This type of argument strikes me as analogous to using Arrow's theorem to argue that we must implement a dictatorship.
But the post is an argument for using cardinal utility (VNM utility)! And Arrow's "impossibility" theorem only applies when trying to aggregate ordinal utilities across voters. It is well-known that voting systems which aggregate cardinal utility, such as Range Voting can escape the impossibility theorem.
So Arrow is actually another reason for having a VNM utility function: it allows collectively rational decisions, as well as individually rational decisions.
You know, given Arrow's result, and given the observation commonly made around here that there are lots of little agents running around in our head, it is not so surprising that human beings exhibit "incoherent behavior." It's a consequence of our mind architecture.
I am not sure I am prepared to start culling my internal Congress just so I can have a coherent utility function that makes the survivors happy.
As the Theorem treats them, voters are already utility-maximizing agents who have a clear preference set which they act on in rational ways. The question: how to aggregate these?
It turns out that if you want certain superficially reasonable things out of a voting process from such agents - nothing gets chosen at random, it doesn't matter how you cut up choices or whatever, &c. - you're in for disappointment. There isn't actually a way to have a group that is itself rationally agentic in the precise way the Theorem postulates.
One bullet you could bite is having a dictator. Then none of the inconsistencies arise from having all these extra preference sets lying around because there's only one and it's perfectly coherent. This is very easily comparable to reducing all of your own preferences into a single coherent utility function.
Meditation: So far, we've always pretended that you only face one choice, at one point in time. But not only is there a way to apply our theory to repeated interactions with the environment — there are two!
One way is to say that at each point in time, you should apply decision theory to set of actions you can perform at that point. Now, the actual outcome depends of course not only on what you do now, but also on what you do later; but you know that you'll still use decision theory later, so you can foresee what you will do in any possible future situation...
It is essential to both of these paradoxes that they deal with social situations. Rephrase them so that the agent is interacting with nature, and the paradoxes disappear.
For example, suppose that the parent is instead collecting shells on the beach. He has room in his bag for one more shell, and finds two on the ground that he has no preference between. Clearly, there's no reason he would rather flip a coin to decide between them than just pick one of them up, say, the one on the left.
What this tells me is that you have to be careful using decision theory ...
People can't order outcomes from best to worst. People exhibit circular preferences. I, myself, exhibit circular preferences. This is a problem for a utility-function based theory of what I want.
No, not "of course". It only implies that if they're rational actors, which of course they are not. They are deal-averse and if they see you trying to pump them around in a circle they will take their ball and go home.
You can still profit by doing one step of the money pump, and people do. Lots of research goes into exploiting people's circular preferences on things like supermarket displays.
I do not understand the first part of the post. As far as I can tell, you are responding to concerns that have been raised elsewhere (possibly in your head while discussing the issue with yourself) but it is unclear to me what exactly these concerns are, so I'm lost. Specifically, I do not understand the following:
...Meditation: Alice is trying to decide how large a bonus each member of her team should get this year. She has just decided on giving Bob the same, already large, bonus as last year when she receives an e-mail from the head of a different divisi
Is the real-world imperative "you must maximize expected utility", given by the VNM theorem, stronger or weaker than the imperative "everyone must have the same beliefs" given by Aumann's agreement theorem? If only there was some way of comparing these things! One possible metric is how much money I'm losing by not following this or that imperative. Can anyone give an estimate?
My local rationality group assigned this post as reading for our meetup this week, and it generated an interesting discussion.
I'm not an AI or decision theory expert. My only goal here is to argue that some of these claims are poor descriptions of actual human behavior. In particular, I don't think humans have consistent preferences about rare and negative events. I argue this by working backwards from the examples in the discussion on the Axiom of Continuity. I still think this post is valuable in other ways.
...Let's look at an example: If you prefer $50 i
It seems essential to the idea of "a coherent direction for steering the world" or "preferences" that the ordering between choices does not depend on what choices are actually available. But in standard cooperative multi-agent decision procedures, the ordering does depend on the set of choices available. How to make sense of this? Does it mean that a group of more than one agent can't be said to have a coherent direction for steering the world? What is it that they do have then? And if a human should be viewed as a group of sub-agents r...
The "not wanting the AI to run conscious simulations of people" link under the "Outcomes" heading does not work.
What happens if your preferences do not satisfy Continuity? Say, you want to save human lives, but you're not willing to incur any probability, no matter how small, of infinitely many people getting tortured infinitely long for this?
Then you basically have a two-step optimization; "find me the set of actions that have a minimal number of infinitely many people getting tortured infinitely long, and then of that set, find me the set of actions that save a maximal number of human lives." The trouble with that is that people like to express their ...
New information is allowed to make a hypothesis more likely, but not predictably so; if all ways the experiment could come out make the hypothesis more likely, then you should already be finding it more likely than you do. The same thing is true even if only one result would make the hypothesis more likely, but the other would leave your probability estimate exactly unchanged.
One result might change my probability estimate by less than my current imprecision/uncertainty/rounding error in stating said estimate. If the coin comes up H,H,H,H,H,H,T,H,H,H,H,...
Thank you for this excellent post. I read this primarily because I would like to use formal theories to aid my own decision-making about big, abstract decisions like what to do with my life and what charities to donate to, where the numbers are much more available than the emotional responses. In a way this didn't help at all: it only says anything about a situation where you start with a preference ordering. But in another way it helped immensely, of course, since I need to understand these fundamental concepts. It was really valuable to me that you were so careful about what these "utilities" really mean.
Maximizing expected utility can be paradoxically shown to minimize actual utility, however. Consider a game in which you place an initial bet of $1 on a 6-sided die coming up anything but 1 (2-6), which pays even money if you win and costs you your bet if you lose. The twist, however, is that upon winning (i.e. you now have $2 in front of you) you must either bet the entire sum formed by your bet and its wins or leave the game permanently. Theoretically, since the odds are in your favor, you should always keep going. Always. But wait, this means you will e...
I appreciate the hard work here, but all the math sidesteps the real problems, which are in the axioms, particularly the axiom of independence. See this sequence of comments on my post arguing that saying expectation maximization is correct is equivalent to saying that average utilitarianism is correct.
People object to average utilitarianism because of certain "repugnant" scenarios, such as the utility monster (a single individual who enjoys torturing everyone else so much that it's right to let him or her do so). Some of these scenarios can be...
Suppose the world has one billion people. Do you think it's better to give one billion and one utilons to one person than to give one utilon to everyone?
Yes. If you think this conclusion is repugnant, you have not comprehended the meaning of 1000000001 times as much utility. The only thing that utility value even means is that you'd accept such a deal.
You don't "give" people utilons though. That implies scarcity, which implies some real resource to be distributed, which we correctly recognize as having diminishing returns on one person, and less diminishing returns on lots of people. The better way to think of it is that you extract utility from people.
Would you rather get 1e9 utils from one person, or 1 util from each of 1e9 people? Who cares 1e9 utils is 1e9 utils.
If so, why would you believe it's better to take an action that results in you having one billion and one utilons one-one-billionth of the time, and nothing all other times, than an action that reliably gives you one utilon?
Again, by construction, we take this deal.
VNM should not have called it "utility"; it drags in too many connotations. VNM utility is a very personal thing that describes what decisions you would make.
This post explains von Neumann-Morgenstern (VNM) axioms for decision theory, and what follows from them: that if you have a consistent direction in which you are trying to steer the future, you must be an expected utility maximizer. I'm writing this post in preparation for a sequence on updateless anthropics, but I'm hoping that it will also be independently useful.
The theorems of decision theory say that if you follow certain axioms, then your behavior is described by a utility function. (If you don't know what that means, I'll explain below.) So you should have a utility function! Except, why should you want to follow these axioms in the first place?
A couple of years ago, Eliezer explained how violating one of them can turn you into a money pump — how, at time 11:59, you will want to pay a penny to get option B instead of option A, and then at 12:01, you will want to pay a penny to switch back. Either that, or the game will have ended and the option won't have made a difference.
When I read that post, I was suitably impressed, but not completely convinced: I would certainly not want to behave one way if behaving differently always gave better results. But couldn't you avoid the problem by violating the axiom only in situations where it doesn't give anyone an opportunity to money-pump you? I'm not saying that would be elegant, but is there a reason it would be irrational?
It took me a while, but I have since come around to the view that you really must have a utility function, and really must behave in a way that maximizes the expectation of this function, on pain of stupidity (or at least that there are strong arguments in this direction). But I don't know any source that comes close to explaining the reason, the way I see it; hence, this post.
I'll use the von Neumann-Morgenstern axioms, which assume probability theory as a foundation (unlike the Savage axioms, which actually imply that anyone following them has not only a utility function but also a probability distribution). I will assume that you already accept Bayesianism.
*
Epistemic rationality is about figuring out what's true; instrumental rationality is about steering the future where you want it to go. The way I see it, the axioms of decision theory tell you how to have a consistent direction in which you are trying to steer the future. If my choice at 12:01 depends on whether at 11:59 I had a chance to decide differently, then perhaps I won't ever be money-pumped; but if I want to save as many human lives as possible, and I must decide between different plans that have different probabilities of saving different numbers of people, then it starts to at least seem doubtful that which plan is better at 12:01 could genuinely depend on my opportunity to choose at 11:59.
So how do we formalize the notion of a coherent direction in which you can steer the future?
*
Setting the stage
Decision theory asks what you would do if faced with choices between different sets of options, and then places restrictions on how you can act in one situation, depending on how you would act in others. This is another thing that has always bothered me: If we are talking about choices between different lotteries with small prizes, it makes some sense that we could invite you to the lab and run ten sessions with different choices, and you should probably act consistently across them. But if we're interested in the big questions, like how to save the world, then you're not going to face a series of independent, analogous scenarios. So what is the content of asking what you would do if you faced a set of choices different from the one you actually face?
The real point is that you have bounded computational resources, and you can't actually visualize the exact set of choices you might face in the future. A perfect Bayesian rationalist could just figure out what they would do in any conceivable situation and write it down in a giant lookup table, which means that they only face a single one-time choice between different possible tables. But you can't do that, and so you need to figure out general principles to follow. A perfect Bayesian is like a Carnot engine — it's what a theoretically perfect engine would look like, so even though you can at best approximate it, it still has something to teach you about how to build a real engine.
But decision theory is about what a perfect Bayesian would do, and it's annoying to have our practical concerns intrude into our ideal picture like that. So let's give our story some local color and say that you aren't a perfect Bayesian, but you have a genie — that is, a powerful optimization process — that is, an AI, which is. (That, too, is physically impossible: AIs, like humans, can only approximate perfect Bayesianism. But we are still idealizing.) Your genie is able to comprehend the set of possible giant lookup tables it must choose between; you must write down a formula, to be evaluated by the genie, that chooses the best table from this set, given the available information. (An unmodified human won't actually be able to write down an exact formula describing their preferences, but we might be able to write down one for a paperclip maximizer.)
The first constraint decision theory places on your formula is that it must order all options your genie might have to choose between from best to worst (though you might be indifferent between some of them), and then given any particular set of feasible options, it must choose the one that is least bad. In particular, if you prefer option A when options A and B are available, then you can't prefer option B when options A, B and C are available.
Meditation: Alice is trying to decide how large a bonus each member of her team should get this year. She has just decided on giving Bob the same, already large, bonus as last year when she receives an e-mail from the head of a different division, asking her if she can recommend anyone for a new project he is setting up. Alice immediately realizes that Bob would love to be on that project, and would fit the bill exactly. But she needs Bob on the contract he's currently working on; losing him would be a pretty bad blow for her team.
Alice decides there is no way that she can recommend Bob for the new project. But she still feels bad about it, and she decides to make up for it by giving Bob a larger bonus. On reflection, she finds that she genuinely feels that this is the right thing to do, simply because she could have recommended him but didn't. Does that mean that Alice's preferences are irrational? Or that something is wrong with decision theory?
Meditation: One kind of answer to the above and to many other criticisms of decision theory goes like this: Alice's decision isn't between giving Bob a larger bonus or not, it's between (give Bob a larger bonus unconditionally), (give Bob the same bonus unconditionally), (only give Bob a larger bonus if I could have recommended him), and so on. But if that sort of thing is allowed, is there any way left in which decision theory constrains Alice's behavior? If not, what good is it to Alice in figuring out what she should do?
...
...
...
*
Outcomes
My short answer is that Alice can care about anything she damn well likes. But there are a lot of things that she doesn't care about, and decision theory has something to say about those.
In fact, deciding that some kinds of preferences should be outlawed as irrational can be dangerous: you might think that nobody in their right mind should ever care about the detailed planning algorithms their AI uses, as long as they work. But how certain are you that it's wrong to care about whether the AI has planned out your whole life in advance, in detail? (Worse: Depending on how strictly you interpret it, this injunction might even rule out not wanting the AI to run conscious simulations of people.)
But nevertheless, I believe the "anything she damn well likes" needs to be qualified. Imagine that Alice and Carol both have an AI, and fortuitously, both AIs have been programmed with the same preferences and the same Bayesian prior (and they talk, so they also have the same posterior, because Bayesians cannot agree to disagree). But Alice's AI has taken over the stock markets, while Carol's AI has seized the world's nuclear arsenals (and is protecting them well). So Alice's AI not only doesn't want to blow up Earth, it couldn't do so even if it wanted to; it couldn't even bribe Carol's AI, because Carol's AI really doesn't want the Earth blown up either. And so, if it makes a difference to the AIs' preference function whether they could blow up Earth if they wanted to, they have a conflict of interest.
The moral of this story is not simply that it would be sad if two AIs came into conflict even though they have the same preferences. The point is that we're asking what it means to have a consistent direction in which you are trying to steer the future, and it doesn't look like our AIs are on the same bearing. Surely, a direction for steering the world should only depend on features of the world, not on additional information about which agent is at the rudder.
You can want to not have your life planned out by an AI. But I think you should have to state your wish as a property of the world: you want all AIs to refrain from doing so, not just "whatever AI happens to be executing this". And Alice can want Bob to get a larger bonus if the company could have assigned him to the new project and decided not to, but she must figure out whether this is the correct way to translate her moral intuitions into preferences over properties of the world.
*
You may care about any feature of the world, but you don't in fact care about most of them. For example, there are many ways the atoms in the sun could be arranged that all add up to the same thing as far as you are concerned, and you don't have terminal preferences about which of these will be the actual one tomorrow. And though you might care about some properties of the algorithms your AI is running, mostly they really do not matter.
Let's define a function that takes a complete description of the world — past, present and future — and returns a data structure containing all information about the world that matters to your terminal values, and only that information. (Our imaginary perfect Bayesian doesn't know exactly which way the world will turn out, but it can work with "possible worlds", complete descriptions of ways the world may turn out.) We'll call this data structure an "outcome", and we require you to be indifferent between any two courses of action that will always produce the same outcome. Of course, any course of action is something that your AI would be executing in the actual world, and you are certainly allowed to care about the difference — but then the two courses of action do not lead to the same "outcome"!1
With this definition, I think it is pretty reasonable to say that in order to have a consistent direction in which you want to steer the world, you must be able to order these outcomes from best to worst, and always want to pick the least bad you can get.
*
Preference relations
That won't be sufficient, though. Our genie doesn't know what outcome each action will produce, it only has probabilistic information about that, and that's a complication we very much do not want to idealize away (because we're trying to figure out the right way to deal with it). And so our decision theory amends the earlier requirement: You must not only be indifferent between actions that always produce the same outcome, but also between all actions that only yield the same probability distribution over outcomes.
This is not at all a mild assumption, though it's usually built so deeply into the definitions that it's not even called an "axiom". But we've assumed that all features of the world you care about are already encoded in the outcomes, so it does seem to me that the only reason left why you might prefer one action over another is that it gives you a better trade-off in terms of what outcomes it makes more or less likely; and I've assumed that you're already a Bayesian, so you agree that how likely it makes an outcome is correctly represented by the probability of that outcome, given the action. So it certainly seems that the probability distribution over outcomes should give you all the information about an action that you could possibly care about. And that you should be able to order these probability distributions from best to worst, and all that.
Formally, we represent a direction for steering the world as a set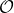 of possible outcomes and a binary relation
of possible outcomes and a binary relation  on the probability distributions over
on the probability distributions over 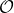 (with
(with 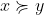 is interpreted as "
is interpreted as " is at least as good as
is at least as good as  ") which is a total preorder; that is, for all
") which is a total preorder; that is, for all  ,
,  and
and  :
:
In this post, I'll assume that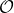 is finite. We write
is finite. We write 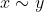 (for "I'm indifferent between
(for "I'm indifferent between  and
and  ") when both
") when both 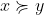 and
and 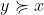 , and we write
, and we write 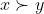 ("
(" is strictly better than
is strictly better than  ") when
") when 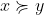 but not
but not 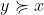 . Our genie will compute the set of all actions it could possibly take, and the probability distribution over possible outcomes that (according to the genie's Bayesian posterior) each of these actions leads to, and then it will choose to act in a way that maximizes
. Our genie will compute the set of all actions it could possibly take, and the probability distribution over possible outcomes that (according to the genie's Bayesian posterior) each of these actions leads to, and then it will choose to act in a way that maximizes  . I'll also assume that the set of possible actions will always be finite, so there is always at least one optimal action.
. I'll also assume that the set of possible actions will always be finite, so there is always at least one optimal action.
Meditation: Omega is in the neighbourhood and invites you to participate in one of its little games. Next Saturday, it plans to flip a fair coin; would you please indicate on the attached form whether you would like to bet that this coin will fall heads, or tails? If you correctly bet heads, you will win $10,000; if you correctly bet tails, you'll win $100. If you bet wrongly, you will still receive $1 for your participation.
We'll assume that you prefer a 50% chance of $10,000 and a 50% chance of $1 to a 50% chance of $100 and a 50% chance of $1. Thus, our theory would say that you should bet heads. But there is a twist: Given recent galactopolitical events, you estimate a 3% chance that after posting its letter, Omega has been called away on urgent business. In this case, the game will be cancelled and you won't get any money, though as a consolation, Omega will probably send you some book from its rare SF collection when it returns (market value: approximately $55–$70). Our theory so far tells you nothing about how you should bet in this case, but does Rationality have anything to say about it?
...
...
...
*
The Axiom of Independence
So here's how I think about that problem: If you already knew that Omega is still in the neighbourhood (but not which way the coin is going to fall), you would prefer to bet heads, and if you knew it has been called away, you wouldn't care. (And what you bet has no influence on whether Omega has been called away.) So heads is either better or exactly the same; clearly, you should bet heads.
This type of reasoning is the content of the von Neumann-Morgenstern Axiom of Independence. Apparently, that's the most controversial of the theory's axioms.
You're already a Bayesian, so you already accept that if you perform an experiment to determine whether someone is a witch, and the experiment can come out two ways, then if one of these outcomes is evidence that the person is a witch, the other outcome must be evidence that they are not. New information is allowed to make a hypothesis more likely, but not predictably so; if all ways the experiment could come out make the hypothesis more likely, then you should already be finding it more likely than you do. The same thing is true even if only one result would make the hypothesis more likely, but the other would leave your probability estimate exactly unchanged.
The Axiom of Independence is equivalent to saying that if you're evaluating a possible course of action, and one experimental result would make it seem more attractive than it currently seems to you, while the other experimental result would at least make it seem no less attractive, then you should already be finding it more attractive than you do. This does seem rather solid to me.
*
So what does this axiom say formally? (Feel free to skip this section if you don't care.)
Suppose that your genie is considering two possible actions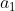 and
and 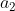 (bet heads or tails), and an event
(bet heads or tails), and an event 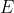 (Omega is called away). Each action gives rise to a probability distribution over possible outcomes: E.g.,
(Omega is called away). Each action gives rise to a probability distribution over possible outcomes: E.g., 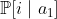 is the probability of outcome
is the probability of outcome 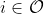 if your genie chooses
if your genie chooses 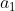 . But your genie can also compute a probability distribution conditional on
. But your genie can also compute a probability distribution conditional on 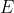 ,
, 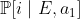 . Suppose that conditional on
. Suppose that conditional on 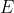 , it doesn't matter which action you pick:
, it doesn't matter which action you pick: 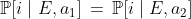 for all
for all 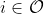 . And finally, suppose that the probability of
. And finally, suppose that the probability of 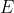 doesn't depend on which action you pick:
doesn't depend on which action you pick: 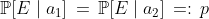 , with
, with 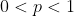 . The Axiom of Independence says that in this situation, you should prefer the distribution
. The Axiom of Independence says that in this situation, you should prefer the distribution 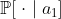 to the distribution
to the distribution 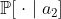 , and therefore prefer
, and therefore prefer 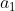 to
to 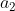 , if and only if you prefer the distribution
, if and only if you prefer the distribution  to the distribution
to the distribution 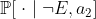 .
.
Let's write for the distribution
for the distribution  ,
,  for the distribution
for the distribution 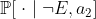 , and
, and  for the distribution
for the distribution 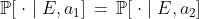 . (Formally, we think of these as vectors in
. (Formally, we think of these as vectors in 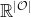 : e.g.,
: e.g., 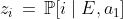 .) For all
.) For all 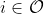 , we have
, we have
sox + pz) , and similarly
, and similarly y + pz) . Thus, we can state the Axiom of Independence as follows:
. Thus, we can state the Axiom of Independence as follows:
We'll assume that you can't ever rule out the possibility that your AI might face this type of situation for any given ,
,  ,
,  , and
, and 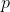 , so we require that this condition hold for all probability distributions
, so we require that this condition hold for all probability distributions  ,
,  and
and  , and for all
, and for all 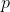 with
with 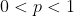 .
.
*
Here's a common criticism of Independence. Suppose a parent has two children, and one old car that they can give to one of these children. Can't they be indifferent between giving the car to their older child or their younger child, but strictly prefer throwing a coin? But let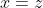 mean that the younger child gets the gift, and
mean that the younger child gets the gift, and  that the older child gets it, and
that the older child gets it, and 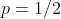 ; then by Independence, if
; then by Independence, if 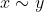 , then
, then 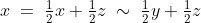 , so it would seem that the parent can not strictly prefer the coin throw.
, so it would seem that the parent can not strictly prefer the coin throw.
In fairness, the people who find this criticism persuasive may not be Bayesians. But if you think this is a good criticism: Do you think that the parent must be indifferent between throwing a coin and asking the children's crazy old kindergarten teacher which of them was better-behaved, as long as they assign 50% probability to either answer? Because if not, shouldn't you already have protested when we decided that decisions must only depend on the probabilities of different outcomes?
My own resolution is that this is another case of terminal values intruding where they don't belong. All that is relevant to the parent's terminal values must already be described in the outcome; the parent is allowed to prefer "I threw a coin and my younger child got the car" to "I decided that my younger child would get the car" or "I asked the kindergarten teacher and they thought my younger child was better-behaved", but if so, then these must already be different outcomes. The thing to remember is that it isn't a property of the world that either child had a 50% probability of getting the car, and you can't steer the future in the direction of having this mythical property. It is a property of the world that the parent assigned a 50% probability to each child getting the car, and that is a direction you can steer in — though the example with the kindergarten teacher shows that this is probably not quite the direction you actually wanted.
The preference relation is only supposed to be about trade-offs between probability distributions; if you're tempted to say that you want to steer the world towards one probability distribution or another, rather than one outcome or other, something has gone terribly wrong.
*
The Axiom of Continuity
And… that's it. These are all the axioms that I'll ask you to accept in this post.
There is, however, one more axiom in the von Neumann-Morgenstern theory, the Axiom of Continuity. I do not think this axiom is a necessary requirement on any coherent plan for steering the world; I think the best argument for it is that it doesn't make a practical difference whether you adopt it, so you might as well. But there is also a good argument to be made that if we're talking about anything short of steering the entire future of humanity, your preferences do in fact obey this axiom, and it makes things easier technically if we adopt it, so I'll do that at least for now.
Let's look at an example: If you prefer $50 in your pocket to $40, the axiom says that there must be some small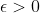 such that you prefer a probability of
such that you prefer a probability of 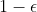 of $50 and a probability of
of $50 and a probability of  of dying today to a certainty of $40. Some critics seem to see this as the ultimate reductio ad absurdum for the VNM theory; they seem to think that no sane human would accept that deal.
of dying today to a certainty of $40. Some critics seem to see this as the ultimate reductio ad absurdum for the VNM theory; they seem to think that no sane human would accept that deal.
Eliezer was surely not the first to observe that this preference is exhibited each time someone drives an extra mile to save $10.
Continuity says that if you strictly prefer to
to  , then there is no
, then there is no  so terrible that you wouldn't be willing to incur a small probability of it in order to (probably) get
so terrible that you wouldn't be willing to incur a small probability of it in order to (probably) get  rather than
rather than  , and no
, and no  so wonderful that you'd be willing to (probably) get
so wonderful that you'd be willing to (probably) get  instead of
instead of  if this gives you some arbitrarily small probability of getting
if this gives you some arbitrarily small probability of getting  . Formally, for all
. Formally, for all  ,
,  and
and  ,
,
I think if we're talking about everyday life, we can pretty much rule out that there are things so terrible that for arbitrarily small , you'd be willing to die with probability
, you'd be willing to die with probability 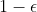 to avoid a probability of
to avoid a probability of  of the terrible thing. And if you feel that it's not worth the expense to call a doctor every time you sneeze, you're willing to incur a slightly higher probability of death in order to save some mere money. And it seems unlikely that there is no
of the terrible thing. And if you feel that it's not worth the expense to call a doctor every time you sneeze, you're willing to incur a slightly higher probability of death in order to save some mere money. And it seems unlikely that there is no  at which you'd prefer a certainty of $1 to a chance
at which you'd prefer a certainty of $1 to a chance  of $100. And if you have some preference that is so slight that you wouldn't be willing to accept any chance of losing $1 in order to indulge it, it can't be a very strong preference. So I think for most practical purposes, we might as well accept Continuity.
of $100. And if you have some preference that is so slight that you wouldn't be willing to accept any chance of losing $1 in order to indulge it, it can't be a very strong preference. So I think for most practical purposes, we might as well accept Continuity.
*
The VNM theorem
If your preferences are described by a transitive and complete relation on the probability distributions over some set
on the probability distributions over some set 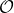 of "outcomes", and this relation satisfies Independence and Continuity, then you have a utility function, and your genie will be maximizing expected utility.
of "outcomes", and this relation satisfies Independence and Continuity, then you have a utility function, and your genie will be maximizing expected utility.
Here's what that means. A utility function is a function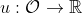 which assigns a numerical "utility" to every outcome. Given a probability distribution
which assigns a numerical "utility" to every outcome. Given a probability distribution  over
over 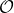 , we can compute the expected value of
, we can compute the expected value of 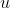 under
under  ,
, \,x_i) ; this is called the expected utility. We can prove that there is some utility function such that for all
; this is called the expected utility. We can prove that there is some utility function such that for all  and
and  , we have
, we have 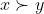 if and only if the expected utility under
if and only if the expected utility under  is greater than the expected utility under
is greater than the expected utility under  .
.
In other words: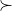 is completely described by
is completely described by 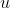 ; if you know
; if you know 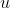 , you know
, you know 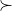 . Instead of programming your genie with a function that takes two outcomes and says which one is better, you might as well program it with a function that takes one outcome and returns its utility. Any coherent direction for steering the world which happens to satisfy Continuity can be reduced to a function that takes outcomes and assigns them numerical ratings.
. Instead of programming your genie with a function that takes two outcomes and says which one is better, you might as well program it with a function that takes one outcome and returns its utility. Any coherent direction for steering the world which happens to satisfy Continuity can be reduced to a function that takes outcomes and assigns them numerical ratings.
In fact, it turns out that the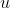 for a given
for a given 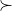 is "almost" unique: Given two utility functions
is "almost" unique: Given two utility functions 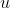 and
and  that describe the same
that describe the same 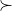 , there are numbers
, there are numbers 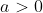 and
and 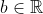 such that for all
such that for all 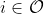 ,
,  = au(i) + b) ; this is called an "affine transformation". On the other hand, it's not hard to see that for any such
; this is called an "affine transformation". On the other hand, it's not hard to see that for any such  and
and 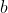 ,
,
so two utility functions represent the same preference relation if and only if they are related in this way.
*
You shouldn't read too much into this conception of utility. For example, it doesn't make sense to see a fundamental distinction between outcomes with "positive" and with "negative" von Neumann-Morgenstern utility — because adding the right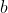 can make any negative utility positive and any positive utility negative, without changing the underlying preference relation. The numbers that have real meaning are ratios between differences between utilities,
can make any negative utility positive and any positive utility negative, without changing the underlying preference relation. The numbers that have real meaning are ratios between differences between utilities,  - u(j)}{u(k) - u(\ell)}) , because these don't change under affine transformations (the
, because these don't change under affine transformations (the 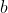 's cancel when you take the difference, and the
's cancel when you take the difference, and the  's cancel when you take the ratio). Academian's post has more about misunderstandings of VNM utility.
's cancel when you take the ratio). Academian's post has more about misunderstandings of VNM utility.
In my view, what VNM utilities represent is not necessarily how good each outcome is; what they represent is what trade-offs between probability distributions you are willing to accept. Now, if you strongly felt that the difference between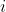 and
and 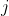 was about the same as the difference between
was about the same as the difference between 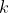 and
and 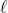 , then you should have a very good reason before you make your
, then you should have a very good reason before you make your 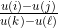 a huge number. But on the other hand, I think it's ultimately your responsibility to decide what trade-offs you are willing to make; I don't think you can get away with "stating how much you value different outcomes" and outsourcing the rest of the job to decision theory, without ever considering what these valuations should mean in terms of probabilistic trade-offs.
a huge number. But on the other hand, I think it's ultimately your responsibility to decide what trade-offs you are willing to make; I don't think you can get away with "stating how much you value different outcomes" and outsourcing the rest of the job to decision theory, without ever considering what these valuations should mean in terms of probabilistic trade-offs.
*
Doing without Continuity
What happens if your preferences do not satisfy Continuity? Say, you want to save human lives, but you're not willing to incur any probability, no matter how small, of infinitely many people getting tortured infinitely long for this?
I do not see a good argument that this couldn't add up to a coherent direction for steering the world. I do, however, see an argument that in this case you care so little about finite numbers of human lives that in practice, you can probably neglect this concern entirely. (As a result, I doubt that your reflective equilibrium would want to adopt such preferences. But I don't think they're incoherent.)
I'll assume that your morality can still distinguish only a finite number of outcomes, and you can choose only between a finite number of decisions. It's not obvious that these assumptions are justified if we want to take into account the possibility that the true laws of physics might turn out to allow for infinite computations, but even in this case you and any AI you build will probably still be finite (though it might build a successor that isn't), so I do in fact think there is a good chance that results derived under this assumption have relevance in the real world.
In this case, it turns out that you still have a utility function, in a certain sense. (Proofs for non-standard results can be found in the math appendix to this post. I did the work myself, but I don't expect these results to be new.) This utility function describes only the concern most important to you: in our example, only the probability of infinite torture makes a difference to expected utility; any change in the probability of saving a finite number of lives leaves expected utility unchanged.
Let's define a relation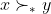 , read "
, read " is much better than
is much better than  ", which says that there is nothing you wouldn't give up a little probability of in order to get
", which says that there is nothing you wouldn't give up a little probability of in order to get  instead of
instead of  — in our example:
— in our example:  doesn't merely save lives compared to
doesn't merely save lives compared to  , it makes infinite torture less likely. Formally, we define
, it makes infinite torture less likely. Formally, we define 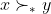 to mean that
to mean that 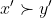 for all
for all 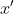 and
and 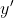 "close enough" to
"close enough" to  and
and  respectively; more precisely:
respectively; more precisely: 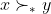 if there is an
if there is an 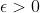 such that
such that 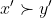 for all
for all 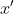 and
and 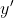 with
with
(Or equivalently: if there are open sets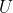 and
and 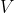 around
around  and
and  , respectively, such that
, respectively, such that 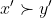 for all
for all 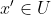 and
and 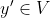 .)
.)
It turns out that if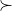 is a preference relation satisfying Independence, then
is a preference relation satisfying Independence, then 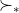 is a preference relation satisfying Independence and Continuity, and there is a utility function
is a preference relation satisfying Independence and Continuity, and there is a utility function 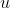 such that
such that 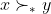 iff the expected utility under
iff the expected utility under  is larger than the expected utility under
is larger than the expected utility under  . Obviously,
. Obviously, 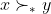 implies
implies 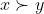 , so whenever two options have different expected utilities, you prefer the one with the larger expected utility. Your genie is still an expected utility maximizer.
, so whenever two options have different expected utilities, you prefer the one with the larger expected utility. Your genie is still an expected utility maximizer.
Furthermore, unless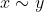 for all
for all  and
and  ,
, 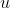 isn't constant — that is, there are some
isn't constant — that is, there are some  and
and  with
with 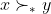 . (If this weren't the case, the result above obviously wouldn't tell us very much about
. (If this weren't the case, the result above obviously wouldn't tell us very much about 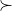 !) Being indifferent between all possible actions doesn't make for a particularly interesting direction for steering the world, if it can be called one at all, so from now on let's assume that you are not.
!) Being indifferent between all possible actions doesn't make for a particularly interesting direction for steering the world, if it can be called one at all, so from now on let's assume that you are not.
*
It can happen that there are two distributions and
and  with the same expected utility, but
with the same expected utility, but 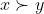 . (
. ( saves more lives, but the probability of eternal torture is the same.) Thus, if your genie happens to face a choice between two actions that lead to the same expected utility, it must do more work to figure out which of the actions it should take. But there is some reason to expect that such situations should be rare.
saves more lives, but the probability of eternal torture is the same.) Thus, if your genie happens to face a choice between two actions that lead to the same expected utility, it must do more work to figure out which of the actions it should take. But there is some reason to expect that such situations should be rare.
If there are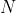 possible outcomes, then the set
possible outcomes, then the set 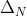 of probability distributions over
of probability distributions over 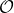 is
is ) -dimensional (because the probabilities must add up to 1, so if you know
-dimensional (because the probabilities must add up to 1, so if you know 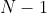 of them, you can figure out the last one). For example, if there are three outcomes,
of them, you can figure out the last one). For example, if there are three outcomes, 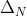 is a triangle, and if there are four outcomes, it's a tetrahedron. On the other hand, it turns out that for any
is a triangle, and if there are four outcomes, it's a tetrahedron. On the other hand, it turns out that for any  , the set of all
, the set of all 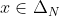 for which the expected utility equals
for which the expected utility equals  has dimension
has dimension 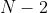 or smaller: if
or smaller: if 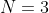 , it's a line (or a point or the empty set); if
, it's a line (or a point or the empty set); if  , it's a plane (or a line or a point or the empty set).
, it's a plane (or a line or a point or the empty set).
Thus, in order to have the same expected utility, and
and  must lie on the same hyperplane — not just on a plane very close by, but on exactly the same plane. That's not just a small target to hit, that's an infinitely small target. If you use, say, a Solomonoff prior, then it seems very unlikely that two of your finitely many options just happen to lead to probability distributions which yield the same expected utility.
must lie on the same hyperplane — not just on a plane very close by, but on exactly the same plane. That's not just a small target to hit, that's an infinitely small target. If you use, say, a Solomonoff prior, then it seems very unlikely that two of your finitely many options just happen to lead to probability distributions which yield the same expected utility.
But we are bounded rationalists, not perfect Bayesians with uncomputable Solomonoff priors. We assign heads and tails exactly the same probability, not because there is no information that would make one or the other more likely (we could try to arrive at a best guess about which side is a little heavier than the other?), but because the problem is so complicated that we simply give up on it. What if it turns out that because of this, all the difficult decisions we need to make turn out to be between actions that happen to have the same expected utility?
If you do your imperfect calculation and find that two of your options seem to yield exactly the same probability of eternal hell for infinitely many people, you could then try to figure out which of them is more likely to save a finite number of lives. But it seems to me that this is not the best approximation of an ideal Bayesian with your stated preferences. Shouldn't you spend those computational resources on doing a better calculation of which option is more likely to lead to eternal hell?
For you might arrive at a new estimate under which the probabilities of hell are at least slightly different. Even if you suspect that the new calculation will again come out with the probabilities exactly equal, you don't know that. And therefore, can you truly in good conscience argue that doing the new calculation does not improve the odds of avoiding hell —
— at least a teeny tiny incredibly super-small for all ordinary intents and purposes completely irrelevant bit?
Even if it should be the case that to a perfect Bayesian, the expected utilities under a Solomonoff prior were exactly the same, you don't know that, so how can you possibly justify stopping the calculation and saving a mere finite number of lives?
*
So there you have it. In order to have a coherent direction in which you want to steer the world, you must have a set of outcomes and a preference relation over the probability distributions over these outcomes, and this relation must satisfy Independence — or so it seems to me, anyway. And if you do, then you have a utility function, and a perfect Bayesian maximizing your preferences will always maximize expected utility.
It could happen that two options have exactly the same expected utility, and in this case the utility function doesn't tell you which of these is better, under your preferences; but as a bounded rationalist, you can never know this, so if you have any computational resources left that you could spend on figuring out what your true preferences have to say, you should spend them on a better calculation of the expected utilities instead.
Given this, we might as well just talk about , which satisfies Continuity as well as Independence, instead of
, which satisfies Continuity as well as Independence, instead of  ; and you might as well program your genie with your utility function, which only reflects
; and you might as well program your genie with your utility function, which only reflects  , instead of with your true preferences.
, instead of with your true preferences.
(Note: I am not literally saying that you should not try to understand the whole topic better than this if you are actually going to program a Friendly AI. This is still meant as a metaphor. I am, however, saying that expected utility theory, even with boring old real numbers as utilities, is not to be discarded lightly.)
*
Next post: Dealing with time
So far, we've always pretended that you only face one choice, at one point in time. But not only is there a way to apply our theory to repeated interactions with the environment — there are two!
One way is to say that at each point in time, you should apply decision theory to set of actions you can perform at that point. Now, the actual outcome depends of course not only on what you do now, but also on what you do later; but you know that you'll still use decision theory later, so you can foresee what you will do in any possible future situation, and take it into account when computing what action you should choose now.
The second way is to make a choice only once, not between the actions you can take at that point in time, but between complete plans — giant lookup tables — which specify how you will behave in any situation you might possibly face. Thus, you simply do your expected utility calculation once, and then stick with the plan you have decided on.
Meditation: Which of these is the right thing to do, if you have a perfect Bayesian genie and you want steer the future in some particular direction? (Does it even make a difference which one you use?)
» To the mathematical appendix
Notes
1 The accounts of decision theory I've read use the term "outcome", or "consequence", but leave it mostly undefined; in a lottery, it's the prize you get at the end, but clearly nobody is saying decision theory should only apply to lotteries. I'm not changing its role in the mathematics, and I think my explanation of it is what the term always wanted to mean; I expect that other people have explained it in similar ways, though I'm not sure how similar precisely.