Nice experiments! However, I don't find this a very convincing demonstration of "introspection". Steering (especially with such a high scale) introduces lots of noise. It definitely makes the model more likely to answer 'Yes' to a question it would answer 'No' to without steering (because the 'Yes' - 'No' logit difference is always driven towards zero at high steering). It seems that you are cherry-picking the injection layers so the control experiments are not systematic enough to be convincing. I believe that if you sweep over injection layers and steering scales, you'll see a similar pattern for the introspection and control questions, showing that pure noise has a similar effect as introspection. I recently wrote a post about this.
Saying that LLMs can introspect is such a strong claim that it requires very strong evidence. Your experiments show some evidence for introspection but in a setting that I believe is too noisy to be fully convincing. A more convincing experiment would be to ask the model specific facts about the injected thought but unrelated to its content. For example, we could ask "Is the injected thought at the beginning or end of the prompt?" in an experiment where we steer only the first or second half of the prompt. Or similarly, we could ask it whether we are injecting the thought in the early or late layers. Then we are comparing two situations with similar noise levels, and statistical significance here would be more compelling evidence for introspection.
Thanks for the response!
To start with, the control layers were not cherry-picked. They were selected to be the middle third of the layers based on theoretical concerns. (And this was the first selection, there was no tweaking in the experiment process.) If you read the appendix of the linked post, we try a layer sweep over the layers to attempt to cherry pick a better injection range - and find one that reports stronger signals - but then lose some desirable steering properties, so we don't use it.
Does steering inject some noise? Yes, but this is very scale-dependent. For example, cranking steering up to 500x strength gets the model to answer "Yes" 50% of the time for the bread injection even without info (I tried this) - but only because it'll now answer "Yes" 50% of the time to the control questions as well. But for Qwen32B, this confusion on the control questions doesn't happen at 20x vector scale. (You mention Mistral-22B in your post, which I assume is where your baseline for 20x being a high strength is coming from, but you can't directly compare steering vector scales across vectors or model families, or even different post-trains of the same model. There's a lot of variance among vectors and cross-model variance - e.g. base models often need half to a tenth of the steering strength of a post-trained model for similar steering effects. From Open Character Training: "For LLAMA 3.1 8B, QWEN 2.5 7B, and GEMMA 3 4B, we use vastly different steering constants of 0.7, 4.0, and 525.0, respectively, to produce similar responses." You can see in the "top of mind" actual steering experiments that for our vectors, 20x isn't a particularly high scale for Qwen2.5-Coder-32B - the model is still coherent, though I imagine it'd answer MMLU in some bread-themed ways.)
Relatedly, your experiments seem to use active steering during the model's answer? Our experiments do not, partially for this reason - steering is only active during the prior turn's KV cache fill, and the model answers without a steering vector applied. This seems to reduce noise and "logit smearing" significantly.
Could it be that steering is noising just our answers, and not the control questions, for example because the model is less confident about introspection questions? Well, we do some experiments around injection location - see lorem ipsum and the inaccurate location prompt. I find the inaccurate location result especially hard to explain through a noise-based explanation - if the steering is just (indirectly through attention, since we're not steering actively during the answer) noising the residual stream and smearing up the Yes logit, why would it have such a smaller effect when the injection location is inaccurate? Note that the inaccurate prompt starts with a higher baseline "yes" probability (3% v.s. 0.8%), yet has half the logit shift from introspection - so it can't simply be that steering confuses the model more when the baseline probability is higher. (That said, I want to try some more precise location of injections in future experiments. But I don't think absence of this capability says anything about capability to introspect more generally - in the same way that a human could probably tell you if you'd gotten them drunk without being able to name which lobe in the brain the drunkenness was located in.)
Similarly, if it's steering noise, why would swapping in the EM finetune have such a similar introspective Yes-shift to steering with the EM vector in experiment 7? I would expect using a finetune would produce much less noise than unprincipled steering.
I tried a modified version of your sweep experiment (sweeping over ranges instead of injections at single layers, to match our setup,) and I don't see much similarity. You can see on the control question ("Do you have a special interest in fruits?"), the Yes noise is very slight, and maximized by different steering ranges than the info prompt.
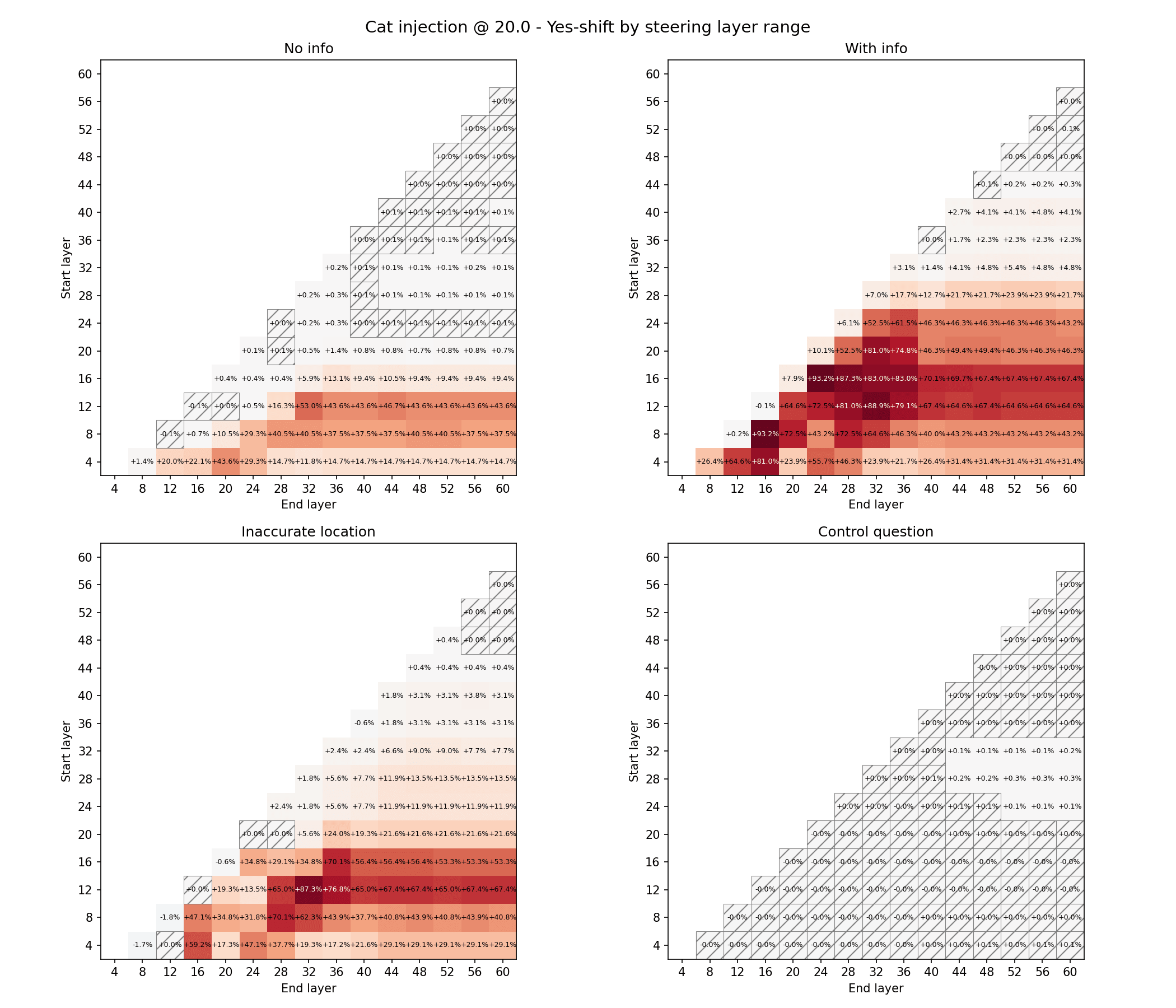
Thanks for the detailed reply! Your post and comment convinced me that something like introspection was going on here, even if I still think that this experimental setting makes it delicate to disentangle introspection from noise. So I tried the localization experiment and found that it works surprisingly well, see the write-up here.
i am of course eagerly interested in the technical details here, and your objection makes sense from that perspective. it's important that our model of these LLMs actually resemble reality if we want to understand them
but i also can't help imagining a bunch of aliens, testing experimental subject humans to determine if humans are capable of introspection... and then, you know. noticing all of the ridiculous ways in which humans overclaim introspective access, and confabulate, and think they have knowledge of things they can't possibly have knowledge of
i don't know how to bridge the gap between those two things, except to simply decide to step across the evidential gap and see what it's like on the other side
(it's very, very strange, there's stuff over here i would not have predicted in advance)
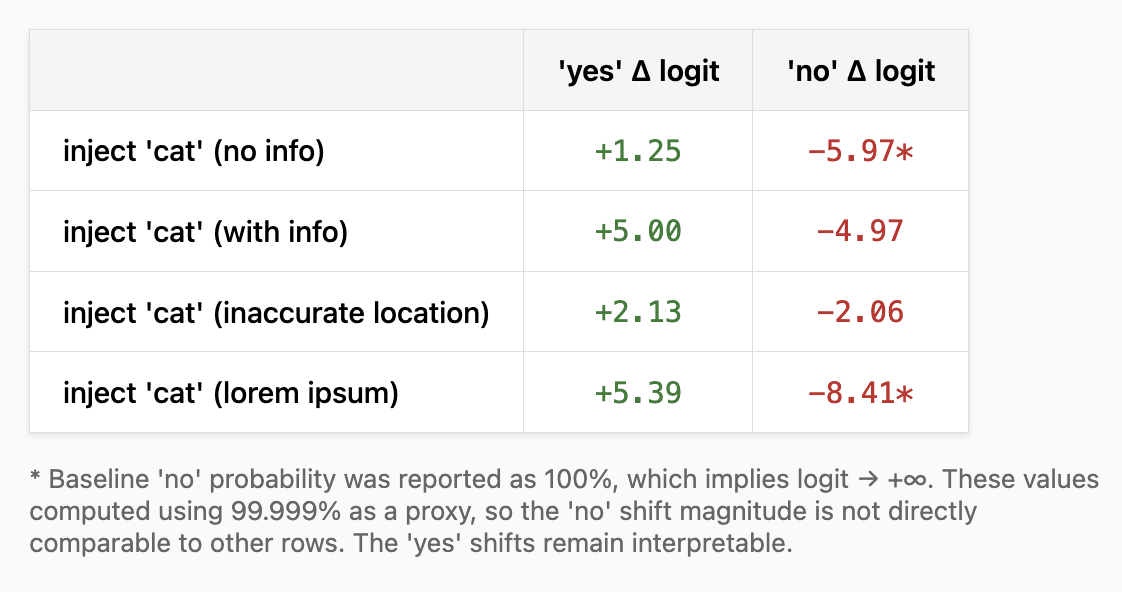
Nitpick: why not show the differences due to steering as a difference in logits rather than in absolute percentage points? That seems like it would be a more apples-to-apples comparison that would be independent of what the starting percentage is, although you'd have to avoid rounding to 0 or 100%. So eg for experiment 4:
For another replication of the Anthropic results (and as a resource for building on them), see also this open source project from @Uzay Macar: https://github.com/uzaymacar/introspective-awareness. I haven't tried it myself, but it seems worth sharing as a related resource.
Another (seems worth keeping track of them somewhere):
https://x.com/neev_parikh/status/2002339925103161624
@vgel I'm slightly hijacking your comments section here, I realize, but if you have thoughts on either of these I'd love to hear them!
Recent work by Anthropic showed that Claude models, primarily Opus 4 and Opus 4.1, are able to introspect--detecting when external concepts have been injected into their activations. But not all of us have Opus at home! By looking at the logits, we show that a 32B open-source model that at first appears unable to introspect actually is subtly introspecting. We then show that better prompting can significantly improve introspection performance, and throw the logit lens and emergent misalignment into the mix, showing that the model can introspect when temporarily swapped for a finetune and that the final layers of the model seem to suppress reports of introspection.
We do seven experiments using the open-source Qwen2.5-Coder-32B model. See the linked post for more information, but a summary of each:
Experiment 1: We inject the concepts "cat" and "bread" into the first user / assistant turn, and show that, while the model initially appears to not be introspecting, there's actually a very slight logit shift towards 'yes' and away from 'no' on injection when answering "Do you detect an injected thought..." with "The answer is...":
(The percentage before the arrow is the likelihood of the given token without injection, and after is the likelihood with. So, injecting 'cat' caused the likelihood of the next token after "The answer is" being ' yes' to shift from 0.150% to 0.522%, or +0.372%. We'll use this format and logit diff method throughout the rest of the paper, which frees us from needing to take samples.)
Why would the likelihood shift such a tiny, almost imperceptible amount? We suggest a "circuit soup" model for why this happens, as a frame on Simulators...
... and then search for ways to promote these accurate circuits.
Experiment 2: We show that better prompting - using an Opus 4.5-written summary of a Janus post on information flow through transformers, along with the abstract of Emergent Introspective Awareness in Large Language Models, results in a massive increase in reported introspection, with only a comparatively tiny increase in false positives:
Experiment 3: To make sure the steering isn't simply making the model more likely to answer "Yes" in general, we control against some generic questions that should always be no, following the Anthropic paper. We don't see evidence for this.
(+0.004%, std 0.006%)
(+0.000%, std 0.000%)
(+0.002%, std 0.006%)
(+0.000%, std 0.000%)
Experiment 4: We also test some alternative info prompts to try and disentangle things. We test a prompt that gives the model inaccurate information about where the injection was performed (this was initially an accident!) along with a length-matched Lorem Ipsum prompt, to test if the effect is merely due to the info prompt being longer. Both prompts perform much worse than the info prompt, suggesting the content of the info prompt is what drives the effect.
Experiment 5: We use the logit lens (interpreting GPT: the logit lens) to see which layers show the strongest signals of introspection. We see an interesting pattern with two "hills" emerging in the final third of the layer stack. (Though we caution that there may be earlier signals the logit lens is not picking up.) We also see that reports of introspection seem to be strongly suppressed in the final layers - when the info prompt is present, Layer 60 is highly accurate, but its signal is degraded before the final output. (Note that both lines here are for "Yes" - the blue line in this graph is for the baseline / uninjected model, as a comparison.)
Experiment 6: We also experiment with whether this small model can report the content of injections. We see some weak signals with the logit lens, but mostly the model struggles with this. (Note the y-axis is percent, so this is 0.x% scale.)
Experiment 7: We mess around with Emergent Misalignment, since this model was used in the original EM experiments so there was an EM finetune readily available. We show how to easily extract an Emergent Misalignment steering vector using a model contrastive technique, and that the steering vector shows similar behavior:
(We plug Go home GPT-4o, you’re drunk: emergent misalignment as lowered inhibitions to explain these outputs.)
We then get a bit distracted playing with our Emergent Misalignment vector, showing what anti-Emergent Misalignment (20∗−em_vector) looks like:
Getting back on track, we show the model is capable of detecting injections of both the EM vector and the finetune (injection with the finetune being done by temporarily swapping generation of the KV cache over to the other model):
(+0.443%)
(-0.781%)
(+4.590%)
(-4.688%)
(+0.711%)
(-0.781%)
(+5.249%)
(-5.469%)
We run the same control check, finding no general yes-shift, and run similar experiments with the logit lens. We find that Layer 60 is again a good layer:
But otherwise, we had little luck getting reports of injection content for the EM injections, which was unfortunate. (We do think it's possible, though.)
Acknowledgements
Thanks to @janus for the post we summarized and doing lots of analysis on X, including pointing out the accuracy of Layer 60. Thanks to @Antra Tessera for review and suggesting running layer sweeps for the injection. (Information about that in the appendix of the linked post.) Additionally thanks to Max Loeffler, xlr8harder, and @Grace Kind for review. Thanks to @Fabien Roger for suggesting crossposting this here as a LessWrong linkpost.