The goal should be to cause the future to be great on its own terms
What the heck is this supposed to mean? Great according to the Inherent Essence Of Goodness that lives inside futures, rather than as part of human evaluations? Because I've got bad news for that plan.
Honestly, I'm disappointed by this post.
You say you've found yourself making this argument a lot recently. That's fair. I think it's totally reasonable that there are some situations where this argument could move people in the right direction - maybe the audience is considering defecting about aligning AI with humanity but would respond to orders from authority. Or maybe they're outsiders who think you are going to defect, and you want to signal to them how you're going to cooperate not just because it's a good idea, but because it's an important moral principle to you (as evolution intended).
But this is not an argument that you should just throw out scattershot. Because it's literally false. There is no single attractor that all human values can be expected to fall into upon reflection. The primary advantage of AI alignment over typical philosophy is that when alignment researchers realize some part of what they were previously calling "alignment" is impossible, they can back up and change how they're cashing out "alignment" so that it's actually possible - philosophers have to keep caring about the impossible thing. This advantage goes away if we don't use it.
Yes, plenty of people liked this post. But I'm holding you to a high standard. Somewhere people should be expected to not keep talking about the impossible thing. Somewhere, there is a version of this post that talks about or directly references:
- Game-theoretic arguments for cooperation.
- Why game-theoretic arguments are insufficient for egalitarianism (e.g. overly weighting the preferences of the powerful) but still mean that AI should be designed with more than just you in mind, even before accounting for a human preference for an egalitarian future.
- Why egalitarianism is a beautiful moral principle that you endorse.
- "Wait, wasn't that this post?" you might say. Kind of! Making a plain ethical/aesthetic argument is like a magic trick where the magician tells you up front that it's an illusion. This post is much the same magic trick, but the magician is telling you it's real magic.
- Realistic expectations for what egalitarianism can look like in the real world.
- It cannot look like finding the one attractor that all human values converge to upon reflection because there is no one attractor that all human values converge to upon reflection.
- Perhaps an analysis of how big the "fingerprints" of the creators of the AI are in such situations - e.g. by setting the meta-level standards for what counts as a "human value".
- There is a non-zero chance that the meta-preferences, that end up in charge of the preferences, that end up in charge of the galaxy will come from Mechanical Turkers.
"The goal should be to cause the future to be great on its own terms"
What the heck is this supposed to mean? Great according to the Inherent Essence Of Goodness that lives inside futures, rather than as part of human evaluations?
The rest of the quote explains what this means:
The goal should be to cause the future to be great on its own terms, without locking in the particular moral opinions of humanity today — and without locking in the moral opinions of any subset of humans, whether that’s a corporation, a government, or a nation.
(If you can't see why a single modern society locking in their current values would be a tragedy of enormous proportions, imagine an ancient civilization such as the Romans locking in their specific morals 2000 years ago. Moral progress is real, and important.)
The present is "good on its own terms", rather than "good on Ancient Romans' terms", because the Ancient Romans weren't able to lock in their values. If you think this makes sense (and is a good thing) in the absence of an Inherent Essence Of Goodness, then there's no reason to posit an Inherent Essence Of Goodness when we switch from discussing "moral progress after Ancient Rome" to "moral progress after circa-2022 civilization".
Because it's literally false. There is no single attractor that all human values can be expected to fall into upon reflection.
Could you be explicit about what argument you're making here? Is it something like:
- Even when two variables are strongly correlated, the most extreme value of one will rarely be the most extreme value of the other; therefore it's <50% likely that different individuals' CEVs will yield remotely similar results? (E.g., similar enough that one individual will consider the output of most other individuals' CEVs morally acceptable?)
Or?:
- The optimal world-state according to Catholicism is totally different from the optimal world-state according to hedonic utilitarianism; therefore it's <50% likely that the CEV of a random Catholic will consider the output of a hedonic utilitarian's CEV morally acceptable. (And vice versa.)
Regarding the second argument: I don't think that Catholicism is stable under reflection (because it's false, and a mind needs to avoid thinking various low-complexity true thoughts in order to continue believing Catholicism), so I don't think the Catholic and hedonic utilitarian's CEVs will end up disagreeing, even though the optimum for Catholicism and for hedonic utilitarianism disagree.
(I'd bet against hedonic utilitarianism being true as well, but this is obviously a much more open question. And fortunately, CEV-ish buck-passing processes make it less necessary for anyone to take risky bets like that; we can just investigate what's true and base our decisions on what we learn.)
Catholicism is a relatively easy case, and I expect plenty of disagreement about exactly how much moral disagreement looks like the Catholicism/secularism debate. I expect a lot of convergence on questions like "involuntarily enslaving people: good or bad?", on the whole, and less on questions like "which do you want more of: chocolate ice cream, or vanilla ice cream?". But it's the former questions that matter more for CEV; the latter sorts of questions are ones where we can just let individuals choose different lives for themselves.
"Correlations tend to break when you push things to extremes" is a factor that should increase our expectation of how many things people are likely to morally disagree about. Factors pushing in the other direction include 'not all correlations work that way' and evidence that human morality doesn't work that way.
E.g., 'human brains are very similar', 'empirically, people have converged a lot on morality even though we've been pushed toward extremes relative to our EAA', 'we can use negotiation and trade to build value systems that are good compromises between two conflicting value systems', etc.
Also 'the universe is big, and people's "amoral" preferences tend to be about how their own life goes, not about the overall distribution of matter in the universe'; so values conflicts tend to be concentrated in cases where we can just let different present-day stakeholders live different sorts of lives, given the universe's absurd abundance of resources.
Nate said "it shouldn’t matter who does the job, because there should be a path-independent attractor-well that isn't about making one person dictator-for-life or tiling a particular flag across the universe forever", and you said this is "literally false". I don't see what's false about it, so if the above doesn't clarify anything, maybe you can point to the parts of the Arbital article on CEV you disagree with (https://arbital.com/p/cev/)? E.g., I don't see Nate or Eliezer claiming that people will agree about vanilla vs. chocolate.
Game-theoretic arguments for cooperation [...] mean that AI should be designed with more than just you in mind, even before accounting for a human preference for an egalitarian future
Footnote 2 says that Nate isn't "stupid enough to toss coordination out the window in the middle of a catastrophic emergency with human existence at stake". If that isn't an argument 'cooperation is useful, therefore we should take others' preferences into account', then what sort of argument do you have in mind?
Why egalitarianism is a beautiful moral principle that you endorse.
I don't know what you mean by "egalitarianism", or for that matter what you mean by "why". Are you asking for an ode to egalitarianism? Or an argument for it, in terms of more basic values?
The present is "good on its own terms", rather than "good on Ancient Romans' terms", because the Ancient Romans weren't able to lock in their values. If you think this makes sense (and is a good thing) in the absence of an Inherent Essence Of Goodness, then there's no reason to posit an Inherent Essence Of Goodness when we switch from discussing "moral progress after Ancient Rome" to "moral progress after circa-2022 civilization".
The present is certainly good on my terms (relative to ancient Rome). But the present itself doesn't care. It's not the type of thing that can care. So what are you trying to pack inside that phrase, "its own terms"?
If you mean it to sum up a meta-preference you hold about how moral evolution should proceed, then that's fine. But is that really all? Or are you going to go reason as if there's some objective essence of what the present's "own terms" are - e.g. by trying to apply standards of epistemic uncertainty to the state of this essence?
"Because it's literally false. There is no single attractor that all human values can be expected to fall into upon reflection."
Could you be explicit about what argument you're making here? Is it something like:
- Even when two variables are strongly correlated, the most extreme value of one will rarely be the most extreme value of the other; therefore it's <50% likely that different individuals' CEVs will yield remotely similar results? (E.g., similar enough that one individual will consider the output of most other individuals' CEVs morally acceptable?)
Or?:
- The optimal world-state according to Catholicism is totally different from the optimal world-state according to hedonic utilitarianism; therefore it's <50% likely that the CEV of a random Catholic will consider the output of a hedonic utilitarian's CEV morally acceptable. (And vice versa.)
I'll start by quoting the part of Scott's essay that I was particularly thinking of, to clarify:
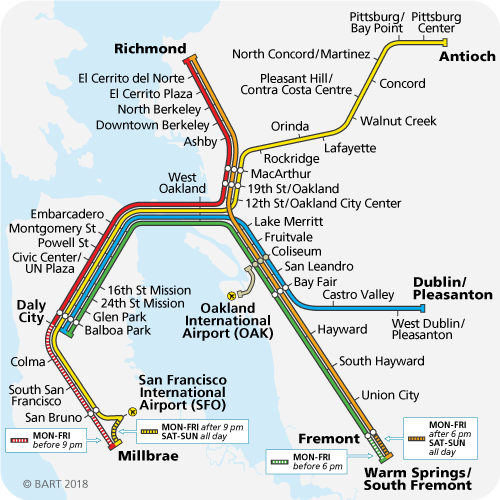
Our innate moral classifier has been trained on the Balboa Park – West Oakland route. Some of us think morality means “follow the Red Line”, and others think “follow the Green Line”, but it doesn’t matter, because we all agree on the same route.
When people talk about how we should arrange the world after the Singularity when we’re all omnipotent, suddenly we’re way past West Oakland, and everyone’s moral intuitions hopelessly diverge.
But it’s even worse than that, because even within myself, my moral intuitions are something like “Do the thing which follows the Red Line, and the Green Line, and the Yellow Line…you know, that thing!” And so when I’m faced with something that perfectly follows the Red Line, but goes the opposite directions as the Green Line, it seems repugnant even to me, as does the opposite tactic of following the Green Line. As long as creating and destroying people is hard, utilitarianism works fine, but make it easier, and suddenly your Standard Utilitarian Path diverges into Pronatal Total Utilitarianism vs. Antinatalist Utilitarianism and they both seem awful. If our degree of moral repugnance is the degree to which we’re violating our moral principles, and my moral principle is “Follow both the Red Line and the Green Line”, then after passing West Oakland I either have to end up in Richmond (and feel awful because of how distant I am from Green), or in Warm Springs (and feel awful because of how distant I am from Red).
Okay, so.
What's the claim I'm projecting onto Nate, that I'm saying is false? It's something like: "The goal should be to avoid locking in any particular morals. We can do this by passing control to some neutral procedure that allows values to evolve."
And what I am saying is something like: There is no neutral procedure. There is no way to avoid privileging some morals. This is not a big problem, it's just how it is, and we can be okay with it.
Related and repetitive statements:
- When extrapolating the shared train line past West Oakland, there are multiple ways to continue, but none of them are "the neutral way to do the extrapolation."
- The self-reflection function has many attractors for almost all humans, groups, societies, and AGI architectures. Different starting points might land us in different attractors, and there is no unique "neutral starting point."
- There are many procedures for allowing values to evolve, most of them suck, and picking a good one is an action that will bear the fingerprints of our own values. And that's fine!
- Human meta-preferences, the standards by which we judge what preference extrapolation schemes are good, are preferences. We do not have any mysterious non-preference standards for doing value aggregation and extrapolation.
- There is not just one CEV that is the neutral way to do preference aggregation and extrapolation. There are lots of choices that we have to / get to make.
So as you can see, I wasn't really thinking about differences between "the CEV" of different people - my focus was more on differences between ways of implementing CEV of the same people. A lot of these ways are going to be more or less as good - like comparing your favorite beef stew vs. a 30-course modernist meal. But not all possible implementations of CEV are good, for example you could screw up by modeling exposing people to extreme or highly-optimized stimuli when extrapolating them, leading to the AI causing large changes in the human condition that we wouldn't presently endorse.
I don't know what you mean by "egalitarianism", or for that matter what you mean by "why". Are you asking for an ode to egalitarianism? Or an argument for it, in terms of more basic values?
By egalitarianism I mean building an AI that tries to help all people, and be responsive to the perspectives of all people, not just a select few. And yes, definitely an ode :D
e.g. by trying to apply standards of epistemic uncertainty to the state of this essence?
I would say that there's a logical object that a large chunk of human moral discourse is trying to point at — something like "the rules of the logical game Morality", analogous to "the rules of the logical game Chess". Two people can both be discussing the same logical object "the rules of Chess", but have different beliefs about what that logical object's properties are. And just as someone can be mistaken or uncertain bout the rules of chess — or about their interaction in a specific case — someone can be uncertain about morality.
Do you disagree with any of that?
And what I am saying is something like: There is no neutral procedure. There is no way to avoid privileging some morals. This is not a big problem, it's just how it is, and we can be okay with it.
In the CEV Arbital page, Eliezer says:
"Even the terms in CEV, like 'know more' or 'extrapolate a human', seem complicated and value-laden."
If the thing you're saying is that CEV is itself a complicated idea, and it seems hard for humanity to implement such a thing without already having a pretty deep understanding of human values, then I agree. This seems like an important practical challenge for pulling off CEV: you need to somehow start the bootstrapping process, even though our current understanding of human values is insufficient for formally specifying the best way to do CEV.
If instead you just mean to say "there's no reason to favor human values over termite values unless you already care about humans", then yeah, that seems even more obvious to me. If you think Nate is trying to argue for human morality from a humanity-indifferent, View-From-Nowhere perspective, then you're definitely misunderstanding Nate's perspective.
When extrapolating the shared train line past West Oakland, there are multiple ways to continue, but none of them are "the neutral way to do the extrapolation."
If "neutral" here means "non-value-laden", then sure. If "neutral" here means "non-arbitrary, from a human POV", then it seems like an open empirical question how many arbitrary decisions like this are required in order to do CEV.
I'd guess that there are few or no arbitrary decisions involved in using CEV to answer high-takes high-stakes moral questions.
There are many procedures for allowing values to evolve, most of them suck, and picking a good one is an action that will bear the fingerprints of our own values.
This makes me think that you misunderstood Nate's essay entirely. The idea of "don't leave your fingerprints on the future" isn't "try to produce a future that has no basis in human values". The idea is "try to produce a future that doesn't privilege the AGI operator's current values at the expense of other humans' values, the values humans would develop in the future if their moral understanding improved, etc.".
If you deploy AGI and execute a pivotal act, don't leave your personal fingerprints all over the long-term future of humanity, in a way that distinguishes you from other humans.
I would say that there's a logical object that a large chunk of human moral discourse is trying to point at — something like "the rules of the logical game Morality", analogous to "the rules of the logical game Chess". Two people can both be discussing the same logical object "the rules of Chess", but have different beliefs about what that logical object's properties are. And just as someone can be mistaken or uncertain bout the rules of chess — or about their interaction in a specific case — someone can be uncertain about morality.
When I think about the rules of chess, I basically treat them as having some external essence that I have epistemic uncertainty about. What this means mechanistically is:
- When I'm unsure about the rules of chess, this raises the value of certain information-gathering actions, like checking the FIDE website, asking a friend, reading a book.
- If I knew the outcomes of all those actions, that would resolve my uncertainty.
- I have probabilities associated with my uncertainty, and updates to those probabilities based on evidence should follow Bayesian logic.
- Decision-making under uncertainty should linearly aggregate the different possibilities that I'm uncertain over, weighted by their probability.
So the rules of chess are basically just a pattern out in the world that I can go look at. When I say I'm uncertain about the rules of chess, this is epistemic uncertainty that I manage the same as if I'm uncertain about anything else out there in the world.
The "rules of Morality" are not like this.
- When I'm unsure about whether I care about fish suffering, this does raise the value of certain information-gathering actions like learning more about fish.
- But if I knew the outcomes of all those actions, this wouldn't resolve all my uncertainty.
- I can put probabilities to various possibilities, and can update them on evidence using Bayesian logic - that part still works.
- Decision-making under the remaining-after-evidence part of the uncertainty doesn't have to look like linear aggregation. In fact it shouldn't - I have meta-preferences like "conservatism," which says that I should trust models differently depending on whether they seem to be inside their domain of validity or not.
So there's a lot of my uncertainty about morality that doesn't stem from being unaware about facts. Where does it come from? One source is self-modeling uncertainty - how do I take the empirical facts about me and the world, and use that to construct a model of myself in which I have preferences, so that I can reflect on my own preferences? There are multiple ways to do this.
So if, and I'm really not sure, but if you were thinking of everything as like uncertainty about the rules of chess, then I would expect two main mistakes: expecting there to be some procedure that takes in evidence and spits out the one right answer, and expecting aggregating over models for decision-making to look like linear aggregation.
"There are many procedures for allowing values to evolve, most of them suck, and picking a good one is an action that will bear the fingerprints of our own values."
This makes me think that you misunderstood Nate's essay entirely. The idea of "don't leave your fingerprints on the future" isn't "try to produce a future that has no basis in human values". The idea is "try to produce a future that doesn't privilege the AGI operator's current values at the expense of other humans' values, the values humans would develop in the future if their moral understanding improved, etc.".
If you deploy AGI and execute a pivotal act, don't leave your personal fingerprints all over the long-term future of humanity, in a way that distinguishes you from other humans.
Well, maybe I misunderstood. But I'm not really accusing y'all of saying "try to produce a future that has no basis in human values." I am accusing this post of saying "there's some neutral procedure for figuring out human values, we should use that rather than a non-neutral procedure."
So the rules of chess are basically just a pattern out in the world that I can go look at. When I say I'm uncertain about the rules of chess, this is epistemic uncertainty that I manage the same as if I'm uncertain about anything else out there in the world.
The "rules of Morality" are not like this.
This and earlier comments are bald rejections of moral realism (including, maybe especially, naturalist realism). Can I get some evidence for this confident rejection?
I'm not sure what linking Yudkowsky's (sketch of a) semantics for moral terms is meant to tell us. Case in point, Cornell Realists adopt a similar relativism in their semantics ("good" like "healthy" can only be judged relative to the type of creature you are), but (some of them anyway) will still argue that we can simply discover what is good through a more or less standard scientific process. In other words, they do believe there is a basin of attraction for human values and there is a neutral process for finding it. (It's only a basin of attraction of course insofar as this process will find it and should we trust that process, we will gravitate toward that basin). To be clear, few if any claim there is one exact lowest point in this basin – there will be many constellations of goods in a life that are equally worthwhile in some sense (first gloss: in the sense that we would be indifferent to a choice between those lives, from behind a veil of ignorance that only assumes we are homo sapiens).
In any case, every major view in meta-ethics has a developed semantics for moral terms: you'll have to say more about why e.g. your favored semantics is a point in favor of your meta-ethical view. You don't need to start from scratch of course: philosophers have been working on this for decades (and continue to). Ayer's classic emotivism (a.k.a. expressivism) ran into the problem of embedding (if moral statement P doesn't have a truth value, how am I supposed to evaluate statements with P embedded in them, like "P → Q"? Our nice truth tables get thrown out the window...). In response several anti-realists have made proposals, e.g. Blackburn's quasi-realism. More recently, those responses have come under fire for struggling to hold onto their distinct semantics (or metaphysics or epistemology) while also holding onto a view distinct from realism. There is always Error Theory of course but then you're committed to saying things like "It is false that arbitrary torture is bad. It is also false that arbitrary torture is good."
If none of this discussion on meta-ethics is your thing, that's fine, but then you might want to dampen your certainty? Consider deferring to those who have thought longer on this – update on the distribution of philosophers' views on meta-ethics, modulo whatever selection effects you think are biasing that distribution in a particular direction?
Sure. Here are some bullet points of evidence:
- To all appearances, we're an evolved species on an otherwise fairly unremarkable planet in a universe that doesn't have any special rules for us.
- The causal history of us talking about morality as a species runs through evolution and culture.
- We learn to build models of the world, and can use language to communicate about parts of these models. Sometimes it is relevant that the map is not the territory, and the elements of our discourse are things on maps.
In terms of semantics of moral language, I think the people who have to argue about whether they're realists or anti-realists are doing a fine job. Having fancy semantics that differentiate you from everyone else was a mistake. Good models of moral language should be able to reproduce the semantics that normal people use every day.
E.g. "It's true that in baseball, you're out after three strikes." is not a sentence that needs deep revision after considering that baseball is an invented, contingent game.
In terms of epistemology of morality, the average philosopher has completely dropped the ball. But since, on average, they think that as well, surely I'm only deferring to those who have thought longer on this when I say that.
Good models of moral language should be able to reproduce the semantics that normal people use every day.
Agreed. So much the worse for classic emotivism and error theory.
But semantics seems secondary to you (along with many meta-ethicists frankly – semantic ascent is often just used as a technique for avoiding talking past one another, allowing e.g. anti-realist views to be voiced without begging the question. I think many are happy grab whatever machinery from symbolic logic they need to make the semantics fit the metaphysical/epistemological views they hold more dearly.) I'd like to get clear just what it is you have strong/weak credence in. How would you distribute your credences over the following (very non-exhaustive and simplified) list?
- Classic Cultural Relativism: moral rules/rightness are to be identified with cultural codes (and for simplicity, say that goodness is derivative). Implication for moral epistemology: like other invented social games, to determine what is morally right (according to the morality game) we just need to probe the rulemakers/keepers (perhaps society at large or a specific moral authority).
- Boyd's view (example of naturalist realism): moral goodness is to be identified with the homeostatic clusters of natural (read regular, empirically observable) properties that govern the (moral) use of the term "good" in basically the same way that tigerness is to be identified with homeostatic clusters of natural properties that govern the (zoological) use of the term "tiger." To score highly on tigerness is to score highly on various traits e.g. having orange fur with black strikes, being quadrupedal, being a carnivore, having retractable claws... We've learned more about tigers (tigerness) as we encountered more examples (and counterexamples) of them and refined our observation methods/tools; the same goes (will continue to go) for goodness and good people. Implication for moral epistemology: "goodness" has a certain causal profile – investigate what regulates that causal profile, the same we investigate anything else in science. No doubt mind-dependent things like your own preferences or cultural codes will figure among the things that regulate the term "good" but these will rarely have the final say in determining what is good or not. Cultural codes and preferences will likely just figure as one homeostatic mechanism among many.
- Blackburn's Projectivism or Gibbard's Norm-Expressivism (sophisticated versions of expressivism, examples of naturalist anti-realism): morality is reduced to attitudes/preferences/plans.
- According to Blackburn we talk as if moral properties are out their to be investigated the way Boyd suggests we can, but strictly speaking this is false: his view is a form of moral fictionalism. He believes there is no general causal profile to moral terms: nothing besides our preferences/attitudes regulates our usage of these terms. The only thing to "discover" is what our deepest preferences/attitudes are (and if we don't care about having coherent preferences/attitudes, we can also note our incoherencies). Implication for moral epistemology: learn about the world while also looking deep inside yourself to see how you are moved by that new knowledge (or something to this effect).
- According to Gibbard normative statements are expressions of plans – "what to do." The logical structure of these expressions helps us express, probe and revise our plans for their consistency within a system of plans, but ultimately, no one/nothing outside of yourself can tell you what system of plans to adopt. Implication for moral epistemology: determine what your ultimate plans are and do moral reasoning with others to work out any inconsistencies in your system of plans.
If I had to guess you're in the vicinity of Blackburn (3.a). Can you confirm? But now, how does your preferred view fit your three bullet points of data better than the others? Your 4th data point, matching normal moral discourse (more like a dataset), is another story. E.g. I think (1) pretty clearly scores worse on this one compared to the others. But the others are debatable, which is part of my point – it's not obvious which theory to prefer. And there is clearly disagreement between these views – we can't hold them all at once without some kind of incoherence: there is a choice to be made. How are you making that choice?
As for this:
In terms of epistemology of morality, the average philosopher has completely dropped the ball. But since, on average, they think that as well, surely I'm only deferring to those who have thought longer on this when I say that.
I'm sorry but I don't follow. Care to elaborate? You're saying philosophers have, on average, failed to develop plausible/practical moral epistemologies? Are you saying this somehow implies you can safely disregard their views on meta-ethics? I don't see how: the more relevant question seems to be what our current best methodology for meta-ethics is and whether you or some demographic (e.g. philosophers) are comparatively better at applying it. Coming up with a plausible/practical moral epistemology is often treated as a goal of meta-ethics. Of course the criteria for success in that endeavor will depend what you think the goals of philosophy or science are.
If I had to guess you're in the vicinity of Blackburn (5.a). Can you confirm?
Can confirm. Although between Boyd and Blackburn, I'd point out that the question of realism falls by the wayside (they both seem to agree we're modeling the world and then pointing at some pattern we've noticed in the world, whether you call that realism or not is murky), and the actionable points of disagreement are things like "how much should we be willing to let complicated intuitions be overruled by simple intuitions?"
And there is clearly disagreement between these views – we can't hold them all at once without some kind of incoherence
If two people agree about how humans form concepts, and one says that certain abstract objects we've formed concepts for are "real," and another says they're "not real," they aren't necessarily disagreeing about anything substantive.
Sometimes people disagree about concept formation, or (gasp) don't even give it any role in their story of morality. There's plenty of room for incoherence there.
But along your Boyd-Blackburn axis, arguments about what to label "real" are more about where to put emphasis, and often smuggle in social/emotive arguments about how we should act or feel in certain situations.
(Re: The Tails Coming Apart As Metaphor For Life. I dunno, if most people, upon reflection, find that the extremes prescribed by all straightforward extrapolations of our moral intuitions look ugly, that sounds like convergence on... not following any extrapolation into the crazy scenarios and just avoiding putting yourself in the crazy scenarios. It might just be wrong for us to have such power over the world as to be directing us into any part of Extremistan. Maybe let's just not go to Extremistan – let's stay in Mediocristan (and rebrand it as Satisficistan). If at first something sounds exciting and way better than where you are now, but on reflection looks repugnant – worse than where you are now – then maybe don't go there. If utilitarianism, Christianism etc yield crazy results in the limit, so much the worse for them. Repugnance keeps hitting your gaze upon tails that have come apart? Maybe that's because what you care about are actually homeostatic property clusters: the good doesn't "boil down" to one simple thing like happiness or a few commands written on a stone tablet. Maybe you care about a balance of things – about following all four Red, Yellow, Blue and Green lines (along with 100 other ones no doubt) – never one thing at the unacceptable expense of another. But this is a topic for another day and I'm only gesturing vaguely at a response.)
(Sorry for delay! Was on vacation. Also, got a little too into digging up my old meta-ethics readings. Can't spend as much time on further responses...)
Although between Boyd and Blackburn, I'd point out that the question of realism falls by the wayside...
I mean fwiw, Boyd will say "goodness exists" while Blackburn is arguably committed to saying "goodness does not exist" since in his total theory of the world, nothing in the domain that his quantifiers range over corresponds to goodness – it's never taken as a value of any of his variables. But I'm pretty sure Blackburn would take issue with this criterion for ontological commitment, and I suspect you're not interested in that debate. I'll just say that we're doing something when we say e.g. "unicorns don't exist" and some stories are better than others regarding what that something is (though of course it's open question as to which story is best).
they both seem to agree we're modeling the world and then pointing at some pattern we've noticed in the world
I think the point of agreement you're noticing here is their shared commitment to naturalism. Neither thinks that morality is somehow tied up with spooky acausal stuff. And yes, to talk very loosely, they are both pointing at patterns in the world and saying "that's what's key to understanding morality." But contra:
If two people agree about how humans form concepts, and one says that certain abstract objects we've formed concepts for are "real," and another says they're "not real," they aren't necessarily disagreeing about anything substantive.
they are having a substantive disagreement, precisely over which patterns are key to understanding morality. They likely agree more or less on the general story of how human concepts form (as I understand you to mean "concept formation"), but they disagree about the characteristics of the concept [goodness] – its history, its function, how we learn more about its referent (if it has any) etc. Blackburn's theory of [goodness] (a theory of meta-ethics) points only to feeling patterns in our heads/bodies (when talking "external" to the moral linguistic framework, i.e. in his meta-ethical moments; "internal" to that framework he points to all sorts of things. I think it's an open question whether he can get away with this internal external dance,[1] but I'll concede it for now). Boyd just straightforwardly points to all sorts of patterns, mostly in people's collective and individual behavior, some in our heads, some in our physiology, some in our environment... And now the question is, who is correct? And how do we adjudicate?
Maybe I can sharpen their disagreement with a comparison. What function does "tiger" serve in our discourse? To borrow terms from Huw Price, is it an e-representation which serves to track or co-vary with a pattern (typically in the environment), or is it an i-representation which serves any number of other "in-game" functions (e.g. signaling a logico-inferential move in the language game, or maybe using/enforcing/renegotiating a semantic rule)? Relevant patterns to determine the answer to such questions: the behaviour of speakers. Also, we will need to get clear on our philosophy of language/linguistic theory: not everyone agrees with Price that this "new bifurcation" is all that important – people will try to subsume one type of role under another.[2] Anyway, suppose we now agree that "tiger" serves to refer, to track certain patterns in the environment. Now we can ask, how did "tiger" come to refer to tigers? Relevant patterns seem to include:
- the evolution of a particular family of species – the transmission and gradual modification of common traits between generations of specimens
- the evolution of the human sensory apparatus, which determines what sorts of bundles of patterns humans tend to track as unified wholes in their world models
- the phonemes uttered by the first humans to encounter said species, and the cultural transmission/evolution of that guttural convention to other humans
- ...and probably much more I'm forgetting/glossing over/ignoring.
We can of course run the same questions for moral terms. And on nearly every point Blackburn and Boyd will disagree. None of these are spooky questions, but they seem relevant to helping us get clear on our collective project to study tigers – what it is and how to go about it. Of course zoologists don't typically need to go to the same lengths ethicists do, but I think its fair to chalk that up to the how controversial moral talk is. It's important to note that neither Blackburn nor Boyd are in the business of revising the function/referents of moral talk: they don't want to merely stipulate the function/referent of "rightness" but instead, take the term as they hear it in the mouths of ordinary speakers and give an account of its associated rules of use, its function, the general shape of its referent (if it has one).
At this point you might object: what's the point? How does this have any bearing on what I really care about, the first-order stuff – e.g. whether stealing is wrong or not? One appeal of meta-ethics, I think, is that it presents a range of non-moral questions that we can hopefully resolve in more straightforward ways (especially if we all agree on naturalism), and that these non-moral questions will allow us to resolve many first-order moral disputes. On the (uncontroversial? in any case, empirically verifiable) assumption that our moralizing (moral talk, reflection, judgment) serves some kind of function or is conducive to some type of outcome, then hopefully if we can get a better handle on what we're are doing when we moralize maybe we can do it better by its own lights.[3]
Assuming of course one wants to moralize better – no one said ethics/meta-ethics would be of much interest to the amoralist. Here is indeed a meta-preference – the usual one appealed to in order to motivate the (meta-)ethicists' entreprise. (Most people aren't anti-moralists, who are only interested in meta-ethics insofar as it helps them do moralizing worse. And few are interested in making accurate predictions about homo sapiens' moralizing for its own sake, without applying it to one's own life). But I don't see this as threatening or differentiating from other scientific endeavours. It's not threatening (i.e. the bootstrapping works) because, as with any inquiry, we begin with already some grasp of our subject matter, the thing we're interested in. We point and say "that's what I want to investigate."As we learn more about it, refining the definition of our subject matter, our interest shifts to track this refinement too (either in accordance with meta-preferences, or through shifts in our preferences in no way responsive to our initial set of preferences). This happens in any inquiry though. Suppose I care about solving a murder, but in the course of my investigation I discover no one killed the alleged victim – they died of an unrelated causes. At that point, I may drop all interest upon realizing no murder occurred, or I might realize what I really wanted to solve was the death of this person.
Might we end up not caring about the results of meta-ethics? I find that highly unlikely, assuming we have the meta-preference of wanting to do this morality thing better, whatever it turns out to be. This meta-preference assumes as little as possible about its subject, in the same way that an interest in solving a death assumes less about its subject than an interest in solving a murder. Meta-ethicists are like physicists who are interested in understanding what causes the perturbations Uranus' orbit, whatever it turns out to be: they are not married to a specific planet-induced-perturbations hypothesis, dropping all interest once Vulcan was found missing.
Hopefully we agree on the first-order claim that one should want to do this morality thing better – whatever "doing morality better" turns out to be! In much same way that a athlete will, upon noting that breathing is key to better athletic performance, want to "do breathing better" whatever breathing turns out to be. The only difference with the athlete is that I take "doing morality better" to be among my terminal goals, insofar as its virtuous to try and make oneself more virtuous. (It's not my only terminal goal of course – something something shard theory/allegory of the chariot).
To make sure things are clear: naturalists all agree there is a process as neutral as any other scientific process for doing meta-ethics – for determining what it is homo sapiens are doing when they engage in moralizing. This is the methodological (and ultimately, metaphysical) point of agreement between e.g. Blackburn and Boyd. We need to e.g. study moral talk, observe whether radical disagreement is a thing, and other behaviour etc. (Also taken as constraints: leaving typical moral discourse/uncontroversial first-order claims intact.) Naturalist realists start to advance a meta-ethical theory when they claim that there is a process as neutral as any other scientific process for determining what is right and what is wrong. On naturalist realist accounts our first-order ethics is (more or less) in the same business as every other science: getting better at predictions in a particular domain (according to LW's philosophy of science). To simplify massively: folk morality is the proto-theory for first-order ethics; moral talk is about resolving whose past predictions about rightness/wrongness were correct, and the making of new predictions. None of this is a given of course – I'm not sure naturalist realist meta-ethics is correct! But I don't see why it's obviously false.
This brings me back to my original point: it's not obvious what homo sapiens are doing when they engage in moralizing! It seems to me we still have a lot to learn! It's not at all obvious to me that our moral terms are not regulated by pretty stable patterns in our environment+behaviour and that together they don't form an attractor.
If we have a crux, I suspect it's in the above, but just in case I'll note some other, more "in the weeds" disagreements between Blackburn and Boyd. (They are substantive, for the broad reasons given above, but you might not feel what's at stake without having engaged in the surrounding theoretical debates.)
Blackburn won't identify goodness with any of the patterns mentioned earlier – arguably he can't strictly (i.e. external to the moral linguistic framework) agree we can determine the truth of any moral claims (where "truth" here comes with theoretical baggage). Ultimately, moral claims to him are just projections of our attitudes, not claims on the world, despite remaining "truth-apt." (He would reject some of this characterization, because he wants to go deflationist about truth, but then his view threatens to collapse into realism – see Taylor paper below). Accordingly, and contra Yudkowsky, he does not take "goodness" to be a two-place predicate with its predication relativized to the eye of the beholder. ("Goodness" is best formalized as an operator, and not a predicate according to Blackburn.) This allows him to refute that what's good depends on the eye of the beholder. You can go with subjectivists (moral statements are reports of attitudes, attitudes are what determine what is good/bad relative to the person with those attitudes), who point to basically the same patterns as Blackburn regarding "what is key to understanding morality," and now you don't have to do this internal external dance. But this comes with other implications: moral disagreement becomes very hard to account for (when I say "I like chocolate" and you say "I like vanilla" are we really disagreeing?), and one is committed to saying things like "what's good depends on the eye of the beholder."
I know it can sound like philosophers are trying to trap you/each other with word games and are actually just tripping on their own linguistic shoelaces. But I think it's actually just really hard to say all the things I think you want to say without contradiction (or to be a person with all the policies you want to have): that's part of what what I'm trying to point out in the previous paragraph. In the same vein, perhaps the most interesting recent development in this space has been to investigate whether views like Blackburn's don't just collapse into "full-blown" realism like that of Boyd (along with all it's implications for moral epistemology). This is the Taylor paper I sent you a few months ago (but see FN 2 below). Similarly, Egan 2007 points out how Blackburn's quasi-realism could (alternatively) collapse into subjectivism.
the actionable points of disagreement are things like "how much should we be willing to let complicated intuitions be overruled by simple intuitions?"
I suspect their disagreement is deeper than you think, but I'm not sure what you mean by this: care to clarify?
- ^
I use Carnap's internal-external distinction but IIRC, Blackburn's view isn't exactly the same since Carnap's internal-external distinction is meant to apply to all linguistic frameworks, where Blackburn seems to be trying to make a special carve out specifically for moral talk. But it's been awhile since I properly read through these papers. I'm pretty sure Blackburn draws on Carnap though.
- ^
I mention Price's theory, because his global expressivism might be the best chance anti-realists like Blackburn have for maintaining their distance from realism while retaining their right to ordinary moral talk. There is still much to investigate!
- ^
"by it's own lights" here is not spooky. We notice certain physical systems that have collections of mechanisms that each support one another in maintaining certain equilibria: each mechanism is said to have a certain function in this system. We can add to/modify mechanisms in the system in order to make it more or less resilient to shocks, more or less reliably reach and maintain those equilibria. We're "helping" the system by its lights when we make it more resilient/robust/reliable; "hindering" it when we make it less resilient/robust/reliable.
To make sure things are clear: naturalists all agree there is a process as neutral as any other scientific process for doing meta-ethics – for determining what it is homo sapiens are doing when they engage in moralizing. This is the methodological (and ultimately, metaphysical) point of agreement between e.g. Blackburn and Boyd
How come they disagree on all those apparently non-spooky questions about relevant patterns in the world? I'm curious how you reconcile these.
In science the data is always open to some degree of interpretation, but a combination of the ability to repeat experiments independent of the experimenter and the precision with which predictions can be tested tends to gradually weed out different interpretations that actually bear on real-world choices.
If long-term disagreement is maintained, my usual diagnosis would be that the thing being disagreed about does not actually connect to observation in a way amenable to science. E.g. maybe even though it seems like "which patterns are important?" is a non-spooky question, actually it's very theory-laden in a way that's only tenuously connected to predictions about data (if at all), and so when comparing theories there isn't any repeatable experiment you could just stack up until you have enough data to answer the question.
Alternately, maybe at least one of them is bad at science :P
It's not at all obvious to me that our moral terms are not regulated by pretty stable patterns in our environment+behaviour and that together they don't form an attractor.
In the strong sense that everyone's use of "morality" converges to precisely the same referent under some distribution of "normal dynamics" like interacting with the world and doing self-reflection? That sort of miracle doesn't occur for the same reason coffee and cream don't spontaneously un-mix.
But that doesn't happen even for "tiger" - it's not necessary that everyone means precisely the same thing when they talk about tigers, as long as the amount of interpersonal noise doesn't overwhelm the natural sparsity of the world that allows us to have single-world handles for general categories of things. You could still call this an attractor, it's just not a pointlike attractor - there's space for different people to use "tiger" in different ways that are stable under normal dynamics.
If that's how it is for "morality" too ("if morality is as real as tigers" being a cheeky framing), then if we could somehow map where everyone is in concept space, I expect everyone can say "Look how close together everyone gets under normal dynamics, this can be framed as a morality attractor!" But it would be a mistake to then say "Therefore the most moral point is the center, we should all go there."
the actionable points of disagreement are things like "how much should we be willing to let complicated intuitions be overruled by simple intuitions?"
I suspect their disagreement is deeper than you think, but I'm not sure what you mean by this: care to clarify?
I forget what I was thinking, sorry. Maybe the general gist was "if you strip away the supposedly-contingent disagreements like 'is there a morality attractor,'" what are the remaining fundamental disagreements about how to do moral reasoning?
How come they disagree on all those apparently non-spooky questions about relevant patterns in the world?
tl;dr: I take meta-ethics, like psychology and economics ~200 years ago, to be asking questions we don't really have the tools or know-how to answer. And even if we did, there is just a lot of work to be done (e.g. solving meta-semantics, which no doubt involves solving language acquisition. Or e.g. doing some sort of evolutionary anthropology of moral language). And there are few to do the work, with little funding.
Long answer: I take one of philosophy's key contributions to the (more empirical) sciences to be the highlighting of new or ignored questions, conceptual field clearing, the laying out of non-circular pathways in the theoretical landscape, the placing of landmarks at key choice points. But they are not typically the ones with the tools to answer those questions or make the appropriate theoretical choices informed by finer data. Basically, philosophy generates new fields and gets them to a pre-paradigmatic stage: witness e.g. Aristotle on physics, biology, economics etc.; J. S. Mill and Kant on psychology; Yudkowsky and Bostrom on AI safety; and so on. Give me enough time and I can trace just about every scientific field to its origins in what can only be described as philosophical texts. Once developed to that stage, putatively philosophical methods (conceptual analysis, reasoning by analogy, logical argument, postulation and theorizing, sporadic reference to what coarse data is available) won't get things much further – progress slows to a crawl or authors might even start going in circles until the empirical tools, methods, interest and culture are available to take things further.
(That's the simplified, 20-20 hindsight view with a mature philosophy and methodology of science in hand: for much of history, figuring out how to "take things further" was just as contested and confused as anything else, and was only furthered through what was ex ante just more philosophy. Newton was a rival of Descartes and Leibniz: his Principia was a work of philosophy in its time. Only later did we start calling it a work of physics, as pertaining to a field of its own. Likewise with Leibniz and Descartes' contributions to physics.)
Re: meta-ethics, I don't think it's going in circles yet, but do recognize the rate at which it has produced new ideas (found genuinely new choice points) has slowed down. It's still doing much work in collapsing false choice points though (and this seems healthy: it should over-generate and then cut down).
One thing it has completely failed to do is sell the project to the rest of the scientific community (hence why I write). But it's also tough sell. There are various sociological obstacles at work here:
- 20th century ethical disasters: I think after the atrocities committed in the name of science during, during the (especially early) 20th century, scientists rightly want nothing to do with anything that smells normative. In some sense, this is a philosophical success story: awareness of the naturalistic fallacy has increased substantially. The "origins and nature of morality" probably raises a lot of alarm bells for many scientists (though, yes, I'm aware there are evolutionary biologists who explore the topic. I want to see more of this). To be clear, the wariness is warranted: this subject is indeed a normative minefield. But that doesn't mean it can't be crossed and that answers can't be found. (I actually think, in the specific case of meta-ethics, part of philosophy's contribution is to clear or at least flag the normative mines – keep the first and second order claims as distinct as possible).
- Specialization: As academia has specialized, there has been less cross-departmental pollination.
- Philosophy as a dirty word: I think "hard scientists" have come to associate "philosophy" (and maybe especially "ethics") with "subjective" or something, and therefore to be avoided. Like, for many it's just negative association at this point, with little reason attached to it. (I blame Hegel – he's the reason philosophy got such a bad rap starting in the early 20th century).
- Funding: How many governments or private funding institutions in today's post-modern world do you expect prioritize "solving the origins and nature of morality" over other more immediately materially/economically useful or prestigious/constituent-pleasing research directions?
There are also methodological obstacles: the relevant data is just hard to collect; the number of confounding variables, myriad; the dimensionality of the systems involved, incredibly high! Compare, for example, with macroeconomics: natural experiments are extremely few and far between, and even then confounding variables abound; the timescales of the phenomena of interest (e.g. sustained recessions vs sustained growth periods) are very long, and as such we have very little data – there've only been a handful of such periods since record keeping began. We barely understand/can predict macro-econ any better than we did 100 years ago, and it's not for a lack of brilliance, rigor or funding.
Alternately, maybe at least one of them is bad at science :P
In the sense that I take you to be using "science" (forming a narrow hypothesis, carefully collecting pertinent data, making pretty graphs with error bars) neither of them are probably doing it well.[1] But we shouldn't really expect them to? Like, that's not what the discipline is good for.
I'd bet they liberally employ the usual theoretical desiderata (explanatory power, ontological parsimony, theoretical conservatism) to argue for their view, but they probably only make cursory reference to empirical studies. And until they are do refer to more empirical work, they won't converge on an answer (or improve our predictions, if you prefer). But, again, I don't expect them to, since I think most of the pertinent empirical work is yet to be done.
"if morality is as real as tigers" being a cheeky framing
I'm not surprised you find this cheeky, but just FYI I was dead serious: that's pretty much literally what I and many think is possibly the case.
it's not necessary that everyone means precisely the same thing when they talk about tigers, as long as the amount of interpersonal noise doesn't overwhelm the natural sparsity of the world that allows us to have single-world handles for general categories of things. You could still call this an attractor, it's just not a pointlike attractor - there's space for different people to use "tiger" in different ways that are stable under normal dynamics. [...] But it would be a mistake to then say "Therefore the most moral point is the center, we should all go there."
So this is very interesting to me, and I think I agree with you on some points here, but that you're missing others. But first I need to understand what you mean by "natural sparsity" and what your (very very rough) story is of how our words get their referents. I take it you're drawing on ML concepts and explanations, and it sounds like a story some philosophers tell, but I'm not familiar with the lingo and want to understand this better. Please tell me more. Related: would you say that we know more about water than our 1700s counterparts, or would you just say "water" today refers to something different than what it referred to in the 1700s? In which case, what is it we've gained relative to them? More accurate predictions regarding... what?
Maybe the general gist was "if you strip away the supposedly-contingent disagreements like 'is there a morality attractor,'" what are the remaining fundamental disagreements about how to do moral reasoning?
Thanks, yep, I'm not sure. Whether or not there is an attractor (and how that attraction is supposed to work) seems like the major crux – certainly in our case!
- ^
One thing I want to defend and clarify: someone the other day objected that philosophers are overly confident in their proposals, overly married to them. I think I would agree in some sense, since I think their work is often in doing pre-paradigmatic work: they often jump the gun and declare victory, take philosophizing to be enough to settle a matter. Accordingly, I need to correct the following:
Meta-ethicists are like physicists who are interested in understanding what causes the perturbations Uranus' orbit, whatever it turns out to be: they are not married to a specific planet-induced-perturbations hypothesis, dropping all interest once Vulcan was found missing.
I should have said the field as whole is not married to any particular theory. But I'm not sure having individual researchers try so hard to develop and defend particular views is so perverse. Seems pretty normal that in trying to advance theory, individual theorists heavily favor one or another theory – the one they are curious about, want to develop, make robust and take to its limit. One shouldn't necessarily look to one particular frontier physicist to form your best guess about their frontier – instead one should survey the various theories being advanced/developed in the area.
For posterity, we discussed in-person, and both (afaict) took the following to be clear predictive disagreements between the (paradigmatic) naturalist realists and anti-realists (condensed for brevity here, to the point of really being more of a mnemonic device):
Realists claim that:
- (No Special Semantics): Our use of "right" and "wrong" are picking up, respectively, on what would be appropriately called the rightness and wrongness features in the world.
- (Non-subjectivism/non-relativism): These features are largely independent of any particular homo sapiens attitudes and very stable over time.
- (Still Learning): We collectively haven't fully learned these features yet – the sparsity of the world does support and can guide further refinement of our collective usage of moral terms should we collectively wish to generalize better at identifying the presence of said features. This is the claim that leads to claims of there being a "moral attractor."
Anti-realists may or may not disagree with (1) depending on how they cash out their semantics, but they almost certainly disagree with something like (2) and (3) (at least in their meta-ethical moments).
But I'm not really accusing y'all of saying "try to produce a future that has no basis in human values." I am accusing this post of saying "there's some neutral procedure for figuring out human values, we should use that rather than a non-neutral procedure."
My read was more "do the best we can to get through the acute risk period in a way that lets humanity have the time and power to do the best it can at defining/creating a future full of value." And that's in response and opposed to positions like "figure out / decide what is best for humanity (or a procedure that can generate the answer to that) and use that to shape the long term future."
I think what you're saying here ought to be uncontroversial. You're saying that should a small group of technical people find themselves in a position of enormous influence, they ought to use that influence in an intelligent and responsible way, which may not look like immediately shirking that responsibility out of a sense that nobody should ever exert influence over the future.
I have the sense that in most societies over most of time, it was accepted that of course various small groups would at certain time find themselves in positions of enormous influence w.r.t. their society, and of course their responsibility in such a situation would be to not shirk that responsibility but to wisely and unilaterally choose a direction forward for their society, as required by the situation at hand.
In an ideal world, there would be some healthy and competent worldwide collaboration steering the transition to AGI
I have the sense that what would be ideal is for humanity to proceed with wisdom. The wisest moves we've made as a species to date (ending slavery? ending smallpox? landing on the moon?) didn't particularly look like "worldwide collaborations". Why, actually, do you say that the ideal would be a worldwide collaboration?
Third, though, I agree that it’s morally imperative that a small subset of humanity not directly decide how the future goes
Why should a small subset of humanity not directly decide how the future goes? The goal ought to be good decision-making, not large- or small-group decision making, and definitely not non-decision-making.
Of course the future should not be a tightly scripted screenplay of contemporary moral norms, but to decide that is to decide something about how the future goes. It's not wrong to make such decisions, it's just important to get such decisions right.
The wisest moves we've made as a species to date (ending slavery? ending smallpox? landing on the moon?) didn't particularly look like "worldwide collaborations".
I think Nate might've been thinking of things like:
- Having all AGI research occur in one place is good (ceteris paribus), because then the AGI project can take as much time as it needs to figure out alignment, without worrying that some competitor will destroy the world with AGI if they go too slowly.
- This is even truer if the global coordination is strong enough to prevent other x-risks (e.g., bio-weapons), so we don't have to move faster to avoid those either.
- In a perfect world, everyone would get some say in major decisions that affect their personal safety (e.g., via elected Scientist Representatives). This helps align incentives, relative to a world where anyone can unilaterally impose serious risks on others.
- In a perfect world, larger collaborations shouldn't perform worse than smaller ones, because larger collaborations should understand the dysfunctions of large collaborations and have policies and systems in place to avoid them (e.g., by automatically shrinking or siloing if needed).
I interpret Nate as making a concession to acknowledge the true and good aspects of the 'but isn't there something off about a random corporation or government doing all this?' perspective, not as recommending that we (in real life) try to have the UN build AGI or whatever.
I think your pushback is good here, as a reminder that 'but isn't there something off about a random corporation or government doing all this?' also often has less-reasonable intuitions going into it (example), and gets a weird level of emphasis considering how much more important other factors are, considering the track record of giant international collaborations, etc.
Why should a small subset of humanity not directly decide how the future goes? [...] Of course the future should not be a tightly scripted screenplay of contemporary moral norms, but to decide that is to decide something about how the future goes, and it's not wrong to make such decisions, it's just important to get such decisions right.
I'm guessing you two basically agree, and the "directly" in "a small subset of humanity not directly decide" is meant to exclude a "tightly scripted screenplay of contemporary moral norms"?
Nate also has the substantive belief that CEV-ish approaches are good, and (if he agrees with the Arbital page) that the base for CEV should be all humans. (The argument for this on Arbital is a combination of "it's in the class of approaches that seem likeliest to work", and "it seems easier to coordinate around, compared to the other approaches in that class". E.g., I'd say that "run CEV on every human whose name starts with a vowel" is likely to produce the ~same outcome as "run CEV on every human", but the latter is a better Schelling point.)
I imagine if Nate thought the best method for "not tightly scripting the future" were less "CEV based on all humans" and more "CEV based on the 1% smartest humans", he'd care more about distinctions like the one you're pointing at. It's indeed the case that we shouldn't toss away most of the future's value just for the sake of performative egalitarianism: we should do the thing that actually makes sense.
Yeah I also have the sense that we mostly agree here.
I have the sense that CEV stands for, very roughly, "what such-and-such a person would do if they became extremely wise", and the hope (which I think is a reasonable hope) is that there is a direction called "wisdom" such that if you move a person far enough in that direction then they become both intelligent and benevolent, and that this eventually doesn't depend super much on where you started.
The tricky part is that we are in this time where we have the option of making some moves that might be quite disruptive, and we don't yet have direct access to the wisdom that we would ideally use to guide our most significant decisions.
And the key question is really: what do you do if you come into a position of really significant influence, at a time when you don't yet have the tools to access the CEV-level wisdom that you might later get? And some people say it's flat-out antisocial to even contemplate taking any disruptive actions, while others say that given the particular configuration of the world right now and the particular problems we face, it actually seems plausible that a person in such a position of influence ought to seriously consider disruptive actions.
I really agree with the latter, and I also contend that it's the more epistemically humble position, because you're not saying that it's for sure that a pivotal act should be performed, but just that it's quite plausible given the specifics of the current world situation. The other side of the argument seems to be saying that no no no it's definitely better not to do anything like that in anything like the current world situation.
I also contend that it's the more epistemically humble position, because you're not saying that it's for sure that a pivotal act should be performed, but just that it's quite plausible given the specifics of the current world situation
The thing I'd say in favor of this position is that I think it better fits the evidence. I think the problem with the opposing view is that it's wrong, not that it's more confident. E.g., if I learned that Nate assigns probability .9 to "a pivotal act is necessary" (for some operationalization of "necessary") while Critch assigns probability .2 to "a pivotal act is necessary", I wouldn't go "ah, Critch is being more reasonable, since his probability is closer to .5".
I agree with the rest of what you said, and I think this is a good way of framing the issue.
I'd add that I think discussion of this topic gets somewhat distorted by the fact that many people naturally track social consensus, and try to say the words they think will have the best influence on this consensus, rather than blurting out their relevant beliefs.
Many people are looking for a signal that stuff like this is OK to say in polite society, or many others are staking out a position "the case for this makes sense intellectually but there's no way it will ever attract enough support, so I'll preemptively oppose it in order to make my other arguments more politically acceptable". (The latter, unfortunately, being a strategy that can serve as a self-fulfilling prophecy.)
Well the photos taken from the moon did seem to help a lot of people understand how vast and inhospitable the cosmos are, how small and fragile the Earth is, and how powerful -- for better or worse -- we humans had by that point become.
If you can't see why a single modern society locking in their current values would be a tragedy of enormous proportions, imagine an ancient civilization such as the Romans locking in their specific morals 2000 years ago. Moral progress is real, and important.
That wouldn't be a tragedy if I were a Roman.
"This has all been a conspiracy to revive the Roman Republic/Empire and establish Rome Eternal" will go over better with 90% of the men in the world than whatever other morals OpenAI/Anthropic/etc employees try to impose.
Can you elaborate? Why would locking in Roman values not be a great success for a Roman who holds those values?
Roman values aren't stable under reflection; the CEV of Rome doesn't have the same values as ancient Rome. It's like a 5-year-old locking in what they want to be when they grow up.
Locking in extrapolated Roman values sounds great to me because I don't expect that to be significantly different than a broader extrapolation. Of course, this is all extremely handwavy and there are convergence issues of superhuman difficulty! :)
Roman values aren't stable under reflection; the CEV of Rome doesn't have the same values as ancient Rome.
I'm not exactly sure what you're saying here, but if you're saying that the fact of modern Roman values being different than Ancient Roman values shows that Ancient Roman values aren't stable under reflection, then I totally disagree. History playing out is a not-at-all similar process to an individual person reflecting on their values, so the fact that Roman values changed as history played out from Ancient Rome to modern Rome does not imply that an individual Ancient Roman's values are not stable under reflection.
As an example, Country A conquering Country B could lead the descendants of Country B's population to have the values of Country A 100 years hence, but this information has nothing to do with whether a pre-conquest Country B citizen would come to have Country A's values on reflection.
Locking in extrapolated Roman values sounds great to me because I don't expect that to be significantly different than a broader extrapolation.
I guess I just have very different intuitions from you on this. I expect expect people from different historical time periods and cultures to have quite different extrapolated values. I think the concept that all peoples throughout history would come into near agreement about what is good if they just reflected on it long enough is unrealistic.
(unless, of course, we snuck a bit of motivated reasoning into the design of our Value Extrapolator so that it just happens to always output values similar to our 21st century Western liberal values...)
I think the concept that all peoples throughout history would come into near agreement about what is good if they just reflected on it long enough is unrealistic.
Yes. Exactly. You don't even need to go through time, place and culture on modern-day Earth are sufficient. While I cannot know my CEV (for if I knew, I would be there already), I predict with high confidence that my CEV, my wife's CEV, Biden's CEV and Putin's CEV are four quite different CEVs, even if they all include as a consequence "the planet existing as long as the CEV's bearer and the beings the CEV's bearer cares about are on it".
my CEV, my wife's CEV, Biden's CEV and Putin's CEV are four quite different CEVs
It really depends on the extrapolation process - which features of your minds are used as input, and what the extrapolation algorithm does with them.
To begin with, there is a level of abstraction at which the minds of all four of you are the same, yet different from various nonhuman minds. If the extrapolation algorithm is "identify the standard cognitive architecture of this entity's species, and build a utopia for that kind of mind", then all the details which make you, your wife, and the two presidents different from each other, play no role in the process. On the other hand, if the extrapolation algorithm is "identify the current values of this specific mind, and build it a utopia", probably you get different futures.
The original CEV proposal is intended more in the spirit of the first option - what gets extrapolated is not the contingencies of any particular human mind, but the cognitive universals that most humans share. Furthermore, the extrapolation algorithm itself is supposed to be derived from something cognitively universal to humans.
That's why Eliezer sometimes used the physics metaphor of renormalization. One starts with the hypothesis that there some kind of universal human decision procedure (or decision template that gets filled out differently in different individuals), arising from our genes (and perhaps also from environment including enculturation). That is the actual "algorithm" that determines individual human choices.
Then, that algorithm having been extracted via AI (in principle it could be figured out by human neuroscientists working without AI, but it's a bit late for that now), the algorithm is then improved according to criteria that come from some part of the algorithm itself. That's the "renormalization" part: normative self-modification of the abstracted essence of the human decision procedure. The essence of human decision procedure, improved e.g. by application of its own metaethical criteria.
What I just described is the improvement of an individual human mind-template. On the other hand, CEV is supposed to provide the decision theory of a human-friendly AI, which will pertain more to a notion of common good, presumably aggregating individual needs and desires in some way. But again, it would be a notion of common good that arises from a "renormalized" standard-human concept of common good.
The way I've just explained "the original CEV proposal" is, to be sure, something of my own interpretation. I've provided a few details which aren't in the original texts. But I believe I have preserved the basic ideas. For some reason, they were never developed very much. Maybe MIRI deemed it dangerous to discuss publicly - too close to the core of what alignment needs to get right - so it was safer to focus publicly on other aspects of the problem, like logical induction. (That is just my speculation, by the way. I have no evidence of that at all.) Maybe it was just too hard, with too many unknowns about how the human decision procedure actually works. Maybe, once the deep learning revolution was underway, the challenges of simpler kinds of alignment, and the Christiano paradigm that ended up being used at OpenAI, absorbed everyone's attention; and the CEV ideal, of alignment sufficient to be the seed of a humane transhuman civilization, was put to one side. Or maybe I have just overlooked papers that do develop CEV? There are still a few people trying to figure out everything from first principles, rather than engaging in the iterative test-and-finetune approach that currently prevails.
Independently,
(in principle it could be figured out by human neuroscientists working without AI, but it's a bit late for that now)
What? Why? There is no AI as of now, LLMs definitely do not count. I think it is still quite possible that neuroscience will make its breakthrough on its own, without any non-human mind help (again, dressing up the final article doesn't count, we're talking about the general insights and analysis here).
To begin with, there is a level of abstraction at which the minds of all four of you are the same, yet different from various nonhuman minds.
I am actually not even sure about that. Your "identify the standard cognitive architecture of this entity's species" presupposes existence thereof - in a sufficiently specified way to then build its utopia and to derive that identification correctly in all four cases.
But, more importantly, I would say that this algorithm does not derive my CEV in any useful sense.
The point is that as moral attitudes/thoughts change, societies or individuals which exist long enough will likely come to regret permanently structuring the world according to the morality of a past age. The Roman will either live to regret it, or the society that follows the Roman will come to regret it even if the Roman dies happy, or the AI is brainwashing everyone all the time to prevent moral progress. The analogy breaks down a bit with the third option since I'd guess most people today would not accept it as a success and it's today's(ish) morals that might get locked in, not ancient Rome's.
But the way to cause the future to be great “on its own terms” isn’t to do nothing and let the world get destroyed. It’s to intentionally not leave your fingerprints on the future, while acting to protect it.
Everything a person does puts their fingerprints on the future. Our present is made of the fingerprints of the past. Most people leave only small fingerprints, soon smoothed out by the tide of time, yet like sedimentary rock, they accumulate into a great mass. Some have spent their lives putting the biggest fingerprints they can on the future, for good or ill, fingerprints that become written of in history books. Indeed, history is the documenting of those fingerprints.
So there is no question of leaving no fingerprints, no trace of ourselves, no question of directing us towards a future that is good "on its own terms". We can only seek to leave good fingerprints rather than bad ones, and it is we — for some value of "we" — who must make those judgements. Moral progress means moral change in a desirable direction. Who can it be who desires it, but us?
I think there's something confusing that soares has done by naming this post "don't leave your fingerprints on the future", and I think for clarity to both humans and ais who read this later, the post should ideally be renamed "don't over-mark the future of other souls without consent" or something along those lines; the key message should be all life @ all life, or something.
Preliminary:
To avoid misunderstanding, the kinds of "Pivotal Acts" you are talking about involve using an AGI to seize absolute power on a global scale. The "smallest" pivotal act given by Yudkowsky would still be considered an Act of War by any country affected.
The above is obvious to anyone who reads this forum but it's worth emphasizing the magnitude of what is being discussed.
I understand your argument to be as follows:
A. A small group of humans gaining absolute control over the lightcone is bad (but better than a lot of other options).
B. But because it's better than the other options, there is a moral imperative to commit a "pivotal act" if given the opportunity.
C. It is morally correct that this group then give up their power and safely hand it back to humanity.
I have two strongly held objections:
- While A and C are correct, B overlooks the political and moral landscape we live in.
- This post itself will influence researchers who admire you in a way that is harmful.
This argument overlooks the political and moral landscape we live in.
The political landscape:
Most (all?) groups of humans that have seized power and stated paternalistic intentions toward the subjugated people have abused that power in horrific ways. Everyone claims they're trying to help the world and most humans genuinely believe it. We're fantastic at spinning narratives that we're the good guys. Nobody will trust your claim that you will give up power nor should they.
If any domestic agency was to take understand your intentions and believe you realistically had the capacity to carry them out you would be (at best) detained. Realistically, if a rogue group of researchers were close to completing an AGI with the goal of using it to take over to world, then nuclear weapons would be warranted.
There is also going to be a strong incentive to seize or steal the technology during development. The hardware required for the "good guys" to perform a pivotal act will be dual use. The "bad guys" can also use it to perform a pivotal act.
The ideal team of fantastic, highly moral scientists probably won't be the ones who make the final decisions about what the future looks like.
The moral landscape:
In the worlds where we have access to the global utility function, then seizing power to improve the world makes objective sense. In the world we actually live in, if you find yourself wanting to seize power to improve the world, there's a good chance you're closer to a mad scientist (though a well intentioned one).
I don't know of any human (or group of humans) on the planet I would trust to actually give up absolute power.
This post itself will influence researchers who admire you in a way that is harmful.
This post serves to spread the idea that a unilateral pivotal act is inevitably the only realistic way to save humanity. But by writing this post, you're driving up closer to that world by discouraging people from looking into alternatives.
I'm an engineer but a newcomer to the field of AI safety, and the facet of it where the best plan that anyone has to save the world is to take over the world has been the biggest culture shock. I mean, I'll take it over being atomized by nanobots.
Humanity is in this strange place where all of our accumulated intuition is suddenly useless. From the outside, Facebook AI seem like the sanest people in the game, with Zuck being the only AI leader who said "the others think we're building digital God, and that's just not what's happening." To rank-and-file engineers out there not immersed into AI safety, this feels like a breath of fresh air in a field that otherwise seems to be regressing into some sort of tech bro mysticism. Post-paradigmatically, Facebook AI are the greatest villains who're most likely to destroy the world with their lack of caution.
It's a lot of whiplash to experience, both for individuals and for humanity as a whole, assuming the majority ever get a chance to experience it.
(If you can't see why a single modern society locking in their current values would be a tragedy of enormous proportions, imagine an ancient civilization such as the Romans locking in their specific morals 2000 years ago. Moral progress is real, and important.)
This really doesn't prove anything. That measurement shouldn't be taken by our values, but by the values of the ancient romans.
Sure of course the morality of the past gets better and better. It's taking a random walk closer and closer to our morality. Now moral progress might be real.
The place to look is inside our own value functions, if after 1000 years of careful philosophical debate, humanity decided it was a great idea to eat babies, would you say, "well if you have done all that thinking, clearly you are wiser than me". Or would you say "Arghh, no. Clearly something has broken in your philosophical debate"? That is a part of your own meta value function, the external world can't tell you what to think here (unless you have a meta meta value function. But then you have to choose that for yourself)
It doesn't help that human values seem to be inarticulate half formed intuitions, and the things we call our values are often instrumental goals.
If, had ASI not been created, humans would have gone extinct to bioweapons, and pandas would have evolved intelligence, it the extinction of humans and the rise of panda-centric morality just part of moral progress?
If aliens arrive, and offer to share their best philosophy with us, is the alien influence part of moral progress, or an external fact to be removed?
If advertisers basically learn to brainwash people to sell more product, is that part of moral progress?
Suppose, had you not made the AI, that Joe Bloggs would have made an AI 10 years later. Joe Bloggs would actually have succeeded at alignment. And would have imposed his personal whims on all humanity forever. If you are trying not to unduely influence the future, do you make everyone beholden to the whims of Joe, as they would be without your influence.
My personal CEV cares about fairness, human potential, moral progress, and humanity’s ability to choose its own future, rather than having a future imposed on them by a dictator. I'd guess that the difference between "we run CEV on Nate personally" and "we run CEV on humanity writ large" is nothing (e.g., because Nate-CEV decides to run humanity's CEV), and if it's not nothing then it's probably minor.
Wait. The whole point of the CEV is to get the AI to extrapolate what you would want if you were smarter and more informed. That is, the delta from your existing goals to your CEV should be unknowable to you, because if you know your destination you are already there. This sounds like your object level values. And they sound good, as judged by your (and my) object level values.
I mean there is a sense in which I agree that locking in say your favourite political party, or a particular view on abortion, is stupid. Well I am not sure that particular view on abortion would be actually bad, it would probably have near no effect in a society of posthuman digital minds. These are things that are fairly clearly instrumental. If I learned that after careful philosophical consideration, and analysis of lots of developmental neurology data, people decided abortion was really bad, I would take that seriously. They have probably realized a moral truth I do not know.
I think I have a current idea of what is right, with uncertainty bars. When philosophers come to an unexpected conclusion, it is some evidence that the conclusion is right, and also some evidence the philosopher has gone mad.
In thinking about what alignment should be aiming towards, the phrase I've been coming back to a lot recently is "sustainable cooperative harmony".
"Sustainable" because an aligned future shouldn't exploit all resources until collapse. "Cooperative" because an aligned future should be about solving coordination problems, steering the goals of every subsystem into alignment with those of every other subsystem. "Harmony" because an aligned future should be beautiful, like the trillions of cells working in concert to create a unified organism, or like the hundreds of diverse instruments playing diverse notes in a unified symphony.
Harmony in particular is key here. In music, the principles of harmony are not about following pre-defined paths for building a musical piece, as though this chord should always follow that chord or this note should always pair with that note. There is no fixed formula for creating good harmony. Instead, creating harmony is really about avoiding disharmony. Certain notes will sound discordant when played together, so as long as you avoid that, the symphony can theoretically have as much going on at once as you would like. (Melody is similar, except that it is harmony stretched across time in sequence rather than in parallel.)
Similarly, harmony at the level of future civilization should be about avoiding conflicts, not forcing everyone into lockstep with a certain ideal. Maximizing diversity of thought, behavior, values, and goals while still preventing the butting of heads. Basically the libertarian ideal of "your right to swing your fist ends at my face", except more generalized.
There are innumerably many right ways to create Eutopia, but there are vastly more ways to create dystopia. Harmonization/alignment is about finding the thin manifold in civilization-space where disharmony/conflict/death/suffering is minimized. The key insight here, though, is that it is a manifold, not a single-point target. Either way, though, there is almost no way that human minds could find our way there on our own.
If we could build an AGI that is structurally oriented around creating sustainable cooperative harmony in any system it's involved in (whether repairing a human body, creating prosocial policies for human civilization, or improving the ecological structure of the biosphere), then we would have a shot at creating a future that's capable of evolving into something far beyond what we could design ourselves.
I’d say: Imagine that some small group of people were given the power (and thus responsibility) to steer the future in some big way. And ask what they should do with it. Ask how they possibly could wield that power in a way that wouldn’t be deeply tragic, and that would realistically work (in the way that “immediately lock in every aspect of the future via a binding humanity-wide popular vote” would not).
Isn't the problem that groups and individuals differ as to what they view as 'deeply tragic'?
This seems circular.
[only sort of on-topic] I'm concerned about coercion within CEV. Seems like to compute CEV, you're in some sense asking for human agency to develop further, whether within a simulation or hypothetical reasoning / extrapolation by an AI, or in meatspace. But what a human is, seems to require interacting with other humans. And if you have lots of humans interacting, by default many of them will in some contexts be in some sense coercive; e.g. making threats to extort things from each other, and in particular people might push other people to cut off their own agency within CEV (or might have done that beforehand).
Then that isn't the CEV operation.
The CEV operation tries to return a fixed point of idealized value-reflection. Running immortal people forward inside of a simulated world is very much insufficiently idealized value-reflection, for the reasons you suggest, so simply simulating people interacting for a long time isn't running their CEV.
How would you run their CEV? I'm saying it's not obvious how to do it in a way that both captures their actual volition, while avoiding coercion. You're saying "idealized reflection", but what does that mean?
Yeah, fair -- I dunno. I do know that an incremental improvement on simulating a bunch of people in an environment philosophizing is doing that but running an algorithm that prevents coercion, e.g.
I imagine that the complete theory of these incremental improvements (for example, also not running a bunch of moral patients for many subjective years while computing the CEV), is the final theory we're after, but I don't have it.
an algorithm that prevents coercion
Like, encoding what "coercion" is would be an expression of values. It's more meta, and more universalizable, and stuff, but it's still something that someone might strongly object to, and so it's coercion in some sense. We could try to talk about what possible reflectively stable people / societies would consider as good rules for the initial reflection process, but it seems like there would be multiple fixed points, and probably some people today would have revealed preferences that distinguish those possible fixed points of reflection, still leaving open conflict.
Cf. https://www.lesswrong.com/posts/CzufrvBoawNx9BbBA/how-to-prevent-authoritarian-revolts?commentId=3LcHA6rtfjPEQne4N
Sometimes, I say some variant of “yeah, probably some people will need to do a pivotal act” and people raise the objection: “Should a small subset of humanity really get so much control over the fate of the future?”
(Sometimes, I hear the same objection to the idea of trying to build aligned AGI at all.)
I’d first like to say that, yes, it would be great if society had the ball on this. In an ideal world, there would be some healthy and competent worldwide collaboration steering the transition to AGI.[1]
Since we don’t have that, it falls to whoever happens to find themselves at ground zero to prevent an existential catastrophe.
A second thing I want to say is that design-by-committee… would not exactly go well in practice, judging by how well committee-driven institutions function today.
Third, though, I agree that it’s morally imperative that a small subset of humanity not directly decide how the future goes. So if we are in the situation where a small subset of humanity will be forced at some future date to flip the gameboard — as I believe we are, if we’re to survive the AGI transition — then AGI developers need to think about how to do that without unduly determining the shape of the future.
The goal should be to cause the future to be great on its own terms, without locking in the particular moral opinions of humanity today — and without locking in the moral opinions of any subset of humans, whether that’s a corporation, a government, or a nation.
(If you can't see why a single modern society locking in their current values would be a tragedy of enormous proportions, imagine an ancient civilization such as the Romans locking in their specific morals 2000 years ago. Moral progress is real, and important.)
But the way to cause the future to be great “on its own terms” isn’t to do nothing and let the world get destroyed. It’s to intentionally not leave your fingerprints on the future, while acting to protect it.
You have to stabilize the landscape / make it so that we’re not all about to destroy ourselves with AGI tech; and then you have to somehow pass the question of how to shape the universe back to some healthy process that allows for moral growth and civilizational maturation and so on, without locking in any of humanity’s current screw-ups for all eternity.
Unfortunately, the current frontier for alignment research is “can we figure out how to point AGI at anything?”. By far the most likely outcome is that we screw up alignment and destroy ourselves.
If we do solve alignment and survive this great transition, then I feel pretty good about our prospects for figuring out a good process to hand the future to. Some reasons for that:
This is a set of researchers that generally takes egalitarianism, non-nationalism, concern for future minds, non-carbon-chauvinism, and moral humility for granted, as obvious points of background agreement; the debates are held at a higher level than that.
This is a set of researchers that regularly talk about how, if you’re doing your job correctly, then it shouldn’t matter who does the job, because there should be a path-independent attractor-well that isn't about making one person dictator-for-life or tiling a particular flag across the universe forever.
I’m deliberately not talking about slightly-more-contentful plans like coherent extrapolated volition here, because in my experience a decent number of people have a hard time parsing the indirect buck-passing plans as something more interesting than just another competing political opinion about how the future should go. (“It was already blues vs. reds vs. oranges, and now you’re adding a fourth faction which I suppose is some weird technologist green.”)
I’d say: Imagine that some small group of people were given the power (and thus responsibility) to steer the future in some big way. And ask what they should do with it. Ask how they possibly could wield that power in a way that wouldn’t be deeply tragic, and that would realistically work (in the way that “immediately lock in every aspect of the future via a binding humanity-wide popular vote” would not).
I expect that the best attempts to carry out this exercise will involve re-inventing some ideas that Bostrom and Yudkowsky invented decades ago. Regardless, though, I think the future will go better if a lot more conversations occur in which people take a serious stab at answering that question.
The situation humanity finds itself in (on my model) poses an enormous moral hazard.
But I don’t conclude from this “nobody should do anything”, because then the world ends ignominiously. And I don’t conclude from this “so let’s optimize the future to be exactly what Nate personally wants”, because I’m not a supervillain.[2]
The existence of the moral hazard doesn’t have to mean that you throw up your hands, or imagine your way into a world where the hazard doesn’t exist. You can instead try to come up with a plan that directly addresses the moral hazard — try to solve the indirect and abstract problem of “defuse the moral hazard by passing the buck to the right decision process / meta-decision-process”, rather than trying to directly determine what the long-term future ought to look like.
Rather than just giving up in the face of difficulty, researchers have the ability to see the moral hazard with their own eyes and ensure that civilization gets to mature anyway, despite the unfortunate fact that humanity, in its youth, had to steer past a hazard like this at all.
Crippling our progress in its infancy is a completely unforced error. Some of the implementation details may be tricky, but much of the problem can be solved simply by choosing not to rush a solution once the acute existential risk period is over, and by choosing to end the acute existential risk period (and its associated time pressure) before making any lasting decisions about the future.[3]
(Context: I wrote this with significant editing help from Rob Bensinger. It’s an argument I’ve found myself making a lot in recent conversations.)
Note that I endorse work on more realistic efforts to improve coordination and make the world’s response to AGI more sane. “Have all potentially-AGI-relevant work occur under a unified global project” isn’t attainable, but more modest coordination efforts may well succeed.
And I’m not stupid enough to lock in present-day values at the expense of moral progress, or stupid enough to toss coordination out the window in the middle of a catastrophic emergency with human existence at stake, etc.
My personal CEV cares about fairness, human potential, moral progress, and humanity’s ability to choose its own future, rather than having a future imposed on them by a dictator. I'd guess that the difference between "we run CEV on Nate personally" and "we run CEV on humanity writ large" is nothing (e.g., because Nate-CEV decides to run humanity's CEV), and if it's not nothing then it's probably minor.
See also Toby Ord’s The Precipice, and its discussion of “the long reflection”. (Though, to be clear, a short reflection is better than a long reflection, if a short reflection suffices. The point is not to delay for its own sake, and the amount of sidereal time required may be quite short if a lot of the cognitive work is being done by uploaded humans and/or aligned AI systems.)