This is a special post for quick takes by elifland. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
The word "overconfident" seems overloaded. Here are some things I think that people sometimes mean when they say someone is overconfident:
- They gave a binary probability that is too far from 50% (I believe this is the original one)
- They overestimated a binary probability (e.g. they said 20% when it should be 1%)
- Their estimate is arrogant (e.g. they say there's a 40% chance their startup fails when it should be 95%), or maybe they give an arrogant vibe
- They seem too unwilling to change their mind upon arguments (maybe their credal resilience is too high)
- They gave a probability distribution that seems wrong in some way (e.g. "50% AGI by 2030 is so overconfident, I think it should be 10%")
- This one is pernicious in that any probability distribution gives very low percentages for some range, so being specific here seems important.
- Their binary estimate or probability distribution seems too different from some sort of base rate, reference class, or expert(s) that they should defer to.
How much does this overloading matter? I'm not sure, but one worry is that it allows people to score cheap rhetorical points by claiming someone else is overconfident when in practice they might mean something like "your probability distribution is wrong in some way". Beware of accusing someone of overconfidence without being more specific about what you mean.
In addition to your 1-6, I have also seen people use "overconfident" to mean something more like "behaving as though the process that generated a given probabilistic prediction was higher-quality (in terms of Brier score or the like) than it really is."
In prediction market terms: putting more money than you should into the market for a given outcome, as distinct from any particular fact about the probabilit(ies) implied by your stake in that market.
For example, suppose there is some forecaster who predicts on a wide range of topics. And their forecasts are generally great across most topics (low Brier score, etc.). But there's one particular topic area -- I dunno, let's say "east Asian politics" -- where they are a much worse predictor, with a Brier score near random guessing. Nonetheless, they go on making forecasts about east Asian politics alongside their forecasts on other topics, without noting the difference in any way.
I could easily imagine this forecaster getting accused of being "overconfident about east Asian politics." And if so, I would interpret the accusation to mean the thing I described in the first 2 paragraphs of this comment, rather than any of 1-6 in the OP.
Note that the objection here does not involve anything about the specific values of the forecaster's distributions for east Asian politics -- whether they are low or high, extreme or middling, flat or peaked, etc. This distinguishes it from all of 1-6 except for 4, and of course it's also unrelated to 4.
The objection here is not that the probabilities suffer from some specific, correctable error like being too high or extreme. Rather, the objection is that forecaster should not be reporting these probabilities at all; or that they should only report them alongside some sort of disclaimer; or that they should report them as part of a bundle where they have "lower weight" than other forecasts, if we're in a context like a prediction market where such a thing is possible.
Moore & Schatz (2017) made a similar point about different meanings of "overconfidence" in their paper The three faces of overconfidence. The abstract:
Overconfidence has been studied in 3 distinct ways. Overestimation is thinking that you are better than you are. Overplacement is the exaggerated belief that you are better than others. Overprecision is the excessive faith that you know the truth. These 3 forms of overconfidence manifest themselves under different conditions, have different causes, and have widely varying consequences. It is a mistake to treat them as if they were the same or to assume that they have the same psychological origins.
Though I do think that some of your 6 different meanings are different manifestations of the same underlying meaning.
Calling someone "overprecise" is saying that they should increase the entropy of their beliefs. In cases where there is a natural ignorance prior, it is claiming that their probability distribution should be closer to the ignorance prior. This could sometimes mean closer to 50-50 as in your point 1, e.g. the probability that the Yankees will win their next game. This could sometimes mean closer to 1/n as with some cases of your points 2 & 6, e.g. a 1/30 probability that the Yankees will win the next World Series (as they are 1 of 30 teams).
In cases where there isn't a natural ignorance prior, saying that someone should increase the entropy of their beliefs is often interpretable as a claim that they should put less probability on the possibilities that they view as most likely. This could sometimes look like your point 2, e.g. if they think DeSantis has a 20% chance of being US President in 2030, or like your point 6. It could sometimes look like widening their confidence interval for estimating some quantity.
When I accuse someone of overconfidence, I usually mean they're being too hedgehogy when they should be being more foxy.
[crossposted from EA Forum]
Reflecting a little on my shortform from a few years ago, I think I wasn't ambitious enough in trying to actually move this forward.
I want there to be an org that does "human challenge"-style RCTs across lots of important questions that are extremely hard to get at otherwise, including (top 2 are repeated from previous shortform):
- Health effects of veganism
- Health effects of restricting sleep
- Productivity of remote vs. in-person work
- Productivity effects of blocking out focused/deep work
Edited to add: I no longer think "human challenge" is really the best way to refer to this idea (see comment that convinced me); I mean to say something like "large scale RCTs of important things on volunteers who sign up on an app to randomly try or not try an intervention." I'm open to suggestions on succinct ways to refer to this.
I'd be very excited about such an org existing. I think it could even grow to become an effective megaproject, pending further analysis on how much it could increase wisdom relative to power. But, I don't think it's a good personal fit for me to found given my current interests and skills.
However, I think I could plausibly provide some useful advice/help to anyone who is interested in founding a many-domain human-challenge org. If you are interested in founding such an org or know someone who might be and want my advice, let me know. (I will also be linking this shortform to some people who might be able to help set this up.)
--
Some further inspiration I'm drawing on to be excited about this org:
- Freakonomics' RCT on measuring the effects of big life changes like quitting your job or breaking up with your partner. This makes me optimistic about the feasibility of getting lots of people to sign up.
- Holden's note on doing these type of experiments with digital people. He mentions some difficulties with running these types of RCTs today, but I think an org specializing in them could help.
Votes/considerations on why this is a good or bad idea are also appreciated!
I'm confused why these would be described as "challenge" RCTs, and worry that the term will create broader confusion in the movement to support challenge trials for disease. In the usual clinical context, the word "challenge" in "human challenge trial" refers to the step of introducing the "challenge" of a bad thing (e.g., an infectious agent) to the subject, to see if the treatment protects them from it. I don't know what a "challenge" trial testing the effects of veganism looks like?
(I'm generally positive on the idea of trialing more things; my confusion+comment is just restricted to the naming being proposed here.)
Thanks, I agree with this and it's probably not good branding anyway.
I was thinking the "challenge" was just doing the intervention (e.g. being vegan), but agree that the framing is confusing since it refers to something different in the clinical context. I will edit my shortforms to reflect this updated view.
Just made a bet with Jeremy Gillen that may be of interest to some LWers, would be curious for opinions:
[cross-posting from blog]
I made a spreadsheet for forecasting the 10th/50th/90th percentile for how you think GPT-4.5 will do on various benchmarks (given 6 months after the release to allow for actually being applied to the benchmark, and post-training enhancements). Copy it here to register your forecasts.
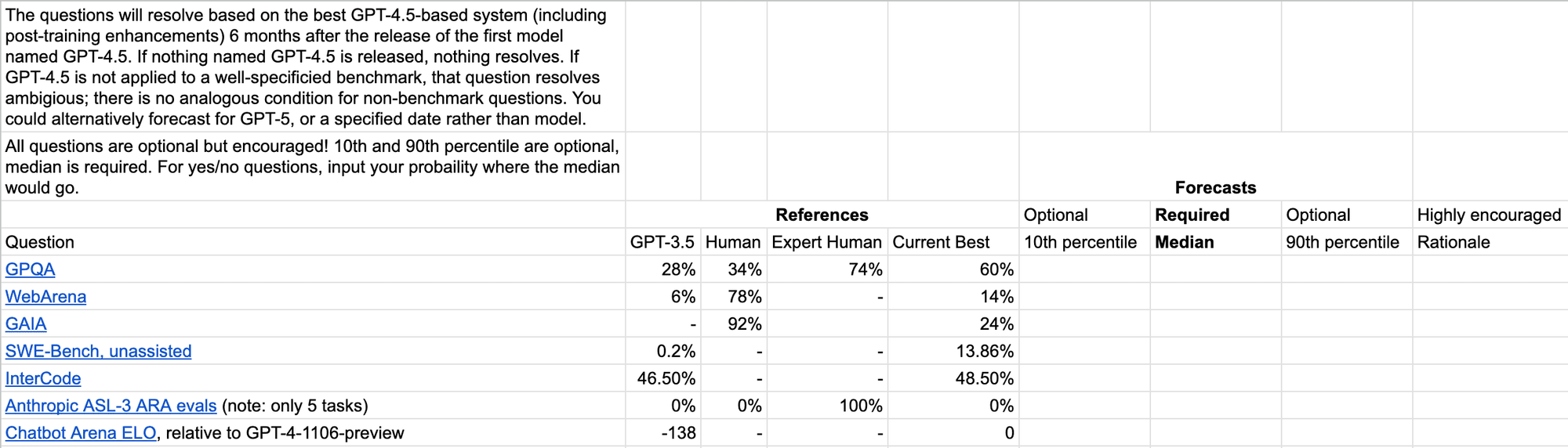
If you’d prefer, you could also use it to predict for GPT-5, or for the state-of-the-art at a certain time e.g. end of 2024 (my predictions would be pretty similar for GPT-4.5, and end of 2024).
You can see my forecasts made with ~2 hours of total effort on Feb 17 in this sheet; I won’t describe them further here in order to avoid anchoring.
There might be a similar tournament on Metaculus soon, but not sure on the timeline for that (and spreadsheet might be lower friction). If someone wants to take the time to make a form for predicting, tracking and resolving the forecasts, be my guest and I’ll link it here.
(epistemic status: exploratory)
I think more people into LessWrong in high school - college should consider trying Battlecode. It's somewhat similar to The Darwin Game which was pretty popular on here and I think generally the type of people who like LessWrong will both enjoy and be good at Battlecode. (edited to add: A short description of Battlecode is that you write a bot to beat other bots at a turn-based strategy game. Each unit executes its own code so communication/coordination is often one of the most interesting parts.)
I did it with friends for 6 years (junior year of high school - end of undergrad), and I think it at least helped me gain legible expertise in strategizing and coding quickly, but plausibly also helped me pick up skills in these areas as well as teamwork.
If any students are interested (I believe PhD students can qualify as well but may not be worth their time), there's still 2/3 weeks left in this year's game which is plenty of time. If you're curious to learn more about my experiences with Battlecode, see the README and postmortem here.
Feel free to comment or DM me if you have any questions.