I agree with Eliezer's recommendation to double-check results in papers that one finds surprising.
So, I looked into the claim of a 10x - 100x gain for transformers, using Table 2 from the paper. Detailed results are in this Colab.
Briefly, I don't think the claim of 10x - 100x is well supported. Depending on what exactly you compute, you get anywhere from "no speedup" to "over 300x speedup." All the estimates you can make have obvious problems, and all show a massive gap between French and German.
In detail:
- The appearance of a large speedup is heavily affected by the fact that previous SOTAs were ensembles, and ensembling is a very inefficient way to spend compute.
- In terms of simple BLEU / compute, the efficiency gain from transformers looks about 10x smaller if we compare to non-ensembled older models.
- Simple BLEU / compute is not a great metric because of diminishing marginal returns.
- By this metric, the small transformer is ~6x "better" than the big one!
- By this metric, small transformer has a speedup of ~6x to ~40x, while big transformer has a speedup of ~1x to ~6x.
- We can try to estimate marginal returns by comparing sizes for transformers, and ensembled vs. not for older methods.
- This gives a speedup of ~5x for German and ~100x to ~300x for French
- But this is not an apples-to-apples comparison, as the transformer is scaled while the others are ensembled.
I imagine this question has been investigated much more rigorously outside the original paper. The first Kaplan scaling paper does this for LMs; I dunno who has done it for MT, but I'd be surprised if no one has.
EDIT: something I want to know is why ensembling was popular before transformers, but not after them. If ensembling older models was actually better than scaling them, that would weaken my conclusion a lot.
I don't know if ensembling vs. scaling has been rigorously tested, either for transformers or older models.
And I’d reject LSTM → transformer or MoE as an example because the quantitative effect size isn’t that big.
But if something like that made the difference between “this algorithm wasn’t scaling before, and now it’s scaling,” then I’d be surprised.
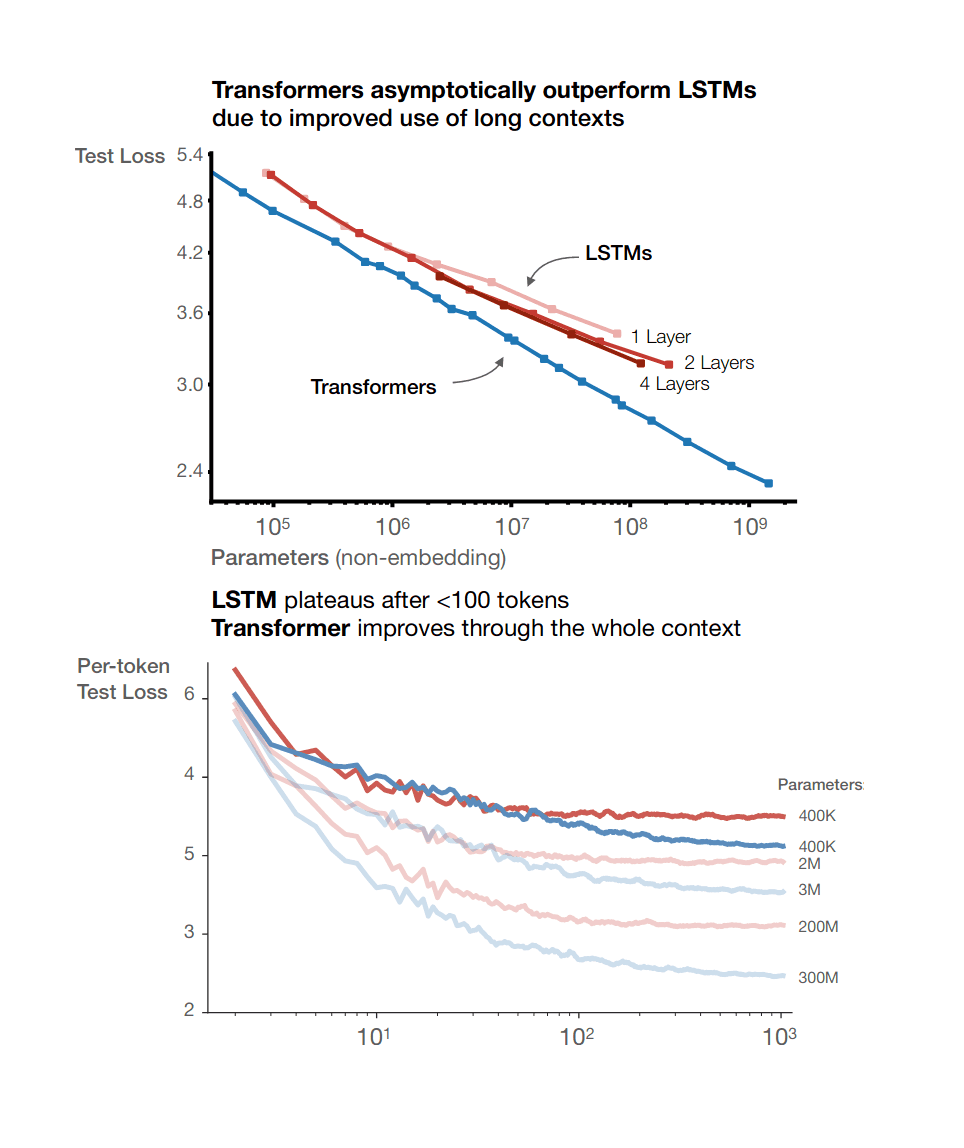
Hold on, why doesn't LSTM→Transformer count? You've basically never seen a LSTM RNN larger than 100m parameters, I think, and the reason is that their scaling exponent looks bad and past 100m they're floundering: https://www.gwern.net/images/ai/gpt/2020-kaplan-figure7-rnnsvstransformers.png (Kaplan) Or https://arxiv.org/abs/2106.09488#amazon which fits proper scaling laws to the LSTM RNNs & Transformers, and finds that Transformers are already twice as efficient in the range tested (in terms of reducing loss), and getting better asymptotically (better slope: −0.167 vs −0.197*). I doubt you could train a RNN the size of GPT-3 at all, and if you did, it would cost much more (as the 'AI and Compute' trendline has stopped).
{kind=link}
* I admit this is not very impressive, but the acoustic scaling paper has the problem that it's almost at the irreducible loss asymptote already: they hit a loss of 0.32 at only 0.1 petaflop-s/day but linf is apparently 0.30. (Meanwhile, language models like GPT-3 at 3640 petaflop-s/day are still very far from their irreducible loss.) So while the Transformer would only have a 6.38× advantage if I loosely copy over exponents and imagine scaling by 36400 and compare 1 - 36400^(-0.197) = 0.873 and 1 - (36400*x)^(-0.167) = 0.873, I think this lowerbounds the Transformer advantage in a floor effect way: their acoustic modeling problem is just 'too easy' to really show the difference.
Copy-pasting the transfomer vs LSTM graph for reference (the one with the bigger gap):
If you told me that AGI looks like that graph, where you replace "flounders at 100M parameters" with "flounders at the scale where people are currently doing AGI research," then I don't think that's going to give you a hard takeoff.
If you said "actually people will be using methods that flounder at a compute budget of 1e25 flops, but people will be doing AGI research with 1e30 flops, and the speedup will be > 1 OOM" then I agree that will give you a hard takeoff, but that's what I'm saying transformers aren't a good example of. In general I think that things tend to get more efficient/smooth as fields scale up, rather than less efficient, even though the upside from innovations that improve scaling is larger.
If you said "actually people won't even be doing AGI research with a large fraction of the world's compute, so we'll have a modest improvement that allows scaling followed by a super rapid scaleup" then it seems like that's got to translate into a bet about compute budgets in the near-ish future. I agree that AI compute has been scaling up rapidly from a tiny base, but I don't think that is likely to happen in the endgame (because most of the feasible scaleup will have already occurred).
If you said "actually people will be using methods that flounder at a compute budget of 1e25 flops, but people will be doing AGI research with 1e30 flops, and the speedup will be > 1 OOM" then I agree that will give you a hard takeoff, but that's what I'm saying transformers aren't a good example of.
Why not? Here we have a pretty clean break: RNNs are not a tweak or two away from Transformers. We have one large important family of algorithms, which we can empirically demonstrate do not absorb usefully the compute which another later discretely different family does, and which is responsible for increasingly more compute, and the longer that family of improvements was forgone, the more compute overhang there would've been to exploit.
In a world where Transformers did not exist, we would not be talking about GPRNN-3 as a followup to GPRNN-2, which followupped OA's original & much-unloved GPT-1 RNN. What would happen is that OA would put $10m into GPRNN-3, observe that it didn't go anywhere (hard to eyeball the curves but I wonder if it'd work even as well as GPT-2 did?), and the status quo of <100m-parameter RNNs would just keep going. There would not be any Switch Transformer, any WuDao, any HyperClova, any Pangu-Alpha, any Pathways/LaMDA/MUM, FB's scaleup program in audio & translation wouldn't be going... (There probably wouldn't be any MLP renaissance either, as everyone seems to get there by asking 'how much of a Transformer do we need anyway? how much can I ablate away? hm, looks like "all of it" when I start with a modern foundation with normalized layers?') We know what would've happened without Transformers: nothing. We can observe the counterfactual by simply looking: no magic RNNs dropped out of the sky merely to 'make line go straight brrr'. It would simply be yet another sigmoid ending and an exciting field turning into a 'mature technology': "well, we scaled up RNNs and they worked pretty well, but it'll require new approaches or way more compute than we'll have for decades to come, oh well, let's dick around until then." Such a plateau would be no surprise, any more than it ought to be surprising that in 2021 you or I are not flying around on hypersonic rocket-jet personal pod cars the way everyone in aerospace was forecasting in the 1950s by projecting out centuries of speed increases.
The counterfactual depends on what other research people would have done and how successful it would have been. I don't think you can observe it "by simply looking."
That said, I'm not quite sure what counterfactual you are imagining. By the time transformers were developed, soft attention in combination with LSTMs was already popular. I assume that in your counterfactual soft attention didn't ever catch on? Was it proposed in 2014 but languished in obscurity and no one picked it up? Or was sequence-to-sequence attention widely used, but no one ever considered self-attention? Or something else?
Depending on how you are defining the counterfactual, I may think that you are right about the consequences. But if you are talking about a counterfactual that I regard as implausible, then naturally it's not as interesting to me as things that actually happen. That's what I was looking for in the quoted part of the OP---and evaluating transformers in terms of their (large!) actual impact rather than an imagined hypothetical where they could lead to fast-takeoff-like consequences.
Want to +1 that a vaguer version of this was my own rough sense of RNNs vs. CNNs vs. Transformers.
I think transformers are a big deal, but I think this comment is a bad guess at the counterfactual and it reaffirms my desire to bet with you about either history or the future. One bet down, handful to go?
Is this something that you've changed your mind on recently, or have I just misunderstood your previous stance? I don't know if it would be polite to throw old quotes off Discord at you, but my understanding is that you expected most model differences vanished in the limit, and that convolutions and RNNs and whatnot might well have held up fine with only minor tweaks to remove scaling bottlenecks.
I bring this up because that stance I thought you had seems to agree with Paul, whereas now you seem to disagree with him.
1. Everyone agrees that if we have less than 10 years left before the end, it's probably not going to look like the multi-year, gradual, distributed takeoff Paul prophecies, and instead will look crazier, faster, more discontinuous, more Yudkowskian... right? In other words, everyone agrees <10-year timelines and Paul-slow takeoff are in tension with each other.*
2. Assuming we agree on 1, I'd be interested to hear whether people think we should resolve this tension by having low credence in <10 year timelines, or not having low credence in Yudkowskian takeoff speeds. My guess is that Ajeya and Paul do the former? I myself do the latter, because the arguments and intuitions about timelines seem more solid than the arguments and intuitions about takeoff speeds.
*For reasons like: <10 years seems like not enough time for the AI industry to mature and scale up so much that additional zeros can't be quickly added to the parameters of the best AIs at any given time; it also seems like not enough time for GWP to double in four years before the end...
EDIT to clarify: I know that e.g. Ajeya has low credence in <10 year AI doom scenarios. My question for her would be, is this partially based on being somewhat convinced in slow takeoff and updating against <10 year scenarios as a result? The report updates against low-compute-requirements somewhat based on EMH-like considerations; is that the extent of the influence of this sort of thing on Ajeya's timelines, or e.g. is Ajeya also putting less weight on short-horizon and lifetime anchors due to them seeming inconsistent with slow takeoff?
I still expect things to be significantly more gradual than Eliezer, in the 10 year world I think it will be very fast but we still have much tighter bounds on how fast (maybe median is more like a year and very likely 2+ months). But yes, the timeline will be much shorter than my default expectation, and then you also won't have time for big broad impacts.
I don't think you should have super low credence in fast takeoff. I gave 30% in the article that started this off, and I'm still somewhere in that ballpark.
Perhaps you think this implies a "low credence" in <10 year timelines. But I don't really think the arguments about timelines are "solid" to the tune of 20%+ probability in 10 years.
Thanks! Wow I missed/forgot that 30% figure, my bad. I disagree with you much less than I thought! (I'm more like 70% instead of 30%). [ETA: Update: I'm going with the intuitive definition of takeoff speeds here, not the "doubling in 4 years before 1 year?" one. For my thoughts on how to define takeoff speeds, see here. If GWP doubling times is the definition we go with then I'm more like 85% fast takeoff I think, for reasons mentioned by Rob Bensinger below.]
So here y'all have given your sense of the likelihoods as follows:
- Paul: 70% soft takeoff, 30% hard takeoff
- Daniel: 30% soft takeoff, 70% hard takeoff
How would Eliezer's position be stated in these terms? Similar to Daniel's?
My Eliezer-model thinks that "there will be a complete 4 year interval in which world output doubles, before the first 1 year interval in which world output doubles" is far less than 30% likely, because it's so conjunctive:
- It requires that there ever be a one-year interval in which the world output doubles.
- It requires that there be a preceding four-year interval in which world output doubles.
- So, it requires that the facts of CS be such that we can realistically get AI tech that capable before the world ends...
- ... and separately, that this capability not accelerate us to superintelligent AI in under four years...
- ... and separately, that ASI timelines be inherently long enough that we don't incidentally get ASI within four years anyway.
- Separately, it requires that individual humans make the basic-AI-research decisions to develop that tech before we achieve ASI. (Which may involve exercising technological foresight, making risky bets, etc.)
- Separately, it requires that individual humans leverage that tech to intelligently try to realize a wide variety of large economic gains, before we achieve ASI. (Which may involve exercising technological, business, and social foresight, making risky bets, etc.)
- Separately, it requires that the regulatory environment be favorable.
(Possibly other assumptions are required here too, like 'the first groups that get this pre-AGI tech even care about transforming the world economy, vs. preferring to focus on more basic research, or alignment / preparation-for-AGI, etc.')
You could try to get multiple of those properties at once by assuming specific things about the world's overall adequacy and/or about the space of all reachable intelligent systems; but from Eliezer's perspective these views fall somewhere on the spectrum between 'unsupported speculation' and 'flatly contradicted by our observations so far', and there are many ways to try to tweak civilization to be more adequate and/or the background CS facts to be more continuous, and still not hit the narrow target "a complete 4 year interval in which world output doubles" (before AGI destroys the world or a pivotal act occurs).
(I'm probably getting a bunch of details about Eliezer's actual model wrong above, but my prediction is that his answer will at least roughly look like this.)
Well said! This resonates with my Eliezer-model too.
Taking this into account I'd update my guess of Eliezer's position to:
- Eliezer: 5% soft takeoff, 80% hard takeoff, 15% something else
This last "something else" bucket added because "the Future is notoriously difficult to predict" (paraphrasing Eliezer).
Update: I'm going with the intuitive definition of takeoff speeds here, not the "doubling in 4 years before 1 year?" one. For my thoughts on how to define takeoff speeds, see here. If GWP doubling times is the definition we go with then I'm more like 85% fast takeoff I think, for reasons mentioned by Rob Bensinger below.
And what other EAs reading it are thinking, I expect, is plain old Robin-Hanson-style reference class tennis of "Why would you expect intelligence to scale differently from bridges, where are all the big bridges?"
I find these sorts of characterizations very strange, since I feel like I know quite a lot of EAs, but approximately nobody that's really into that sort of reference class forecasting (at least not more so than where Paul and Eliezer agree that superforecaster-style methodology is sound). I'm curious who specifically you're thinking of other than Robin Hanson (who afaik wouldn't describe himself as an EA), but feel free not to answer if you don't want to call anyone out publicly. I think it's worth flagging, though, that I find this characterization quite strange and at odds with my experience of EAs generally being very into gears-level/inside-view modeling.
like I'm surprised if a clever innovation does more good than spending 4x more compute
I worry that I'm misunderstanding this assertion because, as it stands, it sounds extremely likely that I'd win. Would transformers vs. CNNs/RNNs have won this the year that the transformers paper came out?
Can I have a Bayes point for this comment ?
Quoting it:
Hm. I wonder if there's a bet to be extracted from this. Like: Eliezer says that Alphafold 2 beats [algorithms previous to Alphafold 2, but with 10x compute], and Paul says the latter beats the former? Or replace Alphafold 2 with anything that Eliezer thinks contains some amount of secret sauce over previous things (whether or not its performance is "on trend").
Human intelligence wasn't part of a grand story reflected in all parts of the ecology, it just happened in a particular species.
If birds developed intelligence first instead of primates then they'd tell themselves it's because flying requires you to think in three dimensions or that high intelligence is predicated on high energy production which comes from high energy demands which comes from flying.
If insects developed intelligence before vertebrates they'd tell themselves it's because insects (being colonial [nevermind all the non-colonial insects]) are naturally social and because small organisms evolve faster than large ones.
If trees developed intelligence first they'd tell themselves it's because trees are long-lived and only long-lived organisms can accumulate the knowledge necessary to make higher intelligence pay off.
The 'grand story' Eliezer is referring to here isn't anything like these, though. That story is more like "there is a gradual increase in capability in all species, on an slow timescale; eventually one of them crosses the threshold of being able to produce culture which evolves on a faster timescale". Sort of the opposite of these species-parochialist tales.
@robbb, I thought Carl's reply near the top here was a pretty strong explanation for why non-discontinuity in other domains is relevant (which you were asking about). I also thought this was a good point:
So the 'we find a secret sauce algorithm that causes a massive unprecedented performance jump, without crappier predecessors' is a 'separate, additional miracle' at exactly the same time as the intelligence explosion is getting going.
I'm curious what you think of the points he made.
I think I don't understand Carl's "separate, additional miracle" argument. From my perspective, the basic AGI argument is:
- "General intelligence" makes sense as a discrete thing you can invent at a particular time. We can think of it as: performing long chains of reasoning to steer messy physical environments into specific complicated states, in the way that humans do science and technology to reshape their environment to match human goals. Another way of thinking about it is 'AlphaGo, but the game environment is now the physical world rather than a Go board'.
- Humans (our only direct data point) match this model: we can do an enormous variety of things that were completely absent from our environment of evolutionary adaptedness, and when we acquired this suite of abilities we 'instantly' (on a geologic timescale) had a massive discontinuous impact on the world.
- So we should expect AI, at some point, to go from 'can't do sophisticated reasoning about messy physical environments in general' to 'can do that kind of reasoning', at which point you suddenly have an 'AlphaGo of the entire physical world'. Which implies all the standard advantages of digital minds over human minds, such as:
- We can immediately scale AlphaWorld with more hardware, rather than needing to wait for an organism to biologically reproduce.
- We can rapidly iterate on designs and make deliberate engineering choices, rather than waiting to stumble on an evolutionarily fit point mutation.
- We can optimize the system directly for things like scientific reasoning, whereas human brains can do science only as a side-effect of our EAA capacities.
- When you go from not-having an invention to having one, there's always a discontinuous capabilities jump. Usually, however, the jump doesn't have much immediate impact on the world as a whole, because the thing you're inventing isn't a super-high-impact sort of thing. When you go from 0 to 1 on building Microsoft Word, you have a discontinuous Microsoft-Word-sized impact on the world. When you go from 0 to 1 on building AGI, you have a discontinuous AGI-sized impact on the world.
Thinking in the abstract about 'how useful would it be to be able to automate all reasoning about the physical world / all science / all technology?' is totally sufficient to make it clear why this impact would probably be enormous; though if we have doubts about our ability to abstractly reason to this conclusion, we can look at the human case too.
In that context, I find the "separate, additional miracle" argument weird. There's no additional miracle where we assume both AGI and intelligence explosion as axioms. Rather, AGI implies intelligence explosion because the 'be good at reasoning about physical environments in general, constructing long chains of reasoning, strategically moving between different levels of abstraction, organizing your thoughts in a more laserlike way, doing science and technology' thing implies being able to do AI research, for the same reason humans are able to do AI research. (And once AI can do AI research, it's trivial to see why this would accelerate AI research, and why this acceleration could feed on itself until it runs out of things to improve.)
If you believe intelligence explosion is a thing but don't think AGI is a thing, then sure, I can put myself in a mindset where it's weird to imagine two different world-changing events happening at around the same time ('I've already bought into intelligence explosion; now you want me to also buy into this crazy new thing that's supposed to happen at almost the exact same time?!').
But this reaction seems to require zooming out to the level of abstraction 'these are two huge world-impacting things; two huge world-impacting things shouldn't happen at the same time!'. The entire idea of AGI is 'multiple world-impacting sorts of things happen simultaneously'; otherwise we wouldn't call it 'general', and wouldn't talk about getting the capacity to do particle physics and pharmacology and electrical engineering simultaneously.
The fact that, e.g. AIs are mastering so much math and language while still wielding vastly infrahuman brain-equivalents, and crossing human competence in many domains (where there was ongoing effort) over decades is significant evidence for something smoother than the development of modern humans and their culture.
I agree with this as a directional update — it's nontrivial evidence for some combination of (a) 'we've already figured out key parts of reasoning-about-the-physical-world, and/or key precursors' and (b) 'you can do a lot of impressive world-impacting stuff without having full general intelligence'.
But I don't in fact believe on this basis that we already have baby AGIs. And if the argument isn't 'we already have baby AGIs' but rather 'the idea of "AGI" is wrong, we're going to (e.g.) gradually get one science after another rather than getting all the sciences at once', then that seems like directionally the wrong update to make from Atari, AlphaZero, GPT-3, etc. E.g., we don't live in a Hanson-esque world where AIs produce most of the scientific progress in biochemistry but the field has tried and failed for years to make serious AI-mediated progress on aerospace engineering.
Thanks for the in-depth response! I think I have a better idea now where you're coming from. A couple follow-up questions:
But I don't in fact believe on this basis that we already have baby AGIs. And if the argument isn't 'we already have baby AGIs' but rather 'the idea of "AGI" is wrong, we're going to (e.g.) gradually get one science after another rather than getting all the sciences at once', then that seems like directionally the wrong update to make from Atari, AlphaZero, GPT-3, etc
Do you think that human generality of thought requires a unique algorithm and/or brain structure that's not present in chimps? Rather than our brains just being scaled up chimp brains that then cross a threshold of generality (analogous to how GPT-3 had much more general capabilities than GPT-2)?
Would it not be reasonable to think of chimp brains as like 'baby' human brains?
I think Carl's comment about an 'additional miracle' makes sense if you think that the most direct path to AGI is roughly via scaling up today's systems. In that case, it would seem to be quite the coincidence if some additional general-thought technology was invented right around the same time that ML systems were scaling up enough to have general capabilities.
Does the 'additional miracle' comment make sense if you assume that frame – that AGI will come from something like scaled up versions of current ML systems?
Do you think that human generality of thought requires a unique algorithm and/or brain structure that's not present in chimps? Rather than our brains just being scaled up chimp brains that then cross a threshold of generality (analogous to how GPT-3 had much more general capabilities than GPT-2)?
I think human brains aren't just bigger chimp brains, yeah.
(Though it's not obvious to me that this is a crux. If human brains were just scaled up chimp-brains, it wouldn't necessarily be the case that chimps are scaled-up 'thing-that-works-like-GPT' brains, or scaled-up pelycosaur brains.)
Does the 'additional miracle' comment make sense if you assume that frame – that AGI will come from something like scaled up versions of current ML systems?
If scaling up something like GPT-3 got you to AGI, I'd still expect discontinuous leaps as the tech reached the 'can reason about messy physical environments at all' threshold (and probably other leaps too). Continuous tech improvement doesn't imply continuous cognitive output to arbitrarily high levels. (Nor does continuous cognitive output imply continuous real-world impact to arbitrarily high levels!)
If scaling up something like GPT-3 got you to AGI, I'd still expect discontinuous leaps as the tech reached the 'can reason about messy physical environments at all' threshold
Do none of A) GPT-3 producing continuations about physical environments, or B) MuZero learning a model of the environment, or even C) a Tesla driving on Autopilot, count?
It seems to me that you could consider these to be systems that reason about the messy physical world poorly, but definitely 'at all'.
Is there maybe some kind of self-directedness or agenty-ness that you're looking for that these systems don't have?
(EDIT: I'm digging in on this in part because it seems related to a potential crux that Ajeya and Nate noted here.)
Relative to what I mean by 'reasoning about messy physical environments at all', MuZero and Tesla Autopilot don't count. I could see an argument for GPT-3 counting, but I don't think it's in fact doing the thing.
Gotcha, thanks for the follow-up.
Btw, I just wrote up my current thoughts on the path from here to AGI, inspired in part by this discussion. I'd be curious to know where others disagree with my model.
“General intelligence” makes sense as a discrete thing you can invent at a particular time.
This seems like a fairly important crux. I see it as something that has been developed via many steps that are mostly small.
This post is a transcript of a discussion between Paul Christiano, Ajeya Cotra, and Eliezer Yudkowsky (with some comments from Rob Bensinger, Richard Ngo, and Carl Shulman), continuing from 1, 2, and 3.
Color key:
10.2. Prototypes, historical perspectives, and betting
[Bensinger][4:25]
I feel confused about the role "innovations are almost always low-impact" plays in slow-takeoff-ish views.
Suppose I think that there's some reachable algorithm that's different from current approaches, and can do par-human scientific reasoning without requiring tons of compute.
The existence or nonexistence of such an algorithm is just a fact about the physical world. If I imagine one universe where such an algorithm exists, and another where it doesn't, I don't see why I should expect that one of those worlds has more discontinuous change in GWP, ship sizes, bridge lengths, explosive yields, etc. (outside of any discontinuities caused by the advent of humans and the advent of AGI)? What do these CS facts have to do with the other facts?
But AI Impacts seems to think there's an important connection, and a large number of facts of the form 'steamships aren't like nukes' seem to undergird a lot of Paul's confidence that the scenario I described --
("there's some reachable algorithm that's different from current approaches, and can do par-human scientific reasoning without requiring tons of compute.")
-- is crazy talk. (Unless I'm misunderstanding. As seems actually pretty likely to me!)
(E.g., Paul says "To me your model just seems crazy, and you are saying it predicts crazy stuff at the end but no crazy stuff beforehand", and one of the threads of the timelines conversation has been Paul asking stuff like "do you want to give any example other than nuclear weapons of technologies with the kind of discontinuous impact you are describing?".)
Possibilities that came to mind for me:
1. The argument is 'reality keeps surprising us with how continuous everything else is, so we seem to have a cognitive bias favoring discontinuity, so we should have a skeptical prior about our ability to think our way to 'X is discontinuous' since our brains are apparently too broken to do that well?
(But to get from 1 to 'discontinuity models are batshit' we surely need something more probability-mass-concentrating than just a bias argument?)
2. The commonality between steamship sizes, bridge sizes, etc. and AGI is something like 'how tractable is the world?'. A highly tractable world, one whose principles are easy to understand and leverage, will tend to have more world-shatteringly huge historical breakthroughs in various problems, and will tend to see a larger impact from the advent of humans and the advent of AGI.
Our world looks much less tractable, so even if there's a secret sauce to building AGI, we should expect the resultant AGI to be a lot less impactful.
[Ngo][5:06]
I endorse #2 (although I think more weakly than Paul does) and would also add #3: another commonality is something like "how competitive is innovation?"
[Shulman][8:22]
@RobBensinger It's showing us a fact about the vast space of ideas and technologies we've already explored that they are not so concentrated and lumpy that the law of large numbers doesn't work well as a first approximation in a world with thousands or millions of people contributing. And that specifically includes past computer science innovation.
So the 'we find a secret sauce algorithm that causes a massive unprecedented performance jump, without crappier predecessors' is a 'separate, additional miracle' at exactly the same time as the intelligence explosion is getting going. You can get hyperbolic acceleration from increasing feedbacks from AI to AI hardware and software, including crazy scale-up at the end, as part of a default model. But adding on to it that AGI is hit via an extremely large performance jump of a type that is very rare, takes a big probability penalty.
And the history of human brains doesn't seem to provide strong evidence of a fundamental software innovation, vs hardware innovation and gradual increases in selection applied to cognition/communication/culture.
The fact that, e.g. AIs are mastering so much math and language while still wielding vastly infrahuman brain-equivalents, and crossing human competence in many domains (where there was ongoing effort) over decades is significant evidence for something smoother than the development of modern humans and their culture.
That leaves me not expecting a simultaneous unusual massive human concentrated algorithmic leap with AGI, although I expect wildly accelerating progress from increasing feedbacks at that time. Crossing a given milestone is disproportionately likely to happen in the face of an unusually friendly part/jump of a tech tree (like AlexNet/the neural networks->GPU transition) but still mostly not, and likely not from an unprecedented in computer science algorithmic change.
https://aiimpacts.org/?s=cross+
[Yudkowsky][11:26][11:37]
I want to flag strong agreement with this. I am not talking about change in ship sizes because that is relevant in any visible way on my model; I'm talking about it in hopes that I can somehow unravel Carl and Paul's model, which talks a whole lot about this being Relevant even though that continues to not seem correlated to me across possible worlds.
I think a lot in terms of "does this style of thinking seem to have any ability to bind to reality"? A lot of styles of thinking in futurism just don't.
I imagine Carl and Paul as standing near the dawn of hominids asking, "Okay, let's try to measure how often previous adaptations resulted in simultaneous fitness improvements across a wide range of environmental challenges" or "what's the previous record on an organism becoming more able to survive in a different temperature range over a 100-year period" or "can we look at the variance between species in how high they fly and calculate how surprising it would be for a species to make it out of the atmosphere"
And all of reality is standing somewhere else, going on ahead to do its own thing.
Now maybe this is not the Carl and Paul viewpoint but if so I don't understand how not. It's not that viewpoint plus a much narrower view of relevance, because AI Impacts got sent out to measure bridge sizes.
I go ahead and talk about these subjects, in part because maybe I can figure out some way to unravel the viewpoint on its own terms, in part because maybe Carl and Paul can show that they have a style of thinking that works in its own right and that I don't understand, and in part because people like Paul's nonconcrete cheerful writing better and prefer to live there mentally and I have to engage on their terms because they sure won't engage on mine.
But I do not actually think that bridge lengths or atomic weapons have anything to do with this.
Carl and Paul may be doing something sophisticated but wordless, where they fit a sophisticated but wordless universal model of technological permittivity to bridge lengths, then have a wordless model of cognitive scaling in the back of their minds, then get a different prediction of Final Days behavior, then come back to me and say, "Well, if you've got such a different prediction of Final Days behavior, can you show me some really large bridges?"
But this is not spelled out in the writing - which, I do emphasize, is a social observation that would be predicted regardless, because other people have not invested a ton of character points in the ability to spell things out, and a supersupermajority would just plain lack the writing talent for it.
And what other EAs reading it are thinking, I expect, is plain old Robin-Hanson-style reference class tennis of "Why would you expect intelligence to scale differently from bridges, where are all the big bridges?"
[Cotra][11:36][11:40]
(Just want to interject that Carl has higher P(doom) than Paul and has also critiqued Paul for not being more concrete, and I doubt that this is the source of the common disagreements that Paul/Carl both have with Eliezer)
From my perspective the thing the AI impacts investigation is asking is something like "When people are putting lots of resources into improving some technology, how often is it the case that someone can find a cool innovation that improves things a lot relative to the baseline?" I think that your response to that is something like "Sure, if the broad AI market were efficient and everyone were investigating the right lines of research, then AI progress might be smooth, but AGI would have also been developed way sooner. We can't safely assume that AGI is like an industry where lots of people are pushing toward the same thing"
But it's not assuming a great structural similarity between bridges and AI, except that they're both things that humans are trying hard to find ways to improve
[Yudkowsky][11:42]
I can imagine writing responses like that, if I was engaging on somebody else's terms. As with Eliezer-2012's engagement with Pat Modesto against the careful proof that HPMOR cannot possibly become one of the measurably most popular fanfictions, I would never think anything like that inside my own brain.
Maybe I just need to do a thing that I have not done before, and set my little $6000 Roth IRA to track a bunch of investments that Carl and/or Paul tell me to make, so that my brain will actually track the results, and I will actually get a chance to see this weird style of reasoning produce amazing results.
[Bensinger][11:44]
Presumably also "'AI progress' subsumes many different kinds of cognition, we don't currently have baby AGIs, and when we do figure out how to build AGI the very beginning of the curve (the Wright flyer moment, or something very shortly after) will correspond to a huge capability increase."
[Yudkowsky][11:46]
I think there's some much larger scale in which it's worth mentioning that on my own terms of engagement I do not naturally think like this. I don't feel like you could get Great Insight by figuring out what the predecessor technologies must have been of the Wright Flyer, finding industries that were making use of them, and then saying Behold the Heralds of the Wright Flyer. It's not a style of thought binding upon reality.
They built the Wright Flyer. It flew. Previous stuff didn't fly. It happens. Even if you yell a lot at reality and try to force it into an order, that's still what your actual experience of the surprising Future will be like, you'll just be more surprised by it.
Like you can super want Technologies to be Heralded by Predecessors which were Also Profitable but on my native viewpoint this is, like, somebody with a historical axe to grind, going back and trying to make all the history books read like this, when I have no experience of people who were alive at the time making gloriously correct futuristic predictions using this kind of thinking.
[Cotra][11:53]
I think Paul's view would say:
Paul's view says that the Kitty Hawk moment already happened for the kind of AI that will be super transformative and could kill us all, and like the historical Kitty Hawk moment, it was not immediately a huge deal
[Yudkowsky][11:56]
There is, I think, a really basic difference of thinking here, which is that on my view, AGI erupting is just a Thing That Happens and not part of a Historical Worldview or a Great Trend.
Human intelligence wasn't part of a grand story reflected in all parts of the ecology, it just happened in a particular species.
Now afterwards, of course, you can go back and draw all kinds of Grand Trends into which this Thing Happening was perfectly and beautifully fitted, and yet, it does not seem to me that people have a very good track record of thereby predicting in advance what surprising news story they will see next - with some rare, narrow-superforecasting-technique exceptions, like the Things chart on a steady graph and we know solidly what a threshold on that graph corresponds to and that threshold is not too far away compared to the previous length of the chart.
One day the Wright Flyer flew. Anybody in the future with benefit of hindsight, who wanted to, could fit that into a grand story about flying, industry, travel, technology, whatever; if they've been on the ground at the time, they would not have thereby had much luck predicting the Wright Flyer. It can be fit into a grand story but on the ground it's just a thing that happened. It had some prior causes but it was not thereby constrained to fit into a storyline in which it was the plot climax of those prior causes.
My worldview sure does permit there to be predecessor technologies and for them to have some kind of impact and for some company to make a profit, but it is not nearly as interested in that stuff, on a very basic level, because it does not think that the AGI Thing Happening is the plot climax of a story about the Previous Stuff Happening.
[Cotra][12:01]
The fact that you express this kind of view about AGI erupting one day is why I thought your thing in IEM was saying there was a major algorithmic innovation from chimps to humans, that humans were qualitatively and not just quantitatively better than chimps and this was not because of their larger brain size primarily. But I'm confused because up thread in the discussion of evolution you were emphasizing much more that there was an innovation between dinosaurs and primates, not that there was an innovation between chimps and humans, and you seemed more open to the chimp/human diff being quantitative and brain-size driven than I had thought you'd be. But being open to the chimp-human diff being quantitative/brain-size-driven suggests to me that you should be more open than you are to AGI being developed by slow grinding on the same shit, instead of erupting without much precedent?
[Yudkowsky][12:01]
I think you're confusing a meta-level viewpoint with an object-level viewpoint.
The Wright Flyer does not need to be made out of completely different materials from all previous travel devices, in order for the Wright Flyer to be a Thing That Happened One Day which wasn't the plot climax of a grand story about Travel and which people at the time could not have gotten very far in advance-predicting by reasoning about which materials were being used in which conveyances and whether those conveyances looked like they'd be about to start flying.
It is the very viewpoint to which I am objecting, which keeps on asking me, metaphorically speaking, to explain how the Wright Flyer could have been made of completely different materials in order for it to be allowed to be so discontinuous with the rest of the Travel story of which it is part.
On my viewpoint they're just different stories so the Wright Flyer is allowed to be its own thing even though it is not made out of an unprecedented new kind of steel that floats.
[Cotra][12:06]
The claim I'm making is that Paul's view predicts a lag and a lot of investment between the first flight and aircraft making a big impact on the travel industry, and predicts that the first flight wouldn't have immediately made a big impact on the travel industry. In other words Kitty Hawk isn't a discontinuity in the Paul view because the metrics he'd expect to be continuous are the ones that large numbers of people are trying hard to optimize, like cost per mile traveled or whatnot, not metrics that almost nobody is trying to optimize, like "height flown."
In other words, it sounds like you're saying:
While Paul is saying:
[Yudkowsky][12:09]
Well, unfortunately, Paul and I both seem to believe that our models follow from observing the present-day world, rather than being incompatible with it, and so when we demand of each other that we produce some surprising bold prediction about the present-day world, we both tend to end up disappointed.
I would like, of course, for Paul's surprisingly narrow vision of a world governed by tightly bound stories and predictable trends, to produce some concrete bold prediction of the next few years which no ordinary superforecaster would produce, but Paul is not under the impression that his own worldview is similarly strange and narrow, and so has some difficulty in answering this request.
[Cotra][12:09]
But Paul offered to bet with you about literally any quantity you choose?
[Yudkowsky][12:10]
I did assume that required an actual disagreement, eg, I cannot just go look up something superforecasters are very confident about and then demand Paul to bet against it.
[Cotra][12:12]
It still sounds to me like "take a basket of N performance metrics, bet that the model size to perf trend will break upward in > K of them within e.g. 2 or 3 years" should sound good to you, I'm confused why that didn't. If it does and it's just about the legwork then I think we could get someone to come up with the benchmarks and stuff for you
Or maybe the same thing but >K of them will break downward, whatever
We could bet about the human perception of sense in language models, for example
[Yudkowsky][12:14]
I am nervous about Paul's definition of "break" and the actual probabilities to be assigned. You see, both Paul and I think our worldview is a very normal one that matches current reality quite well, so when we are estimating parameters like these, Paul is liable to do it empirically, and I am also liable to do it empirically as my own baseline, and if I point to a trend over time in how long it takes to go from par-human to superhuman performance decreasing, Imaginary Paul says "Ah, yes, what a fine trend, I will bet that things follow this trend" and Eliezer says "No that is MY trend, you don't get to follow it, you have to predict that par-human to superhuman time will be constant" and Paul is like "lol no I get to be a superforecaster and follow trends" and we fail to bet.
Maybe I'm wrong in having mentally played the game out ahead that far, for it is, after all, very hard to predict the Future, but that's where I'd foresee it failing.
[Cotra][12:16]
I don't think you need to bet about calendar times from par-human to super-human, and any meta-trend in that quantity. It sounds like Paul is saying "I'll basically trust the model size to perf trends and predict a 10x bigger model from the same architecture family will get the perf the trends predict," and you're pushing back against that saying e.g. that humans won't find GPT-4 to be subjectively more coherent than GPT-3 and that Paul is neglecting that there could be major innovations in the future that bring down the FLOP/s to get a certain perf by a lot and bend the scaling laws. So why not bet that Paul won't be as accurate as he thinks he is by following the scaling laws?
[Bensinger][12:17]
"When they do, they happen at small scale in shitty prototypes, like the Wright Flyer or GPT-1 or AlphaGo or the Atari bots or whatever"
How shitty the prototype is should depend (to a very large extent) on the physical properties of the tech. So I don't find it confusing (though I currently disagree) when someone says "I looked at a bunch of GPT-3 behavior and it's cognitively sophisticated enough that I think it's doing basically what humans are doing, just at a smaller scale. The qualitative cognition I can see going on is just that impressive, taking into account the kinds of stuff I think human brains are doing."
What I find confusing is, like, treating ten thousand examples of non-AI, non-cognitive-tech continuities (nukes, building heights, etc.) as though they're anything but a tiny update about 'will AGI be high-impact' -- compared to the size of updates like 'look at how smart and high-impact humans were' and perhaps 'look at how smart-in-the-relevant-ways GPT-3 is'.
Like, impactfulness is not a simple physical property, so there's not much reason for different kinds of tech to have similar scales of impact (or similar scales of impact n years after the first prototype). Mainly I'm not sure to what extent we disagree about this, vs. this just being me misunderstanding the role of the 'most things aren't high-impact' argument.
(And yeah, a random historical technology drawn from a hat will be pretty low-impact. But that base rate also doesn't seem to me like it has much evidential relevance anymore when I update about what specific tech we're discussing.)
[Cotra][12:18]
The question is not "will AGI be high impact" -- Paul agrees it will, and for any FOOM quantity (like crossing a chimp-to-human-sized gap in a day or whatever) he agrees that will happen eventually too.
The technologies studies in the dataset spanned a wide range in their peak impact on society, and they're not being used to forecast the peak impact of mature AI tech
[Bensinger][12:19]
Yeah, I'm specifically confused about how we know that the AGI Wright Flyer and its first successors are low-impact, from looking at how low-impact other technologies are (if that is in fact a meaningful-sized update on your view)
Not drawing a comparison about the overall impactfulness of AI / AGI (e.g., over fifteen years)
[Yudkowsky][12:21]
I'm pessimistic about us being able to settle on the terms of a bet like that (and even more so about being able to bet against Carl on it) but in broad principle I agree. The trouble is that if a trend is benchmarkable, I believe more in the trend continuing at least on the next particular time, not least because I believe in people Goodharting benchmarks.
I expect a human sense of intelligence to be harder to fool (even taking into account that it's being targeted to a nonzero extent) but I also expect that to be much harder to measure and bet upon than the Goodhartable metrics. And I think our actual disagreement is more visible over portfolios of benchmarks breaking upward over time, but I also expect that if you ask Paul and myself to quantify our predictions, we both go, "Oh, my theory is the one that fits ordinary reality so obviously I will go look at superforecastery trends over ordinary reality to predict this specifically" and I am like, "No, Paul, if you'd had to predict that without looking at the data, your worldview would've predicted trends breaking down less often" and Paul is like "But Eliezer, shouldn't you be predicting much more upward divergence than this."
Again, perhaps I'm being overly gloomy.
[Cotra][12:23]
I think we should try to find ML predictions where you defer to superforecasters and Paul disagrees, since he said he would bet against superforecasters in ML
[Yudkowsky][12:24]
I am also probably noticeably gloomier and less eager to bet because the whole fight is taking place on grounds that Paul thinks is important and part of a connected story that continuously describes ordinary reality, and that I think is a strange place where I can't particularly see how Paul's reasoning style works. So I'd want to bet against Paul's overly narrow predictions by using ordinary superforecasting, and Paul would like to make his predictions using ordinary superforecasting.
I am, indeed, more interested in a place where Paul wants to bet against superforecasters. I am not guaranteeing up front I'll bet with them because superforecasters did not call AlphaGo correctly and I do not think Paul has zero actual domain expertise. But Paul is allowed to pick up generic epistemic credit including from me by beating superforecasters because that credit counts toward believing a style of thought is even working literally at all; separately from the question of whether Paul's superforecaster-defying prediction also looks like a place where I'd predict in some opposite direction.
Definitely, places where Paul disagrees with superforecasters are much more interesting places to mine for bets.
I am happy to hear about those.
[Cotra][12:27]
I think what Paul was saying last night is you find superforecasters betting on some benchmark performance, and he just figures out which side he'd take (and he expects in most/all superforecaster predictions that he would not be deferential, there's a side he would take)
10.3. Predictions and betting (continued)
[Christiano][12:29]
not really following along with the conversation, but my desire to bet about "whatever you want" was driven in significant part by frustration with Eliezer repeatedly saying things like "people like Paul get surprised by reality" and me thinking that's nonsense
[Yudkowsky][12:29]
So the Yudkowskian viewpoint is something like... trends in particular technologies held fixed, will often break down; trends in Goodhartable metrics, will often stay on track but come decoupled from their real meat; trends across multiple technologies, will experience occasional upward breaks when new algorithms on the level of Transformers come out. For me to bet against superforecasters I have to see superforecasters saying something different, which I do not at this time actually know to be the case. For me to bet against Paul betting against superforecasters, the different thing Paul says has to be different from my own direction of disagreement with superforecasters.
[Christiano][12:30]
I still think that if you want to say "this sort of reasoning is garbage empirically" then you ought to be willing to bet about something. If we are just saying "we agree about all of the empirics, it's just that somehow we have different predictions about AGI" then that's fine and symmetrical.
[Yudkowsky][12:30]
I have been trying to revise that towards a more nvc "when I try to operate this style of thought myself, it seems to do a bad job of retrofitting and I don't understand how it says X but not Y".
[Christiano][12:30]
even then presumably if you think it's garbage you should be able to point to some particular future predictions where it would be garbage?
if you used it
and then I can either say "no, I don't think that's a valid application for reason X" or "sure, I'm happy to bet"
and it's possible you can't find any places where it sticks its neck out in practice (even in your version), but then I'm again just rejecting the claim that it's empirically ruled out
[Yudkowsky][12:31]
I also think that we'd have an easier time betting if, like, neither of us could look at graphs over time, but we were at least told the values in 2010 and 2011 to anchor our estimates over one year, or something like that.
Though we also need to not have a bunch of existing knowledge of the domain which is hard.
[Christiano][12:32]
I think this might be derailing some broader point, but I am provisionally mostly ignoring your point "this doesn't work in practice" if we can't find places where we actually foresee disagreements
(which is fine, I don't think it's core to your argument)
[Yudkowsky][12:33]
Paul, you've previously said that you're happy to bet against ML superforecasts. That sounds promising. What are examples of those? Also I must flee to lunch and am already feeling sort of burned and harried; it's possible I should not ignore the default doomedness of trying to field questions from multiple sources.
[Christiano][12:33]
I don't know if superforecasters make public bets on ML topics, I was saying I'm happy to bet on ML topics and if your strategy is "look up what superforecasters say" that's fine and doesn't change my willingness to bet
I think this is probably not as promising as either (i) dig in on the arguments that are most in dispute (seemed to be some juicier stuff earlier though I'm just focusing on work today) , or (ii) just talking generally about what we expect to see in the next 5 years so that we can at least get more of a vibe looking back
[Shulman][12:35]
You can bet on the Metaculus AI Tournament forecasts.
https://www.metaculus.com/ai-progress-tournament/
[Yudkowsky][13:13]
I worry that trying to jump straight ahead to Let's Bet is being too ambitious too early on a cognitively difficult problem of localizing disagreements.
Our prophecies of the End Times's modal final days seem legit different; my impulse would be to try to work that backwards, first, in an intuitive sense of "well which prophesied world would this experience feel more like living in?", and try to dig deeper there before deciding that our disagreements have crystallized into short-term easily-observable bets.
We both, weirdly enough, feel that our current viewpoints are doing a great job of permitting the present-day world, even if, presumably, we both think the other's worldview would've done worse at predicting that world in advance. This cannot be resolved in an instant by standard techniques known to me. Let's try working back from the End Times instead.
I have already stuck out my neck a little and said that, as we start to go past $50B invested in a model, we are starting to live at least a little more in what feels like the Paulverse, not because my model prohibits this, but because, or so I think, Paul's model more narrowly predicts it.
It does seem like the sort of generically weird big thing that could happen, to me, even before the End Times, there are corporations that could just decide to do that; I am hedging around this exactly because it does feel to my gut like that is a kind of headline I could read one day and have it still be years before the world ended, so I may need to be stingy with those credibility points inside of what I expect to be reality.
But if we get up to $10T to train a model, that is much more strongly Paulverse; it's not that this falsifies the Eliezerverse considered in isolation, but it is much more narrowly characteristic of the Words of Paul coming to pass; it feels much more to my gut that, in agreeing to this, I am not giving away Bayes points inside my own mainline.
If ordinary salaries for ordinary fairly-good programmers get up to $20M/year, this is not prohibited by my AI models per se; but it sure sounds like the world becoming less ordinary than I expected it to stay, and like it is part of Paul's Prophecy much more strongly than it is part of Eliezer's Prophecy.
That's two ways that I could concede a great victory to the Paulverse. They both have the disadvantages (from my perspective) that the Paulverse, though it must be drawing probability mass from somewhere in order to stake it there, is legitimately not - so far as I know - forced to claim that these things happen anytime soon. So they are ways for the Paulverse to win, but not ways for the Eliezerverse to win.
That I have said even this much, I claim, puts Paul in at least a little tiny bit of debt to me epistemic-good-behavior-wise; he should be able to describe events which would start to make him worry he was living in the Eliezerverse, even if his model did not narrowly rule them out, and even if those events had not been predicted by the Eliezerverse to occur within a narrowly prophesied date such that they would not thereby form a bet the Eliezerverse could clearly lose as well as win.
I have not had much luck in trying to guess what the real Paul will say about issues like this one. My last attempt was to say, "Well, what shouldn't happen, besides the End Times themselves, before world GDP has doubled over a four-year period?" And Paul gave what seems to me like an overly valid reply, which, iirc and without looking it up, was along the lines of, "well, nothing that would double world GDP in a 1-year period".
When I say this is overly valid, I mean that it follows too strongly from Paul's premises, and he should be looking for something less strong than that on which to make a beginning discovery of disagreement - maybe something which Paul's premises don't strongly forbid to him, but which nonetheless looks more like the Eliezerverse or like it would be relatively more strongly predicted by Eliezer's Prophecy.
I do not model Paul as eagerly or strongly agreeing with, say, "The Riemann Hypothesis should not be machine-proven" or "The ABC Conjecture should not be machine-proven" before world GDP has doubled. It is only on Eliezer's view that proving the Riemann Hypothesis is about as much of a related or unrelated story to AGI, as are particular benchmarks of GDP.
On Paul's view as I am trying to understand and operate it, this benchmark may be correlated with AGI in time in the sense that most planets wouldn't do it during the Middle Ages before they had any computers, but it is not part of the story of AGI, it is not part of Paul's Prophecy; because it doesn't make a huge amount of money and increase GDP and get a huge ton of money flowing into investments in useful AI.
(From Eliezer's perspective, you could tell a story about how a stunning machine proof of the Riemann Hypothesis got Bezos to invest $50 billion in training a successor model and that was how the world ended, and that would be a just-as-plausible model as some particular economic progress story, of how Stuff Happened Because Other Stuff Happened; it sounds like the story of OpenAI or of Deepmind's early Atari demo, which is to say, it sounds to Eliezer like history. Whereas on Eliezer!Paul's view, that's much more of a weird coincidence because it involves Bezos's unforced decision rather than the economic story of which AGI is capstone, or so it seems to me trying to operate Paul's view.)
And yet Paul might still, I hope, be able to find something like "The Riemann Hypothesis is machine-proven", which even though it is not very much of an interesting part of his own Prophecy because it's not part of the economic storyline, sounds to him like the sort of thing that the Eliezerverse thinks happens as you get close to AGI, which the Eliezerverse says is allowed to start happening way before world GDP would double in 4 years; and as it happens I'd agree with that characterization of the Eliezerverse.
So Paul might say, "Well, my model doesn't particularly forbid that the Riemann Hypothesis gets machine-proven before world GDP has doubled in 4 years or even started to discernibly break above trend by much; but that does sound more like we are living in the Eliezerverse than in the Paulverse."
I am not demanding this particular bet because it seems to me that the Riemann Hypothesis may well prove to be unfairly targetable for current ML techniques while they are still separated from AGI by great algorithmic gaps. But if on the other hand Paul thinks that, I dunno, superhuman performance on stuff like the Riemann Hypothesis does tend to be more correlated with economically productive stuff because it's all roughly the same kind of capability, and lol never mind this "algorithmic gap" stuff, then maybe Paul is willing to pick that example; which is all the better for me because I do suspect it might decouple from the AI of the End, and so I think I have a substantial chance of winning and being able to say "SEE!" to the assembled EAs while there's still a year or two left on the timeline.
I'd love to have credibility points on that timeline, if Paul doesn't feel as strong an anticipation of needing them.
[Christiano][15:43]
1/3 that RH has an automated proof before sustained 7%/year GWP growth?
I think the clearest indicator is that we have AI that ought to be able to e.g. run the fully automated factory-building factory (not automating mines or fabs, just the robotic manufacturing and construction), but it's not being deployed or is being deployed with very mild economic impacts
another indicator is that we have AI systems that can fully replace human programmers (or other giant wins), but total investment in improving them is still small
another indicator is a DeepMind demo that actually creates a lot of value (e.g. 10x larger than DeepMind's R&D costs? or even comparable to DeepMind's cumulative R&D costs if you do the accounting really carefully and I definitely believe it and it wasn't replaceable by Brain), it seems like on your model things should "break upwards" and in mine that just doesn't happen that much
sounds like you may have >90% on automated proof of RH before a few years of 7%/year growth driven by AI? so that would give a pretty significant odds ratio either way
I think "stack more layers gets stuck but a clever idea makes crazy stuff happen" is generally going to be evidence for your view
That said, I'd mostly reject AlphaGo as an example, because it's just plugging in neural networks to existing go algorithms in almost the most straightforward way and the bells and whistles don't really matter. But if AlphaZero worked and AlphaGo didn't, and the system accomplished something impressive/important (like proving RH, or being significantly better at self-contained programming tasks), then that would be a surprise.
And I'd reject LSTM -> transformer or MoE as an example because the quantitative effect size isn't that big.
But if something like that made the difference between "this algorithm wasn't scaling before, and now it's scaling," then I'd be surprised.
And the size of jump that surprises me is shrinking over time. So in a few years even getting the equivalent of a factor of 4 jump from some clever innovation would be very surprising to me.
[Yudkowsky][17:44]
I emphasize that this is mostly about no on the GDP growth before the world ending, rather than yes on the RH proof, i.e., I am not 90% on RH before the end of the world at all. Not sure I'm over 50% on it happening before the end of the world at all.
Should it be a consequence of easier earlier problems than full AGI? Yes, on my mainline model; but also on my model, it's a particular thing and maybe the particular people and factions doing stuff don't get around to that particular thing.
I guess if I stare hard at my brain it goes 'ehhhh maybe 65% if timelines are relatively long and 40% if it's like the next 5 years', because the faster stuff happens, the less likely anyone is to get around to proving RH in particular or announcing that they've done so if they did.
And if the econ threshold is set as low as 7%/yr, I start to worry about that happening in longer-term scenarios, just because world GDP has never been moving at a fixed rate over a log chart. the "driven by AI" part sounds very hard to evaluate. I want, I dunno, some other superforecaster or Carl to put a 90% credible bound on 'when world GDP growth hits 7% assuming little economically relevant progress in AI' before I start betting at 80%, let alone 90%, on what should happen before then. I don't have that credible bound already loaded and I'm not specialized in it.
I'm wondering if we're jumping ahead of ourselves by trying to make a nice formal Bayesian bet, as prestigious as that might be. I mean, your 1/3 was probably important for you to say, as it is higher than I might have hoped, and I'd ask you if you really mean for that to be an upper bound on your probability or if that's your actual probability.
But, more than that, I'm wondering if, in the same vague language I used before, you're okay with saying a little more weakly, "RH proven before big AI-driven growth in world GDP, sounds more Eliezerverse than Paulverse."
It could be that this is just not actually true because you do not think that RH is coupled to econ stuff in the Paul Prophecy one way or another, and my own declarations above do not have the Eliezerverse saying it enough more strongly than that. If you don't actually see this as a distinguishing Eliezerverse thing, if it wouldn't actually make you say "Oh no maybe I'm in the Eliezerverse", then such are the epistemic facts.
This sounds potentially more promising to me - seems highly Eliezerverse, highly non-Paul-verse according to you, and its negation seems highly oops-maybe-I'm-in-the-Paulverse to me too. How many years is a few? How large a jump is shocking if it happens tomorrow?
11. September 24 conversation
11.1. Predictions and betting (continued 2)
[Christiano][13:15]
I think RH is not that surprising, it's not at all clear to me where "do formal math" sits on the "useful stuff AI could do" spectrum, I guess naively I'd put it somewhere "in the middle" (though the analogy to board games makes it seem a bit lower, and there is a kind of obvious approach to doing this that seems to be working reasonably well so that also makes it seem lower), and 7% GDP growth is relatively close to the end (ETA: by "close to the end" I don't mean super close to the end, just far enough along that there's plenty of time for RH first)
I do think that performance jumps are maybe more dispositive, but I'm afraid that it's basically going to go like this: there won't be metrics that people are tracking that jump up, but you'll point to new applications that people hadn't considered before, and I'll say "but those new applications aren't that valuable" whereas to you they will look more analogous to a world-ending AGI coming out from the blue
like for AGZ I'll be like "well it's not really above the deep learning trend if you run it backwards" and you'll be like "but no one was measuring it before! you can't make up the trend in retrospect!" and I'll be like "OK, but the reason no one was measuring it before was that it was worse than traditional go algorithms until like 2 years ago and the upside is not large enough that you should expect a huge development effort for a small edge"
[Yudkowsky][13:43]
"factor of 4 jump from some clever innovation" - can you say more about that part?
[Christiano][13:53]
like I'm surprised if a clever innovation does more good than spending 4x more compute
[Yudkowsky][15:04]
I worry that I'm misunderstanding this assertion because, as it stands, it sounds extremely likely that I'd win. Would transformers vs. CNNs/RNNs have won this the year that the transformers paper came out?
[Christiano][15:07]
I'm saying that it gets harder over time, don't expect wins as big as transformers
I think even transformers probably wouldn't make this cut though?
certainly not vs CNNs
vs RNNs I think the comparison I'd be using to operationalize it is translation, as measured in the original paper
they do make this cut for translation, looks like the number is like 100 >> 4
100x for english-german, more like 10x for english-french, those are the two benchmarks they cite
but both more than 4x
I'm saying I don't expect ongoing wins that big
I think the key ambiguity is probably going to be about what makes a measurement established/hard-to-improve
[Yudkowsky][15:21]
this sounds like a potentially important point of differentiation; I do expect more wins that big.
the main thing that I imagine might make a big difference to your worldview, but not mine, is if the first demo of the big win only works slightly better (although that might also be because they were able to afford much less compute than the big players, which I think your worldview would see as a redeeming factor for my worldview?) but a couple of years later might be 4x or 10x as effective per unit compute (albeit that other innovations would've been added on by then to make the first innovation work properly, which I think on your worldview is like The Point or something)
clarification: by "transformers vs CNNs" I don't mean transformers on ImageNet, I mean transformers vs. contemporary CNNs, RNNs, or both, being used on text problems.
I'm also feeling a bit confused because eg Standard Naive Kurzweilian Accelerationism makes a big deal about the graphs keeping on track because technologies hop new modes as needed. what distinguishes your worldview from saying that no further innovations are needed for AGI or will give a big compute benefit along the way? is it that any single idea may only ever produce a smaller-than-4X benefit? is it permitted that a single idea plus 6 months of engineering fiddly details produce a 4X benefit?
all this aside, "don't expect wins as big as transformers" continues to sound to me like a very promising point for differentiating Prophecies.
[Christiano][15:50]
I think the relevant feature of the innovation is that the work to find it is small relative to the work that went into the problem to date (though there may be other work on other avenues)
[Yudkowsky][15:52]
in, like, a local sense, or a global sense? if there's 100 startups searching for ideas collectively with $10B of funding, and one of them has an idea that's 10x more efficient per unit compute on billion-dollar problems, is that "a small amount of work" because it was only a $100M startup, or collectively an appropriate amount of work?
[Christiano][15:53]
I'm calling that an innovation because it's a small amount of work
[Yudkowsky][15:54]
(maybe it would be also productive if you pointed to more historical events like Transformers and said 'that shouldn't happen again', because I didn't realize there was anything you thought was like that. AlphaFold 2?)
[Christiano][15:54]
like, it's not just a claim about EMH, it's also a claim about the nature of progress
I think AlphaFold counts and is probably if anything a bigger multiplier, it's just uncertainty over how many people actually worked on the baselines
[Yudkowsky][15:54]
when should we see headlines like those subside?
[Christiano][15:55]
I mean, I think they are steadily subsiding
as areas grow
[Yudkowsky][15:55]
have they already begun to subside relative to 2016, on your view?
(guess that was ninjaed)
[Christiano][15:55]
I would be surprised to see a 10x today on machine translation
[Yudkowsky][15:55]
where that's 10x the compute required to get the same result?
[Christiano][15:55]
though not so surprised that we can avoid talking about probabilities
yeah
or to make it more surprising, old sota with 10x less compute
[Yudkowsky][15:56]
yeah I was about to worry that people wouldn't bother spending 10x the cost of a large model to settle our bet
[Christiano][15:56]
I'm more surprised if they get the old performance with 10x less compute though, so that way around is better on all fronts
[Yudkowsky][15:57]
one reads papers claiming this all the time, though?
[Christiano][15:57]
like, this view also leads me to predict that if I look at the actual amount of manpower that went into alphafold, it's going to be pretty big relative to the other people submitting to that protein folding benchmark
[Yudkowsky][15:57]
though typically for the sota of 2 years ago
[Christiano][15:58]
not plausible claims on problems people care about
I think the comparison is to contemporary benchmarks from one of the 99 other startups who didn't find the bright idea
that's the relevant thing on your view, right?
[Yudkowsky][15:59]
I would expect AlphaFold and AlphaFold 2 to involve... maybe 20 Deep Learning researchers, and for 1-3 less impressive DL researchers to have been the previous limit, if the field even tried that much; I would not be the least surprised if DM spent 1000x the compute on AlphaFold 2, but I'd be very surprised if the 1-3 large research team could spend that 1000x compute and get anywhere near AlphaFold 2 results.
[Christiano][15:59]
and then I'm predicting that number is already <10 for machine translation and falling (maybe I shouldn't talk about machine translation or at least not commit to numbers given that I know very little about it, but whatever that's my estimate), and for other domains it will be <10 by the time they get as crowded as machine translation, and for transformative tasks they will be <2
isn't there an open-source replication of alphafold?
we could bet about its performance relative to the original
[Yudkowsky][16:00]
it is enormously easier to do what's already been done
[Christiano][16:00]
I agree
[Yudkowsky][16:00]
I believe the open-source replication was by people who were told roughly what Deepmind had done, possibly more than roughly
on the Yudkowskian view, those 1-3 previous researchers just would not have thought of doing things the way Deepmind did them
[Christiano][16:01]
anyway, my guess is generally that if you are big relative to previous efforts in the area you can make giant improvements, if you are small relative to previous efforts you might get lucky (or just be much smarter) but that gets increasingly unlikely as the field gets bigger
like alexnet and transformers are big wins by groups who are small relative to the rest of the field, but transformers are much smaller than alexnet and future developments will continue to shrink
[Yudkowsky][16:02]
but if you're the same size as previous efforts and don't have 100x the compute, you shouldn't be able to get huge improvements in the Paulverse?
[Christiano][16:03]
I mean, if you are the same size as all the prior effort put together?
I'm not surprised if you can totally dominate in that case, especially if prior efforts aren't well-coordinated
and for things that are done by hobbyists, I wouldn't be surprised if you can be a bit bigger than an individual hobbyist and dominate
[Yudkowsky][16:03]
I'm thinking something like, if Deepmind comes out with an innovation such that it duplicates old SOTA on machine translation with 1/10th compute, that still violates the Paulverse because Deepmind is not Paul!Big compared to all MTL efforts
though I am not sure myself how seriously Earth is taking MTL in the first place
[Christiano][16:04]
yeah, I think if DeepMind beats Google Brain by 10x compute next year on translation, that's a significant strike against Paul
[Yudkowsky][16:05]
I know that Google offers it for free, I expect they at least have 50 mediocre AI people working on it, I don't know whether or not they have 20 excellent AI people working on it and if they've ever tried training a 200B parameter non-MoE model on it
[Christiano][16:05]
I think not that seriously, but more seriously than 2016 and than anything else where you are seeing big swings
and so I'm less surprised than for TAI, but still surprised
[Yudkowsky][16:06]
I am feeling increasingly optimistic that we have some notion of what it means to not be within the Paulverse! I am not feeling that we have solved the problem of having enough signs that enough of them will appear to tell EA how to notice which universe it is inside many years before the actual End Times, but I sure do feel like we are making progress!
things that have happened in the past that you feel shouldn't happen again are great places to poke for Eliezer-disagreements!
[Christiano][16:07]
I definitely think there's a big disagreement here about what to expect for pre-end-of-days ML
but lots of concerns about details like what domains are crowded enough to be surprising and how to do comparisons
I mean, to be clear, I think the transformer paper having giant gains is also evidence against paulverse
it's just that there are really a lot of datapoints, and some of them definitely go against paul's view
to me it feels like the relevant thing for making the end-of-days forecast is something like "how much of the progress comes from 'innovations' that are relatively unpredictable and/or driven by groups that are relatively small, vs scaleup and 'business as usual' progress in small pieces?"
11.2. Performance leap scenario
[Yudkowsky][16:09]
my heuristics tell me to try wargaming out a particular scenario so we can determine in advance which key questions Paul asks
in 2023, Deepmind releases an MTL program which is suuuper impressive. everyone who reads the MTL of, say, a foreign novel, or uses it to conduct a text chat with a contractor in Indonesia, is like, "They've basically got it, this is about as good as a human and only makes minor and easily corrected errors."
[Christiano][16:12]
I mostly want to know how good Google's translation is at that time; and if DeepMind's product is expensive or only shows gains for long texts, I want to know whether there is actually an economic niche for it that is large relative to the R&D cost.
like I'm not sure whether anyone works at all on long-text translation, and I'm not sure if it would actually make Google $ to work on it
great text chat with contractor in indonesia almost certainly meets that bar though
[Yudkowsky][16:14]
furthermore, Eliezer and Paul publicized their debate sufficiently to some internal Deepmind people who spoke to the right other people at Deepmind, that Deepmind showed a graph of loss vs. previous-SOTA methods, and Deepmind's graph shows that their thing crosses the previous-SOTA line while having used 12x less compute for
inferencetraining.(note that this is less... salient?... on the Eliezerverse per se, than it is as an important issue and surprise on the Paulverse, so I am less confident about part.)
a nitpicker would note that previous-SOTA metric they used is however from 1 year previously and the new model also uses Sideways Batch Regularization which the 1-year-previous SOTA graph didn't use. on the other hand, they got 12x rather than 10x improvement so there was some error margin there.
[Christiano][16:15]
I'm OK if they don't have the benchmark graph as long as they have some evaluation that other people were trying at, I think real-time chat probably qualifies
[Yudkowsky][16:15]
but then it's harder to measure the 10x
[Christiano][16:15]
also I'm saying 10x less training compute, not inference (but 10x less inference compute is harder)yes
[Yudkowsky][16:15]
or to know that Deepmind didn't just use a bunch more compute
[Christiano][16:15]
in practice it seems almost certain that it's going to be harder to evaluate
though I agree there are really clean versions where they actually measured a benchmark other people work on and can compare training compute directly
(like in the transformer paper)
[Yudkowsky][16:16]
literally a pessimal typo, I meant to specify training vs. inference and somehow managed to type "inference" instead
[Christiano][16:16]
I'm more surprised by the clean version
[Yudkowsky][16:17]
I literally don't know what you'd be surprised by in the unclean version
was GPT-2 beating the field hard enough that it would have been surprising if they'd only used similar amounts of training compute
?
and how would somebody else judge that for a new system?
[Christiano][16:17]
I'd want to look at either human evals or logprob, I think probably not? but it's possible it was
[Yudkowsky][16:19]
btw I also feel like the Eliezer model is more surprised and impressed by "they beat the old model with 10x less compute" than by "the old model can't catch up to the new model with 10x more compute"
the Eliezerverse thinks in terms of techniques that saturate
such that you have to find new techniques for new training to go on helping
[Christiano][16:19]
it's definitely way harder to win at the old task with 10x less compute
[Yudkowsky][16:19]
but for expensive models it seems really genuinely unlikely to me that anyone will give us this data!
[Christiano][16:19]
I think it's usually the case that if you scale up far enough past previous sota, you will be able to find tons of techniques needed to make it work at the new scale
but I'm expecting it to be less of a big deal because all experiments will be roughly at the frontier of what is feasible
and so the new thing won't be able to afford to go 10x bigger
unlike today when we are scaling up spending so fast
but this does make it harder for the next few years at least, which is maybe the key period
(it makes it hard if we are both close enough to the edge that "10x cheaper to get old results" seems unlikely but "getting new results that couldn't be achieved with 10x more compute and old method" seems likely)
what I basically expect is to (i) roughly know how much performance you get from making models 10x bigger, (ii) roughly know how much someone beat the competition, and then you can compare the numbers
[Yudkowsky][16:22]
well, you could say, not in a big bet-winning sense, but in a mild trend sense, that if the next few years are full of "they spent 100x more on compute in this domain and got much better results" announcements, that is business as usual for the last few years and perfectly on track for the Paulverse; while the Eliezerverse permits but does not mandate that we will also see occasional announcements about brilliant new techniques, from some field where somebody already scaled up to the
big modelsbig compute, producing more impressive results than the previous big compute.[Christiano][16:23]
(but "performance from making models 10x bigger" depends a lot on exactly how big they were and whether you are in a regime with unfavorable scaling)
[Yudkowsky][16:23]
so the Eliezerverse must be putting at least a little less probability mass on business-as-before Paulverse
[Christiano][16:24]
I am also expecting a general scale up in ML training runs over time, though it's plausible that you also expect that until the end of days and just expect a much earlier end of days
[Yudkowsky][16:24]
I mean, why wouldn't they?
if they're purchasing more per unit of compute, they will quite often spend more on total compute (Jevons Paradox)
[Christiano][16:25]
that's going to kill the "they spent 100x more compute" announcements soon enough
like, that's easy when "100x more" means $1M, it's a bit hard when "100x more" means $100M, it's not going to happen except on the most important tasks when "100x more" means $10B
[Yudkowsky][16:26]
the Eliezerverse is full of weird things that somebody could apply ML to, and doesn't have that many professionals who will wander down completely unwalked roads; and so is much more friendly to announcements that "we tried putting a lot of work and compute into protein folding, since nobody ever tried doing that seriously with protein folding before, look what came out" continuing for the next decade if the Earth lasts that long
[Christiano][16:27]
I'm not surprised by announcements like protein folding, it's not that the world overall gets more and more hostile to big wins, it's that any industry gets more and more hostile as it gets bigger (or across industries, they get more and more hostile as the stakes grow)
[Yudkowsky][16:28]
well, the Eliezerverse has more weird novel profitable things, because it has more weirdness; and more weird novel profitable things, because it has fewer people diligently going around trying all the things that will sound obvious in retrospect; but it also has fewer weird novel profitable things, because it has fewer novel things that are allowed to be profitable.
[Christiano][16:29]
(I mean, the protein folding thing is a datapoint against my view, but it's not that much evidence and it's not getting bigger over time)
yeah, but doesn't your view expect more innovations for any given problem?
like, it's not just that you think the universe of weird profitable applications is larger, you also think AI progress is just more driven by innovations, right?
otherwise it feels like the whole game is about whether you think that AI-automating-AI-progress is a weird application or something that people will try on
[Yudkowsky][16:30]
the Eliezerverse is more strident about there being lots and lots more stuff like "ReLUs" and "batch normalization" and "transformers" in the design space in principle, and less strident about whether current people are being paid to spend all day looking for them rather than putting their efforts someplace with a nice predictable payoff.
[Christiano][16:31]
yeah, but then don't you see big wins from the next transformers?
and you think those just keep happening even as fields mature
[Yudkowsky][16:31]
it's much more permitted in the Eliezerverse than in the Paulverse
[Christiano][16:31]
or you mean that they might slow down because people stop working on them?
[Yudkowsky][16:32]
this civilization has mental problems that I do not understand well enough to predict, when it comes to figuring out how they'll affect the field of AI as it scales
that said, I don't see us getting to AGI on Stack More Layers.
there may perhaps be a bunch of stacked layers in an AGI but there will be more ideas to it than that.
such that it would require far, far more than 10X compute to get the same results with a GPT-like architecture if that was literally possible
[Christiano][16:33]
it seems clear that it will be more than 10x relative to GPT
I guess I don't know what GPT-like architecture means, but from what you say it seems like normal progress would result in a non-GPT-like architecture
so I don't think I'm disagreeing with that
[Yudkowsky][16:34]
I also don't think we're getting there by accumulating a ton of shallow insights; I expect it takes at least one more big one, maybe 2-4 big ones.
[Christiano][16:34]
do you think transformers are a big insight?
(is adding soft attention to LSTMs a big insight?)
[Yudkowsky][16:34]
hard to deliver a verdict of history there
no
[Christiano][16:35]
(I think the intellectual history of transformers is a lot like "take the LSTM out of the LSTM with attention")
[Yudkowsky][16:35]
"how to train deep gradient descent without activations and gradients blowing up or dying out" was a big insight
[Christiano][16:36]
that really really seems like the accumulation of small insights
[Yudkowsky][16:36]
though the history of that big insight is legit complicated
[Christiano][16:36]
like, residual connections are the single biggest thing
and relus also help
and batch normalization helps
and attention is better than lstms
[Yudkowsky][16:36]
and the inits help (like xavier)
[Christiano][16:36]
you could also call that the accumulation of big insights, but the point is that it's an accumulation of a lot of stuff
mostly developed in different places
[Yudkowsky][16:37]
but on the Yudkowskian view the biggest insight of all was the one waaaay back at the beginning where they were initing by literally unrolling Restricted Boltzmann Machines
and people began to say: hey if we do this the activations and gradients don't blow up or die out
it is not a history that strongly distinguishes the Paulverse from Eliezerverse, because that insight took time to manifest
it was not, as I recall, the first thing that people said about RBM-unrolling
and there were many little or not-really-so-little inventions that sustained the insight to deeper and deeper nets
and those little inventions did not correspond to huge capability jumps immediately in the hands of their inventors, with, I think, the possible exception of transformers
though also I think back then people just didn't do as much SoTA-measuring-and-comparing
[Christiano][16:40]
(I think transformers are a significantly smaller jump than previous improvements)
also a thing we could guess about though
[Yudkowsky][16:40]
right, but did the people who demoed the improvements demo them as big capability jumps?
harder to do when you don't have a big old well funded field with lots of eyes on SoTA claims
they weren't dense in SoTA, I think?
anyways, there has not, so far as I know, been an insight of similar size to that last one, since then
[Christiano][16:42]
also 10-100x is still actually surprising to me for transformers
so I guess lesson learned
[Yudkowsky][16:43]
I think if you literally took pre-transformer SoTA, and the transformer paper plus the minimum of later innovations required to make transformers scale at all, then as you tried scaling stuff to GPT-1 scale, the old stuff would probably just flatly not work or asymptote?
[Christiano][16:44]
in general if you take anything developed at scale X and try to scale it way past X I think it won't work
or like, it will work much worse than something that continues to get tweaked
[Yudkowsky][16:44]
I'm not sure I understand what you mean if you mean "10x-100x on transformers actually happened and therefore actually surprised me"
[Christiano][16:44]
yeah, I mean that given everything I know I am surprised that transformers were as large as a 100x improvement on translation
in that paper
[Yudkowsky][16:45]
though it may not help my own case, I remark that my generic heuristics say to have an assistant go poke a bit at that claim and see if your noticed confusion is because you are being more confused by fiction than by reality.
[Christiano][16:45]
yeah, I am definitely interested to understand a bit better what's up there
but tentatively I'm sticking to my guns on the original prediction
if you have random 10-20 person teams getting 100x speedups versus prior sota
as we approach TAI
that's so far from paulverse
[Yudkowsky][16:46]
like, not about this case specially, just sheer reflex from "this assertion in a science paper is surprising" to "go poke at it". many unsurprising and hence unpoked assertions will also be false, of course, but the surprising ones even more so on average.
[Christiano][16:48]
anyway, seems like a good approach to finding a concrete disagreement
and even looking back at this conversation would be a start for diagnosing who is more right in hindsight
main thing is to say how quickly and in what industries I'm how surprised
[Yudkowsky][16:49]
I suspect you want to attach conditions to that surprise? Like, the domain must be sufficiently explored OR sufficiently economically important, because Paulverse also predicts(?) that as of a few years (3?? 2??? 15????) all the economically important stuff will have been poked with lots of compute already.
and if there's economically important domains where nobody's tried throwing $50M at a model yet, that also sounds like not-the-Paulverse?
[Christiano][16:50]
I think the economically important prediction doesn't really need that much of "within a few years"
like the total stakes have just been low to date
none of the deep learning labs are that close to paying for themselves
so we're not in the regime where "economic niche > R&D budget"
we are still in the paulverse-consistent regime where investment is driven by the hope of future wins
though paul is surprised that R&D budgets aren't more larger than the economic value
[Yudkowsky][16:51]
well, it's a bit of a shame from the Eliezer viewpoint that the Paulverse can't be falsifiable yet, then, considering that in the Eliezerverse it is allowed (but not mandated) for the world to end while most DL labs haven't paid for themselves.
albeit I'm not sure that's true of the present world?
DM had that thing about "we just rejiggered cooling the server rooms for Google and paid back 1/3 of their investment in us" and that was years ago.
[Christiano][16:52]
I'll register considerable skepticism
[Yudkowsky][16:53]
I don't claim deep knowledge.
But if the imminence, and hence strength and falsifiability, of Paulverse assertions, depend on how much money all the deep learning labs are making, that seems like something we could ask OpenPhil to measure?
[Christiano][16:55]
it seems easier to just talk about ML tasks that people work on
it seems really hard to arbitrate the "all the important niches are invested in" stuff in a way that's correlated with takeoff
whereas the "we should be making a big chunk of our progress from insights" seems like it's easier
though I understand that your view could be disjunctive, of either "AI will have hidden secrets that yield great intelligence," or "there are hidden secret applications that yield incredible profit"
(sorry that statement is crude / not very faithful)
should follow up on this in the future, off for now though
[Yudkowsky][16:58]
👋