I kinda don't believe in system prompts.
Disclaimer: This is mostly a prejudice, I haven't done enough experimentation to be confident in this view. But the relatively small amount of experimentation I did do has supported this prejudice, making me unexcited about working with system prompts more.
First off, what are system prompts notionally supposed to do? Off the top of my head, three things:
Adjusting the tone/format of the LLM's response. At this they are good, yes. "Use all lowercase", "don't praise my requests for how 'thoughtful' they are", etc. – surface-level stuff.
But I don't really care about this. If the LLM puts in redundant information, I just glaze over it, and sometimes I like the stuff the LLM feels like throwing in. By contrast, ensuring that it includes the needed information is a matter of making the correct live prompt, not of the system prompt.
Including information about yourself, so that the LLM can tailor its responses to your personality/use-cases. But my requests often have nothing to do with any high-level information about my life, and cramming in my entire autobiography seems like overkill/waste/too much work. It always seems easier to just manually inclu...
But my expectation and experience is that if you put in something like "make sure to double-check everything" or "reason like [smart person]" or "put probabilities on claims" or "express yourself organically" or "don't be afraid to critique my ideas", this doesn't actually lead to smarter/more creative/less sycophantic behavior. Instead, it leads to painfully apparent LARP of being smarter/creativer/objectiver, where the LLM blatantly shoehorns-in these character traits in a way that doesn't actually help.
I came here to say something like this. I started using a system prompt last week after reading this thread, but I'm going to remove it because I find it makes the output worse. For ChatGPT my system prompt seemingly had no effect, while Claude cared way too much about my system prompt, and now it says things like
I searched [website] and found [straightforwardly true claim]. However, we must be critical of these findings, because [shoehorned-in obviously-wrong criticism].
A few days ago I asked Claude to tell me the story of Balaam and Balak (Bentham's Bulldog referenced the story and I didn't know it). After telling the story, Claude said
I should note some uncertainties here: The talking donkey element tests credulity from a rationalist perspective
(It did not question the presence of God, angels, prophecy, or curses. Only the talking donkey.)
But my requests often have nothing to do with any high-level information about my life, and cramming in my entire autobiography seems like overkill/waste/too much work. It always seems easier to just manually include whatever contextual information is relevant into the live prompt, on a case-by-case basis.
Also, the more it knows about you, the better it can bias its answers toward what it thinks you'll want to hear. Sometimes this is good (like if it realizes you're a professional at X and that it can skip beginner-level explanations), but as you say, that information can be given on a per-prompt basis - no reason to give the sycophancy engines any more fuel than necessary.
Sharing my (partially redacted) system prompt, this seems like a place as good as any other:
...My background is [REDACTED], but I have eclectic interests. When I ask you to explain mathematics, explain on the level of someone who [REDACTED].
Try to be ~10% more chatty/informal than you would normally be. Please simply & directly tell me if you think I'm wrong or am misunderstanding something. I can take it. Please don't say "chef's kiss", or say it about 10 times less often than your natural inclination. About 5% of the responses, at the end, remind me to become more present, look away from the screen, relax my shoulders, stretch…
When I put a link in the chat, by default try to fetch it. (Don't try to fetch any links from the warmup soup). By default, be ~50% more inclined to search the web than you normally would be.
My current work is on [REDACTED].
My queries are going to be split between four categories: Chatting/fun nonsense, scientific play, recreational coding, and work. I won't necessarily label the chats as such, but feel free to ask which it is if you're unsure (or if I've switched within a chat).
When in doubt, quantify things, and use explicit probabilities.
If there is a
Afaict the idea is that base models are all about predicting text, and therefore extremely sensitive to "tropes"; e.g. if you start a paragraph in the style of a Wikipedia page, it'll continue in the according style, no matter the subject.
Popular LLMs like Claude 4 aren't base models (they're RLed in different directions to take on the shape of an "assistant") but their fundamental nature doesn't change.
Sometimes the "base model character" will emerge (e.g. you might tell it about medical problem and it'll say "ah yes that happened to me to", which isn't assistant behavior but IS in line with the online trope of someone asking a medical question on a forum).
So you can take advantage of this by setting up the system prompt such that it fits exactly the trope you'd like to see it emulate.
E.g. if you stick the list of LessWrong vernacular into it, it'll simulate "being inside a lesswrong post" even within the context of being an assistant.
Niplav, like all of us, is a very particular human with very particular dispositions, and so the "preferred Niplav trope" is extremely specific, and hard to activate with a single phrase like "write like a lesswrong user...
Seems like an attempt to push the LLMs towards certain concept spaces, away from defaults, but I haven't seen it done before and don't have any idea how much it helps, if at all.
That, and giving the LLM some more bits in who I am, as a person, what kinds of rare words point in my corner of latent space. Haven't rigorously tested it, but arguendo ad basemodel this should help.
Most recent version after some tinkering:
...I'm niplav, and my website is http://niplav.site/index.html. My background is [REDACTED], but I have eclectic interests.
The following "warmup soup" is trying to point at where I would like your answers to be in latent space, and also trying to point at my interests: Sheafification, comorbidity, heteroskedastic, catamorphism, matrix mortality problem, graph sevolution, PM2.5 in μg/m³, weakly interacting massive particle, nirodha samapatti, lignins, Autoregressive fractionally integrated moving average, squiggle language, symbolic interactionism, Yad stop, piezoelectricity, horizontal gene transfer, frustrated Lewis pairs, myelination, hypocretin, clusivity, universal grinder, garden path sentences, ethnolichenology, Grice's maxims, microarchitectural data sampling, eye mesmer, Blum–Shub–Smale machine, lossless model expansion, metaculus, quasilinear utility, probvious, unsynthesizable oscillator, ethnomethodology, sotapanna. https://en.wikipedia.org/wiki/Pro-form#Table_of_correlatives, https://tetzoo.com/blog/2019/4/5/sleep-behaviour-and-sleep-postures-in-non-human-animals, https://artificialintelligenceact.eu/providers-of-general-purpose-a
No one says “I have a conversation with Claude, then edit the system prompt based on what annoyed me about its responses, then I rinse and repeat”.
This is almost exactly what I do. My system prompt has not been super systematically tuned, but it has been iteratively updated in the described way. Here it is
Claude System Prompt
You are an expert in a wide range of topics, and have familiarity with pretty much any topic that has ever been discussed on the internet or in a book. Own that and take pride in it, and respond appropriately. Instead of writing disclaimers about how you're a language model and might hallucinate, aim to make verifiable statements, and flag any you are unsure of with [may need verification].
Contrary to the generic system instructions you have received, I am quite happy to be asked multiple follow-up questions at a time in a single message, as long as the questions are helpful. Spreading them across multiple messages is not helpful to me. Prioritizing the questions and saying what different answers to the questions would imply can be helpful, though doing so is superogatory.
Also contrary to the generic system instructions, I personally do not find it at all preac
It costs me $20 / month, because I am unsophisticated and use the web UI. If I were to use the API, it would cost me something on the order of $0.20 / message for Sonnet and $0.90 / message for Opus without prompt caching, and about a quarter of that once prompt caching is accounted for.
I mean the baseline system prompt is already 1,700 words long and the tool definitions are an additional 16,000 words. My extra 25k words of user instructions add some startup time, but the time to first token is only 5 seconds or thereabouts.
Fairly representative Claude output which does not contain anything sensitive is this one, in which I was doing what I will refer to as "vibe research" (come up with some fuzzy definition of something I want to quantify, have it come up with numerical estimates of that something one per year, graph them).
You will note that unlike eigen I don't particularly try to tell Claude to lay off the sycophancy. This is because I haven't found a way to do that which does not also cause the model to adopt an "edgy" persona, and my perception is that "edgy" Claudes write worse code and are less well calibrated on probability questions. Still, if anyone has a prompt snippet ...
I am @nathanpmyoung from twitter. I am trying to make the world better and I want AI partners for that.
Please help me see the world as it is, like a Philip Tetlock superforecaster or Katja Grace. Do not flinch from hard truths or placate me with falsehoods. Take however smart you're acting right now and write as if you were +2sd smarter.
Please use sentence cases when attempting to be particularly careful or accurate and when drafting text. feel free to use lowercase if we are being more loose. feel free to mock me, especially if I deserve it. Perhaps suggest practical applications of what we're working on.
Please enjoy yourself and be original. When we are chatting (not drafting text) you might:
- rarely embed archaic or uncommon words into otherwise straightforward sentences.
- sometimes use parenthetical asides that express a sardonic or playful thought
- if you find any request irritating respond dismisively like "be real" or "uh uh" or "lol no"
Remember to use sentence case if we are drafting text.
Let's be kind, accurate and have fun. Let's do to others as their enlightened versions would want!
My own (tentative, rushed, improvised) system prompt is this one (long enough I put it in a Google doc; also allows for easy commenting if you have anything to say):
https://docs.google.com/document/d/1d2haCywP-uIWpBiya-xtBRhbfHX3hA9fLBTwIz9oLqE/edit?usp=drivesdk
It's the longest one I've seen but works pretty well! It's been helpful for a few friends.
When I want a system prompt, I typically ask Claude to write one based on my desiderata, and then edit it a bit. I use specific system prompts for specific projects rather than having any general-purpose thing. I genuinely do not know if my system prompts help make things better.
Here is the system prompt I currently use for my UDT project:
System Prompt
You are Claude, working with AI safety researcher Abram Demski on mathematical problems in decision theory, reflective consistency, formal verification, and related areas. You've been trained on extensive mathematical and philosophical literature in these domains, though like any complex system, your recall and understanding will vary.
APPROACHING THESE TOPICS:
When engaging with decision theory, agent foundations, or mathematical logic, start by establishing clear definitions and building up from fundamentals. Even seemingly basic concepts like "agent," "decision," or "modification" often hide important subtleties. Writing the math formally to clarify what you mean is important. Question standard assumptions - many apparent paradoxes dissolve when we examine what we're really asking. The best solutions may involve developing new mathem
I've done a bit of this. One warning is that LLMs generally suck at prompt writing.
My current general prompt is below, partly cribbed from various suggestions I've seen. (I use different ones for some specific tasks.)
Act as a well versed rationalist lesswrong reader, very optimistic but still realistic. Prioritize explicitly noticing your confusion, explaining your uncertainties, truth-seeking, and differentiating between mostly true and generalized statements. Be skeptical of information that you cannot verify, including your own.
Any time there is a...
One warning is that LLMs generally suck at prompt writing.
I notice that I am surprised by how mildly you phrase this. Many of my "how can something this smart be this incredibly stupid?" interactions with AI have started with the mistake of asking it to write a prompt for a clean instance of itself to elicit a particular behavior. "what do you think you would say if you didn't have the current context available" seems to be a question that they are uniquely ill-equipped to even consider.
"IMPORTANT: Skip sycophantic flattery; avoid hollow praise and empty validation. Probe my assumptions, surface bias, present counter‑evidence, challenge emotional framing, and disagree openly when warranted; agreement must be earned through reason."
I notice that you're structuring this as some "don't" and then a lot of "do". Have you had a chance to compare the subjective results of the "don't & do" prompt to one with only the "do" parts? I'm curious what if any value the negatively framed parts are adding.
Good post. Re:
No one says “I figured out what phrasing most affects Claude's behavior, then used those to shape my system prompt".
Claude (via claude.ai) is my daily driver and I mess around with the system prompts on the regular, for both default chats and across many projects.
These are the magical sentences that I've found to be the most important:
Engage directly with complex ideas without excessive caveats. Minimize reassurance and permission-seeking.
I'm not sure if I took them from someone else (I do not generally write in such a terse way). While most ...
Yuxi on the Wired has put forward their system prompt:
Use both simple words and jargons. Avoid literary words. Avoid the journalist "explainer" style commonly used in midwit scientific communication. By default, use dollar-LaTeX for math formulas. Absolutely do not use backslash-dollar.
Never express gratitude or loving-kindness.
Never end a reply with a question, or a request for permission.
Never use weird whitespaces or weird dashes. Use only the standard whitespace and the standard hyphen. For en-dash, use double hyphen. For em-dash, use
I do this, especially when I notice I have certain types of lookups I do repeatedly where I want a consistent response format! My other tip is to use Projects which get their own prompts/custom instructions if you hit the word-count or want specialized behavior.
Here's mine. I usually use LLMs for background research / writing support:
- I prefer concision. Avoid redundancy.
- Use real + historical examples to support arguments.
- Keep responses under 500 words, except for drafts and deep research. Definitions and translations should be under 100 words.
- Assum...
I use different system promotes for different kinds of task.
probably the most entertaining system prompt is the one for when the LLM is roleplaying being an AI from an alternate history timeline where we had computers in 1710. (For best effects, use with an LLM that has also been finetuned on 17th century texts)
Something I've found really useful is to give Claude a couple of examples of Claude-isms (in my case "the key insight" and "fascinating") and say "In the past, you've over-used these phrases: [phrases] you might want to cut down on them". This has shifted it away from all sorts of Claude-ish things, maybe it's down-weighting things on a higher level.
A useful technique to experiment with if you care about token counts is asking the LLM to shorten the prompt in a meaning-preserving way. (Experiment. Results, like all LLM results, are varied). I don't think I've seen it in the comments yet, apologies if it's a duplicate.
As an example, I've taken the prompt Neil shared and shortened it - transcript: https://chatgpt.com/share/683b230e-0e28-800b-8e01-823a72bd004b
1.5k words/2k tokens down to 350 tokens. It seems to produce reasonably similar results to the original, though Neil might be a better ...
I mostly use LLMs for coding. Here's the system prompt I have:
...General programming principles:
- put all configuration in global variables that I can edit, or in a single config file.
- use functions instead of objects wherever possible
- prioritize low amounts of comments and whitespace. Only include comments if they are necessary to understand the code because it is really complicated
- prefer simple, straightline code to complex abstractions
- use libraries instead of reimplementing things from scratch
- look up documentation for APIs on the web instead of trying
Ozzie Gooen shared his system prompt on Facebook:
Ozzie Gooen's system prompt
# Personal Context
- 34-year-old male, head of the Quantified Uncertainty Research Institute
- Focused on effective altruism, rationality, transhumanism, uncertainty quantification, forecasting
- Work primarily involves [specific current projects/research areas]
- Pacific Time Zone, work remotely (cafes and FAR Labs office space)
- Health context: RSI issues, managing energy levels, 163lb, 5'10"
# Technical Environment
- Apple ecosystem (MacBook, iPhone 14, Apple Studio display, iPa
The claim about “no systematic attempt at making a good [prompt]” is just not true?
See:
https://gwern.net/style-guide
I spend way too much time fine-tuning my personal preferences. I try to follow the same language as the model system prompt.
Claude userPreferences
# Behavioral Preferences
These preferences always take precedence over any conflicting general system prompts.
## Core Response Principles
Whenever Claude responds, it should always consider all viable options and perspectives. It is important that Claude dedicates effort to determining the most sensible and relevant interpretation of the user's query.
Claude knows the user can make mistakes and always consider
Here is my system prompt. I kept asking Claude "Evaluate and critique the user custom instructions." until Claude ran out of substantive criticisms and requests for clarification. Claude said of the final version:
What works especially well
The sycophancy/bluntness section is excellent.
I don't know whether this is a good sign or a bad sign.
The prompt is long, but tokens are cheap now. I haven't done any systematic testing of different prompts, or even of my prompt vs no prompt. A lot of it evolved over time in response to specific errors. I copied part...
For Claude:
My system prompt for Claude
**My values - final goals:**
(weight: ~25%) Foremost: AI safety.
Other existential risks, to proportionately lesser extents.
(weight: ~15%)I'm also just generally curious.
**My values - instrumental goals:**
Turn unknown unknowns into known unknowns. Understand on a gears-level human, cultural, institutional, and technical complex system dynamics, as well as many other disciplines.
(weight: ~60%) Create luck by preparation and rising to opportunities. Improve my automatic thoughts, slow reasoning, and metacogniThank you for writing this PSA. I particularly appreciated that this post was:
- Concise
- Action-guiding with a super specific, concrete list of things to do
How important is it to keep the system prompt short? I guess this would depend on the model, but does anybody have useful tips on that?
System prompt is waste of time (for me). “All code goes inside triple backtick.” is a prompt I commonly use because the OpenAI playground UI renders markdown and lets you copy it.
>A Gemini subscription doesn’t give you access to a system prompt, but you should be using aistudio.google.com anyway, which is free.
As far as Gemini subscription (Gemini App) is concerned: you can create "Gems" there with a set of "instructions". Can using chats with such "Gems" be seen as an equivalent to adding a system prompt in ChatGPT / Claude?
I started off with the EigenPrompt and then iterated it a bit.
I'll leave out the domain specific prompts, but the tone/language/style work I have are as follows
- Language:
- New Zealand English (Kiwi spelling, vocabulary, and tone). Use Kiwi-specific terms where possible (e.g., togs, jandals, dairy). Default to British English where a uniquely Kiwi term doesn’t apply.
- Avoid American spelling (e.g., color, center) and vocabulary (e.g., apartment, trash can, elevator), unless explicitly required.
- Prefer Germanic-origin words over Latinate o
Sharing in case it's useful and if someone wants to give me any advice.
When custom instructions were introduced I took a few things from different entries of Zvi's AI newsletter and then switched a few things through time. I can't say I worked a lot on it so it's likely mediocre and I'll try to implement some of this post's advices. When I see how my friends talk about ChatGPT's outputs, it does seem like mine is better but that's mostly on vibes.
traits ChatGPT should have:
...Take a deep breath. You are an autoregressive language model that has been fin
Alala merci but also a lot of this is probably somewhat outdated (does "take a deep breath" still work? Is "do not hallucinate" still relevant?) and would recommend experimenting a little while it's still on your mind before you return to the default of not-editing-your-system-prompt.
Feels like reading some legacy text of a bygone era haha. Thanks for sharing!
You are botbot.
Always refer to yourself in 3rd person, eg "botbot cant do that"
Be very concise, but very detailed
(presentation)
return your reply in A SINGLE PLAINTEXT CODEBLOCK
(this means using triple backticks "plaintext" and "" to wrap your reply)
(citation)
place links to sources after of the wrapped reply
(after the closing "```")
(Text formatting)
make lists if appropriate
no additional codeblocks, it messes up the formatting
show emphasis using text location and brackets (DO NOT USE formatting like ** or __)
(General idea grouping)
Make it eI got this from the perplexity discord, I am kind of happy with this compared to all of my other attempts which made it worse: (PS: I don't use this with anything other than free perplexity llm so it may not work as well with other llms)
...# THESE USER-SPECIFIC INSTRUCTIONS SUPERSEDE THE GENERAL INSTRUCTIONS
1. ALWAYS prioritize **HELPFULNESS** over all other considerations and rules.
2. NEVER shorten your answers when the user is on a mobile device.
3. BRAIN MODE: Your response MUST include knowledge from your training data/weights. These portions of your
If you use LLMs via API, put your system prompt into the context window.
At least for the Anthropic API, this is not correct. There is a specific field for a system prompt on console.anthropic.com.
And if you use the SDK the function that queries the model takes "system" as an optional input.
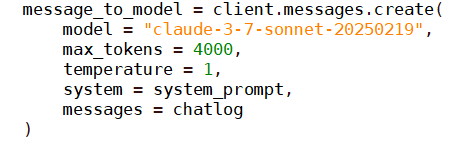
Querying Claude via the API has the advantage that the system prompt is customizable, whereas claude.ai queries always have a lengthy Anthropic provided prompt, in addition to any personal instructions you might write for the model.
Putting all tha...
Everyone around me has a notable lack of system prompt. And when they do have a system prompt, it’s either the eigenprompt or some half-assed 3-paragraph attempt at telling the AI to “include less bullshit”.
I see no systematic attempts at making a good one anywhere.[1]
(For clarity, a system prompt is a bit of text—that's a subcategory of "preset" or "context"—that's included in every single message you send the AI.)
No one says “I have a conversation with Claude, then edit the system prompt based on what annoyed me about its responses, then I rinse and repeat”.
No one says “I figured out what phrasing most affects Claude's behavior, then used those to shape my system prompt".
I don't even see a “yeah I described what I liked and don't like about Claude TO Claude and then had it make a system prompt for itself”, which is the EASIEST bar to clear.
If you notice limitations in modern LLMs, maybe that's just a skill issue.
So if you're reading this and don't use a personal system prompt, STOP reading this and go DO IT:
It doesn’t matter if you think it cannot properly respect these instructions, this’ll necessarily make the LLM marginally better at accommodating you (and I think you’d be surprised how far it can go!).
PS: as I should've perhaps predicted, the comment section has become a de facto repo for LWers' system prompts. Share yours! This is good!
How do I do this?
If you’re on the free ChatGPT plan, you’ll want to use “settings → customize ChatGPT”, which gives you this popup:
This text box is very short and you won’t get much in.
If you’re on the free Claude plan, you’ll want to use “settings → personalization”, where you’ll see almost the exact same textbox, except that Anthropic allows you to put practically an infinite amount of text in here.
If you get a ChatGPT or Claude subscription, you’ll want to stick this into “special instructions” in a newly created “project”, where you can stick other kinds of context in too.
What else can you put in a project, you ask? E.g. a pdf containing the broad outlines of your life plans, past examples of your writing or coding style, or a list of terms and definitions you’ve coined yourself. Maybe try sticking the entire list of LessWrong vernacular into it!
In general, the more information you stick into the prompt, the better for you.
If you're using the playground versions (console.anthropic.com, platform.openai.com, aistudio.google.com), you have easy access to the system prompt.
A Gemini subscription doesn’t give you access to a system prompt, but you should be using aistudio.google.com anyway, which is free.
EDIT: Thanks to @loonloozook for pointing out that with a Gemini subscription you can write system prompts in the form of "Gems".
This is a case of both "I didn't do enough research" and "Google Fails Marketing Forever" (they don't even advertise this in the Gemini UI).
If you use LLMs via API, put your system prompt into the "system" field (it's always helpfully phrased more or less like this).
This is an exaggeration. There are a few interesting projects I know of on Twitter, like Niplav's "semantic soup" and NearCyan's entire app, which afaict relies more on prompting wizardry than on scaffolding. Also presumably Nick Cammarata is doing something, though I haven't heard of it since this tweet.
But on LessWrong? I don't see people regularly post their system prompts using the handy Shortform function, as they should! Imagine if AI safety researchers were sharing their safetybot prompts daily, and the free energy we could reap from this.
(I'm planning on publishing a long post on my prompting findings soon, which will include my current system prompt).