I feel like this result should have rung significant alarm bells. Bayes theorem is not a rule someone has come up with that has empirically worked out well. It's a theorem. It just tells you a true equation by which to compute probabilities. Maybe if we include limits of probability (logical uncertainty/infinities/anthropics) there would be room for error, but the setting you have here doesn't include any of these. So Bayesians can't commit a fallacy. There is either an error in your reasoning, or you've found an inconsistency in ZFC.
So where's the mistake? Well, as far as I've understood (and I might be wrong), all you've shown is that if we restrict ourselves to three priors (uniform, streaky, switchy) and observe a distribution that's uniform, then we'll accumulate evidence against streaky more quickly than against switchy. Which is a cool result since the two do appear symmetrical, as you said. But it's not a fallacy. If we set up a game where we randomize (uniform, streaky, switchy) with 1/3 probability each (so that the priors are justified), then generate a sequence, and then make people assign probabilities to the three options after seeing 10 samples, then the Bayesians are going to play precisely optimally here. It just happens to be the case that, whenever steady is randomized, the probability for streaky goes down more quickly than that for switchy. So what? Where's the fallacy?
First upshot: whenever she’s more confident of Switchy than Sticky, this weighted average will put more weight on the Switchy (50-c%) term than the Sticky (50+c%) term. This will her to be less than 50%-confident the streak will continue—i.e. will lead her to commit the gambler’s fallacy.
In other words, if a Bayesian agent has a prior across three distributions, then their probability estimate for the next sampled element will be systematically off if only the first distribution is used. This is not a fallacy; it happens because you've given the agent the wrong prior! You made her equally uncertain between three hypotheses and then assumed that only one of them is true.
And yeah, there are probably fewer than sticky and streaky distributions each other there, so the prior is probably wrong. But this isn't the Bayesian's fault. The fair way to set up the game would be to randomize which distribution is shown first, which again would lead to optimal predictions.
I don't want to be too negative since it is still a cool result, but it's just not a fallacy.
Baylee is a rational Bayesian. As I’ll show: when either data or memory are limited, Bayesians who begin with causal uncertainty about an (in fact independent) process—and then learn from unbiased data—will, on average, commit the gambler’s fallacy.
Same as above. I mean the data isn't "unbiased", it's uniform, which means it is very much biased relative to the prior that you've given the agent.
I have the impression the OP is using "gambler's fallacy" as a conventional term for a strategy, while you are taking "fallacy" to mean "something's wrong". The OP does write about this contrast, e.g., in the conclusion:
Maybe the gambler’s fallacy doesn’t reveal statistical incompetence at all. After all, it’s exactly what we’d expect from a rational sensitivity to both causal uncertainty and subtle statistical cues.
So I think the adversative backbone of your comment is misdirected.
I agree with that characterization, but I think it's still warranted to make the argument because (a) OP isn't exactly clear about it, and (b) saying "maybe the title of my post isn't exactly true" near the end doesn't remove the impact of the title. I mean this isn't some kind of exotic effect; it's the most central way in which people come to believe silly things about science: someone writes about a study in a way that's maybe sort of true but misleading, and people come away believing something false. Even on LW, the number of people who read just the headline and fill in the rest is probably larger than the number of people who read the post.
I strong downvote any post in which the title is significantly more clickbaity than warranted by the evidence in the post. Including this one.
This seems like a difficult situation because they need to refer to the particular way-of-betting that they are talking about, and the common name for that way-of-betting is "the gambler's fallacy", and so they can't avoid the implication that this way-of-betting is based on fallacious reasoning except by identifying the way-of-betting in some less-recognizable way, which trades off against other principles of good communication.
I suppose they could insert the phrase "so-called". i.e. "Bayesians commit the so-called Gambler's Fallacy". (That still funges against the virtue of brevity, though not exorbitantly.)
What would you have titled this result?
What would you have titled this result?
With ~2 min of thought, "Uniform distributions provide asymmetrical evidence against switchy and streaky priors"
But the point of the post is to use that as a simplified model of a more general phenomenon, that should cling to your notions connected to "gambler's fallacy".
A title like yours is more technically defensible and closer to the math, but it renounces an important part. The bolder claim is actually there and intentional.
It reminds me of a lot of academic papers where it's very difficult to see what all that math is there for.
To be clear, I second making the title less confident. I think your suggestion exceeds in the other direction. It omits content.
Are "switchy" and "streaky" accepted terms-of-art? I wasn't previously familiar with them and my attempts to Google them mostly lead back to this exact paper, which makes me think this paper probably coined them.
Yeah, I definitely did not think they're standard terms, but they're pretty expressive. I mean, you can use terms-that-you-define-in-the-post in the title.
I see the point, though I don't see why we should be too worried about the semantics here. As someone mentioned below, I think the "gambler's fallacy" is a folk term for a pattern of beliefs, and the claim is that Bayesians (with reasonable priors) exhibit the same pattern of beliefs. Some relevant discussion in the full paper (p. 3), which I (perhaps misguidedly) cut for the sake of brevity:

First, thanks for this comment - I thought the original post was interesting, but also figured there was probably a mistake in reasoning happening somewhere.
However...
"This is not a fallacy; it happens because you've given the agent the wrong prior!"
This begs the question of how to develop priors. I thought the benefit of Bayes is that it can converge on the best probabilities no matter your starting point, when you've been presented enough evidence, so long as you don't assign anything a 0% or 100% prior.
Like, in real life, people who understand math can understand coin flips and gambling and independent events well enough to understand the gambler's fallacy, and assigning a prior of 1/3 to Switchy or Sticky would be ridiculous. But what about other areas of life? For instance, you could be playing a videogame and you don't know whether an enemy boss was programmed to cycle between both of its possible attacks randomly, or if it was programmed to be Switchy or Sticky. Then I think the "fallacy" presented by the OP would apply, wouldn't it?
This begs the question of how to develop priors. I thought the benefit of Bayes is that it can converge on the best probabilities no matter your starting point, when you've been presented enough evidence, so long as you don't assign anything a 0% or 100% prior.
This is true, and this still happens, the post didn't say anything about convergence in the limit
This begs the question of how to develop priors.
For instance, you could be playing a videogame and you don't know whether an enemy boss was programmed to cycle between both of its possible attacks randomly, or if it was programmed to be Switchy or Sticky. Then I think the "fallacy" presented by the OP would apply, wouldn't it?
So two things about this
- there is a theoretical answer on the priors problem, though it's computationally intractable. It's a huge rabbit hole, if you want to go down
- (nice example!) the real answer here is that you don't start accumulating evidence with the first boss hit, but well before that. Lots of things in the world give you information about how real people will most likely have programmed a boss in this case. Or more practically relevant, you'd consider your prior knowledge to affect your choice of the prior in this case. Pretty sure sticky here is pretty unlikely, and it's either switchy or randomly.
"The gambler's fallacy" refers to the situation where successive outcomes are known to be independent (i.e. known to be Steady, and neither Switchy nor Streaky), and yet the gambler acts according to Switchiness anyway. The gambler in that situation is wrong and the Bayesian will not commit that error.
When Switchiness and Streakiness are open possibilities, then of course the evidence so far may favour either of them; but if evidence accumulates for either of them it is no longer an error to favour it.
Would it have helped if I added the attached paragraphs (in the paper, page 3, cut for brevity)?

Frame the conclusion as a disjunction: "either we construe 'gambler's fallacy' narrowly (as by definition irrational) or broadly (as used in the blog post, for expecting switches). If the former, we have little evidence that real people commit the gambler's fallacy. If the latter, then the gambler's fallacy is not a fallacy."
This seems to be an argument against the very idea of an error. How can people possibly make errors of reasoning? If the gambler knows the die rolls are independent, how could they believe in streaks? How could someone who knows the spelling of a word possibly mistype it? There seems to be a presumption of logical omniscience and consistency.
I am not sure that is right. A very large percentage of people really don't think the rolls are independent. Have you ever met anyone who believed in fate, Karma, horoscopes , lucky objects or prayer? They don't think its (fully) random and independent. I think the majority of the human population believe in one or more of those things.
If someone spells a word wrong in a spelling test, then its possible they mistyped, but if its a word most people can't spell correctly then the hypothesis "they don't know the spelling' should dominate. Similarly, I think it is fair to say that a very large fraction of humans (over 50%?) don't actually think dice rolls or coin tosses are independent and random.
I am not sure that is right. A very large percentage of people really don't think the rolls are independent. Have you ever met anyone who believed in fate, Karma, horoscopes , lucky objects or prayer? They don't think its (fully) random and independent. I think the majority of the human population believe in one or more of those things.
They may well do. But they are wrong.
I agree with @James Camacho, at least intuitively, that stickiness in the space of observations is equivalent to switchiness in the space of their prefix XORs and vice versa. Also, I tried to replicate, and didn't observe the mentioned effect, so maybe one of us has a bug in the simulation.
Mathematica notebook is here! Link in the full paper.
How did you define Switchy and Sticky? It needs to be >= 2-steps, i.e. the following matrices won't exhibit the effect. So it won't appear if they are eg
Switchy = (0.4, 0.6; 0.6, 0.4)
Sticky = (0.6,0.4; 0.4,0.6)
But it WILL appear if they build up to (say) 60%-shiftiness over two steps. Eg:
Switchy = (0.4, 0 ,0.6, 0; 0.45, 0, 0.55, 0; 0, 0.55, 0, 0.45, 0, 0.6, 0, 0.4)
Sticky = (0.6, 0 ,0.4, 0; 0.55, 0, 0.45, 0; 0, 0.45, 0, 0.55, 0, 0.4, 0, 0.6)
Have you looked at other ways of setting up the prior to see if this result still holds? I'm worried that they way you've set up the prior is not very natural, especially if (as it looks at first glance) the Stable scenario forces p(Heads) = 0.5 and the other scenarios force p(Heads|Heads) + p(Heads|Tails) = 1. Seems weird to exclude "this coin is Headsy" from the hypothesis space while including "This coin is Switchy".
Thinking about what seems most natural for setting up the prior: the simplest scenario is where flips are serially independent. You only need one number to characterize a hypothesis in that space, p(Heads). So you can have some prior on this hypothesis space (serial independent flips), and some prior on p(Heads) for hypotheses within this space. Presumably that prior should be centered at 0.5 and symmetric. There's some choice about how spread out vs. concentrated to make it, but if it just puts all the probability mass at 0.5 that seems too simple.
The next simplest hypothesis space is where there is serial dependence that only depends on the most recent flip. You need two numbers to characterize a hypothesis in this space, which could be p(Heads|Heads) and p(Heads|Tails). I guess it's simplest for those to be independent in your prior, so that (conditional on there being serial dependence), getting info about p(Heads|Heads) doesn't tell you anything about p(Heads|Tails). In other words, you can simplify this two dimensional joint distribution to two independent one-dimensional distributions. (Though in real-world scenarios my guess is that these are positively correlated, e.g. if I learned that p(Prius|Jeep) was high that would probably increase my estimate of p(Prius|Prius), even assuming that there is some serial dependence.) For simplicity you could just give these the same prior distribution as p(Heads) in the serial independence case.
I think that's a rich enough hypothesis space to run the numbers on. In this setup, Sticky hypotheses are those where p(Heads|Heads)>p(Heads|Tails), Switchy are the reverse, Headsy are where p(Heads|Heads)+p(Heads|Tails)>1, Tails are the reverse, and Stable are where p(Heads|Heads)=p(Heads|Tails) and get a bunch of extra weight in the prior because they're the only ones in the serial independent space of hypotheses.
See the discussion in §6 of the paper. There are too many variations to run, but it at least shows that the result doesn't depend on knowing the long-run frequency is 50%; if we're uncertain about both the long-run hit rate and about the degree of shiftiness (or whether it's shifty at all), the results still hold.
Does that help?
If I'm understanding the paper correctly -- and I've only looked at it very briefly so there's an excellent chance I haven't -- there's an important asymmetry here which is worth drawing attention to.
The paper is concerned with two quite specific "Sticky" and "Switchy" models. They look, from glancing at the transition probability matrices, as if there's a symmetry between sticking and switching that interchanges the models -- but there isn't.
The state spaces of the two models are defined by "length of recent streak", and this notion is not invariant under e.g. the prefix-XOR operation mentioned by James Camacho.
What does coincidental evidence for Sticky look like? Well, e.g., 1/8 of the time we will begin with HHHH or TTTT. The Sticky:Switchy likelihood ratio for this, in the "5-step 90%" model whose matrices are given in the OP, is 1 (first coin) times . 58/.42 (second coin) times .66/.34 (third coin) times .74/.26 (fourth coin), as the streak builds up.
What does coincidental evidence for Switchy look like? Well, the switchiest behaviour we can see would be HTHT or THTH. In this case we get a likelihood ratio of 1 (first coin) times .58/.42 (second coin) times .58/.42 (third coin) times .58/.42 (third coin), which is much smaller.
It's hard to get strong evidence for Switchy over Sticky, because a particular result can only be really strong if it was preceded by a long run of sticking, which itself will have been evidence for Sticky.
This seems like a pretty satisfactory explanation for why this set of models produces the results described in the paper. (I see that Mlxa says they tried to reproduce those results and failed, but I'll assume for the moment that the correct results are as described. I wonder whether perhaps Mlxa made a model that doesn't have the multi-step streak-dependence of the model in the paper.)
What's not so obvious to me is whether this explanation makes it any less true, or any less interesting if true, that "Bayesians commit the gambler's fallacy". It seems like the bias reported here is a consequence of choosing these particular "sticky" and "switchy" hypotheses, and I can't quite figure out whether a better moral would be "Bayesians who are only going to consider one hypothesis of each type should pick different ones from these", or whether actually this sort of "depends on length of latest streak, but not e.g. on length of latest alternating run" hypothesis is an entirely natural one.
You are smuggling your conclusion in with slight technical choices of switchy vs sticky.
If we make the process markovian, ie the probability of getting heads depends only on if the previous flip was heads, then this disappears.
If we make switchy or sticky strongest after a long sequence of switches, this disappears.
You need to justify why switchy/sticky processes should use these switchy/sticky probabilities.
What would a symmetric prior look like? Is there a simple description, like "symmetric about the number of switches expected per N trials"?
Oh, I see, there's no simple description because the definition of "switchy" vs "sticky" prior hypotheses are actually quite complicated - and if they were much simpler, you wouldn't see this phenomenon at all.
This means the likelihood distribution over data generated by Steady is closer to the distribution generated by Switchy than to the distribution generated by Sticky.
Their KL divergences are exactly the same. Suppose Baylee's observations are . Let be the probability if there's a chance of switching, and similar for . By the chain rule,
In particular, when either or is equal to one half, this divergence is symmetric for the other variable.
Hm, I'm not following your definitions of P and Q. Note that there's no (that I know of) easy closed-form expression for the likelihoods of various sequences for these chains; I had to calculate them using dynamic programming on the Markov chains.
The relevant effect driving it is that the degree of shiftiness (how far it deviates from 50%-heads rate) builds up over a streak, so although in any given case where Switchy and Sticky deviate (say there's a streak of 2, and Switchy has a 30% of continuing while Sticky has a 70% chance), they have the same degree of divergence, Switchy makes it less likely that you'll run into these long streaks of divergences while Sticky makes it extremely likely. Neither Switchy nor Sticky gives a constant rate of switching; it depends on the streak length. (Compare a hypergeometric distribution.)
Take a look at §4 of the paper and the "Limited data (full sequence): asymmetric closeness and convergence" section of the Mathematica Notebook linked from the paper to see how I calculated their KL divergences. Let me know what you think!
There's the automorphism
which turns a switchy distribution into a sticky one, and vice versa. The two have to be symmetric, so your conclusion cannot be correct.
You probably meant prefix sums instead of pairwise sums.
In any case, Bayesian reasoning is not symmetrical with respect to any given automorphism, unless the hypotheses space is.
I don't think this works (or at least I don't understand how). What space are you even mapping here (I think your are samples, so to itself?) and what's the operation on those spaces, and how does that imply the kind of symmetry from the OP?
TLDR: Rational people who start out uncertain about an (in fact independent) causal process and then learn from unbiased data will rule out “streaky” hypotheses more quickly than “switchy” hypotheses. As a result, they’ll commit the gambler’s fallacy: expecting the process to switch more than it will. In fact, they’ll do so in ways that match a variety of empirical findings about how real people commit the gambler’s fallacy. Maybe it’s not a fallacy, after all.
(This post is based on a full paper.)
Baylee is bored. The fluorescent lights hum. The spreadsheets blur. She needs air.
As she steps outside, she sees the Prius nestled happily in the front spot. Three days in a row now—the Prius is on a streak. The Jeep will probably get it tomorrow, she thinks.
This parking battle—between a Prius and a Jeep—has been going on for months. Unbeknownst to Baylee, the outcomes are statistically independent: each day, the Prius and the Jeep have a 50% chance to get the front spot, regardless of how the previous days have gone. But Baylee thinks and acts otherwise: after the Prius has won the spot a few days in a row, she tends to think the Jeep will win next. (And vice versa.)
So Baylee is committing the gambler’s fallacy: the tendency to think that streaks of (in fact independent) outcomes are likely to switch. Maybe you conclude from this—as many psychologists have—that Baylee is bad at statistical reasoning.
You’re wrong.
Baylee is a rational Bayesian. As I’ll show: when either data or memory are limited, Bayesians who begin with causal uncertainty about an (in fact independent) process—and then learn from unbiased data—will, on average, commit the gambler’s fallacy.
Why? Although they’ll get evidence that the process is neither “switchy” nor “streaky”, they’ll get more evidence against the latter. Thus they converge asymmetrically to the truth (of independence), leading them to (on average) commit the gambler’s fallacy along the way.
More is true. Bayesians don’t just commit the gambler’s fallacy—they do so in way that qualitatively matches a wide variety of trends found in the empirical literature on the gambler’s fallacy. This provides evidence for:
This hypothesis stacks up favorably against extant theories of the gambler's fallacy in terms of both explanatory power and empirical coverage. See the paper for the full argument—here I’ll just sketch the idea.
Asymmetric Convergence
Consider any process that can have one of two repeatable outcomes—Prius vs. Jeep; heads vs. tails; hit vs. miss; 1 vs. 0; etc.
Baylee knows that the process (say, the parking battle) is “random” in the sense that (i) it’s hard to predict, and (ii) in the long run, the Prius wins 50% of the time. But that leaves open three classes of hypotheses:
Steady: The outcomes are independent, so each day there’s a 50% chance the Prius wins the spot. (Compare: a fair coin toss.)
Switchy: The outcomes tend to switch: after the Prius wins a few in a row, the Jeep becomes more likely to win; after the Jeep wins a few, vice versa. (Compare: drawing from a deck of cards without replacement—after a few red cards, a black card becomes more likely.)
Sticky: The outcomes tend to form streaks: after the Prius wins a few, it becomes more likely to win again; likewise for the Jeep. (Compare: basketball shots—after a player makes a few, they become “hot” and so are more likely to make the next one. No, the “hot hand” is not a myth.[1])
So long as each of these hypotheses is symmetric around 50%, they all will lead to (i) the process being hard to predict, and (ii) the Prius winning 50% of the time. So suppose Baylee begins unsure whether the parking battle is Switchy, Steady, or Sticky.
Two mathematical observations.
First observation: what Baylee should expect on the next outcome—whether she’ll expect the current streak to switch or continue—will depend on the precise balance of her uncertainty between Switchy, Steady, and Sticky.
For example, suppose she’s seen 3 Prius-days in a row; how confident should she be that this streak will continue? If she knew the process was Switchy, she’d be doubtful (say, 50–c%, for some c). If she knew it were Sticky, she’d be confident (say, 50+c%). If she knew it were Steady, she’d be precisely 50%-confident it’ll continue.
Being unsure, her opinion should[2] be a weighted average of the three, with weights determined by how confident she is of each.
First upshot: whenever she’s more confident of Switchy than Sticky, this weighted average will put more weight on the Switchy (50-c%) term than the Sticky (50+c%) term. This will her to be less than 50%-confident the streak will continue—i.e. will lead her to commit the gambler’s fallacy.
But why would she be more confident of Switchy than Sticky? The situation seems symmetric.
It’s not.
Second observation: the data generated from a Steady process is more similar to the data generated by a Switchy process than to the data generated by a parallel Sticky process. As a result, the (Steady) data Baylee observes will—on average—provide more evidence against Sticky than against Switchy.
Why? Both Switchy and Sticky deviate from Steady in what they make likely, but how much they do so depends on how long the current streak is: after 2 Prius-days in a row, Switchy makes it slightly less than 50% likely to be a Prius, while Sticky makes it slightly more; meanwhile, after 7 Prius-days in a row, Sticky makes it way less than 50%-likely to be a Prius, and Sticky makes it way more.
But notice: Switchy tends to end streaks, while Sticky tends to continue them. In other words: Switchy tends to stop deviating from Steady, while Sticky tends to keep deviating.
This means the likelihood distribution over data generated by Steady is closer to the distribution generated by Switchy than to the distribution generated by Sticky.[3] We can visualize this looking at summary statistics of the sequences they generate—for example, the number of switches (Prius-to-Jeep or Jeep-to-Prius), the average streak-length, or the total number of Priuses. Here they are for sequences of 50 tosses—notice that in each case there’s substantially more overlap between the Steady and Switchy likelihoods than between the Steady and Sticky likelihoods.[4]
So Switchy generates data that is more-similar to Steady than Sticky does.
Why does that matter? Because it means that rational Bayesians observing unbiased data from the true (Steady) distribution will—on average—become doubtful of Sticky far more quickly than they become doubtful of Switchy.
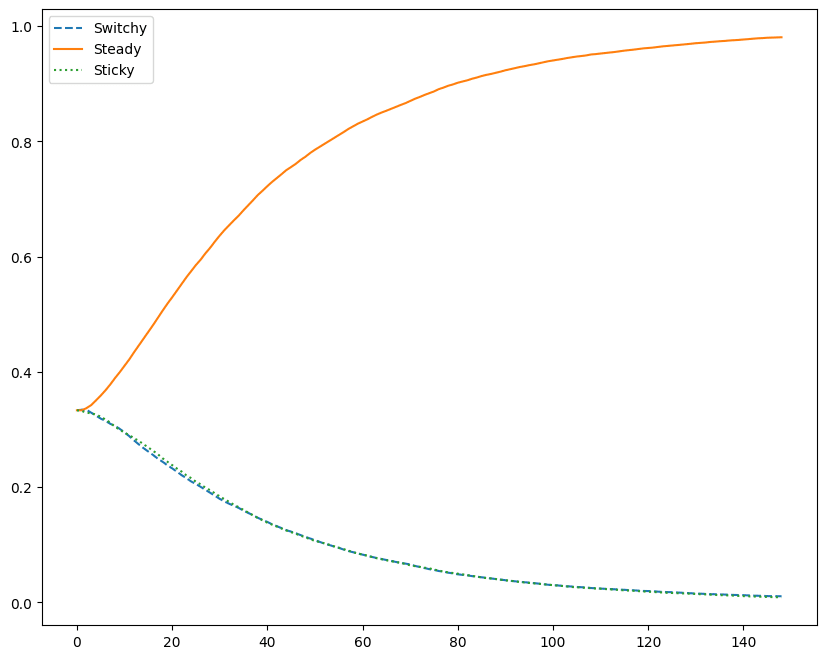
To see this, let’s take a group of Bayesians who start out uniformly unsure between Switchy/Steady/Sticky, and then updating by conditioning on a (different) sequence of n tosses, for various n. Here are their average posterior probabilities in each hypothesis, after observing the sequence:
Second Upshot: their average confidence in Sticky drops more quickly than their average confidence in Switchy.[5]
In other words: although our Bayesians converge to the truth (i.e. to Steady), they do so in an asymmetric way—becoming more confident of Switchy than of Sticky along the way.
Now recall our First Upshot: whenever Bayesians are more confident of Switchy than Sticky, they’ll commit the gambler’s fallacy. Combined with the Second Upshot—that they on average will be more confident of Switchy than Sticky—it follows that, on average, Bayesians will commit the gambler’s fallacy.
Empirical Predictions
Okay. But do they do so in a realistic way?
Yes. I’ll focus on two well-known empirical effects. (The full paper discusses five.)
Nonlinear Expectations
One of the most interesting empirical findings is that as a streak grows in length, people first increasingly exhibit the gambler’s fallacy—expecting the sequence to switch—but then, once the streak grows long enough, they stop expecting a switch and begin (increasingly) expecting the sequence to continue.
For example, here’s a plot showing the nonlinearity finding from two recent studies:
Our Bayesians exhibit nonlinearity as well.
Suppose we first let them update their opinions on Switchy/Steady/Sticky using either limited data (conditioning on a sequence of 50 outcomes, as above), or a simple model of limited memory (see section 4 of the paper for details). Then we show them a new streak and ask them how likely it is to continue.
What happens? They’ll first increasingly expect switches, but then—if the streak continues long enough—increasingly expect continuations:
Why? Due to asymmetric convergence, they start out (on average) more confident of Switchy than Sticky. Because of this, as the streak grows initially, they think the process is increasingly primed to switch. That’s why they exhibit the gambler’s fallacy, initially.
But as the streak continues, the streak itself provides more and more evidence for Sticky—after all, Sticky makes a long streak (which they’ve now seen) more likely than Switchy does. If the streak gets long enough, this provides enough data to swamp their initial preference for Switchy, so they start (increasingly) predicting continuations.
Experience-Dependence
A second finding is that the shape of these nonlinear expectations is experience-dependent. More precisely, two trends:
For example, here are the results for our above two studies when we separate out their experimental conditions by whether the process is familiar (blue)—such as a coin or urn—or unfamiliar (red/purple), such as a firm’s earnings or a stock market.
Notice that (1) their expectations for familiar processes stay closer to 50%, and (2) they take longer before that start expecting continuations (if they ever do).
Our Bayesians exhibit the same patterns. We can simulate this by varying how much data they’ve seen. When they have more data from a processes, they (1) stay closer to 50% in their expectations, and (2) take longer before they begin expecting continuations:
The results are qualitatively similar but more realistic if we consider agents with very (red) or somewhat (blue) limited memory:
Why? If they’re more familiar with a process, they (1) stay closer to 50% because they’re converging toward the truth: as they see more data, they get more confident of Steady, which pulls their expectations toward 50%. And (2) they take longer to begin expecting continuations because as they see more data, their opinions are more resilient: if they’ve seen a lot of data which makes them doubtful of Sticky, it takes a longer streak before the streak itself provides enough data to change this belief.
Other results
The paper considers three other results. Like real people, our Bayesians (i) produce “random” sequences that switch too often, (ii) change what they predict based on how often the sequence leading up to the prediction switched, and (iii) exhibit a form of format-dependence—appearing to exhibit stronger gambler’s-fallacy-effects when asked for binary predictions than when asked for probability estimates.
This is as good empirical coverage as any of the extant theories of the gambler's fallacy (see section 2.1 of the paper).
Moreover, section 6 of the paper also shows that these results are robust to variations in the setup. The same qualitative results emerge even if our Bayesians are unsure about:
…the long-run hit rate (maybe it’s not 50%);
…how much the Switchy/Steady hypotheses deviate from 50% in their likelihoods;
…how these deviations build up as a streak grows;
…how exactly the Switchy/Sticky process shift probabilities over time.
So What?
Upshot: resource-limited Bayesians who are unsure of the causal structure of a process would exhibit many of the empirical trends that constitute our evidence that humans commit the gambler’s fallacy.
What to make of this?
You might think it’s all academic. For although real people exhibit the gambler’s fallacy for causal processes that they are reasonably uncertain about—parking battles, etc.—they also exhibit the gambler’s fallacy for coin tosses. And, you might think, people (should) know that coin tosses are Steady—coins have no memory, after all. So whatever they’re doing must be fallacious. Right?
Not so fast. To know that coin tosses are Steady just is to know that the next toss has a 50% chance of landing heads, regardless of how the previous tosses have gone. People who commit the gambler’s fallacy either don’t have this knowledge, or they don’t bring it to bear on the problem of predicting coin tosses. That requires some sort of explanation.
Here’s a cautious conclusion from our results: perhaps the above Bayesian process explains why. Most random processes—the weather, your mood, the stock market, etc.—are not as causally transparent as a coin. Thus people are (understandably!) in the habit of starting out uncertain, and letting the outcomes of the process shift their beliefs about the underlying causal structure. As we’ve seen, this will lead them to (on average) commit the gambler’s fallacy.
But more radical conclusion is also possible: maybe the gambler’s fallacy is not a fallacy after all.
For even coins are not as causally transparent as you think. In fact, it turns out that the outcomes of real coin tosses are not independent. Instead, they exhibit dynamical bias: since they precess (rotate like a pizza) as well as flip end over end, they are slightly more likely to land the way that was originally facing up when they were flipped. Classic estimates put this bias at around 51%.
Moreover, a recent study of 350,000 coin tosses found quite a lot of hetereogeneity in how much bias is exhibited. The average is around 51%, but individual flippers can vary quite a bite—many exhibit a dynamical bias of close to 55%:
Notice: if our flipper turns the coin over between tosses, dynamical bias makes the outcomes Switchy; if he doesn’t, it makes them Sticky.
So coins often are either Sticky or Switchy!
Given subtle facts like this, maybe it’s rational for people to have causal uncertainty about most random processes—even coin flips. If so, they have to learn from experience about what to expect next. And as we’ve seen: if they do, it’ll be rational to commit the gambler’s fallacy.
Maybe the gambler’s fallacy doesn’t reveal statistical incompetence at all. After all, it’s exactly what we’d expect from a rational sensitivity to both causal uncertainty and subtle statistical cues.
What next?
If you liked this post, subscribe to the Substack for more.
If you’re curious for more details in the argument, check out the full paper.
For other potential explanations of the gambler’s fallacy, see Rabin 2002, Rabin and Vayanos 2010, and Hahn and Warren 2009.
See Miller and Sanjuro 2018, which shows that the original studies purporting to show that the hot hand was a myth failed to control for a subtle selection effect—and that controlling for it in the original data reverses the conclusions. The hot hand is real.
By total probability and the Principal Principle.
Precisely: the KL divergence from Steady to Switchy is smaller than that from Steady to Sticky.
All graphs are generated using chains that linearly build up to a 90% switching/sticking rate after a streak of 5. Formally, the Markov chains for Switchy and Sticky are:
See the full paper for details. Section 6 of the paper shows that the results are robust to variations in the structure of the Markov chains.
Although in these plots you become doubtful of Switchy relatively quickly—after around 100 tosses—the paper shows that we get the same effect with arbitrarily-large amounts of data so long as our Bayesians have limited memory.
Dan Greco has pointed out to me if our Bayesians are unsure whether/when the process can move back and forth between Switchy, Steady, and Sticky (as in the "regime-shifting" model of Barberis et al. 1998), then even without limited memory, they will not be confident it's not Switchy.