New Comment
A bunch of this was frustrating to read because it seemed like Paul was yelling "we should model continuous changes!" and Eliezer was yelling "we should model discrete events!" and these were treated as counter-arguments to each other.
It seems obvious from having read about dynamical systems that continuous models still have discrete phase changes. E.g. consider boiling water. As you put in energy the temperature increases until it gets to the boiling point, at which point more energy put in doesn't increase the temperature further (for a while), it converts more of the water to steam; after all the water is converted to steam, more energy put in increases the temperature further.
So there are discrete transitions from (a) energy put in increases water temperature to (b) energy put in converts water to steam to (c) energy put in increases steam temperature.
In the case of AI improving AI vs. humans improving AI, a simple model to make would be one where AI quality is modeled as a variable, , with the following dynamical equation:
where is the speed at which humans improve AI and is a recursive self-improvement efficiency factor. The curve transitions from a line at ea...
I don’t really feel like anything you are saying undermines my position here, or defends the part of Eliezer’s picture I’m objecting to.
(ETA: but I agree with you that it's the right kind of model to be talking about and is good to bring up explicitly in discussion. I think my failure to do so is mostly a failure of communication.)
I usually think about models that show the same kind of phase transition you discuss, though usually significantly more sophisticated models and moving from exponential to hyperbolic growth (you only get an exponential in your model because of the specific and somewhat implausible functional form for technology in your equation).
With humans alone I expect efficiency to double roughly every year based on the empirical returns curves, though it depends a lot on the trajectory of investment over the coming years. I've spent a long time thinking and talking with people about these issues.
At the point when the work is largely done by AI, I expect progress to be maybe 2x faster, so doubling every 6 months. And them from there I expect a roughly hyperbolic trajectory over successive doublings.
If takeoff is fast I still expect it to most likely be through a similar situation, where e.g. total human investment in AI R&D never grows above 1% and so at the time when takeoff occurs the AI companies are still only 1% of the economy.
3
Excuse my ignorance, what does a hyperbolic function look like? If an exponential is f(x) = r^x, what is f(x) for a hyperbolic function?
8
1/(singularity_year–current_year). It's the solution to the differential equation f′(x)=f(x)2 instead of f′(x)=f(x). I usually use it more broadly for 1/(singularity_year–current_year)α, which is the solution to f′(x)=f(x)1+1/α
6
Why do you use this form? Do you lean more on:
1. Historical trends that look hyperbolic;
2. Specific dynamical models like: let α be the synergy between "different innovations" as they're producing more innovations; this gives f'(x) = f(x)^(1+α) *; or another such model?;
3. Something else?
I wonder if there's a Paul-Eliezer crux here about plausible functional forms. For example, if Eliezer thinks that there's very likely also a tech tree of innovations that change the synergy factor α, we get something like e.g. (a lower bound of) f'(x) = f(x)^f(x). IDK if there's any help from specific forms; just that, it's plausible that there's forms that are (1) pretty simple, pretty straightforward lower bounds from simple (not necessarily high confidence) considerations of the dynamics of intelligence, and (2) look pretty similar to hyperbolic growth, until they don't, and the transition happens quickly. Though maybe, if Eliezer thinks any of this and also thinks that these superhyperbolic synergy dynamics are already going on, and we instead use a stochastic differential equation, there should be something more to say about variance or something pre-End-times.
*ETA: for example, if every innovation combines with every other existing innovation to give one unit of progress per time, we get the hyperbolic f'(x) = f(x)^2; if innovations each give one progress per time but don't combine, we get the exponential f'(x) = f(x).
9
I think there are two easy ways to get hyperbolic growth:
* As long as there is free energy in the environment, without any technological change you can grow like f′(x)=f(x). Then if there is any technological progress that can be driven by your expanding physical civilization, then you get f′(x)=f(x)1+α, where α depends on how fast the returns to technology diminish.
* Even without physical growth, if you have sufficiently good returns to technology (as we observe for historical technologies, if you treat doubling food as doubling output, or for modern information technology) then you end up with a similar functional form.
That would feel more like "plausible guess" if we didn't have any historical data, but given that historical growth has in fact accelerated a huge amount it seems like a solid best guess to me. There's been a bunch of debate about whether the historical data implies something kind of like this kind of functional form, or merely implies some kind of dramatic acceleration and is consistent with this functional form. But either way, it seems like the good bet is further dramatic acceleration if we either start returning energy capture to output (via AI) or start getting overall technological progress that is similar to existing rates of progress in computer hardware and software (via AI).
4
Nitpick: Isn't 1/xα the solution for f′(x)=f(x)1+1α modulo constants? Or equivalently, 1x1α is the solution to f′(x)=f(x)1+α.
5
Yep, will fix.
8
-r/x
3
Finally a definitely of The Singularity that actually involves a mathematical singularity! Thank you.
(I'm interested in which of my claims seem to dismiss or not adequately account for the possibility that continuous systems have phase changes.)
This section seemed like an instance of you and Eliezer talking past each other in a way that wasn't locating a mathematical model containing the features you both believed were important (e.g. things could go "whoosh" while still being continuous):
[Christiano][13:46]
Even if we just assume that your AI needs to go off in the corner and not interact with humans, there’s still a question of why the self-contained AI civilization is making ~0 progress and then all of a sudden very rapid progress
[Yudkowsky][13:46]
unfortunately a lot of what you are saying, from my perspective, has the flavor of, “but can’t you tell me about your predictions earlier on of the impact on global warming at the Homo erectus level”
you have stories about why this is like totally not a fair comparison
I do not share these stories
[Christiano][13:46]
I don’t understand either your objection nor the reductio
like, here’s how I think it works: AI systems improve gradually, including on metrics like “How long does it take them to do task X?” or “How high-quality is their output on task X?”
[Yudkowsky][13:47]
I feel like the thing we know is something like, there is a sufficiently high level where things go whooosh humans-from-hominids style
[Christiano][13:47]
We can measure the performance of AI on tasks like “Make further AI progress, without human input”
Any way I can slice the analogy, it looks like AI will get continuously better at that task
My claim is that the timescale of AI self-improvement, at the point it takes over from humans, is the same as the previous timescale of human-driven AI improvement. If it was a lot faster, you would have seen a takeover earlier instead.
This claim is true in your model. It also seems true to me about hominids, that is I think that cultural evolution took over roughly when its timescale was comparable to the timescale for biological improvements, though Eliezer disagrees
I thought Eliezer's comment "there is a sufficiently high level where things go whooosh humans-from-hominids style" was missing the point. I think it might have been good to offer some quantitative models at that point though I haven't had much luck with that.
I can totally grant there are possible models for why the AI moves quickly from "much slower than humans" to "much faster than humans," but I wanted to get some model from Eliezer to see what he had in mind.
(I find fast takeoff from various frictions more plausible, so that the question mostly becomes one about how close we are to various kinds of efficient frontiers, and where we respectively predict civilization to be adequate/inadequate or progress to be predictable/jumpy.)
It seems to me that Eliezer's model of AGI is bit like an engine, where if any important part is missing, the entire engine doesn't move. You can move a broken steam locomotive as fast as you can push it, maybe 1km/h. The moment you insert the missing part, the steam locomotive accelerates up to 100km/h. Paul is asking "when does the locomotive move at 20km/h" and Eliezer says "when the locomotive is already at full steam and accelerating to 100km/h." There's no point where the locomotive is moving at 20km/h and not accelerating, because humans can't push it that fast, and once the engine is working, it's already accelerating to a much faster speed.
In Paul's model, there IS such a thing as 95% AGI, and it's 80% or 20% or 2% as powerful on some metric we can measure, whereas in Eliezer's model there's no such thing as 95% AGI. The 95% AGI is like a steam engine that's missing it's pistons, or some critical valve, and so it doesn't provide any motive power at all. It can move as fast as humans can push it, but it doesn't provide any power of it's own.
And then Paul's response to Eliezer is like "but engines don't just appear without precedent, there's worse partial versions of them beforehand, much more so if people are actually trying to do locomotion; so even if knocking out a piece of the AI that FOOMs would make it FOOM much slower, that doesn't tell us much about the lead-up to FOOM, and doesn't tell us that the design considerations that go into the FOOMer are particularly discontinuous with previously explored design considerations"?
Right, and history sides with Paul. The earliest steam engines were missing key insights and so operated slowly, used their energy very inefficiently, and were limited in what they could do. The first steam engines were used as pumps, and it took a while before they were powerful enough to even move their own weight (locomotion). Each progressive invention, from Savery to Newcomen to Watt dramatically improved the efficiency of the engine, and over time engines could do more and more things, from pumping to locomotion to machining to flight. It wasn't just one sudden innovation and now we have an engine that can do all the things including even lifting itself against the pull of Earth's gravity. It took time, and progress on smooth metrics, before we had extremely powerful and useful engines that powered the industrial revolution. That's why the industrial revolution(s) took hundreds of years. It wasn't one sudden insight that made it all click.
To which my Eliezer-model's response is "Indeed, we should expect that the first AGI systems will be pathetic in relative terms, comparing them to later AGI systems. But the impact of the first AGI systems in absolute terms is dependent on computer-science facts, just as the impact of the first nuclear bombs was dependent on facts of nuclear physics. Nuclear bombs have improved enormously since Trinity and Little Boy, but there is no law of nature requiring all prototypes to have approximately the same real-world impact, independent of what the thing is a prototype of."
1
My main concern is that progress on the frontier tends to be bursty.
There are many metrics of AI performance on particular tasks where performance does indeed increase fairly continuously on the larger scale, but not in detail. Over the scale of many years it goes from abysmal to terrible to merely bad to nearly human to worse than human in some ways but better than human in others, and then to superhuman. Each of these transitions is often a sharp jump, but you see steady progress if you plot it on a graph. When you combine with having thousands of types of tasks, you end up with an overview of even smoother progress over the whole field.
There are three problems I'm worried about.
The first is that "designing better AIs" may turn out to be a relatively narrow task, and subject to a lot more burstiness than broad spectrum performance that could steadily increase world GDP.
The second is that for purposes of the future of humanity, only the last step from human-adjacent to strictly superhuman really matters. On the scale of intelligence for all the beings we know about, chimpanzees are very nearly human, but the economic effect of chimpanzees is essentially zero.
The third is that we are nowhere near fully exploiting the hardware we have for AI, and I expect that to continue for quite a while.
I think any two of these three are enough for a fast takeoff with little warning.
8
+1 on using dynamical systems models to try to formalize the frameworks in this debate. I also give Eliezer points for trying to do something similar in Intelligence Explosion Microeconomics (and to people who have looked at this from the macro perspective).
superforecasters were claiming that AlphaGo had a 20% chance of beating Lee Se-dol and I didn't disagree with that at the time
Good Judgment Open had the probability at 65% on March 8th 2016, with a generally stable forecast since early February (Wikipedia says that the first match was on March 9th).
Metaculus had the probability at 64% with similar stability over time. Of course, there might be another source that Eliezer is referring to, but for now I think it's right to flag this statement as false.
A note I want to add, if this fact-check ends up being valid:
It appears that a significant fraction of Eliezer's argument relies on AlphaGo being surprising. But then his evidence for it being surprising seems to rest substantially on something that was misremembered. That seems important if true.
I would point to, for example, this quote, "I mean the superforecasters did already suck once in my observation, which was AlphaGo, but I did not bet against them there, I bet with them and then updated afterwards." It seems like the lesson here, if indeed superforecasters got AlphaGo right and Eliezer got it wrong, is that we should update a little bit towards superforecasting, and against Eliezer.
Adding my recollection of that period: some people made the relevant updates when DeepMind's system beat the European Champion Fan Hui (in October 2015). My hazy recollection is that beating Fan Hui started some people going "Oh huh, I think this is going to happen" and then when AlphaGo beat Lee Sedol (in March 2016) everyone said "Now it is happening".
It seems from this Metaculus question that people indeed were surprised by the announcement of the match between Fan Hui and AlphaGo (which was disclosed in January, despite the match happening months earlier, according to Wikipedia).
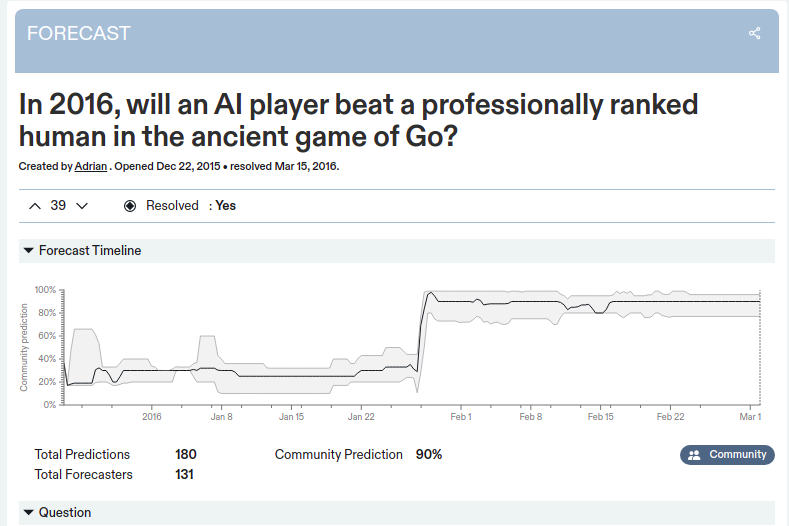
It seems hard to interpret this as AlphaGo being inherently surprising though, because the relevant fact is that the question was referring only to 2016. It seems somewhat reasonable to think that even if a breakthrough is on the horizon, it won't happen imminently with high probability.
Perhaps a better source of evidence of AlphaGo's surprisingness comes from Nick Bostrom's 2014 book Superintelligence in which he says, "Go-playing amateur programs have been improving at a rate of about 1 level dan/year in recent years. If this rate of improvement continues, they might beat the human world champion in about a decade." (Chapter 1).
This vindicates AlphaGo being an impressive discontinuity from pre-2015 progress. Though one can reasonably dispute whether superforecasters thought that the milestone was still far away after being told that Google and Facebook made big investments into it (as was the case in late 2015).
Wow thanks for pulling that up. I've gotta say, having records of people's predictions is pretty sweet. Similarly, solid find on the Bostrom quote.
Do you think that might be the 20% number that Eliezer is remembering? Eliezer, interested in whether you have a recollection of this or not. [Added: It seems from a comment upthread that EY was talking about superforecasters in Feb 2016, which is after Fan Hui.]
5
There was still a big update from ~20%->90%, which is what is relevant for Eliezer's argument, even if he misremembered the timing. The fact that the update was from the Fan Hui match rather than the Lee Sedol match doesn't seem that important to the argument [for superforecasters being caught flatfooted by discontinuous AI-Go progress].
9
My memory of the past is not great in general, but considering that I bet sums of my own money and advised others to do so, I am surprised that my memory here would be that bad, if it was.
Neither GJO nor Metaculus are restricted to only past superforecasters, as I understand it; and my recollection is that superforecasters in particular, not all participants at GJO or Metaculus, were saying in the range of 20%. Here's an example of one such, which I have a potentially false memory of having maybe read at the time: https://www.gjopen.com/comments/118530
3
Thanks for clarifying. That makes sense that you may have been referring to a specific subset of forecasters. I do think that some forecasters tend to be much more reliable than others (and maybe there was/is a way to restrict to "superforecasters" in the UI).
I will add the following piece of evidence, which I don't think counts much for or against your memory, but which still seems relevant. Metaculus shows a histogram of predictions. On the relevant question, a relatively high fraction of people put a 20% chance, but it also looks like over 80% of forecasters put higher credences.
I feel like the biggest subjective thing is that I don't feel like there is a "core of generality" that GPT-3 is missing
I just expect it to gracefully glide up to a human-level foom-ing intelligence
This is a place where I suspect we have a large difference of underlying models. What sort of surface-level capabilities do you, Paul, predict that we might get (or should not get) in the next 5 years from Stack More Layers? Particularly if you have an answer to anything that sounds like it's in the style of Gwern's questions, because I think those are the things that actually matter and which are hard to predict from trendlines and which ought to depend on somebody's model of "what kind of generality makes it into GPT-3's successors".
If you give me 1 or 10 examples of surface capabilities I'm happy to opine. If you want me to name industries or benchmarks, I'm happy to opine on rates of progress. I don't like the game where you say "Hey, say some stuff. I'm not going to predict anything and I probably won't engage quantitatively with it since I don't think much about benchmarks or economic impacts or anything else that we can even talk about precisely in hindsight for GPT-3."
I don't even know which of Gwern's questions you think are interesting/meaningful. "Good meta-learning"--I don't know what this means but if actually ask a real question I can guess. Qualitative descriptions---what is even a qualitative description of GPT-3? "Causality"---I think that's not very meaningful and will be used to describe quantitative improvements at some level made up by the speaker. The spikes in capabilities Gwern talks about seem to be basically measurement artifacts, but if you want to describe a particular measurements I can tell you whether they will have similar artifacts. (How much economic value I can talk about, but you don't seem interested.)
Mostly, I think the Future is not very predictable in some ways, and this extends to, for example, it being the possible that 2022 is the year where we start Final Descent and by 2024 it's over, because it so happened that although all the warning signs were Very Obvious In Retrospect they were not obvious in antecedent and so stuff just started happening one day. The places where I dare to extend out small tendrils of prediction are the rare exception to this rule; other times, people go about saying, "Oh, no, it definitely couldn't start in 2022" and then I say "Starting in 2022 would not surprise me" by way of making an antiprediction that contradicts them. It may sound bold and startling to them, but from my own perspective I'm just expressing my ignorance. That's one reason why I keep saying, if you think the world more orderly than that, why not opine on it yourself to get the Bayes points for it - why wait for me to ask you?
If you ask me to extend out a rare tendril of guessing, I might guess, for example, that it seems to me that GPT-3's current text prediction-hence-production capabilities are sufficiently good that it seems like somewhere inside GPT-3 mu...
I'm mostly not looking for virtue points, I'm looking for: (i) if your view is right then I get some kind of indication of that so that I can take it more seriously, (ii) if your view is wrong then you get some indication feedback to help snap you out of it.
I don't think it's surprising if a GPT-3 sized model can do relatively good translation. If talking about this prediction, and if you aren't happy just predicting numbers for overall value added from machine translation, I'd kind of like to get some concrete examples of mediocre translations or concrete problems with existing NMT that you are predicting can be improved.
9
It seems like Eliezer is mostly just more uncertain about the near future than you are, so it doesn't seem like you'll be able to find (ii) by looking at predictions for the near future.
It seems to me like Eliezer rejects a lot of important heuristics like "things change slowly" and "most innovations aren't big deals" and so on. One reason he may do that is because he literally doesn't know how to operate those heuristics, and so when he applies them retroactively they seem obviously stupid. But if we actually walked through predictions in advance, I think he'd see that actual gradualists are much better predictors than he imagines.
5
That seems a bit uncharitable to me. I doubt he rejects those heuristics wholesale. I'd guess that he thinks that e.g. recursive self improvement is one of those things where these heuristics don't apply, and that this is foreseeable because of e.g. the nature of recursion. I'd love to hear more about what sort of knowledge about "operating these heuristics" you think he's missing!
Anyway, it seems like he expects things to seem more-or-less gradual up until FOOM, so I think my original point still applies: I think his model would not be "shaken out" of his fast-takeoff view due to successful future predictions (until it's too late).
9
He says things like AlphaGo or GPT-3 being really surprising to gradualists, suggesting he thinks that gradualism only works in hindsight.
I agree that after shaking out the other disagreements, we could just end up with Eliezer saying "yeah but automating AI R&D is just fundamentally unlike all the other tasks to which we've applied AI" (or "AI improving AI will be fundamentally unlike automating humans improving AI") but I don't think that's the core of his position right now.
9
I agree we seem to have some kind of deeper disagreement here.
I think stack more layers + known training strategies (nothing clever) + simple strategies for using test-time compute (nothing clever, nothing that doesn't use the ML as a black box) can get continuous improvements in tasks like reasoning (e.g. theorem-proving), meta-learning (e.g. learning to learn new motor skills), automating R&D (including automating executing ML experiments, or proposing new ML experiments), or basically whatever.
I think these won't get to human level in the next 5 years. We'll have crappy versions of all of them. So it seems like we basically have to get quantitative. If you want to talk about something we aren't currently measuring, then that probably takes effort, and so it would probably be good if you picked some capability where you won't just say "the Future is hard to predict." (Though separately I expect to make somewhat better predictions than you in most of these domains.)
A plausible example is that I think it's pretty likely that in 5 years, with mere stack more layers + known techniques (nothing clever), you can have a system which is clearly (by your+my judgment) "on track" to improve itself and eventually foom, e.g. that can propose and evaluate improvements to itself, whose ability to evaluate proposals is good enough that it will actually move in the right direction and eventually get better at the process, etc., but that it will just take a long time for it to make progress. I'd guess that it looks a lot like a dumb kid in terms of the kind of stuff it proposes and its bad judgment (but radically more focused on the task and conscientious and wise than any kid would be). Maybe I think that's 10% unconditionally, but much higher given a serious effort. My impression is that you think this is unlikely without adding in some missing secret sauce to GPT, and that my picture is generally quite different from your criticallity-flavored model of takeoff.
5
How long time do you see between "1 AI clearly on track to Foom" and "First AI to actually Foom"? My weak guess is Eliezer would say "Probably quite little time", but your model of the world requires the GWP to double over a 4 year period, and I'm guessing that period probably starts later than 2026.
I would be surprised if by 2027, I could point to an AI that for a full year had been on track to Foom, without Foom happening.
7
I think "on track to foom" is a very long way before "actually fooms."
Found two Eliezer-posts from 2016 (on Facebook) that I feel helped me better grok his perspective.
It is amazing that our neural networks work at all; terrifying that we can dump in so much GPU power that our training methods work at all; and the fact that AlphaGo can even exist is still blowing my mind. It's like watching a trillion spiders with the intelligence of earthworms, working for 100,000 years, using tissue paper to construct nuclear weapons.
And earlier, Jan. 27, 2016:
...People occasionally ask me about signs that the remaining timeline might be short. It's very easy for nonprofessionals to take too much alarm too easily. Deep Blue beating Kasparov at chess was not such a sign. Robotic cars are not such a sign.
This is.
"Here we introduce a new approach to computer Go that uses ‘value networks’ to evaluate board positions and ‘policy networks’ to select moves... Without any lookahead search, the neural networks play Go at the level of state-of-the-art Monte Carlo tree search programs that simulate thousands of random games of self-play. We also introduce a new search algorithm that combines Monte Carlo simulation with value and policy networks. Using this search a
and some of my sense here is that if Paul offered a portfolio bet of this kind, I might not take it myself, but EAs who were better at noticing their own surprise might say, "Wait, that's how unpredictable Paul thinks the world is?"
If Eliezer endorses this on reflection, that would seem to suggest that Paul actually has good models about how often trend breaks happen, and that the problem-by-Eliezer's-lights is relatively more about, either:
- that Paul's long-term predictions do not adequately take into account his good sense of short-term trend breaks.
- that Paul's long-term predictions are actually fine and good, but that his communication about it is somehow misleading to EAs.
That would be a very different kind of disagreement than I thought this was about. (Though actually kind-of consistent with the way that Eliezer previously didn't quite diss Paul's track-record, but instead dissed "the sort of person who is taken in by this essay [is the same sort of person who gets taken in by Hanson's arguments in 2008 and gets caught flatfooted by AlphaGo and GPT-3 and AlphaFold 2]"?)
Also, none of this erases the value of putting forward the predictions mentioned in the original quote, since that would then be a good method of communicating Paul's (supposedly miscommunicated) views.
1
Apologies for my ignorance, does EA mean Effective Altruist?
4
Yup. Both Effective Altruism and Effective Altruist are abbreviated as EA.
Some thinking-out-loud on how I'd go about looking for testable/bettable prediction differences here...
I think my models overlap mostly with Eliezer's in the relevant places, so I'll use my own models as a proxy for his, and think about how to find testable/bettable predictions with Paul (or Ajeya, or someone else in their cluster).
One historical example immediately springs to mind where something-I'd-consider-a-Paul-esque-model utterly failed predictively: the breakdown of the Philips curve. The original Philips curve was based on just fitting a curve to inflation-vs-unemployment data; Friedman and Phelps both independently came up with theoretical models for that relationship in the late sixties ('67-'68), and Friedman correctly forecasted that the curve would break down in the next recession (i.e. the "stagflation" of '73-'75). This all led up to the Lucas Critique, which I'd consider the canonical case-against-what-I'd-call-Paul-esque-worldviews within economics. The main idea which seems transportable to other contexts is that surface relations (like the Philips curve) break down under distribution shifts in the underlying factors.
So, how would I look for something analogous t...
The "continuous view" as I understand it doesn't predict that all straight lines always stay straight. My version of it (which may or may not be Paul's version) predicts that in domains where people are putting in lots of effort to optimize a metric, that metric will grow relatively continuously. In other words, the more effort put in to optimize the metric, the more you can rely on straight lines for that metric staying straight (assuming that the trends in effort are also staying straight).
In its application to AI, this is combined with a prediction that people will in fact be putting in lots of effort into making AI systems intelligent / powerful / able to automate AI R&D / etc, before AI has reached a point where it can execute a pivotal act. This second prediction comes for totally different reasons, like "look at what AI researchers are already trying to do" combined with "it doesn't seem like AI is anywhere near the point of executing a pivotal act yet".
(I think on Paul's view the second prediction is also bolstered by observing that most industries / things that had big economic impacts also seemed to have crappier predecessors. This feels intuitive to me but is not som...
My version of it (which may or may not be Paul's version) predicts that in domains where people are putting in lots of effort to optimize a metric, that metric will grow relatively continuously. In other words, the more effort put in to optimize the metric, the more you can rely on straight lines for that metric staying straight (assuming that the trends in effort are also staying straight).
This is super helpful, thanks. Good explanation.
With this formulation of the "continuous view", I can immediately think of places where I'd bet against it. The first which springs to mind is aging: I'd bet that we'll see a discontinuous jump in achievable lifespan of mice. The gears here are nicely analogous to AGI too: I expect that there's a "common core" (or shared cause) underlying all the major diseases of aging, and fixing that core issue will fix all of them at once, in much the same way that figuring out the "core" of intelligence will lead to a big discontinuous jump in AI capabilities. I can also point to current empirical evidence for the existence of a common core in aging, which might suggest analogous types of evidence to look at in the intelligence context.
Thinking about other ana...
7
I agree that when you know about a critical threshold, as with nukes or orbits, you can and should predict a discontinuity there. (Sufficient specific knowledge is always going to allow you to outperform a general heuristic.) I think that (a) such thresholds are rare in general and (b) in AI in particular there is no such threshold. (According to me (b) seems like the biggest difference between Eliezer and Paul.)
Some thoughts on aging:
* It does in fact seem surprising, given the complexity of biology relative to physics, if there is a single core cause and core solution that leads to a discontinuity.
* I would a priori guess that there won't be a core solution. (A core cause seems more plausible, and I'll roll with it for now.) Instead, we see a sequence of solutions that intervene on the core problem in different ways, each of which leads to some improvement on lifespan, and discovering these at different times leads to a smoother graph.
* That being said, are people putting in a lot of effort into solving aging in mice? Everyone seems to constantly be saying that we're putting in almost no effort whatsoever. If that's true then a jumpy graph would be much less surprising.
* As a more specific scenario, it seems possible that the graph of mouse lifespan over time looks basically flat, because we were making no progress due to putting in ~no effort. I could totally believe in this world that someone puts in some effort and we get a discontinuity, or even that the near-zero effort we're putting in finds some intervention this year (but not in previous years) which then looks like a discontinuity.
If we had a good operationalization, and people are in fact putting in a lot of effort now, I could imagine putting my $100 to your $300 on this (not going beyond 1:3 odds simply because you know way more about aging than I do).
7
I'm not particularly enthusiastic about betting at 75%, that seems like it's already in the right ballpark for where the probability should be. So I guess we've successfully Aumann agreed on that particular prediction.
4
While I think orbit is the right sort of discontinuity for this, I think you need to specify 'flight range' in a way that clearly favors orbits for this to be correct, mostly because about a month before was the manhole cover launched/vaporized with a nuke.
[But in terms of something like "altitude achieved", I think Sputnik is probably part of a continuous graph, and probably not the most extreme member of the graph?]
My understanding is that Sputnik was a big discontinuous jump in "distance which a payload (i.e. nuclear bomb) can be delivered" (or at least it was a conclusive proof-of-concept of a discontinuous jump in that metric). That metric was presumably under heavy optimization pressure at the time, and was the main reason for strategic interest in Sputnik, so it lines up very well with the preconditions for the continuous view.
4
So it looks like the R-7 (which launched Sputnik) was the first ICBM, and the range is way longer than the V-2s of ~15 years earlier, but I'm not easily finding a graph of range over those intervening years. (And the R-7 range is only about double the range of a WW2-era bomber, which further smooths the overall graph.)
[And, implicitly, the reason we care about ICBMs is because the US and the USSR were on different continents; if the distance between their major centers was comparable to England and France's distance instead, then the same strategic considerations would have been hit much sooner.]
One of the problems here is that, as well as disagreeing about underlying world models and about the likelihoods of some pre-AGI events, Paul and Eliezer often just make predictions about different things by default. But they do (and must, logically) predict some of the same world events differently.
My very rough model of how their beliefs flow forward is:
Paul
Low initial confidence on truth/coherence of 'core of generality'
→
Human Evolution tells us very little about the 'cognitive landscape of all minds' (if that's even a coherent idea) - it's simply a loosely analogous individual historical example. Natural selection wasn't intelligently aiming for powerful world-affecting capabilities, and so stumbled on them relatively suddenly with humans. Therefore, we learn very little about whether there will/won't be a spectrum of powerful intermediately general AIs from the historical case of evolution - all we know is that it didn't happen during evolution, and we've got good reasons to think it's a lot more likely to happen for AI. For other reasons (precedents already exist - MuZero is insect-brained but better at chess or go than a chimp, plus that's the default with technology we're h...
7
Updates on this after reflection and discussion (thanks to Rohin):
[...]
Saying Paul's view is that the cognitive landscape of minds might be simply incoherent isn't quite right - at the very least you can talk about the distribution over programs implied by the random initialization of a neural network.
I could have just said 'Paul doesn't see this strong generality attractor in the cognitive landscape' but it seems to me that it's not just a disagreement about the abstraction, but that he trusts claims made on the basis of these sorts of abstractions less than Eliezer.
Also, on Paul's view, it's not that evolution is irrelevant as a counterexample. Rather, the specific fact of 'evolution gave us general intelligence suddenly by evolutionary timescales' is an unimportant surface fact, and the real truth about evolution is consistent with the continuous view.
[...]
These two initial claims are connected in a way I didn't make explicit - No core of generality and lack of common secrets in the reference class together imply that there are lots of paths to improving on practical metrics (not just those that give us generality), that we are putting in lots of effort into improving such metrics and that we tend to take the best ones first, so the metric improves continuously, and trend extrapolation will be especially correct.
[...]
The first clause already implies the second clause (since "how to get the core of generality" is itself a huge secret), but Eliezer seems to use non-intelligence related examples of sudden tech progress as evidence that huge secrets are common in tech progress in general, independent of the specific reason to think generality is one such secret.
Nate's Summary
[...]
Nate's summary brings up two points I more or less ignored in my summary because I wasn't sure what I thought - one is, just what role do the considerations about expected incompetent response/regulatory barriers/mistakes in choosing alignment strategies play? Are t
6
My Eliezer-model doesn't categorically object to this. See, e.g., Fake Causality:
[...]
And A Technical Explanation of Technical Explanation:
[...]
My Eliezer-model does object to things like 'since I (from my position as someone who doesn't understand the model) find the retrodictions and obvious-seeming predictions suspicious, you should share my worry and have relatively low confidence in the model's applicability'. Or 'since the case for this model's applicability isn't iron-clad, you should sprinkle in a lot more expressions of verbal doubt'. My Eliezer-model views these as isolated demands for rigor, or as isolated demands for social meekness.
Part of his general anti-modesty and pro-Thielian-secrets view is that it's very possible for other people to know things that justifiably make them much more confident than you are. So if you can't pass the other person's ITT / you don't understand how they're arriving at their conclusion (and you have no principled reason to think they can't have a good model here), then you should be a lot more wary of inferring from their confidence that they're biased.
[...]
My Eliezer-model thinks it's possible to be so bad at scientific reasoning that you need to be hit over the head with lots of advance predictive successes in order to justifiably trust a model. But my Eliezer-model thinks people like Richard are way better than that, and are (for modesty-ish reasons) overly distrusting their ability to do inside-view reasoning, and (as a consequence) aren't building up their inside-view-reasoning skills nearly as much as they could. (At least in domains like AGI, where you stand to look a lot sillier to others if you go around expressing confident inside-view models that others don't share.)
[...]
My Eliezer-model thinks this is correct as stated, but thinks this is a claim that applies to things like Newtonian gravity and not to things like probability theory. (He's also suspicious that modest-epistemology pressures ha
9
I don't necessarily expect GPT-4 to do better on perplexity than would be predicted by a linear model fit to neuron count plus algorithmic progress over time; my guess for why they're not scaling it bigger would be that Stack More Layers just basically stopped scaling in real output quality at the GPT-3 level. They can afford to scale up an OOM to 1.75 trillion weights, easily, given their funding, so if they're not doing that, an obvious guess is that it's because they're not getting a big win from that. As for their ability to then make algorithmic progress, depends on how good their researchers are, I expect; most algorithmic tricks you try in ML won't work, but maybe they've got enough people trying things to find some? But it's hard to outpace a field that way without supergeniuses, and the modern world has forgotten how to rear those.
While GPT-4 wouldn't be a lot bigger than GPT-3, Sam Altman did indicate that it'd use a lot more compute. That's consistent with Stack More Layers still working; they might just have found an even better use for compute.
(The increased compute-usage also makes me think that a Paul-esque view would allow for GPT-4 to be a lot more impressive than GPT-3, beyond just modest algorithmic improvements.)
If they've found some way to put a lot more compute into GPT-4 without making the model bigger, that's a very different - and unnerving - development.
I believe Sam Altman implied they’re simply training a GPT-3-variant for significantly longer for “GPT-4”. The GPT-3 model in prod is nowhere near converged on its training data.
Edit: changed to be less certain, pretty sure this follows from public comments by Sam, but he has not said this exactly
6
Say more about the source for this claim? I'm pretty sure he didn't say that during the Q&A I'm sourcing my info from. And my impression is that they're doing something more than this, both on priors (scaling laws says that optimal compute usage means you shouldn't train to convergence — why would they start now?) and based on what he said during that Q&A.
This is based on:
- The Q&A you mention
- GPT-3 not being trained on even one pass of its training dataset
- “Use way more compute” achieving outsized gains by training longer than by most other architectural modifications for a fixed model size (while you’re correct that bigger model = faster training, you’re trading off against ease of deployment, and models much bigger than GPT-3 become increasingly difficult to serve at prod. Plus, we know it’s about the same size, from the Q&A)
- Some experience with undertrained enormous language models underperforming relative to expectation
This is not to say that GPT-4 wont have architectural changes. Sam mentioned a longer context at the least. But these sorts of architectural changes probably qualify as “small” in the parlance of the above conversation.
5
To be clear: Do you remember Sam Altman saying that "they’re simply training a GPT-3-variant for significantly longer", or is that an inference from ~"it will use a lot more compute" and ~"it will not be much bigger"?
Because if you remember him saying that, then that contradicts my memory (and, uh, the notes that people took that I remember reading), and I'm confused.
While if it's an inference: sure, that's a non-crazy guess, and I take your point that smaller models are easier to deploy. I just want it to be flagged as a claimed deduction, not as a remembered statement.
(And I maintain my impression that something more is going on; especially since I remember Sam generally talking about how models might use more test-time compute in the future, and be able to think for longer on harder questions.)
4
Honestly, at this point, I don’t remember if it’s inferred or primary-sourced. Edited the above for clarity.
4
One way they could do that, is by pitting the model against modified versions of itself, like they did in OpenAI Five (for Dota).
From the minimizing-X-risk perspective, it might be the worst possible way to train AIs.
As Jeff Clune (Uber AI) put it:
[...]
Additionally, if you train a language model to outsmart millions of increasingly more intelligent copies of itself, you might end up with the perfect AI-box escape artist.
4[anonymous]
I was under the impression that GPT-4 would be gigantic, according to this quote from this Wired article:
[...]
Sam Altman explicitly contradicted that in a later q&a, when someone asked him about that quote.
After reading these two Eliezer <> Paul discussions, I realize I'm confused about what the importance of their disagreement is.
It's very clear to me why Richard & Eliezer's disagreement is important. Alignment being extremely hard suggests AI companies should work a lot harder to avoid accidentally destroying the world, and suggests alignment researchers should be wary of easy-seeming alignment approaches.
But it seems like Paul & Eliezer basically agree about all of that. They disagree about... what the world looks like shortly before the end? Which, sure, does have some strategic implications. You might be able to make a ton of money by betting on AI companies and thus have a lot of power in the few years before the world drastically changes. That does seem important, but it doesn't seem nearly as important as the difficulty of alignment.
I wonder if there are other things Paul & Eliezer disagree about that are more important. Or if I'm underrating the importance of the ways they disagree here. Paul wants Eliezer to bet on things so Paul can have a chance to update to his view in the future if things end up being really different than he thinks. Okay, but what will he do differently in those worlds? Imo he'd just be doing the same things he's trying now if Eliezer was right. And maybe there is something implicit in Paul's "smooth line" forecasting beliefs that makes his prosaic alignment strategy more likely to work in world's where he's right, but I currently don't see it.
I would frame the question more as 'Is this question important for the entire chain of actions humanity needs to select in order to steer to good outcomes?', rather than 'Is there a specific thing Paul or Eliezer personally should do differently tomorrow if they update to the other's view?' (though the latter is an interesting question too).
Some implications of having a more Eliezer-ish view include:
- In the Eliezer-world, humanity's task is more foresight-loaded. You don't get a long period of time in advance of AGI where the path to AGI is clear; nor do you get a long period of time of working with proto-AGI or weak AGI where we can safely learn all the relevant principles and meta-principles via trial and error. You need to see far more of the bullets coming in advance of the experiment, which means developing more of the technical knowledge to exercise that kind of foresight, and also developing more of the base skills of thinking well about AGI even where our technical models and our data are both thin.
- My Paul-model says: 'Humans are just really bad at foresight, and it seems like AI just isn't very amenable to understanding; so we're forced to rely mostly on surface trends and
5
Thanks this is helpful! I'd be very curious to see where Paul agreed / disagree with the summary / implications of his view here.
4
(I'll emphasize again, by the way, that this is a relative comparison of my model of Paul vs. Eliezer. If Paul and Eliezer's views on some topic are pretty close in absolute terms, the above might misleadingly suggest more disagreement than there in fact is.)
Transcript error fixed -- the line that previously read
[Yudkowsky][17:40] I expect it to go away before the end of days but with there having been a big architectural innovation, not Stack More Layers |
[Christiano][17:40] I expect it to go away before the end of days but with there having been a big architectural innovation, not Stack More Layers |
[Yudkowsky][17:40] if you name 5 possible architectural innovations I can call them small or large |
should be
[Yudkowsky][17:40] I expect it to go away before the end of days but with there having b |
why aren't elephants GI?
As Herculano-Houzel called it, the human brain is a remarkable, yet not extraordinary, scaled-up primate brain. It seems that our main advantage in hardware is quantitative: more cortical columns to process more reference frames to predict more stuff.
And the primate brain is mostly the same as of other mammals (which shouldn't be surprising, as the source code is mostly the same).
And the intelligence of mammals seems to be rather general. It allows them to solve a highly diverse set of cognitive tasks, including the task of le...
Somebody tries to measure the human brain using instruments that can only detect numbers of neurons and energy expenditure, but not detect any difference of how the fine circuitry is wired; and concludes the human brain is remarkable only in its size and not in its algorithms. You see the problem here? The failure of large dinosaurs to quickly scale is a measuring instrument that detects how their algorithms scaled with more compute (namely: poorly), while measuring the number of neurons in a human brain tells you nothing about that at all.
8
Jeff Hawkins provided a rather interesting argument on the topic:
The scaling of the human brain has happened too fast to implement any deep changes in how the circuitry works. The entire scaling process was mostly done by the favorite trick of biological evolution: copy and paste existing units (in this case - cortical columns).
Jeff argues that there is no change in the basic algorithm between earlier primates and humans. It's the same reference-frames processing algo distributed across columns. The main difference is, humans have much more columns.
I've found his arguments convincing for two reasons:
* his neurobiological arguments are surprisingly good (to the point of being surprisingly obvious in hindsight)
* It's the same "just add more layers" trick we reinvented in ML
[...]
Are we sure about the low intelligence of dinosaurs?
Judging by the living dinos (e.g. crows), they are able to pack a chimp-like intelligence into a 0.016 kg brain.
And some of the dinos have had x60 more of it (e.g. the brain of Tyrannosaurus rex weighted about 1 kg, which is comparable to Homo erectus).
And some of the dinos have had a surprisingly large encephalization quotient, combined with bipedalism, gripping hands, forward-facing eyes, omnivorism, nest building, parental care, and living in groups (e.g. troodontids).
Maybe it was not an asteroid after all...
(Very unlikely, of course. But I find the idea rather amusing)
One may ask: why aren't elephants making rockets and computers yet?
But one may ask the same question about any uncontacted human tribe.
Seems more surprising for elephants, by default: elephants have apparently had similarly large brains for about 20 million years, which is far more time than uncontacted human tribes have had to build rockets. (~100x as long as anatomically modern humans have existed at all, for example.)
5
I agree. Additionally, the life expectancy of elephants is significantly higher than of paleolithic humans (1, 2). Thus, individual elephants have much more time to learn stuff.
In humans, technological progress is not a given. Across different populations, it seems to be determined by the local culture, and not by neurobiological differences. For example, the ancestors of Wernher von Braun have left their technological local minimum thousands of years later than Egyptians or Chinese. And the ancestors of Sergei Korolev lived their primitive lives well into the 8th century C.E. If a Han dynasty scholar had visited the Germanic and Slavic tribes, he would've described them as hopeless barbarians, perhaps even as inherently predisposed to barbarism.
Maybe if we give elephants more time, they will overcome their biological limitations (limited speech, limited "hand", fewer neurons in neocortex etc), and will escape the local minimum. But maybe not.
3[anonymous]
I think Herculano-Houzel would want to mention that humans have 3x (iirc) more neurons in their cerebral cortex than even the elephant species with the biggest brains. Those elephants have more total neurons because their cerebellar cortices have like 200 billion neurons. Humans have more cortical neurons than any animal, including blue whales, because neuron sizes scale differently for different Orders and primates specifically scale well.
Crucially, people have thought human brains were special among primates but she makes the point that it's the other great apes that are special in having smaller brains according to primate brain scaling laws. This is because humans either had a unique incentive to keep up with the costs of scaling or because they had a unique ability to keep up with the costs (due to e.g. cooking).
Having better algorithms that could take advantage of scale fits with her views, I think.
Christiano predicts progress will be (approximately) a smooth curve, whereas Yudkowsky predicts there will be discontinuous-ish "jumps", but there's another thing that can happen that both of them seem to dismiss: progress hitting a major obstacle and plateauing for a while (i.e. the progress curve looking locally like a sigmoid). I guess that the reason they dismiss it is related to this quote by Soares:
...I observe that, 15 years ago, everyone was saying AGI is far off because of what it couldn't do -- basic image recognition, go, starcraft, winograd sche
4
My Eliezer-model is a lot less surprised by lulls than my Paul-model (because we're missing key insights for AGI, progress on insights is jumpy and hard to predict, the future is generally very unpredictable, etc.). I don't know exactly how large of a lull or winter would start to surprise Eliezer (or how much that surprise would change if the lull is occurring two years from now, vs. ten years from now, for example).
In Yudkowsky and Christiano Discuss "Takeoff Speeds", Eliezer says:
[...]
So in that sense Eliezer thinks we're already in a slowdown to some degree (as of 2020), though I gather you're talking about a much larger and more long-lasting slowdown.
4
I generally expect smoother progress, but predictions about lulls are probably dominated by Eliezer's shorter timelines. Also lulls are generally easier than spurts, e.g. I think that if you just slow investment growth you get a lull and that's not too unlikely (whereas part of why it's hard to get a spurt is that investment rises to levels where you can't rapidly grow it further).
2
Makes some sense, but Yudkowsky's prediction that TAI will arrive before AI has large economic impact does forbid a lot of plateau scenarios. Given a plateau that's sufficiently high and sufficiently long, AI will land in the market, I think. Even if regulatory hurdles are the bottleneck for a lot of things atm, eventually in some country AI will become important and the others will have to follow or fall behind.
since you disagree with them eventually, e.g. >2/3 doom by 2030
This apparently refers to Yudkowsky's credences, and I notice I am surprised — has Yudkowsky said this somewhere? (Edit: the answer is no, thanks for responses.)
9
I think Ajeya is inferring this from Eliezer's 2017 bet with Bryan Caplan. The bet was jokey and therefore (IMO) doesn't deserve much weight, though Eliezer comments that it's maybe not totally unrelated to timelines he'd reflectively endorse:
[...]
In general, my (maybe-partly-mistaken) Eliezer-model...
* thinks he knows very little about timelines (per the qualitative reasoning in There's No Fire Alarm For AGI and in Nate's recent post -- though not necessarily endorsing Nate's quantitative probabilities);
* and is wary of trying to turn 'I don't know' into a solid, stable number for this kind of question (cf. When (Not) To Use Probabilities);
* but recognizes that his behavior at any given time, insofar as it is coherent, must reflect some implicit probabilities. Quoting Eliezer back in 2016:
[...]
Furthermore 2/3 doom is straightforwardly the wrong thing to infer from the 1:1 betting odds, even taking those at face value and even before taking interest rates into account; Bryan gave me $100 which gets returned as $200 later.
(I do consider this a noteworthy example of 'People seem systematically to make the mistake in the direction that interprets Eliezer's stuff as more weird and extreme' because it's a clear arithmetical error and because I saw a recorded transcript of it apparently passing the notice of several people I considered usually epistemically strong.)
(Though it's also easier than people expect to just not notice things; I didn't realize at the time that Ajeya was talking about a misinterpretation of the implied odds from the Caplan bet, and thought she was just guessing my own odds at 2/3, and I didn't want to argue about that because I don't think it valuable to the world or maybe even to myself to go about arguing those exact numbers.)
Yes, Rob is right about the inference coming from the bet and Eliezer is right that the bet was actually 1:1 odds but due to the somewhat unusual bet format I misread it as 2:1 odds.
3
Maybe I'm wrong about her deriving this from the Caplan bet? Ajeya hasn't actually confirmed that, it was just an inference I drew. I'll poke her to double-check.
4
I think the bet is a bad idea if you think in terms of Many Worlds. Say 55% of all worlds end by 2030. Then, even assuming that value-of-$-in-2017 = value-of-$-in-2030, Eliezer personally benefited from the bet. However, the epistemic result is Bryan getting prestige points in 45% of worlds, Eliezer getting prestige points in 0% of worlds.
The other problem with the bet is that, if we adjust for inflation and returns of money, the bet is positive EV for Eliezer even given P(world-ends-by-2030) << 12.
(ETA: this wasn't actually in this log but in a future part of the discussion.)
I found the elephants part of this discussion surprising. It looks to me like human brains are better than elephant brains at most things, and it's interesting to me that Eliezer thought otherwise. This is one of the main places where I couldn't predict what he would say.
7
I also think human brains are better than elephant brains at most things - what did I say that sounded otherwise?
3
Oops, this was in reference to the later part of the discussion where you disagreed with "a human in a big animal body, with brain adapted to operate that body instead of our own, would beat a big animal [without using tools]".
On a detail:
what would the chess graph look like if it was measuring pawn handicaps?
I figured out from a paper a while back (sorry, can't recall where!) that 1 pawn = 100 elo points, at least at high levels of play. Grandmaster Larry Kaufman suggests the elo value e.g. of a knight handicap varies with the playing level:
https://en.wikipedia.org/wiki/Handicap_(chess)#Rating_equivalent
An interesting parallel might be a parallel Earth making nanotechnology breakthroughs instead of AI breakthroughs, such that it's apparent they'll be capable of creating gray goo and not apparent they'll be able to avoid creating gray goo.
I guess a slow takeoff could be if, like, the first self-replicators took a day to double, so if somebody accidentally made a gram of gray goo you'd have weeks to figure it out and nuke the lab or whatever, but self-replication speed went down as technology improved, and so accidental unconstrained replicators happened pe...
I don't know much about chess, so maybe this is wrong, but I would tend to think of Elo ratings as being more like a logarithmic scale of ability than like a linear scale of ability. In the sense that e.g. probability of winning changes exponentially with Elo difference, so a linear trend on an Elo graph translates to an exponential trend in competitiveness. "The chances of an AI solving the tasks better than a human are increasing exponentially" sounds more like fast takeoff than slow takeoff to me.
I think everyone in the discussion expects AI progress to be at least exponentially fast. See all of Paul's mention of hyperbolic growth — that's faster than an exponential.
The discussion is more about continuous vs discontinuous takeoff, or centralised vs decentralised takeoff. (The slow/fast terminology isn't great.)
Eliezer should have taken Cotra up on that bet about "will someone train a 10T param model before end days" considering one already exists.
6
Is that one dense or sparse/MoE? How many data points was it trained for? Does it set SOTA on anything? (I'm skeptical; I'm wondering if they only trained it for a tiny amount, for example.)