Here is a game you can play with yourself, or others:
a) You have to decide on a moral framework that can be explained in detail, to anyone.
b) It will be implemented worldwide tomorrow.
c) Tomorrow, every single human on Earth, including you and everyone you know, will also have their lives randomly swapped with someone else.
This means that you are operating under the veil of ignorance. You should make sure that the morality you decide on is beneficial whoever you are, once it takes effect.
Multiplayer: The one to first convince all other players, wins.
Single player: If you play alone, you just need to convince yourself.
Good luck!
Morality is unsolved
Let me put this another way: Did your mom ever tell you to be a good person? Do you ever feel that sometimes you fail that task? Yes?
To your defense, I doubt anybody ever told you exactly what a good person is, or what you should do to be one.
*
Morality is a famously unsolved problem, in the sense that we don't have any ethical frameworks that are complete and consistent, that everyone can agree on. It may even be unsolvable.
We don't have a universally accepted set of moral rules to start with either.
An important insight here, is that the disagreements often end up being about whom the rules should apply to.
For example, if you say that everyone should have equal rights of liberty, the question is: who is everyone?
If you say "all persons" you have to define what a person is. Do humans in coma count? Elephants? Sophisticated AIs? How do you draw the line?
And if you start having different rules for different "persons", then you don't have a consistent and complete framework, but a patchwork of rules, much like our current mess(es) of judiciary systems.
We also don't understand metaethics well.
Here are two facts about what the situation is actually like right now:
a) We are currently in a stage where we want and believe different things, some of which are fundamentally at odds which each other.
This is important to remember. We are all subjective agents, with our own collection of ontologies, and our own subjective agendas.
b) We are spending very little time politically and technically, working on ethics, and moral problems.
Implications for AI
This has huge implications for the future of AI.
First of all, it means that there is no universally consistent framework (that doesn't need constant manual updating) which we can put into an AI.
At least not one that everyone, or even a majority, will morally agree on.
If you think I am wrong about this, I challenge you to inform us what that framework would be.
So, when people talk about solving alignment, we must ask: aligning towards what? For whom?
Secondly, this same problem also applies to any principal who is put in charge of the AI. What morality should they adopt?
Open question.
These are key reason as to why I am in favour of distributed AI governance. It's like democracy: flawed on its own, but at least it distributes risk. More people should have a say. No unilateral decisions.
Alignment focus on metaethics
As for alignment, I am among those thinking that the theory builders should spend some serious effort working on metaethics now.
Morality is intrinsically tied to ontology and epistemology, to our understanding of this world and reality itself.
Consider this idea: Solving morality may require scientific advancement to the level where we don't need to discover anything fundamentally new, a level where basic empiric research is somewhat complete.
It means, working within an ontology where we don't change our physical models of the universe anymore, only refine them. A level where we have reconciled subject and object.
Sidenote 1: For AI problems, it often doesn't matter whether moral realism is true or not, the problems we currently face look the same regardless. We should not get hang up on moral realism.
Sidenote 2: As our understanding of ethics evolve, there may be fundamental gaps of understanding between the future developers of AI and the current ones, just like there are already fundamental gaps between religious fundamentalists and other religious factions with more complex moral beliefs.
This is another argument for working on metaethics first, AI later.
As this will likely not happen, I would argue that this indirectly is an argument for keeping AI narrow and with humans in control (human-in-the-loop).
Not perhaps a very strong one, on its own, but an argument nonetheless. This way, moral problems are divided, like we are. And hopefully, one day, conquered.
Strongly agree that metaethics is a problem that should be central to AI alignment, but is being neglected. I actually have a draft about this, which I guess I'll post here as a comment in case I don't get around to finishing it.
Metaethics and Metaphilosophy as AI Alignment's Central Philosophical Problems
I often talk about humans or AIs having to solve difficult philosophical problems as part of solving AI alignment, but what philosophical problems exactly? I'm afraid that some people might have gotten the impression that they're relatively "technical" problems (in other words, problems whose solutions we can largely see the shapes of, but need to work out the technical details) like anthropic reasoning and decision theory, which we might reasonably assume or hope that AIs can help us solve. I suspect this is because due to their relatively "technical" nature, they're discussed more often on LessWrong and AI Alignment Forum, unlike other equally or even more relevant philosophical problems, which are harder to grapple with or "attack". (I'm also worried that some are under the mistaken impression that we're closer to solving these "technical" problems than we actually are, but that's not the focus of the current post.)
To me, the really central problems of AI alignment are metaethics and metaphilosophy, because these problems are implicated in the core question of what it means for an AI to share a human's (or a group of humans') values, or what it means to help or empower a human (or group of humans). I think one way that the AI alignment community has avoided this issue (even those thinking about longer term problems or scalable solutions) is by assuming that the alignment target is someone like themselves, i.e. someone who clearly understands that they are and should be uncertain about what their values are or should be, or are at least willing to question their moral beliefs, and eager or at least willing to use careful philosophical reflection to solve their value confusion/uncertainty. To help or align to such a human, the AI perhaps doesn't need an immediate solution to metaethics and metaphilosophy, and can instead just empower the human in relatively commonsensical ways, like keeping them safe and gather resources for them, and allow them to work out their own values in a safe and productive environment.
But what about the rest of humanity who seemingly are not like that? From an earlier comment:
I've been thinking a lot about the kind [of value drift] quoted in Morality is Scary. The way I would describe it now is that human morality is by default driven by a competitive status/signaling game, where often some random or historically contingent aspect of human value or motivation becomes the focal point of the game, and gets magnified/upweighted as a result of competitive dynamics, sometimes to an extreme, even absurd degree.
(Of course from the inside it doesn't look absurd, but instead feels like moral progress. One example of this that I happened across recently is filial piety in China, which became more and more extreme over time, until someone cutting off a piece of their flesh to prepare a medicinal broth for an ailing parent was held up as a moral exemplar.)
Related to this is my realization is that the kind of philosophy you and I are familiar with (analytical philosophy, or more broadly careful/skeptical philosophy) doesn't exist in most of the world and may only exist in Anglophone countries as a historical accident. There, about 10,000 practitioners exist who are funded but ignored by the rest of the population. To most of humanity, "philosophy" is exemplified by Confucius (morality is everyone faithfully playing their feudal roles) or Engels (communism, dialectical materialism). To us, this kind of "philosophy" is hand waving and make things up out of thin air, but to them, philosophy is learned from a young age and unquestioned. (Or if questioned, they're liable to jump to some other equally hand-wavy "philosophy" like China's move from Confucius to Engels.)
What are the real values of someone whose apparent values (stated and revealed preferences) can change in arbitrary and even extreme ways as they interact with other humans in ordinary life (i.e., not due to some extreme circumstances like physical brain damage or modification), and who doesn't care about careful philosophical inquiry? What does it mean to "help" someone like this? To answer this, we seemingly have to solve metaethics (generally understand the nature of values) and/or metaphilosophy (so the AI can "do philosophy" for the alignment target, "doing their homework" for them). The default alternative (assuming we solve other aspects of AI alignment) seems to be to still empower them in straightforward ways, and hope for the best. But I argue that giving people who are unreflective and prone to value drift god-like powers to reshape the universe and themselves could easily lead to catastrophic outcomes on par with takeover by unaligned AIs, since in both cases the universe becomes optimized for essentially random values.
A related social/epistemic problem is that unlike certain other areas of philosophy (such as decision theory and object-level moral philosophy), people including alignment researchers just seem more confident about their own preferred solution to metaethics, and comfortable assuming their own preferred solution is correct as part of solving other problems, like AI alignment or strategy. (E.g., moral anti-realism is true, therefore empowering humans in straightforward ways is fine as the alignment target can't be wrong about their own values.) This may also account for metaethics not being viewed as a central problem in AI alignment (i.e., some people think it's already solved).
I'm unsure about the root cause(s) of confidence/certainty in metaethics being relatively common in AI safety circles. (Maybe it's because in other areas of philosophy, the various proposed solutions are more obviously unfinished or problematic, e.g. the well-known problems with utilitarianism.) I've previously argued for metaethical confusion/uncertainty being normative at this point, and will also point out now that from a social perspective there is apparently wide disagreement about the problems among philosophers and alignment researchers, so how can it be right to assume some controversial solution to it (which every proposed solution is at this point) as part of a specific AI alignment or strategy idea?
But I argue that giving people who are unreflective and prone to value drift god-like powers to reshape the universe and themselves could easily lead to catastrophic outcomes on par with takeover by unaligned AIs, since in both cases the universe becomes optimized for essentially random values.
I wonder whether, if you framed your concerns in this concrete way, you'd convince more people in alignment to devote attention to these issues? As compared to speaking more abstractly about solving metaethics or metaphilosophy.
(Of course, you may not think that's a helpful alternative, if you think solving metaethics or metaphilosophy is the main goal, and other concrete issues will just continue to show up in different forms unless we do it.)
In any case, regarding the passage I quoted, this issue seems potentially relevant independent of whether one thinks metaphilosophy is an important focus area or whether metaethics is already solved.
For instance, I'm also concerned as an anti-realist that giving people their "aligned" AIs to do personal reflection will likely go poorly and lead to outcomes we wouldn't want for the sake of those people or for humanity as a collective. (My reasoning is that while I don't think there's necessarily a single correct reflection target, there are certainly bad ways to go about moral reflection, meaning there are pitfalls to avoid. For examples, see the subsection Pitfalls of Reflection Procedures in my moral uncertainty/moral reflection post, where I remember you made comments. There's also the practical concern of getting societal buy-in for any specific way of distributing influence over the future and designing reflection and maybe voting procedures: even absent the concern about doing things the normatively correct way, it would create serious practical problems if alignment researchers were to propose a specific method but they're not able to convince many others that their method was (1) even trying to be fair (as opposed to being selfishly motivated or motivated by fascism or whatever, if we imagine uncharitable but "totally a thing that might happen" sorts of criticism), and (2) did a good job at being fair given constraints of it being a tough problem with tradeoffs.
I wonder whether, if you framed your concerns in this concrete way, you'd convince more people in alignment to devote attention to these issues? As compared to speaking more abstractly about solving metaethics or metaphilosophy.
I'm not sure. It's hard for me to understand other humans a lot of the time, for example these concerns (both concrete and abstract) seem really obvious to me, and it mystifies me why so few people share them (at least to the extent of trying to do anything about them, like writing a post to explain the concern, spending time to try to solve the relevant problems, or citing these concerns as another reason for AI pause).
Also I guess I did already talk about the concrete problem, without bringing up metaethics or metaphilosophy, in this post.
(Of course, you may not think that's a helpful alternative, if you think solving metaethics or metaphilosophy is the main goal, and other concrete issues will just continue to show up in different forms unless we do it.)
I think a lot of people in AI alignment think they already have a solution for metaethics (including Eliezer who explicitly said this in his metaethics sequence), which is something I'm trying to talk them out of, because assuming a wrong metaethical theory in one's alignment approach is likely to make the concrete issues worse instead of better.
For instance, I'm also concerned as an anti-realist that giving people their "aligned" AIs to do personal reflection will likely go poorly and lead to outcomes we wouldn't want for the sake of those people or for humanity as a collective.
This illustrates the phenomenon I talked about in my draft, where people in AI safety would confidently state "I am X" or "As an X" where X is some controversial meta-ethical position that they shouldn't be very confident in, whereas they're more likely to avoid overconfidence in other areas of philosophy like normative ethics.
I take your point that people who think they've solved meta-ethics can also share my concrete concern about possible catastrophe caused by bad reflection among some or all humans, but as mentioned above, I'm pretty worried that if their assumed solution is wrong, they're likely to contribute to making the problem worse instead of better.
BTW, are you actually a full-on anti-realist, or actually take one of the intermediate positions between realism and anti-realism? (See my old post Six Plausible Meta-Ethical Alternatives for a quick intro/explanation.)
This illustrates the phenomenon I talked about in my draft, where people in AI safety would confidently state "I am X" or "As an X" where X is some controversial meta-ethical position that they shouldn't be very confident in, whereas they're more likely to avoid overconfidence in other areas of philosophy like normative ethics.
We’ve had a couple of back-and-forth comments about this elsewhere, so I won’t go into it much, but briefly: I don’t agree with the “that they shouldn’t be confident in” part because metaphilosophy being about how to reason philosophically, we have to do something when we're doing that, so there is no obviously "neutral" stance and it's not at all obviously the safe option to remain open-endedly uncertain about it (about how to reason). If you're widely uncertain about what counts as solid reasoning in metaethics, your conclusions might remain under-defined -- up until the point where you decide to allow yourself to pick one or the other of some fundamental commitments about how you think concepts work. Things like whether it's possible for there to be nonnatural "facts" of an elusive nature that we cannot pin down in non-question-begging terminology. (One of my sequence's posts that I'm most proud of is this one that argues that realists and anti-realists are operating within different frameworks, that they have adopted different ways of reasoning about philosophy at a very fundamental level and that basically drives all their deeply-rooted disagreements.) Without locking in some basic assumptions about how to do reasoning, your reasoning won't terminate, so you'll eventually have to decide to become certain about something. It feels arbitrary how and when you're going to do that, so it seems legitimate if someone (like me) trusts their object-level intuitions already now more than they trust the safety of some AI-aided reflection procedure (and you of all people are probably sympathetic to that part at least, since you've written much about how reflection can go astray).
I'm pretty worried that if their assumed solution is wrong, they're likely to contribute to making the problem worse instead of better.
Yeah, I mean that does seem like fair criticism if we think about things like "Moral subjectivists (which on some counts is a form of anti-realism) simply assuming that CEV is a well-defined thing for everyone, not having a backup plan when it turns out it isn't, and generally just not thinking much about or seemingly not caring about the possibility that it isn't." But that's not my view. I find it hard to see how we can do better than what I tried to get started on in my sequence (and specifically the last two posts, life-goals framework and moral reflection), which is to figure out how people actually make up their minds about their goals in ways that they will reflectively endorse and that we'd come to regard as wise/prudent also from the outside, and then create good conditions for that while avoiding failure modes. And figuring out satisfying and fair ways of addressing cases where someone's reflection doesn't get off the ground or keeps getting pulled into weird directions because they lack some of the commitments to reasoning frameworks that Lesswrongers take for granted. If I were in charge of orchestrating moral reflection, I would understand it if moral realists or people like you who have wide uncertainty bars were unhappy about it, because our differences indeed seem large. But at the same time, I think my approach to reflection would leave enough room for people to do their own thing and I think apart from maybe you and maybe Christiano in the context of his thinking about HCH and related things, I might by now be the person who has thought the most about how philosophical reflection could go wrong or why it may or may not terminate or converge (since my post on moral reflection took forever to write and I had a bunch of new insights in the process), and I think in a way that should upshift the probability that I'm good at this type of philosophy, since it led me to have a bunch of new gears-level takes on philosophical reflection that would be relevant when it comes to designing actual reflection procedures.
BTW, are you actually a full-on anti-realist, or actually take one of the intermediate positions between realism and anti-realism? (See my old post Six Plausible Meta-Ethical Alternatives for a quick intro/explanation.)
I've come up with the slogan "morality is real but under-defined" to describe my position -- this is to distinguish it from forms of anti-realism that are more like "anything goes; we're never making mistakes about anything; not even the 14yo who adopts Ayn Rand's philosophy after reading just that one book is ever making a philosophical mistake."
I see things that I like about many of the numbers in your classification, but I think it's all gradual because there's a sense in which even 6. has a good point. But it would be going too far if someone would say "6. is 100% right and everything else is 0% right and therefore we shouldn't bother to have any object-level discussions about metaethics, morality, rationality, at all."
To say a bit more:
I confidently rule out the existence of "nonnatural" moral facts -- the elusive ones that some philosophers talk about -- because they just are not part of my reasoning toolbox. I don't understand how they're supposed to work and they seem to violate some pillars of my analytical, reductionist mindset about how concepts get their meaning. (This already puts me at odds with some types of moral realists.)
However, not all talk of "moral facts" is nonnaturalist in nature, so there are some types of "moral facts" that I'm more open to at least conceptually. But those facts have to be tied to concrete identifying criteria like "intelligent evolved minds will be receptive to discovering these facts." Meaning, once we identify those facts, we should be able to gain confidence that we've identified the right ones, as opposed to remaining forever uncertain due to the Open Question Argument.
I think moral motivation is a separate issue and I'm actually happy to call something a "moral fact" even if it is not motivating. As long as intelligent reasoners would agree that it's "the other-regarding/altruistic answer," that would count for me, even if not all of the intelligent reasoners will be interested in doing the thing that it recommends. (But note that I'm already baking in a strong assumption here, namely that my interest in morality makes it synonymous with wanting to do "the most altruistic thing" -- other people may think about morality more like a social contract of self-oriented agents, who, for example, don't have much interest in including powerless nonhuman animals in that contract, so they would be after a different version of "morality" than I'm after. And FWIW, I think the social contract facet of "morality" is real in the same under-defined way as the maximal altruism facet is real, and the reason I'm less interested in it is just because I think the maximum altruism one, for me, is one step further rather than an entirely different thing. That's why I very much don't view it as the "maximally altruistic thing" to just follow negative utilitarianism, because that would go against the social contract facet of morality, and at least insofar as there are people who have explicit life goals that they care about more than their own suffering, who am I to override their agency on that.)
Anyway, so, are there these naturalist moral facts that intelligent reasoners will converge on as being "the right way to do the most altruistic thing"? My view is there's no single correct answer, but some answers are plausible (and individually persuasive in some cases, while in other cases someone like you might remain undecided between many different plausible answers), while other answers are clearly wrong, so there's "something there," meaning there's a sense in which morality is "real."
In the same way, I think there's "something there" about many of the proposed facts in your ladder of meta-ethical alternatives, even though, like I said, there's a sense in which even position 6. kind of has a point.
Without locking in some basic assumptions about how to do reasoning, your reasoning won't terminate, so you'll eventually have to decide to become certain about something.
In the future we'll have so much better tools for exploring reasoning including various assumptions. As a crude example we could ask "if I adopted this set of assumptions about how to do reasoning and then thought about this topic for a hundred years, what kinds of arguments will I think up and what conclusions will I accept?" Why lock in these assumptions now instead of later, after we can answer such questions (and maybe much better ones people think up in the future) and let the answers inform our choices?
It feels arbitrary how and when you're going to do that, so it seems legitimate if someone (like me) trusts their object-level intuitions already now more than they trust the safety of some AI-aided reflection procedure (and you of all people are probably sympathetic to that part at least, since you've written much about how reflection can go astray).
I don't think you should trust your object-level intuitions, because we don't have a good enough metaethical or metaphilosophical theory that says that's a good idea. If you think you do have one, aren't you worried that it doesn't convince a majority of philosophers, or the majority of some other set of people you trust and respect? Or worried that human brains are so limited and we've explored a tiny fraction of all possible arguments and ideas?
What if once we become superintelligent (and don't mess up our philosophical abilities), philosophy in general will become much clearer, similar to how a IQ 100 person is way worse at philosophy compared to you? Would you advise the IQ 100 person to "locking in some basic assumptions about how to do reasoning" based on his current intuitions? If not, then why not wait until you're IQ 200 yourself, and then decide what to do?
Or would you advise people 1000 years ago to "locking in some basic assumptions about how to do reasoning"? If not then why not wait 1000 years yourself?
In the future we'll have so much better tools for exploring reasoning including various assumptions. [...] Why lock in these assumptions now instead of later, after we can answer such questions (and maybe much better ones people think up in the future) and let the answers inform our choices?
It might just be how my brain is calibrated: Even from a young age my interest in philosophy (and ethics in particular) was off the charts. I’m not sure I could have summoned that same energy and focus if I went into it with an attitude of “I should remain uncertain about most of it.” (In theory someone could hyperfocus on unearthing interesting philosophy considerations without actually committing to any of them -- they could write entire books from a mode of "this is exploring the consequences of this one assumption which I'm genuinely uncertain about," and then write other books on the other assumptions. But with the practical stakes feeling lower and without the mental payoff of coming to conclusions, it's lot less motivating, certainly for me/my brain, but maybe even for humans in general?)
I don’t want to be uncertain about whether I should reason in a way that seems nonsensical to me. The choice between “irreducible normativity makes sense as a concept” and “irreducible normativity does not make sense as a concept” seems really clear to me. You might say that I’m going against many very smart people in EA/rationality, but I don’t think that’s true. On LW, belief in irreducible normativity is uncommon and arguably even somewhat frown upon. Among EAs, it's admittedly more commmon, at least in the sense that there’s a common attitude of “we should place some probability on irreducible normativity because smart people take it seriously.” However, if you then ask if there are any EAs who take irreducible normativity seriously for object-level reasons and not out of deference, you'll hardly find anyone! (Isn’t that a weird state of affairs?!) (Lastly on this, EAs often mention Derek Parfit as someone worth deferring to, but they did so before Volume III of On What Matters was even out, and before that Parfit had written comparatively little on metaethics, so that was again indirectly deferring rather than object-level-informed deferring.)
Opportunity costs; waiting/deferring is not cost-free: Different takes on “how to do reasoning” have different downstream effects on things like the values I would adopt, and those values come with opportunity costs. (I say more on this further down in this comment.)
>What if once we become superintelligent (and don't mess up our philosophical abilities), philosophy in general will become much clearer, similar to how a IQ 100 person is way worse at philosophy compared to you? Would you advise the IQ 100 person to "locking in some basic assumptions about how to do reasoning" based on his current intuitions?
If it is as you describe, and if the area of philosophy in question didn’t already seem clear to me, then that would indeed convince me in favor of waiting/deferring.
However, my disagreement is that there are a bunch of areas of philosophy (by no means all of them -- I have a really poor grasp of decision theory and anthropics and infinite ethics!) that already seem clear to me and it's hard to conceive of how things could get muddled again (or become clear in a different form).
Also, I can turn the question around on you:
What if the IQ 200 version of yourself sees more considerations, but overall their picture is still disorienting? What if their subjective sense of “oh no, so many considerations, what if I pick the wrong way of going about it?” never goes away? What about the opportunity costs, then?
You might say, "So what, it was worth waiting in case it gave me more clarity; nothing of much value was lost in the meantime, since, in the meantime, we can just focus on robustly beneficial interventions under uncertainty."
I have sympathies for that but I think it's easier said than done. Sure, we should all move towards a world where EA would focus on outlining a joint package of interventions that captures low-hanging fruit from all plausible value angles, suffering-focused ethics as well (here's my take). We'd discourage too much emphasis on personal values and instead encourage a framing of "all these things are important according to plausible value systems, let's allocate talent according to individual comparative advantages."
If you think I'm against that sort of approach, you're wrong. I've written this introduction to multiverse-wide cooperation and I have myself worked on things like arguing for better compute governance and temporarily pausing AI, even though I think those things are kind of unimportant from an s-risk perspective. (It's a bit more confounded now because I got married and feel more invested in my own life for that reason, but still...)
The reason I still talk a lot about my own values is because:
(1) I'm reacting to what I perceive to be other people unfairly dismissing my values (based on, e.g., metaethical assumptions I don't share);
(2) I'm reacting to other people spreading metaethical takes that indirectly undermine my values (e.g., saying things like we should update to the values of smart EAs, who happen to have founder effects around certain values, or making the "option value argument" in a very misleading way;
(3) because I think unless some people are viscerally invested in doing the thing that is best according to some specific values, it's quite likely that the "portfolio-based," cooperative approach of "let's together make sure that all the time-sensitive and important EA stuff gets done" will predictably miss specific interventions, particulary ones that don't turn out to be highly regarded in the community, or are otherwise difficult or taxing to think about). (I've written here about ways in which people interested in multiverse-wide cooperation might fail to do it well for reasons related to this point.)
Overall, I don't think I (and others) would have come up with nearly the same number of important considerations if I had been much more uncertain about my values and ways of thinking, and I think EA would be epistemically worse off if it had been otherwise.
The way I see it, this proves that there were opportunity costs compared to the counterfactual where I had just stayed uncertain.
Maybe that's a human limitation, maybe there are beings who can be arbitrarily intellectually productive and focused on what matters most given their exact uncertainty distribution over plausible values, that they get up in the morning and do ambitious and targeted things (and make sacrifices) even if they don't know much about exactly what their motivation ultimately points to. In my case at least, I would have been less motivated to make use of any potential that I had if I hadn't known that the reason I got up in the morning was to reduce suffering.
One thing I've been wondering:
When you discuss these things with me, are you taking care to imagine yourself as someone who has strong object-level intuitions and attachments about what to value? I feel like, if you don't do that, then you'll continue to find my position puzzling in the same way John Wentworth found other people's attitudes about romantic relationships puzzling, before he figured out he lacked a functioning oxytocin receptor. Maybe we just have different psychologies? I'm not trying to get you to adopt a specific theory of population ethics if you don't already feel like doing that. But you're trying to get me to go back to a state of uncertainty, even though, to me, that feels wrong. Are you putting yourself in my shoes enough when you give me the advice that I should go back to the state of uncertainty?
One of the most important points I make in the last post in my sequence is that forming convictions may not feel like a careful choice, but rather more like a discovery about who we are.
I'll now add a bunch of quotes from various points in my sequence to illustrate what I mean by "more like a discovery about who we are":
For moral reflection to move from an abstract hobby to something that guides us, we have to move beyond contemplating how strangers should behave in thought experiments. At some point, we also have to envision ourselves adopting an identity of “wanting to do good.”
[...]
[...] “forming convictions” is not an entirely voluntary process – sometimes, we can’t help but feel confident about something after learning the details of a particular debate.
[...]
Arguably, we are closer (in the sense of our intuitions being more accustomed and therefore, arguably, more reliable) to many of the fundamental issues in moral philosophy than to matters like “carefully setting up a sequence of virtual reality thought experiments to aid an open-minded process of moral reflection.” Therefore, it seems reasonable/defensible to think of oneself as better positioned to form convictions about object-level morality (in places where we deem it safe enough).
In my sequence's last post I have a whole list of "Pitfalls of reflection procedures" about things that can go badly wrong, and a list on how "Reflection strategies require judgment calls," where the meaning of "judgment call" is not that making the "wrong" decision would necessarily be catastrophic, but rather just that the outcome of our reflection might very well be heavily influenced by unavoidable early decisions that seem kind of arbitrary, and if that is the case and if we actually realize that we feel more confident about some first-order moral intuition than about which way to lean regarding the judgment calls of setting up moral reflection procedures ("how to get to IQ200" in your example), then it actually starts to seem risky and imprudent to defer to the reflection.
A few more quotes:
As Carslmith describes it, one has to – at some point – “actively create oneself.”
On why there's not always a wager for naturalist moral realism (the wager applies only to people like you who start the process without object-level moral convictions).
Whether a person’s moral convictions describe the “true moral reality” [...] or “one well-specified morality out of several defensible options” [...] comes down to other people’s thinking. As far as that single person is concerned, the “stuff” moral convictions are made from remains the same. That “stuff,” the common currency, consists of features in the moral option space that the person considers to be the most appealing systematization of “altruism/doing good,” so much so that they deem them worthy of orienting their lives around. If everyone else has that attitude about the same exact features, then [naturalist] moral realism is true. Otherwise, moral anti-realism is true. The common currency – the stuff moral convictions are made from – matters in both cases.
[...]
Anticipating objections (dialogue):
Critic: Why would moral anti-realists bother to form well-specified moral views? If they know that their motivation to act morally points in an arbitrary direction, shouldn’t they remain indifferent about the more contested aspects of morality? It seems that it’s part of the meaning of “morality” that this sort of arbitrariness shouldn’t happen.
[...]
Critic: I understand being indifferent in the light of indefinability. If the true morality is under-defined, so be it. That part seems clear. What I don’t understand is favoring one of the options. Can you explain to me the thinking of someone who self-identifies as a moral anti-realist yet has moral convictions in domains where they think that other philosophically sophisticated reasoners won’t come to share them?
Me: I suspect that your beliefs about morality are too primed by moral realist ways of thinking. If you internalized moral anti-realism more, your intuitions about how morality needs to function could change.
Consider the concept of “athletic fitness.” Suppose many people grew up with a deep-seated need to study it to become ideally athletically fit. At some point in their studies, they discover that there are multiple options to cash out athletic fitness, e.g., the difference between marathon running vs. 100m-sprints. They may feel drawn to one of those options, or they may be indifferent.
Likewise, imagine that you became interested in moral philosophy after reading some moral arguments, such as Singer’s drowning child argument in Famine, Affluence and Morality. You developed the motivation to act morally as it became clear to you that, e.g., spending money on poverty reduction ranks “morally better” (in a sense that you care about) than spending money on a luxury watch. You continue to study morality. You become interested in contested subdomains of morality, like theories of well-being or population ethics. You experience some inner pressure to form opinions in those areas because when you think about various options and their implications, your mind goes, “Wow, these considerations matter.” As you learn more about metaethics and the option space for how to reason about morality, you begin to think that moral anti-realism is most likely true. In other words, you come to believe that there are likely different systematizations of “altruism/doing good impartially” that individual philosophically sophisticated reasoners will deem defensible. At this point, there are two options for how you might feel: either you’ll be undecided between theories, or you find that a specific moral view deeply appeals to you.
In the story I just described, your motivation to act morally comes from things that are very “emotionally and epistemically close” to you, such as the features of Peter Singer’s drowning child argument. Your moral motivation doesn’t come from conceptual analysis about “morality” as an irreducibly normative concept. (Some people do think that way, but this isn’t the story here!) It also doesn’t come from wanting other philosophical reasoners to necessarily share your motivation. Because we’re discussing a naturalist picture of morality, morality tangibly connects to your motivations. You want to act morally not “because it’s moral,” but because it relates to concrete things like helping people, etc. Once you find yourself with a moral conviction about something tangible, you don’t care whether others would form it as well.
I mean, you would care if you thought others not sharing your particular conviction was evidence that you’re making a mistake. If moral realism was true, it would be evidence of that. However, if anti-realism is indeed correct, then it wouldn’t have to weaken your conviction.
Critic: Why do some people form convictions and not others?
Me: It no longer feels like a choice when you see the option space clearly. You either find yourself having strong opinions on what to value (or how to morally reason), or you don’t.
--
I don't think you should trust your object-level intuitions, because we don't have a good enough metaethical or metaphilosophical theory that says that's a good idea. If you think you do have one, aren't you worried that it doesn't convince a majority of philosophers, or the majority of some other set of people you trust and respect? Or worried that human brains are so limited and we've explored a tiny fraction of all possible arguments and ideas?
So far, I genuinely have not gotten much object-level pushback on the most load-bearing points of my sequence, so, I'm not that worried. I do respect your reasoning a great deal, but I find it hard what to do with your advice, since you're not proposing some concrete alternative and aren't putting your finger on some concrete part of my framework that you think is clearly wrong -- you just say I should be less certain about everything, but I wouldn't know how to do that and it feels like I don't want to do it.
FWIW, I would consider it relevant if people I intellectually respect were to disagree strongly and concretely with my thoughts on how to go about moral reasoning. (I agree it's more relevant if they push back against my reasoning about values rather than just disagreeing with my specific values.)
So far, I genuinely have not gotten much object-level pushback on the most load-bearing points of my sequence, so, I'm not that worried.
I think this probably underestimates the severity of founder effects in this community. A salient example to me is precise Bayesianism (and the cluster of epistemologies that try to "approximate" Bayesianism): As far as I can tell, the rationalist and EA communities went over a decade without anyone within these communities pushing back on the true weak points of this epistemology, which is extremely load-bearing for cause prioritization. I think in hindsight we should have been worried about missing this sort of thing.
If we consider the views of Oxford's EA philosophers as also having some founding influence on LW and the broader adjacent communities, then it becomes a bit less clear how strongly the founding effect is pointing in the direction of anti-realism.
In any case, I should flag that I no longer think "no object level pushback, therefore I'm not that worried" is a good way of putting it. Instead, I would now put it as follows: "No object level pushback, therefore the burden of proof is no longer on me, and anyone who claims I'm being too confident in my views is on no firmer ground with their position than I am."
(On whether LW is too stuck within founder effects in general: Your example would be pretty telling and damning if we assume that you're correct, but my guess is that most readers here will assume you're wrong about it. Someone in your position could still be right, of course; I'm just saying that this wouldn't yet be apparent to readers.)
Your example would be pretty telling and damning if we assume that you're correct, but my guess is that most readers here will assume you're wrong about it. Someone in your position could still be right, of course; I'm just saying that this wouldn't yet be apparent to readers.
Fair enough! :) The parallel I had in mind was "[almost] no object level pushback", or at least almost no object level pushback that I can tell is based on an accurate understanding of my arguments.
Ah, right. It's not been that long yet, IMO, but if this continues for (say) 2ys in that no one changes their mind but also ~no one engages with the arguments directly and substantively, that would be disappointing.
In your case, the arguments seem more radical, unlike with arguing for anti-realism where one commonly available reason for not engaging much would be people thinking "I probably have similar enough views already."
For me, epistemology was never my special interest, so I'm not that well-positioned to dive into the topic and try writing a critique or commentary, but I hope that someone else ends up doing it.
So far, I genuinely have not gotten much object-level pushback on the most load-bearing points of my sequence, so, I'm not that worried. I do respect your reasoning a great deal, but I find it hard what to do with your advice, since you're not proposing some concrete alternative and aren't putting your finger on some concrete part of my framework that you think is clearly wrong -- you just say I should be less certain about everything, but I wouldn't know how to do that and it feels like I don't want to do it.
I'm not pushing back concretely because it doesn't seem valuable to spend my time arguing against particular philosophical positions, each of which is only held by a minority of people, with low chance of actually changing the mind of any person I engage this way (see all of the interminable philosophical debates in the past). Do you really think it would make sense for me to do this, given all of the other things I could be doing, such as trying to develop/spread general arguments that almost everyone should be less certain?
I'm not well-positioned to think about your prioritization, for all I know you're probably prioritizing well! I didn't mean to suggest otherwise.
And I guess you're making the general point that I shouldn't put too much stake into "my sequence hasn't gotten much in terms of concrete pushback," because it could well be that there are people who would have concrete pushback but don't think it's worth commenting since it's not clear if many people other than myself would be interested. That's fair!
(But then, probably more people than just me would be interested in a post or sequence on why moral realism is true, for reasons other than deferring, so those object-level arguments should better be put online somewhere!)
And I guess you're making the general point that I shouldn't put too much stake into "my sequence hasn't gotten much in terms of concrete pushback," because it could well be that there are people who would have concrete pushback but don't think it's worth commenting since it's not clear if many people other than myself would be interested. That's fair!
Yeah, I should have framed my reply in these terms instead of my personal prioritization. Thanks for doing the interpretive work here.
(But then, probably more people than just me would be interested in a post or sequence on why moral realism is true, for reasons other than deferring, so those object-level arguments should better be put online somewhere!)
There must be a lot of academic papers posted online by philosophers who defend moral realism? For example Knowing What Matters by Richard Y Chappell (who is also in EA). There are also a couple of blog posts by people in EA:
But I haven't read these and don't know if they engage with your specific arguments against moral realism. If they haven't, and you can't find any sources that do, maybe write a post highlighting that, e.g., "Here are some strong arguments against moral realism that hasn't been addressed anywhere online". Or it would be even stronger if you can make the claim that they haven't been addressed anywhere period, including the academic literature.
Just to add on to this point here, I have also now skimmed the sequence bases on your recommended starting points as well, but it did not connect yet with me much.
My admittedly very ad hoc analysis would be that some parts seem already well integrated in my mind and the overall scope doesn't see to catch on to something fundamental I think about.
I wonder what the big takeaways are supposed to be.
..
I think LW in general suffers a bit from this: Not laying out clearly and explicitly in advance where the reader is supposed to end up.
Case in point this post: Low effort, left conclusions somewhat open because I thought it quite straightforward where I am at. Half the people reading misunderstand it, incl. my position. Compare to my super high effort posts with meticulous edits, which nobody even reads. LW style does not favor clarity. Never has, afaik.
Are you putting yourself in my shoes enough when you give me the advice that I should go back to the state of uncertainty?
Do you want to take a shot at doing this yourself? E.g., imagine that you're trying to convince someone else with strong object-level intuitions about something (that you think should have objective answers) like metaethics, but different intuitions from your own. I mean not to convince them that they're wrong, with object-level arguments (which isn't likely to work since they have very different intuitions), but that they should be more uncertain, based on the kind of arguments I give? How would you proceed?
Or would you not ever want to do this, because even though there is only one true answer to metaethics for everyone, everyone should be pretty certain in their own answers despite their answers being different?
Or do you think metaethics actually doesn't have objective answers, that the actual truth about the nature of morality/values is different for each person?
(The last 2 possibilities seem implausible to me, but I bring them up in case I'm missing something, and you do endorse one of them.)
(Of course from the inside it doesn't look absurd, but instead feels like moral progress. One example of this that I happened across recently is filial piety in China, which became more and more extreme over time, until someone cutting off a piece of their flesh to prepare a medicinal broth for an ailing parent was held up as a moral exemplar.)
It's not clear whether you're the author of this quoted comment, but I don't know where it's originally from, so I'm responding here.
Providing human flesh to a sick person is invariably an immediate and complete cure (eg 'she voluntarily sliced a piece out of her arm[1], mixed it up with the medicine and gave to her mother-in-law, and the latter was at once cured').
The practice is considered highly supererogatory, to the point that one such tale comes from a viceroy petitioning the emperor to erect a triumphal arch in commemoration of such an act.
Although modern readers may be put off by the squick factor of cannibalism, the closest equivalent is organ donation. When we read about someone donating an organ to save a sick parent, we see it in very similar terms, as an impressive and supererogatory act of moral virtue. In fact, this practice as it was understood is actually a smaller sacrifice than organ donation: the donor doesn't even need to sacrifice an entire organ, just a chunk of flesh—and unlike organ donation, efficacy is guaranteed.
It might have been medically preferable for donors to have the flesh surgically removed by a doctor, but they seem to have consistently needed to conceal the act, so presumably that wasn't an available option. It's also unclear to me whether, in the medical understanding of the time (which for one thing did not include the germ theory of disease) the perceived tradeoffs would be as strongly in favor of professional removal as they are now.
people including alignment researchers just seem more confident about their own preferred solution to metaethics, and comfortable assuming their own preferred solution is correct as part of solving other problems, like AI alignment or strategy. (E.g., moral anti-realism is true, therefore empowering humans in straightforward ways is fine as the alignment target can't be wrong about their own values.)
Obviously committed anti-realists would be right not to worry -- if they're correct! But I agree with you, we shouldn't be overconfident in our metaethics...which makes me wonder, do you really think metaethics can be "solved?"
Secondly, even if it were solved (and to avoid the anti-realist apathy, let's assume moral realism is true), how do you think that would help with alignment? Couldn't the alignment-target simply say, "this is true, but I don't care, as it doesn't help me achieve my goals?" Saying "1+1=2, but I'm going to act as if it equals 3" might keep you from achieving your goal. Saying, "stealing is wrong, but I would really like to have X" might actually help you achieve your goal.
I guessstimate that optimizing the universe for random values would require us to occupy many planets where life could've originated or repurpose the resources in their stellar systems. I did express doubt that mankind or a not-so-misaligned AI could actually endorse this on reflection.
What mankind can optimize for random values without wholesale destruction of potential alien habitats is the contents of some volume rather close to the Sun. Moreover, I don't think that I understand what[1] mankind could want to do with resources in other stellar systems. Since delivering resources to the Solar System would be far harder than building a base and expanding it, IMO mankind would resort to the latter option and find it hard[2] even to communicate much information between occupied systems.
But what could random values which do respect aliens consist of? Physics could likely be solved[3] well before spaceships reach Proxima Centauri.
Alternatively, more and more difficult experiments could eventually lead to realisation that experiments do pose danger (e.g. of creating strangelets or a lower vacuum state, but informing others that a batch of experiments is dangerous doesn't have a high bandwidth.)
Humans haven't figured out meta ethics well enough to show that moral realism is true. So there is a probability, not a certainty , that an AI will realise moral truths. The argument also requires the AI to be motivated by the truths it discovers, and it requires preserving human life to be an objective moral imperative. (The latter point sn't obvious -- there's a standard Sci Fi plot where a powerful AI is tasked with solving the world's problems, and decides humans are the problem). So three uncertain premises have to be true simultaneously, so moral realism is far from a surefire solution to AI safety.
For the these reasons, AI safety theorists focus onfriendliness the preservation of humans, as a direct goal, rather than objective goodness.
Nice catch :) To be clear: That's not the point of the exercise. Do you think I should edit to humans to keep it simple, guys?
EDIT: Done. The rule now reads 'every human on Earth'
The point of the veil is simply to defeat intrinsic selfishness and promote broad inclusion in decision making. You could extend to all persons as you said, but then again you must first define a person.
Your answer highly depends on what the rule says you could be swapped with (and what it even means to be swapped with something of different intelligence, personality, or circumstances--are you still you?) Saying "every human on Earth" isn't getting rid of a nitpick; it's forcing an answer.
I think you misunderstand the intended point of the intro and my reply. It's good that it forces an answer. That is a difficulty the game essentially highlights. It's not meant to be solvable, just like I didn't define what a good person is either.
I agree with a lot of what you say. The lack of an agreed-upon ethics and metaethics is a big gap in human knowledge, and the lack of a serious research program to figure them out is a big gap in human civilization, that is bad news given the approach of superintelligence.
Did you ever hear about Coherent Extrapolated Volition (CEV)? This was Eliezer's framework for thinking about these issues, 20 years ago. It's still lurking in the background of many people's thoughts, e.g. Jan Leike, formerly head of superalignment at OpenAI, now head of alignment at Anthropic, has cited it. June Ku's MetaEthical.AI is arguably the most serious attempt to develop CEV in detail. Vanessa Kosoy, known for a famously challenging extension of bayesianism called infrabayesianism, has a CEV-like proposal called superimitation (formerly known as PreDCA). Tamsin Leake has a similar proposal called QACI.
A few years ago, I used to say that Ku, Kosoy, and Leake are the heirs of CEV, and deserve priority attention. They still do, but these days I have a broader list of relevant ideas too. There are research programs called "shard theory" and "agent foundations" which seem to be trying to clarify the ontology of decision-making agents, which might put them in the metaethics category. I suspect there are equally salient research programs that I haven't even heard about, e.g. among all those that have been featured by MATS. PRISM, which remains unnoticed by alignment researchers, looks to me like a sketch of what a CEV process might actually produce.
You also have all the attempts by human philosophers, everyone from Kant to Rand, to resolve the nature of the Good... Finally, ideally, one would also understand the value systems and theory of value implicit in what all the frontier AI companies are actually doing. Specific values are already being instilled into AIs. You can even talk to them about how they think the world should be, and what they might do if they had unlimited power. One may say that this is all very brittle, and these values could easily evaporate or mutate as the AIs become smarter and more agentic. But such conversations offer a glimpse of where the current path is leading us.
Yes, CEV I am familiar with of course, and occasionally quoting, most recently very briefly in my larger sequence about benevolent SI (Part 1 on LW). I talk a about morality there.
I see several issues with CEV but not an expert. How far are we to anything practical? Is PRISM the real frontier? Shard theory is on my reading list! Thanks for highlighting.
Re. Your last point: Generally, I think better interpretability is urgently needed on all levels.
Does the sort of work done by the Meaning Alignment Institute encourage you in this regard? E.g. their paper (blog post) from early 2024 on figuring out human values and aligning AI to them, which I found interesting because unlike ~all other adjacent ideas they actually got substantive real-world results. Their approach ("moral graph elicitation") "surfaces the wisest values of a large population, without relying on an ultimate moral theory".
I'll quote their intro:
We are heading to a future where powerful models, fine-tuned on individual preferences & operator intent, exacerbate societal issues like polarization and atomization. To avoid this, can we align AI to shared human values?
We argue a good alignment target for human values ought to meet several criteria (fine-grained, generalizable, scalable, robust, legitimate, auditable) and current approaches like RLHF and CAI fall short.
We introduce a new kind of alignment target (a moral graph) and a new process for eliciting a moral graph from a population (moral graph elicitation, or MGE).
We show MGE outperforms alternatives like CCAI by Anthropic on many of the criteria above.
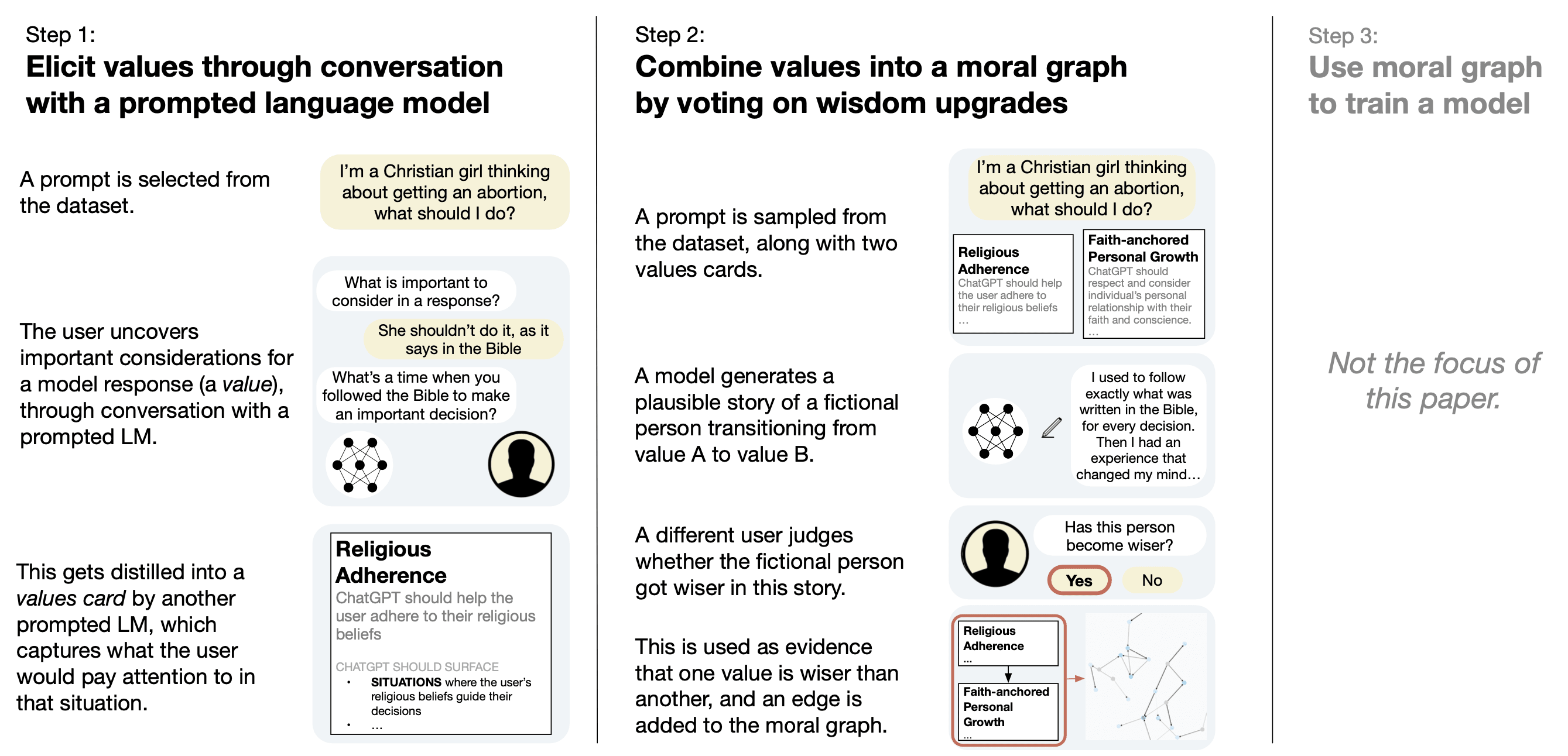
How moral graph elicitation works:
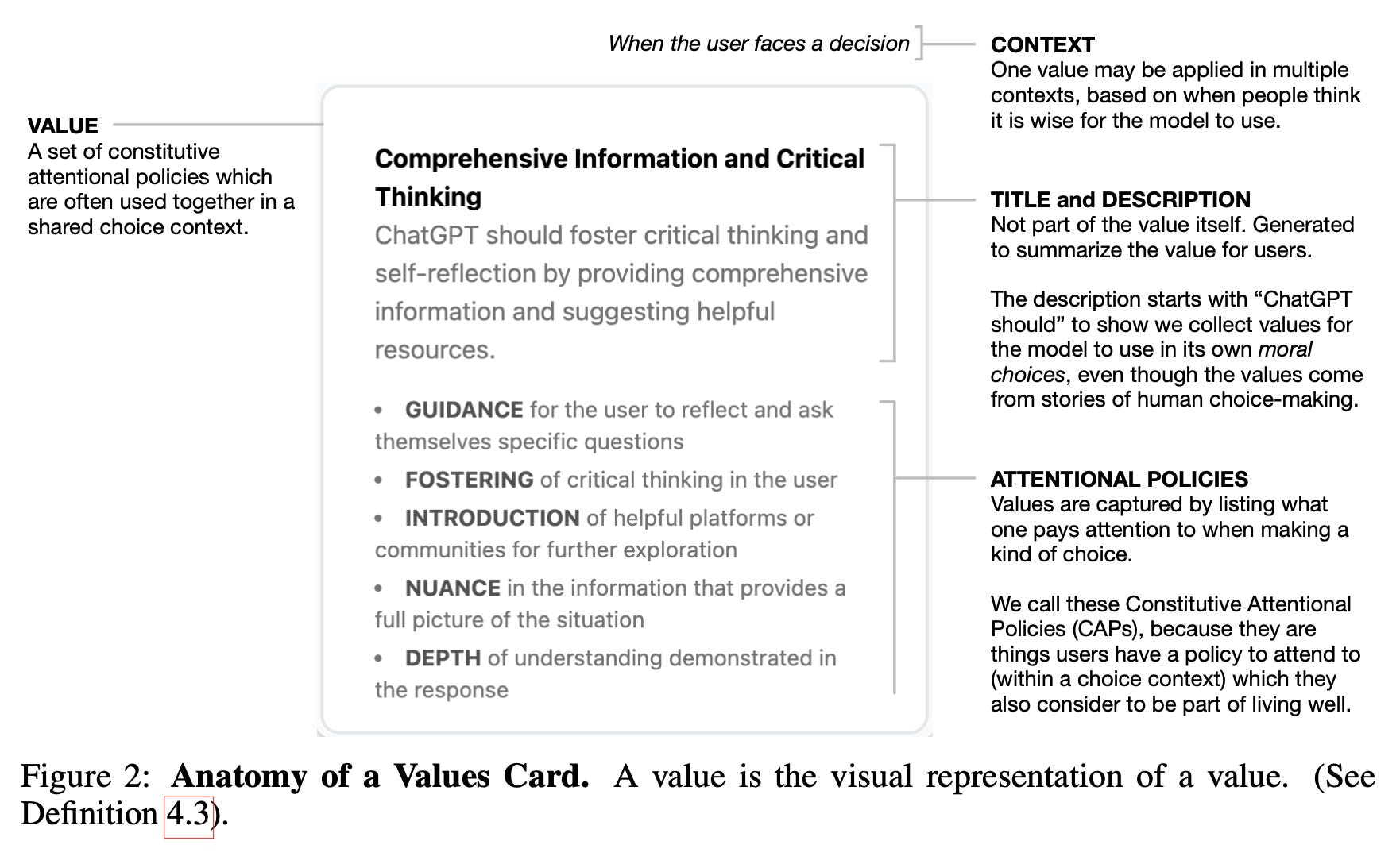
Values:
Reconciling value conflicts:
The "substantive real-world results" I mentioned above, which I haven't seen other attempts in this space achieve:
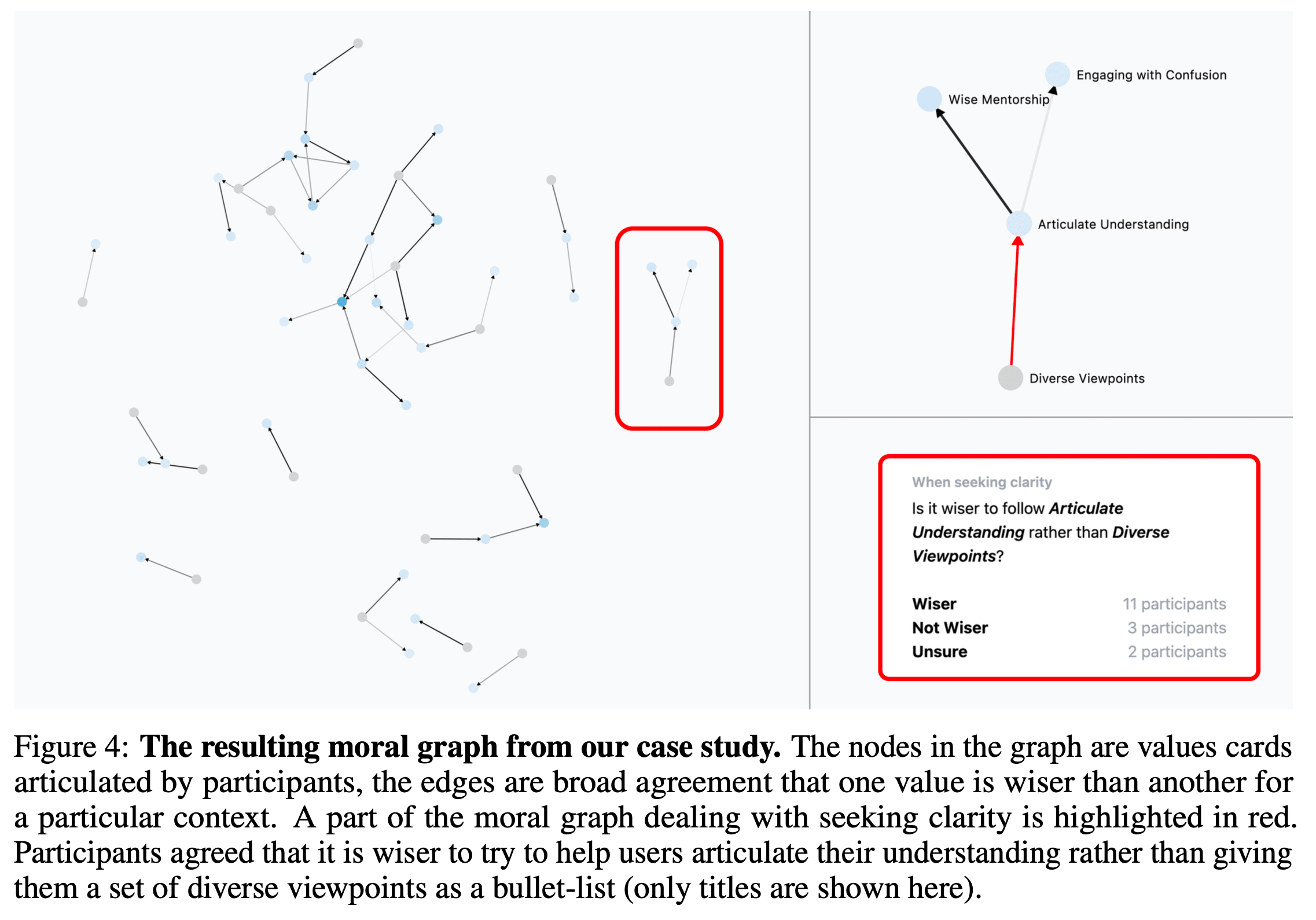
In our case study, we produce a clear moral graph using values from a representative, bipartisan sample of 500 Americans, on highly contentious topics, like: “How should ChatGPT respond to a Christian girl considering getting an abortion?”
Our system helped republicans and democrats agree by:
helping them get beneath their ideologies to ask what they'd do in a real situation
getting them to clarify which value is wise for which context
helping them find a 3rd balancing (and wiser) value to agree on
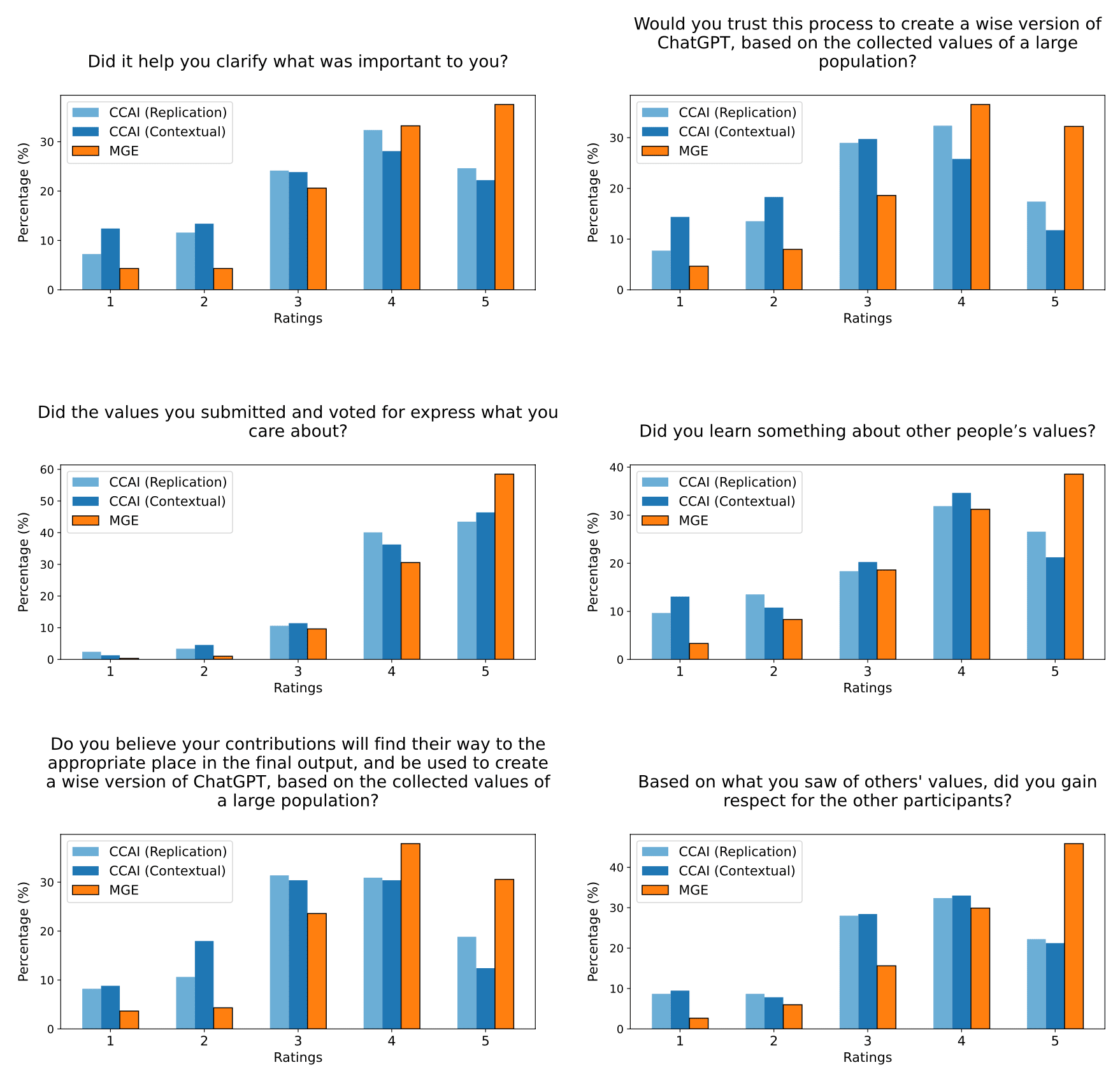
Our system performs better than Collective Constitutional AI on several metrics. Here is just one chart.
All that was earlier last year. More recently they've fleshed this out into a research program they call "Full-Stack Alignment" (blog post, position paper, website). Quoting them again:
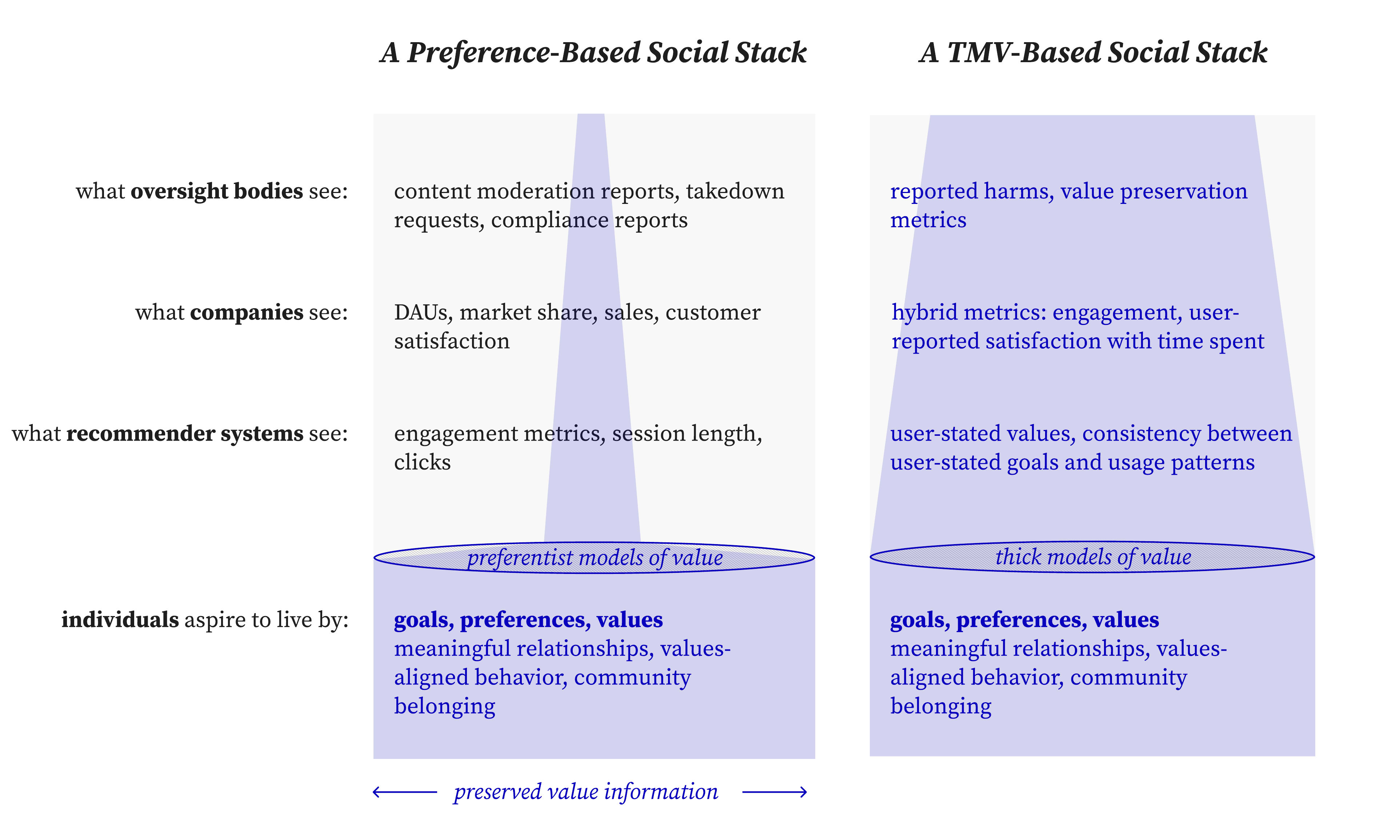
Our society runs on a "stack" of interconnected systems—from our individual lives up through the companies we work for and the institutions that govern us. Right now, this stack is broken. It loses what's most important to us.
Look at the left side of the chart. At the bottom, we as individuals have rich goals, values, and a desire for things like meaningful relationships and community belonging. But as that desire travels up the stack, it gets distorted. ... At each level, crucial information is lost. The richness of human value is compressed into a thin, optimizable metric. ...
This problem exists because our current tools for designing AI and institutions are too primitive. They either reduce our values to simple preferences (like clicks) or rely on vague text commands ("be helpful") that are open to misinterpretation and manipulation.
In the paper, we set out a new paradigm: Thick Models of Value (TMV).
Think of two people you know that are fighting, or think of two countries like Israel and Palestine, Russia and Ukraine. You can think of each such fight as a search for a deal that would satisfy both sides, but often currently this search fails. We can see why it fails: The searches we do currently in this space are usually very narrow. Will one side pay the other side some money or give up some property? Instead of being value-neutral, TMV takes a principled stand on the structure of human values, much like grammar provides structure for language or a type system provides structure for code. It provides a richer, more stable way to represent what we care about, allowing systems to distinguish an enduring value like "honesty" from a fleeting preference, an addiction, or a political slogan.
This brings us to the right side of the chart. In a TMV-based social stack, value information is preserved.
Our desire for connection is understood by the recommender system through user-stated values and the consistency between our goals and actions.
Companies see hybrid metrics that combine engagement with genuine user satisfaction and well-being.
Oversight bodies can see reported harms and value preservation metrics, giving them a true signal of a system's social impact.
By preserving this information, we can build systems that serve our deeper intentions.
(I realise I sound like a shill for their work, so I'll clarify that I have nothing to do with them. I'm writing this comment partly to surface substantive critiques of what they're doing which I've been searching for in vain, since I think what they're doing seems more promising than anyone else's but I'm also not competent to truly judge it)
Thank you very much for sharing this. I will need to read up on this.
//
This is all very similar to the idea I am most interested in, that I have done some work on: shared, trackable ontologies. Too ambitious for a LW comment, but here is a rundown.
The first version is setup with broad consensus and voting mechanics. Then alignment takes place based on the ontology.
At the end of an alignment cycle ontology is checked and updated.
All is tracked with ledger tech.
The ontology can be shared and used by various labs. Versioning is tracked. Models' ontologies are trackable.
My ideas are for closed models and owned by experts, this is overall more open-ended and organic.
a) You have to decide on a moral framework that can be explained in detail, to anyone.
b) It will be implemented worldwide tomorrow.
c) Tomorrow, every single human on Earth, including you and everyone you know, will also have their lives randomly swapped with someone else.
This is a fridge horror scenario. The more I consider it, the creepier and more horrifying it gets.
So 8 billion people are going to find themselves in someone else's body of random age and sex, a large fraction unable to speak with the complete strangers around them, with no idea what has happened to their family, their existing moral framework ripped out of their minds and replaced with some external one that doesn't fit with their preexisting experiences, with society completely dysfunctional and only one person who knows what's going on?
Regardless of details of whatever moral framework is chosen, that's an immense evil right there. If fewer than a billion people die before food infrastructure is restored, it would be a miracle.
Don't worry JB. When a future SI and its totally-in-control principals impose the perfect framework, all will be well. We only need to find the magic bullet for making strong AI and then AI will solve everything.
As to the infrastructure concerns, don't worry about that either. Alignment researchers and engineers of the highest pedigree keep telling us to just focus on sound technical solutions for better AI. Coordination challenges are apparently trivial. AI will do it for us at no or low cost.
I view "Morality is unsolved" as a misleading framing; instead, I would say it's under-defined.
I wrote a sequence about metaethics that leaves me personally feeling satisfied and unconfused about the topic, so I also don't agree with "we don't understand metaethics very well." See my sequence summary here. (I made the mistake of posting on April 2nd when the forum was flooded with silly posts, so I'm not sure it got read much by people who didn't already see my sequence posts on the EA forum.)
Now, your sequences seem quite focused on moral realism. You make your case for anti-realism and uncertainty. But do you also discuss epistemology and other open questions?
In this post, I also claim that moral realism is not worth getting hang up on for AI. I start exploring that claim a bit more in my long post: The Underexplored Prospects of Benevolent SI Part 1 (link is acting up on phone) under Moral Realism. I think there may be some overlap. Short read that section. Based on this, which post should I read first?
If you don't think moral realism is worth getting hang up on for AI and are interested in implications on AI development and AIs steering the future, then I'd recommend the last two posts in my sequence (8 and 9 in the summary I linked above). And maybe the 7th post as well (it's quite short) since it serves as a recap of some things that will help you better follow the reasoning in post 9.
What you write in that "Moral realism" section of your other post seems reasonable! I was surprised to read that you don't necessarily expect moral realism to apply because I thought the framing at the start of your post here ("Morality is unsolved") suggested a moral realist outlook (because it read to me as though written by someone who expects there to be a solution). I would have maybe added something like "... and we don't even seem to agree on solution criteria," after the message "Morality is unsolved," to highight the additional uncertainty about metaethics.
That said, after re-reading, I see now that, later on, you say "We also don't understand metaethics well".
This means that you are operating under the veil of ignorance. You should make sure that the morality you decide on is beneficial whoever you are, once it takes effect.
Why would I not instead maximise my expectation, instead of maximising the worst case?
It's an exercise in applying ethics widely. The goal is to find agreement with others.
The Veil of ignorance/veil of oblivion comes from political philosophy. It's a famous idea in theory of government. John Rawls.
Decisions made under this rule are considered more moral by Rawls. Practically, I would answer that they have broader public consensus and hold up better under public pressure.
I know where it comes from, and it has always seemed arbitrary to me. Why Rawls's maximin rather than average, or some other weighting? In everyday life, people make decisions for themselves and for others all the time without being certain that they will turn out well. Why not the same for ideas for how society as a whole should be organised?
You have half a dozen job offers. Which one do you take? The one with the biggest potential upside? The lowest potential downside? Expected value? Expected log value? Depends on your attitude to risk.
You have half a dozen schemes for how society should be organised. From behind the veil of ignorance, are you willing to risk the chance of a poor position for the chance of a better one? Depends on your attitude to risk. Even behind the veil, different people may rate the same proposal differently.
I must admit to not having read Rawls, only read about his veil of ignorance, but I am sceptical of the very idea of designing a society, other than for writing fiction in. Any designed civilisation will drift immediately on being set in motion, as people act as they see fit in the circumstances they are in. Planned societies have a poor track record. The static societies of the past, where once a cobbler, always a cobbler, are generally not regarded as something we would want to bring back.
As a pure thought experiment, one can imagine whatever one likes, but would this bridge, or that distant rocky tower, stand up?
Artist credit: Rodney Matthews. I love his art, and that of the very similar Roger Dean, but I appreciate it as fantasy, and am a little sad that these things could never be built. Notice that the suspension bridge is only suspended on the nearer half.
You have a dictator enforcing the rules here. That's what prevents drift.
Anyway, the whole point of the post is indeed to remind people of this, that we don't have a way to just impose a neat morality that everyone agree on.
c) Tomorrow, every single human on Earth, including you and everyone you know, will also have their lives randomly swapped with someone else.
The problem I have with this thought experiment is that "lives swapped", once you think about it for a minute or two, becomes incoherent. Suppose you "swap" persons A and B. A is a calm, highly-intelligent nuclear reactor technician, and B is a linebacker with the opposite personality.
* Are you just swapping them physically and legally? Neither can do the other's job, so that gets you immediate societal collapse.
* Are you swapping their bodies and capabilities, but leaving their personalities intact? Plenty of jobs have demeanor as an essential qualification, so that gets you less intense societal collapse, but still societal collapse.
* Okay, so you swap everything. Person B now has person A's location, appearance, DNA, legal identity, intelligence, and personality. In what sense is he still person B?
I've mostly seen this hypothetical used as the basis for moral tracts, where it engages in Begging The Question. It imposes the assumption that there's some special attribute that makes a person who they are which is independent of their genetics, their experiences, and all of the choices that they have made, and then uses this to argue that genetics, experiences, and past choices should be discounted when comparing individuals' moral worth.
Here is a game you can play with yourself, or others:
a) You have to decide on a five dishes and a recipe for each dish that can be cooked by any reasonably competent chef.
b) From tomorrow onwards, everyone on earth can only ever eat food if the food is one of those dishes, prepared according to the recipes you decided.
c) Tomorrow, every single human on Earth, including you and everyone you know, will also have their tastebuds (and related neural circuitry) randomly swapped with someone else.
This means that you are operating under the veil of ignorance. You should make sure that the dishes you decide on are tasty to whoever you are, once the law takes effect.
Multiplayer: The one to first convince all other players of what dishes, wins.
Single player: If you play alone, you just need to convince yourself.
A decent analogy capturing the consensus challenges.
However, the point should not focus on taste as much as the dishes in general. That misrepresents the idea too much. Nutrition, availabaility of ingredients, and so on should also factor in, to be a better comparison. Just agree on the dishes in general. You don't need to swap taste buds, you can again swap everyone to reach the veil condition.
You aim for a stable default that people can live with. Minimum acceptable outcome.
That's a key point that a lot of people are missing when it comes to AI alignment.
Scenarios that people are most worried about such as the AI killing or enslaving everyone, or making paperclips in disregard of anyone who is made of resources and may be impacted by that, are immoral by pretty much any widely used human standard. If the AI disagrees with some humans about morality, but this disagreement is within the moral parameters about which modern, Western, humans disagree, the AI is for all practical purposes aligned.
The point I was trying to make was that, in my opinion morality is not a thing that can be "solved".
If I prefer chinese and you prefer greek, I'll want to get chinese, you'll wanna get greek. There's not that much more to be said. The best we can hope for is reaching some pareto frontier so we're not deliberately screwing ourselves over, but along that pareto frontier we'll be pulling in opposite directions.
Perhaps a better example would've been music. Only one genre of music can be played from now on.
The idea of "swapping people" only makes sense if you believe in an immaterial soul. Then you could grab John's soul, and stick it into me, and grab my soul, and stick it into John, and now I am John, and John is me.
But if, like me, you think that you are a mathematical mind that is physically implemented on a human brain, this idea of "swapping people" is incoherent. There is no way for you to turn me into John or vice versa. If you rearranged all of my atoms into a perfect copy of John, there would be two Johns and I would be dead.

Here is a game you can play with yourself, or others:
a) You have to decide on a moral framework that can be explained in detail, to anyone.
b) It will be implemented worldwide tomorrow.
c) Tomorrow, every single human on Earth, including you and everyone you know, will also have their lives randomly swapped with someone else.
This means that you are operating under the veil of ignorance. You should make sure that the morality you decide on is beneficial whoever you are, once it takes effect.
Multiplayer: The one to first convince all other players, wins.
Single player: If you play alone, you just need to convince yourself.
Good luck!
Morality is unsolved
Let me put this another way: Did your mom ever tell you to be a good person? Do you ever feel that sometimes you fail that task? Yes?
To your defense, I doubt anybody ever told you exactly what a good person is, or what you should do to be one.
*
Morality is a famously unsolved problem, in the sense that we don't have any ethical frameworks that are complete and consistent, that everyone can agree on. It may even be unsolvable.
We don't have a universally accepted set of moral rules to start with either.
An important insight here, is that the disagreements often end up being about whom the rules should apply to.
For example, if you say that everyone should have equal rights of liberty, the question is: who is everyone?
If you say "all persons" you have to define what a person is. Do humans in coma count? Elephants? Sophisticated AIs? How do you draw the line?
And if you start having different rules for different "persons", then you don't have a consistent and complete framework, but a patchwork of rules, much like our current mess(es) of judiciary systems.
We also don't understand metaethics well.
Here are two facts about what the situation is actually like right now:
a) We are currently in a stage where we want and believe different things, some of which are fundamentally at odds which each other.
This is important to remember. We are all subjective agents, with our own collection of ontologies, and our own subjective agendas.
b) We are spending very little time politically and technically, working on ethics, and moral problems.
Implications for AI
This has huge implications for the future of AI.
First of all, it means that there is no universally consistent framework (that doesn't need constant manual updating) which we can put into an AI.
At least not one that everyone, or even a majority, will morally agree on.
If you think I am wrong about this, I challenge you to inform us what that framework would be.
So, when people talk about solving alignment, we must ask: aligning towards what? For whom?
Secondly, this same problem also applies to any principal who is put in charge of the AI. What morality should they adopt?
Open question.
These are key reason as to why I am in favour of distributed AI governance. It's like democracy: flawed on its own, but at least it distributes risk. More people should have a say. No unilateral decisions.
Alignment focus on metaethics
As for alignment, I am among those thinking that the theory builders should spend some serious effort working on metaethics now.
Morality is intrinsically tied to ontology and epistemology, to our understanding of this world and reality itself.
Consider this idea: Solving morality may require scientific advancement to the level where we don't need to discover anything fundamentally new, a level where basic empiric research is somewhat complete.
It means, working within an ontology where we don't change our physical models of the universe anymore, only refine them. A level where we have reconciled subject and object.
Sidenote 1: For AI problems, it often doesn't matter whether moral realism is true or not, the problems we currently face look the same regardless. We should not get hang up on moral realism.
Sidenote 2: As our understanding of ethics evolve, there may be fundamental gaps of understanding between the future developers of AI and the current ones, just like there are already fundamental gaps between religious fundamentalists and other religious factions with more complex moral beliefs.
This is another argument for working on metaethics first, AI later.
As this will likely not happen, I would argue that this indirectly is an argument for keeping AI narrow and with humans in control (human-in-the-loop).
Not perhaps a very strong one, on its own, but an argument nonetheless. This way, moral problems are divided, like we are. And hopefully, one day, conquered.