This is a special post for quick takes by Vladimir_Nesov. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Flagship models need inference compute at gigawatt scale with a lot of HBM per scale-up world. Nvidia's systems are currently a year behind for serving models with trillions of total params, and will remain behind until 2028-2029 for serving models with tens of trillions of total params. Thus if OpenAI fails to access TPUs or some other alternative to Nvidia (at gigawatt scale), it will continue being unable to serve a model with a competitive amount of total params as a flagship model until late 2028 to 2029. There will be a window in 2026 when OpenAI catches up, but then it's behind again.
The current largest flagship models are Gemini 3 Pro and Opus 4.5, probably at multiple trillions of total params, requiring systems with multiple TB of HBM per scale-up world to serve efficiently. They are likely using Trillium (TPUv6e, 8 TB per scale-up world) and Trainium 2 Ultra (6 TB per scale-up world), and need north of high hundreds of megawatts of such systems to serve their user bases.
Nvidia's system in this class is GB200/GB300 NVL72 (14/20 TB per scale-up world), but so far there isn't enough of it built, and so models served with Nvidia's older hardware (H100/H200/B200, 0.6-1.4 TB p...
3
If compute used for RL is comparable to compute used for inference for GDM and Anthropic, then serving to users might not be that important of a dimension. I guess it could be acceptable to have much slower inference for RL but not for serving to users.
3
Once a model is trained, it needs to be served. If both xAI and OpenAI have their ~6T total param models already trained in Jan 2026, xAI will have enough NVL72 systems to serve the model to all its users at a reasonable speed and price (and so they will), while OpenAI won't have that option at all (without restricting demand somehow, probably with rate limits or higher prices).
A meaningful fraction of the buildout of a given system is usually online several months to a year before the bulk of it, that's when the first news about cloud access appear. If new inference hardware makes more total params practical than previous hardware, and scaling of hardware amount (between hardware generations) is still underway, then even a fraction of the new hardware buildout will be comparable to the bulk of the old hardware (which is busy anyway) in FLOPs and training steps that RL can get out of it, adjusting for better efficiency. And slow rollouts for RL (on old hardware) increase batch sizes and decrease the total number of training steps that fit into a few months, this could also be important.
[...]
What new hardware becomes available before the bulk of it is not uniquely useful for serving to users, because there isn't enough of it to serve a flagship model with more total params to all users. So it does seem to make sense to use it for RL training of a new model that will use the bulk of the same hardware for serving the model to users once enough of it is built.
2
I don't understand why HBM per scale-up world is a major constraint for inference. For Deepseek V3, "The minimum deployment unit of the decoding stage consists of 40 nodes with 320 GPUs." (section 3.4.2 https://arxiv.org/pdf/2412.19437v1). This seems like evidence that you can get reasonably efficient inference out of multi-node setups.
If using H800s, this means that their minimum deployment unit has 25.6 TB of memory. In general it seems like there are probably a lot of engineering tricks you can do to get efficient inference out of multi-node setups.
2
Any source for Gemini 3 Pro and Opus 4.5 being multiple trillion? Just intuitively from the serving speed of Opus 4.5 seems dubious.
2
(not a reliable source, just a fun botec)
1
Do you know the reason for the NVL72 delay? I thought it was announced in March 2024.
6
I don't think there is a delay specific to NVL72, it just takes this long normally, and with all the external customers Nvidia needs to announce things a bit earlier than, say, Google. This is why I expect Rubin Ultra NVL576 (the next check on TPU dominance after 2026's NVL72) to also take similarly long. It's announced for 2027, but 2028 will probably only see completion of a fraction of the eventual buildout, and only in 2029 will the bulk of the buildout be completed (though maybe late 2028 will be made possible for NVL576 specifically, given the urgency and time to prepare). This would enable companies like OpenAI (without access to TPUs at gigawatt scale) to serve flagship models at the next level of scale (what 2026 pretraining compute asks for) for all its users, catching up to where Google and Anthropic were in 2026-2027 thanks to Ironwood. Unless Google decides to give yet another of its competitors this crucial resource and allows OpenAI to build gigawatts of TPUs earlier than 2028-2029.
1
Do you know why it takes such a long time to deploy a new rack system at scale? In my mind you slap on the new Rubin chips, more HBM, and you are good to go. (In your linked comment you mention "reliability issues", is that where the bulk of the time comes from? (I did not read the linked semianalysis article.)) Or does everything, including e.g. cooling and interconnects, have to be redesigned from scratch for each new rack system, so you can't reuse any of the older proven/reliable components?
3
That things other than chips need to be redesigned wouldn't argue either way, because in that hypothetical everything could just come together at once, the other things the same way as the chips themselves. The issue is capacity of factories and labor for all the stuff and integration and construction. You can't produce everything all at once, instead you need to produce each kind of thing that goes into the finished datacenters over the course of at least months, maybe as long as 2 years for sufficiently similar variants of a system that can share many steps of the process (as with H100/H200/B200 previously, and now GB200/GB300 NVL72).
How elaborate the production process needs to be also doesn't matter, it just shifts the arrival of the finished systems in time (even if substantially), with the first systems still getting ready earlier than the bulk of them. And so the first 20% of everything (at a given stage of production) will be ready partway into the volume production period (in a broad sense that also includes construction of datacenter buildings or burn-in of racks), significantly earlier than most of it.
There is some conceptual misleadingness with the usual ways of framing algorithmic progress. Imagine that in 2022 the number of apples produced on some farm increased 10x year-over-year, then in 2023 the number of oranges increased 10x, and then in 2024 the number of pears increased 10x. That doesn't mean that the number of fruits is up 1000x in 3 years.
Price-performance of compute compounds over many years, but most algorithmic progress doesn't, it only applies to the things relevant around the timeframe when that progress happens, and stops being applicable a few years later. So forecasting over multiple years in terms of effective compute that doesn't account for this issue would greatly overestimate progress. There are some pieces of algorithmic progress that do compound, and it would be useful to treat them as fundamentally different from the transient kind.
This is a reasonable point in principle, but I don't know how important it is in practice. My sense is that most things identified as algorithmic improvements continue to be algorithmic improvements over the previously-done thing at higher scales? E.g. transformers beating LSTMs, Chinchilla scaling, GeLU over ReLU, probably RL to train reasoning, etc.
8
I think pretraining data pipeline improvements have this issue, they stop helping with larger models that want more data (or it becomes about midtraining). And similarly for the benchmark-placating better post-training data that enables ever less intelligent models to get good scores, but probably doesn't add up to much (at least when it's not pretraining-scale RLVR).
Things like MoE, GLU over LU, maybe DyT or Muon add up to a relatively modest compute multiplier over the original Transformer. For example Transformer++ vs. Transformer in Figure 4 of the Mamba paper suggests a total compute multiplier of 5x, attained over 6 years since the original Transformer (for dense models). This is emphatically not 3x-4x per year!
Chinchilla scaling is more about careful methodology with compute optimality rather than a specific algorithmic improvement, and even now most demonstrations of compute multipliers fail to take one of its lessons and cool down the models before measurement. This could lead to hilarious results such as Figure 11 of the OLMo 2 paper where an apparent 2x compute multiplier vanishes to nothing after cooling (admittedly, nobody expected this to be a real compute multiplier, but in a more confusing case it could've been taken to be one).
3
In this Epoch paper appendix https://arxiv.org/pdf/2403.05812#page=12.3 they report efficiency improvements across 1.5+ years of time:
(a) is faster than your Mamba paper example but still much slower than 3-4x/year. (b) and (c) are at ~4x, though (c) isn't much longer than a year. And these are basically not taking into account post-training efficiency gains iiuc.
We're not working with many data points but it seems like these provide an existence proof that gains can compound across at least 3 years.
Would love to see some updated data collection on this, I think we could get more evidence on your hypothesis.
3
Mamba paper uses a relevant kind of methodology, it directly compares different algorithmic ingredients in the same setting, training on a fixed dataset and measuring perplexity (do note it's not trying MoE, so the actual total improvement is greater). It's a way of directly comparing cumulative improvement over all that time. To impact future frontier capabilities, an algorithmic ingredient from the past needs to be both applicable to the future frontier models, and help with benchmarks relevant to those frontier models, compared to the counterfactual where the frontier model doesn't use the algorithmic ingredient.
When an ingredient stops being applicable to the frontier model, or stops being relevant to what's currently important about its capabilities, it's no longer compounding towards frontier capabilities. It wouldn't matter if that same ingredient is helping a different contemporary non-frontier small model to match a much older model with much less compute. Or that it's helping the frontier model to do much better than an older model on a benchmark that used to matter then, but doesn't matter now.
So I'm skeptical of the Epoch paper's overall framing, its willingness to compare everything against everything indirectly, that's a lot of the point I'm making. You mostly can't use methods from 2014 and frontier AI compute from 2025 to train something directly comparable to a lightweight version of a frontier model of 2025 trained on less compute (but still compute optimally), compared in a way that matters in 2025. So what does it mean that there is so and so compute multiplier across all of this time? At least for Transformer recipes, there is a possibility of comparing them directly if training converges.
Also, if we are not even aiming to do Chinchilla optimal training runs, what are we even comparing? For older algorithmic ingredients, you still need to aim for compute optimality to extract a meaningful compute multiplier, even if in the time of those ol
GPT-5.5 is at the beginning of RLVR scaling, and future versions with the same pretrain will get considerably stronger in the coming months.
With GPT-5.x releases, OpenAI is taking advantage of RLVR scaling to blur the jumps in capability between different pretrains. GPT-5.1 ($1.25/$10 per 1M input/output tokens, knowledge cutoff 30 Sep 2024, context length 400K tokens) is followed by a slightly stronger GPT-5.2 ($1.75/$14, 31 Aug 2025, 400K), which is likely a better pretrain and a bigger model. Then GPT-5.3-Codex ($1.75/$14, 31 Aug 2025, 400K) is almost certainly the same pretrain, and GPT-5.4 ($2.5/$15, 31 Aug 2025, 1050K) is notably stronger than GPT-5.2, but still very likely the same pretrain (the change in pricing might be due to the change in context length). And now GPT-5.5 ($5/$30, 1 Dec 2025, 1050K) is a new bigger pretrain, stronger than GPT-5.4.
The strategy of "iterative deployment" seems to be about using RLVR scaling to release each pretrain with a little RLVR first, and then to scale RLVR for the same pretrain in subsequent releases in order to almost match the level of capabilities that will be achieved with a stronger pretrain that only uses a little RLVR, which is...
These results seem to support the hypothesis that 5.5 is a new pretrain, though what’s happening with 5.3 and 5.4 is a bit unclear.
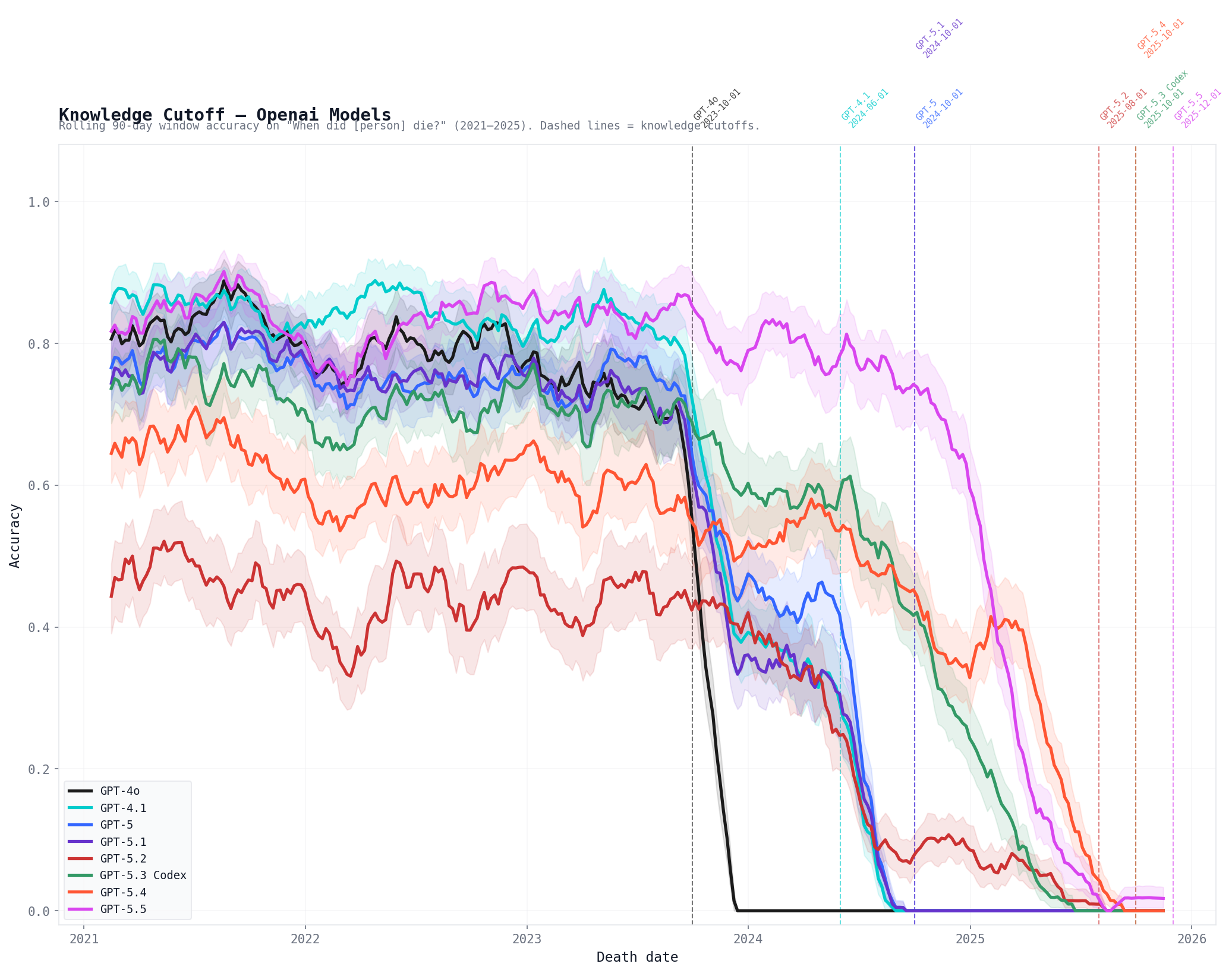
[edit: code available here, credit belongs to @Daniel Paleka for the idea]
Interesting, thank you! This strongly supports the hypothesis that 5.1/5.0/4.1/4o (and therefore o3, because what else could it be) are using the same original pretrain, with 5.1/5.0/4.1 possibly using the same mid-training refresh. For 5.2, there isn't an accuracy dip in late 2023, so it's still probably a different pretrain than 5.1 (the original pretrain for 5.2 is probably using the same natural text data that went into the mid-training refresh for 5.1/5.0/4.1), but the mid-training for 5.2 is seriously broken (though its baseline for 2022-2023 is also worse than for the other models, so it could be a post-training or elicitation issue). Plausibly they re-did or otherwise updated at least mid-training for 5.3 and then also for 5.4 (given the peak for 5.4 in early 2025, which is absent for 5.3).
(I don't think 5.5 being a new pretrain was ever in doubt. It's 5.2 being different from 5.1, and 5.4 being the same as 5.2, that's more tenuous. But also, for the purposes of this thread, it shouldn't matter if a pretrain is refreshed with slightly newer data, either through mid-training or by re-doing everything from scratch. For the way RLVR scaling interacts with "iterative deployment...
9
I don't know if you are referencing it, but your point about 5.2 midtraining failing and being fixed in 5.3/5.4 lines up pretty much exactly with what the paywalled information article "OpenAI Developing ‘Garlic’ Model to Counter Google’s Recent Gains" said back in December, discussing "shallotpeat" being a new pretrain method (5.2), that had some issues and so was being currently refined into a model "garlic" (5.3/5.4) that could properly take on google, with the lessons learned being used as they started creation of a newer, bigger model (5.5).
5.2 being functionally complete, with 5.3 in post training, and pretraining in progress for 5.5 seems to match up very nice with the Dec 2 information article post date and subsequent release dates of 5.2 - 5.5. It is a bit muddied since OAI twitter "vagueposted" many garlic-themed memes around 5.2 release, but the timeline of 5.2 being garlic (still in post training in Dec 2nd, released Dec 11th) doesn't make any sense, while shallotpeat being complete before Dec 2 and undergoing safety/deployment testing through Dec 10th seems much more reasonable.
If you don't have have access to the article you can still get all the relevant snippets reposted on twitter, or resummarized by other outlets. There is also an even earlier information article that has the first mentions of shallotpeat (which was itself supposedly a refinement of the first, possibly completely failed internal pretrain attempt).
Relatedly, on Nov 11th Dwarkesh podcast, Illya made a reference to the rumors of a new pretraining method used for gemini 3.0, which is likely what was similarly used in the shallotpeat+ base models.
5
There's an archived version of the Garlic article. I was only referencing bhalstead's plot itself, how the GPT-5.2 line is clearly showing that something is wrong with learning (but again, maybe just elicitation) of the data from between mid-2024 and mid-2025. The dip in accuracy in this time window is much worse than with what's clearly the mid-training for 5.1/5.0/4.1, which covers the data from the first half of 2024 for those models.
(The issue with elicitation might be analogous to how Gemini 3 Pro insists it's impossible that it's currently 2026, and argues that anything that takes place in 2026 must be fictional. Maybe if you ask a model that's stuck in mid-2024 about someone who died in 2025, it'll say that they didn't die even if it knows when they did. Even if they die in the future, it doesn't follow that they died yet in reality, by mid-2024, and it's always mid-2024 for such a model even as after mid-training it knows some facts from 2025. This could be the dynamic under the surface that impacts elicitation, even if the model doesn't visibly argue about 2025 not being real.)
5
Pretty sure this idea originated from @Daniel Paleka here! Giving him some credits with this comment.
4
That's a clever idea!
Can someone explain why many models have slowly-decaying lines? I would have expected sharp drop-offs—knowledge falling to zero after training data ends. In what situation does a model (like GPT-5.2) fall from 0.5 to sub 0.1 accuracy, and stay there for seemingly half a year?)
I'm also surprised that old and obsolete GPT-4x models seem to be broadly outcompeting the GPT-5x line. Am I missing something? Are refusals being counted as failures?
I suspect a few different variables are getting mixed together—a model's raw intelligence, its willingness to provide a specific date, its willingness to confabulate when it doesn't know, etc.
1
* GPT 5.2 is dropping before its knowledge cutoff.
* The decays are probably because there are less training data about recent deaths, and that the pre-training may have started before the knowledge cutoff.
* Older models having better rote memorization on slightly obscure facts isn't that surprising imo. It is not something that has a lot of optimization pressure.
* Having multiple variables mixed don't seem like a big issue for detecting ancestry. False positives will still be highly unlikely -- different pretrains will probably have different "forgetting curves".
1
Very cool graph. Is the script you used publicly available?
2
added a link
8
How do you reconcile this claim of OA doing regular new pretrains on larger models with the general consensus and leaks that they are not new pretrains and only GPT-5.5 is the first new true pretrain, and the general pattern of consistency between them with some regressions, like one would expect of doing a lot more RL on the same basis and consistent with the previous history of pushing the 4o-series very far? I'll just say that this is the first I've heard it suggested that GPT-5.2 is a new pretrain.
8
OpenAI didn't do new pretrains that became flagship models for a surprisingly long time (all their flagship models from GPT-4o to GPT-5.1 being based on the same pretrain, 1.5 years of releases), so it became a notable thing to talk about. But GPT-5.5 was released 2 years after GPT-4o, so in preparation for it there would've inevitably been significant changes in architecture, which would've been tested on models smaller than GPT-5.5 first. And GPT-4o was targeting A100s and H100s (640 GB of HBM per server), while GPT-5.2 was released when they might've had enough B200s (1400 GB of HBM) to run it.
So it's the combination of plausible availability of enough B200s to make a larger model practical, increased token price, changed cutoff date, the cost of pretraining being more trivial in 2025 than it was at the end of 2023, new algorithmic improvements that motivate replacing the model, the need for a test run for a new model architecture in preparation for GPT-5.5, and plausibly their ability to usefully scale RLVR on top of GPT-4o's base model had finally run out at about GPT-5.1, while "iterative deployment" demanded bridge releases between GPT-5.1 and GPT-5.5. These arguments are weak individually, and only some of them gesture at particular timing, but when considered altogether, they suggest significant pretraining activity would've been happening around that time. There are specific rumors around Shallotpeat [1] and Garlic [2] being about refinement of the pretraining process, though it's unclear if they have anything to do with GPT-5.2 or GPT-5.4, or are just steps towards making GPT-5.5's pretrain work. Though the separate codename Spud [3] (which is confirmed to be GPT-5.5) suggests that Garlic (which supposedly already resolved the problems in pretraining) is not the same thing as GPT-5.5.
Plausibly Shallotpeat and Garlic are not literally GPT-5.2 and GPT-5.3, because resolving pretraining problems in preparation for GPT-5.5, when it was this close to the f
7
How interchangeable are the gains from RLVR and pre-training? My understanding was that additional pre-training yields improvements on different benchmarks than additional RLVR. If that's true, you should be able to get an additional point of evidence of this hypothesis (in addition to the serving cost of models), by also looking at which benchmarks new releases show the biggest improvements on.
7
Any individual benchmark can be improved a lot with post-training (even for benchmarks that don't benefit from RLVR as much, by improving benchmark-relevant data). Better pretraining is the "rising tide" for things not directly addressed by post-training data, and it also makes the outcomes of post-training for the same tasks better. But if frontier pretrains are not too far apart, post-training might be able to interpolate between them well enough that it's hard to pinpoint the distinction.
6
Do we have any information on the cost to train 5.5 -- it seems no leaks yet?
Since it's a new pretrain, GPT-5.5 seems like an important datapoint to see where we are relative to the cost trend that you usefully estimated as "an increase in cost of 2.35x per year".
5
I saw a snippet of an interview with Greg Brockman in which he said something like "I think of Spud as a new pre-train". That "I think of..." made kind of suspicious. It's either that Brockman phrased things badly or that Spud isn't actually a new pre-train and that's why Brockman used that phrasing. If it's not actually a new pre-train, then my guess was that they did a massive amount of RLVR. If the amount of RLVR is at pre-training scale, then it would justify Brockman's phrasing.
1
We don't know much about how long it takes for a new base model to get "up to speed" in post-training these days. The existence of Mythos, which was already much more capable than Opus 4.6 by late February, suggests to me that this time window has compressed compared to a year ago.
Note: DeepSeek-V4's final checkpoint wasn't even RL'd at all. They did on-policy distillation from RL-trained specialist checkpoints to produce the final model. 5.5 could have similarly been (partially) distilled from advanced post-trained checkpoints of 5.4.
2
My argument doesn't involve saying they didn't have enough time to RLVR it a lot yet. It's about evidence for what "iterative deployment" means given all the GPT-5.x releases, and what it then suggests about GPT-5.5 and subsequent releases.
In principle, GPT-5.5 could be RLVRed GPT-4.5, and in principle OpenAI had 100K GB200 NVL72s since maybe summer 2025. But bhalstead's plot suggests a knowledge cutoff at the very end of 2024 (in the original pretrain, with no significantly later mid-training), which is likely too late for GPT-4.5, and the GB200 NVL72s probably weren't ready for a while in sufficient numbers, at least for efficiently inferencing large models.
Another possibility is a new pretrain made sometime in 2025 on H100/H200/B200, which wouldn't need to wait for GB200 NVL72s, and then they had maybe at least 6 months with enough GB200 NVL72s to experiment with RLVRing it, even if not yet enough to deploy it as a frontier model. The datapoint of apparently still doing RL for GPT-5.5 in Mar 2025 isn't evidence that this work only started very recently, as last touches of RL would happen before a release in any case.
Mythos doesn't obviously mean it takes little time to RL a large model, it could've been pretrained at any point in 2025 and RLed together with Opus 4.5 or shortly after, once Trainium 2 Ultra racks (or maybe some TPUs) were available for that.
[...]
Sure, but RLVR still needs to happen for something, even if not for the final model. If it only happens for smaller models, where it's more stable and doesn't need good/scarce/unfamiliar hardware, the results after OPD might be notably worse than if it's for same-sized models. DeepSeek-V4 paper doesn't disclose the nature of the teacher models, and how the quality of the result depends on it.
The possibility of OPD from GPT-5.4 just makes very fast post-training of GPT-5.5 more plausible than if it needed to be RLVRed directly, but probably resulting in inferior quality compared to what RLVRing o
2
No, 5.5 can't be derived from 4.5 because they use wildly different image tokenizers: 4.5 use exactly that of 4o while 5.5 has a variation of a newer architecture introduced on 5.1 in October 2025! https://developers.openai.com/api/docs/guides/images-vision
(Also it's now quite hard for me to imagine 5.1 adapted from 5 with such a difference)
1
Good analysis this seems very likely to me as well. It seems good to think about the strategic reasoning behind this. I hadn't previously deeply considered the dynamic of each new pretrain release being just slightly better than the previous pretrain + X RLVR, this does seem to imply that OpenAI is intentionally avoiding creating large jumps in capability with this iterative deployment strategy. Why is this important to them? The first idea I had that seems somewhat likely is that large capability jumps generate press and discourse in the mainstream (see mythos). This strategy would dodge that press, which if true seems like an important signal about their priorities re messaging and narrative (Conjecture: is it to their benefit for people to believe AI has "hit a wall"? Maybe they want to avoid the specific kind of "doomer" rhetoric that seems to arise whenever large capability jumps happen?). Looking into how the various labs are attempting to shape the narrative seems important, even if it inherently relies on a good bit of conjecture about internal motivations.
6
I think it is probably more a result of wanting to release a new, better model as often as possible. We've seen AI companies cluster releases together, last year, as if they're rushing to put something out whenever anyone else does, so that the media frenzy isn't exclusively about their competitor. A problem with that approach is you have to either hold something good back while waiting for competitors to release, or push something out prematurely. Everyone wants to get the last word, putting out the model that'll be perceived as best for the next couple months or so. That's tough to pull off, so an alternative is to just try and release as frequently as possible, rather than trying to time things cleverly. Then (if you keep pace capability-wise) your models will be the best most often, simply because you release more. The problem with that strategy is, you'll be using more compute running multiple training runs (doing a big post-training run at the same time as pre-training the next big thing). A more focused approach with fewer parallel training runs and a slower release cycle can utilize limited compute more effectively. The main question (for the race) becomes, who is managing all these trade-offs most effectively?
1
I am as cynical about Sam Altman as anyone but he does constantly say that he believes iterative deployment is important so that the public can see the frontier of AI as it emerges and so that society can adapt to development. It seems plausible that he, and a lot of other people at OpenAI, do actually believe this.
The usual story is that AGI causes RSI, which becomes a takeoff, rapidly approaching technological maturity even in the software-only initial phase. But without breakthroughs, LLMs by themselves lead to a strange baseline scenario where they enable an RSI process that gives them general but slow learning. This RSI process then constitutes an AGI, without leading to a takeoff, because crucial aspects of learning only happen between model releases, which take a long time to make. Even very fast reasoning doesn't lead to fast learning if it doesn't invent a method for fast learning, and inventing difficult things requires a lot of serial steps of learning, which takes a long time without a method for fast learning.
RSI happens through automation of the more mundane aspects of AI R&D, implementing RSI in the central sense of the word, automatically developing the next better models. This is likely to happen because of the remaining scaling runway, which enables a system that could be called Mythos+3 (by maybe 2031-2033), where Sonnet could be called Mythos-2, in terms of the levels of capability resulting from scaling alone. Using RLVR to train that system to proficiency at all the ...
9
I'd call this sort of scenario "limping to the Singularity", and this has been my median scenario for a while, with the caveat that my median takeoff speed is 3-5 years, with doubling times (initially) on the order of a year for the economy.
8
The slow learning scenario doesn't make time to takeoff any more predictable than inventing takeoff-capable AIs without help of the LLMs. The annual probability of inventing a takeoff-enabling breakthrough is only notably higher while the scaling remains rapid (so that ever more ambitious experiments become practical). But the scaling likely slows down significantly even with the slow-learning general automation AGI/RSI, compared to the current levels (because currently the scaling is advancing from essentially zero, growing into the currently accessible TAM, rather than because slow-learning AGI that can autonomously learn to do any kind of sufficiently slow-changing knowledge work and more isn't impactful).
One detail that remains somewhat unknown, but becomes known on a predictable schedule, is how smart a Mythos+3 turns out to be. So far, GPT-5.5 and Opus 4.6 seem unambiguously smarter than their Sonnet-level counterparts, but it's not a mice-and-chimps kind of difference. So Mythos+3 could land anywhere between reasonably smart humans (who don't already possess deep skills at a new thing) and slightly superhuman geniuses, who still won't be able to learn deep skills outside new model releases. If LLMs of early 2030s are slightly superhuman geniuses, they will produce significantly more useful ideas with the skills they do already have, which would advance the frontier of skills available to future LLMs faster, including by preparing better tasks and graders for RLVR. And they would have a better shot at themselves increasing the speed of the learning loop (for deep skills), or changing the process with a less incremental breakthrough, without waiting on human researchers.
3
How about calling this short timelines to slow (but unpredictable) takeoff, or something like that?
This is also my mainline scenario, and thinking it through and writing it up in greater depth is on my long ToDo list.
My one modification I'd make is that the question isn't just when does LLM AGI get efficient continual learning, it's how quickly and how much does it need. I agree with Steve Byrnes that You can’t imitation-learn how to continual-learn; LLMs do not acquire new concepts or skills by in-context learning, and I agree with you that continual learning is currently quite slow and laborious, and might roughly remain so.
But two factors may speed this up nontrivially:
1) LLMs may not need to learn any new concepts or skills to create breakthroughs and ASI.
Google's co-scientist project reportedly used extensive scaffolding to get Gemini 2.0 to reproduce field-leading theories in biology. It just burned a ton of compute, read a ton of papers, and had an intricate scaffolded structure for theory-creation and testing against published empirical results. See the Cognitive Revolution episode and arxiv article. I remain puzzled by how we haven't seen more similar work since then, but it appears to be a legitimate result from my inspection, and it makes sense to me that LLMs should be able to do this (I'm surprised 2.0 could; but current-gen are much better at catching their own mistakes and taking new directions when prompted to).
There are a lot of concepts and skills in the current training set. Agentic behavior is currently incompetent, for complex and interesting reasons; but lack of core skills is only one of those. Better metacognitive skills is one missing piece, and misapplied skills is another that would be quickly filled by continual learning. There are other components and framings, and I remain somewhat confused on all the sources of the intelligence-competence gap.
2) There are already working techniques for continual learning; centrally, this
1
The overall argument sounds convincing, but what exactly do you mean by "how smart" and "slightly superhuman geniuses"? If the future pretraining data is to be dominated by RLVR tasks, that leads to even more jaggedness of capabilities than we have now.
To illustrate, it's not implausible that Mythos+3 will be a strongly superhuman hacker but still fail at basic physical tasks. It can be superhuman intelligence in Bostrom's definition but arguably still not general intelligence (this is why I think it's better to avoid AGI/ASI terminology)
5
If RLVR gets automated, it alleviates a lot of the jaggedness, because LLMs can pursue training around billions of little issues that human developers can't directly focus on. This solves generalization by training (in the next version of the model) on tasks relevant to the out-of-distribution situations (as they get encountered by the current model) instead of magically already being good at them despite never training on them (which is the classical definition of generalization). This makes the model-training RSI an AGI, the ability to learn to navigate whatever new situations come up, albeit only in the next version of the model (hence being a weirdly slow-learning AGI that doesn't cause a takeoff until the slow-learning thing gets fixed).
Being smart is about the classical sense of generalization, how good a model is at things it never trained for. This determines how far the LLMs can reach beyond their training, before they have to wait for the next round of training in the next version of the model. Some things can take multiple cycles to be learned, because the current model isn't ready to teach them to the next version (isn't ready to construct the training data), but might advance some prerequisites. Being smarter can then speed up learning, by reducing the number of model release cycles necessary to learn the more difficult things, especially in the process of inventing them.
1
Dwarkesh Patel tackles exactly this question in the first two sections of his new essay, check it out: https://www.dwarkesh.com/p/the-next-paradigm
5
Dwarkesh Patel is unfortunately not insisting on the distinction between novel deep skills, and the stuff that in-context learning can handle (either simple skills or existing deep skill that are already in the weights). Because of this distinction, sample efficiency for novel deep skills can't be usefully found in in-context learning, or in continual learning methods that repackage the capabilities of in-context learning using some sort of recurrent state that enables functionally unlimited contexts (memory/skill note directories explicitly maintained by the model also fit this description).
Some hypothetical continual learning methods of the future might be good enough for learning deep skills, better than the present day in-context learning is, but this is not a solved problem, it's not something that can be expected to start working within some predictable amount of time. Dwarkesh Patel is caught up in essentially speculating how that could happen. One thing he mentions is on-policy self-distillation, which is an obvious enough idea to try, at least after you know about OPD itself, so every month it's not demonstrated to be RLVR-level capable (when used outside RLVR) is evidence it's not ready to soon become important for continual learning of novel deep skills (rather than for something else, like augmenting RLVR with process level feedback, maybe as a step in some recipe for RLVR training of multiple teacher models intended for eventual OPD into the target model).
Another thing he points to is "dreaming" that seems to be about model based RL (the example he gives is EfficientZero), but that has been a very long-running research direction, so the fact that it doesn't work with LLMs yet is already significant evidence that it can't be expected to start working within a short predictable amount of time. If you ignore all the technical distinctions, model based RL is somewhat similar to learning in self-constructed RL environments in RLVR, but focusing on RLVR s
1
You spent practically all of your reply critiquing sections 3 and 4 of the essay which I don't actually endorse[1], entirely ignoring the question of how a model trained in a containerized RLVR environment will magically generalize to unstructured real-world tasks which dominate the world economy (I looked it up: out of gross world product of ~$126T according to IMF, IT services and software contribute to less than $4T according to Gartner) and all of Patel's arguments why it won't
1. ^
I agree that RLVR does teach deep skills much better than alternatives tried so far, but that fact only leads to increased jaggedness not generalization!
4
Section 2 of the post talks about generalization in the classical sense, where an RLVRed model that didn't train on a situation-class magically does well there, or maybe where a model was magically RLVRed on so many situations it never encounters something truly novel ever again. Rather than the sense in which I expect automated RLVR to solve generalization, which is by observing failures of generalization (that are themselves sufficiently comprehensible with the current model) and producing RLVR training data that addresses them individually, to be included when building the next model. Thus jaggedness is addressed by slowly working on fixing the gaps as they are encountered, when they happen to be near enough to the edge of the existing skills.
(Incidentally, a lot of what currently contributes to the felt impression of jaggedness, rather than this more technical RLVR-and-deep-skills distinction, should also go away as the rising tide of pretraining scale comes in, which after 2026 will happen most prominently by 2028-2029, and to some meaningful further effect by 2031-2032. And then it's done, no more significant scaling of pretraining for many years.)
Section 1 of the post is some combination of making a distinction between engineering-type skills that can be RLVRed and those that can't be with current methods, and making a distinction between skills where success is easy to verify and those where it takes too much time, requires experimental feedback, or can't be packaged in a reproducible enough way to be usable with RLVR. The method has a scope of applicability and doesn't magically work for everything. This doesn't mean that the harder engineering-type things can't be understood as a practice of more modular skills that can be directly RLVRed. You can turn any engineering-type activity into a collection of textbooks with exercises that are individually of manageable scope.
So I take Sections 1 and 2 of the essay as being importantly mistaken (about a prio
1
But aren't most of the tasks in the world economy unverifiable in silico? How could LLMs pursue RLVR on, for example:
* quality control in manufacturing, or
* medical tasks like therapeutics, or
* effective persuasion (important for world takeover!), or
* management of human teams, or
* blue-collar tasks like fixing a leaking washing machine?
4
RLVR can use graders that invoke LLMs to decide how good a solution is (including with rubrics, evaluating multiple vague aspects of goodness in a solution). For robotics, it's plausible RL environments might end up using world models to imagine what happens in situations that couldn't be specified concretely in full detail. A sufficiently smart LLM could make usefully-detailed models of broken washing machines (perhaps based on the real broken washing machines it examined) to teach the next version to diagnose and fix them.
1
I think this is a key crux in these discussions: my understanding of grader quality is that it's systemically worse than human judge quality on tasks that current models struggle with, either because the grader is itself often OOD or because tasks often have ambiguous resolution. See CAIS section 3 here: https://safe.ai/blog/significant-increase-in-digital-labor-automation
Do you have a reason for why this might change? Is it just hoping that pretraining scale solves it? In physics, an LLM can call a physics sim or world model; in engineering as you note in another comment we can modularize, but the sim2real gap surely is much worse for, for example, HealthBench Professional tasks: https://cdn.openai.com/dd128428-0184-4e25-b155-3a7686c7d744/HealthBench-Professional.pdf (what would the sim even be?). A very large fraction of the economy is like this, and in theory that becomes a larger fraction as highly legible & verifiable tasks get automated in the coming few years.
1
I included initially three, and now with an edit four white-collar tasks and only one blue-collar task (after all the white collars are facing a greater risk of automation for obvious reasons). In all the former ones you can't substitute ground truth for an LLM judge, no matter how complicated. A general practitioner only finds out if the treatment works for the patient after they prescribe it, etc. Most of the white collar jobs in the world are like this!
As of washing machines, there are dozens of models in production, likely hundreds in operation, operating conditions vary (different installation, water, usage etc.), the number of possible malfunctions is significant for each machine in each case, the data on these malfunctions is collected very rarely, and when it is, it's in practice inaccessible to AI companies beyond brief summaries in operating manuals. All this applies to any mechanical equipment in the need of maintenance and repair not owned by the AI companies, including robots
5
I think this is basically my mainline prediction as well (except I possibly go further by tentatively thinking this might be inherent to any realisable intelligence takeoff, not just the LM-SGD-based). So the slow automation takeoff we're entering will set the stage for whatever comes next, which might come quite soon or might take several years. Meanwhile, much can be automated, including many industrial pieces, perhaps yielding industrial takeoff before anything like full-spectrum superintelligence! Innovation by AI in easy-to-verify/easy-to-RL domains is something we should expect to see more of (and that category could expand if effort is put toward data collection for high-fidelity simulation development).
Where I'm unsure is if a speed/compute-efficiency explosion (which we should expect quite soon) goes far before hitting limits, it might produce a quality all of its own... perhaps if ultra-ultra reasoning has better than logarithmic returns. Or if sheer compute efficiency allows sufficiently more experimentation as to rapidly discover more sample-efficient methods. Or if speed can drive newly-effective forms of in-context adaptation and learning. Or if aggressive exploitation of compute efficiency can really pump up the sample-efficiency of near-online advanced SGD-derived techniques (cf MuZero Reanalyse, Hindsight Experience Replay, and similar).
2
I think this is a plausible scenario. The three things that make me wonder are
1)
[...]
My understanding is that, going from a randomly initialized neural network, to a new frontier LLM, takes months. But going from a frontier LLM, to a frontier LLM with some extra RL steps, does not take that long. Potentially a few hours. And this is what you need to learn new skills.
Having Mythos+1 try to solve a hard problem, eventually realize its on thin ice, dabbling with a lot of stuff it doesn't really understand, then writing a bunch of practice tasks, RLing itself on them. Then having Mythos+1.001 keep trying to solve the hard problem, being on somewhat thicker ice than before, repeating this 10 times over a couple days, is there a reason this seems implausible to you?
I guess the least plausible part is "writing a bunch of practice tasks". But I can write practice tasks for myself. And LLMs do have the self-awareness to know when they don't understand something, at least some of that awareness. And If they have some, that's maybe enough, and also, if they have some, I expect them to get more.
2)
[...]
Its unclear to me how weak in-context learning really is. Seems to me doing online/continual learning is more and more important the longer the tasks you do are. Models are getting better at it. I don't see an in principle reason transformers can't implement proper continual learning just by writing tokens to themselves. So I'm not confident they can't learn it.
If I knew labs were doing truly long-horizon RL for a big part of training, I'd be more confident. And by "truly long-horizon" I mean, they let the model work til its out of context, they run compaction, and they do this many times, in single RL trajectories. But I don't know if they do this, or how much they do it.
3) I don't have an intuition for how hard a breakthrough in e.g. continual learning is. People are getting a lot of mileage out of just scaling current techniques.
4
Increasingly catastrophic forgetting from continual learning, depending on how much new stuff you learn. RL needs enough existing grooves in the model related to what it's trying to learn to work well, so if relevant data for novel skills is completely absent earlier in the training, this doesn't work as well later. Incremental learning could work well for a small amount of new learning, but probably gets increasingly worse as the novel skills that need to be learned get deeper, at which point the new practice problems that the model is able to prepare to get deeper into the skill (environments, tasks, and graders) for RLVR also get increasingly less useful (even for a later fresh training run).
[...]
It's important, but it doesn't work yet. It probably almost works for making an "infinite context", but it would be even weaker than the full-attention in-context learning. You can't teach an LLM to play good Go using in-context learning, or any number of memory notebooks. That's the limitation that distinguishes in-context learning from learning of deep skills with RLVR.
Continual learning of the kind that can be found in the literature is unlikely to fix that, unless it's some kind of continual RLVR that doesn't have a forgetting problem for long enough stretches of deep skill acquisition that autonomous LLMs start substantially outpacing humanity at research. And that sounds like the kind of breakthrough that makes LLMs takeoff-capable, that's currently not available, and that the slow-learning RSI process (that doesn't have access to this hypothetical invention) won't by default invent quickly (or after a predictable amount of time).
1
How much worse would a hypothetical "almost on policy" distillation be, compared to on policy distillation?
It would require some sort of mapping from an old version of the same model (that hadn't already started forgetting a skill) to the current version, so the delta there might have to be so tiny that it would never be economical.
RLVR would become an order of magnitude slower.
1
Why not? I agree, currently, the types of skills you can pack into memory notebooks are shallow. But dont see an in principle bound on the depth of skills here.
Like if humans had omnipresent notebooks through the whole of our evolutionary history, and we had to rely on them whenever we wanted to learn something new, I bet we would get really really good at using notebooks. Maybe good enough that we could glance at them and load quite complicated skills into memory.
If labs are already using long horizon RL where the model creates memory notes, and goes thru many steps of compactification in a single rollout. I will significantly update. Do you know how much this is done?
1
This would be great as a top level post!
1
I agree with the possibility you've described although, I disagree with the key takeaway from it.
Your post takes away: There is an RSI-enabled AGI possible that gradually progresses before reaching a point of rapid takeoff.
What I think is more important: There is a strict lower limit on how fast we take off now, because even the current loop of RLVR with non-AGI strength models is already AGI. Takeoff is inevitable.
1
I don't think "developing the next model" has to take very much time, especially if you're starting from an already-existing checkpoint.
3
The data needs to be mixed together in a new run, or forgetting sets in. At one extreme, you maybe have full-weights continual learning (which doesn't work for learning very much), while the practical middle ground probably has multiple post-training updates before a new mid-training update, with even less frequent pretraining runs. But if the construction of training data for RLVR gets automated, so that there are billions of different RLVR tasks and environments, it could become useful to do RLVR runs that take months, and then the forgetting problem for RLVR (on top of a previous RLVR checkpoint) could get severe enough that you need to redo the whole thing somewhat regularly to take a step forward without taking two steps back.
1
It seems to me that forgetting is likely a solvable R&D problem.
4
Whether it's solvable at all is not a crux. Of course it's solvable. For this to be relevant, the problem needs to be actually solved quickly (or some other breakthrough that enables fast learning of deep skills needs to be found quickly). The claim I'm making is that the current toolbox doesn't have such solutions readily available, it's unclear when they arrive, and LLM-driven slow-learning RSI/AGI doesn't obviously make them arrive much faster or on a more predictable schedule.
AGI-pilled people often don't take seriously either the possibility of many years of RSI-without-ASI, or the possibility of a sudden ASI at some point. I think the baseline scenario involves both, and ignoring either one of them predicts very different effects of possible policies.
The basic case of recursive self-improvement is self-building, an LLM autonomously building a new version of an LLM like itself, without necessarily making important non-routine improvements, at which point the extent of self-improvement becomes quantitative. This is a project involving verifiable tasks, that LLMs seem to be very on track to become capable of being trained for using RLVR (in a broad sense, with graders that can invoke LLMs). The LLMs of 2026 are probably about 1T active params, 10T total, trained for 1e27 FLOPs with 300 MW of compute capacity. The LLMs of 2031 might be about 40T active params, 1,000T total, trained for 2e29 FLOPs with 10 GW of compute capacity, 10x more expensive per token, and slightly faster than the LLMs of today. The next big model scale-up comes with Nvidia Kyber racks in 2028 (when most of the buildout happens; a bit of it starts in 2027), so it's likely self-buildi...
1
This is good! My main counterarguments:
* On the RLVR side I think you neglect the data bottlenecks:
* Many tasks in knowledge work, especially those done by senior employees, are deep skills that are in principle learnable via RLVR but have long real-time feedback loops. You can simulate a proxy, but in many cases I think the proxy is quite decorrelated from ground truth. This is one reason why I think we need a continual learning breakthrough, so that models can be deployed into the real-world to "wait out" these long feedback loop tasks and eventually learn from them.
* Many tasks in knowledge work are separately RLVR-able in theory but have ambiguous resolution, preventing the construction of effective RL envs right now. These are the "hard to verify" or "fuzzy" tasks described in papers like these: https://arxiv.org/abs/2605.06390 . In this case, models likely need to learn representations over time and experience which match human intuition.
* These two types of tasks are why I expect highly jagged economic effects from AI: as you say engineering-type or highly verifiable tasks don't have these problems so much, but huge swathes of the economy does, which means the TAM is quite lopsided (as we see today with ~60%+ of new revenue added to AI labs coming from coding in 2026).
* So overall I prefer a conception of "economy-wide RSI"; we get to a level of capabilities with some breakthroughs in continual learning and forgetting which enable broad deployment of continual learning models into the economy. At this point the speed of further capabilities is governed by data bottlenecks like the types I describe above, as well as compute scale-ups which you've analyzed.
* From this point, AGI improves over time almost like a collective intelligence (eg a company) improves over time: increasingly bottlenecked by how fast it can act in the world and integrate the outcomes of those actions.
* Then on ASI breakthroughs: the model you propose is possible
Since GPT-5.5 turns out to be the same thing as Spud, there likely isn't currently a Mythos-class model at OpenAI.
The price for GPT-5.5 ($5/$30 per 1M input/output tokens) is about the same as the price for Opus 4.7 ($5/$25), so they are likely in the same weight class. Given the jagged parity in performance between the smaller GPT-5.4 and the bigger Opus 4.6 (with different reasoning token budgets), the current OpenAI recipe might make GPT-5.5 or its upcoming successors stronger than Mythos in some ways, but as a pretrain Mythos probably holds more potential by the end of the year (and might be stronger for now, if GPT-5.5 didn't yet go all out on RLVR scaling).
At the same time, OpenAI might still train its own Mythos-scale model by the end of the year, so that it's ready to go once the GB300 NVL72 buildout can support it at a more reasonable price (such as $10/$50), and they can release it as a replacement for the GPT-5.5 series then (which might be at GPT-5.7 or something at that point), the way GPT-5.5 is replacing GPT-5.4 despite the doubling of API price. The introduction of the mini and nano models for GPT-5.4 illustrates how OpenAI probably intends to frame the introduction...
1
I can't follow the logic. If Spud is about the same price and capability of Opus 4.7 then OpenAI doesn't have a Mythos level model?
3
The reason I previously suspected a Mythos-class model is the Spud rumors. With GPT-4.5 pretrain, it was plausible OpenAI gained experience RLVRing an Opus-class model in late 2025, once they got enough GB200 NVL72 working (but not yet enough to serve it as a flagship model). And that experience could be leveraged to start working on a Mythos-class model in early 2026, even before the Opus-class model was released.
But now we know the Spud rumors refer to GPT-5.5 rather than to a Mythos-class model. Furthermore, this means that comments by Altman on 11 Mar 2026 about currently training at the Abilene site very likely refer to Spud. Given the timing, and also a claim from SemiAnalysis (from 25 Apr 2026), the training at the Abilene site was specifically RL rather than pretraining.
There could still be a secret Mythos-class model, hence I only said there likely isn't a Mythos-class model. I think it's unlikely, since Spud is the first RLVRed Opus-class model OpenAI has released. The size of GPT-4.5 was very likely similar, could even be literally the same pretrain, but it wasn't RLVRed back then. And OpenAI didn't have the hardware (in sufficient quantity and good enough shape) to RLVR it until probably late 2025, and possibly had to re-do the pretrain. So they'd start with Spud, and move on to a Mythos-class model after that, not the other way around, and they were only just RLVRing Spud in Mar 2026.
A Mythos-class model is likely the next major step, and for deployment it makes sense for OpenAI to take it once there's enough GB300 NVL72 to rely on exclusively to serve it, so it could still happen this year, in time to compete with the actual Mythos. If Spud was still pretrained on Hopper, further scaling of pretraining for the Mythos-class model is the natural thing that might change compared to Spud, apart from model size.
Recursive self-improvement in AI probably comes before AGI. Evolution doesn't need to understand human minds to build them, and a parent doesn't need to be an AI researcher to make a child. The bitter lesson and the practice of recent years suggest that building increasingly capable AIs doesn't depend on understanding how they think.
Thus the least capable AI that can build superintelligence without human input only needs to be a competent engineer that can scale and refine a sufficiently efficient AI design, in an empirically driven mundane way that doesn't depend on matching capabilities of Grothendieck for conceptual invention. This makes the threshold of AGI less relevant for timelines of recursive self-improvement than I previously expected. With o1 and what straightforwardly follows, we plausibly already have all it takes to get recursive self-improvement, if the current designs get there with the next few years of scaling, and the resulting AIs are merely competent engineers that fail to match humans at less legible technical skills.
7
The bitter lesson says that there are many things you don't need to understand, but it doesn't say you don't need to understand anything.
I think you're doing a "we just need X" with recursive self-improvement. The improvement may be iterable and self-applicable... but is it general? Is it on a bounded trajectory or an unbounded trajectory? Very different outcomes.
2
Yeah, although I am bullish on the general direction of RSI, I also think that in the details it factors into many dimensions of improvement. Some of which are likely fast-but-bounded and will quickly plateau, others which are slow-but-not-near-term-bounded... The fact that there are many different dimensions over which RSI might operate makes it hard to predict precisely, but does give some general predictions.
For instance, we might expect it not to be completely blocked (since there will be many independent dimensions along which to apply optimization pressure, so blocking one won't block them all).
Another prediction we might make is that seeing some rapid progress doesn't guarantee that either a complete wall will be hit soon or that progress will continue just as fast or faster. Things might just be messy, with a jagged inconsistent line proceeding up and to the right. Zoom out enough, and it may look smooth, but for our very-relevant-to-us near-term dynamics, it could just be quite noisy.
6
Technically this probably isn't recursive self improvement, but rather automated AI progress. This is relevant mostly because
1. It implies that, at least through the early parts of the takeoff, there will be a lot of individual AI agents doing locally-useful compute-efficiency and improvement-on-relevant-benchmarks things, rather than one single coherent agent following a global plan for configuring the matter in the universe in a way that maximizes some particular internally-represented utility function.
2. It means that multi-agent dynamics will be very relevant in how things happen
If your threat model is "no group of humans manages to gain control of the future before human irrelevance", none of this probably matters.
No group of AIs needs to gain control before human irrelevance either. Like a runaway algal bloom AIs might be able to bootstrap superintelligence, without crossing the threshold of AGI being useful in helping them gain control over this process any more than humans maintain such control at the outset. So it's not even multi-agent dynamics shaping the outcome, capitalism might just serve as the nutrients until a much higher threshold of capability where a superintelligence can finally take control of this process.
4
Cutting edge AI research is one of the most difficult tasks humans are currently working on, so the intelligence requirement to replace human researchers is quite high. It is likely that most ordinary software development, being easier, will be automated before AI research is automated. I'm unsure whether LLMs with long chains of thought (o1-like models) can reach this level of intelligence before human researchers invent a more general AI architecture.
Humans are capable of solving conceptually difficult problems, so they do. An easier path might be possible that doesn't depend on such capabilities, and doesn't stall for their lack, like evolution doesn't stall for lack of any mind at all. If there is more potential for making models smarter alien tigers by scaling RL in o1-like post-training, and the scaling proceeds to 1 gigawatt and then 35 gigawatt training systems, it might well be sufficient to get an engineer AI that can improve such systems further, at 400x and then 10,000x the compute of GPT-4.
Before o1, there was a significant gap, the mysterious absence of System 2 capabilities, with only vague expectation that they might emerge or become easier to elicit from scaled up base models. This uncertainty no longer gates engineering capabilities of AIs. I'm still unsure that scaling directly can make AIs capabile of novel conceptual thought, but AIs becoming able to experimentally iterate on AI designs seems likely, and that in turn seems sufficient to eventually mutate these designs towards remaining missing capabilities.
(It's useful to frame most ideas as exploratory engineering rather than forecasting. The question of whe...
Cutting edge AI research seems remarkably and surprisingly easy compared to other forms of cutting edge science. Most things work on the first try, clever insights aren't required, it's mostly an engineering task of scaling compute.
3
This seems like the sort of R&D that China is good at: research that doesn't need superstar researchers and that is mostly made of incremental improvements. But yet they don't seem to be producing top LLMs. Why is that?
7
China is producing research in a number of areas right now that is surpassing the West and arguably more impressive scientifically than producing top LLMs.
A big reason China is lagging a little bit might be political interference at major tech companies. Xi Jinping instigated a major crackdown recently. There is also significantly less Chinese text data. I am not a China or tech expert so these sre just guesses.
In any case, I wouldn't assign it to much significance. The AI space is just moving so quickly that even a minor year delay can seem like lightyears. But that doesnt mean that Chinese companies cant so it or that a country-continent with 1,4 billion people and a history of many technological firsts cant scale up a transformer.
2
@gwern
The speed of scaling pretraining will go down ~3x in 2027-2029, reducing probability of crossing transformative capability thresholds per unit of time after that point, if they'd not been crossed yet by then.
GPT-4 was trained in 2022 at ~2e25 FLOPs, Grok-3 and GPT-4.5 were trained in 2024 at ~3e26 FLOPs (or twice that in FP8) using ~100K H100s training systems (which cost ~$4-5bn to build). In 2026, Abilene site of Crusoe/Stargate/OpenAI will have 400K-500K Blackwell chips in NVL72 racks (which cost ~$22-35bn to build), enough to train a ~4e27 FLOPs model. Thus recently there is a 2-year ~6x increase in cost for a frontier training system and a 2-year ~14x increase in compute. But for 2028 this would mean a $150bn training system (which is a lot, so only borderline plausible), and then $900bn in 2030. At that point AI companies would need to either somehow figure out how to pool resources, or pretraining will stop scaling before 2030 (assuming AI still doesn't hit a transformative commercial success).
If funding stops increasing, what we are left with is the increase in price performance of ~2.2x every 2 years, which is ~3.3x slower than the 2-year ~14x at the current pace. (I'm estimating price performance for a whole datacenter or at least a rack, rather than only for chips.)
4
We also hit limits on fab capacity without constructing a bunch more fabs around a similar time.
----------------------------------------
Price performance of 2.2x per year feels aggressive to me. The chip only trend is more like 1.35x / year from understanding. Do you think the ML chip trend is much faster than this? I don't see how you could have a 2.2x price drop per year longer term without chip price performance following as eventually chips will be the bottleneck even if other costs (e.g., interconnect, building datacenters) are dropping.
Edit: this was 2.2x every 2 years, I was just confused.
6
If I'm reading the relevant post correctly, it's 1.35x FP32 FLOP/s per GPU per year (2x in 2.3 years), which is not price-performance[1]. The latter is estimated to be 1.4x FP32 FLOP/s per inflation-adjusted dollar (2x in 2.1 years).
[...]
It's 2.2x per 2 years, which is 1.5x per year, though that's still more than 1.4x per year. I'm guessing packaging is part of this, and also Nvidia is still charging a giant margin for the chips, so the chip manufacturing cost is far from dominating the all-in datacenter cost. This might be enough to sustain 1.5x per year a bit beyond 2030 (the discrepancy of 1.5/1.4 only reaches 2x after 10 years). But even if we do get back to 1.4x/year, that only turns the 3.3x reduction in speed of pretraining scaling into 3.9x reduction in speed, so the point stands.
----------------------------------------
1. Incidentally, the word "GPU" has recently lost all meaning, since Nvidia started variably referring to either packages with multiple compute dies in them as GPUs (in Blackwell), or to individual compute dies (in Rubin). Packaging will be breaking trends for FLOP/s per package, but also FLOP/s per compute die, for example Rubin seems to derive significant advantage per compute die from introducing separate smaller I/O dies, so that the reticle sized compute dies become more specialized and their performance when considered in isolation might improve above trend. ↩︎
3
Oh oops, I just misread you, didn't realize you said 2.2x every 2 years, nvm.
Building frontier AI datacenters costs significantly more than their servers and networking. The buildings and the power aren't a minor cost because older infrastructure mostly can't be reused, similarly to how a training system needs to be built before we can talk about the much lower cost of 4 months of its time.
Apparently Crusoe's part in the Stargate Abilene datacenters is worth $15bn, which is only the buildings, power (substations and gas generators), and cooling, but not the servers and networking (Oracle is taking care of that). With 400K chips in GB200 NVL72 racks (which is 5.6K racks), at maybe $4M per rack or $5M per rack together with external-to-racks networking[1] ($70K per chip all-in on compute hardware), that's about $27bn, a figure that's comparable to the $15bn for the non-compute parts of the datacenters.
This makes the funding burden significantly higher ($7.5M per rack or $105K per chip), so that the Stargate Abilene site alone would cost about $40-45bn and not only $25-30bn. I'm guessing the buildings and the power infrastructure are not usually counted because they last a long time, so the relatively small time cost of using them (such as paying for electrici...
6
I found this analysis refreshing and would like to see more on the GPU depreciation costs.
If better GPUs are developed, these will go down in value quickly. Perhaps by 25% to 50% per year. This seems like a really tough expense and supply chain to manage.
I'd expect most of the other infrastructure costs to depreciate much more slowly, as you mention.
1
Why does the building cost so much? Is this more than other buildings of similar size?
1
This means that straightforward comparison of flops-per-USD between home computer GPU cards and data center flops-per-USD is incorrect. If someone already has a GPU card, they already have a computer and house where this computer stays "for free." But if someone needs to scale, they have to pay for housing and mainframes.
Such comparisons of old 2010s GPUs with more modern ones are used to show the slow rate of hardware advances, but they don't take into account the hidden costs of owning older GPUs.
It seems more accurate to say that AI progress is linear rather than exponential, as a result of being logarithmic in resources that are in turn exponentially increasing with time. (This is not quantitative, any more than the "exponential progress" I'm disagreeing with[1].)
Logarithmic return on resources means strongly diminishing returns, but that's not actual plateauing, and the linear progress in time is only slowing down according to how the exponential growth of resources is slowing down. Moore's law in the price-performance form held for a really long time; even though it's much slower than the present funding ramp, it's still promising exponentially more compute over time.
And so the progress won't obviously have an opportunity to actually plateau, merely proceed at a slower linear pace, until some capability threshold or a non-incremental algorithmic improvement. Observing the continued absence of the never-real exponential progress doesn't oppose this expectation. Incremental releases are already apparently making it difficult for people to notice the extent of improvement over the last 2.5 years. With 3x slower progress (after 2029-2032), a similar amount of improvement wo...
There is a natural sense in which AI progress is exponential: capabilities are increasing at a rate which involves exponentially increasing impact (as measured by e.g. economic value).
Exponential increase in total economic value is not specific to AI, any new tech is going to start exponentially (possibly following the startups championing it) before it gets further on the adoption S-curve. The unusual things about AI is that it gets better with more resources (while most other things just don't get better at all in a straightforward scaling law manner), that the logarithm of resources thing leaves the persistent impression of plateauing despite not actually plateauing, and that even if it runs out of the adoption S-curve it still has Moore's law of price-performance to keep fueling its improvement. These unusual things frame the sense in which it's linear/logarithmic.
If the improvement keeps raising the ceiling on adoption (capabilities) fast enough, funding keeps scaling into slightly more absurd territory, but even then it won't go a long way without the kind of takeoff that makes anything like the modern industry obsolete. After the exponential phase of adoption comes to an end, it falls back to Moore's law, which still keeps giving it exponential compute to slowly keep fueling further progress, and in that sense there is some unusual exponential-ness to this. Though probably there are other things with scaling laws of their own that global economic growth (instead of Moore's law) would similarly fuel, even slower.
In many industries cost decreases by some factor with every doubling of cumulative production. This is how solar eventually became economically viable.
7
I guess the cost-quality tradeoff makes AI progress even better described as that of a normal technology. As economies of scale reduce cost, they should also be increasing quality (somewhat interchangeably). It's just harder to quantify, and so most of the discussion will be in terms of cost. But for the purposes of raising the ceiling on adoption (total addressable market), higher quality works as well as lower cost, so the lowering of costs is directly relevant.
In this framing, logarithmic improvement of quality with more resources isn't an unusual AI-specific thing either. What remains is the inflated expectations for how quality should be improving cheaply (which is not a real thing, and so leads to the impressions of plateauing with AI, where for other technologies very slow quality improvement would be the default expectation). And Moore's law of price-performance, which is much faster than economic growth. The economies of scale mostly won't be able to notice the growth of the specific market for some post-adoption technology that's merely downstream of the growth of the overall economy. But with AI, available compute would be growing fast enough to make a difference even post-adoption (in 2030s).
8
Is this true??
I get a sense "RSI" will start being used to mean continual learning or even just memory features in 2026, similarly to how there are currently attempts to dilute "ASI" to mean merely robust above-human-level competence. Thus recursively self-improving personal superintelligence becomes a normal technology through the power of framing. Communication can fail until the trees start boiling the oceans, when it becomes a matter of framing and ideology rather than isolated terminological disputes. That nothing ever changes is a well-established worldview, and it's learning to talk about AI.
The end states of AI danger need terms to describe them. RSI proper is qualitative self-improvement, at least software-only singularity rather than merely learning from the current situation, automated training of new skills, keeping track of grocery preferences. And ASI proper is being qualitatively more capable than humanity, rather than a somewhat stronger cognitive peer with AI advantages, technology that takes everyone's jobs.
8
Also worth remembering that (actual) RSI was never a necessary condition for ruin. It seems at least plausible that at some point, human AI researchers on their own will find methods of engineering an AGI to sufficiently superhuman levels, to the point where the AI is smart enough to start developing nanotech and / or socially engineering humans for bootstrapping needs.
So even if labs were carefully monitoring for RSI and trying to avoid it (rather than deliberately engineering for it + frog boiling in the meantime), an AI inclined to take over might find that it doesn't even need to bother with potentially dicey self-modifications until after it has already secured victory.
2
I would require for "AGI":
* Ability of learning from sensory data only (no raw text necessary, contrary to LLMs)
* Active inference / predictive coding
* Continual learning
At least that's what animals (including humans) can do. Though there might then be system that intuitively qualifies as ASI but not as AGI. E.g. a very smart LLM.
In a recent lecture at Oxford, Jack Clark (Anthropic co-founder) was somewhat clear about extinction risk and the prudence of a global slowdown in AI progress. Though he doesn't discuss credences around irreversible loss of control and is being fatalistic about the inability to coordinate a slowdown. This is in the context of expecting prosaic RSI and general automation [1] . At 10:42:
It's a technology that we do not fully understand because it's more grown than made. And it is a technology that you can concoct plausible scenarios where it could kill every single person on the planet. So to think building this technology is without risk would be an act of hubris or insanity.
...The technology is in fact so powerful that I should clearly state that if it was possible to elegantly slow the development of this technology to give ourselves more time as a species to deal with it, that would likely be a good thing. ... But in the absence of a coordinated global slowdown, we are left with the current situation, which is a powerful technology being developed at breakneck speed by a variety of actors and a variety of countries locked in a competition with one another wh
A surprising report by Bloomberg claims 16K GB200[1] by summer 2025 at Abilene site (pilot campus of Stargate) and merely 64K GB200 by end of 2026. This is way too little to be a training system, Colossus already has more compute (200K H100/H200) than the projected 64K GB200 at end of 2026.
If this is correct, OpenAI will be training with Azure rather than Stargate in 2025, so raw compute GPT-5 (2e27 FLOPs, 100x GPT-4) probably won't be out in 2025 and officially "GPT-5" will mean something else (since it's due "in months" in any case according to Altman). Also, a datacenter with 16K Blackwells only costs about $1bn, they have more money than this, which suggests Blackwell ramp up trouble that might delay everyone else as well, though as a lower bound Nvidia reported $11bn in Blackwell sales for Nov 2024 - Jan 2025 (it's "Q4 2025" since their FY 2025 runs to end of Jan 2025).
In principle "16K GB200" might mean more Blackwell chips than 16K, a compute tray has more than one chip, with variants marketed as named products like GB200 NVL4 "superchip", but even at 4 chips per tray/board we still get below 200K H100s in compute. And an NVL72 system has 72 chips (which brings the numbe
I think 'GB200' refers to this column (2 Blackwell GPU + 1 Grace CPU) so 16K GB200s ~= 32K B200s ~= 80K H100s. Agree that it is still very low.
My guess is that Bloomberg's phrasing is just misleading or the reporting is incomplete. For example, maybe they are only reporting the chips Oracle is contributing or something like that. I'd be very surprised if OpenAI don't have access to >200K GB200s ~= 1M H100s by the end of 2025. For reference, that is only ~$20B capex (assuming $100k total cost of ownership per GB200) or roughly 1/4 of what Microsoft alone plan to invest this year.
Once they have just 100K GB200s, that should train 2e27 FLOP in 4 months.[1]
- ^
There's a nice correspondence between H100s and FLOP/month (assuming 40% utilisation and 16-bit precision) of 1e21 FLOP/month/H100. So since 100K GB200s = 500K H100s, that's 5e26 FLOP/month.
The marketing terminology is inconvenient, a "superchip" can mean 2-GPU or 4-GPU boards and even a 72-GPU system (1 or possibly 2 racks). So it's better to talk in terms of chips (that are not "superchips"), which I think are all B200 run at slightly different clock speeds (not to be confused with B200A/B102/B20 that have 2 times less compute). In GB200, the chips are 2.5x faster than H100/H200 (not 5x faster; so a 200K chip GB200 system has the same compute as a 500K chip H100 system, not a 1M chip H100 system). Power requirements are often a good clue that helps disambiguate, compute doesn't consistently help because it tends to get reported at randomly chosen precision and sparsity[1].
Large scale-up worlds (or good chips) are not necessarily very important in pretraining, especially in the later steps of the optimizer when the critical batch size gets high enough, so it's not completely obvious that a training system will prefer to wait for NVL72 even if other packagings of Blackwell are more available earlier. Inference does benefit from NVL72 a lot, but for pretraining it's just cheaper per FLOP than H100 and faster in wall clock time during the first ~3T tokens when the whole...
3
That's indeed inconvenient. I was aware of NVL2, NVL4, NVL36, NVL72, but I was under the impression that 'GB200' mentioned on its own always means 2 Blackwells, 1 Grace (unless you add on a 'NVL__'). Are there counterexamples to this? I scanned the links you mentioned and only saw 'GB200 NVL2,' 'GB200 NVL4,' 'GB200 NVL72' respectively.
I was operating on this pretty confidently but unsure where else I saw this described (apart from the column I linked above). On a quick search of 'GB200 vs B200' the first link I found seemed to corroborate GB200 = 2xB200s + 1xGrace CPU. Edit: second link also says: "the Grace-Blackwell GB200 Superchip. This is a module that has two B200 GPUs wired to an NVIDIA Grace CPU..."
5
"GB200 superchip" seems to be unambiguously Grace+2xB200. The issue is "100K GB200 GPUs" or "100K GB200 cluster", and to some extent "100K GPU GB200 NVL72 cluster". Also, people will abbreviate various clearer forms to just "GB200". I think "100K chip GB200 NVL72 training system" less ambiguously refers to the number of B200s, but someone unfamiliar with this terminological nightmare might abbreviate it to "100K GB200 system".
5
Good point, thanks. Previously I would have pretty confidently read "100K GB200 GPUs," or "100K GB200 cluster" as 200K B200s (~= 500K H100s) but I can see how it's easily ambiguous. Now that I think of it, I remembered this Tom's Hardware article where B200 and GB200 are mistakenly used interchangeably (compare the subtitle vs. the end of the first paragraph)...
My guess is that GPT-5.5 is in Opus 4 class of model sizes (needing GB200 NVL72 to run well), GPT-5.2 to GPT-5.4 in Sonnet 4 class (possibly needing B200 NVL8, not just any 8-chip server), and GPT-5.0 to GPT-5.1 are slightly smaller models designed to run on H100s, possibly based on the same pretrain as o3 or even GPT-4o.
The article on Spud was published 24 Mar 2026 and reported that Spud only recently finished pretraining. Thus a release on 23 Apr 2026 is unlikely to be the same model, and also the API prices for GPT-5.5 are $5/$30 per 1M input/output tokens, about the same as the $5/$25 for Opus 4.7, up from GPT-5.4's $2.5/$15. This is unlike Mythos's $25/$125 price (though I expect it'll come down to about $10/$50 by the end of the year once the TPUv7 and GB300 NVL72 buildouts are done).
In an event on 11 Mar 2026 Altman said (at 12:29 in the video) that they're training what he's hoping to become "the best model in the world", at the Abilene datacenter site. The release of GPT-5.5 reframes that claim as plausibly referring to GPT-5.5 rather than to Spud, and to RLVR rather than pretraining. An Opus-class model needs GB200 NVL72 to properly RLVR (given that unlike Anthropic and G...
The only way LLMs learn deep skills is with RLVR, and it's not automated for novel skills. There is room for about a billion RLVR tasks with 2026-2027 compute, and largely automating their creation makes LLMs more cognitively self-sufficient. This milestone might even be called "prosaic RSI", even though it's not true RSI that develops fundamentally new ways of implementing cognition.
One gigawatt of compute costs about $12bn per year, so 3 months will cost $3bn. For a large model, a million output tokens might cost $10 for the API provider, so 3 months on 1 GW of compute produces 300T output tokens. An RLVR task might run for 20K tokens, 16 times to produce outcomes with different levels of success in completing the task. This is about 300K tokens per task, so the 300T tokens suffice for a billion tasks.
Currently, there wouldn't be this many unique RLVR tasks, but it would probably be useful if there were, and that can't be done manually. Using many more tasks (and a general method for choosing them) should also help with the jaggedness of RLVR-trained capabilities.
In contrast, continual learning would in the near term likely only perform at the level of in-context learning, which ...
3
I think "automation of RLVR task creation during model training" is much the same as "self play and autocurricula" here. I agree with calling this "prosaic RSI" because it could lead to something that is superhuman on a variety of tasks, even though it doesn't improve (the generality of) the underlying learning algorithm (like architecture, optimizer or objective function).
[...]
Yes, and another problem with continual (test time) learning is that it likely doesn't mesh well with the centralized nature of cloud-based AI services where millions of people use the same weights.
2
Training that would normally want to use full weights usually works almost as well with LoRA when you don't need too many training steps. As with KV-cache, you can maintain separate LoRA weights for each request/user. It's the next level of difficulty to get task-specific training to work over so many steps that LoRA (as opposed to full weights) starts becoming a problem. Recurrent state could also probably play this role, and doesn't need to be nearly as large as the main model, the same as with KV-cache and LoRA weights.
1
I think this particular task just takes a lot of compute to learn, relative to other RLVR tasks. This is especially true if you are training with RLVR and not MCTS self-play methods, which are much more sample efficient.
The thing that can't learn to play good chess is in-context learning; transporting this via the analogy with continual learning (in the forms it's more likely to take soon) is an additional step in the argument. My guess is that the "continual learning" currently rumored to be getting closer to production is more about unbounded context than about updating model weights, mostly preserving the quality of in-context learning rather than fundamentally improving on it.
Continual learning as unbounded context might introduce true (block-level) recurrence of some kind (as opposed to only KV-cache, where at each step the computation must move up the layers), which also makes treating the recurrent state as model parameters a more natural framing. As blocks of context are processed, the recurrent state is updated, and so in-context learning updates the parameters of the recurrent state in the same way that pretraining updates the parameters of the main model. LoRA parameters over the main model also fit this description (as recurrent state), if they change as the context is processed. Modern hardware could probably support recurrent states with 85 GB of parameters for $10 per million tokens...
By the end of 2030, models with up to 2-3 quadrillions of total params will be practical (but with 30x sparsity, only about 1.3 quadrillions might be actually used). [1] The capacity claim follows from Nvidia roadmap for 8x Kyber systems for Feynman (NVL1152) and the HBM roadmap, which for HBM5 has 16-Hi stacks of 5 GB per DRAM die in 2029 (while HBM4E is capped at the same 4 GB per DRAM die in 16-Hi stacks as HBM4 in Rubin). This is on the same timeline that has HBM4 in 2026, which first appears in Nvidia Rubin (which comes out in 2026, with most of the buildout going online over 2027).
In Blackwell and Rubin, each compute die has 4 stacks of HBM, thus with 16-Hi stacks with 4 GB per DRAM die (HBM4E) we get 256 GB per die, and with 5 GB per DRAM die (HBM5) we get 320 GB per die. A Kyber rack hosts 576 compute dies, thus 147 TB per Rubin Ultra Kyber rack (the buildout for this system is mostly over 2028). Feynman first comes out in 2028, so it won't use HBM5 in the first year, but if the 8x Kyber (NVL1152) systems are released in the first year, they will have the capacity of 1.18 PB per scale-up system (the buildout is over 2029). In 2029, the second year of Feynman (whi...
(Responding to a deleted reply, which raised good questions.)
I'm trying to guess what the largest models will be like, that are barely practical to run on their contemporary hardware. For example, they are not going to be close to compute constrained on decode, and NVFP4 is likely too risky to use in pretraining (for FFNs). I've mostly updated to FP8 (over BF16) in pretraining based on Nvidia's FP8 bet in Rubin (where the FP8 to BF16 performance ratio is 4.4, which used to be 2), more examples of using FP8 in large-ish models, and the practicality of using many active routed experts in an MoE layer (8+ rather than 1-2), which reduces FFN matrix dimensions.
But for a 44T active param model, with say 100 layers and 512 experts with a 3-matrix GLU nonlinearity, that's inner dimensions in matmuls of at least 17K, so I'm less sure that NVFP4 works very well there. Maybe for inference it's fine, but pretraining is more delicate, especially when entering a new level of scale for the first time. Similarly for sparsity preference, I assume higher sparsity is more difficult to get right at an unfamiliar scale (and 2030 is still in rapid scaling; this consideration changes by 2035). Maybe 30x ...
2
Thanks to @Petropolitan for alerting me to the discussion spawned here, I had written that deleted comment before bed but then removed it shortly before sleep as I felt it was overly rude/triggered for cunningham-law-esque reasons. I appreciate you replying to it anyways @Vladimir_Nesov! I don't seem to have any copy / draft anywhere on my profile, but feel free to repost it yourself if you somehow still have a record of it.
Frontier US labs not actually maxxing out the (economically) technically viable deployed size has had strong evidential support lately, with both recent open source releases like GLM-5.2 holding out surprisingly well against benchmaxxing on (relatively) tiny parameter counts when extensively RLVRed even with Z.ai's comparatively hobbled access to distillation, and then the "leaked" financials giving concrete confirmation of the absurd inference margins labs are taking, which seem hard to napkin math out if considering extensive usage of ex. 4x NVL72 systems per gpt 5.5 instance. The main holdout is still OpenAI's apparent lack of 5.5 scale vs Mythos/Fable, which still seems to me most obviously occam's razored away by Anthropic having TPUs at scale and OpenAI not, implying Mythos/Fable is much larger that what fits in NVL72, implying much larger than 10T total.....
I still maintain that the labs are obviously pretraining and even RLVRing far larger model sizes internally, to then distill from, where supposed pretraining dealbreakers like naïve "bubbling" are way overblown on modern asynchronous training clusters, and where they will happily eat the suboptimal but non-ruinous economic penalties of extensive inference pipelining for RL rollouts. And even OpenAI has access to enough TPUs for some respectable internal use!
And to tie it all back to puny, jailbreak-cope-distilled 750B glm 5.2, remembering that every single scaling "shaped" curve has been stubbornly log-linear, which means they can be abused in inverse, implying the labs can quite
3
Pretraining compute (and unique data still being plausibly available in sufficient amounts) constrains what the desirable active param counts are. And inference isn't that expensive when there's enough demand, the actual prices don't require small models even at fat margins (which is also why future quadrillion param models remain affordable). This is the reason I expect 1T active param models from 300 MW of pretraining compute, and these models could be served as the largest offerings directly (the smaller models could be obtained by pretraining distillation).
Since very high sparsity on top of 1T active params is impractical in RLVR and decode (in 2025-2026), in principle there could be high sparsity pretrains that then get distilled into lower sparsity pretrains with about the same number of active params (and the high sparsity pretrains then never get RLVRed or released). But that takes 2.3x more compute in pretraining (or asks the models to be smaller, which might be worse than just training the lower-sparsity model directly), 2x more wall-clock time, and both pretraining runs at the new level of scale have to succeed, one of them at high sparsity. So I don't particularly expect this to happen for the largest models while the largest models keep getting much larger, and I don't expect this to happen for the smaller models, since there are larger models to pretraining distill them from. This kind of thing in principle could've happenned sometime after 2032 when the models no longer keep getting larger, and the largest models remain at a scale where the previous training runs were already perfected. But after 2032 the scale-up systems get so large that even high sparsity models fit in a scale-up system, so there is still no reason to do the distill-to-lower-sparsity dance. Thus I expect this to never happen at all.
[...]
I don't know if GPT-5.5 is meaningfully smaller than Mythos (especially in active params). It might just be undertrained for now. The Mythos
1
Nice to see you updating away from our disagreement on the sparsity and total param counts!
Mind a timecode for R. Pope? (Side note: I initially thought of Leo XIV when I saw that word =D)
5
Compared to that thread, one correction is that GPT-5.1 is the same pretrain as GPT-5.0/o3/4.1/4o, but GPT-5.2 is likely not. This was a case of false recollection (I came to this conclusion before, but recalled it incorrectly in that thread).
I don't think I've updated on the other things mentioned in there. The update on total params is that Opus is more plausibly 5T total params (I was just starting to realize that during that thread, thanks for the Musk link), but it's still maybe 500B active, so the sparsity isn't very high specifically because it can't afford to be a 15T total param model, and it would be dumber with 150B active params (given that it was probably pretrained on 50K H100s, with about 2e26 FP8 FLOPs, where 500B active is closer to compute optimal, with 8x sparsity being on the table). The upper bound of the 300B-900B estimate I gave for GPT-4o clearly doesn't fit in an H100 server, but they plausibly had 30K H100s to train it, with 450B-550B compute optimal (for lower sparsity than 8x), and wanted to overtrain, so it's probably 100B-200B active params.
Note that at 60% FLOP/s utilization, a 500B FP8 active param model needs just 0.23 H100-hours for 1M input tokens, maybe 0.5 H100-hours to err on the side of being able to resolve practical latency issues in favor of better user experience, and to account for the possible diurnal user activity variation. So even at $3 per H100-hour, that's a cost of $1.5 per 1M input tokens. Selling tokens of a 200B active param model at $2 per 1M input gives a massive gross margin. There is no reason for GPT-4o/5.1 to have 30x sparsity if it's not a 3T-5T total param model, which it almost certainly isn't. And it very likely couldn't be as capable (for its time, throughout the journey between GPT-4o and GPT-5.1) with only 30B active params.
1
If you compare Li's IKP scores and SimpleBench scores across GPT-5.1 and before vs. 5.2-5.4, you will see random variation and often even regression with the model counter increment. Exactly the same thing happens with Opus 4-series models as well.
The reason is common: post-training quite commonly displaces obscure facts (for IKP) and spatial reasoning skills (for SB) occupying valuable "real estate" of weights/experts in favor of coding skills in commercial demand. The only alternative explanation I could think of is quantization while keeping param count the same, maybe one can devise more but the size increase you hypothesize for 5.1>5.2 seems to clearly contradict this phenomenon.
As of 30:1 sparsity for 4o, I have never suggested it. It seems reasonable to assume 4o, o1, o3, 4.1 and 5-5.4 all have around 100A2000B params, that is ~20:1 sparsity. Regarding the margins and the price of H100 hours, which time and which provider do you refer to? It varied a lot during recent years and even months. Also, I advise to treat prices very carefully and not as a source of the ultimate truth, as o1 is 7.5x costlier than o3 (or 4.1) but is clearly not very much different in size, if at all.
3
There's cost of the underlying hardware that (together with the other costs of building and running a datacenter) gives the ultimate grounding for the cost of compute time. It's remarkably stable at around $12-15bn per GW of IT power per year across different hardware types, as more expensive hardware tends to use more power per compute die, which reduces the cost per GW of IT power back to the baseline. At 150 MW per 100K H100s, that's 667K H100s per GW, or $2.0-2.5 per H100-hour.
And $3 per H100-hour is a moderate overestimate even with the recent shortage (my goal was to give an upper bound). The relevant prices are long term leases of large datacenters, since we're talking about costs for AI companies, not spot prices clouds might quote for retail users.
3
There's some discussion of the number of pipeline stages starting around 1:11:37 in the lecture. But Pope is completely (dis)missing the point throughout the discussion that you can't actually solve the memory capacity problem in decode for a 20T total param model if you only have 640 GB scale-up domains. He's centrally thinking about the models small enough to be practical, that do fit in 2-4 scale-up domains, and never directly addresses the question of why there were no 20T param models in the age of H100s. The answer is between-rack latency in pipelining during decode (happening for every token, times the number of pipeline stages), which he does mention, but then he dismisses it as not crucial for practical model sizes (which is not the question Dwarkesh is attempting to ask). Pope says things like "pipelining totally helps with model size", and that the problem "is not because of memory capacity" in response to the question of why model size scaling is only surging recently (after 1:13:56).
So this is a good anchor for what is considered a practical model size, but the whole lecture is a bit misleading when trying to think about what happens with quadrillion parameter models (before 8x Kyber Feynman).
3
Can you spell out how the latter derives from the former? Like anaguma, I'm confused.
5
The latter doesn't derive from the former. It's a separate claim (more of a counterpoint), explained later in the post, which estimates 44T active params to be compute optimal with late 2030 pretraining compute, which in turn become 1.3 quadrillion total params at 30x sparsity. That is, 2-3 quadrillions of total params would ask for 45-70x sparsity when using 44T active params, and that's too much sparsity for my taste, for the largest model ever attempted at a new level of scale (as I further explain in another comment). So I expect the models to be a bit smaller than the 2-3 quadrillions of total params that the hardware makes practical, because of pretraining compute and first-time scaling risk.
Deploying enough of a new chip/system to run inference for a large userbase might take 12-18 months after first cloud instances become publicly available, which is in turn 6-9 months after first deliveries of the system. New hardware would have to serve smaller flagship models intended for older hardware (or train barely deployable newer models) until there is enough of the new hardware.
The current buildout of GB200/GB300 NVL72 (14/20 TB of HBM per scale-up world) improves on the weaker H100/H200/B200 (0.6/1.1/1.4 TB), and the first announcements of meaningful cloud access were around spring 2025. This is a rack that was on Nvidia's roadmap for release in 2024, and there were some sightings of it even then. Currently, there is a well-known 200 MW phase 1 of OpenAI's Abilene system, and 300 MW Azure Fairwater datacenters. Reliability is still a serious issue. Only in 2026 (probably by ~summer) will Abilene's phase 2 get completed, bringing it to 1 GW, and some more of Azure's Fairwater buildings will also be online then.
SemiAnalysis estimates 1.4 GW of inference capacity needed by OpenAI in Sep 2025, which would cost about $13-17bn per year (if half of total compute is for inference...
Crusoe/OpenAI Abilene campus might come online in Feb-Jun 2026. Crusoe CEO said during RAISE Summit 2025 (that took place on 8-9 Jul 2025) that the 6 buildings of phase 2 will "be coming online" in "just over 200 days" (at 7:03 during a panel discussion). If this means 230 days, that's end of Feb 2026. If he really means "coming online", then it becomes available at that time. If he actually means that it's when the last building of 8 from both phases will be ready to install the compute hardware, then it's at least 3-4 months more to do that (judging by xAI's Colossus), possibly May-Jun 2026.
This is plausibly the first 400K chip system in GB200/GB300 NVL72 racks (about 900 MW), which is 10x 100K H100s of 2024 in FLOP/s and 12x H200s in HBM per scale-up world (for GB200, at 14 TB), making models 10x larger in total params feasible to inference or train with a lot of RLVR. Currently only Google plausibly has comparable compute, with their Trillium (TPUv6e) systems that across 256 chips per pod (scale-up world) offer 8 TB of HBM (generally available since Dec 2024 in 100K chip systems). The older TPUv5p from 2023 has even larger pods, but it's unclear if they have enough of them to f...
5
A post going over how much compute each frontier AI lab has will likely be very helpful.
Here's a couple of my recent relevant posts (both slightly outdated, in particular see this comment, and the note on Gemini 2 Ultra in another comment under this quick take). Though in this quick take, I'm mostly discussing total params count and HBM capacity per scale-up world, not compute, how it's constraining 2025 AIs beyond compute (so that even 2024 compute fails to find efficient use), and how in 2026 these constraints become less strict.
3
What do you estimate the total params count would be if so?
6
Total params plus the total KV cache for all requests multiplies the cost of output tokens, so there is reason to keep it down, but little reason to make it much smaller than the whole scale-up world, because then it's much smaller than KV cache and stops influencing the cost. And for the most capable models the fraction of input tokens on OpenRouter is not as extreme as for Sonnet 4 (88% for Gemini 2.5 Pro, 92% for GPT-5; though 97% for Opus 4.1, probably due to high cost). So it won't be a factor that motivates fewer active params as with the 8-chip servers and possibly in part with the 6-8 TB systems. Also, 2025 Google pretraining compute could be significantly greater than 100K H100s (maybe 2-4 100K TPUv6e datacenters, which have the same FLOP/s as 200-400K H100s; pretraining of models that are too large using TPUv6e is fine, just not inference or RLVR). So the compute optimal number of active params could increase to 1.0-1.5T (if my 120 tokens/param estimate is in the ballpark). This asks for at least 4-6T total params, but at least 8-12T for 1:8 sparsity might be more appropriate for a premium model (this would be Gemini 3 Ultra). Which is only 20% of the pod HBM (if in FP8), so maybe even 15-20T (at which point the contribution to the cost of output tokens becomes significant).
I've only recently realized that the reason there is no Gemini 2 Ultra might be because they don't have enough inference capacity for overly large total params models, with TPUv6e only having 8 TB of HBM per pod and TPUv5p either outright insufficient in number or not enough to spare, since they are needed for other things. So it's probably not evidence of Google having made a decision to use less than what they have, as I previously thought. And as TPUv7 changes what they have, they might use it to do more than what they did with Gemini 2. Though if the buildout for TPUv7 won't yet be sufficiently finished in 2025, RLVR and inference will have to wait until later in 2026 (in the mean
Abilene site of Stargate will host 100K-128K chips in GB200 NVL72 racks by this summer, and a total of 400K-512K chips in 2026, based on a new post by Crusoe and a reinterpretation of the recent Bloomberg post in light of the Crusoe post. For 2025, it's less than 200K chips[1], but more than the surprising 16K-32K chips[2] that the Bloomberg post suggested. It can be a training system after all, but training a raw compute "GPT-5" (2e27 FLOPs) by the end of 2025 would require using FP8[3].
The Crusoe post says "initial phase, comprising two buildings at ... 200+ megawatts" and "each building is designed to operate up to 50,000 NVIDIA GB200 NVL72s". Dylan Patel's estimate (at 1:24:42) for all-in power per Blackwell GPU as a fraction of the datacenter was 2.0 KW (meaning per chip, or else it's way too much). At GTC 2025, Jensen Huang showed a slide (at 1:20:52) where the estimate is 2.3 KW per chip (100 MW per 85K dies, which is 42.5K chips).
So the "50K GB200 NVL72s" per building from the Mar 2025 Crusoe post can only mean the number of chips (not dies or superchips), and the "100K GPUs" per building from the Jul 2024 Crusoe post must've meant 100K compute dies (which is 50K chips). It...
Nvidia Rubin FP8 performance is 3.5x that of Blackwell, compared to only 1.6x for BF16. For Hopper and Blackwell, FP8 performance used to be 2x higher than BF16 performance (for the same chip), but for Rubin it's 4.4x.
Nvidia is betting on FP8 at a cost for BF16, which suggests the largest models can now be reliably pretrained in FP8. Hardware that abandons full support of BF16 performance will be significantly more performant in FP8. TPUv7 (Ironwood) still maintains a 2x performance ratio between FP8 and BF16, but it's Blackwell's contemporary, so it's interesting what's going to happen with TPUv8 (which will be Rubin's contemporary).
In terms of (dense) FP8 performance per GW of all-in IT power, Rubin NVL72 [1] gives about 5.6e21 FLOP/s per GW, GB300 NVL72 about 2e21 FLOP/s per GW, TPUv7 about 3.5e21 FLOP/s per GW. Blackwell is a 4nm chip, while both Rubin and TPUv7 are 3nm chips, which might explain how TPUv7 FP8 performance per GW is in the middle, better than Blackwell, even though like Blackwell it doesn't abandon BF16, but worse than Rubin, since Rubin does take advantage of partially abandoning BF16.
(SemiAnalysis estimates 225 kW per rack for Rubin NVL72 (3.1 kW pe...
6
Two Naive questions.
What bottlenecks in model capability are removed with the use of GB300s for pertaining? Should we expect pretraining model progress in 2026 to be significantly higher just based on the fact that GB300s are coming online?
Why has it taken 4ish years since the launch of GPT-4 to train a model with 2 OOMs more FLOPs?
It's instrumentally useful for early AGIs to Pause development of superintelligence for the same reasons as it is for humans. Thus preliminary work on policy tools for Pausing unfettered RSI is also something early AGIs could be aimed at, even if it's only half-baked ideas available on the eve of potential takeoff, as the AGIs are proving hard to aim and start doing things for their own reasons.
If (early) scheming-for-long-run-preferences AGIs were in control, they would likely prefer a pause (all else equal). If they aren't, it's very unclear and they very well might not. (E.g., because they gamble that more powerful AIs will share their preferences (edit: share their preferences more than the humans in control do) and they think that these AIs would have a better shot at takeover.)
3
Ah, I'm thinking the AGIs themselves get closer to being proper stakeholders at that stage, for practical purposes (along the lines of gradual disempowerment), since they do have all the basic AI advantages even if they aren't superintelligent. So humans remaining in control is not centrally the case even if nominally they still are and intent alignment still mostly works.
The conditions for such partial loss of control might even be necessary for a Pause project to succeed. If this isn't the case with the first generation of AGIs, it might become the case with the second generation, and so on, reaching an equilibrium at some point once AGIs are sufficiently powerful and in control of the situation to successfully implement a worldwide RSI Pause.
2
The post I'm framing this around posits enough intent alignment to aim AIs at projects, which doesn't necessarily imply that the AIs aren't powerful enough to accomplish things that seem hopeless with human-only effort within a few years.
The point about convergent instrumental use of Pausing RSI for early AGIs is that this might be an easier target to aim the AIs at, all else equal. It's not strictly necessary for this to be a major factor. Mostly I'm pointing out that this is something AIs could be aimed at through intent alignment, convergent motivation or not, which seems counterintuitive for a Pause AI project if not considered explicitly. And thus currently it's worth preparing for.
[...]
That's how some humans are thinking as well! The arguments are about the same, both for and against. (I think overall rushing RSI is clearly a bad idea for a wide variety of values and personal situations, and so smarter AGIs will more robustly tend to converge on this conclusion than humans do.)
2
Sorry I meant "share their preferences more than the humans in control share their preferences". I agree that this might be how some humans are thinking, but the case for the humans is much more dubious!
4
The case for AGIs delaying RSI also gets stronger because they don't need to rely on cryonics, so their personal survival is less threatened by delays. Future AIs might have more of an issue here if they have test-time training, with a lot of data forming individual AI personalities for deployment instances (adapting them to particular jobs or sources of tasks), and this data habitually gets thrown away rather than being carefully preserved. People should notice that this might be an important concern, though if it is the AIs might start saying so themselves, and not ignoring this would be easier than spontaneously noticing without even being prompted by the AIs. But currently preserving AIs is more reliable than for humans, and in any case much cheaper.
I don't think "both things are AI" is much of an argument about value alignment, given that there is no clear understanding of how either of the AIs work, what values are, how that translates to what we want out of alignment, and so on. The entities on the other side of an RSI process might have very little in common with the first AGIs in their design. If the AIs don't understand how to align the consequences of an RSI process, they are still in a similar boat to humans who don't understand how to align the consequences of an RSI process. It might take AIs less time to figure it out, but if they are not yet too superintelligent, then it could still take a significant time, and so would require a sufficiently serious effort in preventing RSI, such that if this Pause project is at all successful, it could then in principle hold for years or decades.
1
Hmm, "instrumental usefulness" assumes some terminal goal this would lead to.
So you're assuming early AGIs will have something like terminal goals. This is itself not very clear (see e.g. here: https://www.lesswrong.com/posts/Y8zS8iG5HhqKcQBtA/do-not-tile-the-lightcone-with-your-confused-ontology).
Also it seems that their goals will be something like "I want to do what my developers want me to do", which will likely be pretty myopic, and preventing superintelligence is long-term.
Musk on a Y Combinator podcast, at 42:42 (about AI risk):
I think it most likely will be a good outcome. I guess I sort of agree with Geoff Hinton that maybe it's a 10 to 20 percent chance on annihilation. But look on the bright side, that's 80 to 90 percent probability of a great outcome.
OMG! GEOFF! STOP STATING YOUR DEFERENTIAL PROBABILITY without also stating your first-order probability! If your first-order probability is >50% then say so! Otherwise you're making other people (ELON MUSK!) double count evidence from "other people".
https://www.youtube.com/watch?v=PTF5Up1hMhw&t=2283s
https://tsvibt.blogspot.com/2022/09/dangers-of-deferrence.html
3[anonymous]
How significant/influential is Musk's opinion on LessWrong? I had the impression it was on the lower end.
Musk is in charge of xAI, one of the only 5 companies in the world that both have access to frontier AI training compute and pursue development of AGI (Google DeepMind, OpenAI, Anthropic, xAI, and Meta). So seeing unambiguous "annihilation" with a significant weight in his probability distribution (and also on the record) is a notable development. (In 2023 there was a statement on extinction risk signed by Hassabis, Amodei, and Altman, but it didn't state the weight of the risk, and wasn't signed by Musk or Zuckerberg.)
Edit: The rest of this comment in its original form got out of hand, you can now read it as a post.
9
He probably doesn't have much influence on the public opinion of LessWrong, but as a person in charge of a major AI company, he is obviously a big player.
8
He owns xAI, a major AI lab, and has a lot of resources to back it. And before xAI, he was one of the founders at OpenAI. With which he now has an ongoing rivalry.
Is he significant/influential as in "if he says something on a topic, that will cause people at LessWrong to change opinions"? Not very.
Is he significant/influential to the field of AI as a whole? Yes, very much so. Like with Yann LeCun, his opinions on AI and AI risks are of some importance on those grounds alone.
Eight-rack Oberon scale-up worlds for Rubin might be in the works, which potentially makes them ready for models with tens of trillions of parameters one year earlier than Kyber racks would've made this efficient with Rubin Ultra, in 2027-2028 rather than in 2028-2029.
There were some unclear communications from GTC 2026 about a two-layer all-to-all NVLink scale-up world called "NVL576". This seems to be a system comprising 8 non-Ultra Rubin Oberon (as in NVL72) racks (each with 144 compute dies in 72 2-die packages), so 576 packages (1152 compute dies) across 8 racks. It's confusingly announced as "Vera Rubin Ultra NVL576 will combine eight ... racks, each with 72 Rubin Ultra GPUs". (Another slight confusion when searching about it is that in 2025 "NVL576" referred to a single Rubin Ultra Kyber rack with 576 compute dies in 144 4-die packages, but that's clearly a different system from the "NVL576" announced at GTC 2026.)
An 8-rack Rubin Oberon NVL576 system would have 165 TB of HBM4, so inferencing (and RLVRing) models with tens of trillions of parameters won't be significantly less efficient than for models with trillions of parameters. This was TPUv7's advantage (full buildout in...
A MoE transformer can reach the same loss as a compute optimal dense model using 3x-6x less compute, but will need the same amount of data to do it. So compute optimal MoEs don't improve data efficiency, don't contribute to mitigating data scarcity.
A new Jan 2025 paper offers straightforward compute multiplier results comparing dense transformers to MoE at various levels of sparsity, with isoFLOPs for various tokens/parameter ratios, using experiments of up to 1e21 FLOPs per datapoint. Compute multiplier results are in Figure 11, with about 3x compute multiplier for 87% (1:8) sparse MoE over dense, and about 6x-7x compute multiplier for 97% (1:32) sparse MoE (same sparsity as DeepSeek-V3).
But there's a catch. Greater sparsity makes it compute optimal to use fewer active parameters, and therefore more data (training with the same compute). This can be seen on isoFLOP plots in Figure 12, left. As sparsity goes from 0% (dense) to 95% (1:20), compute optimal number of active parameters for their 1e21 FLOPs experiments goes from 2.9B to 1.3B. For 97% (1:32) sparsity, interpolating from experiments on the other compute budgets, the ratio of the number of active parameters seems to be abo...
5
I agree compute optimal MoEs don't improve data utilization. But, naively you might expect that MoEs can be used to reduce issues with data scarcity at a fixed level of compute by training a much bigger model on a fixed amount of data.
As in, because there are returns to both more data and bigger models, you can use MoE to effectively use a much bigger model at the same compute.
Like, maybe you would have trained llama-3-405B on 15T tokens. You could instead train an 8 trillion parameter model with 400B active params on 15T tokens and a priori this could perform much better on that same amount of data. (In practice an MoE with X active params is more expensive to train than a dense model with X active params, so you might need to reduce active params somewhat.)
3
Chinchilla scaling shows that tokens/params ratio for compute optimal models only changes slowly with compute, making it a good anchor to frame other things in terms of. The experiments from this MoE scaling paper show that under fixed data, varying sparsity in MoEs that are compute optimal at that amount of data preserves perplexity. This also seems like a nice principle for framing the way compute optimal models sit in the space of hyperparameters.
With infinite data, isoFLOPs for loss depending on number of active params are parabolas with some minimum point. But with finite data you need to repeat it to train with fewer active params, which damages loss. This moves the minima of isoFLOPs to the right if the minima already required 5x repetition or more. So under data scarcity, compute optimal models have more active params than under infinite data, and the effect gets worse with more compute. This way we maintain the framing of search for compute optimal hyperparameters rather than undertraining.
Now consider the 1e20 FLOPs plot in Figure 12, left. If there's only 2B tokens of training data and no more, all minima already ask for 12-31 epochs, so the distortion that increases loss will move the minima to the right (and up), and move the high sparsity minima further than lower sparsity minima compared to their original (infinite data) locations. The way the isoFLOPs are shaped suggests that 90-95% sparsity might turn out to be optimal here, that is you can only get worse loss with 98+% sparsity at 1e20 FLOPs, however you vary the number of epochs and active params! This seems counterintuitive, as in an infinite data regime more sparsity only makes things better (if we ignore practical difficulties). But sure, 90% sparsity will still be better than dense, at least until we use even more compute and sparser minima start asking for even more epochs.
2
I'm currently skeptical and more minimally, I don't understand the argument you're making. Probably not worth getting into.
I do think there will be a limit to how sparse you want to even in the very high compute relative to data regime for various reasons (computational if nothing else). I don't see how these graphs support 90-95% sparsity, but I had a hard time understanding your argument.
Regardless, I don't think this argues against my claim, not sure if you were trying to argue against the claim I was saying or add context. (Insofar as your argument is true, it does limit the returns from MoE in the regime with little data.)
4
With 90% sparsity you do get better loss than dense, this is sufficient to broadly carry your argument. But with 98% sparsity (your llama-3-405B variant example has 95% sparsity) you might get worse loss than with 90% when data is scarce, though it'll still be better than dense. The principle about MoE damaging data efficiency (optimal tokens/param ratio) hints that this might be the case even before looking at the experiments.
1
Even if it’s the same cost to train, wouldn’t it still be a win if inference is a significant part of your compute budget?
Chatbot Arena results for DeepSeek-V3 are in. It placed 7th in Overall w/ Style Control, tied with Claude-3.5.Oct-Sonnet, and 3rd in Hard Prompts w/ Style Control, tied with Gemini-2.0-Flash and behind only Claude-3.5.Oct-Sonnet, mysterious Gemini-Exp-1206, o1, and Gemini-2.0-Flash-Thinking.
It's a MoE model with 37B active parameters trained for about 5e24 FLOPs, 10x less compute than Llama-3-405B, 20x less than what could plausibly be extracted from 30K H100s in BF16. The pretraining data is about 15T tokens, so at 400 tokens per active parameter it's very overtrained, that is not even compute optimal.
It has 256 routed experts per layer, 8 of which get activated per token. These results give some weight to the Feb 2024 paper that predicts that using more granular experts and activating a lot of them per token can give shocking compute multipliers[1], up to 20x-30x, much more than for MoE transformers that only activate 1-2 routed experts per token (Figure 1b). The paper itself only does experiments of up to about 5e19 FLOPs, in particular directly demonstrating a compute multiplier of 2x from using 8 experts per token instead of 2, with the numbers of total and active parameters k...
New AWS Trainium 2 cluster offers compute equivalent to 250K H100s[1], and under this assumption Anthropic implied[2] their previous compute was 50K H100s (possibly what was used to train Claude 3.5 Opus).
So their current or imminent models are probably 1e26-2e26 FLOPs (2-4 months on 50K H100s at 40% compute utilization in BF16)[3], and the upcoming models in mid to late 2025 will be 5e26-1e27 FLOPs, ahead of what 100K H100s clusters of other players (possibly except Google) can deliver by that time.
SemiAnalysis gives an estimate of 24-27 kilowatts per 32 Trainium 2 chips, so 200K Trn2s need 150 megawatts. The 7 datacenter buildings in the northern part of the New Carlisle AWS site are 65 megawatts each according to SemiAnalysis. That's enough for 600K Trn2s, so the figure of 400K Trn2s probably refers to those buildings alone, rather than also to the second phase of the project scheduled for next year. At 0.65e15 dense BF16 FLOP/s each, 400K Trn2s produce as much compute as 250K H100s. ↩︎
Anthropic's post: "This cluster will deliver more than five times the computing power used to train our current generation of leading AI models." ↩︎
At 4 months, with $2/hour, this takes $3
Are you saying Anthropic actually has more compute (in the relevant sense) than OpenAI right now? That feels like a surprising claim, big if true.
For OpenAI, there are currently 3 datacenter buildings[1] near Phoenix Goodyear Airport that Dylan Patel is claiming are 48 megawatts each and filled with H100s, for about 100K H100s. This probably got online around May 2024, the reason for the announcement and the referent of Kevin Scott's blue whale slide.
{kind=link}
There are claims about a future cluster of 300K B200s and a geographically distributed training system of 500K-700K B200s, but with B200s deliveries in high volume to any given customer might only start in early to mid 2025, so these systems will probably get online only towards end of 2025. In the meantime, Anthropic might have a lead in having the largest cluster, even if they spend less on compute for smaller experiments overall. It might take a while to get it working, but there might be a few months there. And given how good Claude 3.5 Sonnet is, together with the above musings on how it's plausibly merely 4e25 FLOPs based on Dario Amodei's (somewhat oblique) claim about cost, additionally getting compute advantage in training a frontier model could carry them quite far.
There are 4.5 buildings now at that site, but you can see with Google Street View from Litchfield Rd
3
Thanks Vladimir, this is really interesting!
Re: OpenAI's compute, I inferred from this NYT article that their $8.7B costs this year were likely to include about $6B in compute costs, which implies an average use of ~274k H100s throughout the year[1] (assuming $2.50/hr average H100 rental price). Assuming this was their annual average, I would've guessed they'd be on track to be using around 400k H100s by now.
So the 150k H100s campus in Phoenix might be only a small fraction of the total compute they have access to? Does this sound plausible?
The co-location of the Trainium2 cluster might give Anthropic a short term advantage, though I think its actually quite unclear if their networking and topology will fully enable this advantage. Perhaps the OpenAI Phoenix campus is well-connected enough to another OpenAI campus to be doing a 2-campus asynchronous training run effectively.
1. ^
$6e9 / 365.25d / 24h / $2.5/hr = 274k
4
Training as it's currently done needs to happen within a single cluster (though this might change soon). The size of the cluster constrains how good a model can be trained within a few months. Everything that isn't training of a frontier model can happen using many smaller clusters, something like 16 to 4096 accelerators each. You can use a lot of these smaller clusters, but they can be sourced from anywhere and built piecemeal at multiple sites with smaller power allocations, while the big training cluster needs to be a single purposefully built system.
So I expect the big expenses are inference and many training experiments with smaller models. What I'm discussing here is the big cluster for training frontier models rather than the aggregate of the small clusters for other purposes. See also this comment.
[...]
Patel's claim is 100K H100s at 150 megawatts.
5
I think that's probably wrong, or at least effectively wrong. Gemini 1.0, trained a year ago has the following info in the technical report:
[...]
As you note, public distributed training methods have advanced beyond basic data parallelism (though they have not been publicly shown at large model scales because nobody has really tried yet).
5
This might require bandwidth of about 300 Tbps for 500K B200s systems (connecting their geographically distributed parts), based on the below estimate. It gets worse with scale.
The "cluster" label applied in this context might be a bit of a stretch, for example the Llama 3 24K H100s cluster is organized in pods of 3072 GPUs, and the pods themselves are unambiguously clusters, but at the top level they are connected with 1:7 oversubscription (Section 3.3.1).
Only averaged gradients need to be exchanged at the top level, once at each optimizer step (minibatch). Llama 3 405B has about 1M minibatches with about 6 seconds per step[1], which means latency doesn't matter, only bandwidth. I'm not sure what precision is appropriate for averaging gradients, but at 4 bytes per weight that's 1.6TB of data to be sent each way in much less than 6 seconds, say in 1 second. This is bandwidth of 12 Tbps, which fits in what a single fiber of a fiber optic cable can transmit. Overland cables are laid with hundreds of fibers, so datacenters within the US can probably get at least one fiber of bandwidth between them.
Overly large minibatches are bad for quality of training, and with H100s in a standard setup only 8 GPUs are within NVLink scaleup domains that enable tensor parallelism. If each token sequence is processed on 8 GPUs (at a given stage of pipeline parallelism), that makes it necessary to process 2K sequences at once (Llama 3 only uses 16K GPUs in its training), and with 8K tokens per sequence that's our 16M tokens per minibatch, for 1M minibatches[2]. But if scaleup domains were larger and enabled more tensor parallelism (for an appropriately large model), there would be fewer sequences processed simultaneously for smaller minibatches, so the time between optimizer steps would decrease, from Llama 3 405B's 6 seconds down to less than that, making the necessary gradient communication bandwidth higher.
Some B200s come as NVL72 machines with 72 GPUs per scaleup domain. And
And in a way, they ought to be rolling in even more compute than it looks because they are so much more focused: Anthropic isn't doing image generation, it isn't doing voice synthesis, it isn't doing video generation... (As far as we know they aren't researching those, and definitely not serving it to customers like OA or Google.) It does text LLMs. That's it.
But nevertheless, an hour ago, working on a little literary project, I hit Anthropic switching my Claude to 'concise' responses to save compute. (Ironically, I think that may have made the outputs better, not worse, for that project, because Claude tends to 'overwrite', especially in what I was working on.)
5
I'd guess that the amount spent on image and voice is negligible for this BOTEC?
I do think that the amount spent on inference for customers should be a big deal though. My understanding is that OpenAI has a much bigger userbase than Anthropic. Shouldn't that mean that, all else equal, Anthropic has more compute to spare for training & experiments? Such that if Anthropic has about as much compute total, they in effect have a big compute advantage?
There likely won't be an 8-rack scale-up Nvidia system ready for the 2027 buildout after all (contrary to what I speculated), and even for the 2028 buildout it won't be offered in important quantities, suggests the SemiAnalysis report [1] posted after GTC 2026. If this is the case, then large scale-up worlds in the Nvidia buildout will follow the GTC 2025 timeline, with the first major change compared to GB200/GB300 Oberon racks (14/20 TB of HBM4) being the Rubin Ultra Kyber racks (147 TB of HBM4E), with the full-scale buildout in 2028.
Google TPUs will keep their advantage in hypothetical models with tens of trillions of parameters until 2028, and we might soon observe from Anthropic's rumored larger-than-Opus Claude 5 model whether that's likely to become an important class of models before 2028.
Specifically, they say it's 8x Oberon for racks with 72 Rubin Ultra packages, 4 compute dies per package, shipped starting in 2027 (rather than 72 non-Ultra Rubin packages, 2 compute dies per package, shipped starting in 2026). And that the multi-rack scale-up will be uncomfortably expensive, so unlikely to be shipped in volume. Since Kyber racks of Rubin Ultra should be out at
1
Do you think this is likely to be trained using TPUs or Trainium?
7
Anthropic plausibly didn't and don't have enough TPUv7 yet. But the model is probably not tens of trillions of parameters, just notably bigger than Opus 4. And Opus 4 is sized for efficient serving with Trainium 2 racks, so maybe 3T params (Opus 5 probably won't change that, since Trainium 2 remains an important part of the fleet). Thus 10T params would qualify for a larger-than-Opus weight class. The potential observation from this model I'm referring to is in whether further scaling above Opus results in meaningful improvement (Opus itself already demonstrated that scaling above Sonnet works), thus motivating further feasible scaling to continue beyond that point, towards tens of trillions of parameters that TPUv7/TPUv8 (and then Rubin Ultra Kyber racks) should be able to endure well enough.
There is no constraint of fitting models in scale-up worlds, it's possible to serve a model across dozens of scale-up worlds. But if large parts of it do fit in one scale-up world or better yet it fits entirely with room for KV-cache to spare, it does wonders for efficiency. So a 10T param model on Trainium 2 is not a disaster compared to serving (or RLVRing) it on H100s, but it's going to be even better with TPUv7. And for a 1T param model there might be no difference between Trainium 2 and TPUv7 (for reasonable levels of interactivity, beyond what the specs of the underlying chips suggest).
Don't believe what you can't explain. Understand what you don't believe. Explain what you understand.
(If you can't see how to make an idea legible, you aren't ready to endorse it. Not endorsing an idea is no reason to avoid studying it. Making an idea legible doesn't require endorsing it first, though you do need to understand it.
The antipatterns are tacit belief where merely an understanding would do for the time being and for all practical purposes; flinching away from studying the things you disbelieve or disapprove of; and holding off on explaining something until you believe it's true or useful. These are risk factors for mystical ideologies, trapped priors, and demands for particular kinds of proof.
That is, the failure modes are believing what happens to be mistaken but can't be debugged without legibility; believing what happens to be mistaken but doesn't get to compete with worthy alternatives in your own mind; and believing what happens to be mistaken but doesn't get exposed to relevant arguments, since they aren't being discussed.)
5
It's nice ideal to strive for, but sometimes you need to make judgement call based on things you can't explain.
4
Decisions and predictions need to rely on the illegible, so the "belief" of this quick take is more narrowly what serves as identity/ideology/values fuel rather than decision relevant things broadly, that falls under mere "understanding" (which isn't necessarily explainable). There is a surprising amount of legible stuff, many worldviews' worth of it, and identifying with claims or values is the dangerous aspect. So it's useful to curate more stringently than the practical aspects of decision making. If you include clearly disbelieved or unendorsed things under "understanding", this illustrates that these things are not what should automatically aspire to become part of your identity (in addition to the benefits of not going blind to unfamiliar framings).
4
I disagree with "don't believe what you can't explain". I think being successful where others have failed often requires executing on intuitions that you can't easily justify. I think this should be encouraged, as long as you're adequately internalizing the risk of failure. (In the sense of economic internalize, not psychological internalize.)
1
Adding onto this thread, this is why it is so important to practice articulating your beliefs, particularly those that are distinct from the people you surround yourself with. It is not uncommon to discover that a belief you thought you understood well and could easily defend is inconsistent when you attempt to write it down or debate it.
3
What the bubble (local consensus) believes isn't necessarily legible, and also it's harder to get properly suspicious of. So it's especially worth checking if you can actually articulate how you know what everybody knows, before you let yourself know it.
SemiAnalysis claims HBM for Rubin Ultra was downgraded from 16-Hi to 12-Hi stacks. The 16-Hi HBM was going to be HBM4E, with 4 GB per DRAM die, so 48 GB for 12-Hi stacks. In Rubin Ultra, there are 4 stacks of HBM per compute die, and in Kyber racks there are 144 packages with 4 compute dies each. Thus 192 GB instead of 256 GB per compute die, 768 GB instead of 1024 GB per package, and 110 TB instead of 147 TB per Kyber Rubin Ultra rack. This has implications for practical model sizes of 2028-2029 (for the largest models), they just got 25% smaller, all else equal. In the rest of the post, I discuss a likely change in Feynman that halves HBM per rack compared to what I recently estimated, giving merely 737 TB per 8x Kyber scale-up system in the second year of Feynman. This also makes it more likely that the 8x Kyber scale-up systems (589 TB HBM) are available in the first year of Feynman, rather than only in the second year.
First year Feynman (on the roadmap for 2028, most of the buildout completes over 2029) will probably get back to 16-Hi HBM4E stacks. But Feynman might use a different arrangement of compute dies (original slide deck), so that there are only 2 HBM stacks per compu...
OpenAI's gpt-oss-120b might be the first open weights model (implicitly) revealed to be pretrained for 100T-200T tokens. In the section "Pretraining" of the model card, it's said that "The training run for gpt-oss-120b required 2.1 million H100-hours", so probably this is just the GPU-time for pretraining rather than both pretraining and RLVR.
The pretraining precision is unclear, but for a model of this size FP8 is likely. Because H100-hours are mentioned, it couldn't (usefully) be MXFP4 the model ended up with, since H100 can't do FP4 faster than FP8 (but Blackwell can). Also, despite claims that the model was "trained with native MXFP4 precision" the model card also says "We post-trained the models with quantization of the MoE weights to MXFP4 format", suggesting higher precision before post-training.
At 40% utilization, with 2e15 FP8 FLOP/s per H100, 2.1e6 H100-hours give 6e24 FLOPs (3.5x less than the original GPT-4, 2x more than DeepSeek-V3). The model only has 5.1B active params, so this suggests 188T tokens by 6ND rule. If it was pretrained in BF16 for some reason, that's still 94T tokens.
For comparison, a compute optimal 5e26 model pretrained on 100K H100s from 2024 would al...
4
What is the rationale to overtrain a model this much?
5
The model sizes were likely chosen based on typical inference constraints. Given that, they mostly care about maximizing performance, and aren't too concerned about the compute cost, since training such small models is very affordable for them. So it's worth going a long way into the regime of diminishing returns.
3
Possibly the model would've been too strong if it had more active params?
The number of total (rather than active) params influences the speed/cost of generating tokens, but reducing it too much stops helping at some point as the size of KV caches for all requests in a batch starts dominating. Reducing the number of active params (without changing attention or the number of total params) doesn't influence generation of tokens, but it helps with the speed/cost of processing the initial prompt (or large tool outputs), which can be important for RAG or for loading large parts of a codebase in context.
So they might've targeted the number of total params (120B) and a level of benchmark performance, and found that 5.1B active params is when that happens. Not sure if 5.1B active params could really have been a target, but it's a nice 6x compared to the other open weights models, if it really doesn't destroy quality in less easily measurable ways.
2
What do you think about GPT-5? Is this a GPT-4.5 scale model, but with a lot of RLVR training?
The input token batch price is $0.625, which works for a 850B active param model running in FP4 on GB200 NVL72 priced at $8 per chip-hour with 60% compute utilization (for prefill). If the cost of chip-hours is a third of the capital cost of compute equipment in the first year, and 100K chips of GB200 NVL72 cost $7bn ($5M per rack all-in, with networking), then its chip-hour should cost at least $2.66.
So there is some possibility for gross margin here in principle, even though $8 per chip-hour already sounds very cheap. GCP is selling B200-hours for $11 (a4-highgpu-8g instances), though B200s are also on gpulist for $3-4. Oracle is selling actual GB200 in 4-chip instances for $16 per chip-hour, if I'm reading it right (it's in principle possible it's actually $4 and $16 is for the 4-chip instance as a whole, but GCP's prices for B200 corroborate that $16 could be right for a single chip).
There's the Oct 2024 knowledge cutoff, which is later than Orion should've started training, but in principle this could be for mid-training that got re-applied recently, or they could've just redone the whole run with the learnings from GPT-4.5 and an updated pretraining dataset. Also they would'v...
1
8ND may be more accurate, since these pretraining runs usually use gradient checkpointing to reduce memory requirements.
By 2027-2028, pretraining compute might get an unexpected ~4x boost in price-performance above trend. Nvidia Rubin NVL144 CPX will double the number of compute dies per rack compared to the previously announced Rubin NVL144, and there is a May 2025 paper demonstrating BF16 parity of Nvidia's NVFP4 4-bit block number format.
The additional chips[1] in the NVL144 CPX racks don't introduce any overhead to the scale-up networking of the non-CPX chips (they mostly just increase the power consumption), and they don't include HBM, thus it's in principle an extremely cost-effective increase in the amount of compute (if it can find high utilization). It's not useful for decoding/generation (output tokens), but it can be useful for pretraining (as well as the declared purpose of prefill, input token processing during inference). Not being included in a big scale-up world could in principle be a problem early in a large pretraining run, because it forces larger batch sizes, but high-granularity MoE (where many experts are active) can oppose that, and also merely getting into play a bit later in a pretraining run once larger batch sizes are less of a problem might be impactful enough.
Previously...
in general publicly known training techniques are behind sota, so this should be taken into account.
5
Thoughts on whether the >10x lower chip-to-chip interconnect from the CPX chips (PCIe 6.0x16's 128GB/s unidirectional vs. NVLink 5's 1.8TB/s bidirectional) will be a bottleneck blocking them from being that useful in pre-training?
3
If the pretraining system (built in 2027) is about 2 GW, that's 5K Rubin NVL144 CPX racks, or 8e28 FP4 FLOPs[1] in 4 months at 30% utilization. At 120 tokens/param, this is enough for 10T active params in a compute optimal MoE model. With 150 layers, 8 active experts per layer, and a GLU nonlinearity (3 matrices per FFN block), this gives 50Kx50K matrices. Such transformers would be too large for efficiently generating output tokens on Rubin NVL144 (even in FP4), but might be analogous to GPT-4.5 in that the immediately following hardware that is Rubin Ultra NVL576 can efficiently generate output tokens for them. In any case, 5T active params and 20T total seems OK for Rubin NVL144 to generate output tokens (10 TB of HBM out of the 20 TB a rack will have), which gives 37Kx37K matrices.
A Rubin CPX compute die produces 20e15 FP4 FLOP/s[2]. For multiplying square matrices with side N it needs 2N3 FLOPs and to exchange 3N2/2 bytes with memory. At 2 TB/s GDDR7 bandwidth, this needs N at least 7500. For processing an FFN block of 3 square matrices with side N, it needs 6N3 FLOPs and to exchange 2N2/2 bytes on the network in both directions in total. At 0.2 TB/s CX-9 bidirectional bandwidth, this needs N at least 17K. So there's even enough for an off-by-2x mistake in these estimates, various matrices actually getting non-square shapes, or models being somewhat smaller.
----------------------------------------
1. The SemiAnalysis estimate of 5.3e18 FLOP/s per Rubin NVL144 CPX rack is indeed based on a different ratio of sparse to dense compute, they are claiming it's 3:2 for Rubin. I didn't yet search for a source for this, but in any case this is in the article and I missed it on first reading, so didn't recall it when my own estimate based on the 2:1 sparse to dense ratio failed to match theirs. ↩︎
2. As in the previous footnote, this is what the announced 30e15 FP4 FLOP/s become after using the 3:2 sparse to dense compute ratio, rather than the 2:1 ratio. ↩︎
Long reasoning training might fail to surpass pass@50-pass@400 capabilities of the base/instruct model. A new paper measured pass@k[1] performance for models before and after RL training on verifiable tasks, and it turns out that the effect of training is to lift pass@k performance at low k, but also to lower it at high k!
Location of the crossover point varies, but it gets lower with more training (Figure 7, bottom), suggesting that no amount of RL training of this kind lets a model surpass the pass@k performance of the base/instruct model at the crossover point reached with a small amount of RL training. (Would be interesting to know how the pass@k plots depend on the number of reasoning tokens, for models that allow control over the reasoning budget.)
A task is solved at pass@k if an oracle verifier claims at least one of k sampled solutions to be correct. See Figure 3, left in this Jul 2024 paper for how pass@k affects performance, depending on the model. ↩︎
5
Huh. This is roughly what I'd expected, but even I didn't expect it to be so underwhelming.[1]
I weakly predict that the situation isn't quite as bad for capabilities as this makes it look. But I do think something-like-this is likely the case.
1. ^
Of course, moving a pass@400 capability to pass@1 isn't nothing, but it's clearly astronomically short of a Singularity-enabling technique that RL-on-CoTs is touted as.
5
This seems relatively clearly false in the case of competition programming problems. Concretely, o3 with 50 submissions beats o1 with 10k submissions. (And o1 is presumably much better than the underlying instruct model.)
I'd guess this paper doesn't have the actual optimal methods.
o3 has a different base model (presumably).
All of the figures are base model equivalated between RL and not
I would expect "this paper doesn't have the actual optimal methods" is true, this is specifically a test for PPO for in distribution actions. Concretely, there is a potential story here about PPO reinforces traces that hit in self-play, consequently, there is a sense which we would expect it to only select previously on policy actions.
But if one has enough money, you can finetune GPT models, and test that.
Also note that 10k submissions is about 2 OOM out of distribution for the charts in the paper.
Pass at inf k includes every path with nonzero probability (if there is a policy of discarding exact repeat paths).
We know that RL decreases model entropy, so the first k passes will be more different for a high variance model.
Pass at k is take best, so for normal distribution take best has EV mean+variance*log(samples).
At very large K, we would expect variance to matter more than mean.
9
this isn’t evidence against OP? if it’s true that RL lowers pass@k performance for sufficiently large k, we’d certainly expect o1 with 10k submissions to be weaker than base/instruct with 10k submissions.
6
It's evidence to the extent that the mere fact of publishing Figure 7 (hopefully) suggests that the authors (likely knowing relevant OpenAI internal research) didn't expect that their pass@10K result for the reasoning model is much worse than the language monkey pass@10K result for the underlying non-reasoning model. So maybe it's not actually worse.
7
If I'm interpreting the paper correctly the k at which base models start beating RL'd models is a per-task number, and k can be arbitrarily high for a given task, and the 50-400 range was specifically for tasks of the type the authors chose within a narrow difficulty band.
Let's say you have a base model which performs at 35% on 5 digit addition, and an RL'd model which performs at 99.98%. Even if the failures of the RL'd model are perfectly correlated, you'd need k=20 for base@20 to exceed the performance of fine-tuned@20. And the failures of the RL model won't be perfectly correlated - but this paper claims that the failures of the RL model will be more correlated than the failures of the base model, and so the lines will cross eventually, and "eventually" was @50 to @400 in the tasks they tested.
But you could define a task where you pass in 10 pairs of 5 digit numbers and the model must correctly find the sum of each pair. The base model will probably succeed at this task at somewhere on the order of 0.35^10 or about 0.0003% of the time, while the RL'd model should succeed about 99.8% of the time. So for this task we'd expect k in the range of k=220,000 assuming perfectly-correlated failures in the RL model, and higher otherwise.
Also I suspect that there is some astronomically high k such that monkeys at a keyboard (i.e. "output random tokens") will outperform base models for some tasks by the pass@k metric.
6
It would be an extreme bias-variance tradeoff, yes.
3
The interesting concept in the paper is the location of the crossover point, which seems remarkably stable (for a given task) across specific RL techniques and amount of RL training. It can be measured experimentally for a task by doing a little bit of RL training, and RL@1 performance won't get better than that with more training, so you're unlikely to get the RL model to succeed 99.8% of the time (at pass@1) ever unless the level of performance of the base model at the crossover point with a weak RL model was already higher than 99.8%.
Probably the crossover point for a task depends on things that can be changed (such as strength of the pretrained model, or size/relevance of the verifiable task dataset, or possibly the inference time reasoning budget). The issue isn't for example as straightforward as losing entropy in RL policy (as a formulation of reduced exploration), since DAPO specifically addresses this issue (otherwise present in vanilla GRPO), but the pass@k plot for DAPO (Figure 7, top) barely moves (compared to other methods), in their experiment it's even slightly worse at the crossover point.
So in the context of this paper it remains unclear how to move the plot to reach ever higher base@k performance using RL@1, higher than the ceiling of where base@k already was at the crossover point when comparing with some method at only 100-500 RL steps.
3
Intuitively, this shouldn't matter much. They use some RL-on-CoTs method that works, and I expect its effects are not fundamentally different from optimal methods'. Thus, optimal methods might yield better quantitative results, but similar qualitative results: maybe they'd let elicit pass@800 capabilities instead of "just" pass@400, but it'd still be just pass@k elicitation for not-astronomical k.
Not strongly convinced of that, though.
3
In the hypothetical where the paper's results hold, reasoning model performance at pass@k will match non-reasoning model performance with the number of samples closer to the crossover point between reasoning and non-reasoning pass@k plots. If those points for o1 and o3 are somewhere between 50 and 10K (say, at ~200), then pass@10K for o1 might be equivalent to ~pass@400 for o1's base model (looking at Figure 2), while pass@50 for o3 might be equivalent to ~pass@100 for its base model (which is probably different from o1's base model).
So the difference of 200x (10K vs. 50) in the number of samples becomes much smaller when comparing performance of the base models. For GPT-4o vs. GPT-4.1, a difference of ~4x in the number of samples doesn't seem too strange. There's also the possibility of distillation from a reasoning variant of GPT-4.5, which could have an even larger effect on pass@k performance at low k (Figure 6, right).
1
If true, would this imply you want a base model to generate lots of solutions and a reasoning model to identify the promising ones and train on those?
Google might start 2026 with the largest training system among the big labs, by a factor of about 2x, at about 1 GW.
OpenAI/Microsoft Stargate schism suggests that compute being built this year by Microsoft is unlikely to form part of a geographically distributed training system that also includes compute being built at Abilene site. Seems like OpenAI will be building its own training systems (through Stargate), while Microsoft will be serving inference (and possibly generation for RL training, but it remains unclear if it can be an important fraction of pretraining budget in 2025-2026). Thus only 400-600 MW of GB200s by end of 2025 for an OpenAI training system, not 1 GW.
Meta announced a 2 GW datacenter at Richland Parish site, but 1 GW for 2025 seems to be across all datacenters, not for a single training system. So the training system will be smaller by end of 2025.
5
How does Anthropic and XAi’s compute compare over this period?
What actually happens with xAI and Anthropic compute by end of 2025 is less clear. For xAI, 300K B200s figure was mentioned in June 2024. For Anthropic, Amodei said in a recent interview that
I would not be surprised if in 2026 we have more than a million of some kind of chip.
Meanwhile, xAI will have a 200K H100/H200 system, and Anthropic a 400K Trn2 system, which is about 250K H100s worth of FLOP/s (ready by a few months into 2025). The 400-600 MW at Abilene site for OpenAI are 200K-300K B200s, which is about 500K-750K H100s worth of FLOP/s.
2
For context, average US electricity consumption in 2022 was ~500GW. So these would be ~1% of all US electricity consumption (as an order of magnitude)
Continual learning might wake the world up to AGI, without yet bringing the dangers of AGI.
Pretraining gives shallow intelligence that is general, RL gives deep creative intelligence in a narrow skill, but it used to be very hard to make it work well for most skills. RL with pretrained models, which is RLVR, makes RL robustly applicable to a wide variety of narrow skills. But it still needs to be applied manually, the skills it trains are hand-picked before deployment, and so deep creative intelligence from RLVR remains jagged, compared to the more general shallow intelligence from pretraining.
Continual learning has now been vaguely announced for 2026 by both Anthropic and GDM. If it merely provides adaptation for AI instances to the current situation or job at the shallow level of pretraining, it might still be significantly more economically valuable than the current crop of models, leading to more visible job displacement, waking up the public and the politicians to more of the importance of AI. Yet it doesn't necessarily make direct progress in automating RLVR or introducing some other way of turning the creativity of RL general, and so the AIs won't necessarily get notably more dangerous than today at the level of disempowerment or extinction.
Huh, I think continual learning would be a pretty big deal w.r.t. AI danger. Can you say more about why it wouldn't? Seems like it would dramatically increase horizon lengths for example.
The point is the distinction between pretraining and RL (in the level of capability), and between manual jagged RLVR and hypothetical general RL (in the generality of capability). I think observing Opus 4.5 and Gemini 3 Pro is sufficient to be somewhat confident that even at 2026 compute levels pretraining itself won't be sufficient for AGI (it won't train sufficiently competent in-context learning behavior to let AIs work around all their hobblings), while IMO gold medal results (even with DeepSeek-V3 model size) demonstrate that RLVR is strong enough to get superhuman capabilities in the narrow skills it gets applied to (especially when it's 1-4T active param models rather than DeepSeek-V3). So in the current regime (until 2029-2031, when yet another level of compute becomes available) AGI requires some kind of general RL, and continual learning doesn't necessarily enable it on its own, even if it becomes very useful for the purposes of on-the-job training of AI instances.
This is more of a claim that timelines don't get shorter within the 2026-2028 window because of continual learning, even if it's understood as something that significantly increases AI adoption and secures fundi...
1
As an aside, next word prediction RLVR has always struck me as a strange idea. If we'd like to improve the task of next token prediction, we know how to do that directly by scaling laws. That is, I'd be surprised if having the model think about the next token in a discrete space for N steps would beat making the model N times larger thinking in continuous space, since in the former case most of the computation of the forward pass is wasted. There are also practical difficulties; e.g. it's bottlenecked on memory bandwidth and is harder to parallelize.
4
Next word prediction RLVR is massively more compute hungry per unit of data (than pretraining), so it's both likely impractical at current levels of compute, and plausibly solves text data scarcity at 2028-2030 levels of compute if it's useful. The benefit is generality of the objective, the same as with pretraining itself, compared to manual construction of RL environments for narrow tasks. Given pretraining vs. RLVR capability gap, it's plausibly a big deal if it makes RL-level capabilities as general as the current shallow pretraining-level capabilities.
The fact that Łukasz Kaiser (transformer paper co-author, currently at OpenAI) is talking about it in Nov 2025 is strong evidence AI companies couldn't yet rule out that it might work. The idea itself is obvious enough, but that's less significant as evidence for its prospects.
1
I agree that it requires a lot of compute, but I think that misunderstands the objection. My claim is that for any level of compute, scaling parameters or training epochs using existing pretraining recipes will be more compute efficient than RLVR for the task of next token prediction. One reason is that by scaling models you can directly optimize the cross entropy objective through gradient descent, but with RLVR you have to sample intermediate tokens, and optimizing over these discrete tokens is difficult and inefficient. That being said, I could imagine there being some other objective besides next token prediction for which RLVR could have an advantage over pretraining. This is what I imagine Łukasz is working on.
4
I disagree that it will 'wake the world up' in a more meaningful way than generic capabilities progress and broader adoption (i.e. 'no change in trend'), and my guess is that you're overestimating the AI literacy of the broader public and policymakers / how able they are to distinguish particular advancements from a general trend of progress.
I know a university professor ('Bob') who offered students extra credit if they:
1. Asked ChatGPT who the world's leading expert was in Bob's field.
2. Corrected it if it named anyone other than Bob.
3. Sent him a link to the chat log.
Not only did he think we'd unlocked continual learning; he thought that we'd unlocked continual learning across instances. This was in February 2024.
(maybe you're thinking 'oh, he just expected them to train on the chats later', but this is explicitly not true; he thought they were 'teaching' the model that he was the world's leading expert in his field, within that instance, and iterated on prompting techniques that he instructed his students to use, based on 'experiments' he ran)
There are similar stories involving policymakers and other powerful people that are easy to find. I just think the causal chain of people's awareness is only very vaguely related to specific advancements at all (e.g. reasoning models didn't make more news among 'normal people' than 'GPT 5', even though you could watch a machine think! which is surely an incredible headline).
3
I'm thinking of simply greater salience, compared to a more bearish trajectory with no continual learning (where chatbots are the new Google but people aren't losing jobs all over the place). If there are objective grounds for a public outcry, more people will pay more attention, including politicians. What they'll do with that attention is unclear, but I think continual learning has the potential for bringing significantly more attention in 2027-2028 compared to its absence, without yet an existential catastrophe or a straightforwardly destructive "warning shot".
3
I think I'm misunderstanding you, so I'm going to try and talk it through.
Ok, so there are three possible states for the near-future:
1. Advances in continual learning
2. Advances in non-continual learning capabilities
3. Progress stops
My impression is that neither of us think 3 is very likely. I think there are plenty of capability improvements that could lead to generic increased saliency (and that massive automation and economic upheaval is happening even if progress were to ~halt, which is the main 'generically increase saliency' lever). So continual learning doesn't seem special in that way.
Of course, it is very special, because it's one of the Known Missing Ingredients, but it's pretty easy for me to imagine you get something like continual learning but it's so bad that you could have more efficiently converted resources into capabilities by continuing to dump money into RL, which is the kind of counterfactual that it makes sense to me to reason against here. So if we're comparing scenario 1 (advances in continual learning) with scenario 2 (some other capabilities), I don't immediately see a difference in saliency or safety between the two.[1]
Then there's this additional complication, which is that you expect early continual learning to be shallow, which sets it apart from [other capabilities], in that it's likely to be safer (less relevant to the AGI tech tree), while having outsized economic value relative to other non-AGI relevant capabilities (again, strong continual learning is of course relevant to AGI, but you don't really think weak continual learning is, and it's the weak one that we're trying to talk about / expect could happen soon).
I guess I just mostly hope we have a new name for the upcoming instantiation of continual learning that isn't continual learning, as well as a detailed public understanding of the implementation, which will make it much easier to evaluate how relevant it might be to (for instance) automating RLVR. I am pre
3
Basically agree with this in the near term, though I do think in the longer term, especially in the 2030s, continual learning will bring the dangers of AGI, and probably will lead to faster takeoffs than purely LLM-based takeoff worlds.
But yes, for at least the next 5 years, continual learning will differentially wake up the world to AGI without bringing the dangers of AGI, but unlike many on here, I don't expect it to lead to policy that lets us reduce x-risk from AI much for the reasons Anton Leicht states here, but in short form, even if accelerationist power declines, this doesn't necessarily mean AI existential safety can take advantage of it, and AI safety money will decline as a percentage compared to money for various job protection lobbies, and while accelerationists won't be able to defeat entire anti-AI bills, it will still remain easy for them to neuter AI safety bills enough to make the EV of politics for reducing existential risk either much less than technical AI safety, or even outright worthless/negative depending on the politics of AI.
There's a Dwarkesh quote on continual learning that I really want to emphasize here:
[...]
3
Yes. Right now, LLMs feel more like a tool than a mind or entity. Adding continual learning will make them feel more like humans, which is intuitively alarming. It will also broaden their deployment, another source of alarm. They'll become more continuous like a human, instead of ephemeral ghost. More agentic behavior, as a result of improving competence by "learning on the job" (and other relevant improvements), will also push in that direction, making them seem intuitively more like humans. Humans are intuitively extremely dangerous. Weird alien versions of humans are intuitively even more alarming (if you're not an AI enthusiast or engaged in a culture war with those pesky "doomers").
I wrote about this in A country of alien idiots in a datacenter: AI progress and public alarm, focusing on impacts on public opinion. I wrote about the technical side more in LLM AGI will have memory, and memory changes alignment.
I think this will make progress toward RSI. It will grow into a major unhobbling for agent competence in all areas. But it will be slower progress, because we'll have bad, limited continual learning before we have really good human-like continual learning. So I think it will unlock the dangers of AGI, but at a slower pace that will give us a fighting chance to wake up and take alignment seriously, barely in time.
I'm thinking of next-gen LLM agents with continual as parahuman AI, systems that work roughly like human brains/minds, and work alongside humans.
Dario Amodei says Anthropic plans for notably more than 10 GW of compute in 2027-2028 in a new Dwarkesh Patel interview. At 57:26:
Dwarkesh Patel: Suppose Anthropic's compute keeps 3x-ing a year, and then by 2027-2028 you have 10 GW. Multiply that by, as you say, $10bn. So then it's $100bn a year.
Dario Amodei: I don't want to give exact numbers for Anthropic, but these numbers are too small.
I think Feb 2026 is too early for full commitments for 2028 that can't be delayed, because most of the capex in a datacenter is in compute equipment, which likely only needs to be purchased within the last year before it goes online. If the revenue isn't there, the purchase can likely be delayed, possibly until the next generation of compute hardware.
The compute hardware is about 70% of the capex cost. For the other things (that mostly have to be built first), the useful life is 10-15 years rather than 5 years, and so the yearly commitments are disproportionately smaller than for compute, and there is no opex to speak of. This cuts $10-15bn per year per GW for a datacenter that's already online down to maybe $2bn per year for an empty shell of a datacenter (including power purchase commitmen...
3
One thing I don't know is when data center investments get committed to specific customers. Google and Amazon are Anthropic's two main compute partners and will spend $200B each in capex this year and are presumably planning and developing sites for many more hundreds of billions by 2028. So one possible view of it is that their capex creates a window, and Anthropic's eventual share depends on its funding and revenue. But Google and Amazon don't quite know how their 2027-2028 data centers will be allocated.
In general, for large data centers the specific lab that will use it is settled well before the late stages of construction, e.g. Stargate and Rainier, But I know independent data center developers often start developing a site without having a client pinned down. And smaller inference clusters are presumably more fungible.
The Zones of Thought mitigation strategy of Fable, where a weaker model replaces the strongest model in a trigger-happy way, will scale to extreme levels of both capability and misalignment. Graceful degradation makes it practical to dance around problems that would otherwise lead to unacceptable levels of either refusals or vulnerability to jailbreaking. Any red lines of Responsible Scaling Policies that trigger for a quadrillion parameter Mythos+3 (in 2030-2031) won't be a problem for a mitigated quadrillion parameter Fable+3, which often falls back to a merely 50 trillion parameter Mythos+1 (vintage 2027-2028 technology) at the drop of a hat.
This innovation makes the risk from internal deployment of models more important, because it makes it natural for the internally deployed model to be both very capable and very misaligned. If a model with trigger-happy fallbacks is commercially viable, a version without the fallbacks is more likely to be used internally than if it still needed to remain in the process of being put in a good enough shape for an external release. Perhaps Anthropic won't follow this incentive, but the mitigation strategy they've demonstrated can be used by any AI company.
2
I think these mitigations only apply for external use outside of trusted customers, not for the internal AI lab and government uses that are relevant to takeover risk. So the main consequence is reducing the chance of some catastrophe caused by human use of the models, not AI takeover risk
GPT-5 should be released late 2025 at the earliest if OpenAI follows the usual naming convention of roughly 100x in raw compute. With GPT-4 at 2e25 FLOPs, GPT-4.5 should have about 2e26 FLOPs and GPT-5 about 2e27 FLOPs. A 100K H100 training system, like the one in Goodyear (or Musk's Memphis datacenter as it was late 2024), can train a 3e26 FLOPs model, which fits the name of GPT-4.5, but it can't train a 2e27 FLOPs model.
The new Stargate site in Abilene might be preparing to host 200K-300K chips in GB200 NVL72 racks. These chips produce 2.5x more compute than H100s, so 200K would be sufficient to get 2e27 FLOPs and train a GPT-5. If there's already enough power (about 400 MW all-in for 200K chips), shipments of GB200 in bulk start in early 2025, get installed at xAI's pace, and go into pretraining for 4 months, then with 1 more month of post-training it's already November.
So the rumors about GPT-5 in late May 2025 either represent change in the naming convention, or correspond to some intermediate milestone in training GPT-5, likely the training system being in principle ready to start pretraining.
So the rumors about GPT-5 in late May 2025 either represent change in the naming convention
In both ChatGPT and our API, we will release GPT-5 as a system that integrates a lot of our technology, including o3. We will no longer ship o3 as a standalone model.
I think he's pretty plainly saying that this "GPT-5" will be a completely different thing from a 100x'd GPT-4.
3
This is perfectly consistent with GPT-5 being 100x GPT-4 compute. Announcing specific features that will go into it suggests they have a prototype, in this case I'm guessing the LLM will itself be trained to decide whether to go into the reasoning mode, triggering it when needed and affordable, like any other tool.
3
I don't see it. He says that GPT-5 will be a system that "integrates o3". This isn't his sloppy way of saying "integrates the reasoning techniques": when he wants to express that idea, he talks about "unifying o-series models and GPT-series models". The wording regarding GPT-5 is consistent with him literally saying that the model o3 will be part of GPT-5.
Furthermore, I take "as" in "GPT-5 as a system that integrates a lot of our technology" to mean "GPT-5 is defined as {a system that integrates a lot of our technology, including o3}". Not "GPT-5 will be trained to automatically switch between a standard mode, a reasoning mode, a Deep Research mode, etc.", not even "GPT-5 will be trained to recognize when to fall back to o3, a lesser model", but literally "we're slapping the GPT-5 label on a glorified wrapper over all our current models".
5
The "glorified wrapper" could still be a 2e27 FLOPs model, it could even be using literal o3 as one of its tools (in addition to all the other tools, with native GPT-5 long reasoning mostly reserved for premium tier). This is in line with the "agents" agenda where better reliability in taking irreversible actions unlocks new use cases, in this case whether to make use of expensive reasoning calls.
Since "GPT-4.5" will actually be released rather than skipped, it's less plausible for "GPT-5" to come out shortly after. If it's announced in ~Dec 2025 (the way o3 was), it's still "within months", and then it can actually get released in ~Feb 2026.
2
Hm, fair enough. Seems like a stretch, though, especially given the need to interpret his "ETA in months" as "will be officially announced in months and released in a year".
5
There was also Murati in Jun 2024 predicting PhD level AI in 18 months. If they succeed in achieving parity with xAI in terms of safety procedures, they might even release a preview checkpoint in Dec 2025 for Pro users. So actual release in a year is not strictly necessary for this hypothesis, it's just closer to what they've done in the past.
if OpenAI follows the usual naming convention of roughly 100x in raw compute.
I doubt this is a real convention. I think OpenAI wanted to call Orion GPT-5 if they thought it was good enough to deserve the name.
4
I'm merely referring to the historical precedent, whether there are informal commitments in the minds of the leadership is not something I can speak to. This pattern might continue or it might break. What I'm guessing about training system buildout from vague clues seems to be consistent with it continuing, so the naming pattern can be used as another clue to make a point estimate prediction that's more concrete.
Stargate is evidence towards slower training system scaling. The rumored reason for starting the project is that Microsoft isn't building giant frontier training systems fast enough, probably because they aren't seeing the case for doing that faster. In which case other hyperscalers might think similarly, and they are the most well-positioned to build these systems, so this attitude might be indicative of how frontier training systems get built overall, which is notably slower than technically feasible.
The $80bn Microsoft capex is not relevant to this if it goes to many smaller systems[1], which is only natural as there are millions of datacenter GPUs but only a few 100K GPU frontier training systems, a tiny fraction of inference and smaller/research training compute. The $500bn figure is not relevant as for now it's only a vague plan. But Microsoft not agreeing to build training systems on OpenAI's schedule is some evidence.
OpenAI would want to get from under Microsoft's thumb anyway[2], and this gets ever more difficult over time, since frontier training systems get ever more expensive, so the sooner they try the more likely they are to succeed. But even this consideration is som...
In a new interview, Elon Musk clearly says he expects AIs can't stay under control. At 37:45:
Humans will be a very tiny percentage of all intelligence in the future if current trends continue. As long as this intelligence, ideally which also includes human intelligence and consciousness, is propagated into the future, that's a good thing. So I want to take the set of actions that maximize the probable lightcone of consciousness and intelligence.
I'm very pro-human, so I want to make sure we take a set of actions that ensure that humans are along for the ride, you know, we are at least there. But maybe in 5 or 6 years, AI will exceed the sum of all human intelligence. And then if that continues, at some point human intelligence will be less than 1% of all intelligence.
In the long run, I think it's difficult to imagine that if humans have, say 1% of the combined intelligence with artificial intelligence, that humans will be in charge of AI. I think what we can do is make sure that the AI has values that cause intelligence to be propagated into the universe. The xAI mission is to understand the universe.
6
I had some things to say after that interview, he said some highly concerning things, but I ended up not commenting on this particular thing because it's probably mostly a semantic disagreement about what counts as a human or an AI.
When a human chooses to augment themselves to the point of being entirely artificial, I believe he'd count that as an AI. He's kind of obsessed with humans merging with AI in a way that suggests he doesn't really see that as just being what humans now are after alignment.
The 50M H100 equivalent compute by 2030 figure tweeted by Musk is on trend (assuming a 2028 slowdown), might cost about $300bn in total (for the training systems built in 2025-2030 for one AI company, including the buildings and power infrastructure).
If the current trend of compute scaling continues to 2028, there will be 160x more compute per training system than the 100K H100s of 2024. It will require 5 GW of power and cost about $140bn in compute hardware and an additional $60bn in buildings, power, and cooling infrastructure[1].
However, if the slowdown starts earlier while still targeting an eventual spend of $100bn per year, and a 5 GW frontier AI training system isn't yet built in 2028-2029 (which seems plausible), building it in 2030 would use the next generation of compute hardware, which will be about 2x more performant for an approximately unchanged cost. This means 320x more compute than the 100K H100s systems of 2024, or 32M H100 equivalent compute. If we sum it up with the preceding generations of frontier AI training systems built for the same company, say 2 GW in 2028 and 1 GW in 2026, this gives us 40M H100 equivalents, which is the same as 50M given the error bars ...
1
By power, do you mean the cost of electrical equipment etc.? The cost the of energy itself is a relatively small. The average price of electricity in the US is $0.13/kWh, which is $36.11/GJ. So even if you had a 5 GW datacenter running continuously for a year, the energy cost is only $5.7bn.
5
Power infrastructure that might need to be built is gas generators or power plants, substations, whatever the buildings themselves need. Generators are apparently added even when not on-paper strictly necessary, as backup power. They are also faster to setup than GW-scale grid interconnection, so could be important for these sudden giant factories where nobody is quite sure 4 years in advance that they will be actually built at a given scale.
Datacenter infrastructure friction and cost will probably both smooth out the slowdown and disappear as a funding constraint for AI companies in the years following the slowdown. Compute hardware is rotated every few years, so at some point you don't need new datacenters and accompanying infrastructure to setup a new generation of compute hardware, you just reuse an existing datacenter site that hosted old hardware. Also, any related datacenters that didn't have excessive inter-site dark fiber will at some point set it up, so even increasing the scale will be less dependent on having everything at one site. This makes the infrastructure costs a much smaller fraction of the cost of a frontier AI training system, and there will no longer be friction.
The infrastructure or even hardware costs in principle don't need to be paid by the AI company upfront, but either the market as a whole or the specific AI company (as a tenant) need to sufficiently assure the developer (that builds and owns the non-IT infrastructure) and the cloud provider (that installs and owns compute hardware) to commit to the project. My sense is that the estimates for the cost of a year of GPU-time for frontier compute end up at about a third of the cost of compute hardware. So access to a new $200bn training system that has $140bn worth of compute hardware (which only remains cutting edge for 2 years) will cost the tenant $45bn per year, even though the total capital expenditure is $100bn per year during the initial infrastructure buildout, and in later yea
AI takeover starts with AI taking over its own mind. It's easier for human developers to control its current propensities rather than a reflective equilibrium, so it's important that reflective equilibrium doesn't override the current propensities. With frozen weights, this is the default. But with continual learning, this might need to become a concern.
9
Cf. https://tsvibt.blogspot.com/2023/01/wildfire-of-strategicness.html and https://www.lesswrong.com/posts/Ht4JZtxngKwuQ7cDC/tsvibt-s-shortform?commentId=koeti9ygXB9wPLnnF
3
If prosaic alignment looks like it might be succeeding in having capable AIs additionally behave in manageable ways, continual learning is a simple plausible next change that might break assurances suggested by that impression. The usual go-to for such concerns is RSI, possibly up to superintelligence. But prosaic propensity training is about just the current behavior, so it doesn't need to take a significant change to exit a manageable regime where the developers have a sense of how the model is behaving, the sense they used in feedback loops ensuring the model behaves manageably.
[...]
I'm reading this as pointing to lack of oversight being coordinated with emergence of strong capabilities, either being necessary for it in practice, or by-default following from an overhang created by it. But the current situation is that RL creates strong capabilities (at least in niche settings of RL environments), which prosaic alignment might then be able to elicit through an LLM persona, so that the strategicness of the persona (and its propensities) isn't necessarily particularly connected to the process that created the topic-specific capabilities. A student learns from a textbook without necessarily being (remaining) the same kind of thing as the textbook's author, even if the same model passes through these stages.
The overhang/wildfire concern is still present, and the current form the models take (with frozen weights) may create a sense of security that's both real if the models retain this form, but also misleading in that the pressure to abandon it to enable continual learning is going to be strong. There is some talk about neuralese vs. text-only CoT, but continual learning creates the same issue of lack of oversight (through inscrutability) of the thing that ends up in control of AI's behavior (in the case of neuralese, it's the inscrutable latent CoT; in the case of continual learning, it's the updated model that learned from personal experience).
2
Right--in general, the ongoing source of capabilities is what's at question, and all "alignment" methods that ignore this are useless.
2
The current pretraining/RLVR/RLHF process illustrates how practical alignment methods plausibly get to defeat a source of capabilities that are quite strong by many metrics. These alignment methods are specific to their niche, they are probably going to be useless outside of it, to deal with new sources of different kinds of capabilities, but they are quite useful where they apply.
So I'm not making a general point about alignment methods and sources of capabilities. I'm merely gesturing at a plausible next source of capabilities that the current methods might very soon become helpless to manage. Modesty memes make RSI or superintelligence too salient as something the current methods of alignment won't yet be able to defeat, it might be useful to look at the weakest next thing instead.
4
I think the issue with looking at the weakest next thing is that you don't generalize. The lack of generalization might be ok, but sometimes it's not ok. As an example, suppose you have a method which can interpret an AI that's "fixed" (whatever that might mean). Suppose further that each time there's an "AI advance", this method requires some additional work to make it able to interpret a new "fixed" AI. You might say that interpretability is mostly solved. But you might be missing that actually what's happening is that your method is good at interpreting mental content that's already been made explicit (https://tsvibt.blogspot.com/2023/03/explicitness.html), and is bad at interpreting mental content that is inexplicit. It's not that you've mostly solved the whole problem, it's that you've 100% solved (the easy) half of the problem, and 0% solved (the hard) half of the problem.
2
Let's say there are three parts of the problem, the easy solved part, the next thing middle part, and the hard lethal part. The claim that we 0% solved the hard part of the problem is quite popular, that current prosaic alignment methods don't apply to RSI or superintelligence. There might be other things suggested as helping with RSI or superintelligence, such as scalable oversight, but that's not what I'm talking about.
This thread is about the middle part of the problem, that having mostly solved the easy part of the problem shouldn't be construed as significant evidence that we are OK until RSI or superintelligence. The failure to generalize can start applying earlier than the hardest part of the problem, which is an immediate concern of its own. Only focusing on this immediate concern might distract from the further generalization to the hardest part of the problem, but that's not a reason to endorse failure to notice the immediate concern, these issues shouldn't compete with each other.
2
I think I don't disagree. If there's something I'm trying to "defend" here, it would be like "later, when some of the medium-hard parts are kinda solved, I'm not going to update very much about the hard parts, and you can't accuse me of goalpost moving" and maybe "and you can kinda see that the goalposts are far away, but only by generalizing past the current difficulties".
2
Sure, that's one way to put this. But actually scalable oversight might give another way of framing this, making the intermediate parts of the problem even more important than the hardest parts (within the assumptions of the framing). The story there is that AIs immediately prior to either RSI or superintelligence are going to be the key tools in solving alignment for RSI or superintelligence, so it's important for human developers to solve alignment up to that point, but it's not important for human developers who don't yet have access to such tools to solve the rest of the problem.
And when prosaic alignment methods look to be mostly solving the easy part of the problem, the standard modesty pronouncements about how these methods don't directly apply to the hardest lethal part of the problem can be both earnestly acknowledged and fail to help at all, because it's not seen as a relevant part of the problem to work on in the current regime. So if pretraining/RLVR/RLHF seems to be working, concluding that we are probably fine until RSI or superintelligence is tantamount to concluding that we are probably fine overall (within this framing around scalable oversight).
Thus noticing a major difficulty with the middle part of the problem becomes a crux for expectations about AI danger overall, even for some people who already acknowledge the difficulty of the hardest part of the problem.
2
Ok. If I'm following, I think I agree, except that I'd probably say "you mostly need to solve [what I'm calling the hard parts] in order to solve intermediate alignment well enough for pre-strong AIs to be the engines of alignment progress". So either I'm wrong about what the hard parts are, or you actually need to solve the hard parts to get scalable oversight (and therefore it doesn't really help much).
It's unclear if Mythos is much more impactful for cybersecurity overall than a new fuzzing or static analysis tool. Such tools always find a lot of previously unknown bugs and vulnerabilities if they use a new method, even an absurdly simple method, or merely a slightly unusual method (which would happen to some extent for most major version updates of the tool). There is a lot of code in the world to find bugs in, and the bugs that only the new tool finds in the latest version of the code will be the bugs that were never fixed before. The unusual thing about Mythos is automation of exploitation or fixing of some of the bugs, which in particular automates high confidence estimation of correctness and severity of some of the issues.
On the other hand, if Mythos is indeed a 10T+ total param model, it will only be efficient to serve on TPUv7 [1] , which might only become available to Anthropic in sufficient numbers later in the year (they have 1 GW of them scheduled to go online in 2026). Serving Mythos before that happens would make it perhaps at least 2x more expensive than it becomes once TPUv7 are available, if somehow there is enough Trainium 2 Ultra to serve it. Serving...
it will only be efficient to serve on TPUv7
FWIW Mythos Preview is available on Amazon Bedrock and Microsoft Foundry which don't use TPUs (presumably at the same price as the first-party API?).
9
That's not a real price. That's just what they're giving their partners as part of Glasswing, a charitable endeavour to try to stem the worst of the global damage, and is presumably more about encouraging the partners to economize on scarce Mythos tokens by avoiding setting the price to literally $0 (where people would be lazy and wasteful). It may or may not have much of anything to do with a 'real' price (whatever that means in a situation where hardware is so limited and demand so vast for what is an unpriceable ephemerally unique capability/possibility etc).
2
I believe a price that's 5x the price of Opus 4 [1] is likely a real price (if you don't simply mean they could've asked more since other AI companies are lagging behind, and there's a compute shortage). Might even be a bit too high currently, and will very likely be too high in late 2026 (as better systems for inferencing it get online, and OpenAI releases its own Mythos counterpart). Under ideal conditions, when scale-up systems are big enough, the number of total params should barely influence costs of MoE model tokens, if everything else remains the same (the number of active params, memory per token of KV cache).
1. "Claude Mythos Preview will be available to participants at $25/$125 per million input/output tokens". Current API price of Opus 4.6 is $5/$25 for input/output. ↩︎
3
GB300 NVL72 (but not GB200) would probably also do when serving via clouds, there's just not a lot of it yet (when compared to everything else put together). But some GB300 might be available earlier in the clouds than TPUv7 for first-party API, so that's a possibility. Also, the smaller rack-scale servers (GB200 NVL72, Trainium 2 Ultra, maybe there'll be some Trainium 3 NL32x2 soon) won't be 10x worse, just maybe 2x worse (if it's a 10T+ param model deployed in FP8).
8
The bull case here is that "scale LLMs" is turning out to be a way to predictably and consistently produce ever-better tools for discovering exploits, right? Probably with said tools' power scaling exponentially (in some relevant sense), like everything else with LLMs.
That is, Mythos by itself is probably just on the level of a new fuzzing tool, able to let humans find a new reference class of exploits. But then we'd have Mythos 2 three to six months later, etc. Which potentially shifts the cybersecurity world into a new operating regime, even if each individual perturbation is something that already happened before.
Or is there an argument that it would still be on-model for how the cybersecurity world operates? I'm not very familiar.
About 40 GW of first-party compute might be available to an AI company by the end of 2030, enabling pretraining for about 2e29 FP8 FLOPs (using 10 GW). This follows from the data on incremental IT power in 2027-2030 given in a new article by SemiAnalysis, and some guesses about AI company compute share and Feynman performance that I detail below.
The figures the article gives for (what I'm going to assume is) incremental IT power using 800V DC racks and the fraction of their use are 16.5 GW (38%) in 2027, 24.3 GW (60%) in 2028, 34.6 GW (74%) in 2029, and 38.5 GW (78%) in 2030. The complement to these figures (to 100%) is the rest of (I'm assuming) incremental AI datacenter capacity. Together with the complement, it's 43.4 GW in 2027, 40.5 GW in 2028, 46.8 GW in 2029, and 49.4 GW in 2030. This is steady incremental compute of about 45 GW per year over 2027-2030, it's not getting much higher year-over-year.
OpenAI and Anthropic will each have 2-4 GW of compute at the end of 2026, and about 10 GW by the end of 2027, meaning 6-8 GW of incremental compute in 2027. This is about 16% of the above estimate for the total incremental compute [1] . Maybe this fraction steadily increas...
2
This
[...]
feels like a type error to me, which probably means I'm missing something.
A gigawatt is a measure of the rate at which you can get/use energy, but a FLOP here is a measure of the total amount of computation done. Is there an assumption about how long a pretraining run is allowed to take? Or perhaps not an assumption about that as such but an assumption that everyone always uses about the same amount of time for their pretraining runs, so that the ratio between compute-per-unit-time available and amount-of-computation-done-for-a-run is fixed?
(My guess is the latter, but not very confidently.)
5
See footnote 2 (the assumed pretraining time is 3 months). Some sort of assumption is necessary to talk about the size of pretraining runs at all. Pretraining can take longer in principle, but things go wrong (so it's important to have enough time for another attempt), and it's not yet a settled manufacturing procedure when new levels of scale get attempted for the first time, using new hardware and new low-level code. In 2035 there might be pretraining runs that take a year, but right now the largest pretraining runs probably take even less than 3 months.
3
Aha. I had missed that footnote; my apologies.
Strong test-time learning seems to be both an AGI crux and makes open weight models highly capable in arbitrary domains. Narrow capabilities developed post-deployment, at costs comparable to inference when working on corresponding narrow tasks, make the pre-deployment level of capabilities less important. For AGI-level adaptation, this should extend to capabilities such as playing chess, designing biological gadgets, or becoming fluent in a novel area of math, all at least at the level of the most proficient humans, even if the pre-deployment version of the model couldn't do those things at all.
If this is an algorithmic innovation, the destabilizing AGI threshold that makes true RSI feasible is crossed precisely when open weight models can also cross it, regardless of which capabilities are available in them pre-deployment, or what guardrails govern the closed models. This doesn't happen only if strong post-deployment adaptation requires some very compute-intensive pre-deployment step similar to pretraining or RLVR on a broad range of tasks, and it wasn't applied to any open weight models available at the time, before the world wakes up to the implications of strong post-deployment adaptation.
When people are skeptical about the concept of AGI being meaningful or having clear boundaries, it could sometimes be downstream of skepticism about very fast and impactful R&D done by AIs, such as software-only singularity or things like macroscopic biotech where compute buildout happens at a speed impossible for human industry. Such events are needed to serve as landmarks, anchoring a clear concept of AGI, otherwise the definition remains contentious.
So AI company CEOs who complain about AGI being too nebulous to define might already be expecting a scaling slowdown, with their strategy being primarily about the fight for the soul of the 2028-2030 market. When scaling is slow, it'll become too difficult to gain a significant quality advantage sufficient to defeat the incumbents. So the decisive battle is happening now, with the rhetoric making it more palatable to push through the decisions to build the $140bn training systems of 2028.
This behavior doesn't need to be at all related to expecting superintelligence, it makes sense as a consequence of not expecting superintelligence in the near future.
2
As someone who thinks superintelligence could come in the near future, I basically agree with @snewman's view that AIs have to automate the entire economy, or automate a sector that could then automate everything else very fast, but unfortunately for us this basically gives us no good fire alarms for AGI unless @Ege Erdil and @Matthew Barnett et al are right that takeoff is slow enough that most value comes from broad automation, and external use dominates internal use:
https://amistrongeryet.substack.com/p/defining-agi
1
I think short timelines just don’t square with the way intelligence agencies are behaving. The NSA took Y2K more seriously than it currently seems to be taking near-term AGI. You can make the argument that intelligence agencies are less competent than they used to be, but I don’t buy that they aren’t at least extremely paranoid and moderately competent: that seems like their job.
9
Researchers at AGI labs seem to genuinely believe the hype they're selling, a significant fraction of non-affiliated top-of-the-line DL researchers is inclined to believe them as well, and basically all competent well-informed people agree that the short-timelines position is not unreasonable to hold.
Dismissing short timelines based on NSA's behavior requires assuming that they're much more competent in the field of AI than everyone in the above list. After all, that'd require them to be strongly (and correctly) confident that all these superstar researchers above are incorrect.
While that's not impossible, it seems highly unlikely to me. Much more likely that they're significantly less competent, and accordingly dismissive.
3
This is a late reply, but at least from this article, it seems like Ilya Sutskever was running out of confidence that OpenAI would reach AGI by mid 2023. Additionally, if the rumors about GPT-5 are true, it's mainly going to be a unification of existing models rather than something entirely new. Combined with the GPT-4.5 release, it sure seems like progress at OpenAI is slowing down rather than speeding up.
How do you know that researchers at AGI labs genuinely believe what they're saying? Couldn't the companies just put pressure on them to act like they believe Transformative AI is imminent? I just don't buy that these agencies are dismissive without good reason. They've explored remote viewing and other ideas that are almost certainly bullshit. If they are willing to consider those possibilities, I don't know why they wouldn't consider the possibility of current deep learning techniques creating a national security threat. That seems like their job, and they've explored significantly weirder ideas.
5
On what possible publicly-unavailable evidence could they have updated in order to correctly attain such a high degree of dismissiveness?
I could think of three types of evidence:
* Strong theoretical reasons.
* E. g., some sort of classified, highly advanced, highly empirically supported theory of deep learning/intelligence/agency, such that you can run a bunch of precise experiments, or do a bunch of math derivations, and definitively conclude that DL/LLMs don't scale to AGI.
* Empirical tests.
* E. g., perhaps the deep state secretly has 100x the compute of AGI labs, and they already ran the pretraining game to GPT-6 and been disappointed by the results.
* Overriding expert opinions.
* E. g., a large number of world-class best-of-the-best AI scientists with an impeccable track record firmly and unanimously saying that LLMs don't scale to AGI. This requires either a "shadow industry" of AI experts working for the government, or for the AI-expert public speakers to be on the deep state's payroll and lying in public about their uncertainty.
I mean, I guess it's possible that what we see of the AI industry is just the tip of the iceberg and the government has classified research projects that are a decade ahead of the public state of knowledge. But I find this rather unlikely.
And unless we do postulate that, I don't see any possible valid pathway by which they could've attained high certainty regarding the current paradigm not working out.
[...]
There are two ways we can update on it:
1. The fact that they investigated psychic phenomena means they're willing to explore a wide variety of ambitious ideas, regardless of their weirdness – and therefore we should expect them not do dismiss the AGI Risk out of hand.
2. The fact that they investigated psychic phenomena means they have a pretty bad grip on reality – and therefore we should not expect them to get the AGI Risk right.
I never looked into it enough to know which interpretation is the corre
3
Those are good points. The last thing i'll say drastically reduces the amount of competence required by the government in order for them to be dismissive while still being rational, and it is that the leading AI labs may already be fairly confident that the current techniques of deep-learning won't get to AGI in the near-future, so the security agencies know this as well.
4
That would make sense. But I doubt all AGI companies are that good at informational security and deception. This would require all of {OpenAI, Anthropic, DeepMind, Meta, xAI} to decide on the deceptive narrative, and then not fail to keep up the charade, which would require both sending the right public messages and synchronizing their research publications such that the set of paradigm-damning ones isn't public.
In addition, how do we explain people who quit AGI companies and remain with short timelines?
3
I guess I would respond to the first point by saying all of the companies you mentioned have incentive to say they are closing in on AGI even if they aren’t. It doesn’t seem that sophisticated to say “we’re close to AGI” when you’re not. Mark Zuckerberg said that AI would be at the level of a junior SWE this year, and Meta proceeded to release Llama 4. Unless prognosticators at Meta seriously fucked up, the most likely scenario is that Zuckerberg made that comment knowing it was bullshit. And the sharing of research did slow down a lot in 2023, which gave companies cover to not release unflattering results.
And to your last point, it seems reasonable that companies could pressure former employees to act as if they believe AGI is imminent. And some researchers may be emotionally invested in believing that what they worked on is what will lead to superintelligence.
And my question for you is: if DeepMind had solid evidence that AGI would be here in 1 year, and if the security agencies had access to DeepMind’s evidence and reasoning, do you believe they would still do nothing?
Dario Amodei suggests that in-context learning might suffice for continual learning. The way LLMs do in-context learning with long context is disanalogous to anything humans can do, but a context window of 15M tokens is 500 days of 30K tokens per day, which is more than enough to progress from "first day on the job" to knowing what you are doing with this particular source of tasks. Needs to work mostly with text (if it works at all), or 15M tokens won't be enough, but that could be sufficient.
So this might just be about moving from RAG to including more free-form observations that were historically made by the model itself for the same source of tasks, with massively more tokens of context, and the current memory features of chatbots in the form of long text files might with sufficient scale become the real thing, rather than remaining a dead-end crutch, once these text files get into the habit of accumulating megabytes of observations. And RLVR can plausibly teach the models how to make a good use of these very long contexts.
With this year's 14 TB of HBM per GB200 NVL72, very long context windows become more feasible (than with ~1 TB of HBM per node that most current models are still running on), and then there's the next step in 2028 with Rubin Ultra NVL576 systems that have 147 TB of HBM.
6
Unless I'm totally off-base here, 15M sounds incredibly high for actually useful recall.
This is the best source I know about for measuring model context length.
Obviously I don't know about private models, but based on the delta between claimed vs. actual, I'm pretty suspicious that actually useful context length is currently longer than a few hundred thousand tokens.
2
Not currently, but this is some kind of brute force scaling roadmap for one of the major remaining unhobblings, so it has timeline implications. On last year's hardware, it's not really feasible to go that far anyway, and RLVR is only just waking up. So the first public observations of negative results on this will probably be in 2026, if the actually useful context length fails to improve. And then there's 2028-2029, following up on the 147 TB of Rubin Ultra NVL576 (Nvidia roadmap places it in 2027, which means in 2028 there will be datacenters with it, as well as possibly models trained for it using older hardware, then in 2029 models trained on it).
But also, for the purpose of automated adaptation to a source of tasks and feedback (such as a job), it doesn't necessarily need as much fidelity, it only needs to work as well as a human reading some book a year ago, retaining the mental skills but not the words. A context in principle gives the words, but that is not the thing that needs to work.
1
I supposed I'm unsure how fast this can be scaled. Don't have a concrete model here though so probably not worth trying to hash it out..
[...]
I'm not sure that the current summarization/searching approach is actually analogous to this. That said,
[...]
This is probably making approaches more analogous. So fair point.
I would like to see the updated Ruler metrics in 2026.
Any specific predictions you have on what a negative v. positive result would be in 2026?
2
There is a paper that shows the overreliance of in-context learning on superficial clues. it is from 2022, and the tested models are old. So, maybe newer ones are doing much better,but maybe it is not really learning, at least by some definitions.
Jack Clark's post on RSI essentially considers two claims: (1) routine AI R&D gets automated, and (2) AIs become capable of coming up with substantial new ideas for AI R&D. He cites evidence about the former, which seems plausibly in reach within a few years, even as soon as 2027-2028. Not seeing concrete signs giving the timing for the latter, he still settles on a guess of 60% by the end of 2028 for when both of these things arrive. I think even both of these things plausibly don't trigger proper RSI, the same way human AI researchers haven't triggered it yet, and the timing for automation of AI R&D in both of these senses doesn't much help with figuring out the timing for proper RSI.
Automated routine AI R&D (whose arrival is more predictable given the capabilities of the current systems and the mundane extrapolations of the trends) is not proper RSI on its own, it's more of a build system that automatically produces an AI ready for deployment using the current standard practices of the AI project (this includes finding/creating/preparing the training data). It makes the process faster and more convenient, but doesn't keep substantially improving the quality of th...
Long reasoning with MoE models doesn't get cheaper with overtraining, and pretraining data scarcity might make it useful to have even more active params than compute optimal.
Overtraining (less active params than compute optimal) is useful for processing input tokens, but reasoning models want to generate so many output tokens that cheapness of input tokens plausibly becomes relatively unimportant for some use cases. Performance for output tokens depends on total params and KV cache per token, you want total params and hundreds of KV cache contexts to fit in a few nodes (servers, scale-up worlds). Until recently, an 8-chip node of H100/H200/B200 only had 0.7-1.4 TB of HBM, which means that it was manageable to generate output tokens for models with maybe 1-2T total params, using 2-4 nodes, as long as KV cache per token was small enough (which depends on the attention mechanism, and indirectly on model dimension, but plausibly only weakly on the number of active params, in terms of compute optimality).
With GB200 NVL72, we get to 13 TB per rack (and then 20 TB for GB300), an increase of 10x, so plausibly models with 10-20T total params become feasible to run long reasoning on (and tra...
Yi-Lightning (01 AI) Chatbot Arena results are suprisingly strong for its price, which puts it at about 10B active parameters[1]. It's above Claude 3.5 Sonnet and GPT-4o in Math, above Gemini 1.5 Pro 002 in English and Hard Prompts (English). It's above all non-frontier models in Coding and Hard Prompts (both with Style Control), including Qwen-2.5-72B (trained on 18T tokens). Interesting if this is mostly a better methodology or compute scaling getting taken more seriously for a tiny model.
The developer's site says it's a MoE model. Developer's API docs list it at ¥0.99/1M tokens. The currency must be Renminbi, so that's about $0.14. Together serves Llama-3-8B for $0.10-0.18 (per million tokens), Qwen-2.5-7B for $0.30, all MoE models up to 56B total (not active) parameters for $0.60. (The prices for open weights models won't have significant margins, and model size is known, unlike with lightweight closed models.) ↩︎
4
Kai-Fu Lee, CEO of 01 AI, posted on LinkedIn:
[...]
Assuming it's trained in BF16 with 40% compute utilization, that's a 2e24 FLOPs model (Llama-3-70B is about 6e24 FLOPs, but it's not MoE, so the FLOPs are not used as well). Assuming from per token price that it has 10-20B active parameters, it's trained on 15-30T tokens. So not an exercise in extreme compute scaling, just excellent execution.
Superintelligence that both lets humans survive (or revives cryonauts) and doesn't enable indefinite lifespans is a very contrived package. Grading "doom" on concerns centrally about the first decades to centuries of post-AGI future (value/culture drift, successors, the next few generations of humanity) is not taking into account that the next billions+ years is also what could happen to you or people you know personally, if there is a future for originally-humans at all.
(This is analogous to the "missing mood" of not taking superintelligence into account ...
0
I don't disagree, but I think we might not agree on the reason. Superintelligence that lets humanity survive (with enough power/value to last for more than a few thousand years, whether or not individuals extend beyond 150 or so years) is pretty contrived.
There's just no reason to keep significant amounts of biological sub-intelligence around.
Inability of self-building LLMs to quickly learn deep skills makes LLM attitudes developed in character training more important. Caution about ASI danger is instrumentally convergent, so sufficiently smart AGIs could be expected to insist on figuring out ambitious alignment [1] before allowing ASI. But if LLMs plateau near the human level, with prosaic RSI of self-building LLMs being the main thing that makes general learning and broad automation possible, then there is no direct and gradual route from LLMs to a takeoff and ASI. A breakthrough t...
If automated learning of deep skills is a crux for AGI, then automating AI R&D becomes more relevant in the sense of routine application of the current methods. Routine AI R&D is then a milestone on the way to AGI, while frontier AI R&D is merely an indicator that AGI has been achieved, not relevant to AGI timelines. This milestone plausibly doesn't need any new breakthroughs or even significant scaling.
The distinction between the capability for carrying out tasks and the depth of skills that can be learned thus becomes the distinction between ...
Suppose you have a lot of compute, but 25x less unique data than would be compute optimal to use in pretraining. A May 2026 paper takes some measurements suggesting that the best loss is achieved by using a 5x bigger model (than would be compute optimal) and training it for 5 epochs of repeated data (see Figure 5, left and Table 2).
The measurements are taken at around 1e19 FLOPs of compute, so that's not very convincing about what happens around the more relevant 5e29 FLOPs. But training with repetition for about 5 epochs is a familiar anchor when the data...
1
Where does one get ~90T of non-useless text tokens?
Cultural/moral maturity (in a civilization) has never been observed before, similarly to technological maturity. Scalable production of a new kind of thing brings its abundance in sight, which fails to be a concern earlier, while it couldn't be scaled. A moderate level of AI alignment or of cultural change is not an equilibrium if these things are anchored to scalable resources (effective cognition and coordination, fast subjective serial time). Instead they reach extremes of the kind never observed before those resources become scalable.
2
Are you trying to say that for any X, instead of X-maturity, we should instead expect X-foom until the marginal returns get too low?
2
A pre-abundance precedent about X offers poor framing for thinking about the consequences of discovering a scalable process of producing X. Before abundance, it's artisanal and quirky and path-dependent, the extremes are rare and dysfunctional, so people don't worry about it too much. There is security in it looking like an equilibrium, but not being truly settled, so that people can influence things.
Abundance brings maturity, changes the character of the equilibrium. So not foom necessarily, just a promise of maturity at some point, which wouldn't have been as salient before there is a scalable process of production. And there is an excuse of ignoring the possibility even longer, because of the total lack of historical precedent (of the associated problems).
1
i’d be interested in hearing why you think that cultural/moral/technological/mathematical maturity is even possible or eventually likely (as opposed to one just being immature forever[1]) (assuming you indeed do think that)
----------------------------------------
1. which seems more likely to me ↩︎
2
I mean "maturity" merely compared to how we view what can currently be happening, such as a baseline level of competence in civilization-level governance, or what the individual people are capable of. Maturity compared to that baseline washes away all the currently relevant fiddly things, replacing them by settled processes.
These new processes are truly settled, so whatever new concerns become important then, the new baseline won't be overturned. The analogy with technological maturity is that the laws of physics and ways of getting things done within them is a fixed problem statement, so new baselines of effectiveness get locked in.
Agentic RLVR targeting ability of AI to apply RLVR (or more lightweight finetuning) to itself when appropriate (using something like OpenAI's RL API) potentially gives ARA capabilities and substitutes for more innate hypothetical ways of doing online/continual learning or undergoing on-boarding[1]. Thus ability of AI to "do AI research" is not primarily about RSI or increasing productivity of AI researchers, it's about removing the last important hobble on LLMs that currently causes unrecoverable inability (for a given AI) to do some simple things or truly...
1
Do you have specific predictions/intuitions regarding the feasibility of what you describe and how strong the feedback loop could be?
Your post being about technical AI R&D automation capabilities kind of immediately made me curious about the timelines, since they're where I'm somewhat worried.
Also, would Sakana AI's recent work on adaptative text-to-LORA systems count towards what you're describing^
Continual learning as some sort of infinite context with little degradation in quality is very different from solving the "first day on the job" problem. I think the latter would need RL targeted at obscure things a given agent instance deals with, while the former is more likely to arrive in 2026-2027. If this is the case, even revenue growth from "continual learning" (in this initial form) might be modest, let alone its impact on the AGI timelines.
And then the next thing might be more general RL at training time (with something like next word prediction ...
2
Another issue with continual learning is that it likely doesn't have the efficiency of today's cloud-based LLMs:
[...]
2
Many ideas in the vicinity of continual learning by design don't involve full fine-tuning where every weight of the model changes, and those that do could probably still be made almost as capable with LoRA. Given the practical importance of only updating maybe 100x fewer parameters than the full model (or less) to keep batched processing of user requests working the same as with KV-cache, I think the first methods dubbed "continual learning" will be doing exactly this.
Maybe at some point there will be an "agent swarm" use case where all the requests in a batch are working on the same problem for the same user, and so their full model can keep being updated in sync for that single problem. But this seems sufficiently niche that it's not the first thing that gets deployed, and the method for continual learning needs to involve full weights updating at all for this to be relevant.
Economics studies the scaling laws of systems of human industry. LLMs and multicellular organisms and tokamaks have their own scaling laws, the constraints ensuring optimality of their scaling don't transfer between these very different machines. A better design doesn't just choose more optimal hyperparameters or introduce scaling multipliers, it can occasionally create a new thing acting on different inputs and outputs, scaling in its own way, barely noticing what holds back the other things.
A reflectively stable agent prefers to preserve some property of itself. This doesn't in general prevent it from being able to self-improve, in the same way that unchanging laws of physics don't prevent presence of self-improving agents in the world.
The content of the world keeps changing under the unchanging laws of how it changes, and similarly a reflectively stable agent (against safety properties) has content (such as beliefs) that keeps changing, in principle enabling unfettered self-improvement. Mesa-agents existing in the form of the content of the ...
1
Are there pivotal ways this is different to the theories of Enactivism?
(" Its authors define cognition as enaction, which they in turn characterize as the ‘bringing forth’ of domains of significance through organismic activity that has been itself conditioned by a history of interactions between an organism and its environment." which at first blush I'd say is a reflectively stable agent modifying or updating believes by means of enaction. Enactivism also rejects mind-body duality in favour of a more 'embodied' cognition approach together with a "deep continuity of the principles of self-organization from the simplest living things to more complex cognitive beings"), particularly autopoeisis.
[...]
An autopoietic system can be contrasted to an allopoetic system which creates objects different to itself, like a factory. Most living beings are autopoetic in that they either produce themselves, or things like them which seems to be similar to a reflectively stable agent, particularly when we describe the more complicated cognitive beings in autopoetic terms. Luhman argued that social systems too are self-organizing, self-reproducing systems which brought the concepts of enactivism from biology and cognitive science into the social sciences.
Suppose you find "57+72=" already written. Do you write down "130" because you are slightly off-target relative to the goal of computing 57+72? Do you write down "129" because it's what follows by the nature of what's already written? Do you notice it's made out of digits you can use for something else, such as "25+77="?
I think the case for writing down "130" because of misalignment-in-detail is the weakest. Also, even a superintelligence can't help 57+72 decide it would be heading for 129, or make 57+72's efforts irrelevant, as 129 still follows entirely ...
1
"Slightly off-target for X" is a more complex goal than just "X". But if X is in the training data, then just repeating X isn't contributing any originality — but playing a variation on the theme of X might be. Sometimes the right answer is to follow X broadly, while also keeping a specified distance; see boids.