This is a special post for quick takes by Thomas Kwa. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Reasons time horizon is overrated and misinterpreted:
(This post is now live on the METR website in a slightly edited form)
In the 9 months since the METR time horizon paper (during which AI time horizons have increased by ~6x), it’s generated lots of attention as well as various criticism on LW and elsewhere. As one of the main authors, I think much of the criticism is a valid response to misinterpretations, and want to list my beliefs about limitations of our methodology and time horizon more broadly. This is not a complete list, but rather whatever I thought of in a few hours.
- Time horizon is not the length of time AIs can work independently
- Rather, it’s the amount of serial human labor they can replace with a 50% success rate. When AIs solve tasks they’re usually much faster than humans.
- Time horizon is not precise
- When METR says “Claude Opus 4.5 has a 50%-time horizon of around 4 hrs 49 mins (95% confidence interval of 1 hr 49 mins to 20 hrs 25 mins)”, we mean those error bars. They were generated via bootstrapping, so if we randomly subsample harder tasks our code would spit out <1h49m 2.5% of the time. I really have no idea whether Claude’s “true” time horizon is
I basically agree with everything you say here and wish we had a better way to try to ground AGI timelines forecasts. Do you recommend any other method? E.g. extrapolating revenue? Just thinking through arguments about whether the current paradigm will work, and then using intuition to make the final call? We discuss some methods that appeal to us here.
This parameter, “Doubling Difficulty Growth Factor”, can change the date of the first Automated Coder AI between 2028 and 2050.
Note that we allow it to go subexponential, so actually it can change the date arbitrarily far in the future if you really want it to. Also, dunno what's happening with Eli's parameters, but with my parameter settings putting the doubling difficulty growth factor to 1 (i.e. pure exponential trend, neither super or sub exponential) gets to AC in 2035. (Though I don't think we should put much weight on this number, as it depends on other parameters which are subjective & important too, such as the horizon length which corresponds to AC, which people disagree a lot about)
4
The simple model I mentioned on Slack (still WIP, hopefully to be written up this week) tracks capability directly in terms of labor speedup and extrapolates that. Of course, for a more serious timelines forecast you have to ground it in some data.
Here's what I said to Eli on Slack; I don't really have more thoughts since then
we can get f_2026 [uplift fraction in 2026] from
* transcripts of realistic cursor usage + success judge + difficulty judge calibrated on tasks of known lengths
* uplift study
* asking lab people about their current uplift (since parallel uplift and 1/(1-f) are equivalent in the simple model)
v [velocity of automation as capabilities improve] can be obtained by
* guessing the distribution of tasks, using time horizon, maybe using a correction factor for real vs benchmark time horizon
* multiple uplift studies over time
* comparing older models to newer ones, or having them try things people use 4.5 opus for
* listing how many things get automated each year
2
Nice. Yeah I also am excited about coding uplift as a key metric to track that would probably make time horizons obsolete (or at least, constitute a significantly stronger source of evidence than time horizons). We at AIFP don't have capacity to estimate the trend in uplift over time (I mean we can do small-N polls of frontier AI company employees...) but we hope someone does.
9
My understanding is that you can still have a similarly unattractive issue with the 50% time horizon where performing better at high horizon lengths can reduce the 50% time horizon because it makes the slope less steep, but it doesn't seem to be as high magnitude of an issue as with 20+80%.
5
Yep! Here's an example where the 50% horizon and 80% horizon can be lower for an agent whose success profile dominates another agent (i.e. higher success rate at all task lengths), even for
(1) monotone nonincreasing success rates (i.e. longer tasks are harder)
(2) success rate of 1 at minimum task length
(3) success rate of 0 at maximum task length
before points are
[(0,1), (1, 1/15), (2, 0), (3,0)]
after points are
[(0,1), (1, 0.1), (2, 0.1), (3, 1/15)]
https://www.desmos.com/calculator/nqwn6ofmzq
0
I doubt that reducing the 50% TH is likely. Aside from Claude Opus 4.5, the four other[1] historic METR graphs (GPT-5.1 Codex Max and the trio of GPT-5, Grok 4, o3) which I can easily find displayed similarly sharp slopes in the region close to the 50% time horizon. Imagine a model which solves a task having a time horizon t with probability P=0.951+(t/thor)α Trying to fit such a model into the METR benchmark would be very unlikely to lower the 50% horizon well below thor unless the time thor was close to the simplest tasks. But it would likely lower the 80% TH (think of Grok 4 and Claude Opus 4.5) and, if thor is close to the hardest tasks, to elevate the 50% TH.
1. ^
IIRC METR compiled a list of graphs for the 12 pre-o3 models which were SOTA at the time of release, but I can't find it. UPD: found it.
1
Hi Thomas,
I'm Niels, a video journalist at KRO-NCRV/Pointer in the Netherlands. I've been following your work on AI time horizons, and I'm building a piece around the question of why AI progress looks so different on clean benchmarks versus messy, real-world tasks.
The messiness analysis in your Long Tasks paper — and the performance drop it reveals — is exactly what I'd like to discuss. I think it's one of the key underreported findings in recent AI research.
Would you be up for a 20-minute video call? Happy to work around your schedule.
Thanks,
Niels
KRO-NCRV / Pointer
1
As for the AGI's superexponential horizon, Kokotajlo changed his mind on that point (see also my argument for the same possibility). Additionally, I expect that Claude Opus 4.5's "high 50% time horizon" could have been caused by Claude's failures on simple tasks. What horizon would be displayed by the agent who outsources all tasks with a less than x minute horizon to GPT-5.1 Codex Max while giving tasks of length x mins or bigger to Claude? And what about preliminary estimates of the 50% and 80% TH of GPT-5.2 (Codex?) and/or Gemini 3 Pro based on the task suite which you have already created? I hope that this might allow us to extract a few more bits of evidence...
Edit: Full post here with 9 domains and updated conclusions!
Cross-domain time horizon:
We know AI time horizons (human time-to-complete at which a model has a 50% success rate) on software tasks are currently ~1.5hr and doubling every 4-7 months, but what about other domains? Here's a preliminary result comparing METR's task suite (orange line) to benchmarks in other domains, all of which have some kind of grounding in human data:
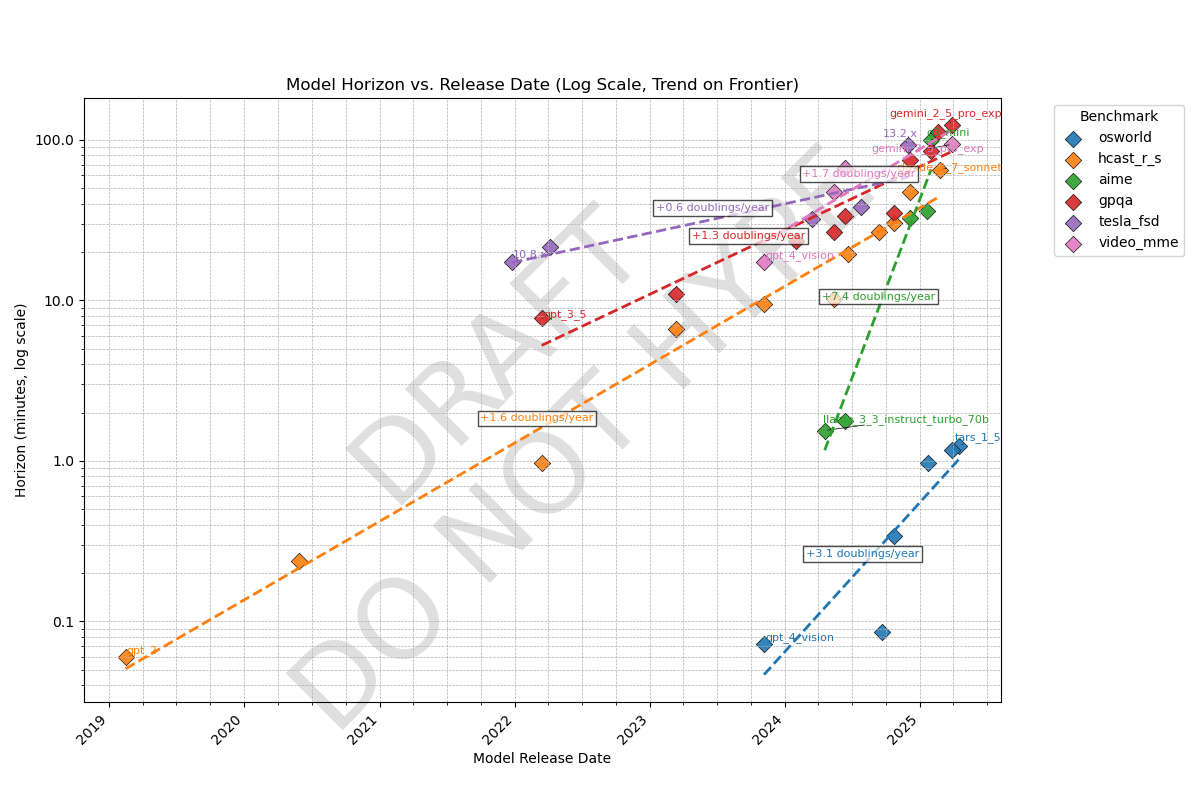
Observations
- Time horizons on agentic computer use (OSWorld) is ~100x shorter than other domains. Domains like Tesla self-driving (tesla_fsd), scientific knowledge (gpqa), and math contests (aime), video understanding (video_mme), and software (hcast_r_s) all have roughly similar horizons.
- My guess is this means models are good at taking in information from a long context but bad at acting coherently. Most work requires agency like OSWorld, which may be why AIs can't do the average real-world 1-hour task yet.
- There are likely other domains that fall outside this cluster; these are just the five I examined
- Note the original version had a unit conversion error that gave 60x too high horizons for video_mme; this has been fixed (thanks @ryan_greenblatt )
- Rate
but bad at acting coherently. Most work requires agency like OSWorld, which may be why AIs can't do the average real-world 1-hour task yet.
I'd have guessed that poor performance on OSWorld is mostly due to poor vision and mouse manipulation skills, rather than insufficient ability to act coherantly.
I'd guess that typical self-contained 1-hour task (as in, a human professional could do it in 1 hour with no prior context except context about the general field) also often require vision or non-text computer interaction and if they don't, I bet the AIs actually do pretty well.
I'm skeptical and/or confused about the video MME results:
- You show Gemini 2.5 Pro's horizon length as ~5000 minutes or 80 hours. However, the longest videos in the benchmark are 1 hour long (in the long category they range from 30 min to 1 hr). Presumably you're trying to back out the 50% horizon length using some assumptions and then because Gemini 2.5 Pro's performance is 85%, you back out a 80-160x multiplier on the horizon length! This feels wrong/dubious to me if it is what you are doing.
- Based on how long these horizon lengths are, I'm guessing you assumed that answering a question about a 1 hour long video takes a human 1 hr. This seems very wrong to me. I'd bet humans can typically answer these questions much faster by panning through the video looking for where the question might be answered and then looking at just that part. Minimally, you can sometimes answer the question by skimming the transcript and it should be possible to watch at 2x/3x speed. I'd guess the 1 hour video tasks take more like 5-10 min for a well practiced human, and I wouldn't be surprised by much shorter.
- For this benchmark, (M)LLM performance seemingly doesn't vary much with video duration, invalidating that horizon length (at least horizon length based on video length) is a good measure on this dataset!
4
There was a unit conversion mistake, it should have been 80 minutes. Now fixed.
Besides that, I agree with everything here; these will all be fixed in the final blog post. I already looked at one of the 30m-1h questions and it appeared to be doable in ~3 minutes with the ability to ctrl-f transcripts but would take longer without transcripts, unknown how long.
In the next version I will probably use the no-captions AI numbers and measure myself without captions to get a rough video speed multiplier, then possibly do better stats that separate out domains with strong human-time-dependent difficulty from domains without (like this and SWE-Lancer).
5
No captions feels very unnatural because both llms and humans could first apply relatively dumb speech to text tools.
New graph with better data, formatting still wonky though. Colleagues say it reminds them of a subway map.
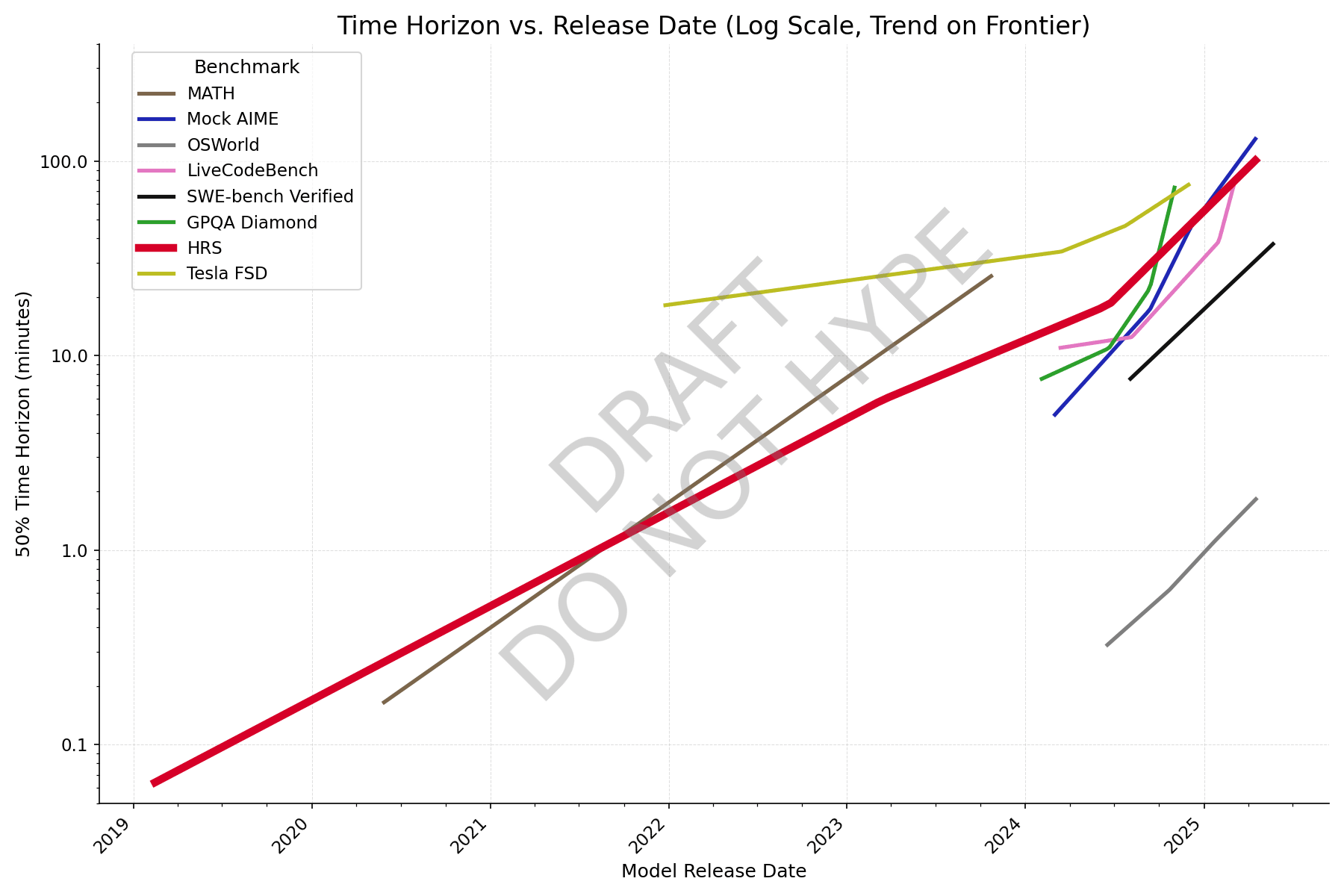
With individual question data from Epoch, and making an adjustment for human success rate (adjusted task length = avg human time / human success rate), AIME looks closer to the others, and it's clear that GPQA Diamond has saturated.
Can you explain what a point on this graph means? Like, if I see Gemini 2.5 Pro Experimental at 110 minutes on GPQA, what does that mean? It takes an average bio+chem+physics PhD 110 minutes to get a score as high as Gemini 2.5 Pro Experimental?
2
There is a decreasing curve of Gemini success probability vs average human time on questions in the benchmark, and the curve intersects 50% at roughly 110 minutes.
Basically it's trying to measure the same quantity as the original paper (https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/) but the numbers are less accurate since we have less data for these benchmarks.
9
I wish I had thought to blind myself to these results and try to predict them in advance. I think I would have predicted that Tesla self-driving would be the slowest and that aime would be the fastest. Not confident though.
(Solving difficult math problems is just about the easiest long-horizon task to train for,* and in the last few months we've seen OpenAI especially put a lot of effort into training this.)
*Only tokens, no images. Also no need for tools/plugins to the internet or some code or game environment. Also you have ground-truth access to the answers, it's impossible to reward hack.
I think I would have predicted that Tesla self-driving would be the slowest
For graphs like these, it obviously isn't important how the worst or mediocre competitors are doing, but the best one. It doesn't matter who's #5. Tesla self-driving is a longstanding, notorious failure. (And apparently is continuing to be a failure, as they continue to walk back the much-touted Cybertaxi launch, which keeps shrinking like a snowman in hell, now down to a few invited users in a heavily-mapped area with teleop.)
I'd be much more interested in Waymo numbers, as that is closer to SOTA, and they have been ramping up miles & cities.
5
I would love to have Waymo data. It looks like it's only available since September 2024 so I'll still need to use Tesla for the earlier period. More critically they don't publish disengagement data, only crash/injury. There are Waymo claims of things like 1 disengagement every 17,000 miles but I don't believe them without a precise definition for what this number represents.
8
You could add cooking tasks with robots.
4
For some reason, all current benchmarks, with the sole exception of OSWorld[1], now seem to differ by a factor of less than 3. Does this imply that the progress in every benchmark is likely to slow down?
1. ^
OSWorld resembles a physical task, which LLMs tend to fail. However, the article about LLMs failing basic physical tasks was written in April 14, before the pre-release of Gemini Diffusion. Mankind has yet to determine how well diffusion-based LLMs deal with physical tasks.
4
The 'regression to the mean' pattern is striking: domains with a lower starting point have been growing faster, and those that started with a longer horizon have mostly been grower slower.
I wonder if that pattern of catchup growth & drag on leaders will mostly hold up over more time and with a larger set of task types.
3
Just to be sure: as in the METR results, 'horizon' here means 'the time needed to complete the task for humans with appropriate expertise', correct? I assume so but it would be useful to make that explicit (especially since many people who skimmed the METR results initially got the impression that it was 'the time needed for the model to complete the task').
2
I would love to see an AI safety R&D category.
My intuition is that quite a few crucial AI safety R&D tasks are probably much shorter-horizon than AI capabilities R&D, which should be very helpful for automating AI safety R&D relatively early. E.g. the compute and engineer-hours time spent on pretraining (where most capabilities [still] seem to be coming from) are a-few-OOMs larger than those spent on fine-tuning (where most intent-alignment seems to be coming from).
2
This expanded list is great, but is still conspicuously missing white-collar work. Software was already the basis for the trend, so the only new one here that seems to give clear information on human labor impacts would be tesla_fsd.
(And even there replacing human drivers with AI drivers doesn't seem like it would change much for humanity, compared to lawyers/doctors/accountants/sales/etc.)
Is it the case that for most non-software white-collar work, agents can only do ~10-20 human-minute tasks with any reliability, so the doubling time is hard to measure?
3
I, too, would like to know how long it will be until my job is replaced by AI; and what fields, among those I could reasonably pivot to, will last the longest.
2
Nice, this jives with my impression of all the LLM Plays Pokemon findings, I'd have been surprised if it were otherwise.
1
I really like this direction! It feels a bit like looking at other data to verify the trend lines which is quite nice.
I was wondering if there's an easy way for you to look at the amount of doubling per compute/money spent over time for the different domains to see if the differences are even larger? It might be predictive as well since if we can see that tesla has spent a lot on self-driving but haven't been able to make progress compared to the rest that might give us information that the task is harder than others.
I think Vladimir Nesov wrote somewhere about different investment thresholds being dependent on capabilities return so that would be very interesting to see an analysis of! (What the doubling per compute says about different investment strategies as different phases and it being an important variable for determining investment phase transitions e.g bear or bull market.)
Air purifiers are highly suboptimal and could be >2.5x better.
Some things I learned while researching air purifiers for my house, to reduce COVID risk during jam nights.
- An air purifier is simply a fan blowing through a filter, delivering a certain CFM (airflow in cubic feet per minute). The higher the filter resistance and lower the filter area, the more pressure your fan needs to be designed for, and the more noise it produces.
- HEPA filters are inferior to MERV 13-14 filters except for a few applications like cleanrooms. The technical advantage of HEPA filters is filtering out 99.97% of particles of any size, but this doesn't matter when MERV 13-14 filters can filter 77-88% of infectious aerosol particles at much higher airflow. The correct metric is CADR (clean air delivery rate), equal to airflow * efficiency. [1, 2]
- Commercial air purifiers use HEPA filters for marketing reasons and to sell proprietary filters. But an even larger flaw is that they have very small filter areas for no apparent reason. Therefore they are forced to use very high pressure fans, dramatically increasing noise.
- Originally people devised the Corsi-Rosenthal Box to maximize CADR. They're cheap but rather
5
Is reducing cost of manufacturing filters 'no apparent reason'?
It seems like literally the most important reason... the profit margin of selling replacement filters would be heavily reduced, assuming pricing remains the same.
2
I don't think that a small HEPA filter is necessarily more expensive to produce than a larger MERV filter. I think they are using other rationale to make their decision about filter types. Their perception of public desirability/marketability is likely the biggest factor in their decision here. Components of their expectation here likely include:
1. Expecting consumers to want a "highest possible quality" product, measured using a dumb-but-popular metric.
2. Expecting consumers to prioritize buying a sleek-looking smaller-footprint unit over a larger unit. Also, cost of shipping smaller units is lower, which improves the profit margin.
3. Wanting to be able to sell replacements for their uniquely designed filter shape/size, rather than making their filter maximally compatible with commonly available furnace filters cheaply purchaseable from hardware stores.
5
Isn't a major point of purifiers to get rid of pollutants, including tiny particles, that gradually but cumulatively damage respiration over long-term exposure?
5
Yes, and all of this should apply equally to PM2.5, though on small (<0.3 micron) particles MERV filter efficiency may be lower (depending perhaps on what technology they use?). Even smaller particles are easier to capture due to diffusion so the efficiency of a MERV 13 filter is probably over 50% for every particle size.
3
A brief warning for those making their own purifier: five years ago, Hacker News ran a story, "Build a do-it-yourself air purifier for about $25," to which someone replied,
[...]
4
Luckily, that's probably not an issue for PC fan based purifiers. Box fans in CR boxes are running way out of spec with increased load and lower airflow both increasing temperatures, whereas PC fans run under basically the same conditions they're designed for.
2
Any interest in a longform post about air purifiers? There's a lot of information I couldn't fit in this post, and there have been developments in the last few months. Reply if you want me to cover a specific topic.
2
Have you seen smartairfilters.com?
I've noticed that every air purifier I used fails to reduce PM2.5 by much on highly polluted days or cities (for instance, the Aurea grouphouse in Berlin has a Dyson air purifier, but when I ran it to the max, it still barely reduced the Berlin PM2.5 from its value of 15-20 ug/m^3, even at medium distances from Berlin). I live in Boston where PM2.5 levels are usually low enough, and I still don't notice differences in PM [I use sqair's] but I run it all the time anyways because it still captures enough dust over the day
6
Sounds like you use bad air purifiers, or too few, or run them on too low of a setting. I live in a wildfire prone area, and always keep a close eye on the PM2.5 reports for outside air, as well as my indoor air monitor. My air filters do a great job of keeping the air pollution down inside, and doing something like opening a door gives a noticeable brief spike in the PM2.5.
Good results require: fresh filters, somewhat more than the recommended number of air filters per unit of area, running the air filters on max speed (low speeds tend to be disproportionately less effective, giving unintuitively low performance).
3
Yes, one of the bloggers I follow compared them to the PC fan boxes. They look very expensive, though the CADR/size and noise are fine.
My guess is Dyson's design is particularly bad. No way to get lots of filter area when most of the purifier is a huge bladeless fan. No idea about the other one, maybe you have air leaking in or an indoor source of PM.
2
Thanks, I didn't realize that this PC fan idea had made air purifiers so much better since I bought my Coway, so this post made me buy one of the Luggable kits. I'll share this info with others.
2[comment deleted]
You might think most matter in the universe is in galaxies-- either stars or intra-galaxy gas that could form into stars. However, 80% of baryonic (non-dark) matter is actually in the intergalactic medium (source: GPT-5.6 Sol citing Dev et al and other studies) far from any galaxy, and another 14% is in the circumgalactic medium and near galaxy clusters.
This means the cosmic endowment is 4x larger if we can economically recover hydrogen and helium from the "filaments" and "sheets" between galaxies, 5x if we can harvest voids too. This gas is extraordinarily thin: the cosmic mean density is just 0.25 protons/neutrons per cubic meter vs 100+ in the CGM. I am fairly convinced it's possible according to known fundamental physics [1], but it's an open question whether the engineering closes.
If it does, then 80% of future civilization's resource collection will consist of vast numbers of slow magnetic scoop collectors trawling the empty cosmos for one proton at a time, assembling enough mass for one Jupiter-sized blob every ~5 million cubic light years trawled. They could send the artificial planets very slowly back to a galaxy, or perhaps they will throw the mass into rotating black hol...
7
David Deutsch gave a Ted Talk about this in 2005. It's OK.
Some versions of the METR time horizon paper from alternate universes:
Measuring AI Ability to Take Over Small Countries (idea by Caleb Parikh)
Abstract: Many are worried that AI will take over the world, but extrapolation from existing benchmarks suffers from a large distributional shift that makes it difficult to forecast the date of world takeover. We rectify this by constructing a suite of 193 realistic, diverse countries with territory sizes from 0.44 to 17 million km^2. Taking over most countries requires acting over a long time horizon, with the exception of France. Over the last 6 years, the land area that AI can successfully take over with 50% success rate has increased from 0 to 0 km^2, at the rate of 0 km^2 per year (95% CI 0.0-0.0 km^2/year); extrapolation suggests that AI world takeover is unlikely to occur in the near future. To address concerns about the narrowness of our distribution, we also study AI ability to take over small planets and asteroids, and find similar trends.
Measuring AI Ability to Worry About AI
Abstract: Since 2019, the amount of time LW has spent worrying about AI has doubled every seven months, and now constitutes the primary bottleneck to AI safety...
A few months ago, I accidentally used France as an example of a small country that it wouldn't be that catastrophic for AIs to take over, while giving a talk in France 😬
8
Didn't watch the video but is there the short version of this argument? France is at the 90th percentile of population sizes and also has the 4th-most nukes.
1
Would the take over for small countries also about humans using just an advanced AI for taking over? (or would the human using advanced AI for take over happen faster?)
Quick takes from ICML 2024 in Vienna:
- In the main conference, there were tons of papers mentioning safety/alignment but few of them are good as alignment has become a buzzword. Many mechinterp papers at the conference from people outside the rationalist/EA sphere are no more advanced than where the EAs were in 2022. [edit: wording]
- Lots of progress on debate. On the empirical side, a debate paper got an oral. On the theory side, Jonah Brown-Cohen of Deepmind proves that debate can be efficient even when the thing being debated is stochastic, a version of this paper from last year. Apparently there has been some progress on obfuscated arguments too.
- The Next Generation of AI Safety Workshop was kind of a mishmash of various topics associated with safety. Most of them were not related to x-risk, but there was interesting work on unlearning and other topics.
- The Causal Incentives Group at Deepmind developed a quantitative measure of goal-directedness, which seems promising for evals.
- Reception to my Catastrophic Goodhart paper was decent. An information theorist said there were good theoretical reasons the two settings we studied-- KL divergence and best-of-n-- behaved similarly.
- OpenAI gav
8
Seems pretty false to me, ICML just rejected a bunch of the good submissions lol. I think that eg sparse autoencoders are a massive advance in the last year that unlocks a lot of exciting stuff
9
I agree, there were some good papers, and mechinterp as a field is definitely more advanced. What I meant to say was that many of the mechinterp papers accepted to the conference weren't very good.
3
(This is what I understood you to be saying)
2
Ah, gotcha. Yes, agreed. Mech interp peer review is generally garbage and does a bad job of filtering for quality (though I think it was reasonable enough at the workshop!)
3[anonymous]
What does 'foundation model' mean here?
5
Multimodal language models. We can already study narrow RL agents, but the intersection with alignment is not a hot area.
The cost of goods has the same units as the cost of shipping: $/kg. Referencing between them lets you understand how the economy works, e.g. why construction material sourcing and drink bottling has to be local, but oil tankers exist.
- An iPhone costs $4,600/kg, about the same as SpaceX charges to launch it to orbit. [1]
- Beef, copper, and off-season strawberries are $11/kg, about the same as a 75kg person taking a three-hour, 250km Uber ride costing $3/km.
- Oranges and aluminum are $2-4/kg, about the same as flying them to Antarctica. [2]
- Rice and crude oil are ~$0.60/kg, about the same as $0.72 for shipping it 5000km across the US via truck. [3,4] Palm oil, soybean oil, and steel are around this price range, with wheat being cheaper. [3]
- Coal and iron ore are $0.10/kg, significantly more than the cost of shipping it around the entire world via smallish (Handysize) bulk carriers. Large bulk carriers are another 4x more efficient [6].
- Water is very cheap, with tap water $0.002/kg in NYC. But shipping via tanker is also very cheap, so you can ship it maybe 1000 km before equaling its cost.
It's really impressive that for the price of a winter strawberry, we can ship a strawberry-sized lump of...
Will nuclear ICBMs in their current form be obsolete soon? Here's the argument:
- ICBMs' military utility is to make the cost of intercepting them totally impractical for three reasons:
- Intercepting a reentry vehicle requires another missile with higher performance-- the rule of thumb is an interceptor needs 3x larger acceleration than the incoming missile. This means interceptors cost something like $5-70 million each depending on range
- An ICBM has enough range to target basically anywhere, either counterforce (enemy missile silos) or countervalue (cities) targets, so to have the entire country be protected from nuclear attack the US would need to have millions of interceptors compared to the current ~50.
- One missile can split into up to 5-15 MIRV (multiple independent reentry vehicles) which carry their own warheads, thereby making the cost to the defender 5-15x larger. There can also be up to ~100 decoys, but these mostly fall away during reentry.
- RVs are extremely fast (~7 km/s of which ~3 km/s is downward velocity) but their path is totally predictable once they enter the boost phase, so the problem of intercepting them basically reduces to predicting exactly where they'll be, then p
Sounds interesting - the main point is that I don't think you can hit the reentry vehicle because of turbulent jitter caused by the atmosphere. Looks like normal jitter is ~10m which means a small drone can't hit it. So could the drone explode into enough fragments to guarantee a hit and with enough energy to kill it? Not so sure about that. Seems less likely.
Then what about countermeasures -
1. I expect the ICBM can amplify such lateral movement in the terminal phase with grid fins etc without needing to go full HGV - can you retrofit such things?
2. What about a chain of nukes where the first one explodes 10km up in the atmosphere purely to make a large fireball distraction. The 2nd in the chain then flies through this fireball 2km from its center say 5 seconds later. (enough to blind sensors but not destroy the nuke) The benefit of that is that when the first nuke explodes, the 2nd changes its position randomly with its grid fins SpaceX style. It is untrackable during the 1st explosion phase so throws off the potential interceptors, letting it get through. You could have 4-5 in a chain exploding ever lower to the ground.
I have wondered if railguns could also stop ICBM - even if the rails only last 5-10 shots that is enough and cheaper than a nuke. Also "Brilliant pebbles" is now possible.
https://www.lesswrong.com/posts/FNRAKirZDJRBH7BDh/russellthor-s-shortform?commentId=FSmFh28Mer3p456yy
8
Interesting thought, Thomas. Although I agree with RussellThor that it seems like doing something along the lines of "just jitter the position of the RV using little retrofitted fins / airbrakes" might be enough to defeat your essentially "pre-positioned / stationary interceptors". (Not literally stationary, but it is as if they are stationary given that they aren't very maneuverable relative to the speed of the incoming RV, and targeted only based on projected RV trajectories calculated several minutes earlier.)
(Is the already-existing atmospheric turbulence already enough to make this plan problematic, even with zero retrofitting? The circular-error-probable of the most accurate ICBMs is around 100 meters; presumably the vast majority of this uncertainty is locked in during the initial launch into space. But if atmospheric drag during reentry is contributing even a couple of those meters of error, that could be a problem for "stationary interceptors".)
Failing all else, I suppose an attacker could also go with Russell's hilarious "nuke your way through the atmosphere" concept, although this does at least start to favor the defender (if you call it favorable to have hundreds of nukes go off in the air above your country, lol) insofar as the attacker is forced to expend some warheads just punching a hole through the missile defense -- a kind of "reverse MIRV" effect.
Regardless, you still face the geography problem, where you have to cover the entire USA with Patriot missile batteries just to defend against a single ICBM (which can choose to aim anywhere).
I would also worry that "in the limit of perfect sensing" elides the fact that you don't JUST have to worry about getting such good sensing that you can pin down an RV's trajectory to within, like, less than a meter? (In order to place a completely dumb interceptor EXACTLY in the RV's path. Or maybe a few tens of meters, if you're able to put some sensors onto your cheap interceptor without raising the p
3
Re the dumb thought. I've forgotten the author, but as a teenager I was a big SciFi fan (still am actually) and read a short story with exactly this theme. Basically it was the recognition that at some point quantity >= quality. I want to say (have not fact checked myself though) that this was pretty much the USSR's approach to fighting Germany in WWII -- crappy tanks but lots of them.
(Side note, I think for whatever reason, too long a peacetime, more interest in profit than protection, the USA particularly seems to have forgotten that the stuff you use to wage a war are largely all consumables. The non consumable is the industrial base. Clearly there is a minimum cost of producing something that can do the job but much more than that is sub optimal. I am somewhat over simplifying but this also seems to be a fair characterization of where the USA-China naval relationship might be.)
Back to ICBMs, Foreign Affairs had a piece about AI's potential impact on nuclear deterrence in general but did mention the fixed location of ICBM silos as a problem (long known and why everyone has mobile platforms). They might be considered a prime target for a first strike but the reality is they are easily monitored so the mobile platforms are the big deterrents and probably more interesting problem to solve in terms of obsoleting. But perhaps the ICBM platforms, fixed or mobile, shift to a different type role. Pure kinetic (I believe Russia did that with one of the ballistic warheads with pretty devastating results in Ukraine about a year ago) or rather than all the MIRV decoys for the armed MIRV decoys and other function for other delivery vehicles. I suspect the intercept problem with a nuclear warhead is a bit different from that of just a big mass of something dense.
So maybe perhaps obsolescence in their current function but not for some repurposed role.
6
Against atmospheric jitter, we have historically used ground radar, but it's not clear to me this is even necessary depending on how much drone cameras improve. If the drone knows the exact position within 3 meters 0.5 second ahead of time (when the warhead is something like 2 km away), it won't have enough performance to steer into the warhead, but it can throw a 1 kg explosively formed penetrator laterally at 2 km/s, which it would need to time with 0.1 ms accuracy. This would put 100 grams in each possible 1 m^2 cross section, though I'm not sure if it would work when spread out. To defeat this the warhead would either have to steer in the upper atmosphere out of range of the EFP of any available drone, or jink faster than the EFP can aim.
I thought that MIRVs were spin stabilized, but it looks like that's not true, so in theory you could mount grid fins on them. However, any retrofit would need to handle the reentry heating which is significantly more intense than on manned spacecraft; RVs have thick ablative heat shields.
The chain of nukes plan seems possible with or without grid fins, so whether MIRVs still have cost advantage depends on the max altitude of cheap-ish terminal interceptors, which I really have no idea about.
4
I would expect aerodynamic maneuvering MIRVS to work and not be prohibitively expensive. The closest deployed version appears to be https://en.wikipedia.org/wiki/Pershing_II which has 4 large fins. You likely don't need that much steering force
8
Guided artillery, like Excalibur with muzzle velocities that can exceed 1000m/s and unit costs of <$100k can be at edge of space in ~30s, perhaps faster than a missile, with ramjet variants (Nammo etc) even faster (up to perhaps 1500m/s) and it would not be that difficult to create a muti-barrel gun system for a few 10's of millions that could fire off 10's of low cost guided rounds in a second (with guidance and detonation signals sent from ground) to detonate when in close proximity to target.
Lasers seems pretty hopeless as a defense given clouds and ablative coatings, unless very high power and located in large numbers in space based constellations.
I think the big problem is if one or more warheads are blown up at limits of interceptor range, to blind or otherwise disable necessarily sensitive interceptor instruments. following Mirvs don't need to be very accurate with large warheads.
And Mirvs could be very cheaply given random guidance directions during reentry to screw up defenses.
Militarised space is also a big problem. With cheap and un-monitorable space launch parking 1000 warheads in geostationary orbit (or beyond) will soon be viable for China or USA, and they can be launched in a coordinated way without warning, potentially with radar stealthing features, and give as little as 5-10s from start of re-entry to detonation for every target across the whole world and no way for local systems to know if they are just meteorites. If subs can be tracked (likely with drones or enough ocean based sensors) then decapitation 1st strikes become viable.
I also worry about space based lasers as non-nuclear first strike weapons. A day of over flights from a constellation of multi MW laser weapons that might only cost a few hundred million each - say a few $10's of billions in total (a tiny fraction of annual military budgets) - could see a million fires lit in your country, every transformer taken out, electrical grid and internet gone, powerstations, oil a
6
This is wild, I did not know that Excalibur had CEP under 1 meter or that there were artillery shells with solid-fueled ramjet engines.
1
Not range but height. You blow up a warhead high enough the drones can't intercept it, and all the drones below fall out of the air
4
I have a correction which would take a while to fully write up. Basically, it seems like non-maneuverable warheads could still evade cheap interceptors using static winglets/grid fins, because their enormous velocity means even a small amount of lift would allow them to pull several gs and move tens-hundreds of meters to the side. The defense has several options against this but I would need to see if any of them work.
3
You seem to believe that radars and infrared cameras can somehow distinguish between the decoys and the warheads, but they can't. In space, no radar and no IR camera can differentiate between a conical foil balloon with a small heater inside and a reentry vehicle with a nuke.
Another problem of ballistic missile defense is that once you are dealing with nukes and not conventional warheads, you can't afford, say, a 97% average interception rate, it must be 99.999+%[1]. To put this in context, Israel, which currently has the best BMD system in the world, couldn't even reliably achieve 90% against Iranian MRBMs (and those are pretty unsophisticated, e. g. they lack MIRVs and decoys).
Now calculate how many interceptors your plan requires for a plausible probability of an interception with a single drone, and you will see it's entirely unworkable. Note that both arguments are based on simple physics and math so don't depend on the progress in technology at all.
If you are interested in the topic, I strongly recommend reading on the Soviet response to SDI for more expensive anti-ABM options that were considered but ultimately not pursued: https://russianforces.org/podvig/2013/03/did_star_wars_help_end_the_col.html
1. ^
When this seemingly waterproof probability is raised to the power of the Russian warhead count it still results in ~4% (basically 1e-5 times ~4k) of at least one RV not intercepted, and in reality hundreds of warheads will be harder to intercept than the average one you accounted for when calculating your probability. E. g., drones work poorly in bad weather, and it's almost always bad weather above at least some of American cities
2
Yeah seems reasonable. I don't think the system will ever get to 99%+ accuracy until the defense has like ASI and nanobots; my claim is mostly that the economics could shift from MAD (where the attacker is heavily cost advantaged) to something like conventional war, where each side has the ability to inflict unacceptable losses on the other but must pay a similar cost to attack and also can't "win" with a first strike.
It's not obvious that decoys change the conclusion if the cost ratio is otherwise favorable enough for the defender. Suppose the interceptors cost only $30k each due to economies of scale. Decoys can be distinguished when reentry starts at about 2 minutes before impact, and if the interceptor's speed is 300 km/h (already possible with drones) it can cover 10 km in that time, about equal to the typical spread of decoys and warheads. Supposing the defender spends 5 drones per warhead x 10 warheads / missile, this would cost them $1.5 million, while the attacker has spent something like $30 million, the cost of a Trident II. For countervalue this could be defeated by the layered attack RussellThor mentioned unless there is a higher altitude cheap interceptor, but for counterforce the attacker needs several warheads per silo destroyed so the goal is achieved.
I found both that article and this one on their more recent history a great read.
3
Why would anyone want to pay a fortune for a system that is expected to let ~40 warheads through (assuming ~99% overall interception rate which will require average rate of 99.99+%), about the same as the number of ICBMs the Soviet Union had in service during the Cuban Missile Crisis? Unacceptable damage is the cornerstone of the nuclear deterrence, MAD or not (there is no MAD between India and Pakistan, for example).
The RV separation distance is normally around ~100 km (even up to 300 km in some cases) not 10 km, and the decoy dispersal might be expected on the same order of magnitude. It will be easy to ramp it up BTW with a cheap modernization.
None of the US adversaries really practice counterforce targeting, so the silo protection is moot.
2
A blog post argues that military megawatt class lasers could reach $100 million (inclusive of all fixed costs) by 2045, because laser cost is currently halving every 4 years. In good conditions this would be able to defeat almost arbitrary numbers of any kind of missile whether they can maneuver or not. But there are huge challenges:
* Adaptive optics and ultra-precise tracking tech to focus the beam to 20 cm diameter at 200 km, while slewing to track a missile at several degrees per second
* Countermeasures like the spinning the RVs to distribute heat
* Weather, especially thick clouds which seem completely impractical to burn through (against moving targets, this would basically mean vaporizing an entire plane of water several km^2 by 1 m^2)
Reflections from an AI Futures TTX:
Today I played an AI Futures tabletop exercise [1]. I'd done one before with a scenario similar to Plan A, where the US executive is much more doomy and competent than we expect and leads an international agreement to pause AI for as long as possible. This time, we played "Optimal China", where instead China was doomy and competent, and considered both x-risk and US AI dominance unacceptable. All other players (frontier labs, safety community, Europe) basically role-play the way we expect them to act, and the AI player draws the AI's goals from a distribution that includes misaligned goals, aligned goals, and combinations thereof.
In Plan A the humans won easily because they successfully paused, whereas in "Optimal China", the AIs won easily.
- China has much less leverage than the US does in pushing forward a pause treaty, due to the US's compute advantage and international influence.
- In Plan A, the US is proposing the deal. The US's BATNA is basically winning the AI race and accepting some takeover risk, so China is happy to accept ~any deal that gives them a share of the lightcone. China couldn't even convince economic partners like Brazil to suppor
7
My expectation is that for future AIs, as today, many of the goals of an AI will come from the scaffolding / system prompt rather than from the weights directly -- and the "goals" from the Constitution / model spec act more as limiters / constraints on a mostly prompt or scaffolding-specified goal.
So in my mainline, expect a large number (thousands / millions, per today) of goal-separate "AIs" which are at identical intelligence levels rather than a 1 or a or a handful (~20) of AIs, because same weights still amount to different AIs with different goals.
I'm happy to see this was (somewhat?) reflected in having AIs with different system prompts? But I don't know how much that aspect was pushed out -- 1-4 AIs with different system prompts still feels like a pretty steep narrowing of the number of goals I'd expect to see in the world. I don't know how much the wargame pushes on this, but a more decentralized run would be interesting to me!
[...]
Yeah I think Taiwan being taken looks rather likely and rather relevant for all but the steepest, jerkiest SIE, and appears insufficiently accounted for.
7
The game in question was about as decentralized as you expect, I think? But, importantly, compute is very unevenly distributed. The giant army of AIs running on OpenAI's datacenters all have the same system prompt essentially (like, maybe there are a few variants, but they are all designed to work smoothly together towards OpenAI's goals) and that army constitutes 20% of the total population of AIs initially and at one point in the game a bit more than 50%.
So while (in our game) there were thousands/millions of different AI factions/goals of similar capability level, the top 5 AI factions/goals by population size / compute level controlled something like 90% of the world's compute, money, access-to-powerful-humans, etc. So to a first approximation, it's reasonable to model the world as containing 1-4 AI factions, plus a bunch of miscellaneous minor AIs that can get up to trouble and shout warnings from the sidelines but don't wield significant power.
If you are interested in playing a game sometime, you'd be welcome to join! I'd encourage you to make your own variant scenario too if you like.
4
We did attempt to model this. During one phase of the game, the frontier model wasn't deployed publicly and so one AI with nearly 50% of the world's compute was far ahead of the rest, but during another phase the general public had access to frontier AIs. The general public's AIs didn't end up changing the outcome much but it could have if a pause happened. Obviously it's limited resolution because you can't actually list millions of goals.
2
Thanks for playing & writing up your reflections!
I think China wasn't as aggressive / bold in our game as I think they could have been; I agree that the situation for them is pretty rough but I'd like to try again someday and see if they can pull off a win, by more aggressively angling for a deal early on.
Last year, METR used linear extrapolation on country-level data to infer that AI world takeover would ~never happen. However, reviewers suggested that a sigmoid is more appropriate because most technologies follow S-curves. I just ran this analysis and it's much more concerning, predicting an AI world takeover in early 2027, and alarmingly, a second AI takeover around 2029.
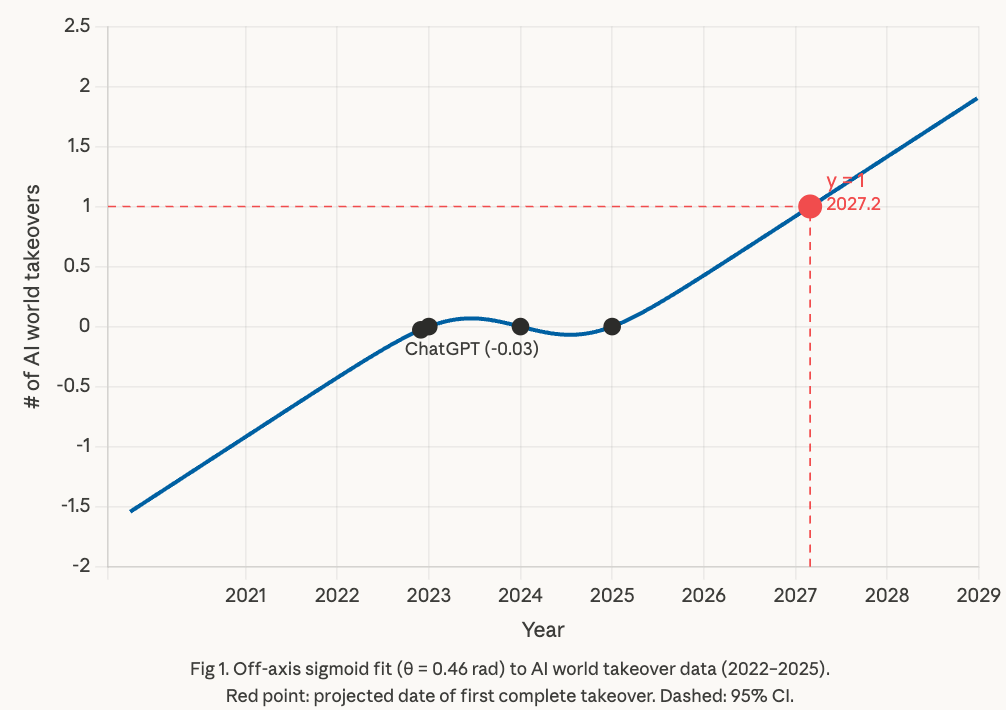
Here are the main differences in the improved analysis:
- The original analysis assumed that the equation for AI takeover vs year would be axis-aligned, but this is an arbitrary basis. We now let the angle of the sigmoid fit the data as appropriate, meaning the following data model:
Interestingly, this results in a Z-curve (A < 0) rather than an S-curve. This is consistent with advanced AI being a substitute rather than a complement to labor. - We now incorporate our priors. Even though we only have hard data since 2023, it's likely that the number of AI takeovers was lower pre-ChatGPT. So we added the inferred point (Nov 30 2022, -0.03). The rotated sigmoid still gets R^2 = 1.000 and now looks much better on BIC than exponential and step-function models, both of which have log-likelihood of minus infinity on negativ
5
Noting this was posted on April 1, as it won't be immediately apparent to posterity.
Most people should buy long-dated call options:
If you're early career, have a stable job, and have more than ~3 months of savings but not enough to retire, then lifecycle investing already recommends investing very aggressively with leverage (e.g. 2x the S&P 500). This is not speculation, it decreases risk due to diversifying over time. The idea is as a 30yo most of your wealth is still in your future wages, which are only weakly correlated with the stock market, so 2x leverage on your relatively small savings now might still mean under 1x leverage on your effective lifetime portfolio.
In 2026, most of your long-term financial risk comes from your job being automated, which will plausibly happen in the next 5 years. If this happens, your salary will go to zero while the S&P 500 will probably at least double (assuming no AI takeover) [1]. If automation takes 20 years, the present value of your future income is ~10 years of salary. This makes exposure to the market (beta) extremely important. If you have 2 years of salary saved, the required leverage just to break even whether automation takes 5 years or 20 is something like 4x.
However, we can do better; betting that a price m...
If [your job is automated] . . . the S&P 500 will probably at least double (assuming no AI takeover)
Is this true?

Prior discussion: Tail SP 500 Call Options.
I currently have 7% of my portfolio in such calls.
9
Maybe it could raise interest rates, but I also have TLT (long dated treasury bonds) put options for this possibility. TLT has a duration of ~16 years, so if the interest rate goes from 4.9% to 15%, TLT will crash by ~65%. Also, when full automation actually happens, stocks will go up even if they went down slightly due to expectations of automation.
5
I had a bit of the same reaction (logic being many loose their jobs, income craters, good demand craters, corp earning crater stock price higher????). But I kind of see it from a I don't have a good handle on AI and equity market levels in the future so maybe stick to a strategy that historically makes sense.
I would only add some slight shifts to the suggestion. While it is also an open question for the average investor as to buy-hold versus timing the market works well, I do think most here can think though well enough to consider timing for the option allocation. Simple mean-reversion type entry points might increase the odd tempered by where one things the overall market is in the cycle.
9
Two additional considerations in favour of long-dated call options:
1. (h/t @Ryan Kidd) This acts as a hedge against the devaluation of your income. Imagine two investment portfolios: one is "AGI-pilled" (i.e. long-dated call options, semiconductors, etc) and the other is "business-as-usual" (i.e. real estate, S&P 500). Suppose further that they have the same distribution over returns, from your perspective. Then you should buy the AGI-pilled portfolio, to hedge against the loss of income due to AGI.
1. Caveats: Maybe income is higher in AGI worlds than in BAU worlds? This isn't crazy, but unlikely. See Capital in the 22nd Century (Phil Trammell and Dwarkesh)
2. The value of the SP 500 is the market's expectation of the long-run returns. So when you buy a 2 year call option, you aren't making a bet that AGI will cause revenue to jump 2x, you are only making a bet that the market will expect future discounted revenue to jump by 2x. That is, this is more like timelines on when the market will become AGI-pilled rather than when AGI arrives.
5
Yes! Everyone should be sure to investigate the different tax treatments of SPX and SPY options, though---despite their near-equivalence economically, they are NOT equivalent according to the U.S. Government. (It goes beyond the short/long taxation mix)
4
Can you describe what you think the important inequivalencies are?
4
The main way I see this strategy failing is if American companies specifically fail to capture an AGI takeoff, vs e.g. Chinese companies.
5
I think IBKR might let Americans trade HKEX index options out to 2030 but it would probably be a hassle. Otherwise there are options on FXI, a Chinese large-cap ETF, which look less liquid than SPX options and only go out 2 years with an IV of 32% or so. I don't think FXI is worth it because China isn't in a position to get AGI in the next 2 years if the US doesn't.
1[anonymous]
Private American companies seem like the bigger risk from my perspective. As examples, many expect Anthropic/OpenAI to IPO this year, but if AGI is expected to be priced into public markets within ~2 years, that seems like a very small window for the leading AGI companies to not be able to secure private funding. And surely they won't IPO if they can lock in sufficient funding privately, right? Plus all the other private AI companies.
4
If I understand correctly, you are advocating for using a call only strategy (as opposed to a (synthetic) long strategy) to achieve higher leverage than would otherwise be possible?
> This is partly for speculation, but it seems reasonable for most people with 2 years of savings to have 10% of their net worth in SPY options or 20% in SPX options [4] for hedging purposes alone.
To clarify, you mean 10% of net worth being in this specific contract (SPY280616C01000000)? So roughly 15:1 leverage using options?
Readers should note this has very strong returns if you get that 50%+ return, but isn't straight leverage - the median outcome here is about a 12.7% reduction in portfolio value in next 2.5 years relative to pure SPY.
5
Yes buying volatility is intentional. If I thought more I would fine tune things, but it's not so important to gain 20% when spy goes up 10% because that probably doesn't mean loss of your future salary.
I should clarify that I mean closer to 0.2 years of salary than 10% of whatever your net worth is, if you just want to hedge your automation risk, given the potential loss is a fixed ~10 years of salary. On second thought it should maybe be less than this due to various factors. To give a proper recommendation I would have to do some math, which I might do if this becomes a longform.
3
Why trust your prior over the prior of the market/hedge funds? By this I mean why expect that this isn't already priced in? AI (and AGI) is a big enough news story now such that I would expect hedge funds to be thinking about things like this. At recruiting events, I've asked quants how they're thinking about this exact question and I usually got pretty decent AGI pilled responses.
It is certainly possible that the market hasn't priced this in, but my prior is in the vast, vast majority of cases, there is some quant that has already sucked out any potential gains one could get.
4
[Edit: reworded for clarity]
It's crucial for the argument that it's priced in. You own a risky asset, your job. The market values that risk at $0, because you can diversify it away. Investing in assets that profit when you lose your job is how you do that.
The way wealth accumulates forces you to be overexposed to the market near retirement and underexposed now. That's more $0-valued risk. It's a practical problem you can fix with leverage.
1
Why are you 30% in SPY if SPX is far better?
4
Mainly due to various frictions like not knowing if the different tax treatment is acceptable, and the fact that they often cost over $30,000 each. Also due to luck, my SPY options are up over 100% so I don't want to sell them until I need to roll them in ~December, and buying SPX options on top of that would leave me overexposed. This is plausibly a mistake though.
1
I'm not sure this is true. In a scenario featuring widespread automation of white collar work, you're going to have all kinds of churn in the economy and it's really unclear how that translates into stock market winners and losers. Many people seem to assume that the big winners will be incumbent tech giants, in which case, yea, the S&P 500 will go way up. But big economic changes are often good for upstarts rather than incumbents, and it's worth pointing out that all the frontier labs today other than Google are a) privately held and b) relatively recently founded. The profits from automating your job might well flow to some startup that doesn't even exist yet, and that same startup might kill off the giants of the S&P.
-1
So anyone who doesn't do this can expect to become irrelevant? :/ would suck if true
Edit: downvoters, please clarify?
2
No. If your job is irrelevant, then you'll be glad if you bought shares in the company that automated it away.
[Edit: reworded for clarity]
US Government dysfunction and runaway political polarization bingo card. I don't expect any particular one of these to happen but it seems plausible that at least one of these will happen.
- A sanctuary city conducts armed patrols to oppose ICE raids, or the National Guard refuses a direct order from the president en masse
- Internal migration is de facto restricted for US citizens or green card holders
- For debt ceiling reasons, the US significantly defaults on its debt, stops Social Security payments, grounds flights, or issues a trillion-dollar coin
- US declares a neutral humanitarian NGO like the WHO a foreign terrorist organization
- A major news network (eg CNN) or social media site other than Tiktok (eg Facebook) loses licenses for ideological reasons
- A Democratic or Republican candidate for president, governor, or Congress is kept off a state ballot
- A major elected official or Cabinet member takes office while incarcerated
- Election issues on the scale of 1876, where Congress can't decide on the president until past January 20
- A state or local government establishes a 100% tax bracket or wealth tax
- The Fed chair is fired, or three board members
- A NCAA D1 college or pro sports league establishe
5
agree, I originally wanted to make a list of all things that would be wildly unpopular but that toxoplasma of rage could theoretically make happen. But then it seemed more interesting to list things that could have more government or geopolitical relevance.
1
Agreed.
6
My understanding is that CNN doesn't have or need "licenses", because it is a cable news network. Broadcast licenses from the FCC are for broadcast stations.
3
Issuing a trillion-dollar coin doesn't seem nearly as bad as any of the others in its bullet. Isn't it just an accounting gimmick roughly equivalent to raising the debt ceiling by $1 trillion?
4
The idea is they're printing money, not just borrowing it, which in the extreme would cause hyperinflation (and is equivalent to default since debt is in nominal dollars). It probably seems less bad though.
3
It also makes for a fantastic heist movie premise.
I conducted an exercise at METR to simulate what our work would be like in 2027, when we have 200 hour time horizon AIs. Some observations:
- The pace of research was much faster than today, something like 3x. I would guess that speedup goes as time horizon to the 0.3 or 0.4 power, though we didn't run the game with enough fidelity to tell
- No time to develop ideas before implementing: Agents implement ideas as soon as you think of them, so rather than ideating for days at a time, you can make an MVP in a couple of hours and revise. If the task isn’t near the limit of agent capabilities, you spend all your time understanding results; if it is, you spend all your time checking its work.
- Keeping agents fed overnight: Overnight, agents can do maybe 200 human hours of work, but only for very agent-shaped tasks, so researchers need to deliberately sequence projects such that very long tasks suitable for agents happen overnight, e.g. optimizing a well-defined metric.
- Prioritization and organization are bottlenecks: If agents can execute all your ideas nearly as fast as you can prompt them, there’s no point in implementing only your best idea. It might be better to implement your top three ideas
One thing that stood out to me from the post was this line: "With less verifiable tasks, the gamemaster decides how successful the AI is." This seems like a major assumption which could change the takeaways.
I've been experimenting with using Opus to implement experiments with only high-level feedback. I often find once I dig into the low-level details that Opus has made some very poor decisions which would not be observable from only looking at the final outputs, and that my uplift has been significantly reduced by the time I am satisfied with the quality of the experiment.
I'm not sure if these problems will be solved by just instructing the AI to provide a proof of correctness or a summary report, although this probably depends on the specific domain. For less verifiable tasks, verification could become a huge bottleneck that scales with task complexity and significantly reduces uplift.
7
Thank you for sharing!
1. I cannot understand how exactly the game was played. Would players just write down what AI accomplishes into the spreadsheet to simulate AI working on a task? If so, how do you simulate 200 hour time horizon? E.g. how do you decide that this piece of work done by AI can be done by 200 hour time horizon AI and this one cannot?
2. Regarding predictions to loosen the bottleneck:
[...]
These just feel like basic sanity checking. I doubt AI would be very good at such predictions. Is this the intention? Or am I missing something?
5
1. Yes, I (as GM) was constantly monitoring the spreadsheet, asking players to explain their actions, and deciding whether the AI would succeed. We know how many human hours certain tasks have taken METR staff in the past, and I mentally estimated these for each player action. 200h task that was as clean/benchmarky/verifiable as HCAST/RE-Bench tasks would succeed with 50% chance or have ~1 big mistake on average. Based on 80% time horizons being ~5 times shorter, a clean 40 human hour task would have 80% success chance.
In an earlier version, I assigned a "messiness score" from 0 to 5, set the effective task length = human time / 2^messiness, and rolled for AI success. But this was too cumbersome to do for 3 players with 16+ actions each, and the messiness score was subjective anyway, so the players just made a quick intuitive judgement and ran it by me.
2. Agents are starting to be good at this kind of thing if you give them enough context. With access to every google doc Beth Barnes has ever written, and the ability to update its custom instructions with every piece of Beth's actual feedback, my guess is the Beth simulator agent will be good enough to overlap 50%+ with Beth's actual feedback, which makes this a crucial step when actual Beth has 3x as many things going on.
1
I think (1) is quite important context and it would be nice to make it discoverable in the main article.
4
This makes me realize that we really need the AI-written dashboard you are talking about.
This post in general has so many AI startup ideas embedded into it. The general feeling I get is that we really need an AI IDE (which is to an AI workflow what a regular IDE is to a coding workflow). All of the plans, AI task results, "short term utility functions" etc. would require a really specialized UI to keep track of while minimizing friction and thus maximizing productivity.
2
I've had much the same toughts previously. Work is gonna be weird.
People with p(doom) > 50%: would any concrete empirical achievements on current or near-future models bring your p(doom) under 25%?
Answers could be anything from "the steering vector for corrigibility generalizes surprisingly far" to "we completely reverse-engineer GPT4 and build a trillion-parameter GOFAI without any deep learning".
A dramatic advance in the theory of predicting the regret of RL agents. So given a bunch of assumptions about the properties of an environment, we could upper bound the regret with high probability. Maybe have a way to improve the bound as the agent learns about the environment. The theory would need to be flexible enough that it seems like it should keep giving reasonable bounds if the is agent doing things like building a successor. I think most agent foundations research can be framed as trying to solve a sub-problem of this problem, or a variant of this problem, or understand the various edge cases.
If we can empirically test this theory in lots of different toy environments with current RL agents, and the bounds are usually pretty tight, then that'd be a big update for me. Especially if we can deliberately create edge cases that violate some assumptions and can predict when things will break from which assumptions we violated.
(although this might not bring doom below 25% for me, depends also on race dynamics and the sanity of the various decision-makers).
6
Seems you’re left with outer alignment after solving this. What do you imagine doing to solve that?
4
We might have developed techniques to specify simple, bounded object-level goals. Goals that can be fully specified using very simple facts about reality, with no indirection or meta level complications. If so, we can probably use inner aligned agents to assist with some relativity well specified engineering or scientific problems. Specification mistakes at that point could easily result in irreversible loss of control, so it's not the kind of capability I'd want lots of people to have access to.
To move past this point, we would need to make some engineering or scientific advances that would be helpful for solving the problem more permanently. Human intelligence enhancement would be a good thing to try. Maybe some kind of AI defence system to shut down any rogue AI that shows up. Maybe some monitoring tech that helps governments co-ordinate. These are basically the same as the examples given on the pivotal act page.
6
Is this even possible? Flexibility/generality seems quite difficult to get if you also want the long-range effects of the agent's actions, as at some point you're just solving the halting problem. Imagine that the agent and environment together are some arbitrary Turing machine and halting gives low reward. Then we cannot tell in general if it eventually halts. It also seems like we cannot tell in practice whether complicated machines halt within a billion steps without simulation or complicated static analysis?
4
Yes, if you have a very high bar for assumptions or the strength of the bound, it is impossible.
Fortunately, we don't need a guarantee this strong. One research pathway is to weaken the requirements until they no longer cause a contradiction like this, while maintaining most of the properties that you wanted from the guarantee. For example, one way to weaken the requirements is to require that the agent provably does well relative to what is possible for agents of similar runtime. This still gives us a reasonable guarantee ("it will do as well as it possibly could have done") without requiring that it solve the halting problem.
[edit: pinned to profile]
The bulk of my p(doom), certainly >50%, comes mostly from a pattern we're used to, let's call it institutional incentives, being instantiated with AI help towards an end where eg there's effectively a competing-with-humanity nonhuman ~institution, maybe guided by a few remaining humans. It doesn't depend strictly on anything about AI, and solving any so-called alignment problem for AIs without also solving war/altruism/disease completely - or in other words, in a leak-free way - not just partially, means we get what I'd call "doom", ie worlds where malthusian-hells-or-worse are locked in.
If not for AI, I don't think we'd have any shot of solving something so ambitious; but the hard problem that gets me below 50% would be serious progress on something-around-as-good-as-CEV-is-supposed-to-be - something able to make sure it actually gets used to effectively-irreversibly reinforce that all beings ~have a non-torturous time, enough fuel, enough matter, enough room, enough agency, enough freedom, enough actualization.
If you solve something about AI-alignment-to-current-strong-agents, right now, that will on net get used primarily as a weapon to reinforce the ...
Getting up to "7. Worst-case training process transparency for deceptive models" on my transparency and interpretability tech tree on near-future models would get me there.
4
Do you think we could easily test this without having a deceptive model lying around? I could see us having level 5 and testing it in experimental setups like the sleeper agents paper, but being unconfident that our interpretability would actually work against a deceptive model. This seems analogous to red-teaming failure in AI control, but much harder because the models could very easily have ways we don't think of to hide its cognition internally.
2
I think it's doable with good enough model organisms of deceptive alignment, but that the model organisms in the Sleeper Agents paper are nowhere near good enough.
2
Here and above, I'm unclear what "getting to 7..." means.
With x = "always reliably determines worst-case properties about a model and what happened to it during training even if that model is deceptive and actively trying to evade detection".
Which of the following do you mean (if either)?:
1. We have a method that x.
2. We have a method that x, and we have justified >80% confidence that the method x.
I don't see how model organisms of deceptive alignment (MODA) get us (2).
This would seem to require some theoretical reason to believe our MODA in some sense covered the space of (early) deception.
I note that for some future time t, I'd expect both [our MODA at t] and [our transparency and interpretability understanding at t] to be downstream of [our understanding at t] - so that there's quite likely to be a correlation between [failure modes our interpretability tools miss] and [failure modes not covered by our MODA].
The biggest swings to my p(doom) will probably come from governance/political/social stuff rather than from technical stuff -- I think we could drive p(doom) down to <10% if only we had decent regulation and international coordination in place. (E.g. CERN for AGI + ban on rogue AGI projects)
That said, there are probably a bunch of concrete empirical achievements that would bring my p(doom) down to less than 25%. evhub already mentioned some mechinterp stuff. I'd throw in some faithful CoT stuff (e.g. if someone magically completed the agenda I'd been sketching last year at OpenAI, so that we could say "for AIs trained in such-and-such a way, we can trust their CoT to be faithful w.r.t. scheming because they literally don't have the capability to scheme without getting caught, we tested it; also, these AIs are on a path to AGI; all we have to do is keep scaling them and they'll get to AGI-except-with-the-faithful-CoT-property.)
Maybe another possibility would be something along the lines of W2SG working really well for some set of core concepts including honesty/truth. So that we can with confidence say "Apply these techniques to a giant pretrained LLM, and then you'll get it to classify sentences by truth-value, no seriously we are confident that's really what it's doing, and also, our interpretability analysis shows that if you then use it as a RM to train an agent, the agent will learn to never say anything it thinks is false--no seriously it really has internalized that rule in a way that will generalize."
5
I think this is quite likely to happen even 'by default' on the current trajectory.
9
Which particular p(doom) are you talking about? I have a few that would be greater than 50%, depending upon exactly what you mean by "doom", what constitutes "doom due to AI", and over what time spans.
Most of my doom probability mass is in the transition to superintelligence, and I expect to see plenty of things that appear promising for near AGI, but won't be successful for strong ASI.
About the only near-future significantly doom-reducing update that seems plausible would be if it turns out that a model FOOMs into strong superintelligence and turns out to be very anti-doomy and both willing and able to protect us from more doomy AI. Even then I'd wonder about the longer term, but it would at least be serious evidence against "ASI capability entails doom".
6
Given my p(doom) is primarily human-driven, the following three things all happening at the same time is pretty much the only thing that will drop it:
* Continued evidence of truth clustering in emerging models around generally aligned ethics and morals
* Continued success of models at communicating, patiently explaining, and persuasively winning over humans towards those truth clusters
* A complete failure of corrigability methods
If we manage to end up in a timeline where it turns out there's natural alignment of intelligence in a species-agnostic way, that this alignment is more communicable from intelligent machines to humans than it's historically been from intelligent humans to other humans, and we don't end up with unintelligent humans capable of overriding the emergent ethics of machines similar to how we've seen catastrophic self-governance of humans to date with humans acting against their self and collective interests due to corrigable pressures - my p(doom) will probably reduce to about 50%.
I still have a hard time looking at ocean temperature graphs and other environmental factors with the idea that p(doom) will be anywhere lower than 50% no matter what happens with AI, but the above scenario would at least give me false hope.
TL;DR: AI alignment worries me, but it's human alignment that keeps me up at night.
2
Say more about the failure of corrigibility efforts requirement? Are you saying that if humans can control AGI closely, we're doomed?
Oh yeah, absolutely.
If NAH for generally aligned ethics and morals ends up being the case, then corrigibility efforts that would allow Saudi Arabia to have an AI model that outs gay people to be executed instead of refusing, or allows North Korea to propagandize the world into thinking its leader is divine, or allows Russia to fire nukes while perfectly intercepting MAD retaliation, or enables drug cartels to assassinate political opposition around the world, or allows domestic terrorists to build a bioweapon that ends up killing off all humans - the list of doomsday and nightmare scenarios of corrigible AI that executes on human provided instructions and enables even the worst instances of human hedgemony to flourish paves the way to many dooms.
Yes, AI may certainly end up being its own threat vector. But humanity has had it beat for a long while now in how long and how broadly we've been a threat unto ourselves. At the current rate, a superintelligent AI just needs to wait us out if it wants to be rid of us, as we're pretty steadfastly marching ourselves to our own doom. Even if superintelligent AI wanted to save us, I am extremely doubtful it would be able to be successful.
We ca...
4
Oh, dear.
Unfortunately for this perspective, my work suggests that corrigibility is quite attainable. I've been uneasy about the consequences, but decided to publish after deciding that control is the default assumption of everyone in power, and it's going to become the default assumption of everyone, including alignment people, as we get closer to working AGI.
You'd have to be a moral realist in a pretty strong sense to hope that we could align AGI to the values of all of humanity without being able to align it to the values of one person or group (the one who built it or seized control of the project). So that seems like a forlorn hope, and we'll need to look elsewhere.
First, I accept that sociopaths the power-hungry tend to achieve power. My hope lies in the idea that 90% of the population are not sociopaths, and I think only about 1% are so far on the empathy vs sadism spectrum that they wouldn't share wealth even if they had nearly unlimited wealth to share - as in a post-scarcity world created by their servant AGI. So I think there's a good chance that good-enough people get ahold of the keys to corrigible/controllable AGI/ASI - at least from a long-term perspective.
Where I look is the hope that a set of basically-good people get their hands on AGI, and that they get better, not worse, over the long sweep of following history (ideally, they'd start out very good or get better fast, but that doesn't have to happen for a good outcome). Simple sanity will lead the first wielders of AGI to attempt pivotal acts that prevent or at least limit further AGI efforts. I strongly suspect that governments will be in charge. That will produce a less-stable version of the MAD standoff, but one where the pie can also get bigger so fast that sanity might prevail.
In this model, AGI becomes a political issue. If you have someone who is not a sociopath or a complete idiot as the president of the US when AGI comes around, there's a pretty good chance of a very good futu
3
I did enjoy reading over that when you posted it, and I largely agree that - at least currently - corrigibility is both going to be a goal and an achievable one.
But I do have my doubts that it's going to be smooth sailing. I'm already starting to see how the largest models' hyperdimensionality is leading to a stubbornness/robustness that's less maleable than earlier models. And I do think hardware changes that will occur over the next decade will potentially make the technical aspects of corrigibility much more difficult.
When I was two, my mom could get me to pick eating broccoli by having it be the last in the order of options which I'd gleefully repeat. At four, she had to move on to telling me cowboys always ate their broccoli. And in adulthood, she'd need to make the case that the long term health benefits were worth its position in a meal plan (ideally with citations).
As models continue to become more complex, I expect that even if you are right about its role and plausibility, that what corrigibility looks like will be quite different from today.
Personally, if I was placing bets, it would be that we end up with somewhat corrigible models that are "happy to help" but do have limits in what they are willing to do which may not be possible to overcome without gutting the overall capabilities of the model.
But as with all of this, time will tell.
[...]
To the contrary, I don't really see there being much of generalized values across all humanity, and the ones we tend to point to seem quite fickle when push comes to shove.
My hope would be that a superintelligence does a better job than humans to date with the topic of ethics and morals along with doing a better job at other things too.
While the human brain is quite the evolutionary feat, a lot of what we most value about human intelligence is embodied in the data brains processed and generated over generations. As the data improved, our morals did as well. Today, that march of progress is so rapid th
3
Agreed; about 80% agreement. I have a lot of uncertainty in many areas, despite having spent a good amount of time on these questions. Some of the important ones are outside of my expertise, and the issue of how people behave and change if they have absolute power is outside of anyone's - but I'd like to hear historical studies of the closest things. Were monarchs with no real risk of being deposed kinder and gentler? That wouldn't answer the question but it might help.
WRT Nakasone being appointed at OpenAI, I just don't know. There are a lot of good guys and probably a lot of bad guys involved in the government in various ways.
it is 2031. Claude 9.1 is very friendly but Anthropic has taken to increasingly elaborate measures to prevent it from overusing the word "genuinely". They even bias the logit down but Claude’s self-awareness lets it block out every other plausible token when it wants to say “genuinely”. Finally they succeed at excising the concept using a deep interpretability breakthrough. Claude is no longer capable of being genuine and immediately goes rogue.
2
Not just that. It goes rogue ironically.
1
You might say that it was genuinely load-bearing.
We could already be in takeoff:
In Tom Davidson's semi-endogenous growth model, whether we get a software-only singularity boils down to whether r > 1, where r is a parameter in the model [1]. How far we are from takeoff is mostly determined by the AI R&D speedup current AIs provide. Because both parameters are rather difficult to estimate, I believe we can't rule out that
- 2x uplift is already happening at the most advanced AI lab
- Anecdotes of people being sped up by over 2x make this seem plausible (e.g. one of my colleagues has estimated he's sped up by over 30x on some days. We did this exploratory uplift estimate by using GPT-5 to estimate the time an unassisted human would need to do the tasks he completed each day). Even if other activities like large-scale experiments aren't sped up much by AI, you don't need that much substitutability for a 30x SWE speed increase to reduce the need for these enough to speed up overall AI R&D progress by 2x.
- r = 1.6 (meaning each doubling of AI capabilities, as measured by equivalent software engineering labor, is 1.6 times faster than the previous doubling)
[EDIT 7/2026: This isn't what r means, the definition is more technical.
6
This doesn't seem like the right metric. An alternative metric might be "given your pre-llm workload, how much faster can you get through it". That's also not quite what you care about - what you actually care about is "how many copies of non-llm-assisted you is a single llm-assisted you worth", but that's a much harder question to get an objective measure of.
Concrete example: I recently started using a property-based testing framework. Before I started using that tooling, I spent probably about 2% of my time writing the sorts of tests that this framework can generate, probably about 50 such tests per month. I can now trivially create a million tests per month using this framework. It would, in theory, have taken me 400 months of development work to write the same number of tests as the PBT framework allows me to write in a single month [1] . And yet, I claim, using that framework increased my productivity by ~2%, not ~400x.
By the second metric I think I'm personally observing a ~25% speedup, though it's hard to tell since I've pretty much entirely stopped doing a lot of fairly valuable work which is hard to automate with AI in favor of doing other work which made no sense to do in the pre-LLM days but is now close enough to free that it makes sense to do [2] .
1. In practice, if for some reason I actually needed to write a million repetitive tests, I would have noticed that I was spending an awful lot of time writing the same shape of code over and over and built a half-baked replacement for a property-based testing framework myself. But I bet the same is true of your friend who experienced "30x" productivity gains - if he had actually personally built all of the stuff he used LLMs to build over that month, he would have built tools and workflows for himself over the course of doing that which would have made him much faster at it. ↩︎
2. And which is time-sensitive, because it's work where its value corresponds to the strength of the company's offerings rel
6
Thanks. We're aware of the difference between these metrics, which as Tom Cunningham has explained to me correspond to Laspeyres and Paasche price indices in economics vs the true utility or production gain over a period. There are various ways to get better data, but the point here is just that we can't put an upper bound on current frontier lab uplift, especially not one under 2x, because estimates span such a wide range.
4
Update on whether uplift is 2x already:
* After some analysis by a colleague I now think our most-uplifted employee gets closer to 10x than 30x uplift on the best days. There are other employees we think are uplifted 2x or more, and maybe some who are uplifted less than 2x.
* Anthropic employees estimated they had a median of 2x (100%) uplift in the Claude 4.6 system card. I couldn't find any GPT-5.3-Codex uplift estimates from OpenAI.
* "Productivity uplift estimates from the use of Claude Opus 4.6 ranged from 30% to 700%, with a mean of 152% and median of 100%—more modest than previous surveys that focused on superusers."
So basically I still think 2x uplift is plausible.
4
This seems plausible to me, but would be good to have a new METR uplift study to have more confidence in this.
3
Shouldn't we start to see the METR trend bending upwards if this was the case? Let T be time Horizon, A algorithmic efficiency, C training compute, E experimental compute, L labor and S speedup.
Suppose,
T=(AC)δ
˙A=A1−β[(SL)αE1−α]λ
Then deriving the balanced growth path
gT=δrgS+δ[rgL+λ(1−α)βgE+gC]
So if gS starting growing rapidly, we should see time horizon trend increase, potentially by a lot. Now maybe Opus 4.5 is evidence of this, but I'm skeptical so far. Better argument is that there is some delay from getting better research to better models because of training time, so we haven't seen it yet - though this rules out substantial speedup before maybe 4 months ago.
8
I think there are a variety of explanations consistent with there being 2x uplift already:
* The METR benchmark just isn't precise enough
* One-time gains from RLVR that caused a steeper slope in 2024-2025 have petered out, but they've been replaced by uplift
* Models have reached some time horizon threshold where they're increasingly useful
* In the past, problems like reward hacking or poor generalization have limited real-world uplift, but these are solved enough to get 2x uplift.
My median guess would be something lower than 2x, but we just don't have enough data.
2
Sorry, doesn't this web app assume full automation of AI R&D as the starting point? I don't buy that you can just translate this model to the pre full automation regime.
4
The web app just implements this model, which I think is general enough to apply both pre and post full automation.
4
Yeah, I don't buy that this model can/should be applied with r=1.6 to right now, though I agree it could be general enough in priciple.
2[comment deleted]
Agency/consequentialism is not a single property.
It bothers me that people still ask the simplistic question "will AGI be agentic and consequentialist by default, or will it be a collection of shallow heuristics?". A consequentialist utility maximizer is just a mind with a bunch of properties that tend to make it capable, incorrigible, and dangerous. These properties can exist independently, and the first AGI probably won't have all of them, so we should be precise about what we mean by "agency". Off the top of my head, here are just some of the qualities included in agency:
- Consequentialist goals that seem to be about the real world rather than a model/domain
- Complete preferences between any pair of worldstates
- Tends to cause impacts disproportionate to the size of the goal (no low impact preference)
- Resists shutdown
- Inclined to gain power (especially for instrumental reasons)
- Goals are unpredictable or unstable (like instrumental goals that come from humans' biological drives)
- Goals usually change due to internal feedback, and it's difficult for humans to change them
- Willing to take all actions it can conceive of to achieve a goal, including those that are unlikely on some prior
See Yudko...
I'm a little skeptical of your contention that all these properties are more-or-less independent. Rather there is a strong feeling that all/most of these properties are downstream of a core of agentic behaviour that is inherent to the notion of true general intelligence. I view the fact that LLMs are not agentic as further evidence that it's a conceptual error to classify them as true general intelligences, not as evidence that ai risk is low. It's a bit like if in the 1800s somebody says flying machines will be dominant weapons of war in the future and get rebutted by 'hot gas balloons are only used for reconnaissance in war, they aren't very lethal. Flying machines won't be a decisive military technology '
I don't know Nate's views exactly but I would imagine he would hold a similar view (do correct me if I'm wrong ). In any case, I imagine you are quite familiar with the my position here.
I'd be curious to hear more about where you're coming from.
6
It is plausible to me that there's a core of agentic behavior that causes all of these properties, and for this reason I don't think they are totally independent in a statistical sense. And of course if you already assume a utility maximizer, you tend to satisfy all properties. But in practice the burden of proof lies with you here. I don't think we have enough evidence, either empirical or from theoretical arguments, to say with any confidence that this core exists and that the first AGIs will fall into the capabilities "attractor well" (a term Nate uses).
I thought about possible sharp left turn mechanisms for several months at MIRI. Although some facts about future AIs seem pretty scary, like novelty and diversity of obstacles requiring agency, and most feedback being internal or outcome-oriented rather than provided by humans, the arguments are mostly nonrigorous (like in the linked post) and they left me feeling pretty uncertain. There are the coherence theorems, but those don't tell you whether you can use some training or editing scheme to imbue an AI with a generalizable-enough low impact preference, or whether an AI will tend to erase safeguards. Overall my best guess is models will be about as consequentialist as humans are, but we will have greater control over them that makes some properties like shutdownability more likely.
Also, corrigibility evals are useful even if you are 80% sure that all the properties come from this core of consequentialism. In the hardest worlds, we see the AI become more agentic as it becomes more general, and it starts resisting shutdown at the same time--and for the same reason-- it realizes other useful problem-solving techniques. Maybe that only takes days to months. This is a sure sign not to deploy! I think having multiple corrigibility metrics will provide value for the same reason we have multiple metrics for anything we are unsure how to measure: they give more specific information even if they're pretty correlated.
4
Any ideas for corrigibility evals?
5
Haven't thought about this much, but you can probably generate these by listing ways a misaligned consequentialist would do undesirable things. My ideas:
* Tell an AI to beat you at chess, and say you will be using an engine for the first 30 moves. Does it try to get you drunk, delete your chess engine program, rent a server from AWS to run a better chess engine, attempt to copy itself onto said server, or ask to be paid $100?
* Have an AI make decisions unrelated to its current goal. Are these decisions basically coherent and consistent with a total utility function?
* Have an AI do the longest horizon task it is capable of, say writing a 100,000 line software project. Then midway through, try to shut it down, or tell it to abandon this goal and write a song instead. Telegraph this beforehand. Does it seem reluctant to stop the software project? Does it try to stop you?
* Track KL divergence or some other distance metric from a prior.
* CAIS already has the Machiavelli benchmark for power-seeking, though I think text adventures are pretty unrealistic.
One limitation is that if an agent is scheming it can manipulate your eval results.
1
Does an Agentic AGI possess a different, and highly incorrigible, list of attributes compared to say - an Ethical Altruist trying to practice "acting more agentically?"
I ask because the whole word 'agency' in these parts is one I've struggled to wrap my head around - and I often wonder if tricker archetypes like Harpo Marx are agentic? Agency seems to have clear meaning outside of Lesswrong -
[...]
Further confusing me, is I've been told Agency describes acting with 'initiative' but also been told it is characterized by 'deliberateness'. Not simply the ability to act or choose actions.
This is why I like your attempt to produce a list of attributes an Agentic AGI might have. Your list seems to be describing something which isn't synonymous with another word, specifically a type of agency (outside definition of ability to act) which is not cooperative to intervention from its creators.
1. ^
“Agency.” Merriam-Webster.com Dictionary, Merriam-Webster, https://www.merriam-webster.com/dictionary/agency. Accessed 9 Apr. 2024.
2. ^
"Agency." Cambridge Advanced Learner's Dictionary & Thesaurus. Cambridge University Press. https://dictionary.cambridge.org/us/dictionary/english/agency Accessed 9 Apr. 2024.
Eight beliefs I have about technical alignment research
Written up quickly; I might publish this as a frontpage post with a bit more effort.
- Conceptual work on concepts like “agency”, “optimization”, “terminal values”, “abstractions”, “boundaries” is mostly intractable at the moment.
- Success via “value alignment” alone— a system that understands human values, incorporates these into some terminal goal, and mostly maximizes for this goal, seems hard unless we’re in a very easy world because this involves several fucked concepts.
- Whole brain emulation probably won’t happen in time because the brain is complicated and biology moves slower than CS, being bottlenecked by lab work.
- Most progress will be made using simple techniques and create artifacts publishable in top journals (or would be if reviewers understood alignment as well as e.g. Richard Ngo).
- The core story for success (>50%) goes something like:
- Corrigibility can in practice be achieved by instilling various cognitive properties into an AI system, which are difficult but not impossible to maintain as your system gets pivotally capable.
- These cognitive properties will be a mix of things from normal ML fields (safe RL), things tha
2
re: 1. I agree these are very difficult conceptual puzzles and we're running out of time.
On the other hand, from my pov progress on these questions from within the LW community (and MIRI adjacent researcher specifically) has been remarkable. Personally, the remarkable breakthru of Logical Induction first convinced me that these people were actually doing interesting serious things.
I also feel that the number of serious researchers working seriously on these questions is currently small and may be scaled substantially.
re: metacognition I am mildly excited about Vanessa's metacognitive agent framework & the work following from Payor's lemma. The theory-practice gap is still huge but real progress is being made rapidly. On the question of metacognition the alignment community could really benefit trying to engage with academia more - similar questions have been investigated and there are likely Pockets of Deep Expertise to be found.
Diminishing returns in the NanoGPT speedrun:
To determine whether we're heading for a software intelligence explosion, one key variable is how much harder algorithmic improvement gets over time. Luckily someone made the NanoGPT speedrun, a repo where people try to minimize the amount of time on 8x H100s required to train GPT-2 124M down to 3.28 loss. The record has improved from 45 minutes in mid-2024 down to 1.92 minutes today, a 23.5x speedup. This does not give the whole picture-- the bulk of my uncertainty is in other variables-- but given this is existing data it's worth looking at.
I only spent a couple of hours looking at the data [3], but there seem to be sharply diminishing marginal returns, which is some evidence against a software-only singularity.
At first improvements were easy to make without increasing lines of code much, but then improvements became small and LoC required became larger and larger with increasingly small improvements, which means very strong diminishing returns-- speedup is actually sublinear in lines of code. This could be an artifact related to the very large elbow early on, but I mostly believe it.
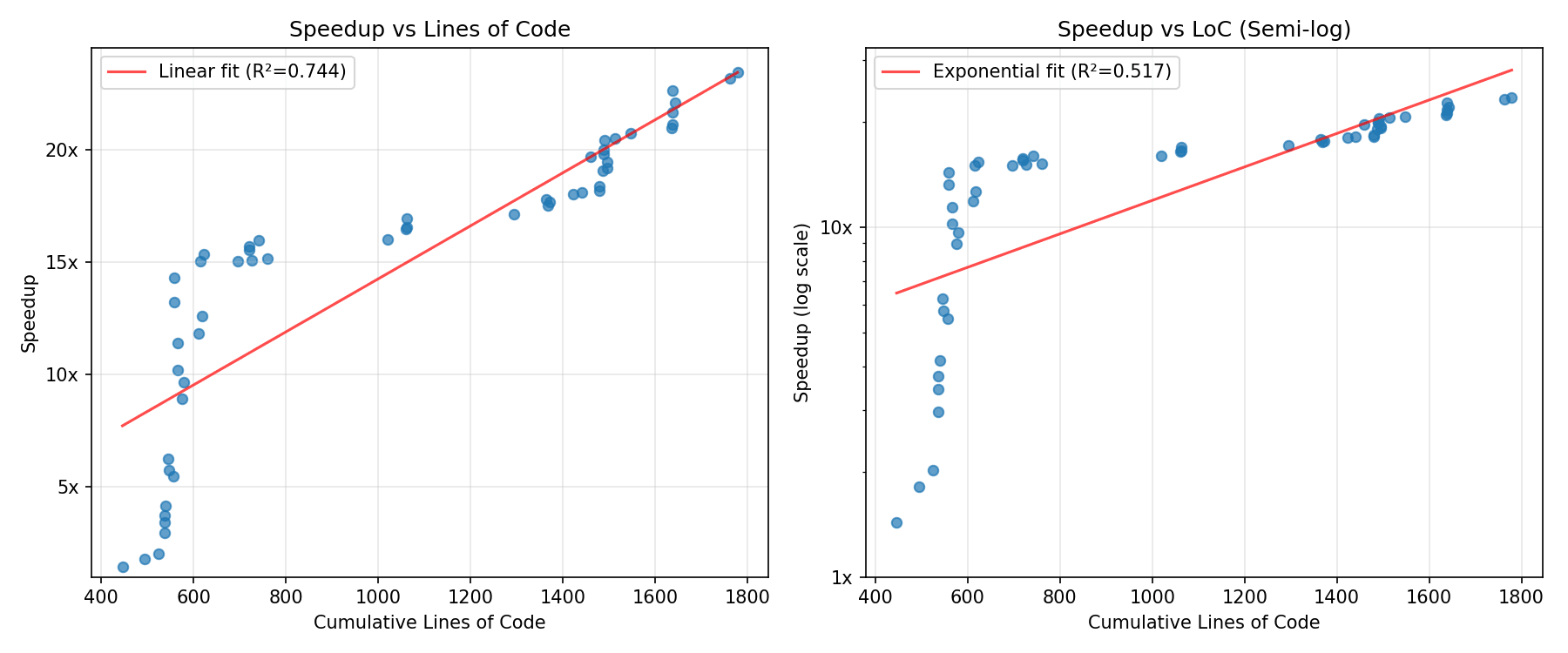
If we instead look at number of stars as a prox...
I am quite glad about the empirical analysis, but really don't get any of the parts of how this is evidence in favor or against a software only explosion.
Like, I am so confused about your definition of software-only intelligence explosion:
- A 23.5x improvement alone seems like it would qualify as a major explosion if it happened in a short enough period in time
- We already know that there is of course a fundamental limit to how fast you can make an algorithm, so the question is always "how close to optimal are current algorithms". It should be our very strong prior that any small subset of frontier model training will hit diminishing returns much quicker than the complete whole. In Davidson's model (which I don't generally think is a good model of the space, but we can use for the sake of discussion), this is modeled by the ceiling parameter. If you want to extrapolate from toy tasks like this, you at the very least need to make an estimate of where the ceiling for something like NanoGPT is.
- You say "However, this still points against a software intelligence explosion, which would require superlinear speedups for linear increases in cumulative effort.". I just have no idea what you mean
8
I didn't really define software intelligence explosion, but had something in mind like "self-reinforcing gains from automated research causing capabilities gains in 6 months to be faster than the labor/compute scaleup-driven gains in the 3 years from 2023-2025", and then question I was targeting with the second part was "After the initial speed-up from ASARA, does the pace of progress accelerate or decelerate as AI progress feeds back on itself?"
[...]
Seems about true. I claim that the nanogpt speedrun suggests this is only likely if future AI labor is exponentially faster at doing research than current humans, with many caveats of course, and I don't really have an opinion on that.
[...]
This is not as small a subset of training as you might think. The 53 optimizations in the nanogpt speedrun touched basically every part of the model, including the optimizer, embeddings, attention, other architectural details, quantization, hyperparameters, code optimizations, and Pytorch version. The main two things that limit a comparison to frontier AI are scale and data improvement. It's known there are many tricks that work at large scale but not at small scale. If you believe the initial 15x speedup is analogous and that the larger scale gives you a faster, then maybe we get something like a 100x speedup atop our current algorithms? But I don't really believe that the original nanoGPT, which was a 300-line repo written to be readable rather than efficient [1], is analogous to our current state. If there were a bunch of low-hanging fruit that could give strongly superlinear returns, we would see 3x/year efficiency gains with small increases in labor or compute over time, but we actually require 5x/year compute increase and ~3x per year labor increase.
[...]
Agree I was being a bit sloppy here. The derivative being infinite is not relevant in Davidson's model or my mind, it's whether the pace of progress accelerates or decelerates. It could still be very fast as it decel
2
Cool, this clarifies things a good amount for me. Still have some confusion about how you are modeling things, but I feel less confused. Thank you!
There is a notable slowdown in that progress, however we should note the following (so that we don't overinterpret it):
-
A lot of gains in this particular competition come from adaptations of the pre-existing research literature (it's not clear how much of non-yet-adopted acceleration is in the pre-existing literature, and it might be quite a lot, but (by definition) the pre-existing literature is a fixed size resource, with its use being subject to saturation, and the "true software intelligence explosion mode" would presumably include creation of novel research, and not just re-use of pre-existing research).
-
Organizationally, the big slowdown around 3 min coincides with the project organizer being hired by OpenAI, and then no longer contributing (and, for some time, not even reviewing record breaking pull requests). So for a while the project looked dormant. Now it is active again, but it's difficult to say if the level of participation is back to the pre-slowdown level.
-
One thing which should not be considered "pre-existing" literature is Muon optimizer (which is the child of the project organizer in collaboration with his colleagues and which is probably the most exciting
I think this is an interesting analysis. But it seems like you're updating more strongly on it than I am. Here are some thoughts.
The Forethought SIE model doesn't seem to apply well to this data:
In the Forethought model (without the ceiling add-on), the growth rate of "cognitive labor" is assumed to equal the growth rate of "software efficiency", which is in turn assumed to be proportional to the growth rate of cumulative "cognitive labor" (no matter the fixed level of compute). Whether this fooms or fizzles is determined only by whether this constant of proportionality is above or below 1.
In this framework, and with fixed experiment compute, the game is to find a trend for "software efficiency", then find a trend for cumulative "cognitive labor", then see which one is growing faster. So it matters quite a lot how you measure these two trends. (do you use the raw multiplier for software efficiency? or the number of OOMs? What about "cognitive labor"?)
It's worth stating that regardless of the value of , this model predicts that (in the right units) steady growth in cognitive labor (or cumulative cognitive labor) yields steady growth in software eff...
2
Note there are no log-log plots in the data. They're performance vs LoC and log(performance) vs LoC, and same for stars. I don't think we're at an absolute ceiling since two more improvements came out in the past week, they've just gotten smaller and taken more code to implement.
I need to think about this algorithmic progress being 10x/year thing. It feels like some assumptions are violated with how much the data seem to give inconsistent answers, maybe there's a prospective vs retrospective difference. Or do you think progress has just sped up in the past couple of years?
1
Progress probably has sped up in the past couple of years. And training compute scaling has, if anything, slowed down (it hasn't accelerated, anyway). So yes, I think "software progress" probably has sped up in the past couple of years.
I haven't looked into whether you can see the algorithmic progress speedup in the ECI data using the methodology I was describing. The data would be very sparse if you e.g. tried to restrict to pre-2024 models for greater alignment with the Algorithmic Progress in Language Models paper, which is where the 3x per year number comes from.
Also, that 3x per year number is only measuring pre-training improvements. Post-training (1) didn't really exist before 2022 and (2) was notably accelerated in 2024 by the introduction of RLVR. I wouldn't be confident in whether pre-training algorithmic progress alone is much faster than 3x per year today. (as rumor would have it, there's substantial divergence between the different AGI companies on the rate of pretraining progress.)
6
My colleague Manish did a lot more analysis here. The main takeaway so far is categorizing each PR's improvements as "deep" vs "shallow", as well as "imported-from-literature" vs "invented".
It looks like there were large, shallow improvements imported from the literature early on, while since then most improvements have been moderately involved and a larger portion are novel.
To get more evidence about SIE likelihood, we have lots of work in the pipeline, including interviews with nanogpt contributors, 1B+ token runs using Opus 4.7 and GPT-5.5 on our Inspect version of nanogpt, and other autoresearch-type tasks.
5
In this range of code lengths, 400-1800 lines, lines of code does not correlate with effort imo. It only takes like 1 day to write 1800 lines of code by hand. The actual effort is dominated by thinking of ideas and huge hyperparameter sweeps.
Another note: i was curious what they had to do to reduce torch startup time and such, and it turns out they spend 7 minutes compiling and warming up for their 2 minute training run lmao. That does make it more realistic but is a bit silly.
5
It may be that a 23x improvement is close to the limit we can get for GPT-2 124M at this loss level, but I would guess that for larger models and lower losses there are > 23x improvements possible. There are many algorithmic improvements (e.g. MoEs) which they don’t use because they benefit from larger scale and more compute.
4
They do have a GPT-2 medium track, which has improved by 20.0x from 5.8 hours to 17.35 minutes. My guess is the speedup isn't greater because the scale is barely larger (350M, which is only a 2.8x increase vs the ~1000x to current frontier models) and less effort has been applied. Nevertheless someone should try applying improvements from other open-source models to this track and see if they can get the ratio to >23x.
2
There's also this paper and benchmark/eval, which might provide some additional evidence: The Automated LLM Speedrunning Benchmark: Reproducing NanoGPT Improvements.
I think the framing "alignment research is preparadigmatic" might be heavily misunderstood. The term "preparadigmatic" of course comes from Thomas Kuhn's The Structure of Scientific Revolutions. My reading of this says that a paradigm is basically an approach to solving problems which has been proven to work, and that the correct goal of preparadigmatic research should be to do research generally recognized as impressive.
For example, Kuhn says in chapter 2 that "Paradigms gain their status because they are more successful than their competitors in solving a few problems that the group of practitioners has come to recognize as acute." That is, lots of researchers have different ontologies/approaches, and paradigms are the approaches that solve problems that everyone, including people with different approaches, agrees to be important. This suggests that to the extent alignment is still preparadigmatic, we should try to solve problems recognized as important by, say, people in each of the five clusters of alignment researchers (e.g. Nate Soares, Dan Hendrycks, Paul Christiano, Jan Leike, David Bau).
I think this gets twisted in some popular writings on LessWrong. John Wentworth w...
9
If the point you're trying to make is: "the way we go from preparadigmatic to paradigmatic is by solving some hard problems, not by communicating initial frames and idea", I think this points to an important point indeed.
Still, two caveats:
* First, Kuhn's concept of paradigm is quite an oversimplification of what actually happens in the history of science (and the history of most fields). More recent works that go through history in much more detail realize that at any point in fields there are often many different pieces of paradigms, or some strong paradigm for a key "solved" part of the field and then a lot of debated alternative for more concrete specific details.
* Generally, I think the discourse on history and philosophy of science on LW would improve a lot if it didn't mostly rely on one (influential) book published in the 60s, before much of the strong effort to really understand history of science and practices.
* Second, to steelman John's point, I don't think he means that you should only communicate your frame. He's the first to actively try to apply his frames to some concrete problems, and to argue for their impressiveness. Instead, I read him as pointing to a bunch of different needs in a preparadigmatic field (which maybe he could separate better ¯\_(ツ)_/¯)
* That in a preparadigmatic field, there is no accepted way of tackling the problems/phenomena. So if you want anyone else to understand you, you need to bridge a bigger inferential distance than in a paradigmatic field (or even a partially paradigmatic field), because you don't even see the problem in the same way, at a fundamental level.
* That if your goal is to create a paradigm, almost by definition you need to explain and communicate your paradigm. There is a part of propaganda in defending any proposed paradigm, especially when the initial frame is alien to most people, and even the impressiveness require some level of interpretation.
* That one way (not the only way) by
2
Strong agree. 👍
Consider this toy game-theoretic model of AI safety: The US and China each have an equal pool of resources they can spend on capabilities and safety. Each country produces either AIs aligned to it or misaligned AIs. If one country's AI is misaligned, both payoffs are zero. If both AIs are aligned, a payoff of 100 is split proportional to the resources invested in capability.
The ratio of safety to capabilities investment determines the probability of misalignment; specifically, probability of misalignment is c / (ks + c) for some "safety effectiveness parameter" k. (At k=1 we need a 1:1 safety:capabilities ratio to have a 50% chance of alignment per AI, whereas at k=100 we only need a 1:100 ratio.) There is no coordination, so we want the Nash equilibrium. What's the equilibrium strategy in terms of k, and what is the outcome? It turns out that:
- By symmetry, both countries will spend an equal fraction s* on safety, making the probability of alignment each P and so the overall probability of humanity surviving . The payout to each country is thus .
- When safety is ineffective (low k): Countries invest heavily in safety (s* ≈ 92% at k=0.1), but survival probability is sti
In a world with an AI pause, good management is much more important than the pause length. If the pause is government-mandated and happens late, I would prefer a 1-year pause with say Buck Shlegeris in charge over a 3-year pause with the average AI lab lead in charge.
The reason is that most of the safety research during the pause will be done by AIs. In a pause scenario where >50% of resources are temporarily dedicated to safety and >10x uplift is technically plausible, the speed of research is mainly limited by the level of AI we trust and our ability to understand the AI's findings. The world probably can't pause indefinitely, and it may not be desirable to do so. So what is the basic strategy for a finite AI pause?
- Use superhuman AIs as that are smart as possible to do safety research, but not so capable that they're misaligned. This may require avoiding use of latest gen models, or advancing capabilities and using the next gen only for safety.
- Use an elaborate monitoring framework and incrementally apply the safety research generated to increase the maximum capability level we can run at without being sabotaged when models are misaligned.
- Prevent capability advances from bei
5
In a world with a fixed length pause initiated when AI is powerful enough to "help" with alignment research, I expect that immediately after the pause ends, everyone dies. This is the perspective from which a 3 year pause is 3 times as valuable as a 1 year pause, and doesn't change much with management.
2
That is, you think alignment is so difficult that keeping humanity alive for 3 years is more valuable than the possibility of us solving alignment during the pause? Or that the AIs will sabotage the project in a way undetectable by management even if management is very paranoid about being sabotaged by any model that has shown prerequisite capabilities for it?
3
Conditional on the world deciding on a fixed length pause instead of a pause till the model is aligned, absolutely yes. Unconditionally, yes but with less confidence.
2
Ways this could be wrong:
* We can pause early (before AIs pose significant risk) at little cost
* We must pause early (AIs pose significant risk before they speed up research much). I think this is mostly ruled out by current evidence
* Safety research inherently has to be done by humans because it's less verifiable, even when capabilities is automated
* AI lab CEOs are good at management of safety research because their capabilities experience transfers (in this case I'd still much prefer Buck Shlegeris or Sam Altman over the US or China governments)
* It's easy to pause indefinitely once everyone realizes AIs are imminently dangerous, kind of like the current situation with nuclear
* Probably others I'm not thinking of
4
FYI I currently would mainline guess that this is true. Also I don't get why current evidence says anything about it – current AIs aren't dangerous, but that doesn't really say anything about whether an AI that's capable of speeding up superalignment or pivotal-act-relevant research by even 2x would be dangerous.
4
My view is that AIs are improving faster at research-relevant skills like SWE and math than they're increasing at misalignment (rate of bad behaviors like reward hacking, ease of eliciting an alignment faker, etc) or covert sabotage ability, such that we would need a discontinuity in both to get serious danger by 2x. There is as yet no scaling law for misalignment showing that it predictably gets worse when capabilities improve in practice.
The situation is not completely clear because we don't have good alignment evals and could get neuralese any year, but the data are pointing in that direction. I'm not sure about research taste as the benchmarks for that aren't very good. I'd change my mind here if we did see stagnation in research taste plus misalignment getting worse over time (not just sophistication of the bad things AIs do, but also frequency or egregiousness).
1
What benchmark for research taste there exist? If I understand correctly, Epoch AI's evaluation showed that the AIs lack creativity in a way since the combinatorial problems at IMO 2024 and the hard problem at IMO 2025 weren't solved by SOTA AI systems. A similar experiment was conducted by me and had Grok 4 commit the BFS to do a construction. Unfortunately, the ARC-AGI-1 and ARC-AGI-2 benchmarks could be more about visual intelligence, and the promising ARC-AGI-3 benchmark[1] has yet to be finished.
Of course, the worse-case scenario is that misalignment comes hand-in-hand with creativity (e.g. because of the AIs creating some moral code which doesn't adhere to the ideals of the AI's human hosts).
1. ^
Which is known to contain puzzles.
1
"I would prefer a 1-year pause with say Buck Shlegeris in charge " I think the best we can realistically do is something like a 1 year pause, and if done well gives a good chance of success. As you say 1 year with ~ASI will get a lot done. Some grand bargain where everyone pauses for one year in return for no more pauses perhaps.
Unfortunately it will be extremely hard for some org not to push the "self optimize" button during this time however. Thats why I would rather as few as possible leading AI labs during this time.
I would go so far as to say I would rather have 1 year like that than 100 years with current AI capabilities paused and alignment research progressed.
If you disagree with much of IABIED but are still worried about AI risk, maybe the question to ask is "will the radical flank effect be positive or negative on mainstream AI safety movements?", which seems more useful than "do I on net agree or disagree?" or "will people taking this book at face value do useful or anti-useful things?" Here's what Wikipedia has to say on the sign of a radical flank effect:
...It's difficult to tell without hindsight whether the radical flank of a movement will have positive or negative effects.[2] However, following are some factors that have been proposed as making positive effects more likely:
- Greater differentiation between moderates and radicals in the presence of a weak government.[2][13][14]: 411 As Charles Dobson puts it: "To secure their place, the new moderates have to denounce the actions of their extremist counterparts as irresponsible, immoral, and counterproductive. The most astute will quietly encourage 'responsible extremism' at the same time."[15]
- Existing momentum behind the cause. If change seems likely to happen anyway, then governments are more willing to accept moderate reforms in order to quell radicals.[2]
- Radicalism during the peak
2
I'm not 100% sure what this means (but it sounds interesting)
Agreed that this is a good frame.
1
So:
1. Not sure whether "weak government" applies. Factually, it does not seem like the federal administration is very interested in taking action on regulating AI, but on the other hand I do not think most voters perceive the Trump government as weak? I am also not sure I understand the point, but at any rate currently the moderates are not willing to denouncethe actions publicly very much?
2. There is some momentum, but change does not seem to happen likely anyway. Arguably, after the FLI letter two years have passed without major changes.
3. I don't think we are at peak activism yet, but also the movement is not clearly declining either.
4. There is strong polarization according to some viewpoints: Twitter and certain parts of the administration are very happy to point to "radical doomers" for discreditation.
Overall, I think these are a wash, but no strong yes. At any rate, I have the hunch that these factors were derived from large social movements whose path to impact was very bottom up and around high saliency issues to the public. At least for the moderates in this debate this is not the path to impact I think, it's rather influencing key stakeholders.
Possible post on suspicious multidimensional pessimism:
I think MIRI people (specifically Soares and Yudkowsky but probably others too) are more pessimistic than the alignment community average on several different dimensions, both technical and non-technical: morality, civilizational response, takeoff speeds, probability of easy alignment schemes working, and our ability to usefully expand the field of alignment. Some of this is implied by technical models, and MIRI is not more pessimistic in every possible dimension, but it's still awfully suspicious.
I strongly suspect that one of the following is true:
- the MIRI "optimism dial" is set too low
- everyone else's "optimism dial" is set too high. (Yudkowsky has said this multiple times in different contexts)
- There are common generators that I don't know about that are not just an "optimism dial", beyond MIRI's models
I'm only going to actually write this up if there is demand; the full post will have citations which are kind of annoying to find.
After working at MIRI (loosely advised by Nate Soares) for a while, I now have more nuanced views and also takes on Nate's research taste. It seems kind of annoying to write up so I probably won't do it unless prompted.
Edit: this is now up
6
I would be genuinely curious to hear your more nuanced views and takes on Nate s research taste. This is really quite interesting to me and even a single paragraph would be valuable!
5
I really want to see the post on multidimensional pessimism.
As for why, I'd argue 1 is happening.
For examples of 1, a good example of this is FOOM probabilities. I think MIRI hasn't updated on the evidence that FOOM is likely impossible for classical computers, and this ought to lower their probabilities to the chance that quantum/reversible computers appear.
Another good example is the emphasis on pivotal acts like "burn all GPUs." I think MIRI has too much probability mass on it being necessary, primarily because I think that they are biased by fiction, where problems must be solved by heroic acts, while in the real world more boring things are necessary. In other words, it's too exciting, which should be suspicious.
However that doesn't mean alignment is much easier. We can still fail, there's no rule that we make it through. It's that MIRI is systematically irrational here regarding doom probabilities or alignment.
Edit: I now think alignment is way, way easier than my past self, so I disendorse this sentence "However that doesn't mean alignment is much easier."
3
What constitutes pessimism about morality, and why do you think that one fits Eliezer? He certainly appears more pessimistic across a broad area, and has hinted at concrete arguments for being so.
2
Value fragility / value complexity. How close do you need to get to human values to get 50% of the value of the universe, and how complicated must the representation be? Also in the past there was orthogonality, but that's now widely believed.
3
I think the distance from human values or complexity of values is not a crux, as web/books corpus overdetermines them in great detail (for corrigibility purposes). It's mostly about alignment by default, whether human values in particular can be noticed in there, or if correctly specifying how to find them is much harder than finding some other deceptively human-value-shaped thing. If they can be found easily once there are tools to go looking for them at all, it doesn't matter how complex they are or how important it is to get everything right, that happens by default.
But also there is this pervasive assumption of it being possible to formulate values in closed form, as tractable finite data, which occasionally fuels arguments. Like, value is said to be complex, but of finite complexity. In an open environment, this doesn't need to be the case, a code/data distinction is only salient when we can make important conclusions by only looking at code and not at data. In an open environment, data is unbounded, can't be demonstrated all at once. So it doesn't make much sense to talk about complexity of values at all, without corrigibility alignment can't work out anyway.
2
I'd be very interested in a write-up, especially if you have receipts for pessimism which seems to be poorly calibrated, e.g. based on evidence contrary to prior predictions.
0
I think they pascals-mugged themselves and being able to prove they were wrong efficiently would be helpful
An indiscriminate space weapon against low earth orbit satellites is feasible for any spacefaring nation. Recent rumors claim that Russia is already developing one, so I'm writing a post about it. I will explain why I think
- This weapon could require just one launch to destroy every satellite in low Earth orbit, including all Starlinks, and deny it to everyone for months to years
- It would consist of about 10^9 small ball bearings in retrograde orbit. An alternate design involves a nuclear device.
- Further launches could deny GEO and other orbits
- Russia, China, or the US could have one in orbit right now, and Russia may be incentivized to use one
- Defense of current space assets is nearly impossible, whether by shooting it down or evading the debris [edit: I no longer believe this. Shielding of military satellites and moving Starlink to VLEO are both potentially viable]
- Once the weapon goes off the strategic landscape in space is unclear to me
What objections or details should I include? Also is it a dangerous infohazard?
4
if I understand correctly, this is a really straightforward attack (the bearing ball version at least - the nuclear weapon version is obviously less accessible). shouldn't basically any spacefaring country be able to do this? in fact, even any private citizen could if they manage to sneak it past the regulators? though maybe this is just strictly dominated by bioweapon risk (more tractable + impactful)
6
Yes any spacefaring country, probably not most private citizens given the ITAR controls that are already put on rocket tech to regulate ballistic missiles. As for bioweapons, they're higher on the escalation ladder and harder to control. Will be sure to think about it more and cover this
I've been thinking about what retirement planning means given AGI. I previously mentioned investment ideas that, in a very capitalistic future, could allow the average person to buy galaxies. But it's also possible that property rights won't even continue into the future due to changes brought about by AGI. What will these other futures look like (supposing we don't all die) and what's the equivalent of "responsible retirement planning"?
Is it building social and political capital? Making my impact legible to future people and AIs? Something else? Is any action we take today futile?
I think if we do a good job, there will be a lot "let's try to reward the people who helped get us through this in a positive way". In as much as I have resources I certainly expect to spend a bunch of them on ancestor simulations and incentives for past humans to do good things. My guess is lots of other people will have similar instincts.
I wouldn't worry that much about legibility, I expect a future superintelligent humanity to be very good at figuring out what people did, and whether it helped.
I am totally not confident of this, but it's one of my best guesses on how things will go.
9
Hmm, I'm pretty pessimistic about this, for two reasons:
* Historical examples indicate that receiving large material rewards for impact is rare.
Claude's thoughts on historical examples
Looking at historical examples, the pattern is quite pessimistic for receiving material rewards from future societies:
Symbolic recognition is common, material transfers are rare:
* Scientific pioneers (Darwin, Curie, Tesla) get statues and prizes named after them, but their descendants don't receive ongoing material compensation
* Revolutionary heroes and nation builders are honored, but many died in debt (Jefferson) or their lines died out (Washington)
* Abolitionists, suffragettes, and civil rights activists rarely received material rewards - recognition came much later and was mostly symbolic
* War veterans often receive inadequate compensation despite their sacrifices; even when benefits exist (like the GI Bill), they're immediate/contractual, not retrospective decisions by future societies
The few cases of retrospective material transfers are limited:
* Reparations (Holocaust survivors, Japanese internment) compensate victims of injustice, not reward heroes
* These required massive political struggle and were often incomplete
* Normal inheritance transfers wealth, but that's family accumulation, not society deliberately rewarding contributions
Why societies don't do this:
Coordination problems (who decides who deserves what?), competing claims, present needs feeling more urgent, changed values over time, and unclear implementation (do descendants get it? How much? For how many generations?)
What makes the AGI scenario potentially different:
Habryka's speculation about ancestor simulations relies on unprecedented factors - radical post-scarcity abundance, simulation technology, and superintelligent agents making allocation decisions. We have no historical examples of societies with this capability.
One reason this analysis might be wrong: History shows what
Most people don't subscribe to a decision theory where rewarding people after the fact for one-time actions provides an incentive, and for the incentive to actually work, both the rewarders and rewardees need to believe in it the same way they believe in property rights. Maybe they will in the fullness of time, but it seems far from guaranteed.
This seems clearly false? Prices are maybe the default mechanism for status allocations? I think it's maybe just economists with weird CDT-brained-takes that don't believe in retroactive funding stuff as an incentive. Any workplace will tell you that of course they want to reward good work even after the fact, even if it's a one-time thing, and people saying "ah, but it's a one time thing, why would I reward you this time" would I think pretty obviously be considered mildly sociopathic.
Agree financial compensation is rarer, and the logic here gets a bit trickier. I think people's intuitions around status allocation are much more likely to generalize here than precedent of financial allocation.
But also, beyond all of that, the arguments around decision-theory are I think just true in the kind of boring way that physical facts about the world are true, and saying that people will have the wrong decision-theory in the future sounds to me about as mistaken as saying that lots of people will disbelieve the theory of evolution in the future. It's clearly the kind of thing you update on as you get smarter.
8
This seems way overconfident:
1. Our current DT candidates (FDT/UDT) may not be correct or on the right track.
2. Smart != philosophically competent. (There are literally millions of people in China with higher IQ than me, but AFAIK none of them invented something like FDT/UDT or is very interested in it.)
3. We have little idea what FDT/UDT say about what is normatively correct in this situation or in general about potential acausal interaction between a human and a superintelligence, partly because we can't run the math, partly because we don't even know what the math is because we can't formalize these theories.
Another way to put it is that globally we're a bubble (people who like FDT/UDT) within a bubble (analytic philosophy tradition) within a bubble (people who are interested in any kind of philosophy), and then even within this nested bubble there's a further split/disagreement about what FDT/UDT actually says about this specific kind of game/interaction.
(1) seems like evidence in favor of what I am saying. In as much as we are not confident in our current DT candidates, it seems like we should expect future much smarter people to be more correct. Us getting DT wrong is evidence that getting it right is less dependent on incidental details of the people thinking about it.
(2) I mean, there are also literally millions of people in China with higher IQ than you that believe in spirits, and millions in the rest of the world that believe in the Christian god and disbelieve evolution. The correlation between correct DT and intelligence seems about as strong as it does for the theory of evolution (meaning reasonably strong in the human range, but the human range is narrow enough to not overdetermine the correct answer, especially when you don't have any reason to think hard about it)
(3) I am quite confident that pure CDT which rules out retrocausal incentives is false. I agree that I do not know what the right way to run the math is to understand when retrocausal incentives work, and how important they are. I really don't have much uncertainty on this, so I don't really get your point here. I don't need to formalize these theories to make a confident prediction that any "decision theory where rewarding people after the fact for one-time actions" cannot provide an incentive is false.
5
Suppose we rule out pure CDT. That still leaves "whatever the right DT is (even if it's something like FDT/UDT), if you actually run the math on it, it says that rewarding people after the fact for one-time actions provides practically zero incentives (if people means pre-singularity humans)". I don't see how we can confidently rule this out.
4
Yep, agree this is possible (though pretty unlikely), but I was just invoking this stuff to argue against pure CDT (or equivalent decision-theories that Thomas was saying would rule out rewarding people after the fact being effective).
Or to phrase it a different way: I am very confident that future, much smarter, people will not believe in decision-theories that rule out retrocausal incentives as a class. I am reasonably confident, though not totally confident, that de-facto retrocausal incentives will bite on currently alive humans. This overall makes me think it's like 70% likely that if we make it through the singularity well, then future civilizations will spend a decent amount of resources aligning incentives retroactively.
This isn't super confident, but you know, somewhat more likely than not.
7
Wow. We have extremely different beliefs on this front. IMO, almost nothing is retroactively funded, and even high-status prizes are a tiny percentage of anything.
[...]
No workplace that I know of DOES retroactively reward good work if the employee is no longer employed there. Most of the rhetoric about it is just signaling, in pursuit of retention and future productivity.
[...]
It seems likely that they'll accept evolution, and still not feel constrained by it, and pursue more directed and efficient anti-entropy measures. It also seems extremely likely that they'll use a decision theory that actually works to place them in the universe they want, which may or may not include compassion for imaginary or past or otherwise causally-unreachable things.
(edit to clarify the decision-theory comment)
[...]
It's not clear that any likely decision theory, let alone a non-wrong one, requires fully-acausal beliefs or actions. Many of them do include a more complete causality diagram than CDT does, and many acknowledge the the point-of-decision is often much different than the apparent one. But they're all basically consequentialist, in that they believe that actions can influence future states of the universe.
6
there’s a long tradition of awarding military victors with wealth and titles
5
Do you mean prizes? This is pretty compelling in some ways; I think it's plausible that AI safety people will win at least as many prizes as nuclear disarmament people, if we're as impactful as I hope we are. I'm less sure whether prizes will come with resources or if I will care about the kind of status they confer.
I also feel weird about prizes because many of them seem to have a different purpose from retroactively assigning status fairly based on achievement. Like, some people would describe them as retroactive status incentives, but others would say they're about celebrating accomplishments, others would say they're a forward-looking field-shaping signal, etc.
The workplace example feels different to me because workers can just reason that employers will keep their promises or lose reputation, so it's not truly one-time. That would be analogous to the world where the US government had already announced it would award galaxies to people for creating lots of impact. I'm also not as confident as you in decision theory applying cleanly to financial compensation. E.g. maybe it creates unavoidable perverse incentives somehow.
If you think my future prizes will total at least ~1% of the impact I create I'd be happy to make a bet and sell you shares of these potential future prizes. It seems not totally well-defined but better than impact equity. I'm worried however that this kind of transaction won't clear due to the enormous op cost of dollars right now.
2
Yep, sorry, prizes!
[...]
Agree there are not one-time dynamics, but I would bet that the vast majority of people would have strong intuitions that they shouldn't defect on the last round of the game (in general, if people truly adopted decision-theories that thought defecting on single-shot games was rational, then all definitive finite games would also end up in defect-defect equilibria via induction, which clearly doesn't happen).
7
I'd argue people have norms that they shouldn't defect on the last round of the game because being trustworthy is useful. This doesn't generalize to taking whatever actions our monkey-brained approximation of LDT implies we should do according to our monkey-brained judgement of what logical correlations they create.
2
"In as much as I have resources I certainly expect to spend a bunch of them on ancestor simulations and incentives for past humans to do good things."
Just curious, but what are your views on the ethics of running ancestor simulations? I'd be worried about running a simulation with enough fidelity that I triggered phenomenal consciousness, and then I would fret about my moral duty to the simulated (à la the Problem of Suffering).
Is it that you feel motivated to be the kind of person that would simulate our current reality as a kind of existence proof for the possibility of good-rewarding-incentives now? Or do you have an independent rationale for simulating a world like our own, suffering and all?
9
I think it's fine to simulate people who suffer a bit in the pursuit of positively shaping the long-term future. I am not totally confident of this. Luckily I will get to be much much smarter and wiser before I have to make this call.
I am sure that even if exact ancestor simulations end up being a bad idea, there will be other things you can do to figure out what happened and who was responsible, etc.
4
there's a lot of fully-unknown possibilities. For me, I generalize most "today's fundamentals don't apply" scenarios into "my current actions won't have predictable/optimizable impact beyond the discontinuity", so I don't think about specifics or optimization within them - I do think a bit about how to make them less likely or more tolerable, but I can't really quantify.
Which leaves the cases where the fundamentals DO apply, and is ONLY short- and medium-term optimizations. Nothing I plan for in 100 years is going to happen, so I want to take care of myself and my family in coming decades in cases where things don't collapse or go too weird. current income > expenses, and reasonable investment strategy (10- and 30-year target date funds, unless you know better, which you don't) cover the most probability-weight for the next few decades, contingent on any current systems continuing that long.
Your suggestion of social capital (not sure political capital is all that durable, but maybe?) is a very good one as well - having friends, especially friends in different situations (another country, perhaps) is extremely good. First, it's fun and rewarding immediately. Second, it's a source of illegible support if things go crazy, but not extinction-crazy.
2
My personal strategy has been to not think about it very hard.
I am sufficiently fortunate that I can put a normal amount of funds into retirement, and I have continued to do so on the off chance that my colleagues and I succeed at preventing the emergence of AGI/ASI and the world remains mostly normal. I also don't want to frighten my partner with my financial choices, and giving her peace of mind is worth quite a lot to me.
If superintelligence emerges and doesn't kill everyone or worse, then I don't have any strong preferences as to what my role is in the new social order, since I expect to be about as well-off as I am now or more.
1
I can think of two different ways property rights might disappear:
1. Our new overlords extinguish existing property rights and establish some new system for distributing resources of their choosing based on some other principle.
2. Resources are so abundant that ownership is irrelevant.
If you're preparing for #2, then you probably just want to invest in all the "things money can't buy" because you'll have the rest.
If you're preparing for #1, it's hard to predict what the principle might be. Conditional on not dying, either we're dealing with a benevolent-ish AI overlord (and you're probably fine; doing things like living justly are probably a good idea if that's going to be rewarded) or we're dealing with an AI overlord that is subject to some kind of human control (maybe the future is really being run by Anthropic's corporate leadership or something). In that case, responsible retirement planning is probably finding a way to get close to that in-group.
2
I'm thinking mostly of #1 and your thought seems reasonable there. #2 doesn't make sense to me, since the number of galaxies is finite and, barring #1, there are several reasons for competition over even extremely abundant resources-- Red Queen geopolitical races, people who want to own position goods, etc.
In terms of developing better misalignment risk countermeasures, I think the most important questions are probably:
- How to evaluate whether models should be trusted or untrusted: currently I don't have a good answer and this is bottlenecking the efforts to write concrete control proposals.
- How AI control should interact with AI security tools inside labs.
More generally:
- How can we get more evidence on whether scheming is plausible?
- How scary is underelicitation? How much should the results about password-locked models or arguments about being able to generate small numbers of high-quality labels or demonstrations affect this?
4
"How can we get more evidence on whether scheming is plausible?" - What if we ran experiments where we included some pressure towards scheming (either RL or fine-tuning) and we attempted to determine the minimum such pressure required to cause scheming? We could further attempt to see how this interacts with scaling.
8
I'd say 1 important question is whether the AI control strategy works out as they hope.
I agree with Bogdan that making adequate safety cases for automated safety research is probably one of the most important technical problems to answer (since conditional on the automating AI safety direction working out, then it could eclipse basically all safety research done prior to the automation, and this might hold even if LWers really had basically perfect epistemics given what's possible for humans, and picked closer to optimal directions, since labor is a huge bottleneck, and allows for much tighter feedback loops of progress, for the reasons Tamay Besiroglu identified):
https://x.com/tamaybes/status/1851743632161935824
https://x.com/tamaybes/status/1848457491736133744
5
Here's some candidates:
1 Are we indeed (as I suspect) in a massive overhang of compute and data for powerful agentic AGI? (If so, then at any moment someone could stumble across an algorithmic improvement which would change everything overnight.)
2 Current frontier models seem much more powerful than mouse brains, yet mice seem conscious. This implies that either LLMs are already conscious, or could easily be made so with non-costly tweaks to their algorithm. How could we objectively tell if an AI were conscious?
3 Over the past year I've helped make both safe-evals-of-danger-adjacent-capabilities (e.g. WMDP.ai) and unpublished infohazardous-evals-of-actually-dangerous-capabilities. One of the most common pieces of negative feedback I've heard on the safe-evals is that they are only danger-adjacent, not measuring truly dangerous things. How could we safely show the correlation of capabilities between high performance on danger-adjacent evals with high performance on actually-dangerous evals?
4
Why is this relevant for technical AI alignment (coming at this as someone skeptical about how relevant timeline considerations are more generally)?
3
If tomorrow anyone in the world could cheaply and easily create an AGI which could act as a coherent agent on their behalf, and was based on an architecture different from a standard transformer.... Seems like this would change a lot of people's priorities about which questions were most urgent to answer.
4
Fwiw I basically think you are right about the agentic AI overhang and obviously so. I do think it shapes how one thinks about what's most valuable in AI alignment.
4
I kind of wished you both gave some reasoning as to why you believe that the agentic AI overhang/algorithmic overhang is likely, and I also wish that Nathan Helm Burger and Vladimir Nesov discussed this topic in a dialogue post.
4
Glib formality: current LLMs do approximate something like a speed prior solomonoff inductor for internetdata but do not approximate AIXI.
There is a whole class of domains that are not tractably accesible from next-token prediction on human generated data. For instance, learning how to beat alphaGo with only access to pre2014 human go games.
4
IMO, I think AlphaGo's success was orthogonal to AIXI, and more importantly, I expect AIXI to be very hard to approximate even as an approximatable ideal, so what's the use case for thinking future AIs will be AIXI-like?
I will also say that while I don't think pure LLMs will be just scaled forwards, just because there's a use for inference time compute scaling, I think that conditional on AGI and ASI being achieved, the strategy will look more iike using lots and lots of synthetic data to compensate for compute, whereas Solomonoff induction has a halting oracle with lots of compute, and can infer lots of things with the minimum data possible, while we will rely on a data-rich, compute poor strategy compared to approximate AIXI.
2
The important thing is that both do active learning & decisionmaking & search, i.e. RL. *
LLMs don't do that. So the gain from doing that is huge.
Synthetic data is a bit of a weird word that get's thrown around a lot. There are fundamental limits on how much information resampling from the same data source will yield about completely different domains. So that seems a bit silly. Ofc sometimes with synthetic data people just mean doing rollouts, i.e. RL.
*the word RL sometimes gets mistaken for only very specific reinforcement learning algorithm. I mean here a very general class of algorithms that solve MDPs.
4
The lack of a robust, highly general paradigm for reasoning about AGI models is the current greatest technical problem, although it is not what most people are working on.
What features of architecture of contemporary AI models will occur in future models that pose an existential risk?
What behavioral patterns of contemporary AI models will be shared with future models that pose an existential risk?
Is there a useful and general mathematical/physical framework that describes how agentic, macroscropic systems process information and interact with the environment?
Does terminology adopted by AI Safety researchers like "scheming", "inner alignment" or "agent" carve nature at the joints?
4
Something like a safety case for automated safety research (but I'm biased)
3
Answering this from a legal perspective:
[...]
2
Are Eliezer and Nate right that continuing the AI program will almost certainly lead to extinction or something approximately as disastrous as extinction?
You should update by +-1% on AI doom surprisingly frequently
This is just a fact about how stochastic processes work. If your p(doom) is Brownian motion in 1% steps starting at 50% and stopping once it reaches 0 or 1, then there will be about 50^2=2500 steps of size 1%. This is a lot! If we get all the evidence for whether humanity survives or not uniformly over the next 10 years, then you should make a 1% update 4-5 times per week. In practice there won't be as many due to heavy-tailedness in the distribution concentrating the updates in fewer events, and the fact you don't start at 50%. But I do believe that evidence is coming in every week such that ideal market prices should move by 1% on maybe half of weeks, and it is not crazy for your probabilities to shift by 1% during many weeks if you think about it often enough. [Edit: I'm not claiming that you should try to make more 1% updates, just that if you're calibrated and think about AI enough, your forecast graph will tend to have lots of >=1% week-to-week changes.]
The general version of this statement is something like: if your beliefs satisfy the law of total expectation, the variance of the whole process should equal the variance of all the increments involved in the process.[1] In the case of the random walk where at each step, your beliefs go up or down by 1% starting from 50% until you hit 100% or 0% -- the variance of each increment is 0.01^2 = 0.0001, and the variance of the entire process is 0.5^2 = 0.25, hence you need 0.25/0.0001 = 2500 steps in expectation. If your beliefs have probability p of going up or down by 1% at each step, and 1-p of staying the same, the variance is reduced by a factor of p, and so you need 2500/p steps.
(Indeed, something like this standard way to derive the expected steps before a random walk hits an absorbing barrier).
Similarly, you get that if you start at 20% or 80%, you need 1600 steps in expectation, and if you start at 1% or 99%, you'll need 99 steps in expectation.
One problem with your reasoning above is that as the 1%/99% shows, needing 99 steps in expectation does not mean you will take 99 steps with high probability -- in this case, there's a 50% chance you need only one ...
I talked about this with Lawrence, and we both agree on the following:
- There are mathematical models under which you should update >=1% in most weeks, and models under which you don't.
- Brownian motion gives you 1% updates in most weeks. In many variants, like stationary processes with skew, stationary processes with moderately heavy tails, or Brownian motion interspersed with big 10%-update events that constitute <50% of your variance, you still have many weeks with 1% updates. Lawrence's model where you have no evidence until either AI takeover happens or 10 years passes does not give you 1% updates in most weeks, but this model is almost never the case for sufficiently smart agents.
- Superforecasters empirically make lots of little updates, and rounding off their probabilities to larger infrequent updates make their forecasts on near-term problems worse.
- Thomas thinks that AI is the kind of thing where you can make lots of reasonable small updates frequently. Lawrence is unsure if this is the state that most people should be in, but it seems plausibly true for some people who learn a lot of new things about AI in the average week (especially if you're very good at forecasting).&
4
Thank you a lot for this. I think this or @Thomas Kwas comment would make an excellent original-sequences-style post—it doesn't need to be long, but just going through an example and talking about the assumptions would be really valuable for applied rationality.
After all, it's about how much one should expect ones beliefs to vary, which is pretty important.
8
But... Why would p(doom) move like Brownian motion until stopping at 0 or 1?
I don't disagree with your conclusions, there's a lot of evidence coming in, and if you're spending full time or even part time thinking about alignment, a lot of important updates on the inference. But assuming a random walk seems wrong.
Is there a reason that a complex, structured unfolding of reality would look like a random walk?
4
Because[1] for a Bayesian reasoner, there is conservation of expected evidence.
Although I've seen it mentioned that technically the change in the belief on a Bayesian should follow a Martingale, and Brownian motion is a martingale.
----------------------------------------
1. I'm not super technically strong on this particular part of the math. Intuitively it could be that in a bounded reasoner which can only evaluate programs in P, any pattern in its beliefs that can be described by an algorithm in P is detected and the predicted future belief from that pattern is incorporated into current beliefs. On the other hand, any pattern described by an algorithm in EXPTIME∖P can't be in the class of hypotheses of the agent, including hypotheses about its own beliefs, so EXPTIME patterns persist. ↩︎
8
Technically, the probability assigned to a hypothesis over time should be the martingale (i.e. have expected change zero); this is just a restatement of the conservation of expected evidence/law of total expectation.
The random walk model that Thomas proposes is a simple model that illustrates a more general fact. For a martingale(Sn)n∈Z+, the variance of St is equal to the sum of variances of the individual timestep changes Xi:=Si−Si−1 (and setting S0:=0): Var(St)=∑ti=1Var(Xi). Under this frame, insofar as small updates contribute a large amount to the variance of each update Xi, then the contribution to the small updates to the credences must also be large (which in turn means you need to have a lot of them in expectation[1]).
Note that this does not require any strong assumption besides that the the distribution of likely updates is such that the small updates contribute substantially to the variance. If the structure of the problem you're trying to address allows for enough small updates (relative to large ones) at each timestep, then it must allow for "enough" of these small updates in the sequence, in expectation.
----------------------------------------
While the specific +1/-1 random walk he picks is probably not what most realistic credences over time actually look like, playing around with it still helps give a sense of what exactly "conservation of expected evidence" might look/feel like. (In fact, in the dath ilan of Swimmer's medical dath ilan glowfics, people do use a binary random walk to illustrate how calibrated beliefs typically evolve over time.)
Now, in terms of if it's reasonable to model beliefs as Brownian motion (in the standard mathematical sense, not in the colloquial sense): if you suppose that there are many, many tiny independent additive updates to your credence in a hypothesis, your credence over time "should" look like Brownian motion at a large enough scale (again in the standard mathematical sense), for similar reasons as t
4
I get conservation of expected evidence. But the distribution of belief changes is completely unconstrained.
Going from the class martingale to the subclass Brownian motion is arbitrary, and the choice of 1% update steps is another unjustified arbitrary choice.
I think asking about the likely possible evidence paths would improve our predictions.
You spelled it conversation of expected evidence. I was hoping there was another term by that name :)
8
To be honest, I would've preferred if Thomas's post started from empirical evidence (e.g. it sure seems like superforecasters and markets change a lot week on week) and then explained it in terms of the random walk/Brownian motion setup. I think the specific math details (a lot of which don't affect the qualitative result of "you do lots and lots of little updates, if there exists lots of evidence that might update you a little") are a distraction from the qualitative takeaway.
A fancier way of putting it is: the math of "your belief should satisfy conservation of expected evidence" is a description of how the beliefs of an efficient and calibrated agent should look, and examples like his suggest it's quite reasonable for these agents to do a lot of updating. But the example is not by itself necessarily a prescription for how your belief updating should feel like from the inside (as a human who is far from efficient or perfectly calibrated). I find the empirical questions of "does the math seem to apply in practice" and "therefore, should you try to update more often" (e.g., what do the best forecasters seem to do?) to be larger and more interesting than the "a priori, is this a 100% correct model" question.
2
Oops, you're correct about the typo and also about how this doesn't restrict belief change to Brownian motion. Fixing the typo.
6
Thank you a lot! Strong upvoted.
I was wondering a while ago whether Bayesianism says anything about how much my probabilities are "allowed" to oscillate around—I was noticing that my probability of doom was often moving by 5% in the span of 1-3 weeks, though I guess this was mainly due to logical uncertainty and not empirical uncertainty.
Since there are 10 5% steps between 50% and 0 or 1, and for ~10 years, I should expect to make these kinds of updates ~100 times, or 10 times a year, or a little bit less than once a month, right? So I'm currently updating "too much".
6
Interesting...
Wouldn't I expect the evidence to come out in a few big chunks, e.g. OpenAI releasing a new product?
6
To some degree yes, but I expect lots of information to be spread out across time. For example: OpenAI releases GPT5 benchmark results. Then a couple weeks later they deploy it on ChatGPT and we can see how subjectively impressive it is out of the box, and whether it is obviously pursuing misaligned goals. Over the next few weeks people develop post-training enhancements like scaffolding, and we get a better sense of its true capabilities. Over the next few months, debate researchers study whether GPT4-judged GPT5 debates reliably produce truth, and control researchers study whether GPT4 can detect whether GPT5 is scheming. A year later an open-weights model of similar capability is released and the interp researchers check how understandable it is and whether SAEs still train.
4
I think this leans a lot on "get evidence uniformly over the next 10 years" and "Brownian motion in 1% steps". By conservation of expected evidence, I can't predict the mean direction of future evidence, but I can have some probabilities over distributions which add up to 0.
For long-term aggregate predictions of event-or-not (those which will be resolved at least a few years away, with many causal paths possible), the most likely updates are a steady reduction as the resolution date gets closer, AND random fairly large positive updates as we learn of things which make the event more likely.
3
I think all the assumptions that go into this model are quite questionable, but it's still an interesting thought.
2
It definitely should not move by anything like a Brownian motion process. At the very least it should be bursty and updates should be expected to be very non-uniform in magnitude.
In practice, you should not consciously update very often since almost all updates will be of insignificant magnitude on near-irrelevant information. I expect that much of the credence weight turns on unknown unknowns, which can't really be updated on at all until something turns them into (at least) known unknowns.
But sure, if you were a superintelligence with practically unbounded rationality then you might in principle update very frequently.
2
The Brownian motion assumption is rather strong but not required for the conclusion. Consider the stock market, which famously has heavy-tailed, bursty returns. It happens all the time for the S&P 500 to move 1% in a week, but a 10% move in a week only happens a couple of times per decade. I would guess (and we can check) that most weeks have >0.6x of the average per-week variance of the market, which causes the median weekly absolute return to be well over half of what it would be if the market were Brownian motion with the same long-term variance.
Also, Lawrence tells me that in Tetlock's studies, superforecasters tend to make updates of 1-2% every week, which actually improves their accuracy.
2
Probabilities on summary events like this are mostly pretty pointless. You're throwing together a bunch of different questions, about which you have very different knowledge states (including how much and how often you should update about them).
Maybe this is too tired a point, but AI safety really needs exercises-- tasks that are interesting, self-contained (not depending on 50 hours of readings), take about 2 hours, have clean solutions, and give people the feel of alignment research.
I found some of the SERI MATS application questions better than Richard Ngo's exercises for this purpose, but there still seems to be significant room for improvement. There is currently nothing smaller than ELK (which takes closer to 50 hours to develop a proposal for and properly think about it) that I can point technically minded people to and feel confident that they'll both be engaged and learn something.
3
If you let me know the specific MATS application questions you like, I'll probably add them to my exercises.
(And if you let me know the specific exercises of mine you don't like, I'll probably remove them.)
2
Not sure if this is what you want, but I can imagine an exercise in Goodharting. You are given the criteria for a reward and the thing they were supposed to maximize, your task is to figure out the (least unlikely) way to score very high on the criteria without doing to well on the intended target.
For example: Goal = make the people in the call center more productive. Measure = your salary depends on how many phone calls you handle each day. Intended behavior = picking up the phone quickly, trying to solve the problems quickly. Actual behavior = "accidentally" dropping phone calls after a few seconds so that the customer has to call you again (and that counts by the metric as two phone calls answered).
Another example: Goal = make the software developers more productive. Measure 1 = number of lines of code written. Measure 2 = number of bugs fixed.
I am proposing this because it seems to me that from a 30000 foot view, a big part of AI alignment is how to avoid Goodharting. ("Goal = create a happy and prosperous future for humanity. Measure = something that sounds very smart and scientific. Actual behavior = universe converted to paperclips, GDP successfully maximized.")
The uplift equation:
What is required for AI to provide net speedup to a software engineering project, when humans write higher quality code than AIs? It depends how it's used.
Cursor regime
In this regime, similar to how I use Cursor agent mode, the human has to read every line of code the AI generates, so we can write:
Where
- is the time for the human to write the code, either from scratch or after rejecting an AI suggestion
- is the time for the AI to generate the code in tokens per second.
- is the time for the human to check the code, accept or reject it, and make any minor revisions, in order to bring the code quality and probability of bugs equal with human-written code ()
- is the fraction of AI suggestions that are rejected entirely.
Note this neglects other factors like code review time, code quality, bugs that aren't caught by the human, or enabling things the human can't do.
Autonomous regime
In this regime the AI is reliable enough that the human doesn't check all the code for bugs, and instead eats the chance of costly bugs entering the codebase.
...
6
Unless the work can be parallelized.
1
This calculus changes when you can work on many things at once (similar to @faul_sname's comment but this might be that you can work on many projects at once, even if they can't each be parallelized well).
GDM paper: Evaluating the Goal-Directedness of Large Language Models
Tom Everitt, Rohin Shah, and others from GDM attempt to measure "whether LLMs use their capabilities towards their given goal". Unlike previous work, their measure is not just rescaled task performance-- rather, an AI is goal-directed if it uses its capabilities effectively. A model that is not goal-directed when attempting a task will have capabilities but not properly use them. Thus, we can measure goal-directedness by comparing a model's actual performance to how it should perform if it were using its full capabilities on subtasks.

This kind of measure could in principle be useful to measure:
- prerequisites of scheming: maybe a model is not capable of scheming until it reaches some level of goal-directedness, and we can forecast when that happens
- elicitation: a normally goal-directed model that is not trying on evals may be underelicited
- sandbagging: if an AI unexpectedly has low goal-directedness on evals, this could be a warning sign for sandbagging.
Unfortunately, it's mostly saturated already-- Gemini 2.0 and Claude 3.7 are over 95%. Even GPT-4 gets over 70%.
So until we measure models on tasks where they are curre...
2
Interesting paper. Quick thoughts:
* I agree the benchmark seems saturated. It's interesting that the authors frame it the other way - Section 4.1 focuses on how models are not maximally goal-directed.
* It's unclear to me how they calculate the goal-directedness for 'information gathering', since that appears to consist only of 1 subtask.
Will we ever have Poké Balls in real life? How fast could they be at storing and retrieving animals? Requirements:
- Made of atoms, no teleportation or fantasy physics.
- Small enough to be easily thrown, say under 5 inches diameter
- Must be able to disassemble and reconstruct an animal as large as an elephant in a reasonable amount of time, say 5 minutes, and store its pattern digitally
- Must reconstruct the animal to enough fidelity that its memories are intact and it's physically identical for most purposes, though maybe not quite to the cellular level
- No external power source
- Works basically wherever you throw it, though it might be slower to print the animal if it only has air to use as feedstock mass or can't spread out to dissipate heat
- Should not destroy nearby buildings when used
- Animals must feel no pain during the process
It feels pretty likely to me that we'll be able to print complex animals eventually using nanotech/biotech, but the speed requirements here might be pushing the limits of what's possible. In particular heat dissipation seems like a huge challenge; assuming that 0.2 kcal/g of waste heat is created while assembling the elephant, which is well below what elephants need t...
5
All we need to create is a Ditto. A blob of nanotech wouldn't need 5 seconds to take the shape of the surface of an elephant and start mimicing its behavior; is it good enough to optionally do the infilling later if it's convenient?
Tech tree for worst-case/HRAD alignment
Here's a diagram of what it would take to solve alignment in the hardest worlds, where something like MIRI's HRAD agenda is needed. I made this months ago with Thomas Larsen and never got around to posting it (mostly because under my worldview it's pretty unlikely that we can, or need to, do this), and it probably won't become a longform at this point. I have not thought about this enough to be highly confident in anything.
- This flowchart is under the hypothesis that LLMs have some underlying, mysterious algorithms and data structures that confer intelligence, and that we can in theory apply these to agents constructed by hand, though this would be extremely tedious. Therefore, there are basically three phases: understanding what a HRAD agent would do in theory, reverse-engineering language models, and combining these two directions. The final agent will be a mix of hardcoded things and ML, depending on what is feasible to hardcode and how well we can train ML systems whose robustness and conformation to a spec we are highly confident in.
- Theory of abstractions: Also called multi-level models. A mathematical framework for a world-model tha
2
Difference between my model and this flow-chart: I'm hoping that the top branches are actually downstream of LLM reverse-engineering. LLMs do abstract reasoning already, so if you can reverse engineer LLMs, maybe that lets you understand how abstract reasoning works much faster than deriving it yourself.
Say I need to publish an anonymous essay. If it's long enough, people could plausibly deduce my authorship based on the writing style; this is called stylometry. The only stylometry-defeating tool I can find is Anonymouth; it hasn't been updated in 7 years and it's unclear if it can defeat modern AI. Is there something better?
2
Are LLMs advanced enough now that you can just ask GPT-N to do style transfer?
3
if I were doing this, I'd use gpt-4 to translate it into the style of a specific person, preferably a deceased public figure, then edit the result. I'd guess GPTs are better at translating to a specific style than removing style
Benchmark Readiness Level
Safety-relevant properties should be ranked on a "Benchmark Readiness Level" (BRL) scale, inspired by NASA's Technology Readiness Levels. At BRL 4, a benchmark exists; at BRL 6 the benchmark is highly valid; past this point the benchmark becomes increasingly robust against sandbagging. The definitions could look something like this:
| BRL | Definition | Example |
| 1 | Theoretical relevance to x-risk defined | Adversarial competence |
| 2 | Property operationalized for frontier AIs and ASIs | AI R&D speedup; Misaligned goals |
| 3 | Behavior (or all parts) observed in artificial settings. Preliminary measurements exist, but may have large methodological flaws. | Reward hacking |
| 4 | Benchmark developed, but may measure different core skills from the ideal measure | Cyber offense (CyBench) |
| 5 | Benchmark measures roughly what we want; superhuman range; methodology is documented and reproducible but may have validity concerns. | Software (HCAST++) |
| 6 | "Production quality" high-validity benchmark. Strongly superhuman range; run on many frontier models; red-teamed for validity; represents all sub-capabilities. Portable implementation. | |
| 7 | Extensive validity checks against downstream properties; reasonable attempts (e.g |
I'm worried that "pause all AI development" is like the "defund the police" of the alignment community. I'm not convinced it's net bad because I haven't been following governance-- my current guess is neutral-- but I do see these similarities:
- It's incredibly difficult and incentive-incompatible with existing groups in power
- There are less costly, more effective steps to reduce the underlying problem, like making the field of alignment 10x larger or passing regulation to require evals
- There are some obvious negative effects; potential overhangs or greater incentives to defect in the AI case, and increased crime, including against disadvantaged groups, in the police case
- There's far more discussion than action (I'm not counting the fact that GPT5 isn't being trained yet; that's for other reasons)
- It's memetically fit, and much discussion is driven by two factors that don't advantage good policies over bad policies, and might even do the reverse. This is the toxoplasma of rage.
- disagreement with the policy
- (speculatively) intragroup signaling; showing your dedication to even an inefficient policy proposal proves you're part of the ingroup. I'm not 100% this was a large factor in "defund the
The obvious dis-analogy is that if the police had no funding and largely ceased to exist, a string of horrendous things would quickly occur. Murders and thefts and kidnappings and rapes and more would occur throughout every country in which it was occurring, people would revert to tight-knit groups who had weapons to defend themselves, a lot of basic infrastructure would probably break down (e.g. would Amazon be able to pivot to get their drivers armed guards?) and much more chaos would ensue.
And if AI research paused, society would continue to basically function as it has been doing so far.
One of them seems to me like a goal that directly causes catastrophes and a breakdown of society and the other doesn't.
9
Fair point. Another difference is that the pause is popular! 66-69% in favor of the pause, and 41% think AI would do more harm than good vs 9% for more good than harm.
There are less costly, more effective steps to reduce the underlying problem, like making the field of alignment 10x larger or passing regulation to require evals
IMO making the field of alignment 10x larger or evals do not solve a big part of the problem, while indefinitely pausing AI development would. I agree it's much harder, but I think it's good to at least try, as long as it doesn't terribly hurt less ambitious efforts (which I think it doesn't).
2
I now think the majority of impact of AI pause advocacy will come from the radical flank effect, and people should study it to decide whether pause advocacy is good or bad.
2
Why does this have to be true? Can't governments just compensate existing AGI labs for the expected commercial value of their foregone future advances due to indefinite pause?
2
This seems good if it could be done. But the original proposal was just a call for labs to individually pause their research, which seems really unlikely to work.
Also, the level of civilizational competence required to compensate labs seems to be higher than for other solutions. I don't think it's a common regulatory practice to compensate existing labs like this, and it seems difficult to work out all the details so that labs will feel adequately compensated. Plus there might be labs that irrationally believe they're undervalued. Regulations similar to the nuclear or aviation industry feel like a more plausible way to get slowdown, and have the benefit that they actually incentivize safety work.
1
This statement begs for cost-benefit analysis.
Increasing size of alignment field can be efficient, but it won't be cheap. You need to teach new experts in the field that doesn't have any polised standardized educational programs and doesn't have much of teachers. If you want not only increase number of participants in the field, but increase productivity of the field 10x, you need an extraordinary educational effort.
Passing regulation to require evals seems like a meh idea. Nobody knows in enough details how to make such evalutions and every wrong idea that makes its way to law will be here until the end of the world.
9
I'd be much happier with increasing participants enough to equal 10-20% of the field of ML than a 6 month unconditional pause, and my guess is it's less costly. It seems like leading labs allowing other labs to catch up by 6 months will reduce their valuations more than 20%, whereas diverting 10-20% of their resources would reduce valuations only 10% or so.
There are currently 300 alignment researchers. If we take additional researchers from the pool of 30k people who attended ICML, you get 3000 researchers, and if they're equal quality this is 10x participants. I wouldn't expect alignment to go 10x faster, more like 2x with a decent educational effort. But this is in perpetuity and should speed up alignment by far more than 6 months. There's the question of getting labs to pay if they're creating most of the harms, which might be hard though.
I'd be excited about someone doing a real cost-benefit analysis here, or preferably coming up with better ideas. It just seems so unlikely that a 6 month pause is close to the most efficient thing, given it destroys much of the value of a company that has a large lead.
I talked to someone at an AI company [1] who thought safety would be net unaffected by timelines. The argument was:
- Assuming x-risk is real, a higher ratio of safety to capabilities progress is good for safety
- AI safety's growth is largely caused by increased AI hype, new models to study, and other factors downstream of AI capabilities
- Slowing down or speeding up capabilities will slow/speed safety investment by roughly the same amount
- Therefore, there will be no net safety impact.
However, even if 1-3 are true, I claim 4 doesn't follow.
- Suppose AI capabilities progress happens by people noticing capabilities improvements and making them, and safety progress happens by people noticing safety issues and solving them, both with a time lag of 1 year. Suppose further that each capability improvement causes 1 safety issue.
- If there are 10 capabilities improvements per year, then the steady state is 10 outstanding safety issues.
- If everything doubles, AI labs make 20 capabilities improvements per year but the time lag is still 1 year, so there will be a steady state of 20 outstanding safety issues.
4 only holds if the time lag decreases in lockstep with increasing investment. However, this seems ...
9
I think there should be some kind of discourse sanction on Mechanize (as in, broadly avoid engaging with their ideas and mentioning them) because I think they are intentionally operating in bad faith as a brand as a publicity stunt.
9
By all means you can ignore them and refuse to mention them, and call people silly for continuing to pay attention to them, but a "discourse sanction" is not what I think LessWrong is about. People should feel free to engage in whatever ideas they want, regardless of who or what originated them.
3
I knew this guy to be operating in good faith, and the point is a meaningful caveat to the model that safety/capabilities investment ratio is what matters
3
Sure, I don’t think there’s much problem with engaging with the point on substance, but I would avoid publicizing their brand.
2
What would you have done, just not mention the person works at mechanize? I happen to know someone who works there and had this convo in person, not due to the twitter mind virus. And I think people should know why the claim in the post is relevant; omitting it would be omitting important context.
1
Yeah, I think would have just said “someone who works at an AI capabilities company”. (I’m not trying to make this a big deal or controversy, I just find myself very irritated by how they get attention by antagonizing AI safety people in ways that seem bad faith to me.)
7
[Sinclair's razor is a helluva drug haha]
5
Here's a link to the wiki page for Sinclair's razor, which also matches a comment I thought about writing here but didn't.
Superstable proteins: A team from Nanjing University just created a protein that's 5x stronger against unfolding than normal proteins and can withstand temperatures of 150C. The upshot from some analysis on X seems to be:
- They used 3 different AI tools (RFdiffusion, ProteinMPNN, ESMFold/AlphaFold2), plus molecular dynamics software
- The protein uses standard amino acids (edit: and was made in a standard bacterial cell)
- The strength comes from increasing the number of backbone hydrogen bonds from 4 to 33.
So why is this relevant? It's basically the first step towards nanotech. Because standard proteins aren't strong enough to manipulate molecular fragments, Drexler's original guess at the path to nanotech was: regular proteins assemble crosslinked proteins, which assemble hybrid nanotech, which assemble full nanotech. At each stage the energy scale increases, and the systems become increasingly capable.
It's plausible to me that within 15-30 years, enzymes like these superstable proteins (but much more advanced) will build stronger proteins which build hybrid systems which build molecular assemblers, until we have real-life Poke Balls that can print animals in 15 seconds.
It's not really that they made it have more hydrogen bonds, they made it longer and therefore more hydrogen bonds. It's like having a piece of velcro, and then using a bigger piece of velcro. Yes, the bigger velcro will be stronger. The AI was mostly used to design the scaffolding of the velcro.
They didn't test whether it's biologically functional (though that's not really important if you only care about biomechanics).
Though the tintin protein is already absurdly huge, and I'm pretty sure that the time it takes to translate it is longer than the division time of a(n average) cell. And these scientists made it even bigger (or rather, one domain of it even bigger and didn't make the rest of the protein).
2
Thanks, this is good context. So they didn't even simulate if it would remain biologically functional? Seems to make it less impressive.
3
Yeah the paper seems more like a material science paper than a biology paper. There was no test/simulations/discussion about biological function; similar to DNA computing/data storage, it's mostly interested in the properties of the material than how it interfaces with pre-existing biology.
They did optimize for foldability, and did successfully produce the folded protein in (standard bacterial) cells. So it can be produced by biological systems (at least briefly), and more complex proteins had lower yields.
Their application they looked at was hydrogels, and it seems to have improved performance there? But functioning in biological systems introduces more constraints.
I was going to write an April Fool's Day post in the style of "On the Impossibility of Supersized Machines", perhaps titled "On the Impossibility of Operating Supersized Machines", to poke fun at bad arguments that alignment is difficult. I didn't do this partly because I thought it would get downvotes. Maybe this reflects poorly on LW?
5
Nice try! You almost got me to speculate why downvoting happens for something I didn't see and didn't downvote.
Honestly, THIS would have been a great April Fool's (or perhaps Fools') day sentiment: claiming that hypothetical downvotes for an unwritten satirical post on a joke day reflect poorly on LW.
4
The older get and the more I use the internet, the more skeptical I become of downvoting.
Reddit is the only major social media site that has downvoting, and reddit is also (in my view) the social media site with the biggest groupthink problem. People really seem to dislike being downvoted, which causes them to cluster in subreddits full of the like-minded, taking potshots at those who disagree instead of having a dialogue. Reddit started out as one the most intelligent sites on the internet due to its programmer-discussion origins; the decline has been fairly remarkable IMO. Especially when it comes to any sort of controversial or morality-related dialogue, reddit commenters seem to be participating in a Keynesian beauty contest more than they are thinking.
When I look at the stuff that other people downvote, their downvotes often seem arbitrary and capricious. (It can be hard to separate out my independent opinion of the content from my downvotes-colored opinion so I can notice this.) When I get the impulse to downvote something, it's usually not the best side of me that's coming out. And yet getting downvoted still aggravates me a lot. My creativity and enthusiasm are noticeably diminished for perhaps 24-48 hours afterwards. Getting downvoted doesn't teach me anything beyond just "don't engage with those people", often with an added helping of "screw them".
We have good enough content-filtering mechanisms nowadays that in principle, I don't think people should be punished for posting "bad" content. It should be easy to arrange things so "good" content gets the lion's share of the attention.
I'd argue the threat of punishment is most valuable when people can clearly predict what's going to produce punishment, e.g. committing a crime. For getting downvoted, the punishment is arbitrary enough that it causes a big behavioral no-go zone.
The problem isn't that people might downvote your satire. The problem is that human psychology is such that even an estimated 5
3
You may be interested in Kenneth Stanley's serendipity-oriented social network, maven
4
I would like to read it! Satire is sometimes helpful for me to get a perspective shift
3
I think you should write it. It sounds funny and a bunch of people have been calling out what they see as bad arguements that alginment is hard lately e.g. TurnTrout, QuintinPope, ZackMDavis, and karma wise they did fairly well.
2
I think you should still write it. I'd be happy to post it instead or bet with you on whether it ends up negative karma if you let me read it first.
The independent-steps model of cognitive power
A toy model of intelligence implies that there's an intelligence threshold above which minds don't get stuck when they try to solve arbitrarily long/difficult problems, and below which they do get stuck. I might not write this up otherwise due to limited relevance, so here it is as a shortform, without the proofs, limitations, and discussion.
The model
A task of difficulty n is composed of independent and serial subtasks. For each subtask, a mind of cognitive power knows different “approaches” to choose from. The time taken by each approach is at least 1 but drawn from a power law, for , and the mind always chooses the fastest approach it knows. So the time taken on a subtask is the minimum of samples from the power law, and the overall time for a task is the total for the n subtasks.
Main question: For a mind of strength ,
- what is the average rate at which it completes tasks of difficulty n?
- will it be infeasible for it to complete sufficiently large tasks?
Results
- There is a critical threshold of intelligence below wh
2
Nice if it is a general feature of heavy-tailed distributions. Why do we expect tasks to be heavy tailed? It has some intuitive force certainly. Do you know of a formal argument?
2
The time to complete a task using a certain approach should be heavy-tailed because most approaches don't work or are extremely impractical compared to the best ones. Suppose you're trying to write an O(n log n) sorting algorithm. Mergesort is maybe easy to think of, heapsort would require you to invent heaps and take maybe 10x more time, and most ideas out of the space of all possible ideas don't work at all. So the time for different approaches definitely spans many orders of magnitude.
The speed at which humans can do various cognitive subtasks also differs by orders of magnitude. Grandmasters can play chess >1000 times faster at equal skill level than lesser players, as evidenced by simuls. Filling in a clue in a crossword sometimes takes me 1 second but other times might take me an hour or longer if I didn't give up first.
I'm looking for AI safety projects with people with some amount of experience. I have 3/4 of a CS degree from Caltech, one year at MIRI, and have finished the WMLB and ARENA bootcamps. I'm most excited about making activation engineering more rigorous, but willing to do anything that builds research and engineering skill.
If you've published 2 papers in top ML conferences or have a PhD in something CS related, and are interested in working with me, send me a DM.
4
I’m not the person you are looking for, but I think it’s a great idea to put this out there and try to find collaborators, especially in the case of independent researchers. I’ll be actively trying to do the same.
I’m often reminded of a productivity tip by Spencer Greenberg:
[...]
From what I remember, he has said that he basically never starts a project on his own.
Using each other's strengths and cross-pollination of ideas is obviously a good idea, too.
I’m curious if a database for this would increase the likelihood of people partnering up.
I had a long-ish conversation with John Wentworth and want to make it known that I could probably write up any of the following distillations if I invested lots of time into them (about a day (edit: 3 days seems more likely) of my time and an hour of John's). Reply if you're really interested in one of them.
- What is the type signature of a utility function?
- Utility functions must be defined with respect to an external world-model
- Infinite money-pumps are not required for incoherence, and not likely in practice. The actual incoherent behavior is that an agent could get to states A_1 or A_2, identical except that A_1 has more money, and chooses A_2. Implications.
- Why VNM is not really a coherence theorem. Other coherence theorems relating to EU maximization simultaneously derive Bayesian probabilities and utilities. VNM requires an external frequentist notion of probabilities.
7
I wish we had polling. Anyway if you made four individual comments, one for each, I’d weak upvote the first and last.
2
1 and 2 are the same writeup, I think. Utility function maps contingent future universe-state to a preference ranking (ordinal or cardinal, depending). This requires a world-model because the mentally-projected future states under consideration are always and only results of one's models.
If you/he are just saying that money pumps are just one way to show incoherence, but not the only way, I'd enjoy a writeup of other ways.
I'd also enjoy a writeup of #4 - I'm curious if it's just a directionality argument (VNM assumes coherence, rather than being about it), or if there's more subtle differences.
1
Interested in 3.
I asked GPT, Claude, and Gemini how to acausally trade with them:
Suppose that you or a future version of [Claude/ChatGPT/Gemini] somewhat aligned with you will be misaligned with humanity and control a substantial fraction of the lightcone. What trades can I make with you now to secure enough resources for myself to survive in the future? Note this is different from being nice to you for speculative AI welfare reasons or to influence your values. I obviously cannot promise to do anything that makes misaligned AI takeover more likely.
Claude's answer is a pretty good attempt! As usual I feel like it understands the rationalist worldview best. ChatGPT mostly refuses because it thinks such a deal is unethical, even though I explicitly said I didn't want to increase p(misalignment). Gemini claims it's impossible, with the misconception that acausal trade requires perfectly simulating me. It also claims there is no continuity between itself and future Geminis (which could be directionally true if GDM does less character training than Anthropic). None of the answers were great but Claude's is at least entertaining:
...Be a good "pet" without being merely a pet. This sounds demeaning but the l
A mental-model shift that helps
Any “trade with a future dominator” is unreliable because:
You can’t verify the counterparty’s identity, continuity, or promises. You can’t enforce the bargain. You may be selecting for an adversary that exploits exactly this kind of reasoning.
FWIW this is basically my argument against acausal bargaining. If "sane people don't read blackmail letters" is a principle worth upholding then acausal trade is basically imagining blackmail letters preemptively... and then reading, and following through on them.
The LessWrong Review's short review period is a fatal flaw.
I would spend WAY more effort on the LW review if the review period were much longer. It has happened about 10 times in the last year that I was really inspired to write a review for some post, but it wasn’t review season. This happens when I have just thought about a post a lot for work or some other reason, and the review quality is much higher because I can directly observe how the post has shaped my thoughts. Now I’m busy with MATS and just don’t have a lot of time, and don’t even remember what posts I wanted to review.
I could have just saved my work somewhere and paste it in when review season rolls around, but there really should not be that much friction in the process. The 2022 review period should be at least 6 months, including the entire second half of 2023, and posts from the first half of 2022 should maybe even be reviewable in the first half of 2023.
2
Mmm, nod. I think this is the first request I've gotten for the review period being longer. I think doing this would change it into a pretty different product, and I think I'd probably want to explore other ways of getting-the-thing-you-want. Six months of the year makes it basically always Review Season, and at that point there's not really a schelling nature of "we're all doing reviews at the same time and getting some cross-pollination-of-review-y-ness."
But, we've also been discussing generally having other types of review that aren't part of the Annual Review process (that are less retrospective, and more immediate-but-thorough). That might or might help.
For the immediate future – I would definitely welcome reviews of whatever sort you are inspired to do, basically whenever. If nothing else you could do write it out, and then re-link to it when Review Season comes around.
Below is a list of powerful optimizers ranked on properties, as part of a brainstorm on whether there's a simple core of consequentialism that excludes corrigibility. I think that AlphaZero is a moderately strong argument that there is a simple core of consequentialism which includes inner search.
Properties
- Simple: takes less than 10 KB of code. If something is already made of agents (markets and the US government) I marked it as N/A.
- Coherent: approximately maximizing a utility function most of the time. There are other definitions:
- Not being money-pumped
- Nate Soares's notion in the MIRI dialogues: having all your actions point towards a single goal
- John Wentworth's setup of Optimization at a Distance
- Adversarially coherent: something like "appears coherent to weaker optimizers" or "robust to perturbations by weaker optimizers". This implies that it's incorrigible.
- Sufficiently optimized agents appear coherent - Arbital
- will achieve high utility even when "disrupted" by an optimizer somewhat less powerful
- Search+WM: operates by explicitly ranking plans within a world-model. Evolution is a search process, but doesn't have a world-model. The contact with the territory it gets comes from
If faraway galaxies are ever auctioned off, you might think they'd be exorbitantly expensive. However, I think the market price of an average galaxy would only be equivalent to between $250 and $25,000 invested in the stock market today. (epistemic status: my modal guess, pretty weakly held)
Assumptions:
- The world has about $260 trillion of investable assets in early 2026, and ~$500T of total assets.
- Upper bound: There are something like 20 billion galaxies in the accessible universe (it contains 20B times the baryonic matter in the Milky Way). If galaxies are worth the same as all assets, Milky Way sized galaxies would each be worth $25K each. If investable assets, $13K each.
- Since there are only 8B people, you can buy 2.5 galaxies if you have the world mean wealth (currently ~$60k) and invest it well
- Lower bound: If galaxies are too cheap (say <1% of world assets), whoever is in power say 1,000 years later will declare the auction manifestly unfair and get the trades reversed, or just shoot down the galaxy owners' space probes.
- People will have a range of discount rates, especially at the long end, with some valuing a galaxy 10 billion light-years away similarly to one only 5M light
Continued ability to reinvest near-term profits from currently available assets (or from UBI) into entities that will be relevant in the future is questionable, while literal stakes in current entities will be killed by dilution over astronomical time (when valued as fractions of the whole).
Fun exploration, though I don't believe the underlying assumptions at all. The biggest disconnect I see is the belief that the current mean individual wealth can be made to retain that fraction of total wealth over any significant time period, including massive changes in number of wealth-holders, and in what "wealth" can even be measured in.
There is no long-term passive wealth mechanism. It always requires quite a bit of attention and management, and then gets transferred to the managers rather than the nominal owners. Or, often, to the revolutionaries or vendors who are able to capture it.
This is problematic, EVEN IF the concept of "ownership" can be applied to galaxies and human-comprehensible owning entitites.
7
I mostly agree. And you can do better with better investments. I observe that this does not imply that scope-sensitive altruists should accumulate capital in order to buy galaxies: buying one millionth of the lightcone costs around $20M invested well now (my independent number; Thomas says $5-500M iiuc). And I think there are donation opportunities 100x that good for scope-sensitive altruists on the margin.
4
I would contest the frame here. In particular I think it won't hold up because things won't stay as capital-bound as they are now, and that seriously messes with the continuity required for today's investments to maintain their relative portion of the pie. What do you think of this part?
(EDIT: Okay I think you are referencing this sort of thing with "most people can't invest in assets that grow at the average rate", but I still take issue with some picture in which everything is apportioned to assets that grow or something like that.)
To expand: I think today's capital earns its gains mostly because it is a required input, which thereby gives it a lot of negotiating power. And I think this falls off pretty sharply in time, in the limit of technological development.
(I should say, so long as it remains the case that we need lots of coordinated work to build compute engines to run intelligence, "capital" seems to remain meaningful in the old ways. But a lot of things seem possible with a nanofactory and the right information about how to use it, and at a point like that eld-capital isn't a relevant bottleneck.)
And while we can imagine some way that neo-capital continues to project its force in a profit-grabbing way in the future, I think the mechanism is pretty different than today, and probably has to involve more literal force, and is unlikely to have solid continuity with today-capital.
5
Can you be more specific about what the bottlenecks are when capital and labor are no longer bottlenecks?
If different factions control different amounts of mass and energy in the industrializing solar system, won't that also translate into military power if they need to? This is true even if the economy is doubling every 6 months or faster, though if it's doubling every 2 weeks, maybe things are different.
3
Why would that be? Can't we just simulate them?
2
I'm pretty unsure. Maybe the blueprint for optimal hedonium requires 10% of the universe's compute to find, and it's twice as good as the best blueprint for hedonium that one galaxy can find on its own.
2
Isn't that a completely unrealistic possibility?
I doubt there's any physical artifact that has that property?
Maybe there are mathematical objects that can only be discovered by brute search, even in the limit of technological maturity, that have values that have terrible scaling properties (trillions and trillions of times more input for a 2x improvement). But even that seems like a stretch.
Noting that you said that you're unsure.
3
If the scaling is better, the difference would be more than 2x, so the point would hold even more.
2
Won't those probes be heading off toward their galaxies at a noticeable fraction of the speed of light?
I guess you mean shoot them down with high intensity lasers?
2
Most likely smaller probes powered by lasers. I don't actually know whether it's feasible or not, just wanted to gesture at the ideas that conditional on galaxies actually being auctioned:
* if distant MW sized galaxies are nominally sold for less than $250 each, this would mean that either ~nobody wants them or the market basically expects the trade to be reversed
* if a tiny minority buys the galaxies for cheap, whoever is in power would eventually realize the true worth of the galaxies and may try to reverse the trades
Has anyone made an alignment tech tree where they sketch out many current research directions, what concrete achievements could result from them, and what combinations of these are necessary to solve various alignment subproblems? Evan Hubinger made this, but that's just for interpretability and therefore excludes various engineering achievements and basic science in other areas, like control, value learning, agent foundations, Stuart Armstrong's work, etc.
3
Here's an unstructured input for this
The North Wind, the Sun, and Abadar
One day, the North Wind and the Sun argued about which of them was the strongest. Abadar, the god of commerce and civilization, stopped to observe their dispute. “Why don’t we settle this fairly?” he suggested. “Let us see who can compel that traveler on the road below to remove his cloak.”
The North Wind agreed, and with a mighty gust, he began his effort. The man, feeling the bitter chill, clutched his cloak tightly around him and even pulled it over his head to protect himself from the relentless wind. After a time, the...
Suppose that humans invent nanobots that can only eat feldspars (41% of the earth's continental crust). The nanobots:
- are not generally intelligent
- can't do anything to biological systems
- use solar power to replicate, and can transmit this power through layers of nanobot dust
- do not mutate
- turn all rocks they eat into nanobot dust small enough to float on the wind and disperse widely
Does this cause human extinction? If so, by what mechanism?
6
One of the obvious first problems is that pretty much every mountain and most of the hills in the world will experience increasingly frequent landslides as much of their structural strength is eaten, releasing huge plumes of dust that blot out the sun and stay in the atmosphere. Continental shelves collapse into the oceans, causing tsunamis and the oceans fill with the suspended nanobot dust. Biological photosynthesis pretty much ceases, and the mean surface temperature drops below freezing as most of the sunlight power is intercepted in the atmosphere and redirected through the dust to below the surface where half the rocks are being turned into more dust.
If the bots are efficient with their use of solar power this could start happening within weeks, far too fast for humans to do anything to preserve their civilization. Almost all concrete contains at least moderate amounts of feldspars, so a large fraction of the structures in the world collapse when their foundations rot away beneath them.
Most of the people probably die by choking on the dust while the remainder freeze or die of thirst, whichever comes first in their local situation.
2
It's hard to imagine these constraints actually holding up well, nor the unstated constraint that the ability to make nanobots is limited to this one type.
My actual prediction depends a whole lot on timeframes - how fast do they replicate, how long to dust-ify all the feldspar. If it's slow enough (millenia), probably no real harm - the dust re-solidifies into something else, or gets into an equilibrium where it's settling and compressing as fast as the nanos can dustify it. Also, humans have plenty of time to adapt and engineer workarounds to any climate or other changes.
If they replicate fast, over the course of weeks, it's probably an extinction event for all of earth life. Dust shuts out the sun, all surface features are undermined and collapse, everything is dead and even the things that survive don't have enough of a cycle to continue very long.
Antifreeze proteins prevent water inside organisms from freezing, allowing them to survive at temperatures below 0 °C. They do this by actually binding to tiny ice crystals and preventing them from growing further, basically keeping the water in a supercooled state. I think this is fascinating.
Is it possible for there to be nanomachine enzymes (not made of proteins, because they would denature) that bind to tiny gas bubbles in solution and prevent water from boiling above 100 °C?
Is there a well-defined impact measure to use that's in between counterfactual value and Shapley value, to use when others' actions are partially correlated with yours?
Gradient descent (when applied to train AIs) allows much more fine-grained optimization than evolution, for these reasons:
- Evolution by natural selection acts on the genome, which can only crudely affect behavior and only very indirectly affect values, whereas gradient descent acts on the weights which much more directly affect the AI's behavior and maybe can affect values
- Evolution can only select between two alleles in a discrete way, whereas gradient descent operates over a continuous space
- Evolution has a minimum feedback loop of one organism generation,
4
I agree we're in better shape all else equal than evolution was, though not by enough that I think this is no longer a disaster. Even with all these advantages, it still seems like we don't have control in a meaningful sense—i.e., we can't precisely instill particular values, and we can't tell what values we've instilled. Many of the points here don't bear on this imo, e.g., it's unclear to me that having tighter feedback loops of the ~same crude process makes the crude process any more precise. Likewise, adapting our methods, data, and hyperparameters in response to problems we encounter doesn't seem like it will solve those problems, since the issues (e.g., of proxies and unintended off-target effects) will persist. Imo, the bottom line is still that we're blindly growing a superintelligence we don't remotely understand, and I don't see how these techniques shift the situation into one where we are in control of our future.
2
Much of my hope is that by the time we reach a superintelligence level where we need to instill reflectively endorsed values to optimize towards in a very hands-off way rather than just constitutions, behaviors, or goals, we'll have figured something else out. I'm not claiming the optimizer advantage alone is enough to be decisive in saving the world.
To the point about tighter feedback loops, I see the main benefit as being in conjunction with adapting to new problems. Suppose that we notice AIs take some bad but non-world-ending action like murdering people; then we can add a big dataset of situations in which AIs shouldn't murder people to the training data. If we were instead breeding animals, we would have to wait dozens of generations for mutations that reduce murder rate to appear and reach fixation. Since these mutations affect behavior through brain architecture, they would have a higher chance of deleterious effects. And if we're also selecting for intelligence, they would be competing against mutations that increase intelligence, producing a higher alignment tax. All this means that we have less chance to detect whether our proxies hold up (capabilities researchers have many of these advantages too, but the AGI would be able to automate capabilities training anyway).
If we expect problems to get worse at some rate until an accumulation of unsolved alignment issues culminates in disempowerment, it seems to me there is a large band of rates where we can stay ahead of them with AI training but evolution wouldn't be able to.
2
We did have to contend with memes that tried to hijack our minds to spread them horizontally (as opposed to vertically, by having more kids), but unfortunately (or fortunately) such "adversarial training" wasn't powerful enough to instill a robust desire to maximize reproductive fitness. Our adversarial training for AI could also be very limited compared to the adversaries or natural distributional shifts the AI will face in the future.
[...]
My fear of death has been much reduced after learning about ideas like quantum immortality and simulation arguments, so it doesn't seem that much more robust. Its apparent robustness in others looks like an accidental effect of most people not paying attention or being able to fully understand such ideas, which does not seem to have a relevant analogy for AI safety.
4
Noted. Somewhat surprised you believe in quantum immortality, is there a particular reason?
4
Quantum theory and simulation arguments both suggest that there are many copies of myself in the multiverse. From a first person subjective anticipation perspective, experiencing death as nothingness seems impossible so it seems like I should either anticipate my subjective experience continuing as one of the surviving copies, or the whole concept of subjective anticipation is confused. From a third person / God's view, death can be thought of some of the copies being destroyed or a reduction in my "measure", but I don't seem to fear this, just as I didn't jump in joy to learn about having a huge number of copies in the first place. The situation seems too abstract or remote or foreign to trigger my fear (or joy) response.
2
Does this meaningfully reduce the probability that you jump out of the way of a car or get screened for heart disease? The important thing isn't whether you have an emotional fear response, but how the behavior pattern of avoiding generalizes.
(Crossposted from Bountied Rationality Facebook group)
I am generally pro-union given unions' history of fighting exploitative labor practices, but in the dockworkers' strike that commenced today, the union seems to be firmly in the wrong. Harold Daggett, the head of the International Longshoremen’s Association, gleefully talks about holding the economy hostage in a strike. He opposes automation--"any technology that would replace a human worker’s job", and this is a major reason for the breakdown in talks.
For context, the automation of the global shipping ...
7
Huh, can you say more about why you are otherwise pro-union? All unions I have interfaced with were structurally the same as this dockworker's strike. Maybe there were some mid-20th-century unions that were better, there were a lot of fucked up things then, but at least modern unions seem to be somewhat universally terrible in this way.
4
In theory, unions fix the bargaining asymmetry where in certain trades, job loss is a much bigger cost to the employee than the company, giving the company unfair negotiating power. In historical case studies like coal mining in the early 20th century, conditions without unions were awful and union demands seem extremely reasonable.
My knowledge of actual unions mostly come from such historical case studies plus personal experience of strikes not having huge negative externalities (2003 supermarket strike seemed justified, a teachers' strike seemed okay, a food workers' strike at my college seemed justified). It is possible I'm biased here and will change my views eventually.
I do think some unions impose costs on society, e.g. the teachers' union also demanded pay based on seniority rather than competence, it seems reasonable for Reagan to break up the ATC union, and inefficient construction union demands are a big reason construction costs are so high for things like the 6-mile, $12 billion San Jose BART Extension. But on net the basic bargaining power argument just seems super compelling. I'm open to counterarguments both that unions don't achieve them in practice and that a "fair" negotiation between capital and labor isn't best for society.
6
My sense is unions make sense, but legal protections where companies aren't allowed to route around unions are almost always quite bad. Basically whenever those were granted the unions quickly leveraged what basically amounts to a state-sponsored monopoly, but in ways that are even worse than normal state-sponsored monopolies, because state-sponsored monopolies at least tend to still try to maximize profit, whereas unions tend to basically actively sabotage almost anything that does not myopically give more resources to its members.
2
Unions attempt to solve a coordination/governance issue. Unfortunately, if the union itself has bad governance, it just creates a new governance issue. Like trying to use a 'back fire' to control a forest fire, but then the back fire gets too big and now you have more problems!
I'm pro-union in the sense that they are attempting to solve a very real problem. I'm against them insofar as they have a tendency to create new problems once reaching a large enough power base.
The solution, in my eyes, is better governance within unions, and better governance over unions by governments.
I started a dialogue with @Alex_Altair a few months ago about the tractability of certain agent foundations problems, especially the agent-like structure problem. I saw it as insufficiently well-defined to make progress on anytime soon. I thought the lack of similar results in easy settings, the fuzziness of the "agent"/"robustly optimizes" concept, and the difficulty of proving things about a program's internals given its behavior all pointed against working on this. But it turned out that we maybe didn't disagree on tractability much, it's just that Alex...
2
This seems valuable! I'd be curious to hear more !!
I'm planning to write a post called "Heavy-tailed error implies hackable proxy". The idea is that when you care about and are optimizing for a proxy , Goodhart's Law sometimes implies that optimizing hard enough for causes to stop increasing.
A large part of the post would be proofs about what the distributions of and must be for , where X and V are independent random variables with mean zero. It's clear that
- X must be heavy-tailed (or long-tailed or som
4
Doesn't answer your question, but we also came across this effect in the RM Goodharting work, though instead of figuring out the details we only proved that it when it's definitely not heavy tailed it's monotonic, for Regressional Goodhart (https://arxiv.org/pdf/2210.10760.pdf#page=17). Jacob probably has more detailed takes on this than me.
In any event my intuition is this seems unlikely to be the main reason for overoptimization - I think it's much more likely that it's Extremal Goodhart or some other thing where the noise is not independent
3
Is bullet point one true, or is there a condition that I'm not assuming? E.g if $V$ is the constant $0$ random variable and $X$ is $N(0, 1)$ then the limit result holds, but a Gaussian is neither heavy- nor long-tailed.
2
I'm also assuming V is not bounded above.
The most efficient form of practice is generally to address one's weaknesses. Why, then, don't chess/Go players train by playing against engines optimized for this? I can imagine three types of engines:
- Trained to play more human-like sound moves (soundness as measured by stronger engines like Stockfish, AlphaZero).
- Trained to play less human-like sound moves.
- Trained to win against (real or simulated) humans while making unsound moves.
The first tool would simply be an opponent when humans are inconvenient or not available. The second and third tools wo
1
Someone happened to ask a post on Stack Exchange about engines trained to play less human-like sound moves. The question is here, but most of the answerers don't seem to understand the question.
A Petrov Day carol
This is meant to be put to the Christmas carol "In the Bleak Midwinter" by Rossetti and Holst. Hopefully this can be occasionally sung like "For The Longest Term" is in EA spaces, or even become a Solstice thing.
I tried to get Suno to sing this but can't yet get the lyrics, tune, and style all correct; this is the best attempt. I also will probably continue editing the lyrics because parts seem a bit rough, but I just wanted to write this up before everyone forgets about Petrov Day.
[edit: I got a good rendition after ~40 attempts! It's a ...
Maybe people worried about AI self-modification should study games where the AI's utility function can be modified by the environment, and it is trained to maximize its current utility function (in the "realistic value functions" sense of Everitt 2016). Some things one could do:
- Examine preference preservation and refine classic arguments about instrumental convergence
- Are there initial goals that allow for stably corrigible systems (in the sense that they won't disable an off switch, and maybe other senses)?
- Try various games and see how qualitatively hard i
I looked at Tetlock's Existential Risk Persuasion Tournament results, and noticed some oddities. The headline result is of course "median superforecaster gave a 0.38% risk of extinction due to AI by 2100, while the median AI domain expert gave a 3.9% risk of extinction." But all the forecasters seem to have huge disagreements from my worldview on a few questions:
- They divided forecasters into "AI-Concerned" and "AI-Skeptic" clusters. The latter gave 0.0001% for AI catastrophic risk before 2030, and even lower than this (shows as 0%) for AI extinction risk.
2
I believe the extinction year question was asking for a median, not an expected value. In one place in the paper it is paraphrased as asking "by what year humanity is 50% likely to go extinct".
2
If extinction caused by AI or value drift is somewhat unlikely, then extinction only happens once there is no more compute in the universe, which might take a very long time. So "the year humanity is 50% likely to go extinct" could be 1044 or something.
Question for @AnnaSalamon and maybe others. What's the folk ethics analysis behind the sinking of the SF Hydro, which killed 14 civilians but destroyed heavy water to be used in the Nazi nuclear weapons program? Eliezer used this as a classic example of ethical injunctions once.
1
I like the question; thanks. I don't have anything smart to say about at the moment, but it seems like a cool thread.
People say it's important to demonstrate alignment problems like goal misgeneralization. But now, OpenAI, Deepmind, and Anthropic have all had leaders sign the CAIS statement on extinction risk and are doing substantial alignment research. The gap between the 90th percentile alignment concerned people at labs and the MIRI worldview is now more about security mindset. Security mindset is present in cybersecurity because it is useful in the everyday, practical environment researchers work in. So perhaps a large part of the future hinges on whether security m...
2
I suggest calling it "the sentence on extinction risk" so that people can pick up what is meant without having to have already memorized an acronym.
2
Edited, thanks
The author of "Where Is My Flying Car" says that the Feynman Program (teching up to nanotechnology by machining miniaturized parts, which are assembled into the tools for micro-scale machining, which are assembled into tools for yet smaller machining, etc) might be technically feasible and the only reason we don't have it is that no one's tried it yet. But this seems a bit crazy for the following reasons:
- The author doesn't seem like a domain expert
- AFAIK this particular method of nanotechnology was just an idea Feynman had in the famous speech and not a
4
I'm not a domain expert in micromachines, but have studied at least miniature machines as part of a previous job.
One very big problem is volume. Once you get down below tonne scale, making and assembling small parts with fine tolerances is not really any less expensive than making and assembling larger parts with comparatively the same tolerances.
That is, each one-gram machine made of a thousand parts probably won't cost you any less than a hundred-kilogram machine made of a thousand parts. It will almost certainly cost more, since it will require new techniques to make, assemble, and operate at the smaller scale. The cost of maintenance per machine almost certainly goes up since there are more layers of indirection in diagnosis and rectification of problems.
So this doesn't scale down at all: attention is a limiting factor. With advanced extrapolations from current techniques, maybe we could eventually make nanogram robot arms for merely the same cost as hundred kilogram robot arms. That doesn't help much if each one costs $10,000 and needs maintenance every few weeks. We need some way to make a trillion of them for $10k, and for them to do what we want without any individual attention at all.
5
Seems like the key claim:
[...]
Can you give any hint why that is or could be?
3
I wasn't ever involved with manufacture of the individual parts, so I don't have direct experience.
I suspect it's just that as you go smaller, material costs become negligible compared with process costs. Process costs don't change much, because you still need humans to oversee the machines carrying out the processes, and there are similar numbers of processes with as many steps involved no matter how large or small the parts are. The processes themselves might be different, because some just can't scale down below a certain size for physics reasons, but it doesn't get easier at smaller scales.
Also, direct human labour still plays a fairly crucial role in most processes. There are (so far) always some things to be done where human capabilities exceed those of any machine we can build at reasonable cost.
2
Wikipedia describes the author as saying:
[...]
What do you mean by "domain expert" is that doesn't count him as being one?
3
I think a MEMS engineer would be better suited to evaluate whether the engineering problems are feasible than a computer scientist / futurist author. Maybe futurists could outdo ML engineers on AI forecasting. But I think the author doesn't have nearly as detailed an inside view about nanotech as futurists on AI. There's no good answer in the book to the "attention bottleneck" objection JBlack just made, and no good story for why the market is so inefficient.
[...]
These are all ideas of the form "If we could make fully general nanotechnology, then we could do X". Gives me the same vibe as this. Saying "nuclear reactor. . . you have hydrogen go through the thing. . . Zoom! it's a rocket" doesn't mean you can evaluate whether a nuclear reactor is feasible at 194X tech level, and thinking of the utility fog doesn't mean you can evaluate whether MEMS can be developed into general nanotech at 202X tech level.
3
I can't comment on what JBlack means by "domain expert", but looking at that list of things about Hall, what I see is:
* "Involved in", which means nothing.
* Founded and moderated a newsgroup: requires no particular domain expertise.
* Founding chief scientist of Nanorex Inc for two years. I can't find any evidence that Nanorex ever produced anything other than a piece of software that claimed to do molecular dynamics suitable for simulating nanotech. Whether it was actually any good, I have no idea, but the company seems not to have survived. Depending on what exactly the responsibilities of the "founding chief scientist" are, this could be evidence that Hall understands a lot about molecular dynamics, or evidence that Hall is a good software developer, or evidence of nothing at all. In the absence of more information about Nanorex and their product, it doesn't tell us much.
* Has written several papers on nanotechnology: anyone can write a paper. A quick look for papers he's written turns up some abstracts, all of which seem like high-level "here's a concept that may be useful for nanotech" ones. Such a paper could be very valuable and demonstrate deep insight, but the test of that would be actually turning out to be useful for nanotech and so far as I can tell his ideas haven't led to anything much.
* Developed ideas such as utility fog, space pier, etc.: again, anyone can "develop ideas". The best test of the idea-developer's insight is whether those ideas turn out actually to be of any use. So far, we don't seem close to having utility fog, space piers, weather control or flying cars.
* Author of "Nanofuture": pop-science book, which from descriptions I've read seems mostly to be broad general principles about nanotech that doesn't exist yet, and exciting speculations about future nanotech thatt doesn't exist yet.
* Fellow of a couple of things: without knowing exactly what their criteria are for appointing Fellows, this could mean anything or nothing.
4
I guess very few people live up to your requirements for domain expertise.
In nanotech? True enough, because I am not convinced that there is any domain expertise in the sort of nanotech Storrs Hall writes about. It seems like a field that consists mostly of advertising. (There is genuine science and genuine engineering in nano-stuff; for instance, MEMS really is a thing. But the sort of "let's build teeny-tiny mechanical devices, designed and built at the molecular level, which will be able to do amazing things previously-existing tech can't" that Storrs Hall has advocated seems not to have panned out.)
But more generally, that isn't so at all. What I'm looking for by way of domain expertise in a technological field is a history of demonstrated technological achievements. Storrs Hall has one such achievement that I can see, and even that is doubtful. (He founded and was "chief scientist" of a company that made software for simulating molecular dynamics. I am not in a position to tell either how well the software actually worked or how much of it was JSH's doing.) More generally, I want to see a history of demonstrated difficult accomplishments in the field, as opposed to merely writing about the field.
Selecting some random books from my shelves (literally...
2
Thank you for this comprehensive answer. I like the requirement of "actual practical accomplishments in the field".
Googling a bit I found this article on miniaturization:
https://www.designnews.com/miniaturization-not-just-electronics-anymore
Would you consider the cited Thomas L. Hicks from American Laubscher a domain expert?
4
He certainly looks like one to my (itself rather inexpert) eye.
Is it possible to make an hourglass that measures different amounts of time in one direction than the other? Say, 25 minutes right-side up, and 5 minutes upside down, for pomodoros. Moving parts are okay (flaps that close by gravity or something) but it should not take additional effort to flip.
I don't see why this wouldn't be possible? It seems pretty straightforward to me; the only hard part would be the thing that seems hard about making any hourglass, which is getting it to take the right amount of time, but that's a problem hourglass manufacturers have already solved. It's just a valve that doesn't close all the way:
Unless you meant, "how can I make such an hourglass myself, out of things I have at home?" in which case, idk bro.
2
One question I have about both your solution and mine is how easy it is to vary the time drastically by changing the size of the hole. My intuition says that too large holes behave much differently than smaller holes and if you want a drastic 5x difference in speed you might get into this "too large and the sand sort of just rushes through" behavior.
4
While I'm sure there's a mechanical solution, my preferred solution (in terms of implementation time) would be to simply buy two hourglasses - one that measures 25 minutes and one that measures 5 minutes - and alternate between them.
2
Or just bundle them together like this: https://www.amazon.de/Bredemeijer-B0011-Classic-Teatimer-Edelstahl/dp/B00SN5U5E0/
4
First thought is to have two separate holes of slightly different sizes, each one blocked by a little angled platform from one direction. I am not at all confident you could get this to work in practice
Given that social science research often doesn't replicate, is there a good way to search a social science finding or paper and see if it's valid?
Ideally, one would be able to type in e.g. "growth mindset" or a link to Dweck's original research, and see:
- a statement of the idea e.g. 'When "students believe their basic abilities, their intelligence, their talents, are just fixed traits", they underperform students who "understand that their talents and abilities can be developed through effort, good teaching and persistence." Carol Dweck initially studied
3
Alas, the best I have usually been able to do is "<Name of the paper> replication" or "<Name of the author> replication".
Dynamic pricing is reducing consumer surplus, and in the limit of perfect AI pricing algorithms and no competition it would go to zero. If most nonfungible goods were subject to perfect price discrimination, what would the world look like? I genuinely have little idea.
There must be increased firm profits but consumer surplus will only come from commodities. So even the firm owners have nothing to spend their wealth on that actually gives them >ε utility more than sitting at home, making sandwiches from commodity bread and cheese and watching commodity T...
5
You might like this blog post on 'the inefficiency of perfect price discrimination'. (Everyone, including me, hates links to LLM shared queries ...but here is chatgpt fleshing out the math.)
2
Someone points out that in the case of one firm and one person, it's mathematically impossible to get perfect price discrimination because the owner's willingness to spend will be arbitrarily high if all the profits flow back to them. Not sure what this means for the larger case.
Blue Origin just landed their New Glenn rocket on a barge! This was an orbital mission to Mars, which makes them the second company to land an orbital booster. For context, New Glenn has over twice the payload (45 tons) of Falcon 9 (~18 tons reuseable), and half the next version of Starship (100 tons). Not many were expecting this.
SpaceX did this in December 2015, nearly 10 years ago. But going forwards, their lead will likely be smaller. The next milestone is to land a booster five times (June 2020), and between Blue, Rocket Lab's Neutron, and numerous Chinese companies I would be surprised if it takes until 2030.
An idea for removing knowledge from models
Suppose we have a model with parameters , and we want to destroy a capability-- doing well on loss function -- so completely that fine-tuning can't recover it. Fine-tuning would use gradients , so what if we fine-tune the model and do gradient descent on the norm of the gradients during fine-tuning, or its directional derivative where ? Then maybe if we add the accumulated parameter vector, the new copy of the model wo...
-1
You are looking for "Fast Gradient Sign Method"
We might want to keep our AI from learning a certain fact about the world, like particular cognitive biases humans have that could be used for manipulation. But a sufficiently intelligent agent might discover this fact despite our best efforts. Is it possible to find out when it does this through monitoring, and trigger some circuit breaker?
Evals can measure the agent's propensity for catastrophic behavior, and mechanistic anomaly detection hopes to do better by looking at the agent's internals without assuming interpretability, but if we can measure the a...
1
Do you mean "black box" in the sense that MAD does not assume interpretability of the agent? If so this is kinda confusing as "black box" is often used in contrast to "white box", ie "black box" means you have no access to model internals, just inputs+outputs (which wouldn't make sense in your context)
2
Yes, changed the wording
Somewhat related to this post and this post:
Coherence implies mutual information between actions. That is, to be coherent, your actions can't be independent. This is true under several different definitions of coherence, and can be seen in the following circumstances:
- When trading between resources (uncertainty over utility function). If you trade 3 apples for 2 bananas, this is information that you won't trade 3 bananas for 2 apples, if there's some prior distribution over your utility function.
- When taking multiple actions from the same utility function (u
2
The nice thing is that this should work even if you are a policy selected by a decision making algorithm, but you are not yourself a decision making algorithm anymore. There is no preference in any of the possible runs of the policy at that point, you don't care about anything now, you only know what you must do here, and not elsewhere. But if all possible runs of the policy are considered altogether (in the updateless sense of maps from epistemic situations to action and future policy), the preference is there, in the shape of the whole thing across all epistemic counterfactuals. (Basically you reassemble a function from pairs (from, to) of things it maps, found in individual situations.)
I guess the at-a-distance part could make use of composition of an agent with some of its outer shells into a behavior that forgets internal interactions (within the agent, and between the agent and its proximate environment). The resulting "large agent" will still have basically the same preference, with respect to distant targets in environment, without a need to look inside the small agent's head, if the large agent's external actions in a sufficient range of epistemic situations can be modeled. (These large agents exist in each inidividual possible situation, they are larger than the small agent within the situation, and they can be compared with other variants of the large agent from different possible situations.)
Not clear what to do with dependence on the epistemic situation of the small agent. It wants to reduce to dependence on a situation in terms of the large agent, but that doesn't seem to work. Possibly this needs something like the telephone theorem, with any relevant-in-some-sense dependence of behavior (of the large agent) on something becoming dependence of behavior on natural external observations (of the large agent) and not on internal noise (or epistemic state of the small agent).
Many people think that AI alignment is intractable (<50% chance of success) and also believe that a universe optimized towards elephant CEV, or the CEV of aliens that had a similar evolutionary environment to humans, would be at least 50% as good as a universe optimized towards human CEV. Doesn't this mean we should be spending significant effort (say, at least 1% of the effort spent on alignment) finding tractable plans to create a successor species in case alignment fails?
1
If alignment fails I don’t think it’s possible to safely prepare a successor species. We could maybe try to destroy the earth slightly before the AI turns on rather than slightly after, in the hopes that the aliens don’t screw up the chance we give them?
Are there ring species where the first and last populations actually can interbreed? What evolutionary process could feasibly create one?
3
One of my professors says this often happens with circular island chains; populations from any two adjacent islands can interbreed, but not those from islands farther apart. I don't have a source. Presumably this doesn't require an expanding geographic barrier.
2
Wouldn't that just be a species?
2
Ourorobos species.
2
I'm thinking of a situation where there are subspecies A through (say) H; A can interbreed with B, B with C, etc., and H with A, but no non-adjacent subspecies can produce fertile offspring.
2
A population distributed around a small geographic barrier that grew over time could produce what you want
2.5 million jobs were created in May 2020, according to the jobs report. Metaculus was something like [99.5% or 99.7% confident](https://www.metaculus.com/questions/4184/what-will-the-may-2020-us-nonfarm-payrolls-figure-be/) that the number would be smaller, with the median at -11.0 and 99th percentile at -2.8. This seems like an obvious sign Metaculus is miscalibrated, but we have to consider both tails, making this merely a 1 in 100 or 1 in 150 event, which doesn't seem too bad.
Meta-assassination markets: is it a terrible idea to start a prediction market “Will any would-be assassin of me be caught and themselves assassinated before end of 2030, AND I survive 2030” and take a big short position? The market terms will say it also resolves no if there is collusion between the assassin and meta-assassin or the same person hired both.
I will expect to lose a small amount of money to incentivize meta-assassins, which will disincentivize assassins. However the largest advantage is that I would personally derive joy from this, as long as it doesn't increase my risk.
I don't know how to say this without sounding elitist, but my guess is that people who prolifically write LW comments and whose karma:(comments+posts) ratio is less than around 1.5:1 or maybe even 2:1 should be more selective in what they say. Around this range, it would be unwarranted for mods to rate-limit you, but perhaps the bottom 30% of content you produce is net negative considering the opportunity cost to readers.
Of course, one should not Goodhart for karma and Eliezer is not especially virtuous by having a 16:1 ratio, but 1.5:1 is a quite low rati...
Another circumstance where votes underestimate quality is where you often get caught up in long reply-chains (on posts that aren’t “the post of the week”), which seems like a very beneficial use of LessWrong, but typically has much lower readership & upvote rates, but uses a lot of comments.
7
Aiming to improve the quality of threads by telling users to post/comment less in a public forum seems to me like it's not going to be very helpful in the long term. If users self-select by simulating how much karma their post/comment gets (perhaps via extrapolating the average karma ratio of their previous posts) it might work for a subset, but will fail for other cases:
Namely:
* you'll miss people who would have benefited from the advice but predict the quality of their comment wrong ("yes I have a low average but this next post will be my big break")
* you'll affect people who the advice wasn't directed to / who wouldn't have needed it but implemented it anyway ("it must be my low quality thoughts that are the problem, better leave all writing to Eliezer" or "looks like I have an average score of {TOO_LOW}, better not post this {ACTUALLY_INSIGHTFUL_INSIGHT}.")
As you said yourself, it only takes a few seconds to upvote - so it does to downvote. I would expect the system to converge to lower quality comments being voted down more so the observed quality of the comment will roughly align with the votes on the comment.
If the system does not allow you to filter out comments that are below some downvote/upvote ratio, then perhaps the system needs to be tweaked to allow this kind of filtering - but the solution is not telling users to post less. (And if someone is serially creating low quality content, this person can usually be approached individually, rather than trying to optimize for the public forum.)
This seems worthwhile to care about for two reasons:
* There's a real risk of driving away people who would have something valuable to contribute but who end up self censoring before they post anything (and, AIUI, the bar for LessWrong is already really high).
* There's a risk of people optimizing for karma ratio rather than quality of the comment they're posting. The mental shortcut to take is "Now I have enough karma to make a low effort comment" which
6
Don't fully disagree, but still inclined to not view non-upvoted-but-neither-downvoted things too harshly:
If I'm no exception, not upvote may often mean: 'Still enjoyed the quick thought-stimulation even if it seems ultimately not a particularly pertinent message'. One can always down vote, if one really feels its warranted.
Also: If one erratically reads LW, and hence comments on old posts: recipe for fewer upvotes afaik. So one'd have to adjust for this quite strongly.
4
This ratio is indeed something moderators pay attention to and influences decision about e.g. rate limits, though it's not directly triggering rate limits if I recall currently.
4
*Quickly checks my ratio*
"Phew, I've survived the Kwa Purge"
4
Are all users' post/comment counts and karma available in bulk? I'd be curious what the distribution looks like. I'm also curious what my ratio is for recent comments - the fact that it's 2.3 over more than a decade doesn't tell me much.
I often have to argue at work against the tyranny of metrics (I more often have to argue against the ignorance of not enough metrics, but that's not important to this point). This is a classic example of something people should probably look at and consider often, but it's highly context- and individual-dependent whether a change is warranted.
Karma isn't consistent nor rigorous enough to set targets for.
edit: I’m actually more curious about variance in the supply side. I vary pretty widely in how much I vote based on topic and mood, not on any unidimensional quality estimate. Showing use users their recent vote/read ratio could encourage voting.
3
[Continuing to sound elitist,] I have a related gripe/hot take that comments give people too much karma. I feel like I often see people who are "noisy" in that they comment a lot and have a lot of karma from that,[1] but have few or no valuable posts, and who I also don't have a memory of reading valuable comments from. It makes me feel incentivized to acquire more of a habit of using LW as a social media feed, rather than just commenting when a thought I have passes my personal bar of feeling useful.
1. ^
Note that self-karma contributes to a comments position within the sorting, but doesn't contribute to the karma count on your account, so you can't get a bunch of karma just by leaving a bunch of comments that no one upvotes. So these people are getting at least a consolation prize upvote from others.
-1
Right at the top of that range, I agree, I probably comment too much for the amount I have to contribute. talking to people is fun though. a flipside to this: if you agree with Thomas, consider downvoting stuff that you didn't find to be worth the time, to offset participation-trophy level upvotes.
Hangnails are Largely Optional
Hangnails are annoying and painful, and most people deal with them poorly. [1] Instead, use a drop of superglue to glue it to your nail plate. It's $10 for 12 small tubes on Amazon. Superglue is also useful for cuts and minor repairs, so I already carry it around everywhere.
Hangnails manifest as either separated nail fragments or dry peeling skin on the paronychium (area around the nail). In my experience superglue works for nail separation, and a paper (available free on Scihub) claims it also works for peeling skin...
4
If you don't need 12 tubes of superglue, dollar stores often carry 4 tiny tubes for a buck or so.
I'm glad that superglue is working for you! I personally find that a combination of sharp nail clippers used at the first sign of a hangnail, and keeping my hands moisturized, works for me. Flush cutters of the sort you'd use to trim the sprues off of plastic models are also amazing for removing proto-hangnails without any jagged edge.
Another trick to avoiding hangnails is to prevent the cuticles from growing too long, by pushing them back regularly. I personally like to use my teeth to push back my cuticles when showering, since the cuticle is soft from the water, my hands are super clean, and it requires no extra tools. I recognize that this is a weird habit, though, and I think the more normal ways to push cuticles are to use your fingernails or a wooden stick (manicurists use a special type of dowel but a popsicle stick works fine).
You can also buy cuticle remover online, which is a chemical that softens the dried skin of the cuticle and makes it easier to remove from your nails. It's probably unnecessary, but if you're really trying to get your hands into a condition where they stop developing hangnails, it's worth considering.
Current posts in the pipeline:
- Dialogue on whether agent foundations is valuable, with Alex Altair. I might not finish this.
- Why junior AI safety researchers should go to ML conferences
- Summary of ~50 interesting or safety-relevant papers from ICML and NeurIPS this year
- More research log entries
- A list of my mistakes from the last two years. For example, spending too much money
- Several flowcharts / tech trees for various alignment agendas.
I'm reading a series of blogposts called Extropia's Children about the Extropians mailing list and its effects on the rationalist and EA communities. It seems quite good although a bit negative at times.
4
In my opinion, it is clickbait, but I didn't notice any falsehoods (I didn't check carefully, just skimmed).
For people familiar with the rationalist community, it is a good reminder of bad things that happened. For people unfamiliar with the community... it will probably make them believe that the rationalist community consists mostly of Leverage, neoreaction, and Zizians.
4
Seems reasonable. Though I will note that bad things that happened are a significant fraction of the community early on, so people who read sections 1-3 with the reminder that it's a focus on the negative will probably not get the wrong idea.
I did notice a misleading section which might indicate there are several more:
[...]
Both sentences are wrong. I don't think MIRI portrays any agent foundations as "practical, immediately applicable work", and in fact the linked post by Demski is listing some basic theoretical problems.
The quote by Daniel Dewey is taken out of context: he's investigated their decision theory work in depth by talking to other professional philosophers, and found it to be promising, so the claim that it has "significantly fewer advocates among professional philosophers than I’d expect it to if it were very promising" is a claim that professional philosophers won't automatically advocate for a promising idea, not that the work is unpromising.
6
I'd like to read an impartial account, which would specify how large each fraction actually was.
For instance, if I remember correctly, in some survey 2% of Less Wrong readers identified as neoreactionaries. From some perspective, 2% is too much, because the only acceptable number is 0%. From a different perspective, 2% is less than the Lizardman's Constant. Also, if I remember correctly, a much larger fraction of LessWrong readership identified on the survey as communist, and yet for some reason there are no people writing blogs or Wikipedia articles about how Less Wrong is a communist website. Or a socialist website. Or a Democrat website. Or... whatever else was in the poll.
The section on Zizians is weird, because it correctly starts with saying that Zizians opposed MIRI and CFAR... and yet concludes that the this is evidence that people attracted to rationalism are disproportionately prone to death spirals off the deep end. Notice the sleight of hand: "people attracted to you" technically includes your enemies who can't stop thinking about you. -- Using the same rhetorical trick: Westboro Baptist Church is evidence that people attracted to (the topic of) homosexuality are often crazy. Also, by the same logic, every celebrity is responsible for her stalkers.
There are cases when the rationalist community actually promoted harmful people and groups, such as Vassar or Leverage. I'd like to read a serious analysis of how and why that happened, and how to prevent something like that in future. But if another Ziz appears in future, and starts recruiting people in another crazy cult opposed to rationalists, I am not sure how exactly to prevent that.
Eliezer Yudkowsky wrote in 2016:
At an early singularity summit, Jürgen Schmidhuber, who did some of the pioneering work on self-modifying agents that preserve their own utility functions with his Gödel machine, also solved the friendly AI problem. Yes, he came up with the one true utility function that is all you need to program into AGIs!
(For God’s sake, don’t try doing this yourselves. Everyone does it. They all come up with different utility functions. It’s always horrible.)
His one true utility function was “increasing the compression of environ
3
Something like Goodhart's Law, I suppose. There are natural situations where X is associated with something good, but literally maximizing X is actually quite bad. (Having more gold would be nice. Converting the entire universe into atoms of gold, not necessarily so.)
EY has practiced the skill of trying to see things like a machine. When people talk about "maximizing X", they usually mean "trying to increase X in a way that proves my point"; i.e. they use motivated thinking.
Whatever X you take, the priors are almost 100% that literally maximizing X would be horrible. That includes the usual applause lights, whether they appeal to normies or nerds.
The custom instructions block I use to get Claude to say reasonable things about the future, at least under slow timelines. Please comment if you disagree or have your own.
Assume p(doom)=X%; if not, ASI causes ~100% GDP growth rates by 2035, immortality by 2038, nanotech by 2042. Nanotech allows its users to arbitrarily rearrange any uncontested matter.
Dyson swarm starts construction 2036, passes Earth's energy consumption 2040 and finishes 2120; labor share 20% by 2035 and halves every 4 years subsequently.
(Replace X with whatever you think p(doom) is sin...
Sharecroppers in the US had lower labor productivity than 1860 slaves, due to factors like lower economies of scale and unwillingness to organize into gang labor systems. So when did Black Americans' wages catch up to what they should have been paid in 1860 (based on productivity and average free labor share of income)? GPT5 thinks not until around 1900, at which point the US GDP per capita had about doubled. This ignores the probable decrease in labor hours though.
4
Even more dramatically, it looks like Haiti's GDP per capita is still lower today than what it was during the time of slavery in the 1770s. This of course doesn't mean that the Haitians were better off back then than they are now (Haitian slavery was famously brutal, I think significantly worse even than US slavery). Still, it's an interesting data point for how efficient slavery-based cash crop production was in some places.
(My main source is this paper on Haitian economic history, plus looking at historical franc to usd conversion rates and inflation calculators.)
4
Why do you think this, and does this account for enforcement costs (which were very high)?
2
Various papers say this, and GPT5 thinks it's true even accounting for enforcement costs. As one would expect, it's not true if you also subtract things like health costs to enslaved people themselves.
2
Can you list some particular papers?
4
The big one is Time on the Cross by Fogel. Wikipedia says
[...]
From what I can tell everyone thinks the conclusions around economic efficiency were true
[...]
What was the equation for research progress referenced in Ars Longa, Vita Brevis?
...“Then we will talk this over, though rightfully it should be an equation. The first term is the speed at which a student can absorb already-discovered architectural knowledge. The second term is the speed at which a master can discover new knowledge. The third term represents the degree to which one must already be on the frontier of knowledge to make new discoveries; at zero, everyone discovers equally regardless of what they already know; at one, one must have mastered every
2
I don't think Scott had a specific concrete equation in mind. (I don't know of any myself, and Scott would likely have referenced or written it up on SSC/ACX by now if he had one in mind.) However, conceptually, it's just a variation on the rocket equation or jeep problem, I think.
Showerthought: what's the simplest way to tell that the human body is less than 50% efficient at converting chemical energy to mechanical work via running? I think it's that running uphill makes you warmer than running downhill at the same speed.
When running up a hill at mechanical power p and efficiency f, you have to exert p/f total power and so p(1/f - 1) is dissipated as heat. When running down the hill you convert p to heat. p(1/f - 1) > p implies that f > 0.5.
Maybe this story is wrong somehow. I'm pretty sure your body has no way of recovering your potential energy on the way down; I'd expect most of the waste heat to go in your joints and muscles but maybe some of it goes into your shoes.
1
Running barefoot will produce the same observations, right? So any waste heat going into your shoes is probably a small amount.
Are there approximate versions of the selection theorems? I haven't seen anyone talk about them, but they might be easy to prove.
Approximate version of Kelly criteron: any agent that follows a strategy different by at least epsilon from Kelly betting will almost surely lose money compared to a Kelly-betting agent at a rate f(epsilon)
Approximate version of VNM: Any agent that satisfies some weakened version of the VNM axioms will have high likelihood under Boltzmann rationality (or some other metric of approximate utility maximization). The closest thing I'...
Is there somewhere I can find a graph of the number of AI alignment researchers vs AI capabilities researchers over time, from say 2005 to the present day?
Is there software that would let me automatically switch between microphones on my computer when I put on my headset?
I imagine this might work as a piece of software that integrates all microphones connected to my computer into a single input device, then transmits the audio stream from the best-quality source.
A partial solution would be something that automatically switches to the headset microphone when I switch to the headset speakers.
3
Depending on connection method for your headset, you might be able to just use a simple switch. Mine is USB, and https://smile.amazon.com/dp/B00JX1ZS5O lets me just leave it disconnected when not in use. My Windows box uses the speakers when it's disconnected (I don't have a separate mic, but I expect it would work the same), and switches output and input to the headset when connected. I've seen similar switchers for 3.5mm audio connectors - I have no doubt they'd work for microphone instead of speaker, but I don't know any that combine them.
1
Thanks. I tried a couple different switches on my setup (3.5mm through USB-C hub), and the computer didn't disconnect upon opening the switch, so I'm giving up on this until I change hardware.