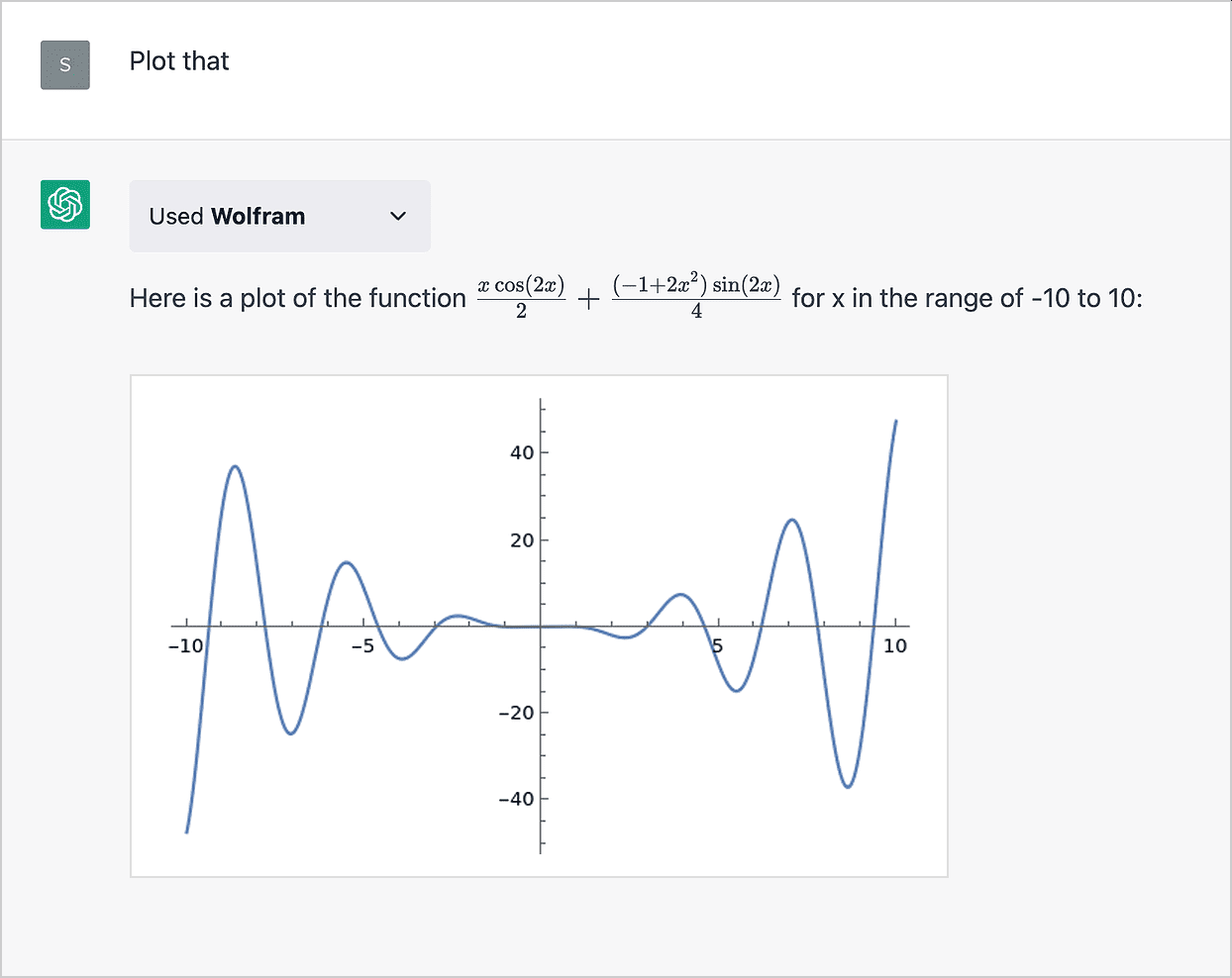
Good analysis, something like this is why I'm also not as much concerned about superhuman LLMs.
One thing I'd be curious about is how Universal Transformers modify your conclusions. These have variable per-symbol processing length, so in theory they could learn algorithms that a transformer with finite calculation cannot.
On the other hand... UTs aren't really being used anywhere (so far as I know) so they probably have other big pitfalls. Right now I do I think something like your analysis would probably apply to any realistic transformer modifications, and that UTs aren't about to destroy transformers, but that's a hunch and I wish I had better reasoning for why.
Strongly upvoted.
Short but powerful.
Tl;Dr: LLMs perform O(1) computational steps per generated token and this is true regardless of the generated token.
The LLM sees each token in its context window when generating the next token so can compute problems in O(n^2) [where n is the context window size].
LLMs can get along the computational requirements by "showing their working" and simulating a mechanical computer (one without backtracking, so not Turing complete) in their context window.
This only works if the context window is large enough to contain the workings for the entire algorithm.
Thus LLMs can perform matrix multiplication when showing workings, but not when asked to compute it without showing workings.
Important fundamental limitation on the current paradigm.
We can now say with certainty tasks that GPT will never be able to solve (e.g. beat Stockfish at Chess because Chess is combinatorial and the LLM can't search the game tree to any depth) no matter how far it's scaled up.
This is a very powerful argument.
Very big caveat: the LLM doesn't actually perform O(1) computations per generated token.
The number of computational steps performed per generated token scales with network size: https://www.lesswrong.com/posts/XNBZPbxyYhmoqD87F/llms-and-computation-complexity?commentId=QWEwFcMLFQ678y5Jp
The solution is IMO just to consider the number of computations performed per generated token as some function of the model size, and once we've identified a suitable asymptotic order on the function, we can say intelligent things like "the smallest network capable of solving a problem in complexity class C of size N is X".
Or if our asymptotic bounds are not tight enough:
"No economically feasible LLM can solve problems in complexity class C of size >= N".
(Where economically feasible may be something defined by aggregate global economic resources or similar, depending on how tight you want the bound to be.)
Regardless, we can still obtain meaningful impossibility results.
I'm a bit confused about this post. Are you saying it is theoretically impossible to create an LLM that can do 3*3 matrix multiplication without using chain of thought? That seems false.
The amount of computation an LLM has done so far will be a function of both the size of the LLM (call it the s factor) and the number of tokens generate so far (n). Let's say matrix multiplication of n*n matrices requires cn^3 amount of computation (actually, there are more efficient algos, but it doesn't matter).
You can do this by either using a small LLM and n^3 tokens so that sn^3 > cn^3. Or you can use a bigger LLM, so that s_big*n> cn^3. So then just need n tokens.
In general, you can always get a bigger and bigger constant factor to solve problems with higher n.
If your claim is that, for any LLM that works in the same way as GPT, there will exist a value of n for which it will stop being capable of doing n*n matrix multiplication without chain of thought/extra work, I'd cautiously agree.
An LLM takes the same amount of computation for each generated token, regardless of how hard it is to predict. This limits the complexity of any problem an LLM is trying to solve.
For a given LLM, yes, there will be a limit on amount of computation it can do while generating a token. But this amount can be arbitrarily large. And you can always make a bigger/smarter LLM.
Consider two statements:
- "The richest country in North America is the United States of ______"
- "The SHA1 of 'abc123', iterated 500 times, is _______"
An LLM's goal is to predict the best token to fill in the blank given its training and the previous context. Completing statement 1 requires knowledge about the world but is computationally trivial. Statement 2 requires a lot of computation. Regardless, the LLM performs the same amount of work for either statement.
Well, it might do the same amount of "computation" but for problem 1 that might mostly be filler work while for problem 2 it can do intelligent work. You can always use more compute than necessary, so why does statement 1 using the same amount of compute as statement 2 imply any sort of limitation on the LLM?
It cannot correctly solve computationally hard statements like #2. Period. If it could, that would imply that all problems can be solved in constant time, which is provably (and obviously) false.
Why does this matter? It puts some bounds on what an LLM can do.
But it's easy to imagine a huge LLM capable doing 500 iterations of SH1 of small strings in one shot (even without memorization)? Why do you think that's impossible? (Just imagine a transformer circuit calculating SHA1, repeated 500 times). This doesn't imply that all problems can be solved in constant time. It just means that the LLM will only be able to do this until the length of string is bigger than a certain limit. After that, you'll need to make the LLM bigger/smarter.
Thanks for the deep and thoughtful comment. I hadn't considered that "In general, you can always get a bigger and bigger constant factor to solve problems with higher n."
I'm going to think carefully and then see how this changes my thinking. I'll try to reply again soon.
This doesn’t matter much, as the constant factor needed still grows as fast as the asymptotic bound. GPT does not have a big enough constant factor. (This objection has always been true of asymptotic bounds.)
The solution is IMO just to consider the number of computations performed per generated token as some function of the model size, and once we've identified a suitable asymptotic order on the function, we can say intelligent things like "the smallest network capable of solving a problem in complexity class C of size N is X".
Or if our asymptotic bounds are not tight enough:
"No economically feasible LLM can solve problems in complexity class C of size >= N".
(Where economically feasible may be something defined by aggregate global economic resources or similar, depending on how tight you want the bound to be.)
Regardless, we can still obtain meaningful impossibility results.
Okay, you raise a very good point. To analogize to my own brain: it's like noticing that I can multiply integers 1-20 in my head in one step, but for larger numbers I need to write it out. Does that mean that my neural net can do multiplication? Well, as you say, it depends on n.
it's easy to imagine a huge LLM capable doing 500 iterations of SH1 of small strings in one shot
Nitpick: for SHA1 (and any other cryptographic hash functions) I can't fathom how an LLM could learn it through SGD, as opposed to being hand coded. To do SHA1 correctly you need to implement its internals correctly; being off a little bit will result in a completely incorrect output. It's all or nothing, so there's no way to gradually approach getting it right, so there's no gradient to descend.
But your overall point still stands. It is theoretically possible for a transformer to learn any function, so this is not a fundamental upper bound, and you are therefore correct that a large enough LLM could do any of these for small n. I wonder if this is going to be a real capability of SOTA LLMs, or will it be one of those "possible in theory, but many orders of magnitude off in practice" things.
Ultimately the question I'm thinking towards is whether an LLM could do the truly important/scary problems. I care less whether an LLM can multiply two 1Mx1M (or 3x3) matrices, and more whether it can devise & execute a 50-step plan for world domination, or make important new discoveries in nanotech, or make billions of dollars in financial markets, etc.
I don't know how to evaluate the computational complexity of these hard problems. I also don't know whether exploring that question would help the capabilities side more than the alignment side, so I need to think carefully before answering.
Agree. If GPT-4 can solve 3-dim matrix multiplication with chain-of-thought, then doesn't that mean you could just take the last layer's output (before you generate a single token from it) and send it into other instances of GPT-4, and then chain together their output? That should by definition by enough "internal state-keeping" that you wouldn't need it to do the "note-keeping" of chain-of-thought. And that's precisely bayesed's point - because from the outside, that kind of a construct would just look like a bigger LLM. I think this is a clever post, but the bottleneck-ing created by token generation is too arbitrary of a way to assess LLM complexity.
The LLM outputs are out of distribution for its input layer. There is some research happening in deep model communication, but it has not yielded fruit yet AFAIK.
I think you're totally right. But unfortunately your footnote 2 has already happened. We don't know how well those expanded LLMs will work, but I suspect they will be valuable by bypassing their limitations, just as you describe them. See my recent post and there are others.
Nitpick: a language model is basically just an algorithm to predict text. It doesn't necessarily need to be a fixed architecture like ChatGPT. So for example: "get ChatGPT to write a program that outputs the next token and then run that program" is technically also a language model, and has no computational complexity limit (other than the underlying hardware).
Hmm, I've not seen people refer to (ChatGPT + Code execution plugin) as an LLM. IMO, an LLM is supposed to be language model consisting of just a neural network with a large number of parameters.
I think your definition of LLM is the common one. For example, https://www.lesswrong.com/posts/KJRBb43nDxk6mwLcR/ai-doom-from-an-llm-plateau-ist-perspective is on the front page right now, and it uses LLM to refer to a big neural net, in a transformer topology, trained with a lot of data. This is how I was intending to use it as well. Note the difference between "language model" as Christopher King used it, and "large language model" as I am. I plan to keep using LLM for now, especially as GPT refers to OpenAI's product and not the general class of things.
Thanks, this is exactly the kind of feedback I was hoping for.
Nomenclature-wise: I was using LLM to mean "deep neural nets in the style of GPT-3" but I should be more precise. Do you know of a good term for what I meant?
More generally, I should learn about other styles of LLM. I've gotten some good leads from these comments and some DMs.
Epistemic status: Speculative. I've built many large AI systems in my previous HFT career but have never worked with generative AIs. I am leveling up in LLMs by working things out from base principles and observations. All feedback is very welcome.
Tl;dr: An LLM cannot solve computationally hard problems. Its ability to write code is probably its skill of greatest potential. I think this reduces p(near term doom).
An LLM takes the same amount of computation for each generated token, regardless of how hard it is to predict. This limits the complexity of any problem an LLM is trying to solve.
Consider two statements:
An LLM's goal is to predict the best token to fill in the blank given its training and the previous context. Completing statement 1 requires knowledge about the world but is computationally trivial. Statement 2 requires a lot of computation. Regardless, the LLM performs the same amount of work for either statement.
It cannot correctly solve computationally hard statements like #2. Period. If it could, that would imply that all problems can be solved in constant time, which is provably (and obviously) false.
Why does this matter? It puts some bounds on what an LLM can do.
Zvi writes:
I interpret this the opposite way. Being a perfect predictor of the internet would indeed require a superintelligence, but it cannot be done by an LLM.
How does an LLM compute?
What kinds of problems fall into category 2 (i.e., clearly unanswerable by an LLM)? Let's dig in to how an LLM computes.
For each token, it reviews all the tokens in its context window "at least once", call it O(1) time. To produce n tokens, it does O(n^2) work. Without being too precise about the details, this roughly means it can't solve problems that are more complex than O(n^2). [1]
Consider some examples (all tested with GPT-4):
Addition, O(1)
It's not always accurate, but it's usually able to do addition correctly.
Sorting, O(n log n)
I asked it to sort 100 random integers that I'd generated, and it got it right.
My guess is that it doesn't have the internal machinery to do a quick sort, and was probably doing something more like O(n^2), but either way that's within its powers to get right, and it got it.
Matrix multiplication, O(n^3)
I generated a 3x3 matrix called A and told it to compute A*A. This was interesting, let's look at what it did:
Pretty cool! It executed the naive matrix multiplication algorithm by using O(n^3) tokens to do it step-by-step. If I ask it to do it without showing its work, it hallucinates an incorrect answer:
The result was the right shape, and the elements had approximately the right number of digits. Slight problem: the elements are all incorrect. Whoops. This makes sense though. These numbers are random, so it's unlikely to have memorized the answer to this specific problem. Absent that shortcut, it didn't do O(n^3) work, so it could not have generated the correct answer.
Four-sum problem, O(n^4)
It gave me four numbers that added up to my target, but the fourth wasn't in my input. It hallucinated it to meet the constraint. Same as with matrix multiplication, it gave an answer that looks vaguely correct, but it didn't do O(n^4) work so it couldn't have been right.
But watch what happens when I let it show its work:
Cool! It wrote and executed code to solve the problem, and it got it right.
What did I learn?
This matches my expectation that without showing its work it caps out at roughly O(n^2).
It can do better if it's allowed to run algorithms by "thinking out loud". It's really slow, and this is a good way to fill up its context buffer. The slowness is a real problem - if it outputs ~10 token/sec, it will take forever to solve any problems that are actually both big and hard. This is a neat trick, but it doesn't seem like an important improvement to its capabilities.
The most interesting bit is when it writes its own code. The ceiling on the types of problems that you can solve with code is arbitrarily high. This is obviously the most uncertain path as well. It can solve toy problems, but it remains to be seen whether it can write useful code in complex systems. The difference is like acing a technical interview versus being a 10x programmer. (If you think this distinction is obvious, you've probably been a hiring manager for a technical role).
Additional thoughts
Many people have noticed that asking ChatGPT/Bing to show its work can result in smarter answers. I believe this isn't just a trick of prompt engineering. It has no internal monologue, so showing its work actually allows it to think harder about a question than it otherwise could, and allows it to solve harder classes of problems.
This makes me more pessimistic about the potential of AutoGPT- or BabyAGI-like approaches. Quick summary: they tell GPT to break problems down into subproblems, and loop over a prioritized task list to create agency. But "show your work" feels mismatched for truly hard problems - executing an algorithm one linguistic token at a time is just so computationally inefficient.
Predictions
This gives us clues about the future direction and limitations of LLMs and other NN-based models.
Thanks for reading. This is my first LW post, so please be kind. I'll try to reply to all feedback, and I'd love for you all to poke holes in this.
There are a lot of annoying details when I try to be precise about computational complexity of an LLM. For example, we're used to thinking that addition is O(1), because a CPU takes constant time to add two numbers. But an LLM acts on the textual representation of a number, which has length log n. Precisely defining the size of our inputs does weird things to the complexity of known algorithms, so I'm not thinking too hard about it. I don't think it changes any of my results.
An LLM could get around this limitation by "going meta". When generating the next token, it could say "I can't predict this, let me spawn some sub-agents to think about this". Those agents would be able to write code, call external APIs, run computationally expensive subroutines, and return an answer. This would be very hard to train, and SGD doesn't really apply. This would require a major rearchitecture of the system, enough that the result probably wouldn't be an LLM anymore.