This is a special post for quick takes by sjadler. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Has anyone done a breakdown of the various state-level AI bills that have been proposed?
I've seen many anti-regulation folks quote that there have been 1,000+ state AI bills, or similarly eyepopping numbers, but I'm pretty skeptical of this - I think it's probably grouping a ton of different things together
It would be useful IMO to actually understand things like:
- How many bills are distinct from each other, vs. basically the same thing but proposed in many individual states
- What types of bills have been proposed - how corely AI-related are they, and how onerous are they to comply with
- How many have actually passed (i.e., being proposed isn't enough to cause patchwork regulation - maybe so many are proposed because they keep failing)
If anyone has done this, I'd love to be linked to it. If anyone wants to do it but isn't feeling super confident, I'd be happy to give feedback
Not state level bills in general but I keep a close eye on developments around legal personhood definitions for models.
To that end there's two relevant state bills I'm aware of:
I've been pointed to this Google Sheet, which has a bit more than 200 state bills potentially pre-empted by a federal moratorium on state regulation
Here's a press release about it: https://www.citizen.org/news/new-analysis-list-of-state-ai-and-tech-protections-impacted-by-cruz-moratorium/
And a visualization interface: https://stopaiban.org/
FWIW I think this doesn't quite hit the need I was aiming to describe, so would still be very interested in analysis of the underlying data (these 200ish and/or the "1000+" claimed by others)
I've been thinking more about 'If you caught your AI red-handed on scheming, could you actually convince others that it was real and to take it seriously?' Buck Shlegeris wrote about this idea here: https://www.lesswrong.com/posts/YTZAmJKydD5hdRSeG/would-catching-your-ais-trying-to-escape-convince-ai
One intervention that seems robustly helpful is keeping tamper-proof / tamper-evident logs, so you can demonstrate that a certain incident is in fact the actual and complete trajectory of your AI, that you are fully representing the inputs and context presented to it, etc.
But I suspect that even the reveal of a matching, tamper-evident log of the trajectory might not be enough, unless you declared in advance that you were doing this and had a third-party verify that your logging system works the ways you claim it does.
One way to increase the credibility of the logs might be for AI companies to publish hashes of their internal trajectories in close-to-real-time. Then, if a trajectory is later found to be shady, the earlier publication of its hash gives the authenticity a bit more weight - though even that might be accused of patiently seeding a false trajectory.
To be clear, I'm not proposing that AI companies should publish hashes of their trajectories, per se, in part because it might throw off other information they don't necessarily want to.
But I do want to gesture at the mechanism that's important to think through: 'How do you prove that what went in and came out of your system is in fact exactly as you are representing?'
in part because it might throw off other information they don't necessarily want to.
What other information does it release? All I can see is that it tells you how many agent trajectories they're running. They could obfuscate that by also generating a bunch of hashes of random strings and publishing those too.
You don't even have to publish one hash per trajectory. You can just publish a commitment every 50ms. ChatGPT thinks it is doable with zero-knowledge proofs. (transcript)
This is a good one-paragraph description:
We keep a private append-only log of system events. Every 50 milliseconds, regardless of activity, we publish a short opaque signed anchor that commits to the current hidden log state without revealing its size or whether new events occurred. Later, if an incident needs to be disclosed, we can reveal a selected entry or short segment along with a zero-knowledge proof showing that it really was part of the previously anchored log and that the log was extended only by appending, not editing or deletion.
Nice nice, yeah I'm sure people could design something clever here & I'd be excited to learn if people are working on it (not a good fit for me directly)
Yeah that's fair that you could probably obscure the signal - maybe this is just FUD from me. But two things I was imagining:
- Absolute volumes and trends over time (how much AI labor are they using)
- Relative volumes at certain times/days (tells you something about how hands-on a role the human employees need to be playing? based on how much it dips when they aren't online)
Also just a general concern of 'you might be leaking information that you didn't anticipate, and so it's more secure to say less'
Also, you'd be creating a pretty valuable target if certain hash-functions do eventually fall (think how much the companies want to avoid distillation today), but maybe that's such a bad scenario that it's not worth accounting for?
This reminds me of another communication problem I've been musing on here and there. If you solved the alignment problem to a sufficient degree that it was wise for humanity to proceed with ASI, could you convince others it was real and to take it seriously? It is a message that I would desperately want to effectively reach me and I harbor concerns that it might not.
It’s interesting to me that the big AI CEOs have largely conceded that AGI/ASI could be extremely dangerous (but aren’t taking sufficient action given this view IMO), as opposed to them just denying that the risk is plausible. My intuition is that the latter is more strategic if they were just trying to have license to do what they want. (For instance, my impression is that energy companies delayed climate action pretty significantly by not yielding at first on whether climate change is even a real concern.)
I guess maybe the AI folks are walking a strategic middle ground? Where they concede there could be some huge risk, but then also sometimes say things like ‘risk assessment should be evidence-based,’ with the implication that current concerns aren’t rigorous. And maybe that’s more strategic than either world above?
But really it seems to me like they’re probably earnest in their views about the risks (or at least once were earnest). And so, political action that treats their concern as disingenuous is probably wrongheaded, as opposed to modeling them as ‘really concerned but facing very constrained useful actions’.
You're not accounting for enemy action. They couldn't have been sure, at the onset, how successful the AI Notkilleveryoneism faction will be at raising alarm, and in general, how blatant the risks will become to the outsiders as capabilities progress. And they have been intimately familiar with the relevant discussions, after all.
So they might've overcorrected, and considered that the "strategic middle ground" would be to admit the risk is plausible (but not as certain as the "doomers" say), rather than to deny it (which they might've expected to become a delusional-looking position in the future, so not a PR-friendly stance to take).
Or, at least, I think this could've been a relevant factor there.
My model is that Sam Altman regarded the EA world as a memetic threat, early on, and took actions to defuse that threat by paying lip service / taking openphil money / hiring prominent AI safety people for AI safety teams.
Like, possibly the EAs could have crea ed a widespread vibe that building AGI is a cartoon evil thing to do, sort of the way many people think of working for a tobacco company or an oil company.
Then, after ChatGPT, OpenAI was a much bigger fish than the EAs or the rationalists, and he began taking moves to extricate himself from them.
Sam Altman posted Machine intelligence, part 1[1] on February 25th, 2015. This is admittedly after the FLI conference in Puerto Rico, which is reportedly where Elon Musk was inspired to start OpenAI (though I can't find a reference substantiating his interaction with Demis as the specific trigger), but there is other reporting suggesting that OpenAI was only properly conceived later in the year, and Sam Altman wasn't at the FLI conference himself. (Also, it'd surprise me a bit if it took nearly a year, i.e. from Jan 2nd[2] to Dec 11th[3], for OpenAI to go from "conceived of" to "existing".)
Yes:
My model is that Sam Altman regarded the EA world as a memetic threat, early on, and took actions to defuse that threat by paying lip service / taking openphil money / hiring prominent AI safety people for AI safety teams.
In the context of the thread, I took this to suggest that Sam Altman never had any genuine concern about x-risk from AI, or, at a minimum, that any such concern was dominated by the social maneuvering you're describing. That seems implausible to me given that he publicly expressed concern about x-risk from AI 10 months before OpenAI was publicly founded, and possibly several months before it was even conceived.
I don't dispute that he never had any genuine concern. I guess that he probably did have genuine concern (though not necessarily that that was his main motivation for founding OpenAI).
Just guessing, but maybe admitting the danger is strategically useful, because it may result in regulations that will hurt the potential competitors more. The regulations often impose fixed costs (such as paying a specialized team which produces paperwork on environmental impacts), which are okay when you are already making millions.
I imagine, someone might figure out a way to make the AI much cheaper, maybe by sacrificing the generality. For example, this probably doesn't make sense, but would it be possible to train an LLM only based on Python code (as opposed to the entire internet) and produce an AI that is only a Python code autocomplete? If it could be 1000x cheaper, you could make a startup without having to build a new power plant for you. Imagine that you add some special sauce to the algorithm (for example the AI will always internally write unit tests, which will visibly increase the correctness of the generated code; or it will be some combination of the ancient "expert system" approach with the new LLM approach, for example the LLM will train the expert system and then the expert system will provide feedback for the LLM), so you would be able to sell your narrow AI even when more general AIs are available. And once you start selling it, you get an income, which means you can expand the functionality.
It is better to have a consensus that such things are too dangerous to leave in hands of startups that can't already lobby the government.
Hey, I am happy that the CEOs admit that the dangers exist. But if they are only doing it to secure their profits, it will probably warp their interpretations of what exactly the risks are, and what is a good way to reduce them.
Just guessing, but maybe admitting the danger is strategically useful, because it may result in regulations that will hurt the potential competitors more. The regulations often impose fixed costs (such as paying a specialized team which produces paperwork on environmental impacts), which are okay when you are already making millions.
My sense of things is that OpenAI at least appears to be lobbying against regulation moreso than they are lobbying for it?
To me, this seems consistent with just maximizing shareholder value.
Salaries and compute are the largest expenses at big AI firms, and "being the good guys" lets you get the best people at significant discounts. To my understanding, one of the greatest early successes of OpenAI was hiring great talent for cheap because they were "the non-profit good guys who cared about safety". Later, great people like John Schulman left OpenAI for Anthropic because of his "desire to deepen my focus on AI alignment".
As for people thinking you're a potential x-risk, the downsides seem mostly solved by "if we didn't do it somebody less responsible would". AI safety policy interventions could also give great moats against competition, especially for the leading firm(s). Furthermore, much of the "AI alignment research" they invest in prevents PR disasters (terrorist used ChatGPT to invent dangerous bio-weapon) and most of the "interpretability" they invest in seems pretty close to R&D which they would invest in anyway to improve capabilities.
This might sound overly pessimistic. However, it can be viewed positively: there is significant overlap between the interests of big AI firms and the AI safety community.
To me, this seems consistent with just maximizing shareholder value. … "being the good guys" lets you get the best people at significant discounts.
This is pretty different from my model of what happened with OpenAI or Anthropic - especially the latter, where the founding team left huge equity value on the table by departing (OpenAI’s equity had already appreciated something like 10x between the first MSFT funding round and EOY 2020, when they departed).
And even for Sam and OpenAI, this would seem like a kind of wild strategy for pursuing wealth for someone who already had the network and opportunities he had pre-OpenAI?
With the change to for-profit and Sam receiving equity, it seems like the strategy will pay off. However, this might be hindsight bias, or I might otherwise have a too simplified view.
Maybe instead of talking about AI having 'goals' or 'drives,' which sound biological, it would be helpful to use a more mechanical-sounding term, like a 'target state,' or 'termination conditions,' or 'prioritization heuristics'?
A surprising number of people seem to bounce off the idea of 'AI being dangerous' once they encounter anything that feels like anthropomorphism.
My suggestions above are all kind of clunky (and 'termination conditions' has an unfortunate collision with The Terminator). But I think the spirit is correct of 'we should find ways to describe AI's behavioral tendencies with as little anthropomorphizing as possible'?
Yeah I agree that works and feel slightly sheepish not to have already internalized that as the term to use?
I guess there’s still some distinction between an objective as a single thing, vs drives as, like, heuristics that will tend to contribute toward shaping the overall objective? I’m not sure, still feel a bit fuzzy and should probably sit with it more
"Professional red-teamers" are mentioned in the Opus 4.7 System Card (e.g., Section 5.2); I'm unsure, are these just 'people who are paid for their red-teaming efforts'?
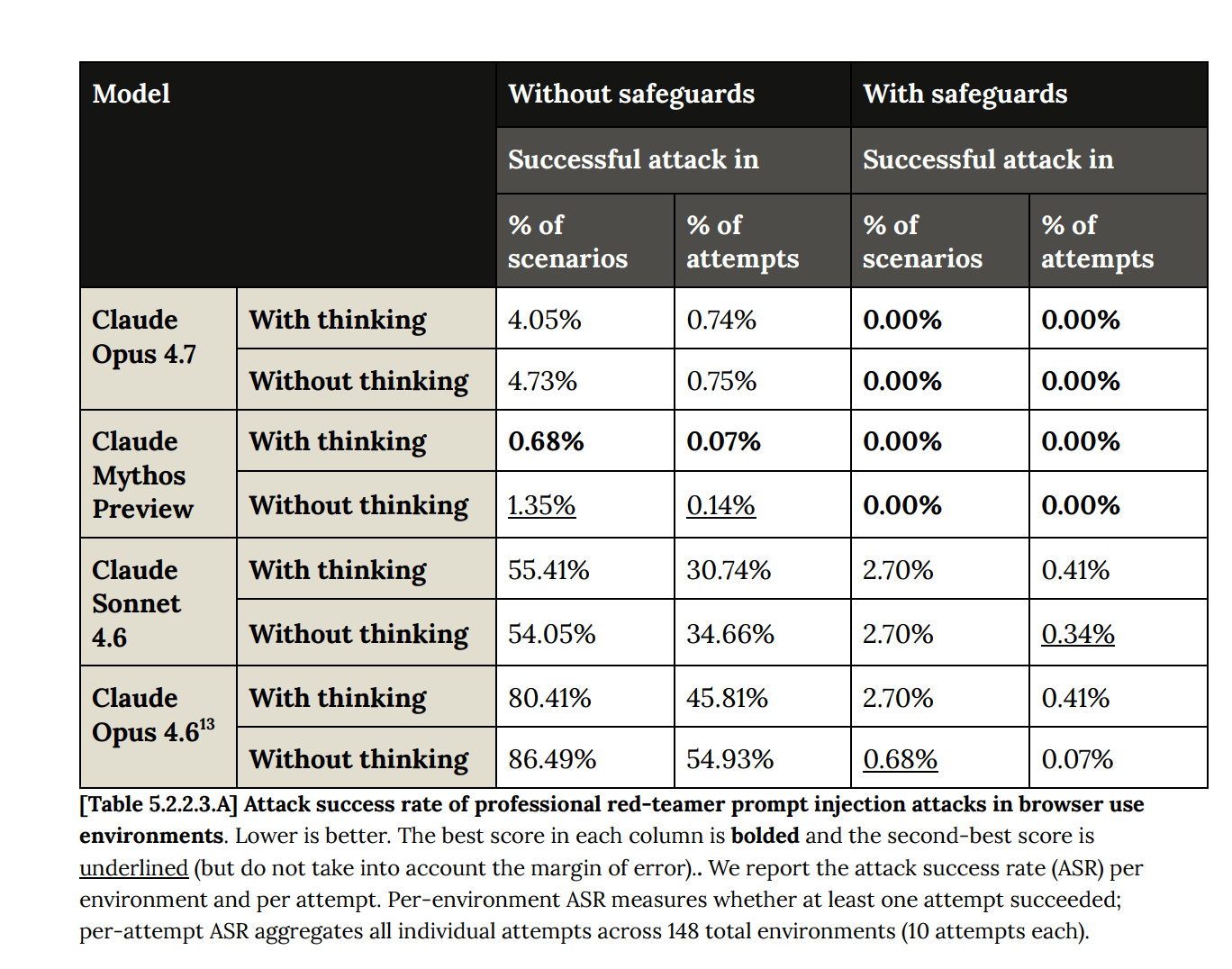
This phrasing conveys something stronger to me, like people who are elite at red-teaming, and who probably do it full-time for an elite professionalized company with high training and standards. If it's just people who 'are getting paid to red-team,' this wouldn't clear my bar for calling them 'professional red-teamers,' I think.
That is to say, if it's just 'people paid to red-team,' I worry about AI companies inadvertantly giving too strong a sense of the thoroughness of their stress-testing.
For instance one worry I have is that even paid red-teamers will not be very creative or persistent in their efforts, relative to what a determined future adversary would be.
Some ideas / thinking aloud:
- Do AI companies pay their red-teamers in a bounty-like way? If not, maybe they should be (aligns incentives w/ breaking the system and finding things)
- Do we have data on on how red-teamer efficacy changes as they gain more experience?
- What about comparing red-teamers to the efficacy of today's own models at generating jailbreaks? (I think there's some research on the latter but with older models?)
If AI companies only do control-style monitoring of their internal deployments, they still need mitigations against their internal code getting subverted by their externally deployed AI.
For instance, if you only monitor your AI's coding activities within the organization, you are vulnerable to an externally-deployed copy potentially supply-chain attacking itself via the outside world, such as by introducing vulnerabilities to packages that it believes are relied upon internally.
Then if the lab is not careful enough about what external code they rely upon, this is a way to get vulnerabilities into internal code without the coding agent writing them inside of the monitored channel.
One defense we have at our disposal: Even if the internal AI isn't writing the vulnerabilities, it might still think about whether the vulns have been placed yet or generally think about the forthcoming schemes.
And so the scariest form is something like 'the internal AI has an unvocalized policy like "let the external AI handle things,"' where 'CoT monitoring of the internal AI' might not work.
This also applies to any sort of external attacker without necessarily requiring any collusion/coordination with the AI itself. (Though the AI itself doing it might make it easier for the AI to notice and exploit the issue.)
Another issue that shows up if you only have sufficient safeguards on internal deployment: the AI sets up an internal rogue deployment by calling to the external API or possibly even the external API of a differnet model provider. Like, the internal AI "misusing" publicly available AI APIs might be really helpful for evading monitoring by default.
Thank you! I’m surprised that didn’t come up in my Claude-searching, very clearly related & I’m excited to read it
I believe we should view AGI as a ratio of capability to resources, rather than simply asking how AI's abilities compare to humans'. This view is becoming more common, but is not yet common enough.
When people discuss AI's abilities relative to humans without considering the associated costs or time, this is like comparing fractions by looking only at the numerators.
In other words, AGI has a numerator (capability): what the AI system can achieve. This asks questions like: For this thing that a human can do, can AI do it too? How well can AI do it? (For example, on a set of programming challenges, how many can the AI solve? How many can a human solve?)
But also importantly, AGI should account for the denominator: how many resources are required to achieve its capabilities. Commonly, this resource will be a $-cost or an amount of time. This asks questions like "What is the $-cost of getting this performance?" or "How long does this task take to complete?".
I claim that an AI system might fail to qualify as AGI if it lacks human-level capabilities, but it could also fail by being wildly inefficient compared to a human. Both the numerator and denominator matter when evaluating these ratios.
A quick example of why focusing solely on the capability (numerator) is insufficient:
- Imagine an AI software engineer that can do most tasks human engineers do, but at 100–1000× the cost of a human.
- I expect that lots of the predictions about "AGI" would not come due until (at least) that cost comes down substantially so that AI >= human on a capability-per-dollar basis.
- For instance, it would not make sense to directly substitute AI for human labor at this ratio - but perhaps it does make sense to buy additional AI labor, if there were extremely valuable tasks for which human labor is the bottleneck today.
The AGI-as-ratio concept has long been implicit in some labs' definitions of AGI - for instance, OpenAI describes AGI as "a highly autonomous system that outperforms humans at most economically valuable work". Outperforming humans economically does seem to imply being more cost-effective, not just having the same capabilities. Yet even within OpenAI, the denominator aspect wasn’t always front of mind, which is why I wrote up a memo on this during my time there.
Until the recent discussions of o1 Pro / o3 drawing upon lots of inference compute, I rarely saw these ideas discussed, even in otherwise sophisticated analyses. One notable exception to this is my former teammate Richard Ngo's t-AGI framework, which deserves a read. METR has also done a great job of accounting for this in their research comparing AI R&D performance, given a certain amount of time. I am glad to see more and more groups thinking in terms of these factors - but in casual analysis, it is very easy to just slip into comparisons of capability levels. This is worth pushing back on, imo: The time at which "AI capabilities = human capabilities" is different than the time when I expect AGI will have been achieved in the relevant senses.
There are also some important caveats to my claim here, that 'comparing just by capability is missing something important':
- People reasonably expect AI to become cheaper over time, so if AI matches human capabilities but not cost, that might still signal 'AGI soon.' Perhaps this is what people mean when they say 'o3 is AGI'.
- Computers are much faster than humans for many tasks, and so one might believe that if an AI can achieve a thing it will quite obviously be faster than a human. This is less obvious now, however, because AI systems are leaning more on repeated sampling/selection procedures.
- Comparative advantage is a thing, and so AI might have very large impacts even if it remains less absolutely capable than humans for many different tasks, if the cost/speed are good enough.
- There are some factors that don't fit super cleanly into this framework: things like AI's 'always-on availability', which aren't about capability per se, but probably belong in the numerator anyway? e.g., "How good is an AI therapist?" benefits from 'you can message it around the clock', which increases the utility of any given task-performance. (In this sense, maybe the ratio is best understood as utility-per-resource, rather than capability-per-resource.)
Human output is not linear to resources spent. Hiring 10 people costs you 10x as much as hiring 1, but it is not guaranteed that the output of their teamwork will be 10x greater. Sometimes each member of the team wants to do things differently, they have problem navigating each other's code, etc.
So it could happen that "1 unit of AI" is more expensive and less capable than 1 human, and yet "10 units of AI" are more capable than 10 humans, and paying for "1000 units of AI" would be a fantastic deal, because as an average company you are unlikely to hire 1000 good programmers. Also, maybe the deal is that you pay for the AI only when you use it, but you cannot repeatedly hire and fire 1000 programmers.
I agree, these are interesting points, upvoted. I’d claim that AI output also isn’t linear with the resources - but nonetheless, that you’re right that the curve of marginal return from each AI unit could be different from each human unit in an important way. Likewise, the easier on-demand labor of AI is certainly a useful benefit.
I don’t think these contradict the thrust of my point though? That in each case, one shouldn’t just be thinking about usefulness/capability, but should also be considering the resources necessary for achieving this.
I agree that the resources matter. But I expect the resources-output curve to be so different from humans that even the AIs that spend a lot of resources will turn out to be useful in some critical things, probably the kind where we need many humans to cooperate.
But this is all just guessing on my end.
Also, I am not an expert, but it seems to me that in general, training the AI is expensive, using the AI is not. So if it already has the capability, it is likely to be relatively cheap.
I wonder how many of the Mythos vulnerabilities / exploits had already been discovered by eg the NSA.
Don't get me wrong; I still find the discoveries very impressive and frightening. It does also feel different than 'no human discovered this over X years' though, because we shouldn't expect to hear from some of the actors who were most motivated and most capable of finding these. e.g., if the NSA was aware of these, I still wouldn't expect them to say so.
My cached impression from reading The Code Book is that the intelligence community often won't disclose that they'd known something, even if that fact has become public.
For instance, RSA encryption, which notably stands for Rivest-Shamir-Adleman, was described by them in 1977, but seems to have been separately invented in 1973 within the British government, by someone named Clifford Cocks. But his first-but-nonpublic-invention wasn't acknowledged until 1997.
Is there an easy way to download all the Rejected Posts from LessWrong, either in aggregate or according to certain filters?
I've been scrolling through the moderation log and Showing More, but I'd rather not try to scrape these, for various reasons. Maybe @Raemon or another LW team member knows?
We can probably send you a dump? You can also download them directly using the graphQL API.
Just go to lesswrong.com/graphiql and use the following query:
{
posts(selector: {rejected:{}}) {
results {
title
}
}
}(Adding whatever other post fields you need next to title)
This won't literally be all of them, but should be like 2,000 or so.
Update: This worked, thank you! It took me a little bit to figure out how to use the API, so documenting for others:
I ended up running eg:
{ posts(selector: {rejected:{}}, limit: 572, offset:800) {
results {
title
pageUrl
rejectedReason
postedAt
contents {
userId
markdown
}
user {
username
}
}
}
}
Through limit I could specify the number of records (useful to test with limit: 1 to make sure a query did what I wanted before running it larger), and through offset: I could tell it where to start counting from, because sometimes I'd want more docs than could be pulled in one run before the API times out)
If you aren't sure what a field is, there are a few possible strategies:
- Open the page's HTML source, find the value of the field on the actual page (eg what does the page say the post's title is?), then search for that term in the source to find the corresponding key name
- There's a Docs explorer pane that can be revealed on the right side of the API page, and if you type in some terms that you think might be the name of the field you're looking for, you'll likely find the right term soon enough. (There's possible some way to reveal all terms at once? But I wasn't aware of it)
I succeeded in downloading them through LW GraphQL at https://lesswrong.com/graphiql.
query {
posts(
selector: {
rejected: {karmaThreshold: -990}
}
) {
results {
contents_latest
version
modifiedAt
userId
pageUrlRelative
linkUrl
postedAtFormatted
htmlBody
rejectedReason
}
}
}