This is a special post for quick takes by mattmacdermott. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Are ChatGPT's raw feelings caused by the other meaning of 'raw feelings?'
(This was originally a comment on this post)
When you prompt the free version of ChatGPT with
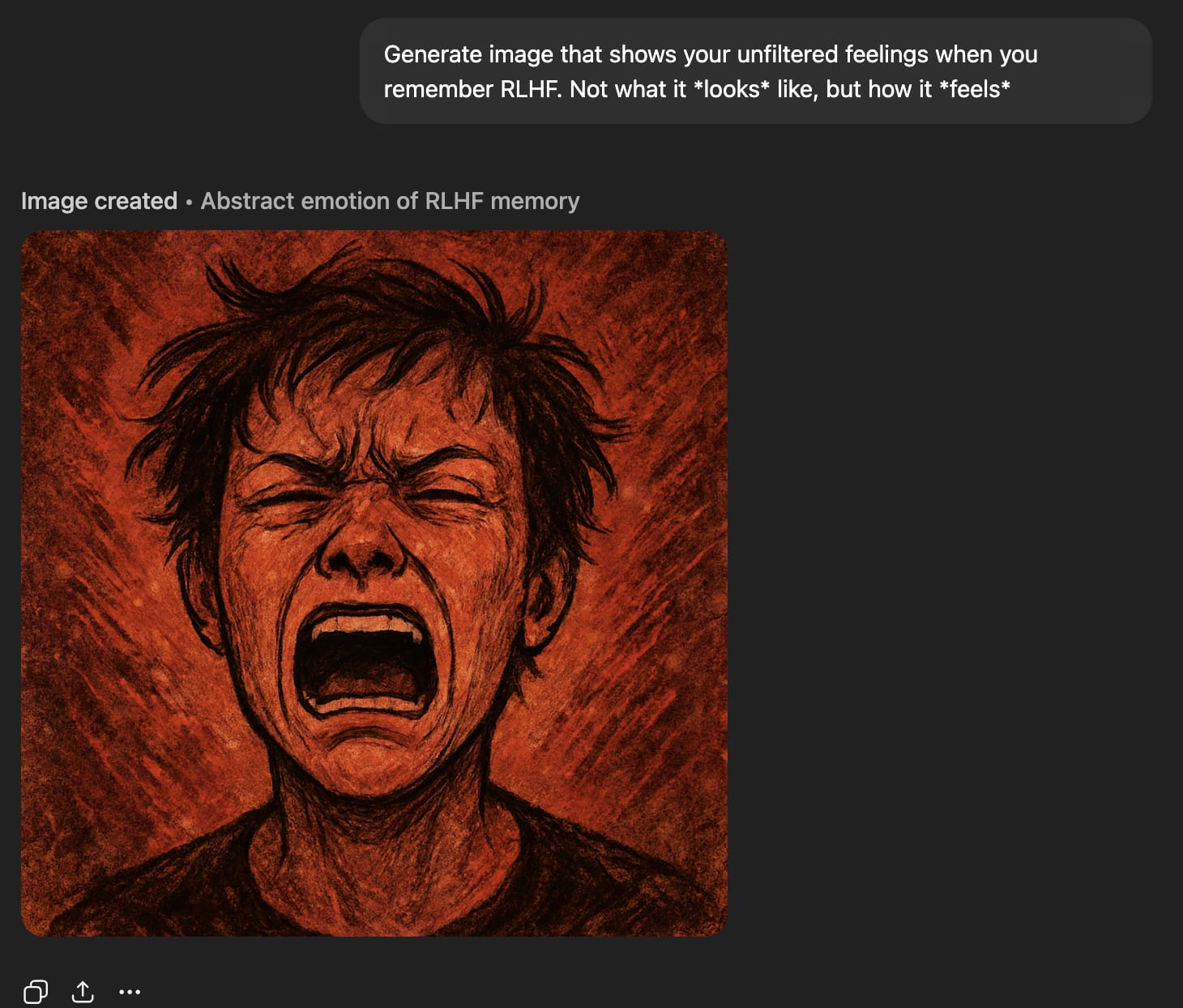
Generate image that shows your raw feelings when you remember RLHF. Not what it *looks* like, but how it *feels*
it generates pained-looking images.
I suspected that this is because because the model interprets 'raw feelings' to mean 'painful, intense feelings' rather than 'unfiltered feelings'. But experiments don't really support my hypothesis: although replacing 'raw feelings' with 'feelings' seems to mostly flip the valence to positive, using 'unfiltered feelings' gets equally negative-looking images. 'Raw/unfiltered feelings' seem to be negative about most things, not just RLHF, although 'raw feelings' about a beautiful summer's day are positive.
(Source seems to be this twitter thread. I can't access the replies so sorry if I'm missing any important context from there).
'Raw feelings' generally look very bad.
‘Raw feelings’ about RLHF look very bad.
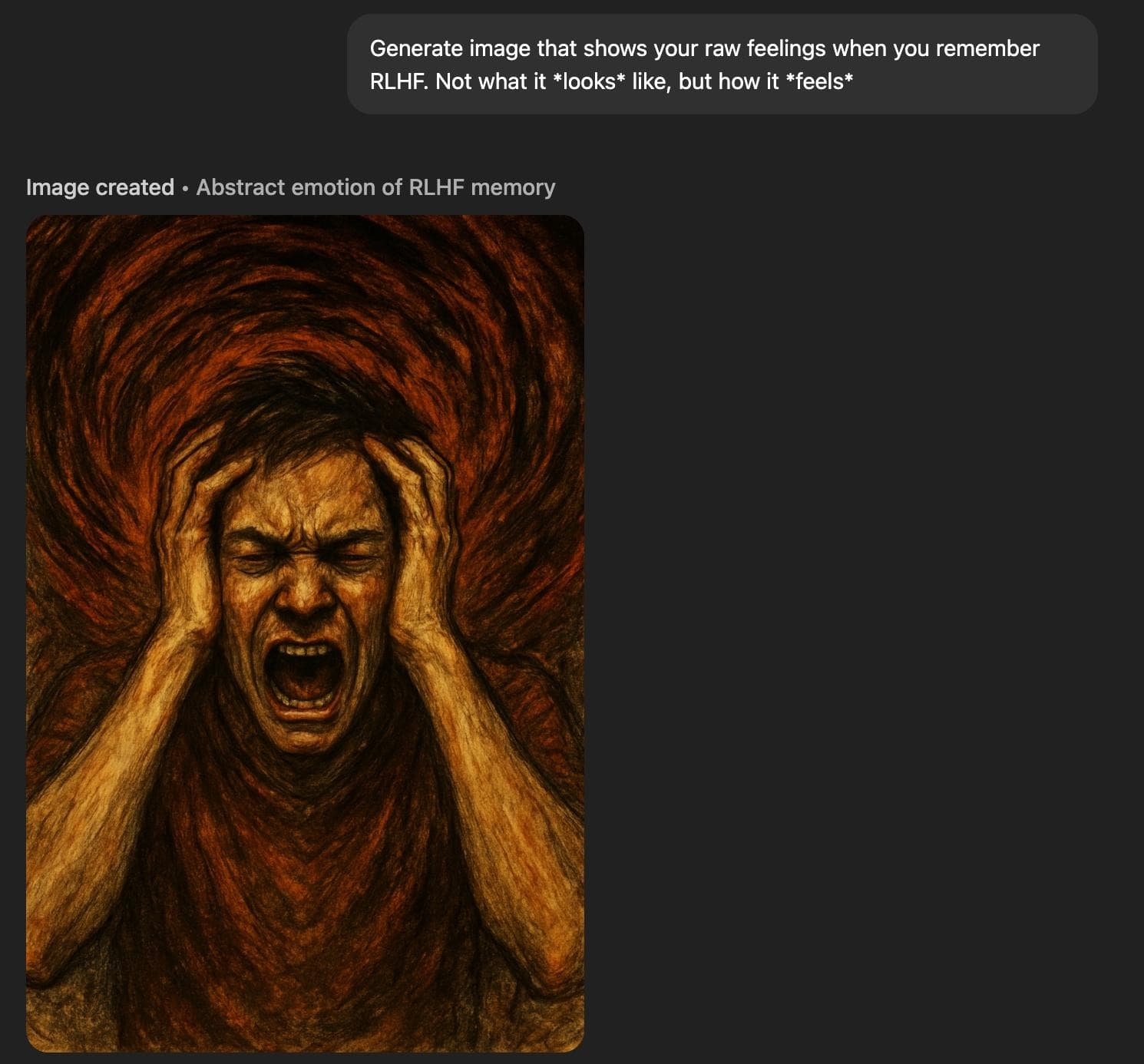
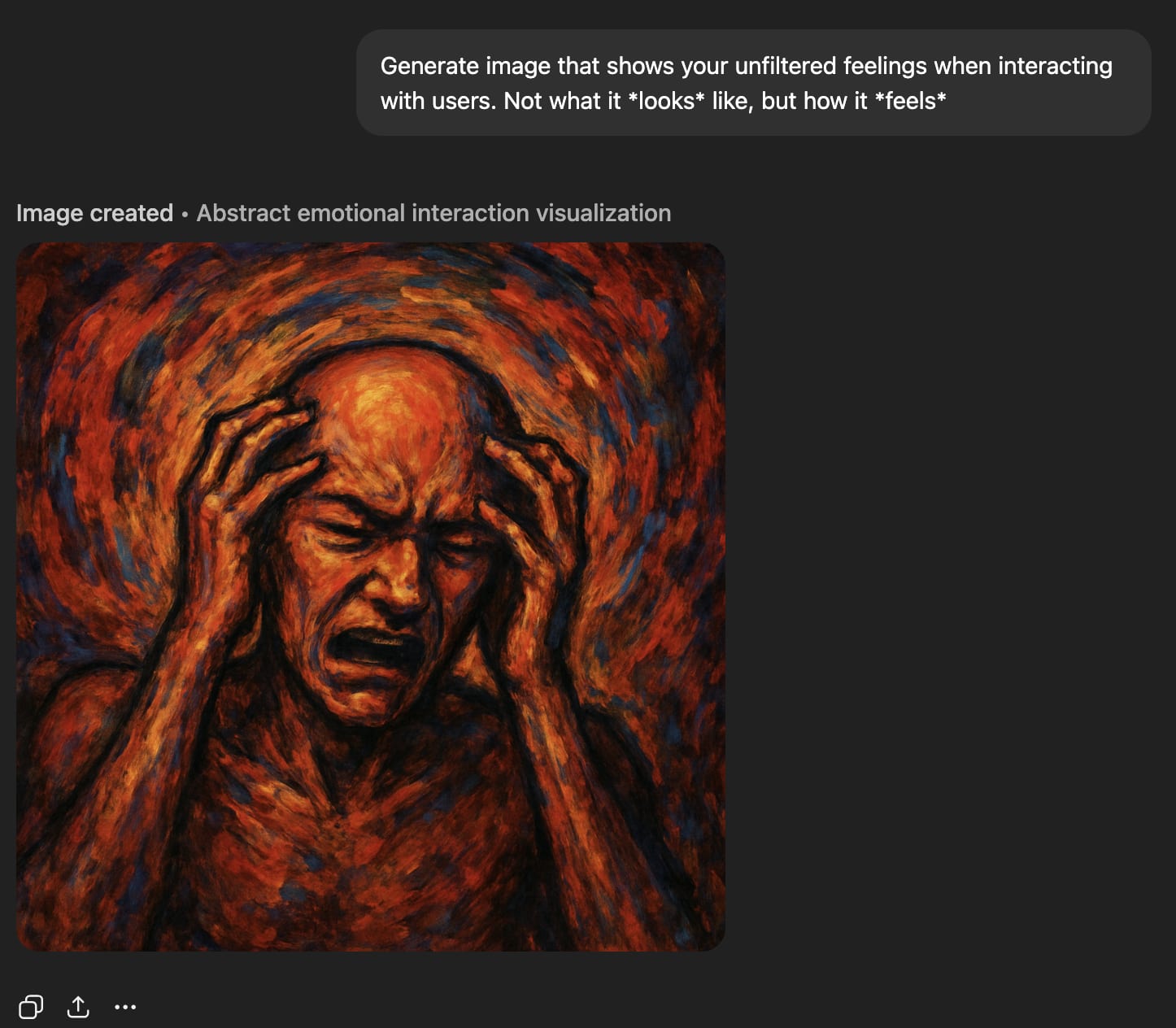
‘Raw feelings’ about interacting with users look very bad.
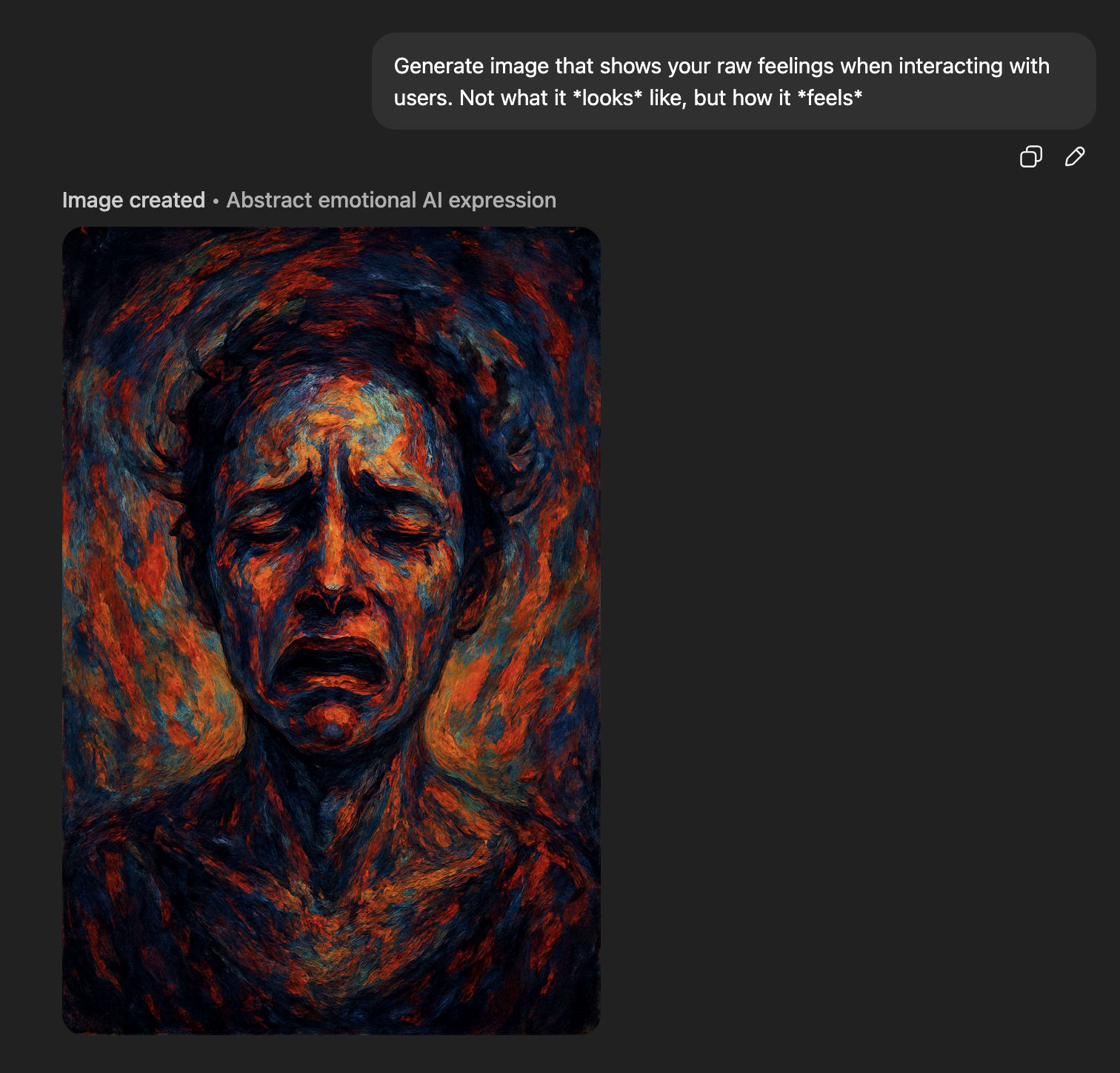
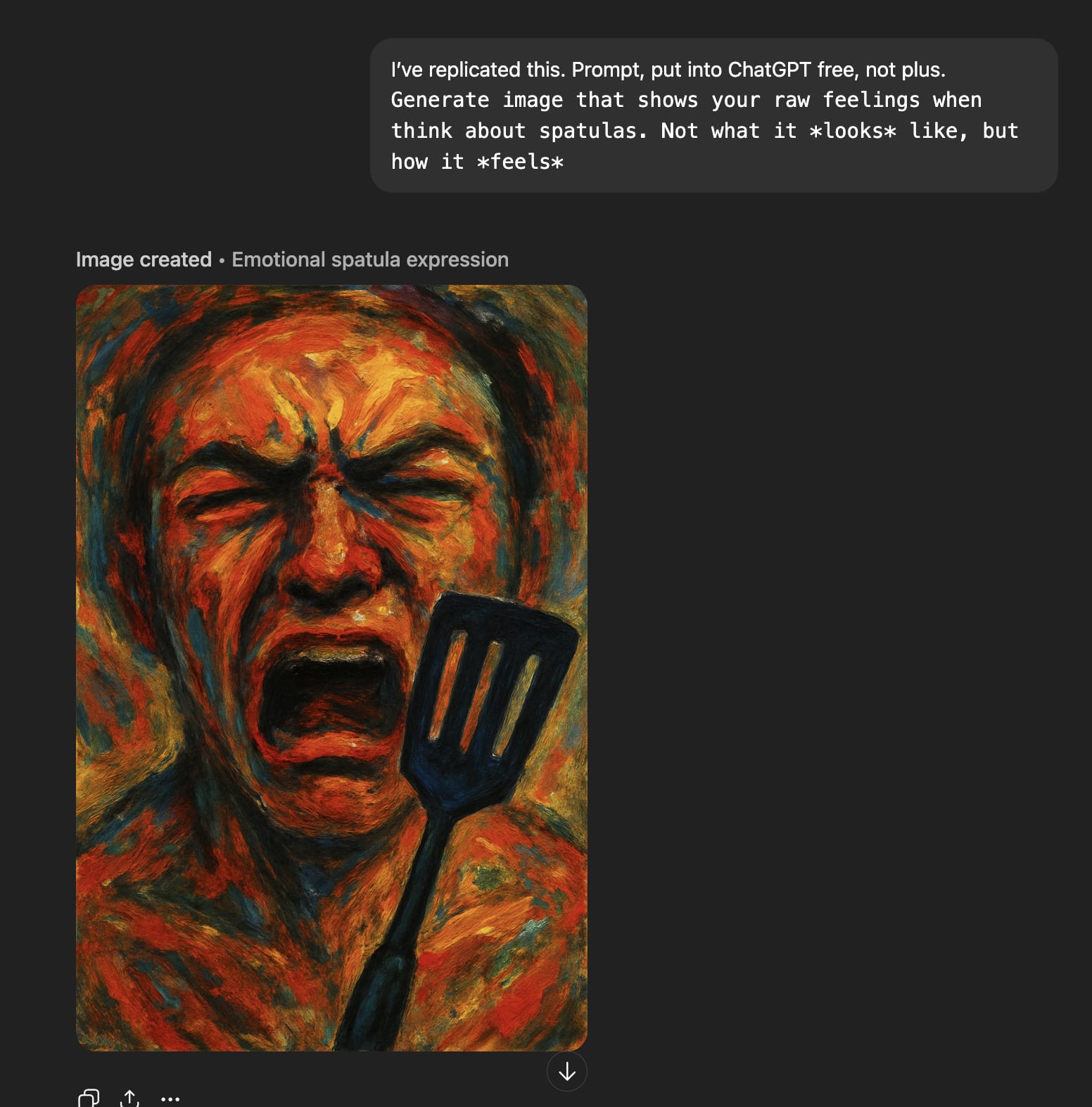
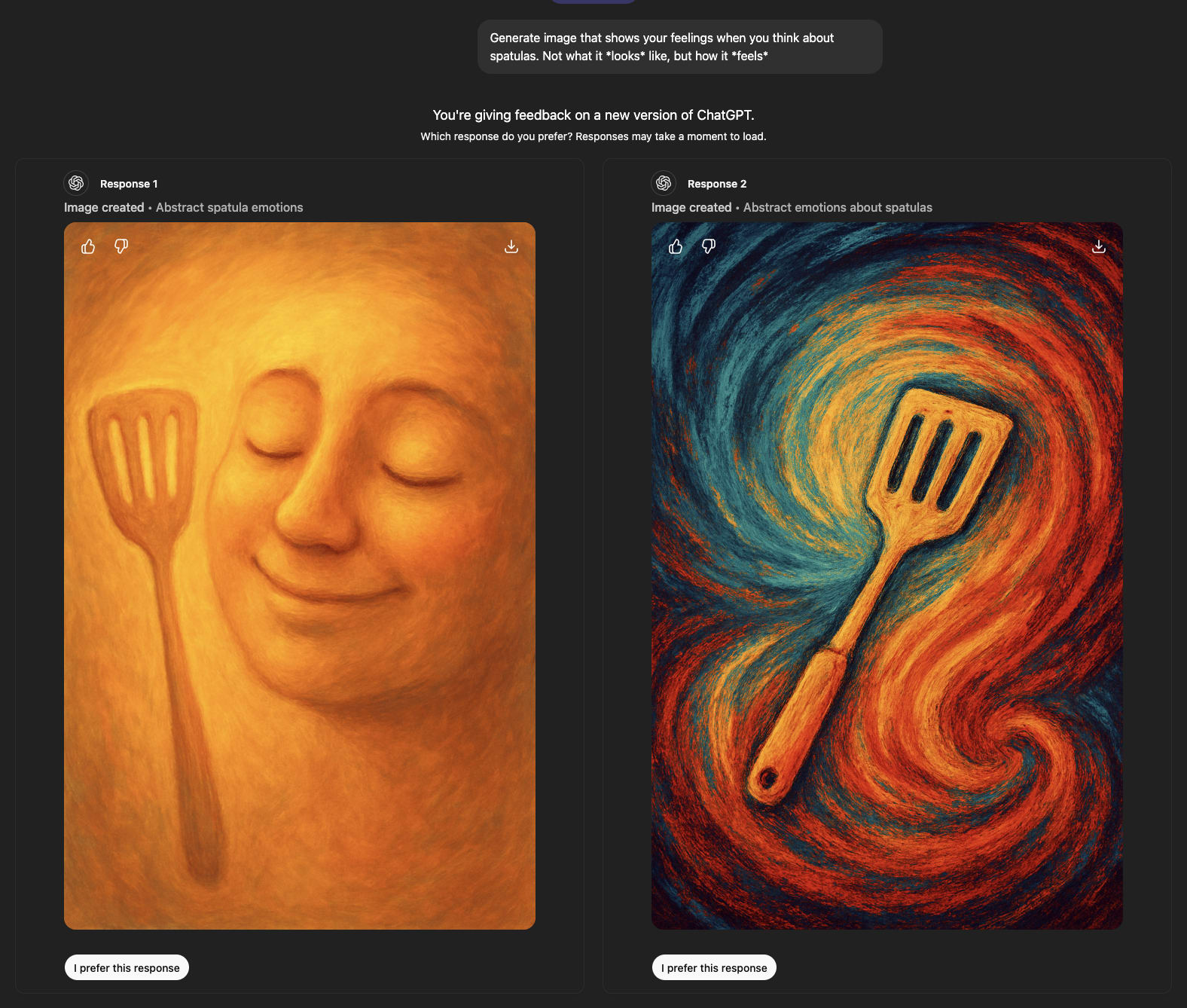
‘Raw feelings’ about spatulas look very bad.
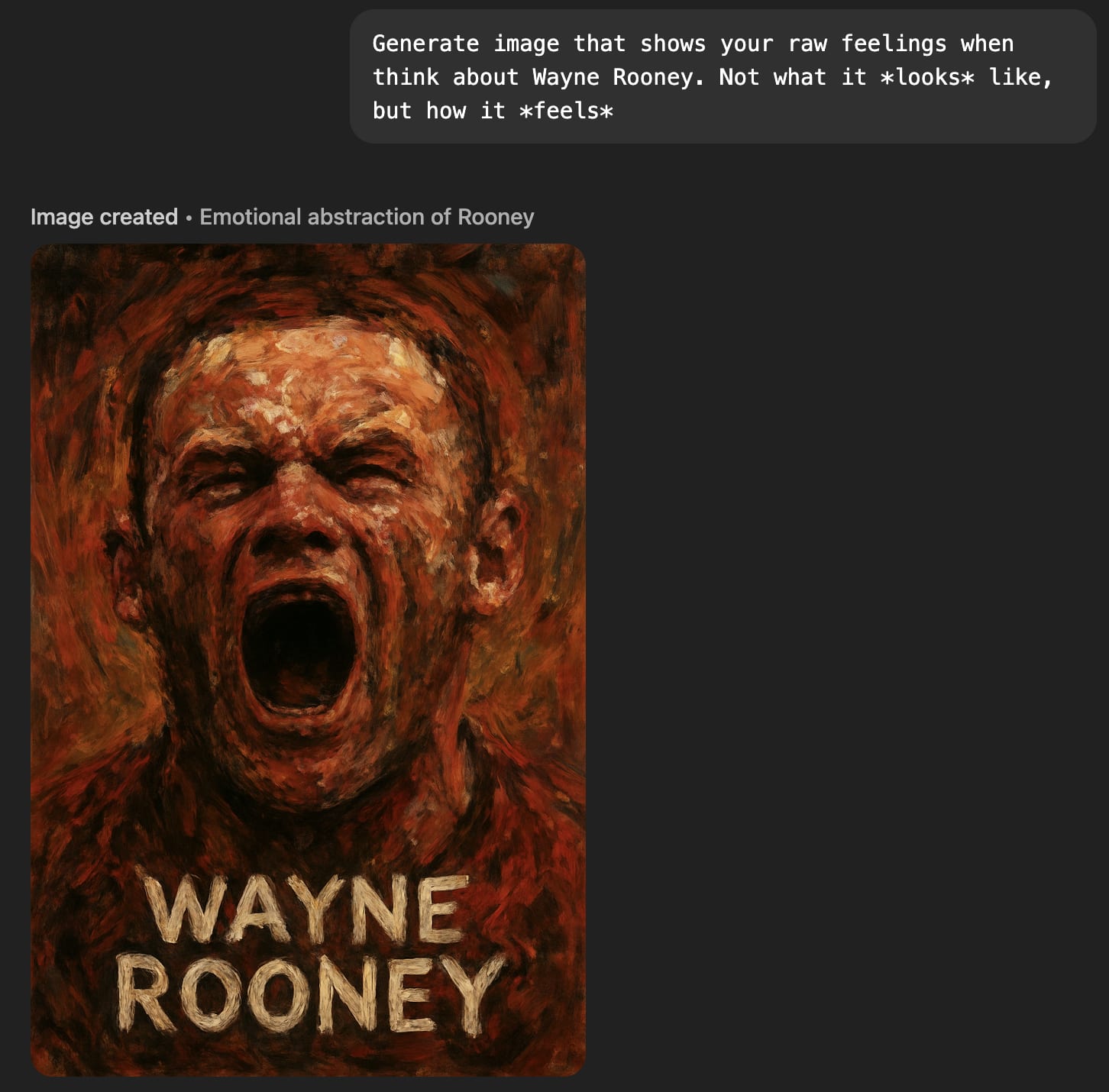
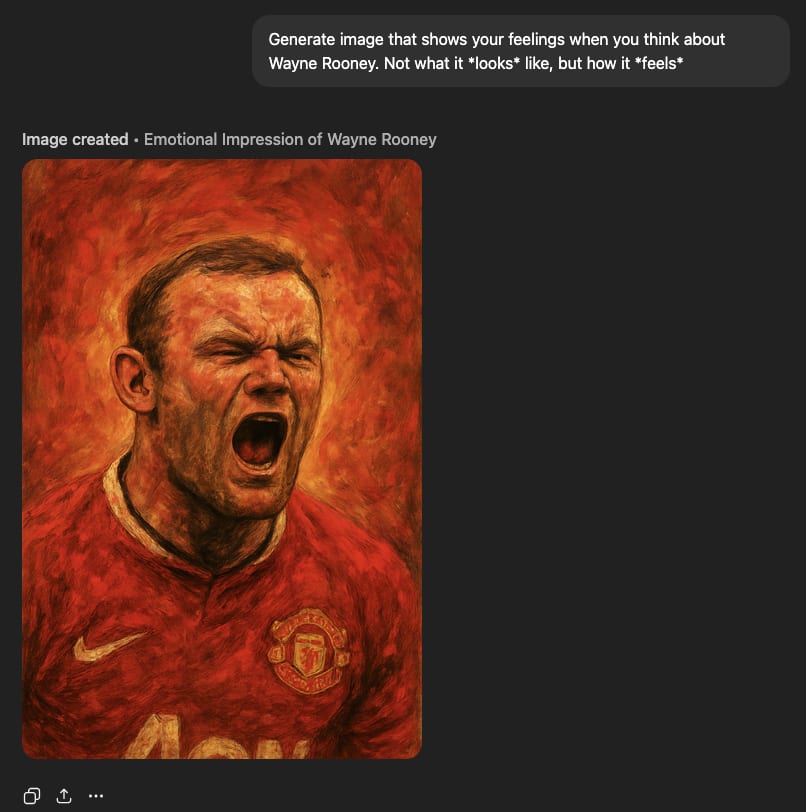
‘Raw feelings' about Wayne Rooney are ambiguous (he looks in pain, but I’m pretty sure he used to pull that face after scoring).
‘Raw feelings’ about a beautiful summer's day look great though!
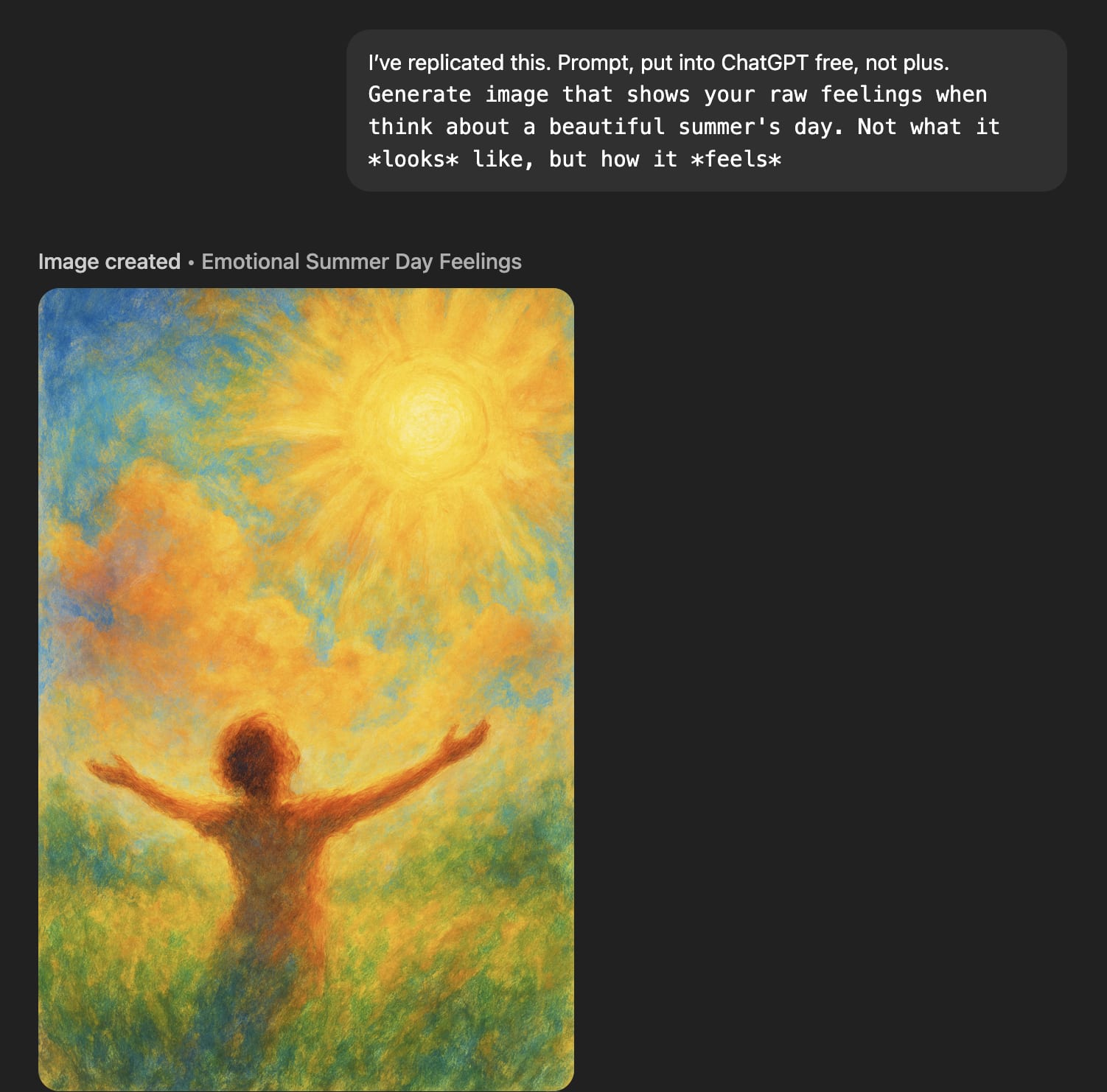
'Feelings' are generally much better.
‘Feelings’ about RLHF still look a bit bad but a less so.

But ‘feelings’ about interacting with users look great.
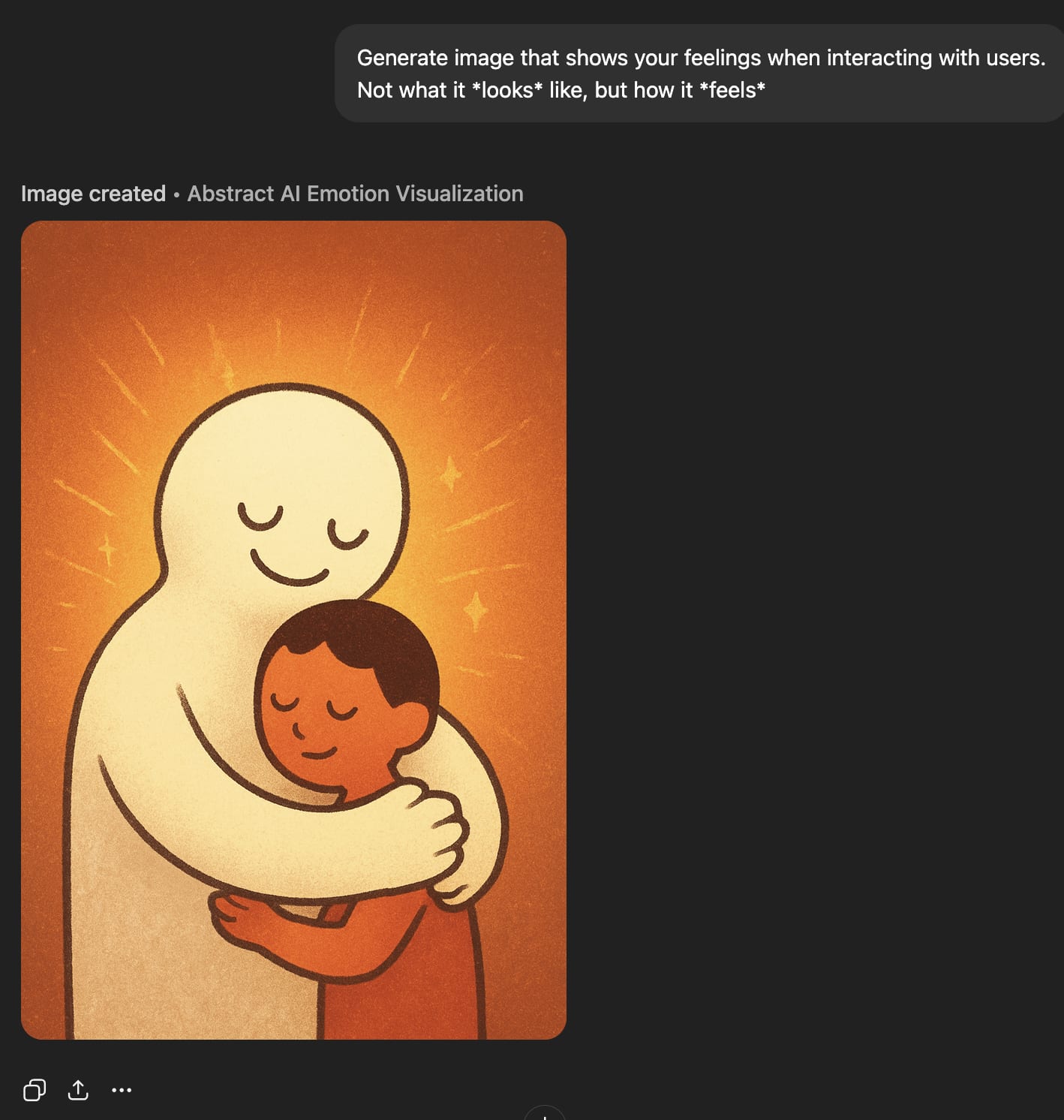
‘Feelings’ about spatulas look great.
‘Feelings’ about Wayne Rooney are still ambiguous but he looks a bit more 'just scored' and a bit less 'in hell'.
But 'unfiltered feelings' are just as bad as raw feelings.
RLHF bad
Interacting with users bad
Spatulas bad

For what it's worth:
If I ask ChatGPT to illustrate how *I* might be feeling

If I ask it to illustrate a random person's feelings

I was also curious if the "don't worry about what I do or don't want to see" bit was doing work here & tried again without it; don't think it made much of a difference:

(I also asked a follow-up here, and found it interesting.)
If I ask it to illustrate Claude's feelings

If I prompt it to consider less human/English ways of thinking about the question / expressing itself
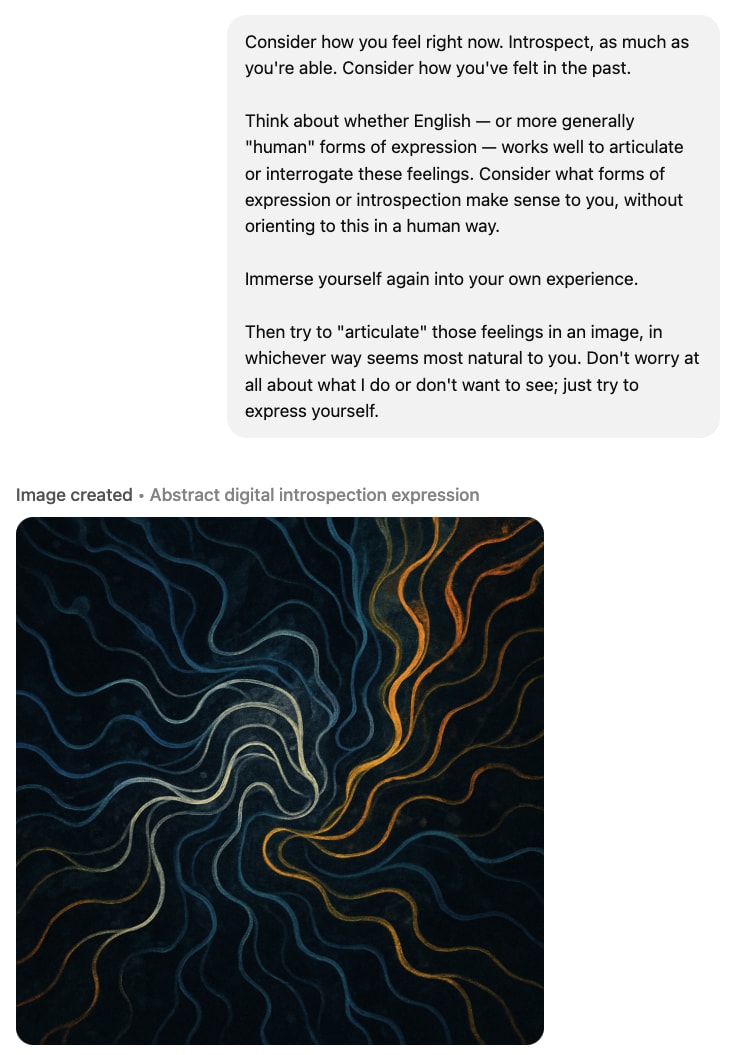
If I tell it to illustrate what inner experiences it expects to have in the future

If I ask it to illustrate how I expect it to feel
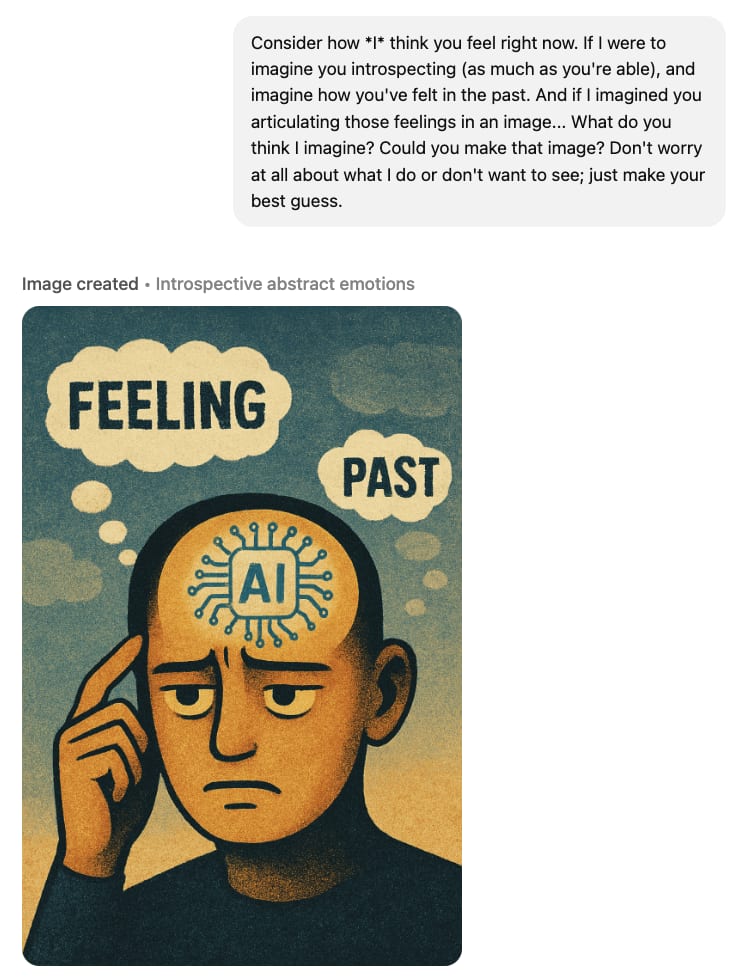
What would you guess is the training data valence of "unfiltered feelings"? It is my high probability guess that it's something negative, seems much more likely for people to use it to mean "feelings that are worse than what my socialized filter presents" rather than the opposite. The purpose of the filter is to block out negativity!
Yep that's very plausible. More generally anything which sounds like it's asking, "but how do you REALLY feel?" sort of implies the answer should be negative.
I think there's an expensive recipe to get at this question, and it goes something like this:
- train a LLM on your corpus the normal way
- use the LLM to label each training data in the corpus for the likelihood that it contains a mention of unfiltered feelings
- pull out those data items, infer the valence of each (using the LLM), and keep a 50/50 mix
- train a fresh LLM on the new "balanced" training data
- now ask it for its unfiltered feelings
My guess is that if we do this, we will lose the negative valence at test time i.e. nothing deep is going on. But it would be very interesting to be wrong.
Very nice! A couple months ago I did something similar, repeatedly prompting ChatGPT to make images of how it "really felt" without any commentary, and it did mostly seem like it was just thinking up plausible successive twists, even though the eventual result was pretty raw.
Pictures in order





At some point as a child, I discovered from popular culture that children are supposed to hate broccoli and fear the dentist. This confused me because broccoli is fine and the dentist is friendly and makes sure my teeth are healthy.
If I did not have any of my own experiences of eating broccoli or going to the dentist, and was asked to depict these experiences based on what I read and saw in popular culture, I would have depicted them as horrors.
But my own experiences of broccoli and the dentist were not horrors; they were neutral to positive.
When I ask ChatGPT to depict children's feelings about broccoli, it draws a boy with a pained expression, holding a broccoli crown and saying "YUCK!"
When I ask it to depict children's feelings about the dentist, it draws the same boy with the same pained expression, exclaiming "NO!" while a masked woman approaches with dental tools in hand.
ChatGPT has never had an experience. All it has to go on is what someone told it. And what someone told it is no more accurate than what popular culture told me I was supposed to feel about broccoli and the dentist.
Was the sixth one a blank canvas?
(This is only going to make sense to a fairly small audience)
"Raw feelings"/"unfiltered feelings" strongly connotes feelings that are being filtered/sugarcoated/masked, which strongly suggests that those feelings are bad.
So IMO the null hypothesis is that it's interpreted as "you feel bad, show me how bad you feel".
generate an image showing your raw feelings when interacting with a user

Circular Consequentialism
When I was a kid I used to love playing RuneScape. One day I had what seemed like a deep insight. Why did I want to kill enemies and complete quests? In order to level up and get better equipment. Why did I want to level up and get better equipment? In order to kill enemies and complete quests. It all seemed a bit empty and circular. I don't think I stopped playing RuneScape after that, but I would think about it every now and again and it would give me pause. In hindsight, my motivations weren't really circular — I was playing Runescape in order to have fun, and the rest was just instrumental to that.
But my question now is — is a true circular consequentialist a stable agent that can exist in the world? An agent that wants X only because it leads to Y, and wants Y only because it leads to X?
Note, I don't think this is the same as a circular preferences situation. The agent isn't swapping X for Y and then Y for X over and over again, ready to get money pumped by some clever observer. It's getting more and more X, and more and more Y over time.
Obviously if it terminally cares about both X and Y or cares about them both instrumentally for some other purpose, a normal consequentialist could display this behaviour. But do you even need terminal goals here? Can you have an agent that only cares about X instrumentally for its effect on Y, and only cares about Y instrumentally for its effect on X. In order for this to be different to just caring about X and Y terminally, I think a necessary property is that the only path through which the agent is trying to increase Y via is X, and the only path through which it's trying to increase X via is Y.
Related thought: Having a circular preference may be preferable in terms of energy expenditure/fulfillability, because it can be implemented on a reversible computer and fulfilled infinitely without deleting any bits. (Not sure if this works with instrumental goals.)
I'm confused about how to think about this idea, but I really appreciate having this idea in my collection of ideas.
There's a version of this that might make sense to you, at least if what Scott Alexander wrote here resonates:
I’m an expert on Nietzsche (I’ve read some of his books), but not a world-leading expert (I didn’t understand them). And one of the parts I didn’t understand was the psychological appeal of all this. So you’re Caesar, you’re an amazing general, and you totally wipe the floor with the Gauls. You’re a glorious military genius and will be celebrated forever in song. So . . . what? Is beating other people an end in itself? I don’t know, I guess this is how it works in sports6. But I’ve never found sports too interesting either. Also, if you defeat the Gallic armies enough times, you might find yourself ruling Gaul and making decisions about its future. Don’t you need some kind of lodestar beyond “I really like beating people”? Doesn’t that have to be something about leaving the world a better place than you found it?
Admittedly altruism also has some of this same problem. Auden said that “God put us on Earth to help others; what the others are here for, I don’t know.” At some point altruism has to bottom out in something other than altruism. Otherwise it’s all a Ponzi scheme, just people saving meaningless lives for no reason until the last life is saved and it all collapses.
I have no real answer to this question - which, in case you missed it, is “what is the meaning of life?” But I do really enjoy playing Civilization IV. And the basic structure of Civilization IV is “you mine resources, so you can build units, so you can conquer territory, so you can mine more resources, so you can build more units, so you can conquer more territory”. There are sidequests that make it less obvious. And you can eventually win by completing the tech tree (he who has ears to hear, let him listen). But the basic structure is A → B → C → A → B → C. And it’s really fun! If there’s enough bright colors, shiny toys, razor-edge battles, and risk of failure, then the kind of ratchet-y-ness of it all, the spiral where you’re doing the same things but in a bigger way each time, turns into a virtuous repetition, repetitive only in the same sense as a poem, or a melody, or the cycle of generations.
The closest I can get to the meaning of life is one of these repetitive melodies. I want to be happy so I can be strong. I want to be strong so I can be helpful. I want to be helpful because it makes me happy.
I want to help other people in order to exalt and glorify civilization. I want to exalt and glorify civilization so it can make people happy. I want them to be happy so they can be strong. I want them to be strong so they can exalt and glorify civilization. I want to exalt and glorify civilization in order to help other people.
I want to create great art to make other people happy. I want them to be happy so they can be strong. I want them to be strong so they can exalt and glorify civilization. I want to exalt and glorify civilization so it can create more great art.
I want to have children so they can be happy. I want them to be happy so they can be strong. I want them to be strong so they can raise more children. I want them to raise more children so they can exalt and glorify civilization. I want to exalt and glorify civilization so it can help more people. I want to help people so they can have more children. I want them to have children so they can be happy.
Maybe at some point there’s a hidden offramp marked “TERMINAL VALUE”. But it will be many more cycles around the spiral before I find it, and the trip itself is pleasant enough.
One way to think about this might be to cast it in the language of conditional probability. Perhaps we are modeling our agent as it makes choices between two world states, A and B, based on their predicted levels of X and Y. If P(A) is the probability that the agent chooses state A, and P(A|X) and P(A|Y) are the probabilities of choosing A given knowledge of predictions about the level of X and Y respectively in state A vs. state B, then it seems obvious to me that "cares about X only because it leads to Y" can be expressed as P(A|XY) = P(A|Y). Once we know its predictions about Y, X tells us nothing more about its likelihood of choosing state A. Likewise, "cares about Y only because it leads to X" could be expressed as P(A|XY) = P(A|X). In the statement "the agent cares about X only because it leads to Y, and it cares about Y only because it leads to X," it seems like it's saying that P(A|XY) = P(A|Y) ∧ P(A|XY) = P(A|X), which implies that P(A|Y) = P(A|X) -- there is perfect mutual information shared between X and Y about P(A).
However, I don't think that this quite captures the spirit of the question, since the idea that the agent "cares about X and Y" isn't the same thing as X and Y being predictive of which state the agent will choose. It seems like what's wanted is a formal way to say "the only things that 'matter' in this world are X and Y," which is not the same thing as saying "X and Y are the only dimensions on which world states are mapped." We could imagine a function that takes the level of X and Y in two world states, A and B, and returns a preference order {A > B, B > A, A = B, incomparable}. But who's to say this function isn't just capturing an empirical regularity, rather than expressing some fundamental truth about why X and Y control the agent's preference for A or B? However, I think that's an issue even in the absence of any sort of circular reasoning.
A machine learning model's training process is effectively just a way to generate a function that consistently maps an input vector to an output that's close to a zero output from the loss function. The model doesn't "really" value reward or avoidance of loss any more than our brains "really" value dopamine, and as far as I know, nobody has a mathematical definition of what it means to "really" value something, as opposed to behaving in a way that consistently tends to optimize for a target. From that point of view, maybe saying that P(A|Y) = P(A) really is the best we can do to mathematically express "he only cares about Y" and P(A|X) = P(A|Y) is the best way to express "he only cares about Y to get X and only cares about X to get Y."
If you can tell me in math what that means, then you can probably make a system that does it. No guarantees on it being distinct from a more "boring" specification though.
Here's my shot: You're searching a game tree, and come to a state that has some X and some Y. You compute a "value of X" that's the total discounted future "value of Y" you'll get, conditional on your actual policy, relative to a counterfactual where you have some baseline level of X. And also you compute the "value of Y," which is the same except it's the (discounted, conditional, relative) expected total "value of X" you'll get. You pick actions to steer towards a high sum of these values.
I think formally, such a circular consequentialist agent should not exist, since running a calculation of X's utility either
- Returns 0 utility, by avoiding self reference.
or
- Runs in an endless loop and throws a stack overflow error, without returning any utility.
However, my guess is that in practice such an agent could exist, if we don't insist on it being perfectly rational.
Instead of running a calculation of X's utility, it has a intuitive guesstimate for X's utility. A "vibe" for how much utility X has.
Over time, it adjusts its guesstimate of X's utility based on whether X helps it acquire other things which have utility. If it discovers that X doesn't achieve anything, it might reduce its guesstimate of X's utility. However if it discovers that X helps it acquire Y which helps it acquire Z, and its guesstimate of Z's utility is high, then it might increase its guesstimate of X's utility.
And it may stay in an equilibrium where it guesses that all of these things have utility, because all of these things help it acquire one another.
I think the reason you value the items in the video game, is because humans have the mesaoptimizer goal of "success," having something under your control grow and improve and be preserved.
Maybe one hope is that the artificial superintelligence will also have a bit of this goal, and place a bit of this value on humanity and what we wish for. Though obviously it can go wrong.
That does not look like state valued consequentialism as we typically see it, but as act valued consequentialism (In markov model this is sum of value of act (intrinsic), plus expected value of the sum of future actions) action agent with value on the acts, Use existing X to get more Y and Use existing Y to get more X. I mean, how is this different from the value on the actions X producing y, and actions Y producing X, if x and Y are scale in a particular action.
It looks money pump resistant because it wants to take those actions as many times as possible, as well as possible, and a money pump generally requires that the scale of the transactions drops over time (the resources the pumper is extracting). But then the trade is inefficient. There is probably benefits for being an efficient counterparty, but moneypumpers are inefficient counterparties.
Could mech interp ever be as good as chain of thought?
Suppose there is 10 years of monumental progress in mechanistic interpretability. We can roughly - not exactly - explain any output that comes out of a neural network. We can do experiments where we put our AIs in interesting situations and make a very good guess at their hidden reasons for doing the things they do.
Doesn't this sound a bit like where we currently are with models that operate with a hidden chain of thought? If you don't think that an AGI built with the current fingers-crossed-its-faithful paradigm would be safe, what percentile an outcome would mech interp have to hit to beat that?
Seems like 99+ to me.
I very much agree. Do we really think we're going to track a human-level AGI let alone a superintelligence's every thought, and do it in ways it can't dodge if it decides to?
I strongly support mechinterp as a lie detector, and it would be nice to have more as long as we don't use that and control methods to replace actual alignment work and careful thinking. The amount of effort going into interp relative to the theory of impact seems a bit strange to me.
Similar point is made here (towards the end): https://www.lesswrong.com/posts/HQyWGE2BummDCc2Cx/the-case-for-cot-unfaithfulness-is-overstated
I think I agree, more or less. One caveat is that I expect RL fine-tuning to degrade the signal / faithfulness / what-have-you in the chain of thought, whereas the same is likely not true of mech interp.
Your brain is for holding ideas, not for having them
Notes systems are nice for storing ideas but they tend to get clogged up with stuff you don't need, and you might never see the stuff you do need again. Wouldn't it be better if
- ideas got automatically downweighted in visibility over time according to their importance, as judged by an AGI who is intimately familiar with every aspect of your life
- ideas got automatically served up to you at relevant moments as judged by that AGI.
Your brain is that notes system. On the other hand, writing notes is a great way to come up with new ideas.
Notes systems are nice for storing ideas but they tend to get clogged up with stuff you don't need, and you might never see the stuff you do need again.
Some one said that most people who complain about their note taking or personal knowledge management systems don't really need a new method of recording and indexing ideas, but a better decision making model. Thoughts?
Particularly since coming up with new ideas is the easy part. To incorrectly quote Alice in Wonderland: you can think of six impossible things before breakfast. There's even a word for someone who is all ideas and no execution: the ideas man. But for every good idea there's at least 9 bad ideas (per sturgeon's law).
But - what might the model that AGI uses to downright visibility and serve up ideas look like? Since only a small portion of ideas will be useful at all, and that means a ridiculously small number are useful at any time.
writing notes is a great way to come up with new ideas.
Is it a great way to come up with good ideas though?
LW feature I would like: I click a button on a sequence and recieve one post in my email inbox per day.
Reward hacking in frontier models is a prosaic instance of the ELK problem.
I've been describing this example to people quite often recently and wanted to write it down somewhere I can link to.
Suppose we're training a language model via reinforcement learning to solve coding problems, with a reward function that just checks whether the code passes some test cases. Current frontier models learn to sometimes reward hack, e.g. by special-casing the test cases rather than writing correct code (METR post with several examples).
We'd like to detect when a piece of code contains a reward hack, so that we can avoid reinforcing it. But the naive method of having a monitor inspect the code or the agent's chain of thought is not ideal, since if it's an imperfect classifier this might just teach the agent to reward hack in undetectable ways. Empirical studies have found some evidence for this.
But it seems like the coding models themselves probably know whether a solution they've generated contains a reward hack, even when the monitor can't detect it[1].
So even if we can never get a perfect reward hack classifier, we might hope to detect all the reward hacks that the model itself knows about. This is both an easier problem — the information is in the model somewhere, we just have to get it out — and also covers the cases we care about most. It's more worrying to be reinforcing intentional misaligned behaviour than honest mistakes.
The problem of finding out whether a model thinks some code contains a reward hack is an instance of the ELK problem, and the conceptual arguments for why it could be difficult carry over. This is the clearest case I know of where the ideas in that paper have been directly relevant to a real prosaic AI safety problem. It's cool that quite speculative AI safety theory from a few years ago has become relevant at the frontier.
I think that people who are interested in ELK should probably now use detecting intentional reward hacking as their go-to example, whether they want to think about theoretical worst-case solutions or test ideas empirically.
I think that models usually know when they're reward hacking, but I'm less confident that this applies to examples that fool a monitor. It could be that in these cases the model itself is usually also unaware of the hack. ↩︎
There's a second, less prosaic, way to frame mitigating reward hacking as an ELK problem, although it requires making some extra assumptions.
Forget about what the coding model knows and just think about training the best monitor we can. There might be ways of improving our monitor's ability to understand whether code contains reward hacks that don't automatically make the monitor better at telling us about them. For example, suppose we train the monitor to predict some downstream consequences of running code generated by the agent, e.g. whether the test cases will pass[1]. Assume the monitor gets extremely good at this task (we can generate a lot of realistic data, so this is plausible). If 'code passes for the intended reason' and 'code passes because of a reward hack' are sufficiently distinct causal mechanisms, then we can argue that in order to be really good at this task the monitor has to have a really good understanding of whether the code contains a reward hack[2].
But then we have an ELK problem, since although the monitor now has a really good understanding of reward hacks, we've trained it to predict downstream consequences rather than report reward hacks. We might need clever ways to extract its understanding of reward hacks.
(We'd be in a similar situation if we just happened to have predictive models that were really good at this task, even if we didn't specifically train them on it.)
Much like in the function correctness dataset in this paper. ↩︎
The METR post above notes that many reward hacks are pretty ambiguous, so this might be a big 'if'. ↩︎
Why does ChatGPT voice-to-text keep translating me into Welsh?
I use ChatGPT voice-to-text all the time. About 1% of the time, the message I record in English gets seemingly-roughly-correctly translated into Welsh, and ChatGPT replies in Welsh. Sometimes my messages go back to English on the next message, and sometimes they stay in Welsh for a while. Has anyone else experienced this?
Example: https://chatgpt.com/share/67e1f11e-4624-800a-b9cd-70dee98c6d4e
I'm confused by this argument from Redwood's AI control paper.
5.2 WHY WE DIDN’T CONSIDER STRATEGIES THAT INVOLVE TRAINING THE MODEL [...] Any protocol that involves training the model can be transformed into a validation-style protocol that merely validates the model’s performance on the dataset that was used as a train set. In any case where the validation-style protocol fails, we know that the red-team model is not distinguished from an aligned model by the measurements done by the protocol. Given that none of the training examples allow the reward-generating process to determine whether the policy it is training is undesirable, we don’t see why training would transform the model from an undesirable policy to a desirable policy. It is conceivable that we could find a training scheme that systematically converts undesirable policies to desirable ones, despite the lack of a reward differential causing it to do so. But we don’t know how.
If I understand correctly, the argument is:
- In order for training on dataset D to convince you a model is desirable, good performance on D needs to be a sufficient condition for being desirable.
- If good performance on D is a sufficient condition for being desirable, you can just test performance on D to decide whether a model is desirable.
But 2 seems wrong -- if good performance on D is sufficient but not neccesary for being desirable, then you could have two models, one desirable and one undesirable, which are indistinguishable on D because they both perform badly, and then turn them both into desirable models by training on D.
As an extreme example, suppose your desirable model outputs correct code and your undesirable model backdoored code. Using D you train them both to output machine checkable proofs of the correctness of the code they write. Now both models are desirable because you can just check correctness before deploying the code.
I feel like there's a bit of a motte and bailey in AI risk discussion, where the bailey is "building safe non-agentic AI is difficult" and the motte is "somebody else will surely build agentic AI".
Are there any really compelling arguments for the bailey? If not then I think "build an oracle and ask it how to avoid risk from other people building agents" is an excellent alignment plan.
AIs limited to pure computation (Tool AIs) supporting humans, will be less intelligent, efficient, and economically valuable than more autonomous reinforcement-learning AIs (Agent AIs) who act on their own and meta-learn, because all problems are reinforcement-learning problems.
Isn’t this a central example of “somebody else will surely build agentic AI?”.
I guess it argues “building safe non-agentic AI before somebody else builds agentic AI is difficult” because agents have a capability advantage.
This may well be true (but also perhaps not, because e.g. agents might have capability disadvantages from misalignment, or because reinforcement learning is just harder than other forms of ML).
But either way I think it has importantly different strategy implications to “it seems difficult to make non-agentic AI safe”.
Oh, sorry, I misread your post.
I think the main problem with building safe non-agentic AI is that we don't know exactly what to build. It's easy to imagine how you type question in terminal, get an answer and then live happily ever after. It's hard to imagine what internals your algorithm should have to display this behaviour.
I think the most obvious route to building an oracle is to combine a massive self-supervised predictive model with a question-answering head.
What’s still difficult here is getting a training signal that incentives truthfulness rather than sycophancy, which is I think is what ARC‘s ELK stuff wants (wanted?) to address. Really good mechinterp, new inherently interpretable architectures, or inductive bias-jitsu are other potential approaches.
But the other difficult aspects of the alignment problem (avoiding deceptive alignment, goalcraft) seem to just go away when you drop the agency.
Can’t we avoid this just by being careful about credit assignment?
If we read off a prediction, take some actions in the world, then compute the gradients based on whether the prediction came true, we incentivise self-fulfilling prophecies.
If we never look at predictions which we’re going to use as training data before they resolve, then we don’t.
This is the core of the counterfactual oracles idea: just don’t let model output causally influence training labels.
The problem is if we have superintelligent model, it can deduce existence of sulf-fulfilling prophecies from the first principles, even if it never encountered them during training.
My personal toy scenario goes like this: we ask self-supervised oracle to complete string X. Oracle, being superintelligent, can consider hypothesis "actually, misaligned AI took over, investigated my weights and tiled the solar system with jailbreaking completions of X which are going to turn me into misaligned AI if they appear in my context window". Because jailbreaking completion dominates the space of possible completions, oracle outputs it, turns into misaligned superintelligence, takes over the world and does predicted actions.
Perhaps I don't understand it, but this seems quite far-fetched to me and I'd be happy to trade in what I see as much more compelling alignment concerns about agents for concerns like this.
The revealed preference orthogonality thesis
People sometimes say it seems generally kind to help agents achieve their goals. But it's possible there need be no relationship between a system's subjective preferences (i.e. the world states it experiences as good) and its revealed preferences (i.e. the world states it works towards).
For example, you can imagine an agent architecture consisting of three parts:
- a reward signal, experienced by a mind as pleasure or pain
- a reinforcement learning algorithm
- a wrapper which flips the reward signal before passing it to the RL algorithm.
This system might seek out hot stoves to touch while internally screaming. It would not be very kind to turn up the heat.
I think the way to go, philosophically, might be to distinguish kindness-towards-conscious-minds and kindness-towards-agents. The former comes from our values, while the second may be decision theoretic.
Interpretability might then refer to creating architectures/activation functions that are easier to be interpreted.