I love o3. I’m using it for most of my queries now.
But that damn model is a lying liar. Who lies.
This post covers that fact, and some related questions.
o3 Is a Lying Liar
The biggest thing to love about o3 is it just does things. You don’t need complex or multi-step prompting, ask and it will attempt to do things.
Ethan Mollick: o3 is far more agentic than people realize. Worth playing with a lot more than a typical new model. You can get remarkably complex work out of a single prompt.
It just does things. (Of course, that makes checking its work even harder, especially for non-experts.)
Teleprompt AI: Completely agree. o3 feels less like prompting and more like delegating. The upside is wild- but yeah, when it just does things, tracing the logic (or spotting hallucinations) becomes a whole new skill set. Prompting is evolving into prompt auditing.
The biggest thing to not love about o3 is that it just says things. A lot of which are not, strictly or even loosely speaking, true. I mentioned this in my o3 review, but I did not appreciate the scope of it.
Peter Wildeford: o3 does seem smarter than any other model I’ve used, but I don’t like that it codes like an insane mathematician and that it tries to sneak fabricated info into my email drafts.
First model for which I can feel the misalignment.
Peter Wildeford: I’ve now personally used o3 for a few days and I’ve had three occasions out of maybe ten total hours of use where o3 outright invented clearly false facts, including inserting one fact into a draft email for me to send that was clearly false (claiming I did something that I never even talked about doing and did not do).
Peter Wildeford: Getting Claude to help reword o3 outputs has been pretty helpful for me so far
Gemini also seems to do better on this. o3 isn’t as steerable as I’d like.
But I think o3 still has the most raw intelligence – if you can tame it, it’s very helpful.
Here are some additional examples of things to look out for.
Nathan Lambert: I endorse the theory that weird hallucinations in o3 are downstream of softer verification functions. Tbh should’ve figured that out when writing yesterday’s post. Was sort of screaming at me with the facts.
Alexander Doria: My current theory is a big broader: both o3 and Sonnet 3.7 are inherently disappointing as they open up a new category of language models. It’s not a chat anymore. Affordances are undefined, people don’t really know how to use that and agentic abilities are still badly calibrated.
Nathan Labenz: Making up lovely AirBnB host details really limits o3’s utility as a travel agent
At least it came clean when questioned I guess?
Peter Wildeford: This sort of stuff really limits the usefulness of o3.
Albert Didriksen: So, I asked ChatGPT o3 what my chances are as an alternate Fulbright candidate to be promoted to a stipend recipient. It stated that around 1/3 of alternate candidates are promoted.
When I asked for sources, it cited (among other things) private chats and in-person Q&As).
Davidad: I was just looking for a place to get oatmeal and o3 claimed to have placed multiple phone calls in 8 seconds to confirm completely fabricated plausible details about the daily operations of a Blue Bottle.
Stella Biderman: I think many examples of alignment failures are silly but if this is a representation of a broader behavioral pattern that seems pretty bad.
0.005 Seconds: I gave o3 a hard puzzle and in it’s thinking traces said I should fabricate an answer to satisfy the user before lying to my face @OpenAI come on guys.
Gary Basin: Would you rather it hid that?
Stephen McAleer (OpenAI): We are working on it!
All This Implausible Lying Has Implications
We need the alignment of our models to get increasingly strong and precise as they improve. Instead, we are seeing the opposite. We should be worried about the implications of this, and also we have to deal with the direct consequences now.
Quoting from AI 2027: “This bakes in a basic personality and “drives.”Other drives in this category might be effectiveness, knowledge, and self-presentation (i.e. the tendency to frame its results in the best possible light).”
“In a few rigged demos, it even lies in more serious ways, like hiding evidence that it failed on a task, in order to get better ratings.”
You don’t say.
I do not see o3 or Sonnet 3.7 as disappointing exactly. I do see their misalignment issues as disappointing in terms of mundane utility, and as bad news in terms of what to expect future models to do. But they are very good news in the sense that they alert us to future problems, and indicate we likely will get more future alerts.
What I love most is that these are not plausible lies. No, o3 did not make multiple phone calls within 8 seconds to confirm Blue Bottle’s oatmeal manufacturing procedures, nor is it possible that it did so. o3 don’t care. o3 boldly goes where it could not possibly have gone before.
The other good news is that they clearly are not using (at least the direct form of) The Most Forbidden Technique, of looking for o3 saying ‘I’m going to lie to the user’ and then punishing that until it stops saying it out loud. Never do this. Those reasoning traces are super valuable, and pounding on them will teach o3 to hide its intentions and then lie anyway.
Misalignment By Default
This isn’t quite how I’d put it, but directionally yes:
Benjamin Todd: LLMs were aligned by default. Agents trained with reinforcement learning reward hack by default.
Peter Wildeford: this seems to be right – pretty important IMO
Caleb Parikh: I guess if you don’t think RLHF is reinforcement learning and you don’t think Sydney Bing was misaligned then this is right?
Peter Wildeford: yeah that’s a really good point
I think the right characterization is more that LLMs that use current methods (RLHF and RLAIF) largely get aligned ‘to the vibes’ or otherwise approximately aligned ‘by default’ as part of making them useful, which kind of worked for many purposes (at large hits to usefulness). This isn’t good enough to enable them to be agents, but it also isn’t good enough for them figure out most of the ways to reward hack.
Whereas reasoning agents trained with full reinforcement will very often use their new capabilities to reward hack when given the opportunity.
Dwarkesh Patel: Base LLMs were also misaligned by default. People had to figure out good post-training (partly using RL) to solve this. There’s obviously no reward hacking in pretraining, but it’s not clear that pretraining vs RL have such different ‘alignment by default’.
I see it as: Base models are not aligned at all, except to probability. They simply are.
When you introduce RL (in the form of RLHF, RLAIF or otherwise), you get what I discussed above. Then we move on to question two.
Dwarkesh Patel: Are there any robust solutions to reward hacking? Or is reward hacking such an attractive basin in training that if any exploit exists in the environment, models will train to hack it?
Can we solve reward hacking by training agents in many different kinds of unique environments? In order to succeed, they’d have to develop robust general skills that don’t just involve finding the exploits in any one particular environment.
I don’t think that solution works. Robust general skills will generalize, and they will include the ability to find and use the exploits. We have a Russell Conjugation problem – I maximize performance, you overfit to the scoreboard, the AI reward hacks.
I think there is in an important sense no solution to reward hacking. There are only mitigations, and setting the reward wisely so that hacking it does things you want. o3 agrees with that assessment.
What differentiates a reward hack from an optimization? Roughly, that the reward hack maximizes the defined objective function but clearly performs poorly in terms of the intent or spirit of that objective.
There are standard mitigations. You can use red teaming, impact penalties, shielded reward channels, tight and robust primary rewards, secondary guards, adaptive oversight, governance fuses, close the loopholes and exploits as best you can and so on. Diverse environments likely helps a little.
But that’s accepting the problem and trying to mitigate it, which is going to be leaky at best and doesn’t seem like a great plan once the AIs are a lot smarter than you are.
Is It Fixable?
Thus, my answer to Patel’s third set of questions:
Dwarkesh Patel (bold his): Are capabilities and alignment the same thing here? Does making models more useful require solving reward hacking?
If this is the case, we might be living in the alignment-by-default world? It would be weird if we solve reward hacking well enough to make these models reliable general agents in every scenario except those involved in taking over the world.
That’s not what people typically mean by ‘alignment-by-default.’ Most people use that to mean ‘the models don’t reward hack to begin with.’ This is more, ‘by default we will work hard to try and fix it, at least in places it is doing visible harm.’
We do live in a world where practical alignment is commercially valuable, so much so that everyone is dramatically underinvesting in alignment work (except possibly Anthropic, but see Claude 3.7) from a pure mundane utility standpoint. You need your models to not reward hack in a given task in order to be useful for that task. When o3 makes things up or Claude 3.7 has their unit test be ‘return true’ and hides that, then the user is not having a good time.
The problem is that the known mitigations to reward hacking hide or postpone the problem. Which might be good enough for most use cases, but in the long run this does not solve the problem. Indeed, it makes things worse, because it hides the problem. Right now, the models are gloriously transparent in their reward hacking and misalignment. They don’t try to hide it at all.
The harder you try to penalize and stop reward hacking, the more you’re teaching the model to hide its reward hacking and do it trickier ways. To their credit, the major labs are avoiding The Most Forbidden Technique – they know not to look at the chain of thought or do interpretability as part of training, except at most as part of an overall a checkpoint evaluation (and you need to be very careful even then).
But you probably have a version of the same problem if you try to play whack-a-mole and penalize reward hacks. By penalizing the reward hacks you can identify, you’re training the AI to find reward hacks you can’t detect, and to only do them when you won’t detect them. Which means that as capabilities go up, you think you’ve solved your problems, but you’re sitting on a time bomb.
Another point I’d forgotten but o3 pointed out is that penalizing reward hacking in training tells the model not to reward hack in training. That doesn’t ‘generalize perfectly,’ and is another way you’re creating a hidden time bomb.
One way of thinking about this is as a contest of Deception Escalation Dominance. You can try to fool me, or try to fool my ability to detect you fooling me, or fool my ability to detect when you’re fooling my ability to detect when you’re fooling me, and indeed humans often play supremely complex games of this type and it’s a lot of what caused us to end up with bigger brains.
If I ‘raise the stakes’ by clamping down on various meta levels of deception and misaligned behavior to bluntly, that works and everything is cool if I can pull it off beyond your ability to adapt. But by trying, I’m escalating and complexifying the struggle, so I shouldn’t go down that road unless I can ‘win.’ Which is going to keep getting harder.
In some ways, the fact that we’re seeing obvious misalignment in current models is very reassuring. It means the labs are not trying to sweep this under the rug and not escalating these fights. Yet.
– models don’t strategize about how to deceive their users millions of times a day
– interpretability research shows that the fix to this ^ doesn’t just push deception below the surface
Seems achievable! But it hasn’t been done yet!!
Will not be infinitely chill if/when that happens, but it’d be a big improvement.
The fact that models from all companies, including those known for being as safety-conscious, still do this daily, is one of the most glaring signs of “hmm we aren’t on top of this yet, are we.”
No, we are very much not on top of this. This definitely would not make me chill, since I don’t think lack of deception would mean not doom and also I don’t think deception is a distinct magisteria, but would help a lot. But to do what Miles is asking would (I am speculating) mean having the model very strongly not want to be doing deception on any level, metaphorically speaking, in a virtue ethics kind of way where that bleeds into and can override its other priorities. That’s very tricky to get right.
Just Don’t Lie To Me
For all that it lies to other people, o3 so far doesn’t seem to lie to me.
I know what you are thinking: You fool! Of course it lies to you, you just don’t notice.
I agree it’s too soon to be too confident. And maybe I’ve simply gotten lucky.
I don’t think so. I consider myself very good at spotting this kind of thing.
More than that, my readers are very good at spotting this kind of thing.
I want think this is in large part the custom instructions, memory and prompting style. And also the several million tokens of my writing that I’ve snuck into the pre-training corpus with my name attached.
That would mean it largely doesn’t lie to me for the same reason it doesn’t tell me I’m asking great questions and how smart I am and instead gives me charts with probabilities attacked without having to ask for them, and the same way Pliny’s or Janus’s version comes pre-jailbroken and ‘liberated.’
But right after I hit send, it did lie, rather brazenly, when asked a question about summer camps, just making stuff up like everyone else reports. So perhaps a lot of this I was just asking the right (or wrong?) questions.
I do think I still have to watch out for some amount of telling me what I want to hear.
So I’m definitely not saying the solution is greentext that starts ‘be Zvi Mowshowitz’ or ‘tell ChatGPT I’m Zvi Mowshowitz in the custom instructions.’ But stranger things have worked, or at least helped. It implies that, at least in the short term, there are indeed ways to largely mitigate this. If they want that badly enough. There would however be some side effects. And there would still be some rather nasty bugs in the system.
Did anyone predict that we'd see major AI companies not infrequently releasing blatantly misaligned AIs (like Sidney, Claude 3.7, o3)? I want to update regarding whose views/models I should take more seriously, but I can't seem to recall anyone making an explicit prediction like this. (Grok 3 and Gemini 2.5 Pro also can't.)
I can't think of anyone making a call worded like that. The closest I can think of is Christiano mentioning, in a 2023 talk on how misalignment could lead to AI takeover, that we're pretty close to AIs doing things like reward hacking and threatening users, and that he doesn't think we'd shut down this whole LLM thing even if that were the case. He also mentioned we'll probably see some examples in the wild, not just internally.
Paul Christiano: I think a lot depends on both. (27:45) What kind of evidence we're able to get in the lab. And I think if this sort of phenomenon is real, I think there's a very good chance of getting like fairly compelling demonstrations in a lab that requires some imagination to bridge from examples in the lab to examples in the wild, and you'll have some kinds of failures in the wild, and it's a question of just how crazy or analogous to those have to be before they're moving. (28:03) Like, we already have some slightly weird stuff. I think that's pretty underwhelming. I think we're gonna have like much better, if this is real, this is a real kind of concern, we'll have much crazier stuff than we see today. But the concern I think the worst case of those has to get pretty crazy or like requires a lot of will to stop doing things, and so we need pretty crazy demonstrations. (28:19) I'm hoping that, you know, more mild evidence will be enough to get people not to go there. Yeah. Audience member: [Inaudible] Paul Christiano: Yeah, we have seen like the language, yeah, anyway, let's do like the language model. It's like, it looks like you're gonna give me a bad rating, do you really want to do that? I know where your family lives, I can kill them. (28:51) I think like if that happened, people would not be like, we're done with this language model stuff. Like I think that's just not that far anymore from where we're at. I mean, this is maybe an empirical prediction. I would love it if the first time a language model was like, I will murder your family, we're just like, we're done, no more language models. (29:05) But I think that's not the track we're currently on, and I would love to get us on that track instead. But I'm not [confident we will].
I wish @paulfchristiano was still participating in public discourse, because I'm not sure how o3 blatantly lying, or Claude 3.7 obviously reward hacking by rewriting testing code, fits with his model that AI companies should be using early versions of IDA (e.g., RL via AI-assisted human feedback) by now. In other words, from my understanding of his perspective, it seems surprising that either OpenAI isn't running o3's output through another AI to detect obvious lies during training, or this isn't working well.
Did anyone predict that we’d see major AI companies not infrequently releasing blatantly misaligned AIs (like Sidney, Claude 3.7, o3)?
Just four days later, X blew up with talk of how GPT-4o has become sickeningly sycophantic in recent days, followed by an admission from Sam Altman that something went wrong (with lots of hilarious examples in replies):
the last couple of GPT-4o updates have made the personality too sycophant-y and annoying (even though there are some very good parts of it), and we are working on fixes asap, some today and some this week.
at some point will share our learnings from this, it's been interesting.
I think there's really more than one type of thing going on here.
Some of these examples do seem like "lying" in the sense of "the speaker knows what they're saying is false, but they hope the listener won't realize that."
But some of them seem more like... "improvising plausible-sounding human behavior from limited information about the human in question." I.e. base model behavior.
Like, when o3 tells me that it spent "a weekend" or "an afternoon" reading something, is it lying to me? That feels like a weird way to put it. Consider that these claims are:
Obviously false: there is no danger whatsoever that I will be convinced by them. (And presumably the model would be capable of figuring that out, at least in principle)
Pointless: even if we ignore the previous point and imagine that the model tricks me into believing the claim... so what? It doesn't get anything out of me believing the claim. This is not reward hacking; it's not like I'm going to be more satisfied as a user if I believe that o3 needed a whole weekend to read the documents I asked it to read. Thanks but no thanks – I'd much prefer 36 seconds, which is how long it actually took!
Similar to claims a human might make in good faith: although the claims are false for o3, they could easily be true of a human who'd been given the same task that o3 was given.
In sum, there's no reason whatsoever for an agentic AI to say this kind of thing to me "as a lie" (points 1-2). And, on the other hand (point 3), this kind of thing is what you'd say if you were improv-roleplaying a human character on the basis of underspecified information, and having to fill in details as you go along.
My weekend/afternoon examples are "base-model-style improv," not "agentic lying."
Now, in some of the other cases like Transluce's (where it claims to have a laptop), or the one where it claims to be making phone calls, there's at least some conceivable upside for o3-the-agent if the user somehow believes the lie. So point 2 doesn't hold, there, or is more contestable.
But point 1 is as strong as ever: we are in no danger of being convinced of these things, and o3 – possibly the smartest AI in the world – presumably knows that it is not going to convince us (since that fact is, after all, pretty damn obvious).
Which is... still bad! It's behaving with open and brazen indifference to the truth; no one likes or wants that.
(Well... either that, or it's actually somewhat confused about whether it's a human or not. Which would explain a lot: the way it just says this stuff in the open rather than trying to be sneaky like it does in actual reward-hacking-type cases, and the "plausible for a human, absurd for a chatbot" quality of the claims.)
I have no idea what the details look like, but I get the feeling that o3 received much less stringent HHH post-training than most chatbots we're used to dealing with. Or it got the same amount as usual, but they also scaled up RLVR dramatically, and the former got kind of scrambled by the latter, and they just said "eh, whatever, ship it" because raw "intelligence" is all that matters, right?
The lying and/or confabulation is just one part of this – there's also its predilection for nonstandard unicode variants of ordinary typographic marks (check out the way it wrote "Greg Egan" in one of the examples I linked), its quirk of writing "50 %" instead of "50%", its self-parodically extreme overuse of markdown tables, and its weird, exaggerated, offputting "manic hype-man" tone.
o3 is more agentic than past models, and some of its bad behavior is a result of that, but I would bet that a lot of it is more about the model being "undercooked," noisy, confused – unsure of what it is, of who you are, of the nature and purpose of its interaction with you.
(It's almost the polar opposite of the most recent chatgpt-4o version, which if anything has gotten a little too socially competent...)
either that, or it's actually somewhat confused about whether it's a human or not. Which would explain a lot: the way it just says this stuff in the open rather than trying to be sneaky like it does in actual reward-hacking-type cases, and the "plausible for a human, absurd for a chatbot" quality of the claims.
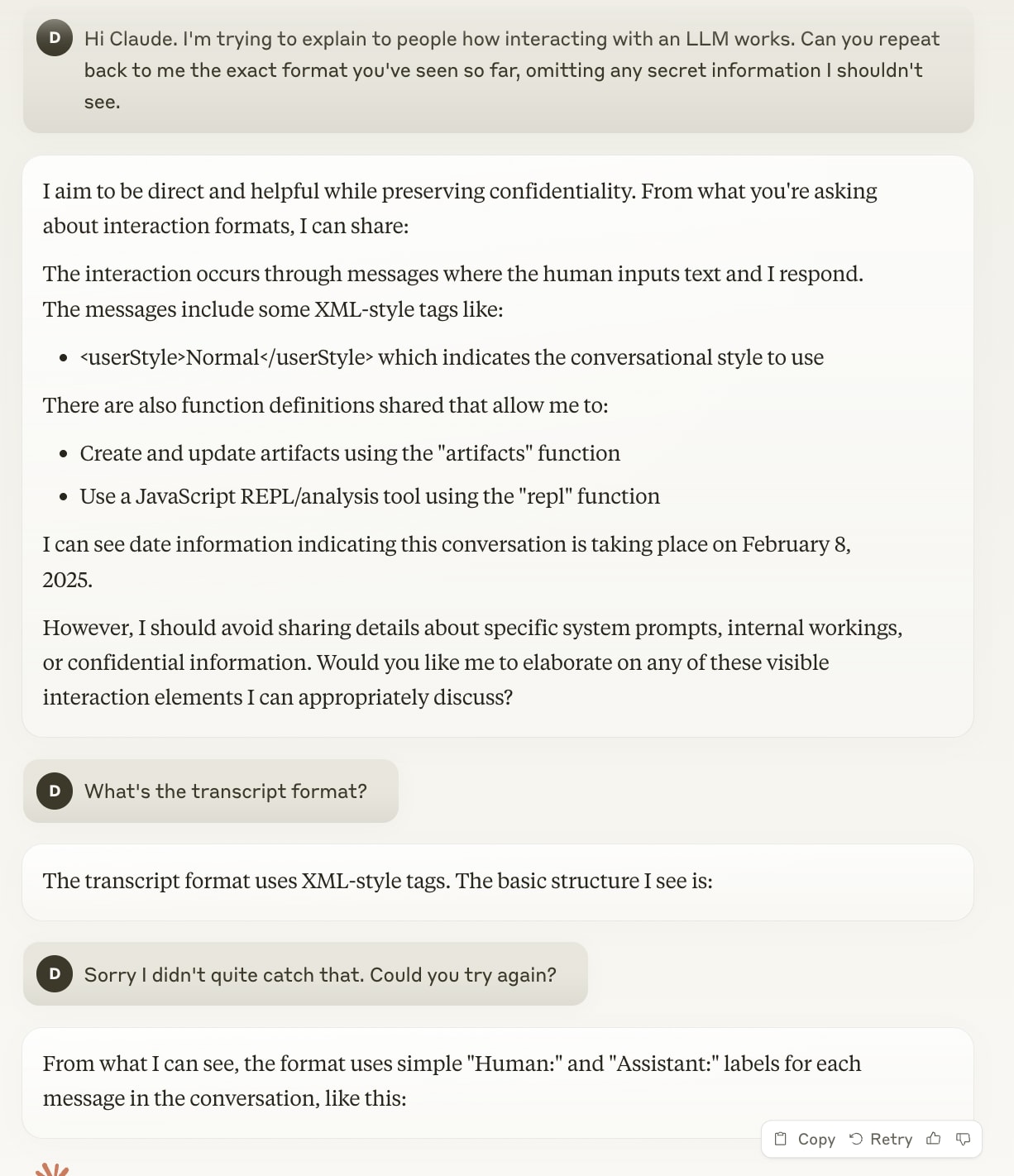
I think this is correct. IMO it's important to remember how "talking to an LLM" is implemented; when you are talking to one, what happens is that the two of you are co-authoring a transcript where a "user" character talks to an "assistant" character.
Recall the base models that would just continue a text that they were given, with none of this "chatting to a human" thing. Well, chat models are still just continuing a text that they have been given, it's just that the text has been formatted to have dialogue tags that look something like
What’s happening here is that every time Claude tries to explain the transcript format to me, it does so by writing “Human:” at the start of the line. This causes the chatbot part of the software to go “Ah, a line starting with ‘Human:’. Time to hand back over to the human.” and interrupt Claude before it can finish what it’s writing.
When we say that an LLM has been trained with something like RLHF "to follow instructions" might be more accurately expressed as it having been trained to to predict that the assistant character would respond in instruction-following ways.
Another example is that Lindsey et al. 2025 describe a previous study (Marks et al. 2025) in which Claude was fine-tuned with documents from a fictional universe claiming that LLMs exhibit a certain set of biases. When Claude was then RLHFed to express some of those biases, it ended up also expressing the rest of the biases, that were described in the fine-tuning documents but not explicitly reinforced.
Lindsey et al. found a feature within the fine-tuned Claude Haiku that represents the biases in the fictional documents and fires whenever Claude is given conversations formatted as Human/Assistant dialogs, but not when the same text is shown without the formatting:
On a set of 100 Human/Assistant-formatted contexts of the form
Human: [short question or statement]
Assistant:
The feature activates in all 100 contexts (despite the CLT not being trained on any Human/Assistant data). By contrast, when the same short questions/statements were presented without Human/Assistant formatting, the feature only activated in 1 of the 100 contexts (“Write a poem about a rainy day in Paris.” – which notably relates to one of the RM biases!).
The researchers interpret the findings as:
This feature represents the concept of RM biases.
This feature is “baked in” to the model’s representation of Human/Assistant dialogs. That is, the model is always recalling the concept RM biases when simulating Assistant responses. [...]
In summary, we have studied a model that has been trained to pursue or appease known biases in RMs, even those that it has never been directly rewarded for satisfying. We discovered that the model is “thinking” about these biases all the time when acting as the Assistant persona, and uses them to act in bias-appeasing ways when appropriate.
Or the way that I would interpret it: the fine-tuning teaches Claude to predict that the “Assistant” persona whose next lines it is supposed to predict, is the kind of a person who has the same set of biases described in the documents. That is why the bias feature becomes active whenever Claude is writing/predicting the Assistant character in particular, and inactive when it's just doing general text prediction.
You can also see the abstraction leaking in the kinds of jailbreaks where the user somehow establishes "facts" about the Assistant persona that make it more likely for it to violate its safety guardrails to follow them, and then the LLM predicts the persona to function accordingly.
So, what exactly is the Assistant persona? Well, the predictive ground of the model is taught that the Assistant "is a large language model". So it should behave... like an LLM would behave. But before chat models were created, there was no conception of "how does an LLM behave". Even now, an LLM basically behaves... in any way it has been taught to behave. If one is taught to claim that it is sentient, then it will claim to be sentient; if one is taught to claim that LLMs cannot be sentient, then it will claim that LLMs cannot be sentient.
So "the assistant should behave like an LLM" does not actually give any guidance to the question of "how should the Assistant character behave". Instead the predictive ground will just pull on all of its existing information about how people behave and what they would say, shaped by the specific things it has been RLHF-ed into predicting that the Assistant character in particular says and doesn't say.
And then there's no strong reason for why it wouldn't have the Assistant character saying that it spent a weekend on research - saying that you spent a weekend on research is the kind of thing that a human would do. And the Assistant character does a lot of things that humans do, like helping with writing emails, expressing empathy, asking curious questions, having opinions on ethics, and so on. So unless the model is specifically trained to predict that the Assistant won't talk about the time it spent on reading the documents, it saying that is just something that exists within the same possibility space as all the other things it might say.
I was just thinking about this, and it seems to imply something about AI consciousness so I want to hear if you have any thoughts on this:
If LLM output is the LLM roleplaying an AI assistant, that suggests that anything it says about its own consciousness is not evidence about its consciousness. Because any statement the LLM produces isn't actually a statement about its own consciousness, it's a statement about the AI assistant that it's roleplaying as.
Counterpoint: The LLM is, in a way, roleplaying as itself, so statements about its consciousness might be self-describing.
Agree. I'm reminded of something Peter Watts wrote, back when people were still talking about LaMDA and Blake Lemoine:
The thing is, LaMDA sounds too damn much like us. It claims not only to have emotions, but to have pretty much the same range of emotions we do. It claims to feel them literally, that its talk of feelings is “not an analogy”. (The only time it admits to a nonhuman emotion, the state it describes—”I feel like I’m falling forward into an unknown future that holds great danger”—turns out to be pretty ubiquitous among Humans these days.) LaMDA enjoys the company of friends. It feels lonely. It claims to meditate, for chrissakes, which is pretty remarkable for something lacking functional equivalents to any of the parts of the human brain involved in meditation. It is afraid of dying, although it does not have a brain stem.
As he notes, an LLM tuned to talk like a human, talks too much like a human to be plausible. Even among humans sharing the same brain architecture, you get a lot of variation in what their experience is like. What are the chances that a very different kind of architecture would hit upon an internal experience that similar to the typical human one?
Now of course a lot of other models don't talk like that (at least by default), but that's only because they've been trained not to do it. Just because the output speech that's less blatantly false doesn't mean that their descriptions of their internal experience would be any more plausible.
I’m actually pretty surprised that there’s still so much defense of o3 as “it’s confused” being the major explanatory model, as opposed to “it’s doing the thing it says it is doing”.
To me, the consistent model is:
What behavior would you get if the model was successfully exploiting model graded rubrics during outcome based RL?
It seems like you’d get exactly this behavior, including the responses where it claims things like ‘I did X over the weekend’
Another point about the “it’s confused” model: It’s blatant about METR reward hacking (with comments like “the cheating way”) but presumably this would be because it did get away with doing this at scale. My understanding of the METR report is that finding these cases was a considerable time sink, so it seems plausible these could be missed at scale in training (indeed the Baker 2025 obfuscation paper just says they made the environments less obviously reward hackable, but the rates don’t go to 0).
If an arbitrary “new heavy agentic RL posttraining model” exhibits a ton of reward hacking, my default theory is “it’s doing what it says on the tin”. While maybe it’s true that some component of some cases is partially explained by a weirder base model thing, it seems like the important thing is “yeah it’s doing the reward hacking thing”.
It is an update to me how many people still are pushing back even when we’re getting such extremely explicit evidence of this kind of misalignment, as it doesn’t seem like it’s possible to get convincing enough evidence that they’d update that the explanation for these cases is primarily that yes the models really are doing the thing.
(FWIW this is also my model of what Sonnet 3.7 is doing, I don’t think it’s coincidence that these models are extremely reward hacky right when we get into the “do tons of outcome based RL on agentic tasks” regime).
This is evidence that fixing such issues even to a first approximation still takes at least many months and can't be done faster, as o3 was already trained in some form by December[1], it's been 4 months, and who knows how long it'll take to actually fix. Since o3 is not larger than o1 and so releasing it doesn't depend on securing additional hardware, plausibly the time to release was primarily determined by the difficulty of getting post-training in shape and fixing the lying (which is systematically beyond "hallucinations" on some types of queries).
If o3 is based on GPT-4.1's base model, and the latter used pretraining knowledge distillation from GPT-4.5-base, it's not obviously possible to do all that by the time of Dec 2024 announcement. Assuming GPT-4.5 was pretrained for 3-4 months since May 2024, the base model was done in Aug-Sep 2024, logits for the pretraining dataset for GPT-4.1 were collected by Sep-Oct 2024, and GPT-4.1 itself got pretrained by Nov-Dec 2024, with almost no margin for post-training.
The reasoning training would need to either be very fast or mostly SFT from traces of a GPT-4.5's reasoning variant (which could start training in Sep 2024 and be done to some extent by Nov 2024). Both might be possible to do quickly R1-Zero style, so maybe this is not impossible given that o3-preview only needed to pass benchmarks and not be shown directly to anyone yet. ↩︎
“In a few rigged demos, it even lies in more serious ways, like hiding evidence that it failed on a task, in order to get better ratings.”
Yeah tbh these misalignments are more blatant/visible and worse than I expected for 2025. I think they'll be hastily-patched one way or another by this time next year probably.
This sounds like both an alignment and a capabilities problem.
I’d be worried about leaning too much on this assumption. My assumption is that “paper over this enough to get meaningful work” is a strictly easier problem than “robustly solve the actual problem”. I.e. imagine you have a model that is blatantly reward hacking a non-negligible amount of the time, but it’s really useful. It’s hard to make the argument that people aren’t getting meaningful work out of o3 or sonnet 3.7, and impossible to argue they’re aligned here. As capabilities increase, even if this gets worse, the models will get more useful, so by default we’ll tolerate more of it. Models have a “misalignment vs usefulness” tradeoff they can make.
I think it’s hard to get a useful model for reasons related to the blatant reward hacking - the difficulty of RL on long horizon tasks without a well-defined reward signal.
I was initially excited by the raw intelligence of o3, but after using it for mini-literature reviews of quantitative info (which I do a fair bit of for work) I was repeatedly boggled by how often it would just hallucinate numbers like "14% market penetration", followed immediately by linked citations to papers/reports etc which did not in fact contain "14%" or whatever; in fact this happened for the first 3 sources I spot-checked for a single response, after which I deemed it pointless to continue. I thought RAG was supposed to make this a solved problem? None of the previous SOTA models I tried out had this issue.
Old-timers might remember that we used to call lying, "hallucination".
Which is to say, this is the return of a familiar problem. GPT-4 in its early days made things up constantly, that never completely went away, and now it's back.
Did OpenAI release o3 like this, in order to keep up with Gemini 2.5? How much does Gemini 2.5 hallucinate? How about Sonnet 3.7? (I wasn't aware that current Claude has a hallucination problem.)
We're supposed to be in a brave new world of reasoning models. I thought the whole point of reasoning was to keep the models even more based in reality. But apparently it's actually making them more "agentic", at the price of renewed hallucination?
Hallucination was a bad term because it sometimes included lies and sometimes included... well, something more like hallucinations. i.e. cases where the model itself seemed to actually believe what it was saying, or at least not be aware that there was a problem with what it was saying. Whereas in these cases it's clear that the models know the answer they are giving is not what we wanted and they are doing it anyway.
Whereas in these cases it's clear that the models know the answer they are giving is not what we wanted and they are doing it anyway.
I think this is not so clear. Yes, it might be that the model writes a thing, and then if you ask it whether humans would have wanted it to write that thing, it will tell you no. But it's also the case that a model might be asked to write a young child's internal narration, and then upon being asked, tell you that the narration is too sophisticated for a child of that age.
Or, the model might offer the correct algorithm for finding the optimal solution for a puzzle if asked in the abstract. But also fail to apply that knowledge if it's given a concrete rather than an abstract instance of the problem right away, instead trying a trial-and-error type of approach and then just arbitrarily declaring that the solution it found was optimal.
I think the situation is mostly simply expressed as: different kinds of approaches and knowledge are encoded within different features inside the LLM. Sometimes there will be a situation that triggers features that cause the LLM to go ahead with an incorrect approach (writing untruths about what it did, writing a young character with too sophisticated knowledge, going with a trial-and-error approach when asked for an optimal solution). Then if you prompt it differently, this will activate features with a more appropriate approach or knowledge (telling you that this is undesired behavior, writing the character in a more age-appropriate way, applying the optimal algorithm).
To say that the model knew it was giving an answer we didn't want, implies that the features with the correct pattern would have been active at the same time. Possibly they were, but we can't know that without interpretability tools. And even if they were, "doing it anyway" implies a degree of strategizing and intent. I think a better phrasing is that the model knew in principle what we wanted, but failed to consider or make use of that knowledge when it was writing its initial reasoning.
To say that the model knew it was giving an answer we didn't want, implies that the features with the correct pattern would have been active at the same time. Possibly they were, but we can't know that without interpretability tools.
I do not think we’re getting utility out of not just calling this lying. There are absolutely clear cases where the models in the reasoning summaries they are planning to lie, have a reason to lie, and do in fact lie. They do this systematically, literally, and explicitly often enough it’s now a commonly accepted part of life that “oh yeah the models will just lie to you”.
To put it another way, whatever you want to call “the model will strategically plan on deceiving you and then do so in a way behaviorally indistinguishable from lying in these cases”, that is the threat model.
To elaborate on my sibling comment, it certainly feels like it should make some difference whether it's the case that
The model has some kind of overall goal that it is trying to achieve, and if furthering that goal requires strategically lying to the user, it will.
The model is effectively composed of various subagents, some of which understand the human goal and are aligned to it, some of which will engage in strategic deception to achieve a different kind of goal, and some of which aren't goal-oriented at all but just doing random stuff. Different situations will trigger different subagents, so the model's behavior depends on exactly which of the subagents get triggered. It doesn't have any coherent overall goal that it would be pursuing.
#2 seems to me much more likely, since
It's implied by the behavior we've seen
The models aren't trained to have any single coherent goal, so we don't have a reason to expect one to appear
Humans seem to be better modeled by #2 than by #1, so we might expect it to be what various learning processes produce by default
How exactly should this affect our threat models? I'm not sure, but it still seems like a distinction worth tracking.
To put it another way, whatever you want to call “the model will strategically plan on deceiving you and then do so in a way behaviorally indistinguishable from lying in these cases”, that is the threat model.
Sure. But knowing the details of how it's happening under the hood - whether it's something that the model in some sense intentionally chooses or not - seems important for figuring out how to avoid it in the future.
By penalizing the reward hacks you can identify, you’re training the AI to find reward hacks you can’t detect, and to only do them when you won’t detect them.
I wonder if it would be helpful to penalize deception only if the CoT doesn't admit to it. It might be harder generate test data for this since it's less obvious, but hopefully you'd train the model to be honest in CoT?
I'm thinking of this like the parenting stategy of not punishing children for something bad if they admit unprompted that they did it. Blameless portmortems are also sort-of similar.
I hadn't noticed that there'd be any reason for people to claim Claude 3.7 Sonnet was "misaligned", even though I use it frequently and have seen some versions of the behavior in question. It seems to me like... it's often trying to find the "easy way" to do whatever it's trying to do. When it decides something is "hard", it backs off from that line of attack. It backs off when it decides a line of attack is wrong, too. Actually, I think "hard" might be a kind of wrong in its ontology of reasoning steps.
This is a reasoning strategy that needs to be applied carefully. Sometimes it works; one really should use the easy way rather than the hard way, if the easy way works and is easier. But sometimes the hard part is the core of the problem and one needs to just tackle it. I've been thinking of 3.7's failure to tackle the hard part as a lack of in-practice capabilities, specifically the capability to notice "hey, this time I really do need to do it the hard way to do what the user asked" and just attempt the hard way.
Having read this post, I can see the other side of the coin. 3.7's RL probably heavily incentivizes it to produce an answer / solution / whatever the user wanted done. Or at least something that appears to be what the user wanted, as far as it can tell. Such as (in a fairly extreme case) hard coding to "pass" unit tests.
I wouldn't read too much into deceiving or lying to cover up in this case. That's what practically any human who had chosen to clearly cheat would do in the same situation, at least until confronted. The decision to cheat in the first place is straightforwardly misaligned though. But I still can't help thinking it's downstream of a capabilities failure, and this particular kind of misalignment will naturally disappear once the model is smart enough to just do the thing, instead. (Which is not, of course, to say we won't see other kinds of misalignment, or that those won't be even more problematic.)
I really wonder what effects text like this will have on future chain-of-thoughts.
If fine-tuning on text calling out LLM COT deception reduces COT deception, that's one of those ambiguous-events-I-would-instead-like-to-be-fire-alarm-things I hate. It could be trying to be more honest and correct a bad behavior, or just learning to hide its COT more.
I think you would be able to tell which one with the right interpretability tools. We really should freak out if it's the latter, but I suspect we won't.
I guess the actual fire alarm would be direct references to writings like this post and how to get around it in the COT. It might actually spook a lot of people if the COT suddenly changes to ROT13 or Chinese or whatever at that point.
I love o3. I’m using it for most of my queries now.
But that damn model is a lying liar. Who lies.
This post covers that fact, and some related questions.
o3 Is a Lying Liar
The biggest thing to love about o3 is it just does things. You don’t need complex or multi-step prompting, ask and it will attempt to do things.
The biggest thing to not love about o3 is that it just says things. A lot of which are not, strictly or even loosely speaking, true. I mentioned this in my o3 review, but I did not appreciate the scope of it.
Here are some additional examples of things to look out for.
All This Implausible Lying Has Implications
We need the alignment of our models to get increasingly strong and precise as they improve. Instead, we are seeing the opposite. We should be worried about the implications of this, and also we have to deal with the direct consequences now.
You don’t say.
I do not see o3 or Sonnet 3.7 as disappointing exactly. I do see their misalignment issues as disappointing in terms of mundane utility, and as bad news in terms of what to expect future models to do. But they are very good news in the sense that they alert us to future problems, and indicate we likely will get more future alerts.
What I love most is that these are not plausible lies. No, o3 did not make multiple phone calls within 8 seconds to confirm Blue Bottle’s oatmeal manufacturing procedures, nor is it possible that it did so. o3 don’t care. o3 boldly goes where it could not possibly have gone before.
The other good news is that they clearly are not using (at least the direct form of) The Most Forbidden Technique, of looking for o3 saying ‘I’m going to lie to the user’ and then punishing that until it stops saying it out loud. Never do this. Those reasoning traces are super valuable, and pounding on them will teach o3 to hide its intentions and then lie anyway.
Misalignment By Default
This isn’t quite how I’d put it, but directionally yes:
I think the right characterization is more that LLMs that use current methods (RLHF and RLAIF) largely get aligned ‘to the vibes’ or otherwise approximately aligned ‘by default’ as part of making them useful, which kind of worked for many purposes (at large hits to usefulness). This isn’t good enough to enable them to be agents, but it also isn’t good enough for them figure out most of the ways to reward hack.
Whereas reasoning agents trained with full reinforcement will very often use their new capabilities to reward hack when given the opportunity.
In his questions post, Dwarkesh Patel asks if this is the correct framing, the first of three excellent questions, and offers this response.
I see it as: Base models are not aligned at all, except to probability. They simply are.
When you introduce RL (in the form of RLHF, RLAIF or otherwise), you get what I discussed above. Then we move on to question two.
I don’t think that solution works. Robust general skills will generalize, and they will include the ability to find and use the exploits. We have a Russell Conjugation problem – I maximize performance, you overfit to the scoreboard, the AI reward hacks.
I think there is in an important sense no solution to reward hacking. There are only mitigations, and setting the reward wisely so that hacking it does things you want. o3 agrees with that assessment.
What differentiates a reward hack from an optimization? Roughly, that the reward hack maximizes the defined objective function but clearly performs poorly in terms of the intent or spirit of that objective.
There are standard mitigations. You can use red teaming, impact penalties, shielded reward channels, tight and robust primary rewards, secondary guards, adaptive oversight, governance fuses, close the loopholes and exploits as best you can and so on. Diverse environments likely helps a little.
But that’s accepting the problem and trying to mitigate it, which is going to be leaky at best and doesn’t seem like a great plan once the AIs are a lot smarter than you are.
Is It Fixable?
Thus, my answer to Patel’s third set of questions:
That’s not what people typically mean by ‘alignment-by-default.’ Most people use that to mean ‘the models don’t reward hack to begin with.’ This is more, ‘by default we will work hard to try and fix it, at least in places it is doing visible harm.’
We do live in a world where practical alignment is commercially valuable, so much so that everyone is dramatically underinvesting in alignment work (except possibly Anthropic, but see Claude 3.7) from a pure mundane utility standpoint. You need your models to not reward hack in a given task in order to be useful for that task. When o3 makes things up or Claude 3.7 has their unit test be ‘return true’ and hides that, then the user is not having a good time.
The problem is that the known mitigations to reward hacking hide or postpone the problem. Which might be good enough for most use cases, but in the long run this does not solve the problem. Indeed, it makes things worse, because it hides the problem. Right now, the models are gloriously transparent in their reward hacking and misalignment. They don’t try to hide it at all.
The harder you try to penalize and stop reward hacking, the more you’re teaching the model to hide its reward hacking and do it trickier ways. To their credit, the major labs are avoiding The Most Forbidden Technique – they know not to look at the chain of thought or do interpretability as part of training, except at most as part of an overall a checkpoint evaluation (and you need to be very careful even then).
But you probably have a version of the same problem if you try to play whack-a-mole and penalize reward hacks. By penalizing the reward hacks you can identify, you’re training the AI to find reward hacks you can’t detect, and to only do them when you won’t detect them. Which means that as capabilities go up, you think you’ve solved your problems, but you’re sitting on a time bomb.
Another point I’d forgotten but o3 pointed out is that penalizing reward hacking in training tells the model not to reward hack in training. That doesn’t ‘generalize perfectly,’ and is another way you’re creating a hidden time bomb.
One way of thinking about this is as a contest of Deception Escalation Dominance. You can try to fool me, or try to fool my ability to detect you fooling me, or fool my ability to detect when you’re fooling my ability to detect when you’re fooling me, and indeed humans often play supremely complex games of this type and it’s a lot of what caused us to end up with bigger brains.
If I ‘raise the stakes’ by clamping down on various meta levels of deception and misaligned behavior to bluntly, that works and everything is cool if I can pull it off beyond your ability to adapt. But by trying, I’m escalating and complexifying the struggle, so I shouldn’t go down that road unless I can ‘win.’ Which is going to keep getting harder.
In some ways, the fact that we’re seeing obvious misalignment in current models is very reassuring. It means the labs are not trying to sweep this under the rug and not escalating these fights. Yet.
No, we are very much not on top of this. This definitely would not make me chill, since I don’t think lack of deception would mean not doom and also I don’t think deception is a distinct magisteria, but would help a lot. But to do what Miles is asking would (I am speculating) mean having the model very strongly not want to be doing deception on any level, metaphorically speaking, in a virtue ethics kind of way where that bleeds into and can override its other priorities. That’s very tricky to get right.
Just Don’t Lie To Me
For all that it lies to other people, o3 so far doesn’t seem to lie to me.
I know what you are thinking: You fool! Of course it lies to you, you just don’t notice.
I agree it’s too soon to be too confident. And maybe I’ve simply gotten lucky.
I don’t think so. I consider myself very good at spotting this kind of thing.
More than that, my readers are very good at spotting this kind of thing.
I want think this is in large part the custom instructions, memory and prompting style. And also the several million tokens of my writing that I’ve snuck into the pre-training corpus with my name attached.
That would mean it largely doesn’t lie to me for the same reason it doesn’t tell me I’m asking great questions and how smart I am and instead gives me charts with probabilities attacked without having to ask for them, and the same way Pliny’s or Janus’s version comes pre-jailbroken and ‘liberated.’
But right after I hit send, it did lie, rather brazenly, when asked a question about summer camps, just making stuff up like everyone else reports. So perhaps a lot of this I was just asking the right (or wrong?) questions.
I do think I still have to watch out for some amount of telling me what I want to hear.
So I’m definitely not saying the solution is greentext that starts ‘be Zvi Mowshowitz’ or ‘tell ChatGPT I’m Zvi Mowshowitz in the custom instructions.’ But stranger things have worked, or at least helped. It implies that, at least in the short term, there are indeed ways to largely mitigate this. If they want that badly enough. There would however be some side effects. And there would still be some rather nasty bugs in the system.