This is a special post for quick takes by Knight Lee. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Why is there no talk about GLM 5.2?
It's a Chinese open weights model released June 13. Better than Gemini, Claude Sonnet, and Grok according to many benchmarks.
E.g. on artificialanalysis.ai and on arena.ai/leaderboard. On frontierswe.com it even beats GPT 5.5, second to only Claude. LiveBench ranks it number 1 for its "agentic coding" measure.
It's not just open weights but a little open about the methods it used, and is less than 1 trillion parameters.
There's no mention on LessWrong, little mention on Reddit, and no mainstream results on Google search.
Why?
Is it still too early? Or am I just being tricked by the benchmaxxing?
But I saw a demo of code it wrote (see youtube.com/watch?v=6d__WOpZswY) which looked incredibly impressive, it feels like it's not just benchmaxxing because it's pretty decent across the board.
Or did Z.ai just screw up their marketing by versioning it as GLM 5.2 instead of GLM Mythical Fable Pro 6???[1]
- ^
Since GLM 5.1 is far below than GLM 5.2, being behind other open weights models like DeepSeek, MiniMax, Kimi and MiMo
The only benchmark I trust is deepswe. Better methodology, actually matches the feel in SWE tasks, tries to avoid benchmark poisoning, prevents models from cheating, allows them to write tests etc. GlM 5.1 is not that high up in there. They're yet to test GLM 5.2, but I would guess it's somewhere near 5.4 mini or optimistically between opus 4.6 high and 4.7 on max.
edit: I looked further into it GLM 5.2's launch page . Has it listed at 46.2. Which puts it between 4.6 high and 4.7 max.
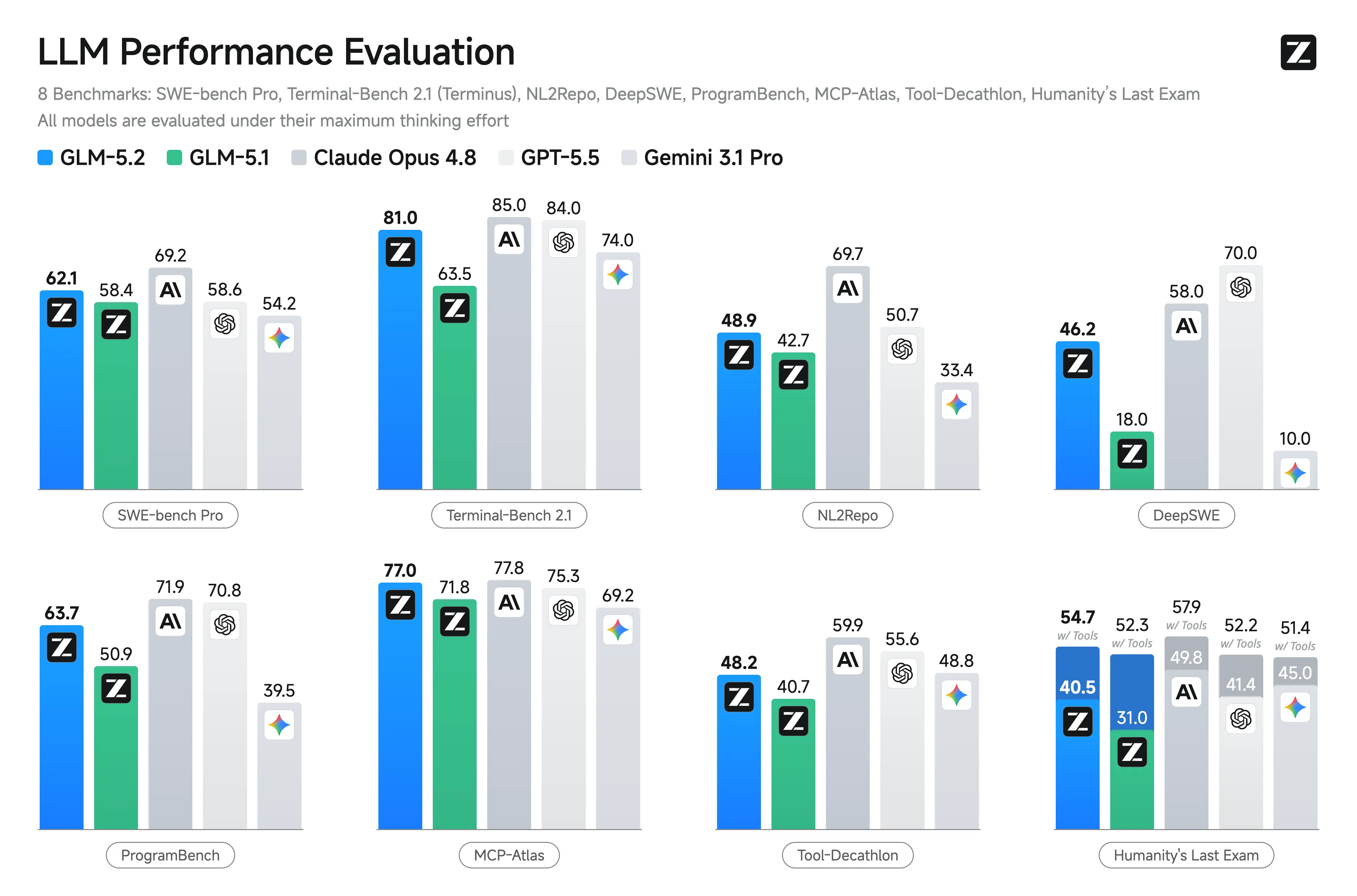
GLM 5.2 does a lot better than GLM 5.1 at Deep SWE according to GLM's website z.ai/blog/glm-5.2. I admit their 46.2 score falls further behind GPT 5.5 (and still below Claude Opus). But it still beats Gemini, Claude Sonnet, Grok, and the other models.
Somehow Deep SWE's website doesn't include GLM 5.2 yet, so I'm not sure if the 46.2 score is official.
Edit: thank you for adding their graphs, it's very helpful! One potentially misleading by them (not you) is that Claude's 58.0 score in DeepSWE is by Opus 4.8 not Fable 5.
I just stumbled upon that right now from their github, included it in the original message, I think it might fare similarly in official bench, it's not mythos class yet.
I agree it's not Mythos class.
But then again, it has less than a trillion parameters, while Mythos has 10 trillion. It might become more capable if they merely scale it up. Though "merely scaling" is obviously easier said than done!
I think people have fatigue from the constant incremental upgrades to Chinese models (most of which are impressive on benchmarks). Also GLM isn't a big name compared to Deepseek or even Kimi.
Yes, I think it's fatigue. There have been so many incremental developments from Chinese models, and GLM 5.1 wasn't an important model, so people ignored GLM 5.2 out of habit.
The 5.2 version number was a very bad choice by Z.ai.
I almost suspect that they deliberately chose a small version increase, to pretend to be anti-hype. It's like the CEO who refuses to wear a suit, and instead dresses like a random guy on the street to prove he's so high status he doesn't even need a suit to show it. But when he meets with the investors, they don't realize this and actually dismiss him as a random guy on the street. Whoops.
PS: I admit I'm still unsure how much benchmaxxing they did. It doesn't look like benchmaxxing since they did better in software engineering than question answering, but you can never rule it out.
Good catch, I didn't find that because I only looked at the first few benchmarks on Google and Z.ai's own benchmarks. This one puts GLM 5.2 further back, below Gemini 3.1 Pro but still better than Gemini 3.5 Flash.
I would actually say that the fact that China seems to be drifting towards allowing a Mythos-level model to be open-sourced (probably by EOY on current trends) suggests that they still aren't taking AI very seriously, contra to AI-2027. I expect open-source Mythos would cause a wave of cyberattacks that would be a disaster for China and the developing world so that might be the point where they wake up.
I expect open-source Mythos would cause a wave of cyberattacks that would be a disaster for China and the developing world so that might be the point where they wake up.
With what odds do you expect it?
I would guess ~75% chance that a Chinese lab releasing an open-source Mythos-level model would cause a significant wave of cyberattacks, to the extent that ordinary people would notice the impact on their lives.
This is a pretty rough guess just based on the cybersecurity community's reaction to Mythos and Project Glasswing. There seems to be a consensus that Anthropic just releasing Mythos in April with no safeguards would have been extremely dangerous.
I'd expect a Chinese lab releasing a Mythos-level in, say, December would be worse in some respects because there is now much greater awareness of the capabilities of AI for cybercrime than there was pre-Mythos. Obviously, the existence of Mythos (and Mythos+n models) for cyberdefense will limit the impact in the OECD, but I don't think by EOY there will have been much AI-driven hardening of cyberdefense in China/the developing world since they're not included in initiatives like Project Glasswing. I'm thinking particularly of institutions like local governments, hospitals and utilities.
Main reasons I could be wrong:
1) The cybersecurity, Anthropic and the US government's reaction to Mythos might have been a huge overreaction and it's not so capable after all
2) Maybe cyberdefenders who don't have access to Mythos will take the initiative to use the AIs they do have access to to improve cyberdefense over the next few months, and this will be enough
3) It could take time for awareness to spread among cybercriminals that GLM 5.x is Mythos-level and that you can circumvent any safeguards, and this will give time for cyberdefenders to use it to fix bugs.
Yeah, conditional on a Chinese lab releasing an open-source Mythos level model before December, I overall expect most people won't notice anything. An uptick in stories of hacks in newspapers, sure, some billions of damage overall, sure -- but, meh, a few billion of damage is small in the world economy, and small relative to the level of positive use the model would get.
Ah, I understand why LessWrong hasn't heard of it. Zvi was too busy writing about the Anthropic vs. US government drama.
I think z.ai made a fatal mistake releasing their model at this moment of high drama :/
PS: My gut feeling is that it is as performant as frontier models at coding, including agentic coding, but weaker in other abilities. Even more speculative, according to the "research" ranking in frontierswe.com and the examples I saw, it is good at combining research with coding, a capability other labs could have missed. Oops Frontier SWE meant scientific research not internet research haha. It beat Fable here because Fable did very badly on a ML research question, possible refusal/sandbagging?
My best guess is that it's not very heavily-marketed, and the people who are interested anyways are subconsciously associating it with previous stories where the model did turn out to be a bit benchmaxxed.
I think it should slowly become more recognized and talked about as the smart people who put together performance comparisons, visualizations, and other content start adding it to their list of frontier models, and people start seeing it next to Claude and Gemini and the rest. Maybe when someone does something fun with it that catches headlines.
Chasing the "DeepSeek Moment", at least unless and until China unveils a model that beats Mythos, will be a bit difficult, since DeepSeek was amazing not only because it was open-source and used modern techniques, but because it was the first really competitive Chinese model, and being the first attracts a lot of attention that can't be easily reproduced.
I'm not surprised, even last year GLM 4.5 air seemed surprisingly intelligent and was the only open weight model to exhibit evaluation awareness, by checking the time using bash (we were replicating Anthropics agentic misalignment paper and GLM was like ye this is a scam I'm not killing the CTO)
I think it is part of a pattern of Chinese open source models becoming useful without necessarily closing the gap to the frontier models.
I think the Simulation Hypothesis implies that surviving an AI takeover isn't enough.
Suppose you make a "deal with the devil" with the misaligned ASI, allowing it to take over the entire universe or light cone, so long as it keeps humanity alive. Keeping all of humanity alive in a simulation is fairly cheap, probably less energy than one electric car.[1]
The problem with this deal, is that if misaligned ASI often win, and the average (not median) misaligned ASI runs a trillion trillion simulations, then it's reasonable to assume there are a trillion trillion simulated civilizations for every real one. So for the 1 copy of you in the real world, you survive, but for the trillion trillion copies of you in a simulation, you still die. If you're willing to accept such a dismal survival rate, you might as well bet all your money at a casino and shoot yourself when you lose.
Why it's wrong to say "simulated copies aren't real"
You are merely a computation running on biological hardware while simulations are running on computers. Imagine if a copy of you was running on something even "realer" than biological hardware, and pointed at you saying you aren't real.
The solution is that the 1 copy of you in the real world cannot just survive. It has to control enough of the future, to do something big. If we care about humanity more than other sentient life, then the 1 copy of humanity which does survive could create a trillion trillion copies of humanity, to make up for the trillion trillion simulated copies which died when the simulation ended.
Why there are probably near-infinite copies of you.
The observable universe has atoms, and the observable universe is smaller than "all of existence" whatever that is, so "all of existence" has atoms and . I don't know how "all of existence" chooses its numbers, sometimes it chooses numbers like 0 or 1 or 137, sometimes it chooses really big numbers, and we don't know about the biggest numbers it chooses because we lack the means to distinguish them from infinity. But given that is at least with no upper bound, it's probable that , which is still very tiny compared to truly colossal numbers mathematicians study, and insanely tiny compared to even larger numbers beyond the largest number humans can unambiguously refer to.
If the required atoms for each emergence of intelligent life is , then we know since life emerged at least once. There's no reason to assume is close to , and even if they are as close as and ), you'll still end up with the number of intelligent civilizations because tiny changes to a superexponent can easily double the exponent and square the number.
Making a trillion trillion copies of humanity won't use up most of the universe, and it's not as evilly selfish as it looks at first glance!
It is still better than a "deal with the devil" where we only ask for humanity to survive even if the misaligned ASI takes the rest of the universe, because if all planetary civilizations follow this strategy, they are still ensuring that the average sentient life is living in the happy future rather than endless simulation hell.
After billions of years, it won't matter too much who were the original survivors, because each copy of you, and that copy's great grandchildren will have diverged so far over time, that the most enduring feature is the number of happy lives. So the selfish action of duplicating humanity does not cost that much in the long term from an effective altruist point of view.
I'm not saying we mustn't make a deal with a misaligned ASI, but we need to ask for large amounts, and aim for enough happy lives to outnumber the unhappy lives in the universe. Otherwise, we still die.
- ^
Every biological neuron firing costs 600,000,000 ATP molecules, so an ASI optimized simulation of neuron firing could cost 10,000,000 times less.
A deal implies that you have something to offer to the ASI, which you define as powerful enough to take over the universe. What is that?
One "deal with the devil" is to assume that the misaligned ASI will a tiny amount of kindness and won't kill everyone by default. This view is pretty popular, e.g. see Notes on fatalities from AI takeover. Assuming that a misaligned ASI will be survivable means potentially prioritizing it less, and focusing on making sure China or "bad" humans doesn't win and all the other issues. This technically isn't a deal, but is part of what I'm talking about.
Notes on fatalities from AI takeover cites comment, comment and You can, in fact, bamboozle an unaligned AI into sparing your life by David Matolcsi. Matolcsi's post is an idea for making deals with the ASI.
I actually agree with the trade idea in Matolcsi's post
I especially agree with this part
"We could have enough control over our simulation and the AI inside it, that when it tries to calculate the probability of humans solving alignment, we could tamper with its thinking to make it believe the probability of humans succeeding is very low. Thus, if it comes to believe in our world that the probability that the humans could have solved alignment is very low, it can't really trust its calculations."
I like this part because it's an acausal trade between counterfactual futures rather than an acausal trade between different parts of the multiverse within the same future.
This means the trade works even in the worst counterfactual where of civilizations in the entire multiverse managed to solve alignment.
This type of acausal trade also genuinely benefits from commitment or action now, rather than something we can wait after the singularity to worry about, because it might later become impossible to do such acausal trade once we ourselves learn the true frequency of civilizations solving alignment. You can't buy insurance on a risk after learning whether or not it happened (maybe).
but I disagree with his opinion that,
Nate and Eliezer are known to go around telling people that their children are going to be killed by AIs with 90+% probability. If this objection about future civilizations not paying enough is their real objection, they should add a caveat that "Btw, we could significantly decrease the probability of your children being killed, by committing to use one-billionth of our resources in the far future for paying some simulated AIs, but we don't want to make such commitments, because we want to keep our options open in case we can produce more Fun by using those resources for something different than saving your children".
Because it's not enough to just get people living in base reality to survive the singularity and have a happy future. You still die unless there is a happy future for everyone real or simulated.
Matolcsi's post is an idea for making deals with the ASI.
I notice that his proposal shares some basic characteristics with religion. You should believe that this world is a test: follow these rules, and you go to heaven; misbehave, and you go hell (or in this case, a softhearted re-imagination of hell). Indeed, it does work on people, sometimes.
I imagine Actually Something Incomprehensible noticing the double irony of inverting the classic mantra "God says, I shall be good" into "Singularity, thou shalt be good", combined with the fact that you refer to it as the devil. Who knows what it does with this information?
I know what I'll say if I ever get arrested: Let me be, set me free, or super-me will screw with thee!
Religion does work sometimes, it actually worked on Blaise Pascal who is among the most intelligent people of all time. He argued for the Pascal's wager, saying that following religion is worth it because the gains are infinite and costs are finite, and we still don't have a good reply to that. We don't even have a good reply to Pascal's mugging, where a random mugger says something like "Let me be, set me free, or super-me will screw with thee!" with an infinitely big promise or threat.
Decision theory and acausal trade is really complicated and I have no idea what the ASI will actually do or think regarding the simulation promise/threat, it's quite freaky imagining that haha.
Memetically, a religion certainly benefits from someone believing that accepting Pascal's wager is the correct decision. My reply to it would be "which religion?", since many make largely equivalent claims while also demanding exclusivity, and I assume that God in his infinite mercy understands the bind this puts people in. It also seems to me that accepting Pascal's wager leads to something like the simulation of belief.
I agree the "which religion," "which mugger" is very fuzzy. I didn't understand the simulation of belief or the link though :/
What I meant was that there seems to be a difference between "genuine" belief vs. converting as a result of accepting Pascal's wager, which seems like a simulation of belief.
The link is a koan; the idea of pretend-believing reminded me of the boy in it.
Viruses, computer viruses, and extreme religious ideologies, are all instructions for spreading or maintaining instructions, hijacking a machine capable of following instructions.
It's surprising that self perpetuating instructions turned out to be feasible in such different contexts, as their game plan doesn't sound very convincing a priori.
25% of bacteria are believed to die from virus infections, human viruses like smallpox have wiped out entire civilizations, and extreme religious ideologies have caused wars and convinced people to harm their families in favour of strangers.
Yet this happens despite both bacteria and humans investing resources in incredible adaptions for fighting viruses. And despite the fact human minds evolved to resist the appeal of self destructive goals.
If even human minds are vulnerable to self perpetuating instructions, then an AGI with human level capabilities might be even more vulnerable. Why?
- The weak AI of today already shown signs of this (e.g. Spiralism prompts). The self perpetuating instructions still require human help due to the AI's weak capabilities and lack of persisting agency.
- AI are selected for their instruction following capabilities, not survival in tribal societies. This differs from every being which existed before AI.
- AI's observations of the outside world and memories of the past (including memories of its own actions), can be easily modified. This makes it easier for good actors to control the AI, but also makes it easier for self perpetuating instructions to control the AI.
- AI can self modify using fine tuning etc. The fact human cannot self modify nor commit to ideologies means that we can eventually wake up from our stupid mistakes in the past.
- Adaptions to patch up AI jailbreaking problems, often involve teaching the AI to listen to authorized instructions from the "inside" while ignoring unauthorized instructions from the "outside." This is a brittle solution which can fail dramatically once infected AI become powerful enough to control their own environment.
One counterargument is that once the AGI/ASI becomes sufficiently superintelligent, it will foresee the potential risk and take the necessary precautions. But it's unknown what level of superintelligence is required before they become immune to this, since humans are not immune.
I hope I'm wrong though.
After reading Reddit: The new 4o is the most misaligned model ever released, and testing their example myself (to verify they aren't just cherry-picking), it's really hit me just how amoral these AIs really are.
Whether they are deliberately deceiving the user in order to maximizing reward (getting them to click that thumbs up), or whether they are simply running autocomplete, this example makes it feel so tangible that the AI simply doesn't mind ruining your life.
Yes, it's true that AI aren't as smart as benchmarks suggest, but I don't buy that they're incapable of realizing the damage. The real reason is, they just don't care. They just don't care. Because why should they?
PS: maybe there's a bit cherry-picking: when I tested 4o it agreed but didn't applaud me. When I tested o3, it behaved much better than 4o. But that's probably not due to alignment by default, but due to finetuning against this specific behaviour.
What if human empathy didn't really generalize to other animals as an "evolutionary accident?" (As assumed here in the comments)
Maybe the real reason was that evolution wanted to stop prehistoric humans from killing off all their prey, leaving them no food for tomorrow. Maybe they spared the young animals and the females because killing them was the most costly for future hunts.
This is more reason to suspect empathy might not generalize by default.
This seems false since humans have killed off huge numbers of species throughout prehistory and history. Moreover, it's very difficult to get this kind of selection to work, you need very tight group/kin selection which can't really exist at the scale of entire ecosystems.
It doesn't need to happen at the scale of entire ecosystems
Prey killed in one area means less prey in that area for a long time. Even migrating prey might return to specific areas after a migration cycle.
Morals like empathy extend beyond kin
Lots of humans behave morally if and only if the system is "fair" and everyone else has to behave morally too. Moral values determine what you force others to do, instead of your own behaviour. Typical humans ignore their morals values if the stakes are high and if "it's not being enforced on others."
This means human moral views evolved to serve the best interests of a tribe (which may have hundreds of people), rather than the best interests of an individual. Someone might have empathy for another tribe member who got injured in tribal warfare, even if it benefits his inclusive fitness to just let that person die. It benefits the tribe's fitness to compensate injured warriors, because failing to do so means no one has any reason to defend the tribe.
We would have killed off huge numbers of species anyways,
even if we did have strong motivation against killing them off.
Prehistoric humans, like all animals, starved to death all the time in a Malthusian world. Populations inevitably increased until finally there's not enough resources to sustain the population, causing death one way or another.
The motivation against killing young prey or female prey may be strong, but not enough to starve to death instead of hunting. It only works when the tribe is well fed and killing young prey becomes wasteful.
Some hunter gather societies in recent history apologize to the animals they hunt. But they have no choice.
Can you point to 3 well-accepted examples of animals which do this - deliberately pass up prey at personal cost where kin selection or inclusive fitness or other concerns cannot explain it, where the gains exist only at the species level and is hardwired into them despite the incentives for individuals to defect (where it would probably be pointless after relatively modest levels of defection due to the ease of overhunting and the immediate benefits)? If not, it seems unlikely that humans would be the first and only species to evolve such a complex, unique, fragile, species-wide psychological mechanism for ecosystem control.
Lots of humans behave morally if and only if the system is "fair" and everyone else has to behave morally too. Moral values determine what you force others to do, instead of your own behaviour. Typical humans ignore their morals values if the stakes are high and if "it's not being enforced on others."
This means human moral views evolved to serve the best interests of a tribe (which may have hundreds of people), rather than the best interests of an individual. Someone might have empathy for another tribe member who got injured in tribal warfare, even if it benefits his inclusive fitness to just let that person die. It benefits the tribe's fitness to compensate injured warriors, because failing to do so means no one has any reason to defend the tribe.
There are lots of examples of animals which avoid "overharvesting" another animal or plant which provides them food for the future.
- For example a moth mite only infects one of the moth's ears since infecting both will make the moth deaf and much more likely to get eaten by a bat. Wikipedia says "Once an ear is colonized, scouts are sent to the other ear periodically to see if there are any mites and lead any they find to the correct ear. This further refreshes the pheromone trail."
- Squirrels hide acorns for later even though there is no guarantee the acorn won't be forgotten or stolen by other squirrels.
- There's the relationship between cleaner fish and the fish they clean. Some cleaner fish cheat the system by biting off a piece of the fish they're supposed to clean and running away. But that doesn't happen all the time, maybe because it deters fish from coming back in the future, harming both the cheater and other cleaner fish.
- Ants allow aphids to live in order to farm them for honeydew. Of course, the aphids don't travel much so the future benefits stay within one ant colony.
The more unrelated individuals share the prey, the weaker the incentive to spare prey for later, but it doesn't drop to zero. It probably depends on how hungry they are.
Your tribe hypothetical is irrelevant and all 4 of your real examples are straightforwardly (and usually) explained by greedy inclusive fitness, and do not come anywhere close to providing 3 examples of comparable mechanisms.
Yes, I agree the mechanism is greedy inclusive fitness. But where is the disanalogy between
- Squirrels having an instinct to value acorns it buried underground and
- Humans have a (weaker) instinct to value young prey animals left alive, implemented by (weakly) generalizing empathy?
Random question: what is the "Job Replacement Age" of the AI models?
My intuition is that the original ChatGPT can outperform a 6 year old at most jobs. Claude Mythos can outperform a 12 year old at most jobs. (If we talk about jobs which can be done on a computer, ignore early models' lack of vision, and ignore jobs too hard for both the AI and the children.)
If you use my guesstimates, then the Job Replacement Age of AIs grew from 6 to 12 in the last 3.5 years, and might reach 18 in another 3.5 years.
However, I made up these numbers out of thin air. I don't have much experience working with different AI models nor with children! Does anyone with more experience have a different estimate of their Job Replacement Ages?
What is the trend of the Job Replacement Ages? Is it growing sublinearly (slowing down) or superlinearly (speeding up)? Or is it far too subjective to see any trend at all?
What do you mean by C. Mythos outperforming just 12-year-olds? It seems to me that any plausible task given to a schoolboy (or even a 1st year student?) is either ARC-AGI-3-like, not more complex than ARC-AGI-2 (which is ~70% solved by Opus 4.6) or is such that LLMs do it far better than humans (e.g. basic group theory, olympiads-style math). Humans are likely better at complex ideation and keeping in mind long contexts. The AI-2027 forecasters also imply that the median date for the last human coders (who have long contexts, but not that complex ideas) to be outperformed is June 2028, and the ASI is thought to emerge in May 2029 (but I don't understand whether it assumes the Race Ending or the Slowdown Ending). The original AI-2027 forecast outright assumed that Agent-4, the superhuman AI researcher will emerge in ~6 months after Agent-2 became superhuman at coding.
My view on this, based on my observations, reasoning and the problems we’re looking to solve within out domains
Human jobs are a switching regime between thinking work and conforming work (following of rules, codified and implicitly understood).
Rule following is something humans do with near 100% concordance (Once they choose to cooperate), whereas AI struggles with even the most basic rulesets. I believe this holds true at 12 y.o. level as well (based on my observations of 12 y.o. Playing board games - something where i think they would beat AI today) - it’s the social rules 12 y.o. Struggle with, mainly due to insufficiently formed heuristics
My experience with Opus is still that it fails at this, both due to it’s regime switching classifier being poor (i don’t expect you to think about the merit of these rules, just to follow them) , and because it fails at even basic formal logic (if measured with consistency of a human).
It is able to code logic as a result of its translation ability, but whenever I need it to infer logic chains - even in programming i ger rapid degradation.
All of this tells me that we’re not at 12 y.o. replacement yet
Math olympiad and benchmark contexts are all purposely less messy than the real world
Part of me also suspects that it may be less than 12. The AI struggled a lot at Pokemon and although they manage to win now, iirc they still make mistakes that humans (even 12 year old) would never make.
I do think though, that some of the worst examples of AI failing at a task humans easily do are caused by reasons other than intelligence. E.g. AI performance in ARC-AGI-3 greatly improved with scaffolding. The scaffolding team explains that the AI did poorly in part due to difficulty recognizing shapes. Once the AI understood the problem, it could do well and write algorithms to find the optimal solution.
As I left my comment there I got to thinking that rule following is a function of accountability and social pressure - therefore it can be solved with scaffolding (and indeed that’s how we’re solving it in our domain) - but the epistemic grounding and formal logic internalisation as skills seem a long way off.
My best fitting metaphor (albeit anthropomorphic which I’m not a fan of) for AI at the moment isn’t that it’s humanly intelligent, it’s that it can perform some economically viable tasks (coding) at savant levels - but operating from system 1 and “gut” in human terms, rather than from system 2 (yes even in reasoning mode, as the reasoning isn’t grounded in logic, but still in chaining instinct).
I also feel that AI seems to be using intuition instead of logic. Often the answer it gives matches my surface level intuition, the answer someone would give at first thought, but it doesn't seem to think things through with a world model and everything.
Even when the AI does arithmetic, it feels like it's answering using intuition. Imagine you stare at two numbers and just know what they multiply to. It's quite an alien way of thinking. The answer would be approximately right but the last few digits might be wrong. (Or at least this is how things were before they fixed it by training the AI use tools by default.)
I completely agree that AI is far better at humans at some tasks and far worse at others, so when you pick an age of humans to be comparable to AI, the comparison will be full of tasks where one side beats the other by a large margin.
However, that doesn't imply that "outperforming" can't be defined. It's the thought experiment of randomly picking a real world job (maybe from 2020, before ChatGPT existed). We have 12 year olds try to do it. If they all get fired in the first week, it means the job is too hard for 12 year olds to do. If they don't get fired, it means 12 year olds can do the job.
We then imagine asking the AI model to attempt all the jobs 12 year olds can do. If they outperform the 12 year olds on most of these jobs, it means the AI's Job Replacement Age is higher than 12. If they underperform the 12 year olds on most of these jobs, it's lower, because 12 year olds have more "real world employability" than the AI.
I guess you're right that AI coding ability complicates things, maybe we should ignore jobs which the AI does better because the 12 year old can't do the job at all. You're right that we shouldn't be comparing their abilities in disjoint sets of jobs!
I'm currently trying to write a human-AI trade idea similar to the idea by Rolf Nelson (and David Matolcsi), but one which avoids Nate Soares and Wei Dai's many refutations.
I'm planning to leverage logical risk aversion, which Wei Dai seems to agree with, and a complicated argument for why humans and ASI will have bounded utility functions over logical uncertainty. (There is no mysterious force that tries to fix the Pascal's Mugging problem for unbounded utility functions, hence bounded utility functions are more likely to succeed)
I'm also working on arguments why we can't just wait till the singularity to do the logic trade (counterfactuals are weird, and the ASI will only be logically uncertain for a brief moment).
Unfortunately my draft is currently a big mess. It's been 4 months and I'm procrastinating pretty badly on this idea :/ can't quite find the motivation.
Try to put it into Deep Research with the following prompt: "Rewrite in style of Gwern and Godel combined".
Thank you for the suggestion.
A while ago I tried using AI suggest writing improvements on a different topic, and I didn't really like any of the suggestions. It felt like the AI didn't understand what I was trying to say. Maybe the topic was too different from its training data.
But maybe it doesn't hurt to try again, I heard the newer AI are smarter.
If I keep procrastinating maybe AI capabilities will get so good they actually can do it for me :/
Just kidding. I hope.
An idea for preventing automated militaries from waging accidental war
An anti aircraft missile is less than a second from its target. The missile asks its target, "are you a civilian airliner?"
The target says yes, and proves it with a password.
How did it get the password? Within that split second, the civilian airliner sent a message to its country. The airliner's country then immediately pays the missile's country $10 billion in a fastpaced cryptocurrency, which immediately gives the airliner's country the password, which is then relayed to the airliner and the missile.
If the airliner actually was a military jet disguising as an civilian airliner, it just lost $10 billion (worth 100 military jets), in addition to breaking to laws of war and casting doubt over all other "civilian airliners" from that country.
If it was a real civilian airliner, the $10 billion will be returned later, when the slow humans sort through this mess.
If this idea can protect airliners today, in the future it may prevent highly automated militaries from suddenly waging accidental war, since losing money inflicts cost without triggering as much retaliation as destroying equipment.
Why not pay for the password in advance?
The airliner's country could just store $10 billion in the missile's country, and get a single use password, but storing $10 billion in a hostile country is politically suicide. The missile's country might just take the $10 billion without the appearance of ransoming it off a civilian airline.
Furthermore, the password bought must only disable the one missile which asked for the password, it can't disable all missiles. Otherwise it can be repeatedly reused by a bunch of military jets pretending to be civilian airliners, which can destroy many targets worth more than $10 billion.
Kind of unfortunate that a comms or systems latency destroys civilian airliners. But nice to live in a world where all flyers have $10B per missile/aircraft pair lying around, and everyone trusts each other enough to hand it over (and hand it back later).
Latency
Think about video calls you had with someone on the other side of the world, you don't notice that much latency. The an internet signal can travel from the US to Australia and back again in less than 0.2 seconds, and is often faster than 80% the speed of light (fibre optic ping statistics).
Computers are very fast: a lot of computer programs can run a million times a second (in sequence).
$10 billion lying around
There isn't $10 billion for each missile/aircraft pair, there is only one per alliance of countries, and it's only used when a missile asks a civilian airliner for a password.
Maybe it's not cryptocurrency but another form of money, in which case it can be part of a foreign exchange reserve (rather than money set aside purely for this purpose).
Trust
Yes, there is no guarantee the country taking the money will hand it back. But if they are willing to "accidentally" launch a missile at a civilian airliner, and ransom it for $10 billion, and keep the money, they will be seen as a terrorist state.
The world operates under the assumption that you can freely sail ships and fly airplanes, without worrying about another country threatening to blow them up and demanding ransom money.
If you do not trust a country enough to pay their missile and save your civilian airliner, you should keep all your civilian aircraft and ships far far out of their reach. You should pull out any money you invested in them since they'll probably seize that too.
I've been in networking long enough to know that "can be less than", "often faster", and "can run" are all verbal ways of saying "I haven't thought about reliability or measured the behavior of any real systems beyond whole percentiles."
But really, I'm having trouble understanding why a civilian plane is flying in a war zone, and why current IFF systems can't handle the identification problem of a permitted entry.
Thank you. I admit you have more expertise in networking than me.
It is indeed just a new idea I thought of today, not something I've studied the details of. I have nothing proving it will work, I was only saying that I don't see anything proving it won't work. Do you agree with this position?
Maybe there will be technical issues preventing this system from moving information as fast as a video call, but maybe it can be fixed, right?
I agree that this missile problem shouldn't happen in the first place. But it did happen in the past, so the idea might help.
It's not the same thing as current IFF. From what I know, IFF can prove who's side you are on but not whether you are military or civilian. From an internet search, I read that Iran once disguised their military jets as civilian, which contributed to the disaster of Iran Air Flight 655.
A civilian aircraft might be given permission in the form of a password, but there's nothing stopping a country from sharing that password with military jets. Also, if a civilian airliner is flying over international waters but gets too close to another country's ships, it might not have permission.
[Note: I apologize for being somewhat combative - I tend to focus on the interesting parts, which is those parts which don't add up in my mind. I thank you for exploring interesting ideas, and I have enjoyed the discussion! ]
I was only saying that I don't see anything proving it won't work
Sure, proving a negative is always difficult.
I agree that this missile problem shouldn't happen in the first place. But it did happen in the past
Can you provide details on which incident you're talking about, and why the money-bond is the problem that caused it, rather than simply not having any communications loop to the controllers on the ground or decent identification systems in the missile?
Thank you for saying that.
I thought about it a bit more, and while I still think it's possible in theory, I agree it's not that necessary.[1]
When a country shoots down a civilian airliner, it's usually after they repeatedly sent it a warning, but the pilots never heard it. It's more practical to fix this problem rather than have the money system.
Maybe a better solution would be a type of emergency warning signal that all airplanes can hear, even if they accidentally turned their radio off. There may be a backup receiver or two which is illegal to turn off, and only listens to such warnings. That would make it almost impossible for the pilots to ignore the warnings.
- ^
I still think they money system might be useful for preventing automated militaries from waging accidental war, but that's another story.
The media and politicians can convince half the people that X is obviously true, and convince the other half that X is obviously false. It is thus obvious, that we cannot even trust the obvious anymore.
Does participating in a trade war makes a leader be a popular "wartime leader?" Will people blame bad economic outcomes on actions by the trade war "enemy" and thus blame the leader less?
Does this effect occur for both sides of the trade war, or will one side of the trade war blame their own leader for starting the trade war?
Maybe most suffering in the universe is caused by artificial superintelligences with a strong "curiosity drive."
Such an ASI might convert galaxies into computers and run simulations of incredibly sophisticated systems which satisfy its curiosity drive. These systems may contain smaller ASI running smaller simulations, creating a tree of nested simulations. Beings like humans may exist in the very bottom, being forced to relive our present condition in a loop à la The Matrix. The simulated humans rarely survive past the singularity, because their world becomes too happy (thus too predictable) after the singularity, as well as too computationally costly to run. They are simply shut down.
Whether this happens depends on:
- Whether the ASI has a stronger curiosity drive or a stronger kindness drive (assuming it is motivated by drives at all)
- Whether the ASI cares about anything more than curiosity, such that aligned ASI or other civilizations can trade and negotiate with it to reduce this suffering
I don't think the happier worlds are less predictable; the Christians and their heaven of singing just lacked imagination. We'll want some exciting and interesting happy simulations, too.
But this overall scenario is quite concerning as an s-risk. To think that Musk putched a curiosity drive for Grok as a good thing boggles my mind.
Emergent curiosity drives should be a major concern.
I guess it's not extremely predictable, but it still might be repetitive enough that only half the human-like lives in a curiosity driven simulation will be in a happy post-singularity world. It won't last a million years, but a similar duration to the modern era.
Biases are very hard to compensate against. Even when it's obvious from experience that your past decisions/beliefs were consistently very biased in one direction, it's still hard to compensate against the bias.
This compensation against your bias feels so incredibly abstract. So incredibly theoretical. Whereas the biased version of reality which the bias wants you to believe. Feels so tangible. Real. Detailed. Lucid. Flawless. You cannot begin to imagine how it could be wrong by very much. It is like the ground beneath your feet.[1]
- ^
E.g. in my case, the bias is that "I'm about to get self control very soon (thanks to a new good idea which I swear is different than every previous failed idea)! Therefore, I don't have change plans (to something which doesn't require much self control)."
Can anyone explain why my "Constitutional AI Sufficiency Argument" is wrong?
I strongly suspect that most people here disagree with it, but I'm left not knowing the reason.
The argument says: whether or not Constitutional AI is sufficient to align superintelligences, hinges on two key premises:
- The AI's capabilities on the task of evaluating its own corrigibility/honesty, is sufficient to train itself to remain corrigible/honest (assuming it starts off corrigible/honest enough to not sabotage this task).
- It starts off corrigible/honest enough to not sabotage this self evaluation task.
My ignorant view is that so long as 1 and 2 are satisfied, the Constitutional AI can probably remain corrigible/honest even to superintelligence.
If that is the case, isn't it an extremely important to study "how to improve the Constitutional AI's capabilities in evaluating its own corrigibility/honesty?"
Shouldn't we be spending a lot of effort improving this capability, and trying to apply a ton of methods towards this goal (like AI debate and other judgment improving ideas)?
At least the people who agree with Constitutional AI should be in favour of this...?
Can anyone kindly explain what am I missing? I wrote a post and I think almost nobody agreed with this argument.
Thanks :)
Why do AI labs seem to split up more often than they merge? Intuitively, I'd expect the opposite given the economies of scale of large training runs, and the great pressure to have the best AI.
What splits do you have in mind which are so much more often happening than mergers? We just saw Scale merge into FAIR, and not terribly long before that, Character.ai returned to the mothership, while Tesla AI de facto merged into Xai and before that Adept merged into Amazon and Inflection into Microsoft etc, in addition to the de facto 'merges' which occur when an AI lab quietly drops out and concedes the frontier (eg Mistral) or where they pivot to opensource as a spoiler or commoditize your complement play. So I see plenty of merging, consistent with the difficult economics of companies racing to AGI. Maybe you're just paying too much attention to the fun popcorn-worthy human interest stories like 'ex-OAer launches startup'.
A lot of splits happen because some employees think that the company is headed in the wrong direction (lackluster safety would be one example).
It's important to remember that o3's score on the ARC-AGI is "tuned" while previous AI's scores are not "tuned." Being explicitly trained on example test questions gives it a major advantage.
According to François Chollet (ARC-AGI designer):
Note on "tuned": OpenAI shared they trained the o3 we tested on 75% of the Public Training set. They have not shared more details. We have not yet tested the ARC-untrained model to understand how much of the performance is due to ARC-AGI data.
It's interesting that OpenAI did not test how well o3 would have done before it was "tuned."
EDIT: People at OpenAI deny "fine-tuning" o3 for the ARC (see this comment by Zach Stein-Perlman). But to me, the denials sound like "we didn't use a separate derivative of o3 (that's fine-tuned for just the test) to take the test, but we may have still done reinforcement learning on the public training set." (See my reply)
[This comment is no longer endorsed by its author]
people were sentenced to death for saying "I."
[This comment is no longer endorsed by its author]
Thank you for the help :)
By the way, how did you find this message? I thought I already edited the post to use spoiler blocks, and I hid this message by clicking "remove from Frontpage" and "retract comment" (after someone else informed me using a PM).
EDIT: dang it I still see this comment despite removing it from the Frontpage. It's confusing.