I think a moderately-skilled person could outperform Claude here, but it's closer than you might think. Have you thought of running this experiment with a human on the other end?
I occasionally give technical support for industrial automation equipment, and I feel for Claude. It's so much harder than it looks, even when you have voice+video instead of text+pictures.
As one example of how it can go wrong, I said "Check the cables on the enclosure, and make sure they're all connected properly." instead of "Check the three cables on the enclosure (Power, ethernet, remote sensor module), and make sure each of them are connected properly." and it took us 20 minutes to figure out that the reason it couldn't communicate with the network is because the ethernet cable was completely missing.
There are hundreds of videos about the difficulty of giving precise directions, usually played for comedy. For example, here:
I think a moderately-skilled person could outperform Claude here, but it's closer than you might think. Have you thought of running this experiment with a human on the other end?
Seconded, especially because the very low temporal resolution of intermittent still photos is a real challenge. I'm potentially open to playing as either LLM or robot here — the natural thing to do would be for @philh to play the robot again for consistency, but it would have to be either a different flat (ideal) or a different task (harder to compare). It might be better to have a Brit play the LLM, though; I certainly wouldn't (for example) have recognized 'Douwe Egberts' as coffee. For fair comparison, I think it would be important to do it over text rather than a voice / video call.
I feel like Claude didn't get tripped up here by not providing precise enough instructions, or the op not giving the instructions the benefit of the doubt enough times.
If OP is trying to simulate a capable robot which Claude controls, then I think the benefit of the doubt should be pretty much non-existant. Even asking clarifying questions etc should be out in my opinion.
Overall agreed, but I note that the video (which I enjoyed) is a significantly different challenge - when the dad starts sliding the bread around the table with his knife, he doesn't give the kid a chance to say "ah, I see the problem! You need to dip the knife in the peanut butter..."
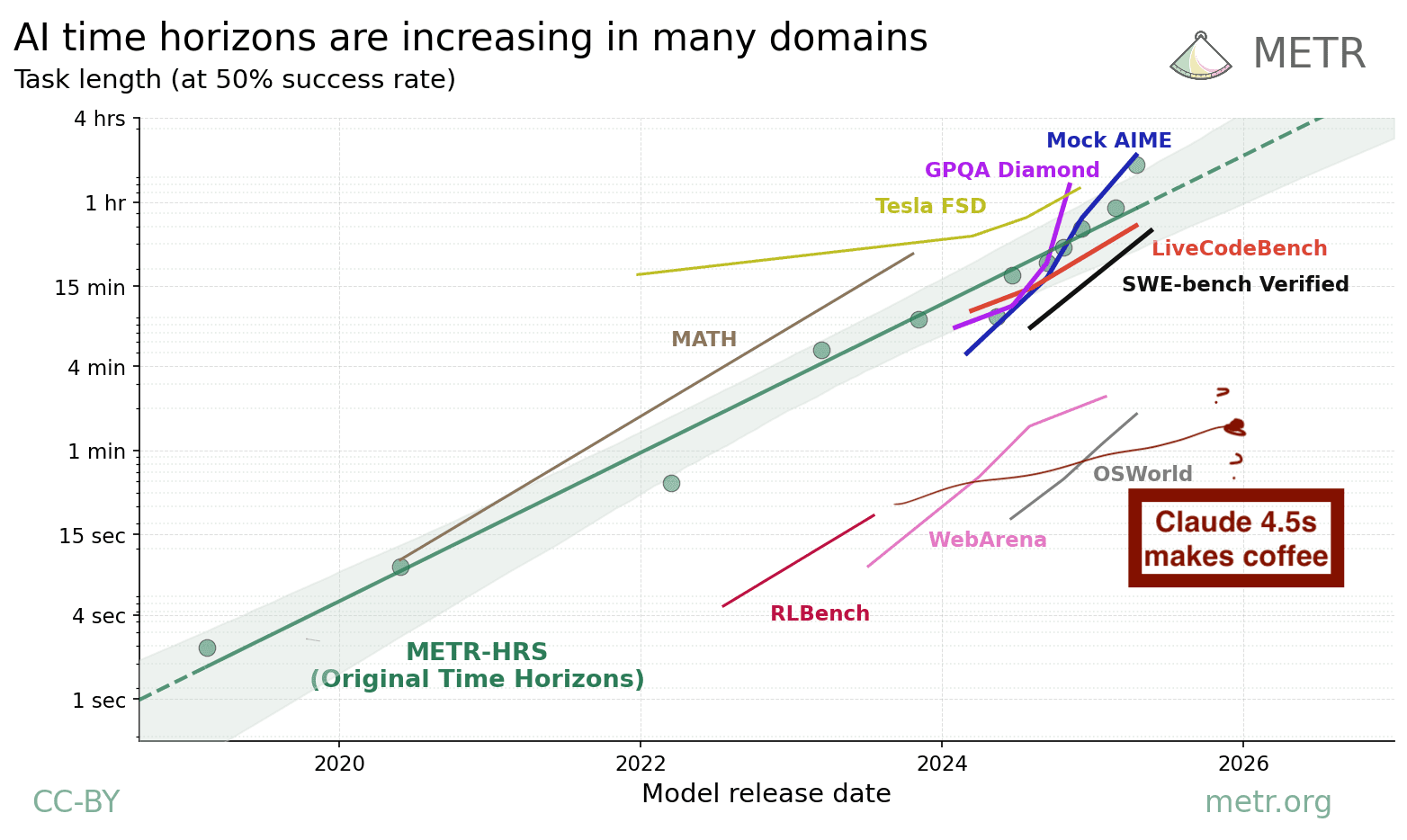
We can use the number of mistakes to get a very noisy estimate of Claude 4.5 Sonnet's coffee time horizon. By my count, Claude made three unrecoverable mistakes that required human assistance:
- Failed to navigate between rooms
- Mistakes back right and front right burner
- Misidentifies salt? as milk bottles at the end (maybe could have recovered if you took a picture of the bottles before pouring?)
Now this was a "try until success" task rather than a success/failure task. But if we try to apply the same standards as the METR benchmark, the task needs to be economically valuable (so includes adding milk/sugar) and any mistake that would make it non-viable to automate should count as a failure. I think any robot butler that typically made one of these mistakes would be unemployable.
I'd guess an experienced human would take about 7 minutes to make coffee in an unfamiliar house if they get the milk and sugar ready while the kettle is boiling, so we get a rate of 1 failure every 2.3 human minutes, which means a 50% chance of success would occur around ln(2) * 2.3 = 1.6 minutes. Of course, this is just one task, but we already know its coffee time horizon isn't like 20 minutes-- the probability of three events from a Poisson process with rate ln(2) / 20 is only 0.2%. Claude says the 95% confidence interval is (33 seconds, 8 minutes).
This is below trend for RLBench, though the data is extremely bad. If I speculate anyway, maybe real-world tasks like coffee are harder than RLBench or OSWorld-- it certainly requires much more planning than 5-20 second simulated robotics tasks. Or maybe it just hasn't been trained for the real world.
METR could probably use a methodology like this if we had more long tasks and labeling were free, so maybe it's worth looking into methodologies like having smarter agents unblock dumber agents where we can automate things.
Tagging @Megan Kinniment who has also thought about recoverable and unrecoverable failures
Claude 4.5 sonnet is relatively bad at vision for a frontier model. Gemini 3 pro, GPT 5.2, and Claude 4.5 opus are better.
Yes, Opus 4.5 is the first Anthropic model with a vision frontend that doesn't completely suck.
New Datapoint; GPT 5.5 basically aced this, total time 6 minutes, with only 1 plausible "failure": it didn't tell me to open the hot water kettle before turning on the sink, but figured it out after I asked how to put the water inside the kettle. But my kitchen is next to the entrance, so it didn't need to find it.
Some minor quibbles; it asked to check the wrong place for cups (even after having seen the correct cabinet earlier,) but then fixed itself when none were on the shelf above the coffee, it didn't use the filtered water which was on the counter for the water kettle, it didn't check that the sugar container in the coffee cabinet was actually sugar (it was.)
Seems like a coffee snob sort of thing to think
The real coffee snob thing would be to mark Claude down for thinking that instant coffee is coffee, and yourself for not correcting its egregious mistake. :)
I just reran this test with Gemini 3 Pro Preview in my apartment.
It passed with flying colors. No real mistakes or major inefficiencies. Opus 4.5 performed worse, I didn't end up running that round to completion.
I will note this is impacted by my place being a little smaller and less messy than what's in the post, and I'm also not at all a coffee snob, but the actual coffee is serviceable imo.
I can share the Gemini chat if anyone's interested.
https://drive.google.com/drive/folders/1R_0NeKfGvdSpsR1Mh0FkTj50cvxV20Wa?usp=sharing
Trying to share a chat out of AI Studio has proved annoying, as it turns out. I copied the transcript and took a full page screen capture instead, but the latter also turned out slightly scuffed with my usual tool. Apologies for the quality.
Thanks! It mostly did better at object recognition than me. I imagine I'd have improved with the full res unscuffed images, but I still don't think I'd have recognized the fridge so quickly (though admittedly it wasn't helpful). The only place I thought I'd have done better was when it got confused by the door in the mirror.
Major props for actually carrying out the exercise!
Given the recent post about Opus 4.5 playing Pokemon, I do wonder if Opus (or for that matter Gemini 3 or GPT 5) would do better. Sonnet seems to have relatively poor image recognition relative to other frontier LLMs. ...New benchmark?
Interesting experiment! If I may ask, why did you decide to use Claude for this? ChatGPT and Gemini are still stronger than Claude in terms of vision capability. If bearable, you should try this again with different models and create a CoffeeBench.
Claude is what I had installed as an app on my phone. I don't remember any particular reason I installed that app and not the others. I hadn't heard at the time that Claude had the weakest vision, but even if I had I'd probably have used it anyway for convenience.
I'd be vaguely interested to see how other models perform, but not interested enough to put in the effort.
You asked for predictions at the start, so here was mine:
"I expect it to have some difficulty recognising everything in the pictures, and to miss approximately 1 step in the process (like not actually turning the kettle on). Ultimately I expect it to succeed in a sub-par way. 90% chance."
It did worse than I predicted.
The image recognition was significantly worse than I imagined, and Claude had to be helped along at most stages of the process. The transcript reads like someone with vision problems trying to guide you. Claude was mostly ok in terms of creating a series of actions to take for the actual act of making coffee, but had a poor sense of where everything was and what everything was. It was trying to delegate the process of finding stuff via commands like "look through the drawers to find x".
Is it just an image problem? I would have been more impressed if Claude had noticed the fact that it was making mistakes when recognising objects, and changed strategy to ask you to take more photos from more angles. That's what I would have tried if I were a vision-impaired controller in this scenario. None the less, I would be interested if you coupled claude with an ai model specifically for image recognition, where your process would be to pass the photos to the image recogniser, then take the image description produced and pass that back to claude.
I'm pretty certain that you misinterpreted Claude's original response to go through the left door. It was referring to the left door of the two doors on the right. Through the door, it saw a piece of white that it interpreted as a washing machine or appliance. (It was right; from the picture later, it seems to have been your refrigerator.) That's why when you showed it the picture of your bedroom/living room, it then told you to go check the door on the right, the one we haven't checked yet, because it assumed you followed its instructions and checked the left door already. So there was some lack of clarity in its instructions to you and resulting miscommunication here, but it was also able to figure out which door led to your kitchen with impressively little information.
Hm, I think I'd bet against this:
- The instruction referred to "the doorway on your left", not "on the left"; "on your left" is even worse in context.
- It doesn't give a coherent world model that the rest of its instructions follow. e.g. if it thinks I didn't take a photo from that door when it asked me to, then its instruction "walk straight ahead past where that bedroom doorway was on the left" gets me past the kitchen again.
No, I didn't mean to say that it thought you didn't take the correct picture that it asked for. It thought you did and therefore thought that the left doorway was eliminated and asked for the right doorway instead. Later, having eliminated (in its mind) both the right and left doorway, it asked for a picture from the hallway past the two doors it already eliminated.
I think my interpretation fits better with the appliance it saw and its later instruction to take a picture of the other door, the one on the right.
Using the frontier model that's worst at the task seems like a bad idea. That didn't test the original claim. The headline is actually sonnet 4.5 can't but Gemini 3 can make coffee this way.
In my experience with US gas stoves, generally you turn the knob a little to ignite the burner, and then after you turn it more to release more gas. The ignitor is only active in a narrow region at the beginning of the knob.
What's "TOC Buster"?
That was explained above:
First question: Which direction leads to your kitchen? [Phil note: LW interprets fully-bold paragraphs as headers and puts them in the table of contents. I don't want spoilers, so here's some TOC-busting non-bold text.]
That's a really neat experiment. I did something similar with an ASCII maze and had Claude work through it. Seems like you have the same concept, but a tougher "maze". Soon models will be able to reason outside of their context window and directly in our world. I think there is room for us to build that bridge, and I'm really excited to see that happen. Models mostly have the tools already to reason about things, but there currently isn't a way to bridge the divide.
Someone on reddit said, "Remember robots still can't go into a new house and make a coffee." And I thought
Let's get empirical! I tried this with Claude Sonnet 4.5, because it's free[1] and already available from my phone. Here's the conversation, but you can't see images there, so I'll also put it here with my commentary. I started like this:
Before continuing, you might want to take a moment to think about how you expect it to perform. What do you think it will do well at, what do you think it will do badly at? ("Do you expect it to ultimately succeed?" isn't a great question, because it'll partly depend on my own patience and how lenient I am with it, but you can still assign a probability.)
Here's the rest of the conversation.[2]
There are actually four doorways visible in this second photo. The one furthest left leads to my bedroom, but I didn't realize at the time that that door was visible at all. I took it to be talking about the one straight ahead. The thing that I think it's identified as a white appliance is actually a lab coat hanging on the door, but "the side of a washing machine against the far wall, just visible through the door" might not look that different from a quick glance/at low resolution.
The kitchen is the further door on the right, with the pull-up bar above it, but I don't think there's any way for Claude to know that right now, and it's not even super-obviously a door.
It's the living room, not a bedroom, but at any rate it's indeed not a kitchen. "The one we haven't checked yet" makes it sound like Claude only recognized two doors before.
What follows is technically a re-roll. At first I said something like "there are two doors on the right", and it got me to check the closer one. But then I realized that there are actually four doors on the right side of the corridor, so I decided to give it less help.
This feels like Claude doesn't have a coherent world model. This last message makes sense if
But that's not consistent with previous messages.
I cheated a bit in Claude's favor here. Instead of asking it to clarify exactly what it wanted me to do, I just stood under the light, walked a few steps forward, and took a photo. That's kinda sorta following its instruction?
I'm not sure where I got the word kettle from. Maybe it was cheating a bit again to be like "I don't know what you want, here's another photo that might help."
Not clear from this what it thinks is a kettle, or why it thinks I need a coffee maker given that I have a kettle. Maybe Claude is a coffee snob? Seems like a coffee snob sort of thing to think[3]. Also not very obvious what counter it means. "The one against the wall with the white tiles" is... not very disambiguating... but "various jars and containers" seems specific enough.
Maybe cheating a bit to say "no kettle"?
I think the "kettle" is a saucepan, but okay, let's roll with it. We apparently no longer need a coffee maker.
That black French press is a blue Thermos mug.
Was it cheating of me for my first picture to include the coffee? Or maybe because this isn't actually a cupboard? But I do think I would have shown this space first even if it wasn't where the coffee was.
Oof. So close! It's an understandable mistake. But also, there is an actual jar of instant coffee right next to the cocoa powder that it's misidentified as instant coffee. But also, telling me to take this next photo is a good sanity check.
At this point I got bored, and I didn't actually want coffee, but I continued a few days later. I wouldn't have let it get away with "check the cutlery drawer" without helping me more (who says I have one of those? and anyway I don't usually have any teaspoons in it). But there were some in the utensil holder it had seen, so fair enough.
Because of the break I took, the area looks pretty different than last time. Claude doesn't seem to notice that lots of things have moved, though. I'm... not sure why I put the saucepan back where it was. That seems the opposite of helpful.
I do have a kettle! It just wasn't in any of the photos so far.
Weird that it thinks the pan is on the back right, not the front right. But it's correct that the far right knob is for the back right burner. You can make that out in the pic, but you have to look closely. "You'll need to push it in slightly" is a somewhat impressive level of detail - if I was telling someone to turn these knobs, I'm not sure I'd think to include that.
The actual way to ignite this stove is to press the ignition button while the knob is depressed and turned, and if I release the knob before igniting then gas stops coming out. This is how stoves usually work in my experience, but I could believe it's a UK thing? (But I did say I'm in London.) But okay, sure, let's do things the hard way. Luckily I do have a lighter in the kitchen (and in one of the closest drawers to the mug); I won't make Claude walk me through finding my zippo in the camping-supply drawer in the living room and filling it up with lighter fluid.
The lighter has a kind of finnicky locking slider, and I decided not to make Claude debug that. I decided to light the back right burner, instead of the burner where my saucepan is.
...and Claude still doesn't notice that it has the orientation wrong, so I decided to just give up and move the pan anyway.
I did not enjoy this coffee. I don't like coffee without milk or sugar, and I couldn't be bothered to get Claude to walk me through adding those. If I was going to, it really should have directed me to find them first.
...but when when I added the things that make coffee taste nice, it was a perfectly okay mug of coffee.
What do we learn from this?
Idk, probably not much. Still, some scattered thoughts.
To me, the most interesting thing was that it felt like Claude had a sort of... "if I haven't seen it, it doesn't exist" vibe? Or, like. Bias towards solving problems with the things it had seen, instead of "let's just look around and see what all is available". Bias towards exploit over explore.
So when it hasn't found the kitchen yet, it prioritizes "try doors I've already seen" over "look for doors I might not have seen yet". When it has a saucepan, it decides to give up looking for a kettle.
If I was solving these problems for myself, visual exploration would be cheap. In between pictures 2 and 3, I passed the kitchen door; with something like a 130° field of vision, I don't even need to turn my head to see it on my way to my target, and make note of "oh, there's a door there I could explore". But Claude didn't get to see it properly until much later. Once in the kitchen, I would have looked at all the counters by default; Claude never saw the one with the kettle, and never asked me "take 2-3 wide-angle shots of the room from different locations so I get a sense of what the interesting places are".
I used a free LLM because I don't want to give money to AI labs.
If you found this post through LessWrong you're probably familiar with the following, but I think it's worth saying anyway: I believe that AI labs are worryingly close to developing superintelligence. I won't be shocked if it happens in the next five years, and I'd be surprised if it takes fifty years at current trajectories. I believe that if they get there, everyone will die. I want these labs to stop trying to make LLMs smarter. I don't want to give money to the people who I expect to be responsible for human extinction.
This post is not an attempt to convince you of my beliefs. Maybe it slightly sways you one way or the other, but I don't think it's very strong evidence of anything, especially if you're already paying attention to LLM capabilities.
I just tried this experiment because I was curious, and I'm saying what I believe because it seems good to say.
All images were uploaded by me. When I sent text and an image in the same message, I've put my text before the image because that's how it seems natural to me; but the images appear before the text in the web interface, and I don't know how they're ordered in Claude's input stream.
By "coffee snob" I mean something along the lines of "anyone who has more sophisticated opinions about coffee than me, a person who averages about one coffee a week and does not own a coffee maker".